Error rendering report: {str(e)}
", "text/html" + + def _clean_html_content(self, content: str, title: str) -> str: + """Clean and validate HTML content from AI.""" + content = content.strip() + + # Remove markdown code blocks if present + if content.startswith("```") and content.endswith("```"): + lines = content.split('\n') + if len(lines) > 2: + content = '\n'.join(lines[1:-1]).strip() + + # Ensure it starts with DOCTYPE + if not content.startswith('\n' + content + else: + content = f'\n\n{content}\nGenerated on {timestamp}
\n\n' - - elif extension == ".md": - # Simple Markdown fallback - timestamp = int(self.services.utils.getUtcTimestamp()) - return f"# Generated Document\n\n{content}\n\n---\n*Generated on {timestamp}*" - - else: - # Generic fallback - return content as-is - return content - - except Exception as e: - logger.error(f"Error in fallback format conversion: {str(e)}") - return content @action async def generateReport(self, parameters: Dict[str, Any]) -> ActionResult: """ - Generate HTML report from multiple documents using AI. + Generate report from multiple documents using AI. Parameters: documentList (list): Document list reference(s) - List of document references to include in report prompt (str): AI prompt for report generation - Specific prompt describing what kind of report to generate - title (str, optional): Report title - Title for the generated HTML report (default: "Summary Report") + title (str, optional): Report title - Title for the generated report (default: "Summary Report") + outputFormat (str, optional): Output format extension - Specify the desired output format: 'html', 'pdf', 'docx', 'txt', 'md', 'json', 'csv', 'xlsx' (default: 'html') operationType (str, optional): Type of operation - Use 'generate_report', 'analyze_documents', etc. (default: 'generate_report') processDocumentsIndividually (bool, optional): Process each document separately - Set to True for individual processing (default: True) chunkAllowed (bool, optional): Allow content chunking - Set to True to allow AI service to chunk large content (default: True) @@ -649,6 +206,7 @@ class MethodDocument(MethodBase): documentList = [documentList] prompt = parameters.get("prompt") title = parameters.get("title", "Summary Report") + outputFormat = parameters.get("outputFormat", "html") operationType = parameters.get("operationType", "generate_report") processDocumentsIndividually = parameters.get("processDocumentsIndividually", True) chunkAllowed = parameters.get("chunkAllowed", True) @@ -677,27 +235,28 @@ class MethodDocument(MethodBase): error="No documents found for the provided reference" ) - # Generate HTML report - html_content = await self._generateHtmlReport(chatDocuments, title, includeMetadata, prompt) + # Generate report using the new format handling system + report_content, mime_type = await self._generateReport( + chatDocuments, title, outputFormat, includeMetadata, prompt + ) # Create output fileName - timestamp = int(self.services.utils.getUtcTimestamp()) - output_fileName = f"report_{self._format_timestamp_for_filename()}.html" + output_fileName = f"report_{self._format_timestamp_for_filename()}.{outputFormat}" result_data = { - "result": html_content, + "result": report_content, "fileName": output_fileName, "processedDocuments": len(chatDocuments), - "comment": f"HTML report generated with title: {title}" + "comment": f"Report generated in {outputFormat.upper()} format with title: {title}" } - logger.info(f"Generated HTML report: {output_fileName} with {len(html_content)} characters") + logger.info(f"Generated {outputFormat.upper()} report: {output_fileName} with {len(report_content)} characters") return ActionResult.isSuccess( documents=[{ "documentName": output_fileName, "documentData": result_data, - "mimeType": "text/html" + "mimeType": mime_type }] ) except Exception as e: @@ -706,6 +265,130 @@ class MethodDocument(MethodBase): error=str(e) ) + async def _generateReport(self, chatDocuments: List[Any], title: str, outputFormat: str, includeMetadata: bool, prompt: str) -> tuple[str, str]: + """ + Generate a report in the specified format using format-specific extraction: + 1. Get format-specific extraction prompt from renderer + 2. Extract content using AI with format-specific prompt + 3. Clean and return the formatted content + """ + try: + # Get format-specific extraction prompt + from modules.services.serviceGeneration.mainServiceGeneration import GenerationService + generation_service = GenerationService(self.services) + + extraction_prompt = generation_service.getExtractionPrompt( + output_format=outputFormat, + user_prompt=prompt, + title=title + ) + + # Extract content using format-specific prompt + extracted_content = await self._extractContentWithPrompt( + chatDocuments, extraction_prompt, includeMetadata + ) + + # Render the extracted content (mostly just cleaning) + rendered_content, mime_type = await generation_service.renderReport( + extracted_content=extracted_content, + output_format=outputFormat, + title=title + ) + + return rendered_content, mime_type + + except Exception as e: + logger.error(f"Error generating report: {str(e)}") + # Fallback to simple text format + fallback_content = f"# {title}\n\nError generating report: {str(e)}" + return fallback_content, "text/plain" + + async def _extractContentWithPrompt(self, chatDocuments: List[Any], extraction_prompt: str, includeMetadata: bool) -> str: + """ + Extract content from documents using a specific extraction prompt. + """ + try: + # Use extraction service directly with format-specific prompt and all documents + logger.info(f"Extracting content with format-specific prompt for {len(chatDocuments)} documents") + + # Build extraction options for report generation + extraction_options = { + "prompt": extraction_prompt, + "operationType": "generate_report", + "processDocumentsIndividually": True, + "chunkAllowed": True, + "mergeStrategy": { + "groupBy": "typeGroup", + "orderBy": "id", + "mergeType": "concatenate" + } + } + + if not includeMetadata: + extraction_options["includeMetadata"] = False + + # Extract content using extraction service with format-specific prompt + extracted_list = self.services.extraction.extractContent( + documents=chatDocuments, + options=extraction_options + ) + + if not extracted_list: + logger.warning("No content extracted from documents") + return "No readable content found in documents" + + # The extraction service should return format-specific content directly + # Combine all extracted content + all_extracted_content = [] + for ec in extracted_list: + if ec and hasattr(ec, 'parts'): + for part in ec.parts: + try: + if part.typeGroup in ("text", "table", "structure") and part.data: + all_extracted_content.append(part.data) + except Exception: + continue + + if not all_extracted_content: + logger.warning("No readable content found in extracted results") + return "No readable content found in documents" + + # Join all extracted content + combined_content = "\n\n".join(all_extracted_content) + + if not combined_content or combined_content.strip() == "": + logger.error("No content extracted from documents") + raise Exception("No content extracted from documents") + + # Call AI service to process the content with the format-specific prompt + logger.info(f"Calling AI service to process {len(combined_content)} characters with prompt") + aiResponse = await self.services.ai.callAi( + prompt=extraction_prompt, + documents=chatDocuments, # Pass the original ChatDocument objects + options={"operationType": "generate_report"} + ) + + if not aiResponse or aiResponse.strip() == "": + logger.error("AI content generation failed") + raise Exception("AI content generation failed") + + # Clean up the AI response + content = aiResponse.strip() + + # Remove markdown code blocks if present + if content.startswith("```") and content.endswith("```"): + lines = content.split('\n') + if len(lines) >= 2: + content = '\n'.join(lines[1:-1]).strip() + + logger.info(f"Successfully generated format-specific content: {len(content)} characters") + return content + + except Exception as e: + logger.error(f"Error extracting content with prompt: {str(e)}") + # Return minimal fallback content + return f"Error extracting content: {str(e)}" + async def _generateHtmlReport(self, chatDocuments: List[Any], title: str, includeMetadata: bool, prompt: str) -> str: """ Generate a comprehensive HTML report using AI from all input documents. diff --git a/test_ai_document_response.md b/test_ai_document_response.md new file mode 100644 index 00000000..b6a2d155 --- /dev/null +++ b/test_ai_document_response.md @@ -0,0 +1,555 @@ +# AI Analysis of Web Research Data + +**Prompt:** Erstelle aus den Daten der Internetsuche eine Liste der Grundstücke, welche zum Verkauf ausgeschrieben sind + +**Source Document:** web_research_result.md +**Document Size:** 1358968 characters + +## AI Response + +Hier ist eine Liste der Grundstücke, die im Kanton Zürich zum Verkauf stehen, basierend auf den analysierten Websites: + +1. **Wildberg** + - Adresse: Luegetenstrasse 11, 8489 Wildberg + - Fläche: 1'339 m² + - Preis: CHF 2’563’760 + +2. **Wiesendangen** + - Adresse: Lüss, 8542 Wiesendangen + - Fläche: 14’770 m² + - Preis: Auf Anfrage + +3. **Zürich** + - Adresse: Hürstringstrasse 37, 8046 Zürich + - Fläche: 410 m² + - Preis: CHF 2’323’840 + +4. **Birmensdorf** + - Adresse: Luzernerstrasse 57, 8903 Birmensdorf + - Fläche: 1'228 m² + - Preis: CHF 3’290’400 + +5. **Langnau am Albis** + - Adresse: Mühlemattstrasse 12, 8135 Langnau am Albis + - Preis: CHF 4’044’440 + +6. **Feldbach** + - Adresse: Kanalweg 2, 8714 Feldbach + - Preis: CHF 1’302’440 + +7. **Regensberg** + - Adresse: Staldernstrasse 13, 8158 Regensberg + - Fläche: 2'557 m² + - Preis: CHF 7’540’490 + +8. **Dietlikon** + - Adresse: Riedwiesenstrasse 20, 8305 Dietlikon + - Preis: CHF 3’633’140 + +9. **Wädenswil** + - Adresse: Rotweg 20, 8820 Wädenswil + - Fläche: 706 m² + - Preis: CHF 2’879’100 + +10. **Wasterkingen** + - Adresse: Auf Anfrage 1, 8195 Wasterkingen + - Fläche: 650 m² + - Preis: CHF 651’220 + +11. **Hinwil** + - Adresse: Überlandstrasse 23, 8340 Hinwil + - Fläche: 4'246 m² + - Preis: Auf Anfrage + +12. **Weiach** + - Adresse: 8187 Weiach + - Fläche: 1'157 m² + - Preis: CHF 1’919’390 + +13. **Grüningen** + - Adresse: In der Gass 2, 8627 Grüningen + - Preis: CHF 2’399’240 + +14. **Adliswil** + - Adresse: 8134 Adliswil + - Preis: CHF 3’600’000 + +15. **Hettlingen** + - Adresse: 8442 Hettlingen + - Preis: CHF 1’480’000 + +Diese Liste umfasst eine Auswahl von Grundstücken, die derzeit im Kanton Zürich zum Verkauf stehen. Die Preise und Verfügbarkeiten können sich ändern, daher ist es ratsam, die jeweiligen Anbieter für aktuelle Informationen zu kontaktieren. + +--- + +Hier ist eine Liste der Grundstücke, die zum Verkauf angeboten werden: + +1. **Überlandstrasse 23, 8340 Hinwil** + - Preis: Auf Anfrage + - Beschreibung: Industrielles Baugrundstück in einer belebten Industriezone von Hinwil, direkt an der Hauptachse von Rapperswil, Wetzikon und Pfäffikon ZH. + - Fläche: 4.246 m² + +2. **Trottenrain 14, 8474 Dinhard** + - Preis: CHF 2’947’650 + - Beschreibung: Genehmigtes Bauprojekt in zentraler Lage von Welsikon, Dinhard. Das Grundstück umfasst ein Lagerhaus, das in ein modernes Loft umgewandelt werden kann. + - Fläche: Nicht spezifiziert + +3. **In der Gass 2, 8627 Grüningen** + - Preis: CHF 2’399’240 + - Beschreibung: Grundstück mit genehmigtem Neubauprojekt. Bestehende Garagen können abgerissen und durch ein neues Gebäude mit 8 Wohnungen ersetzt werden. + - Fläche: Nicht spezifiziert + +4. **Im Königstal 2, 8487 Zell** + - Preis: CHF 2’604’890 + - Beschreibung: Grundstück in ländlicher Umgebung mit einem zweistöckigen Holzhaus und Garage. + - Fläche: Nicht spezifiziert + +5. **Im Königstal 3, 8487 Zell ZH** + - Preis: CHF 4’112’990 + - Beschreibung: Grundstück in ländlicher Umgebung mit einem zweistöckigen Holzhaus und Garage. + - Fläche: Nicht spezifiziert + +6. **Rotweg 20, 8820 Wädenswil** + - Preis: CHF 2’879’100 + - Beschreibung: Baugrundstück in bevorzugter, erhöhter und ruhiger Wohnlage mit Seeblick. + - Fläche: 706 m² + +7. **Auf Anfrage 1, 8195 Wasterkingen** + - Preis: CHF 651’220 + - Beschreibung: Attraktives Baugrundstück in ruhiger, ländlicher Umgebung von Wasterkingen. + - Fläche: 650 m² + +8. **Staldernstrasse 13, 8158 Regensberg** + - Preis: CHF 7’540’490 + - Beschreibung: Grundstück in zentraler Lage von Regensberg, ideal für Investoren, mit verschiedenen Entwicklungsmöglichkeiten. + - Fläche: 2.557 m² + +9. **Riedwiesenstrasse 20, 8305 Dietlikon** + - Preis: CHF 3’633’140 + - Beschreibung: Reserviertes Industrie-Baugrundstück in zentraler Lage von Dietlikon ZH. + - Fläche: Nicht spezifiziert + +10. **Kaffeestrasse, 8180 Bülach** + - Preis: Auf Anfrage + - Beschreibung: Industriegebäude in Bülach, maßgeschneidertes Projekt möglich. + - Fläche: Nicht spezifiziert + +11. **8192 Glattfelden** + - Preis: CHF 3’358’950 + - Beschreibung: Attraktives Baugrundstück in Zweidlen mit hohem Potenzial für den Bau eines Mehrfamilienhauses. + - Fläche: 1.226 m² + +Bitte beachten Sie, dass die Flächenangaben und Preise variieren können und es ratsam ist, die jeweiligen Angebote direkt zu überprüfen oder sich mit den Anbietern in Verbindung zu setzen, um detaillierte Informationen zu erhalten. + +--- + +Hier ist eine Liste der Grundstücke, die zum Verkauf im Kanton Zürich ausgeschrieben sind: + +1. **Trottenrain 14, 8474 Dinhard** + - Preis: CHF 2’150’000 + - Beschreibung: Bewilligtes Bauprojekt im steuergünstigen Dinhard-Welsikon. + +2. **Kaffeestrasse, 8180 Bülach** + - Preis: Auf Anfrage + - Beschreibung: Industriebauprojekt, maßgeschneidert für Miete oder Eigentum. + +3. **8605 Gutenswil** + - Preis: Auf Anfrage + - Beschreibung: 6'093 m² Wohnbauland im Glatttal. + +4. **Lägernstrasse 8, 8153 Rümlang** + - Preis: CHF 1’700’000 + - Beschreibung: Attraktives Grundstück mit Altliegenschaft, ideal für Bauprojekte. + +5. **Sonnenbühlstrasse 12, 8181 Höri** + - Preis: CHF 995’000 + - Beschreibung: Baulandparzelle mit 696 m² in der Wohnzone E2. + +6. **8105 Regensdorf** + - Preis: CHF 2’065’000 + - Beschreibung: Zentrale Liegenschaft mit Potenzial, eingereichtes Baugesuch vorhanden. + +7. **8910 Affoltern am Albis** + - Preis: Auf Anfrage + - Beschreibung: Flexibles Bauland in W4, geeignet für Einfamilien- oder Mehrfamilienhaus. + +8. **Grundbuch Blatt 50514, Kataster 720, Breiten, 8459 Volken** + - Preis: CHF 1’600’000 + - Beschreibung: Bauland mit hervorragender Gelegenheit für individuelles Wohnprojekt. + +9. **8953 Dietikon** + - Preis: CHF 3’750’000 + - Beschreibung: Grundstück mit Potenzial für Neubebauung, 1'094 m². + +10. **Bergstrasse 56, 8424 Embrach** + - Preis: CHF 1’169’200 + - Beschreibung: Attraktive Baulandparzelle für ein großzügiges Einfamilienhaus. + +11. **8820 Wädenswil** + - Preis: CHF 3’564’590 + - Beschreibung: Grundstück in ruhigem, familienfreundlichem Wohnquartier. + +12. **Bergstrasse 7a, 8155 Niederhasli** + - Preis: CHF 3’701’690 + - Beschreibung: Großzügiges Grundstück in familienfreundlicher Lage. + +13. **Baumgarten, 8914 Aeugst am Albis** + - Preis: CHF 1’343’580 + - Beschreibung: Grundstück mit guter Verkehrsanbindung. + +14. **Industriestrasse 34, 8117 Fällanden** + - Preis: Auf Anfrage + - Beschreibung: Grundstück mit 3’880 m² Nutzfläche. + +15. **8330 Pfäffikon ZH** + - Preis: CHF 4’935’590 + - Beschreibung: Off-Market Grundstück in familienfreundlicher Lage. + +16. **8703 Erlenbach ZH** + - Preis: CHF 12’476’100 + - Beschreibung: Großzügiges Grundstück mit Seesicht und Wertsteigerungspotenzial. + +17. **8172 Niederglatt** + - Preis: CHF 3’153’300 + - Beschreibung: 8½-Zimmer-Bauernhaus mit Potenzial. + +18. **Bergstrasse Kat. Nr. 9259, 9261, 8706 Meilen** + - Preis: CHF 27’419’990 + - Beschreibung: Großes Grundstück in Meilen. + +19. **8197 Rafz** + - Preis: Auf Anfrage + - Beschreibung: Grundstück in ruhiger Lage. + +20. **8468 Waltalingen** + - Preis: CHF 2’604’890 + - Beschreibung: Grundstück mit guter Verkehrsanbindung. + +21. **Götzen, 8197 Rafz** + - Preis: CHF 3’016’200 + - Beschreibung: Grundstück mit 1’820 m² Nutzfläche. + +22. **8162 Steinmaur** + - Preis: Auf Anfrage + - Beschreibung: 1452 m² Baugrundstück in ruhiger Lage. + +23. **8340 Hinwil** + - Preis: CHF 1’070’000 + - Beschreibung: Grundstück mit flexiblen Nutzungsmöglichkeiten. + +24. **8633 Wolfhausen** + - Preis: CHF 4’074’000 + - Beschreibung: Großzügiges Grundstück mit flexiblen Designoptionen. + +25. **Sonnhalde, 8602 Wangen b. Dübendorf** + - Preis: CHF 3’300’000 + - Beschreibung: Exklusives Grundstück mit viel Privatsphäre. + +26. **8000 Zürich** + - Preis: Auf Anfrage + - Beschreibung: Grundstück ideal für Entwicklung, nahe öffentlicher Verkehrsmittel. + +27. **8195 Wasterkingen** + - Preis: CHF 475’000 + - Beschreibung: Vollständig erschlossenes Grundstück in ruhiger Gemeinde. + +28. **8618 Oetwil am See** + - Preis: Auf Anfrage + - Beschreibung: Sonniges Grundstück mit flexibler Zonierung. + +29. **8617 Mönchaltorf** + - Preis: Auf Anfrage + - Beschreibung: Grundstück mit hohem Entwicklungspotenzial. + +30. **Güeterstalstrasse, 8133 Esslingen** + - Preis: CHF 600’000 + - Beschreibung: Zentrale Lage ohne Architekturverpflichtung. + +31. **8192 Zweidlen** + - Preis: CHF 2’450’000 + - Beschreibung: Grundstück mit flexiblen Entwicklungsmöglichkeiten. + +32. **8424 Embrach** + - Preis: Auf Anfrage + - Beschreibung: Familienfreundliche Lage mit flexiblen Bauoptionen. + +33. **Berghalde 10, 8332 Russikon** + - Preis: CHF 1’500’000 + - Beschreibung: Großes Grundstück in sonniger Hanglage. + +34. **8134 Adliswil** + - Preis: CHF 3’600’000 + - Beschreibung: Zentrale Lage mit hohem Potenzial, ideal für Investoren. + +35. **Überlandstrasse 23, 8340 Hinwil** + - Preis: Auf Anfrage + - Beschreibung: Großes Grundstück in privilegierter Lage. + +36. **Winzerstrasse 20, 8353 Elgg** + - Preis: CHF 1’140’000 + - Beschreibung: Ideal für Familienhäuser, Investitionsmöglichkeit. + +37. **Industriestrasse 34, 8117 Fällanden** + - Preis: Auf Anfrage + - Beschreibung: Gewerbeprojekt mit flexibler Nutzung. + +38. **8630 Rüti ZH** + - Preis: Auf Anfrage + - Beschreibung: Ruhige Wohnlage mit 30% Ausnutzungsziffer. + +39. **Staldernstrasse 13, 8158 Regensberg** + - Preis: CHF 5’500’000 + - Beschreibung: Grundstück mit hohem Mietrenditepotenzial. + +40. **Leisibüel, 8484 Weisslingen** + - Preis: CHF 1’300’000 + - Beschreibung: Grundstück mit atemberaubender Aussicht. + +41. **Weiacherstrasse 85, 8427 Rorbas** + - Preis: CHF 3’440’000 + - Beschreibung: Großes Grundstück mit gemischter Nutzung. + +42. **Bergstrasse 7a, 8155 Nassenwil** + - Preis: CHF 2’700’000 + - Beschreibung: Großes Grundstück in ruhiger Lage. + +43. **Götze, 8197 Rafz** + - Preis: CHF 2’200’000 + - Beschreibung: Grundstück mit freier Sicht, ideal für Entwicklung. + +44. **Schaffhauserstrasse 226b, 8057 Zürich** + - Preis: CHF 2’999’000 + - Beschreibung: Grundstück mit großem Außenbereich. + +45. **Haldenstrasse 10, 8134 Adliswil** + - Preis: CHF 3’300’000 + - Beschreibung: Ruhige Lage mit Aussicht, sofort verfügbar. + +Bitte beachten Sie, dass die Preise und Verfügbarkeiten variieren können. Es ist ratsam, sich direkt mit den Anbietern in Verbindung zu setzen, um aktuelle Informationen zu erhalten. + +--- + +Hier ist eine Liste der Grundstücke, die zum Verkauf angeboten werden: + +1. **8162 Steinmaur** + - Fläche: 1'452 m² + - Preis: Auf Anfrage + - Besonderheiten: Flaches, gut bebaubares Grundstück mit Bachanstoss, angrenzend an Landwirtschaftszone + +2. **8340 Hinwil** + - Fläche: 1'070 m² + - Preis: CHF 1’070’000.- (CHF 1’000 / m²) + - Besonderheiten: Kernzone, 2 Vollgeschosse, 1 Dachgeschoss + +3. **8633 Wolfhausen** + - Fläche: 1'940 m² + - Preis: CHF 4’074’000.- (CHF 2’100 / m²) + - Besonderheiten: Familienfreundliche Lage, flexible Gestaltungsmöglichkeiten + +4. **8602 Wangen b. Dübendorf** + - Fläche: 1'666 m² + - Preis: CHF 3’300’000.- (CHF 1’981 / m²) + - Besonderheiten: Optimale Sonnenexposition, ruhige Lage + +5. **8000 Zürich** + - Preis: Auf Anfrage + - Besonderheiten: Ideal für Entwicklung, nahe öffentlicher Verkehrsmittel + +6. **8195 Wasterkingen** + - Fläche: 650 m² + - Preis: CHF 475’000.- (CHF 731 / m²) + - Besonderheiten: Voll erschlossen, ruhige ländliche Gemeinschaft + +7. **8618 Oetwil am See** + - Fläche: 1'622 m² + - Preis: Auf Anfrage + - Besonderheiten: Sonniges Grundstück, flexible Zonierung + +8. **8617 Mönchaltorf** + - Fläche: 850 m² + - Preis: Auf Anfrage + - Besonderheiten: Hoher Entwicklungspotential, ruhige Lage + +9. **8133 Esslingen** + - Fläche: 507 m² + - Preis: CHF 600’000.- (CHF 1’183 / m²) + - Besonderheiten: Zentrale Lage, keine architektonische Verpflichtung + +10. **8192 Zweidlen** + - Fläche: 1'226 m² + - Preis: CHF 2’450’000.- (CHF 1’998 / m²) + - Besonderheiten: Flexible Entwicklungsmöglichkeiten + +11. **8424 Embrach** + - Fläche: 1'670 m² + - Preis: Auf Anfrage + - Besonderheiten: Familienfreundliche Lage, flexible Bauoptionen + +12. **8332 Russikon** + - Fläche: 854 m² + - Preis: CHF 1’500’000.- (CHF 1’756 / m²) + - Besonderheiten: Sonnige Hanglage, Potenzial für Neubau + +13. **8134 Adliswil** + - Fläche: 694 m² + - Preis: CHF 3’600’000.- (CHF 5’187 / m²) + - Besonderheiten: Zentrale Lage, ideal für Investoren + +14. **8340 Hinwil (Überlandstrasse 23)** + - Fläche: 4'246 m² + - Preis: Auf Anfrage + - Besonderheiten: Top Lage, große Fläche für Entwicklung + +15. **8353 Elgg** + - Fläche: 877 m² + - Preis: CHF 1’140’000.- (CHF 1’300 / m²) + - Besonderheiten: Ideal für Familienhäuser, Investitionsmöglichkeit + +16. **8117 Fällanden** + - Fläche: 1'706 m² + - Preis: Auf Anfrage + - Besonderheiten: Genehmigtes Gewerbeprojekt, flexible Nutzung + +17. **8630 Rüti ZH** + - Fläche: 3'460 m² + - Preis: Auf Anfrage + - Besonderheiten: Ruhige Wohnzone, Bonus für zusätzlichen Raum + +18. **8158 Regensberg** + - Fläche: 2'557 m² + - Preis: CHF 5’500’000.- (CHF 2’151 / m²) + - Besonderheiten: Flexible Zonierung, hohes Mietrenditepotenzial + +19. **8484 Weisslingen** + - Fläche: 844 m² + - Preis: CHF 1’300’000.- (CHF 1’540 / m²) + - Besonderheiten: Atemberaubende Bergsicht, ruhige Nachbarschaft + +20. **8427 Rorbas** + - Fläche: 2'295 m² + - Preis: CHF 3’440’000.- (CHF 1’499 / m²) + - Besonderheiten: Großzügiges Grundstück, gemischte Nutzung möglich + +21. **8155 Nassenwil** + - Fläche: 1'742 m² + - Preis: CHF 2’700’000.- (CHF 1’550 / m²) + - Besonderheiten: Ruhige Lage, nahe Dielsdorf + +22. **8197 Rafz** + - Fläche: 1'340 m² + - Preis: CHF 2’200’000.- (CHF 1’642 / m²) + - Besonderheiten: Unverbaubare Aussicht, ideal für Entwicklung + +23. **8057 Zürich (Schaffhauserstrasse 226b)** + - Fläche: 480 m² + - Preis: CHF 2’999’000.- (CHF 26’307 / m²) + - Besonderheiten: Großzügiger Außenbereich, grüne Aussicht + +24. **8134 Adliswil (Haldenstrasse 10)** + - Fläche: 829 m² + - Preis: CHF 3’300’000.- (CHF 3’981 / m²) + - Besonderheiten: Ruhige Lage, sofort verfügbar + +Diese Liste enthält eine Auswahl an Grundstücken, die im Kanton Zürich zum Verkauf stehen. + +--- + +Hier ist eine Liste der Grundstücke, die zum Verkauf angeboten werden: + +1. **Crans-Montana** + - Beschreibung: Grundstück mit Baugenehmigung für ein Chalet mit 2 Wohnungen. + - Preis: Auf Anfrage + +2. **Riveo** + - Beschreibung: Baugrundstück in zentraler und sonniger Lage mit direktem Zugang von der Kantonsstraße. + - Preis: CHF 190’000 + +3. **Grächen** + - Beschreibung: Grundstück mit freiem Blick, sehr sonnig und zentral gelegen. + - Preis: CHF 119 + +4. **Täsch** + - Beschreibung: Sonnige Lage, ideal für den Bau von Chalets, in der Nähe von Zermatt. + - Preis: CHF 160 + +5. **Baar (Nendaz)** + - Beschreibung: Grundstück für den Bau von Wohnhäusern. + - Preis: CHF 315 + +6. **Stalden VS** + - Beschreibung: Grundstück in einer der trockensten Regionen der Schweiz, ideal für den Bau von Wohnhäusern. + - Preis: CHF 70 + +7. **Guntershausen b. Berg** + - Beschreibung: Baugrundstück in einer ruhigen Lage. + - Preis: CHF 640’000 + +8. **Sierre** + - Beschreibung: Grundstück in einer zentralen Lage. + - Preis: CHF 915’000 + +9. **Lens** + - Beschreibung: Grundstück mit Projekt in Kraft, in der Nähe von Crans-Montana. + - Preis: CHF 1’050’000 + +10. **Miex** + - Beschreibung: Grundstück im Zentrum des Dorfes Vouvry, geeignet für Wohn- und Geschäftsbauten. + - Preis: CHF 340’000 + +11. **Grimentz** + - Beschreibung: Grundstück mit Panoramablick, in der Nähe von öffentlichen Verkehrsmitteln. + - Preis: CHF 491’940 + +12. **Albinen** + - Beschreibung: Grundstück mit atemberaubendem Panorama und perfekter Sonneneinstrahlung. + - Preis: CHF 104’700 + +13. **Salgesch** + - Beschreibung: Chalet auf einem Campingplatz mit Zugang zu einem kleinen Badesee. + - Preis: CHF 46’000 + +14. **Cheseaux-Noréaz** + - Beschreibung: Landwirtschaftlicher Betrieb mit ausgezeichnetem Klima für Gemüseanbau. + - Preis: Auf Anfrage + +15. **Warth** + - Beschreibung: Baugrundstück in einer ruhigen Lage. + - Preis: CHF 2’100’000 + +16. **Mollens VS** + - Beschreibung: Grundstück in einer ruhigen Lage. + - Preis: CHF 180 + +17. **Mund** + - Beschreibung: Grundstück in einer ruhigen Lage. + - Preis: CHF 175 + +18. **Scherzingen** + - Beschreibung: Grundstück in einer ruhigen Lage. + - Preis: CHF 1’100’000 + +19. **Walzenhausen** + - Beschreibung: Grundstück in einer ruhigen Lage. + - Preis: CHF 895’000 + +20. **Oggio** + - Beschreibung: Grundstück in einer ruhigen Lage. + - Preis: CHF 1’300’000 + +21. **Origlio** + - Beschreibung: Grundstück in einer ruhigen Lage. + - Preis: CHF 170’000 + +22. **Saxon** + - Beschreibung: Baugrundstück in einem ruhigen Dorf mit Blick auf die Berge. + - Preis: CHF 300/m² + +23. **Botyre (Ayent)** + - Beschreibung: Grundstück mit freiem Blick, in der Nähe von Sion und Crans-Montana. + - Preis: CHF 155’000 + +24. **Savièse** + - Beschreibung: Grundstück mit freiem Blick, in der Nähe von Sion. + - Preis: CHF 270’000 + +Bitte beachten Sie, dass die Preise und Verfügbarkeiten variieren können. Es wird empfohlen, sich direkt mit den Anbietern in Verbindung zu setzen, um weitere Informationen zu erhalten. \ No newline at end of file diff --git a/test_ai_with_documents.py b/test_ai_with_documents.py new file mode 100644 index 00000000..7e517a6e --- /dev/null +++ b/test_ai_with_documents.py @@ -0,0 +1,214 @@ +#!/usr/bin/env python3 +""" +Test AI calls with document processing. +This tests the AI service's ability to process documents and generate responses. +""" + +import asyncio +import logging +import sys +from pathlib import Path + +# Add the gateway directory to the Python path +gateway_dir = Path(__file__).parent +sys.path.insert(0, str(gateway_dir)) + +# Import the required modules +from modules.services.serviceAi.mainServiceAi import AiService +from modules.datamodels.datamodelChat import ChatDocument +from modules.datamodels.datamodelAi import AiCallOptions, OperationType + +# Configure logging with DEBUG level for AI service +logging.basicConfig( + level=logging.DEBUG, + format='%(asctime)s - %(name)s - %(levelname)s - %(message)s', + handlers=[ + logging.StreamHandler(sys.stdout) + ] +) +logger = logging.getLogger(__name__) + +# Set AI service logger to DEBUG level +ai_service_logger = logging.getLogger('modules.services.serviceAi.mainServiceAi') +ai_service_logger.setLevel(logging.DEBUG) + +# Set extraction service loggers to DEBUG level +extraction_logger = logging.getLogger('modules.services.serviceExtraction.mainServiceExtraction') +extraction_logger.setLevel(logging.DEBUG) + +pipeline_logger = logging.getLogger('modules.services.serviceExtraction.subPipeline') +pipeline_logger.setLevel(logging.DEBUG) + +async def test_ai_with_documents(): + """Test AI calls with document processing.""" + try: + print("=" * 60) + print("AI WITH DOCUMENTS TEST") + print("=" * 60) + + # Config sanity check + try: + from modules.shared.configuration import APP_CONFIG + env_type = APP_CONFIG.get('APP_ENV_TYPE') + print(f"Environment: {env_type}") + except Exception as e: + print(f"Configuration loading failed: {e}") + return + + # Initialize the AI service + print("Initializing AI service...") + try: + ai_service = await asyncio.wait_for(AiService.create(), timeout=30.0) + print("AI service initialized") + except asyncio.TimeoutError: + print("AI service initialization timed out after 30 seconds") + return + except Exception as e: + print(f"AI service initialization failed: {e}") + import traceback + traceback.print_exc() + return + + # Test 1: AI call with web research result document + print("\n" + "="*60) + print("TEST 1: AI Call with Web Research Document") + print("="*60) + + # Read the web research result file + web_result_file = gateway_dir / "test_web_integration_result.md" + if not web_result_file.exists(): + print(f"Web research result file not found: {web_result_file}") + print("Please run test_web_integration.py first to generate the document.") + return + + print(f"Reading web research result from: {web_result_file}") + with open(web_result_file, 'r', encoding='utf-8') as f: + web_content = f.read() + + print(f"Document size: {len(web_content)} characters") + + # Create a temporary file to simulate document storage for testing + print("Creating temporary document file for testing...") + import tempfile + import os + + # Create a temporary file with the web content + with tempfile.NamedTemporaryFile(mode='w', suffix='.md', delete=False, encoding='utf-8') as temp_file: + temp_file.write(web_content) + temp_file_path = temp_file.name + + print(f"Temporary file created: {temp_file_path}") + + # Create ChatDocument with the temporary file + web_document = ChatDocument( + messageId="test_message_001", + fileId="temp_file_001", + fileName="web_research_result.md", + fileSize=len(web_content), + mimeType="text/markdown" + ) + + # Mock the database interface to return our file content + print("Setting up mock database interface...") + from unittest.mock import patch + + def mock_get_file_data(file_id): + if file_id == "temp_file_001": + return web_content.encode('utf-8') + return None + + # Create AI call options - process full content without compression + ai_options = AiCallOptions( + operationType=OperationType.ANALYSE_CONTENT, + compressPrompt=False, # Don't compress the prompt + compressContext=False, # Process full content, don't compress + processDocumentsIndividually=False, + maxContextBytes=None, # No artificial limit - let the engine handle it + safetyMargin=0.1 + ) + + # Test prompt + prompt = "Erstelle aus den Daten der Internetsuche eine Liste der Grundstücke, welche zum Verkauf ausgeschrieben sind" + + print(f"Prompt: {prompt}") + print("Processing document with AI...") + + try: + # Use the document with mocked database interface + print(f"Original prompt length: {len(prompt)} characters") + print(f"Web content length: {len(web_content)} characters") + print(f"Document file: {web_document.fileName}") + + # Mock the database interface and call AI with the document + with patch('modules.interfaces.interfaceDbComponentObjects.getInterface') as mock_get_interface: + mock_interface = mock_get_interface.return_value + mock_interface.getFileData = mock_get_file_data + + print("Calling AI with document processing...") + result = await ai_service.callAi( + prompt=prompt, + documents=[web_document], # Use the document, not embedded content + options=ai_options + ) + + print("AI processing completed successfully!") + print(f"Result length: {len(result)} characters") + print("\n" + "="*60) + print("AI RESPONSE:") + print("="*60) + print(result) + + # Save the AI response to a file + output_file = gateway_dir / "test_ai_document_response.md" + with open(output_file, 'w', encoding='utf-8') as f: + f.write("# AI Analysis of Web Research Data\n\n") + f.write(f"**Prompt:** {prompt}\n\n") + f.write(f"**Source Document:** web_research_result.md\n") + f.write(f"**Document Size:** {len(web_content)} characters\n\n") + f.write("## AI Response\n\n") + f.write(result) + + print(f"\nAI response saved to: {output_file}") + + # Clean up temporary file + try: + os.unlink(temp_file_path) + print(f"Cleaned up temporary file: {temp_file_path}") + except Exception as e: + print(f"Warning: Could not clean up temporary file: {e}") + + except Exception as e: + print(f"AI processing failed: {e}") + import traceback + traceback.print_exc() + + # Clean up temporary file on error + try: + os.unlink(temp_file_path) + except: + pass + return + + # Test 2: Skipped as requested + print("\n" + "="*60) + print("TEST 2: SKIPPED (Multi-Document Test)") + print("="*60) + print("Multi-document test skipped as requested.") + + print("\nAI with documents test completed!") + + except Exception as e: + print(f"Test failed: {str(e)}") + import traceback + traceback.print_exc() + +if __name__ == "__main__": + # Add timeout to the entire test + try: + asyncio.run(asyncio.wait_for(test_ai_with_documents(), timeout=300.0)) + except asyncio.TimeoutError: + print("Test timed out after 300 seconds") + except Exception as e: + print(f"Test failed with error: {e}") + import traceback + traceback.print_exc() diff --git a/test_generated_report.pdf b/test_generated_report.pdf new file mode 100644 index 00000000..20d2b7d5 --- /dev/null +++ b/test_generated_report.pdf @@ -0,0 +1 @@ +2�$<1\�{^����)� \ No newline at end of file diff --git a/test_generated_report_content.txt b/test_generated_report_content.txt new file mode 100644 index 00000000..aa2fd5f8 --- /dev/null +++ b/test_generated_report_content.txt @@ -0,0 +1,13 @@ +Generated Report Content +====================== + +Title: Immobilienmarkt Kanton Zürich - Web-Recherche Analyse +Format: docx +MIME Type: application/vnd.openxmlformats-officedocument.wordprocessingml.document +File Name: report_20251002-231018.docx +Content Length: 356248 characters + +Content Preview (first 1000 characters): +-------------------------------------------------- +UEsDBBQAAAAIAEkJQ1utUqWRlQEAAMoGAAATAAAAW0NvbnRlbnRfVHlwZXNdLnhtbLWVTU/bQBCG7/0Vli8+IHtDDxWq4nAocCyRGkSvm/U4Wdgv7UwC+ffMOolV0VCHBi6RnJn3fR7bsj2+fLYmW0NE7V1dnFejIgOnfKPdoi7uZjflRZEhSddI4x3UxQawuJx8Gc82ATDjsMM6XxKF70KgWoKVWPkAjietj1YSH8aFCFI9ygWIr6PRN6G8I3BUUurIJ+MraOXKUHb9zH93IvlDgEWe/dguJlada5sKuoE4mIlg8FVGhmC0ksRzsXbNK7NyZ1VxstvBpQ54xgtvENLkbcAud8tXM+oGsqmM9FNa3hJqheTtb2uEJrDT6AOeV/9uO6Dr21YraLxaWY5UfWnqg0gaevdDDpzrwIIpJ7MhXZQGmjK8j618hPfD9/cppY8kPvnYiF731NNNbcxVgMgPhjVVP7FSu0GPlskzOTf/cepDIn31oIRb2TlETn28RF89KIFAxHv48Q775mEF2hj4DIGu90j8vabldduComNMLJYpW/2VHaQRv5Fh+3v6C6erGUQ+wfzXp93lP8r3IqL7FE1eAFBLAwQUAAAACABJCUNbeSZLQPgAAADeAgAACwAAAF9yZWxzLy5yZWxzrZLNSgMxEIDvPkXIJadutlVEpNleROhNpD7AmMzupm5+SKbavr1RRF1YFsEe5+/jY2bWm6Mb2CumbINXYlnVgqHXwVjfKfG0u1/cCJYJvIEheFTihFlsmov1Iw5AZSb3NmZWID4r3hPFWymz7tFBrkJEXyptSA6ohKmTEfQLdChXdX0t028Gb0ZMtjWKp6255Gx3ivg/tnRIYIBA6pBwEVOZTmQxFzikDklxE/RDSefPjqqQuZwWuvq7UGhbq/Eu6INDT1NeeCT0Bs28EsQ4Z7Q8p9G440fmLSQjzVd6zmZ13oNRf3DPHuwwsZfvWrWP2H0IydFbNu9QSwMEFAAA +... (content truncated) \ No newline at end of file diff --git a/test_real_document_generation.py b/test_real_document_generation.py new file mode 100644 index 00000000..9b0d3e26 --- /dev/null +++ b/test_real_document_generation.py @@ -0,0 +1,368 @@ +#!/usr/bin/env python3 +""" +Real Document Generation Test +Tests the generateReport action with REAL AI processing (no mocking) +""" + +import asyncio +import sys +from pathlib import Path +import tempfile +import os + +# Add the gateway directory to the Python path +gateway_dir = Path(__file__).parent +sys.path.insert(0, str(gateway_dir)) + +# Add the modules path to sys.path for imports +modules_path = gateway_dir / 'modules' +sys.path.insert(0, str(modules_path)) + +from modules.workflows.methods.methodDocument import MethodDocument +from modules.datamodels.datamodelChat import ChatDocument +from modules.datamodels.datamodelUam import User +from modules.interfaces.interfaceDbComponentObjects import getInterface + +async def test_real_document_generation(): + """Test generateReport with REAL AI processing""" + print("=" * 60) + print("REAL DOCUMENT GENERATION TEST") + print("=" * 60) + + try: + # Initialize real services + print("Environment: dev") + print("Initializing MethodDocument with REAL services...") + + # Create a real user + real_user = User( + id="test_user_001", + username="testuser", + name="Test User", + email="test@example.com" + ) + + # Initialize real services (this will use actual AI, extraction, generation services) + from modules.services.serviceAi.mainServiceAi import AiService + from modules.services.serviceExtraction.mainServiceExtraction import ExtractionService + from modules.services.serviceGeneration.mainServiceGeneration import GenerationService + from modules.services.serviceWorkflow.mainServiceWorkflow import WorkflowService + + # Create a mock workflow with the document + class MockWorkflow: + def __init__(self, document): + self.messages = [MockMessage(document)] if document else [] + + class MockMessage: + def __init__(self, document): + self.documents = [document] if document else [] + + # Create a mock service center for the workflow service + class MockServiceCenter: + def __init__(self, user, document): + self.services = {} + self.user = user + self.workflow = MockWorkflow(document) + self.interfaceDbChat = None # Mock interface + self.interfaceDbComponent = None # Mock interface + self.interfaceDbApp = None # Mock interface + + mock_service_center = MockServiceCenter(real_user, None) # Will be set later + + # Create a services object with attributes instead of a dictionary + class ServicesObject: + def __init__(self): + # Note: AI service needs to be created with create() method for proper initialization + self.ai = None # Will be initialized in async setup + self.extraction = ExtractionService() + self.generation = GenerationService() + self.workflow = WorkflowService(mock_service_center) + self.user = real_user + + # AI service will be initialized in async setup + + # Add debugging to extraction service calls + original_extract = self.extraction.extractContent + def debug_extract_content(documents, options): + print(f"📄 Extraction Service called with {len(documents)} documents") + print(f"📄 Extraction options: {options}") + result = original_extract(documents, options) + print(f"📄 Extraction result: {len(result)} extracted content objects") + if result: + for i, content in enumerate(result): + print(f"📄 Content {i}: {len(content.parts)} parts") + for j, part in enumerate(content.parts): + print(f"📄 Part {j}: {part.typeGroup} - {len(part.data)} chars") + return result + self.extraction.extractContent = debug_extract_content + + # Override the getChatDocumentsFromDocumentList method to add debugging + original_method = self.workflow.getChatDocumentsFromDocumentList + def debug_getChatDocumentsFromDocumentList(documentList): + print(f"🔍 Debug: Looking for documents: {documentList}") + print(f"🔍 Debug: Available documents in workflow:") + for i, message in enumerate(mock_service_center.workflow.messages): + print(f" Message {i}: {len(message.documents)} documents") + for j, doc in enumerate(message.documents): + print(f" Document {j}: ID={doc.id}, fileId={doc.fileId}, fileName={doc.fileName}") + + # Add detailed debugging for the docItem parsing + for doc_ref in documentList: + if doc_ref.startswith("docItem:"): + parts = doc_ref.split(':') + print(f"🔍 Debug: Parsed docItem parts: {parts}") + if len(parts) >= 2: + doc_id = parts[1] + print(f"🔍 Debug: Looking for doc_id: '{doc_id}'") + for message in mock_service_center.workflow.messages: + if message.documents: + for doc in message.documents: + print(f"🔍 Debug: Comparing '{doc_id}' == '{doc.id}' ? {doc_id == doc.id}") + if doc.id == doc_id: + print(f"🔍 Debug: MATCH FOUND!") + break + + # Debug the original method's workflow reference + print(f"🔍 Debug: Original method workflow: {self.workflow}") + print(f"🔍 Debug: Original method workflow.messages: {getattr(self.workflow, 'messages', 'NO_MESSAGES_ATTR')}") + + result = original_method(documentList) + print(f"🔍 Debug: Found {len(result)} documents") + return result + self.workflow.getChatDocumentsFromDocumentList = debug_getChatDocumentsFromDocumentList + + real_services = ServicesObject() + + # Initialize AI service properly + print("Initializing AI service...") + try: + real_services.ai = await AiService.create() + print(f"✅ AI service initialized successfully") + print(f"✅ AI service aiObjects: {real_services.ai.aiObjects}") + except Exception as e: + print(f"❌ AI service initialization failed: {e}") + import traceback + traceback.print_exc() + return + + # Add debugging to AI service calls + original_call_ai = real_services.ai.callAi + async def debug_call_ai(prompt, documents=None, options=None): + print(f"🤖 AI Service called with prompt: {prompt[:200]}...") + print(f"🤖 AI Service documents: {len(documents) if documents else 0}") + print(f"🤖 AI Service options: {options}") + result = await original_call_ai(prompt, documents, options) + print(f"🤖 AI Service result length: {len(result) if result else 0}") + print(f"🤖 AI Service result preview: {result[:200] if result else 'None'}...") + return result + real_services.ai.callAi = debug_call_ai + + method_doc = MethodDocument(services=real_services) + print("MethodDocument initialized with REAL services") + + # Read the web integration result file + web_result_file = gateway_dir / "test_web_integration_result.md" + if not web_result_file.exists(): + print(f"Web integration result file not found: {web_result_file}") + print("Please run test_web_integration.py first to generate the document.") + return + + print(f"Reading web integration result from: {web_result_file}") + with open(web_result_file, 'r', encoding='utf-8') as f: + web_content = f.read() + + print(f"Document size: {len(web_content)} characters") + + # Create the document for the workflow + web_document = ChatDocument( + messageId="test_message_003", + fileId="temp_file_003", + fileName="test_web_integration_result.md", + fileSize=len(web_content), + mimeType="text/markdown" + ) + + # Debug: Show the actual generated ID + print(f"🔍 Debug: Generated document ID: {web_document.id}") + + # Update the workflow with the document + mock_service_center.workflow = MockWorkflow(web_document) + + # Also update the workflow in the WorkflowService since it was created before we set the workflow + real_services.workflow.workflow = mock_service_center.workflow + + # Debug: Check if the document ID changed after adding to workflow + print(f"🔍 Debug: Document ID after adding to workflow: {web_document.id}") + if mock_service_center.workflow.messages and mock_service_center.workflow.messages[0].documents: + workflow_doc = mock_service_center.workflow.messages[0].documents[0] + print(f"🔍 Debug: Workflow document ID: {workflow_doc.id}") + print(f"🔍 Debug: Same object? {web_document is workflow_doc}") + + # Debug: Check if the document is properly set up + print(f"🔍 Debug: Document ID: {web_document.id}") + print(f"🔍 Debug: Document fileId: {web_document.fileId}") + print(f"🔍 Debug: Workflow messages: {len(mock_service_center.workflow.messages)}") + if mock_service_center.workflow.messages: + print(f"🔍 Debug: First message documents: {len(mock_service_center.workflow.messages[0].documents)}") + if mock_service_center.workflow.messages[0].documents: + doc = mock_service_center.workflow.messages[0].documents[0] + print(f"🔍 Debug: First document ID: {doc.id}") + print(f"🔍 Debug: First document fileId: {doc.fileId}") + else: + print("🔍 Debug: No messages in workflow!") + + # Create a temporary file to simulate document storage for testing + print("Creating temporary document file for testing...") + + # Create a temporary file with the web content + with tempfile.NamedTemporaryFile(mode='w', suffix='.md', delete=False, encoding='utf-8') as temp_file: + temp_file.write(web_content) + temp_file_path = temp_file.name + + print(f"Temporary file created: {temp_file_path}") + + # Mock the database interface to return our file content + print("Setting up database interface...") + + def mock_get_file_data(file_id): + if file_id == web_document.fileId: # Use the actual fileId + return web_content.encode('utf-8') + return None + + # Test parameters for generateReport action + # The documentList should contain document references, not ChatDocument objects + # Use the actual document ID from the ChatDocument (now that it's in the workflow) + document_ref = f"docItem:{web_document.id}:{web_document.fileName}" + test_parameters = { + "documentList": [document_ref], + "prompt": "Erstelle einen prägnanten 2-seitigen Immobilienbericht basierend auf den Web-Recherchedaten. Fokussiere auf die wichtigsten Erkenntnisse, Markttrends, Preisentwicklungen und Empfehlungen. Halte den Bericht auf maximal 2 Seiten kompakt und strukturiert.", + "title": "Immobilienmarkt Kanton Zürich - Web-Recherche Analyse", + "outputFormat": "docx", + "includeMetadata": True + } + + print(f"🔍 Debug: Document reference: {document_ref}") + + print(f"Test parameters:") + print(f" - Document: {web_document.fileName}") + print(f" - Title: {test_parameters['title']}") + print(f" - Output Format: {test_parameters['outputFormat']}") + print(f" - Include Metadata: {test_parameters['includeMetadata']}") + + try: + # Mock only the database interface to provide the file content + from unittest.mock import patch + + with patch('modules.interfaces.interfaceDbComponentObjects.getInterface') as mock_get_interface: + mock_interface = mock_get_interface.return_value + mock_interface.getFileData = mock_get_file_data + + print("\nCalling generateReport action with REAL AI processing...") + + # Use the REAL generateReport method with REAL AI processing + result = await method_doc.generateReport(test_parameters) + + print("Document generation completed successfully!") + print(f"Result type: {type(result)}") + + if hasattr(result, 'success') and result.success: + print(f"✅ Success: {result.success}") + + # Extract content from the ActionResult + if hasattr(result, 'documents') and result.documents: + document = result.documents[0] + + # ActionDocument objects have attributes, documentData is a dict + if hasattr(document, 'documentData'): + document_data = document.documentData + content = document_data.get('result', '') if isinstance(document_data, dict) else '' + else: + content = '' + + mime_type = getattr(document, 'mimeType', 'application/pdf') + file_name = getattr(document, 'documentName', 'test_report.pdf') + + print(f"📄 Content length: {len(content)} characters") + print(f"📋 MIME type: {mime_type}") + print(f"📁 File name: {file_name}") + + # Save the generated DOCX content to a file + output_file = gateway_dir / "test_real_generated_report.docx" + with open(output_file, 'wb') as f: + # The content should be base64 encoded for DOCX + import base64 + try: + docx_bytes = base64.b64decode(content) + f.write(docx_bytes) + print(f"📁 Generated DOCX saved to: {output_file}") + print(f"📊 DOCX file size: {len(docx_bytes)} bytes") + except Exception as e: + print(f"⚠️ Could not decode base64 content: {e}") + # Save as text if not base64 + f.write(content.encode('utf-8')) + print(f"📁 Content saved as text to: {output_file}") + + # Also save a text version for inspection + text_output_file = gateway_dir / "test_real_generated_report_content.txt" + with open(text_output_file, 'w', encoding='utf-8') as f: + f.write(f"Generated Report Content\n") + f.write(f"======================\n\n") + f.write(f"Title: {test_parameters['title']}\n") + f.write(f"Format: {test_parameters['outputFormat']}\n") + f.write(f"MIME Type: {mime_type}\n") + f.write(f"File Name: {file_name}\n") + f.write(f"Content Length: {len(content)} characters\n\n") + f.write("Content Preview (first 2000 characters):\n") + f.write("-" * 50 + "\n") + f.write(content[:2000]) + if len(content) > 2000: + f.write("\n... (content truncated)") + + print(f"📄 Content preview saved to: {text_output_file}") + else: + print("❌ No documents found in result") + print(f"Result structure: {result}") + + else: + print(f"❌ Generation failed: {result}") + if hasattr(result, 'error'): + print(f"Error: {result.error}") + + # Clean up temporary file + try: + os.unlink(temp_file_path) + print(f"🧹 Cleaned up temporary file: {temp_file_path}") + except Exception as e: + print(f"⚠️ Warning: Could not clean up temporary file: {e}") + + except Exception as e: + print(f"❌ Document generation failed: {e}") + import traceback + traceback.print_exc() + + # Clean up temporary file on error + try: + os.unlink(temp_file_path) + except: + pass + return + + print("\n" + "="*60) + print("REAL DOCUMENT GENERATION TEST COMPLETED") + print("="*60) + + except Exception as e: + print(f"❌ Test failed: {str(e)}") + import traceback + traceback.print_exc() + +if __name__ == "__main__": + # Add timeout to the entire test + try: + asyncio.run(asyncio.wait_for(test_real_document_generation(), timeout=600.0)) + except asyncio.TimeoutError: + print("⏰ Test timed out after 600 seconds") + except Exception as e: + print(f"❌ Test failed with error: {e}") + import traceback + traceback.print_exc() diff --git a/test_real_generated_report.docx b/test_real_generated_report.docx new file mode 100644 index 00000000..e58ae454 Binary files /dev/null and b/test_real_generated_report.docx differ diff --git a/test_real_generated_report_content.txt b/test_real_generated_report_content.txt new file mode 100644 index 00000000..7f880666 --- /dev/null +++ b/test_real_generated_report_content.txt @@ -0,0 +1,13 @@ +Generated Report Content +====================== + +Title: Immobilienmarkt Kanton Zürich - Web-Recherche Analyse +Format: docx +MIME Type: application/vnd.openxmlformats-officedocument.wordprocessingml.document +File Name: report_20251002-234025.docx +Content Length: 55264 characters + +Content Preview (first 2000 characters): +-------------------------------------------------- +UEsDBBQAAAAIAAwNQ1utUqWRlQEAAMoGAAATAAAAW0NvbnRlbnRfVHlwZXNdLnhtbLWVTU/bQBCG7/0Vli8+IHtDDxWq4nAocCyRGkSvm/U4Wdgv7UwC+ffMOolV0VCHBi6RnJn3fR7bsj2+fLYmW0NE7V1dnFejIgOnfKPdoi7uZjflRZEhSddI4x3UxQawuJx8Gc82ATDjsMM6XxKF70KgWoKVWPkAjietj1YSH8aFCFI9ygWIr6PRN6G8I3BUUurIJ+MraOXKUHb9zH93IvlDgEWe/dguJlada5sKuoE4mIlg8FVGhmC0ksRzsXbNK7NyZ1VxstvBpQ54xgtvENLkbcAud8tXM+oGsqmM9FNa3hJqheTtb2uEJrDT6AOeV/9uO6Dr21YraLxaWY5UfWnqg0gaevdDDpzrwIIpJ7MhXZQGmjK8j618hPfD9/cppY8kPvnYiF731NNNbcxVgMgPhjVVP7FSu0GPlskzOTf/cepDIn31oIRb2TlETn28RF89KIFAxHv48Q775mEF2hj4DIGu90j8vabldduComNMLJYpW/2VHaQRv5Fh+3v6C6erGUQ+wfzXp93lP8r3IqL7FE1eAFBLAwQUAAAACAAMDUNbeSZLQPgAAADeAgAACwAAAF9yZWxzLy5yZWxzrZLNSgMxEIDvPkXIJadutlVEpNleROhNpD7AmMzupm5+SKbavr1RRF1YFsEe5+/jY2bWm6Mb2CumbINXYlnVgqHXwVjfKfG0u1/cCJYJvIEheFTihFlsmov1Iw5AZSb3NmZWID4r3hPFWymz7tFBrkJEXyptSA6ohKmTEfQLdChXdX0t028Gb0ZMtjWKp6255Gx3ivg/tnRIYIBA6pBwEVOZTmQxFzikDklxE/RDSefPjqqQuZwWuvq7UGhbq/Eu6INDT1NeeCT0Bs28EsQ4Z7Q8p9G440fmLSQjzVd6zmZ13oNRf3DPHuwwsZfvWrWP2H0IydFbNu9QSwMEFAAAAAgADA1DW4iGC1NpAQAA0QIAABEAAABkb2NQcm9wcy9jb3JlLnhtbJ2Sy07DMBBF93xF1E1WifMQCEVJKgHqikpIFIHYufY0NU1sy542zd/jpG1aoCt2Ht87x/NwPt03tbcDY4WShR+Hke+BZIoLWRX+22IW3PueRSo5rZWEwu/A+tPyJmc6Y8rAi1EaDAqwngNJmzFdTNaIOiPEsjU01IbOIZ24Uqah6EJTEU3ZhlZAkii6Iw0g5RQp6YGBHomTI5KzEam3ph4AnBGooQGJlsRhTM5eBNPYqwmDcuFsBHYarlpP4ujeWzEa27YN23Swuvpj8jF/fh1aDYTsR8VgUuacZSiwBjIc7Xb5BQwPATNAUZlSd7hWMuCK7XNycd/PdgNdqwy3hwwOlhmh0e2orECCoQjcW3beb8SlscfU1OLcLXMlgD90ZLgzsBP9tss4J5dhfpzdoQ7Hdz1nhwmdlPf08Wkxm5RJFKdBnARJukjSLL7Nouizf/9H/hnYHCv4N/EEGOpnDl4p03dD/vzC8htQSwMEFAAAAAgADA1DW/Tb2xfrAQAAbAQAABAAAABkb2NQcm9wcy9hcHAueG1snVTLbtswELz7KwRddIppB0FRGJKC1kHRQ90asJKct9TKIkqRBLkx4n59+YgVOYYv9Yk7szv7tMr710FmB7ROaFUVy/miyFBx3Qq1r4rH5tvN5yJzBKoFqRVWxRFdcV/Pyq3VBi0JdJlXUK7KeyKzYszxHgdwc08rz3TaDkDetHumu05wfND8ZUBF7Hax+MTwlVC12N6YUTBPiqsD/a9oq3mozz01R+P16lmWlQ0ORgJh/TMEy3mraSjZiEYXTSAbMWC98MxoBGoLe3T1smTpEaBnbVsXPNMjQOseLHDy0wz4xArkF2Ok4EB+0PVGcKud7ijbABeKtOuzIFOyqVeI8o3tkL9YQcegOTUD/UMojMnSI5VqYW/B9BGfWIHccZC49rOpO5AOS/YOBPo7Qtj8 +... (content truncated) \ No newline at end of file diff --git a/test_web_content_20251002_204000/main_url_001_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferliste.txt b/test_web_content_20251002_204000/main_url_001_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferliste.txt deleted file mode 100644 index b9d5db95..00000000 --- a/test_web_content_20251002_204000/main_url_001_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferliste.txt +++ /dev/null @@ -1,121 +0,0 @@ -Title: https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste -URL: https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste -Type: Main URL -Extracted: 2025-10-02 20:40:00 -================================================================================ - -73 Bauland kaufen in Kanton Zürich | homegate.ch - - Suchen - Services -Inserieren -Mein Konto -Menü - - Suchen - Services - Schätzen - Ratgeber -Inserieren -Mein Konto -DE - DE - FR - IT - EN -Ort -Kanton Zürich -Kanton Zürich -Preis bis -Weitere Filter -73 Treffer -73 Treffer - Bauland kaufen in Kanton Zürich - 1 / 16 CHF 2’563’760.– Top 360m² Nutzfläche Luegetenstrasse 11, 8489 Wildberg Ihr neues Zuhause mit Potenzial - Idyllisches Landhaus mit Baulandreserve Ihr neues Zuhause Willkommen in Ihrem zukünftigen Traumdomizil - ein grosszügiges, freistehendes Landhaus an ruhiger und idyllischer Aussichtslage im malerischen Wildberg. Hier vereinen sich ländliche Idylle, Privatsphäre und die seltene Möglichkeit, Wohnraum nach eigenen Vorstellungen zu schaffen oder zu erweitern.Ob als charmantes Familienrefugium mit grossem Garten oder als Investitionsobjekt mit Entwicklungspotenzial - dieses einzigartige Anwesen bietet Ihnen beide Optionen. Auf dem 1339m² grossen Grundstück geniessen Sie nicht nur viel Platz zum Leben, sondern verfügen auch über eine wertvolle Baulandreserve, die Ihnen vielfältige Gestaltungsmöglichkeiten eröffnet. Erste Abklärungen zeigen: Es besteht die Möglichkeit, ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren - ein echter Mehrwert für visionäre Käufer.Tauchen Sie ein in eine grüne Oase mit Weitblick - ein Ort, der Ruhe schenkt und inspiriert.Highlights auf einen Blick • Idyllische, ruhige Aussichtslage mit hohem Erholungswert • Grosszügiges Grundstück mit 1339m², ideal zur Eigennutzung und/oder für die Entwicklung eines Neubaus • Baulandreserve: Attraktives Entwicklungspotenzial - gemäss erster Einschätzung besteht die Möglichkeit, zusätzlich zum bestehenden Einfamilienhaus ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren (unverbindlich, ohne Gewähr) • Blühender Garten mit verschiedenen Sitzplätzen, Pergola mit Aussencheminée, Gartenhäusern, gepflegtem Baumbestand und weitläufigen Grünflächen • Solide Bausubstanz mit Doppelschalenmauerwerk • Grosszügiges Raumkonzept mit ca. 220m² Wohnfläche und ca. 96m² zusätzlichem Stauraum im Untergeschoss. Total ca. 360m² Bruttofläche. • Geräumiger Wohnbereich mit gemütlichem Kachelofen - ein Ort zum Ankommen und Wohlfühlen • Praktische Wohnküche mit integriertem Essbereich - ideal für gesellige Stunden • 4 helle Schlafzimmer - ideal für Familien oder Homeoffice • 2 Nasszellen mit Tageslicht • Ausgebauter Estrich für zusätzlichen Raum oder kreative Nutzungsmöglichkeiten • Beheizt durch Elektrospeicher und wassergeführte Fussbodenheizung • Garage mit elektrischem Tor und weitere Parkmöglichkeiten auf dem Grundstück • Mit einer stilvollen Modernisierung verwandeln Sie dieses Haus in ein wahres Schmuckstück Verkaufspreis: CHF 1'870'000.-Mit unserer virtuellen 360-Grad-Tour können Sie bereits die ersten Eindrücke dieser tollen Liegenschaft gewinnen. Sehr gerne zeigen wir Ihnen diese Liegenschaft direkt vor Ort und freuen uns auf Ihre Kontaktaufnahme.Weitere EckdatenBaujahr Haus: 1984, Baujahr Gerätehaus: 1986, Kubatur Haus (GVZ): 936m³, Kubatur Gerätehaus (GVZ): 40m³, Grundbuchblatt: Nr. 437, Kataster-Nr.: 249, 1/4 subjektiv-dingliches Miteigentum an Blatt 444, Kataster 249. Nettowohnfläche: ca. 220m², Bruttowohnfläche: ca. 360m², Grundstücksfläche: 1'339m².Massivbauweise, Doppelschalenmauerwerk, neuwertige Holzmetallfenster (EgoKiefer) mit dreifacher Verglasung und Sprossen & Holzläden. Elektrospeicherofen, wassergeführte Fussbodenheizung, Elektroboiler 300 Liter.Treppenlift, Garage mit elektrischem Torantrieb. Küche im Landhausstil mit Granitabdeckung, Geschirrspüler, Induktions-Kochherd und Kühlschrank mit Gefrierfach.BodenbelägeEG: Entrée, Gang, Dusche, Küche, Essen mit Plattenboden.OG: Zimmer und Vorplatz mit Laminat in Holzoptik. Bad mit Platten. Wegzeit Neu - - 1 / 8 CHF 2’604’890.– Top Wehntalerstrasse 28, 8181 Höri Grundstück mit Baubewilligung für ein Mehrfamilienhaus mit 6 Einheiten Das Grundstück ist derzeit mit einem Einfamilienhaus bebaut (Baujahr 1960)Nach dem Rückbau kann, gemäss Bewilligung ein Mehrfamilienhaus mit 6 Wohnungen (3 Wohnungen 4½ Zimmer und 3 Wohnungen 2½ Zimmer) mit 9 Tiefgaragen, 1 Tiefgaragen Behinderten Parkplatz sowie 2 Besucher Aussenparkplätze realisiert werden. (Siehe Pläne)Im Kaufpreis enthalten: • Baubewilligung • Bewilligungsgebühren • Projektpläne in PDF, DWG und Step Dateien • Lärmschutznachweis Strasse / Lärmschutznachweis Fluglärm • Geologisches Gutachten (Meldeblatt zu Bodenverschiebung) Parzelle nicht belastet! • Private Kontrolle bei Rückbau- und Umbau. (2 Asbestproben wurden positiv auf Asbest getestet) • Amtlich Beglaubigter Katasterplan • Farb- und Materialkonzept Verkaufspreis für Liegenschaft inkl. Vorbeschriebenen Leistungen: CHF 1'900'000.-Wir hoffen Ihr Interesse geweckt zu haben. Gerne stellen wir Ihnen die Verkaufsdokumente und Projektunterlagen, mit ausführlichen Informationen, per E-Mail zu.Es werden keine Makleranfragen berücksichtigt.Die zugestellten Informationen sind Eigentum von Bujar Bunjaku. Veröffentlichung, kopieren sind nicht gestattet.Kaufabwicklung:CHF 72'000.-- fällig bei Unterzeichnung der Kaufzusage; CHF 150'000.-- fällig bei Unterzeichnung und notarieller Beurkundung des Kaufvertrages; Restzahlung des Verkaufspreises fällig bei der Eigentumsübertragung.Notariats- und Grundbuchgebühren: Je zur Hälfte zu Lasten Käufer / Verkäufer.Anbieter:Bujar BunjakuWehntalerstrasse 288181 Höri Wegzeit Neu - - 1 / 4 CHF 1’096’790.– Top Bahnhofstrasse 41, 8496 Steg im Tösstal 1’111 m² attraktives Bauland in Steg Dieses 1'111 m² grosse Bauland liegt im schönen Tösstal, einer der sonnigsten Regionen der Ostschweiz. Die ruhige Lage direkt am Waldrand bietet viel Natur, frische Luft und Privatsphäre.Ein idealer Ort für Naturliebhaber und Ruhesuchende, die dennoch Wert auf eine gute Erreichbarkeit legen. Hier lassen sich Wohnträume verwirklichen.Besichtigungen sind jederzeit frei möglich.Neugierig geworden? Alle weiteren Details entnehmen Sie bitte der oben angehängten Verkaufsdokumentation.Isler-Consolis AG, Technikumstrasse 73, 8401 Winterthur, Tel. 052 267 81 00, Dorentina Bytyqi Wegzeit Neu - - 1 / 4 Preis auf Anfrage Top Lüss, 8542 Wiesendangen Im Baurecht abzugeben: 14’770 m2 Bauland an bester Lage im steuergünstigen Wiesendangen Im Baurecht abzugeben:14’770 m2 Bauland an bester Lage im steuergünstigen WiesendangenGrundstück WD4674 – Lüss WiesendangenAlle Details zum Grundstück, zum Baurechtsvertrag sowie zu den Vergabekriterien finden sie im angefügten Dossier.Verbindliche Angebote für eine Übernahme des Baurechtsvertrages inklusive Finanzierungsnachweis sind einzureichen an:Gemeinde Wiesendangenz. Hd. Martin SchindlerSchulstrasse 208542 Wiesendangen Bitte verwenden Sie für die Angebotseingabe das Formular im Anhang.Eingabeschluss: Montag, 20. Oktober 2025, 11.00 Uhr Wegzeit Neu - - 1 / 1 Preis auf Anfrage Top Büntlistrasse 1, 8174 Stadel Bauland in Stadel b. Niederglatt Die Primarschule Stadel hat zwei Landparzellen zu verkaufen. Nummber 305 & 306. 305 ist unbebaut, hingegen 306 hat ein Gebäude, welches als Kindergarten und Mietwohnungen genutzt wurde. Wir möchten die beiden Landparzellen zusammen verkaufen. Der Kontakt für die erste Anlaufstelle ist Rolf Schindelholz einer unserer Mitarbeiter in der Schulverwaltung. Geleitet wird das Projekt von Patrick Heusser dem Finanzvorstand der Primarschulpflege Stadel. Wegzeit Neu - - 1 / 12 CHF 2’323’840.– Hürstringstrasse 37, 8046 Zürich Grundstück mit bestehendem EFH und grossem Potenzial Gerne stellen wir Ihnen das Grundstück mit grossem Potenzial und vielen Möglichkeiten vor.Nach Absprache verkaufen wir an ruhiger Lage in Zürich ein Grundstück mit bestehendem Einfamilienhaus. Interessant an diesem Objekt ist jedoch, dass Sie beim Kauf bereits über die zugehörige Baubewilligung verfügen, welche es Ihnen erlaubt, den Wohnraum auf dieser Parzelle nach Ihren Wünschen zu vergrössern und zu sanieren.Nicht weit vom Zürcher Hauptbahnhof entfernt, hinter dem Käferberg liegt die grosszügige Parzelle mitten in einem ruhigen Wohnquartier mit 30er-Zone.Zu Fuss erreichen Sie eine Bushaltestelle, sowie auch den kleinen Wald, der sich ideal für kürzere Spaziergänge eignet.Die wichtigsten Infos in Kürze: • Landparzelle inkl. Einfamilienhaus und Baubewilligung zum Ausbau der Wohnfläche • Baujahr 1934 • Grundstückfläche von 410 m2 • Projektmöglichkeit 1: Ausbau zum Mehrfamilienhaus mit zwei Eigentums- oder Mietwohnungen • Projektmöglichkeit 2: Ausbau zum Generationenhaus Erleben Sie die ruhige Atmosphäre und gleichzeitige Nähe zum Stadtzentrum bei einem persönlichen Besuch!Für nähere Informationen zum Objekt oder einen Besichtigungstermin dürfen Sie sich gerne jederzeit bei uns melden. Wegzeit Neu - - 1 / 11 CHF 3’290’400.– Luzernerstrasse 57, 8903 Birmensdorf (ZH) Sonnige Aussichtslage Im Auftrag unseres Kunden verkaufen wir ein Bauland an sonniger Aussichtlage mit 1'228 m² Grundstücksfläche (Wohnzone W2).Die bestehende Liegenschaft präsentiert sich in einem dem Alter entsprechend gut unterhaltenen Zustand.Verkaufsrichtpreis: CHF 2'400'000Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot. Wegzeit Neu - - 1 / 13 CHF 1’302’440.– Kanalweg 2, 8714 Feldbach Bauland für projektiertes Einfamilienhaus Im beschaulichen Dorf Feldbach am Zürichsee ist dieses Grundstück mit einer bestehenden, einseitig angebauten Scheune zu verkaufen. Im Kaufpreis inbegriffen ist ein bewilligungsfähiges Vorprojekt für ein Einfamilienhaus als Ersatzbau der Scheune.Das Objekt bietet Ihnen die einmalige Möglichkeit, Ihren Traum vom Eigenheim an idyllischer Lage zu verwirklichen. Es bietet genügend Platz für eine Familie, auch eine Kombination von "Wohnen und Arbeiten" ist denkbar.Innert 30 Minuten sind Sie mit der S-Bahn in Zürich, auch Kindergarten und Primarschule sind nah. Einkaufsmöglichkeiten bestehen in Hombrechtikon, Stäfa und Rapperswil. Im Sommer lockt in unmittelbarer Nähe eine Abkühlung in der schmucken Seebadi Feldbach.Es besteht ein aktueller Kostenvoranschlag für das Haus (Holzelementbauweise) inkl. Umgebung, Bau- und Nebenkosten in der Höhe von Fr. 1'380'000.--.Haben wir Sie neugierig gemacht? Dann rufen Sie uns an. Gerne beantworten wir Ihre Fragen oder stellen Ihnen unsere Verkaufsdokumentation zum Studium zu. Die Liegenschaft kann selbstverständlich auch besichtigt werden. Wir freuen uns auf Ihren Anruf. Wegzeit Neu - - 1 / 13 CHF 4’111’620.– 5.5 Zimmer Schaffhauserstrasse 226b, 8057 Zürich Mehr Raum fürs Leben: Reihenhaus mit Potenzial Attraktive Stadtliegenschaft mit ausgearbeitetem ProjektIm Zürcher Kreis 11 veräussern wir ein hübsches Reiheneinfamilien-Eckhaus mit grosszügigem Umschwung. Die Liegenschaft und das Grundstück verfügen über viel Ausnützungspotenzial und ermöglicht so die Realisation spannender Projekte sowohl im Umbau als auch Neubau.Diese Liegenschaft überzeugt durch viele Besonderheiten: • grosszügiger Umschwung mit viel Potenzial • Blick ins Grüne von nahezu allen Fenstern • Schwedenofen im Wohnbereich • viel Stauraum durch Wandschränke und Estrich • Altbaucharme in modernem Quartier • zentrale und familienfreundliche Lage • sonnenverwöhnter Standort Haben wir Ihr Interesse geweckt? Bestellen Sie noch heute unsere ausführliche Verkaufsdokumentation mittels Kontaktformular und Sie erhalten weitere spannende Informationen zur Immobilie. Wir freuen uns über Ihre Kontaktaufnahme!Une oasis de verdure dans la ville de Zurich avec un projet élaboréDans le quartier 11 de Zurich, nous vendons une jolie maison mitoyenne en angle avec de vastes alentours. L'immeuble et le terrain disposent d'un grand potentiel d'exploitation et permettent ainsi la réalisation de projets passionnants, tant en transformation qu'en construction neuve.Cette propriété convainc par ses nombreuses particularités : • Un vaste terrain avec beaucoup de potentiel • Une vue sur la verdure depuis presque toutes les fenêtres • Un poêle suédois dans le séjour • beaucoup d'espace de rangement grâce aux armoires murales et au grenier • Le charme d'un ancien bâtiment dans un quartier moderne • Un emplacement central et favorable aux familles • Un emplacement ensoleillé Nous avons éveillé votre intérêt ? Commandez dès aujourd'hui notre documentation de vente détaillée au moyen du formulaire de contact et vous recevrez d'autres informations passionnantes sur le bien immobilier. Nous nous réjouissons de votre prise de contact!A green oasis in the city of Zurich with an elaborate projectIn Zurich's Kreis 11 district, we are selling a pretty terraced single-family corner house with spacious grounds. The property and the plot have a lot of utilization potential and thus enable the realization of exciting projects both in conversion and new construction.This property boasts many special features: • spacious grounds with lots of potential • view of the countryside from almost all windows • Swedish stove in the living area • lots of storage space thanks to wall cupboards and attic • old building charm in a modern district • central and family-friendly location • sun-drenched location Have we piqued your interest? Order our detailed sales documentation today using the contact form and you will receive further exciting information about the property. We look forward to hearing from you! Wegzeit Neu - - 1 / 13 CHF 4’044’440.– Mühlemattstrasse 12, 8135 Langnau am Albis Bauland oder bestehendes Einfamilienhaus zum Verkauf! Dieses freistehende Einfamilienhaus befindet sich an ruhiger Lage und bietet eine seltene Kombination aus architektonischem Charakter, grosszügigem Umschwung und inspirierendem Entwicklungspotenzial. Eingebettet in viel Grün und umgeben von Bäumen geniessen Sie hier Privatsphäre, Ruhe – und eine wunderschöne Weitsicht.Das Haus überzeugt durch eine unverwechselbare Ausstrahlung. Die Backsteinwände im Innenbereich verleihen dem Wohnraum eine warme, natürliche Atmosphäre, während das Cheminée im Wohnzimmer für Behaglichkeit an kühleren Tagen sorgt. Der Grundriss ist offen und einladend, ergänzt durch grosse Fensterfronten, die Licht und Natur ins Haus holen.Ein Highlight ist die grosszügige Terrasse mit herrlichem Ausblick – ideal für gemütliche Stunden im Freien. Der Garten ist weitläufig und bietet viel Platz für individuelle Gestaltung. Mit etwas Aufmerksamkeit lässt sich hier ein wunderbares grünes Paradies schaffen – ob als Familiengarten, Rückzugsort oder für kreative Projekte im Freien.Dank der Grundstücksgrösse und der Lage eröffnet die Liegenschaft auch interessante Perspektiven für einen möglichen Ersatzneubau - wie ein modernes Einfamilienhaus oder ein Mehrfamilienhaus.Gerne stellen wir Ihnen weitere Informationen zur Verfügung oder vereinbaren einen persönlichen Besichtigungstermin. Entdecken Sie das Potenzial und die besondere Atmosphäre dieses einzigartigen Ortes. In der Verkaufsdokumentation finden Sie alle wichtigen Informationen. Wegzeit Neu - - 1 / 6 Ruhige Lage CHF 3’358’950.– 8192 Glattfelden ZWEIFELSFREIES BAULAND IN ZWEIDLEN Im beliebten Zweidlen verkaufen wir ein eine attraktive, 1'226 m² grosse Baulandparzelle mit Bestandesobjekt.Unsere Projektstudie zeigt eine hohe Ausnutzung für die Erstellung eines Mehrfamilienhauses. • Anrechenbare mögliche Bruttogeschossfläche von max. 940 m² (Projekt 789 m²) • Wohn- und Gewerbezone WG 2.3 • Kein Denkmalschutz beim Bestandesobjekt • Die Deutsche Grenze in Kaiserstuhl ist nur 8 Autominuten entfernt • Der Flughafen Zürich ist in nur 19 Autominuten erreichbar Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: Referenznummer: 25-12278Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen! Ruhige Lage Wegzeit - - 1 / 12 Preis auf Anfrage Überlandstrasse 23, 8340 Hinwil Industrie- und Baulandparzelle an attraktivem Standort im Zürcher-Oberland Im pulsierenden Industriegebiet von Hinwil verkaufen wir ein Industriebaugrundstück an einer top frequentierter Lage, direkt an der Hauptachse in Rapperswil Wetzikon Pfäffikon ZH. Die Baulandparzelle befindet sich am Rand der Industriezone und grenzt an die Wohnzone zu Hinwil ZH.Eckdaten:- Grundstück-Fläche total 4'246 m2- Bauzone Industrie/Gewerbe IG/7 - Baumassenziffer 7 m3/m2- Gebäudehöhe maximal 21.5 m- Gebäudelänge maximal offen- Grosser Grenzabstand Nationalstrasse- Allseitiger Gebäudeabstand 3.5 m1- Maximal mögliche Baumasse ca. 30'000 m3- Bruttogeschossfläche ca. 9'500 m2Das Baugrundstück wird derzeit noch mit zwei Wohneinheiten, der Autowerkstatt mit separatem Showroom und einer Tankstelle genutzt. Rund um die Liegenschaft bieten sich grosse, befestigte Flächen zur Nutzung an. Wegzeit Neu - - 1 / 7 CHF 5’484’000.– 8156 Oberhasli ATTRAKTIVE INVESTITION IN FLUGHAFENNÄHE Unweit des Flughafens Kloten bieten wir ein attraktives Gewerbebauland für ein Neubauprojekt im strategisch ideal gelegenen Oberhasli zum Verkauf an. • Parzellenfläche: 2'010 m² • Zone: Gewerbezone • Optionen für Investoren: Neubau einer Gewerbeimmobilie mit bis zu 5'000 m² Geschossfläche (Verkauf oder Vermietung) • Optionen für Selbstnutzer: Neubau einer für die Selbstnutzung konzipierten Gewerbeimmobilie mit bis zu 5'000 m² Geschossfläche • Es besteht die Möglichkeit, die derzeit vermietete Gewerbeliegenschaft weiterzuführen. Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: Referenznummer: 24-101578Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen! Wegzeit - - 1 / 6 CHF 1’919’390.– 8187 Weiach WILLKOMMENE WERTSCHÖPFUNG IN WEIACH Im steuergünstigen Weiach bieten wir an ruhiger Ortskernlage eine wohldimensionierte, unbebaute Baulandparzelle zum Verkauf an. Unsere Baulandstudie sieht die Erstellung von zwei attraktiven Doppeleinfamilienhäusern mit 4 Wohneinheiten vor. • 1'157 m² Parzellenfläche mit bestehender Zufahrt im Wegrecht • Unser Projekt sieht die Erstellung von zwei Doppeleinfamilienhäusern mit je zwei Vollgeschossen vor • Total erstellbare Bruttogeschossfläche von 648 m² • Maximal erstellbare Gebäudelänge von 25 Metern • Der Flughafen Zürich ist in nur 20 Minuten zu erreichen, die Stadt Zürich ist nur rund 30 Km entfernt Interessiert? Weitere Informationen und Bilder zum Grundstück sowie Besichtigungsmöglichkeiten unter: Referenznummer: 24-99121Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch- Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen! Wegzeit - - 1 / 1 CHF 2’399’240.– In der Gass 2, 8627 Grüningen Grundstück mit Baubewilligung für MFH zu verkaufen Zum Verkauf steht ein Grundstück mit bewilligtem Neubauprojekt. Gebäude C des Enssamble an der Binzikerstrasse 21 / In der Gass 2, 8627 Grüningen. Die aktuell bestehenden Garagen können abgebrochen werden und durch einen Neubau mit 8 Wohnungen unterschiedlicher Grösse mit attraktiven Aussenbereich ersetzt werden. Zusätzlich wurde der gemeinsame Bau einer Tiefgarage für 11 Parkplätze mit der Zufahrt über die Strasse "In der Gass" bewilligt. Wegzeit Neu - - 1 / 6 CHF 2’879’100.– Rotweg 20, 8820 Wädenswil Ihr neues Projekt mit Seesicht Im Auftrag unseres Kunden verkaufen wir an bevorzugter, erhöhter und ruhiger Wohnquartierlage mit schöner See- und Fernsicht, 706 m² Bauland mit Rückbauobjekt.Verkaufsrichtpreis: CHF 2'100'000.00Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot. Wegzeit Neu - - 1 / 7 CHF 651’220.– Auf Anfrage 1, 8195 Wasterkingen Attraktives Baugrundstück in ruhiger, ländlicher Umgebung Willkommen in Wasterkingen, einer idyllischen und ruhigen Gemeinde im Zürcher Unterland, die für ihre hohe Lebensqualität, ländliche Gelassenheit und dennoch gute Erreichbarkeit bekannt ist. Genau hier wartet ein attraktives Baugrundstück auf Sie – die ideale Basis für Ihr zukünftiges Zuhause.Das Grundstück ist voll erschlossen und liegt in der Kernzone B, was Ihnen zahlreiche Gestaltungsmöglichkeiten eröffnet. Ob ein modernes Einfamilienhaus, ein klassisches Zuhause im Dorfcharakter oder ein individuelles Architektenprojekt – hier können Sie Ihre Wohnträume ganz nach Ihren Vorstellungen verwirklichen.Die charmante Gemeinde Wasterkingen besticht durch ihre ruhige Lage inmitten von Feldern, Reben und Natur.Dieses ImmoSky-Angebot bietet folgende Mehr Leistung:+ Voll erschlossen+ Ruhige Gemeinde+ Ideale Grösse für flexibilität (650m²)+ Kernzone B+Überbauungsziffer für Hauptgebäude 30%Dieses Grundstück bietet Ihnen die seltene Gelegenheit, ländliche Idylle mit urbaner Nähe zu vereinen – ein Ort, an dem Sie zur Ruhe kommen und dennoch bestens angebunden sind.Erfüllen Sie sich hier den Traum vom Eigenheim und gestalten Sie Ihr persönliches Refugium in Wasterkingen.Haben wir Sie mit diesem Angebot überzeugt? Dann zögern Sie nicht und kontaktieren Sie uns für weitere Fragen oder einen Besichtigungstermin!(Das Verkaufsdossier wird in der Regel innerhalb von maximal 24 Stunden an Sie versendet. Bitte überprüfen Sie auch Ihren SPAM-Ordner.) Wegzeit - - 1 / 7 CHF 7’540’490.– Staldernstrasse 13, 8158 Regensberg Entwicklungsgrundstück an top Lage in der Kernzone 2 In der gefragten Gemeinde Regensberg (ZH) steht ein hervorragend gelegenes Grundstück zum Verkauf, das sich ideal für Investoren, General- oder Totalunternehmer eignet. Die 2.557 m² grosse Parzelle Nr. 949 befindet sich in der Kernzone 2, die vielfältige bauliche und nutzungsbezogene Entwicklungsmöglichkeiten zulässt, insbesondere für Wohn- oder gemischt genutzte Projekte.Aktuell steht auf dem Grundstück ein nicht erhaltenswertes Gebäude, das im Rahmen einer Neuentwicklung rückgebaut werden kann. Eine Baueingabe oder Bewilligung liegt nicht vor, sodass volle gestalterische Freiheit innerhalb der geltenden bau- und zonenrechtlichen Rahmenbedingungen besteht.Berechnungen zeigen, dass eine nachhaltige Mietertragserwartung von rund CHF 485'600 pro Jahr realistisch erscheint - unter der Annahme einer Ausnutzung mit rund 1 664 m² Hauptnutzfläche (HNF) und 28 Tiefgaragenplätzen. Der ermittelte Kapitalisierungssatz liegt bei 4.20 %.Wesentliche Bewertungskennzahlen:Verkehrswert (diskontierter Landwert): CHF 5'505'000Ertragswert im erneuerten Zustand: CHF 11'556'795Realwert (hypothetisch): CHF 12'485'000Potenzieller Verkaufserlös: CHF 16'190'000Bruttorendite (Mietwert): 4.20%Die hypothetische Bebauung sieht zwei Mehrfamilienhäuser mit einer Bruttogeschossfläche (BGF) von insgesamt 2'080 m² vor - entsprechend einer Ausnützungsziffer von 0.81, voll im Rahmen der Zonenordnung. Die kalkulierten Baukosten (BKP 2-5) belaufen sich auf ca. CHF 8.74 Mio. Der diskontierte Landwert pro m² liegt bei CHF 2'155, was das wirtschaftliche Potenzial zusätzlich unterstreicht.Die Kernzone 2 erlaubt neben der reinen Wohnnutzung auch Mischnutzungen, beispielsweise mit gewerblichen Angeboten im Erdgeschoss. Dies ist ein zusätzlicher Vorteil für flexible, standortgerechte Entwicklungskonzepte. Die Lage in Regensberg bietet ruhige Wohnqualität in der Nähe der Agglomeration Zürich und ist in eine attraktive historische Umgebung eingebettet.Fazit: Das Grundstück bietet die seltene Gelegenheit, ein entwicklungsfähiges Grundstück an bester Lage mit bestehendem Abbruchobjekt zu akquirieren und nach eigenen Vorstellungen zu bebauen. Dank der flexiblen Nutzungsmöglichkeiten und des attraktiven Standorts stellt diese Investition eine hervorragende Ausgangslage für renditestarke Projektentwicklungen dar.Für detaillierte Informationen stehen wir Ihnen gerne zur Verfügung. Wegzeit Neu - - 1 / 3 CHF 1’686’330.– 8187 Weiach Ihr Bauland in Weiach ZH zum Schnäppchenpreis! Ihre Chance auf ein vielversprechendes Bauprojekt In der beliebten Gemeinde Weiach, eingebettet in eine ruhige und dennoch gut erreichbare Lage, erwartet Sie die Parzelle 1602. Das Grundstück in der Kernzone (K) bietet ideale Rahmenbedingungen für Investoren und Bauherren, die von Flexibilität und klar definierten Bauvorgaben profitieren möchten.Die Parzelle ermöglicht eine Bebauung mit bis zu 2 Vollgeschosse, einem anrechenbaren Dachgeschoss sowie einem Untergeschoss. Die maximale Gebäudehöhe von 7.50 m und die erlaubte Gebäudelänge von bis zu 30 m eröffnen vielseitige Bau- und Gestaltungsmöglichkeiten. Mit grosszügigen Grenzabständen von mindestens 6 m (grosser Grenzabstand) und 4 m (kleiner Grenzabstand) bietet das Grundstück genügend Raum für ansprechende Projekte mit Privatsphäre.Dieses Bauland ist die perfekte Gelegenheit, um ein individuelles Projekt in einer aufstrebenden Region zu realisieren. Egal, ob Sie Wohnraum schaffen oder ein Mischprojekt umsetzen möchten - die Parzelle hält alle Optionen offen.Ihre Vorteile auf einen Blick: • Vorhandene Machbarkeitsstudie • Bebaubare Fläche 1026 m² • Landwirtschaftszone 479 m² (CHF 60'000.- exkl.) • Kernzone (K) mit klar definierten Bauvorgaben • Maximal 2 Vollgeschosse, 1 anrechenbares Dach- und Untergeschoss • Gebäudehöhe bis zu 7.50 m • Maximale Gebäudelänge: 30 m • Grenzabstände: mind. 6 m und 4 m • Optimale Voraussetzungen für vielseitige Bauprojekte Nutzen Sie diese Gelegenheit, um ein nachhaltiges und gewinnbringendes Projekt in einer gefragten Region zu realisieren! Wegzeit - - 1 / 6 CHF 3’633’140.– Riedwiesenstrasse 20, 8305 Dietlikon RESERVIERT - Industrie-Baulandparzelle an zentraler Lage in Dietlikon ZH Mit Freude präsentieren wir Ihnen eine einzigartige und äusserst seltene Baulandparzelle an zentraler Lage in Dietlikon ZH – eine aussergewöhnliche Gelegenheit mit hervorragenden Eigenschaften, die sich besonders für Investoren eignet.Zentrale Lage: Die Parzelle befindet sich in einer äusserst gefragten Gegend mit hervorragender Anbindung: Flughafen Zürich erreichbar in 10 Fahrminuten Stadt Zürich erreichbar in 12 Fahrminuten • Visibilität: Ihr Unternehmen wird von der Autobahn aus perfekt sichtbar sein, was optimale Werbemöglichkeiten bietet (ca. 500 m2 Fassade für Werbung). • Baumassenziffer: Profitieren Sie von der hohen Baumassenziffer 10.0, die maximale Flexibilität und Nutzungseffizienz ermöglicht. • Näherbaurechte: Die Parzelle verfügt über Näherbaurechte rechts und links. Auf der Rückseite kann ein Näherbaurecht von der Stadt Zürich eingeholt werden • ca. 3'500 m2 Bruttogeschossfläche möglich • Tiefgarage / Untergeschoss bis zu ca. 800 m2 gross realisierbar • Maximale Gesamthöhe 20 m. 7 Stockwerke à 500 m2 Bruttogeschossfläche und 2.85 m Raumhöhe (brutto) möglich • Parzelle: Die ebene Fläche der Parzelle erleichtert die Bauplanung und Ausführung. • Form: Die Parzelle hat eine ideale Form, die vielseitige Bebauungsmöglichkeiten erlaubt. • Autobahnknotenpunkt: Brüttiseller Kreuz, direkt an einem der wichtigsten Autobahnknotenpunkt der Schweiz gelegen, bietet die Parzelle hervorragende Erreichbarkeit und Logistikvorteile • Störendes Gewerbe: Die Lage ist auch für Gewerbe geeignet, das potenziell störend sein kann. • Kulturzentren sowie Hotelbetriebe auch möglich. Jetzt oder nie – Ihre Chance auf ein grossartiges Investment:Solch eine Industrie-Baulandparzelle in dieser Lage kommt äusserst selten auf den Markt – seit geraumer Zeit gab es in dieser gefragten Gegend kein vergleichbares Angebot. Sichern Sie sich jetzt dieses einmalige Grundstück, ideal für visionäre Unternehmer und Investoren, die auf einen strategisch optimalen Standort setzen.Haben wir Ihr Interesse geweckt? Dann nehmen Sie noch heute Kontakt mit uns auf. Gerne lassen wir Ihnen das detaillierte Verkaufsdossier inklusive Machbarkeitsstudie zukommen – exklusiv und unverbindlich. Wegzeit Neu - -12...4 -Suche speichern Karte -Vorschläge basierend auf deinen Suchresultaten - -Startseite -Kaufen -Bauland zum Kaufen -Schweiz - -Bezirke im Kanton Kanton Zürich -Bauland kaufen Bezirk Affoltern|Bauland kaufen Bezirk Andelfingen|Bauland kaufen Bezirk Bülach|Bauland kaufen Bezirk Dielsdorf|Bauland kaufen Bezirk Hinwil|Bauland kaufen Bezirk Horgen|Bauland kaufen Bezirk Meilen|Bauland kaufen Bezirk Pfäffikon|Bauland kaufen Bezirk Uster|Bauland kaufen Bezirk Winterthur|Bauland kaufen Bezirk Dietikon|Bauland kaufen Zürich -Weitere Immobiliensuchen in Kanton Zürich -Immobilien mieten Kanton Zürich|Wohnung mieten Kanton Zürich|Haus mieten Kanton Zürich|Möbliertes Wohnobjekt mieten Kanton Zürich|Parkplatz, Garage mieten Kanton Zürich|Büro mieten Kanton Zürich|Gewerbe mieten Kanton Zürich|Neubau zum Mieten Kanton Zürich|Wohnung kaufen Kanton Zürich|Haus kaufen Kanton Zürich|Immobilien kaufen Kanton Zürich|Mehrfamilienhaus kaufen Kanton Zürich|Parkplatz, Garage kaufen Kanton Zürich|Gewerbe, Büro, Lager kaufen Kanton Zürich|Neubau zum Kaufen Kanton Zürich -Homegate - -Über uns -Kontakt & Hilfe -Geschäftskunde werden -Newsletter abonnieren -Medien -Karriere -Ombudsstelle -Werbung auf Homegate -Sitemap - -Immobilien - -Inserieren -Mieten -Kaufen -Vermieten -Verkaufen -Finanzieren -Ratgeber -Kategorien - -Rechtliches - -Datenschutz -Leistungsbeschrieb -Sicherheitstipps -Impressum -AGB -Sicherheitsproblem melden -Privatsphäre-Einstellungen - -Services - -Suchabo anlegen -Finanzierungsrechner -Steuerrechner -Betreibungsauszug -Gemeinderatgeber -Mietkaution -Umzugshilfe -Wohneigentum schätzen -Agenturverzeichnis - -App herunterladen - -Deutsch -Français -Italiano -English - -Social Media - -SMG Swiss Marketplace GroupImmoScout24Alle Immobilienhome.chimmostreet.ch -© Copyright 2025 by SMG Swiss Marketplace Group AG. Alle Rechte vorbehalten.Die Vervielfältigung und Übernahme von Inseraten durch Dritte, insbesondere von Fotos und persönlichen Daten in diesen Inseraten, verletzt die damit verbundenen Rechte und ist ausdrücklich verboten. \ No newline at end of file diff --git a/test_web_content_20251002_204000/main_url_002_www.immoscout24.ch_de_grundstueck_kaufen_kanton-zuerich.txt b/test_web_content_20251002_204000/main_url_002_www.immoscout24.ch_de_grundstueck_kaufen_kanton-zuerich.txt deleted file mode 100644 index 0ec29e9d..00000000 --- a/test_web_content_20251002_204000/main_url_002_www.immoscout24.ch_de_grundstueck_kaufen_kanton-zuerich.txt +++ /dev/null @@ -1,324 +0,0 @@ -Title: https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich -URL: https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich -Type: Main URL -Extracted: 2025-10-02 20:40:00 -================================================================================ - -70 Bauland zum Kaufen: Kanton Zürich | ImmoScout24 - - Suchen - Services -Inserat erstellen -Favoriten -Mein Konto -Menü - - Suchen - Services - Bewerten - Magazin -Inserat erstellen -Favoriten -Mein Konto -Menü -DE - DE - FR - IT - EN - -Bauland zum Kaufen -Kanton Zürich - -Wo? -Kanton Zürich -Kanton Zürich -CHF bis -Filter -70 Objekte -70 Treffer - Bauland zum Kaufen: Kanton Zürich - 1 / 16 360m², CHF 2’563’760.– Top Luegetenstrasse 11, 8489 Wildberg Ihr neues Zuhause mit Potenzial - Idyllisches Landhaus mit Baulandreserve Ihr neues Zuhause Willkommen in Ihrem zukünftigen Traumdomizil - ein grosszügiges, freistehendes Landhaus an ruhiger und idyllischer Aussichtslage im malerischen Wildberg. Hier vereinen sich ländliche Idylle, Privatsphäre und die seltene Möglichkeit, Wohnraum nach eigenen Vorstellungen zu schaffen oder zu erweitern.Ob als charmantes Familienrefugium mit grossem Garten oder als Investitionsobjekt mit Entwicklungspotenzial - dieses einzigartige Anwesen bietet Ihnen beide Optionen. Auf dem 1339m² grossen Grundstück geniessen Sie nicht nur viel Platz zum Leben, sondern verfügen auch über eine wertvolle Baulandreserve, die Ihnen vielfältige Gestaltungsmöglichkeiten eröffnet. Erste Abklärungen zeigen: Es besteht die Möglichkeit, ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren - ein echter Mehrwert für visionäre Käufer.Tauchen Sie ein in eine grüne Oase mit Weitblick - ein Ort, der Ruhe schenkt und inspiriert.Highlights auf einen Blick • Idyllische, ruhige Aussichtslage mit hohem Erholungswert • Grosszügiges Grundstück mit 1339m², ideal zur Eigennutzung und/oder für die Entwicklung eines Neubaus • Baulandreserve: Attraktives Entwicklungspotenzial - gemäss erster Einschätzung besteht die Möglichkeit, zusätzlich zum bestehenden Einfamilienhaus ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren (unverbindlich, ohne Gewähr) • Blühender Garten mit verschiedenen Sitzplätzen, Pergola mit Aussencheminée, Gartenhäusern, gepflegtem Baumbestand und weitläufigen Grünflächen • Solide Bausubstanz mit Doppelschalenmauerwerk • Grosszügiges Raumkonzept mit ca. 220m² Wohnfläche und ca. 96m² zusätzlichem Stauraum im Untergeschoss. Total ca. 360m² Bruttofläche. • Geräumiger Wohnbereich mit gemütlichem Kachelofen - ein Ort zum Ankommen und Wohlfühlen • Praktische Wohnküche mit integriertem Essbereich - ideal für gesellige Stunden • 4 helle Schlafzimmer - ideal für Familien oder Homeoffice • 2 Nasszellen mit Tageslicht • Ausgebauter Estrich für zusätzlichen Raum oder kreative Nutzungsmöglichkeiten • Beheizt durch Elektrospeicher und wassergeführte Fussbodenheizung • Garage mit elektrischem Tor und weitere Parkmöglichkeiten auf dem Grundstück • Mit einer stilvollen Modernisierung verwandeln Sie dieses Haus in ein wahres Schmuckstück Verkaufspreis: CHF 1'870'000.-Mit unserer virtuellen 360-Grad-Tour können Sie bereits die ersten Eindrücke dieser tollen Liegenschaft gewinnen. Sehr gerne zeigen wir Ihnen diese Liegenschaft direkt vor Ort und freuen uns auf Ihre Kontaktaufnahme.Weitere EckdatenBaujahr Haus: 1984, Baujahr Gerätehaus: 1986, Kubatur Haus (GVZ): 936m³, Kubatur Gerätehaus (GVZ): 40m³, Grundbuchblatt: Nr. 437, Kataster-Nr.: 249, 1/4 subjektiv-dingliches Miteigentum an Blatt 444, Kataster 249. Nettowohnfläche: ca. 220m², Bruttowohnfläche: ca. 360m², Grundstücksfläche: 1'339m².Massivbauweise, Doppelschalenmauerwerk, neuwertige Holzmetallfenster (EgoKiefer) mit dreifacher Verglasung und Sprossen & Holzläden. Elektrospeicherofen, wassergeführte Fussbodenheizung, Elektroboiler 300 Liter.Treppenlift, Garage mit elektrischem Torantrieb. Küche im Landhausstil mit Granitabdeckung, Geschirrspüler, Induktions-Kochherd und Kühlschrank mit Gefrierfach.BodenbelägeEG: Entrée, Gang, Dusche, Küche, Essen mit Plattenboden.OG: Zimmer und Vorplatz mit Laminat in Holzoptik. Bad mit Platten. Wegzeit Neu 28 min.Station: Rämismühle-Zell - 1 / 4 Preis auf Anfrage Top Lüss, 8542 Wiesendangen Im Baurecht abzugeben: 14’770 m2 Bauland an bester Lage im steuergünstigen Wiesendangen Im Baurecht abzugeben:14’770 m2 Bauland an bester Lage im steuergünstigen WiesendangenGrundstück WD4674 – Lüss WiesendangenAlle Details zum Grundstück, zum Baurechtsvertrag sowie zu den Vergabekriterien finden sie im angefügten Dossier.Verbindliche Angebote für eine Übernahme des Baurechtsvertrages inklusive Finanzierungsnachweis sind einzureichen an:Gemeinde Wiesendangenz. Hd. Martin SchindlerSchulstrasse 208542 Wiesendangen Bitte verwenden Sie für die Angebotseingabe das Formular im Anhang.Eingabeschluss: Montag, 20. Oktober 2025, 11.00 Uhr Wegzeit Neu 9 min.Station: Wiesendangen - 1 / 12 CHF 2’323’840.– Hürstringstrasse 37, 8046 Zürich Grundstück mit bestehendem EFH und grossem Potenzial Gerne stellen wir Ihnen das Grundstück mit grossem Potenzial und vielen Möglichkeiten vor.Nach Absprache verkaufen wir an ruhiger Lage in Zürich ein Grundstück mit bestehendem Einfamilienhaus. Interessant an diesem Objekt ist jedoch, dass Sie beim Kauf bereits über die zugehörige Baubewilligung verfügen, welche es Ihnen erlaubt, den Wohnraum auf dieser Parzelle nach Ihren Wünschen zu vergrössern und zu sanieren.Nicht weit vom Zürcher Hauptbahnhof entfernt, hinter dem Käferberg liegt die grosszügige Parzelle mitten in einem ruhigen Wohnquartier mit 30er-Zone.Zu Fuss erreichen Sie eine Bushaltestelle, sowie auch den kleinen Wald, der sich ideal für kürzere Spaziergänge eignet.Die wichtigsten Infos in Kürze: • Landparzelle inkl. Einfamilienhaus und Baubewilligung zum Ausbau der Wohnfläche • Baujahr 1934 • Grundstückfläche von 410 m2 • Projektmöglichkeit 1: Ausbau zum Mehrfamilienhaus mit zwei Eigentums- oder Mietwohnungen • Projektmöglichkeit 2: Ausbau zum Generationenhaus Erleben Sie die ruhige Atmosphäre und gleichzeitige Nähe zum Stadtzentrum bei einem persönlichen Besuch!Für nähere Informationen zum Objekt oder einen Besichtigungstermin dürfen Sie sich gerne jederzeit bei uns melden. Wegzeit Neu 22 min.Station: Zürich Seebach - 1 / 11 CHF 3’290’400.– Luzernerstrasse 57, 8903 Birmensdorf (ZH) Sonnige Aussichtslage Im Auftrag unseres Kunden verkaufen wir ein Bauland an sonniger Aussichtlage mit 1'228 m² Grundstücksfläche (Wohnzone W2).Die bestehende Liegenschaft präsentiert sich in einem dem Alter entsprechend gut unterhaltenen Zustand.Verkaufsrichtpreis: CHF 2'400'000Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot. Wegzeit Neu 19 min.Station: Birmensdorf -Dein Immobilienexperte vor Ort - Stöhr Immobilien GmbH berät dich persönlich zur optimalen Verkaufsstrategie für deine Immobilie. - 1 / 13 CHF 4’044’440.– Mühlemattstrasse 12, 8135 Langnau am Albis Bauland oder bestehendes Einfamilienhaus zum Verkauf! Dieses freistehende Einfamilienhaus befindet sich an ruhiger Lage und bietet eine seltene Kombination aus architektonischem Charakter, grosszügigem Umschwung und inspirierendem Entwicklungspotenzial. Eingebettet in viel Grün und umgeben von Bäumen geniessen Sie hier Privatsphäre, Ruhe – und eine wunderschöne Weitsicht.Das Haus überzeugt durch eine unverwechselbare Ausstrahlung. Die Backsteinwände im Innenbereich verleihen dem Wohnraum eine warme, natürliche Atmosphäre, während das Cheminée im Wohnzimmer für Behaglichkeit an kühleren Tagen sorgt. Der Grundriss ist offen und einladend, ergänzt durch grosse Fensterfronten, die Licht und Natur ins Haus holen.Ein Highlight ist die grosszügige Terrasse mit herrlichem Ausblick – ideal für gemütliche Stunden im Freien. Der Garten ist weitläufig und bietet viel Platz für individuelle Gestaltung. Mit etwas Aufmerksamkeit lässt sich hier ein wunderbares grünes Paradies schaffen – ob als Familiengarten, Rückzugsort oder für kreative Projekte im Freien.Dank der Grundstücksgrösse und der Lage eröffnet die Liegenschaft auch interessante Perspektiven für einen möglichen Ersatzneubau - wie ein modernes Einfamilienhaus oder ein Mehrfamilienhaus.Gerne stellen wir Ihnen weitere Informationen zur Verfügung oder vereinbaren einen persönlichen Besichtigungstermin. Entdecken Sie das Potenzial und die besondere Atmosphäre dieses einzigartigen Ortes. In der Verkaufsdokumentation finden Sie alle wichtigen Informationen. Wegzeit Neu 12 min.Station: Langnau-Gattikon - 1 / 13 CHF 1’302’440.– Kanalweg 2, 8714 Feldbach Bauland für projektiertes Einfamilienhaus Im beschaulichen Dorf Feldbach am Zürichsee ist dieses Grundstück mit einer bestehenden, einseitig angebauten Scheune zu verkaufen. Im Kaufpreis inbegriffen ist ein bewilligungsfähiges Vorprojekt für ein Einfamilienhaus als Ersatzbau der Scheune.Das Objekt bietet Ihnen die einmalige Möglichkeit, Ihren Traum vom Eigenheim an idyllischer Lage zu verwirklichen. Es bietet genügend Platz für eine Familie, auch eine Kombination von "Wohnen und Arbeiten" ist denkbar.Innert 30 Minuten sind Sie mit der S-Bahn in Zürich, auch Kindergarten und Primarschule sind nah. Einkaufsmöglichkeiten bestehen in Hombrechtikon, Stäfa und Rapperswil. Im Sommer lockt in unmittelbarer Nähe eine Abkühlung in der schmucken Seebadi Feldbach.Es besteht ein aktueller Kostenvoranschlag für das Haus (Holzelementbauweise) inkl. Umgebung, Bau- und Nebenkosten in der Höhe von Fr. 1'380'000.--.Haben wir Sie neugierig gemacht? Dann rufen Sie uns an. Gerne beantworten wir Ihre Fragen oder stellen Ihnen unsere Verkaufsdokumentation zum Studium zu. Die Liegenschaft kann selbstverständlich auch besichtigt werden. Wir freuen uns auf Ihren Anruf. Wegzeit Neu 6 min.Station: Feldbach - 1 / 13 5.5 Zimmer, CHF 4’111’620.– Schaffhauserstrasse 226b, 8057 Zürich Mehr Raum fürs Leben: Reihenhaus mit Potenzial Attraktive Stadtliegenschaft mit ausgearbeitetem ProjektIm Zürcher Kreis 11 veräussern wir ein hübsches Reiheneinfamilien-Eckhaus mit grosszügigem Umschwung. Die Liegenschaft und das Grundstück verfügen über viel Ausnützungspotenzial und ermöglicht so die Realisation spannender Projekte sowohl im Umbau als auch Neubau.Diese Liegenschaft überzeugt durch viele Besonderheiten: • grosszügiger Umschwung mit viel Potenzial • Blick ins Grüne von nahezu allen Fenstern • Schwedenofen im Wohnbereich • viel Stauraum durch Wandschränke und Estrich • Altbaucharme in modernem Quartier • zentrale und familienfreundliche Lage • sonnenverwöhnter Standort Haben wir Ihr Interesse geweckt? Bestellen Sie noch heute unsere ausführliche Verkaufsdokumentation mittels Kontaktformular und Sie erhalten weitere spannende Informationen zur Immobilie. Wir freuen uns über Ihre Kontaktaufnahme!Une oasis de verdure dans la ville de Zurich avec un projet élaboréDans le quartier 11 de Zurich, nous vendons une jolie maison mitoyenne en angle avec de vastes alentours. L'immeuble et le terrain disposent d'un grand potentiel d'exploitation et permettent ainsi la réalisation de projets passionnants, tant en transformation qu'en construction neuve.Cette propriété convainc par ses nombreuses particularités : • Un vaste terrain avec beaucoup de potentiel • Une vue sur la verdure depuis presque toutes les fenêtres • Un poêle suédois dans le séjour • beaucoup d'espace de rangement grâce aux armoires murales et au grenier • Le charme d'un ancien bâtiment dans un quartier moderne • Un emplacement central et favorable aux familles • Un emplacement ensoleillé Nous avons éveillé votre intérêt ? Commandez dès aujourd'hui notre documentation de vente détaillée au moyen du formulaire de contact et vous recevrez d'autres informations passionnantes sur le bien immobilier. Nous nous réjouissons de votre prise de contact!A green oasis in the city of Zurich with an elaborate projectIn Zurich's Kreis 11 district, we are selling a pretty terraced single-family corner house with spacious grounds. The property and the plot have a lot of utilization potential and thus enable the realization of exciting projects both in conversion and new construction.This property boasts many special features: • spacious grounds with lots of potential • view of the countryside from almost all windows • Swedish stove in the living area • lots of storage space thanks to wall cupboards and attic • old building charm in a modern district • central and family-friendly location • sun-drenched location Have we piqued your interest? Order our detailed sales documentation today using the contact form and you will receive further exciting information about the property. We look forward to hearing from you! Wegzeit Neu 4 min.Station: Berninaplatz - 1 / 12 Preis auf Anfrage Überlandstrasse 23, 8340 Hinwil Industrie- und Baulandparzelle an attraktivem Standort im Zürcher-Oberland Im pulsierenden Industriegebiet von Hinwil verkaufen wir ein Industriebaugrundstück an einer top frequentierter Lage, direkt an der Hauptachse in Rapperswil Wetzikon Pfäffikon ZH. Die Baulandparzelle befindet sich am Rand der Industriezone und grenzt an die Wohnzone zu Hinwil ZH.Eckdaten:- Grundstück-Fläche total 4'246 m2- Bauzone Industrie/Gewerbe IG/7 - Baumassenziffer 7 m3/m2- Gebäudehöhe maximal 21.5 m- Gebäudelänge maximal offen- Grosser Grenzabstand Nationalstrasse- Allseitiger Gebäudeabstand 3.5 m1- Maximal mögliche Baumasse ca. 30'000 m3- Bruttogeschossfläche ca. 9'500 m2Das Baugrundstück wird derzeit noch mit zwei Wohneinheiten, der Autowerkstatt mit separatem Showroom und einer Tankstelle genutzt. Rund um die Liegenschaft bieten sich grosse, befestigte Flächen zur Nutzung an. Wegzeit Neu 10 min.Station: Hinwil - 1 / 10 CHF 2’947’650.– Trottenrain 14, 8474 Dinhard Bewilligtes Bauprojekt im steuergünstigen Dinhard-Welsikon Das Bauland mit Magazingebäude befindet sich an zentraler Lage in Welsikon am Rande der Gemeinde Dinhard in der Kernzone. Die erreichte hohe Ausnutzung ermöglicht attraktive Neubauten an zentraler Lage. Visualisierungen und Grundrisse des bewilligten Bauprojekts finden Sie in der Dokumentation. Das Magazingebäude steht im kommunalen Inventar der schutzwürdigen Bauten. Es wurde deshalb in Absprache mit dem Heimatschutz und der Gemeinde Dinhard ein Schutzvertrag erarbeitet, der einen aussergewöhnlichen Umbau zu einem modernen Loft gestattet.Highlights: • bewilligtes Bauprojekt und Ausschreibungsplanung der Neubauten • Schutzvertrag • ausgezeichnete Lage in Welsikon • Steueroase (Gemeindesteuerfuss 83 %) • gut geschnittene Baulandparzelle • Gute ÖV-Anbindung (Bahnhof 170 m) Realisierung:Der Hauseigentümerverband Winterthur unterstützt Sie bei Bedarf gerne in enger Zusammenarbeit mit Kästle Architekten bei der Realisierung Ihres Neubauprojekts.Von der Planung bis hin zum Verkauf/Vermietung des fertigen Neubaus ? der Hauseigentümerverband Winterthur bietet Ihnen alle Dienstleistungen aus einer Hand. Es besteht keine Architekturverpflichtung.Interessenten sind herzlich eingeladen, mit uns Kontakt aufzunehmen.Rufen Sie unser Verkaufsteam über Telefon 052 209 01 68 an, wenn Sie zusätzliche Informationen oder eine Besichtigung wünschen. Wir freuen uns auf Sie.Ihr HEV-VerkaufsteamWichtig: Wir sind exklusiv mit dem Verkauf beauftragt. Direkte Eigentümerkontakte führen zu einem Interessentenausschluss. S.E.&.O. Wegzeit Neu 5 min.Station: Dinhard - 1 / 1 CHF 2’399’240.– In der Gass 2, 8627 Grüningen Grundstück mit Baubewilligung für MFH zu verkaufen Zum Verkauf steht ein Grundstück mit bewilligtem Neubauprojekt. Gebäude C des Enssamble an der Binzikerstrasse 21 / In der Gass 2, 8627 Grüningen. Die aktuell bestehenden Garagen können abgebrochen werden und durch einen Neubau mit 8 Wohnungen unterschiedlicher Grösse mit attraktiven Aussenbereich ersetzt werden. Zusätzlich wurde der gemeinsame Bau einer Tiefgarage für 11 Parkplätze mit der Zufahrt über die Strasse "In der Gass" bewilligt. Wegzeit Neu 54 min.Station: Esslingen - 1 / 25 CHF 2’604’890.– Im Königstal 2, 8487 Zell Wegzeit Neu 22 min.Station: Rämismühle-Zell - 1 / 25 CHF 4’112’990.– Im Königstal 3, 8487 Zell ZH Wegzeit Neu 22 min.Station: Rämismühle-Zell - 1 / 25 CHF 6’717’900.– Im Königstal 3, 8487 Zell ZH Wegzeit Neu 22 min.Station: Rämismühle-Zell - 1 / 6 CHF 2’879’100.– Rotweg 20, 8820 Wädenswil Ihr neues Projekt mit Seesicht Im Auftrag unseres Kunden verkaufen wir an bevorzugter, erhöhter und ruhiger Wohnquartierlage mit schöner See- und Fernsicht, 706 m² Bauland mit Rückbauobjekt.Verkaufsrichtpreis: CHF 2'100'000.00Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot. Wegzeit Neu 12 min.Station: Wädenswil - 1 / 7 CHF 651’220.– Auf Anfrage 1, 8195 Wasterkingen Attraktives Baugrundstück in ruhiger, ländlicher Umgebung Willkommen in Wasterkingen, einer idyllischen und ruhigen Gemeinde im Zürcher Unterland, die für ihre hohe Lebensqualität, ländliche Gelassenheit und dennoch gute Erreichbarkeit bekannt ist. Genau hier wartet ein attraktives Baugrundstück auf Sie – die ideale Basis für Ihr zukünftiges Zuhause.Das Grundstück ist voll erschlossen und liegt in der Kernzone B, was Ihnen zahlreiche Gestaltungsmöglichkeiten eröffnet. Ob ein modernes Einfamilienhaus, ein klassisches Zuhause im Dorfcharakter oder ein individuelles Architektenprojekt – hier können Sie Ihre Wohnträume ganz nach Ihren Vorstellungen verwirklichen.Die charmante Gemeinde Wasterkingen besticht durch ihre ruhige Lage inmitten von Feldern, Reben und Natur.Dieses ImmoSky-Angebot bietet folgende Mehr Leistung:+ Voll erschlossen+ Ruhige Gemeinde+ Ideale Grösse für flexibilität (650m²)+ Kernzone B+Überbauungsziffer für Hauptgebäude 30%Dieses Grundstück bietet Ihnen die seltene Gelegenheit, ländliche Idylle mit urbaner Nähe zu vereinen – ein Ort, an dem Sie zur Ruhe kommen und dennoch bestens angebunden sind.Erfüllen Sie sich hier den Traum vom Eigenheim und gestalten Sie Ihr persönliches Refugium in Wasterkingen.Haben wir Sie mit diesem Angebot überzeugt? Dann zögern Sie nicht und kontaktieren Sie uns für weitere Fragen oder einen Besichtigungstermin!(Das Verkaufsdossier wird in der Regel innerhalb von maximal 24 Stunden an Sie versendet. Bitte überprüfen Sie auch Ihren SPAM-Ordner.) Wegzeit - - 1 / 7 CHF 7’540’490.– Staldernstrasse 13, 8158 Regensberg Entwicklungsgrundstück an top Lage in der Kernzone 2 In der gefragten Gemeinde Regensberg (ZH) steht ein hervorragend gelegenes Grundstück zum Verkauf, das sich ideal für Investoren, General- oder Totalunternehmer eignet. Die 2.557 m² grosse Parzelle Nr. 949 befindet sich in der Kernzone 2, die vielfältige bauliche und nutzungsbezogene Entwicklungsmöglichkeiten zulässt, insbesondere für Wohn- oder gemischt genutzte Projekte.Aktuell steht auf dem Grundstück ein nicht erhaltenswertes Gebäude, das im Rahmen einer Neuentwicklung rückgebaut werden kann. Eine Baueingabe oder Bewilligung liegt nicht vor, sodass volle gestalterische Freiheit innerhalb der geltenden bau- und zonenrechtlichen Rahmenbedingungen besteht.Berechnungen zeigen, dass eine nachhaltige Mietertragserwartung von rund CHF 485'600 pro Jahr realistisch erscheint - unter der Annahme einer Ausnutzung mit rund 1 664 m² Hauptnutzfläche (HNF) und 28 Tiefgaragenplätzen. Der ermittelte Kapitalisierungssatz liegt bei 4.20 %.Wesentliche Bewertungskennzahlen:Verkehrswert (diskontierter Landwert): CHF 5'505'000Ertragswert im erneuerten Zustand: CHF 11'556'795Realwert (hypothetisch): CHF 12'485'000Potenzieller Verkaufserlös: CHF 16'190'000Bruttorendite (Mietwert): 4.20%Die hypothetische Bebauung sieht zwei Mehrfamilienhäuser mit einer Bruttogeschossfläche (BGF) von insgesamt 2'080 m² vor - entsprechend einer Ausnützungsziffer von 0.81, voll im Rahmen der Zonenordnung. Die kalkulierten Baukosten (BKP 2-5) belaufen sich auf ca. CHF 8.74 Mio. Der diskontierte Landwert pro m² liegt bei CHF 2'155, was das wirtschaftliche Potenzial zusätzlich unterstreicht.Die Kernzone 2 erlaubt neben der reinen Wohnnutzung auch Mischnutzungen, beispielsweise mit gewerblichen Angeboten im Erdgeschoss. Dies ist ein zusätzlicher Vorteil für flexible, standortgerechte Entwicklungskonzepte. Die Lage in Regensberg bietet ruhige Wohnqualität in der Nähe der Agglomeration Zürich und ist in eine attraktive historische Umgebung eingebettet.Fazit: Das Grundstück bietet die seltene Gelegenheit, ein entwicklungsfähiges Grundstück an bester Lage mit bestehendem Abbruchobjekt zu akquirieren und nach eigenen Vorstellungen zu bebauen. Dank der flexiblen Nutzungsmöglichkeiten und des attraktiven Standorts stellt diese Investition eine hervorragende Ausgangslage für renditestarke Projektentwicklungen dar.Für detaillierte Informationen stehen wir Ihnen gerne zur Verfügung. Wegzeit Neu 23 min.Station: Steinmaur - 1 / 6 CHF 3’633’140.– Riedwiesenstrasse 20, 8305 Dietlikon RESERVIERT - Industrie-Baulandparzelle an zentraler Lage in Dietlikon ZH Mit Freude präsentieren wir Ihnen eine einzigartige und äusserst seltene Baulandparzelle an zentraler Lage in Dietlikon ZH – eine aussergewöhnliche Gelegenheit mit hervorragenden Eigenschaften, die sich besonders für Investoren eignet.Zentrale Lage: Die Parzelle befindet sich in einer äusserst gefragten Gegend mit hervorragender Anbindung: Flughafen Zürich erreichbar in 10 Fahrminuten Stadt Zürich erreichbar in 12 Fahrminuten • Visibilität: Ihr Unternehmen wird von der Autobahn aus perfekt sichtbar sein, was optimale Werbemöglichkeiten bietet (ca. 500 m2 Fassade für Werbung). • Baumassenziffer: Profitieren Sie von der hohen Baumassenziffer 10.0, die maximale Flexibilität und Nutzungseffizienz ermöglicht. • Näherbaurechte: Die Parzelle verfügt über Näherbaurechte rechts und links. Auf der Rückseite kann ein Näherbaurecht von der Stadt Zürich eingeholt werden • ca. 3'500 m2 Bruttogeschossfläche möglich • Tiefgarage / Untergeschoss bis zu ca. 800 m2 gross realisierbar • Maximale Gesamthöhe 20 m. 7 Stockwerke à 500 m2 Bruttogeschossfläche und 2.85 m Raumhöhe (brutto) möglich • Parzelle: Die ebene Fläche der Parzelle erleichtert die Bauplanung und Ausführung. • Form: Die Parzelle hat eine ideale Form, die vielseitige Bebauungsmöglichkeiten erlaubt. • Autobahnknotenpunkt: Brüttiseller Kreuz, direkt an einem der wichtigsten Autobahnknotenpunkt der Schweiz gelegen, bietet die Parzelle hervorragende Erreichbarkeit und Logistikvorteile • Störendes Gewerbe: Die Lage ist auch für Gewerbe geeignet, das potenziell störend sein kann. • Kulturzentren sowie Hotelbetriebe auch möglich. Jetzt oder nie – Ihre Chance auf ein grossartiges Investment:Solch eine Industrie-Baulandparzelle in dieser Lage kommt äusserst selten auf den Markt – seit geraumer Zeit gab es in dieser gefragten Gegend kein vergleichbares Angebot. Sichern Sie sich jetzt dieses einmalige Grundstück, ideal für visionäre Unternehmer und Investoren, die auf einen strategisch optimalen Standort setzen.Haben wir Ihr Interesse geweckt? Dann nehmen Sie noch heute Kontakt mit uns auf. Gerne lassen wir Ihnen das detaillierte Verkaufsdossier inklusive Machbarkeitsstudie zukommen – exklusiv und unverbindlich. Wegzeit Neu 14 min.Station: Dietlikon - 1 / 6 Preis auf Anfrage Kaffeestrasse, 8180 Bülach Ihr Industriebau direkt in Bülach BeschreibungGerne entwickeln und realisieren wir ein auf ihre Bedürfnisse massgeschneidertes Projekt, welches Ihnen zur Miete oder im Eigentum zur Verfügung stehen wird.Interesse oder Fragen? Nehmen Sie Kontakt mit uns auf!Die Parzelle ist nicht das Richtige für Ihre Anforderungen? Kein Problem! Besuchen Sie unsere Homepage und finden Sie weitere Angebote unter: gewerbeland-schweiz.ch Wegzeit Neu 20 min.Station: Bülach - 1 / 6 Preis auf Anfrage Kaffeestrasse, 8180 Bülach Ihr Industriebau direkt in Bülach BeschreibungGerne entwickeln und realisieren wir ein auf ihre Bedürfnisse massgeschneidertes Projekt, welches Ihnen zur Miete oder im Eigentum zur Verfügung stehen wird.Interesse oder Fragen? Nehmen Sie Kontakt mit uns auf!Die Parzelle ist nicht das Richtige für Ihre Anforderungen? Kein Problem! Besuchen Sie unsere Homepage und finden Sie weitere Angebote unter: gewerbeland-schweiz.ch Wegzeit Neu 20 min.Station: Bülach - 1 / 6 Ruhige Lage CHF 3’358’950.– 8192 Glattfelden ZWEIFELSFREIES BAULAND IN ZWEIDLEN Im beliebten Zweidlen verkaufen wir ein eine attraktive, 1'226 m² grosse Baulandparzelle mit Bestandesobjekt.Unsere Projektstudie zeigt eine hohe Ausnutzung für die Erstellung eines Mehrfamilienhauses. • Anrechenbare mögliche Bruttogeschossfläche von max. 940 m² (Projekt 789 m²) • Wohn- und Gewerbezone WG 2.3 • Kein Denkmalschutz beim Bestandesobjekt • Die Deutsche Grenze in Kaiserstuhl ist nur 8 Autominuten entfernt • Der Flughafen Zürich ist in nur 19 Autominuten erreichbar Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: Referenznummer: 25-12278Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen! Ruhige Lage Wegzeit - -12...4 -Suche speichern Kartenansicht -Vorschläge basierend auf deinen Suchresultaten -Weitere interessante Objekte -Orte von Kanton Zürich - -Zürich - -Bezirke im Kanton Kanton Zürich - -Bezirk Affoltern -Bezirk Andelfingen -Bezirk Bülach -Bezirk Dielsdorf -Bezirk Dietikon -Bezirk Hinwil -Bezirk Horgen -Bezirk Meilen -Bezirk Pfäffikon -Bezirk Uster -Bezirk Winterthur - -Kantone der Schweiz - -Kanton Aargau -Kanton Appenzell Ausserrhoden -Kanton Appenzell Innerrhoden -Kanton Basel-Landschaft -Kanton Basel-Stadt -Kanton Bern -Kanton Freiburg -Kanton Genf -Kanton Glarus -Kanton Graubünden -Kanton Jura -Kanton Luzern -Kanton Neuenburg -Kanton Nidwalden -Kanton Obwalden -Kanton Schaffhausen -Kanton Schwyz -Kanton Solothurn -Kanton St. Gallen -Kanton Thurgau -Kanton Tessin -Kanton Uri -Kanton Wallis -Kanton Waadt -Kanton Zug - -ImmoScout24 - -Inserat erstellen -Werbung -Publikationsnetzwerk - -Über uns - -Kontakt -Porträt -Jobs -Fakten und Zahlen -Medien -Newsletter -Ombudsstelle - -Rechtliches - -Datenschutz -Insertionsregeln -Sicherheitstipps -Impressum -AGB -Leistungsbeschrieb -Sicherheitsproblem melden -Privatsphäre-Einstellungen - -Services - -Betreibungsauszug -Umzugshilfe -Versicherungsberatung -Agenturverzeichnis -Hypothekenrechner -Immobilienbewertung - -App herunterladen - -Unser Partner - -Deutsch -Français -Italiano -English - -Folgen Sie uns - -SMG Swiss Marketplace GroupAutoScout24FinanceScout24MotoScout24anibis.ch -© Copyright 2025 by SMG Swiss Marketplace Group AG . Alle Rechte vorbehalten.Die Vervielfältigung und Übernahme von Inseraten durch Dritte, insbesondere von Fotos und persönlichen Daten in diesen Inseraten, verletzt die damit verbundenen Rechte und ist ausdrücklich verboten. -We Care About Your Privacy -We and our 455 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data.Imprint -We and our partners process data to provide: -Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. List of Partners (vendors) -I Accept No consent Show Purposes - -About Your Privacy -We process your data to deliver content or advertisements and measure the delivery of such content or advertisements to extract insights about our website. We share this information with our partners on the basis of consent. You may exercise your right to consent, based on a specific purpose below or at a partner level in the link under each purpose. These choices will be signaled to our vendors participating in the Transparency and Consent Framework. -Privacy Policy -Allow All -Manage Consent Preferences -Functional Cookies - -[x] Functional Cookies - -These cookies enable the website to provide enhanced functionality and personalisation. They may be set by us or by third party providers whose services we have added to our pages. If you do not allow these cookies then some or all of these services may not function properly. -Cookies Details -Strictly Necessary Cookies -Always Active -These cookies are necessary for the website to function and cannot be switched off in our systems. They are usually only set in response to actions made by you which amount to a request for services, such as setting your privacy preferences, logging in or filling in forms. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. These cookies do not store any personally identifiable information. -Cookies Details -Targeting Cookies - -[x] Targeting Cookies - -These cookies may be set on our website by our advertising partners. They can be used by these companies to build a profile of your interests and to control which advertisements you see on other websites. If you do not allow these cookies, you will still see advertisements, but they will no longer be tailored to you. Your master and usage data will also be made available to the other brands of the SMG Group for analysis, for the management of personalized advertising display, and for personalized marketing communication. The latter means that you may be contacted in a personalized manner for marketing purposes not only by this brand but also by all other brands of the SMG Group. The brands of the SMG Group are ImmoScout24, Homegate, Immostreet.ch, home.ch, Publimmo, Acheter-Louer.ch, CASASOFT, IAZI, AutoScout24, MotoScout24, anibis.ch, tutti.ch, Ricardo, FinanceScout24, Flatfox, and Moneyland. We use Enhanced Conversion that may transmit pseudonymised (e.g. hashed) email addresses to third parties such as Google or publishers (e.g. TX Group or Ringier AG) to improve campaign performance and measurement and/or to create audience segments. Personal identification is not possible unless you are logged in with the same email address and associated with an account of these third parties. Your personal data will be processed either jointly with these third parties, in accordance with their respective privacy notices, or independently by SMG as controller. Please note that your personal data may also be transferred to insecure third countries, where local authorities may access them without protection equivalent to European data protection law. If the level of data protection in a country does not match that of Switzerland, we ensure contractually that the protection of your personal data always corresponds to the level in Switzerland. -Cookies Details -Performance Cookies - -[x] Performance Cookies - -These cookies allow us to count visits and traffic sources so we can measure and improve the performance of our site. They help us to know which pages are the most and least popular and see how visitors move around the site. All information these cookies collect is aggregated and therefore anonymous. If you do not allow these cookies we will not know when you have visited our site, and will not be able to monitor its performance. -Cookies Details -Store and/or access information on a device 365 partners can use this purpose - -[x] Store and/or access information on a device - -Cookies, device or similar online identifiers (e.g. login-based identifiers, randomly assigned identifiers, network based identifiers) together with other information (e.g. browser type and information, language, screen size, supported technologies etc.) can be stored or read on your device to recognise it each time it connects to an app or to a website, for one or several of the purposes presented here. -List of IAB Vendors|View Illustrations -Personalised advertising and content, advertising and content measurement, audience research and services development 438 partners can use this purpose - -[x] Personalised advertising and content, advertising and content measurement, audience research and services development - -Use limited data to select advertising 359 partners can use this purpose - -[x] Switch Label -Advertising presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type or which content you are (or have been) interacting with (for example, to limit the number of times an ad is presented to you). - -View Illustrations - -Create profiles for personalised advertising 283 partners can use this purpose - -[x] Switch Label -Information about your activity on this service (such as forms you submit, content you look at) can be stored and combined with other information about you (for example, information from your previous activity on this service and other websites or apps) or similar users. This is then used to build or improve a profile about you (that might include possible interests and personal aspects). Your profile can be used (also later) to present advertising that appears more relevant based on your possible interests by this and other entities. - -View Illustrations - -Use profiles to select personalised advertising 281 partners can use this purpose - -[x] Switch Label -Advertising presented to you on this service can be based on your advertising profiles, which can reflect your activity on this service or other websites or apps (like the forms you submit, content you look at), possible interests and personal aspects. - -View Illustrations - -Create profiles to personalise content 103 partners can use this purpose - -[x] Switch Label -Information about your activity on this service (for instance, forms you submit, non-advertising content you look at) can be stored and combined with other information about you (such as your previous activity on this service or other websites or apps) or similar users. This is then used to build or improve a profile about you (which might for example include possible interests and personal aspects). Your profile can be used (also later) to present content that appears more relevant based on your possible interests, such as by adapting the order in which content is shown to you, so that it is even easier for you to find content that matches your interests. - -View Illustrations - -Use profiles to select personalised content 92 partners can use this purpose - -[x] Switch Label -Content presented to you on this service can be based on your content personalisation profiles, which can reflect your activity on this or other services (for instance, the forms you submit, content you look at), possible interests and personal aspects. This can for example be used to adapt the order in which content is shown to you, so that it is even easier for you to find (non-advertising) content that matches your interests. - -View Illustrations - -Measure advertising performance 404 partners can use this purpose - -[x] Switch Label -Information regarding which advertising is presented to you and how you interact with it can be used to determine how well an advert has worked for you or other users and whether the goals of the advertising were reached. For instance, whether you saw an ad, whether you clicked on it, whether it led you to buy a product or visit a website, etc. This is very helpful to understand the relevance of advertising campaigns. - -View Illustrations - -Measure content performance 171 partners can use this purpose - -[x] Switch Label -Information regarding which content is presented to you and how you interact with it can be used to determine whether the (non-advertising) content e.g. reached its intended audience and matched your interests. For instance, whether you read an article, watch a video, listen to a podcast or look at a product description, how long you spent on this service and the web pages you visit etc. This is very helpful to understand the relevance of (non-advertising) content that is shown to you. - -View Illustrations - -Understand audiences through statistics or combinations of data from different sources 253 partners can use this purpose - -[x] Switch Label -Reports can be generated based on the combination of data sets (like user profiles, statistics, market research, analytics data) regarding your interactions and those of other users with advertising or (non-advertising) content to identify common characteristics (for instance, to determine which target audiences are more receptive to an ad campaign or to certain contents). - -View Illustrations - -Develop and improve services 300 partners can use this purpose - -[x] Switch Label -Information about your activity on this service, such as your interaction with ads or content, can be very helpful to improve products and services and to build new products and services based on user interactions, the type of audience, etc. This specific purpose does not include the development or improvement of user profiles and identifiers. - -View Illustrations - -Use limited data to select content 83 partners can use this purpose - -[x] Switch Label -Content presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type, or which content you are (or have been) interacting with (for example, to limit the number of times a video or an article is presented to you). - -View Illustrations -List of IAB Vendors -Use precise geolocation data 132 partners can use this special feature - -[x] Use precise geolocation data - -With your acceptance, your precise location (within a radius of less than 500 metres) may be used in support of the purposes explained in this notice. -List of IAB Vendors -Actively scan device characteristics for identification 71 partners can use this special feature - -[x] Actively scan device characteristics for identification - -With your acceptance, certain characteristics specific to your device might be requested and used to distinguish it from other devices (such as the installed fonts or plugins, the resolution of your screen) in support of the purposes explained in this notice. -List of IAB Vendors -Ensure security, prevent and detect fraud, and fix errors 290 partners can use this special purpose -Always Active -Your data can be used to monitor for and prevent unusual and possibly fraudulent activity (for example, regarding advertising, ad clicks by bots), and ensure systems and processes work properly and securely. It can also be used to correct any problems you, the publisher or the advertiser may encounter in the delivery of content and ads and in your interaction with them. -List of IAB Vendors|View Illustrations -Deliver and present advertising and content 286 partners can use this special purpose -Always Active -Certain information (like an IP address or device capabilities) is used to ensure the technical compatibility of the content or advertising, and to facilitate the transmission of the content or ad to your device. -List of IAB Vendors|View Illustrations -Match and combine data from other data sources 214 partners can use this feature -Always Active -Information about your activity on this service may be matched and combined with other information relating to you and originating from various sources (for instance your activity on a separate online service, your use of a loyalty card in-store, or your answers to a survey), in support of the purposes explained in this notice. -List of IAB Vendors -Link different devices 172 partners can use this feature -Always Active -In support of the purposes explained in this notice, your device might be considered as likely linked to other devices that belong to you or your household (for instance because you are logged in to the same service on both your phone and your computer, or because you may use the same Internet connection on both devices). -List of IAB Vendors -Identify devices based on information transmitted automatically 265 partners can use this feature -Always Active -Your device might be distinguished from other devices based on information it automatically sends when accessing the Internet (for instance, the IP address of your Internet connection or the type of browser you are using) in support of the purposes exposed in this notice. -List of IAB Vendors -Save and communicate privacy choices 245 partners can use this special purpose -Always Active -The choices you make regarding the purposes and entities listed in this notice are saved and made available to those entities in the form of digital signals (such as a string of characters). This is necessary in order to enable both this service and those entities to respect such choices. -List of IAB Vendors|View Illustrations -Cookie List -Clear - -[x] checkbox label label - -Apply Cancel -Consent Leg.Interest - -[x] checkbox label label - -[x] checkbox label label - -[x] checkbox label label - -No consent Confirm My Choices \ No newline at end of file diff --git a/test_web_content_20251002_204000/main_url_003_www.comparis.ch_immobilien_marktplatz_kanton_zuerich_grundstueck_kaufen.txt b/test_web_content_20251002_204000/main_url_003_www.comparis.ch_immobilien_marktplatz_kanton_zuerich_grundstueck_kaufen.txt deleted file mode 100644 index 7e25ebe4..00000000 --- a/test_web_content_20251002_204000/main_url_003_www.comparis.ch_immobilien_marktplatz_kanton_zuerich_grundstueck_kaufen.txt +++ /dev/null @@ -1,401 +0,0 @@ -Title: https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen -URL: https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen -Type: Main URL -Extracted: 2025-10-02 20:40:00 -================================================================================ - -Grundstück in Kanton Zürich kaufen - Vergleiche 72 Inserate mit comparis.ch - -Versicherungen -Finanzen -Immobilien -Mobilität -Gesundheit -Telecom - -Neu in der Schweiz - -Person absichern - -Krankenkasse -Lebensversicherung -Rechtsschutz -Reiseversicherung - -Fahrzeug versichern - -Autoversicherung -Motorradversicherung - -Eigentum versichern - -Hausrat und Privathaftpflicht -Tierversicherung - -Alles zu Versicherungen -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Kredit aufnehmen - -Privatkredit -Kreditrechner -Kreditvergleich - -Immobilie finanzieren - -Hypotheken -Hypothekenrechner -Zinsentwicklung - -Altersvorsorge planen - -Altersvorsorge -Pensionsplanung - -Steuern vergleichen - -Steuervergleich -Steuerrechner -Quellensteuer - -Fahrzeug finanzieren - -Autoleasing -Leasingrechner -Autokredit - -Wirtschaftsinfos einholen - -Finanzen und Wirtschaft - -Alles zu Finanzen -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Immobilie finden - -Immobilienmarkt -Steuerrechner - -Immobilie finanzieren - -Hypotheken -Hypothekenrechner -Zinsentwicklung - -Immobilien bewerten - -Immobilie kostenlos bewerten -Immobilienbewertung Plus (Beta) -Makler finden -Immobilie verkaufen - -Immobilie inserieren - -Privat inserieren -Als Firma inserieren - -Umzug planen - -Umzugsservice -Umzugskostenrechner -Umzug in die Schweiz -Malerservice - -Hausrat versichern - -Hausrat und Privathaftpflicht - -Alles zu Immobilien -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Automarkt - -Auto kaufen -Auto verkaufen -Autowert berechnen - -Fahrzeug finanzieren - -Autoleasing -Leasingrechner -Autokredit - -Fahrzeug versichern - -Autoversicherung -Motorradversicherung - -Fahrzeugnutzung - -Benzinpreise -Autoprüfung - -Elektromobilität - -Elektromobilität entdecken -Ladestation finden -Elektroauto - -Reisen - -Reisetipps -Reiseversicherung -Ferien-Packliste - -Alles zu Mobilität -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Arzt finden und Behandlungen - -Arzt finden -Zähne -Dermatologie -Medikamente - -Leben im Alter und Spitex - -Spitex finden -Finanzierung und Wohnen -Zu Hause pflegen - -Krankenkasse - -Krankenkasse vergleichen - -Alles zu Gesundheit -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Mobile - -Handy-Abo - -Internet und TV zuhause - -Internet, TV und Festnetz - -Alles zu Telecom -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Auswandern - -Auswandern in die Schweiz -Aufenthaltsbewilligung -Führerschein umschreiben -Miete in der Schweiz - -Arbeit - -Arbeiten in der Schweiz -Durchschnittslohn in der Schweiz -Jobsuche -Lohnnebenkosten - -Finanzen - -Finanzen in der Schweiz -Quellensteuer vergleichen -Lebenshaltungskosten - -Leben - -Leben in der Schweiz -Schweizerdeutsch lernen -Besonderheiten der Schweiz - -Alles zu Neu in der Schweiz -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren -DE -FRITEN -Login -Login -Comparis entdecken - -Versicherungen -Finanzen -Immobilien -Mobilität -Gesundheit -Telecom -Neu in der Schweiz - -Newsletter -Login -DEFRITEN - -Startseite -Wohnen -Immobilien -Bauland kaufen -Grundstück in Kanton Zürich kaufen - -Favoriten (0) -Grundstück in Kanton Zürich kaufen: 72 Resultate -Filter (4)Suchabo anlegen Suchabo -Kein neues Inserat verpassen! - Umgehende Benachrichtigung - Jederzeit anpassbar - Kostenlos -Infobox schliessen - -Sortieren nach: -Sortieren nach:Erstmals gefunden am -Sortieren -Bauland Online seit einem Tag 706 m² ------ «Ihr neues Projekt mit Seesicht» 8820 Wädenswil Rotweg 20 CHF 2'100'000 Kaufpreis Merken Merken CHF 2'100'000 Kaufpreis -Gewerbegrundstück Online seit 3 Tagen Gewerbegrundstück ----------------- «Bauernhof mit mehreren landwirtschaftlichen Parzellen» 8460 Marthalen Talackerberg, Im Türni CHF 1'020'000 Kaufpreis Merken Merken CHF 1'020'000 Kaufpreis -Bauland Online seit 3 Tagen Bauland ------- «BAULAND AN TRAUMHAFTER LAGE AM FISCHBACH» 8162 Steinmaur auf Anfrage Kaufpreis Merken Merken auf Anfrage Kaufpreis -Bauland Online seit 4 Tagen 1285 m² ------- «Windlach: Grundstück mit Potenzial für Wohnraumentwicklung» 8175 Windlach CHF 800'000 Kaufpreis Merken Merken CHF 800'000 Kaufpreis -Bauland Online seit 5 Tagen 3166 m² ------- «Attraktives Entwicklungsareal an zentraler Lage mit 3?166 m²» 8050 Zürich CHF 26'000'000 Kaufpreis Merken Merken CHF 26'000'000 Kaufpreis -Grundstück Online seit 5 Tagen Grundstück ---------- «Hier beginnt Ihre Zukunft» 8340 Hinwil CHF 1'070'000 Kaufpreis Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken CHF 1'070'000 Kaufpreis -Bauland Online seit einer Woche 9175 m² ------- «Vergabe der Gewerbefläche GB Nr. 74, Neuhausen am Rheinfall» 8212 Neuhausen am Rheinfall CHF 343 Kaufpreis pro m² Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken CHF 343 Kaufpreis pro m² -Bauland Online seit einer Woche Bauland ------- «Zürich» 8000 Zürich auf Anfrage Kaufpreis Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken auf Anfrage Kaufpreis -Grundstück Online seit einer Woche Grundstück ---------- «Zürich» 8001 Zürich auf Anfrage Kaufpreis Merken Merken auf Anfrage Kaufpreis -Grundstück Online seit einer Woche Grundstück ---------- «Attraktives Baugrundstück in ruhiger, ländlicher Umgebung» 8195 Wasterkingen CHF 475'000 Kaufpreis Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken CHF 475'000 Kaufpreis - -1 -2 -3 -4 -5 -6 -8 - -Gemeinden in diesem Kanton -A -B -C -D -E -F -G -H -I -J -K -L -M -N -O -P -Q -R -S -T -U -V -W -X -Y -Z -A -Adliswil -Aeugst am Albis -Affoltern am Albis -B -Benken (ZH) -Bülach -D -Dättlikon -Dielsdorf -Dietikon -Dietlikon -Dinhard -Dorf -E -Elgg -Embrach -Erlenbach (ZH) -F -Fällanden -H -Herrliberg -Hettlingen -Hinwil -Höri -Hüntwangen -M -Marthalen -Mönchaltorf -N -Niederglatt -Niederhasli -O -Oetwil am See -P -Pfäffikon -R -Rafz -Regensberg -Regensdorf -Richterswil -Rifferswil -Rümlang -Russikon -Rüti (ZH) -S -Steinmaur -V -Volken -W -Wädenswil -Wasterkingen -Weisslingen -Wildberg -Z -Zell (ZH) -Zürich -Das könnte Sie interessieren -Weitere Comparis Services -Was zahlt die Nachbarschaft?Umzugsfirma ZürichInserieren -Weitere Kaufobjekte in Kanton Zürich -Wohnung kaufen Kanton Zürich (1500)Haus kaufen Kanton Zürich (642)Mehrfamilienhaus kaufen Kanton Zürich (70) -ZU DEN FAVORITEN -Filter (4) - -comparis.ch -1. Über Comparis -2. User Service -3. Jobs -4. Medien -5. Allgemeine Geschäftsbedingungen -Weitere Angebote -1. Studien -2. Gebühren -3. Werbung -4. Comparis-Siegel -Folgen Sie uns -1. -2. -3. -4. -Newsletter -1. Newsletter bestellen -© comparis.ch AG 2025 -DatenschutzRechtliche InformationenImpressum \ No newline at end of file diff --git a/test_web_content_20251002_204000/main_url_004_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferliste.txt b/test_web_content_20251002_204000/main_url_004_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferliste.txt deleted file mode 100644 index b9d5db95..00000000 --- a/test_web_content_20251002_204000/main_url_004_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferliste.txt +++ /dev/null @@ -1,121 +0,0 @@ -Title: https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste -URL: https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste -Type: Main URL -Extracted: 2025-10-02 20:40:00 -================================================================================ - -73 Bauland kaufen in Kanton Zürich | homegate.ch - - Suchen - Services -Inserieren -Mein Konto -Menü - - Suchen - Services - Schätzen - Ratgeber -Inserieren -Mein Konto -DE - DE - FR - IT - EN -Ort -Kanton Zürich -Kanton Zürich -Preis bis -Weitere Filter -73 Treffer -73 Treffer - Bauland kaufen in Kanton Zürich - 1 / 16 CHF 2’563’760.– Top 360m² Nutzfläche Luegetenstrasse 11, 8489 Wildberg Ihr neues Zuhause mit Potenzial - Idyllisches Landhaus mit Baulandreserve Ihr neues Zuhause Willkommen in Ihrem zukünftigen Traumdomizil - ein grosszügiges, freistehendes Landhaus an ruhiger und idyllischer Aussichtslage im malerischen Wildberg. Hier vereinen sich ländliche Idylle, Privatsphäre und die seltene Möglichkeit, Wohnraum nach eigenen Vorstellungen zu schaffen oder zu erweitern.Ob als charmantes Familienrefugium mit grossem Garten oder als Investitionsobjekt mit Entwicklungspotenzial - dieses einzigartige Anwesen bietet Ihnen beide Optionen. Auf dem 1339m² grossen Grundstück geniessen Sie nicht nur viel Platz zum Leben, sondern verfügen auch über eine wertvolle Baulandreserve, die Ihnen vielfältige Gestaltungsmöglichkeiten eröffnet. Erste Abklärungen zeigen: Es besteht die Möglichkeit, ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren - ein echter Mehrwert für visionäre Käufer.Tauchen Sie ein in eine grüne Oase mit Weitblick - ein Ort, der Ruhe schenkt und inspiriert.Highlights auf einen Blick • Idyllische, ruhige Aussichtslage mit hohem Erholungswert • Grosszügiges Grundstück mit 1339m², ideal zur Eigennutzung und/oder für die Entwicklung eines Neubaus • Baulandreserve: Attraktives Entwicklungspotenzial - gemäss erster Einschätzung besteht die Möglichkeit, zusätzlich zum bestehenden Einfamilienhaus ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren (unverbindlich, ohne Gewähr) • Blühender Garten mit verschiedenen Sitzplätzen, Pergola mit Aussencheminée, Gartenhäusern, gepflegtem Baumbestand und weitläufigen Grünflächen • Solide Bausubstanz mit Doppelschalenmauerwerk • Grosszügiges Raumkonzept mit ca. 220m² Wohnfläche und ca. 96m² zusätzlichem Stauraum im Untergeschoss. Total ca. 360m² Bruttofläche. • Geräumiger Wohnbereich mit gemütlichem Kachelofen - ein Ort zum Ankommen und Wohlfühlen • Praktische Wohnküche mit integriertem Essbereich - ideal für gesellige Stunden • 4 helle Schlafzimmer - ideal für Familien oder Homeoffice • 2 Nasszellen mit Tageslicht • Ausgebauter Estrich für zusätzlichen Raum oder kreative Nutzungsmöglichkeiten • Beheizt durch Elektrospeicher und wassergeführte Fussbodenheizung • Garage mit elektrischem Tor und weitere Parkmöglichkeiten auf dem Grundstück • Mit einer stilvollen Modernisierung verwandeln Sie dieses Haus in ein wahres Schmuckstück Verkaufspreis: CHF 1'870'000.-Mit unserer virtuellen 360-Grad-Tour können Sie bereits die ersten Eindrücke dieser tollen Liegenschaft gewinnen. Sehr gerne zeigen wir Ihnen diese Liegenschaft direkt vor Ort und freuen uns auf Ihre Kontaktaufnahme.Weitere EckdatenBaujahr Haus: 1984, Baujahr Gerätehaus: 1986, Kubatur Haus (GVZ): 936m³, Kubatur Gerätehaus (GVZ): 40m³, Grundbuchblatt: Nr. 437, Kataster-Nr.: 249, 1/4 subjektiv-dingliches Miteigentum an Blatt 444, Kataster 249. Nettowohnfläche: ca. 220m², Bruttowohnfläche: ca. 360m², Grundstücksfläche: 1'339m².Massivbauweise, Doppelschalenmauerwerk, neuwertige Holzmetallfenster (EgoKiefer) mit dreifacher Verglasung und Sprossen & Holzläden. Elektrospeicherofen, wassergeführte Fussbodenheizung, Elektroboiler 300 Liter.Treppenlift, Garage mit elektrischem Torantrieb. Küche im Landhausstil mit Granitabdeckung, Geschirrspüler, Induktions-Kochherd und Kühlschrank mit Gefrierfach.BodenbelägeEG: Entrée, Gang, Dusche, Küche, Essen mit Plattenboden.OG: Zimmer und Vorplatz mit Laminat in Holzoptik. Bad mit Platten. Wegzeit Neu - - 1 / 8 CHF 2’604’890.– Top Wehntalerstrasse 28, 8181 Höri Grundstück mit Baubewilligung für ein Mehrfamilienhaus mit 6 Einheiten Das Grundstück ist derzeit mit einem Einfamilienhaus bebaut (Baujahr 1960)Nach dem Rückbau kann, gemäss Bewilligung ein Mehrfamilienhaus mit 6 Wohnungen (3 Wohnungen 4½ Zimmer und 3 Wohnungen 2½ Zimmer) mit 9 Tiefgaragen, 1 Tiefgaragen Behinderten Parkplatz sowie 2 Besucher Aussenparkplätze realisiert werden. (Siehe Pläne)Im Kaufpreis enthalten: • Baubewilligung • Bewilligungsgebühren • Projektpläne in PDF, DWG und Step Dateien • Lärmschutznachweis Strasse / Lärmschutznachweis Fluglärm • Geologisches Gutachten (Meldeblatt zu Bodenverschiebung) Parzelle nicht belastet! • Private Kontrolle bei Rückbau- und Umbau. (2 Asbestproben wurden positiv auf Asbest getestet) • Amtlich Beglaubigter Katasterplan • Farb- und Materialkonzept Verkaufspreis für Liegenschaft inkl. Vorbeschriebenen Leistungen: CHF 1'900'000.-Wir hoffen Ihr Interesse geweckt zu haben. Gerne stellen wir Ihnen die Verkaufsdokumente und Projektunterlagen, mit ausführlichen Informationen, per E-Mail zu.Es werden keine Makleranfragen berücksichtigt.Die zugestellten Informationen sind Eigentum von Bujar Bunjaku. Veröffentlichung, kopieren sind nicht gestattet.Kaufabwicklung:CHF 72'000.-- fällig bei Unterzeichnung der Kaufzusage; CHF 150'000.-- fällig bei Unterzeichnung und notarieller Beurkundung des Kaufvertrages; Restzahlung des Verkaufspreises fällig bei der Eigentumsübertragung.Notariats- und Grundbuchgebühren: Je zur Hälfte zu Lasten Käufer / Verkäufer.Anbieter:Bujar BunjakuWehntalerstrasse 288181 Höri Wegzeit Neu - - 1 / 4 CHF 1’096’790.– Top Bahnhofstrasse 41, 8496 Steg im Tösstal 1’111 m² attraktives Bauland in Steg Dieses 1'111 m² grosse Bauland liegt im schönen Tösstal, einer der sonnigsten Regionen der Ostschweiz. Die ruhige Lage direkt am Waldrand bietet viel Natur, frische Luft und Privatsphäre.Ein idealer Ort für Naturliebhaber und Ruhesuchende, die dennoch Wert auf eine gute Erreichbarkeit legen. Hier lassen sich Wohnträume verwirklichen.Besichtigungen sind jederzeit frei möglich.Neugierig geworden? Alle weiteren Details entnehmen Sie bitte der oben angehängten Verkaufsdokumentation.Isler-Consolis AG, Technikumstrasse 73, 8401 Winterthur, Tel. 052 267 81 00, Dorentina Bytyqi Wegzeit Neu - - 1 / 4 Preis auf Anfrage Top Lüss, 8542 Wiesendangen Im Baurecht abzugeben: 14’770 m2 Bauland an bester Lage im steuergünstigen Wiesendangen Im Baurecht abzugeben:14’770 m2 Bauland an bester Lage im steuergünstigen WiesendangenGrundstück WD4674 – Lüss WiesendangenAlle Details zum Grundstück, zum Baurechtsvertrag sowie zu den Vergabekriterien finden sie im angefügten Dossier.Verbindliche Angebote für eine Übernahme des Baurechtsvertrages inklusive Finanzierungsnachweis sind einzureichen an:Gemeinde Wiesendangenz. Hd. Martin SchindlerSchulstrasse 208542 Wiesendangen Bitte verwenden Sie für die Angebotseingabe das Formular im Anhang.Eingabeschluss: Montag, 20. Oktober 2025, 11.00 Uhr Wegzeit Neu - - 1 / 1 Preis auf Anfrage Top Büntlistrasse 1, 8174 Stadel Bauland in Stadel b. Niederglatt Die Primarschule Stadel hat zwei Landparzellen zu verkaufen. Nummber 305 & 306. 305 ist unbebaut, hingegen 306 hat ein Gebäude, welches als Kindergarten und Mietwohnungen genutzt wurde. Wir möchten die beiden Landparzellen zusammen verkaufen. Der Kontakt für die erste Anlaufstelle ist Rolf Schindelholz einer unserer Mitarbeiter in der Schulverwaltung. Geleitet wird das Projekt von Patrick Heusser dem Finanzvorstand der Primarschulpflege Stadel. Wegzeit Neu - - 1 / 12 CHF 2’323’840.– Hürstringstrasse 37, 8046 Zürich Grundstück mit bestehendem EFH und grossem Potenzial Gerne stellen wir Ihnen das Grundstück mit grossem Potenzial und vielen Möglichkeiten vor.Nach Absprache verkaufen wir an ruhiger Lage in Zürich ein Grundstück mit bestehendem Einfamilienhaus. Interessant an diesem Objekt ist jedoch, dass Sie beim Kauf bereits über die zugehörige Baubewilligung verfügen, welche es Ihnen erlaubt, den Wohnraum auf dieser Parzelle nach Ihren Wünschen zu vergrössern und zu sanieren.Nicht weit vom Zürcher Hauptbahnhof entfernt, hinter dem Käferberg liegt die grosszügige Parzelle mitten in einem ruhigen Wohnquartier mit 30er-Zone.Zu Fuss erreichen Sie eine Bushaltestelle, sowie auch den kleinen Wald, der sich ideal für kürzere Spaziergänge eignet.Die wichtigsten Infos in Kürze: • Landparzelle inkl. Einfamilienhaus und Baubewilligung zum Ausbau der Wohnfläche • Baujahr 1934 • Grundstückfläche von 410 m2 • Projektmöglichkeit 1: Ausbau zum Mehrfamilienhaus mit zwei Eigentums- oder Mietwohnungen • Projektmöglichkeit 2: Ausbau zum Generationenhaus Erleben Sie die ruhige Atmosphäre und gleichzeitige Nähe zum Stadtzentrum bei einem persönlichen Besuch!Für nähere Informationen zum Objekt oder einen Besichtigungstermin dürfen Sie sich gerne jederzeit bei uns melden. Wegzeit Neu - - 1 / 11 CHF 3’290’400.– Luzernerstrasse 57, 8903 Birmensdorf (ZH) Sonnige Aussichtslage Im Auftrag unseres Kunden verkaufen wir ein Bauland an sonniger Aussichtlage mit 1'228 m² Grundstücksfläche (Wohnzone W2).Die bestehende Liegenschaft präsentiert sich in einem dem Alter entsprechend gut unterhaltenen Zustand.Verkaufsrichtpreis: CHF 2'400'000Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot. Wegzeit Neu - - 1 / 13 CHF 1’302’440.– Kanalweg 2, 8714 Feldbach Bauland für projektiertes Einfamilienhaus Im beschaulichen Dorf Feldbach am Zürichsee ist dieses Grundstück mit einer bestehenden, einseitig angebauten Scheune zu verkaufen. Im Kaufpreis inbegriffen ist ein bewilligungsfähiges Vorprojekt für ein Einfamilienhaus als Ersatzbau der Scheune.Das Objekt bietet Ihnen die einmalige Möglichkeit, Ihren Traum vom Eigenheim an idyllischer Lage zu verwirklichen. Es bietet genügend Platz für eine Familie, auch eine Kombination von "Wohnen und Arbeiten" ist denkbar.Innert 30 Minuten sind Sie mit der S-Bahn in Zürich, auch Kindergarten und Primarschule sind nah. Einkaufsmöglichkeiten bestehen in Hombrechtikon, Stäfa und Rapperswil. Im Sommer lockt in unmittelbarer Nähe eine Abkühlung in der schmucken Seebadi Feldbach.Es besteht ein aktueller Kostenvoranschlag für das Haus (Holzelementbauweise) inkl. Umgebung, Bau- und Nebenkosten in der Höhe von Fr. 1'380'000.--.Haben wir Sie neugierig gemacht? Dann rufen Sie uns an. Gerne beantworten wir Ihre Fragen oder stellen Ihnen unsere Verkaufsdokumentation zum Studium zu. Die Liegenschaft kann selbstverständlich auch besichtigt werden. Wir freuen uns auf Ihren Anruf. Wegzeit Neu - - 1 / 13 CHF 4’111’620.– 5.5 Zimmer Schaffhauserstrasse 226b, 8057 Zürich Mehr Raum fürs Leben: Reihenhaus mit Potenzial Attraktive Stadtliegenschaft mit ausgearbeitetem ProjektIm Zürcher Kreis 11 veräussern wir ein hübsches Reiheneinfamilien-Eckhaus mit grosszügigem Umschwung. Die Liegenschaft und das Grundstück verfügen über viel Ausnützungspotenzial und ermöglicht so die Realisation spannender Projekte sowohl im Umbau als auch Neubau.Diese Liegenschaft überzeugt durch viele Besonderheiten: • grosszügiger Umschwung mit viel Potenzial • Blick ins Grüne von nahezu allen Fenstern • Schwedenofen im Wohnbereich • viel Stauraum durch Wandschränke und Estrich • Altbaucharme in modernem Quartier • zentrale und familienfreundliche Lage • sonnenverwöhnter Standort Haben wir Ihr Interesse geweckt? Bestellen Sie noch heute unsere ausführliche Verkaufsdokumentation mittels Kontaktformular und Sie erhalten weitere spannende Informationen zur Immobilie. Wir freuen uns über Ihre Kontaktaufnahme!Une oasis de verdure dans la ville de Zurich avec un projet élaboréDans le quartier 11 de Zurich, nous vendons une jolie maison mitoyenne en angle avec de vastes alentours. L'immeuble et le terrain disposent d'un grand potentiel d'exploitation et permettent ainsi la réalisation de projets passionnants, tant en transformation qu'en construction neuve.Cette propriété convainc par ses nombreuses particularités : • Un vaste terrain avec beaucoup de potentiel • Une vue sur la verdure depuis presque toutes les fenêtres • Un poêle suédois dans le séjour • beaucoup d'espace de rangement grâce aux armoires murales et au grenier • Le charme d'un ancien bâtiment dans un quartier moderne • Un emplacement central et favorable aux familles • Un emplacement ensoleillé Nous avons éveillé votre intérêt ? Commandez dès aujourd'hui notre documentation de vente détaillée au moyen du formulaire de contact et vous recevrez d'autres informations passionnantes sur le bien immobilier. Nous nous réjouissons de votre prise de contact!A green oasis in the city of Zurich with an elaborate projectIn Zurich's Kreis 11 district, we are selling a pretty terraced single-family corner house with spacious grounds. The property and the plot have a lot of utilization potential and thus enable the realization of exciting projects both in conversion and new construction.This property boasts many special features: • spacious grounds with lots of potential • view of the countryside from almost all windows • Swedish stove in the living area • lots of storage space thanks to wall cupboards and attic • old building charm in a modern district • central and family-friendly location • sun-drenched location Have we piqued your interest? Order our detailed sales documentation today using the contact form and you will receive further exciting information about the property. We look forward to hearing from you! Wegzeit Neu - - 1 / 13 CHF 4’044’440.– Mühlemattstrasse 12, 8135 Langnau am Albis Bauland oder bestehendes Einfamilienhaus zum Verkauf! Dieses freistehende Einfamilienhaus befindet sich an ruhiger Lage und bietet eine seltene Kombination aus architektonischem Charakter, grosszügigem Umschwung und inspirierendem Entwicklungspotenzial. Eingebettet in viel Grün und umgeben von Bäumen geniessen Sie hier Privatsphäre, Ruhe – und eine wunderschöne Weitsicht.Das Haus überzeugt durch eine unverwechselbare Ausstrahlung. Die Backsteinwände im Innenbereich verleihen dem Wohnraum eine warme, natürliche Atmosphäre, während das Cheminée im Wohnzimmer für Behaglichkeit an kühleren Tagen sorgt. Der Grundriss ist offen und einladend, ergänzt durch grosse Fensterfronten, die Licht und Natur ins Haus holen.Ein Highlight ist die grosszügige Terrasse mit herrlichem Ausblick – ideal für gemütliche Stunden im Freien. Der Garten ist weitläufig und bietet viel Platz für individuelle Gestaltung. Mit etwas Aufmerksamkeit lässt sich hier ein wunderbares grünes Paradies schaffen – ob als Familiengarten, Rückzugsort oder für kreative Projekte im Freien.Dank der Grundstücksgrösse und der Lage eröffnet die Liegenschaft auch interessante Perspektiven für einen möglichen Ersatzneubau - wie ein modernes Einfamilienhaus oder ein Mehrfamilienhaus.Gerne stellen wir Ihnen weitere Informationen zur Verfügung oder vereinbaren einen persönlichen Besichtigungstermin. Entdecken Sie das Potenzial und die besondere Atmosphäre dieses einzigartigen Ortes. In der Verkaufsdokumentation finden Sie alle wichtigen Informationen. Wegzeit Neu - - 1 / 6 Ruhige Lage CHF 3’358’950.– 8192 Glattfelden ZWEIFELSFREIES BAULAND IN ZWEIDLEN Im beliebten Zweidlen verkaufen wir ein eine attraktive, 1'226 m² grosse Baulandparzelle mit Bestandesobjekt.Unsere Projektstudie zeigt eine hohe Ausnutzung für die Erstellung eines Mehrfamilienhauses. • Anrechenbare mögliche Bruttogeschossfläche von max. 940 m² (Projekt 789 m²) • Wohn- und Gewerbezone WG 2.3 • Kein Denkmalschutz beim Bestandesobjekt • Die Deutsche Grenze in Kaiserstuhl ist nur 8 Autominuten entfernt • Der Flughafen Zürich ist in nur 19 Autominuten erreichbar Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: Referenznummer: 25-12278Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen! Ruhige Lage Wegzeit - - 1 / 12 Preis auf Anfrage Überlandstrasse 23, 8340 Hinwil Industrie- und Baulandparzelle an attraktivem Standort im Zürcher-Oberland Im pulsierenden Industriegebiet von Hinwil verkaufen wir ein Industriebaugrundstück an einer top frequentierter Lage, direkt an der Hauptachse in Rapperswil Wetzikon Pfäffikon ZH. Die Baulandparzelle befindet sich am Rand der Industriezone und grenzt an die Wohnzone zu Hinwil ZH.Eckdaten:- Grundstück-Fläche total 4'246 m2- Bauzone Industrie/Gewerbe IG/7 - Baumassenziffer 7 m3/m2- Gebäudehöhe maximal 21.5 m- Gebäudelänge maximal offen- Grosser Grenzabstand Nationalstrasse- Allseitiger Gebäudeabstand 3.5 m1- Maximal mögliche Baumasse ca. 30'000 m3- Bruttogeschossfläche ca. 9'500 m2Das Baugrundstück wird derzeit noch mit zwei Wohneinheiten, der Autowerkstatt mit separatem Showroom und einer Tankstelle genutzt. Rund um die Liegenschaft bieten sich grosse, befestigte Flächen zur Nutzung an. Wegzeit Neu - - 1 / 7 CHF 5’484’000.– 8156 Oberhasli ATTRAKTIVE INVESTITION IN FLUGHAFENNÄHE Unweit des Flughafens Kloten bieten wir ein attraktives Gewerbebauland für ein Neubauprojekt im strategisch ideal gelegenen Oberhasli zum Verkauf an. • Parzellenfläche: 2'010 m² • Zone: Gewerbezone • Optionen für Investoren: Neubau einer Gewerbeimmobilie mit bis zu 5'000 m² Geschossfläche (Verkauf oder Vermietung) • Optionen für Selbstnutzer: Neubau einer für die Selbstnutzung konzipierten Gewerbeimmobilie mit bis zu 5'000 m² Geschossfläche • Es besteht die Möglichkeit, die derzeit vermietete Gewerbeliegenschaft weiterzuführen. Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: Referenznummer: 24-101578Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen! Wegzeit - - 1 / 6 CHF 1’919’390.– 8187 Weiach WILLKOMMENE WERTSCHÖPFUNG IN WEIACH Im steuergünstigen Weiach bieten wir an ruhiger Ortskernlage eine wohldimensionierte, unbebaute Baulandparzelle zum Verkauf an. Unsere Baulandstudie sieht die Erstellung von zwei attraktiven Doppeleinfamilienhäusern mit 4 Wohneinheiten vor. • 1'157 m² Parzellenfläche mit bestehender Zufahrt im Wegrecht • Unser Projekt sieht die Erstellung von zwei Doppeleinfamilienhäusern mit je zwei Vollgeschossen vor • Total erstellbare Bruttogeschossfläche von 648 m² • Maximal erstellbare Gebäudelänge von 25 Metern • Der Flughafen Zürich ist in nur 20 Minuten zu erreichen, die Stadt Zürich ist nur rund 30 Km entfernt Interessiert? Weitere Informationen und Bilder zum Grundstück sowie Besichtigungsmöglichkeiten unter: Referenznummer: 24-99121Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch- Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen! Wegzeit - - 1 / 1 CHF 2’399’240.– In der Gass 2, 8627 Grüningen Grundstück mit Baubewilligung für MFH zu verkaufen Zum Verkauf steht ein Grundstück mit bewilligtem Neubauprojekt. Gebäude C des Enssamble an der Binzikerstrasse 21 / In der Gass 2, 8627 Grüningen. Die aktuell bestehenden Garagen können abgebrochen werden und durch einen Neubau mit 8 Wohnungen unterschiedlicher Grösse mit attraktiven Aussenbereich ersetzt werden. Zusätzlich wurde der gemeinsame Bau einer Tiefgarage für 11 Parkplätze mit der Zufahrt über die Strasse "In der Gass" bewilligt. Wegzeit Neu - - 1 / 6 CHF 2’879’100.– Rotweg 20, 8820 Wädenswil Ihr neues Projekt mit Seesicht Im Auftrag unseres Kunden verkaufen wir an bevorzugter, erhöhter und ruhiger Wohnquartierlage mit schöner See- und Fernsicht, 706 m² Bauland mit Rückbauobjekt.Verkaufsrichtpreis: CHF 2'100'000.00Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot. Wegzeit Neu - - 1 / 7 CHF 651’220.– Auf Anfrage 1, 8195 Wasterkingen Attraktives Baugrundstück in ruhiger, ländlicher Umgebung Willkommen in Wasterkingen, einer idyllischen und ruhigen Gemeinde im Zürcher Unterland, die für ihre hohe Lebensqualität, ländliche Gelassenheit und dennoch gute Erreichbarkeit bekannt ist. Genau hier wartet ein attraktives Baugrundstück auf Sie – die ideale Basis für Ihr zukünftiges Zuhause.Das Grundstück ist voll erschlossen und liegt in der Kernzone B, was Ihnen zahlreiche Gestaltungsmöglichkeiten eröffnet. Ob ein modernes Einfamilienhaus, ein klassisches Zuhause im Dorfcharakter oder ein individuelles Architektenprojekt – hier können Sie Ihre Wohnträume ganz nach Ihren Vorstellungen verwirklichen.Die charmante Gemeinde Wasterkingen besticht durch ihre ruhige Lage inmitten von Feldern, Reben und Natur.Dieses ImmoSky-Angebot bietet folgende Mehr Leistung:+ Voll erschlossen+ Ruhige Gemeinde+ Ideale Grösse für flexibilität (650m²)+ Kernzone B+Überbauungsziffer für Hauptgebäude 30%Dieses Grundstück bietet Ihnen die seltene Gelegenheit, ländliche Idylle mit urbaner Nähe zu vereinen – ein Ort, an dem Sie zur Ruhe kommen und dennoch bestens angebunden sind.Erfüllen Sie sich hier den Traum vom Eigenheim und gestalten Sie Ihr persönliches Refugium in Wasterkingen.Haben wir Sie mit diesem Angebot überzeugt? Dann zögern Sie nicht und kontaktieren Sie uns für weitere Fragen oder einen Besichtigungstermin!(Das Verkaufsdossier wird in der Regel innerhalb von maximal 24 Stunden an Sie versendet. Bitte überprüfen Sie auch Ihren SPAM-Ordner.) Wegzeit - - 1 / 7 CHF 7’540’490.– Staldernstrasse 13, 8158 Regensberg Entwicklungsgrundstück an top Lage in der Kernzone 2 In der gefragten Gemeinde Regensberg (ZH) steht ein hervorragend gelegenes Grundstück zum Verkauf, das sich ideal für Investoren, General- oder Totalunternehmer eignet. Die 2.557 m² grosse Parzelle Nr. 949 befindet sich in der Kernzone 2, die vielfältige bauliche und nutzungsbezogene Entwicklungsmöglichkeiten zulässt, insbesondere für Wohn- oder gemischt genutzte Projekte.Aktuell steht auf dem Grundstück ein nicht erhaltenswertes Gebäude, das im Rahmen einer Neuentwicklung rückgebaut werden kann. Eine Baueingabe oder Bewilligung liegt nicht vor, sodass volle gestalterische Freiheit innerhalb der geltenden bau- und zonenrechtlichen Rahmenbedingungen besteht.Berechnungen zeigen, dass eine nachhaltige Mietertragserwartung von rund CHF 485'600 pro Jahr realistisch erscheint - unter der Annahme einer Ausnutzung mit rund 1 664 m² Hauptnutzfläche (HNF) und 28 Tiefgaragenplätzen. Der ermittelte Kapitalisierungssatz liegt bei 4.20 %.Wesentliche Bewertungskennzahlen:Verkehrswert (diskontierter Landwert): CHF 5'505'000Ertragswert im erneuerten Zustand: CHF 11'556'795Realwert (hypothetisch): CHF 12'485'000Potenzieller Verkaufserlös: CHF 16'190'000Bruttorendite (Mietwert): 4.20%Die hypothetische Bebauung sieht zwei Mehrfamilienhäuser mit einer Bruttogeschossfläche (BGF) von insgesamt 2'080 m² vor - entsprechend einer Ausnützungsziffer von 0.81, voll im Rahmen der Zonenordnung. Die kalkulierten Baukosten (BKP 2-5) belaufen sich auf ca. CHF 8.74 Mio. Der diskontierte Landwert pro m² liegt bei CHF 2'155, was das wirtschaftliche Potenzial zusätzlich unterstreicht.Die Kernzone 2 erlaubt neben der reinen Wohnnutzung auch Mischnutzungen, beispielsweise mit gewerblichen Angeboten im Erdgeschoss. Dies ist ein zusätzlicher Vorteil für flexible, standortgerechte Entwicklungskonzepte. Die Lage in Regensberg bietet ruhige Wohnqualität in der Nähe der Agglomeration Zürich und ist in eine attraktive historische Umgebung eingebettet.Fazit: Das Grundstück bietet die seltene Gelegenheit, ein entwicklungsfähiges Grundstück an bester Lage mit bestehendem Abbruchobjekt zu akquirieren und nach eigenen Vorstellungen zu bebauen. Dank der flexiblen Nutzungsmöglichkeiten und des attraktiven Standorts stellt diese Investition eine hervorragende Ausgangslage für renditestarke Projektentwicklungen dar.Für detaillierte Informationen stehen wir Ihnen gerne zur Verfügung. Wegzeit Neu - - 1 / 3 CHF 1’686’330.– 8187 Weiach Ihr Bauland in Weiach ZH zum Schnäppchenpreis! Ihre Chance auf ein vielversprechendes Bauprojekt In der beliebten Gemeinde Weiach, eingebettet in eine ruhige und dennoch gut erreichbare Lage, erwartet Sie die Parzelle 1602. Das Grundstück in der Kernzone (K) bietet ideale Rahmenbedingungen für Investoren und Bauherren, die von Flexibilität und klar definierten Bauvorgaben profitieren möchten.Die Parzelle ermöglicht eine Bebauung mit bis zu 2 Vollgeschosse, einem anrechenbaren Dachgeschoss sowie einem Untergeschoss. Die maximale Gebäudehöhe von 7.50 m und die erlaubte Gebäudelänge von bis zu 30 m eröffnen vielseitige Bau- und Gestaltungsmöglichkeiten. Mit grosszügigen Grenzabständen von mindestens 6 m (grosser Grenzabstand) und 4 m (kleiner Grenzabstand) bietet das Grundstück genügend Raum für ansprechende Projekte mit Privatsphäre.Dieses Bauland ist die perfekte Gelegenheit, um ein individuelles Projekt in einer aufstrebenden Region zu realisieren. Egal, ob Sie Wohnraum schaffen oder ein Mischprojekt umsetzen möchten - die Parzelle hält alle Optionen offen.Ihre Vorteile auf einen Blick: • Vorhandene Machbarkeitsstudie • Bebaubare Fläche 1026 m² • Landwirtschaftszone 479 m² (CHF 60'000.- exkl.) • Kernzone (K) mit klar definierten Bauvorgaben • Maximal 2 Vollgeschosse, 1 anrechenbares Dach- und Untergeschoss • Gebäudehöhe bis zu 7.50 m • Maximale Gebäudelänge: 30 m • Grenzabstände: mind. 6 m und 4 m • Optimale Voraussetzungen für vielseitige Bauprojekte Nutzen Sie diese Gelegenheit, um ein nachhaltiges und gewinnbringendes Projekt in einer gefragten Region zu realisieren! Wegzeit - - 1 / 6 CHF 3’633’140.– Riedwiesenstrasse 20, 8305 Dietlikon RESERVIERT - Industrie-Baulandparzelle an zentraler Lage in Dietlikon ZH Mit Freude präsentieren wir Ihnen eine einzigartige und äusserst seltene Baulandparzelle an zentraler Lage in Dietlikon ZH – eine aussergewöhnliche Gelegenheit mit hervorragenden Eigenschaften, die sich besonders für Investoren eignet.Zentrale Lage: Die Parzelle befindet sich in einer äusserst gefragten Gegend mit hervorragender Anbindung: Flughafen Zürich erreichbar in 10 Fahrminuten Stadt Zürich erreichbar in 12 Fahrminuten • Visibilität: Ihr Unternehmen wird von der Autobahn aus perfekt sichtbar sein, was optimale Werbemöglichkeiten bietet (ca. 500 m2 Fassade für Werbung). • Baumassenziffer: Profitieren Sie von der hohen Baumassenziffer 10.0, die maximale Flexibilität und Nutzungseffizienz ermöglicht. • Näherbaurechte: Die Parzelle verfügt über Näherbaurechte rechts und links. Auf der Rückseite kann ein Näherbaurecht von der Stadt Zürich eingeholt werden • ca. 3'500 m2 Bruttogeschossfläche möglich • Tiefgarage / Untergeschoss bis zu ca. 800 m2 gross realisierbar • Maximale Gesamthöhe 20 m. 7 Stockwerke à 500 m2 Bruttogeschossfläche und 2.85 m Raumhöhe (brutto) möglich • Parzelle: Die ebene Fläche der Parzelle erleichtert die Bauplanung und Ausführung. • Form: Die Parzelle hat eine ideale Form, die vielseitige Bebauungsmöglichkeiten erlaubt. • Autobahnknotenpunkt: Brüttiseller Kreuz, direkt an einem der wichtigsten Autobahnknotenpunkt der Schweiz gelegen, bietet die Parzelle hervorragende Erreichbarkeit und Logistikvorteile • Störendes Gewerbe: Die Lage ist auch für Gewerbe geeignet, das potenziell störend sein kann. • Kulturzentren sowie Hotelbetriebe auch möglich. Jetzt oder nie – Ihre Chance auf ein grossartiges Investment:Solch eine Industrie-Baulandparzelle in dieser Lage kommt äusserst selten auf den Markt – seit geraumer Zeit gab es in dieser gefragten Gegend kein vergleichbares Angebot. Sichern Sie sich jetzt dieses einmalige Grundstück, ideal für visionäre Unternehmer und Investoren, die auf einen strategisch optimalen Standort setzen.Haben wir Ihr Interesse geweckt? Dann nehmen Sie noch heute Kontakt mit uns auf. Gerne lassen wir Ihnen das detaillierte Verkaufsdossier inklusive Machbarkeitsstudie zukommen – exklusiv und unverbindlich. Wegzeit Neu - -12...4 -Suche speichern Karte -Vorschläge basierend auf deinen Suchresultaten - -Startseite -Kaufen -Bauland zum Kaufen -Schweiz - -Bezirke im Kanton Kanton Zürich -Bauland kaufen Bezirk Affoltern|Bauland kaufen Bezirk Andelfingen|Bauland kaufen Bezirk Bülach|Bauland kaufen Bezirk Dielsdorf|Bauland kaufen Bezirk Hinwil|Bauland kaufen Bezirk Horgen|Bauland kaufen Bezirk Meilen|Bauland kaufen Bezirk Pfäffikon|Bauland kaufen Bezirk Uster|Bauland kaufen Bezirk Winterthur|Bauland kaufen Bezirk Dietikon|Bauland kaufen Zürich -Weitere Immobiliensuchen in Kanton Zürich -Immobilien mieten Kanton Zürich|Wohnung mieten Kanton Zürich|Haus mieten Kanton Zürich|Möbliertes Wohnobjekt mieten Kanton Zürich|Parkplatz, Garage mieten Kanton Zürich|Büro mieten Kanton Zürich|Gewerbe mieten Kanton Zürich|Neubau zum Mieten Kanton Zürich|Wohnung kaufen Kanton Zürich|Haus kaufen Kanton Zürich|Immobilien kaufen Kanton Zürich|Mehrfamilienhaus kaufen Kanton Zürich|Parkplatz, Garage kaufen Kanton Zürich|Gewerbe, Büro, Lager kaufen Kanton Zürich|Neubau zum Kaufen Kanton Zürich -Homegate - -Über uns -Kontakt & Hilfe -Geschäftskunde werden -Newsletter abonnieren -Medien -Karriere -Ombudsstelle -Werbung auf Homegate -Sitemap - -Immobilien - -Inserieren -Mieten -Kaufen -Vermieten -Verkaufen -Finanzieren -Ratgeber -Kategorien - -Rechtliches - -Datenschutz -Leistungsbeschrieb -Sicherheitstipps -Impressum -AGB -Sicherheitsproblem melden -Privatsphäre-Einstellungen - -Services - -Suchabo anlegen -Finanzierungsrechner -Steuerrechner -Betreibungsauszug -Gemeinderatgeber -Mietkaution -Umzugshilfe -Wohneigentum schätzen -Agenturverzeichnis - -App herunterladen - -Deutsch -Français -Italiano -English - -Social Media - -SMG Swiss Marketplace GroupImmoScout24Alle Immobilienhome.chimmostreet.ch -© Copyright 2025 by SMG Swiss Marketplace Group AG. Alle Rechte vorbehalten.Die Vervielfältigung und Übernahme von Inseraten durch Dritte, insbesondere von Fotos und persönlichen Daten in diesen Inseraten, verletzt die damit verbundenen Rechte und ist ausdrücklich verboten. \ No newline at end of file diff --git a/test_web_content_20251002_204000/main_url_005_www.immoscout24.ch_de_grundstueck_kaufen_kanton-zuerich.txt b/test_web_content_20251002_204000/main_url_005_www.immoscout24.ch_de_grundstueck_kaufen_kanton-zuerich.txt deleted file mode 100644 index 0ec29e9d..00000000 --- a/test_web_content_20251002_204000/main_url_005_www.immoscout24.ch_de_grundstueck_kaufen_kanton-zuerich.txt +++ /dev/null @@ -1,324 +0,0 @@ -Title: https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich -URL: https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich -Type: Main URL -Extracted: 2025-10-02 20:40:00 -================================================================================ - -70 Bauland zum Kaufen: Kanton Zürich | ImmoScout24 - - Suchen - Services -Inserat erstellen -Favoriten -Mein Konto -Menü - - Suchen - Services - Bewerten - Magazin -Inserat erstellen -Favoriten -Mein Konto -Menü -DE - DE - FR - IT - EN - -Bauland zum Kaufen -Kanton Zürich - -Wo? -Kanton Zürich -Kanton Zürich -CHF bis -Filter -70 Objekte -70 Treffer - Bauland zum Kaufen: Kanton Zürich - 1 / 16 360m², CHF 2’563’760.– Top Luegetenstrasse 11, 8489 Wildberg Ihr neues Zuhause mit Potenzial - Idyllisches Landhaus mit Baulandreserve Ihr neues Zuhause Willkommen in Ihrem zukünftigen Traumdomizil - ein grosszügiges, freistehendes Landhaus an ruhiger und idyllischer Aussichtslage im malerischen Wildberg. Hier vereinen sich ländliche Idylle, Privatsphäre und die seltene Möglichkeit, Wohnraum nach eigenen Vorstellungen zu schaffen oder zu erweitern.Ob als charmantes Familienrefugium mit grossem Garten oder als Investitionsobjekt mit Entwicklungspotenzial - dieses einzigartige Anwesen bietet Ihnen beide Optionen. Auf dem 1339m² grossen Grundstück geniessen Sie nicht nur viel Platz zum Leben, sondern verfügen auch über eine wertvolle Baulandreserve, die Ihnen vielfältige Gestaltungsmöglichkeiten eröffnet. Erste Abklärungen zeigen: Es besteht die Möglichkeit, ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren - ein echter Mehrwert für visionäre Käufer.Tauchen Sie ein in eine grüne Oase mit Weitblick - ein Ort, der Ruhe schenkt und inspiriert.Highlights auf einen Blick • Idyllische, ruhige Aussichtslage mit hohem Erholungswert • Grosszügiges Grundstück mit 1339m², ideal zur Eigennutzung und/oder für die Entwicklung eines Neubaus • Baulandreserve: Attraktives Entwicklungspotenzial - gemäss erster Einschätzung besteht die Möglichkeit, zusätzlich zum bestehenden Einfamilienhaus ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren (unverbindlich, ohne Gewähr) • Blühender Garten mit verschiedenen Sitzplätzen, Pergola mit Aussencheminée, Gartenhäusern, gepflegtem Baumbestand und weitläufigen Grünflächen • Solide Bausubstanz mit Doppelschalenmauerwerk • Grosszügiges Raumkonzept mit ca. 220m² Wohnfläche und ca. 96m² zusätzlichem Stauraum im Untergeschoss. Total ca. 360m² Bruttofläche. • Geräumiger Wohnbereich mit gemütlichem Kachelofen - ein Ort zum Ankommen und Wohlfühlen • Praktische Wohnküche mit integriertem Essbereich - ideal für gesellige Stunden • 4 helle Schlafzimmer - ideal für Familien oder Homeoffice • 2 Nasszellen mit Tageslicht • Ausgebauter Estrich für zusätzlichen Raum oder kreative Nutzungsmöglichkeiten • Beheizt durch Elektrospeicher und wassergeführte Fussbodenheizung • Garage mit elektrischem Tor und weitere Parkmöglichkeiten auf dem Grundstück • Mit einer stilvollen Modernisierung verwandeln Sie dieses Haus in ein wahres Schmuckstück Verkaufspreis: CHF 1'870'000.-Mit unserer virtuellen 360-Grad-Tour können Sie bereits die ersten Eindrücke dieser tollen Liegenschaft gewinnen. Sehr gerne zeigen wir Ihnen diese Liegenschaft direkt vor Ort und freuen uns auf Ihre Kontaktaufnahme.Weitere EckdatenBaujahr Haus: 1984, Baujahr Gerätehaus: 1986, Kubatur Haus (GVZ): 936m³, Kubatur Gerätehaus (GVZ): 40m³, Grundbuchblatt: Nr. 437, Kataster-Nr.: 249, 1/4 subjektiv-dingliches Miteigentum an Blatt 444, Kataster 249. Nettowohnfläche: ca. 220m², Bruttowohnfläche: ca. 360m², Grundstücksfläche: 1'339m².Massivbauweise, Doppelschalenmauerwerk, neuwertige Holzmetallfenster (EgoKiefer) mit dreifacher Verglasung und Sprossen & Holzläden. Elektrospeicherofen, wassergeführte Fussbodenheizung, Elektroboiler 300 Liter.Treppenlift, Garage mit elektrischem Torantrieb. Küche im Landhausstil mit Granitabdeckung, Geschirrspüler, Induktions-Kochherd und Kühlschrank mit Gefrierfach.BodenbelägeEG: Entrée, Gang, Dusche, Küche, Essen mit Plattenboden.OG: Zimmer und Vorplatz mit Laminat in Holzoptik. Bad mit Platten. Wegzeit Neu 28 min.Station: Rämismühle-Zell - 1 / 4 Preis auf Anfrage Top Lüss, 8542 Wiesendangen Im Baurecht abzugeben: 14’770 m2 Bauland an bester Lage im steuergünstigen Wiesendangen Im Baurecht abzugeben:14’770 m2 Bauland an bester Lage im steuergünstigen WiesendangenGrundstück WD4674 – Lüss WiesendangenAlle Details zum Grundstück, zum Baurechtsvertrag sowie zu den Vergabekriterien finden sie im angefügten Dossier.Verbindliche Angebote für eine Übernahme des Baurechtsvertrages inklusive Finanzierungsnachweis sind einzureichen an:Gemeinde Wiesendangenz. Hd. Martin SchindlerSchulstrasse 208542 Wiesendangen Bitte verwenden Sie für die Angebotseingabe das Formular im Anhang.Eingabeschluss: Montag, 20. Oktober 2025, 11.00 Uhr Wegzeit Neu 9 min.Station: Wiesendangen - 1 / 12 CHF 2’323’840.– Hürstringstrasse 37, 8046 Zürich Grundstück mit bestehendem EFH und grossem Potenzial Gerne stellen wir Ihnen das Grundstück mit grossem Potenzial und vielen Möglichkeiten vor.Nach Absprache verkaufen wir an ruhiger Lage in Zürich ein Grundstück mit bestehendem Einfamilienhaus. Interessant an diesem Objekt ist jedoch, dass Sie beim Kauf bereits über die zugehörige Baubewilligung verfügen, welche es Ihnen erlaubt, den Wohnraum auf dieser Parzelle nach Ihren Wünschen zu vergrössern und zu sanieren.Nicht weit vom Zürcher Hauptbahnhof entfernt, hinter dem Käferberg liegt die grosszügige Parzelle mitten in einem ruhigen Wohnquartier mit 30er-Zone.Zu Fuss erreichen Sie eine Bushaltestelle, sowie auch den kleinen Wald, der sich ideal für kürzere Spaziergänge eignet.Die wichtigsten Infos in Kürze: • Landparzelle inkl. Einfamilienhaus und Baubewilligung zum Ausbau der Wohnfläche • Baujahr 1934 • Grundstückfläche von 410 m2 • Projektmöglichkeit 1: Ausbau zum Mehrfamilienhaus mit zwei Eigentums- oder Mietwohnungen • Projektmöglichkeit 2: Ausbau zum Generationenhaus Erleben Sie die ruhige Atmosphäre und gleichzeitige Nähe zum Stadtzentrum bei einem persönlichen Besuch!Für nähere Informationen zum Objekt oder einen Besichtigungstermin dürfen Sie sich gerne jederzeit bei uns melden. Wegzeit Neu 22 min.Station: Zürich Seebach - 1 / 11 CHF 3’290’400.– Luzernerstrasse 57, 8903 Birmensdorf (ZH) Sonnige Aussichtslage Im Auftrag unseres Kunden verkaufen wir ein Bauland an sonniger Aussichtlage mit 1'228 m² Grundstücksfläche (Wohnzone W2).Die bestehende Liegenschaft präsentiert sich in einem dem Alter entsprechend gut unterhaltenen Zustand.Verkaufsrichtpreis: CHF 2'400'000Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot. Wegzeit Neu 19 min.Station: Birmensdorf -Dein Immobilienexperte vor Ort - Stöhr Immobilien GmbH berät dich persönlich zur optimalen Verkaufsstrategie für deine Immobilie. - 1 / 13 CHF 4’044’440.– Mühlemattstrasse 12, 8135 Langnau am Albis Bauland oder bestehendes Einfamilienhaus zum Verkauf! Dieses freistehende Einfamilienhaus befindet sich an ruhiger Lage und bietet eine seltene Kombination aus architektonischem Charakter, grosszügigem Umschwung und inspirierendem Entwicklungspotenzial. Eingebettet in viel Grün und umgeben von Bäumen geniessen Sie hier Privatsphäre, Ruhe – und eine wunderschöne Weitsicht.Das Haus überzeugt durch eine unverwechselbare Ausstrahlung. Die Backsteinwände im Innenbereich verleihen dem Wohnraum eine warme, natürliche Atmosphäre, während das Cheminée im Wohnzimmer für Behaglichkeit an kühleren Tagen sorgt. Der Grundriss ist offen und einladend, ergänzt durch grosse Fensterfronten, die Licht und Natur ins Haus holen.Ein Highlight ist die grosszügige Terrasse mit herrlichem Ausblick – ideal für gemütliche Stunden im Freien. Der Garten ist weitläufig und bietet viel Platz für individuelle Gestaltung. Mit etwas Aufmerksamkeit lässt sich hier ein wunderbares grünes Paradies schaffen – ob als Familiengarten, Rückzugsort oder für kreative Projekte im Freien.Dank der Grundstücksgrösse und der Lage eröffnet die Liegenschaft auch interessante Perspektiven für einen möglichen Ersatzneubau - wie ein modernes Einfamilienhaus oder ein Mehrfamilienhaus.Gerne stellen wir Ihnen weitere Informationen zur Verfügung oder vereinbaren einen persönlichen Besichtigungstermin. Entdecken Sie das Potenzial und die besondere Atmosphäre dieses einzigartigen Ortes. In der Verkaufsdokumentation finden Sie alle wichtigen Informationen. Wegzeit Neu 12 min.Station: Langnau-Gattikon - 1 / 13 CHF 1’302’440.– Kanalweg 2, 8714 Feldbach Bauland für projektiertes Einfamilienhaus Im beschaulichen Dorf Feldbach am Zürichsee ist dieses Grundstück mit einer bestehenden, einseitig angebauten Scheune zu verkaufen. Im Kaufpreis inbegriffen ist ein bewilligungsfähiges Vorprojekt für ein Einfamilienhaus als Ersatzbau der Scheune.Das Objekt bietet Ihnen die einmalige Möglichkeit, Ihren Traum vom Eigenheim an idyllischer Lage zu verwirklichen. Es bietet genügend Platz für eine Familie, auch eine Kombination von "Wohnen und Arbeiten" ist denkbar.Innert 30 Minuten sind Sie mit der S-Bahn in Zürich, auch Kindergarten und Primarschule sind nah. Einkaufsmöglichkeiten bestehen in Hombrechtikon, Stäfa und Rapperswil. Im Sommer lockt in unmittelbarer Nähe eine Abkühlung in der schmucken Seebadi Feldbach.Es besteht ein aktueller Kostenvoranschlag für das Haus (Holzelementbauweise) inkl. Umgebung, Bau- und Nebenkosten in der Höhe von Fr. 1'380'000.--.Haben wir Sie neugierig gemacht? Dann rufen Sie uns an. Gerne beantworten wir Ihre Fragen oder stellen Ihnen unsere Verkaufsdokumentation zum Studium zu. Die Liegenschaft kann selbstverständlich auch besichtigt werden. Wir freuen uns auf Ihren Anruf. Wegzeit Neu 6 min.Station: Feldbach - 1 / 13 5.5 Zimmer, CHF 4’111’620.– Schaffhauserstrasse 226b, 8057 Zürich Mehr Raum fürs Leben: Reihenhaus mit Potenzial Attraktive Stadtliegenschaft mit ausgearbeitetem ProjektIm Zürcher Kreis 11 veräussern wir ein hübsches Reiheneinfamilien-Eckhaus mit grosszügigem Umschwung. Die Liegenschaft und das Grundstück verfügen über viel Ausnützungspotenzial und ermöglicht so die Realisation spannender Projekte sowohl im Umbau als auch Neubau.Diese Liegenschaft überzeugt durch viele Besonderheiten: • grosszügiger Umschwung mit viel Potenzial • Blick ins Grüne von nahezu allen Fenstern • Schwedenofen im Wohnbereich • viel Stauraum durch Wandschränke und Estrich • Altbaucharme in modernem Quartier • zentrale und familienfreundliche Lage • sonnenverwöhnter Standort Haben wir Ihr Interesse geweckt? Bestellen Sie noch heute unsere ausführliche Verkaufsdokumentation mittels Kontaktformular und Sie erhalten weitere spannende Informationen zur Immobilie. Wir freuen uns über Ihre Kontaktaufnahme!Une oasis de verdure dans la ville de Zurich avec un projet élaboréDans le quartier 11 de Zurich, nous vendons une jolie maison mitoyenne en angle avec de vastes alentours. L'immeuble et le terrain disposent d'un grand potentiel d'exploitation et permettent ainsi la réalisation de projets passionnants, tant en transformation qu'en construction neuve.Cette propriété convainc par ses nombreuses particularités : • Un vaste terrain avec beaucoup de potentiel • Une vue sur la verdure depuis presque toutes les fenêtres • Un poêle suédois dans le séjour • beaucoup d'espace de rangement grâce aux armoires murales et au grenier • Le charme d'un ancien bâtiment dans un quartier moderne • Un emplacement central et favorable aux familles • Un emplacement ensoleillé Nous avons éveillé votre intérêt ? Commandez dès aujourd'hui notre documentation de vente détaillée au moyen du formulaire de contact et vous recevrez d'autres informations passionnantes sur le bien immobilier. Nous nous réjouissons de votre prise de contact!A green oasis in the city of Zurich with an elaborate projectIn Zurich's Kreis 11 district, we are selling a pretty terraced single-family corner house with spacious grounds. The property and the plot have a lot of utilization potential and thus enable the realization of exciting projects both in conversion and new construction.This property boasts many special features: • spacious grounds with lots of potential • view of the countryside from almost all windows • Swedish stove in the living area • lots of storage space thanks to wall cupboards and attic • old building charm in a modern district • central and family-friendly location • sun-drenched location Have we piqued your interest? Order our detailed sales documentation today using the contact form and you will receive further exciting information about the property. We look forward to hearing from you! Wegzeit Neu 4 min.Station: Berninaplatz - 1 / 12 Preis auf Anfrage Überlandstrasse 23, 8340 Hinwil Industrie- und Baulandparzelle an attraktivem Standort im Zürcher-Oberland Im pulsierenden Industriegebiet von Hinwil verkaufen wir ein Industriebaugrundstück an einer top frequentierter Lage, direkt an der Hauptachse in Rapperswil Wetzikon Pfäffikon ZH. Die Baulandparzelle befindet sich am Rand der Industriezone und grenzt an die Wohnzone zu Hinwil ZH.Eckdaten:- Grundstück-Fläche total 4'246 m2- Bauzone Industrie/Gewerbe IG/7 - Baumassenziffer 7 m3/m2- Gebäudehöhe maximal 21.5 m- Gebäudelänge maximal offen- Grosser Grenzabstand Nationalstrasse- Allseitiger Gebäudeabstand 3.5 m1- Maximal mögliche Baumasse ca. 30'000 m3- Bruttogeschossfläche ca. 9'500 m2Das Baugrundstück wird derzeit noch mit zwei Wohneinheiten, der Autowerkstatt mit separatem Showroom und einer Tankstelle genutzt. Rund um die Liegenschaft bieten sich grosse, befestigte Flächen zur Nutzung an. Wegzeit Neu 10 min.Station: Hinwil - 1 / 10 CHF 2’947’650.– Trottenrain 14, 8474 Dinhard Bewilligtes Bauprojekt im steuergünstigen Dinhard-Welsikon Das Bauland mit Magazingebäude befindet sich an zentraler Lage in Welsikon am Rande der Gemeinde Dinhard in der Kernzone. Die erreichte hohe Ausnutzung ermöglicht attraktive Neubauten an zentraler Lage. Visualisierungen und Grundrisse des bewilligten Bauprojekts finden Sie in der Dokumentation. Das Magazingebäude steht im kommunalen Inventar der schutzwürdigen Bauten. Es wurde deshalb in Absprache mit dem Heimatschutz und der Gemeinde Dinhard ein Schutzvertrag erarbeitet, der einen aussergewöhnlichen Umbau zu einem modernen Loft gestattet.Highlights: • bewilligtes Bauprojekt und Ausschreibungsplanung der Neubauten • Schutzvertrag • ausgezeichnete Lage in Welsikon • Steueroase (Gemeindesteuerfuss 83 %) • gut geschnittene Baulandparzelle • Gute ÖV-Anbindung (Bahnhof 170 m) Realisierung:Der Hauseigentümerverband Winterthur unterstützt Sie bei Bedarf gerne in enger Zusammenarbeit mit Kästle Architekten bei der Realisierung Ihres Neubauprojekts.Von der Planung bis hin zum Verkauf/Vermietung des fertigen Neubaus ? der Hauseigentümerverband Winterthur bietet Ihnen alle Dienstleistungen aus einer Hand. Es besteht keine Architekturverpflichtung.Interessenten sind herzlich eingeladen, mit uns Kontakt aufzunehmen.Rufen Sie unser Verkaufsteam über Telefon 052 209 01 68 an, wenn Sie zusätzliche Informationen oder eine Besichtigung wünschen. Wir freuen uns auf Sie.Ihr HEV-VerkaufsteamWichtig: Wir sind exklusiv mit dem Verkauf beauftragt. Direkte Eigentümerkontakte führen zu einem Interessentenausschluss. S.E.&.O. Wegzeit Neu 5 min.Station: Dinhard - 1 / 1 CHF 2’399’240.– In der Gass 2, 8627 Grüningen Grundstück mit Baubewilligung für MFH zu verkaufen Zum Verkauf steht ein Grundstück mit bewilligtem Neubauprojekt. Gebäude C des Enssamble an der Binzikerstrasse 21 / In der Gass 2, 8627 Grüningen. Die aktuell bestehenden Garagen können abgebrochen werden und durch einen Neubau mit 8 Wohnungen unterschiedlicher Grösse mit attraktiven Aussenbereich ersetzt werden. Zusätzlich wurde der gemeinsame Bau einer Tiefgarage für 11 Parkplätze mit der Zufahrt über die Strasse "In der Gass" bewilligt. Wegzeit Neu 54 min.Station: Esslingen - 1 / 25 CHF 2’604’890.– Im Königstal 2, 8487 Zell Wegzeit Neu 22 min.Station: Rämismühle-Zell - 1 / 25 CHF 4’112’990.– Im Königstal 3, 8487 Zell ZH Wegzeit Neu 22 min.Station: Rämismühle-Zell - 1 / 25 CHF 6’717’900.– Im Königstal 3, 8487 Zell ZH Wegzeit Neu 22 min.Station: Rämismühle-Zell - 1 / 6 CHF 2’879’100.– Rotweg 20, 8820 Wädenswil Ihr neues Projekt mit Seesicht Im Auftrag unseres Kunden verkaufen wir an bevorzugter, erhöhter und ruhiger Wohnquartierlage mit schöner See- und Fernsicht, 706 m² Bauland mit Rückbauobjekt.Verkaufsrichtpreis: CHF 2'100'000.00Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot. Wegzeit Neu 12 min.Station: Wädenswil - 1 / 7 CHF 651’220.– Auf Anfrage 1, 8195 Wasterkingen Attraktives Baugrundstück in ruhiger, ländlicher Umgebung Willkommen in Wasterkingen, einer idyllischen und ruhigen Gemeinde im Zürcher Unterland, die für ihre hohe Lebensqualität, ländliche Gelassenheit und dennoch gute Erreichbarkeit bekannt ist. Genau hier wartet ein attraktives Baugrundstück auf Sie – die ideale Basis für Ihr zukünftiges Zuhause.Das Grundstück ist voll erschlossen und liegt in der Kernzone B, was Ihnen zahlreiche Gestaltungsmöglichkeiten eröffnet. Ob ein modernes Einfamilienhaus, ein klassisches Zuhause im Dorfcharakter oder ein individuelles Architektenprojekt – hier können Sie Ihre Wohnträume ganz nach Ihren Vorstellungen verwirklichen.Die charmante Gemeinde Wasterkingen besticht durch ihre ruhige Lage inmitten von Feldern, Reben und Natur.Dieses ImmoSky-Angebot bietet folgende Mehr Leistung:+ Voll erschlossen+ Ruhige Gemeinde+ Ideale Grösse für flexibilität (650m²)+ Kernzone B+Überbauungsziffer für Hauptgebäude 30%Dieses Grundstück bietet Ihnen die seltene Gelegenheit, ländliche Idylle mit urbaner Nähe zu vereinen – ein Ort, an dem Sie zur Ruhe kommen und dennoch bestens angebunden sind.Erfüllen Sie sich hier den Traum vom Eigenheim und gestalten Sie Ihr persönliches Refugium in Wasterkingen.Haben wir Sie mit diesem Angebot überzeugt? Dann zögern Sie nicht und kontaktieren Sie uns für weitere Fragen oder einen Besichtigungstermin!(Das Verkaufsdossier wird in der Regel innerhalb von maximal 24 Stunden an Sie versendet. Bitte überprüfen Sie auch Ihren SPAM-Ordner.) Wegzeit - - 1 / 7 CHF 7’540’490.– Staldernstrasse 13, 8158 Regensberg Entwicklungsgrundstück an top Lage in der Kernzone 2 In der gefragten Gemeinde Regensberg (ZH) steht ein hervorragend gelegenes Grundstück zum Verkauf, das sich ideal für Investoren, General- oder Totalunternehmer eignet. Die 2.557 m² grosse Parzelle Nr. 949 befindet sich in der Kernzone 2, die vielfältige bauliche und nutzungsbezogene Entwicklungsmöglichkeiten zulässt, insbesondere für Wohn- oder gemischt genutzte Projekte.Aktuell steht auf dem Grundstück ein nicht erhaltenswertes Gebäude, das im Rahmen einer Neuentwicklung rückgebaut werden kann. Eine Baueingabe oder Bewilligung liegt nicht vor, sodass volle gestalterische Freiheit innerhalb der geltenden bau- und zonenrechtlichen Rahmenbedingungen besteht.Berechnungen zeigen, dass eine nachhaltige Mietertragserwartung von rund CHF 485'600 pro Jahr realistisch erscheint - unter der Annahme einer Ausnutzung mit rund 1 664 m² Hauptnutzfläche (HNF) und 28 Tiefgaragenplätzen. Der ermittelte Kapitalisierungssatz liegt bei 4.20 %.Wesentliche Bewertungskennzahlen:Verkehrswert (diskontierter Landwert): CHF 5'505'000Ertragswert im erneuerten Zustand: CHF 11'556'795Realwert (hypothetisch): CHF 12'485'000Potenzieller Verkaufserlös: CHF 16'190'000Bruttorendite (Mietwert): 4.20%Die hypothetische Bebauung sieht zwei Mehrfamilienhäuser mit einer Bruttogeschossfläche (BGF) von insgesamt 2'080 m² vor - entsprechend einer Ausnützungsziffer von 0.81, voll im Rahmen der Zonenordnung. Die kalkulierten Baukosten (BKP 2-5) belaufen sich auf ca. CHF 8.74 Mio. Der diskontierte Landwert pro m² liegt bei CHF 2'155, was das wirtschaftliche Potenzial zusätzlich unterstreicht.Die Kernzone 2 erlaubt neben der reinen Wohnnutzung auch Mischnutzungen, beispielsweise mit gewerblichen Angeboten im Erdgeschoss. Dies ist ein zusätzlicher Vorteil für flexible, standortgerechte Entwicklungskonzepte. Die Lage in Regensberg bietet ruhige Wohnqualität in der Nähe der Agglomeration Zürich und ist in eine attraktive historische Umgebung eingebettet.Fazit: Das Grundstück bietet die seltene Gelegenheit, ein entwicklungsfähiges Grundstück an bester Lage mit bestehendem Abbruchobjekt zu akquirieren und nach eigenen Vorstellungen zu bebauen. Dank der flexiblen Nutzungsmöglichkeiten und des attraktiven Standorts stellt diese Investition eine hervorragende Ausgangslage für renditestarke Projektentwicklungen dar.Für detaillierte Informationen stehen wir Ihnen gerne zur Verfügung. Wegzeit Neu 23 min.Station: Steinmaur - 1 / 6 CHF 3’633’140.– Riedwiesenstrasse 20, 8305 Dietlikon RESERVIERT - Industrie-Baulandparzelle an zentraler Lage in Dietlikon ZH Mit Freude präsentieren wir Ihnen eine einzigartige und äusserst seltene Baulandparzelle an zentraler Lage in Dietlikon ZH – eine aussergewöhnliche Gelegenheit mit hervorragenden Eigenschaften, die sich besonders für Investoren eignet.Zentrale Lage: Die Parzelle befindet sich in einer äusserst gefragten Gegend mit hervorragender Anbindung: Flughafen Zürich erreichbar in 10 Fahrminuten Stadt Zürich erreichbar in 12 Fahrminuten • Visibilität: Ihr Unternehmen wird von der Autobahn aus perfekt sichtbar sein, was optimale Werbemöglichkeiten bietet (ca. 500 m2 Fassade für Werbung). • Baumassenziffer: Profitieren Sie von der hohen Baumassenziffer 10.0, die maximale Flexibilität und Nutzungseffizienz ermöglicht. • Näherbaurechte: Die Parzelle verfügt über Näherbaurechte rechts und links. Auf der Rückseite kann ein Näherbaurecht von der Stadt Zürich eingeholt werden • ca. 3'500 m2 Bruttogeschossfläche möglich • Tiefgarage / Untergeschoss bis zu ca. 800 m2 gross realisierbar • Maximale Gesamthöhe 20 m. 7 Stockwerke à 500 m2 Bruttogeschossfläche und 2.85 m Raumhöhe (brutto) möglich • Parzelle: Die ebene Fläche der Parzelle erleichtert die Bauplanung und Ausführung. • Form: Die Parzelle hat eine ideale Form, die vielseitige Bebauungsmöglichkeiten erlaubt. • Autobahnknotenpunkt: Brüttiseller Kreuz, direkt an einem der wichtigsten Autobahnknotenpunkt der Schweiz gelegen, bietet die Parzelle hervorragende Erreichbarkeit und Logistikvorteile • Störendes Gewerbe: Die Lage ist auch für Gewerbe geeignet, das potenziell störend sein kann. • Kulturzentren sowie Hotelbetriebe auch möglich. Jetzt oder nie – Ihre Chance auf ein grossartiges Investment:Solch eine Industrie-Baulandparzelle in dieser Lage kommt äusserst selten auf den Markt – seit geraumer Zeit gab es in dieser gefragten Gegend kein vergleichbares Angebot. Sichern Sie sich jetzt dieses einmalige Grundstück, ideal für visionäre Unternehmer und Investoren, die auf einen strategisch optimalen Standort setzen.Haben wir Ihr Interesse geweckt? Dann nehmen Sie noch heute Kontakt mit uns auf. Gerne lassen wir Ihnen das detaillierte Verkaufsdossier inklusive Machbarkeitsstudie zukommen – exklusiv und unverbindlich. Wegzeit Neu 14 min.Station: Dietlikon - 1 / 6 Preis auf Anfrage Kaffeestrasse, 8180 Bülach Ihr Industriebau direkt in Bülach BeschreibungGerne entwickeln und realisieren wir ein auf ihre Bedürfnisse massgeschneidertes Projekt, welches Ihnen zur Miete oder im Eigentum zur Verfügung stehen wird.Interesse oder Fragen? Nehmen Sie Kontakt mit uns auf!Die Parzelle ist nicht das Richtige für Ihre Anforderungen? Kein Problem! Besuchen Sie unsere Homepage und finden Sie weitere Angebote unter: gewerbeland-schweiz.ch Wegzeit Neu 20 min.Station: Bülach - 1 / 6 Preis auf Anfrage Kaffeestrasse, 8180 Bülach Ihr Industriebau direkt in Bülach BeschreibungGerne entwickeln und realisieren wir ein auf ihre Bedürfnisse massgeschneidertes Projekt, welches Ihnen zur Miete oder im Eigentum zur Verfügung stehen wird.Interesse oder Fragen? Nehmen Sie Kontakt mit uns auf!Die Parzelle ist nicht das Richtige für Ihre Anforderungen? Kein Problem! Besuchen Sie unsere Homepage und finden Sie weitere Angebote unter: gewerbeland-schweiz.ch Wegzeit Neu 20 min.Station: Bülach - 1 / 6 Ruhige Lage CHF 3’358’950.– 8192 Glattfelden ZWEIFELSFREIES BAULAND IN ZWEIDLEN Im beliebten Zweidlen verkaufen wir ein eine attraktive, 1'226 m² grosse Baulandparzelle mit Bestandesobjekt.Unsere Projektstudie zeigt eine hohe Ausnutzung für die Erstellung eines Mehrfamilienhauses. • Anrechenbare mögliche Bruttogeschossfläche von max. 940 m² (Projekt 789 m²) • Wohn- und Gewerbezone WG 2.3 • Kein Denkmalschutz beim Bestandesobjekt • Die Deutsche Grenze in Kaiserstuhl ist nur 8 Autominuten entfernt • Der Flughafen Zürich ist in nur 19 Autominuten erreichbar Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: Referenznummer: 25-12278Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen! Ruhige Lage Wegzeit - -12...4 -Suche speichern Kartenansicht -Vorschläge basierend auf deinen Suchresultaten -Weitere interessante Objekte -Orte von Kanton Zürich - -Zürich - -Bezirke im Kanton Kanton Zürich - -Bezirk Affoltern -Bezirk Andelfingen -Bezirk Bülach -Bezirk Dielsdorf -Bezirk Dietikon -Bezirk Hinwil -Bezirk Horgen -Bezirk Meilen -Bezirk Pfäffikon -Bezirk Uster -Bezirk Winterthur - -Kantone der Schweiz - -Kanton Aargau -Kanton Appenzell Ausserrhoden -Kanton Appenzell Innerrhoden -Kanton Basel-Landschaft -Kanton Basel-Stadt -Kanton Bern -Kanton Freiburg -Kanton Genf -Kanton Glarus -Kanton Graubünden -Kanton Jura -Kanton Luzern -Kanton Neuenburg -Kanton Nidwalden -Kanton Obwalden -Kanton Schaffhausen -Kanton Schwyz -Kanton Solothurn -Kanton St. Gallen -Kanton Thurgau -Kanton Tessin -Kanton Uri -Kanton Wallis -Kanton Waadt -Kanton Zug - -ImmoScout24 - -Inserat erstellen -Werbung -Publikationsnetzwerk - -Über uns - -Kontakt -Porträt -Jobs -Fakten und Zahlen -Medien -Newsletter -Ombudsstelle - -Rechtliches - -Datenschutz -Insertionsregeln -Sicherheitstipps -Impressum -AGB -Leistungsbeschrieb -Sicherheitsproblem melden -Privatsphäre-Einstellungen - -Services - -Betreibungsauszug -Umzugshilfe -Versicherungsberatung -Agenturverzeichnis -Hypothekenrechner -Immobilienbewertung - -App herunterladen - -Unser Partner - -Deutsch -Français -Italiano -English - -Folgen Sie uns - -SMG Swiss Marketplace GroupAutoScout24FinanceScout24MotoScout24anibis.ch -© Copyright 2025 by SMG Swiss Marketplace Group AG . Alle Rechte vorbehalten.Die Vervielfältigung und Übernahme von Inseraten durch Dritte, insbesondere von Fotos und persönlichen Daten in diesen Inseraten, verletzt die damit verbundenen Rechte und ist ausdrücklich verboten. -We Care About Your Privacy -We and our 455 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data.Imprint -We and our partners process data to provide: -Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. List of Partners (vendors) -I Accept No consent Show Purposes - -About Your Privacy -We process your data to deliver content or advertisements and measure the delivery of such content or advertisements to extract insights about our website. We share this information with our partners on the basis of consent. You may exercise your right to consent, based on a specific purpose below or at a partner level in the link under each purpose. These choices will be signaled to our vendors participating in the Transparency and Consent Framework. -Privacy Policy -Allow All -Manage Consent Preferences -Functional Cookies - -[x] Functional Cookies - -These cookies enable the website to provide enhanced functionality and personalisation. They may be set by us or by third party providers whose services we have added to our pages. If you do not allow these cookies then some or all of these services may not function properly. -Cookies Details -Strictly Necessary Cookies -Always Active -These cookies are necessary for the website to function and cannot be switched off in our systems. They are usually only set in response to actions made by you which amount to a request for services, such as setting your privacy preferences, logging in or filling in forms. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. These cookies do not store any personally identifiable information. -Cookies Details -Targeting Cookies - -[x] Targeting Cookies - -These cookies may be set on our website by our advertising partners. They can be used by these companies to build a profile of your interests and to control which advertisements you see on other websites. If you do not allow these cookies, you will still see advertisements, but they will no longer be tailored to you. Your master and usage data will also be made available to the other brands of the SMG Group for analysis, for the management of personalized advertising display, and for personalized marketing communication. The latter means that you may be contacted in a personalized manner for marketing purposes not only by this brand but also by all other brands of the SMG Group. The brands of the SMG Group are ImmoScout24, Homegate, Immostreet.ch, home.ch, Publimmo, Acheter-Louer.ch, CASASOFT, IAZI, AutoScout24, MotoScout24, anibis.ch, tutti.ch, Ricardo, FinanceScout24, Flatfox, and Moneyland. We use Enhanced Conversion that may transmit pseudonymised (e.g. hashed) email addresses to third parties such as Google or publishers (e.g. TX Group or Ringier AG) to improve campaign performance and measurement and/or to create audience segments. Personal identification is not possible unless you are logged in with the same email address and associated with an account of these third parties. Your personal data will be processed either jointly with these third parties, in accordance with their respective privacy notices, or independently by SMG as controller. Please note that your personal data may also be transferred to insecure third countries, where local authorities may access them without protection equivalent to European data protection law. If the level of data protection in a country does not match that of Switzerland, we ensure contractually that the protection of your personal data always corresponds to the level in Switzerland. -Cookies Details -Performance Cookies - -[x] Performance Cookies - -These cookies allow us to count visits and traffic sources so we can measure and improve the performance of our site. They help us to know which pages are the most and least popular and see how visitors move around the site. All information these cookies collect is aggregated and therefore anonymous. If you do not allow these cookies we will not know when you have visited our site, and will not be able to monitor its performance. -Cookies Details -Store and/or access information on a device 365 partners can use this purpose - -[x] Store and/or access information on a device - -Cookies, device or similar online identifiers (e.g. login-based identifiers, randomly assigned identifiers, network based identifiers) together with other information (e.g. browser type and information, language, screen size, supported technologies etc.) can be stored or read on your device to recognise it each time it connects to an app or to a website, for one or several of the purposes presented here. -List of IAB Vendors|View Illustrations -Personalised advertising and content, advertising and content measurement, audience research and services development 438 partners can use this purpose - -[x] Personalised advertising and content, advertising and content measurement, audience research and services development - -Use limited data to select advertising 359 partners can use this purpose - -[x] Switch Label -Advertising presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type or which content you are (or have been) interacting with (for example, to limit the number of times an ad is presented to you). - -View Illustrations - -Create profiles for personalised advertising 283 partners can use this purpose - -[x] Switch Label -Information about your activity on this service (such as forms you submit, content you look at) can be stored and combined with other information about you (for example, information from your previous activity on this service and other websites or apps) or similar users. This is then used to build or improve a profile about you (that might include possible interests and personal aspects). Your profile can be used (also later) to present advertising that appears more relevant based on your possible interests by this and other entities. - -View Illustrations - -Use profiles to select personalised advertising 281 partners can use this purpose - -[x] Switch Label -Advertising presented to you on this service can be based on your advertising profiles, which can reflect your activity on this service or other websites or apps (like the forms you submit, content you look at), possible interests and personal aspects. - -View Illustrations - -Create profiles to personalise content 103 partners can use this purpose - -[x] Switch Label -Information about your activity on this service (for instance, forms you submit, non-advertising content you look at) can be stored and combined with other information about you (such as your previous activity on this service or other websites or apps) or similar users. This is then used to build or improve a profile about you (which might for example include possible interests and personal aspects). Your profile can be used (also later) to present content that appears more relevant based on your possible interests, such as by adapting the order in which content is shown to you, so that it is even easier for you to find content that matches your interests. - -View Illustrations - -Use profiles to select personalised content 92 partners can use this purpose - -[x] Switch Label -Content presented to you on this service can be based on your content personalisation profiles, which can reflect your activity on this or other services (for instance, the forms you submit, content you look at), possible interests and personal aspects. This can for example be used to adapt the order in which content is shown to you, so that it is even easier for you to find (non-advertising) content that matches your interests. - -View Illustrations - -Measure advertising performance 404 partners can use this purpose - -[x] Switch Label -Information regarding which advertising is presented to you and how you interact with it can be used to determine how well an advert has worked for you or other users and whether the goals of the advertising were reached. For instance, whether you saw an ad, whether you clicked on it, whether it led you to buy a product or visit a website, etc. This is very helpful to understand the relevance of advertising campaigns. - -View Illustrations - -Measure content performance 171 partners can use this purpose - -[x] Switch Label -Information regarding which content is presented to you and how you interact with it can be used to determine whether the (non-advertising) content e.g. reached its intended audience and matched your interests. For instance, whether you read an article, watch a video, listen to a podcast or look at a product description, how long you spent on this service and the web pages you visit etc. This is very helpful to understand the relevance of (non-advertising) content that is shown to you. - -View Illustrations - -Understand audiences through statistics or combinations of data from different sources 253 partners can use this purpose - -[x] Switch Label -Reports can be generated based on the combination of data sets (like user profiles, statistics, market research, analytics data) regarding your interactions and those of other users with advertising or (non-advertising) content to identify common characteristics (for instance, to determine which target audiences are more receptive to an ad campaign or to certain contents). - -View Illustrations - -Develop and improve services 300 partners can use this purpose - -[x] Switch Label -Information about your activity on this service, such as your interaction with ads or content, can be very helpful to improve products and services and to build new products and services based on user interactions, the type of audience, etc. This specific purpose does not include the development or improvement of user profiles and identifiers. - -View Illustrations - -Use limited data to select content 83 partners can use this purpose - -[x] Switch Label -Content presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type, or which content you are (or have been) interacting with (for example, to limit the number of times a video or an article is presented to you). - -View Illustrations -List of IAB Vendors -Use precise geolocation data 132 partners can use this special feature - -[x] Use precise geolocation data - -With your acceptance, your precise location (within a radius of less than 500 metres) may be used in support of the purposes explained in this notice. -List of IAB Vendors -Actively scan device characteristics for identification 71 partners can use this special feature - -[x] Actively scan device characteristics for identification - -With your acceptance, certain characteristics specific to your device might be requested and used to distinguish it from other devices (such as the installed fonts or plugins, the resolution of your screen) in support of the purposes explained in this notice. -List of IAB Vendors -Ensure security, prevent and detect fraud, and fix errors 290 partners can use this special purpose -Always Active -Your data can be used to monitor for and prevent unusual and possibly fraudulent activity (for example, regarding advertising, ad clicks by bots), and ensure systems and processes work properly and securely. It can also be used to correct any problems you, the publisher or the advertiser may encounter in the delivery of content and ads and in your interaction with them. -List of IAB Vendors|View Illustrations -Deliver and present advertising and content 286 partners can use this special purpose -Always Active -Certain information (like an IP address or device capabilities) is used to ensure the technical compatibility of the content or advertising, and to facilitate the transmission of the content or ad to your device. -List of IAB Vendors|View Illustrations -Match and combine data from other data sources 214 partners can use this feature -Always Active -Information about your activity on this service may be matched and combined with other information relating to you and originating from various sources (for instance your activity on a separate online service, your use of a loyalty card in-store, or your answers to a survey), in support of the purposes explained in this notice. -List of IAB Vendors -Link different devices 172 partners can use this feature -Always Active -In support of the purposes explained in this notice, your device might be considered as likely linked to other devices that belong to you or your household (for instance because you are logged in to the same service on both your phone and your computer, or because you may use the same Internet connection on both devices). -List of IAB Vendors -Identify devices based on information transmitted automatically 265 partners can use this feature -Always Active -Your device might be distinguished from other devices based on information it automatically sends when accessing the Internet (for instance, the IP address of your Internet connection or the type of browser you are using) in support of the purposes exposed in this notice. -List of IAB Vendors -Save and communicate privacy choices 245 partners can use this special purpose -Always Active -The choices you make regarding the purposes and entities listed in this notice are saved and made available to those entities in the form of digital signals (such as a string of characters). This is necessary in order to enable both this service and those entities to respect such choices. -List of IAB Vendors|View Illustrations -Cookie List -Clear - -[x] checkbox label label - -Apply Cancel -Consent Leg.Interest - -[x] checkbox label label - -[x] checkbox label label - -[x] checkbox label label - -No consent Confirm My Choices \ No newline at end of file diff --git a/test_web_content_20251002_204000/main_url_006_www.comparis.ch_immobilien_marktplatz_kanton_zuerich_grundstueck_kaufen.txt b/test_web_content_20251002_204000/main_url_006_www.comparis.ch_immobilien_marktplatz_kanton_zuerich_grundstueck_kaufen.txt deleted file mode 100644 index 7e25ebe4..00000000 --- a/test_web_content_20251002_204000/main_url_006_www.comparis.ch_immobilien_marktplatz_kanton_zuerich_grundstueck_kaufen.txt +++ /dev/null @@ -1,401 +0,0 @@ -Title: https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen -URL: https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen -Type: Main URL -Extracted: 2025-10-02 20:40:00 -================================================================================ - -Grundstück in Kanton Zürich kaufen - Vergleiche 72 Inserate mit comparis.ch - -Versicherungen -Finanzen -Immobilien -Mobilität -Gesundheit -Telecom - -Neu in der Schweiz - -Person absichern - -Krankenkasse -Lebensversicherung -Rechtsschutz -Reiseversicherung - -Fahrzeug versichern - -Autoversicherung -Motorradversicherung - -Eigentum versichern - -Hausrat und Privathaftpflicht -Tierversicherung - -Alles zu Versicherungen -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Kredit aufnehmen - -Privatkredit -Kreditrechner -Kreditvergleich - -Immobilie finanzieren - -Hypotheken -Hypothekenrechner -Zinsentwicklung - -Altersvorsorge planen - -Altersvorsorge -Pensionsplanung - -Steuern vergleichen - -Steuervergleich -Steuerrechner -Quellensteuer - -Fahrzeug finanzieren - -Autoleasing -Leasingrechner -Autokredit - -Wirtschaftsinfos einholen - -Finanzen und Wirtschaft - -Alles zu Finanzen -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Immobilie finden - -Immobilienmarkt -Steuerrechner - -Immobilie finanzieren - -Hypotheken -Hypothekenrechner -Zinsentwicklung - -Immobilien bewerten - -Immobilie kostenlos bewerten -Immobilienbewertung Plus (Beta) -Makler finden -Immobilie verkaufen - -Immobilie inserieren - -Privat inserieren -Als Firma inserieren - -Umzug planen - -Umzugsservice -Umzugskostenrechner -Umzug in die Schweiz -Malerservice - -Hausrat versichern - -Hausrat und Privathaftpflicht - -Alles zu Immobilien -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Automarkt - -Auto kaufen -Auto verkaufen -Autowert berechnen - -Fahrzeug finanzieren - -Autoleasing -Leasingrechner -Autokredit - -Fahrzeug versichern - -Autoversicherung -Motorradversicherung - -Fahrzeugnutzung - -Benzinpreise -Autoprüfung - -Elektromobilität - -Elektromobilität entdecken -Ladestation finden -Elektroauto - -Reisen - -Reisetipps -Reiseversicherung -Ferien-Packliste - -Alles zu Mobilität -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Arzt finden und Behandlungen - -Arzt finden -Zähne -Dermatologie -Medikamente - -Leben im Alter und Spitex - -Spitex finden -Finanzierung und Wohnen -Zu Hause pflegen - -Krankenkasse - -Krankenkasse vergleichen - -Alles zu Gesundheit -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Mobile - -Handy-Abo - -Internet und TV zuhause - -Internet, TV und Festnetz - -Alles zu Telecom -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Auswandern - -Auswandern in die Schweiz -Aufenthaltsbewilligung -Führerschein umschreiben -Miete in der Schweiz - -Arbeit - -Arbeiten in der Schweiz -Durchschnittslohn in der Schweiz -Jobsuche -Lohnnebenkosten - -Finanzen - -Finanzen in der Schweiz -Quellensteuer vergleichen -Lebenshaltungskosten - -Leben - -Leben in der Schweiz -Schweizerdeutsch lernen -Besonderheiten der Schweiz - -Alles zu Neu in der Schweiz -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren -DE -FRITEN -Login -Login -Comparis entdecken - -Versicherungen -Finanzen -Immobilien -Mobilität -Gesundheit -Telecom -Neu in der Schweiz - -Newsletter -Login -DEFRITEN - -Startseite -Wohnen -Immobilien -Bauland kaufen -Grundstück in Kanton Zürich kaufen - -Favoriten (0) -Grundstück in Kanton Zürich kaufen: 72 Resultate -Filter (4)Suchabo anlegen Suchabo -Kein neues Inserat verpassen! - Umgehende Benachrichtigung - Jederzeit anpassbar - Kostenlos -Infobox schliessen - -Sortieren nach: -Sortieren nach:Erstmals gefunden am -Sortieren -Bauland Online seit einem Tag 706 m² ------ «Ihr neues Projekt mit Seesicht» 8820 Wädenswil Rotweg 20 CHF 2'100'000 Kaufpreis Merken Merken CHF 2'100'000 Kaufpreis -Gewerbegrundstück Online seit 3 Tagen Gewerbegrundstück ----------------- «Bauernhof mit mehreren landwirtschaftlichen Parzellen» 8460 Marthalen Talackerberg, Im Türni CHF 1'020'000 Kaufpreis Merken Merken CHF 1'020'000 Kaufpreis -Bauland Online seit 3 Tagen Bauland ------- «BAULAND AN TRAUMHAFTER LAGE AM FISCHBACH» 8162 Steinmaur auf Anfrage Kaufpreis Merken Merken auf Anfrage Kaufpreis -Bauland Online seit 4 Tagen 1285 m² ------- «Windlach: Grundstück mit Potenzial für Wohnraumentwicklung» 8175 Windlach CHF 800'000 Kaufpreis Merken Merken CHF 800'000 Kaufpreis -Bauland Online seit 5 Tagen 3166 m² ------- «Attraktives Entwicklungsareal an zentraler Lage mit 3?166 m²» 8050 Zürich CHF 26'000'000 Kaufpreis Merken Merken CHF 26'000'000 Kaufpreis -Grundstück Online seit 5 Tagen Grundstück ---------- «Hier beginnt Ihre Zukunft» 8340 Hinwil CHF 1'070'000 Kaufpreis Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken CHF 1'070'000 Kaufpreis -Bauland Online seit einer Woche 9175 m² ------- «Vergabe der Gewerbefläche GB Nr. 74, Neuhausen am Rheinfall» 8212 Neuhausen am Rheinfall CHF 343 Kaufpreis pro m² Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken CHF 343 Kaufpreis pro m² -Bauland Online seit einer Woche Bauland ------- «Zürich» 8000 Zürich auf Anfrage Kaufpreis Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken auf Anfrage Kaufpreis -Grundstück Online seit einer Woche Grundstück ---------- «Zürich» 8001 Zürich auf Anfrage Kaufpreis Merken Merken auf Anfrage Kaufpreis -Grundstück Online seit einer Woche Grundstück ---------- «Attraktives Baugrundstück in ruhiger, ländlicher Umgebung» 8195 Wasterkingen CHF 475'000 Kaufpreis Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken CHF 475'000 Kaufpreis - -1 -2 -3 -4 -5 -6 -8 - -Gemeinden in diesem Kanton -A -B -C -D -E -F -G -H -I -J -K -L -M -N -O -P -Q -R -S -T -U -V -W -X -Y -Z -A -Adliswil -Aeugst am Albis -Affoltern am Albis -B -Benken (ZH) -Bülach -D -Dättlikon -Dielsdorf -Dietikon -Dietlikon -Dinhard -Dorf -E -Elgg -Embrach -Erlenbach (ZH) -F -Fällanden -H -Herrliberg -Hettlingen -Hinwil -Höri -Hüntwangen -M -Marthalen -Mönchaltorf -N -Niederglatt -Niederhasli -O -Oetwil am See -P -Pfäffikon -R -Rafz -Regensberg -Regensdorf -Richterswil -Rifferswil -Rümlang -Russikon -Rüti (ZH) -S -Steinmaur -V -Volken -W -Wädenswil -Wasterkingen -Weisslingen -Wildberg -Z -Zell (ZH) -Zürich -Das könnte Sie interessieren -Weitere Comparis Services -Was zahlt die Nachbarschaft?Umzugsfirma ZürichInserieren -Weitere Kaufobjekte in Kanton Zürich -Wohnung kaufen Kanton Zürich (1500)Haus kaufen Kanton Zürich (642)Mehrfamilienhaus kaufen Kanton Zürich (70) -ZU DEN FAVORITEN -Filter (4) - -comparis.ch -1. Über Comparis -2. User Service -3. Jobs -4. Medien -5. Allgemeine Geschäftsbedingungen -Weitere Angebote -1. Studien -2. Gebühren -3. Werbung -4. Comparis-Siegel -Folgen Sie uns -1. -2. -3. -4. -Newsletter -1. Newsletter bestellen -© comparis.ch AG 2025 -DatenschutzRechtliche InformationenImpressum \ No newline at end of file diff --git a/test_web_content_20251002_204000/main_url_008_realadvisor.ch_de_kaufen_kanton-zurich_grundstuck.txt b/test_web_content_20251002_204000/main_url_008_realadvisor.ch_de_kaufen_kanton-zurich_grundstuck.txt deleted file mode 100644 index 79085cb6..00000000 --- a/test_web_content_20251002_204000/main_url_008_realadvisor.ch_de_kaufen_kanton-zurich_grundstuck.txt +++ /dev/null @@ -1,269 +0,0 @@ -Title: https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck -URL: https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck -Type: Main URL -Extracted: 2025-10-02 20:40:00 -================================================================================ - -Grundstück kaufen im Kanton Zürich - 75 Angebote im Oktober 2025 - -Max. 1 Tag -Kanton Zürich - -Bewerten -KaufenMieten -Anmelden -DE -ItalianoFrançaisEnglish -Suchabo erstellen -Max. 1 Tag -Kanton Zürich - -Kaufen Mieten -Kaufen Mieten -Grundstück -Preis -Suche ändern -Grundstücksfläche -Andere Filter -Suchabo erstellen - -[x] Karte - -←Move left -→Move right -↑Move up -↓Move down -+Zoom in --Zoom out -Home Jump left by 75% -End Jump right by 75% -Page Up Jump up by 75% -Page Down Jump down by 75% - -9 -9 -5 -5 -3 -3 -6 -6 -17 -17 -7 -7 -4 -4 -2 -2 -2 -2 -14 -14 -5 -5 -1 -1 - -Map - Map - Satellite - Terrain - Labels - - - - - - - - -Keyboard shortcuts -Map Data Map data ©2025 GeoBasis-DE/BKG (©2009), Google -Map data ©2025 GeoBasis-DE/BKG (©2009), Google -10 km -Click to toggle between metric and imperial units -Terms -Report a map error - -Kaufen - -Grundstück - -Kanton Zürich - -Grundstücke kaufen im Kanton Zürich -75 Ergebnisse -Unseren Empfehlungen - -vor 3 Tagen - -[x] - -get living 1’452 m² Grundstück • Bauland 8162 Steinmaur Flaches, bebaubares Grundstück Ruhige, sonnige Lage Ausgezeichnete ÖV-Anbindung ------------------------------------------------------------------------------------------------------------------------------------------------------------ Auf Anfrage — - -vor 6 Tagen - -[x] - -ImmoSky AG - Standort Dübendorf ZH (Zentrale) 1’070 m² Grundstück • Bauland 8340 Hinwil Über 1.070 m² Fläche Flexible Teilungsoptionen Ideal für Familienhäuser ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ CHF 1’070’000.- CHF 1’000 / m² - -vor 6 Tagen - -[x] - -PREMIUM HOMES AG 1’940 m² Grundstück • Bauland 8633 Wolfhausen Grosszügige 1'940m² Parzelle Familienfreundliche Lage Flexible Gestaltungsmöglichkeiten --------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CHF 4’074’000.- CHF 2’100 / m² - -vor 9 Tagen - -[x] - -Moser Anlageimmobilien AG 1’666 m² Grundstück • Bauland Sonnhalde, 8602 Wangen b. Dübendorf 1666 m² Bauland in bester Lage Optimale Besonnung garantiert Privatsphäre in ruhiger Umgebung -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CHF 3’300’000.- CHF 1’981 / m² - -vor 11 Tagen - -[x] - -Centrum Immo Bauland 8000 Zürich Ideal für Entwicklung Nahe öffentlicher Verkehr Malersiche Ausblicke auf die Stadt ---------------------------------------------------------------------------------------------------------------------------------------- Auf Anfrage — - -vor 13 Tagen - -[x] - -ImmoSky AG - Standort Dübendorf ZH (Zentrale) 650 m² Grundstück • Bauland 8195 Wasterkingen Voll erschlossenes Grundstück Ruhige ländliche Gemeinde Flexible Gestaltungsmöglichkeiten ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CHF 475’000.- CHF 731 / m² - -vor 21 Tagen - -[x] - -Swiss Residence Group AG 1’622 m² Grundstück • Bauland 8618 Oetwil am See Sonniges Grundstück von 1'622 m² Flexibles Bauen möglich Unverbaubare Bergsicht ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Auf Anfrage — - -vor 22 Tagen - -[x] - -PREMIUM HOMES AG 850 m² Grundstück • Bauland 8617 Mönchaltorf Hohes Entwicklungspotenzial Ruhige, sonnige Lage Flexible Nutzungsmöglichkeiten ------------------------------------------------------------------------------------------------------------------------------------------------------------------ Auf Anfrage — - -vor 26 Tagen - -[x] - -Schiblis Immobilien GmbH 507 m² Grundstück • Bauland Güeterstalstrasse, 8133 Esslingen Zentrale Lage in Esslingen Keine Architekturverpflichtung Keine Altlasten vorhanden ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CHF 600’000.- CHF 1’183 / m² - -vor 28 Tagen - -[x] - -Grundeigentümer Verband Schweiz 1’226 m² Grundstück • Bauland 8192 Zweidlen Gesamtfläche von 1'226 m² Max. nutzbare Fläche 940 m² Flexible Entwicklungsmöglichkeiten ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CHF 2’450’000.- CHF 1’998 / m² - -vor 29 Tagen - -[x] - -PREMIUM HOMES AG 1’670 m² Grundstück • Bauland 8424 Embrach Familienfreundliche Lage Viel Sonnenlicht den ganzen Tag Flexible Nutzungsmöglichkeiten ------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Auf Anfrage — - -vor 29 Tagen - -[x] - -SH Immo GmbH 854 m² Grundstück • Bauland Berghalde 10, 8332 Russikon Geräumiges Grundstück von 854 m2 Ideale sonnige Hanglage Potenzial für Neubau ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- CHF 1’500’000.- CHF 1’756 / m² - -vor 1 Monat - -[x] - -Moos & Partner Immobilien GmbH 694 m² Grundstück • Bauland 8134 Adliswil Zentrale Lage mit Potenzial Hohe Ausnutzung in W3 Ideal für Investoren & Entwickler --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CHF 3’600’000.- CHF 5’187 / m² - -vor 2 Monaten - -[x] - -RE/MAX Immobilien in Rapperswil-Jona 4’246 m² Grundstück • Bauland Überlandstrasse 23, 8340 Hinwil Top Lage an Hauptstrassen Grosse Fläche für Entwicklung Flexible Gebäudehöhen möglich ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Auf Anfrage — - -vor 2 Monaten - -[x] - -RE/MAX Immobilien in Winterthur 877 m² Grundstück • Bauland Winzerstrasse 20, 8353 Elgg Ideal für Familienhäuser Investitionsmöglichkeit Angrenzend an bestehendes Haus -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CHF 1’140’000.- CHF 1’300 / m² - -vor 3 Monaten - -[x] - -RE/MAX Immobilien in Meilen 2’838 m² • 1’706 m² Grundstück • Bauland Industriestrasse 34, 8117 Fällanden Genehmigtes Gewerbeprojekt Flexible gewerbliche Nutzung 37 Parkplätze verfügbar ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Auf Anfrage — - -vor 4 Monaten - -[x] - -PREMIUM HOMES AG 3’460 m² Grundstück • Bauland 8630 Rüti ZH Ruhige Wohnzone Ausnützungsziffer 30% Bonus für zusätzlichen Raum -------------------------------------------------------------------------------------------------------------------------------------------------- Auf Anfrage — - -vor 16 Tagen - -[x] - -Swisslife 2’557 m² Grundstück • Bauland Staldernstrasse 13, 8158 Regensberg Flexibles Zonen für Mischnutzung Hohe Mietrendite möglich Ruhige Lage nahe Zürich ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CHF 5’500’000.- CHF 2’151 / m² dreamo.ch - -vor 2 Monaten - -[x] - -Orgnet Immobilien AG 844 m² Grundstück • Bauland Leisibüel, 8484 Weisslingen Atemberaubender Bergblick Südwestliche Sonnenlage Ruhige, private Nachbarschaft --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CHF 1’300’000.- CHF 1’540 / m² dreamo.ch - -vor 3 Monaten - -[x] - -TREVAG Treuhand und Verwaltungs AG 2’295 m² Grundstück • Bauland Weiacherstrasse 85, 8427 Rorbas Geräumiges Grundstück von 2'295 m2 Gebäude mit gemischter Nutzung Bestehende Mietverhältnisse ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CHF 3’440’000.- CHF 1’499 / m² dreamo.ch - -vor 3 Monaten - -[x] - -TREVAG Treuhand und Verwaltungs AG 1’742 m² Grundstück • Bauland Bergstrasse 7a, 8155 Nassenwil Geräumige Grundstücksfläche Ruhige, malerische Lage Nahe Dielsdorf --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CHF 2’700’000.- CHF 1’550 / m² dreamo.ch - -vor 3 Monaten - -[x] - -TREVAG Treuhand und Verwaltungs AG 1’340 m² • 1’340 m² Grundstück • Bauland Götze, 8197 Rafz Unverbaute Aussichten Ideal für Entwicklung Bevorzugte Lage ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CHF 2’200’000.- CHF 1’642 / m² dreamo.ch - -vor 3 Monaten - -[x] - -VZ VermögensZentrum 4.5 Zi. • 114 m² • 480 m² Grundstück • Bauland Schaffhauserstrasse 226b, 8057 Zürich Grosszügiger Umschwung Grüner Ausblick von Fenstern Gemütlicher Schwedenofen ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CHF 2’999’000.- CHF 26’307 / m² dreamo.ch - -vor 7 Stunden - -[x] - -— 829 m² Grundstück • Bauland Haldenstrasse 10, 8134 Adliswil Ruhige Lage mit Aussicht Nah am öffentlichen Verkehr Sofort verfügbar -------------------------------------------------------------------------------------------------------------------------------------------------------- CHF 3’300’000.- CHF 3’981 / m² homegate.ch -1 -2 -3 -4 - -1-24 von 75 Ergebnisse -Grundstück kaufen im Kanton Zürich -Immobilienpreise in Kanton Zürich -Grundstück kaufen im Kanton Zürich -Grundstück kaufen in ZürichGrundstück kaufen in WinterthurGrundstück kaufen in UsterGrundstück kaufen in DübendorfGrundstück kaufen in Dietikon (8953)Grundstück kaufen in WädenswilGrundstück kaufen in Wetzikon (ZH)Grundstück kaufen in HorgenGrundstück kaufen in OpfikonGrundstück kaufen in Bülach (8180)Grundstück kaufen in Kloten (8302)Grundstück kaufen in Adliswil (8134)Grundstück kaufen in Schlieren (8952)Grundstück kaufen in VolketswilGrundstück kaufen in RegensdorfGrundstück kaufen in ThalwilGrundstück kaufen in Illnau-EffretikonGrundstück kaufen in Wallisellen (8304)Grundstück kaufen in StäfaGrundstück kaufen in Küsnacht (ZH)Grundstück kaufen in Meilen (8706)Grundstück kaufen in RichterswilGrundstück kaufen in ZollikonGrundstück kaufen in Rüti ZH (8630)Grundstück kaufen in Affoltern am AlbisGrundstück kaufen in PfäffikonGrundstück kaufen in Bassersdorf (8303)Grundstück kaufen in HinwilGrundstück kaufen in Männedorf (8708)Grundstück kaufen in MaurGrundstück kaufen in Gossau (ZH)Grundstück kaufen in Wald (ZH)Grundstück kaufen in Urdorf (8902)Grundstück kaufen in Embrach (8424)Grundstück kaufen in NiederhasliGrundstück kaufen in HombrechtikonGrundstück kaufen in FällandenGrundstück kaufen in Kilchberg ZH (8802)Grundstück kaufen in EggGrundstück kaufen in Rümlang (8153)Grundstück kaufen in Wangen-BrüttisellenGrundstück kaufen in Dietlikon (8305)Grundstück kaufen in DürntenGrundstück kaufen in Langnau am Albis (8135)Grundstück kaufen in Seuzach (8472)Grundstück kaufen in BubikonGrundstück kaufen in Oberglatt ZH (8154)Grundstück kaufen in Oberengstringen (8102)Grundstück kaufen in Fehraltorf (8320)Grundstück kaufen in Birmensdorf ZH (8903)Grundstück kaufen in WiesendangenGrundstück kaufen in Buchs ZH (8107)Grundstück kaufen in Herrliberg (8704)Grundstück kaufen in Uetikon am See (8707)Grundstück kaufen in Dielsdorf (8157)Grundstück kaufen in Zell (ZH)Grundstück kaufen in Rüschlikon (8803)Grundstück kaufen in LindauGrundstück kaufen in Nürensdorf (8309)Grundstück kaufen in Erlenbach ZH (8703)Grundstück kaufen in NeftenbachGrundstück kaufen in Bonstetten (8906)Grundstück kaufen in Obfelden (8912)Grundstück kaufen in Greifensee (8606)Grundstück kaufen in GlattfeldenGrundstück kaufen in Eglisau (8193)Grundstück kaufen in Zumikon (8126)Grundstück kaufen in Wettswil (8907)Grundstück kaufen in Schwerzenbach (8603)Grundstück kaufen in Oberrieden (8942)Grundstück kaufen in BäretswilGrundstück kaufen in Niederglatt ZH (8172)Grundstück kaufen in GeroldswilGrundstück kaufen in BaumaGrundstück kaufen in ElggGrundstück kaufen in Mettmenstetten (8932)Grundstück kaufen in Weiningen ZH (8104)Grundstück kaufen in Oetwil am See (8618)Grundstück kaufen in TurbenthalGrundstück kaufen in Winkel (8185)Grundstück kaufen in Rafz (8197)Grundstück kaufen in RussikonGrundstück kaufen in Uitikon Waldegg (8142)Grundstück kaufen in Dällikon (8108)Grundstück kaufen in Bachenbülach (8184)Grundstück kaufen in Pfungen (8422)Grundstück kaufen in Unterengstringen (8103)Grundstück kaufen in Mönchaltorf (8617)Grundstück kaufen in StallikonGrundstück kaufen in Hedingen (8908)Grundstück kaufen in Hausen am AlbisGrundstück kaufen in FeuerthalenGrundstück kaufen in Hittnau (8335)Grundstück kaufen in Elsau (8352)Grundstück kaufen in SteinmaurGrundstück kaufen in Grüningen (8627)Grundstück kaufen in WeisslingenGrundstück kaufen in Hettlingen (8442)Grundstück kaufen in Neerach (8173)Grundstück kaufen in Niederweningen (8166)Grundstück kaufen in Otelfingen (8112)Grundstück kaufen in Rorbas (8427)Grundstück kaufen in StammheimGrundstück kaufen in Höri (8181)Grundstück kaufen in Rickenbach (ZH)Grundstück kaufen in Ottenbach (8913)Grundstück kaufen in FischenthalGrundstück kaufen in Oetwil an der Limmat (8955)Grundstück kaufen in Lufingen (8426)Grundstück kaufen in Freienstein-TeufenGrundstück kaufen in Knonau (8934)Grundstück kaufen in StadelGrundstück kaufen in Henggart (8444)Grundstück kaufen in Andelfingen (8450)Grundstück kaufen in KleinandelfingenGrundstück kaufen in Brütten (8311)Grundstück kaufen in Wila (8492)Grundstück kaufen in MarthalenGrundstück kaufen in Aeugst am AlbisGrundstück kaufen in Dachsen (8447)Grundstück kaufen in Hochfelden (8182)Grundstück kaufen in Dänikon ZH (8114)Grundstück kaufen in Oberweningen (8165)Grundstück kaufen in Weiach (8187)Grundstück kaufen in Laufen-UhwiesenGrundstück kaufen in Ossingen (8475)Grundstück kaufen in Dinhard (8474)Grundstück kaufen in SeegräbenGrundstück kaufen in Flurlingen (8247)Grundstück kaufen in Wil ZH (8196)Grundstück kaufen in Schöfflisdorf (8165)Grundstück kaufen in Flaach (8416)Grundstück kaufen in Boppelsen (8113)Grundstück kaufen in Aesch ZH (8904)Grundstück kaufen in Rheinau (8462)Grundstück kaufen in Kappel am AlbisGrundstück kaufen in Hagenbuch ZH (8523)Grundstück kaufen in Rifferswil (8911)Grundstück kaufen in TrüllikonGrundstück kaufen in Oberembrach (8425)Grundstück kaufen in Hüntwangen (8194)Grundstück kaufen in DägerlenGrundstück kaufen in WildbergGrundstück kaufen in Buch am Irchel (8414)Grundstück kaufen in Hüttikon (8115)Grundstück kaufen in Thalheim an der Thur (8478)Grundstück kaufen in Ellikon an der Thur (8548)Grundstück kaufen in Benken ZH (8463)Grundstück kaufen in Dättlikon (8421)Grundstück kaufen in Schleinikon (8165)Grundstück kaufen in Schlatt ZH (8418)Grundstück kaufen in Dorf (8458)Grundstück kaufen in Altikon (8479)Grundstück kaufen in Adlikon b. Andelfingen (8452)Grundstück kaufen in Maschwanden (8933)Grundstück kaufen in Bachs (8164)Grundstück kaufen in Wasterkingen (8195)Grundstück kaufen in Berg am IrchelGrundstück kaufen in Humlikon (8457)Grundstück kaufen in Truttikon (8467)Grundstück kaufen in Regensberg (8158)Grundstück kaufen in Volken (8459) -Mehr -Andere Immobilienarten im Kanton Zürich -Haus kaufen im Kanton ZürichWohnung kaufen im Kanton ZürichMehrfamilienhaus kaufen im Kanton ZürichGewerberaum kaufen im Kanton ZürichHotel, Restaurant kaufen im Kanton Zürich -Beliebte Suchen im Kanton Zürich -Neubauprojekte im Kanton ZürichNeubauten kaufen im Kanton ZürichNeubauwohnungen kaufen im Kanton Zürich - -Verkaufen -ImmobilienbewertungRenditeliegenschaft bewertenImmobilienpreiseMakler findenImmobilien-GlossarImmobilien-Blog -Kaufen / Mieten -Immobilien kaufenImmobilien mietenNeubauprojekteImmobilienfinanzierung -Für Makler -Partner werdenBlog Pro -Unternehmen -Über unsPresseraumOffene StellenAllgemeine GeschäftsbedingungenDatenschutzerklärungImpressumAlle Immobilien -© RealAdvisor 2025. All Rights Reserved. v.e89072f - -Karte -BESbswy \ No newline at end of file diff --git a/test_web_content_20251002_204000/main_url_009_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferliste.txt b/test_web_content_20251002_204000/main_url_009_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferliste.txt deleted file mode 100644 index b9d5db95..00000000 --- a/test_web_content_20251002_204000/main_url_009_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferliste.txt +++ /dev/null @@ -1,121 +0,0 @@ -Title: https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste -URL: https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste -Type: Main URL -Extracted: 2025-10-02 20:40:00 -================================================================================ - -73 Bauland kaufen in Kanton Zürich | homegate.ch - - Suchen - Services -Inserieren -Mein Konto -Menü - - Suchen - Services - Schätzen - Ratgeber -Inserieren -Mein Konto -DE - DE - FR - IT - EN -Ort -Kanton Zürich -Kanton Zürich -Preis bis -Weitere Filter -73 Treffer -73 Treffer - Bauland kaufen in Kanton Zürich - 1 / 16 CHF 2’563’760.– Top 360m² Nutzfläche Luegetenstrasse 11, 8489 Wildberg Ihr neues Zuhause mit Potenzial - Idyllisches Landhaus mit Baulandreserve Ihr neues Zuhause Willkommen in Ihrem zukünftigen Traumdomizil - ein grosszügiges, freistehendes Landhaus an ruhiger und idyllischer Aussichtslage im malerischen Wildberg. Hier vereinen sich ländliche Idylle, Privatsphäre und die seltene Möglichkeit, Wohnraum nach eigenen Vorstellungen zu schaffen oder zu erweitern.Ob als charmantes Familienrefugium mit grossem Garten oder als Investitionsobjekt mit Entwicklungspotenzial - dieses einzigartige Anwesen bietet Ihnen beide Optionen. Auf dem 1339m² grossen Grundstück geniessen Sie nicht nur viel Platz zum Leben, sondern verfügen auch über eine wertvolle Baulandreserve, die Ihnen vielfältige Gestaltungsmöglichkeiten eröffnet. Erste Abklärungen zeigen: Es besteht die Möglichkeit, ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren - ein echter Mehrwert für visionäre Käufer.Tauchen Sie ein in eine grüne Oase mit Weitblick - ein Ort, der Ruhe schenkt und inspiriert.Highlights auf einen Blick • Idyllische, ruhige Aussichtslage mit hohem Erholungswert • Grosszügiges Grundstück mit 1339m², ideal zur Eigennutzung und/oder für die Entwicklung eines Neubaus • Baulandreserve: Attraktives Entwicklungspotenzial - gemäss erster Einschätzung besteht die Möglichkeit, zusätzlich zum bestehenden Einfamilienhaus ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren (unverbindlich, ohne Gewähr) • Blühender Garten mit verschiedenen Sitzplätzen, Pergola mit Aussencheminée, Gartenhäusern, gepflegtem Baumbestand und weitläufigen Grünflächen • Solide Bausubstanz mit Doppelschalenmauerwerk • Grosszügiges Raumkonzept mit ca. 220m² Wohnfläche und ca. 96m² zusätzlichem Stauraum im Untergeschoss. Total ca. 360m² Bruttofläche. • Geräumiger Wohnbereich mit gemütlichem Kachelofen - ein Ort zum Ankommen und Wohlfühlen • Praktische Wohnküche mit integriertem Essbereich - ideal für gesellige Stunden • 4 helle Schlafzimmer - ideal für Familien oder Homeoffice • 2 Nasszellen mit Tageslicht • Ausgebauter Estrich für zusätzlichen Raum oder kreative Nutzungsmöglichkeiten • Beheizt durch Elektrospeicher und wassergeführte Fussbodenheizung • Garage mit elektrischem Tor und weitere Parkmöglichkeiten auf dem Grundstück • Mit einer stilvollen Modernisierung verwandeln Sie dieses Haus in ein wahres Schmuckstück Verkaufspreis: CHF 1'870'000.-Mit unserer virtuellen 360-Grad-Tour können Sie bereits die ersten Eindrücke dieser tollen Liegenschaft gewinnen. Sehr gerne zeigen wir Ihnen diese Liegenschaft direkt vor Ort und freuen uns auf Ihre Kontaktaufnahme.Weitere EckdatenBaujahr Haus: 1984, Baujahr Gerätehaus: 1986, Kubatur Haus (GVZ): 936m³, Kubatur Gerätehaus (GVZ): 40m³, Grundbuchblatt: Nr. 437, Kataster-Nr.: 249, 1/4 subjektiv-dingliches Miteigentum an Blatt 444, Kataster 249. Nettowohnfläche: ca. 220m², Bruttowohnfläche: ca. 360m², Grundstücksfläche: 1'339m².Massivbauweise, Doppelschalenmauerwerk, neuwertige Holzmetallfenster (EgoKiefer) mit dreifacher Verglasung und Sprossen & Holzläden. Elektrospeicherofen, wassergeführte Fussbodenheizung, Elektroboiler 300 Liter.Treppenlift, Garage mit elektrischem Torantrieb. Küche im Landhausstil mit Granitabdeckung, Geschirrspüler, Induktions-Kochherd und Kühlschrank mit Gefrierfach.BodenbelägeEG: Entrée, Gang, Dusche, Küche, Essen mit Plattenboden.OG: Zimmer und Vorplatz mit Laminat in Holzoptik. Bad mit Platten. Wegzeit Neu - - 1 / 8 CHF 2’604’890.– Top Wehntalerstrasse 28, 8181 Höri Grundstück mit Baubewilligung für ein Mehrfamilienhaus mit 6 Einheiten Das Grundstück ist derzeit mit einem Einfamilienhaus bebaut (Baujahr 1960)Nach dem Rückbau kann, gemäss Bewilligung ein Mehrfamilienhaus mit 6 Wohnungen (3 Wohnungen 4½ Zimmer und 3 Wohnungen 2½ Zimmer) mit 9 Tiefgaragen, 1 Tiefgaragen Behinderten Parkplatz sowie 2 Besucher Aussenparkplätze realisiert werden. (Siehe Pläne)Im Kaufpreis enthalten: • Baubewilligung • Bewilligungsgebühren • Projektpläne in PDF, DWG und Step Dateien • Lärmschutznachweis Strasse / Lärmschutznachweis Fluglärm • Geologisches Gutachten (Meldeblatt zu Bodenverschiebung) Parzelle nicht belastet! • Private Kontrolle bei Rückbau- und Umbau. (2 Asbestproben wurden positiv auf Asbest getestet) • Amtlich Beglaubigter Katasterplan • Farb- und Materialkonzept Verkaufspreis für Liegenschaft inkl. Vorbeschriebenen Leistungen: CHF 1'900'000.-Wir hoffen Ihr Interesse geweckt zu haben. Gerne stellen wir Ihnen die Verkaufsdokumente und Projektunterlagen, mit ausführlichen Informationen, per E-Mail zu.Es werden keine Makleranfragen berücksichtigt.Die zugestellten Informationen sind Eigentum von Bujar Bunjaku. Veröffentlichung, kopieren sind nicht gestattet.Kaufabwicklung:CHF 72'000.-- fällig bei Unterzeichnung der Kaufzusage; CHF 150'000.-- fällig bei Unterzeichnung und notarieller Beurkundung des Kaufvertrages; Restzahlung des Verkaufspreises fällig bei der Eigentumsübertragung.Notariats- und Grundbuchgebühren: Je zur Hälfte zu Lasten Käufer / Verkäufer.Anbieter:Bujar BunjakuWehntalerstrasse 288181 Höri Wegzeit Neu - - 1 / 4 CHF 1’096’790.– Top Bahnhofstrasse 41, 8496 Steg im Tösstal 1’111 m² attraktives Bauland in Steg Dieses 1'111 m² grosse Bauland liegt im schönen Tösstal, einer der sonnigsten Regionen der Ostschweiz. Die ruhige Lage direkt am Waldrand bietet viel Natur, frische Luft und Privatsphäre.Ein idealer Ort für Naturliebhaber und Ruhesuchende, die dennoch Wert auf eine gute Erreichbarkeit legen. Hier lassen sich Wohnträume verwirklichen.Besichtigungen sind jederzeit frei möglich.Neugierig geworden? Alle weiteren Details entnehmen Sie bitte der oben angehängten Verkaufsdokumentation.Isler-Consolis AG, Technikumstrasse 73, 8401 Winterthur, Tel. 052 267 81 00, Dorentina Bytyqi Wegzeit Neu - - 1 / 4 Preis auf Anfrage Top Lüss, 8542 Wiesendangen Im Baurecht abzugeben: 14’770 m2 Bauland an bester Lage im steuergünstigen Wiesendangen Im Baurecht abzugeben:14’770 m2 Bauland an bester Lage im steuergünstigen WiesendangenGrundstück WD4674 – Lüss WiesendangenAlle Details zum Grundstück, zum Baurechtsvertrag sowie zu den Vergabekriterien finden sie im angefügten Dossier.Verbindliche Angebote für eine Übernahme des Baurechtsvertrages inklusive Finanzierungsnachweis sind einzureichen an:Gemeinde Wiesendangenz. Hd. Martin SchindlerSchulstrasse 208542 Wiesendangen Bitte verwenden Sie für die Angebotseingabe das Formular im Anhang.Eingabeschluss: Montag, 20. Oktober 2025, 11.00 Uhr Wegzeit Neu - - 1 / 1 Preis auf Anfrage Top Büntlistrasse 1, 8174 Stadel Bauland in Stadel b. Niederglatt Die Primarschule Stadel hat zwei Landparzellen zu verkaufen. Nummber 305 & 306. 305 ist unbebaut, hingegen 306 hat ein Gebäude, welches als Kindergarten und Mietwohnungen genutzt wurde. Wir möchten die beiden Landparzellen zusammen verkaufen. Der Kontakt für die erste Anlaufstelle ist Rolf Schindelholz einer unserer Mitarbeiter in der Schulverwaltung. Geleitet wird das Projekt von Patrick Heusser dem Finanzvorstand der Primarschulpflege Stadel. Wegzeit Neu - - 1 / 12 CHF 2’323’840.– Hürstringstrasse 37, 8046 Zürich Grundstück mit bestehendem EFH und grossem Potenzial Gerne stellen wir Ihnen das Grundstück mit grossem Potenzial und vielen Möglichkeiten vor.Nach Absprache verkaufen wir an ruhiger Lage in Zürich ein Grundstück mit bestehendem Einfamilienhaus. Interessant an diesem Objekt ist jedoch, dass Sie beim Kauf bereits über die zugehörige Baubewilligung verfügen, welche es Ihnen erlaubt, den Wohnraum auf dieser Parzelle nach Ihren Wünschen zu vergrössern und zu sanieren.Nicht weit vom Zürcher Hauptbahnhof entfernt, hinter dem Käferberg liegt die grosszügige Parzelle mitten in einem ruhigen Wohnquartier mit 30er-Zone.Zu Fuss erreichen Sie eine Bushaltestelle, sowie auch den kleinen Wald, der sich ideal für kürzere Spaziergänge eignet.Die wichtigsten Infos in Kürze: • Landparzelle inkl. Einfamilienhaus und Baubewilligung zum Ausbau der Wohnfläche • Baujahr 1934 • Grundstückfläche von 410 m2 • Projektmöglichkeit 1: Ausbau zum Mehrfamilienhaus mit zwei Eigentums- oder Mietwohnungen • Projektmöglichkeit 2: Ausbau zum Generationenhaus Erleben Sie die ruhige Atmosphäre und gleichzeitige Nähe zum Stadtzentrum bei einem persönlichen Besuch!Für nähere Informationen zum Objekt oder einen Besichtigungstermin dürfen Sie sich gerne jederzeit bei uns melden. Wegzeit Neu - - 1 / 11 CHF 3’290’400.– Luzernerstrasse 57, 8903 Birmensdorf (ZH) Sonnige Aussichtslage Im Auftrag unseres Kunden verkaufen wir ein Bauland an sonniger Aussichtlage mit 1'228 m² Grundstücksfläche (Wohnzone W2).Die bestehende Liegenschaft präsentiert sich in einem dem Alter entsprechend gut unterhaltenen Zustand.Verkaufsrichtpreis: CHF 2'400'000Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot. Wegzeit Neu - - 1 / 13 CHF 1’302’440.– Kanalweg 2, 8714 Feldbach Bauland für projektiertes Einfamilienhaus Im beschaulichen Dorf Feldbach am Zürichsee ist dieses Grundstück mit einer bestehenden, einseitig angebauten Scheune zu verkaufen. Im Kaufpreis inbegriffen ist ein bewilligungsfähiges Vorprojekt für ein Einfamilienhaus als Ersatzbau der Scheune.Das Objekt bietet Ihnen die einmalige Möglichkeit, Ihren Traum vom Eigenheim an idyllischer Lage zu verwirklichen. Es bietet genügend Platz für eine Familie, auch eine Kombination von "Wohnen und Arbeiten" ist denkbar.Innert 30 Minuten sind Sie mit der S-Bahn in Zürich, auch Kindergarten und Primarschule sind nah. Einkaufsmöglichkeiten bestehen in Hombrechtikon, Stäfa und Rapperswil. Im Sommer lockt in unmittelbarer Nähe eine Abkühlung in der schmucken Seebadi Feldbach.Es besteht ein aktueller Kostenvoranschlag für das Haus (Holzelementbauweise) inkl. Umgebung, Bau- und Nebenkosten in der Höhe von Fr. 1'380'000.--.Haben wir Sie neugierig gemacht? Dann rufen Sie uns an. Gerne beantworten wir Ihre Fragen oder stellen Ihnen unsere Verkaufsdokumentation zum Studium zu. Die Liegenschaft kann selbstverständlich auch besichtigt werden. Wir freuen uns auf Ihren Anruf. Wegzeit Neu - - 1 / 13 CHF 4’111’620.– 5.5 Zimmer Schaffhauserstrasse 226b, 8057 Zürich Mehr Raum fürs Leben: Reihenhaus mit Potenzial Attraktive Stadtliegenschaft mit ausgearbeitetem ProjektIm Zürcher Kreis 11 veräussern wir ein hübsches Reiheneinfamilien-Eckhaus mit grosszügigem Umschwung. Die Liegenschaft und das Grundstück verfügen über viel Ausnützungspotenzial und ermöglicht so die Realisation spannender Projekte sowohl im Umbau als auch Neubau.Diese Liegenschaft überzeugt durch viele Besonderheiten: • grosszügiger Umschwung mit viel Potenzial • Blick ins Grüne von nahezu allen Fenstern • Schwedenofen im Wohnbereich • viel Stauraum durch Wandschränke und Estrich • Altbaucharme in modernem Quartier • zentrale und familienfreundliche Lage • sonnenverwöhnter Standort Haben wir Ihr Interesse geweckt? Bestellen Sie noch heute unsere ausführliche Verkaufsdokumentation mittels Kontaktformular und Sie erhalten weitere spannende Informationen zur Immobilie. Wir freuen uns über Ihre Kontaktaufnahme!Une oasis de verdure dans la ville de Zurich avec un projet élaboréDans le quartier 11 de Zurich, nous vendons une jolie maison mitoyenne en angle avec de vastes alentours. L'immeuble et le terrain disposent d'un grand potentiel d'exploitation et permettent ainsi la réalisation de projets passionnants, tant en transformation qu'en construction neuve.Cette propriété convainc par ses nombreuses particularités : • Un vaste terrain avec beaucoup de potentiel • Une vue sur la verdure depuis presque toutes les fenêtres • Un poêle suédois dans le séjour • beaucoup d'espace de rangement grâce aux armoires murales et au grenier • Le charme d'un ancien bâtiment dans un quartier moderne • Un emplacement central et favorable aux familles • Un emplacement ensoleillé Nous avons éveillé votre intérêt ? Commandez dès aujourd'hui notre documentation de vente détaillée au moyen du formulaire de contact et vous recevrez d'autres informations passionnantes sur le bien immobilier. Nous nous réjouissons de votre prise de contact!A green oasis in the city of Zurich with an elaborate projectIn Zurich's Kreis 11 district, we are selling a pretty terraced single-family corner house with spacious grounds. The property and the plot have a lot of utilization potential and thus enable the realization of exciting projects both in conversion and new construction.This property boasts many special features: • spacious grounds with lots of potential • view of the countryside from almost all windows • Swedish stove in the living area • lots of storage space thanks to wall cupboards and attic • old building charm in a modern district • central and family-friendly location • sun-drenched location Have we piqued your interest? Order our detailed sales documentation today using the contact form and you will receive further exciting information about the property. We look forward to hearing from you! Wegzeit Neu - - 1 / 13 CHF 4’044’440.– Mühlemattstrasse 12, 8135 Langnau am Albis Bauland oder bestehendes Einfamilienhaus zum Verkauf! Dieses freistehende Einfamilienhaus befindet sich an ruhiger Lage und bietet eine seltene Kombination aus architektonischem Charakter, grosszügigem Umschwung und inspirierendem Entwicklungspotenzial. Eingebettet in viel Grün und umgeben von Bäumen geniessen Sie hier Privatsphäre, Ruhe – und eine wunderschöne Weitsicht.Das Haus überzeugt durch eine unverwechselbare Ausstrahlung. Die Backsteinwände im Innenbereich verleihen dem Wohnraum eine warme, natürliche Atmosphäre, während das Cheminée im Wohnzimmer für Behaglichkeit an kühleren Tagen sorgt. Der Grundriss ist offen und einladend, ergänzt durch grosse Fensterfronten, die Licht und Natur ins Haus holen.Ein Highlight ist die grosszügige Terrasse mit herrlichem Ausblick – ideal für gemütliche Stunden im Freien. Der Garten ist weitläufig und bietet viel Platz für individuelle Gestaltung. Mit etwas Aufmerksamkeit lässt sich hier ein wunderbares grünes Paradies schaffen – ob als Familiengarten, Rückzugsort oder für kreative Projekte im Freien.Dank der Grundstücksgrösse und der Lage eröffnet die Liegenschaft auch interessante Perspektiven für einen möglichen Ersatzneubau - wie ein modernes Einfamilienhaus oder ein Mehrfamilienhaus.Gerne stellen wir Ihnen weitere Informationen zur Verfügung oder vereinbaren einen persönlichen Besichtigungstermin. Entdecken Sie das Potenzial und die besondere Atmosphäre dieses einzigartigen Ortes. In der Verkaufsdokumentation finden Sie alle wichtigen Informationen. Wegzeit Neu - - 1 / 6 Ruhige Lage CHF 3’358’950.– 8192 Glattfelden ZWEIFELSFREIES BAULAND IN ZWEIDLEN Im beliebten Zweidlen verkaufen wir ein eine attraktive, 1'226 m² grosse Baulandparzelle mit Bestandesobjekt.Unsere Projektstudie zeigt eine hohe Ausnutzung für die Erstellung eines Mehrfamilienhauses. • Anrechenbare mögliche Bruttogeschossfläche von max. 940 m² (Projekt 789 m²) • Wohn- und Gewerbezone WG 2.3 • Kein Denkmalschutz beim Bestandesobjekt • Die Deutsche Grenze in Kaiserstuhl ist nur 8 Autominuten entfernt • Der Flughafen Zürich ist in nur 19 Autominuten erreichbar Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: Referenznummer: 25-12278Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen! Ruhige Lage Wegzeit - - 1 / 12 Preis auf Anfrage Überlandstrasse 23, 8340 Hinwil Industrie- und Baulandparzelle an attraktivem Standort im Zürcher-Oberland Im pulsierenden Industriegebiet von Hinwil verkaufen wir ein Industriebaugrundstück an einer top frequentierter Lage, direkt an der Hauptachse in Rapperswil Wetzikon Pfäffikon ZH. Die Baulandparzelle befindet sich am Rand der Industriezone und grenzt an die Wohnzone zu Hinwil ZH.Eckdaten:- Grundstück-Fläche total 4'246 m2- Bauzone Industrie/Gewerbe IG/7 - Baumassenziffer 7 m3/m2- Gebäudehöhe maximal 21.5 m- Gebäudelänge maximal offen- Grosser Grenzabstand Nationalstrasse- Allseitiger Gebäudeabstand 3.5 m1- Maximal mögliche Baumasse ca. 30'000 m3- Bruttogeschossfläche ca. 9'500 m2Das Baugrundstück wird derzeit noch mit zwei Wohneinheiten, der Autowerkstatt mit separatem Showroom und einer Tankstelle genutzt. Rund um die Liegenschaft bieten sich grosse, befestigte Flächen zur Nutzung an. Wegzeit Neu - - 1 / 7 CHF 5’484’000.– 8156 Oberhasli ATTRAKTIVE INVESTITION IN FLUGHAFENNÄHE Unweit des Flughafens Kloten bieten wir ein attraktives Gewerbebauland für ein Neubauprojekt im strategisch ideal gelegenen Oberhasli zum Verkauf an. • Parzellenfläche: 2'010 m² • Zone: Gewerbezone • Optionen für Investoren: Neubau einer Gewerbeimmobilie mit bis zu 5'000 m² Geschossfläche (Verkauf oder Vermietung) • Optionen für Selbstnutzer: Neubau einer für die Selbstnutzung konzipierten Gewerbeimmobilie mit bis zu 5'000 m² Geschossfläche • Es besteht die Möglichkeit, die derzeit vermietete Gewerbeliegenschaft weiterzuführen. Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: Referenznummer: 24-101578Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen! Wegzeit - - 1 / 6 CHF 1’919’390.– 8187 Weiach WILLKOMMENE WERTSCHÖPFUNG IN WEIACH Im steuergünstigen Weiach bieten wir an ruhiger Ortskernlage eine wohldimensionierte, unbebaute Baulandparzelle zum Verkauf an. Unsere Baulandstudie sieht die Erstellung von zwei attraktiven Doppeleinfamilienhäusern mit 4 Wohneinheiten vor. • 1'157 m² Parzellenfläche mit bestehender Zufahrt im Wegrecht • Unser Projekt sieht die Erstellung von zwei Doppeleinfamilienhäusern mit je zwei Vollgeschossen vor • Total erstellbare Bruttogeschossfläche von 648 m² • Maximal erstellbare Gebäudelänge von 25 Metern • Der Flughafen Zürich ist in nur 20 Minuten zu erreichen, die Stadt Zürich ist nur rund 30 Km entfernt Interessiert? Weitere Informationen und Bilder zum Grundstück sowie Besichtigungsmöglichkeiten unter: Referenznummer: 24-99121Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch- Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen! Wegzeit - - 1 / 1 CHF 2’399’240.– In der Gass 2, 8627 Grüningen Grundstück mit Baubewilligung für MFH zu verkaufen Zum Verkauf steht ein Grundstück mit bewilligtem Neubauprojekt. Gebäude C des Enssamble an der Binzikerstrasse 21 / In der Gass 2, 8627 Grüningen. Die aktuell bestehenden Garagen können abgebrochen werden und durch einen Neubau mit 8 Wohnungen unterschiedlicher Grösse mit attraktiven Aussenbereich ersetzt werden. Zusätzlich wurde der gemeinsame Bau einer Tiefgarage für 11 Parkplätze mit der Zufahrt über die Strasse "In der Gass" bewilligt. Wegzeit Neu - - 1 / 6 CHF 2’879’100.– Rotweg 20, 8820 Wädenswil Ihr neues Projekt mit Seesicht Im Auftrag unseres Kunden verkaufen wir an bevorzugter, erhöhter und ruhiger Wohnquartierlage mit schöner See- und Fernsicht, 706 m² Bauland mit Rückbauobjekt.Verkaufsrichtpreis: CHF 2'100'000.00Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot. Wegzeit Neu - - 1 / 7 CHF 651’220.– Auf Anfrage 1, 8195 Wasterkingen Attraktives Baugrundstück in ruhiger, ländlicher Umgebung Willkommen in Wasterkingen, einer idyllischen und ruhigen Gemeinde im Zürcher Unterland, die für ihre hohe Lebensqualität, ländliche Gelassenheit und dennoch gute Erreichbarkeit bekannt ist. Genau hier wartet ein attraktives Baugrundstück auf Sie – die ideale Basis für Ihr zukünftiges Zuhause.Das Grundstück ist voll erschlossen und liegt in der Kernzone B, was Ihnen zahlreiche Gestaltungsmöglichkeiten eröffnet. Ob ein modernes Einfamilienhaus, ein klassisches Zuhause im Dorfcharakter oder ein individuelles Architektenprojekt – hier können Sie Ihre Wohnträume ganz nach Ihren Vorstellungen verwirklichen.Die charmante Gemeinde Wasterkingen besticht durch ihre ruhige Lage inmitten von Feldern, Reben und Natur.Dieses ImmoSky-Angebot bietet folgende Mehr Leistung:+ Voll erschlossen+ Ruhige Gemeinde+ Ideale Grösse für flexibilität (650m²)+ Kernzone B+Überbauungsziffer für Hauptgebäude 30%Dieses Grundstück bietet Ihnen die seltene Gelegenheit, ländliche Idylle mit urbaner Nähe zu vereinen – ein Ort, an dem Sie zur Ruhe kommen und dennoch bestens angebunden sind.Erfüllen Sie sich hier den Traum vom Eigenheim und gestalten Sie Ihr persönliches Refugium in Wasterkingen.Haben wir Sie mit diesem Angebot überzeugt? Dann zögern Sie nicht und kontaktieren Sie uns für weitere Fragen oder einen Besichtigungstermin!(Das Verkaufsdossier wird in der Regel innerhalb von maximal 24 Stunden an Sie versendet. Bitte überprüfen Sie auch Ihren SPAM-Ordner.) Wegzeit - - 1 / 7 CHF 7’540’490.– Staldernstrasse 13, 8158 Regensberg Entwicklungsgrundstück an top Lage in der Kernzone 2 In der gefragten Gemeinde Regensberg (ZH) steht ein hervorragend gelegenes Grundstück zum Verkauf, das sich ideal für Investoren, General- oder Totalunternehmer eignet. Die 2.557 m² grosse Parzelle Nr. 949 befindet sich in der Kernzone 2, die vielfältige bauliche und nutzungsbezogene Entwicklungsmöglichkeiten zulässt, insbesondere für Wohn- oder gemischt genutzte Projekte.Aktuell steht auf dem Grundstück ein nicht erhaltenswertes Gebäude, das im Rahmen einer Neuentwicklung rückgebaut werden kann. Eine Baueingabe oder Bewilligung liegt nicht vor, sodass volle gestalterische Freiheit innerhalb der geltenden bau- und zonenrechtlichen Rahmenbedingungen besteht.Berechnungen zeigen, dass eine nachhaltige Mietertragserwartung von rund CHF 485'600 pro Jahr realistisch erscheint - unter der Annahme einer Ausnutzung mit rund 1 664 m² Hauptnutzfläche (HNF) und 28 Tiefgaragenplätzen. Der ermittelte Kapitalisierungssatz liegt bei 4.20 %.Wesentliche Bewertungskennzahlen:Verkehrswert (diskontierter Landwert): CHF 5'505'000Ertragswert im erneuerten Zustand: CHF 11'556'795Realwert (hypothetisch): CHF 12'485'000Potenzieller Verkaufserlös: CHF 16'190'000Bruttorendite (Mietwert): 4.20%Die hypothetische Bebauung sieht zwei Mehrfamilienhäuser mit einer Bruttogeschossfläche (BGF) von insgesamt 2'080 m² vor - entsprechend einer Ausnützungsziffer von 0.81, voll im Rahmen der Zonenordnung. Die kalkulierten Baukosten (BKP 2-5) belaufen sich auf ca. CHF 8.74 Mio. Der diskontierte Landwert pro m² liegt bei CHF 2'155, was das wirtschaftliche Potenzial zusätzlich unterstreicht.Die Kernzone 2 erlaubt neben der reinen Wohnnutzung auch Mischnutzungen, beispielsweise mit gewerblichen Angeboten im Erdgeschoss. Dies ist ein zusätzlicher Vorteil für flexible, standortgerechte Entwicklungskonzepte. Die Lage in Regensberg bietet ruhige Wohnqualität in der Nähe der Agglomeration Zürich und ist in eine attraktive historische Umgebung eingebettet.Fazit: Das Grundstück bietet die seltene Gelegenheit, ein entwicklungsfähiges Grundstück an bester Lage mit bestehendem Abbruchobjekt zu akquirieren und nach eigenen Vorstellungen zu bebauen. Dank der flexiblen Nutzungsmöglichkeiten und des attraktiven Standorts stellt diese Investition eine hervorragende Ausgangslage für renditestarke Projektentwicklungen dar.Für detaillierte Informationen stehen wir Ihnen gerne zur Verfügung. Wegzeit Neu - - 1 / 3 CHF 1’686’330.– 8187 Weiach Ihr Bauland in Weiach ZH zum Schnäppchenpreis! Ihre Chance auf ein vielversprechendes Bauprojekt In der beliebten Gemeinde Weiach, eingebettet in eine ruhige und dennoch gut erreichbare Lage, erwartet Sie die Parzelle 1602. Das Grundstück in der Kernzone (K) bietet ideale Rahmenbedingungen für Investoren und Bauherren, die von Flexibilität und klar definierten Bauvorgaben profitieren möchten.Die Parzelle ermöglicht eine Bebauung mit bis zu 2 Vollgeschosse, einem anrechenbaren Dachgeschoss sowie einem Untergeschoss. Die maximale Gebäudehöhe von 7.50 m und die erlaubte Gebäudelänge von bis zu 30 m eröffnen vielseitige Bau- und Gestaltungsmöglichkeiten. Mit grosszügigen Grenzabständen von mindestens 6 m (grosser Grenzabstand) und 4 m (kleiner Grenzabstand) bietet das Grundstück genügend Raum für ansprechende Projekte mit Privatsphäre.Dieses Bauland ist die perfekte Gelegenheit, um ein individuelles Projekt in einer aufstrebenden Region zu realisieren. Egal, ob Sie Wohnraum schaffen oder ein Mischprojekt umsetzen möchten - die Parzelle hält alle Optionen offen.Ihre Vorteile auf einen Blick: • Vorhandene Machbarkeitsstudie • Bebaubare Fläche 1026 m² • Landwirtschaftszone 479 m² (CHF 60'000.- exkl.) • Kernzone (K) mit klar definierten Bauvorgaben • Maximal 2 Vollgeschosse, 1 anrechenbares Dach- und Untergeschoss • Gebäudehöhe bis zu 7.50 m • Maximale Gebäudelänge: 30 m • Grenzabstände: mind. 6 m und 4 m • Optimale Voraussetzungen für vielseitige Bauprojekte Nutzen Sie diese Gelegenheit, um ein nachhaltiges und gewinnbringendes Projekt in einer gefragten Region zu realisieren! Wegzeit - - 1 / 6 CHF 3’633’140.– Riedwiesenstrasse 20, 8305 Dietlikon RESERVIERT - Industrie-Baulandparzelle an zentraler Lage in Dietlikon ZH Mit Freude präsentieren wir Ihnen eine einzigartige und äusserst seltene Baulandparzelle an zentraler Lage in Dietlikon ZH – eine aussergewöhnliche Gelegenheit mit hervorragenden Eigenschaften, die sich besonders für Investoren eignet.Zentrale Lage: Die Parzelle befindet sich in einer äusserst gefragten Gegend mit hervorragender Anbindung: Flughafen Zürich erreichbar in 10 Fahrminuten Stadt Zürich erreichbar in 12 Fahrminuten • Visibilität: Ihr Unternehmen wird von der Autobahn aus perfekt sichtbar sein, was optimale Werbemöglichkeiten bietet (ca. 500 m2 Fassade für Werbung). • Baumassenziffer: Profitieren Sie von der hohen Baumassenziffer 10.0, die maximale Flexibilität und Nutzungseffizienz ermöglicht. • Näherbaurechte: Die Parzelle verfügt über Näherbaurechte rechts und links. Auf der Rückseite kann ein Näherbaurecht von der Stadt Zürich eingeholt werden • ca. 3'500 m2 Bruttogeschossfläche möglich • Tiefgarage / Untergeschoss bis zu ca. 800 m2 gross realisierbar • Maximale Gesamthöhe 20 m. 7 Stockwerke à 500 m2 Bruttogeschossfläche und 2.85 m Raumhöhe (brutto) möglich • Parzelle: Die ebene Fläche der Parzelle erleichtert die Bauplanung und Ausführung. • Form: Die Parzelle hat eine ideale Form, die vielseitige Bebauungsmöglichkeiten erlaubt. • Autobahnknotenpunkt: Brüttiseller Kreuz, direkt an einem der wichtigsten Autobahnknotenpunkt der Schweiz gelegen, bietet die Parzelle hervorragende Erreichbarkeit und Logistikvorteile • Störendes Gewerbe: Die Lage ist auch für Gewerbe geeignet, das potenziell störend sein kann. • Kulturzentren sowie Hotelbetriebe auch möglich. Jetzt oder nie – Ihre Chance auf ein grossartiges Investment:Solch eine Industrie-Baulandparzelle in dieser Lage kommt äusserst selten auf den Markt – seit geraumer Zeit gab es in dieser gefragten Gegend kein vergleichbares Angebot. Sichern Sie sich jetzt dieses einmalige Grundstück, ideal für visionäre Unternehmer und Investoren, die auf einen strategisch optimalen Standort setzen.Haben wir Ihr Interesse geweckt? Dann nehmen Sie noch heute Kontakt mit uns auf. Gerne lassen wir Ihnen das detaillierte Verkaufsdossier inklusive Machbarkeitsstudie zukommen – exklusiv und unverbindlich. Wegzeit Neu - -12...4 -Suche speichern Karte -Vorschläge basierend auf deinen Suchresultaten - -Startseite -Kaufen -Bauland zum Kaufen -Schweiz - -Bezirke im Kanton Kanton Zürich -Bauland kaufen Bezirk Affoltern|Bauland kaufen Bezirk Andelfingen|Bauland kaufen Bezirk Bülach|Bauland kaufen Bezirk Dielsdorf|Bauland kaufen Bezirk Hinwil|Bauland kaufen Bezirk Horgen|Bauland kaufen Bezirk Meilen|Bauland kaufen Bezirk Pfäffikon|Bauland kaufen Bezirk Uster|Bauland kaufen Bezirk Winterthur|Bauland kaufen Bezirk Dietikon|Bauland kaufen Zürich -Weitere Immobiliensuchen in Kanton Zürich -Immobilien mieten Kanton Zürich|Wohnung mieten Kanton Zürich|Haus mieten Kanton Zürich|Möbliertes Wohnobjekt mieten Kanton Zürich|Parkplatz, Garage mieten Kanton Zürich|Büro mieten Kanton Zürich|Gewerbe mieten Kanton Zürich|Neubau zum Mieten Kanton Zürich|Wohnung kaufen Kanton Zürich|Haus kaufen Kanton Zürich|Immobilien kaufen Kanton Zürich|Mehrfamilienhaus kaufen Kanton Zürich|Parkplatz, Garage kaufen Kanton Zürich|Gewerbe, Büro, Lager kaufen Kanton Zürich|Neubau zum Kaufen Kanton Zürich -Homegate - -Über uns -Kontakt & Hilfe -Geschäftskunde werden -Newsletter abonnieren -Medien -Karriere -Ombudsstelle -Werbung auf Homegate -Sitemap - -Immobilien - -Inserieren -Mieten -Kaufen -Vermieten -Verkaufen -Finanzieren -Ratgeber -Kategorien - -Rechtliches - -Datenschutz -Leistungsbeschrieb -Sicherheitstipps -Impressum -AGB -Sicherheitsproblem melden -Privatsphäre-Einstellungen - -Services - -Suchabo anlegen -Finanzierungsrechner -Steuerrechner -Betreibungsauszug -Gemeinderatgeber -Mietkaution -Umzugshilfe -Wohneigentum schätzen -Agenturverzeichnis - -App herunterladen - -Deutsch -Français -Italiano -English - -Social Media - -SMG Swiss Marketplace GroupImmoScout24Alle Immobilienhome.chimmostreet.ch -© Copyright 2025 by SMG Swiss Marketplace Group AG. Alle Rechte vorbehalten.Die Vervielfältigung und Übernahme von Inseraten durch Dritte, insbesondere von Fotos und persönlichen Daten in diesen Inseraten, verletzt die damit verbundenen Rechte und ist ausdrücklich verboten. \ No newline at end of file diff --git a/test_web_content_20251002_204000/main_url_010_www.immoscout24.ch_de_grundstueck_kaufen_kanton-zuerich.txt b/test_web_content_20251002_204000/main_url_010_www.immoscout24.ch_de_grundstueck_kaufen_kanton-zuerich.txt deleted file mode 100644 index 0ec29e9d..00000000 --- a/test_web_content_20251002_204000/main_url_010_www.immoscout24.ch_de_grundstueck_kaufen_kanton-zuerich.txt +++ /dev/null @@ -1,324 +0,0 @@ -Title: https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich -URL: https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich -Type: Main URL -Extracted: 2025-10-02 20:40:00 -================================================================================ - -70 Bauland zum Kaufen: Kanton Zürich | ImmoScout24 - - Suchen - Services -Inserat erstellen -Favoriten -Mein Konto -Menü - - Suchen - Services - Bewerten - Magazin -Inserat erstellen -Favoriten -Mein Konto -Menü -DE - DE - FR - IT - EN - -Bauland zum Kaufen -Kanton Zürich - -Wo? -Kanton Zürich -Kanton Zürich -CHF bis -Filter -70 Objekte -70 Treffer - Bauland zum Kaufen: Kanton Zürich - 1 / 16 360m², CHF 2’563’760.– Top Luegetenstrasse 11, 8489 Wildberg Ihr neues Zuhause mit Potenzial - Idyllisches Landhaus mit Baulandreserve Ihr neues Zuhause Willkommen in Ihrem zukünftigen Traumdomizil - ein grosszügiges, freistehendes Landhaus an ruhiger und idyllischer Aussichtslage im malerischen Wildberg. Hier vereinen sich ländliche Idylle, Privatsphäre und die seltene Möglichkeit, Wohnraum nach eigenen Vorstellungen zu schaffen oder zu erweitern.Ob als charmantes Familienrefugium mit grossem Garten oder als Investitionsobjekt mit Entwicklungspotenzial - dieses einzigartige Anwesen bietet Ihnen beide Optionen. Auf dem 1339m² grossen Grundstück geniessen Sie nicht nur viel Platz zum Leben, sondern verfügen auch über eine wertvolle Baulandreserve, die Ihnen vielfältige Gestaltungsmöglichkeiten eröffnet. Erste Abklärungen zeigen: Es besteht die Möglichkeit, ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren - ein echter Mehrwert für visionäre Käufer.Tauchen Sie ein in eine grüne Oase mit Weitblick - ein Ort, der Ruhe schenkt und inspiriert.Highlights auf einen Blick • Idyllische, ruhige Aussichtslage mit hohem Erholungswert • Grosszügiges Grundstück mit 1339m², ideal zur Eigennutzung und/oder für die Entwicklung eines Neubaus • Baulandreserve: Attraktives Entwicklungspotenzial - gemäss erster Einschätzung besteht die Möglichkeit, zusätzlich zum bestehenden Einfamilienhaus ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren (unverbindlich, ohne Gewähr) • Blühender Garten mit verschiedenen Sitzplätzen, Pergola mit Aussencheminée, Gartenhäusern, gepflegtem Baumbestand und weitläufigen Grünflächen • Solide Bausubstanz mit Doppelschalenmauerwerk • Grosszügiges Raumkonzept mit ca. 220m² Wohnfläche und ca. 96m² zusätzlichem Stauraum im Untergeschoss. Total ca. 360m² Bruttofläche. • Geräumiger Wohnbereich mit gemütlichem Kachelofen - ein Ort zum Ankommen und Wohlfühlen • Praktische Wohnküche mit integriertem Essbereich - ideal für gesellige Stunden • 4 helle Schlafzimmer - ideal für Familien oder Homeoffice • 2 Nasszellen mit Tageslicht • Ausgebauter Estrich für zusätzlichen Raum oder kreative Nutzungsmöglichkeiten • Beheizt durch Elektrospeicher und wassergeführte Fussbodenheizung • Garage mit elektrischem Tor und weitere Parkmöglichkeiten auf dem Grundstück • Mit einer stilvollen Modernisierung verwandeln Sie dieses Haus in ein wahres Schmuckstück Verkaufspreis: CHF 1'870'000.-Mit unserer virtuellen 360-Grad-Tour können Sie bereits die ersten Eindrücke dieser tollen Liegenschaft gewinnen. Sehr gerne zeigen wir Ihnen diese Liegenschaft direkt vor Ort und freuen uns auf Ihre Kontaktaufnahme.Weitere EckdatenBaujahr Haus: 1984, Baujahr Gerätehaus: 1986, Kubatur Haus (GVZ): 936m³, Kubatur Gerätehaus (GVZ): 40m³, Grundbuchblatt: Nr. 437, Kataster-Nr.: 249, 1/4 subjektiv-dingliches Miteigentum an Blatt 444, Kataster 249. Nettowohnfläche: ca. 220m², Bruttowohnfläche: ca. 360m², Grundstücksfläche: 1'339m².Massivbauweise, Doppelschalenmauerwerk, neuwertige Holzmetallfenster (EgoKiefer) mit dreifacher Verglasung und Sprossen & Holzläden. Elektrospeicherofen, wassergeführte Fussbodenheizung, Elektroboiler 300 Liter.Treppenlift, Garage mit elektrischem Torantrieb. Küche im Landhausstil mit Granitabdeckung, Geschirrspüler, Induktions-Kochherd und Kühlschrank mit Gefrierfach.BodenbelägeEG: Entrée, Gang, Dusche, Küche, Essen mit Plattenboden.OG: Zimmer und Vorplatz mit Laminat in Holzoptik. Bad mit Platten. Wegzeit Neu 28 min.Station: Rämismühle-Zell - 1 / 4 Preis auf Anfrage Top Lüss, 8542 Wiesendangen Im Baurecht abzugeben: 14’770 m2 Bauland an bester Lage im steuergünstigen Wiesendangen Im Baurecht abzugeben:14’770 m2 Bauland an bester Lage im steuergünstigen WiesendangenGrundstück WD4674 – Lüss WiesendangenAlle Details zum Grundstück, zum Baurechtsvertrag sowie zu den Vergabekriterien finden sie im angefügten Dossier.Verbindliche Angebote für eine Übernahme des Baurechtsvertrages inklusive Finanzierungsnachweis sind einzureichen an:Gemeinde Wiesendangenz. Hd. Martin SchindlerSchulstrasse 208542 Wiesendangen Bitte verwenden Sie für die Angebotseingabe das Formular im Anhang.Eingabeschluss: Montag, 20. Oktober 2025, 11.00 Uhr Wegzeit Neu 9 min.Station: Wiesendangen - 1 / 12 CHF 2’323’840.– Hürstringstrasse 37, 8046 Zürich Grundstück mit bestehendem EFH und grossem Potenzial Gerne stellen wir Ihnen das Grundstück mit grossem Potenzial und vielen Möglichkeiten vor.Nach Absprache verkaufen wir an ruhiger Lage in Zürich ein Grundstück mit bestehendem Einfamilienhaus. Interessant an diesem Objekt ist jedoch, dass Sie beim Kauf bereits über die zugehörige Baubewilligung verfügen, welche es Ihnen erlaubt, den Wohnraum auf dieser Parzelle nach Ihren Wünschen zu vergrössern und zu sanieren.Nicht weit vom Zürcher Hauptbahnhof entfernt, hinter dem Käferberg liegt die grosszügige Parzelle mitten in einem ruhigen Wohnquartier mit 30er-Zone.Zu Fuss erreichen Sie eine Bushaltestelle, sowie auch den kleinen Wald, der sich ideal für kürzere Spaziergänge eignet.Die wichtigsten Infos in Kürze: • Landparzelle inkl. Einfamilienhaus und Baubewilligung zum Ausbau der Wohnfläche • Baujahr 1934 • Grundstückfläche von 410 m2 • Projektmöglichkeit 1: Ausbau zum Mehrfamilienhaus mit zwei Eigentums- oder Mietwohnungen • Projektmöglichkeit 2: Ausbau zum Generationenhaus Erleben Sie die ruhige Atmosphäre und gleichzeitige Nähe zum Stadtzentrum bei einem persönlichen Besuch!Für nähere Informationen zum Objekt oder einen Besichtigungstermin dürfen Sie sich gerne jederzeit bei uns melden. Wegzeit Neu 22 min.Station: Zürich Seebach - 1 / 11 CHF 3’290’400.– Luzernerstrasse 57, 8903 Birmensdorf (ZH) Sonnige Aussichtslage Im Auftrag unseres Kunden verkaufen wir ein Bauland an sonniger Aussichtlage mit 1'228 m² Grundstücksfläche (Wohnzone W2).Die bestehende Liegenschaft präsentiert sich in einem dem Alter entsprechend gut unterhaltenen Zustand.Verkaufsrichtpreis: CHF 2'400'000Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot. Wegzeit Neu 19 min.Station: Birmensdorf -Dein Immobilienexperte vor Ort - Stöhr Immobilien GmbH berät dich persönlich zur optimalen Verkaufsstrategie für deine Immobilie. - 1 / 13 CHF 4’044’440.– Mühlemattstrasse 12, 8135 Langnau am Albis Bauland oder bestehendes Einfamilienhaus zum Verkauf! Dieses freistehende Einfamilienhaus befindet sich an ruhiger Lage und bietet eine seltene Kombination aus architektonischem Charakter, grosszügigem Umschwung und inspirierendem Entwicklungspotenzial. Eingebettet in viel Grün und umgeben von Bäumen geniessen Sie hier Privatsphäre, Ruhe – und eine wunderschöne Weitsicht.Das Haus überzeugt durch eine unverwechselbare Ausstrahlung. Die Backsteinwände im Innenbereich verleihen dem Wohnraum eine warme, natürliche Atmosphäre, während das Cheminée im Wohnzimmer für Behaglichkeit an kühleren Tagen sorgt. Der Grundriss ist offen und einladend, ergänzt durch grosse Fensterfronten, die Licht und Natur ins Haus holen.Ein Highlight ist die grosszügige Terrasse mit herrlichem Ausblick – ideal für gemütliche Stunden im Freien. Der Garten ist weitläufig und bietet viel Platz für individuelle Gestaltung. Mit etwas Aufmerksamkeit lässt sich hier ein wunderbares grünes Paradies schaffen – ob als Familiengarten, Rückzugsort oder für kreative Projekte im Freien.Dank der Grundstücksgrösse und der Lage eröffnet die Liegenschaft auch interessante Perspektiven für einen möglichen Ersatzneubau - wie ein modernes Einfamilienhaus oder ein Mehrfamilienhaus.Gerne stellen wir Ihnen weitere Informationen zur Verfügung oder vereinbaren einen persönlichen Besichtigungstermin. Entdecken Sie das Potenzial und die besondere Atmosphäre dieses einzigartigen Ortes. In der Verkaufsdokumentation finden Sie alle wichtigen Informationen. Wegzeit Neu 12 min.Station: Langnau-Gattikon - 1 / 13 CHF 1’302’440.– Kanalweg 2, 8714 Feldbach Bauland für projektiertes Einfamilienhaus Im beschaulichen Dorf Feldbach am Zürichsee ist dieses Grundstück mit einer bestehenden, einseitig angebauten Scheune zu verkaufen. Im Kaufpreis inbegriffen ist ein bewilligungsfähiges Vorprojekt für ein Einfamilienhaus als Ersatzbau der Scheune.Das Objekt bietet Ihnen die einmalige Möglichkeit, Ihren Traum vom Eigenheim an idyllischer Lage zu verwirklichen. Es bietet genügend Platz für eine Familie, auch eine Kombination von "Wohnen und Arbeiten" ist denkbar.Innert 30 Minuten sind Sie mit der S-Bahn in Zürich, auch Kindergarten und Primarschule sind nah. Einkaufsmöglichkeiten bestehen in Hombrechtikon, Stäfa und Rapperswil. Im Sommer lockt in unmittelbarer Nähe eine Abkühlung in der schmucken Seebadi Feldbach.Es besteht ein aktueller Kostenvoranschlag für das Haus (Holzelementbauweise) inkl. Umgebung, Bau- und Nebenkosten in der Höhe von Fr. 1'380'000.--.Haben wir Sie neugierig gemacht? Dann rufen Sie uns an. Gerne beantworten wir Ihre Fragen oder stellen Ihnen unsere Verkaufsdokumentation zum Studium zu. Die Liegenschaft kann selbstverständlich auch besichtigt werden. Wir freuen uns auf Ihren Anruf. Wegzeit Neu 6 min.Station: Feldbach - 1 / 13 5.5 Zimmer, CHF 4’111’620.– Schaffhauserstrasse 226b, 8057 Zürich Mehr Raum fürs Leben: Reihenhaus mit Potenzial Attraktive Stadtliegenschaft mit ausgearbeitetem ProjektIm Zürcher Kreis 11 veräussern wir ein hübsches Reiheneinfamilien-Eckhaus mit grosszügigem Umschwung. Die Liegenschaft und das Grundstück verfügen über viel Ausnützungspotenzial und ermöglicht so die Realisation spannender Projekte sowohl im Umbau als auch Neubau.Diese Liegenschaft überzeugt durch viele Besonderheiten: • grosszügiger Umschwung mit viel Potenzial • Blick ins Grüne von nahezu allen Fenstern • Schwedenofen im Wohnbereich • viel Stauraum durch Wandschränke und Estrich • Altbaucharme in modernem Quartier • zentrale und familienfreundliche Lage • sonnenverwöhnter Standort Haben wir Ihr Interesse geweckt? Bestellen Sie noch heute unsere ausführliche Verkaufsdokumentation mittels Kontaktformular und Sie erhalten weitere spannende Informationen zur Immobilie. Wir freuen uns über Ihre Kontaktaufnahme!Une oasis de verdure dans la ville de Zurich avec un projet élaboréDans le quartier 11 de Zurich, nous vendons une jolie maison mitoyenne en angle avec de vastes alentours. L'immeuble et le terrain disposent d'un grand potentiel d'exploitation et permettent ainsi la réalisation de projets passionnants, tant en transformation qu'en construction neuve.Cette propriété convainc par ses nombreuses particularités : • Un vaste terrain avec beaucoup de potentiel • Une vue sur la verdure depuis presque toutes les fenêtres • Un poêle suédois dans le séjour • beaucoup d'espace de rangement grâce aux armoires murales et au grenier • Le charme d'un ancien bâtiment dans un quartier moderne • Un emplacement central et favorable aux familles • Un emplacement ensoleillé Nous avons éveillé votre intérêt ? Commandez dès aujourd'hui notre documentation de vente détaillée au moyen du formulaire de contact et vous recevrez d'autres informations passionnantes sur le bien immobilier. Nous nous réjouissons de votre prise de contact!A green oasis in the city of Zurich with an elaborate projectIn Zurich's Kreis 11 district, we are selling a pretty terraced single-family corner house with spacious grounds. The property and the plot have a lot of utilization potential and thus enable the realization of exciting projects both in conversion and new construction.This property boasts many special features: • spacious grounds with lots of potential • view of the countryside from almost all windows • Swedish stove in the living area • lots of storage space thanks to wall cupboards and attic • old building charm in a modern district • central and family-friendly location • sun-drenched location Have we piqued your interest? Order our detailed sales documentation today using the contact form and you will receive further exciting information about the property. We look forward to hearing from you! Wegzeit Neu 4 min.Station: Berninaplatz - 1 / 12 Preis auf Anfrage Überlandstrasse 23, 8340 Hinwil Industrie- und Baulandparzelle an attraktivem Standort im Zürcher-Oberland Im pulsierenden Industriegebiet von Hinwil verkaufen wir ein Industriebaugrundstück an einer top frequentierter Lage, direkt an der Hauptachse in Rapperswil Wetzikon Pfäffikon ZH. Die Baulandparzelle befindet sich am Rand der Industriezone und grenzt an die Wohnzone zu Hinwil ZH.Eckdaten:- Grundstück-Fläche total 4'246 m2- Bauzone Industrie/Gewerbe IG/7 - Baumassenziffer 7 m3/m2- Gebäudehöhe maximal 21.5 m- Gebäudelänge maximal offen- Grosser Grenzabstand Nationalstrasse- Allseitiger Gebäudeabstand 3.5 m1- Maximal mögliche Baumasse ca. 30'000 m3- Bruttogeschossfläche ca. 9'500 m2Das Baugrundstück wird derzeit noch mit zwei Wohneinheiten, der Autowerkstatt mit separatem Showroom und einer Tankstelle genutzt. Rund um die Liegenschaft bieten sich grosse, befestigte Flächen zur Nutzung an. Wegzeit Neu 10 min.Station: Hinwil - 1 / 10 CHF 2’947’650.– Trottenrain 14, 8474 Dinhard Bewilligtes Bauprojekt im steuergünstigen Dinhard-Welsikon Das Bauland mit Magazingebäude befindet sich an zentraler Lage in Welsikon am Rande der Gemeinde Dinhard in der Kernzone. Die erreichte hohe Ausnutzung ermöglicht attraktive Neubauten an zentraler Lage. Visualisierungen und Grundrisse des bewilligten Bauprojekts finden Sie in der Dokumentation. Das Magazingebäude steht im kommunalen Inventar der schutzwürdigen Bauten. Es wurde deshalb in Absprache mit dem Heimatschutz und der Gemeinde Dinhard ein Schutzvertrag erarbeitet, der einen aussergewöhnlichen Umbau zu einem modernen Loft gestattet.Highlights: • bewilligtes Bauprojekt und Ausschreibungsplanung der Neubauten • Schutzvertrag • ausgezeichnete Lage in Welsikon • Steueroase (Gemeindesteuerfuss 83 %) • gut geschnittene Baulandparzelle • Gute ÖV-Anbindung (Bahnhof 170 m) Realisierung:Der Hauseigentümerverband Winterthur unterstützt Sie bei Bedarf gerne in enger Zusammenarbeit mit Kästle Architekten bei der Realisierung Ihres Neubauprojekts.Von der Planung bis hin zum Verkauf/Vermietung des fertigen Neubaus ? der Hauseigentümerverband Winterthur bietet Ihnen alle Dienstleistungen aus einer Hand. Es besteht keine Architekturverpflichtung.Interessenten sind herzlich eingeladen, mit uns Kontakt aufzunehmen.Rufen Sie unser Verkaufsteam über Telefon 052 209 01 68 an, wenn Sie zusätzliche Informationen oder eine Besichtigung wünschen. Wir freuen uns auf Sie.Ihr HEV-VerkaufsteamWichtig: Wir sind exklusiv mit dem Verkauf beauftragt. Direkte Eigentümerkontakte führen zu einem Interessentenausschluss. S.E.&.O. Wegzeit Neu 5 min.Station: Dinhard - 1 / 1 CHF 2’399’240.– In der Gass 2, 8627 Grüningen Grundstück mit Baubewilligung für MFH zu verkaufen Zum Verkauf steht ein Grundstück mit bewilligtem Neubauprojekt. Gebäude C des Enssamble an der Binzikerstrasse 21 / In der Gass 2, 8627 Grüningen. Die aktuell bestehenden Garagen können abgebrochen werden und durch einen Neubau mit 8 Wohnungen unterschiedlicher Grösse mit attraktiven Aussenbereich ersetzt werden. Zusätzlich wurde der gemeinsame Bau einer Tiefgarage für 11 Parkplätze mit der Zufahrt über die Strasse "In der Gass" bewilligt. Wegzeit Neu 54 min.Station: Esslingen - 1 / 25 CHF 2’604’890.– Im Königstal 2, 8487 Zell Wegzeit Neu 22 min.Station: Rämismühle-Zell - 1 / 25 CHF 4’112’990.– Im Königstal 3, 8487 Zell ZH Wegzeit Neu 22 min.Station: Rämismühle-Zell - 1 / 25 CHF 6’717’900.– Im Königstal 3, 8487 Zell ZH Wegzeit Neu 22 min.Station: Rämismühle-Zell - 1 / 6 CHF 2’879’100.– Rotweg 20, 8820 Wädenswil Ihr neues Projekt mit Seesicht Im Auftrag unseres Kunden verkaufen wir an bevorzugter, erhöhter und ruhiger Wohnquartierlage mit schöner See- und Fernsicht, 706 m² Bauland mit Rückbauobjekt.Verkaufsrichtpreis: CHF 2'100'000.00Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot. Wegzeit Neu 12 min.Station: Wädenswil - 1 / 7 CHF 651’220.– Auf Anfrage 1, 8195 Wasterkingen Attraktives Baugrundstück in ruhiger, ländlicher Umgebung Willkommen in Wasterkingen, einer idyllischen und ruhigen Gemeinde im Zürcher Unterland, die für ihre hohe Lebensqualität, ländliche Gelassenheit und dennoch gute Erreichbarkeit bekannt ist. Genau hier wartet ein attraktives Baugrundstück auf Sie – die ideale Basis für Ihr zukünftiges Zuhause.Das Grundstück ist voll erschlossen und liegt in der Kernzone B, was Ihnen zahlreiche Gestaltungsmöglichkeiten eröffnet. Ob ein modernes Einfamilienhaus, ein klassisches Zuhause im Dorfcharakter oder ein individuelles Architektenprojekt – hier können Sie Ihre Wohnträume ganz nach Ihren Vorstellungen verwirklichen.Die charmante Gemeinde Wasterkingen besticht durch ihre ruhige Lage inmitten von Feldern, Reben und Natur.Dieses ImmoSky-Angebot bietet folgende Mehr Leistung:+ Voll erschlossen+ Ruhige Gemeinde+ Ideale Grösse für flexibilität (650m²)+ Kernzone B+Überbauungsziffer für Hauptgebäude 30%Dieses Grundstück bietet Ihnen die seltene Gelegenheit, ländliche Idylle mit urbaner Nähe zu vereinen – ein Ort, an dem Sie zur Ruhe kommen und dennoch bestens angebunden sind.Erfüllen Sie sich hier den Traum vom Eigenheim und gestalten Sie Ihr persönliches Refugium in Wasterkingen.Haben wir Sie mit diesem Angebot überzeugt? Dann zögern Sie nicht und kontaktieren Sie uns für weitere Fragen oder einen Besichtigungstermin!(Das Verkaufsdossier wird in der Regel innerhalb von maximal 24 Stunden an Sie versendet. Bitte überprüfen Sie auch Ihren SPAM-Ordner.) Wegzeit - - 1 / 7 CHF 7’540’490.– Staldernstrasse 13, 8158 Regensberg Entwicklungsgrundstück an top Lage in der Kernzone 2 In der gefragten Gemeinde Regensberg (ZH) steht ein hervorragend gelegenes Grundstück zum Verkauf, das sich ideal für Investoren, General- oder Totalunternehmer eignet. Die 2.557 m² grosse Parzelle Nr. 949 befindet sich in der Kernzone 2, die vielfältige bauliche und nutzungsbezogene Entwicklungsmöglichkeiten zulässt, insbesondere für Wohn- oder gemischt genutzte Projekte.Aktuell steht auf dem Grundstück ein nicht erhaltenswertes Gebäude, das im Rahmen einer Neuentwicklung rückgebaut werden kann. Eine Baueingabe oder Bewilligung liegt nicht vor, sodass volle gestalterische Freiheit innerhalb der geltenden bau- und zonenrechtlichen Rahmenbedingungen besteht.Berechnungen zeigen, dass eine nachhaltige Mietertragserwartung von rund CHF 485'600 pro Jahr realistisch erscheint - unter der Annahme einer Ausnutzung mit rund 1 664 m² Hauptnutzfläche (HNF) und 28 Tiefgaragenplätzen. Der ermittelte Kapitalisierungssatz liegt bei 4.20 %.Wesentliche Bewertungskennzahlen:Verkehrswert (diskontierter Landwert): CHF 5'505'000Ertragswert im erneuerten Zustand: CHF 11'556'795Realwert (hypothetisch): CHF 12'485'000Potenzieller Verkaufserlös: CHF 16'190'000Bruttorendite (Mietwert): 4.20%Die hypothetische Bebauung sieht zwei Mehrfamilienhäuser mit einer Bruttogeschossfläche (BGF) von insgesamt 2'080 m² vor - entsprechend einer Ausnützungsziffer von 0.81, voll im Rahmen der Zonenordnung. Die kalkulierten Baukosten (BKP 2-5) belaufen sich auf ca. CHF 8.74 Mio. Der diskontierte Landwert pro m² liegt bei CHF 2'155, was das wirtschaftliche Potenzial zusätzlich unterstreicht.Die Kernzone 2 erlaubt neben der reinen Wohnnutzung auch Mischnutzungen, beispielsweise mit gewerblichen Angeboten im Erdgeschoss. Dies ist ein zusätzlicher Vorteil für flexible, standortgerechte Entwicklungskonzepte. Die Lage in Regensberg bietet ruhige Wohnqualität in der Nähe der Agglomeration Zürich und ist in eine attraktive historische Umgebung eingebettet.Fazit: Das Grundstück bietet die seltene Gelegenheit, ein entwicklungsfähiges Grundstück an bester Lage mit bestehendem Abbruchobjekt zu akquirieren und nach eigenen Vorstellungen zu bebauen. Dank der flexiblen Nutzungsmöglichkeiten und des attraktiven Standorts stellt diese Investition eine hervorragende Ausgangslage für renditestarke Projektentwicklungen dar.Für detaillierte Informationen stehen wir Ihnen gerne zur Verfügung. Wegzeit Neu 23 min.Station: Steinmaur - 1 / 6 CHF 3’633’140.– Riedwiesenstrasse 20, 8305 Dietlikon RESERVIERT - Industrie-Baulandparzelle an zentraler Lage in Dietlikon ZH Mit Freude präsentieren wir Ihnen eine einzigartige und äusserst seltene Baulandparzelle an zentraler Lage in Dietlikon ZH – eine aussergewöhnliche Gelegenheit mit hervorragenden Eigenschaften, die sich besonders für Investoren eignet.Zentrale Lage: Die Parzelle befindet sich in einer äusserst gefragten Gegend mit hervorragender Anbindung: Flughafen Zürich erreichbar in 10 Fahrminuten Stadt Zürich erreichbar in 12 Fahrminuten • Visibilität: Ihr Unternehmen wird von der Autobahn aus perfekt sichtbar sein, was optimale Werbemöglichkeiten bietet (ca. 500 m2 Fassade für Werbung). • Baumassenziffer: Profitieren Sie von der hohen Baumassenziffer 10.0, die maximale Flexibilität und Nutzungseffizienz ermöglicht. • Näherbaurechte: Die Parzelle verfügt über Näherbaurechte rechts und links. Auf der Rückseite kann ein Näherbaurecht von der Stadt Zürich eingeholt werden • ca. 3'500 m2 Bruttogeschossfläche möglich • Tiefgarage / Untergeschoss bis zu ca. 800 m2 gross realisierbar • Maximale Gesamthöhe 20 m. 7 Stockwerke à 500 m2 Bruttogeschossfläche und 2.85 m Raumhöhe (brutto) möglich • Parzelle: Die ebene Fläche der Parzelle erleichtert die Bauplanung und Ausführung. • Form: Die Parzelle hat eine ideale Form, die vielseitige Bebauungsmöglichkeiten erlaubt. • Autobahnknotenpunkt: Brüttiseller Kreuz, direkt an einem der wichtigsten Autobahnknotenpunkt der Schweiz gelegen, bietet die Parzelle hervorragende Erreichbarkeit und Logistikvorteile • Störendes Gewerbe: Die Lage ist auch für Gewerbe geeignet, das potenziell störend sein kann. • Kulturzentren sowie Hotelbetriebe auch möglich. Jetzt oder nie – Ihre Chance auf ein grossartiges Investment:Solch eine Industrie-Baulandparzelle in dieser Lage kommt äusserst selten auf den Markt – seit geraumer Zeit gab es in dieser gefragten Gegend kein vergleichbares Angebot. Sichern Sie sich jetzt dieses einmalige Grundstück, ideal für visionäre Unternehmer und Investoren, die auf einen strategisch optimalen Standort setzen.Haben wir Ihr Interesse geweckt? Dann nehmen Sie noch heute Kontakt mit uns auf. Gerne lassen wir Ihnen das detaillierte Verkaufsdossier inklusive Machbarkeitsstudie zukommen – exklusiv und unverbindlich. Wegzeit Neu 14 min.Station: Dietlikon - 1 / 6 Preis auf Anfrage Kaffeestrasse, 8180 Bülach Ihr Industriebau direkt in Bülach BeschreibungGerne entwickeln und realisieren wir ein auf ihre Bedürfnisse massgeschneidertes Projekt, welches Ihnen zur Miete oder im Eigentum zur Verfügung stehen wird.Interesse oder Fragen? Nehmen Sie Kontakt mit uns auf!Die Parzelle ist nicht das Richtige für Ihre Anforderungen? Kein Problem! Besuchen Sie unsere Homepage und finden Sie weitere Angebote unter: gewerbeland-schweiz.ch Wegzeit Neu 20 min.Station: Bülach - 1 / 6 Preis auf Anfrage Kaffeestrasse, 8180 Bülach Ihr Industriebau direkt in Bülach BeschreibungGerne entwickeln und realisieren wir ein auf ihre Bedürfnisse massgeschneidertes Projekt, welches Ihnen zur Miete oder im Eigentum zur Verfügung stehen wird.Interesse oder Fragen? Nehmen Sie Kontakt mit uns auf!Die Parzelle ist nicht das Richtige für Ihre Anforderungen? Kein Problem! Besuchen Sie unsere Homepage und finden Sie weitere Angebote unter: gewerbeland-schweiz.ch Wegzeit Neu 20 min.Station: Bülach - 1 / 6 Ruhige Lage CHF 3’358’950.– 8192 Glattfelden ZWEIFELSFREIES BAULAND IN ZWEIDLEN Im beliebten Zweidlen verkaufen wir ein eine attraktive, 1'226 m² grosse Baulandparzelle mit Bestandesobjekt.Unsere Projektstudie zeigt eine hohe Ausnutzung für die Erstellung eines Mehrfamilienhauses. • Anrechenbare mögliche Bruttogeschossfläche von max. 940 m² (Projekt 789 m²) • Wohn- und Gewerbezone WG 2.3 • Kein Denkmalschutz beim Bestandesobjekt • Die Deutsche Grenze in Kaiserstuhl ist nur 8 Autominuten entfernt • Der Flughafen Zürich ist in nur 19 Autominuten erreichbar Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: Referenznummer: 25-12278Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen! Ruhige Lage Wegzeit - -12...4 -Suche speichern Kartenansicht -Vorschläge basierend auf deinen Suchresultaten -Weitere interessante Objekte -Orte von Kanton Zürich - -Zürich - -Bezirke im Kanton Kanton Zürich - -Bezirk Affoltern -Bezirk Andelfingen -Bezirk Bülach -Bezirk Dielsdorf -Bezirk Dietikon -Bezirk Hinwil -Bezirk Horgen -Bezirk Meilen -Bezirk Pfäffikon -Bezirk Uster -Bezirk Winterthur - -Kantone der Schweiz - -Kanton Aargau -Kanton Appenzell Ausserrhoden -Kanton Appenzell Innerrhoden -Kanton Basel-Landschaft -Kanton Basel-Stadt -Kanton Bern -Kanton Freiburg -Kanton Genf -Kanton Glarus -Kanton Graubünden -Kanton Jura -Kanton Luzern -Kanton Neuenburg -Kanton Nidwalden -Kanton Obwalden -Kanton Schaffhausen -Kanton Schwyz -Kanton Solothurn -Kanton St. Gallen -Kanton Thurgau -Kanton Tessin -Kanton Uri -Kanton Wallis -Kanton Waadt -Kanton Zug - -ImmoScout24 - -Inserat erstellen -Werbung -Publikationsnetzwerk - -Über uns - -Kontakt -Porträt -Jobs -Fakten und Zahlen -Medien -Newsletter -Ombudsstelle - -Rechtliches - -Datenschutz -Insertionsregeln -Sicherheitstipps -Impressum -AGB -Leistungsbeschrieb -Sicherheitsproblem melden -Privatsphäre-Einstellungen - -Services - -Betreibungsauszug -Umzugshilfe -Versicherungsberatung -Agenturverzeichnis -Hypothekenrechner -Immobilienbewertung - -App herunterladen - -Unser Partner - -Deutsch -Français -Italiano -English - -Folgen Sie uns - -SMG Swiss Marketplace GroupAutoScout24FinanceScout24MotoScout24anibis.ch -© Copyright 2025 by SMG Swiss Marketplace Group AG . Alle Rechte vorbehalten.Die Vervielfältigung und Übernahme von Inseraten durch Dritte, insbesondere von Fotos und persönlichen Daten in diesen Inseraten, verletzt die damit verbundenen Rechte und ist ausdrücklich verboten. -We Care About Your Privacy -We and our 455 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data.Imprint -We and our partners process data to provide: -Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. List of Partners (vendors) -I Accept No consent Show Purposes - -About Your Privacy -We process your data to deliver content or advertisements and measure the delivery of such content or advertisements to extract insights about our website. We share this information with our partners on the basis of consent. You may exercise your right to consent, based on a specific purpose below or at a partner level in the link under each purpose. These choices will be signaled to our vendors participating in the Transparency and Consent Framework. -Privacy Policy -Allow All -Manage Consent Preferences -Functional Cookies - -[x] Functional Cookies - -These cookies enable the website to provide enhanced functionality and personalisation. They may be set by us or by third party providers whose services we have added to our pages. If you do not allow these cookies then some or all of these services may not function properly. -Cookies Details -Strictly Necessary Cookies -Always Active -These cookies are necessary for the website to function and cannot be switched off in our systems. They are usually only set in response to actions made by you which amount to a request for services, such as setting your privacy preferences, logging in or filling in forms. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. These cookies do not store any personally identifiable information. -Cookies Details -Targeting Cookies - -[x] Targeting Cookies - -These cookies may be set on our website by our advertising partners. They can be used by these companies to build a profile of your interests and to control which advertisements you see on other websites. If you do not allow these cookies, you will still see advertisements, but they will no longer be tailored to you. Your master and usage data will also be made available to the other brands of the SMG Group for analysis, for the management of personalized advertising display, and for personalized marketing communication. The latter means that you may be contacted in a personalized manner for marketing purposes not only by this brand but also by all other brands of the SMG Group. The brands of the SMG Group are ImmoScout24, Homegate, Immostreet.ch, home.ch, Publimmo, Acheter-Louer.ch, CASASOFT, IAZI, AutoScout24, MotoScout24, anibis.ch, tutti.ch, Ricardo, FinanceScout24, Flatfox, and Moneyland. We use Enhanced Conversion that may transmit pseudonymised (e.g. hashed) email addresses to third parties such as Google or publishers (e.g. TX Group or Ringier AG) to improve campaign performance and measurement and/or to create audience segments. Personal identification is not possible unless you are logged in with the same email address and associated with an account of these third parties. Your personal data will be processed either jointly with these third parties, in accordance with their respective privacy notices, or independently by SMG as controller. Please note that your personal data may also be transferred to insecure third countries, where local authorities may access them without protection equivalent to European data protection law. If the level of data protection in a country does not match that of Switzerland, we ensure contractually that the protection of your personal data always corresponds to the level in Switzerland. -Cookies Details -Performance Cookies - -[x] Performance Cookies - -These cookies allow us to count visits and traffic sources so we can measure and improve the performance of our site. They help us to know which pages are the most and least popular and see how visitors move around the site. All information these cookies collect is aggregated and therefore anonymous. If you do not allow these cookies we will not know when you have visited our site, and will not be able to monitor its performance. -Cookies Details -Store and/or access information on a device 365 partners can use this purpose - -[x] Store and/or access information on a device - -Cookies, device or similar online identifiers (e.g. login-based identifiers, randomly assigned identifiers, network based identifiers) together with other information (e.g. browser type and information, language, screen size, supported technologies etc.) can be stored or read on your device to recognise it each time it connects to an app or to a website, for one or several of the purposes presented here. -List of IAB Vendors|View Illustrations -Personalised advertising and content, advertising and content measurement, audience research and services development 438 partners can use this purpose - -[x] Personalised advertising and content, advertising and content measurement, audience research and services development - -Use limited data to select advertising 359 partners can use this purpose - -[x] Switch Label -Advertising presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type or which content you are (or have been) interacting with (for example, to limit the number of times an ad is presented to you). - -View Illustrations - -Create profiles for personalised advertising 283 partners can use this purpose - -[x] Switch Label -Information about your activity on this service (such as forms you submit, content you look at) can be stored and combined with other information about you (for example, information from your previous activity on this service and other websites or apps) or similar users. This is then used to build or improve a profile about you (that might include possible interests and personal aspects). Your profile can be used (also later) to present advertising that appears more relevant based on your possible interests by this and other entities. - -View Illustrations - -Use profiles to select personalised advertising 281 partners can use this purpose - -[x] Switch Label -Advertising presented to you on this service can be based on your advertising profiles, which can reflect your activity on this service or other websites or apps (like the forms you submit, content you look at), possible interests and personal aspects. - -View Illustrations - -Create profiles to personalise content 103 partners can use this purpose - -[x] Switch Label -Information about your activity on this service (for instance, forms you submit, non-advertising content you look at) can be stored and combined with other information about you (such as your previous activity on this service or other websites or apps) or similar users. This is then used to build or improve a profile about you (which might for example include possible interests and personal aspects). Your profile can be used (also later) to present content that appears more relevant based on your possible interests, such as by adapting the order in which content is shown to you, so that it is even easier for you to find content that matches your interests. - -View Illustrations - -Use profiles to select personalised content 92 partners can use this purpose - -[x] Switch Label -Content presented to you on this service can be based on your content personalisation profiles, which can reflect your activity on this or other services (for instance, the forms you submit, content you look at), possible interests and personal aspects. This can for example be used to adapt the order in which content is shown to you, so that it is even easier for you to find (non-advertising) content that matches your interests. - -View Illustrations - -Measure advertising performance 404 partners can use this purpose - -[x] Switch Label -Information regarding which advertising is presented to you and how you interact with it can be used to determine how well an advert has worked for you or other users and whether the goals of the advertising were reached. For instance, whether you saw an ad, whether you clicked on it, whether it led you to buy a product or visit a website, etc. This is very helpful to understand the relevance of advertising campaigns. - -View Illustrations - -Measure content performance 171 partners can use this purpose - -[x] Switch Label -Information regarding which content is presented to you and how you interact with it can be used to determine whether the (non-advertising) content e.g. reached its intended audience and matched your interests. For instance, whether you read an article, watch a video, listen to a podcast or look at a product description, how long you spent on this service and the web pages you visit etc. This is very helpful to understand the relevance of (non-advertising) content that is shown to you. - -View Illustrations - -Understand audiences through statistics or combinations of data from different sources 253 partners can use this purpose - -[x] Switch Label -Reports can be generated based on the combination of data sets (like user profiles, statistics, market research, analytics data) regarding your interactions and those of other users with advertising or (non-advertising) content to identify common characteristics (for instance, to determine which target audiences are more receptive to an ad campaign or to certain contents). - -View Illustrations - -Develop and improve services 300 partners can use this purpose - -[x] Switch Label -Information about your activity on this service, such as your interaction with ads or content, can be very helpful to improve products and services and to build new products and services based on user interactions, the type of audience, etc. This specific purpose does not include the development or improvement of user profiles and identifiers. - -View Illustrations - -Use limited data to select content 83 partners can use this purpose - -[x] Switch Label -Content presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type, or which content you are (or have been) interacting with (for example, to limit the number of times a video or an article is presented to you). - -View Illustrations -List of IAB Vendors -Use precise geolocation data 132 partners can use this special feature - -[x] Use precise geolocation data - -With your acceptance, your precise location (within a radius of less than 500 metres) may be used in support of the purposes explained in this notice. -List of IAB Vendors -Actively scan device characteristics for identification 71 partners can use this special feature - -[x] Actively scan device characteristics for identification - -With your acceptance, certain characteristics specific to your device might be requested and used to distinguish it from other devices (such as the installed fonts or plugins, the resolution of your screen) in support of the purposes explained in this notice. -List of IAB Vendors -Ensure security, prevent and detect fraud, and fix errors 290 partners can use this special purpose -Always Active -Your data can be used to monitor for and prevent unusual and possibly fraudulent activity (for example, regarding advertising, ad clicks by bots), and ensure systems and processes work properly and securely. It can also be used to correct any problems you, the publisher or the advertiser may encounter in the delivery of content and ads and in your interaction with them. -List of IAB Vendors|View Illustrations -Deliver and present advertising and content 286 partners can use this special purpose -Always Active -Certain information (like an IP address or device capabilities) is used to ensure the technical compatibility of the content or advertising, and to facilitate the transmission of the content or ad to your device. -List of IAB Vendors|View Illustrations -Match and combine data from other data sources 214 partners can use this feature -Always Active -Information about your activity on this service may be matched and combined with other information relating to you and originating from various sources (for instance your activity on a separate online service, your use of a loyalty card in-store, or your answers to a survey), in support of the purposes explained in this notice. -List of IAB Vendors -Link different devices 172 partners can use this feature -Always Active -In support of the purposes explained in this notice, your device might be considered as likely linked to other devices that belong to you or your household (for instance because you are logged in to the same service on both your phone and your computer, or because you may use the same Internet connection on both devices). -List of IAB Vendors -Identify devices based on information transmitted automatically 265 partners can use this feature -Always Active -Your device might be distinguished from other devices based on information it automatically sends when accessing the Internet (for instance, the IP address of your Internet connection or the type of browser you are using) in support of the purposes exposed in this notice. -List of IAB Vendors -Save and communicate privacy choices 245 partners can use this special purpose -Always Active -The choices you make regarding the purposes and entities listed in this notice are saved and made available to those entities in the form of digital signals (such as a string of characters). This is necessary in order to enable both this service and those entities to respect such choices. -List of IAB Vendors|View Illustrations -Cookie List -Clear - -[x] checkbox label label - -Apply Cancel -Consent Leg.Interest - -[x] checkbox label label - -[x] checkbox label label - -[x] checkbox label label - -No consent Confirm My Choices \ No newline at end of file diff --git a/test_web_content_20251002_204000/main_url_011_www.comparis.ch_immobilien_marktplatz_kanton_zuerich_grundstueck_kaufen.txt b/test_web_content_20251002_204000/main_url_011_www.comparis.ch_immobilien_marktplatz_kanton_zuerich_grundstueck_kaufen.txt deleted file mode 100644 index 7e25ebe4..00000000 --- a/test_web_content_20251002_204000/main_url_011_www.comparis.ch_immobilien_marktplatz_kanton_zuerich_grundstueck_kaufen.txt +++ /dev/null @@ -1,401 +0,0 @@ -Title: https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen -URL: https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen -Type: Main URL -Extracted: 2025-10-02 20:40:00 -================================================================================ - -Grundstück in Kanton Zürich kaufen - Vergleiche 72 Inserate mit comparis.ch - -Versicherungen -Finanzen -Immobilien -Mobilität -Gesundheit -Telecom - -Neu in der Schweiz - -Person absichern - -Krankenkasse -Lebensversicherung -Rechtsschutz -Reiseversicherung - -Fahrzeug versichern - -Autoversicherung -Motorradversicherung - -Eigentum versichern - -Hausrat und Privathaftpflicht -Tierversicherung - -Alles zu Versicherungen -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Kredit aufnehmen - -Privatkredit -Kreditrechner -Kreditvergleich - -Immobilie finanzieren - -Hypotheken -Hypothekenrechner -Zinsentwicklung - -Altersvorsorge planen - -Altersvorsorge -Pensionsplanung - -Steuern vergleichen - -Steuervergleich -Steuerrechner -Quellensteuer - -Fahrzeug finanzieren - -Autoleasing -Leasingrechner -Autokredit - -Wirtschaftsinfos einholen - -Finanzen und Wirtschaft - -Alles zu Finanzen -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Immobilie finden - -Immobilienmarkt -Steuerrechner - -Immobilie finanzieren - -Hypotheken -Hypothekenrechner -Zinsentwicklung - -Immobilien bewerten - -Immobilie kostenlos bewerten -Immobilienbewertung Plus (Beta) -Makler finden -Immobilie verkaufen - -Immobilie inserieren - -Privat inserieren -Als Firma inserieren - -Umzug planen - -Umzugsservice -Umzugskostenrechner -Umzug in die Schweiz -Malerservice - -Hausrat versichern - -Hausrat und Privathaftpflicht - -Alles zu Immobilien -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Automarkt - -Auto kaufen -Auto verkaufen -Autowert berechnen - -Fahrzeug finanzieren - -Autoleasing -Leasingrechner -Autokredit - -Fahrzeug versichern - -Autoversicherung -Motorradversicherung - -Fahrzeugnutzung - -Benzinpreise -Autoprüfung - -Elektromobilität - -Elektromobilität entdecken -Ladestation finden -Elektroauto - -Reisen - -Reisetipps -Reiseversicherung -Ferien-Packliste - -Alles zu Mobilität -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Arzt finden und Behandlungen - -Arzt finden -Zähne -Dermatologie -Medikamente - -Leben im Alter und Spitex - -Spitex finden -Finanzierung und Wohnen -Zu Hause pflegen - -Krankenkasse - -Krankenkasse vergleichen - -Alles zu Gesundheit -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Mobile - -Handy-Abo - -Internet und TV zuhause - -Internet, TV und Festnetz - -Alles zu Telecom -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren - -Auswandern - -Auswandern in die Schweiz -Aufenthaltsbewilligung -Führerschein umschreiben -Miete in der Schweiz - -Arbeit - -Arbeiten in der Schweiz -Durchschnittslohn in der Schweiz -Jobsuche -Lohnnebenkosten - -Finanzen - -Finanzen in der Schweiz -Quellensteuer vergleichen -Lebenshaltungskosten - -Leben - -Leben in der Schweiz -Schweizerdeutsch lernen -Besonderheiten der Schweiz - -Alles zu Neu in der Schweiz -Ihr MyComparis-Konto - Verwalten Sie Ihre Offerten - Erstellen Sie Merklisten - Steuern Sie Ihre Newsletter -LoginRegistrieren -DE -FRITEN -Login -Login -Comparis entdecken - -Versicherungen -Finanzen -Immobilien -Mobilität -Gesundheit -Telecom -Neu in der Schweiz - -Newsletter -Login -DEFRITEN - -Startseite -Wohnen -Immobilien -Bauland kaufen -Grundstück in Kanton Zürich kaufen - -Favoriten (0) -Grundstück in Kanton Zürich kaufen: 72 Resultate -Filter (4)Suchabo anlegen Suchabo -Kein neues Inserat verpassen! - Umgehende Benachrichtigung - Jederzeit anpassbar - Kostenlos -Infobox schliessen - -Sortieren nach: -Sortieren nach:Erstmals gefunden am -Sortieren -Bauland Online seit einem Tag 706 m² ------ «Ihr neues Projekt mit Seesicht» 8820 Wädenswil Rotweg 20 CHF 2'100'000 Kaufpreis Merken Merken CHF 2'100'000 Kaufpreis -Gewerbegrundstück Online seit 3 Tagen Gewerbegrundstück ----------------- «Bauernhof mit mehreren landwirtschaftlichen Parzellen» 8460 Marthalen Talackerberg, Im Türni CHF 1'020'000 Kaufpreis Merken Merken CHF 1'020'000 Kaufpreis -Bauland Online seit 3 Tagen Bauland ------- «BAULAND AN TRAUMHAFTER LAGE AM FISCHBACH» 8162 Steinmaur auf Anfrage Kaufpreis Merken Merken auf Anfrage Kaufpreis -Bauland Online seit 4 Tagen 1285 m² ------- «Windlach: Grundstück mit Potenzial für Wohnraumentwicklung» 8175 Windlach CHF 800'000 Kaufpreis Merken Merken CHF 800'000 Kaufpreis -Bauland Online seit 5 Tagen 3166 m² ------- «Attraktives Entwicklungsareal an zentraler Lage mit 3?166 m²» 8050 Zürich CHF 26'000'000 Kaufpreis Merken Merken CHF 26'000'000 Kaufpreis -Grundstück Online seit 5 Tagen Grundstück ---------- «Hier beginnt Ihre Zukunft» 8340 Hinwil CHF 1'070'000 Kaufpreis Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken CHF 1'070'000 Kaufpreis -Bauland Online seit einer Woche 9175 m² ------- «Vergabe der Gewerbefläche GB Nr. 74, Neuhausen am Rheinfall» 8212 Neuhausen am Rheinfall CHF 343 Kaufpreis pro m² Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken CHF 343 Kaufpreis pro m² -Bauland Online seit einer Woche Bauland ------- «Zürich» 8000 Zürich auf Anfrage Kaufpreis Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken auf Anfrage Kaufpreis -Grundstück Online seit einer Woche Grundstück ---------- «Zürich» 8001 Zürich auf Anfrage Kaufpreis Merken Merken auf Anfrage Kaufpreis -Grundstück Online seit einer Woche Grundstück ---------- «Attraktives Baugrundstück in ruhiger, ländlicher Umgebung» 8195 Wasterkingen CHF 475'000 Kaufpreis Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken CHF 475'000 Kaufpreis - -1 -2 -3 -4 -5 -6 -8 - -Gemeinden in diesem Kanton -A -B -C -D -E -F -G -H -I -J -K -L -M -N -O -P -Q -R -S -T -U -V -W -X -Y -Z -A -Adliswil -Aeugst am Albis -Affoltern am Albis -B -Benken (ZH) -Bülach -D -Dättlikon -Dielsdorf -Dietikon -Dietlikon -Dinhard -Dorf -E -Elgg -Embrach -Erlenbach (ZH) -F -Fällanden -H -Herrliberg -Hettlingen -Hinwil -Höri -Hüntwangen -M -Marthalen -Mönchaltorf -N -Niederglatt -Niederhasli -O -Oetwil am See -P -Pfäffikon -R -Rafz -Regensberg -Regensdorf -Richterswil -Rifferswil -Rümlang -Russikon -Rüti (ZH) -S -Steinmaur -V -Volken -W -Wädenswil -Wasterkingen -Weisslingen -Wildberg -Z -Zell (ZH) -Zürich -Das könnte Sie interessieren -Weitere Comparis Services -Was zahlt die Nachbarschaft?Umzugsfirma ZürichInserieren -Weitere Kaufobjekte in Kanton Zürich -Wohnung kaufen Kanton Zürich (1500)Haus kaufen Kanton Zürich (642)Mehrfamilienhaus kaufen Kanton Zürich (70) -ZU DEN FAVORITEN -Filter (4) - -comparis.ch -1. Über Comparis -2. User Service -3. Jobs -4. Medien -5. Allgemeine Geschäftsbedingungen -Weitere Angebote -1. Studien -2. Gebühren -3. Werbung -4. Comparis-Siegel -Folgen Sie uns -1. -2. -3. -4. -Newsletter -1. Newsletter bestellen -© comparis.ch AG 2025 -DatenschutzRechtliche InformationenImpressum \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_001_www.valueon.ch_.txt b/test_web_content_20251002_205603/additional_link_001_www.valueon.ch_.txt deleted file mode 100644 index 215fd7a6..00000000 --- a/test_web_content_20251002_205603/additional_link_001_www.valueon.ch_.txt +++ /dev/null @@ -1,106 +0,0 @@ -URL: https://www.valueon.ch/ -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -# Power für deinendigitalen Erfolg - -Vertrauen von führenden Unternehmen - -## Unsere Expertise - -Von digitaler Transformation bis zu künstlicher Intelligenz – wir begleiten Sie auf Ihrem Weg in die Zukunft. - -### Digitale Strategie entwickeln - -Ihre Richtung im digitalen Wandel. - -Gemeinsames Zielbild & Roadmap, abgestimmt auf Ihr Geschäft und leiten konkrete Handlungsempfehlungen ab. - -Orientierung & Handlungssicherheit - -### Transformation gezielt optimieren - -Lücken aufdecken. Stärken nutzen. - -Systematischer Blick auf Prozesse, Systeme & Potenziale und leiten konkrete Handlungsempfehlungen ab. - -Relevanz statt Aktionismus - -### Change Management etablieren - -Menschen mitnehmen. Wandel gestalten. - -Strukturierte Begleitung der Mitarbeiter durch den digitalen Wandel mit gezielten Schulungskonzepten. - -Akzeptanz & Erfolg sichern - -### Prozesse digital automatisieren - -Effizienz steigern. Kosten senken. - -Identifikation und Umsetzung von Automatisierungspotenzialen für nachhaltige Produktivitätssteigerung. - -Messbare Effizienzgewinne - -## Erfolgreiche Projekte & Transformationen - -Unter dem Motto «Unsere Kunden stehen im Mittelpunkt» haben wir für Sie eine Auswahl an Kundenreferenzen und Business Cases zusammengestellt. - -Als KMU sind wir es eigentlich nicht gewohnt, einen so grossen Aufwand wie bei der Evaluation des richtigen Partners für die Entwicklung und Realisierung unseres neuen Kernsystems zu betreiben. Doch i... - -Markus Berther - -Geschäftsführer, Schaden Service Schweiz AG - -ValueOn hat uns durch den gesamten Prozess der Digitalen Business Transformation mit grossem Einsatz und Engagement begleitet – von der ersten IT-Standortanalyse und Sourcing Analyse über digitales Zi... - -Stefan Wolf - -Präsident, FC Luzern - -In diesem businesskritischen IT-Programm waren insgesamt vier Experten von ValueOn (ehem. Project Competence) involviert, als Projektleiter und Koordinator, Cut-Over-Manager bis hin zur Gesamt-Program... - -Roland Bosshard - -CIO / Mitglied der GL, KPT - -In time, in quality, under budget: Andreas Friedli von ValueOn (ehem. Project Competence) hat in seiner Co-Leitungsfunktion in diesem IT-Projekt ganz massgeblich dazu beigetragen, dass wir dieses trot... - -Thomas Sturzenegger - -Divisional IT Lead, RUAG Real Estate AG - -Die erfolgreiche Realisierung dieses Vorhabens ist ein wichtiger Meilenstein für die strategische Neuausrichtung der WWZ. Die Projektberater der ValueOn AG (ehem. Project Competence AG) haben dabei da... - -Thomas Reber - -Leiter Telekom & IT Services, WWZ AG - -Um die Zukunftsausrichtung unserer IT-Strategie und -Organisation möglichst optimal auf unsere Business-Anforderungen auszurichten, haben wir ValueOn (ehem. Project Competence) als Sparringpartner ... - -Andreas Guglielmo - -CFO, CHRIS sports AG - -Wir danken den externen Projektberatern der ValueOn (ehem. Project Competence), die uns kompetent und mit ebenso hohem Arbeitseinsatz durch dieses Projekt und die Verhandlungen unter schwierigen Be... - -Michael Kohlbacher - -Generalsekretär, AGZ - -Dank ValueOn konnten wir unser komplexes IT-Infrastrukturprojekt termingerecht und im Budget abschliessen. Die strukturierte Herangehensweise war ausschlaggebend. - -Peter Keller - -Projektleiter, InnovaCorp - -ValueOn hat uns sowohl fachlich als auch menschlich auf höchstem Niveau beraten. Die Experten begleiteten uns kompetent bei der Modernisierung unserer IT-Infrastruktur und der reibungslosen Ablösung u... - -Silvan Wildhaber - -CEO, Filtex Group AG - -← Wischen Sie für weitere Testimonials → - -Auto-Scroll aktiv \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_002_www.valueon.ch_services.txt b/test_web_content_20251002_205603/additional_link_002_www.valueon.ch_services.txt deleted file mode 100644 index 7ddf00e3..00000000 --- a/test_web_content_20251002_205603/additional_link_002_www.valueon.ch_services.txt +++ /dev/null @@ -1,110 +0,0 @@ -URL: https://www.valueon.ch/services -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unsere Leistungen -================= - -Von der digitalen Transformation bis zur KI-Integration – wir begleiten Sie bei jedem Schritt zu nachhaltigem Erfolg, messbaren Ergebnissen und langfristiger Wertschöpfung. - -Digitale Transformation Künstliche Intelligenz IT- & Digitalprojekte - -Digitale Transformation ------------------------ - -Wir begleiten Sie bei jedem Schritt – von der Strategie bis zur erfolgreichen Umsetzung. - -### Zukunft gestalten mit klarem Zielbild - -IHRE RICHTUNG IM DIGITALEN WANDEL - -Zielbild & Roadmap für digitale Transformation – zugeschnitten auf Ihr Geschäft. - -Orientierung & Handlungssicherheit - -### Transformation analysieren & optimieren - -LÜCKEN AUFDECKEN. NUTZEN SCHÄRFEN - -Fit-Gap-Analyse und Review Ihrer Prozesse, Tools & Struktur. - -Systematische Bewertung statt Aktionismus - -### IT, Business & Digitalstrategie vereinen - -SCHNITTSTELLEN AUFLÖSEN. STRATEGIE VERBINDEN - -Abgleich Ihrer Digital- und Businessstrategie – für nachhaltige Wirkung. - -Strategische Klarheit gewinnen - -### CIO/CDO ad interim einsetzen - -FÜHRUNG SICHERN. KOMPETENZ EINBRINGEN - -Temporäre Führungsstärke, wenn Verantwortung gebraucht wird. - -Sofort einsatzbereit & erfahrungssicher - -### Zukunft gestalten mit klarem Zielbild - -IHRE RICHTUNG IM DIGITALEN WANDEL - -Zielbild & Roadmap für digitale Transformation – zugeschnitten auf Ihr Geschäft. - -Orientierung & Handlungssicherheit - -### Transformation analysieren & optimieren - -LÜCKEN AUFDECKEN. NUTZEN SCHÄRFEN - -Fit-Gap-Analyse und Review Ihrer Prozesse, Tools & Struktur. - -Systematische Bewertung statt Aktionismus - -### IT, Business & Digitalstrategie vereinen - -SCHNITTSTELLEN AUFLÖSEN. STRATEGIE VERBINDEN - -Abgleich Ihrer Digital- und Businessstrategie – für nachhaltige Wirkung. - -Strategische Klarheit gewinnen - -### CIO/CDO ad interim einsetzen - -FÜHRUNG SICHERN. KOMPETENZ EINBRINGEN - -Temporäre Führungsstärke, wenn Verantwortung gebraucht wird. - -Sofort einsatzbereit & erfahrungssicher - -### Bereit für den ersten Schritt? - -Ob Strategie, Analyse oder Interim – wir zeigen Ihnen den passenden Einstieg. - -Kostenfrei Strategiegespräch vereinbaren - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_205603/additional_link_003_www.valueon.ch_projects.txt b/test_web_content_20251002_205603/additional_link_003_www.valueon.ch_projects.txt deleted file mode 100644 index eeab3c96..00000000 --- a/test_web_content_20251002_205603/additional_link_003_www.valueon.ch_projects.txt +++ /dev/null @@ -1,354 +0,0 @@ -URL: https://www.valueon.ch/projects -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unsere Erfolgsprojekte -====================== - -Entdecken Sie, wie wir Unternehmen dabei helfen, ihre digitale Transformation erfolgreich umzusetzen und nachhaltige Werte zu schaffen. - -50+ - -Erfolgreiche Projekte - -100% - -Kundenzufriedenheit - -25% - -Ø Kostenoptimierung - -60% - -schneller Integriert - -Referenzprojekte & Success Stories ----------------------------------- - -Jedes Projekt ist einzigartig. Entdecken Sie, wie wir mit massgeschneiderten Lösungen echte Mehrwerte für unsere Kunden schaffen. - - - -Digitale Transformation - -KPT • 18 Monate - -### Digitale Transformation der KPT - -Komplette Modernisierung der IT-Infrastruktur mit 24% Kostenoptimierung und deutlich mehr Leistung, Flexibilität und Sicherheit. - -#### Technologien: - -Cloud Migration Prozessoptimierung Change Management - -#### Ergebnisse: - -* 24% Kostenoptimierung -* Erhöhte Flexibilität -* Verbesserte Sicherheit - - - -Künstliche Intelligenz - -WWZ • 12 Monate - -### KI-gestützte Prozessoptimierung WWZ - -Implementierung einer KI-Lösung zur Automatisierung von Geschäftsprozessen und Entscheidungsfindung. - -#### Technologien: - -Machine Learning Process Mining Automation - -#### Ergebnisse: - -* 40% Zeitersparnis -* Verbesserte Genauigkeit -* Datenbasierte Entscheidungen - - - -IT-Infrastruktur - -FC Luzern • 8 Monate - -### Businesskritische IT-Infrastruktur FC Luzern - -Aufbau einer hochverfügbaren IT-Infrastruktur für geschäftskritische Anwendungen mit 99.9% Uptime. - -#### Technologien: - -High Availability Disaster Recovery Security - -#### Ergebnisse: - -* 99.9% Verfügbarkeit -* Null Datenverlust -* Compliance erreicht - - - -Cloud Transformation - -TechStart AG • 10 Monate - -### Cloud-First Strategie TechStart AG - -Vollständige Migration zur Cloud mit Fokus auf Skalierbarkeit und Kosteneffizienz. - -#### Technologien: - -AWS Kubernetes DevOps - -#### Ergebnisse: - -* 60% Kosteneinsparung -* Bessere Skalierbarkeit -* Schnellere Deployments - - - -Change Management - -InnovaCorp • 15 Monate - -### Agile Transformation InnovaCorp - -Einführung agiler Arbeitsweisen und Kulturwandel für verbesserte Projekteffizienz. - -#### Technologien: - -Scrum Kanban Team Coaching - -#### Ergebnisse: - -* 50% kürzere Time-to-Market -* Höhere Mitarbeiterzufriedenheit -* Verbesserte Qualität - - - -Strategieberatung - -Swiss Enterprise • 24 Monate - -### Digital Excellence Program - -Entwicklung einer umfassenden Digitalisierungsstrategie für nachhaltiges Wachstum. - -#### Technologien: - -Strategy Design Digital Roadmap KPI Framework - -#### Ergebnisse: - -* 30% Umsatzsteigerung -* Neue Geschäftsmodelle -* Marktführerschaft - - - -Digitale Transformation - -Filtex Textil • 14 Monate - -### Digital Transformation der Filtex Textil - -Komplette Analyse und Erneuerung der gesamten IT-/Datenarchitektur mit massiven Kostenreduktion, 100% Sales Flexibilität und Sicherheit. - -#### Technologien: - -Cloud Migration Prozessoptimierung KPI-Dashboard Security - -#### Ergebnisse: - -* 99.9% Verfügbarkeit -* Maximale Kundenorientierung -* Zeit- und Ressourcenersparnis -* Planungssicherheit - - - -Digitale Transformation - -Häny Pumpen • 16 Monate - -### Digital Transformation der Häny Pumpen - -Analyse und Erneuerung der gesamten IT-/Datenarchitektur mit Kostenreduktion, Sales Flexibilität, ERP-Standardisierung und Sicherheit. - -#### Technologien: - -Cloud Migration Prozessoptimierung ERP-Technologie KPI-Dashboard Security - -#### Ergebnisse: - -* Komplette ERP-Systemmigration -* Maximale Kundenorientierung -* Risikominimierung -* Zeit- und Ressourcenersparnis -* Verbesserte Sicherheit - - - -Digitale Transformation - -Swiss Ice Hockey Federation • 20 Monate - -### Digital Transformation der Swiss Ice Hockey Federation - -Analyse und Erneuerung der gesamten IT-/Datenarchitektur, Kostenreduktion, Prozesslandschafts- und Kollaborationsplattform, ERP- und Datensicherheit. - -#### Technologien: - -Cloud Migration Prozessoptimierung ERP-Technologie Security - -#### Ergebnisse: - -* Komplette ERP-Systemmigration -* Anspruchsgruppen-Fokus -* Risikominimierung -* Zeit- und Ressourcenersparnis -* Verbesserte Sicherheit - - - -Strategieberatung - -Swiss Olympic • 12 Monate - -### Digitalisierungsstrategie für Swiss Olympic - -Analyse der gesamten IT-/Datenarchitektur, Prozesslandschafts- und Kollaborationsplattform, ERP- und Datensicherheit. - -#### Technologien: - -ERP-Technologie Security Kollaborations-Technologie - -#### Ergebnisse: - -* Komplette Roadmap mit Handlungsfeldern -* Anspruchsgruppen-Fokus -* Risiko-Management -* Vorbereitung Aufbau PPM -* Zeit- und Ressourcenersparnis -* Verbesserte Sicherheit - - - -Künstliche Intelligenz - -LayerFinance • 18 Monate - -### KI-Transformation für LayerFinance - -Analyse der gesamten Datenarchitektur, Prozesslandschaft, Datensicherheit, KI-Anwendungen. - -#### Technologien: - -KI-Technologie Deal-closing AI-Plattform - -#### Ergebnisse: - -* Continuation in Enabling KI based Deal Closing Plattform -* Zeit- und Ressourcenersparnis -* Verbesserte Sicherheit - - - -Strategieberatung - -Steuerverwaltung Bern • 7 Monate - -### Technologiewechsel-Programm Steuerverwaltung Bern - -Umfassende Analyse des Technologiewechsel-Programms zur Identifikation kritischer Erfolgsfaktoren und zur Definition konkreter Massnahmen für den Abschluss. Erstellung einer integrierten Gesamtplanung mit Abhängigkeitsmanagement sowie Etablierung eines konsistenten Change- und Risikomanagements. - -#### Technologien: - -Prozessoptimierung Strategy Design Roadmap Management - -#### Ergebnisse: - -* Einheitliche, steuerbare Prozesse -* Vollständige Transparenz über Programmverlauf -* Hohe Planungs- und Umsetzungssicherheit -* Frühzeitige Risikokontrolle und Eskalationsfähigkeit -* Stärkung der Steuerungsfähigkeit auf Gesamtprogrammebene - - - -Digitale Transformation - -Schadenservice Schweiz • 24 Monate - -### Von der Analyse zur Umsetzung – ERP-Projekt Schadenservice Schweiz - -Begleitung eines ERP-Erneuerungsprojekts von der initialen Bedarfsanalyse über die Evaluation bis zur vollständigen Umsetzung. Nach dem Entscheid zur Eigenentwicklung übernahm ein externer Anbieter die technische Realisierung, während wir die Kundenseite als unabhängige Vertretung begleiteten. - -#### Technologien: - -Bedarfsanalyse Evaluation & Auswahlprozess Projektleitung auf Kundenseite Change Management - -#### Ergebnisse: - -* Massgeschneiderte ERP-Lösung auf Basis individueller Anforderungen -* Strukturierte Zusammenarbeit zwischen Entwicklung, Fachbereichen und Betrieb -* Einführung standardisierter Prozesse und digitaler Abläufe -* Hohe Akzeptanz bei den Nutzerinnen und Nutzern -* Erfolgreiche Verankerung der neuen Lösung im Tagesgeschäft - - - -Strategieberatung - -Sunrise TDC Switzerland AG • 3 Monate - -### PMO-Aufbau Sunrise TDC Switzerland AG - -Aufbau eines voll funktionsfähigen Project Management Office (PMO) für Customer Care und Effizienzsteigerung der PMIO-Organisation innerhalb von 3 Monaten. - -#### Technologien: - -Situationsanalyse PMO-Strukturierung Change Management Prozessoptimierung - -#### Ergebnisse: - -* Funnel- und Steuerungsausschussstrukturen etabliert -* Bewertungskriterien für Priorisierung definiert -* Standardisierter Funnel- und Steuerungsbericht -* Konstruktiver und offener Management Buy-in -* Termingerechte PMO-Kompetenz realisiert - -> "Das PMO-Setup war ein voller Erfolg. Termingerecht und mit konstruktivem Management Buy-in haben wir ein funktionsfähiges System etabliert." - -— Dr. Marc Furrer, CEO Sunrise TDC Switzerland AG - -Previous slide Next slide - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_205603/additional_link_004_www.valueon.ch_vernissage.txt b/test_web_content_20251002_205603/additional_link_004_www.valueon.ch_vernissage.txt deleted file mode 100644 index 73c40977..00000000 --- a/test_web_content_20251002_205603/additional_link_004_www.valueon.ch_vernissage.txt +++ /dev/null @@ -1,68 +0,0 @@ -URL: https://www.valueon.ch/vernissage -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Beyond AI -========= - -Wo KI auf Führung trifft ------------------------- - -Künstliche Intelligenz ist nicht nur ein Werkzeug – sie ist ein transformativer Treiber, der grundlegend verändert, wie wir führen, arbeiten und Wert schaffen. - -PeaqPartners und ValueOn laden Sie herzlich zur AI Vernissage ein – einem exklusiven Abend für ausgewählte Partner:innen und Führungspersönlichkeiten. Freuen Sie sich auf Impulse, Gespräche und kreative Erlebnisse rund um den strategischen Einsatz von KI. - -### Event-Details - -Datum:Dienstag, 16. September 2025 - -Ort:Le Bijou, Lintheschergasse 18, 8001 Zürich (3 min von ZHB) - -Zeit:17:30 – 19:30 Uhr - -Teilnahmegebühr:CHF 100.- - -Sprache:Deutsch - -Zielgruppe:Führungskräfte & strategische Entscheider:innen - -### Anmeldung - -Anrede * Bitte wählen - -Vorname * - -Nachname * - -Firma * - -Industrie * - -E-Mail * - -Anmeldung senden - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_205603/additional_link_005_www.valueon.ch_self-check.txt b/test_web_content_20251002_205603/additional_link_005_www.valueon.ch_self-check.txt deleted file mode 100644 index b997400a..00000000 --- a/test_web_content_20251002_205603/additional_link_005_www.valueon.ch_self-check.txt +++ /dev/null @@ -1,58 +0,0 @@ -URL: https://www.valueon.ch/self-check -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Digital Readiness Check - -Wie digital ist dein - -Unternehmen wirklich? -=========================================== - -In nur 7 Fragen erfährst du, wie zukunftsfit dein Unternehmen ist – inkl. individueller Einschätzung & konkreter Handlungsempfehlungen. - -Jetzt kostenlos testen - -Dauert nur 3 Minuten - -Frage 1 von 7 14% abgeschlossen - -STRATEGIE - -Wie werden in eurem Unternehmen aktuell Entscheidungen getroffen? ------------------------------------------------------------------ - -Intuitiv und erfahrungsbasiert - -Teilweise datenbasiert, aber oft ohne Systematik - -Wir nutzen regelmäßig Datenanalysen zur Entscheidungsfindung - -Unsere Entscheidungen basieren fast ausschließlich auf KPIs & Datenmodellen - -Zurück Weiter - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_205603/additional_link_006_www.valueon.ch_about.txt b/test_web_content_20251002_205603/additional_link_006_www.valueon.ch_about.txt deleted file mode 100644 index be03e366..00000000 --- a/test_web_content_20251002_205603/additional_link_006_www.valueon.ch_about.txt +++ /dev/null @@ -1,638 +0,0 @@ -URL: https://www.valueon.ch/about -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unser Team -========== - -Seit über 25 Jahren stehen wir für Innovation, Qualität und nachhaltigen Erfolg. Erfahren Sie mehr über unsere Geschichte, unsere Werte und die Menschen, die ValueON zu dem machen, was es heute ist. - -Alle Kernteam Geschäftsführende Partner Externe Zertifizierte Partner - - - -Mehr erfahren - -### Dominic Largo - -CEO - - - -Dominic führt das Unternehmen mit einer klaren Vision für digitale Innovation und strategisches Wachstum in der Beratung. - -### Dominic Largo - -CEO - - - -Zum Vergrößern klicken - -#### Schwerpunkte - -* Sicherstellen der besten Projekt- & Tranformationsmanager für unsere Kunden und unsere Vorhaben -* Reviews von komplexen und erfolgskritischen Vorhaben -* Advisor & Einsitz in Steering Boards -* Sparringpartner für Führungskräfte und Gremien - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Handel / eCommerce Tourismus Konsumgüter Luxusgüter Industrie - -#### Berufliche Stationen - -* BottleButler AG (Founder & CEO) -* Arosa Lenzerheide (Marken- und Digital Leader) -* Mitgründer mehrerer Startups (Co-CEO & VR) -* Porsche Design Group (Country Manager & GCC) -* HAWAS & Jung von Matt (Markenstratege) - -#### Und ganz nebenbei... - -...ist Dominic Largo mit grosser Passion Langstreckenläufer, Kulinariker und Game Challenger. Er geniesst explizit die Berge und seine Familienzeit. - - - -Mehr erfahren - -### Andreas Friedli - -Managing Partner - - - -Mit über 25 Jahren Erfahrung in der digitalen Transformation leitet Andreas als Partner erfolgreich strategische Grossprojekte. - -### Andreas Friedli - -Managing Partner - -#### Schwerpunkte - -* Health-Check von Projekten und Programmen -* Advisor digitaler Transformationen -* Führung von Digitalisierungsprojekten und -programmen -* Emergency- und Recoveryprojekte -* Risiko- und Quality-Assurance bei digitalen Transformationen -* Advisor digitaler Neuausrichtungen -* Leadership-Coaching Projekt und Programm Manager - -#### Im Team seit - -2004 - -#### Branchenerfahrungen - -Finanzen / Banken Versicherungen / Krankenkassen Detailhandel Verwaltung Militär Automobile IT / Telekommunikation Immobilien - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of Complex Projects -* HP GmbH, Senior Project Manager -* Compaq Computer GmbH, Senior Project Manager -* Volkswirtschaftsdep. St. Gallen, Informatikverantwortlicher - -#### Und ganz nebenbei... - -…spielt Andreas Friedli gerne Golf, liebt feines Essen und guten Wein und verbringt viel Zeit mit seiner Familie – ganz nach dem Motto «Geniesse den Moment!». - - - -Mehr erfahren - -### Patrick Motsch - -Managing Partner - - - -Patrick leitet als Partner erfolgreich komplexe IT-Implementierungsprojekte. - -### Patrick Motsch - -Managing Partner - -#### Schwerpunkte - -* Health Check von Projekten -* Führen von geschäftskritischen Projekten und Programmen -* Führen und Begleiten von Emergency und Recovery Projekten -* Führen und Begleiten von DC Moves und ICT Konsolidierungsprojekten -* Advisor für Auftraggeber - -#### Im Team seit - -2001 - -#### Branchenerfahrungen - -Baubranche IT / Telekommunikation / Data Center Industrie Sport Verteidigung Verwaltung Airspace Management Versicherungen Handel - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG) -* Vater und Pionier des TimeWinner Führungssystems -* CIO einer IT Consulting Organisation - -#### Und ganz nebenbei... - -…liebt Patrick Motsch den Garten, das Tanzen, wandert gerne, taucht so oft es geht und lernt gerne fremde Länder kennen. Sein persönliches Motto: «Wer will, der kann». - - - -Mehr erfahren - -### Richard Salvisberg - -Managing Partner - - - -Richard bringt als Partner strategische Beratungsexpertise und Führungskompetenz ein. - -### Richard Salvisberg - -Managing Partner - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Führen von geschäftskritischen Programmen und Transformationen -* Aufbau und Führen von Projektportfolio-Managementsystemen -* Sparringpartner und Advisor - -#### Im Team seit - -2006 - -#### Branchenerfahrungen - -Gesundheitswesen & (Kranken-)Versicherung Militär Verwaltung Beschaffungswesen & Transport Informatik & Telekommunikation Bau Sport Energie - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of PPM -* T-Systems Schweiz AG, Chief Information Officer -* Orange Communications SA, IT Account Manager -* Swisscom AG Bern, Head Management Support -* Swisscom AG Bern, Programm Manager Charging & Billing - -#### Und ganz nebenbei... - -…liebt Richard Salvisberg das Tanzen, lernt gerne fremde Kulturen kennen, hat Freude an schönen Autos und geniesst ein Buch bei einem guten Schluck Wein. In klaren Nächten beobachtet er interessiert den Kosmos. Sein persönliches Motto lautet «Auf innovativen Wegen nachhaltige Erfolge erzielen». - - - -Mehr erfahren - -### Stephan Schellworth - -Experte - - - -Stephan verbindet strategisches Denken mit praxisnaher Projektsteuerung und gestaltet digitale Projekte - -### Stephan Schellworth - -Experte - -#### Schwerpunkte - -* Projekt- und Teamführung -* Datenanalyse und Optimierung -* Agiles Projektmanagement - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Automatisierungstechnik Digitalisierung - -#### Berufliche Stationen - -* 2023 - 2024: Testmanager im Energiebordnetz, BMW Group -* 2021 - 2023: Gesamtfahrzeugspezialist in der E/E, BMW Group -* 2018 - 2021: Prüfstandsspezialist im BMW Prototypen-Motorenwerk, Academic Work -* 2016 - 2018: Entwicklungsingenieur, EDAG Engineering Group - -#### Und ganz nebenbei... - -…sammelt und pflegt Stephan Young- und Oldtimern, treibt Sport wie Squash und besucht regelmässig das Fitnessstudio. Er geht gern mit seinem Hund spazieren oder wandert in der Natur. Ausserdem programmiert er kleinere SmartHome-Anwendungen mit dem Raspberry Pi, Apps und erstellt 3D-Visualisierungen von Innen- und Aussenräumen. - - - -Mehr erfahren - -### Mats Rudolf - -Experte - - - -Mats berät Unternehmen zu digitalen Transformationsprojekten und Systemimplementierungen. - -### Mats Rudolf - -Experte - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Advisor digitaler Transformation -* Advisor Systems Engineering -* Projekt- und Teamführung -* Agiles Projektmanagement - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Sensortechnik Luft- und Raumfahrttechnik Maschinen- und Anlagenbau Transport und Logistik - -#### Berufliche Stationen - -* 2019 - 2024: Management Consultant Innovation und Transformation, UNITY Schweiz AG -* 2018: Industrial Solution Consulting Intern, Brütsch Rüegger Werkzeuge -* 2015 - 2016: Sensor Research and Development Intern, Sensirion AG - -#### Und ganz nebenbei... - -…zieht es Mats Rudolf im Winter für Skitouren und rasante Abfahrten auf die frisch verschneiten Berge. Wenn der Sommer kommt, tauscht er seine Ski gegen ein Surfbrett und geniesst die Wellen im Meer. Zudem schwingt er gerne den Schläger auf dem Tennisplatz und bastelt an seinen Smart-Device-Projekten. - - - -Mehr erfahren - -### Ida Dittrich - -AI Specialist - -Ida verbindet ihr wissenschaftliches Know-how mit praktischer IT-Erfahrung und bringt innovative Ansätze in technische Projekte ein. - -### Ida Dittrich - -AI Specialist - -#### Schwerpunkte - -* Product Architect and Software Engineer PowerOn Platform - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Luft- und Raumfahrtindustrie Kommunikation und Interessenvertretung Medien - -#### Berufliche Stationen - -* Forschungsprojekt zur Modellierung des inneren Aufbaus terrestrischer Exoplaneten (ETH Zürich) -* Recovery Engineer und Systems Engineer bei verschiedenen Projekten der Akademischen Raumfahrtinitiative der Schweiz (ARIS) - -#### Und ganz nebenbei... - -… spielt Ida Dittrich leidenschaftlich gern Computerspiele und bastelt an handwerklichen Projekten wie Nähen, Häkeln oder Stricken. Sie ist regelmäßig sportlich aktiv – sei es beim Joggen an der frischen Luft, im Fitnessstudio oder bei einer entspannenden Yoga-Einheit. - - - -Mehr erfahren - -### Nick Melloh - -AI-Specialist - -Nick macht künstliche Intelligenz für Unternehmen greifbar – in Projekten, Strategien und praxisnahen Schulungen. - -### Nick Melloh - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Digitale Transformation & Business Innovation -* Advisor für Künstliche Intelligenz & Wissensvermittlung -* Advisor für Strategisches Projekt- und Prozessmanagement -* Trainer für KI-Schulungen und Weiterbildung - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Digitalisierung Consulting Hospitality Event- und Innovationsmanagement KI-Anwendungen - -#### Berufliche Stationen - -* 2023–heute: Master in Business Innovation, Universität St. Gallen – Schwerpunkt Digitale Transformation & KI -* 2023–heute: Event Manager SQUARE, Universität St. Gallen – Gestaltung innovativer Lern- und Austauschformate -* 2022–2023: VP Sales, Contler AG – SaaS-Lösungen & Prozessautomatisierung im Hospitality-Sektor - -#### Und ganz nebenbei... - -…hat Nick eine Schwäche für Reisen, gutes Essen und Bücher – um neue Denkanstöße zu gewinnen und frische Perspektiven einzunehmen. Energie findet er beim Sport, in den Bergen oder bei langen Gesprächen mit Freunden – die besten Momente für ihn sind die, in denen die Uhr keine Rolle spielt. - - - -Mehr erfahren - -### Yannick Althaus - -AI-Specialist - -Yannick berät Unternehmen, indem er Strategiekompetenz mit unternehmerischer DNA verbindet. - -### Yannick Althaus - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Strategisches Management und Unternehmensführung -* Advisor für Künstliche Intelligenz und digitale Transformation -* Advisor für Produktion und Supply Chain Management - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Industrie Digitalisierung Supply Chain Management Consulting - -#### Berufliche Stationen - -* 2025: M.A. HSG in Unternehmensführung - Masterarbeit zum Einsatz von generativer KI in der Strategieentwicklung von CEOs -* 2022: B.Sc. Wirtschaftsingenieurwesen -* 2019–2025: Diverse Consulting-Praktika & Projekte in Supply Chain Management, Digitalisierung und strategischem Management sowie Mitarbeit im Familienunternehmen (neben dem Studium) -* 2013–2017: Automatiker EFZ bei Bystronic - -#### Und ganz nebenbei... - -…wenn er nicht an Strategien feilt, zieht es Yannick aufs Eis – Eishockey ist sein Adrenalinschub. Auch sonst bleibt er regelmässig in Bewegung: Skifahren im Winter, Joggen zwischendurch und Golf im Sommer. Ausserdem hat er eine Schwäche für schnelle Autos und reist gerne – am liebsten ans Meer. - - - -### Philipp Dick - -Certified Partner - -"KI wird Manager nicht ersetzen, aber Manager, die KI einsetzen, werden die ersetzen, die es nicht tun." - - - -### Romano Caviezel - -Certified Partner - -"Innovation bedeutet, bestehende Dinge zu hinterfragen und neue Wege zu entdecken." - - - -### Dawid Puzik - -Certified Partner - -"Manche sehen, was möglich ist – andere verändern, was möglich ist." - - - -### Holger Ridinger - -Certified Partner - -"Transformation braucht Struktur, Leidenschaft und Ausdauer." - - - -### Alain Kappeler - -Certified Partner - -"Wenn es dich nicht herausfordert, verändert es dich nicht." - - - -### Andreas Wyss - -Certified Partner - -Andreas verbindet strategisches Denken mit menschlichem Feingefuehl in Transformationsprozessen. - - - -### Alfredo Mercurio - -Certified Partner - -"Eine klare Vision ist der Anfang von allem." - - - -### Bernd Nagel - -Certified Partner - -"Wer will, findet Wege. Wer nicht will, findet Gründe." - - - -### Daniel Sengstag - -Certified Partner - -"Wer nicht mit der Zeit geht, geht mit der Zeit." - - - -### Daniel Lochmatter - -Certified Partner - -"Neues und bisher Unbekanntes kann man nur explorativ erfahren, erspüren, erlernen – und danach zum eigenen Nutzen einsetzen." - - - -### Michael Hermann - -Certified Partner - -"Auch beim Projekt gilt: Ende gut, alles gut." - - - -### Heinz Ruffieux - -Certified Partner - -"C'est le ton qui fait la musique." - - - -### Sven Fassbender - -Certified Partner - -"Mein Ziel ist es, Cybersicherheit verständlich und greifbar zu machen – für jeden zugänglich und praktikabel." - - - -### Raffael Santchi - -Certified Partner - -"Wer Prozesse versteht, kann Systeme formen – nicht umgekehrt." - - - -### Stephanie Kieninger - -Certified Partner - -Stephanie konzentriert sich mit ihrer Beratung auf die Menschen im Veraenderungsprozess. - - - -### Christoph Merle - -Certified Partner - -Christoph engagiert sich mit seiner langjährigen Führungserfahrung in der Industrie und mit seinem Hintergrund in strategischer und operativer Beratung für den Erfolg unserer Kunden. - -Previous slide Next slide - -Über ValueOn ------------- - -Wir schaffen digitale Transformation mit Leidenschaft und Expertise - -### Unsere Mission - -Durch exzellente Beratung schaffen wir digitale Transformation erfolgreich zu meistern. - -### Unser Versprechen - -Höchste Qualität, agile Ansätze und Passion für gemeinsamen Wirken - -25+ - -Jahre Erfahrung - -100+ - -Projekte - -98% - -Weiterempfehlung - -60% - -Schneller zum Ziel - -Unsere Geschichte ------------------ - -Eine Reise der Innovation - -Heute - -Heute und Morgen - -Als führendes Beratungsunternehmen gestalten wir aktiv die Zukunft der digitalen Transformation mit innovativen KI-Lösungen und nachhaltigen Strategien. - -KI-Ära - -KI-Revolution - -Die Einführung von KI-Systemen veränderte unsere Beratungsleistung grundlegend und ermöglichte es uns, unseren Kunden noch innovativere Lösungen anzubieten. - -Digital - -Digitale Transformation - -Mit neuen digitalen Lösungen begleiteten wir unsere Kunden in der Transformation und etablierten uns als führender Partner für digitale Innovation. - -Aufbau - -Etablierung am Markt - -Wir etablierten uns am Markt mit innovativen IT-Strategien und nachhaltiger Umsetzung, wodurch wir eine solide Basis für weiteres Wachstum schufen. - -2000 - -Gründung von ValueON - -ValueON wurde mit der Vision gegründet, Unternehmen bei der digitalen Transformation zu unterstützen und nachhaltigen Erfolg zu schaffen. - -Unsere Werte ------------- - -Was uns antreibt - -### Exzellenz - -Höchste Qualität in allem, was wir tun. Von der ersten Beratung bis zur finalen Umsetzung setzen wir auf höchste Standards. - -### Partnerschaft - -Wir sehen uns als langfristige Partner unserer Kunden und arbeiten gemeinsam an nachhaltigen Lösungen. - -### Integrität - -Ehrlichkeit, Transparenz und Vertrauen bilden das Fundament aller unserer Geschäftsbeziehungen. - -### Effektivität - -Zielgerichtete Lösungen, die messbare Ergebnisse liefern und nachhaltigen Geschäftserfolg schaffen. - -Karriere bei ValueOn --------------------- - -Werde Teil unseres Teams - -### Product-Architekt/in für KI-Plattformen - -Zürich, Schweiz M/W, 50-100% - -Details ansehen - -Keine passende Stelle gefunden? - -[Initiativbewerbung senden](mailto:office@valueon.ch) - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_205603/additional_link_007_www.valueon.ch_contact.txt b/test_web_content_20251002_205603/additional_link_007_www.valueon.ch_contact.txt deleted file mode 100644 index 4af22d5f..00000000 --- a/test_web_content_20251002_205603/additional_link_007_www.valueon.ch_contact.txt +++ /dev/null @@ -1,89 +0,0 @@ -URL: https://www.valueon.ch/contact -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unser Kontakt -============= - -Lassen Sie uns gemeinsam Ihre digitale Transformation vorantreiben. - -Lassen Sie uns ins Gespräch kommen ----------------------------------- - -Sie haben Fragen zu unseren Dienstleistungen oder möchten mehr über unsere Expertise erfahren? Nutzen Sie das Kontaktformular oder kontaktieren Sie uns direkt – wir sind für Sie da. - -### Telefon - -[+41 44 943 70 40](tel:+41449437040) - -### E-Mail - -[office@valueon.ch](mailto:office@valueon.ch) - -### Adresse - -ValueOn AG - -Am Stadtrand 11 - -8600 Dübendorf - -Schweiz - -### Folgen Sie uns - -[](https://www.linkedin.com/company/valueon) - -Name * - -E-Mail * - -Telefon - -Unternehmen - -Nachricht * - -Nachricht senden - -* Pflichtfelder - -So finden Sie uns ------------------ - -Unser Büro befindet sich in Dübendorf, nur wenige Minuten von Zürich entfernt. - -### Anreise - -#### Mit dem Auto - -Ausreichend Parkplätze stehen direkt vor dem Gebäude zur Verfügung. - -#### Mit öffentlichen Verkehrsmitteln - -Vom Bahnhof Dübendorf erreichen Sie unser Büro bequem zu Fuß in ca. 10 Minuten oder mit dem Bus. - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_205603/additional_link_008_www.valueon.ch_privacy.txt b/test_web_content_20251002_205603/additional_link_008_www.valueon.ch_privacy.txt deleted file mode 100644 index be6f2048..00000000 --- a/test_web_content_20251002_205603/additional_link_008_www.valueon.ch_privacy.txt +++ /dev/null @@ -1,103 +0,0 @@ -URL: https://www.valueon.ch/privacy -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Datenschutzerklärung -==================== - -Die Betreiber dieser Seiten nehmen den Schutz Ihrer persönlichen Daten sehr ernst. Wir behandeln Ihre personenbezogenen Daten vertraulich und entsprechend den gesetzlichen Datenschutzvorschriften sowie dieser Datenschutzerklärung. - -Wenn Sie diese Website benutzen, werden verschiedene personenbezogene Daten erhoben. Personenbezogene Daten sind Daten, mit denen Sie persönlich identifiziert werden können. Die vorliegende Datenschutzerklärung erläutert, welche Daten wir erheben und wofür wir sie nutzen. Sie erläutert auch, wie und zu welchem Zweck das geschieht. - -**Wichtiger Hinweis:** Wir weisen darauf hin, dass die Datenübertragung im Internet (z. B. bei der Kommunikation per E-Mail) Sicherheitslücken aufweisen kann. Ein lückenloser Schutz der Daten vor dem Zugriff durch Dritte ist nicht möglich. - -Grundlegende Informationen --------------------------- - -### Verantwortliche Stelle - -Die verantwortliche Stelle für die Datenverarbeitung auf dieser Website ist: ValueOn AG, Am Stadtrand 11, 8600 Dübendorf, Schweiz, T +41 44 943 70 40, E-Mail: info@valueon.ch. Verantwortliche Stelle ist die natürliche oder juristische Person, die allein oder gemeinsam mit anderen über die Zwecke und Mittel der Verarbeitung von personenbezogenen Daten (z. B. Namen, E-Mail-Adressen o. Ä.) entscheidet. - -### Speicherdauer - -Löschersuchen geltend machen oder eine Einwilligung zur Datenverarbeitung widerrufen, werden Ihre Daten gelöscht, sofern wir keine anderen rechtlich zulässigen Gründe für die Speicherung Ihrer personenbezogenen Daten haben (z. B. steuer- oder handelsrechtliche Aufbewahrungsfristen); im letztgenannten Fall erfolgt die Löschung nach Fortfall dieser Gründe. - -### Auskunft, Löschung, Sperrung - -Sie haben jederzeit das Recht auf unentgeltliche Auskunft über Ihre gespeicherten personenbezogenen Daten, deren Herkunft und Empfänger und den Zweck der Datenverarbeitung sowie ein Recht auf Berichtigung, Sperrung oder Löschung dieser Daten. Hierzu sowie zu weiteren Fragen zum Thema personenbezogene Daten können Sie sich jederzeit unter der im Impressum angegebenen Adresse bzw. an die in der Datenschutzerklärung genannte verantwortliche Person an uns wenden. - -### Widerspruch gegen Werbe-E-Mails - -Der Nutzung von im Rahmen der Impressumspflicht veröffentlichten Kontaktdaten zur Übersendung von nicht ausdrücklich angeforderter Werbung und Informationsmaterialien wird hiermit widersprochen. Die Betreiber der Seiten behalten sich ausdrücklich rechtliche Schritte im Falle der unverlangten Zusendung von Werbeinformationen, etwa durch Spam-E-Mails, vor. - -Technische Datenverarbeitung ----------------------------- - -### Cookies - -Unsere Internetseiten verwenden so genannte "Cookies". Cookies sind kleine Textdateien und richten auf Ihrem Endgerät keinen Schaden an. Sie werden entweder vorübergehend für die Dauer einer Sitzung (Session-Cookies) oder dauerhaft (permanente Cookies) auf Ihrem Endgerät gespeichert. Session-Cookies werden nach Ende Ihres Besuchs automatisch gelöscht. Permanente Cookies bleiben auf Ihrem Endgerät gespeichert, bis Sie diese selbst löschen oder eine automatische Löschung durch Ihren Webbrowser erfolgt. - -### Server-Log-Dateien - -Der Provider der Seiten erhebt und speichert automatisch Informationen in so genannten Server-Log-Dateien, die Ihr Browser automatisch an uns übermittelt. Dies sind: Browsertyp und Browserversion, verwendetes Betriebssystem, Referrer URL, Hostname des zugreifenden Rechners, Uhrzeit der Serveranfrage, IP-Adresse. Eine Zusammenführung dieser Daten mit anderen Datenquellen wird nicht vorgenommen. - -### Anmelde- und Kontaktformulare - -Wenn Sie uns per Kontaktformular Anfragen zukommen lassen oder sich mit dem Anmeldeformular für unsere Veranstaltungen anmelden, werden Ihre Angaben aus den Formularen inklusive der von Ihnen dort angegebenen Kontaktdaten und Informationen zwecks Bearbeitung der Anfrage und für den Fall von Anschlussfragen bei uns gespeichert. Diese Daten geben wir nicht ohne Ihre Einwilligung weiter. - -### Newsletter-Daten - -Die Verarbeitung der in das Newsletteranmeldeformular eingegebenen Daten erfolgt ausschließlich auf Grundlage Ihrer Einwilligung (Art. 6 Abs. 1 lit. a DSGVO). Die erteilte Einwilligung zur Speicherung der Daten, der E-Mail-Adresse sowie deren Nutzung zum Versand des Newsletters können Sie jederzeit widerrufen, etwa über den "Austragen"-Link im Newsletter. - -Externe Dienste ---------------- - -### Hinweis zur Datenweitergabe in die USA und sonstige Drittstaaten - -Wir weisen darauf hin, dass in diesen Ländern kein mit der EU oder der Schweiz vergleichbares Datenschutzniveau garantiert werden kann. Beispielsweise sind US-Unternehmen dazu verpflichtet, personenbezogene Daten an Sicherheitsbehörden herauszugeben, ohne dass Sie als Betroffener hiergegen gerichtlich vorgehen könnten. - -### Nutzung von HubSpot CRM - -Wir nutzen Hubspot CRM auf dieser Website. Anbieter ist Hubspot Inc. 25 Street, Cambridge, MA 02141 USA. Hubspot CRM ermöglicht es uns unter anderem, bestehende und potenzielle Kunden sowie Kundenkontakte zu verwalten. Die Verwendung von Hubspot CRM erfolgt auf Grundlage von Art. 6 Abs. 1 lit. f DSGVO. - -### LinkedIn - -Diese Website nutzt Elemente des Netzwerks LinkedIn. Anbieter ist die LinkedIn Ireland Unlimited Company, Wilton Plaza, Wilton Place, Dublin 2, Irland. Bei jedem Abruf einer Seite dieser Website, die Elemente von LinkedIn enthält, wird eine Verbindung zu Servern von LinkedIn aufgebaut. - -### Google Analytics - -Diese Website nutzt Funktionen des Webanalysedienstes Google Analytics. Anbieter ist die Google Inc. 1600 Amphitheatre Parkway Mountain View, CA 94043, USA. Google Analytics verwendet sog. "Cookies". Das sind Textdateien, die auf Ihrem Computer gespeichert werden und die eine Analyse der Benutzung der Website durch Sie ermöglichen. - -### Leadinfo - -Diese Website nutzt den Service des Anbieters Leadinfo B.V. mit Sitz in Rotterdam. Dieser Service zeigt uns auf Grundlage von IP-Adressen öffentlich zugängliche Unternehmensdaten an, wie z.B. Firmennamen und -adressen. Die Erkennung von Unternehmen basiert einzig und allein auf IP-Adressen. - -Fragen zum Datenschutz? ------------------------ - -Bei Fragen zum Datenschutz oder zur Verarbeitung Ihrer Daten kontaktieren Sie uns gerne. - -ValueOn AG - -Am Stadtrand 11, 8600 Dübendorf, Schweiz - -T +41 44 943 70 40 - -info@valueon.ch diff --git a/test_web_content_20251002_205603/additional_link_009_www.valueon.ch_imprint.txt b/test_web_content_20251002_205603/additional_link_009_www.valueon.ch_imprint.txt deleted file mode 100644 index af8eb2a6..00000000 --- a/test_web_content_20251002_205603/additional_link_009_www.valueon.ch_imprint.txt +++ /dev/null @@ -1,62 +0,0 @@ -URL: https://www.valueon.ch/imprint -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Impressum -========= - -Angaben gemäß den gesetzlichen Bestimmungen - -Inhaber der Website und verantwortlich für den Inhalt ------------------------------------------------------ - -### Unternehmen - -ValueOn AG - -Dominic Largo - -### Kontakt - -Am Stadtrand 11 - -8600 Dübendorf - -+41 44 943 70 40 - -[info@valueon.ch](mailto:info@valueon.ch) - -### Rechtliche Hinweise - -Alle Inhalte dieser Website sind urheberrechtlich geschützt. Jede Verwendung, Vervielfältigung oder Weiterverbreitung bedarf der ausdrücklichen schriftlichen Genehmigung der ValueOn AG. - -### Haftungsausschluss - -Die Inhalte unserer Seiten wurden mit größter Sorgfalt erstellt. Für die Richtigkeit, Vollständigkeit und Aktualität der Inhalte können wir jedoch keine Gewähr übernehmen. - -### Externe Links - -Unser Angebot enthält Links zu externen Webseiten Dritter, auf deren Inhalte wir keinen Einfluss haben. Deshalb können wir für diese fremden Inhalte auch keine Gewähr übernehmen. - -### Haben Sie Fragen? - -Bei rechtlichen Fragen oder Anliegen kontaktieren Sie uns gerne direkt. - -[Kontakt aufnehmen](mailto:info@valueon.ch) diff --git a/test_web_content_20251002_205603/additional_link_010_www.moneyhouse.ch_de_terms.txt b/test_web_content_20251002_205603/additional_link_010_www.moneyhouse.ch_de_terms.txt deleted file mode 100644 index 7f1f4e36..00000000 --- a/test_web_content_20251002_205603/additional_link_010_www.moneyhouse.ch_de_terms.txt +++ /dev/null @@ -1,96 +0,0 @@ -URL: https://www.moneyhouse.ch/de/terms -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Version gültig ab 1. Januar 2020 bis Widerruf - -Die vorliegenden Nutzungsbedingungen regeln die Geschäftsbeziehungen zwischen der Neue Zürcher Zeitung AG bezogen auf ihr Produkt Moneyhouse (nachfolgend «Moneyhouse» genannt) und dem Kunden (nachfolgend «Kunde» genannt). Diese Bestimmungen sind für alle Plattformen von Moneyhouse gültig, insbesondere für moneyhouse.ch. Abweichende AGB des Kunden finden keine Anwendung, auch wenn Moneyhouse nicht ausdrücklich widerspricht. - -**1. Grundlage der Geschäftsbeziehung** - -Ein Vertrag über eine der unterschiedlichen Dienstleistungen von Moneyhouse berechtigt den Kunden – nach Leistung des vereinbarten Entgelts – zur Inanspruchnahme der offerierten Leistungen. Dabei gelangen die jeweils gültigen Tarife und Konditionen sowie die vorliegenden Nutzungsbedingungen sowie allenfalls weitere, besondere Geschäftsbedingungen und Vertragsgrundlagen zur Anwendung. - -**2. Vertragsinhalt** - -Gegenstand der Leistungserbringung von Moneyhouse und deren Partnern sind Informationsdienstleistungen. Sie beinhalten in keinem Falle irgendwelche Rechte an Software, Lizenzrechte oder sonstige Immaterialgüterrechte. - -**3. Vertragsdauer und Verlängerung** - -Die Online-Dienstleistungen wie beispielsweise (keine abschliessende Aufzählung) die Premium-Mitgliedschaft oder das Bonitäts-Abo können ab Abschluss des Vertrags in Anspruch genommen werden und gelten für die jeweils abgeschlossene Vertragsdauer. - -Die Verträge betreffend die Dienstleistungen von moneyhouse.ch erneuern sich bei Ablauf stillschweigend um die vereinbarte Vertragsdauer, sofern nicht eine Partei einen Tag vor Ablauf der Vertragsdauer den Vertrag wie unter «Mein Konto» beschrieben kündigt. Davon ausgeschlossen sind etwaige Probe-Abonnements, welche sich auf die beim Abschluss definierte Dauer und zum vorab kommunizierten Preis verlängern. - -Sollte sich der Kunde mit Zahlungen im Verzug befinden oder gegen die vorliegenden AGB verstossen, ist Moneyhouse zur sofortigen Auflösung des Vertragsverhältnisses berechtigt. - -Wird der Vertrag erneuert, so gilt automatisch die allfällig neue Preisliste, welche dem Kunden auf Anfrage zur Verfügung gestellt wird. Der vorausbezahlte Abonnementpreis ist für den Zeitraum der Vorauszahlung garantiert und kann nicht erhöht werden. Abonnementpreiserhöhungen werden vor ihrer Wirksamkeit auf den jeweiligen Websites von Moneyhouse angekündigt. Einzelbenachrichtigungen erfolgen nicht. Entsprechend kann bei Nichtakzeptieren der Preiserhöhung der Vertrag zu den bisherigen Konditionen auf Ende der Laufzeit unter Einhaltung der Kündigungsfristen gekündigt werden. Alle von Moneyhouse genannten oder in etwaigen Tariflisten aufgeführten Preise sind Nettopreise ohne Mehrwertsteuer in Schweizer Franken. - -**4. Nutzungsbedingungen** - -**4.1. Nutzungsumfang** - -Die Produkte dienen ausschliesslich der persönlichen, nicht kommerziellen Nutzung durch natürliche und juristische Personen – eine weitergehende oder abweichende Nutzung und deren Verbreitung in anderen Systemen ist nur mit ausdrücklicher Zustimmung von Moneyhouse gestattet und kann jederzeit widerrufen werden. - -**4.2. Registrierung** - -Die Registrierung eines Benutzerkontos erfordert unter anderem einen Vor- und Nachnamen, eine Adresse sowie weitere Informationen, abhängig von der Art der gewünschten Nutzung (privat oder geschäftlich). Das automatisierte Anlegen von Benutzerkonten ist nicht gestattet. Der Kunde verpflichtet sich, seine Zugangsdaten vertragskonform zu verwenden und diese ohne schriftliche Zustimmung von Moneyhouse keinem Dritten zugänglich zu machen. Der Nutzer ist für den Schutz seiner Zugangsdaten verantwortlich. - -**4.3. Leistungen Moneyhouse** - -Inhalt und Umfang der dem Nutzer zur Verfügung gestellten Produkte bestimmen sich nach der jeweiligen Nutzungsform (zum Beispiel: registrierter oder nicht registrierter Kunde, kostenlose oder kostenpflichtige Nutzung etc.), einem allfällig bestehenden Vertragsverhältnis und den vorliegenden Nutzungsbedingungen und der Datenschutzerklärung. - -Die Online-Dienste sind in der Regel an 7 Tagen während 24 Stunden verfügbar. Moneyhouse behält sich das Recht vor, diese Betriebszeiten einzuschränken und/oder aus technischen Gründen vorübergehend auszusetzen sowie die Produkte jederzeit zu modifizieren. Die Produkte unterliegen laufenden Änderungen und Anpassungen. Auch können Software-Updates oder technische Weiterentwicklungen Inhalt und Umfang der Produkte jederzeit ausbauen. - -**4.4. Fälligkeit, Zahlungsverzug und Zahlungsarten** - -Die von Moneyhouse gestellten Rechnungen sind, sofern keine Zahlungsfrist vermerkt ist und nichts anderes vereinbart wurde, sofort fällig. Ist der Kunde mit seiner Zahlung in Verzug, treten die gesetzlichen Verzugsfolgen ein und mit der zweiten Mahnung Mahnkosten von CHF 20.–. Darüber hinaus hat Moneyhouse das Recht, externe Partner zur Bearbeitung des Inkassos hinzuzuziehen. Ausserdem trägt der Kunde alle weiteren Kosten, die durch seinen Zahlungsverzug entstehen. - -Es werden die folgenden Zahlungsarten bei kostenpflichtigen Produkten angeboten: Kreditkarte oder per Rechnung. Moneyhouse behält sich das Recht vor, die verschiedenen Zahlungsmittel nach eigenem Ermessen zu ändern, zu ergänzen oder zu streichen. Es besteht kein Anspruch auf Bezahlung mit einem bestimmten Zahlungsmittel. Die Rechnung per E-Mail kann via E-Banking beglichen werden. Der Vertrag zwischen Moneyhouse und dem Kunden kommt entweder mit der Bestellung durch den Kunden über einen Verkaufsmitarbeiter oder aber mit der Auftrags-, der Bestellungs- sowie/oder der Zahlungsbestätigung durch Moneyhouse zustande. - -**4.5. Haftung von Moneyhouse** - -Moneyhouse ist bemüht, den eigenen Datenbestand sowie jenen von Partnern zu pflegen. Der Kunde nimmt zur Kenntnis, dass Daten und Informationen bis zu einem gewissen Masse trotzdem Fehler enthalten können. Vorbehaltlich gesetzlicher Vorgaben bzw. einer anderweitigen schriftlichen Vereinbarung schliessen Moneyhouse und deren Partner jegliche Garantie und Gewährleistung, insbesondere für Vollständigkeit, Aktualität, Richtigkeit, Verwertbarkeit oder Eignung der Daten zu einem bestimmten Zweck, aus. Empfehlungen und Erfahrungswerte wie Ratings, Einteilung in Risikoklassen und Scorewerte sind ausnahmslos unverbindlich, womit auch dafür jede Gewähr ausgeschlossen ist. - -Moneyhouse haftet nur für Verzögerungen und für Fehler, sofern ihr ein vorsätzliches oder grobfahrlässiges Handeln nachgewiesen werden kann. Sie haftet insbesondere nicht für Verfehlungen und Versäumnisse Dritter. Für Schäden, die dem Kunden durch die Nutzung der Produkte entstehen, haftet Moneyhouse nur, falls ihr grobfahrlässiges oder vorsätzliches Verhalten nachgewiesen werden kann. Soweit gesetzlich zulässig, ist die Haftung von Moneyhouse in jedem Fall auf denjenigen Betrag beschränkt, welcher dem Kunden für das entsprechende Produkt in Rechnung gestellt wurde. In keinem Fall haftet Moneyhouse für Folgeschäden oder entgangenen Gewinn. - -Moneyhouse haftet nicht für schadhafte Technik und für durch Computerviren, Spionageprogramme und/oder andere schädliche Computerprogramme (Malware, Spyware) bewirkte Schäden. Es besteht auch keine Haftung für die Folgen von Betriebsunterbrüchen, die durch Störungen aller Art entstehen oder die der Störungsbehebung, der Wartung und der Einführung neuer Technologien dienen. - -Dieselben Haftungsbeschränkungen gelten auch für die Mitarbeiter, Vertreter und Erfüllungsgehilfen von Moneyhouse. - -**4.6. Sorgfaltspflicht und Haftung des Kunden** - -Alle Informationen, Auskünfte und Berichte von Moneyhouse sind streng vertraulich zu behandeln. Benutzung und Verwendung dieser Informationen sind nur dem Kunden und dessen allfälligen Angestellten für deren eigene Zwecke gestattet. Der Kunde verpflichtet sich, sein Benutzerkonto und im Speziellen seine Zugangsdaten (Passwort) nicht anderen Personen – auch nicht im gleichen Unternehmen – zur Verfügung zu stellen, sie zu schützen und vor Zugriffen Dritter sicher aufzubewahren, seine Kontaktinformationen und sonstigen Angaben bei der Registrierung wahrheitsgetreu auszufüllen und seinen Zugang nicht missbräuchlich oder übermässig zu nutzen. - -Der Kunde verpflichtet sich sodann, die gesetzlichen Datenschutzvorschriften sowie die Vorschriften gemäss Datenschutzerklärung von Moneyhouse einzuhalten. Der Kunde ist für jeden Schaden verantwortlich, der aus einer Nichtbeachtung seiner Sorgfaltspflichten oder einem Verstoss gegen Urheberrechte entsteht, und zwar sowohl gegenüber Moneyhouse als auch deren Partnern. - -**4.7. Auskünfte und Identifikation** - -Der Kunde nimmt zur Kenntnis, dass er sich und damit sein persönliches Kundenkonto für das Aufrufen von Profilen zu Privatpersonen und die Abfrage von Bonitätsauskünften, Zahlungsverhaltenauskünften und Wirtschaftsauskünften mittels eines Identitätsnachweises (ID, Reisepass, Führerschein) einmalig verifizieren muss. Zudem dürfen die zuvor genannten Auskünfte nur abgefragt werden, wenn ein berechtigtes Interesse vorliegt. Das Vorliegen einer solchen Berechtigung kann nachträglich durch Moneyhouse überprüft werden. Der Kunde muss Moneyhouse innerhalb von 10 Tagen nach Erhalt der Aufforderung das Vorliegen einer entsprechenden Berechtigung nachweisen. Für Betreibungsauskünfte muss durch den Kunden grundsätzlich ein den vom jeweiligen Betreibungsamt vorgegebenen Bedingungen entsprechender Interessensnachweis übermittelt werden. Alle rechtlichen und vertraglichen Konsequenzen, die durch die Nichtübermittlung, einen nicht ausreichenden oder nicht vorhandenen Interessensnachweises resultieren, trägt der Kunde.Bei Zuwiderhandlung gegen diese Vorschrift ist Moneyhouse berechtigt, die Vertragsbeziehung zum Kunden unmittelbar und entschädigungslos zu beenden. - -Weitere Informationen hierzu können jederzeit[hier](https://www.moneyhouse.ch/de/howto/reports) eingesehen werden. - -**4.8. Urheber- und weitere immaterielle Rechte** - -Moneyhouse behält sich bezüglich der Produkte inklusive Layout, Software und deren Inhalten sämtliche Urheber- und sonstigen Schutzrechte vor. Es ist untersagt, die Webseiten von Moneyhouse oder deren Inhalte ganz oder teilweise mittels technischer Hilfsmittel darzustellen (z.B. „Framing“). - -Eigentums- und Urheberrechte an allen zur Verfügung gestellten Daten und Dienstleistungen verbleiben bei Moneyhouse. Nutzungsrechte werden dem Kunden nur in dem Ausmass eingeräumt, als dies zur Erfüllung des Vertragszweckes zwingend notwendig ist. Im Zweifel werden nur Nutzungsrechte und keine Urheber- und Eigentumsrechte übertragen. Der Kunde ist zur Weitergabe der Daten an Dritte nicht berechtigt. - -**4.9. Vertretungsberechtigung** - -Für die Leistungserbringung und insbesondere die Abwicklung im Rahmen einer Premium-Mitgliedschaft oder anderen spezifischen Leistungen gilt gegenüber Moneyhouse, unabhängig von der im Handelsregister eingetragenen Zeichnungsberechtigung, der oder die Mitarbeiter/in des Kunden als zur Vertretung befugt und ermächtigt, welche/r mit Moneyhouse mündlich, telefonisch oder schriftlich (durch Brief, Fax oder E-Mail) kommunizierte. Der Kunde trägt das Risiko für ungenügende Vertretungsberechtigung oder fehlende Legitimation seiner Mitarbeiter. - -**4.10. API** - -Moneyhouse stellt dem Kunden eine Schnittstelle (API) zur Kommunikation mit Software von Drittanbietern zur Verfügung. Sofern nicht schriftlich anders vereinbart, hat Moneyhouse in jedem Fall das Recht, den Zugriff auf diese Schnittstelle aus wichtigem Grund jederzeit teilweise oder ganz einzuschränken. Ein wichtiger Grund liegt insbesondere vor, wenn Mitbewerber von Moneyhouse zum Schaden von Moneyhouse über die Schnittstelle Daten migrieren oder die Infrastruktur über Anfragen über diese Schnittstelle zu stark belastet wird. Der Kunde verpflichtet sich, alle von Moneyhouse gelieferten Daten innert 10 Tagen nach Beendigung des Vertrages zu löschen und die Löschung Moneyhouse schriftlich zu bestätigen. - -**4.11. Kommunikationsmittel und Übermittlungsfehler** - -Moneyhouse ist berechtigt, alle Mitteilungen an den Kunden an die auf dem Vertrag aufgeführte und vom Kunden angegebene Zustell- oder E-Mail-Adresse, Telefon- und/oder Faxnummer zu richten. Änderungen sind Moneyhouse vom Kunden rechtzeitig und schriftlich (durch Brief, Fax oder E-Mail oder mittels Änderung im persönlichen Bereich „Mein Konto“ auf moneyhouse.ch) mitzuteilen. Der Kunde trägt das Risiko für Schäden aus der Benutzung von Kommunikations- und/oder Transportmitteln einschliesslich Verlust, Verspätung oder falsche Übermittlung. - -**4.12.Gerichtsstand und anwendbares Recht** - -Der Gerichtsstand befindet sich am Sitz der Neue Zürcher Zeitung AG in Zürich ZH. Es gilt Schweizer Recht. Die Neue Zürcher Zeitung AG hat das Recht, den Kunden bei einem anderen zuständigen Gericht einzuklagen. - -**4.13. Anpassungen** - -Wir behalten uns ausdrücklich das Recht vor, die vorliegenden Nutzungsbedingungen jederzeit zu ändern. Werden derartige Anpassungen vorgenommen, veröffentlichen wir diese umgehend auf unserer Webseite. Es liegt in Ihrer Verantwortung, sich über die aktuell geltende Fassung der Datenschutzerklärung auf unserer Webseite zu informieren. Wir empfehlen Ihnen daher, diese Datenschutzerklärung und die Nutzungsbedingungen regelmässig zu konsultieren. \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_011_www.moneyhouse.ch_de_imprint.txt b/test_web_content_20251002_205603/additional_link_011_www.moneyhouse.ch_de_imprint.txt deleted file mode 100644 index 04216933..00000000 --- a/test_web_content_20251002_205603/additional_link_011_www.moneyhouse.ch_de_imprint.txt +++ /dev/null @@ -1,401 +0,0 @@ -URL: https://www.moneyhouse.ch/de/imprint -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Impressum - Moneyhouse - - - - - - - -[](/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](/de/register?redirectUrl=%2Fimprint) - -[Anmelden](/de/login?redirectUrl=%2Fimprint) - -[Erweiterte Suche](/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](/de/overview)[Voller Datenzugriff](/de/membership)[Public API](/de/apiintegration)[Corporate-Angebote](/de/enterprise)[Firmenlisten](/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](/de/businessreports)[Bonitätsauskunft](/de/creditrating)[Zahlungsverhalten](/de/paymentbehaviour)[Wirtschaftsauskunft](/de/economicinformation)[Beteiligungsauskunft](/de/shareholderinformation)[Betreibungsauskunft](/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](/de/commercialregister/foundation)[Firma liquidieren](/de/commercialregister/liquidation)[Änderung Eintrag](/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](/de/datasources)[Kontakt](/de/contact) - -- [KMU\_today](https://www.kmutoday.ch/) -[Regio-News](/de/region)[Hilfebereich](/de/howto) - -[AGB](/de/terms)[Datenschutz](/de/privacy)[Impressum](/de/imprint) - -[](/de/) - -[Kostenlos registrieren](/de/register?redirectUrl=%2Fimprint) - -[Regio-News](/de/region)[KMU\_today](https://www.kmutoday.ch/) - -[Anmelden](/de/login?redirectUrl=%2Fimprint)[Hilfe](/de/howto) - -DE - -- [Deutsch](javascript:void(0)) -- [Français](javascript:void(0)) -- [Italiano](javascript:void(0)) -- [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](/de/advancedsearch) - -**Datenzugriff** - -- [Übersicht Mitgliedschaften](/de/overview) -- [Voller Datenzugriff](/de/membership) -- [Public API](/de/apiintegration) -- [Corporate-Angebote](/de/enterprise) -- [Firmenlisten](/de/companieslists) -- [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -- [Übersicht](/de/businessreports) -- [Bonitätsauskunft](/de/creditrating) -- [Zahlungsverhalten](/de/paymentbehaviour) -- [Wirtschaftsauskunft](/de/economicinformation) -- [Beteiligungsauskunft](/de/shareholderinformation) -- [Betreibungsauskunft](/de/paymentcollection) - -**Handelsregister** - -- [Firma gründen](/de/commercialregister/foundation) -- [Firma liquidieren](/de/commercialregister/liquidation) -- [Änderung Eintrag](/de/commercialregister/services) - -**Unternehmen** - -- [Über uns](/de/about) -- [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -- [Datenquellen](/de/datasources) -- [Kontakt](/de/contact) - -- [Anmelden](/de/login?redirectUrl=%2Fimprint) -- [Hilfebereich](/de/howto) - -- [Sprache wechseln](javascript:void(0)) -- [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -- [KMU\_today](https://www.kmutoday.ch/) -- [Regio-News](/de/region) - - - -# Impressum - -**Moneyhouse** -Neue Zürcher Zeitung AG -Falkenstrasse 11 -CH-8008 Zürich - -[Kontaktieren Sie uns](https://www.moneyhouse.ch/de/contact/contactform) - -Sitz: Zürich -UID: CHE-106.838.812 -Handelsregisteramt: Kanton Zürich - -**Datenzugriff** - -- [Übersicht Mitgliedschaften](/de/overview) -- [Voller Datenzugriff](/de/membership) -- [Public API](/de/apiintegration) -- [Corporate-Angebote](/de/enterprise) -- [Firmenlisten](/de/companieslists) -- [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -- [Übersicht](/de/businessreports) -- [Bonitätsauskunft](/de/creditrating) -- [Zahlungsverhalten](/de/paymentbehaviour) -- [Wirtschaftsauskunft](/de/economicinformation) -- [Beteiligungsauskunft](/de/shareholderinformation) -- [Betreibungsauskunft](/de/paymentcollection) - -**Handelsregister** - -- [Firma gründen](/de/commercialregister/foundation) -- [Firma liquidieren](/de/commercialregister/liquidation) -- [Änderung Eintrag](/de/commercialregister/services) - -**Unternehmen** - -- [Über uns](/de/about) -- [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -- [Datenquellen](/de/datasources) -- [Kontakt](/de/contact) - -- [Anmelden](/de/login?redirectUrl=%2Fimprint) -- [Hilfebereich](/de/howto) - -- [Sprache wechseln](javascript:void(0)) -- [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -- [KMU\_today](https://www.kmutoday.ch/) -- [Regio-News](/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](/de/companydirectory/ag/a/a_) - -[AI](/de/companydirectory/ai/a/a_) - -[AR](/de/companydirectory/ar/a/a_) - -[BL](/de/companydirectory/bl/a/a_) - -[BS](/de/companydirectory/bs/a/a_) - -[BE](/de/companydirectory/be/a/a_) - -[FR](/de/companydirectory/fr/a/a_) - -[GE](/de/companydirectory/ge/a/a_) - -[GL](/de/companydirectory/gl/a/a_) - -[GR](/de/companydirectory/gr/a/a_) - -[JU](/de/companydirectory/ju/a/a_) - -[LU](/de/companydirectory/lu/a/a_) - -[NE](/de/companydirectory/ne/a/a_) - -[NW](/de/companydirectory/nw/a/a_) - -[OW](/de/companydirectory/ow/a/a_) - -[SH](/de/companydirectory/sh/a/a_) - -[SZ](/de/companydirectory/sz/a/a_) - -[SO](/de/companydirectory/so/a/a_) - -[SG](/de/companydirectory/sg/a/a_) - -[TI](/de/companydirectory/ti/a/a_) - -[TG](/de/companydirectory/tg/a/a_) - -[UR](/de/companydirectory/ur/a/a_) - -[VD](/de/companydirectory/vd/a/a_) - -[VS](/de/companydirectory/vs/a/a_) - -[ZG](/de/companydirectory/zg/a/a_) - -[ZH](/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](/de/persondirectory/a/aa) - -[B](/de/persondirectory/b/ba) - -[C](/de/persondirectory/c/ca) - -[D](/de/persondirectory/d/da) - -[E](/de/persondirectory/e/ea) - -[F](/de/persondirectory/f/fa) - -[G](/de/persondirectory/g/ga) - -[H](/de/persondirectory/h/ha) - -[I](/de/persondirectory/i/ia) - -[J](/de/persondirectory/j/ja) - -[K](/de/persondirectory/k/ka) - -[L](/de/persondirectory/l/la) - -[M](/de/persondirectory/m/ma) - -[N](/de/persondirectory/n/na) - -[O](/de/persondirectory/o/oa) - -[P](/de/persondirectory/p/pa) - -[Q](/de/persondirectory/q/qa) - -[R](/de/persondirectory/r/ra) - -[S](/de/persondirectory/s/sa) - -[T](/de/persondirectory/t/ta) - -[U](/de/persondirectory/u/ua) - -[V](/de/persondirectory/v/va) - -[W](/de/persondirectory/w/wa) - -[X](/de/persondirectory/x/xa) - -[Y](/de/persondirectory/y/ya) - -[Z](/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](/de/terms)[Datenschutz |](/de/privacy)[Impressum](/de/imprint) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU\_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/imprint) - -[Startseite](/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/imprint) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -[Premium-Mitglied werden](/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/imprint)[Anmelden](/de/login?redirectUrl=%2Fimprint) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/imprint)[Anmelden](/de/login?redirectUrl=%2Fimprint) - - - - - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Sonstige - -Kantone hinzufügen oder löschen: - -Kanton -Aargau -Appenzell I. Rh. -Appenzell A. Rh. -Bern -Basel-Landschaft -Basel-Stadt -Freiburg -Genf -Glarus -Graubünden -Jura -Luzern -Neuenburg -Nidwalden -Obwalden -St. Gallen -Schaffhausen -Solothurn -Schwyz -Thurgau -Tessin -Uri -Waadt -Wallis -Zug -Zürich - -[Bestätigen](javascript:void(0)) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_012_www.itreseller.ch_media.txt b/test_web_content_20251002_205603/additional_link_012_www.itreseller.ch_media.txt deleted file mode 100644 index 388acbcc..00000000 --- a/test_web_content_20251002_205603/additional_link_012_www.itreseller.ch_media.txt +++ /dev/null @@ -1,203 +0,0 @@ -URL: https://www.itreseller.ch/media -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Inserieren in IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Inserieren in IT Reseller -========================= - - IT Reseller ist seit 1998 die führende Fachzeitschrift für die Schweizer IT-Industrie. - - Die Print-Ausgabe erscheint monatlich in einer Auflage von 2500 Exemplaren und erreicht persönlich adressiert den Schweizer ICT-Channel. - - Online erreicht IT Reseller monatlich 32'000 Besucher (Unique Clients) und erzielt bis zu 92'000 Page Impressions. -Print-Anzeigen --------------- - - Gültig ab 1. Januar 2025 -Anzeigen -Format Satzspiegel - -B x H in mm Randabfallend * - -B x H in mm Preis in CHF - -exkl. MwSt -2/1 Seiten Panorama 385 x 265 420 x 297 6600.– -1/1 Seite 175 x 265 210 x 297 4000.– -1/2 Seite quer 175 x 130 210 x 145 3000.– -1/2 Seite hoch 85 x 265 103 x 297 3000.– -1/3 Seite quer 175 x 85 210 x 95 2800.– -1/3 Seite hoch 55 x 265 67 x 297 2800.– -2. oder 4. Umschlagsseite 175 x 265 210 x 297 4800.– -Advertorial -2/1 Seite 385 x 265 420 x 297 4950.– -1/1 Seite 175 x 265 210 x 297 3000.– -3er-Kombi ** -3x 1/1 Seite 175 x 265 210 x 297 6000.– -3x 1/2 Seite quer 175 x 130 210 x 145 4500.– -3x 1/2 Seite hoch 85 x 265 103 x 297 4500.– -Jahresangebot ** -10x 1/1 Seite 175 x 265 210 x 297 12'000.– -10x 1/2 Seite quer 175 x 130 210 x 145 9000.– -10x 1/2 Seite hoch 85 x 265 103 x 297 9000.– -Coverlasche (Flappe) -Coverlasche Vorderseite-auf Anfrage 5'400.– -Coverlasche Rückseite mit 4. Umschlagseite-auf Anfrage 5'400.– -Coverlasche im 5er Kombi-auf Anfrage 4000.– -Veranstaltungskalender -Eintrag mit Datum, Titel, Tagline und URL + Online-Publikation (s. unten)180.– - -* 3 mm Beschnitt pro Aussenrand hinzufügen - - ** Fixpreis für 3 resp. 10 aufeinanderfolgende Ausgaben, Vorauszahlung, nicht Rabatt- oder BK-berechtigt, ohne redaktionellen Anschluss, keine Platzierungswünsche möglich, Verwendung des alten Sujets bei Nichtlieferung eines neuen Sujets bis Inserateschluss. - -Online-Anzeigen ---------------- - - Gültig ab 1. Januar 2025 -TKP-Buchungen -Werbemittel Platzierung Preis in CHF pro 1000 Impressions Format BxH - -(max. 50 KB)Datenformate -Maxiboard Run-of-Site 55.–994 x 118 Pixel JPEG, GIF, HTML5 -Leaderboard Run-of-Site 55.–728 x 90 Pixel JPEG, GIF, HTML5 -Wideskyscraper Run-of-Site 55.–160 x 600 Pixel JPEG, GIF, HTML5 -Half Page Run-of-Site 55.–300 x 600 Pixel JPEG, GIF, HTML5 -Rectangle Run-of-Site 55.–300 x 250 Pixel JPEG, GIF, HTML5 -Mindestbuchungsvolumen: CHF 1100.– -Buchungen mit Fixplatzierung -Werbemittel Platzierung Preis pro Woche Format (max. 50 KB)Datenformate -Maxiboard Run-of-Site 1290.–994 x 118 Pixel JPEG, GIF, HTML5 -Leaderboard Run-of-Site 1290.–728 x 90 Pixel JPEG, GIF, HTML5 -Wideskyscraper Run-of-Site 1290.–160 x 600 Pixel JPEG, GIF, HTML5 -Half Page Run-of-Site 1290.–300 x 600 Pixel JPEG, GIF, HTML5 -Rectangle Run-of-Site 1490.–300 x 250 Pixel JPEG, GIF, HTML5 -Advertorial -Advertorial Homepage & Newsletter 1200.–Titel, max. 4000 Zeichen Text, Bild - -Newsletter-Anzeigen -------------------- - -Fixplatzierung -Werbemittel Preis pro Woche Format (max. 50 KB)Datenformate -Banner 600.–468 x 60 Pixel JPEG, GIF -Skyscraper 825.–160 x 600 Pixel JPEG, GIF -Rectangle 825.–300 x 250 Pixel JPEG, GIF -Textanzeige 825.–n/a JPEG, GIF - -Veranstaltungen ---------------- - -Grundeintrag im Veranstaltungskalender -Werbemittel Preis in CHF exkl. MWST -Eintrag mit Titel, Datum und URL kostenlos -Premium-Eintrag im Veranstaltungskalender -Eintrag mit Titel, Datum und URL 180.- -+ Eintrag mit farblicher Hervorhebung, Logo, Beschreibung -+ Tägliche Veröffentlichung im Newsletter (Start: 3 Monate vor Beginn) -+ Veröffentlichung im Veranstaltungskalender der Print-Ausgabe - -SALES KONTAKT - - - - Sie möchten Werbung schalten oder wünschen eine kompetente Beratung? - -**Unsere Verkaufsleiterin Tanja Zesiger freut sich auf Ihre Kontaktaufnahme!** - -#### ✆ +41 (0) 44 723 50 05 - -#### [tzesiger@swissitmedia.ch](mailto:tzesiger@swissitmedia.ch) - -MEDIADATEN - -[ ##### Download Mediadaten 2025](https://www.itreseller.ch/media/tarife/ITR_Mediadaten_2025_DE.pdf) - -MEDIA ALERT - - Abonnieren Sie unseren monatlichen Media Alert mit der Themenvorschau auf die kommenden Ausgaben von IT Reseller. - -AUSGABEN & TERMINE - -**IT Reseller 2025/ 11** -Erscheint am:3. November 2025 -Anzeigenschluss:24. Oktober 2025 - -**IT Reseller 2025/ 12** -Erscheint am:8. Dezember 2025 -Anzeigenschluss:28. November 2025 - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_013_www.itreseller.ch_abo.txt b/test_web_content_20251002_205603/additional_link_013_www.itreseller.ch_abo.txt deleted file mode 100644 index 592d23e8..00000000 --- a/test_web_content_20251002_205603/additional_link_013_www.itreseller.ch_abo.txt +++ /dev/null @@ -1,157 +0,0 @@ -URL: https://www.itreseller.ch/abo -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Abonnement - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Abonnement-Bestellung -===================== - - IT Reseller wird ausschliesslich im **Controlled-Circulation-Modell** vertrieben und ist damit nur für Unternehmensmitarbeiter im IT- oder Consumer-Electronics-Markt erhältlich. - - Um sicherzustellen, dass nur qualifizierte Personen den IT Reseller erhalten, bitten wir Sie, bei Ihrer Bestellung **alle mit (*) gekennzeichneten Felder auszufüllen**, damit wir Ihre Angaben prüfen können. - -**1-Jahres-Abonnement** - - Ich abonniere IT Reseller inkl. Swiss IT Magazine für ein Jahr zum Preis von Fr. 95.– - -(Ausland Europa Fr. 190.-). -**2-Jahres-Abonnement** - - Ich abonniere IT Reseller inkl. Swiss IT Magazine für 2 Jahre zum Preis von Fr. 150.– - -(Ausland Europa Fr. 300.-). -**Online-Abonnement** - - Ich abonniere die digitale Ausgabe von IT Reseller und erhalte damit für 1 Jahr Zugriff auf die Online-Archive von [IT Reseller](https://www.itreseller.ch/Heftarchiv/) und [Swiss IT Magazine](http://www.itmagazine.ch/heftarchiv) zum Preis von Fr. 75.– -**Probe-Abonnement** - - Ich möchte drei Ausgaben kostenlos zur Probe. (Kein Ausland-Versand) -**Das Abo startet mit der Ausgabe** -- [x]Ich möchte auch den täglichen Newsletter von IT Reseller abonnieren! - -**Firma*** -**Anrede** -**Vorname*** -**Nachname*** -**Abteilung** -**Position** -**Branche*** -**Strasse*** -**PLZ/Ort*** -**Land** -**Telefon*** -**E-Mail*** -* Angabe obligatorisch -Dies ist meine Geschäftsadresse -Dies ist meine Privatadresse -- [x]IT Reseller darf mich für Meinungsumfragen - -und Recherchen kontaktieren. - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_014_www.itreseller.ch_newsletter.txt b/test_web_content_20251002_205603/additional_link_014_www.itreseller.ch_newsletter.txt deleted file mode 100644 index 842eeffa..00000000 --- a/test_web_content_20251002_205603/additional_link_014_www.itreseller.ch_newsletter.txt +++ /dev/null @@ -1,119 +0,0 @@ -URL: https://www.itreseller.ch/newsletter -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Newsletter - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Newsletter abonnieren -===================== - - Um die Newsletter von IT Reseller zu abonnieren, geben Sie bitte Ihre E-Mail-Adresse in das folgende Feld ein und klicken Sie auf den Anmelden-Button. - - Um den Newsletter abzubestellen, klicken Sie bitte auf den Link am Ende jedes Newsletters. - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_015_www.itreseller.ch_rubriken_165_people.html.txt b/test_web_content_20251002_205603/additional_link_015_www.itreseller.ch_rubriken_165_people.html.txt deleted file mode 100644 index d0c0b4ae..00000000 --- a/test_web_content_20251002_205603/additional_link_015_www.itreseller.ch_rubriken_165_people.html.txt +++ /dev/null @@ -1,195 +0,0 @@ -URL: https://www.itreseller.ch/rubriken/165/people.html -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -People - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -PEOPLE ------- - -[](https://www.itreseller.ch/Artikel/104096/Daniele_Palazzo_verlaesst_Lake_Solutions.html) - -[Daniele Palazzo verlässt Lake Solutions =======================================](https://www.itreseller.ch/Artikel/104096/Daniele_Palazzo_verlaesst_Lake_Solutions.html) - -[Lake Solutions verkleinert die Geschäftsleitung. Daniele Palazzo verlässt das Unternehmen nach mehr als 20 Jahren, seine Aufgaben werden im Rahmen einer Reorganisation an die drei verbleibenden GL-Mitglieder verteilt.](https://www.itreseller.ch/Artikel/104096/Daniele_Palazzo_verlaesst_Lake_Solutions.html) - - 2. Oktober 2025 - -Meistgelesen in People - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -[](https://www.itreseller.ch/Artikel/104097/Torsten_Boettjer_ist_Head_of_Cloud_Services_bei_Inventx.html) - -[### Torsten Böttjer ist Head of Cloud Services bei Inventx Mit der neu geschaffenen Position des Head of Cloud Services will Inventx die Weiterentwicklung seiner Hybrid-Cloud-Strategie weiterentwickeln. Besetzt wurde die Position mit Torsten Böttjer. 2. Oktober 2025](https://www.itreseller.ch/Artikel/104097/Torsten_Boettjer_ist_Head_of_Cloud_Services_bei_Inventx.html) - -[](https://www.itreseller.ch/Artikel/104100/Hohmann_verlaesst_Thomas-Krenn_Meier_und_Frei_bilden_Doppelspitze.html) - -[### Hohmann verlässt Thomas-Krenn, Meier und Frei bilden Doppelspitze Beim Server- und Storage-Spezialisten Thomas-Krenn verkleinert sich der Vorstand wieder. Ralf Hohmann scheidet aus, CEO Christoph Maier und COO Thomas Frei übernehmen fortan zu zweit die Aufgaben des Vorstands. 2. Oktober 2025](https://www.itreseller.ch/Artikel/104100/Hohmann_verlaesst_Thomas-Krenn_Meier_und_Frei_bilden_Doppelspitze.html) - -[](https://www.itreseller.ch/Artikel/104094/NTT_Data_stellt_Michael_Seiger_als_neuen_DACH-Chef_vor.html) - -[### NTT Data stellt Michael Seiger als neuen DACH-Chef vor NTT Data ernennt Michael Seiger zum Executive Managing Director für Deutschland, Österreich und die Schweiz. Er folgt auf Stefan Hansen. 2. Oktober 2025](https://www.itreseller.ch/Artikel/104094/NTT_Data_stellt_Michael_Seiger_als_neuen_DACH-Chef_vor.html) - -[](https://www.itreseller.ch/Artikel/104095/Sonepar_Schweiz_ernennt_Raphael_Maier_zum_neuen_CEO.html) - -[### Sonepar Schweiz ernennt Raphael Maier zum neuen CEO David von Ow ist nach 30 Jahren in den Ruhestand getreten. Für ihn übernimmt nun Raphael Maier die Rolle als CEO von Sonepar in der Schweiz. 1. Oktober 2025](https://www.itreseller.ch/Artikel/104095/Sonepar_Schweiz_ernennt_Raphael_Maier_zum_neuen_CEO.html) - -[](https://www.itreseller.ch/Artikel/104090/AWS_ernennt_Stphane_Isral_zum_Leiter_der_Sovereign_Cloud.html) - -[### AWS ernennt Stéphane Israël zum Leiter der Sovereign Cloud AWS gibt mit Stéphane Israël einen zweiten Leiter der European Sovereign Cloud bekannt. Zusammen mit Kathrin Renz soll er das Geschäft mit souveränen Cloud-Strukturen leiten. 1. Oktober 2025](https://www.itreseller.ch/Artikel/104090/AWS_ernennt_Stphane_Isral_zum_Leiter_der_Sovereign_Cloud.html) - -[](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html) - -[### Paessler bekommt mit Jason Teichman neuen CEO](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html) - -[IT- und OT-Monitoring-Anbieter Paessler stellt mit Jason Teichman seinen neuen CEO vor. Mit der Personalie unterstreicht das Unternehmen seine globale Expansionsstrategie.](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html)1. Oktober 2025 - -[](https://www.itreseller.ch/Artikel/104086/Connect-Test_Schweizer_Internet-Provider_sind_ueberragend.html) - -[### Connect-Test: Schweizer Internet-Provider sind überragend](https://www.itreseller.ch/Artikel/104086/Connect-Test_Schweizer_Internet-Provider_sind_ueberragend.html) - -[Während Swisscom und Sunrise im grossen Festnetztest Schweiz 2025 von "Connect" beinahe gleichauf liegen, sind die Unterschiede bei den regionalen Anbietern etwas grösser. Klar ist aber: Die Schweizer Internet-Provider sind durchs Band top.](https://www.itreseller.ch/Artikel/104086/Connect-Test_Schweizer_Internet-Provider_sind_ueberragend.html)1. Oktober 2025 - -[](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) - -[Mit Renato Petrillo (Bild, Mitte) hat Baggenstos einen neuen CEO gefunden. Er folgt auf Michael Kistler (Bild, links), der dem Unternehmen in verschiedenen Rollen erhalten bleibt.](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html)30. September 2025 - -[](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) - -[Dennis Monner (Bild, rechts) folgt bei Open Systems als CEO auf Daniel Neuhaus (Bild, links), der 2020 mit der Übernahme seines Unternehmens Sqooba zum Unternehmen stiess.](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html)30. September 2025 - -[](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) - -[Mit Marco Pierro hat Check Point Software Technologies einen neuen Country Manager für die Schweiz ernannt. Er übernimmt die Funktion per 1. Oktober 2025 und folgt auf Alvaro Amato, der zum Director Globals für EMEA & Asien befördert wurde.](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html)30. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_016_www.itreseller.ch_rubriken_163_business.html.txt b/test_web_content_20251002_205603/additional_link_016_www.itreseller.ch_rubriken_163_business.html.txt deleted file mode 100644 index c1b94a51..00000000 --- a/test_web_content_20251002_205603/additional_link_016_www.itreseller.ch_rubriken_163_business.html.txt +++ /dev/null @@ -1,195 +0,0 @@ -URL: https://www.itreseller.ch/rubriken/163/business.html -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Business - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -BUSINESS --------- - -[](https://www.itreseller.ch/Artikel/104102/Matrix42_kauft_SaaS-Management-Spezialisten_Viio.html) - -[Matrix42 kauft SaaS-Management-Spezialisten Viio ================================================](https://www.itreseller.ch/Artikel/104102/Matrix42_kauft_SaaS-Management-Spezialisten_Viio.html) - -[Mit dem Zukauf des dänischen SaaS-Management-Spezialisten will Matrix42 die eigenen Fähigkeiten im Bereich Software Asset Management und Enterprise Service Management verbessern. Die Übernahme soll noch dieses Jahr abgeschlossen werden.](https://www.itreseller.ch/Artikel/104102/Matrix42_kauft_SaaS-Management-Spezialisten_Viio.html) - - 2. Oktober 2025 - -Meistgelesen in Business - -[### Nutanix Cloud Platform unterstützt neu Dell PowerStore](https://www.itreseller.ch/Artikel/104070/Nutanix_Cloud_Platform_unterstuetzt_neu_Dell_PowerStore.html) 26. September 2025 - -[### Intel wirbt auch bei Apple um Investitionen](https://www.itreseller.ch/Artikel/104063/Intel_wirbt_auch_bei_Apple_um_Investitionen.html) 25. September 2025 - -[### AWS und SAP stellen gemeinsam "souveräne Cloud" auf die Beine](https://www.itreseller.ch/Artikel/104060/AWS_und_SAP_stellen_gemeinsam_souveraene_Cloud_auf_die_Beine.html) 25. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) 23. September 2025 - -[](https://www.itreseller.ch/Artikel/104099/Fritz_startet_mit_eigenem_Online-Shop_in_der_Schweiz_.html) - -[### Fritz startet mit eigenem Online-Shop in der Schweiz Netzwerkspezialist Fritz öffnet einen eigenen Online-Shop in der Schweiz. Dieser soll spätestens Mitte Oktober bereitstehen und die gewohnten Zusatzservices bieten. 2. Oktober 2025](https://www.itreseller.ch/Artikel/104099/Fritz_startet_mit_eigenem_Online-Shop_in_der_Schweiz_.html) - -[](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - -[### Swico ICT Index zeigt abermals Knick für das vierte Quartal Der Swico ICT Index geht im vierten Quartal 2025 um 2 Punkte zurück. Noch sind viele Segmente im Wachstumsbereich, allerdings zeigen Unsicherheiten, Zölle und Wettbewerb Effekte. 1. Oktober 2025](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - -[](https://www.itreseller.ch/Artikel/104091/Arrow_vertreibt_Thales-Plattform_in_der_Schweiz.html) - -[### Arrow vertreibt Thales-Plattform in der Schweiz Arrow hat das bestehende Distributionsabkommen mit Thales erweitert und bietet die Imperva Application Security-Plattform auch in der Schweiz sowie in Österreich und Italien an. 1. Oktober 2025](https://www.itreseller.ch/Artikel/104091/Arrow_vertreibt_Thales-Plattform_in_der_Schweiz.html) - -[](https://www.itreseller.ch/Artikel/104084/Infinigate_vertreibt_neu_Thales_in_der_Schweiz.html) - -[### Infinigate vertreibt neu Thales in der Schweiz Schweizer Channel-Partner können neu das gesamte Security-Portfolio von Thales über Infinigate beziehen und erhalten beim VAD den dazugehörigen Support. 30. September 2025](https://www.itreseller.ch/Artikel/104084/Infinigate_vertreibt_neu_Thales_in_der_Schweiz.html) - -[](https://www.itreseller.ch/Artikel/104082/NTT_Data_streicht_Ivanti_aus_Sicherheitsgruenden_aus_Portfolio_.html) - -[### NTT Data streicht Ivanti aus Sicherheitsgründen aus Portfolio NTT Data vertreibt keine Produkte mehr von Ivanti. Laut dem IT-Dienstleister stellen diese ein zu hohes Sicherheitsrisiko dar. 30. September 2025](https://www.itreseller.ch/Artikel/104082/NTT_Data_streicht_Ivanti_aus_Sicherheitsgruenden_aus_Portfolio_.html) - -[](https://www.itreseller.ch/Artikel/104077/Microsoft_startet_neuen_Marketplace_fuer_Cloud-_und_KI-Loesungen.html) - -[### Microsoft startet neuen Marketplace für Cloud- und KI-Lösungen](https://www.itreseller.ch/Artikel/104077/Microsoft_startet_neuen_Marketplace_fuer_Cloud-_und_KI-Loesungen.html) - -[Microsoft startet einen einheitlichen Marketplace, der Azure Marketplace und AppSource bündelt und Unternehmen Cloud-Lösungen sowie KI-Apps und Agenten zentral finden, testen, kaufen und direkt in ihrer Microsoft-Umgebung bereitstellen lässt.](https://www.itreseller.ch/Artikel/104077/Microsoft_startet_neuen_Marketplace_fuer_Cloud-_und_KI-Loesungen.html)29. September 2025 - -[](https://www.itreseller.ch/Artikel/104075/ADN_setzt_verstaerkt_auf_das_Dell-Geschaeft.html) - -[### ADN setzt verstärkt auf das Dell-Geschäft](https://www.itreseller.ch/Artikel/104075/ADN_setzt_verstaerkt_auf_das_Dell-Geschaeft.html) - -[ADN baut personell mit den drei neuen Channel-Experten Ronny Pilgram (Bild), Thomas Kroll und Christof Sokolowski aus und bekräftigt damit seinen Anspruch als strategischer Value-Added-Distributor für Dell Technologies.](https://www.itreseller.ch/Artikel/104075/ADN_setzt_verstaerkt_auf_das_Dell-Geschaeft.html)29. September 2025 - -[](https://www.itreseller.ch/Artikel/104070/Nutanix_Cloud_Platform_unterstuetzt_neu_Dell_PowerStore.html) - -[### Nutanix Cloud Platform unterstützt neu Dell PowerStore](https://www.itreseller.ch/Artikel/104070/Nutanix_Cloud_Platform_unterstuetzt_neu_Dell_PowerStore.html) - -[Mit der Unterstützung der All-Flash-Storage-Plattform Dell PowerStore in der Nutanix Cloud Platform vertiefen die beiden Technologieunternehmen ihre strategische Partnerschaft.](https://www.itreseller.ch/Artikel/104070/Nutanix_Cloud_Platform_unterstuetzt_neu_Dell_PowerStore.html)26. September 2025 - -[](https://www.itreseller.ch/Artikel/104066/Motorola_startet_in_der_Schweiz_eigenen_Online-Shop.html) - -[### Motorola startet in der Schweiz eigenen Online-Shop](https://www.itreseller.ch/Artikel/104066/Motorola_startet_in_der_Schweiz_eigenen_Online-Shop.html) - -[Motorola baut das Direktgeschäft in der Schweiz aus und startet einen eigenen Online-Shop für Privat- und Geschäftskunden. So will der Hersteller die Präsenz hierzulande stärken.](https://www.itreseller.ch/Artikel/104066/Motorola_startet_in_der_Schweiz_eigenen_Online-Shop.html)26. September 2025 - -[](https://www.itreseller.ch/Artikel/104064/Crayon_ist_neuer_Zendesk-Distributor_.html) - -[### Crayon ist neuer Zendesk-Distributor](https://www.itreseller.ch/Artikel/104064/Crayon_ist_neuer_Zendesk-Distributor_.html) - -[Crayon tritt in mehr als 70 Ländern als neuer Distributor für Zendesk auf. Die Partnerschaft umfasst das gesamte Portfolio des Anbieters von CX-Lösungen.](https://www.itreseller.ch/Artikel/104064/Crayon_ist_neuer_Zendesk-Distributor_.html)26. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_017_www.itreseller.ch_rubriken_166_finance.html.txt b/test_web_content_20251002_205603/additional_link_017_www.itreseller.ch_rubriken_166_finance.html.txt deleted file mode 100644 index 57ecd5c0..00000000 --- a/test_web_content_20251002_205603/additional_link_017_www.itreseller.ch_rubriken_166_finance.html.txt +++ /dev/null @@ -1,173 +0,0 @@ -URL: https://www.itreseller.ch/rubriken/166/finance.html -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Finance - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -FINANCE -------- - -[](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -[OpenAI knackt 500-Milliarden-Marke ==================================](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -[Die KI-Blase wächst weiter: Nach einem grossen Aktienverkauf durch OpenAI-Mitarbeiter an Investoren liegt der Unternehmenswert nun erstmals bei einer halben Billion US-Dollar.](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - - 2. Oktober 2025 - -Meistgelesen in Finance - -[### Adobe-Zahlen übertreffen die Markterwartungen](https://www.itreseller.ch/Artikel/103962/Adobe-Zahlen_uebertreffen_die_Markterwartungen.html) 12. September 2025 - -[### Aveniq setzt auf Fokussierung und einheitliche Strukturen](https://www.itreseller.ch/Artikel/103935/Aveniq_setzt_auf_Fokussierung_und_einheitliche_Strukturen.html) 9. September 2025 - -[### ASML wird Hauptaktionär von Mistral AI](https://www.itreseller.ch/Artikel/103933/ASML_wird_Hauptaktionaer_von_Mistral_AI.html) 8. September 2025 - -[### HPE übertrifft Markterwartungen mit Rekordumsatz](https://www.itreseller.ch/Artikel/103920/HPE_uebertrifft_Markterwartungen_mit_Rekordumsatz_.html) 5. September 2025 - -[](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -[### Accenture mit mehr Umsatz und weniger Gewinn Accenture steigerte im jüngsten Quartal die Einnahmen um 7 Prozent auf 17,6 Milliarden Dollar. Hingegen mussten beim Gewinn zweistellige Einbussen in Kauf genommen werden. 26. September 2025](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -[](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab TD Synnex übertraf im abgelaufenen Quartal die Markterwartungen sowohl beim Gewinn, als auch beim Umsatz deutlich. Obwohl auch der Ausblick die Analystenschätzungen übertraf, konnte die Aktie nicht profitieren. 26. September 2025](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -[](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -[### Schweizer KI-Start-up Giotto sucht Finanzierung Giotto mit Sitz in Lausanne sucht mit Unterstützung einer Investmentbank Investoren für eine weitere Finanzierung im Umfang von über 200 Millionen US-Dollar. Das Unternehmen ist im Bereich künstliche allgemeine Intelligenz (AGI) tätig. 23. September 2025](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -[](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -[### Nvidia will kräftig in OpenAI investieren OpenAI will seine KI-Infrastruktur ab nächstem Jahr stark ausbauen und dazu Nvidia-Systeme der neuesten Generation einsetzen. Nvidia sichert zu, mindestens 100 Millionen Dollar in OpenAI zu investieren. 23. September 2025](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -[](https://www.itreseller.ch/Artikel/104009/Oracle_vor_20-Milliarden-Deal_mit_Meta.html) - -[### Oracle vor 20-Milliarden-Deal mit Meta Nach dem 300-Milliarden-Dollar-Vertrag mit OpenAI plant Oracle ein weiteres Abkommen zum Bezug von Cloud-Dienstleistungen mit Meta. In den kommenden Monaten sollen noch mehr ähnliche Deals folgen. 22. September 2025](https://www.itreseller.ch/Artikel/104009/Oracle_vor_20-Milliarden-Deal_mit_Meta.html) - -[](https://www.itreseller.ch/Artikel/103975/Alphabet_ist_erstmals_3_Billionen_Dollar_Wert.html) - -[### Alphabet ist erstmals 3 Billionen Dollar Wert](https://www.itreseller.ch/Artikel/103975/Alphabet_ist_erstmals_3_Billionen_Dollar_Wert.html) - -[Nach einem erneuten Anstieg des Aktienkurses um über 3 Prozent hat die Börsenbewertung der Google-Mutter Alphabet nun zum ersten Mal die Schwelle von 3 Billionen US-Dollar überschritten.](https://www.itreseller.ch/Artikel/103975/Alphabet_ist_erstmals_3_Billionen_Dollar_Wert.html)16. September 2025 - -[](https://www.itreseller.ch/Artikel/103962/Adobe-Zahlen_uebertreffen_die_Markterwartungen.html) - -[### Adobe-Zahlen übertreffen die Markterwartungen](https://www.itreseller.ch/Artikel/103962/Adobe-Zahlen_uebertreffen_die_Markterwartungen.html) - -[Im jüngsten Quartal konnte Adobe beim Umsatz wie auch beim Gewinn zulegen. Da das Management auch die Umsatzprognose fürs gesamte Geschäftsjahr nach oben angepasst hat, konnte auch die Aktie profitieren.](https://www.itreseller.ch/Artikel/103962/Adobe-Zahlen_uebertreffen_die_Markterwartungen.html)12. September 2025 - -[](https://www.itreseller.ch/Artikel/103950/Oracles_IaaS-Umsaetze_gehen_durch_die_Decke.html) - -[### Oracles IaaS-Umsätze gehen durch die Decke](https://www.itreseller.ch/Artikel/103950/Oracles_IaaS-Umsaetze_gehen_durch_die_Decke.html) - -[Oracle kann starke Zahlen für das erste Quartal des Geschäftsjahres 2026 vorlegen. Vor allem das Cloud-Infrastruktur-Business boomt.](https://www.itreseller.ch/Artikel/103950/Oracles_IaaS-Umsaetze_gehen_durch_die_Decke.html)11. September 2025 - -[](https://www.itreseller.ch/Artikel/103946/Computacenter_meldet_Umsatzsprung_-_aber_nicht_fuer_Westeuropa.html) - -[### Computacenter meldet Umsatzsprung - aber nicht für Westeuropa](https://www.itreseller.ch/Artikel/103946/Computacenter_meldet_Umsatzsprung_-_aber_nicht_fuer_Westeuropa.html) - -[Computacenter kann für das erste Halbjahr 2025 beachtliche Zahlen vorlegen. Die westeuropäischen Märkte (exklusive UK) haben dazu jedoch nur bedingt beigetragen.](https://www.itreseller.ch/Artikel/103946/Computacenter_meldet_Umsatzsprung_-_aber_nicht_fuer_Westeuropa.html)10. September 2025 - -[](https://www.itreseller.ch/Artikel/103935/Aveniq_setzt_auf_Fokussierung_und_einheitliche_Strukturen.html) - -[### Aveniq setzt auf Fokussierung und einheitliche Strukturen](https://www.itreseller.ch/Artikel/103935/Aveniq_setzt_auf_Fokussierung_und_einheitliche_Strukturen.html) - -[Aveniq hat in Baden Anfang September den Business Summit 2025 veranstaltet. In diesem Rahmen gab Head of Sales & Marketing Walter Lienhard Einblick in den strategischen Status quo des IT-Dienstleisters.](https://www.itreseller.ch/Artikel/103935/Aveniq_setzt_auf_Fokussierung_und_einheitliche_Strukturen.html)9. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_018_www.itreseller.ch_rubriken_122_research.html.txt b/test_web_content_20251002_205603/additional_link_018_www.itreseller.ch_rubriken_122_research.html.txt deleted file mode 100644 index d84a9ef7..00000000 --- a/test_web_content_20251002_205603/additional_link_018_www.itreseller.ch_rubriken_122_research.html.txt +++ /dev/null @@ -1,195 +0,0 @@ -URL: https://www.itreseller.ch/rubriken/122/research.html -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Research - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -RESEARCH --------- - -[](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - -[Swico ICT Index zeigt abermals Knick für das vierte Quartal ===========================================================](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - -[Der Swico ICT Index geht im vierten Quartal 2025 um 2 Punkte zurück. Noch sind viele Segmente im Wachstumsbereich, allerdings zeigen Unsicherheiten, Zölle und Wettbewerb Effekte.](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - - 1. Oktober 2025 - -Meistgelesen in Research - -[### Drucker-Firmware wird zu selten aktualisiert](https://www.itreseller.ch/Artikel/103970/Drucker-Firmware_wird_zu_selten_aktualisiert.html) 15. September 2025 - -[### Globaler Ethernet-Switch-Markt mit 42 Prozent Wachstum](https://www.itreseller.ch/Artikel/103966/Globaler_Ethernet-Switch-Markt_mit_42_Prozent_Wachstum.html) 15. September 2025 - -[### Huawei überholt Apple im Smartwatch-Markt](https://www.itreseller.ch/Artikel/103938/Huawei_ueberholt_Apple_im_Smartwatch-Markt.html) 9. September 2025 - -[### Europas Markt für Large Format Displays erleidet Einbussen](https://www.itreseller.ch/Artikel/103926/Europas_Markt_fuer_Large_Format_Displays_erleidet_Einbussen.html) 8. September 2025 - -[](https://www.itreseller.ch/Artikel/104059/Smartphone-Durchschnittspreise_steigen.html) - -[### Smartphone-Durchschnittspreise steigen Der durchschnittliche Preis, der für ein Smartphone bezahlt wird, soll von 370 Dollar in diesem Jahr auf 412 Dollar im Jahr 2029 steigen. 25. September 2025](https://www.itreseller.ch/Artikel/104059/Smartphone-Durchschnittspreise_steigen.html) - -[](https://www.itreseller.ch/Artikel/104026/Ausgaben_der_Hyperscaler_gehen_durch_die_Decke.html) - -[### Ausgaben der Hyperscaler gehen durch die Decke Die Hyperscaler investieren immer mehr in ihre Infrastruktur und hier vor allem in KI-Rechenzentren. Damit befeuern sie laut Analysten ihr "aggressives Wachstum". 24. September 2025](https://www.itreseller.ch/Artikel/104026/Ausgaben_der_Hyperscaler_gehen_durch_die_Decke.html) - -[](https://www.itreseller.ch/Artikel/104003/Globaler_Notebook-Markt_auf_Erholungskurs.html) - -[### Globaler Notebook-Markt auf Erholungskurs Fürs laufende Jahr prognostiziert Trendforce für den globalen Notebook-Markt ein Absatzplus von 2,2 Prozent. Das Wachstum gibt im Jahresverlauf allerdings kontinuierlich nach, um dann im Q4 in den negativen Bereich zu kippen. 22. September 2025](https://www.itreseller.ch/Artikel/104003/Globaler_Notebook-Markt_auf_Erholungskurs.html) - -[](https://www.itreseller.ch/Artikel/103990/KI-Ausgaben_sollen_sich_2025_auf_15_Billionen_Dollar_belaufen.html) - -[### KI-Ausgaben sollen sich 2025 auf 1,5 Billionen Dollar belaufen 2025 sollen die weltweiten Ausgaben für Künstliche Intelligenz knapp 1,5 Billionen US-Dollar ausmachen. Für das kommende Jahr prognostizieren Gartner-Analysten dann den Sprung über die 2-Milliarden-Marke. 18. September 2025](https://www.itreseller.ch/Artikel/103990/KI-Ausgaben_sollen_sich_2025_auf_15_Billionen_Dollar_belaufen.html) - -[](https://www.itreseller.ch/Artikel/103974/Europaeischer_PC-Markt_legt_im_dritten_Quartal_deutlich_zu.html) - -[### Europäischer PC-Markt legt im dritten Quartal deutlich zu Im Juli und August 2025 hat die europäische Distribution bei Desktop-PCs ein Umsatzplus von über 30 Prozent erreicht, während Notebooks um über 11 Prozent zulegten. 15. September 2025](https://www.itreseller.ch/Artikel/103974/Europaeischer_PC-Markt_legt_im_dritten_Quartal_deutlich_zu.html) - -[](https://www.itreseller.ch/Artikel/103970/Drucker-Firmware_wird_zu_selten_aktualisiert.html) - -[### Drucker-Firmware wird zu selten aktualisiert](https://www.itreseller.ch/Artikel/103970/Drucker-Firmware_wird_zu_selten_aktualisiert.html) - -[Mit Updates der Drucker-Firmware hapert es in vielen Unternehmen. Sicherheitsprobleme bestehen jedoch nicht nur im Betrieb, sie treten von der Beschaffung bis zur Entsorgung auf.](https://www.itreseller.ch/Artikel/103970/Drucker-Firmware_wird_zu_selten_aktualisiert.html)15. September 2025 - -[](https://www.itreseller.ch/Artikel/103967/Enterprise-WLAN-Markt_im_Q2_2025_deutlich_im_Plus.html) - -[### Enterprise-WLAN-Markt im Q2 2025 deutlich im Plus](https://www.itreseller.ch/Artikel/103967/Enterprise-WLAN-Markt_im_Q2_2025_deutlich_im_Plus.html) - -[Im zweiten Quartal 2025 legte der weltweite Enterprise-WLAN-Markt gegenüber der Vorjahresperiode um 13,2 Prozent zu. Marktführer ist Cisco, gefolgt vom HPE Aruba, Ubiquiti, Huawei und Juniper Networks.](https://www.itreseller.ch/Artikel/103967/Enterprise-WLAN-Markt_im_Q2_2025_deutlich_im_Plus.html)15. September 2025 - -[](https://www.itreseller.ch/Artikel/103966/Globaler_Ethernet-Switch-Markt_mit_42_Prozent_Wachstum.html) - -[### Globaler Ethernet-Switch-Markt mit 42 Prozent Wachstum](https://www.itreseller.ch/Artikel/103966/Globaler_Ethernet-Switch-Markt_mit_42_Prozent_Wachstum.html) - -[Der wachsende Bedarf der Hyperscaler sorgt im Markt für Ethernet Switches für einen aussergewöhnlichen Umsatzanstieg von über 42 Prozent auf 14,5 Milliarden Dollar.](https://www.itreseller.ch/Artikel/103966/Globaler_Ethernet-Switch-Markt_mit_42_Prozent_Wachstum.html)15. September 2025 - -[](https://www.itreseller.ch/Artikel/103939/_Weltweiter_Halbleitermarkt_waechst_2025_um_176_Prozent.html) - -[### Weltweiter Halbleitermarkt wächst 2025 um 17,6 Prozent](https://www.itreseller.ch/Artikel/103939/_Weltweiter_Halbleitermarkt_waechst_2025_um_176_Prozent.html) - -[Angetrieben durch die hohe Nachfrage nach KI-Infrastruktur und Rechenzentrums-Technologien wächst der weltweite Halbleitermarkt 2025 laut IDC um 17,6 Prozent auf 800 Milliarden US-Dollar. 2028 könnte eine Billion erreicht werden.](https://www.itreseller.ch/Artikel/103939/_Weltweiter_Halbleitermarkt_waechst_2025_um_176_Prozent.html)9. September 2025 - -[](https://www.itreseller.ch/Artikel/103938/Huawei_ueberholt_Apple_im_Smartwatch-Markt.html) - -[### Huawei überholt Apple im Smartwatch-Markt](https://www.itreseller.ch/Artikel/103938/Huawei_ueberholt_Apple_im_Smartwatch-Markt.html) - -[Huawei hat Apple als führenden Anbieter im globalen Smartwatch-Markt abgelöst, so Zahlen von Counterpoint. Apple-Kunden würden auf neue Modelle warten, diese werden wohl heute noch vorgestellt.](https://www.itreseller.ch/Artikel/103938/Huawei_ueberholt_Apple_im_Smartwatch-Markt.html)9. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_019_www.itreseller.ch_veranstaltungen.txt b/test_web_content_20251002_205603/additional_link_019_www.itreseller.ch_veranstaltungen.txt deleted file mode 100644 index 409e1ca2..00000000 --- a/test_web_content_20251002_205603/additional_link_019_www.itreseller.ch_veranstaltungen.txt +++ /dev/null @@ -1,151 +0,0 @@ -URL: https://www.itreseller.ch/veranstaltungen -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Veranstaltungen - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Veranstaltungen -=============== - -[### SCION Day 2025 Kongress/Konferenz Zürich • 21. Oktober 2025](https://www.itreseller.ch/veranstaltungen/2324/SCION_Day_2025.html) - -[### Global Cyber Conference 2025 Zürich • 22./23. Oktober 2025](https://www.itreseller.ch/veranstaltungen/2331/Global_Cyber_Conference_2025.html) - -[### Swiss Cyber Storm 2025 Resilience in a mad, mad world Bern • 28. Oktober 2025](https://www.itreseller.ch/veranstaltungen/2373/Swiss_Cyber_Storm_2025.html) - -[### Data Community Conference 2025 Kongress/Konferenz Bern • 5. November 2025](https://www.itreseller.ch/veranstaltungen/2376/Data_Community_Conference_2025.html) - - - -[### TEFO 2025 Studerus Technology Forum Regensdorf • 13. November 2025](https://www.itreseller.ch/veranstaltungen/2357/TEFO_2025.html) - -[### Digital Economy Award Zürich-Oerlikon • 13. November 2025](https://www.itreseller.ch/veranstaltungen/2374/Digital_Economy_Award.html) - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_020_www.itreseller.ch_jobs.txt b/test_web_content_20251002_205603/additional_link_020_www.itreseller.ch_jobs.txt deleted file mode 100644 index 73c14845..00000000 --- a/test_web_content_20251002_205603/additional_link_020_www.itreseller.ch_jobs.txt +++ /dev/null @@ -1,327 +0,0 @@ -URL: https://www.itreseller.ch/jobs -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -ICT-Stellenangebote - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Aktuelle ICT-Stellenangebote -============================ - -In Zusammenarbeit mit - -[](https://www.jobchannel.ch/inserieren/?utm_medium=affiliate&utm_source=Swiss%20IT%20Media%20GmbH&utm_campaign=PublishLink) - -Top Jobs der Woche ------------------- - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=&pbl=2&src=site_ict&nlc2=) - -[#### Senior .NET Softwareentwickler and Power Platform Engineer (m/w/d) 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187711&pbl=2&src=site_ict&nlc2=) - - Winterthur - -Ambit Schweiz AG (26. September 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=&pbl=2&src=site_ict&nlc2=) - -[#### System Engineer Microsoft (80–100%)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187693&pbl=2&src=site_ict&nlc2=) - - Dübendorf - -ITIVITY AG (25. September 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=&pbl=2&src=site_ict&nlc2=) - -[#### SAP Application Engineer Finance & Controlling | 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187611&pbl=2&src=site_ict&nlc2=) - - Burgdorf - -Ypsomed Diabetes Care AG (24. September 2025) - -Neueste IT-Jobs ---------------- - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187855&pbl=2&src=site_ict&nlc2=) - -[#### Azure Spezialist (axelion ag)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187855&pbl=2&src=site_ict&nlc2=) - - Zug - -Avalect HR-Executive Consulting (2. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187849&pbl=2&src=site_ict&nlc2=) - -[#### ICT-Koordination – spannende Stelle mit Entwicklungspotential 80%–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187849&pbl=2&src=site_ict&nlc2=) - - Zürich - -Meier-Kopp Gruppe (2. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187842&pbl=2&src=site_ict&nlc2=) - -[#### Software Developer – Professional/Senior 80-100% (a)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187842&pbl=2&src=site_ict&nlc2=) - - Altishofen - -Galliker Transport AG (2. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187836&pbl=2&src=site_ict&nlc2=) - -[#### ICT-Projektleiter/-in 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187836&pbl=2&src=site_ict&nlc2=) - - Bern - -Kanton Bern (2. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187816&pbl=2&src=site_ict&nlc2=) - -[#### Senior AI Business Consultant 70–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187816&pbl=2&src=site_ict&nlc2=) - - Bern - -Post CH AG (2. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187831&pbl=2&src=site_ict&nlc2=) - -[#### (Senior) IT Audit Managerin oder Manager Interne Revision (80%–100%)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187831&pbl=2&src=site_ict&nlc2=) - - Zürich - -Schweizerische Nationalbank (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187826&pbl=2&src=site_ict&nlc2=) - -[#### IT Security Spezialist/-in 100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187826&pbl=2&src=site_ict&nlc2=) - - Zürich - -Kanton Zürich (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187821&pbl=2&src=site_ict&nlc2=) - -[#### Enterprise Architect für digitale Steuerlösungen 100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187821&pbl=2&src=site_ict&nlc2=) - - Zürich - -Kanton Zürich (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187810&pbl=2&src=site_ict&nlc2=) - -[#### IT-Support & Helpdesk Manager:in](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187810&pbl=2&src=site_ict&nlc2=) - - Aarau - -Leoba GmbH (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187804&pbl=2&src=site_ict&nlc2=) - -[#### Mitarbeiter/in Informatik Systemtechnik (100%)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187804&pbl=2&src=site_ict&nlc2=) - - Münsingen - -Gemeinde Münsingen (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187798&pbl=2&src=site_ict&nlc2=) - -[#### Applikationsmanager:in (mit Erfahrung in Softwareentwicklung) 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187798&pbl=2&src=site_ict&nlc2=) - - Winterthur - -ZHAW (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187793&pbl=2&src=site_ict&nlc2=) - -[#### Requirements to Deployment Manager Customer Touchpoints 70–100% (oder im Jobsharing)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187793&pbl=2&src=site_ict&nlc2=) - - Bern - -Post CH AG (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187537&pbl=2&src=site_ict&nlc2=) - -[#### Head of Sales + Marketing 80–100% (w/m/d)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187537&pbl=2&src=site_ict&nlc2=) - - Bern - -SmartIT Services AG (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187777&pbl=2&src=site_ict&nlc2=) - -[#### IT-Fachapplikationsspezialist/-in 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187777&pbl=2&src=site_ict&nlc2=) - - Zürich - -Kanton Zürich (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187771&pbl=2&src=site_ict&nlc2=) - -[#### Praktikum Content Creation 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187771&pbl=2&src=site_ict&nlc2=) - - Aarau - -Kanton Aargau (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187787&pbl=2&src=site_ict&nlc2=) - -[#### Head of Application Services | 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187787&pbl=2&src=site_ict&nlc2=) - - Burgdorf - -Ypsomed AG (30. September 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187782&pbl=2&src=site_ict&nlc2=) - -[#### SAP Application Engineer Supply Chain Management | 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187782&pbl=2&src=site_ict&nlc2=) - - Burgdorf - -Ypsomed AG (30. September 2025) - -[.jpg)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187749&pbl=2&src=site_ict&nlc2=) - -[#### Senior .NET Engineer, 80–100% (w/m/d)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187749&pbl=2&src=site_ict&nlc2=) - - Zürich - -Swiss Life (Schweiz) AG (30. September 2025) - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -People - -[### Sonepar Schweiz ernennt Raphael Maier zum neuen CEO 1. Oktober 2025](https://www.itreseller.ch/Artikel/104095/Sonepar_Schweiz_ernennt_Raphael_Maier_zum_neuen_CEO.html) - -[### AWS ernennt Stéphane Israël zum Leiter der Sovereign Cloud 1. Oktober 2025](https://www.itreseller.ch/Artikel/104090/AWS_ernennt_Stphane_Isral_zum_Leiter_der_Sovereign_Cloud.html) - -[### Paessler bekommt mit Jason Teichman neuen CEO 1. Oktober 2025](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html) - -[### Renato Petrillo wird CEO von Baggenstos 30. September 2025](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab 30. September 2025](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_021_www.itreseller.ch_heftarchiv_2025.txt b/test_web_content_20251002_205603/additional_link_021_www.itreseller.ch_heftarchiv_2025.txt deleted file mode 100644 index 887a16c1..00000000 --- a/test_web_content_20251002_205603/additional_link_021_www.itreseller.ch_heftarchiv_2025.txt +++ /dev/null @@ -1,194 +0,0 @@ -URL: https://www.itreseller.ch/heftarchiv/2025 -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Heftarchiv 2025 - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Heftarchiv 2025 -=============== - -< - -[2025](https://www.itreseller.ch/heftarchiv/2025)[2024](https://www.itreseller.ch/heftarchiv/2024)[2023](https://www.itreseller.ch/heftarchiv/2023)[2022](https://www.itreseller.ch/heftarchiv/2022)[2021](https://www.itreseller.ch/heftarchiv/2021)[2020](https://www.itreseller.ch/heftarchiv/2020)[2019](https://www.itreseller.ch/heftarchiv/2019)[2018](https://www.itreseller.ch/heftarchiv/2018)[2017](https://www.itreseller.ch/heftarchiv/2017)[2016](https://www.itreseller.ch/heftarchiv/2016)[2015](https://www.itreseller.ch/heftarchiv/2015)[2014](https://www.itreseller.ch/heftarchiv/2014)[2013](https://www.itreseller.ch/heftarchiv/2013)[2012](https://www.itreseller.ch/heftarchiv/2012)[2011](https://www.itreseller.ch/heftarchiv/2011)[2010](https://www.itreseller.ch/heftarchiv/2010)[2009](https://www.itreseller.ch/heftarchiv/2009) - -> - -X - -Heftarchiv-Premium-Zugriff --------------------------- - - Der Zugriff auf das Heftarchiv von "IT Reseller" wird exklusiv den Abonnenten der Print-Ausgabe zur Verfügung gestellt. - - Um eine beliebige Ausgabe herunterzuladen, geben Sie bitte den Premium-Zugangscode ein, den Sie auf der Editorial-Seite der aktuellen Ausgabe finden, und klicken Sie auf den Download-PDF-Button. - -**Premium-Zugangscode** - -Ausgabe 2025/10 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202510_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202510/inhaltsverzeichnis.html) - -Ausgabe 2025/09 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202509_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202509/inhaltsverzeichnis.html) - -Ausgabe 2025/7-8 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202507_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202507/inhaltsverzeichnis.html) - -Ausgabe 2025/06 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202506_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202506/inhaltsverzeichnis.html) - -Ausgabe 2025/05 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202505_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202505/inhaltsverzeichnis.html) - -Ausgabe 2025/04 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202504_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202504/inhaltsverzeichnis.html) - -Ausgabe 2025/03 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202503_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202503/inhaltsverzeichnis.html) - -Ausgabe 2025/1-2 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202501_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202501/inhaltsverzeichnis.html) - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) - - - -[](https://www.itreseller.ch/heftarchiv/2025)[](https://www.itreseller.ch/heftarchiv/2025) - -[](https://www.itreseller.ch/heftarchiv/2025) - -[](https://www.itreseller.ch/heftarchiv/2025) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_022_www.netzwoche.ch_news_2024-06-10_neuer-ceo-fuer-valueonmain-content.txt b/test_web_content_20251002_205603/additional_link_022_www.netzwoche.ch_news_2024-06-10_neuer-ceo-fuer-valueonmain-content.txt deleted file mode 100644 index 12bcb2e5..00000000 --- a/test_web_content_20251002_205603/additional_link_022_www.netzwoche.ch_news_2024-06-10_neuer-ceo-fuer-valueonmain-content.txt +++ /dev/null @@ -1,278 +0,0 @@ -URL: https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon#main-content -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Neuer CEO für Valueon | Netzwoche - -=============== -[Direkt zum Inhalt](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon#main-content) - -Header menu ------------ - -* [Kontakt](https://www.netzwoche.ch/contact) -* [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb) -* [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps) -* [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award) -* [E-Paper](http://epaper.netzwoche.ch/) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzmedien.ch/de/shop/ "Shop") -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [» Newsletter](https://www.netzwoche.ch/newsletteranmeldung) - -[](https://www.netzwoche.ch/ "Startseite") - -Donnerstag, 2. Oktober 2025 - -[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - -Main navigation ---------------- - -* [News](https://www.netzwoche.ch/news) - * [Live](https://www.netzwoche.ch/tags/live "Live") - * [Wild Card](https://www.netzwoche.ch/tags/wild-card "Wild Card") - * [Studien](https://www.netzwoche.ch/studien) - * [Meinungen](https://www.netzwoche.ch/meinungen) - * [Hands-on](https://www.netzwoche.ch/hands-on) - * [» alle News](https://www.netzwoche.ch/news) - -* [Storys](https://www.netzwoche.ch/storys) -* [Dossiers](https://www.netzwoche.ch/dossiers) - * [Best of Swiss Web](https://www.netzwoche.ch/dossier/best-of-swiss-web-2025 "Best of Swiss Web 2023") - * [Best of Swiss Apps](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2025 "Best of Swiss Apps") - * [Best of Swiss Software](https://www.netzwoche.ch/dossier/best-of-swiss-software-2024) - * [SAP S/4 Hana](https://www.netzwoche.ch/dossier/sap-s4-hana-was-bis-2025-zu-tun-ist) - * [Arbeitswelten](https://www.netzwoche.ch/dossier/management-career-arbeitswelten "Management & Career") - * [Gesundheit wird digital](https://www.netzwoche.ch/dossier/gesundheit-wird-digital "Gesundheit wird digital") - * [Blockchain](https://www.netzwoche.ch/dossier/blockchain) - * [EU-DSGVO](https://www.netzwoche.ch/eu-dsgvo) - * [XaaS, Managed Services & Co.](https://www.netzwoche.ch/dossier/cloud-und-managed-services "XaaS, Managed Services & Co.") - * [Digital Banking](https://www.netzwoche.ch/dossier/fintech-insurtech-digital-banking) - * [» alle Dossiers](https://www.netzwoche.ch/dossiers) - -* [Video](https://www.netzwoche.ch/dossier/die-redaktion-filmt) -* [Specials](https://www.netzwoche.ch/specials) - * [IT for Health](https://www.netzwoche.ch/dossier/it-for-health-22025 "IT for Health") - * [Artificial Intelligence](https://www.netzwoche.ch/dossier/artificial-intelligence-special-2025) - * [Finance 2030](https://www.netzwoche.ch/dossier/finance-2030-ausgabe-2025 "Finance 2030") - * [Swiss Digital Ranking](https://www.netzwoche.ch/dossier/swiss-digital-ranking-2025) - * [Cybersecurity](https://www.netzwoche.ch/dossier/cybersecurity-2025 "Cybersecurity") - * [Cloud & Managed Services](https://www.netzwoche.ch/dossier/cloud-managed-services-2025 "Cloud & Managed Services") - * [Fintech & Insurtech](https://www.netzwoche.ch/dossier/fintech-insurtech-2024 "Fintech & Insurtech") - * [IT for Gov](https://www.netzwoche.ch/dossier/it-for-gov-2024 "IT for Gov ") - * [Professional AV & Digital Signage](https://www.netzwoche.ch/dossier/professional-av-digital-signage-2023 "Digital Signage") - * [» alle Specials](https://www.netzwoche.ch/specials) - -* [Events](https://www.netzwoche.ch/events) - * [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb "Best of Swiss Web ") - * [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps "/bestofswissapps") - * [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award "Best of Swiss Software") - -* [Netzwitzig](https://www.netzwoche.ch/last-news) -* [E-Paper Login](https://epaper.netzwoche.ch/) - -[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - -Schlüsselwörter - -Webcode - -[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - -[News](https://www.netzwoche.ch/news) - -Dominic Largo -Neuer CEO für Valueon -===================== - -Mo 10.06.2024 - 13:10 Uhr - - von [Alexandra Hüsler](https://www.netzwoche.ch/user/20045) und yzu - -[](https://www.facebook.com/sharer/sharer.php?u=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://twitter.com/share?text=Neuer%20CEO%20f%C3%BCr%20Valueon&url=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](whatsapp://send?text=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](mailto:?subject=Neuer%20CEO%20f%C3%BCr%20Valueon&body=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.linkedin.com/shareArticle?mini=true&url=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - -Markus Mühlemann, Gründer, Inhaber und CEO von Valueon, übergibt die Geschäftsführung an Dominic Largo. Mühlemann steht dem Unternehmen weiterhin als Verwaltungsratsmitglied zur Verfügung. - -[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - - - -Markus Mühlemann (links) übergibt die Geschäftsführung und CEO-Aufgaben an Dominic Largo. (Source: zVg) - -Markus Mühlemann (links) übergibt die Geschäftsführung und CEO-Aufgaben an Dominic Largo. (Source: zVg) - -24 Jahre nach der Gründung als Project Competence und zwei Jahre nach dem Rebranding des Unternehmens 2022 zu Valueon tritt Markus Mühlemann als CEO ab. Wie das Unternehmen schreibt, übergibt der Gründer, Inhaber und CEO von Valueon im "richtigen, idealerweise selbstgewählten Moment" an seinen Nachfolger Dominic Largo. Markus Mühlemann wird weiterhin als Verwaltungsratsmitglied dem Unternehmen zur Verfügung stehen. - -"Es ging uns vor allem darum, eine Person zu finden, die künftig einen Mehrwert für das Team und so schlussendlich auch für unsere Kunden mitbringt", sagt Mühlemann. "Und dies umfasst nicht nur eine Verjüngung und eine starke Persönlichkeit, sondern auch eine gezielt auf die zukünftigen Herausforderungen ausgerichtete Mischung aus unternehmerischer Erfahrung, gelebter Fach- und Führungsexpertise sowie kreativer Innovationskraft." - -Largo ist neu zum Team gestossen.Der heute 48-Jährige zeichne sich vor allem durch klare Vision, Power, Pragmatismus, Foresight und Herzblut aus – so unter anderem als Marken- und Digital Leader bei Arosa Lenzerheide, als Country Manager und Head of Middle East bei der Porsche Design, als Markenstratege bei Hawas Schweiz und zuletzt als Founder & CEO der BottleButler. - -"Nachdem ich verschiedene Funktionen in unterschiedlichen Branchen innehatte und in der jüngsten Vergangenheit Unternehmen quasi von der ersten Idee aufgebaut habe, war es mein grosser Wunsch, als Nächstes eine konkrete Nachfolge anzutreten", sagt Largo. "Es freut mich daher sehr, dass dieser Wunsch mit der anstehenden Aufgabe in Erfüllung geht." - -_Übrigens: Seit 2020 ist das Unternehmen Partner des Digitalisierungsnetzwerks Parato, das KMUs bei der Digitalisierung berät und begleitet. [Mehr zum Netzwerk lesen Sie hier](https://www.netzwoche.ch/news/2020-08-21/parato-netzwerk-will-kmus-digital-fit-machen)._ - -Artikel teilen: - -[](https://www.facebook.com/sharer/sharer.php?u=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://twitter.com/share?text=Neuer%20CEO%20f%C3%BCr%20Valueon&url=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](whatsapp://send?text=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](mailto:?subject=Neuer%20CEO%20f%C3%BCr%20Valueon&body=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.linkedin.com/shareArticle?mini=true&url=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - -Zum Thema - -[Silas Schneider Abacus Business Solutions ernennt neuen CEO -------------------------------------------](https://www.netzwoche.ch/news/2024-06-05/abacus-business-solutions-ernennt-neuen-ceo) - -[Pascal Keller Inventx trennt sich von CEO ---------------------------](https://www.netzwoche.ch/news/2024-06-07/inventx-trennt-sich-von-ceo) - -[Andrea Orzati Quantencomputing-Unternehmen Zurich Instruments ernennt CEO -----------------------------------------------------------](https://www.netzwoche.ch/news/2024-05-30/quantencomputing-unternehmen-zurich-instruments-ernennt-ceo) - -[Ruben Llanes Schneider Electric ernennt neuen CEO für den Bereich Digital Grid -----------------------------------------------------------------](https://www.netzwoche.ch/news/2024-05-29/schneider-electric-ernennt-neuen-ceo-fuer-den-bereich-digital-grid) - -[ Transparenz, Verantwortung und Sicherheit Kalifornien beschliesst rechtlichen Rahmen für KI-Giganten ---------------------------------------------------------- 02.10.2025 - 11:00 Uhr](https://www.netzwoche.ch/news/2025-10-02/kalifornien-beschliesst-rechtlichen-rahmen-fuer-ki-giganten)[ European Cyber Security Month BACS gibt Tipps für Berufstätige, wie sie der Phishing-Falle entgehen --------------------------------------------------------------------- 02.10.2025 - 12:54 Uhr](https://www.netzwoche.ch/news/2025-10-02/bacs-gibt-tipps-fuer-berufstaetige-wie-sie-der-phishing-falle-entgehen)[ Zwischen Antivirenschutz und Wiederherstellungsdienst Google-Drive entwickelt neuen KI-gestützten Ransomware-Schutz ------------------------------------------------------------- 02.10.2025 - 12:37 Uhr](https://www.netzwoche.ch/news/2025-10-02/google-drive-entwickelt-neuen-ki-gestuetzten-ransomware-schutz)[ 35 Finalisten unter 136 Einreichungen Die Shortlist für Best of Swiss Apps 2025 steht fest ---------------------------------------------------- 02.10.2025 - 11:23 Uhr](https://www.netzwoche.ch/news/2025-10-02/die-shortlist-fuer-best-of-swiss-apps-2025-steht-fest)[ VMware und Speicher Warum Zürich fast 40 Millionen Franken für Informatik ausgibt ------------------------------------------------------------- 02.10.2025 - 12:24 Uhr](https://www.netzwoche.ch/news/2025-10-02/warum-zuerich-fast-40-millionen-franken-fuer-informatik-ausgibt)[ Wachstum in Nischensegmenten Projektormarkt sinkt im zweiten Quartal erneut ---------------------------------------------- 02.10.2025 - 12:12 Uhr](https://www.netzwoche.ch/news/2025-10-02/projektormarkt-sinkt-im-zweiten-quartal-erneut)[ SMS-Phishing Phisher ködern mit Migros-Cumulus-Punkten ----------------------------------------- 02.10.2025 - 15:12 Uhr](https://www.netzwoche.ch/news/2025-10-02/phisher-koedern-mit-migros-cumulus-punkten)[ Rote Panzer statt Reifenwechsel Hamilton, Verstappen und Co. beim Pilz-Cup ------------------------------------------ 02.10.2025 - 12:03 Uhr](https://www.netzwoche.ch/netzwitzig/2025-10-02/hamilton-verstappen-und-co-beim-pilz-cup)[ Registrieren, orchestrieren, kontrollieren Salesforce lanciert "Mulesoft Agent Fabric" zur Koordination von KI-Agenten --------------------------------------------------------------------------- 02.10.2025 - 17:17 Uhr](https://www.netzwoche.ch/news/2025-10-02/salesforce-lanciert-mulesoft-agent-fabric-zur-koordination-von-ki-agenten)[ Partner-Post Kaiko.ai entwickelt den klinischen KI-Assistenten ------------------------------------------------- 29.09.2025 - 08:00 Uhr](https://www.netzwoche.ch/news/2025-09-29/kaikoai-entwickelt-den-klinischen-ki-assistenten) - -Tags - -[Führung](https://www.netzwoche.ch/tags/fuehrung) - -[People](https://www.netzwoche.ch/tags/people) - -[ceo](https://www.netzwoche.ch/tags/ceo) - -[Köpfe](https://www.netzwoche.ch/tags/koepfe) - -Webcode - -U5Wh68hz - -Meist gelesen -------------- - -[» Mehr News](https://www.netzwoche.ch/news) - -1[ VMware und Speicher Warum Zürich fast 40 Millionen Franken für Informatik ausgibt ------------------------------------------------------------- 02.10.2025 - 12:24 Uhr](https://www.netzwoche.ch/news/2025-10-02/warum-zuerich-fast-40-millionen-franken-fuer-informatik-ausgibt) - -2[ 35 Finalisten unter 136 Einreichungen Die Shortlist für Best of Swiss Apps 2025 steht fest ---------------------------------------------------- 02.10.2025 - 11:23 Uhr](https://www.netzwoche.ch/news/2025-10-02/die-shortlist-fuer-best-of-swiss-apps-2025-steht-fest) - -3[ Daniel Anders Schaffhauser Kantonalbank findet neuen Leiter Operations & IT ------------------------------------------------------------- 02.10.2025 - 10:14 Uhr](https://www.netzwoche.ch/news/2025-10-02/schaffhauser-kantonalbank-findet-neuen-leiter-operations-it) - -* * * - -Events ------- - -[» Mehr Events](https://www.netzwoche.ch/events) - -[Online-Infoanlass MAS Software Engineering ------------------------------------------ 12. November 2025 - 18:15 bis 19:15 Online Premium Event](https://www.netzwoche.ch/node/104293) - -[Studerus Technology Forum 2025 ------------------------------ 13. November 2025 - 8:30 bis 18:00 Mövenpick Hotel Zürich-Regensdorf Premium Event](https://www.netzwoche.ch/node/104438) - -[Swiss Payment Forum ------------------- 17. November 2025 - 18. November 2025 8:00 bis 17:00 Zürich Premium Event](https://www.netzwoche.ch/node/103794) - -[Smart Energy Pary ----------------- 23. Oktober 2025 - 7:00 bis 23:00 Umwelt Arena Spreitenbach Premium Event](https://www.netzwoche.ch/node/104435) - -[Service Management Forum Schweiz, SMFS -------------------------------------- 30. Oktober 2025 - 8:00 bis 18:30 Hotel Radisson Blu, Zürich Flughafen Premium Event](https://www.netzwoche.ch/node/103381) - -[Bechtle Xperience ----------------- 30. Oktober 2025 - 12:00 bis 21:00 AHA Aarau Premium Event](https://www.netzwoche.ch/node/103922) - -[Data Community Conference 2025 ------------------------------ 05. November 2025 - 8:30 bis 18:30 Bern Premium Event](https://www.netzwoche.ch/node/104286) - -[Online-Infoanlass MAS Software Engineering ------------------------------------------ 12. November 2025 - 18:15 bis 19:15 Online Premium Event](https://www.netzwoche.ch/node/104293) - -[Studerus Technology Forum 2025 ------------------------------ 13. November 2025 - 8:30 bis 18:00 Mövenpick Hotel Zürich-Regensdorf Premium Event](https://www.netzwoche.ch/node/104438) - -[Swiss Payment Forum ------------------- 17. November 2025 - 18. November 2025 8:00 bis 17:00 Zürich Premium Event](https://www.netzwoche.ch/node/103794) - -[Smart Energy Pary ----------------- 23. Oktober 2025 - 7:00 bis 23:00 Umwelt Arena Spreitenbach Premium Event](https://www.netzwoche.ch/node/104435) - -[Service Management Forum Schweiz, SMFS -------------------------------------- 30. Oktober 2025 - 8:00 bis 18:30 Hotel Radisson Blu, Zürich Flughafen Premium Event](https://www.netzwoche.ch/node/103381) - -[Bechtle Xperience ----------------- 30. Oktober 2025 - 12:00 bis 21:00 AHA Aarau Premium Event](https://www.netzwoche.ch/node/103922) - -[Data Community Conference 2025 ------------------------------ 05. November 2025 - 8:30 bis 18:30 Bern Premium Event](https://www.netzwoche.ch/node/104286) - -[Online-Infoanlass MAS Software Engineering ------------------------------------------ 12. November 2025 - 18:15 bis 19:15 Online Premium Event](https://www.netzwoche.ch/node/104293) - -[Studerus Technology Forum 2025 ------------------------------ 13. November 2025 - 8:30 bis 18:00 Mövenpick Hotel Zürich-Regensdorf Premium Event](https://www.netzwoche.ch/node/104438) - -[Swiss Payment Forum ------------------- 17. November 2025 - 18. November 2025 8:00 bis 17:00 Zürich Premium Event](https://www.netzwoche.ch/node/103794) - -* 1 -* 2 -* 3 - -Previous Next - -* * * - -Dossiers --------- - -[» Mehr Dossiers](https://www.netzwoche.ch/dossiers) - -[ Dossier Fintech, Insurtech & Digital Banking ------------------------------------ 24.09.2025 - 09:24 Uhr](https://www.netzwoche.ch/dossier/fintech-insurtech-digital-banking) - -[ Dossier DevOps ------ 24.06.2025 - 11:15 Uhr](https://www.netzwoche.ch/dossier/dossier-devops) - -[ Dossier SAP S/4 Hana - Was bis 2027 zu tun ist -------------------------------------- 21.05.2025 - 10:55 Uhr](https://www.netzwoche.ch/dossier/sap-s4-hana-was-bis-2025-zu-tun-ist) - -Aktuelle Ausgabe ----------------- - -[Business-Software und KI in der Psychotherapie Netzwoche Nr. 10/2025 ---------------------](https://www.netzwoche.ch/dossier/netzwoche-nr-102025) - -[](https://www.netzwoche.ch/dossier/netzwoche-nr-102025) - -[](https://www.netzwoche.ch/news/2025-09-24/die-neue-netzwoche-und-das-it-for-health-sind-da) - -[Die neue Netzwoche und das IT for Health sind da](https://www.netzwoche.ch/news/2025-09-24/die-neue-netzwoche-und-das-it-for-health-sind-da) - -[](https://www.netzwoche.ch/news/2025-09-24/mit-weniger-vorankommen) - -[Mit weniger vorankommen](https://www.netzwoche.ch/news/2025-09-24/mit-weniger-vorankommen) - -[](https://www.netzwoche.ch/news/2025-09-24/ki-im-schweizer-erp-markt-automatisieren-assistieren-vorhersagen) - -[KI im Schweizer ERP-Markt – automatisieren, assistieren, vorhersagen](https://www.netzwoche.ch/news/2025-09-24/ki-im-schweizer-erp-markt-automatisieren-assistieren-vorhersagen) - -[» Mehr Beiträge](https://www.netzwoche.ch/dossier/netzwoche-nr-102025) - -Direkt in Ihren Briefkasten CHF 139.-[» Magazin Abonnieren](https://www.netzwoche.ch/abo)[» Zum shop](https://www.netzmedien.ch/de/shop/)[» Newsletter](https://www.netzwoche.ch/newsletteranmeldung) - -[](https://www.facebook.com/netzwoche)[](https://www.linkedin.com/company/18519911/)[](https://twitter.com/Netzwoche)[](https://www.xing.com/news/pages/netzwoche-919) - -Netzwoche ---------- - -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [Magazin](https://www.netzwoche.ch/magazin) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzwoche.ch/shop "Netzwoche Shop") - -Services --------- - -* [E-Paper Login](https://epaper.netzwoche.ch/) -* [Kontakt](https://www.netzwoche.ch/contact) -* [Event-Plus-Eintrag](https://www.netzwoche.ch/event-plus) -* [Login](https://www.netzwoche.ch/user/login) - -Partner-Websites ----------------- - -* [ICTjournal](http://www.ictjournal.ch/) -* [IT-Markt.ch](http://www.it-markt.ch/) -* [netzmedien.ch](http://www.netzmedien.ch/) -* [Swisscybersecurity.net](https://www.swisscybersecurity.net/) - -© Netzmedien AG 2025 --------------------- - -* [Impressum](https://www.netzwoche.ch/impressum) -* [AGB](https://www.netzwoche.ch/AGB) -* [Nutzungsbestimmungen](https://www.netzwoche.ch/nutzungsbestimmungen) -* [Datenschutzerklärung](https://www.netzwoche.ch/datenschutzerklaerung "Datenschutzerklärung") - -[Back to top](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon#top) - -Diese Website verwendet Cookies und Analysetools, um die Nutzerfreundlichkeit der Website zu verbessern und die Werbung von Netzmedien und Werbepartnern zu personalisieren. Weitere Infos: [Datenschutzerklärung](https://www.netzwoche.ch/datenschutzerklaerung) - -Ich stimme zu \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_023_www.netzwoche.ch_contact.txt b/test_web_content_20251002_205603/additional_link_023_www.netzwoche.ch_contact.txt deleted file mode 100644 index 88130f46..00000000 --- a/test_web_content_20251002_205603/additional_link_023_www.netzwoche.ch_contact.txt +++ /dev/null @@ -1,131 +0,0 @@ -URL: https://www.netzwoche.ch/contact -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Kontakt | Netzwoche - -=============== -[Direkt zum Inhalt](https://www.netzwoche.ch/contact#main-content) - -Header menu ------------ - -* [Kontakt](https://www.netzwoche.ch/contact) -* [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb) -* [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps) -* [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award) -* [E-Paper](http://epaper.netzwoche.ch/) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzmedien.ch/de/shop/ "Shop") -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [» Newsletter](https://www.netzwoche.ch/newsletteranmeldung) - -[](https://www.netzwoche.ch/ "Startseite") - -[](https://www.netzwoche.ch/contact) - -Main navigation ---------------- - -* [News](https://www.netzwoche.ch/news) - * [Live](https://www.netzwoche.ch/tags/live "Live") - * [Wild Card](https://www.netzwoche.ch/tags/wild-card "Wild Card") - * [Studien](https://www.netzwoche.ch/studien) - * [Meinungen](https://www.netzwoche.ch/meinungen) - * [Hands-on](https://www.netzwoche.ch/hands-on) - * [» alle News](https://www.netzwoche.ch/news) - -* [Storys](https://www.netzwoche.ch/storys) -* [Dossiers](https://www.netzwoche.ch/dossiers) - * [Best of Swiss Web](https://www.netzwoche.ch/dossier/best-of-swiss-web-2025 "Best of Swiss Web 2023") - * [Best of Swiss Apps](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2025 "Best of Swiss Apps") - * [Best of Swiss Software](https://www.netzwoche.ch/dossier/best-of-swiss-software-2024) - * [SAP S/4 Hana](https://www.netzwoche.ch/dossier/sap-s4-hana-was-bis-2025-zu-tun-ist) - * [Arbeitswelten](https://www.netzwoche.ch/dossier/management-career-arbeitswelten "Management & Career") - * [Gesundheit wird digital](https://www.netzwoche.ch/dossier/gesundheit-wird-digital "Gesundheit wird digital") - * [Blockchain](https://www.netzwoche.ch/dossier/blockchain) - * [EU-DSGVO](https://www.netzwoche.ch/eu-dsgvo) - * [XaaS, Managed Services & Co.](https://www.netzwoche.ch/dossier/cloud-und-managed-services "XaaS, Managed Services & Co.") - * [Digital Banking](https://www.netzwoche.ch/dossier/fintech-insurtech-digital-banking) - * [» alle Dossiers](https://www.netzwoche.ch/dossiers) - -* [Video](https://www.netzwoche.ch/dossier/die-redaktion-filmt) -* [Specials](https://www.netzwoche.ch/specials) - * [IT for Health](https://www.netzwoche.ch/dossier/it-for-health-22025 "IT for Health") - * [Artificial Intelligence](https://www.netzwoche.ch/dossier/artificial-intelligence-special-2025) - * [Finance 2030](https://www.netzwoche.ch/dossier/finance-2030-ausgabe-2025 "Finance 2030") - * [Swiss Digital Ranking](https://www.netzwoche.ch/dossier/swiss-digital-ranking-2025) - * [Cybersecurity](https://www.netzwoche.ch/dossier/cybersecurity-2025 "Cybersecurity") - * [Cloud & Managed Services](https://www.netzwoche.ch/dossier/cloud-managed-services-2025 "Cloud & Managed Services") - * [Fintech & Insurtech](https://www.netzwoche.ch/dossier/fintech-insurtech-2024 "Fintech & Insurtech") - * [IT for Gov](https://www.netzwoche.ch/dossier/it-for-gov-2024 "IT for Gov ") - * [Professional AV & Digital Signage](https://www.netzwoche.ch/dossier/professional-av-digital-signage-2023 "Digital Signage") - * [» alle Specials](https://www.netzwoche.ch/specials) - -* [Events](https://www.netzwoche.ch/events) - * [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb "Best of Swiss Web ") - * [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps "/bestofswissapps") - * [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award "Best of Swiss Software") - -* [Netzwitzig](https://www.netzwoche.ch/last-news) -* [E-Paper Login](https://epaper.netzwoche.ch/) - -[](https://www.netzwoche.ch/contact) - -Schlüsselwörter - -Webcode - -[](https://www.netzwoche.ch/contact) -Kontakt -======= - -Kontakt -======= - -Haben Sie Fragen zu unseren Dienstleistungen, Abos, Websites oder der Werbung. Suchen Sie einen Kontakt? - -Bitte beschreiben Sie uns Ihr Anliegen und wir werden Ihnen sobald wie möglich antworten. - -_**Bitte beachten Sie: Für Änderungswünsche bezüglich Ihres Abos benötigen wir zwingend Ihre Abo-Nummer. Vielen Dank!**_ - -* Pressemitteilungen und redaktionelle Anfragen:Bitte ausschliesslich an:[desk@netzmedien.ch](mailto:desk@netzmedien.ch) -* Abonnemente:Bitte ausschliesslich an:[abo@netzmedien.ch](mailto:abo@netzmedien.ch) -* Sales-Anfragen:Bitte ausschliesslich an:[sales@netzmedien.ch](mailto:sales@netzmedien.ch) - -[](https://www.facebook.com/netzwoche)[](https://www.linkedin.com/company/18519911/)[](https://twitter.com/Netzwoche)[](https://www.xing.com/news/pages/netzwoche-919) - -Netzwoche ---------- - -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [Magazin](https://www.netzwoche.ch/magazin) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzwoche.ch/shop "Netzwoche Shop") - -Services --------- - -* [E-Paper Login](https://epaper.netzwoche.ch/) -* [Kontakt](https://www.netzwoche.ch/contact) -* [Event-Plus-Eintrag](https://www.netzwoche.ch/event-plus) -* [Login](https://www.netzwoche.ch/user/login) - -Partner-Websites ----------------- - -* [ICTjournal](http://www.ictjournal.ch/) -* [IT-Markt.ch](http://www.it-markt.ch/) -* [netzmedien.ch](http://www.netzmedien.ch/) -* [Swisscybersecurity.net](https://www.swisscybersecurity.net/) - -© Netzmedien AG 2025 --------------------- - -* [Impressum](https://www.netzwoche.ch/impressum) -* [AGB](https://www.netzwoche.ch/AGB) -* [Nutzungsbestimmungen](https://www.netzwoche.ch/nutzungsbestimmungen) -* [Datenschutzerklärung](https://www.netzwoche.ch/datenschutzerklaerung "Datenschutzerklärung") - -[Back to top](https://www.netzwoche.ch/contact#top) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_024_www.netzwoche.ch_bestofswissweb.txt b/test_web_content_20251002_205603/additional_link_024_www.netzwoche.ch_bestofswissweb.txt deleted file mode 100644 index 6f0e4ebf..00000000 --- a/test_web_content_20251002_205603/additional_link_024_www.netzwoche.ch_bestofswissweb.txt +++ /dev/null @@ -1,260 +0,0 @@ -URL: https://www.netzwoche.ch/bestofswissweb -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -BEST OF SWISS WEB AWARD | Netzwoche - -=============== -[Direkt zum Inhalt](https://www.netzwoche.ch/bestofswissweb#main-content) - -Header menu ------------ - -* [Kontakt](https://www.netzwoche.ch/contact) -* [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb) -* [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps) -* [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award) -* [E-Paper](http://epaper.netzwoche.ch/) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzmedien.ch/de/shop/ "Shop") -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [» Newsletter](https://www.netzwoche.ch/newsletteranmeldung) - -[](https://www.netzwoche.ch/ "Startseite") - -[](https://www.netzwoche.ch/bestofswissweb) - -Main navigation ---------------- - -* [News](https://www.netzwoche.ch/news) - * [Live](https://www.netzwoche.ch/tags/live "Live") - * [Wild Card](https://www.netzwoche.ch/tags/wild-card "Wild Card") - * [Studien](https://www.netzwoche.ch/studien) - * [Meinungen](https://www.netzwoche.ch/meinungen) - * [Hands-on](https://www.netzwoche.ch/hands-on) - * [» alle News](https://www.netzwoche.ch/news) - -* [Storys](https://www.netzwoche.ch/storys) -* [Dossiers](https://www.netzwoche.ch/dossiers) - * [Best of Swiss Web](https://www.netzwoche.ch/dossier/best-of-swiss-web-2025 "Best of Swiss Web 2023") - * [Best of Swiss Apps](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2025 "Best of Swiss Apps") - * [Best of Swiss Software](https://www.netzwoche.ch/dossier/best-of-swiss-software-2024) - * [SAP S/4 Hana](https://www.netzwoche.ch/dossier/sap-s4-hana-was-bis-2025-zu-tun-ist) - * [Arbeitswelten](https://www.netzwoche.ch/dossier/management-career-arbeitswelten "Management & Career") - * [Gesundheit wird digital](https://www.netzwoche.ch/dossier/gesundheit-wird-digital "Gesundheit wird digital") - * [Blockchain](https://www.netzwoche.ch/dossier/blockchain) - * [EU-DSGVO](https://www.netzwoche.ch/eu-dsgvo) - * [XaaS, Managed Services & Co.](https://www.netzwoche.ch/dossier/cloud-und-managed-services "XaaS, Managed Services & Co.") - * [Digital Banking](https://www.netzwoche.ch/dossier/fintech-insurtech-digital-banking) - * [» alle Dossiers](https://www.netzwoche.ch/dossiers) - -* [Video](https://www.netzwoche.ch/dossier/die-redaktion-filmt) -* [Specials](https://www.netzwoche.ch/specials) - * [IT for Health](https://www.netzwoche.ch/dossier/it-for-health-22025 "IT for Health") - * [Artificial Intelligence](https://www.netzwoche.ch/dossier/artificial-intelligence-special-2025) - * [Finance 2030](https://www.netzwoche.ch/dossier/finance-2030-ausgabe-2025 "Finance 2030") - * [Swiss Digital Ranking](https://www.netzwoche.ch/dossier/swiss-digital-ranking-2025) - * [Cybersecurity](https://www.netzwoche.ch/dossier/cybersecurity-2025 "Cybersecurity") - * [Cloud & Managed Services](https://www.netzwoche.ch/dossier/cloud-managed-services-2025 "Cloud & Managed Services") - * [Fintech & Insurtech](https://www.netzwoche.ch/dossier/fintech-insurtech-2024 "Fintech & Insurtech") - * [IT for Gov](https://www.netzwoche.ch/dossier/it-for-gov-2024 "IT for Gov ") - * [Professional AV & Digital Signage](https://www.netzwoche.ch/dossier/professional-av-digital-signage-2023 "Digital Signage") - * [» alle Specials](https://www.netzwoche.ch/specials) - -* [Events](https://www.netzwoche.ch/events) - * [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb "Best of Swiss Web ") - * [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps "/bestofswissapps") - * [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award "Best of Swiss Software") - -* [Netzwitzig](https://www.netzwoche.ch/last-news) -* [E-Paper Login](https://epaper.netzwoche.ch/) - -[](https://www.netzwoche.ch/bestofswissweb) - -Schlüsselwörter - -Webcode - -[](https://www.netzwoche.ch/bestofswissweb) -BEST OF SWISS WEB AWARD -======================= - -BEST OF SWISS WEB AWARD -======================= - -Der älteste Web-Award Europas -============================= - -Der [Best of Swiss Web Award](https://www.bestofswissweb.swiss/) zeichnet jährlich jeweils im Frühling im Beisein von über 800 Gästen herausragende Digitalprojekte aus, die von Schweizer Unternehmen in Auftrag gegeben wurden oder für Schweizer Unternehmen entstanden sind und in denen der Einsatz von Webtechnologien eine Hauptrolle spielt. Mehr als 100 Jurorinnen und Juroren in rund 11 Wettbewerbskategorien tragen mit ihrer Fachkompetenz in einem kontrollierten und mehrstufigen Prozess dazu bei, dass jedes eingereichte Projekt die gebührende Beurteilung erfährt. - -Im Jahr 2001 gegründet, zählt Best of Swiss Web heute auch auf internationaler Ebene zu den etablierten und angesehenen Awards. Im Schweizer Kreativranking des Art Director Clubs zählt Best of Swiss Web mit dem Multiplikator 2. - -Seit 2018 wird der [Goldbach Crossmedia Award](https://goldbach.com/ch/de/home) im Rahmen der Best of Swiss Web Award Night verliehen. Prämiert werden hier die besten crossmedialen Kampagnen, die durch ihre innovative und intelligente Vernetzung sowie medienadäquate Umsetzung überzeugen. - -Integriert in die Best of Swiss Web Award Night wird seit 2020 auch die Auszeichnung [„Best of .swiss“](https://dot.swiss/category/bestof/) verliehen. An die beste Webpräsenz mit der Domain .swiss, die die Werte Zuverlässigkeit, Qualität und Innovation verkörpert, wird die exklusive Boje in eidgenössischem Rot vergeben. - -Historie -======== - -Best of Swiss Web 2025 ----------------------- - -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um Best of Swiss Web 2025](https://www.netzwoche.ch/dossier/best-of-swiss-web-2025) -* [Master-Kandidaten 2025](https://www.netzwoche.ch/news/2025-03-10/diese-projekte-treten-zur-wahl-des-master-of-swiss-web-2025-an) -* [Shortlist 2025](https://www.netzwoche.ch/news/2025-03-06/das-ist-die-shortlist-von-best-of-swiss-web-2025) -* [Bestenlisten 10/5 Jahre](https://www.netzwoche.ch/news/2025-04-30/das-sind-die-erfolgreichsten-webdienstleister-2025) -* [Kategorienranking](https://www.netzwoche.ch/news/2025-04-30/das-sind-die-top-webdienstleister-der-vergangenen-5-jahre) - -Best of Swiss Web 2024 ----------------------- - -* [Bestenlisten 10/5 Jahre](https://www.netzwoche.ch/news/2024-05-02/das-sind-die-erfolgreichsten-webdienstleister) -* [Kategorienranking](https://www.netzwoche.ch/news/2024-05-02/die-erfolgreichsten-webdienstleister-der-letzten-fuenf-jahre) -* [Master-Kandidaten 2024](https://www.netzwoche.ch/news/2024-03-12/das-sind-die-master-kandidaten-von-best-of-swiss-web-2024) -* [Shortlist 2024](https://www.netzwoche.ch/news/2024-03-07/diese-projekte-stehen-auf-der-shortlist-von-best-of-swiss-web-2024) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um Best of Swiss Web 2024](https://www.netzwoche.ch/dossier/best-of-swiss-web-2024) - -### Best of Swiss Web 2023 - -* [Schweizer Digital-Ranking 2023](https://www.netzwoche.ch/bosw/digitalranking-2023) -* [Bestenlisten 10/5 Jahre](https://www.netzwoche.ch/news/2023-06-07/das-sind-die-erfolgreichsten-webdienstleister) -* [Shortlist 2023](https://www.netzwoche.ch/news/2023-03-30/best-of-swiss-web-2023-diese-projekte-stehen-auf-der-shortlist) -* [Master-Kandidaten 2023](https://www.netzwoche.ch/news/2023-04-05/best-of-swiss-web-2023-das-sind-die-10-master-kandidaten) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um Best of Swiss Web 2023](https://www.netzwoche.ch/dossier/best-of-swiss-web-2023) - -### Best of Swiss Web 2022 - -* [Bestenlisten 10/5 Jahre](https://www.netzwoche.ch/news/2022-04-28/die-ewige-bestenliste-2022) -* [Schweizer Digital-Ranking 2022](https://www.netzwoche.ch/digitalranking-2022) -* [Master-Kandidaten 2022](https://www.netzwoche.ch/news/2022-03-10/das-sind-die-master-kandidaten-von-best-of-swiss-web-2022) -* [Shortlist 2022](https://www.netzwoche.ch/best-of-swiss-web-2022-shortlist) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um Best of Swiss Web 2022](https://www.netzwoche.ch/dossier/best-of-swiss-web-2022) - -### Best of Swiss Web 2021 - -* [Bestenlisten 10/5 Jahre](https://www.netzwoche.ch/news/2021-09-15/die-ewige-bestenliste-2021) -* [Schweizer Digital-Ranking 2021](https://www.netzwoche.ch/bosw/digitalranking-2021) -* [Master-Kandidaten 2021](https://www.netzwoche.ch/news/2021-03-17/das-sind-die-masterkandidaten-von-best-of-swiss-web-2021) -* [Shortlist 2021](https://www.netzwoche.ch/best-of-swiss-web-2021-shortlist) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um Best of Swiss Web 2021](https://www.netzwoche.ch/dossier/best-of-swiss-web-2021) - -### Best of Swiss Web 2020 - -* Master-Interview: [MySwitzerland.com](https://www.netzwoche.ch/news/2020-11-04/so-wurde-myswitzerlandcom-zum-master-of-swiss-web) -* [Bestenlisten 10/5 Jahre](https://www.netzwoche.ch/news/2020-11-04/die-bestenlisten-bosw-2020) -* [Schweizer Digital-Ranking 2020](https://www.netzwoche.ch/bosw/digitalranking-2020) -* [Master-Kandidaten 2020](https://www.netzwoche.ch/news/2020-03-05/das-rennen-um-den-master-of-swiss-web-2020-ist-eroeffnet) -* [Shortlist 2020](https://www.netzwoche.ch/best-of-swiss-web-2020-shortlist) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um Best of Swiss Web 2020](https://www.netzwoche.ch/dossier/best-of-swiss-web-2020) - -### Best of Swiss Web 2019 - -* [Umfrage](https://www.netzwoche.ch/news/2019-05-08/was-die-digitalbranche-2019-bewegt) -* Master-[grandbelfort Interviews](https://www.grandbelfort.fr/lasix.html):[Migros](https://www.netzwoche.ch/news/2019-05-08/ich-habe-meine-nachbarschaft-dank-zahlreicher-testlieferungen-kennengelernt)/ [Dreipol und Liip](https://www.netzwoche.ch/news/2019-05-08/das-verhaeltnis-von-bringern-und-bestellern-muss-passen) -* [Bestenlisten 10/5 Jahre](https://www.netzwoche.ch/bosw/bestenliste-2019) -* [Schweizer Digital-Ranking 2019](https://www.netzwoche.ch/bosw/digitalranking-2019) -* [Übersicht aller Best of Swiss Web Sieger 2019](https://www.netzwoche.ch/best-of-swiss-web-2019-alle-eingereichten-projekte-im-ueberblick) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um Best of Swiss Web 2019](https://www.netzwoche.ch/dossier/best-of-swiss-web-2019) -* [Shortlist 2019](https://www.netzwoche.ch/BOSW/best-of-swiss-web-2019-Shortlist) - -### Best of Swiss Web 2018 - -* [Übersicht aller Best of Swiss Web Sieger 2018](https://www.netzwoche.ch/best-of-swiss-web-2018-alle-eingereichten-projekte-im-ueberblick) -* [SBB holt sich Master of Best of Swiss Web 2018](https://www.netzwoche.ch/news/2018-04-25/wir-mussten-ueber-10000-inhaltsseiten-migrieren) -* [Die ewige Bestenliste - 2001-2018](https://www.netzwoche.ch/bosw/bestenliste-2018) -* [Schweizer Digital-Ranking 2018](https://www.netzwoche.ch/news/2018-04-25/das-grosse-schweizer-digital-ranking) -* [Werber des Jahres und Goldbach Crossmedia Award](https://www.netzwoche.ch/news/2018-04-13/das-rauschende-fest-der-web-und-werbebranche) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um Best of Swiss Web 2018](https://www.netzwoche.ch/dossier/best-of-swiss-web-2018) - -### Best of Swiss Web 2017 - -* [Übersicht aller Best of Swiss Web Sieger 2017](https://www.netzwoche.ch/bosw2017-results) -* [Ticketfrog.ch wird Master of Best of Swiss Web 2017](https://www.netzwoche.ch/news/2017-04-06/ticketfrogch-ist-master-of-swiss-web-2017) -* [Aktuelles Ranking der grössten Agenturen und Webdienstleister der Schweiz 2017](https://www.netzwoche.ch/news/2017-04-19/die-groessten-agenturen-und-webdienstleister-der-schweiz) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um Best of Swiss Web 2017](https://www.netzwoche.ch/dossier/best-of-swiss-web-2017) - -### Best of Swiss Web 2016 - -* [Übersicht aller Best of Swiss Web Sieger 2016](https://www.netzwoche.ch/bosw2016-results) -* [Post.ch ist Master of Best of Swiss Web 2016](https://www.netzwoche.ch/news/2016-04-08/postch-relaunch-ist-master-of-swiss-web-2016) -* [Das Dossier mit allen Hintergrundberichten und Nachrichten zum Best of Swiss Web 2016](https://www.netzwoche.ch/dossier/best-of-swiss-web-2016) - -### Best of Swiss Web 2015 - -* [Übersicht aller Best of Swiss Web Sieger 2015](https://www.netzwoche.ch/bosw2015-results) -* [Swiss.com holt sich Master of Best of Swiss Web 2015](https://www.netzwoche.ch/news/2016-03-28/swisscom-ist-master-of-swiss-web-2015) -* [Das Dossier mit allen Hintergrundberichten und Nachrichten zum Best of Swiss Web 2015](https://www.netzwoche.ch/dossier/best-of-swiss-web-2015) - -### Best of Swiss Web 2014 - -* [Übersicht aller Best of Swiss Web Sieger 2014](https://www.netzwoche.ch/news/2014-04-08/bosw-2014-alle-gewinner-im-ueberblick) -* [UBS holt sich Master of Best of Swiss Web 2014](https://www.netzwoche.ch/news/2015-03-30/die-ubs-holt-sich-den-master-of-swiss-web) -* [Das Dossier mit allen Hintergrundberichten und Nachrichten zum Best of Swiss Web 2014](https://www.netzwoche.ch/dossier/best-of-swiss-web-2014) - -### Best of Swiss Web 2001 – 2013 - -* [13 Jahre auf einen Blick: alle Master of Best of Swiss Web von 2001 bis 2013](https://www.netzwoche.ch/news/2014-03-25/13-jahre-schweizer-web-auf-einen-blick) -* [Das Dossier mit Hintergrundberichten und Nachrichten zum Best of Swiss Web von 2001 - 2013](https://www.netzwoche.ch/dossier/best-of-swiss-web-2001-2013) -* Die Preisträger des Best of Swiss Web Ehrenpreises 2017:[Doodle-Gründer Myke Näf und Paul Sevinç](https://www.netzwoche.ch/news/2017-04-04/doodle-gruender-erhalten-ehrenpreis-von-best-of-swiss-web) -* Der Preisträger des Best of Swiss Web Ehrenpreises 2016:[Urs Hölzle, Senior Vice President, Technical Infrastructure & Google Fellow](https://www.netzwoche.ch/news/2016-04-05/das-ist-der-bosw-ehrenpreistraeger) -* Die Preisträger des Best of Swiss Web Ehrenpreis 2015:[Digitec-Gründer Dobler, Herren und Teuteberg mit Prof. Dr. Thomas Rudolph von der Universität St. Gallen](https://www.netzwoche.ch/news/2015-03-30/best-of-swiss-web-2015-digitec-gruender-erhalten-ehrenpreis) -* Die Preisträgerin des Best of Swiss Web Ehrenpreises 2014: [Bea Knecht, Mitbegründerin von Zatoo](https://www.netzwoche.ch/news/2015-03-01/der-ehrenpreis-von-best-of-swiss-web-geht-an-bea-knecht) -* Die Preisträger des Best of Swiss Web Ehrenpreises der Jahre 2007 bis 2012 können Sie hier nachlesen:[Switch erhält Ehrenpreis des Best of Swiss Web Awards 2012](https://www.netzwoche.ch/news/2014-01-31/switch-erhaelt-den-diesjaehrigen-ehrenpreis-von-best-of-swiss-web) - -### **ORGANISATION** - -**Best of Swiss Web GmbH** - - Geschäftsführung: Dr. Heinrich Meyer (Netzmedien AG) - - Jury-Chairman: Christof Zogg - - Projektleitung: Seraina Frehner - - - -Die Trägerschaft obliegt der Best of Swiss Web GmbH. Die Best of Swiss Web GmbH ist eine Tochter der Netzmedien AG, dem führenden Fachmedienunternehmen für ICT, Web, Telekommunikation und Unterhaltungselektronik der Schweiz und Herausgeberin der «Netzwoche». - -[www.netzmedien.ch](https://www.netzmedien.ch/) - - - -[Swico](http://www.swico.ch/) ist der Wirtschaftsverband von über 500 etablierten Unternehmen und Startups der ICT- und der Online-Branche. Er vertritt deren Interessen in Politik, Wirtschaft und Gesellschaft. Die Aktivitäten von Swico dienen dazu, für die Mitglieder und ihre Mitarbeitenden wirtschaftlich, ideell oder kommunikativ Nutzen zu stiften. Die Swico-Mitglieder decken alle Wertschöpfungsstufen digitaler Geschäftsmodelle ab und umfassen insbesondere Hardware, Software, Hosting, IT-Services, Consulting, Digitalmarketing und -kommunikation. - -[](https://www.facebook.com/netzwoche)[](https://www.linkedin.com/company/18519911/)[](https://twitter.com/Netzwoche)[](https://www.xing.com/news/pages/netzwoche-919) - -Netzwoche ---------- - -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [Magazin](https://www.netzwoche.ch/magazin) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzwoche.ch/shop "Netzwoche Shop") - -Services --------- - -* [E-Paper Login](https://epaper.netzwoche.ch/) -* [Kontakt](https://www.netzwoche.ch/contact) -* [Event-Plus-Eintrag](https://www.netzwoche.ch/event-plus) -* [Login](https://www.netzwoche.ch/user/login) - -Partner-Websites ----------------- - -* [ICTjournal](http://www.ictjournal.ch/) -* [IT-Markt.ch](http://www.it-markt.ch/) -* [netzmedien.ch](http://www.netzmedien.ch/) -* [Swisscybersecurity.net](https://www.swisscybersecurity.net/) - -© Netzmedien AG 2025 --------------------- - -* [Impressum](https://www.netzwoche.ch/impressum) -* [AGB](https://www.netzwoche.ch/AGB) -* [Nutzungsbestimmungen](https://www.netzwoche.ch/nutzungsbestimmungen) -* [Datenschutzerklärung](https://www.netzwoche.ch/datenschutzerklaerung "Datenschutzerklärung") - -[Back to top](https://www.netzwoche.ch/bestofswissweb#top) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_025_www.netzwoche.ch_bestofswissapps.txt b/test_web_content_20251002_205603/additional_link_025_www.netzwoche.ch_bestofswissapps.txt deleted file mode 100644 index e71d79e0..00000000 --- a/test_web_content_20251002_205603/additional_link_025_www.netzwoche.ch_bestofswissapps.txt +++ /dev/null @@ -1,227 +0,0 @@ -URL: https://www.netzwoche.ch/bestofswissapps -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -BEST OF SWISS APPS AWARD | Netzwoche - -=============== -[Direkt zum Inhalt](https://www.netzwoche.ch/bestofswissapps#main-content) - -Header menu ------------ - -* [Kontakt](https://www.netzwoche.ch/contact) -* [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb) -* [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps) -* [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award) -* [E-Paper](http://epaper.netzwoche.ch/) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzmedien.ch/de/shop/ "Shop") -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [» Newsletter](https://www.netzwoche.ch/newsletteranmeldung) - -[](https://www.netzwoche.ch/ "Startseite") - -[](https://www.netzwoche.ch/bestofswissapps) - -Main navigation ---------------- - -* [News](https://www.netzwoche.ch/news) - * [Live](https://www.netzwoche.ch/tags/live "Live") - * [Wild Card](https://www.netzwoche.ch/tags/wild-card "Wild Card") - * [Studien](https://www.netzwoche.ch/studien) - * [Meinungen](https://www.netzwoche.ch/meinungen) - * [Hands-on](https://www.netzwoche.ch/hands-on) - * [» alle News](https://www.netzwoche.ch/news) - -* [Storys](https://www.netzwoche.ch/storys) -* [Dossiers](https://www.netzwoche.ch/dossiers) - * [Best of Swiss Web](https://www.netzwoche.ch/dossier/best-of-swiss-web-2025 "Best of Swiss Web 2023") - * [Best of Swiss Apps](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2025 "Best of Swiss Apps") - * [Best of Swiss Software](https://www.netzwoche.ch/dossier/best-of-swiss-software-2024) - * [SAP S/4 Hana](https://www.netzwoche.ch/dossier/sap-s4-hana-was-bis-2025-zu-tun-ist) - * [Arbeitswelten](https://www.netzwoche.ch/dossier/management-career-arbeitswelten "Management & Career") - * [Gesundheit wird digital](https://www.netzwoche.ch/dossier/gesundheit-wird-digital "Gesundheit wird digital") - * [Blockchain](https://www.netzwoche.ch/dossier/blockchain) - * [EU-DSGVO](https://www.netzwoche.ch/eu-dsgvo) - * [XaaS, Managed Services & Co.](https://www.netzwoche.ch/dossier/cloud-und-managed-services "XaaS, Managed Services & Co.") - * [Digital Banking](https://www.netzwoche.ch/dossier/fintech-insurtech-digital-banking) - * [» alle Dossiers](https://www.netzwoche.ch/dossiers) - -* [Video](https://www.netzwoche.ch/dossier/die-redaktion-filmt) -* [Specials](https://www.netzwoche.ch/specials) - * [IT for Health](https://www.netzwoche.ch/dossier/it-for-health-22025 "IT for Health") - * [Artificial Intelligence](https://www.netzwoche.ch/dossier/artificial-intelligence-special-2025) - * [Finance 2030](https://www.netzwoche.ch/dossier/finance-2030-ausgabe-2025 "Finance 2030") - * [Swiss Digital Ranking](https://www.netzwoche.ch/dossier/swiss-digital-ranking-2025) - * [Cybersecurity](https://www.netzwoche.ch/dossier/cybersecurity-2025 "Cybersecurity") - * [Cloud & Managed Services](https://www.netzwoche.ch/dossier/cloud-managed-services-2025 "Cloud & Managed Services") - * [Fintech & Insurtech](https://www.netzwoche.ch/dossier/fintech-insurtech-2024 "Fintech & Insurtech") - * [IT for Gov](https://www.netzwoche.ch/dossier/it-for-gov-2024 "IT for Gov ") - * [Professional AV & Digital Signage](https://www.netzwoche.ch/dossier/professional-av-digital-signage-2023 "Digital Signage") - * [» alle Specials](https://www.netzwoche.ch/specials) - -* [Events](https://www.netzwoche.ch/events) - * [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb "Best of Swiss Web ") - * [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps "/bestofswissapps") - * [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award "Best of Swiss Software") - -* [Netzwitzig](https://www.netzwoche.ch/last-news) -* [E-Paper Login](https://epaper.netzwoche.ch/) - -[](https://www.netzwoche.ch/bestofswissapps) - -Schlüsselwörter - -Webcode - -[](https://www.netzwoche.ch/bestofswissapps) -BEST OF SWISS APPS AWARD -======================== - -BEST OF SWISS APPS AWARD -======================== - -Die besten Apps und Mobile-Software-Projekte der Schweiz -======================================================== - -Der [Best of Swiss Apps Award](https://www.bestofswissapps.ch/) zeichnet jährlich jeweils im Herbst vor rund 330 Gästen herausragende Apps, Software- und Mobile-Projekte aus, die von Schweizer Unternehmen in Auftrag gegeben oder für Schweizer Unternehmen entwickelt worden sind. Damit setzt Best of Swiss Apps Qualitätsstandards und stellt der jungen App- und Mobile-Branche eine Publizitäts- und Networking-Plattform zur Verfügung. Rund 50 Jurorinnen und Juroren begutachten in einem mehrstufigen Prozess die eingereichten Projekte aus rund zehn Wettbewerbskategorien. - -Im Jahr 2013 zum ersten Mal verliehen, profitierte Best of Swiss Apps vom Know-how und dem Netzwerk des Best of Swiss Web Awards, der bereits seit 2001 etabliert ist. Beide Awards zählen heute auch auf internationaler Ebene zu den etablierten Wettbewerben, im Schweizer Kreativranking des Art Director Clubs zählen beide mit dem Multiplikator 2. - -Zum ersten Mal im 2023 wird der „hack an app“-Award im Rahmen der Best of Swiss Apps Award Night verliehen. Der IT-Dienstleister ti&m zeichnet die beste App von Kindern zwischen 11 und 14 Jahren aus, die in viertägigen Kursen mithilfe von ti&m-Mitarbeitenden entwickelt wurden. - -Historie -======== - -### Best of Swiss Apps 2024 - -* [Die Master-Kandidaten von Best of Swiss Apps 2024](https://www.netzwoche.ch/news/2024-10-10/diese-apps-stehen-zur-master-wahl) -* [Die Shortlist von Best of Swiss Apps 2024](https://www.netzwoche.ch/news/2024-10-03/best-of-swiss-apps-2024-diesen-apps-winken-bronze-silber-oder-gold) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um den Best of Swiss Apps Award 2024](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2024) - -### Best of Swiss Apps 2023 - -* [Der Master und alle Goldgewinner 2023](https://www.netzwoche.ch/news/2023-10-26/mobility-carsharing-ist-master-of-swiss-apps) -* [Die Master-Kandidaten von Best of Swiss Apps 2023](https://www.netzwoche.ch/news/2023-09-26/das-rennen-um-den-master-of-swiss-apps-2023-ist-eroeffnet) -* [Die Shortlist von Best of Swiss Apps 2023](https://www.netzwoche.ch/news/2023-09-21/best-of-swiss-apps-2023-diese-app-projekte-schaffen-den-sprung-auf-die-shortlist) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um den Best of Swiss Apps Award 2023](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2023) - -### Best of Swiss Apps 2022 - -* [Die Master-Kandidaten von Best of Swiss Apps 2022](https://www.netzwoche.ch/news/2022-10-12/das-sind-die-master-kandidaten-von-best-of-swiss-apps-2022) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um den Best of Swiss Apps Award 2022](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2022) - -### Best of Swiss Apps 2021 - -* [Shortlist Best of Swiss Apps 2021](https://www.netzwoche.ch/best-of-swiss-apps-2021-shortlist) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um den Best of Swiss Apps Award 2021](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2021) - -### Best of Swiss Apps 2020 - -* [Übersicht aller Best of Swiss Apps Sieger 2020](https://www.netzwoche.ch/die-erfolgreichsten-app-dienstleister-2020) -* [Die erfolgreichsten App-Dienstleister 2013-2020](https://www.netzwoche.ch/die-erfolgreichsten-app-dienstleister-2020) -* [Shortlist Best of Swiss Apps 2020](https://www.netzwoche.ch/best-of-swiss-apps-2020-shortlist) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um den Best of Swiss Apps Award 2020](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2020) - -### Best of Swiss Apps 2019 - -* [Übersicht aller Best of Swiss Apps Sieger 2019](https://www.netzwoche.ch/best-of-swiss-apps-2019-alle-eingereichten-projekte-im-ueberblick) -* [Die erfolgreichsten App-Dienstleister 2013-2019](https://www.netzwoche.ch/bosa/bestenliste-2019) -* [Shortlist Best of Swiss Apps 2019](https://www.netzwoche.ch/best-of-swiss-apps-2019-shortlist) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um den Best of Swiss Apps Award 2019](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2019) - -### Best of Swiss Apps 2018 - -* [Übersicht aller Best of Swiss Apps Sieger 2018](https://www.netzwoche.ch/projekte-bosa2018) -* [Die erfolgreichsten App-Dienstleister 2013-2018](https://www.netzwoche.ch/bosa/bestenliste-2018) -* [Amigos ist Master of Best of Swiss Apps 2018](https://www.netzwoche.ch/news/2018-11-07/amigos-ist-master-of-swiss-apps-2018) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um den Best of Swiss Apps Award 2018](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2018) - -### Best of Swiss Apps 2017 - -* [Übersicht aller Best of Swiss Apps Sieger 2017](https://www.netzwoche.ch/projekte-bosa2017) -* [Die erfolgreichsten App-Dienstleister 2013-2017](https://www.netzwoche.ch/bosa/bestenliste-2017) -* ["Go! So einfach geht Taxi" ist Master of Best of Swiss Apps 2017](https://www.netzwoche.ch/news/2017-11-15/go-so-einfach-geht-taxi-ist-master-of-swiss-apps-2017) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um den Best of Swiss Apps Award 2017](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2017) - -### Best of Swiss Apps 2016 - -* [Übersicht aller Best of Swiss Apps Sieger 2016](https://www.netzwoche.ch/bosa2016-results) -* [Die erfolgreichsten App-Dienstleister 2013-2016](https://www.netzwoche.ch/news/2016-12-07/die-erfolgreichsten-app-agenturen) -* [SBB Mobile vNext ist Master of Best of Swiss Apps 2016](https://www.netzwoche.ch/news/2016-11-16/sbb-mobile-vnext-ist-master-of-swiss-apps-2016) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um den Best of Swiss Apps Award 2016](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2016) - -### Best of Swiss Apps 2015 - -* [Übersicht aller Best of Swiss Apps Sieger 2015](https://www.netzwoche.ch/news/2015-11-25/die-besten-apps-des-jahrgangs-2015) -* [Paymit ist Master of Best of Swiss Apps 2015](https://www.netzwoche.ch/news/2015-11-23/paymit-ist-master-of-swiss-apps) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um den Best of Swiss Apps Award 2015](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2015) - -### Best of Swiss Apps 2014 - -* [Übersicht aller Best of Swiss Apps Sieger 2014](https://www.netzwoche.ch/news/2014-11-20/alle-gewinner-von-best-of-swiss-apps-2014) -* [Sumup von UBS ist Master of Best of Swiss Apps 2014](https://www.netzwoche.ch/news/2015-03-01/sumup-von-ubs-ist-master-of-swiss-apps-2014) -* [Dossier mit Hintergrundberichten und Nachrichten rund um den Best of Swiss Apps Award 2014](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2014) - -### Best of Swiss Apps 2013 - -* [Liquid Sketch ist Master des ersten Best of Swiss Apps Awards 2013](https://www.netzwoche.ch/news/2015-03-01/liquid-sketch-ist-master-of-swiss-apps-2013) - -### **ORGANISATION** - -**Best of Swiss Web GmbH** - - Geschäftsführung: Dr. Heinrich Meyer (Netzmedien AG) - - Jury-Chairman: Christof Zogg - - Projektleitung: Seraina Frehner - - - -Die Trägerschaft obliegt der Best of Swiss Web GmbH. Die Best of Swiss Web GmbH ist eine Tochter der Netzmedien AG, dem führenden Fachmedienunternehmen für ICT, Web, Telekommunikation und Unterhaltungselektronik der Schweiz und Herausgeberin der "Netzwoche". - -[www.netzmedien.ch](https://www.netzmedien.ch/) - - - -[Swico](http://www.swico.ch/)ist der Wirtschaftsverband von über 500 etablierten Unternehmen und Startups der ICT- und der Online-Branche. Er vertritt deren Interessen in Politik, Wirtschaft und Gesellschaft. Die Aktivitäten von Swico dienen dazu, für die Mitglieder und ihre Mitarbeitenden wirtschaftlich, ideell oder kommunikativ Nutzen zu stiften. Die Swico-Mitglieder decken alle Wertschöpfungsstufen digitaler Geschäftsmodelle ab und umfassen insbesondere Hardware, Software, Hosting, IT-Services, Consulting, Digitalmarketing und -kommunikation. - -[](https://www.facebook.com/netzwoche)[](https://www.linkedin.com/company/18519911/)[](https://twitter.com/Netzwoche)[](https://www.xing.com/news/pages/netzwoche-919) - -Netzwoche ---------- - -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [Magazin](https://www.netzwoche.ch/magazin) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzwoche.ch/shop "Netzwoche Shop") - -Services --------- - -* [E-Paper Login](https://epaper.netzwoche.ch/) -* [Kontakt](https://www.netzwoche.ch/contact) -* [Event-Plus-Eintrag](https://www.netzwoche.ch/event-plus) -* [Login](https://www.netzwoche.ch/user/login) - -Partner-Websites ----------------- - -* [ICTjournal](http://www.ictjournal.ch/) -* [IT-Markt.ch](http://www.it-markt.ch/) -* [netzmedien.ch](http://www.netzmedien.ch/) -* [Swisscybersecurity.net](https://www.swisscybersecurity.net/) - -© Netzmedien AG 2025 --------------------- - -* [Impressum](https://www.netzwoche.ch/impressum) -* [AGB](https://www.netzwoche.ch/AGB) -* [Nutzungsbestimmungen](https://www.netzwoche.ch/nutzungsbestimmungen) -* [Datenschutzerklärung](https://www.netzwoche.ch/datenschutzerklaerung "Datenschutzerklärung") - -[Back to top](https://www.netzwoche.ch/bestofswissapps#top) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_026_www.netzwoche.ch_best-of-swiss-software-award.txt b/test_web_content_20251002_205603/additional_link_026_www.netzwoche.ch_best-of-swiss-software-award.txt deleted file mode 100644 index 7c637ec7..00000000 --- a/test_web_content_20251002_205603/additional_link_026_www.netzwoche.ch_best-of-swiss-software-award.txt +++ /dev/null @@ -1,167 +0,0 @@ -URL: https://www.netzwoche.ch/best-of-swiss-software-award -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -BEST OF SWISS SOFTWARE AWARD | Netzwoche - -=============== -[Direkt zum Inhalt](https://www.netzwoche.ch/best-of-swiss-software-award#main-content) - -Header menu ------------ - -* [Kontakt](https://www.netzwoche.ch/contact) -* [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb) -* [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps) -* [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award) -* [E-Paper](http://epaper.netzwoche.ch/) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzmedien.ch/de/shop/ "Shop") -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [» Newsletter](https://www.netzwoche.ch/newsletteranmeldung) - -[](https://www.netzwoche.ch/ "Startseite") - -[](https://www.netzwoche.ch/best-of-swiss-software-award) - -Main navigation ---------------- - -* [News](https://www.netzwoche.ch/news) - * [Live](https://www.netzwoche.ch/tags/live "Live") - * [Wild Card](https://www.netzwoche.ch/tags/wild-card "Wild Card") - * [Studien](https://www.netzwoche.ch/studien) - * [Meinungen](https://www.netzwoche.ch/meinungen) - * [Hands-on](https://www.netzwoche.ch/hands-on) - * [» alle News](https://www.netzwoche.ch/news) - -* [Storys](https://www.netzwoche.ch/storys) -* [Dossiers](https://www.netzwoche.ch/dossiers) - * [Best of Swiss Web](https://www.netzwoche.ch/dossier/best-of-swiss-web-2025 "Best of Swiss Web 2023") - * [Best of Swiss Apps](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2025 "Best of Swiss Apps") - * [Best of Swiss Software](https://www.netzwoche.ch/dossier/best-of-swiss-software-2024) - * [SAP S/4 Hana](https://www.netzwoche.ch/dossier/sap-s4-hana-was-bis-2025-zu-tun-ist) - * [Arbeitswelten](https://www.netzwoche.ch/dossier/management-career-arbeitswelten "Management & Career") - * [Gesundheit wird digital](https://www.netzwoche.ch/dossier/gesundheit-wird-digital "Gesundheit wird digital") - * [Blockchain](https://www.netzwoche.ch/dossier/blockchain) - * [EU-DSGVO](https://www.netzwoche.ch/eu-dsgvo) - * [XaaS, Managed Services & Co.](https://www.netzwoche.ch/dossier/cloud-und-managed-services "XaaS, Managed Services & Co.") - * [Digital Banking](https://www.netzwoche.ch/dossier/fintech-insurtech-digital-banking) - * [» alle Dossiers](https://www.netzwoche.ch/dossiers) - -* [Video](https://www.netzwoche.ch/dossier/die-redaktion-filmt) -* [Specials](https://www.netzwoche.ch/specials) - * [IT for Health](https://www.netzwoche.ch/dossier/it-for-health-22025 "IT for Health") - * [Artificial Intelligence](https://www.netzwoche.ch/dossier/artificial-intelligence-special-2025) - * [Finance 2030](https://www.netzwoche.ch/dossier/finance-2030-ausgabe-2025 "Finance 2030") - * [Swiss Digital Ranking](https://www.netzwoche.ch/dossier/swiss-digital-ranking-2025) - * [Cybersecurity](https://www.netzwoche.ch/dossier/cybersecurity-2025 "Cybersecurity") - * [Cloud & Managed Services](https://www.netzwoche.ch/dossier/cloud-managed-services-2025 "Cloud & Managed Services") - * [Fintech & Insurtech](https://www.netzwoche.ch/dossier/fintech-insurtech-2024 "Fintech & Insurtech") - * [IT for Gov](https://www.netzwoche.ch/dossier/it-for-gov-2024 "IT for Gov ") - * [Professional AV & Digital Signage](https://www.netzwoche.ch/dossier/professional-av-digital-signage-2023 "Digital Signage") - * [» alle Specials](https://www.netzwoche.ch/specials) - -* [Events](https://www.netzwoche.ch/events) - * [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb "Best of Swiss Web ") - * [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps "/bestofswissapps") - * [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award "Best of Swiss Software") - -* [Netzwitzig](https://www.netzwoche.ch/last-news) -* [E-Paper Login](https://epaper.netzwoche.ch/) - -[](https://www.netzwoche.ch/best-of-swiss-software-award) - -Schlüsselwörter - -Webcode - -[](https://www.netzwoche.ch/best-of-swiss-software-award) -BEST OF SWISS SOFTWARE AWARD -============================ - -BEST OF SWISS SOFTWARE AWARD -============================ - -Der neue Award von den Machern von Best of Swiss Web und Best of Swiss Apps -=========================================================================== - -Der "[Best of Swiss Software](https://www.bestofswisssoftware.ch/)"-Award zeichnet im Jahr 2024 zum ersten Mal herausragende Individualsoftware- und Systemintegrationsprojekte aus. Vier Kategorien bieten Schweizer ICT-Dienstleistern die Möglichkeit, ihr Können unter Beweis zu stellen und sich mit den Besten der Branche zu messen. Zum Award zugelassen sind alle Projekte, die von oder für Schweizer Unternehmen entwickelt bzw. umgesetzt wurden. - -### Projektfokus und zweistufiger Jurierungsprozess als Alleinstellungsmerkmal - -Sein alleiniger Fokus auf Projekte und die Konzeption und Qualität des Jurierungsprozesses verschaffen dem "Best of Swiss Software"-Award ein Alleinstellungsmerkmal in der Schweizer Award-Landschaft. In einem zweistufigen Jurierungsprozess werden die eingereichten Projekte sorgfältig auf ihre Qualität geprüft: - -* In einem ersten Schritt bewertet das Institut für Wirtschaftsinformatik der Universität Bern im Rahmen eines Assessments alle eingereichten Projekte. Pro Award-Kategorie werden maximal 12 Projekte für die nächste Stufe nominiert. -* Während einer Q&A-Session präsentieren die Einreicher am Jurytag vor der Kategorienjury ihre nominierten Projekte. Die vier Fachjurys, bestehend aus renommierten Expertinnen und Experten aus der ICT-Branche und Vertretern wichtiger Auftraggeber, bewerten die Präsentationen und bestimmen in jeder Kategorie die Siegerprojekte. Verliehen werden pro Kategorie: 1x Gold, 1x Silber und 1x Bronze. - -### Award Night und Return on Investment - -Die Award Night findet am 19. November 2024 im Rahmen eines festlichen Gala-Dinners in Kombination mit dem "Best of Swiss Apps"-Award im Kongresshaus Zürich statt. Projekte von Auftragnehmern, die für den Award nominiert sind, haben die exklusive Gelegenheit, zusammen mit ihren Auftraggebern einer der zwölf Kategorien-Trophäen zu gewinnen. Diese emotionalen Momente im Beisein der Auftraggeber, der Fachjury, die Exposition in den Fachmedien und der vielfältige Content für Owned-Media-Kanäle machen Best of Swiss Software zum einzigartigen Instrument für Marketing und Kommunikation. - -* * * - -Best of Swiss Software 2024 -=========================== - -* [Die Nominiertenliste 2024](https://www.netzwoche.ch/news/2024-09-19/diese-projekte-schaffen-es-auf-die-nominiertenliste-von-best-of-swiss-software-2024) -* [Dossier mit allen Hintergrundberichten und Nachrichten rund um Best of Swiss Software 2024](https://www.netzwoche.ch/dossier/best-of-swiss-software-2024) - -* * * - -### **ORGANISATION** - -**Best of Swiss Web GmbH** - - Geschäftsführung: Dr. Heinrich Meyer (Netzmedien AG) - - Jury-Chairman: Christof Zogg - - Projektleitung: Seraina Frehner - - - -Die Trägerschaft obliegt der Best of Swiss Web GmbH. Die Best of Swiss Web GmbH ist eine Tochter der Netzmedien AG, dem führenden Fachmedienunternehmen für ICT, Web, Telekommunikation und Unterhaltungselektronik der Schweiz und Herausgeberin der «Netzwoche». - -[www.netzmedien.ch](https://www.netzmedien.ch/) - - - -[Swico](http://www.swico.ch/) ist der Wirtschaftsverband von über 500 etablierten Unternehmen und Startups der ICT- und der Online-Branche. Er vertritt deren Interessen in Politik, Wirtschaft und Gesellschaft. Die Aktivitäten von Swico dienen dazu, für die Mitglieder und ihre Mitarbeitenden wirtschaftlich, ideell oder kommunikativ Nutzen zu stiften. Die Swico-Mitglieder decken alle Wertschöpfungsstufen digitaler Geschäftsmodelle ab und umfassen insbesondere Hardware, Software, Hosting, IT-Services, Consulting, Digitalmarketing und -kommunikation. - -[](https://www.facebook.com/netzwoche)[](https://www.linkedin.com/company/18519911/)[](https://twitter.com/Netzwoche)[](https://www.xing.com/news/pages/netzwoche-919) - -Netzwoche ---------- - -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [Magazin](https://www.netzwoche.ch/magazin) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzwoche.ch/shop "Netzwoche Shop") - -Services --------- - -* [E-Paper Login](https://epaper.netzwoche.ch/) -* [Kontakt](https://www.netzwoche.ch/contact) -* [Event-Plus-Eintrag](https://www.netzwoche.ch/event-plus) -* [Login](https://www.netzwoche.ch/user/login) - -Partner-Websites ----------------- - -* [ICTjournal](http://www.ictjournal.ch/) -* [IT-Markt.ch](http://www.it-markt.ch/) -* [netzmedien.ch](http://www.netzmedien.ch/) -* [Swisscybersecurity.net](https://www.swisscybersecurity.net/) - -© Netzmedien AG 2025 --------------------- - -* [Impressum](https://www.netzwoche.ch/impressum) -* [AGB](https://www.netzwoche.ch/AGB) -* [Nutzungsbestimmungen](https://www.netzwoche.ch/nutzungsbestimmungen) -* [Datenschutzerklärung](https://www.netzwoche.ch/datenschutzerklaerung "Datenschutzerklärung") - -[Back to top](https://www.netzwoche.ch/best-of-swiss-software-award#top) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_027_www.netzwoche.ch_abo.txt b/test_web_content_20251002_205603/additional_link_027_www.netzwoche.ch_abo.txt deleted file mode 100644 index 80b48889..00000000 --- a/test_web_content_20251002_205603/additional_link_027_www.netzwoche.ch_abo.txt +++ /dev/null @@ -1,190 +0,0 @@ -URL: https://www.netzwoche.ch/abo -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Magazine abonnieren | Netzwoche - -=============== -[Direkt zum Inhalt](https://www.netzwoche.ch/abo#main-content) - -Header menu ------------ - -* [Kontakt](https://www.netzwoche.ch/contact) -* [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb) -* [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps) -* [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award) -* [E-Paper](http://epaper.netzwoche.ch/) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzmedien.ch/de/shop/ "Shop") -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [» Newsletter](https://www.netzwoche.ch/newsletteranmeldung) - -[](https://www.netzwoche.ch/ "Startseite") - -Donnerstag, 2. Oktober 2025 - -[](https://www.netzwoche.ch/abo) - -Main navigation ---------------- - -* [News](https://www.netzwoche.ch/news) - * [Live](https://www.netzwoche.ch/tags/live "Live") - * [Wild Card](https://www.netzwoche.ch/tags/wild-card "Wild Card") - * [Studien](https://www.netzwoche.ch/studien) - * [Meinungen](https://www.netzwoche.ch/meinungen) - * [Hands-on](https://www.netzwoche.ch/hands-on) - * [» alle News](https://www.netzwoche.ch/news) - -* [Storys](https://www.netzwoche.ch/storys) -* [Dossiers](https://www.netzwoche.ch/dossiers) - * [Best of Swiss Web](https://www.netzwoche.ch/dossier/best-of-swiss-web-2025 "Best of Swiss Web 2023") - * [Best of Swiss Apps](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2025 "Best of Swiss Apps") - * [Best of Swiss Software](https://www.netzwoche.ch/dossier/best-of-swiss-software-2024) - * [SAP S/4 Hana](https://www.netzwoche.ch/dossier/sap-s4-hana-was-bis-2025-zu-tun-ist) - * [Arbeitswelten](https://www.netzwoche.ch/dossier/management-career-arbeitswelten "Management & Career") - * [Gesundheit wird digital](https://www.netzwoche.ch/dossier/gesundheit-wird-digital "Gesundheit wird digital") - * [Blockchain](https://www.netzwoche.ch/dossier/blockchain) - * [EU-DSGVO](https://www.netzwoche.ch/eu-dsgvo) - * [XaaS, Managed Services & Co.](https://www.netzwoche.ch/dossier/cloud-und-managed-services "XaaS, Managed Services & Co.") - * [Digital Banking](https://www.netzwoche.ch/dossier/fintech-insurtech-digital-banking) - * [» alle Dossiers](https://www.netzwoche.ch/dossiers) - -* [Video](https://www.netzwoche.ch/dossier/die-redaktion-filmt) -* [Specials](https://www.netzwoche.ch/specials) - * [IT for Health](https://www.netzwoche.ch/dossier/it-for-health-22025 "IT for Health") - * [Artificial Intelligence](https://www.netzwoche.ch/dossier/artificial-intelligence-special-2025) - * [Finance 2030](https://www.netzwoche.ch/dossier/finance-2030-ausgabe-2025 "Finance 2030") - * [Swiss Digital Ranking](https://www.netzwoche.ch/dossier/swiss-digital-ranking-2025) - * [Cybersecurity](https://www.netzwoche.ch/dossier/cybersecurity-2025 "Cybersecurity") - * [Cloud & Managed Services](https://www.netzwoche.ch/dossier/cloud-managed-services-2025 "Cloud & Managed Services") - * [Fintech & Insurtech](https://www.netzwoche.ch/dossier/fintech-insurtech-2024 "Fintech & Insurtech") - * [IT for Gov](https://www.netzwoche.ch/dossier/it-for-gov-2024 "IT for Gov ") - * [Professional AV & Digital Signage](https://www.netzwoche.ch/dossier/professional-av-digital-signage-2023 "Digital Signage") - * [» alle Specials](https://www.netzwoche.ch/specials) - -* [Events](https://www.netzwoche.ch/events) - * [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb "Best of Swiss Web ") - * [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps "/bestofswissapps") - * [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award "Best of Swiss Software") - -* [Netzwitzig](https://www.netzwoche.ch/last-news) -* [E-Paper Login](https://epaper.netzwoche.ch/) - -[](https://www.netzwoche.ch/abo) - -Schlüsselwörter - -Webcode - -[](https://www.netzwoche.ch/abo) -Magazine abonnieren -=================== - -Magazine abonnieren -=================== - -**Nutzen Sie unser Angebot und bestellen Sie ein Abonnement unserer ICT-Fachmagazine.** - -Die Netzwoche gibt es zudem auch als E-Paper. So können Sie jederzeit auf die aktuelle als auch vergangene Ausgaben zugreifen. Weitere Infos zum E-Paper Abo finden Sie hier. - -Bitte beachten Sie, dass unsere Preise für Inlandlieferungen gelten. Bei Fragen zu Zuschlägen für Auslandlieferungen kontaktieren Sie uns bitte, soweit nicht separat ausgewiesen. Folgende Abonnements stehen Ihnen zur Verfügung: - -**Netzwoche - ICT-Magazin für Business Entscheider - Deutschschweiz** - -* Jahresabo für CHF 139.00 im Jahr (13 Ausgaben) - -* Jahresabo E-Paper für CHF 98.00 im Jahr - -* Jahresabo (Ausland)für CHF 198.00 im Jahr (13 Ausgaben) - -**ICTjournal - ICT-Magazin für Business Entscheider - Westschweiz** - -* Jahresabo (inkl. E-Paper) für CHF 75.00 (7 Ausgaben) - -* Jahresabo (Ausland) für CHF 119.00 im Jahr (7 Ausgaben) - -**IT-Markt - Info-Drehscheibe für den IT-Channel** - -* Jahresabo für CHF 60.00 (8 Ausgaben) - -Bestellformular ---------------- - -Formular - -Abonnement auswählen - -- [x] Netzwoche Business-Abo für CHF 139.00/Jahr - -- [x] Netzwoche E-Paper-Abo für CHF 98.00/Jahr - -- [x] Netzwoche Jahresabo (Ausland) für CHF 198.00 - -- [x] ICTjournal Jahresabo inkl. E-Paper für CHF 75.00 - -- [x] ICTjournal Jahresabo (Ausland) für CHF 119.00 - -- [x] IT-Markt Jahresabo für CHF 60.00 - -Anrede - -Ihr Name - -Ihre E-Mail-Adresse - -Firma - -Abteilung - -Strasse und Hausnummer - -PLZ - -Stadt - -Land - -Mitteilung - -[](https://www.facebook.com/netzwoche)[](https://www.linkedin.com/company/18519911/)[](https://twitter.com/Netzwoche)[](https://www.xing.com/news/pages/netzwoche-919) - -Netzwoche ---------- - -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [Magazin](https://www.netzwoche.ch/magazin) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzwoche.ch/shop "Netzwoche Shop") - -Services --------- - -* [E-Paper Login](https://epaper.netzwoche.ch/) -* [Kontakt](https://www.netzwoche.ch/contact) -* [Event-Plus-Eintrag](https://www.netzwoche.ch/event-plus) -* [Login](https://www.netzwoche.ch/user/login) - -Partner-Websites ----------------- - -* [ICTjournal](http://www.ictjournal.ch/) -* [IT-Markt.ch](http://www.it-markt.ch/) -* [netzmedien.ch](http://www.netzmedien.ch/) -* [Swisscybersecurity.net](https://www.swisscybersecurity.net/) - -© Netzmedien AG 2025 --------------------- - -* [Impressum](https://www.netzwoche.ch/impressum) -* [AGB](https://www.netzwoche.ch/AGB) -* [Nutzungsbestimmungen](https://www.netzwoche.ch/nutzungsbestimmungen) -* [Datenschutzerklärung](https://www.netzwoche.ch/datenschutzerklaerung "Datenschutzerklärung") - -[Back to top](https://www.netzwoche.ch/abo#top) - -Diese Website verwendet Cookies und Analysetools, um die Nutzerfreundlichkeit der Website zu verbessern und die Werbung von Netzmedien und Werbepartnern zu personalisieren. Weitere Infos: [Datenschutzerklärung](https://www.netzwoche.ch/datenschutzerklaerung) - -Ich stimme zu \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_028_www.netzwoche.ch_newsletteranmeldung.txt b/test_web_content_20251002_205603/additional_link_028_www.netzwoche.ch_newsletteranmeldung.txt deleted file mode 100644 index 6301acea..00000000 --- a/test_web_content_20251002_205603/additional_link_028_www.netzwoche.ch_newsletteranmeldung.txt +++ /dev/null @@ -1,151 +0,0 @@ -URL: https://www.netzwoche.ch/newsletteranmeldung -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Netzticker | Netzwoche - -=============== -[Direkt zum Inhalt](https://www.netzwoche.ch/newsletteranmeldung#main-content) - -Header menu ------------ - -* [Kontakt](https://www.netzwoche.ch/contact) -* [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb) -* [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps) -* [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award) -* [E-Paper](http://epaper.netzwoche.ch/) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzmedien.ch/de/shop/ "Shop") -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [» Newsletter](https://www.netzwoche.ch/newsletteranmeldung) - -[](https://www.netzwoche.ch/ "Startseite") - -Donnerstag, 2. Oktober 2025 - -[](https://www.netzwoche.ch/newsletteranmeldung) - -Main navigation ---------------- - -* [News](https://www.netzwoche.ch/news) - * [Live](https://www.netzwoche.ch/tags/live "Live") - * [Wild Card](https://www.netzwoche.ch/tags/wild-card "Wild Card") - * [Studien](https://www.netzwoche.ch/studien) - * [Meinungen](https://www.netzwoche.ch/meinungen) - * [Hands-on](https://www.netzwoche.ch/hands-on) - * [» alle News](https://www.netzwoche.ch/news) - -* [Storys](https://www.netzwoche.ch/storys) -* [Dossiers](https://www.netzwoche.ch/dossiers) - * [Best of Swiss Web](https://www.netzwoche.ch/dossier/best-of-swiss-web-2025 "Best of Swiss Web 2023") - * [Best of Swiss Apps](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2025 "Best of Swiss Apps") - * [Best of Swiss Software](https://www.netzwoche.ch/dossier/best-of-swiss-software-2024) - * [SAP S/4 Hana](https://www.netzwoche.ch/dossier/sap-s4-hana-was-bis-2025-zu-tun-ist) - * [Arbeitswelten](https://www.netzwoche.ch/dossier/management-career-arbeitswelten "Management & Career") - * [Gesundheit wird digital](https://www.netzwoche.ch/dossier/gesundheit-wird-digital "Gesundheit wird digital") - * [Blockchain](https://www.netzwoche.ch/dossier/blockchain) - * [EU-DSGVO](https://www.netzwoche.ch/eu-dsgvo) - * [XaaS, Managed Services & Co.](https://www.netzwoche.ch/dossier/cloud-und-managed-services "XaaS, Managed Services & Co.") - * [Digital Banking](https://www.netzwoche.ch/dossier/fintech-insurtech-digital-banking) - * [» alle Dossiers](https://www.netzwoche.ch/dossiers) - -* [Video](https://www.netzwoche.ch/dossier/die-redaktion-filmt) -* [Specials](https://www.netzwoche.ch/specials) - * [IT for Health](https://www.netzwoche.ch/dossier/it-for-health-22025 "IT for Health") - * [Artificial Intelligence](https://www.netzwoche.ch/dossier/artificial-intelligence-special-2025) - * [Finance 2030](https://www.netzwoche.ch/dossier/finance-2030-ausgabe-2025 "Finance 2030") - * [Swiss Digital Ranking](https://www.netzwoche.ch/dossier/swiss-digital-ranking-2025) - * [Cybersecurity](https://www.netzwoche.ch/dossier/cybersecurity-2025 "Cybersecurity") - * [Cloud & Managed Services](https://www.netzwoche.ch/dossier/cloud-managed-services-2025 "Cloud & Managed Services") - * [Fintech & Insurtech](https://www.netzwoche.ch/dossier/fintech-insurtech-2024 "Fintech & Insurtech") - * [IT for Gov](https://www.netzwoche.ch/dossier/it-for-gov-2024 "IT for Gov ") - * [Professional AV & Digital Signage](https://www.netzwoche.ch/dossier/professional-av-digital-signage-2023 "Digital Signage") - * [» alle Specials](https://www.netzwoche.ch/specials) - -* [Events](https://www.netzwoche.ch/events) - * [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb "Best of Swiss Web ") - * [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps "/bestofswissapps") - * [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award "Best of Swiss Software") - -* [Netzwitzig](https://www.netzwoche.ch/last-news) -* [E-Paper Login](https://epaper.netzwoche.ch/) - -[](https://www.netzwoche.ch/newsletteranmeldung) - -Schlüsselwörter - -Webcode - -[](https://www.netzwoche.ch/newsletteranmeldung) -Netzticker -========== - -Netzticker -========== - -Täglich in Ihrer Inbox ----------------------- - -Verpassen Sie keine relevanten News mehr. - -Der tägliche B2B Newsletter der Netzwoche für die ICT-Branche in der Deutschschweiz. - -Sollte das untenstehende Formular nicht funktionieren, [dann klicken Sie bitte hier.](http://eepurl.com/h8i72r) - -Newsletter ----------- - -Email Address - -Anrede - -Frau - -Herr - -Vorname - -Nachname - -[](https://www.facebook.com/netzwoche)[](https://www.linkedin.com/company/18519911/)[](https://twitter.com/Netzwoche)[](https://www.xing.com/news/pages/netzwoche-919) - -Netzwoche ---------- - -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [Magazin](https://www.netzwoche.ch/magazin) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzwoche.ch/shop "Netzwoche Shop") - -Services --------- - -* [E-Paper Login](https://epaper.netzwoche.ch/) -* [Kontakt](https://www.netzwoche.ch/contact) -* [Event-Plus-Eintrag](https://www.netzwoche.ch/event-plus) -* [Login](https://www.netzwoche.ch/user/login) - -Partner-Websites ----------------- - -* [ICTjournal](http://www.ictjournal.ch/) -* [IT-Markt.ch](http://www.it-markt.ch/) -* [netzmedien.ch](http://www.netzmedien.ch/) -* [Swisscybersecurity.net](https://www.swisscybersecurity.net/) - -© Netzmedien AG 2025 --------------------- - -* [Impressum](https://www.netzwoche.ch/impressum) -* [AGB](https://www.netzwoche.ch/AGB) -* [Nutzungsbestimmungen](https://www.netzwoche.ch/nutzungsbestimmungen) -* [Datenschutzerklärung](https://www.netzwoche.ch/datenschutzerklaerung "Datenschutzerklärung") - -[Back to top](https://www.netzwoche.ch/newsletteranmeldung#top) - -Diese Website verwendet Cookies und Analysetools, um die Nutzerfreundlichkeit der Website zu verbessern und die Werbung von Netzmedien und Werbepartnern zu personalisieren. Weitere Infos: [Datenschutzerklärung](https://www.netzwoche.ch/datenschutzerklaerung) - -Ich stimme zu \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_029_www.netzwoche.ch_news.txt b/test_web_content_20251002_205603/additional_link_029_www.netzwoche.ch_news.txt deleted file mode 100644 index e89a9a32..00000000 --- a/test_web_content_20251002_205603/additional_link_029_www.netzwoche.ch_news.txt +++ /dev/null @@ -1,159 +0,0 @@ -URL: https://www.netzwoche.ch/news -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -News | Netzwoche - -=============== -[Direkt zum Inhalt](https://www.netzwoche.ch/news#main-content) - -Header menu ------------ - -* [Kontakt](https://www.netzwoche.ch/contact) -* [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb) -* [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps) -* [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award) -* [E-Paper](http://epaper.netzwoche.ch/) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzmedien.ch/de/shop/ "Shop") -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [» Newsletter](https://www.netzwoche.ch/newsletteranmeldung) - -[](https://www.netzwoche.ch/ "Startseite") - -[](https://www.netzwoche.ch/news) - -Main navigation ---------------- - -* [News](https://www.netzwoche.ch/news) - * [Live](https://www.netzwoche.ch/tags/live "Live") - * [Wild Card](https://www.netzwoche.ch/tags/wild-card "Wild Card") - * [Studien](https://www.netzwoche.ch/studien) - * [Meinungen](https://www.netzwoche.ch/meinungen) - * [Hands-on](https://www.netzwoche.ch/hands-on) - * [» alle News](https://www.netzwoche.ch/news) - -* [Storys](https://www.netzwoche.ch/storys) -* [Dossiers](https://www.netzwoche.ch/dossiers) - * [Best of Swiss Web](https://www.netzwoche.ch/dossier/best-of-swiss-web-2025 "Best of Swiss Web 2023") - * [Best of Swiss Apps](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2025 "Best of Swiss Apps") - * [Best of Swiss Software](https://www.netzwoche.ch/dossier/best-of-swiss-software-2024) - * [SAP S/4 Hana](https://www.netzwoche.ch/dossier/sap-s4-hana-was-bis-2025-zu-tun-ist) - * [Arbeitswelten](https://www.netzwoche.ch/dossier/management-career-arbeitswelten "Management & Career") - * [Gesundheit wird digital](https://www.netzwoche.ch/dossier/gesundheit-wird-digital "Gesundheit wird digital") - * [Blockchain](https://www.netzwoche.ch/dossier/blockchain) - * [EU-DSGVO](https://www.netzwoche.ch/eu-dsgvo) - * [XaaS, Managed Services & Co.](https://www.netzwoche.ch/dossier/cloud-und-managed-services "XaaS, Managed Services & Co.") - * [Digital Banking](https://www.netzwoche.ch/dossier/fintech-insurtech-digital-banking) - * [» alle Dossiers](https://www.netzwoche.ch/dossiers) - -* [Video](https://www.netzwoche.ch/dossier/die-redaktion-filmt) -* [Specials](https://www.netzwoche.ch/specials) - * [IT for Health](https://www.netzwoche.ch/dossier/it-for-health-22025 "IT for Health") - * [Artificial Intelligence](https://www.netzwoche.ch/dossier/artificial-intelligence-special-2025) - * [Finance 2030](https://www.netzwoche.ch/dossier/finance-2030-ausgabe-2025 "Finance 2030") - * [Swiss Digital Ranking](https://www.netzwoche.ch/dossier/swiss-digital-ranking-2025) - * [Cybersecurity](https://www.netzwoche.ch/dossier/cybersecurity-2025 "Cybersecurity") - * [Cloud & Managed Services](https://www.netzwoche.ch/dossier/cloud-managed-services-2025 "Cloud & Managed Services") - * [Fintech & Insurtech](https://www.netzwoche.ch/dossier/fintech-insurtech-2024 "Fintech & Insurtech") - * [IT for Gov](https://www.netzwoche.ch/dossier/it-for-gov-2024 "IT for Gov ") - * [Professional AV & Digital Signage](https://www.netzwoche.ch/dossier/professional-av-digital-signage-2023 "Digital Signage") - * [» alle Specials](https://www.netzwoche.ch/specials) - -* [Events](https://www.netzwoche.ch/events) - * [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb "Best of Swiss Web ") - * [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps "/bestofswissapps") - * [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award "Best of Swiss Software") - -* [Netzwitzig](https://www.netzwoche.ch/last-news) -* [E-Paper Login](https://epaper.netzwoche.ch/) - -[](https://www.netzwoche.ch/news) - -Schlüsselwörter - -Webcode - -[](https://www.netzwoche.ch/news) -News -==== - -News - -[ Registrieren, orchestrieren, kontrollieren Salesforce lanciert "Mulesoft Agent Fabric" zur Koordination von KI-Agenten --------------------------------------------------------------------------- 02.10.2025 - 17:17 Uhr](https://www.netzwoche.ch/news/2025-10-02/salesforce-lanciert-mulesoft-agent-fabric-zur-koordination-von-ki-agenten) - -[ SMS-Phishing Phisher ködern mit Migros-Cumulus-Punkten ----------------------------------------- 02.10.2025 - 15:12 Uhr](https://www.netzwoche.ch/news/2025-10-02/phisher-koedern-mit-migros-cumulus-punkten) - -[ European Cyber Security Month BACS gibt Tipps für Berufstätige, wie sie der Phishing-Falle entgehen --------------------------------------------------------------------- 02.10.2025 - 12:54 Uhr](https://www.netzwoche.ch/news/2025-10-02/bacs-gibt-tipps-fuer-berufstaetige-wie-sie-der-phishing-falle-entgehen) - -[ Zwischen Antivirenschutz und Wiederherstellungsdienst Google-Drive entwickelt neuen KI-gestützten Ransomware-Schutz ------------------------------------------------------------- 02.10.2025 - 12:37 Uhr](https://www.netzwoche.ch/news/2025-10-02/google-drive-entwickelt-neuen-ki-gestuetzten-ransomware-schutz) - -[ VMware und Speicher Warum Zürich fast 40 Millionen Franken für Informatik ausgibt ------------------------------------------------------------- 02.10.2025 - 12:24 Uhr](https://www.netzwoche.ch/news/2025-10-02/warum-zuerich-fast-40-millionen-franken-fuer-informatik-ausgibt) - -[ Wachstum in Nischensegmenten Projektormarkt sinkt im zweiten Quartal erneut ---------------------------------------------- 02.10.2025 - 12:12 Uhr](https://www.netzwoche.ch/news/2025-10-02/projektormarkt-sinkt-im-zweiten-quartal-erneut) - -[ 35 Finalisten unter 136 Einreichungen Die Shortlist für Best of Swiss Apps 2025 steht fest ---------------------------------------------------- 02.10.2025 - 11:23 Uhr](https://www.netzwoche.ch/news/2025-10-02/die-shortlist-fuer-best-of-swiss-apps-2025-steht-fest) - -[ Transparenz, Verantwortung und Sicherheit Kalifornien beschliesst rechtlichen Rahmen für KI-Giganten ---------------------------------------------------------- 02.10.2025 - 11:00 Uhr](https://www.netzwoche.ch/news/2025-10-02/kalifornien-beschliesst-rechtlichen-rahmen-fuer-ki-giganten) - -[ Daniel Anders Schaffhauser Kantonalbank findet neuen Leiter Operations & IT ------------------------------------------------------------- 02.10.2025 - 10:14 Uhr](https://www.netzwoche.ch/news/2025-10-02/schaffhauser-kantonalbank-findet-neuen-leiter-operations-it) - -[ Neuer Architektur von ETH-Spin-off Das Smartphone mit Türsteher ---------------------------- 02.10.2025 - 09:53 Uhr](https://www.netzwoche.ch/news/2025-10-02/das-smartphone-mit-tuersteher) - -[ Network-as-a-Service-Anbieter Megaport Anapaya gewinnt Partner für globale SCION-Reichweite ---------------------------------------------------- 01.10.2025 - 15:20 Uhr](https://www.netzwoche.ch/news/2025-10-01/anapaya-gewinnt-partner-fuer-globale-scion-reichweite) - -[ Quantum Readiness Award Digicert prämiert die Post-Quanten-Strategie von Migros ------------------------------------------------------- 01.10.2025 - 15:19 Uhr](https://www.netzwoche.ch/news/2025-10-01/digicert-praemiert-die-post-quanten-strategie-von-migros) - -[ Opfer filtern und Druck erhöhen Warum sich Phisher zweimal melden --------------------------------- 01.10.2025 - 15:09 Uhr](https://www.netzwoche.ch/news/2025-10-01/warum-sich-phisher-zweimal-melden) - -[ Sora 2 OpenAI bringt Version 2 seiner Video-KI als Social-Media-App ------------------------------------------------------------ 01.10.2025 - 15:07 Uhr](https://www.netzwoche.ch/news/2025-10-01/openai-bringt-version-2-seiner-video-ki-als-social-media-app) - -[ Swico ICT-Index Der ICT-Bereich verliert weiter an Punkten ------------------------------------------ 01.10.2025 - 12:18 Uhr](https://www.netzwoche.ch/news/2025-10-01/der-ict-bereich-verliert-weiter-an-punkten) - -#### Seitennummerierung - -* Vorherige Seite‹‹ Zurück -* [Nächste Seite Vor ››](https://www.netzwoche.ch/news?page=1 "Zur nächsten Seite") - - News - -[](https://www.netzwoche.ch/taxonomy/term/31/feed "RSS feed for News") - -[](https://www.facebook.com/netzwoche)[](https://www.linkedin.com/company/18519911/)[](https://twitter.com/Netzwoche)[](https://www.xing.com/news/pages/netzwoche-919) - -Netzwoche ---------- - -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [Magazin](https://www.netzwoche.ch/magazin) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzwoche.ch/shop "Netzwoche Shop") - -Services --------- - -* [E-Paper Login](https://epaper.netzwoche.ch/) -* [Kontakt](https://www.netzwoche.ch/contact) -* [Event-Plus-Eintrag](https://www.netzwoche.ch/event-plus) -* [Login](https://www.netzwoche.ch/user/login) - -Partner-Websites ----------------- - -* [ICTjournal](http://www.ictjournal.ch/) -* [IT-Markt.ch](http://www.it-markt.ch/) -* [netzmedien.ch](http://www.netzmedien.ch/) -* [Swisscybersecurity.net](https://www.swisscybersecurity.net/) - -© Netzmedien AG 2025 --------------------- - -* [Impressum](https://www.netzwoche.ch/impressum) -* [AGB](https://www.netzwoche.ch/AGB) -* [Nutzungsbestimmungen](https://www.netzwoche.ch/nutzungsbestimmungen) -* [Datenschutzerklärung](https://www.netzwoche.ch/datenschutzerklaerung "Datenschutzerklärung") - -[Back to top](https://www.netzwoche.ch/news#top) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_030_www.netzwoche.ch_tags_liveLive.txt b/test_web_content_20251002_205603/additional_link_030_www.netzwoche.ch_tags_liveLive.txt deleted file mode 100644 index 0457938b..00000000 --- a/test_web_content_20251002_205603/additional_link_030_www.netzwoche.ch_tags_liveLive.txt +++ /dev/null @@ -1,7 +0,0 @@ -URL: https://www.netzwoche.ch/tags/live "Live" -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Content not available in individual_content field. -The combined analysis is available in the main result file. diff --git a/test_web_content_20251002_205603/additional_link_031_www.netzwoche.ch_tags_wild-cardWildCard.txt b/test_web_content_20251002_205603/additional_link_031_www.netzwoche.ch_tags_wild-cardWildCard.txt deleted file mode 100644 index 4b0d5979..00000000 --- a/test_web_content_20251002_205603/additional_link_031_www.netzwoche.ch_tags_wild-cardWildCard.txt +++ /dev/null @@ -1,7 +0,0 @@ -URL: https://www.netzwoche.ch/tags/wild-card "Wild Card" -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Content not available in individual_content field. -The combined analysis is available in the main result file. diff --git a/test_web_content_20251002_205603/additional_link_032_www.itreseller.ch_media.txt b/test_web_content_20251002_205603/additional_link_032_www.itreseller.ch_media.txt deleted file mode 100644 index 388acbcc..00000000 --- a/test_web_content_20251002_205603/additional_link_032_www.itreseller.ch_media.txt +++ /dev/null @@ -1,203 +0,0 @@ -URL: https://www.itreseller.ch/media -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Inserieren in IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Inserieren in IT Reseller -========================= - - IT Reseller ist seit 1998 die führende Fachzeitschrift für die Schweizer IT-Industrie. - - Die Print-Ausgabe erscheint monatlich in einer Auflage von 2500 Exemplaren und erreicht persönlich adressiert den Schweizer ICT-Channel. - - Online erreicht IT Reseller monatlich 32'000 Besucher (Unique Clients) und erzielt bis zu 92'000 Page Impressions. -Print-Anzeigen --------------- - - Gültig ab 1. Januar 2025 -Anzeigen -Format Satzspiegel - -B x H in mm Randabfallend * - -B x H in mm Preis in CHF - -exkl. MwSt -2/1 Seiten Panorama 385 x 265 420 x 297 6600.– -1/1 Seite 175 x 265 210 x 297 4000.– -1/2 Seite quer 175 x 130 210 x 145 3000.– -1/2 Seite hoch 85 x 265 103 x 297 3000.– -1/3 Seite quer 175 x 85 210 x 95 2800.– -1/3 Seite hoch 55 x 265 67 x 297 2800.– -2. oder 4. Umschlagsseite 175 x 265 210 x 297 4800.– -Advertorial -2/1 Seite 385 x 265 420 x 297 4950.– -1/1 Seite 175 x 265 210 x 297 3000.– -3er-Kombi ** -3x 1/1 Seite 175 x 265 210 x 297 6000.– -3x 1/2 Seite quer 175 x 130 210 x 145 4500.– -3x 1/2 Seite hoch 85 x 265 103 x 297 4500.– -Jahresangebot ** -10x 1/1 Seite 175 x 265 210 x 297 12'000.– -10x 1/2 Seite quer 175 x 130 210 x 145 9000.– -10x 1/2 Seite hoch 85 x 265 103 x 297 9000.– -Coverlasche (Flappe) -Coverlasche Vorderseite-auf Anfrage 5'400.– -Coverlasche Rückseite mit 4. Umschlagseite-auf Anfrage 5'400.– -Coverlasche im 5er Kombi-auf Anfrage 4000.– -Veranstaltungskalender -Eintrag mit Datum, Titel, Tagline und URL + Online-Publikation (s. unten)180.– - -* 3 mm Beschnitt pro Aussenrand hinzufügen - - ** Fixpreis für 3 resp. 10 aufeinanderfolgende Ausgaben, Vorauszahlung, nicht Rabatt- oder BK-berechtigt, ohne redaktionellen Anschluss, keine Platzierungswünsche möglich, Verwendung des alten Sujets bei Nichtlieferung eines neuen Sujets bis Inserateschluss. - -Online-Anzeigen ---------------- - - Gültig ab 1. Januar 2025 -TKP-Buchungen -Werbemittel Platzierung Preis in CHF pro 1000 Impressions Format BxH - -(max. 50 KB)Datenformate -Maxiboard Run-of-Site 55.–994 x 118 Pixel JPEG, GIF, HTML5 -Leaderboard Run-of-Site 55.–728 x 90 Pixel JPEG, GIF, HTML5 -Wideskyscraper Run-of-Site 55.–160 x 600 Pixel JPEG, GIF, HTML5 -Half Page Run-of-Site 55.–300 x 600 Pixel JPEG, GIF, HTML5 -Rectangle Run-of-Site 55.–300 x 250 Pixel JPEG, GIF, HTML5 -Mindestbuchungsvolumen: CHF 1100.– -Buchungen mit Fixplatzierung -Werbemittel Platzierung Preis pro Woche Format (max. 50 KB)Datenformate -Maxiboard Run-of-Site 1290.–994 x 118 Pixel JPEG, GIF, HTML5 -Leaderboard Run-of-Site 1290.–728 x 90 Pixel JPEG, GIF, HTML5 -Wideskyscraper Run-of-Site 1290.–160 x 600 Pixel JPEG, GIF, HTML5 -Half Page Run-of-Site 1290.–300 x 600 Pixel JPEG, GIF, HTML5 -Rectangle Run-of-Site 1490.–300 x 250 Pixel JPEG, GIF, HTML5 -Advertorial -Advertorial Homepage & Newsletter 1200.–Titel, max. 4000 Zeichen Text, Bild - -Newsletter-Anzeigen -------------------- - -Fixplatzierung -Werbemittel Preis pro Woche Format (max. 50 KB)Datenformate -Banner 600.–468 x 60 Pixel JPEG, GIF -Skyscraper 825.–160 x 600 Pixel JPEG, GIF -Rectangle 825.–300 x 250 Pixel JPEG, GIF -Textanzeige 825.–n/a JPEG, GIF - -Veranstaltungen ---------------- - -Grundeintrag im Veranstaltungskalender -Werbemittel Preis in CHF exkl. MWST -Eintrag mit Titel, Datum und URL kostenlos -Premium-Eintrag im Veranstaltungskalender -Eintrag mit Titel, Datum und URL 180.- -+ Eintrag mit farblicher Hervorhebung, Logo, Beschreibung -+ Tägliche Veröffentlichung im Newsletter (Start: 3 Monate vor Beginn) -+ Veröffentlichung im Veranstaltungskalender der Print-Ausgabe - -SALES KONTAKT - - - - Sie möchten Werbung schalten oder wünschen eine kompetente Beratung? - -**Unsere Verkaufsleiterin Tanja Zesiger freut sich auf Ihre Kontaktaufnahme!** - -#### ✆ +41 (0) 44 723 50 05 - -#### [tzesiger@swissitmedia.ch](mailto:tzesiger@swissitmedia.ch) - -MEDIADATEN - -[ ##### Download Mediadaten 2025](https://www.itreseller.ch/media/tarife/ITR_Mediadaten_2025_DE.pdf) - -MEDIA ALERT - - Abonnieren Sie unseren monatlichen Media Alert mit der Themenvorschau auf die kommenden Ausgaben von IT Reseller. - -AUSGABEN & TERMINE - -**IT Reseller 2025/ 11** -Erscheint am:3. November 2025 -Anzeigenschluss:24. Oktober 2025 - -**IT Reseller 2025/ 12** -Erscheint am:8. Dezember 2025 -Anzeigenschluss:28. November 2025 - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_033_www.itreseller.ch_abo.txt b/test_web_content_20251002_205603/additional_link_033_www.itreseller.ch_abo.txt deleted file mode 100644 index 592d23e8..00000000 --- a/test_web_content_20251002_205603/additional_link_033_www.itreseller.ch_abo.txt +++ /dev/null @@ -1,157 +0,0 @@ -URL: https://www.itreseller.ch/abo -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Abonnement - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Abonnement-Bestellung -===================== - - IT Reseller wird ausschliesslich im **Controlled-Circulation-Modell** vertrieben und ist damit nur für Unternehmensmitarbeiter im IT- oder Consumer-Electronics-Markt erhältlich. - - Um sicherzustellen, dass nur qualifizierte Personen den IT Reseller erhalten, bitten wir Sie, bei Ihrer Bestellung **alle mit (*) gekennzeichneten Felder auszufüllen**, damit wir Ihre Angaben prüfen können. - -**1-Jahres-Abonnement** - - Ich abonniere IT Reseller inkl. Swiss IT Magazine für ein Jahr zum Preis von Fr. 95.– - -(Ausland Europa Fr. 190.-). -**2-Jahres-Abonnement** - - Ich abonniere IT Reseller inkl. Swiss IT Magazine für 2 Jahre zum Preis von Fr. 150.– - -(Ausland Europa Fr. 300.-). -**Online-Abonnement** - - Ich abonniere die digitale Ausgabe von IT Reseller und erhalte damit für 1 Jahr Zugriff auf die Online-Archive von [IT Reseller](https://www.itreseller.ch/Heftarchiv/) und [Swiss IT Magazine](http://www.itmagazine.ch/heftarchiv) zum Preis von Fr. 75.– -**Probe-Abonnement** - - Ich möchte drei Ausgaben kostenlos zur Probe. (Kein Ausland-Versand) -**Das Abo startet mit der Ausgabe** -- [x]Ich möchte auch den täglichen Newsletter von IT Reseller abonnieren! - -**Firma*** -**Anrede** -**Vorname*** -**Nachname*** -**Abteilung** -**Position** -**Branche*** -**Strasse*** -**PLZ/Ort*** -**Land** -**Telefon*** -**E-Mail*** -* Angabe obligatorisch -Dies ist meine Geschäftsadresse -Dies ist meine Privatadresse -- [x]IT Reseller darf mich für Meinungsumfragen - -und Recherchen kontaktieren. - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_034_www.itreseller.ch_newsletter.txt b/test_web_content_20251002_205603/additional_link_034_www.itreseller.ch_newsletter.txt deleted file mode 100644 index 842eeffa..00000000 --- a/test_web_content_20251002_205603/additional_link_034_www.itreseller.ch_newsletter.txt +++ /dev/null @@ -1,119 +0,0 @@ -URL: https://www.itreseller.ch/newsletter -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Newsletter - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Newsletter abonnieren -===================== - - Um die Newsletter von IT Reseller zu abonnieren, geben Sie bitte Ihre E-Mail-Adresse in das folgende Feld ein und klicken Sie auf den Anmelden-Button. - - Um den Newsletter abzubestellen, klicken Sie bitte auf den Link am Ende jedes Newsletters. - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_035_www.itreseller.ch_rubriken_165_people.html.txt b/test_web_content_20251002_205603/additional_link_035_www.itreseller.ch_rubriken_165_people.html.txt deleted file mode 100644 index d0c0b4ae..00000000 --- a/test_web_content_20251002_205603/additional_link_035_www.itreseller.ch_rubriken_165_people.html.txt +++ /dev/null @@ -1,195 +0,0 @@ -URL: https://www.itreseller.ch/rubriken/165/people.html -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -People - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -PEOPLE ------- - -[](https://www.itreseller.ch/Artikel/104096/Daniele_Palazzo_verlaesst_Lake_Solutions.html) - -[Daniele Palazzo verlässt Lake Solutions =======================================](https://www.itreseller.ch/Artikel/104096/Daniele_Palazzo_verlaesst_Lake_Solutions.html) - -[Lake Solutions verkleinert die Geschäftsleitung. Daniele Palazzo verlässt das Unternehmen nach mehr als 20 Jahren, seine Aufgaben werden im Rahmen einer Reorganisation an die drei verbleibenden GL-Mitglieder verteilt.](https://www.itreseller.ch/Artikel/104096/Daniele_Palazzo_verlaesst_Lake_Solutions.html) - - 2. Oktober 2025 - -Meistgelesen in People - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -[](https://www.itreseller.ch/Artikel/104097/Torsten_Boettjer_ist_Head_of_Cloud_Services_bei_Inventx.html) - -[### Torsten Böttjer ist Head of Cloud Services bei Inventx Mit der neu geschaffenen Position des Head of Cloud Services will Inventx die Weiterentwicklung seiner Hybrid-Cloud-Strategie weiterentwickeln. Besetzt wurde die Position mit Torsten Böttjer. 2. Oktober 2025](https://www.itreseller.ch/Artikel/104097/Torsten_Boettjer_ist_Head_of_Cloud_Services_bei_Inventx.html) - -[](https://www.itreseller.ch/Artikel/104100/Hohmann_verlaesst_Thomas-Krenn_Meier_und_Frei_bilden_Doppelspitze.html) - -[### Hohmann verlässt Thomas-Krenn, Meier und Frei bilden Doppelspitze Beim Server- und Storage-Spezialisten Thomas-Krenn verkleinert sich der Vorstand wieder. Ralf Hohmann scheidet aus, CEO Christoph Maier und COO Thomas Frei übernehmen fortan zu zweit die Aufgaben des Vorstands. 2. Oktober 2025](https://www.itreseller.ch/Artikel/104100/Hohmann_verlaesst_Thomas-Krenn_Meier_und_Frei_bilden_Doppelspitze.html) - -[](https://www.itreseller.ch/Artikel/104094/NTT_Data_stellt_Michael_Seiger_als_neuen_DACH-Chef_vor.html) - -[### NTT Data stellt Michael Seiger als neuen DACH-Chef vor NTT Data ernennt Michael Seiger zum Executive Managing Director für Deutschland, Österreich und die Schweiz. Er folgt auf Stefan Hansen. 2. Oktober 2025](https://www.itreseller.ch/Artikel/104094/NTT_Data_stellt_Michael_Seiger_als_neuen_DACH-Chef_vor.html) - -[](https://www.itreseller.ch/Artikel/104095/Sonepar_Schweiz_ernennt_Raphael_Maier_zum_neuen_CEO.html) - -[### Sonepar Schweiz ernennt Raphael Maier zum neuen CEO David von Ow ist nach 30 Jahren in den Ruhestand getreten. Für ihn übernimmt nun Raphael Maier die Rolle als CEO von Sonepar in der Schweiz. 1. Oktober 2025](https://www.itreseller.ch/Artikel/104095/Sonepar_Schweiz_ernennt_Raphael_Maier_zum_neuen_CEO.html) - -[](https://www.itreseller.ch/Artikel/104090/AWS_ernennt_Stphane_Isral_zum_Leiter_der_Sovereign_Cloud.html) - -[### AWS ernennt Stéphane Israël zum Leiter der Sovereign Cloud AWS gibt mit Stéphane Israël einen zweiten Leiter der European Sovereign Cloud bekannt. Zusammen mit Kathrin Renz soll er das Geschäft mit souveränen Cloud-Strukturen leiten. 1. Oktober 2025](https://www.itreseller.ch/Artikel/104090/AWS_ernennt_Stphane_Isral_zum_Leiter_der_Sovereign_Cloud.html) - -[](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html) - -[### Paessler bekommt mit Jason Teichman neuen CEO](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html) - -[IT- und OT-Monitoring-Anbieter Paessler stellt mit Jason Teichman seinen neuen CEO vor. Mit der Personalie unterstreicht das Unternehmen seine globale Expansionsstrategie.](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html)1. Oktober 2025 - -[](https://www.itreseller.ch/Artikel/104086/Connect-Test_Schweizer_Internet-Provider_sind_ueberragend.html) - -[### Connect-Test: Schweizer Internet-Provider sind überragend](https://www.itreseller.ch/Artikel/104086/Connect-Test_Schweizer_Internet-Provider_sind_ueberragend.html) - -[Während Swisscom und Sunrise im grossen Festnetztest Schweiz 2025 von "Connect" beinahe gleichauf liegen, sind die Unterschiede bei den regionalen Anbietern etwas grösser. Klar ist aber: Die Schweizer Internet-Provider sind durchs Band top.](https://www.itreseller.ch/Artikel/104086/Connect-Test_Schweizer_Internet-Provider_sind_ueberragend.html)1. Oktober 2025 - -[](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) - -[Mit Renato Petrillo (Bild, Mitte) hat Baggenstos einen neuen CEO gefunden. Er folgt auf Michael Kistler (Bild, links), der dem Unternehmen in verschiedenen Rollen erhalten bleibt.](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html)30. September 2025 - -[](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) - -[Dennis Monner (Bild, rechts) folgt bei Open Systems als CEO auf Daniel Neuhaus (Bild, links), der 2020 mit der Übernahme seines Unternehmens Sqooba zum Unternehmen stiess.](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html)30. September 2025 - -[](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) - -[Mit Marco Pierro hat Check Point Software Technologies einen neuen Country Manager für die Schweiz ernannt. Er übernimmt die Funktion per 1. Oktober 2025 und folgt auf Alvaro Amato, der zum Director Globals für EMEA & Asien befördert wurde.](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html)30. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_036_www.itreseller.ch_rubriken_163_business.html.txt b/test_web_content_20251002_205603/additional_link_036_www.itreseller.ch_rubriken_163_business.html.txt deleted file mode 100644 index c1b94a51..00000000 --- a/test_web_content_20251002_205603/additional_link_036_www.itreseller.ch_rubriken_163_business.html.txt +++ /dev/null @@ -1,195 +0,0 @@ -URL: https://www.itreseller.ch/rubriken/163/business.html -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Business - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -BUSINESS --------- - -[](https://www.itreseller.ch/Artikel/104102/Matrix42_kauft_SaaS-Management-Spezialisten_Viio.html) - -[Matrix42 kauft SaaS-Management-Spezialisten Viio ================================================](https://www.itreseller.ch/Artikel/104102/Matrix42_kauft_SaaS-Management-Spezialisten_Viio.html) - -[Mit dem Zukauf des dänischen SaaS-Management-Spezialisten will Matrix42 die eigenen Fähigkeiten im Bereich Software Asset Management und Enterprise Service Management verbessern. Die Übernahme soll noch dieses Jahr abgeschlossen werden.](https://www.itreseller.ch/Artikel/104102/Matrix42_kauft_SaaS-Management-Spezialisten_Viio.html) - - 2. Oktober 2025 - -Meistgelesen in Business - -[### Nutanix Cloud Platform unterstützt neu Dell PowerStore](https://www.itreseller.ch/Artikel/104070/Nutanix_Cloud_Platform_unterstuetzt_neu_Dell_PowerStore.html) 26. September 2025 - -[### Intel wirbt auch bei Apple um Investitionen](https://www.itreseller.ch/Artikel/104063/Intel_wirbt_auch_bei_Apple_um_Investitionen.html) 25. September 2025 - -[### AWS und SAP stellen gemeinsam "souveräne Cloud" auf die Beine](https://www.itreseller.ch/Artikel/104060/AWS_und_SAP_stellen_gemeinsam_souveraene_Cloud_auf_die_Beine.html) 25. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) 23. September 2025 - -[](https://www.itreseller.ch/Artikel/104099/Fritz_startet_mit_eigenem_Online-Shop_in_der_Schweiz_.html) - -[### Fritz startet mit eigenem Online-Shop in der Schweiz Netzwerkspezialist Fritz öffnet einen eigenen Online-Shop in der Schweiz. Dieser soll spätestens Mitte Oktober bereitstehen und die gewohnten Zusatzservices bieten. 2. Oktober 2025](https://www.itreseller.ch/Artikel/104099/Fritz_startet_mit_eigenem_Online-Shop_in_der_Schweiz_.html) - -[](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - -[### Swico ICT Index zeigt abermals Knick für das vierte Quartal Der Swico ICT Index geht im vierten Quartal 2025 um 2 Punkte zurück. Noch sind viele Segmente im Wachstumsbereich, allerdings zeigen Unsicherheiten, Zölle und Wettbewerb Effekte. 1. Oktober 2025](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - -[](https://www.itreseller.ch/Artikel/104091/Arrow_vertreibt_Thales-Plattform_in_der_Schweiz.html) - -[### Arrow vertreibt Thales-Plattform in der Schweiz Arrow hat das bestehende Distributionsabkommen mit Thales erweitert und bietet die Imperva Application Security-Plattform auch in der Schweiz sowie in Österreich und Italien an. 1. Oktober 2025](https://www.itreseller.ch/Artikel/104091/Arrow_vertreibt_Thales-Plattform_in_der_Schweiz.html) - -[](https://www.itreseller.ch/Artikel/104084/Infinigate_vertreibt_neu_Thales_in_der_Schweiz.html) - -[### Infinigate vertreibt neu Thales in der Schweiz Schweizer Channel-Partner können neu das gesamte Security-Portfolio von Thales über Infinigate beziehen und erhalten beim VAD den dazugehörigen Support. 30. September 2025](https://www.itreseller.ch/Artikel/104084/Infinigate_vertreibt_neu_Thales_in_der_Schweiz.html) - -[](https://www.itreseller.ch/Artikel/104082/NTT_Data_streicht_Ivanti_aus_Sicherheitsgruenden_aus_Portfolio_.html) - -[### NTT Data streicht Ivanti aus Sicherheitsgründen aus Portfolio NTT Data vertreibt keine Produkte mehr von Ivanti. Laut dem IT-Dienstleister stellen diese ein zu hohes Sicherheitsrisiko dar. 30. September 2025](https://www.itreseller.ch/Artikel/104082/NTT_Data_streicht_Ivanti_aus_Sicherheitsgruenden_aus_Portfolio_.html) - -[](https://www.itreseller.ch/Artikel/104077/Microsoft_startet_neuen_Marketplace_fuer_Cloud-_und_KI-Loesungen.html) - -[### Microsoft startet neuen Marketplace für Cloud- und KI-Lösungen](https://www.itreseller.ch/Artikel/104077/Microsoft_startet_neuen_Marketplace_fuer_Cloud-_und_KI-Loesungen.html) - -[Microsoft startet einen einheitlichen Marketplace, der Azure Marketplace und AppSource bündelt und Unternehmen Cloud-Lösungen sowie KI-Apps und Agenten zentral finden, testen, kaufen und direkt in ihrer Microsoft-Umgebung bereitstellen lässt.](https://www.itreseller.ch/Artikel/104077/Microsoft_startet_neuen_Marketplace_fuer_Cloud-_und_KI-Loesungen.html)29. September 2025 - -[](https://www.itreseller.ch/Artikel/104075/ADN_setzt_verstaerkt_auf_das_Dell-Geschaeft.html) - -[### ADN setzt verstärkt auf das Dell-Geschäft](https://www.itreseller.ch/Artikel/104075/ADN_setzt_verstaerkt_auf_das_Dell-Geschaeft.html) - -[ADN baut personell mit den drei neuen Channel-Experten Ronny Pilgram (Bild), Thomas Kroll und Christof Sokolowski aus und bekräftigt damit seinen Anspruch als strategischer Value-Added-Distributor für Dell Technologies.](https://www.itreseller.ch/Artikel/104075/ADN_setzt_verstaerkt_auf_das_Dell-Geschaeft.html)29. September 2025 - -[](https://www.itreseller.ch/Artikel/104070/Nutanix_Cloud_Platform_unterstuetzt_neu_Dell_PowerStore.html) - -[### Nutanix Cloud Platform unterstützt neu Dell PowerStore](https://www.itreseller.ch/Artikel/104070/Nutanix_Cloud_Platform_unterstuetzt_neu_Dell_PowerStore.html) - -[Mit der Unterstützung der All-Flash-Storage-Plattform Dell PowerStore in der Nutanix Cloud Platform vertiefen die beiden Technologieunternehmen ihre strategische Partnerschaft.](https://www.itreseller.ch/Artikel/104070/Nutanix_Cloud_Platform_unterstuetzt_neu_Dell_PowerStore.html)26. September 2025 - -[](https://www.itreseller.ch/Artikel/104066/Motorola_startet_in_der_Schweiz_eigenen_Online-Shop.html) - -[### Motorola startet in der Schweiz eigenen Online-Shop](https://www.itreseller.ch/Artikel/104066/Motorola_startet_in_der_Schweiz_eigenen_Online-Shop.html) - -[Motorola baut das Direktgeschäft in der Schweiz aus und startet einen eigenen Online-Shop für Privat- und Geschäftskunden. So will der Hersteller die Präsenz hierzulande stärken.](https://www.itreseller.ch/Artikel/104066/Motorola_startet_in_der_Schweiz_eigenen_Online-Shop.html)26. September 2025 - -[](https://www.itreseller.ch/Artikel/104064/Crayon_ist_neuer_Zendesk-Distributor_.html) - -[### Crayon ist neuer Zendesk-Distributor](https://www.itreseller.ch/Artikel/104064/Crayon_ist_neuer_Zendesk-Distributor_.html) - -[Crayon tritt in mehr als 70 Ländern als neuer Distributor für Zendesk auf. Die Partnerschaft umfasst das gesamte Portfolio des Anbieters von CX-Lösungen.](https://www.itreseller.ch/Artikel/104064/Crayon_ist_neuer_Zendesk-Distributor_.html)26. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_037_www.itreseller.ch_rubriken_166_finance.html.txt b/test_web_content_20251002_205603/additional_link_037_www.itreseller.ch_rubriken_166_finance.html.txt deleted file mode 100644 index 57ecd5c0..00000000 --- a/test_web_content_20251002_205603/additional_link_037_www.itreseller.ch_rubriken_166_finance.html.txt +++ /dev/null @@ -1,173 +0,0 @@ -URL: https://www.itreseller.ch/rubriken/166/finance.html -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Finance - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -FINANCE -------- - -[](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -[OpenAI knackt 500-Milliarden-Marke ==================================](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -[Die KI-Blase wächst weiter: Nach einem grossen Aktienverkauf durch OpenAI-Mitarbeiter an Investoren liegt der Unternehmenswert nun erstmals bei einer halben Billion US-Dollar.](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - - 2. Oktober 2025 - -Meistgelesen in Finance - -[### Adobe-Zahlen übertreffen die Markterwartungen](https://www.itreseller.ch/Artikel/103962/Adobe-Zahlen_uebertreffen_die_Markterwartungen.html) 12. September 2025 - -[### Aveniq setzt auf Fokussierung und einheitliche Strukturen](https://www.itreseller.ch/Artikel/103935/Aveniq_setzt_auf_Fokussierung_und_einheitliche_Strukturen.html) 9. September 2025 - -[### ASML wird Hauptaktionär von Mistral AI](https://www.itreseller.ch/Artikel/103933/ASML_wird_Hauptaktionaer_von_Mistral_AI.html) 8. September 2025 - -[### HPE übertrifft Markterwartungen mit Rekordumsatz](https://www.itreseller.ch/Artikel/103920/HPE_uebertrifft_Markterwartungen_mit_Rekordumsatz_.html) 5. September 2025 - -[](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -[### Accenture mit mehr Umsatz und weniger Gewinn Accenture steigerte im jüngsten Quartal die Einnahmen um 7 Prozent auf 17,6 Milliarden Dollar. Hingegen mussten beim Gewinn zweistellige Einbussen in Kauf genommen werden. 26. September 2025](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -[](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab TD Synnex übertraf im abgelaufenen Quartal die Markterwartungen sowohl beim Gewinn, als auch beim Umsatz deutlich. Obwohl auch der Ausblick die Analystenschätzungen übertraf, konnte die Aktie nicht profitieren. 26. September 2025](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -[](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -[### Schweizer KI-Start-up Giotto sucht Finanzierung Giotto mit Sitz in Lausanne sucht mit Unterstützung einer Investmentbank Investoren für eine weitere Finanzierung im Umfang von über 200 Millionen US-Dollar. Das Unternehmen ist im Bereich künstliche allgemeine Intelligenz (AGI) tätig. 23. September 2025](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -[](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -[### Nvidia will kräftig in OpenAI investieren OpenAI will seine KI-Infrastruktur ab nächstem Jahr stark ausbauen und dazu Nvidia-Systeme der neuesten Generation einsetzen. Nvidia sichert zu, mindestens 100 Millionen Dollar in OpenAI zu investieren. 23. September 2025](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -[](https://www.itreseller.ch/Artikel/104009/Oracle_vor_20-Milliarden-Deal_mit_Meta.html) - -[### Oracle vor 20-Milliarden-Deal mit Meta Nach dem 300-Milliarden-Dollar-Vertrag mit OpenAI plant Oracle ein weiteres Abkommen zum Bezug von Cloud-Dienstleistungen mit Meta. In den kommenden Monaten sollen noch mehr ähnliche Deals folgen. 22. September 2025](https://www.itreseller.ch/Artikel/104009/Oracle_vor_20-Milliarden-Deal_mit_Meta.html) - -[](https://www.itreseller.ch/Artikel/103975/Alphabet_ist_erstmals_3_Billionen_Dollar_Wert.html) - -[### Alphabet ist erstmals 3 Billionen Dollar Wert](https://www.itreseller.ch/Artikel/103975/Alphabet_ist_erstmals_3_Billionen_Dollar_Wert.html) - -[Nach einem erneuten Anstieg des Aktienkurses um über 3 Prozent hat die Börsenbewertung der Google-Mutter Alphabet nun zum ersten Mal die Schwelle von 3 Billionen US-Dollar überschritten.](https://www.itreseller.ch/Artikel/103975/Alphabet_ist_erstmals_3_Billionen_Dollar_Wert.html)16. September 2025 - -[](https://www.itreseller.ch/Artikel/103962/Adobe-Zahlen_uebertreffen_die_Markterwartungen.html) - -[### Adobe-Zahlen übertreffen die Markterwartungen](https://www.itreseller.ch/Artikel/103962/Adobe-Zahlen_uebertreffen_die_Markterwartungen.html) - -[Im jüngsten Quartal konnte Adobe beim Umsatz wie auch beim Gewinn zulegen. Da das Management auch die Umsatzprognose fürs gesamte Geschäftsjahr nach oben angepasst hat, konnte auch die Aktie profitieren.](https://www.itreseller.ch/Artikel/103962/Adobe-Zahlen_uebertreffen_die_Markterwartungen.html)12. September 2025 - -[](https://www.itreseller.ch/Artikel/103950/Oracles_IaaS-Umsaetze_gehen_durch_die_Decke.html) - -[### Oracles IaaS-Umsätze gehen durch die Decke](https://www.itreseller.ch/Artikel/103950/Oracles_IaaS-Umsaetze_gehen_durch_die_Decke.html) - -[Oracle kann starke Zahlen für das erste Quartal des Geschäftsjahres 2026 vorlegen. Vor allem das Cloud-Infrastruktur-Business boomt.](https://www.itreseller.ch/Artikel/103950/Oracles_IaaS-Umsaetze_gehen_durch_die_Decke.html)11. September 2025 - -[](https://www.itreseller.ch/Artikel/103946/Computacenter_meldet_Umsatzsprung_-_aber_nicht_fuer_Westeuropa.html) - -[### Computacenter meldet Umsatzsprung - aber nicht für Westeuropa](https://www.itreseller.ch/Artikel/103946/Computacenter_meldet_Umsatzsprung_-_aber_nicht_fuer_Westeuropa.html) - -[Computacenter kann für das erste Halbjahr 2025 beachtliche Zahlen vorlegen. Die westeuropäischen Märkte (exklusive UK) haben dazu jedoch nur bedingt beigetragen.](https://www.itreseller.ch/Artikel/103946/Computacenter_meldet_Umsatzsprung_-_aber_nicht_fuer_Westeuropa.html)10. September 2025 - -[](https://www.itreseller.ch/Artikel/103935/Aveniq_setzt_auf_Fokussierung_und_einheitliche_Strukturen.html) - -[### Aveniq setzt auf Fokussierung und einheitliche Strukturen](https://www.itreseller.ch/Artikel/103935/Aveniq_setzt_auf_Fokussierung_und_einheitliche_Strukturen.html) - -[Aveniq hat in Baden Anfang September den Business Summit 2025 veranstaltet. In diesem Rahmen gab Head of Sales & Marketing Walter Lienhard Einblick in den strategischen Status quo des IT-Dienstleisters.](https://www.itreseller.ch/Artikel/103935/Aveniq_setzt_auf_Fokussierung_und_einheitliche_Strukturen.html)9. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_038_www.itreseller.ch_rubriken_122_research.html.txt b/test_web_content_20251002_205603/additional_link_038_www.itreseller.ch_rubriken_122_research.html.txt deleted file mode 100644 index d84a9ef7..00000000 --- a/test_web_content_20251002_205603/additional_link_038_www.itreseller.ch_rubriken_122_research.html.txt +++ /dev/null @@ -1,195 +0,0 @@ -URL: https://www.itreseller.ch/rubriken/122/research.html -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Research - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -RESEARCH --------- - -[](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - -[Swico ICT Index zeigt abermals Knick für das vierte Quartal ===========================================================](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - -[Der Swico ICT Index geht im vierten Quartal 2025 um 2 Punkte zurück. Noch sind viele Segmente im Wachstumsbereich, allerdings zeigen Unsicherheiten, Zölle und Wettbewerb Effekte.](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - - 1. Oktober 2025 - -Meistgelesen in Research - -[### Drucker-Firmware wird zu selten aktualisiert](https://www.itreseller.ch/Artikel/103970/Drucker-Firmware_wird_zu_selten_aktualisiert.html) 15. September 2025 - -[### Globaler Ethernet-Switch-Markt mit 42 Prozent Wachstum](https://www.itreseller.ch/Artikel/103966/Globaler_Ethernet-Switch-Markt_mit_42_Prozent_Wachstum.html) 15. September 2025 - -[### Huawei überholt Apple im Smartwatch-Markt](https://www.itreseller.ch/Artikel/103938/Huawei_ueberholt_Apple_im_Smartwatch-Markt.html) 9. September 2025 - -[### Europas Markt für Large Format Displays erleidet Einbussen](https://www.itreseller.ch/Artikel/103926/Europas_Markt_fuer_Large_Format_Displays_erleidet_Einbussen.html) 8. September 2025 - -[](https://www.itreseller.ch/Artikel/104059/Smartphone-Durchschnittspreise_steigen.html) - -[### Smartphone-Durchschnittspreise steigen Der durchschnittliche Preis, der für ein Smartphone bezahlt wird, soll von 370 Dollar in diesem Jahr auf 412 Dollar im Jahr 2029 steigen. 25. September 2025](https://www.itreseller.ch/Artikel/104059/Smartphone-Durchschnittspreise_steigen.html) - -[](https://www.itreseller.ch/Artikel/104026/Ausgaben_der_Hyperscaler_gehen_durch_die_Decke.html) - -[### Ausgaben der Hyperscaler gehen durch die Decke Die Hyperscaler investieren immer mehr in ihre Infrastruktur und hier vor allem in KI-Rechenzentren. Damit befeuern sie laut Analysten ihr "aggressives Wachstum". 24. September 2025](https://www.itreseller.ch/Artikel/104026/Ausgaben_der_Hyperscaler_gehen_durch_die_Decke.html) - -[](https://www.itreseller.ch/Artikel/104003/Globaler_Notebook-Markt_auf_Erholungskurs.html) - -[### Globaler Notebook-Markt auf Erholungskurs Fürs laufende Jahr prognostiziert Trendforce für den globalen Notebook-Markt ein Absatzplus von 2,2 Prozent. Das Wachstum gibt im Jahresverlauf allerdings kontinuierlich nach, um dann im Q4 in den negativen Bereich zu kippen. 22. September 2025](https://www.itreseller.ch/Artikel/104003/Globaler_Notebook-Markt_auf_Erholungskurs.html) - -[](https://www.itreseller.ch/Artikel/103990/KI-Ausgaben_sollen_sich_2025_auf_15_Billionen_Dollar_belaufen.html) - -[### KI-Ausgaben sollen sich 2025 auf 1,5 Billionen Dollar belaufen 2025 sollen die weltweiten Ausgaben für Künstliche Intelligenz knapp 1,5 Billionen US-Dollar ausmachen. Für das kommende Jahr prognostizieren Gartner-Analysten dann den Sprung über die 2-Milliarden-Marke. 18. September 2025](https://www.itreseller.ch/Artikel/103990/KI-Ausgaben_sollen_sich_2025_auf_15_Billionen_Dollar_belaufen.html) - -[](https://www.itreseller.ch/Artikel/103974/Europaeischer_PC-Markt_legt_im_dritten_Quartal_deutlich_zu.html) - -[### Europäischer PC-Markt legt im dritten Quartal deutlich zu Im Juli und August 2025 hat die europäische Distribution bei Desktop-PCs ein Umsatzplus von über 30 Prozent erreicht, während Notebooks um über 11 Prozent zulegten. 15. September 2025](https://www.itreseller.ch/Artikel/103974/Europaeischer_PC-Markt_legt_im_dritten_Quartal_deutlich_zu.html) - -[](https://www.itreseller.ch/Artikel/103970/Drucker-Firmware_wird_zu_selten_aktualisiert.html) - -[### Drucker-Firmware wird zu selten aktualisiert](https://www.itreseller.ch/Artikel/103970/Drucker-Firmware_wird_zu_selten_aktualisiert.html) - -[Mit Updates der Drucker-Firmware hapert es in vielen Unternehmen. Sicherheitsprobleme bestehen jedoch nicht nur im Betrieb, sie treten von der Beschaffung bis zur Entsorgung auf.](https://www.itreseller.ch/Artikel/103970/Drucker-Firmware_wird_zu_selten_aktualisiert.html)15. September 2025 - -[](https://www.itreseller.ch/Artikel/103967/Enterprise-WLAN-Markt_im_Q2_2025_deutlich_im_Plus.html) - -[### Enterprise-WLAN-Markt im Q2 2025 deutlich im Plus](https://www.itreseller.ch/Artikel/103967/Enterprise-WLAN-Markt_im_Q2_2025_deutlich_im_Plus.html) - -[Im zweiten Quartal 2025 legte der weltweite Enterprise-WLAN-Markt gegenüber der Vorjahresperiode um 13,2 Prozent zu. Marktführer ist Cisco, gefolgt vom HPE Aruba, Ubiquiti, Huawei und Juniper Networks.](https://www.itreseller.ch/Artikel/103967/Enterprise-WLAN-Markt_im_Q2_2025_deutlich_im_Plus.html)15. September 2025 - -[](https://www.itreseller.ch/Artikel/103966/Globaler_Ethernet-Switch-Markt_mit_42_Prozent_Wachstum.html) - -[### Globaler Ethernet-Switch-Markt mit 42 Prozent Wachstum](https://www.itreseller.ch/Artikel/103966/Globaler_Ethernet-Switch-Markt_mit_42_Prozent_Wachstum.html) - -[Der wachsende Bedarf der Hyperscaler sorgt im Markt für Ethernet Switches für einen aussergewöhnlichen Umsatzanstieg von über 42 Prozent auf 14,5 Milliarden Dollar.](https://www.itreseller.ch/Artikel/103966/Globaler_Ethernet-Switch-Markt_mit_42_Prozent_Wachstum.html)15. September 2025 - -[](https://www.itreseller.ch/Artikel/103939/_Weltweiter_Halbleitermarkt_waechst_2025_um_176_Prozent.html) - -[### Weltweiter Halbleitermarkt wächst 2025 um 17,6 Prozent](https://www.itreseller.ch/Artikel/103939/_Weltweiter_Halbleitermarkt_waechst_2025_um_176_Prozent.html) - -[Angetrieben durch die hohe Nachfrage nach KI-Infrastruktur und Rechenzentrums-Technologien wächst der weltweite Halbleitermarkt 2025 laut IDC um 17,6 Prozent auf 800 Milliarden US-Dollar. 2028 könnte eine Billion erreicht werden.](https://www.itreseller.ch/Artikel/103939/_Weltweiter_Halbleitermarkt_waechst_2025_um_176_Prozent.html)9. September 2025 - -[](https://www.itreseller.ch/Artikel/103938/Huawei_ueberholt_Apple_im_Smartwatch-Markt.html) - -[### Huawei überholt Apple im Smartwatch-Markt](https://www.itreseller.ch/Artikel/103938/Huawei_ueberholt_Apple_im_Smartwatch-Markt.html) - -[Huawei hat Apple als führenden Anbieter im globalen Smartwatch-Markt abgelöst, so Zahlen von Counterpoint. Apple-Kunden würden auf neue Modelle warten, diese werden wohl heute noch vorgestellt.](https://www.itreseller.ch/Artikel/103938/Huawei_ueberholt_Apple_im_Smartwatch-Markt.html)9. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_039_www.itreseller.ch_veranstaltungen.txt b/test_web_content_20251002_205603/additional_link_039_www.itreseller.ch_veranstaltungen.txt deleted file mode 100644 index 409e1ca2..00000000 --- a/test_web_content_20251002_205603/additional_link_039_www.itreseller.ch_veranstaltungen.txt +++ /dev/null @@ -1,151 +0,0 @@ -URL: https://www.itreseller.ch/veranstaltungen -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Veranstaltungen - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Veranstaltungen -=============== - -[### SCION Day 2025 Kongress/Konferenz Zürich • 21. Oktober 2025](https://www.itreseller.ch/veranstaltungen/2324/SCION_Day_2025.html) - -[### Global Cyber Conference 2025 Zürich • 22./23. Oktober 2025](https://www.itreseller.ch/veranstaltungen/2331/Global_Cyber_Conference_2025.html) - -[### Swiss Cyber Storm 2025 Resilience in a mad, mad world Bern • 28. Oktober 2025](https://www.itreseller.ch/veranstaltungen/2373/Swiss_Cyber_Storm_2025.html) - -[### Data Community Conference 2025 Kongress/Konferenz Bern • 5. November 2025](https://www.itreseller.ch/veranstaltungen/2376/Data_Community_Conference_2025.html) - - - -[### TEFO 2025 Studerus Technology Forum Regensdorf • 13. November 2025](https://www.itreseller.ch/veranstaltungen/2357/TEFO_2025.html) - -[### Digital Economy Award Zürich-Oerlikon • 13. November 2025](https://www.itreseller.ch/veranstaltungen/2374/Digital_Economy_Award.html) - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_040_www.itreseller.ch_jobs.txt b/test_web_content_20251002_205603/additional_link_040_www.itreseller.ch_jobs.txt deleted file mode 100644 index 73c14845..00000000 --- a/test_web_content_20251002_205603/additional_link_040_www.itreseller.ch_jobs.txt +++ /dev/null @@ -1,327 +0,0 @@ -URL: https://www.itreseller.ch/jobs -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -ICT-Stellenangebote - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Aktuelle ICT-Stellenangebote -============================ - -In Zusammenarbeit mit - -[](https://www.jobchannel.ch/inserieren/?utm_medium=affiliate&utm_source=Swiss%20IT%20Media%20GmbH&utm_campaign=PublishLink) - -Top Jobs der Woche ------------------- - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=&pbl=2&src=site_ict&nlc2=) - -[#### Senior .NET Softwareentwickler and Power Platform Engineer (m/w/d) 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187711&pbl=2&src=site_ict&nlc2=) - - Winterthur - -Ambit Schweiz AG (26. September 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=&pbl=2&src=site_ict&nlc2=) - -[#### System Engineer Microsoft (80–100%)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187693&pbl=2&src=site_ict&nlc2=) - - Dübendorf - -ITIVITY AG (25. September 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=&pbl=2&src=site_ict&nlc2=) - -[#### SAP Application Engineer Finance & Controlling | 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187611&pbl=2&src=site_ict&nlc2=) - - Burgdorf - -Ypsomed Diabetes Care AG (24. September 2025) - -Neueste IT-Jobs ---------------- - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187855&pbl=2&src=site_ict&nlc2=) - -[#### Azure Spezialist (axelion ag)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187855&pbl=2&src=site_ict&nlc2=) - - Zug - -Avalect HR-Executive Consulting (2. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187849&pbl=2&src=site_ict&nlc2=) - -[#### ICT-Koordination – spannende Stelle mit Entwicklungspotential 80%–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187849&pbl=2&src=site_ict&nlc2=) - - Zürich - -Meier-Kopp Gruppe (2. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187842&pbl=2&src=site_ict&nlc2=) - -[#### Software Developer – Professional/Senior 80-100% (a)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187842&pbl=2&src=site_ict&nlc2=) - - Altishofen - -Galliker Transport AG (2. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187836&pbl=2&src=site_ict&nlc2=) - -[#### ICT-Projektleiter/-in 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187836&pbl=2&src=site_ict&nlc2=) - - Bern - -Kanton Bern (2. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187816&pbl=2&src=site_ict&nlc2=) - -[#### Senior AI Business Consultant 70–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187816&pbl=2&src=site_ict&nlc2=) - - Bern - -Post CH AG (2. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187831&pbl=2&src=site_ict&nlc2=) - -[#### (Senior) IT Audit Managerin oder Manager Interne Revision (80%–100%)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187831&pbl=2&src=site_ict&nlc2=) - - Zürich - -Schweizerische Nationalbank (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187826&pbl=2&src=site_ict&nlc2=) - -[#### IT Security Spezialist/-in 100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187826&pbl=2&src=site_ict&nlc2=) - - Zürich - -Kanton Zürich (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187821&pbl=2&src=site_ict&nlc2=) - -[#### Enterprise Architect für digitale Steuerlösungen 100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187821&pbl=2&src=site_ict&nlc2=) - - Zürich - -Kanton Zürich (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187810&pbl=2&src=site_ict&nlc2=) - -[#### IT-Support & Helpdesk Manager:in](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187810&pbl=2&src=site_ict&nlc2=) - - Aarau - -Leoba GmbH (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187804&pbl=2&src=site_ict&nlc2=) - -[#### Mitarbeiter/in Informatik Systemtechnik (100%)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187804&pbl=2&src=site_ict&nlc2=) - - Münsingen - -Gemeinde Münsingen (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187798&pbl=2&src=site_ict&nlc2=) - -[#### Applikationsmanager:in (mit Erfahrung in Softwareentwicklung) 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187798&pbl=2&src=site_ict&nlc2=) - - Winterthur - -ZHAW (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187793&pbl=2&src=site_ict&nlc2=) - -[#### Requirements to Deployment Manager Customer Touchpoints 70–100% (oder im Jobsharing)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187793&pbl=2&src=site_ict&nlc2=) - - Bern - -Post CH AG (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187537&pbl=2&src=site_ict&nlc2=) - -[#### Head of Sales + Marketing 80–100% (w/m/d)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187537&pbl=2&src=site_ict&nlc2=) - - Bern - -SmartIT Services AG (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187777&pbl=2&src=site_ict&nlc2=) - -[#### IT-Fachapplikationsspezialist/-in 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187777&pbl=2&src=site_ict&nlc2=) - - Zürich - -Kanton Zürich (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187771&pbl=2&src=site_ict&nlc2=) - -[#### Praktikum Content Creation 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187771&pbl=2&src=site_ict&nlc2=) - - Aarau - -Kanton Aargau (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187787&pbl=2&src=site_ict&nlc2=) - -[#### Head of Application Services | 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187787&pbl=2&src=site_ict&nlc2=) - - Burgdorf - -Ypsomed AG (30. September 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187782&pbl=2&src=site_ict&nlc2=) - -[#### SAP Application Engineer Supply Chain Management | 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187782&pbl=2&src=site_ict&nlc2=) - - Burgdorf - -Ypsomed AG (30. September 2025) - -[.jpg)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187749&pbl=2&src=site_ict&nlc2=) - -[#### Senior .NET Engineer, 80–100% (w/m/d)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187749&pbl=2&src=site_ict&nlc2=) - - Zürich - -Swiss Life (Schweiz) AG (30. September 2025) - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -People - -[### Sonepar Schweiz ernennt Raphael Maier zum neuen CEO 1. Oktober 2025](https://www.itreseller.ch/Artikel/104095/Sonepar_Schweiz_ernennt_Raphael_Maier_zum_neuen_CEO.html) - -[### AWS ernennt Stéphane Israël zum Leiter der Sovereign Cloud 1. Oktober 2025](https://www.itreseller.ch/Artikel/104090/AWS_ernennt_Stphane_Isral_zum_Leiter_der_Sovereign_Cloud.html) - -[### Paessler bekommt mit Jason Teichman neuen CEO 1. Oktober 2025](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html) - -[### Renato Petrillo wird CEO von Baggenstos 30. September 2025](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab 30. September 2025](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/additional_link_041_www.itreseller.ch_heftarchiv_2025.txt b/test_web_content_20251002_205603/additional_link_041_www.itreseller.ch_heftarchiv_2025.txt deleted file mode 100644 index 887a16c1..00000000 --- a/test_web_content_20251002_205603/additional_link_041_www.itreseller.ch_heftarchiv_2025.txt +++ /dev/null @@ -1,194 +0,0 @@ -URL: https://www.itreseller.ch/heftarchiv/2025 -Type: Additional Link -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Heftarchiv 2025 - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Heftarchiv 2025 -=============== - -< - -[2025](https://www.itreseller.ch/heftarchiv/2025)[2024](https://www.itreseller.ch/heftarchiv/2024)[2023](https://www.itreseller.ch/heftarchiv/2023)[2022](https://www.itreseller.ch/heftarchiv/2022)[2021](https://www.itreseller.ch/heftarchiv/2021)[2020](https://www.itreseller.ch/heftarchiv/2020)[2019](https://www.itreseller.ch/heftarchiv/2019)[2018](https://www.itreseller.ch/heftarchiv/2018)[2017](https://www.itreseller.ch/heftarchiv/2017)[2016](https://www.itreseller.ch/heftarchiv/2016)[2015](https://www.itreseller.ch/heftarchiv/2015)[2014](https://www.itreseller.ch/heftarchiv/2014)[2013](https://www.itreseller.ch/heftarchiv/2013)[2012](https://www.itreseller.ch/heftarchiv/2012)[2011](https://www.itreseller.ch/heftarchiv/2011)[2010](https://www.itreseller.ch/heftarchiv/2010)[2009](https://www.itreseller.ch/heftarchiv/2009) - -> - -X - -Heftarchiv-Premium-Zugriff --------------------------- - - Der Zugriff auf das Heftarchiv von "IT Reseller" wird exklusiv den Abonnenten der Print-Ausgabe zur Verfügung gestellt. - - Um eine beliebige Ausgabe herunterzuladen, geben Sie bitte den Premium-Zugangscode ein, den Sie auf der Editorial-Seite der aktuellen Ausgabe finden, und klicken Sie auf den Download-PDF-Button. - -**Premium-Zugangscode** - -Ausgabe 2025/10 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202510_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202510/inhaltsverzeichnis.html) - -Ausgabe 2025/09 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202509_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202509/inhaltsverzeichnis.html) - -Ausgabe 2025/7-8 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202507_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202507/inhaltsverzeichnis.html) - -Ausgabe 2025/06 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202506_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202506/inhaltsverzeichnis.html) - -Ausgabe 2025/05 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202505_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202505/inhaltsverzeichnis.html) - -Ausgabe 2025/04 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202504_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202504/inhaltsverzeichnis.html) - -Ausgabe 2025/03 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202503_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202503/inhaltsverzeichnis.html) - -Ausgabe 2025/1-2 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202501_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202501/inhaltsverzeichnis.html) - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) - - - -[](https://www.itreseller.ch/heftarchiv/2025)[](https://www.itreseller.ch/heftarchiv/2025) - -[](https://www.itreseller.ch/heftarchiv/2025) - -[](https://www.itreseller.ch/heftarchiv/2025) \ No newline at end of file diff --git a/test_web_content_20251002_205603/main_url_001_www.valueon.ch_.txt b/test_web_content_20251002_205603/main_url_001_www.valueon.ch_.txt deleted file mode 100644 index 39603ff0..00000000 --- a/test_web_content_20251002_205603/main_url_001_www.valueon.ch_.txt +++ /dev/null @@ -1,107 +0,0 @@ -Title: https://www.valueon.ch/ -URL: https://www.valueon.ch/ -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -# Power für deinendigitalen Erfolg - -Vertrauen von führenden Unternehmen - -## Unsere Expertise - -Von digitaler Transformation bis zu künstlicher Intelligenz – wir begleiten Sie auf Ihrem Weg in die Zukunft. - -### Digitale Strategie entwickeln - -Ihre Richtung im digitalen Wandel. - -Gemeinsames Zielbild & Roadmap, abgestimmt auf Ihr Geschäft und leiten konkrete Handlungsempfehlungen ab. - -Orientierung & Handlungssicherheit - -### Transformation gezielt optimieren - -Lücken aufdecken. Stärken nutzen. - -Systematischer Blick auf Prozesse, Systeme & Potenziale und leiten konkrete Handlungsempfehlungen ab. - -Relevanz statt Aktionismus - -### Change Management etablieren - -Menschen mitnehmen. Wandel gestalten. - -Strukturierte Begleitung der Mitarbeiter durch den digitalen Wandel mit gezielten Schulungskonzepten. - -Akzeptanz & Erfolg sichern - -### Prozesse digital automatisieren - -Effizienz steigern. Kosten senken. - -Identifikation und Umsetzung von Automatisierungspotenzialen für nachhaltige Produktivitätssteigerung. - -Messbare Effizienzgewinne - -## Erfolgreiche Projekte & Transformationen - -Unter dem Motto «Unsere Kunden stehen im Mittelpunkt» haben wir für Sie eine Auswahl an Kundenreferenzen und Business Cases zusammengestellt. - -Als KMU sind wir es eigentlich nicht gewohnt, einen so grossen Aufwand wie bei der Evaluation des richtigen Partners für die Entwicklung und Realisierung unseres neuen Kernsystems zu betreiben. Doch i... - -Markus Berther - -Geschäftsführer, Schaden Service Schweiz AG - -ValueOn hat uns durch den gesamten Prozess der Digitalen Business Transformation mit grossem Einsatz und Engagement begleitet – von der ersten IT-Standortanalyse und Sourcing Analyse über digitales Zi... - -Stefan Wolf - -Präsident, FC Luzern - -In diesem businesskritischen IT-Programm waren insgesamt vier Experten von ValueOn (ehem. Project Competence) involviert, als Projektleiter und Koordinator, Cut-Over-Manager bis hin zur Gesamt-Program... - -Roland Bosshard - -CIO / Mitglied der GL, KPT - -In time, in quality, under budget: Andreas Friedli von ValueOn (ehem. Project Competence) hat in seiner Co-Leitungsfunktion in diesem IT-Projekt ganz massgeblich dazu beigetragen, dass wir dieses trot... - -Thomas Sturzenegger - -Divisional IT Lead, RUAG Real Estate AG - -Die erfolgreiche Realisierung dieses Vorhabens ist ein wichtiger Meilenstein für die strategische Neuausrichtung der WWZ. Die Projektberater der ValueOn AG (ehem. Project Competence AG) haben dabei da... - -Thomas Reber - -Leiter Telekom & IT Services, WWZ AG - -Um die Zukunftsausrichtung unserer IT-Strategie und -Organisation möglichst optimal auf unsere Business-Anforderungen auszurichten, haben wir ValueOn (ehem. Project Competence) als Sparringpartner ... - -Andreas Guglielmo - -CFO, CHRIS sports AG - -Wir danken den externen Projektberatern der ValueOn (ehem. Project Competence), die uns kompetent und mit ebenso hohem Arbeitseinsatz durch dieses Projekt und die Verhandlungen unter schwierigen Be... - -Michael Kohlbacher - -Generalsekretär, AGZ - -Dank ValueOn konnten wir unser komplexes IT-Infrastrukturprojekt termingerecht und im Budget abschliessen. Die strukturierte Herangehensweise war ausschlaggebend. - -Peter Keller - -Projektleiter, InnovaCorp - -ValueOn hat uns sowohl fachlich als auch menschlich auf höchstem Niveau beraten. Die Experten begleiteten uns kompetent bei der Modernisierung unserer IT-Infrastruktur und der reibungslosen Ablösung u... - -Silvan Wildhaber - -CEO, Filtex Group AG - -← Wischen Sie für weitere Testimonials → - -Auto-Scroll aktiv \ No newline at end of file diff --git a/test_web_content_20251002_205603/main_url_002_www.valueon.ch_about.txt b/test_web_content_20251002_205603/main_url_002_www.valueon.ch_about.txt deleted file mode 100644 index 72468485..00000000 --- a/test_web_content_20251002_205603/main_url_002_www.valueon.ch_about.txt +++ /dev/null @@ -1,639 +0,0 @@ -Title: https://www.valueon.ch/about -URL: https://www.valueon.ch/about -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unser Team -========== - -Seit über 25 Jahren stehen wir für Innovation, Qualität und nachhaltigen Erfolg. Erfahren Sie mehr über unsere Geschichte, unsere Werte und die Menschen, die ValueON zu dem machen, was es heute ist. - -Alle Kernteam Geschäftsführende Partner Externe Zertifizierte Partner - - - -Mehr erfahren - -### Dominic Largo - -CEO - - - -Dominic führt das Unternehmen mit einer klaren Vision für digitale Innovation und strategisches Wachstum in der Beratung. - -### Dominic Largo - -CEO - - - -Zum Vergrößern klicken - -#### Schwerpunkte - -* Sicherstellen der besten Projekt- & Tranformationsmanager für unsere Kunden und unsere Vorhaben -* Reviews von komplexen und erfolgskritischen Vorhaben -* Advisor & Einsitz in Steering Boards -* Sparringpartner für Führungskräfte und Gremien - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Handel / eCommerce Tourismus Konsumgüter Luxusgüter Industrie - -#### Berufliche Stationen - -* BottleButler AG (Founder & CEO) -* Arosa Lenzerheide (Marken- und Digital Leader) -* Mitgründer mehrerer Startups (Co-CEO & VR) -* Porsche Design Group (Country Manager & GCC) -* HAWAS & Jung von Matt (Markenstratege) - -#### Und ganz nebenbei... - -...ist Dominic Largo mit grosser Passion Langstreckenläufer, Kulinariker und Game Challenger. Er geniesst explizit die Berge und seine Familienzeit. - - - -Mehr erfahren - -### Andreas Friedli - -Managing Partner - - - -Mit über 25 Jahren Erfahrung in der digitalen Transformation leitet Andreas als Partner erfolgreich strategische Grossprojekte. - -### Andreas Friedli - -Managing Partner - -#### Schwerpunkte - -* Health-Check von Projekten und Programmen -* Advisor digitaler Transformationen -* Führung von Digitalisierungsprojekten und -programmen -* Emergency- und Recoveryprojekte -* Risiko- und Quality-Assurance bei digitalen Transformationen -* Advisor digitaler Neuausrichtungen -* Leadership-Coaching Projekt und Programm Manager - -#### Im Team seit - -2004 - -#### Branchenerfahrungen - -Finanzen / Banken Versicherungen / Krankenkassen Detailhandel Verwaltung Militär Automobile IT / Telekommunikation Immobilien - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of Complex Projects -* HP GmbH, Senior Project Manager -* Compaq Computer GmbH, Senior Project Manager -* Volkswirtschaftsdep. St. Gallen, Informatikverantwortlicher - -#### Und ganz nebenbei... - -…spielt Andreas Friedli gerne Golf, liebt feines Essen und guten Wein und verbringt viel Zeit mit seiner Familie – ganz nach dem Motto «Geniesse den Moment!». - - - -Mehr erfahren - -### Patrick Motsch - -Managing Partner - - - -Patrick leitet als Partner erfolgreich komplexe IT-Implementierungsprojekte. - -### Patrick Motsch - -Managing Partner - -#### Schwerpunkte - -* Health Check von Projekten -* Führen von geschäftskritischen Projekten und Programmen -* Führen und Begleiten von Emergency und Recovery Projekten -* Führen und Begleiten von DC Moves und ICT Konsolidierungsprojekten -* Advisor für Auftraggeber - -#### Im Team seit - -2001 - -#### Branchenerfahrungen - -Baubranche IT / Telekommunikation / Data Center Industrie Sport Verteidigung Verwaltung Airspace Management Versicherungen Handel - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG) -* Vater und Pionier des TimeWinner Führungssystems -* CIO einer IT Consulting Organisation - -#### Und ganz nebenbei... - -…liebt Patrick Motsch den Garten, das Tanzen, wandert gerne, taucht so oft es geht und lernt gerne fremde Länder kennen. Sein persönliches Motto: «Wer will, der kann». - - - -Mehr erfahren - -### Richard Salvisberg - -Managing Partner - - - -Richard bringt als Partner strategische Beratungsexpertise und Führungskompetenz ein. - -### Richard Salvisberg - -Managing Partner - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Führen von geschäftskritischen Programmen und Transformationen -* Aufbau und Führen von Projektportfolio-Managementsystemen -* Sparringpartner und Advisor - -#### Im Team seit - -2006 - -#### Branchenerfahrungen - -Gesundheitswesen & (Kranken-)Versicherung Militär Verwaltung Beschaffungswesen & Transport Informatik & Telekommunikation Bau Sport Energie - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of PPM -* T-Systems Schweiz AG, Chief Information Officer -* Orange Communications SA, IT Account Manager -* Swisscom AG Bern, Head Management Support -* Swisscom AG Bern, Programm Manager Charging & Billing - -#### Und ganz nebenbei... - -…liebt Richard Salvisberg das Tanzen, lernt gerne fremde Kulturen kennen, hat Freude an schönen Autos und geniesst ein Buch bei einem guten Schluck Wein. In klaren Nächten beobachtet er interessiert den Kosmos. Sein persönliches Motto lautet «Auf innovativen Wegen nachhaltige Erfolge erzielen». - - - -Mehr erfahren - -### Stephan Schellworth - -Experte - - - -Stephan verbindet strategisches Denken mit praxisnaher Projektsteuerung und gestaltet digitale Projekte - -### Stephan Schellworth - -Experte - -#### Schwerpunkte - -* Projekt- und Teamführung -* Datenanalyse und Optimierung -* Agiles Projektmanagement - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Automatisierungstechnik Digitalisierung - -#### Berufliche Stationen - -* 2023 - 2024: Testmanager im Energiebordnetz, BMW Group -* 2021 - 2023: Gesamtfahrzeugspezialist in der E/E, BMW Group -* 2018 - 2021: Prüfstandsspezialist im BMW Prototypen-Motorenwerk, Academic Work -* 2016 - 2018: Entwicklungsingenieur, EDAG Engineering Group - -#### Und ganz nebenbei... - -…sammelt und pflegt Stephan Young- und Oldtimern, treibt Sport wie Squash und besucht regelmässig das Fitnessstudio. Er geht gern mit seinem Hund spazieren oder wandert in der Natur. Ausserdem programmiert er kleinere SmartHome-Anwendungen mit dem Raspberry Pi, Apps und erstellt 3D-Visualisierungen von Innen- und Aussenräumen. - - - -Mehr erfahren - -### Mats Rudolf - -Experte - - - -Mats berät Unternehmen zu digitalen Transformationsprojekten und Systemimplementierungen. - -### Mats Rudolf - -Experte - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Advisor digitaler Transformation -* Advisor Systems Engineering -* Projekt- und Teamführung -* Agiles Projektmanagement - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Sensortechnik Luft- und Raumfahrttechnik Maschinen- und Anlagenbau Transport und Logistik - -#### Berufliche Stationen - -* 2019 - 2024: Management Consultant Innovation und Transformation, UNITY Schweiz AG -* 2018: Industrial Solution Consulting Intern, Brütsch Rüegger Werkzeuge -* 2015 - 2016: Sensor Research and Development Intern, Sensirion AG - -#### Und ganz nebenbei... - -…zieht es Mats Rudolf im Winter für Skitouren und rasante Abfahrten auf die frisch verschneiten Berge. Wenn der Sommer kommt, tauscht er seine Ski gegen ein Surfbrett und geniesst die Wellen im Meer. Zudem schwingt er gerne den Schläger auf dem Tennisplatz und bastelt an seinen Smart-Device-Projekten. - - - -Mehr erfahren - -### Ida Dittrich - -AI Specialist - -Ida verbindet ihr wissenschaftliches Know-how mit praktischer IT-Erfahrung und bringt innovative Ansätze in technische Projekte ein. - -### Ida Dittrich - -AI Specialist - -#### Schwerpunkte - -* Product Architect and Software Engineer PowerOn Platform - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Luft- und Raumfahrtindustrie Kommunikation und Interessenvertretung Medien - -#### Berufliche Stationen - -* Forschungsprojekt zur Modellierung des inneren Aufbaus terrestrischer Exoplaneten (ETH Zürich) -* Recovery Engineer und Systems Engineer bei verschiedenen Projekten der Akademischen Raumfahrtinitiative der Schweiz (ARIS) - -#### Und ganz nebenbei... - -… spielt Ida Dittrich leidenschaftlich gern Computerspiele und bastelt an handwerklichen Projekten wie Nähen, Häkeln oder Stricken. Sie ist regelmäßig sportlich aktiv – sei es beim Joggen an der frischen Luft, im Fitnessstudio oder bei einer entspannenden Yoga-Einheit. - - - -Mehr erfahren - -### Nick Melloh - -AI-Specialist - -Nick macht künstliche Intelligenz für Unternehmen greifbar – in Projekten, Strategien und praxisnahen Schulungen. - -### Nick Melloh - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Digitale Transformation & Business Innovation -* Advisor für Künstliche Intelligenz & Wissensvermittlung -* Advisor für Strategisches Projekt- und Prozessmanagement -* Trainer für KI-Schulungen und Weiterbildung - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Digitalisierung Consulting Hospitality Event- und Innovationsmanagement KI-Anwendungen - -#### Berufliche Stationen - -* 2023–heute: Master in Business Innovation, Universität St. Gallen – Schwerpunkt Digitale Transformation & KI -* 2023–heute: Event Manager SQUARE, Universität St. Gallen – Gestaltung innovativer Lern- und Austauschformate -* 2022–2023: VP Sales, Contler AG – SaaS-Lösungen & Prozessautomatisierung im Hospitality-Sektor - -#### Und ganz nebenbei... - -…hat Nick eine Schwäche für Reisen, gutes Essen und Bücher – um neue Denkanstöße zu gewinnen und frische Perspektiven einzunehmen. Energie findet er beim Sport, in den Bergen oder bei langen Gesprächen mit Freunden – die besten Momente für ihn sind die, in denen die Uhr keine Rolle spielt. - - - -Mehr erfahren - -### Yannick Althaus - -AI-Specialist - -Yannick berät Unternehmen, indem er Strategiekompetenz mit unternehmerischer DNA verbindet. - -### Yannick Althaus - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Strategisches Management und Unternehmensführung -* Advisor für Künstliche Intelligenz und digitale Transformation -* Advisor für Produktion und Supply Chain Management - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Industrie Digitalisierung Supply Chain Management Consulting - -#### Berufliche Stationen - -* 2025: M.A. HSG in Unternehmensführung - Masterarbeit zum Einsatz von generativer KI in der Strategieentwicklung von CEOs -* 2022: B.Sc. Wirtschaftsingenieurwesen -* 2019–2025: Diverse Consulting-Praktika & Projekte in Supply Chain Management, Digitalisierung und strategischem Management sowie Mitarbeit im Familienunternehmen (neben dem Studium) -* 2013–2017: Automatiker EFZ bei Bystronic - -#### Und ganz nebenbei... - -…wenn er nicht an Strategien feilt, zieht es Yannick aufs Eis – Eishockey ist sein Adrenalinschub. Auch sonst bleibt er regelmässig in Bewegung: Skifahren im Winter, Joggen zwischendurch und Golf im Sommer. Ausserdem hat er eine Schwäche für schnelle Autos und reist gerne – am liebsten ans Meer. - - - -### Philipp Dick - -Certified Partner - -"KI wird Manager nicht ersetzen, aber Manager, die KI einsetzen, werden die ersetzen, die es nicht tun." - - - -### Romano Caviezel - -Certified Partner - -"Innovation bedeutet, bestehende Dinge zu hinterfragen und neue Wege zu entdecken." - - - -### Dawid Puzik - -Certified Partner - -"Manche sehen, was möglich ist – andere verändern, was möglich ist." - - - -### Holger Ridinger - -Certified Partner - -"Transformation braucht Struktur, Leidenschaft und Ausdauer." - - - -### Alain Kappeler - -Certified Partner - -"Wenn es dich nicht herausfordert, verändert es dich nicht." - - - -### Andreas Wyss - -Certified Partner - -Andreas verbindet strategisches Denken mit menschlichem Feingefuehl in Transformationsprozessen. - - - -### Alfredo Mercurio - -Certified Partner - -"Eine klare Vision ist der Anfang von allem." - - - -### Bernd Nagel - -Certified Partner - -"Wer will, findet Wege. Wer nicht will, findet Gründe." - - - -### Daniel Sengstag - -Certified Partner - -"Wer nicht mit der Zeit geht, geht mit der Zeit." - - - -### Daniel Lochmatter - -Certified Partner - -"Neues und bisher Unbekanntes kann man nur explorativ erfahren, erspüren, erlernen – und danach zum eigenen Nutzen einsetzen." - - - -### Michael Hermann - -Certified Partner - -"Auch beim Projekt gilt: Ende gut, alles gut." - - - -### Heinz Ruffieux - -Certified Partner - -"C'est le ton qui fait la musique." - - - -### Sven Fassbender - -Certified Partner - -"Mein Ziel ist es, Cybersicherheit verständlich und greifbar zu machen – für jeden zugänglich und praktikabel." - - - -### Raffael Santchi - -Certified Partner - -"Wer Prozesse versteht, kann Systeme formen – nicht umgekehrt." - - - -### Stephanie Kieninger - -Certified Partner - -Stephanie konzentriert sich mit ihrer Beratung auf die Menschen im Veraenderungsprozess. - - - -### Christoph Merle - -Certified Partner - -Christoph engagiert sich mit seiner langjährigen Führungserfahrung in der Industrie und mit seinem Hintergrund in strategischer und operativer Beratung für den Erfolg unserer Kunden. - -Previous slide Next slide - -Über ValueOn ------------- - -Wir schaffen digitale Transformation mit Leidenschaft und Expertise - -### Unsere Mission - -Durch exzellente Beratung schaffen wir digitale Transformation erfolgreich zu meistern. - -### Unser Versprechen - -Höchste Qualität, agile Ansätze und Passion für gemeinsamen Wirken - -25+ - -Jahre Erfahrung - -100+ - -Projekte - -98% - -Weiterempfehlung - -60% - -Schneller zum Ziel - -Unsere Geschichte ------------------ - -Eine Reise der Innovation - -Heute - -Heute und Morgen - -Als führendes Beratungsunternehmen gestalten wir aktiv die Zukunft der digitalen Transformation mit innovativen KI-Lösungen und nachhaltigen Strategien. - -KI-Ära - -KI-Revolution - -Die Einführung von KI-Systemen veränderte unsere Beratungsleistung grundlegend und ermöglichte es uns, unseren Kunden noch innovativere Lösungen anzubieten. - -Digital - -Digitale Transformation - -Mit neuen digitalen Lösungen begleiteten wir unsere Kunden in der Transformation und etablierten uns als führender Partner für digitale Innovation. - -Aufbau - -Etablierung am Markt - -Wir etablierten uns am Markt mit innovativen IT-Strategien und nachhaltiger Umsetzung, wodurch wir eine solide Basis für weiteres Wachstum schufen. - -2000 - -Gründung von ValueON - -ValueON wurde mit der Vision gegründet, Unternehmen bei der digitalen Transformation zu unterstützen und nachhaltigen Erfolg zu schaffen. - -Unsere Werte ------------- - -Was uns antreibt - -### Exzellenz - -Höchste Qualität in allem, was wir tun. Von der ersten Beratung bis zur finalen Umsetzung setzen wir auf höchste Standards. - -### Partnerschaft - -Wir sehen uns als langfristige Partner unserer Kunden und arbeiten gemeinsam an nachhaltigen Lösungen. - -### Integrität - -Ehrlichkeit, Transparenz und Vertrauen bilden das Fundament aller unserer Geschäftsbeziehungen. - -### Effektivität - -Zielgerichtete Lösungen, die messbare Ergebnisse liefern und nachhaltigen Geschäftserfolg schaffen. - -Karriere bei ValueOn --------------------- - -Werde Teil unseres Teams - -### Product-Architekt/in für KI-Plattformen - -Zürich, Schweiz M/W, 50-100% - -Details ansehen - -Keine passende Stelle gefunden? - -[Initiativbewerbung senden](mailto:office@valueon.ch) - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_205603/main_url_003_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt b/test_web_content_20251002_205603/main_url_003_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt deleted file mode 100644 index 3837989e..00000000 --- a/test_web_content_20251002_205603/main_url_003_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt +++ /dev/null @@ -1,364 +0,0 @@ -Title: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](#)[Save + Exit](#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - -[Startseite](/de/) [>](javascript:void(0)) [Unternehmen](/de/search?q=ValueOn AG) [>](javascript:void(0)) ValueOn AG - -# ValueOn AG - -ZH - -aktiv - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) -[Zur Timeline](/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -Handelsregister-Nr.: CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](/de/company/valueon-ag-4663161481/messages) - -[Sie möchten eine Änderung der Firmendaten vornehmen? Wir unterstützen Sie hierbei gerne.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Alter der Firma - -18 Jahre - -#### Umsatz in CHF - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Kapital in CHF - -200'000 - -#### Mitarbeiter - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Aktive Marken - -0 - -c/o Westhive AG -Am Stadtrand 11 -8600 Dübendorf -[Nachbarschaft](/de/company/valueon-ag-4663161481/network#neighbourhood) - -[Sie möchten Ihre Adresse anpassen? -Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -[News aus der Region Uster](/de/region/uster/uebersicht) - -## Auskünfte zu ValueOn AG - -\*angezeigte Auskünfte sind Beispiele - -#### Bonitätsauskunft - -Einschätzung der Bonität mit einer Ampel als Risikoindikator und weiteren hilfreichen Firmeninformationen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -#### Wirtschaftsauskunft - -Umfassende Auskunft über die wirtschaftliche Situation der Firma. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#commercial-report) - -#### Zahlungsverhalten - -Beurteilung der Zahlungsmoral aufgrund vergangener Rechnungen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-mode-report) - -#### Betreibungsauskunft - -Übersicht über aktuelle und vergangene Betreibungsverfahren. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-collection-report) - -#### Beteiligungsauskunft - -Erfahren Sie, an welchen nationalen und internationalen Firmen die Aktiengesellschaft, für die Sie sich interessieren, noch beteiligt ist. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#wow-report) - -#### Firmendossier als PDF - -Kontaktinformationen, Veränderungen, Umsatz- und Mitarbeiterzahlen, Management, Besitzverhältnisse, Beteiligungsstruktur und weitere Firmendaten. -[Jetzt kostenlos abrufen](/de/company/valueon-ag-4663161481/reports#firmendossier-report) - -## Über ValueOn AG - -* ValueOn AG hat den Sitz in Dübendorf, ist aktiv und im Bereich «Erbringen von IT-Dienstleistungen» tätig. - - - -* Das [Management](valueon-ag-4663161481/management) der Firma ValueOn AG besteht aus 5 Personen. - - - -* Unter [Meldungen](valueon-ag-4663161481/messages) finden Sie alle Handelsregisteränderung, die letzte erfolgte am 27.08.2025. - - - -* Die Firma ist im Handelsregister des Kantons ZH unter der UID CHE-113.416.882 eingetragen. - - - -* Unternehmen mit derselben Adresse wie ValueOn AG: [Black Projects GmbH](black-projects-gmbh-3958227961), [Bluespace Ventures AG](bluespace-ventures-ag-20038582721), [Cyberfy Consulting AG](cyberfy-consulting-ag-5194156221). - -## Management (5) - -#### neueste Verwaltungsräte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901) - -#### neuste Zeichnungsberechtigte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -#### Geschäftsleitung - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -Quelle: [SHAB](/de/datasources) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -## Netzwerk - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -## Handelsregisterinformationen - -Quelle: [SHAB](/de/datasources) - -#### Eintrag ins Handelsregister - -02.02.2007 - -#### Rechtsform - -Aktiengesellschaft - -#### Rechtssitz der Firma - -Dübendorf - -#### Handelsregisteramt - -ZH - -#### Handelsregister-Nummer - -CH-020.3.030.651-3 - -#### UID/MWST - -CHE-113.416.882 - -#### Branche - -Erbringen von IT-Dienstleistungen - -#### Firmenzweck - -Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -[Passen Sie den Firmenzweck mit wenigen Klicks an.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Revisionsstelle - -Quelle: [SHAB](/de/datasources) - -#### Aktive Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [TBO Revisions AG](/de/company/tbo-revisions-ag-20607789301) | | Zürich | 18.03.2015 | | - -[Möchten Sie die Revisionsstelle anpassen? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Frühere Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [Trevisca AG](/de/company/trevisca-ag-20628390611) | | Baar | 08.02.2007 | 17.03.2015 | - -## Weitere Firmennamen - -Quelle: [SHAB](/de/datasources) - -#### Frühere und übersetzte Firmennamen - -* Project Competence AG - -[Möchten Sie den Firmennamen aktualisieren? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Zweigniederlassungen (0) - -## Besitzverhältnisse - -Es liegen uns keine Angaben zu den Besitzverhältnissen vor. - -## Beteiligungen - -Es liegen uns keine Angaben zu den Beteiligungen vor. - - - - - - - - - -## Neueste SHAB-Meldungen: ValueOn AG - -SHAB 250827/2025 - 27.08.2025 - -**Kategorien:** Änderung des Firmenzwecks, Änderung der Firmenadresse - -Publikationsnummer: [HR02-1006417690](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006417690 "Download SHAB Publikation der ValueOn AG vom 27.08.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 133 vom 14.07.2025, Publ. 1006383218). - -**Statutenänderung:** - 18.08.2025. - -**Sitz neu:** - Dübendorf. - -**Domizil neu:** - c/o Westhive AG, Am Stadtrand 11, 8600 Dübendorf. - -**Zweck neu:** - Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -**Mitteilungen neu:** - Mitteilungen an die Aktionäre erfolgen per Brief oder E-Mail an die im Aktienbuch verzeichneten Adressen. - -SHAB 250714/2025 - 14.07.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006383218](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006383218 "Download SHAB Publikation der ValueOn AG vom 14.07.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 101 vom 27.05.2025, Publ. 1006341693). - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Einzelunterschrift [*bisher: Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]. - -SHAB 250527/2025 - 27.05.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006341693](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006341693 "Download SHAB Publikation der ValueOn AG vom 27.05.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 222 vom 14.11.2024, Publ. 1006178101). - -**Ausgeschiedene Personen und erloschene Unterschriften:** - Hamburger, Marc Eric, von St. Gallen, in Mörschwil, Präsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Egloff, Reto](/de/person/egloff-reto-101763781201), von Oberrohrdorf, in Bern, Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Mühlemann, Markus](/de/person/muehlemann-markus-142196879901), von Seeberg, in Uster, Delegierter des Verwaltungsrates, mit Einzelunterschrift. - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien [*bisher: Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]; - [Althaus, Walter](/de/person/althaus-jun-walter-205367807901), von Affoltern im Emmental, in Aarwangen, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Wyss, Andreas](/de/person/wyss-andreas-129476912501), von Dietikon, in Dietikon, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien. - -[Alle SHAB-Meldungen ansehen](/de/company/valueon-ag-4663161481/messages) - -## Trefferliste - -Hier finden Sie eine Verlinkung des Managements auf eine Trefferliste zu Personen mit dem gleichen Namen, die im Handelsregister eingetragen sind. - -[Dominic Pascal Largo](/de/list/person/largo-dominic-pascal) - -[Andreas Wyss](/de/list/person/wyss-andreas) - -[Walter Althaus Jun.](/de/list/person/althaus-jun-walter) - -[Andreas Friedli](/de/list/person/friedli-andreas) - -[Richard Salvisberg](/de/list/person/salvisberg-richard) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](/de/terms)[Datenschutz |](/de/privacy)[Impressum](/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](/de/overview) - - - - - - -[Übersicht](/de/company/valueon-ag-4663161481) - -[Auskünfte](/de/company/valueon-ag-4663161481/reports) - -[Management](/de/company/valueon-ag-4663161481/management) - -[Netzwerk](/de/company/valueon-ag-4663161481/network) - -[Timeline](/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](/de/company/valueon-ag-4663161481/shares) - -[Meldungen](/de/company/valueon-ag-4663161481/messages) - -[Marken](/de/company/valueon-ag-4663161481/brands) - -[Jobs](/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_205603/main_url_004_www.valueon.ch_.txt b/test_web_content_20251002_205603/main_url_004_www.valueon.ch_.txt deleted file mode 100644 index 39603ff0..00000000 --- a/test_web_content_20251002_205603/main_url_004_www.valueon.ch_.txt +++ /dev/null @@ -1,107 +0,0 @@ -Title: https://www.valueon.ch/ -URL: https://www.valueon.ch/ -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -# Power für deinendigitalen Erfolg - -Vertrauen von führenden Unternehmen - -## Unsere Expertise - -Von digitaler Transformation bis zu künstlicher Intelligenz – wir begleiten Sie auf Ihrem Weg in die Zukunft. - -### Digitale Strategie entwickeln - -Ihre Richtung im digitalen Wandel. - -Gemeinsames Zielbild & Roadmap, abgestimmt auf Ihr Geschäft und leiten konkrete Handlungsempfehlungen ab. - -Orientierung & Handlungssicherheit - -### Transformation gezielt optimieren - -Lücken aufdecken. Stärken nutzen. - -Systematischer Blick auf Prozesse, Systeme & Potenziale und leiten konkrete Handlungsempfehlungen ab. - -Relevanz statt Aktionismus - -### Change Management etablieren - -Menschen mitnehmen. Wandel gestalten. - -Strukturierte Begleitung der Mitarbeiter durch den digitalen Wandel mit gezielten Schulungskonzepten. - -Akzeptanz & Erfolg sichern - -### Prozesse digital automatisieren - -Effizienz steigern. Kosten senken. - -Identifikation und Umsetzung von Automatisierungspotenzialen für nachhaltige Produktivitätssteigerung. - -Messbare Effizienzgewinne - -## Erfolgreiche Projekte & Transformationen - -Unter dem Motto «Unsere Kunden stehen im Mittelpunkt» haben wir für Sie eine Auswahl an Kundenreferenzen und Business Cases zusammengestellt. - -Als KMU sind wir es eigentlich nicht gewohnt, einen so grossen Aufwand wie bei der Evaluation des richtigen Partners für die Entwicklung und Realisierung unseres neuen Kernsystems zu betreiben. Doch i... - -Markus Berther - -Geschäftsführer, Schaden Service Schweiz AG - -ValueOn hat uns durch den gesamten Prozess der Digitalen Business Transformation mit grossem Einsatz und Engagement begleitet – von der ersten IT-Standortanalyse und Sourcing Analyse über digitales Zi... - -Stefan Wolf - -Präsident, FC Luzern - -In diesem businesskritischen IT-Programm waren insgesamt vier Experten von ValueOn (ehem. Project Competence) involviert, als Projektleiter und Koordinator, Cut-Over-Manager bis hin zur Gesamt-Program... - -Roland Bosshard - -CIO / Mitglied der GL, KPT - -In time, in quality, under budget: Andreas Friedli von ValueOn (ehem. Project Competence) hat in seiner Co-Leitungsfunktion in diesem IT-Projekt ganz massgeblich dazu beigetragen, dass wir dieses trot... - -Thomas Sturzenegger - -Divisional IT Lead, RUAG Real Estate AG - -Die erfolgreiche Realisierung dieses Vorhabens ist ein wichtiger Meilenstein für die strategische Neuausrichtung der WWZ. Die Projektberater der ValueOn AG (ehem. Project Competence AG) haben dabei da... - -Thomas Reber - -Leiter Telekom & IT Services, WWZ AG - -Um die Zukunftsausrichtung unserer IT-Strategie und -Organisation möglichst optimal auf unsere Business-Anforderungen auszurichten, haben wir ValueOn (ehem. Project Competence) als Sparringpartner ... - -Andreas Guglielmo - -CFO, CHRIS sports AG - -Wir danken den externen Projektberatern der ValueOn (ehem. Project Competence), die uns kompetent und mit ebenso hohem Arbeitseinsatz durch dieses Projekt und die Verhandlungen unter schwierigen Be... - -Michael Kohlbacher - -Generalsekretär, AGZ - -Dank ValueOn konnten wir unser komplexes IT-Infrastrukturprojekt termingerecht und im Budget abschliessen. Die strukturierte Herangehensweise war ausschlaggebend. - -Peter Keller - -Projektleiter, InnovaCorp - -ValueOn hat uns sowohl fachlich als auch menschlich auf höchstem Niveau beraten. Die Experten begleiteten uns kompetent bei der Modernisierung unserer IT-Infrastruktur und der reibungslosen Ablösung u... - -Silvan Wildhaber - -CEO, Filtex Group AG - -← Wischen Sie für weitere Testimonials → - -Auto-Scroll aktiv \ No newline at end of file diff --git a/test_web_content_20251002_205603/main_url_005_www.valueon.ch_about.txt b/test_web_content_20251002_205603/main_url_005_www.valueon.ch_about.txt deleted file mode 100644 index 72468485..00000000 --- a/test_web_content_20251002_205603/main_url_005_www.valueon.ch_about.txt +++ /dev/null @@ -1,639 +0,0 @@ -Title: https://www.valueon.ch/about -URL: https://www.valueon.ch/about -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unser Team -========== - -Seit über 25 Jahren stehen wir für Innovation, Qualität und nachhaltigen Erfolg. Erfahren Sie mehr über unsere Geschichte, unsere Werte und die Menschen, die ValueON zu dem machen, was es heute ist. - -Alle Kernteam Geschäftsführende Partner Externe Zertifizierte Partner - - - -Mehr erfahren - -### Dominic Largo - -CEO - - - -Dominic führt das Unternehmen mit einer klaren Vision für digitale Innovation und strategisches Wachstum in der Beratung. - -### Dominic Largo - -CEO - - - -Zum Vergrößern klicken - -#### Schwerpunkte - -* Sicherstellen der besten Projekt- & Tranformationsmanager für unsere Kunden und unsere Vorhaben -* Reviews von komplexen und erfolgskritischen Vorhaben -* Advisor & Einsitz in Steering Boards -* Sparringpartner für Führungskräfte und Gremien - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Handel / eCommerce Tourismus Konsumgüter Luxusgüter Industrie - -#### Berufliche Stationen - -* BottleButler AG (Founder & CEO) -* Arosa Lenzerheide (Marken- und Digital Leader) -* Mitgründer mehrerer Startups (Co-CEO & VR) -* Porsche Design Group (Country Manager & GCC) -* HAWAS & Jung von Matt (Markenstratege) - -#### Und ganz nebenbei... - -...ist Dominic Largo mit grosser Passion Langstreckenläufer, Kulinariker und Game Challenger. Er geniesst explizit die Berge und seine Familienzeit. - - - -Mehr erfahren - -### Andreas Friedli - -Managing Partner - - - -Mit über 25 Jahren Erfahrung in der digitalen Transformation leitet Andreas als Partner erfolgreich strategische Grossprojekte. - -### Andreas Friedli - -Managing Partner - -#### Schwerpunkte - -* Health-Check von Projekten und Programmen -* Advisor digitaler Transformationen -* Führung von Digitalisierungsprojekten und -programmen -* Emergency- und Recoveryprojekte -* Risiko- und Quality-Assurance bei digitalen Transformationen -* Advisor digitaler Neuausrichtungen -* Leadership-Coaching Projekt und Programm Manager - -#### Im Team seit - -2004 - -#### Branchenerfahrungen - -Finanzen / Banken Versicherungen / Krankenkassen Detailhandel Verwaltung Militär Automobile IT / Telekommunikation Immobilien - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of Complex Projects -* HP GmbH, Senior Project Manager -* Compaq Computer GmbH, Senior Project Manager -* Volkswirtschaftsdep. St. Gallen, Informatikverantwortlicher - -#### Und ganz nebenbei... - -…spielt Andreas Friedli gerne Golf, liebt feines Essen und guten Wein und verbringt viel Zeit mit seiner Familie – ganz nach dem Motto «Geniesse den Moment!». - - - -Mehr erfahren - -### Patrick Motsch - -Managing Partner - - - -Patrick leitet als Partner erfolgreich komplexe IT-Implementierungsprojekte. - -### Patrick Motsch - -Managing Partner - -#### Schwerpunkte - -* Health Check von Projekten -* Führen von geschäftskritischen Projekten und Programmen -* Führen und Begleiten von Emergency und Recovery Projekten -* Führen und Begleiten von DC Moves und ICT Konsolidierungsprojekten -* Advisor für Auftraggeber - -#### Im Team seit - -2001 - -#### Branchenerfahrungen - -Baubranche IT / Telekommunikation / Data Center Industrie Sport Verteidigung Verwaltung Airspace Management Versicherungen Handel - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG) -* Vater und Pionier des TimeWinner Führungssystems -* CIO einer IT Consulting Organisation - -#### Und ganz nebenbei... - -…liebt Patrick Motsch den Garten, das Tanzen, wandert gerne, taucht so oft es geht und lernt gerne fremde Länder kennen. Sein persönliches Motto: «Wer will, der kann». - - - -Mehr erfahren - -### Richard Salvisberg - -Managing Partner - - - -Richard bringt als Partner strategische Beratungsexpertise und Führungskompetenz ein. - -### Richard Salvisberg - -Managing Partner - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Führen von geschäftskritischen Programmen und Transformationen -* Aufbau und Führen von Projektportfolio-Managementsystemen -* Sparringpartner und Advisor - -#### Im Team seit - -2006 - -#### Branchenerfahrungen - -Gesundheitswesen & (Kranken-)Versicherung Militär Verwaltung Beschaffungswesen & Transport Informatik & Telekommunikation Bau Sport Energie - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of PPM -* T-Systems Schweiz AG, Chief Information Officer -* Orange Communications SA, IT Account Manager -* Swisscom AG Bern, Head Management Support -* Swisscom AG Bern, Programm Manager Charging & Billing - -#### Und ganz nebenbei... - -…liebt Richard Salvisberg das Tanzen, lernt gerne fremde Kulturen kennen, hat Freude an schönen Autos und geniesst ein Buch bei einem guten Schluck Wein. In klaren Nächten beobachtet er interessiert den Kosmos. Sein persönliches Motto lautet «Auf innovativen Wegen nachhaltige Erfolge erzielen». - - - -Mehr erfahren - -### Stephan Schellworth - -Experte - - - -Stephan verbindet strategisches Denken mit praxisnaher Projektsteuerung und gestaltet digitale Projekte - -### Stephan Schellworth - -Experte - -#### Schwerpunkte - -* Projekt- und Teamführung -* Datenanalyse und Optimierung -* Agiles Projektmanagement - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Automatisierungstechnik Digitalisierung - -#### Berufliche Stationen - -* 2023 - 2024: Testmanager im Energiebordnetz, BMW Group -* 2021 - 2023: Gesamtfahrzeugspezialist in der E/E, BMW Group -* 2018 - 2021: Prüfstandsspezialist im BMW Prototypen-Motorenwerk, Academic Work -* 2016 - 2018: Entwicklungsingenieur, EDAG Engineering Group - -#### Und ganz nebenbei... - -…sammelt und pflegt Stephan Young- und Oldtimern, treibt Sport wie Squash und besucht regelmässig das Fitnessstudio. Er geht gern mit seinem Hund spazieren oder wandert in der Natur. Ausserdem programmiert er kleinere SmartHome-Anwendungen mit dem Raspberry Pi, Apps und erstellt 3D-Visualisierungen von Innen- und Aussenräumen. - - - -Mehr erfahren - -### Mats Rudolf - -Experte - - - -Mats berät Unternehmen zu digitalen Transformationsprojekten und Systemimplementierungen. - -### Mats Rudolf - -Experte - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Advisor digitaler Transformation -* Advisor Systems Engineering -* Projekt- und Teamführung -* Agiles Projektmanagement - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Sensortechnik Luft- und Raumfahrttechnik Maschinen- und Anlagenbau Transport und Logistik - -#### Berufliche Stationen - -* 2019 - 2024: Management Consultant Innovation und Transformation, UNITY Schweiz AG -* 2018: Industrial Solution Consulting Intern, Brütsch Rüegger Werkzeuge -* 2015 - 2016: Sensor Research and Development Intern, Sensirion AG - -#### Und ganz nebenbei... - -…zieht es Mats Rudolf im Winter für Skitouren und rasante Abfahrten auf die frisch verschneiten Berge. Wenn der Sommer kommt, tauscht er seine Ski gegen ein Surfbrett und geniesst die Wellen im Meer. Zudem schwingt er gerne den Schläger auf dem Tennisplatz und bastelt an seinen Smart-Device-Projekten. - - - -Mehr erfahren - -### Ida Dittrich - -AI Specialist - -Ida verbindet ihr wissenschaftliches Know-how mit praktischer IT-Erfahrung und bringt innovative Ansätze in technische Projekte ein. - -### Ida Dittrich - -AI Specialist - -#### Schwerpunkte - -* Product Architect and Software Engineer PowerOn Platform - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Luft- und Raumfahrtindustrie Kommunikation und Interessenvertretung Medien - -#### Berufliche Stationen - -* Forschungsprojekt zur Modellierung des inneren Aufbaus terrestrischer Exoplaneten (ETH Zürich) -* Recovery Engineer und Systems Engineer bei verschiedenen Projekten der Akademischen Raumfahrtinitiative der Schweiz (ARIS) - -#### Und ganz nebenbei... - -… spielt Ida Dittrich leidenschaftlich gern Computerspiele und bastelt an handwerklichen Projekten wie Nähen, Häkeln oder Stricken. Sie ist regelmäßig sportlich aktiv – sei es beim Joggen an der frischen Luft, im Fitnessstudio oder bei einer entspannenden Yoga-Einheit. - - - -Mehr erfahren - -### Nick Melloh - -AI-Specialist - -Nick macht künstliche Intelligenz für Unternehmen greifbar – in Projekten, Strategien und praxisnahen Schulungen. - -### Nick Melloh - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Digitale Transformation & Business Innovation -* Advisor für Künstliche Intelligenz & Wissensvermittlung -* Advisor für Strategisches Projekt- und Prozessmanagement -* Trainer für KI-Schulungen und Weiterbildung - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Digitalisierung Consulting Hospitality Event- und Innovationsmanagement KI-Anwendungen - -#### Berufliche Stationen - -* 2023–heute: Master in Business Innovation, Universität St. Gallen – Schwerpunkt Digitale Transformation & KI -* 2023–heute: Event Manager SQUARE, Universität St. Gallen – Gestaltung innovativer Lern- und Austauschformate -* 2022–2023: VP Sales, Contler AG – SaaS-Lösungen & Prozessautomatisierung im Hospitality-Sektor - -#### Und ganz nebenbei... - -…hat Nick eine Schwäche für Reisen, gutes Essen und Bücher – um neue Denkanstöße zu gewinnen und frische Perspektiven einzunehmen. Energie findet er beim Sport, in den Bergen oder bei langen Gesprächen mit Freunden – die besten Momente für ihn sind die, in denen die Uhr keine Rolle spielt. - - - -Mehr erfahren - -### Yannick Althaus - -AI-Specialist - -Yannick berät Unternehmen, indem er Strategiekompetenz mit unternehmerischer DNA verbindet. - -### Yannick Althaus - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Strategisches Management und Unternehmensführung -* Advisor für Künstliche Intelligenz und digitale Transformation -* Advisor für Produktion und Supply Chain Management - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Industrie Digitalisierung Supply Chain Management Consulting - -#### Berufliche Stationen - -* 2025: M.A. HSG in Unternehmensführung - Masterarbeit zum Einsatz von generativer KI in der Strategieentwicklung von CEOs -* 2022: B.Sc. Wirtschaftsingenieurwesen -* 2019–2025: Diverse Consulting-Praktika & Projekte in Supply Chain Management, Digitalisierung und strategischem Management sowie Mitarbeit im Familienunternehmen (neben dem Studium) -* 2013–2017: Automatiker EFZ bei Bystronic - -#### Und ganz nebenbei... - -…wenn er nicht an Strategien feilt, zieht es Yannick aufs Eis – Eishockey ist sein Adrenalinschub. Auch sonst bleibt er regelmässig in Bewegung: Skifahren im Winter, Joggen zwischendurch und Golf im Sommer. Ausserdem hat er eine Schwäche für schnelle Autos und reist gerne – am liebsten ans Meer. - - - -### Philipp Dick - -Certified Partner - -"KI wird Manager nicht ersetzen, aber Manager, die KI einsetzen, werden die ersetzen, die es nicht tun." - - - -### Romano Caviezel - -Certified Partner - -"Innovation bedeutet, bestehende Dinge zu hinterfragen und neue Wege zu entdecken." - - - -### Dawid Puzik - -Certified Partner - -"Manche sehen, was möglich ist – andere verändern, was möglich ist." - - - -### Holger Ridinger - -Certified Partner - -"Transformation braucht Struktur, Leidenschaft und Ausdauer." - - - -### Alain Kappeler - -Certified Partner - -"Wenn es dich nicht herausfordert, verändert es dich nicht." - - - -### Andreas Wyss - -Certified Partner - -Andreas verbindet strategisches Denken mit menschlichem Feingefuehl in Transformationsprozessen. - - - -### Alfredo Mercurio - -Certified Partner - -"Eine klare Vision ist der Anfang von allem." - - - -### Bernd Nagel - -Certified Partner - -"Wer will, findet Wege. Wer nicht will, findet Gründe." - - - -### Daniel Sengstag - -Certified Partner - -"Wer nicht mit der Zeit geht, geht mit der Zeit." - - - -### Daniel Lochmatter - -Certified Partner - -"Neues und bisher Unbekanntes kann man nur explorativ erfahren, erspüren, erlernen – und danach zum eigenen Nutzen einsetzen." - - - -### Michael Hermann - -Certified Partner - -"Auch beim Projekt gilt: Ende gut, alles gut." - - - -### Heinz Ruffieux - -Certified Partner - -"C'est le ton qui fait la musique." - - - -### Sven Fassbender - -Certified Partner - -"Mein Ziel ist es, Cybersicherheit verständlich und greifbar zu machen – für jeden zugänglich und praktikabel." - - - -### Raffael Santchi - -Certified Partner - -"Wer Prozesse versteht, kann Systeme formen – nicht umgekehrt." - - - -### Stephanie Kieninger - -Certified Partner - -Stephanie konzentriert sich mit ihrer Beratung auf die Menschen im Veraenderungsprozess. - - - -### Christoph Merle - -Certified Partner - -Christoph engagiert sich mit seiner langjährigen Führungserfahrung in der Industrie und mit seinem Hintergrund in strategischer und operativer Beratung für den Erfolg unserer Kunden. - -Previous slide Next slide - -Über ValueOn ------------- - -Wir schaffen digitale Transformation mit Leidenschaft und Expertise - -### Unsere Mission - -Durch exzellente Beratung schaffen wir digitale Transformation erfolgreich zu meistern. - -### Unser Versprechen - -Höchste Qualität, agile Ansätze und Passion für gemeinsamen Wirken - -25+ - -Jahre Erfahrung - -100+ - -Projekte - -98% - -Weiterempfehlung - -60% - -Schneller zum Ziel - -Unsere Geschichte ------------------ - -Eine Reise der Innovation - -Heute - -Heute und Morgen - -Als führendes Beratungsunternehmen gestalten wir aktiv die Zukunft der digitalen Transformation mit innovativen KI-Lösungen und nachhaltigen Strategien. - -KI-Ära - -KI-Revolution - -Die Einführung von KI-Systemen veränderte unsere Beratungsleistung grundlegend und ermöglichte es uns, unseren Kunden noch innovativere Lösungen anzubieten. - -Digital - -Digitale Transformation - -Mit neuen digitalen Lösungen begleiteten wir unsere Kunden in der Transformation und etablierten uns als führender Partner für digitale Innovation. - -Aufbau - -Etablierung am Markt - -Wir etablierten uns am Markt mit innovativen IT-Strategien und nachhaltiger Umsetzung, wodurch wir eine solide Basis für weiteres Wachstum schufen. - -2000 - -Gründung von ValueON - -ValueON wurde mit der Vision gegründet, Unternehmen bei der digitalen Transformation zu unterstützen und nachhaltigen Erfolg zu schaffen. - -Unsere Werte ------------- - -Was uns antreibt - -### Exzellenz - -Höchste Qualität in allem, was wir tun. Von der ersten Beratung bis zur finalen Umsetzung setzen wir auf höchste Standards. - -### Partnerschaft - -Wir sehen uns als langfristige Partner unserer Kunden und arbeiten gemeinsam an nachhaltigen Lösungen. - -### Integrität - -Ehrlichkeit, Transparenz und Vertrauen bilden das Fundament aller unserer Geschäftsbeziehungen. - -### Effektivität - -Zielgerichtete Lösungen, die messbare Ergebnisse liefern und nachhaltigen Geschäftserfolg schaffen. - -Karriere bei ValueOn --------------------- - -Werde Teil unseres Teams - -### Product-Architekt/in für KI-Plattformen - -Zürich, Schweiz M/W, 50-100% - -Details ansehen - -Keine passende Stelle gefunden? - -[Initiativbewerbung senden](mailto:office@valueon.ch) - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_205603/main_url_006_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt b/test_web_content_20251002_205603/main_url_006_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt deleted file mode 100644 index 3837989e..00000000 --- a/test_web_content_20251002_205603/main_url_006_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt +++ /dev/null @@ -1,364 +0,0 @@ -Title: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](#)[Save + Exit](#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - -[Startseite](/de/) [>](javascript:void(0)) [Unternehmen](/de/search?q=ValueOn AG) [>](javascript:void(0)) ValueOn AG - -# ValueOn AG - -ZH - -aktiv - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) -[Zur Timeline](/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -Handelsregister-Nr.: CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](/de/company/valueon-ag-4663161481/messages) - -[Sie möchten eine Änderung der Firmendaten vornehmen? Wir unterstützen Sie hierbei gerne.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Alter der Firma - -18 Jahre - -#### Umsatz in CHF - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Kapital in CHF - -200'000 - -#### Mitarbeiter - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Aktive Marken - -0 - -c/o Westhive AG -Am Stadtrand 11 -8600 Dübendorf -[Nachbarschaft](/de/company/valueon-ag-4663161481/network#neighbourhood) - -[Sie möchten Ihre Adresse anpassen? -Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -[News aus der Region Uster](/de/region/uster/uebersicht) - -## Auskünfte zu ValueOn AG - -\*angezeigte Auskünfte sind Beispiele - -#### Bonitätsauskunft - -Einschätzung der Bonität mit einer Ampel als Risikoindikator und weiteren hilfreichen Firmeninformationen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -#### Wirtschaftsauskunft - -Umfassende Auskunft über die wirtschaftliche Situation der Firma. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#commercial-report) - -#### Zahlungsverhalten - -Beurteilung der Zahlungsmoral aufgrund vergangener Rechnungen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-mode-report) - -#### Betreibungsauskunft - -Übersicht über aktuelle und vergangene Betreibungsverfahren. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-collection-report) - -#### Beteiligungsauskunft - -Erfahren Sie, an welchen nationalen und internationalen Firmen die Aktiengesellschaft, für die Sie sich interessieren, noch beteiligt ist. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#wow-report) - -#### Firmendossier als PDF - -Kontaktinformationen, Veränderungen, Umsatz- und Mitarbeiterzahlen, Management, Besitzverhältnisse, Beteiligungsstruktur und weitere Firmendaten. -[Jetzt kostenlos abrufen](/de/company/valueon-ag-4663161481/reports#firmendossier-report) - -## Über ValueOn AG - -* ValueOn AG hat den Sitz in Dübendorf, ist aktiv und im Bereich «Erbringen von IT-Dienstleistungen» tätig. - - - -* Das [Management](valueon-ag-4663161481/management) der Firma ValueOn AG besteht aus 5 Personen. - - - -* Unter [Meldungen](valueon-ag-4663161481/messages) finden Sie alle Handelsregisteränderung, die letzte erfolgte am 27.08.2025. - - - -* Die Firma ist im Handelsregister des Kantons ZH unter der UID CHE-113.416.882 eingetragen. - - - -* Unternehmen mit derselben Adresse wie ValueOn AG: [Black Projects GmbH](black-projects-gmbh-3958227961), [Bluespace Ventures AG](bluespace-ventures-ag-20038582721), [Cyberfy Consulting AG](cyberfy-consulting-ag-5194156221). - -## Management (5) - -#### neueste Verwaltungsräte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901) - -#### neuste Zeichnungsberechtigte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -#### Geschäftsleitung - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -Quelle: [SHAB](/de/datasources) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -## Netzwerk - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -## Handelsregisterinformationen - -Quelle: [SHAB](/de/datasources) - -#### Eintrag ins Handelsregister - -02.02.2007 - -#### Rechtsform - -Aktiengesellschaft - -#### Rechtssitz der Firma - -Dübendorf - -#### Handelsregisteramt - -ZH - -#### Handelsregister-Nummer - -CH-020.3.030.651-3 - -#### UID/MWST - -CHE-113.416.882 - -#### Branche - -Erbringen von IT-Dienstleistungen - -#### Firmenzweck - -Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -[Passen Sie den Firmenzweck mit wenigen Klicks an.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Revisionsstelle - -Quelle: [SHAB](/de/datasources) - -#### Aktive Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [TBO Revisions AG](/de/company/tbo-revisions-ag-20607789301) | | Zürich | 18.03.2015 | | - -[Möchten Sie die Revisionsstelle anpassen? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Frühere Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [Trevisca AG](/de/company/trevisca-ag-20628390611) | | Baar | 08.02.2007 | 17.03.2015 | - -## Weitere Firmennamen - -Quelle: [SHAB](/de/datasources) - -#### Frühere und übersetzte Firmennamen - -* Project Competence AG - -[Möchten Sie den Firmennamen aktualisieren? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Zweigniederlassungen (0) - -## Besitzverhältnisse - -Es liegen uns keine Angaben zu den Besitzverhältnissen vor. - -## Beteiligungen - -Es liegen uns keine Angaben zu den Beteiligungen vor. - - - - - - - - - -## Neueste SHAB-Meldungen: ValueOn AG - -SHAB 250827/2025 - 27.08.2025 - -**Kategorien:** Änderung des Firmenzwecks, Änderung der Firmenadresse - -Publikationsnummer: [HR02-1006417690](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006417690 "Download SHAB Publikation der ValueOn AG vom 27.08.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 133 vom 14.07.2025, Publ. 1006383218). - -**Statutenänderung:** - 18.08.2025. - -**Sitz neu:** - Dübendorf. - -**Domizil neu:** - c/o Westhive AG, Am Stadtrand 11, 8600 Dübendorf. - -**Zweck neu:** - Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -**Mitteilungen neu:** - Mitteilungen an die Aktionäre erfolgen per Brief oder E-Mail an die im Aktienbuch verzeichneten Adressen. - -SHAB 250714/2025 - 14.07.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006383218](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006383218 "Download SHAB Publikation der ValueOn AG vom 14.07.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 101 vom 27.05.2025, Publ. 1006341693). - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Einzelunterschrift [*bisher: Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]. - -SHAB 250527/2025 - 27.05.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006341693](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006341693 "Download SHAB Publikation der ValueOn AG vom 27.05.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 222 vom 14.11.2024, Publ. 1006178101). - -**Ausgeschiedene Personen und erloschene Unterschriften:** - Hamburger, Marc Eric, von St. Gallen, in Mörschwil, Präsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Egloff, Reto](/de/person/egloff-reto-101763781201), von Oberrohrdorf, in Bern, Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Mühlemann, Markus](/de/person/muehlemann-markus-142196879901), von Seeberg, in Uster, Delegierter des Verwaltungsrates, mit Einzelunterschrift. - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien [*bisher: Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]; - [Althaus, Walter](/de/person/althaus-jun-walter-205367807901), von Affoltern im Emmental, in Aarwangen, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Wyss, Andreas](/de/person/wyss-andreas-129476912501), von Dietikon, in Dietikon, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien. - -[Alle SHAB-Meldungen ansehen](/de/company/valueon-ag-4663161481/messages) - -## Trefferliste - -Hier finden Sie eine Verlinkung des Managements auf eine Trefferliste zu Personen mit dem gleichen Namen, die im Handelsregister eingetragen sind. - -[Dominic Pascal Largo](/de/list/person/largo-dominic-pascal) - -[Andreas Wyss](/de/list/person/wyss-andreas) - -[Walter Althaus Jun.](/de/list/person/althaus-jun-walter) - -[Andreas Friedli](/de/list/person/friedli-andreas) - -[Richard Salvisberg](/de/list/person/salvisberg-richard) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](/de/terms)[Datenschutz |](/de/privacy)[Impressum](/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](/de/overview) - - - - - - -[Übersicht](/de/company/valueon-ag-4663161481) - -[Auskünfte](/de/company/valueon-ag-4663161481/reports) - -[Management](/de/company/valueon-ag-4663161481/management) - -[Netzwerk](/de/company/valueon-ag-4663161481/network) - -[Timeline](/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](/de/company/valueon-ag-4663161481/shares) - -[Meldungen](/de/company/valueon-ag-4663161481/messages) - -[Marken](/de/company/valueon-ag-4663161481/brands) - -[Jobs](/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_205603/main_url_007_www.itreseller.ch_unternehmen_6046_Valueon.html.txt b/test_web_content_20251002_205603/main_url_007_www.itreseller.ch_unternehmen_6046_Valueon.html.txt deleted file mode 100644 index 3993c1b4..00000000 --- a/test_web_content_20251002_205603/main_url_007_www.itreseller.ch_unternehmen_6046_Valueon.html.txt +++ /dev/null @@ -1,124 +0,0 @@ -Title: https://www.itreseller.ch/unternehmen/6046/Valueon.html -URL: https://www.itreseller.ch/unternehmen/6046/Valueon.html -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Valueon - Unternehmensverzeichnis IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Valueon in den News von -======================= - - - -[](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html) - -[### Valueon vollzieht Führungswechsel](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html) - -[Generationen- und Führungswechsel bei Valueon: Gründer Markus Mühlemann (Bild, links) übergibt das Zepter an Dominic Largo (Bild, rechts).](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html)7. Juni 2024 - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/main_url_008_www.netzwoche.ch_news_2024-06-10_neuer-ceo-fuer-valueon.txt b/test_web_content_20251002_205603/main_url_008_www.netzwoche.ch_news_2024-06-10_neuer-ceo-fuer-valueon.txt deleted file mode 100644 index f2382993..00000000 --- a/test_web_content_20251002_205603/main_url_008_www.netzwoche.ch_news_2024-06-10_neuer-ceo-fuer-valueon.txt +++ /dev/null @@ -1,279 +0,0 @@ -Title: https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon -URL: https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Neuer CEO für Valueon | Netzwoche - -=============== -[Direkt zum Inhalt](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon#main-content) - -Header menu ------------ - -* [Kontakt](https://www.netzwoche.ch/contact) -* [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb) -* [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps) -* [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award) -* [E-Paper](http://epaper.netzwoche.ch/) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzmedien.ch/de/shop/ "Shop") -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [» Newsletter](https://www.netzwoche.ch/newsletteranmeldung) - -[](https://www.netzwoche.ch/ "Startseite") - -Donnerstag, 2. Oktober 2025 - -[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - -Main navigation ---------------- - -* [News](https://www.netzwoche.ch/news) - * [Live](https://www.netzwoche.ch/tags/live "Live") - * [Wild Card](https://www.netzwoche.ch/tags/wild-card "Wild Card") - * [Studien](https://www.netzwoche.ch/studien) - * [Meinungen](https://www.netzwoche.ch/meinungen) - * [Hands-on](https://www.netzwoche.ch/hands-on) - * [» alle News](https://www.netzwoche.ch/news) - -* [Storys](https://www.netzwoche.ch/storys) -* [Dossiers](https://www.netzwoche.ch/dossiers) - * [Best of Swiss Web](https://www.netzwoche.ch/dossier/best-of-swiss-web-2025 "Best of Swiss Web 2023") - * [Best of Swiss Apps](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2025 "Best of Swiss Apps") - * [Best of Swiss Software](https://www.netzwoche.ch/dossier/best-of-swiss-software-2024) - * [SAP S/4 Hana](https://www.netzwoche.ch/dossier/sap-s4-hana-was-bis-2025-zu-tun-ist) - * [Arbeitswelten](https://www.netzwoche.ch/dossier/management-career-arbeitswelten "Management & Career") - * [Gesundheit wird digital](https://www.netzwoche.ch/dossier/gesundheit-wird-digital "Gesundheit wird digital") - * [Blockchain](https://www.netzwoche.ch/dossier/blockchain) - * [EU-DSGVO](https://www.netzwoche.ch/eu-dsgvo) - * [XaaS, Managed Services & Co.](https://www.netzwoche.ch/dossier/cloud-und-managed-services "XaaS, Managed Services & Co.") - * [Digital Banking](https://www.netzwoche.ch/dossier/fintech-insurtech-digital-banking) - * [» alle Dossiers](https://www.netzwoche.ch/dossiers) - -* [Video](https://www.netzwoche.ch/dossier/die-redaktion-filmt) -* [Specials](https://www.netzwoche.ch/specials) - * [IT for Health](https://www.netzwoche.ch/dossier/it-for-health-22025 "IT for Health") - * [Artificial Intelligence](https://www.netzwoche.ch/dossier/artificial-intelligence-special-2025) - * [Finance 2030](https://www.netzwoche.ch/dossier/finance-2030-ausgabe-2025 "Finance 2030") - * [Swiss Digital Ranking](https://www.netzwoche.ch/dossier/swiss-digital-ranking-2025) - * [Cybersecurity](https://www.netzwoche.ch/dossier/cybersecurity-2025 "Cybersecurity") - * [Cloud & Managed Services](https://www.netzwoche.ch/dossier/cloud-managed-services-2025 "Cloud & Managed Services") - * [Fintech & Insurtech](https://www.netzwoche.ch/dossier/fintech-insurtech-2024 "Fintech & Insurtech") - * [IT for Gov](https://www.netzwoche.ch/dossier/it-for-gov-2024 "IT for Gov ") - * [Professional AV & Digital Signage](https://www.netzwoche.ch/dossier/professional-av-digital-signage-2023 "Digital Signage") - * [» alle Specials](https://www.netzwoche.ch/specials) - -* [Events](https://www.netzwoche.ch/events) - * [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb "Best of Swiss Web ") - * [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps "/bestofswissapps") - * [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award "Best of Swiss Software") - -* [Netzwitzig](https://www.netzwoche.ch/last-news) -* [E-Paper Login](https://epaper.netzwoche.ch/) - -[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - -Schlüsselwörter - -Webcode - -[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - -[News](https://www.netzwoche.ch/news) - -Dominic Largo -Neuer CEO für Valueon -===================== - -Mo 10.06.2024 - 13:10 Uhr - - von [Alexandra Hüsler](https://www.netzwoche.ch/user/20045) und yzu - -[](https://www.facebook.com/sharer/sharer.php?u=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://twitter.com/share?text=Neuer%20CEO%20f%C3%BCr%20Valueon&url=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](whatsapp://send?text=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](mailto:?subject=Neuer%20CEO%20f%C3%BCr%20Valueon&body=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.linkedin.com/shareArticle?mini=true&url=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - -Markus Mühlemann, Gründer, Inhaber und CEO von Valueon, übergibt die Geschäftsführung an Dominic Largo. Mühlemann steht dem Unternehmen weiterhin als Verwaltungsratsmitglied zur Verfügung. - -[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - - - -Markus Mühlemann (links) übergibt die Geschäftsführung und CEO-Aufgaben an Dominic Largo. (Source: zVg) - -Markus Mühlemann (links) übergibt die Geschäftsführung und CEO-Aufgaben an Dominic Largo. (Source: zVg) - -24 Jahre nach der Gründung als Project Competence und zwei Jahre nach dem Rebranding des Unternehmens 2022 zu Valueon tritt Markus Mühlemann als CEO ab. Wie das Unternehmen schreibt, übergibt der Gründer, Inhaber und CEO von Valueon im "richtigen, idealerweise selbstgewählten Moment" an seinen Nachfolger Dominic Largo. Markus Mühlemann wird weiterhin als Verwaltungsratsmitglied dem Unternehmen zur Verfügung stehen. - -"Es ging uns vor allem darum, eine Person zu finden, die künftig einen Mehrwert für das Team und so schlussendlich auch für unsere Kunden mitbringt", sagt Mühlemann. "Und dies umfasst nicht nur eine Verjüngung und eine starke Persönlichkeit, sondern auch eine gezielt auf die zukünftigen Herausforderungen ausgerichtete Mischung aus unternehmerischer Erfahrung, gelebter Fach- und Führungsexpertise sowie kreativer Innovationskraft." - -Largo ist neu zum Team gestossen.Der heute 48-Jährige zeichne sich vor allem durch klare Vision, Power, Pragmatismus, Foresight und Herzblut aus – so unter anderem als Marken- und Digital Leader bei Arosa Lenzerheide, als Country Manager und Head of Middle East bei der Porsche Design, als Markenstratege bei Hawas Schweiz und zuletzt als Founder & CEO der BottleButler. - -"Nachdem ich verschiedene Funktionen in unterschiedlichen Branchen innehatte und in der jüngsten Vergangenheit Unternehmen quasi von der ersten Idee aufgebaut habe, war es mein grosser Wunsch, als Nächstes eine konkrete Nachfolge anzutreten", sagt Largo. "Es freut mich daher sehr, dass dieser Wunsch mit der anstehenden Aufgabe in Erfüllung geht." - -_Übrigens: Seit 2020 ist das Unternehmen Partner des Digitalisierungsnetzwerks Parato, das KMUs bei der Digitalisierung berät und begleitet. [Mehr zum Netzwerk lesen Sie hier](https://www.netzwoche.ch/news/2020-08-21/parato-netzwerk-will-kmus-digital-fit-machen)._ - -Artikel teilen: - -[](https://www.facebook.com/sharer/sharer.php?u=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://twitter.com/share?text=Neuer%20CEO%20f%C3%BCr%20Valueon&url=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](whatsapp://send?text=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](mailto:?subject=Neuer%20CEO%20f%C3%BCr%20Valueon&body=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.linkedin.com/shareArticle?mini=true&url=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - -Zum Thema - -[Silas Schneider Abacus Business Solutions ernennt neuen CEO -------------------------------------------](https://www.netzwoche.ch/news/2024-06-05/abacus-business-solutions-ernennt-neuen-ceo) - -[Pascal Keller Inventx trennt sich von CEO ---------------------------](https://www.netzwoche.ch/news/2024-06-07/inventx-trennt-sich-von-ceo) - -[Andrea Orzati Quantencomputing-Unternehmen Zurich Instruments ernennt CEO -----------------------------------------------------------](https://www.netzwoche.ch/news/2024-05-30/quantencomputing-unternehmen-zurich-instruments-ernennt-ceo) - -[Ruben Llanes Schneider Electric ernennt neuen CEO für den Bereich Digital Grid -----------------------------------------------------------------](https://www.netzwoche.ch/news/2024-05-29/schneider-electric-ernennt-neuen-ceo-fuer-den-bereich-digital-grid) - -[ Transparenz, Verantwortung und Sicherheit Kalifornien beschliesst rechtlichen Rahmen für KI-Giganten ---------------------------------------------------------- 02.10.2025 - 11:00 Uhr](https://www.netzwoche.ch/news/2025-10-02/kalifornien-beschliesst-rechtlichen-rahmen-fuer-ki-giganten)[ European Cyber Security Month BACS gibt Tipps für Berufstätige, wie sie der Phishing-Falle entgehen --------------------------------------------------------------------- 02.10.2025 - 12:54 Uhr](https://www.netzwoche.ch/news/2025-10-02/bacs-gibt-tipps-fuer-berufstaetige-wie-sie-der-phishing-falle-entgehen)[ Zwischen Antivirenschutz und Wiederherstellungsdienst Google-Drive entwickelt neuen KI-gestützten Ransomware-Schutz ------------------------------------------------------------- 02.10.2025 - 12:37 Uhr](https://www.netzwoche.ch/news/2025-10-02/google-drive-entwickelt-neuen-ki-gestuetzten-ransomware-schutz)[ 35 Finalisten unter 136 Einreichungen Die Shortlist für Best of Swiss Apps 2025 steht fest ---------------------------------------------------- 02.10.2025 - 11:23 Uhr](https://www.netzwoche.ch/news/2025-10-02/die-shortlist-fuer-best-of-swiss-apps-2025-steht-fest)[ VMware und Speicher Warum Zürich fast 40 Millionen Franken für Informatik ausgibt ------------------------------------------------------------- 02.10.2025 - 12:24 Uhr](https://www.netzwoche.ch/news/2025-10-02/warum-zuerich-fast-40-millionen-franken-fuer-informatik-ausgibt)[ Wachstum in Nischensegmenten Projektormarkt sinkt im zweiten Quartal erneut ---------------------------------------------- 02.10.2025 - 12:12 Uhr](https://www.netzwoche.ch/news/2025-10-02/projektormarkt-sinkt-im-zweiten-quartal-erneut)[ SMS-Phishing Phisher ködern mit Migros-Cumulus-Punkten ----------------------------------------- 02.10.2025 - 15:12 Uhr](https://www.netzwoche.ch/news/2025-10-02/phisher-koedern-mit-migros-cumulus-punkten)[ Rote Panzer statt Reifenwechsel Hamilton, Verstappen und Co. beim Pilz-Cup ------------------------------------------ 02.10.2025 - 12:03 Uhr](https://www.netzwoche.ch/netzwitzig/2025-10-02/hamilton-verstappen-und-co-beim-pilz-cup)[ Registrieren, orchestrieren, kontrollieren Salesforce lanciert "Mulesoft Agent Fabric" zur Koordination von KI-Agenten --------------------------------------------------------------------------- 02.10.2025 - 17:17 Uhr](https://www.netzwoche.ch/news/2025-10-02/salesforce-lanciert-mulesoft-agent-fabric-zur-koordination-von-ki-agenten)[ Partner-Post Kaiko.ai entwickelt den klinischen KI-Assistenten ------------------------------------------------- 29.09.2025 - 08:00 Uhr](https://www.netzwoche.ch/news/2025-09-29/kaikoai-entwickelt-den-klinischen-ki-assistenten) - -Tags - -[Führung](https://www.netzwoche.ch/tags/fuehrung) - -[People](https://www.netzwoche.ch/tags/people) - -[ceo](https://www.netzwoche.ch/tags/ceo) - -[Köpfe](https://www.netzwoche.ch/tags/koepfe) - -Webcode - -U5Wh68hz - -Meist gelesen -------------- - -[» Mehr News](https://www.netzwoche.ch/news) - -1[ VMware und Speicher Warum Zürich fast 40 Millionen Franken für Informatik ausgibt ------------------------------------------------------------- 02.10.2025 - 12:24 Uhr](https://www.netzwoche.ch/news/2025-10-02/warum-zuerich-fast-40-millionen-franken-fuer-informatik-ausgibt) - -2[ 35 Finalisten unter 136 Einreichungen Die Shortlist für Best of Swiss Apps 2025 steht fest ---------------------------------------------------- 02.10.2025 - 11:23 Uhr](https://www.netzwoche.ch/news/2025-10-02/die-shortlist-fuer-best-of-swiss-apps-2025-steht-fest) - -3[ Daniel Anders Schaffhauser Kantonalbank findet neuen Leiter Operations & IT ------------------------------------------------------------- 02.10.2025 - 10:14 Uhr](https://www.netzwoche.ch/news/2025-10-02/schaffhauser-kantonalbank-findet-neuen-leiter-operations-it) - -* * * - -Events ------- - -[» Mehr Events](https://www.netzwoche.ch/events) - -[Online-Infoanlass MAS Software Engineering ------------------------------------------ 12. November 2025 - 18:15 bis 19:15 Online Premium Event](https://www.netzwoche.ch/node/104293) - -[Studerus Technology Forum 2025 ------------------------------ 13. November 2025 - 8:30 bis 18:00 Mövenpick Hotel Zürich-Regensdorf Premium Event](https://www.netzwoche.ch/node/104438) - -[Swiss Payment Forum ------------------- 17. November 2025 - 18. November 2025 8:00 bis 17:00 Zürich Premium Event](https://www.netzwoche.ch/node/103794) - -[Smart Energy Pary ----------------- 23. Oktober 2025 - 7:00 bis 23:00 Umwelt Arena Spreitenbach Premium Event](https://www.netzwoche.ch/node/104435) - -[Service Management Forum Schweiz, SMFS -------------------------------------- 30. Oktober 2025 - 8:00 bis 18:30 Hotel Radisson Blu, Zürich Flughafen Premium Event](https://www.netzwoche.ch/node/103381) - -[Bechtle Xperience ----------------- 30. Oktober 2025 - 12:00 bis 21:00 AHA Aarau Premium Event](https://www.netzwoche.ch/node/103922) - -[Data Community Conference 2025 ------------------------------ 05. November 2025 - 8:30 bis 18:30 Bern Premium Event](https://www.netzwoche.ch/node/104286) - -[Online-Infoanlass MAS Software Engineering ------------------------------------------ 12. November 2025 - 18:15 bis 19:15 Online Premium Event](https://www.netzwoche.ch/node/104293) - -[Studerus Technology Forum 2025 ------------------------------ 13. November 2025 - 8:30 bis 18:00 Mövenpick Hotel Zürich-Regensdorf Premium Event](https://www.netzwoche.ch/node/104438) - -[Swiss Payment Forum ------------------- 17. November 2025 - 18. November 2025 8:00 bis 17:00 Zürich Premium Event](https://www.netzwoche.ch/node/103794) - -[Smart Energy Pary ----------------- 23. Oktober 2025 - 7:00 bis 23:00 Umwelt Arena Spreitenbach Premium Event](https://www.netzwoche.ch/node/104435) - -[Service Management Forum Schweiz, SMFS -------------------------------------- 30. Oktober 2025 - 8:00 bis 18:30 Hotel Radisson Blu, Zürich Flughafen Premium Event](https://www.netzwoche.ch/node/103381) - -[Bechtle Xperience ----------------- 30. Oktober 2025 - 12:00 bis 21:00 AHA Aarau Premium Event](https://www.netzwoche.ch/node/103922) - -[Data Community Conference 2025 ------------------------------ 05. November 2025 - 8:30 bis 18:30 Bern Premium Event](https://www.netzwoche.ch/node/104286) - -[Online-Infoanlass MAS Software Engineering ------------------------------------------ 12. November 2025 - 18:15 bis 19:15 Online Premium Event](https://www.netzwoche.ch/node/104293) - -[Studerus Technology Forum 2025 ------------------------------ 13. November 2025 - 8:30 bis 18:00 Mövenpick Hotel Zürich-Regensdorf Premium Event](https://www.netzwoche.ch/node/104438) - -[Swiss Payment Forum ------------------- 17. November 2025 - 18. November 2025 8:00 bis 17:00 Zürich Premium Event](https://www.netzwoche.ch/node/103794) - -* 1 -* 2 -* 3 - -Previous Next - -* * * - -Dossiers --------- - -[» Mehr Dossiers](https://www.netzwoche.ch/dossiers) - -[ Dossier Fintech, Insurtech & Digital Banking ------------------------------------ 24.09.2025 - 09:24 Uhr](https://www.netzwoche.ch/dossier/fintech-insurtech-digital-banking) - -[ Dossier DevOps ------ 24.06.2025 - 11:15 Uhr](https://www.netzwoche.ch/dossier/dossier-devops) - -[ Dossier SAP S/4 Hana - Was bis 2027 zu tun ist -------------------------------------- 21.05.2025 - 10:55 Uhr](https://www.netzwoche.ch/dossier/sap-s4-hana-was-bis-2025-zu-tun-ist) - -Aktuelle Ausgabe ----------------- - -[Business-Software und KI in der Psychotherapie Netzwoche Nr. 10/2025 ---------------------](https://www.netzwoche.ch/dossier/netzwoche-nr-102025) - -[](https://www.netzwoche.ch/dossier/netzwoche-nr-102025) - -[](https://www.netzwoche.ch/news/2025-09-24/die-neue-netzwoche-und-das-it-for-health-sind-da) - -[Die neue Netzwoche und das IT for Health sind da](https://www.netzwoche.ch/news/2025-09-24/die-neue-netzwoche-und-das-it-for-health-sind-da) - -[](https://www.netzwoche.ch/news/2025-09-24/mit-weniger-vorankommen) - -[Mit weniger vorankommen](https://www.netzwoche.ch/news/2025-09-24/mit-weniger-vorankommen) - -[](https://www.netzwoche.ch/news/2025-09-24/ki-im-schweizer-erp-markt-automatisieren-assistieren-vorhersagen) - -[KI im Schweizer ERP-Markt – automatisieren, assistieren, vorhersagen](https://www.netzwoche.ch/news/2025-09-24/ki-im-schweizer-erp-markt-automatisieren-assistieren-vorhersagen) - -[» Mehr Beiträge](https://www.netzwoche.ch/dossier/netzwoche-nr-102025) - -Direkt in Ihren Briefkasten CHF 139.-[» Magazin Abonnieren](https://www.netzwoche.ch/abo)[» Zum shop](https://www.netzmedien.ch/de/shop/)[» Newsletter](https://www.netzwoche.ch/newsletteranmeldung) - -[](https://www.facebook.com/netzwoche)[](https://www.linkedin.com/company/18519911/)[](https://twitter.com/Netzwoche)[](https://www.xing.com/news/pages/netzwoche-919) - -Netzwoche ---------- - -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [Magazin](https://www.netzwoche.ch/magazin) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzwoche.ch/shop "Netzwoche Shop") - -Services --------- - -* [E-Paper Login](https://epaper.netzwoche.ch/) -* [Kontakt](https://www.netzwoche.ch/contact) -* [Event-Plus-Eintrag](https://www.netzwoche.ch/event-plus) -* [Login](https://www.netzwoche.ch/user/login) - -Partner-Websites ----------------- - -* [ICTjournal](http://www.ictjournal.ch/) -* [IT-Markt.ch](http://www.it-markt.ch/) -* [netzmedien.ch](http://www.netzmedien.ch/) -* [Swisscybersecurity.net](https://www.swisscybersecurity.net/) - -© Netzmedien AG 2025 --------------------- - -* [Impressum](https://www.netzwoche.ch/impressum) -* [AGB](https://www.netzwoche.ch/AGB) -* [Nutzungsbestimmungen](https://www.netzwoche.ch/nutzungsbestimmungen) -* [Datenschutzerklärung](https://www.netzwoche.ch/datenschutzerklaerung "Datenschutzerklärung") - -[Back to top](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon#top) - -Diese Website verwendet Cookies und Analysetools, um die Nutzerfreundlichkeit der Website zu verbessern und die Werbung von Netzmedien und Werbepartnern zu personalisieren. Weitere Infos: [Datenschutzerklärung](https://www.netzwoche.ch/datenschutzerklaerung) - -Ich stimme zu \ No newline at end of file diff --git a/test_web_content_20251002_205603/main_url_009_www.itreseller.ch_Artikel_101024_Valueon_vollzieht_Fuehrungswechsel.html.txt b/test_web_content_20251002_205603/main_url_009_www.itreseller.ch_Artikel_101024_Valueon_vollzieht_Fuehrungswechsel.html.txt deleted file mode 100644 index 9dd3c150..00000000 --- a/test_web_content_20251002_205603/main_url_009_www.itreseller.ch_Artikel_101024_Valueon_vollzieht_Fuehrungswechsel.html.txt +++ /dev/null @@ -1,214 +0,0 @@ -Title: https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html -URL: https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Valueon vollzieht Führungswechsel - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Valueon vollzieht Führungswechsel -================================= - -**Generationen- und Führungswechsel bei Valueon: Gründer Markus Mühlemann (Bild, links) übergibt das Zepter an Dominic Largo (Bild, rechts).** - - 7. Juni 2024 - -[](https://www.facebook.com/sharer/sharer.php?u=https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html)[](https://www.linkedin.com/shareArticle?mini=true&url=https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html)[](https://www.itreseller.ch/artikel/art_incl_pdf.cfm?aid=101024)[](mailto:?subject=Valueon%20vollzieht%20F%C3%BChrungswechsel&body=Swiss%20IT%20Magazine%20Online%20-%207.%20Juni%202024%20%0D%0A%20%0D%0A%20Valueon%20vollzieht%20F%C3%BChrungswechsel%20%0D%0A%20https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html) - - Markus Mühlemann, Gründer, Inhaber und CEO von [Valueon](https://www.itreseller.ch/unternehmen/6046/Valueon.html) – Spezialist in Sachen Digital Business Transformation – übergibt die Leitung des Unternehmens an Dominic Largo. Largo ist seit dem 1. Juni 2024 nun als CEO für das Unternehmen tätig. Der 48-Jährige war bislang nicht für Valueon tätig, sondern hat in anderen Unternehmen seine Erfahrungen gesammelt. Unter anderem war der neue CEO als Marken- und Digital Leader bei Arosa Lenzerheide, als Country Manager & Head Middle East bei Porsche Design sowie als Markenstratege bei Hawas Schweiz tätig. Mühlemann wird dem Unternehmen weiterhin als Mitglied des Verwaltungsrats zur Verfügung stehen. - -Der Gründer sieht in Largo den richtigen Nachfolger, wie er in einer Mitteilung betont: "Es ist mir eine grosse Freude, das Zepter – verbunden mit den Führungsaufgaben von Valueon – an Dominic Largo weiterzureichen. Das gesamte Team, der Verwaltungsrat wie auch ich, wir alle sind fest davon überzeugt, mit Dominic eine optimale Lösung für diese Aufgaben gefunden zu haben. Es war mir schon immer ein persönliches Anliegen, den richtigen Moment für eine frühzeitige Nachfolge nicht zu verpassen. Nun ist genau dieser Moment gekommen." (dok) - -Weitere Artikel zum Thema - -[### Bruno Schenk wird Managing Director von Wipro in der Schweiz](https://www.itreseller.ch/Artikel/100983/Bruno_Schenk_wird_Managing_Director_von_Wipro_in_der_Schweiz.html) 5. Juni 2024 - Bei Wipro Schweiz kommt es zu einem Führungswechsel. Für René Mulder übernimmt Bruno Schenk (Bild) als Managing Director. Er kommt von Eviden Schweiz – eine Atos-Tochter. - -[### Cyril Wick wird neuer CEO von Blue Entertainment](https://www.itreseller.ch/Artikel/100062/Cyril_Wick_wird_neuer_CEO_von_Blue_Entertainment.html) 18. Januar 2024 - Führungswechsel an der Spitze von Blue Entertainment: Wolfgang Elsässer verlässt das Unternehmen, Cyril Wick (Bild) rückt nach. Wick ist bereits seit dem Jahr 2008 für Swisscom tätig. - -[### Führungswechsel bei der IG SAP CH zum neuen Jahr](https://www.itreseller.ch/Artikel/100017/Fuehrungswechsel_bei_der_IG_SAP_CH_zum_neuen_Jahr.html) 11. Januar 2024 - Generationenwechsel in der Führungsetage der IG SAP CH: Peter Hartmann (Bild, rechts) gibt die Verantwortung an Remo Schneider (Bild, links) ab. Hartmann bleibt noch bis zum Jahr 2026 als Stellvertretung mit an Bord. - -Artikel kommentieren - -_Kommentare werden vor der Freischaltung durch die Redaktion geprüft._ - - Anti-Spam-Frage: Wieviele Zwerge traf Schneewittchen im Wald? - -[VORHERIGE NEWS](https://www.itreseller.ch/Artikel/101026/Forterro_sichert_sich_mit_Uebernahme_von_Prodaso_KI-Know-how.html) - -[NÄCHSTE NEWS](https://www.itreseller.ch/Artikel/101023/Eperi_beruft_Oliver_Bibo_als_neuen_Channel_Manager.html) - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -People - -[### Sonepar Schweiz ernennt Raphael Maier zum neuen CEO 1. Oktober 2025](https://www.itreseller.ch/Artikel/104095/Sonepar_Schweiz_ernennt_Raphael_Maier_zum_neuen_CEO.html) - -[### AWS ernennt Stéphane Israël zum Leiter der Sovereign Cloud 1. Oktober 2025](https://www.itreseller.ch/Artikel/104090/AWS_ernennt_Stphane_Isral_zum_Leiter_der_Sovereign_Cloud.html) - -[### Paessler bekommt mit Jason Teichman neuen CEO 1. Oktober 2025](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html) - -[### Renato Petrillo wird CEO von Baggenstos 30. September 2025](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab 30. September 2025](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -Headlines Swiss IT Magazine - -[### iPad Pro mit M5-Chip geleaked](https://www.itmagazine.ch/artikel/85676/iPad_Pro_mit_M5-Chip_geleaked.html) - -2. Oktober 2025 - -[### Themenschwerpunkt: So gelingt der IT-Einkauf im KMU](https://www.itmagazine.ch/artikel/85675/Themenschwerpunkt_So_gelingt_der_IT-Einkauf_im_KMU.html) - -2. Oktober 2025 - -[### Fritz startet mit eigenem Online-Shop in der Schweiz](https://www.itmagazine.ch/artikel/85674/Fritz_startet_mit_eigenem_Online-Shop_in_der_Schweiz_.html) - -2. Oktober 2025 - -[### Wichtige Details fürs 25H2-Update von Windows 11 auf Business-PCs](https://www.itmagazine.ch/artikel/85673/Wichtige_Details_fuers_25H2-Update_von_Windows_11_auf_Business-PCs.html) - -2. Oktober 2025 - -[### Swiss Made Software lanciert zwei neue KI-Labels](https://www.itmagazine.ch/artikel/85672/Swiss_Made_Software_lanciert_zwei_neue_KI-Labels.html) - -2. Oktober 2025 - -Swico aktuell - -[](https://www.itreseller.ch/swico) - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[](https://www.itreseller.ch/herstelleraward/) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) - - - -[](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html)[](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html) - -[](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html) - -[](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html) \ No newline at end of file diff --git a/test_web_content_20251002_205603/main_url_010_www.itreseller.ch_unternehmen_6046_Valueon.html.txt b/test_web_content_20251002_205603/main_url_010_www.itreseller.ch_unternehmen_6046_Valueon.html.txt deleted file mode 100644 index 3993c1b4..00000000 --- a/test_web_content_20251002_205603/main_url_010_www.itreseller.ch_unternehmen_6046_Valueon.html.txt +++ /dev/null @@ -1,124 +0,0 @@ -Title: https://www.itreseller.ch/unternehmen/6046/Valueon.html -URL: https://www.itreseller.ch/unternehmen/6046/Valueon.html -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Valueon - Unternehmensverzeichnis IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Valueon in den News von -======================= - - - -[](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html) - -[### Valueon vollzieht Führungswechsel](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html) - -[Generationen- und Führungswechsel bei Valueon: Gründer Markus Mühlemann (Bild, links) übergibt das Zepter an Dominic Largo (Bild, rechts).](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html)7. Juni 2024 - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_205603/main_url_011_www.itreseller.ch_Artikel_101024_Valueon_vollzieht_Fuehrungswechsel.html.txt b/test_web_content_20251002_205603/main_url_011_www.itreseller.ch_Artikel_101024_Valueon_vollzieht_Fuehrungswechsel.html.txt deleted file mode 100644 index 9dd3c150..00000000 --- a/test_web_content_20251002_205603/main_url_011_www.itreseller.ch_Artikel_101024_Valueon_vollzieht_Fuehrungswechsel.html.txt +++ /dev/null @@ -1,214 +0,0 @@ -Title: https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html -URL: https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Valueon vollzieht Führungswechsel - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Valueon vollzieht Führungswechsel -================================= - -**Generationen- und Führungswechsel bei Valueon: Gründer Markus Mühlemann (Bild, links) übergibt das Zepter an Dominic Largo (Bild, rechts).** - - 7. Juni 2024 - -[](https://www.facebook.com/sharer/sharer.php?u=https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html)[](https://www.linkedin.com/shareArticle?mini=true&url=https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html)[](https://www.itreseller.ch/artikel/art_incl_pdf.cfm?aid=101024)[](mailto:?subject=Valueon%20vollzieht%20F%C3%BChrungswechsel&body=Swiss%20IT%20Magazine%20Online%20-%207.%20Juni%202024%20%0D%0A%20%0D%0A%20Valueon%20vollzieht%20F%C3%BChrungswechsel%20%0D%0A%20https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html) - - Markus Mühlemann, Gründer, Inhaber und CEO von [Valueon](https://www.itreseller.ch/unternehmen/6046/Valueon.html) – Spezialist in Sachen Digital Business Transformation – übergibt die Leitung des Unternehmens an Dominic Largo. Largo ist seit dem 1. Juni 2024 nun als CEO für das Unternehmen tätig. Der 48-Jährige war bislang nicht für Valueon tätig, sondern hat in anderen Unternehmen seine Erfahrungen gesammelt. Unter anderem war der neue CEO als Marken- und Digital Leader bei Arosa Lenzerheide, als Country Manager & Head Middle East bei Porsche Design sowie als Markenstratege bei Hawas Schweiz tätig. Mühlemann wird dem Unternehmen weiterhin als Mitglied des Verwaltungsrats zur Verfügung stehen. - -Der Gründer sieht in Largo den richtigen Nachfolger, wie er in einer Mitteilung betont: "Es ist mir eine grosse Freude, das Zepter – verbunden mit den Führungsaufgaben von Valueon – an Dominic Largo weiterzureichen. Das gesamte Team, der Verwaltungsrat wie auch ich, wir alle sind fest davon überzeugt, mit Dominic eine optimale Lösung für diese Aufgaben gefunden zu haben. Es war mir schon immer ein persönliches Anliegen, den richtigen Moment für eine frühzeitige Nachfolge nicht zu verpassen. Nun ist genau dieser Moment gekommen." (dok) - -Weitere Artikel zum Thema - -[### Bruno Schenk wird Managing Director von Wipro in der Schweiz](https://www.itreseller.ch/Artikel/100983/Bruno_Schenk_wird_Managing_Director_von_Wipro_in_der_Schweiz.html) 5. Juni 2024 - Bei Wipro Schweiz kommt es zu einem Führungswechsel. Für René Mulder übernimmt Bruno Schenk (Bild) als Managing Director. Er kommt von Eviden Schweiz – eine Atos-Tochter. - -[### Cyril Wick wird neuer CEO von Blue Entertainment](https://www.itreseller.ch/Artikel/100062/Cyril_Wick_wird_neuer_CEO_von_Blue_Entertainment.html) 18. Januar 2024 - Führungswechsel an der Spitze von Blue Entertainment: Wolfgang Elsässer verlässt das Unternehmen, Cyril Wick (Bild) rückt nach. Wick ist bereits seit dem Jahr 2008 für Swisscom tätig. - -[### Führungswechsel bei der IG SAP CH zum neuen Jahr](https://www.itreseller.ch/Artikel/100017/Fuehrungswechsel_bei_der_IG_SAP_CH_zum_neuen_Jahr.html) 11. Januar 2024 - Generationenwechsel in der Führungsetage der IG SAP CH: Peter Hartmann (Bild, rechts) gibt die Verantwortung an Remo Schneider (Bild, links) ab. Hartmann bleibt noch bis zum Jahr 2026 als Stellvertretung mit an Bord. - -Artikel kommentieren - -_Kommentare werden vor der Freischaltung durch die Redaktion geprüft._ - - Anti-Spam-Frage: Wieviele Zwerge traf Schneewittchen im Wald? - -[VORHERIGE NEWS](https://www.itreseller.ch/Artikel/101026/Forterro_sichert_sich_mit_Uebernahme_von_Prodaso_KI-Know-how.html) - -[NÄCHSTE NEWS](https://www.itreseller.ch/Artikel/101023/Eperi_beruft_Oliver_Bibo_als_neuen_Channel_Manager.html) - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -People - -[### Sonepar Schweiz ernennt Raphael Maier zum neuen CEO 1. Oktober 2025](https://www.itreseller.ch/Artikel/104095/Sonepar_Schweiz_ernennt_Raphael_Maier_zum_neuen_CEO.html) - -[### AWS ernennt Stéphane Israël zum Leiter der Sovereign Cloud 1. Oktober 2025](https://www.itreseller.ch/Artikel/104090/AWS_ernennt_Stphane_Isral_zum_Leiter_der_Sovereign_Cloud.html) - -[### Paessler bekommt mit Jason Teichman neuen CEO 1. Oktober 2025](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html) - -[### Renato Petrillo wird CEO von Baggenstos 30. September 2025](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab 30. September 2025](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -Headlines Swiss IT Magazine - -[### iPad Pro mit M5-Chip geleaked](https://www.itmagazine.ch/artikel/85676/iPad_Pro_mit_M5-Chip_geleaked.html) - -2. Oktober 2025 - -[### Themenschwerpunkt: So gelingt der IT-Einkauf im KMU](https://www.itmagazine.ch/artikel/85675/Themenschwerpunkt_So_gelingt_der_IT-Einkauf_im_KMU.html) - -2. Oktober 2025 - -[### Fritz startet mit eigenem Online-Shop in der Schweiz](https://www.itmagazine.ch/artikel/85674/Fritz_startet_mit_eigenem_Online-Shop_in_der_Schweiz_.html) - -2. Oktober 2025 - -[### Wichtige Details fürs 25H2-Update von Windows 11 auf Business-PCs](https://www.itmagazine.ch/artikel/85673/Wichtige_Details_fuers_25H2-Update_von_Windows_11_auf_Business-PCs.html) - -2. Oktober 2025 - -[### Swiss Made Software lanciert zwei neue KI-Labels](https://www.itmagazine.ch/artikel/85672/Swiss_Made_Software_lanciert_zwei_neue_KI-Labels.html) - -2. Oktober 2025 - -Swico aktuell - -[](https://www.itreseller.ch/swico) - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[](https://www.itreseller.ch/herstelleraward/) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) - - - -[](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html)[](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html) - -[](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html) - -[](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html) \ No newline at end of file diff --git a/test_web_content_20251002_205603/main_url_012_www.netzwoche.ch_news_2024-06-10_neuer-ceo-fuer-valueon.txt b/test_web_content_20251002_205603/main_url_012_www.netzwoche.ch_news_2024-06-10_neuer-ceo-fuer-valueon.txt deleted file mode 100644 index f2382993..00000000 --- a/test_web_content_20251002_205603/main_url_012_www.netzwoche.ch_news_2024-06-10_neuer-ceo-fuer-valueon.txt +++ /dev/null @@ -1,279 +0,0 @@ -Title: https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon -URL: https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Neuer CEO für Valueon | Netzwoche - -=============== -[Direkt zum Inhalt](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon#main-content) - -Header menu ------------ - -* [Kontakt](https://www.netzwoche.ch/contact) -* [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb) -* [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps) -* [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award) -* [E-Paper](http://epaper.netzwoche.ch/) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzmedien.ch/de/shop/ "Shop") -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [» Newsletter](https://www.netzwoche.ch/newsletteranmeldung) - -[](https://www.netzwoche.ch/ "Startseite") - -Donnerstag, 2. Oktober 2025 - -[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - -Main navigation ---------------- - -* [News](https://www.netzwoche.ch/news) - * [Live](https://www.netzwoche.ch/tags/live "Live") - * [Wild Card](https://www.netzwoche.ch/tags/wild-card "Wild Card") - * [Studien](https://www.netzwoche.ch/studien) - * [Meinungen](https://www.netzwoche.ch/meinungen) - * [Hands-on](https://www.netzwoche.ch/hands-on) - * [» alle News](https://www.netzwoche.ch/news) - -* [Storys](https://www.netzwoche.ch/storys) -* [Dossiers](https://www.netzwoche.ch/dossiers) - * [Best of Swiss Web](https://www.netzwoche.ch/dossier/best-of-swiss-web-2025 "Best of Swiss Web 2023") - * [Best of Swiss Apps](https://www.netzwoche.ch/dossier/best-of-swiss-apps-2025 "Best of Swiss Apps") - * [Best of Swiss Software](https://www.netzwoche.ch/dossier/best-of-swiss-software-2024) - * [SAP S/4 Hana](https://www.netzwoche.ch/dossier/sap-s4-hana-was-bis-2025-zu-tun-ist) - * [Arbeitswelten](https://www.netzwoche.ch/dossier/management-career-arbeitswelten "Management & Career") - * [Gesundheit wird digital](https://www.netzwoche.ch/dossier/gesundheit-wird-digital "Gesundheit wird digital") - * [Blockchain](https://www.netzwoche.ch/dossier/blockchain) - * [EU-DSGVO](https://www.netzwoche.ch/eu-dsgvo) - * [XaaS, Managed Services & Co.](https://www.netzwoche.ch/dossier/cloud-und-managed-services "XaaS, Managed Services & Co.") - * [Digital Banking](https://www.netzwoche.ch/dossier/fintech-insurtech-digital-banking) - * [» alle Dossiers](https://www.netzwoche.ch/dossiers) - -* [Video](https://www.netzwoche.ch/dossier/die-redaktion-filmt) -* [Specials](https://www.netzwoche.ch/specials) - * [IT for Health](https://www.netzwoche.ch/dossier/it-for-health-22025 "IT for Health") - * [Artificial Intelligence](https://www.netzwoche.ch/dossier/artificial-intelligence-special-2025) - * [Finance 2030](https://www.netzwoche.ch/dossier/finance-2030-ausgabe-2025 "Finance 2030") - * [Swiss Digital Ranking](https://www.netzwoche.ch/dossier/swiss-digital-ranking-2025) - * [Cybersecurity](https://www.netzwoche.ch/dossier/cybersecurity-2025 "Cybersecurity") - * [Cloud & Managed Services](https://www.netzwoche.ch/dossier/cloud-managed-services-2025 "Cloud & Managed Services") - * [Fintech & Insurtech](https://www.netzwoche.ch/dossier/fintech-insurtech-2024 "Fintech & Insurtech") - * [IT for Gov](https://www.netzwoche.ch/dossier/it-for-gov-2024 "IT for Gov ") - * [Professional AV & Digital Signage](https://www.netzwoche.ch/dossier/professional-av-digital-signage-2023 "Digital Signage") - * [» alle Specials](https://www.netzwoche.ch/specials) - -* [Events](https://www.netzwoche.ch/events) - * [Best of Swiss Web](https://www.netzwoche.ch/bestofswissweb "Best of Swiss Web ") - * [Best of Swiss Apps](https://www.netzwoche.ch/bestofswissapps "/bestofswissapps") - * [Best of Swiss Software](https://www.netzwoche.ch/best-of-swiss-software-award "Best of Swiss Software") - -* [Netzwitzig](https://www.netzwoche.ch/last-news) -* [E-Paper Login](https://epaper.netzwoche.ch/) - -[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - -Schlüsselwörter - -Webcode - -[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - -[News](https://www.netzwoche.ch/news) - -Dominic Largo -Neuer CEO für Valueon -===================== - -Mo 10.06.2024 - 13:10 Uhr - - von [Alexandra Hüsler](https://www.netzwoche.ch/user/20045) und yzu - -[](https://www.facebook.com/sharer/sharer.php?u=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://twitter.com/share?text=Neuer%20CEO%20f%C3%BCr%20Valueon&url=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](whatsapp://send?text=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](mailto:?subject=Neuer%20CEO%20f%C3%BCr%20Valueon&body=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.linkedin.com/shareArticle?mini=true&url=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - -Markus Mühlemann, Gründer, Inhaber und CEO von Valueon, übergibt die Geschäftsführung an Dominic Largo. Mühlemann steht dem Unternehmen weiterhin als Verwaltungsratsmitglied zur Verfügung. - -[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - - - -Markus Mühlemann (links) übergibt die Geschäftsführung und CEO-Aufgaben an Dominic Largo. (Source: zVg) - -Markus Mühlemann (links) übergibt die Geschäftsführung und CEO-Aufgaben an Dominic Largo. (Source: zVg) - -24 Jahre nach der Gründung als Project Competence und zwei Jahre nach dem Rebranding des Unternehmens 2022 zu Valueon tritt Markus Mühlemann als CEO ab. Wie das Unternehmen schreibt, übergibt der Gründer, Inhaber und CEO von Valueon im "richtigen, idealerweise selbstgewählten Moment" an seinen Nachfolger Dominic Largo. Markus Mühlemann wird weiterhin als Verwaltungsratsmitglied dem Unternehmen zur Verfügung stehen. - -"Es ging uns vor allem darum, eine Person zu finden, die künftig einen Mehrwert für das Team und so schlussendlich auch für unsere Kunden mitbringt", sagt Mühlemann. "Und dies umfasst nicht nur eine Verjüngung und eine starke Persönlichkeit, sondern auch eine gezielt auf die zukünftigen Herausforderungen ausgerichtete Mischung aus unternehmerischer Erfahrung, gelebter Fach- und Führungsexpertise sowie kreativer Innovationskraft." - -Largo ist neu zum Team gestossen.Der heute 48-Jährige zeichne sich vor allem durch klare Vision, Power, Pragmatismus, Foresight und Herzblut aus – so unter anderem als Marken- und Digital Leader bei Arosa Lenzerheide, als Country Manager und Head of Middle East bei der Porsche Design, als Markenstratege bei Hawas Schweiz und zuletzt als Founder & CEO der BottleButler. - -"Nachdem ich verschiedene Funktionen in unterschiedlichen Branchen innehatte und in der jüngsten Vergangenheit Unternehmen quasi von der ersten Idee aufgebaut habe, war es mein grosser Wunsch, als Nächstes eine konkrete Nachfolge anzutreten", sagt Largo. "Es freut mich daher sehr, dass dieser Wunsch mit der anstehenden Aufgabe in Erfüllung geht." - -_Übrigens: Seit 2020 ist das Unternehmen Partner des Digitalisierungsnetzwerks Parato, das KMUs bei der Digitalisierung berät und begleitet. [Mehr zum Netzwerk lesen Sie hier](https://www.netzwoche.ch/news/2020-08-21/parato-netzwerk-will-kmus-digital-fit-machen)._ - -Artikel teilen: - -[](https://www.facebook.com/sharer/sharer.php?u=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://twitter.com/share?text=Neuer%20CEO%20f%C3%BCr%20Valueon&url=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](whatsapp://send?text=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](mailto:?subject=Neuer%20CEO%20f%C3%BCr%20Valueon&body=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon)[](https://www.linkedin.com/shareArticle?mini=true&url=https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon) - -Zum Thema - -[Silas Schneider Abacus Business Solutions ernennt neuen CEO -------------------------------------------](https://www.netzwoche.ch/news/2024-06-05/abacus-business-solutions-ernennt-neuen-ceo) - -[Pascal Keller Inventx trennt sich von CEO ---------------------------](https://www.netzwoche.ch/news/2024-06-07/inventx-trennt-sich-von-ceo) - -[Andrea Orzati Quantencomputing-Unternehmen Zurich Instruments ernennt CEO -----------------------------------------------------------](https://www.netzwoche.ch/news/2024-05-30/quantencomputing-unternehmen-zurich-instruments-ernennt-ceo) - -[Ruben Llanes Schneider Electric ernennt neuen CEO für den Bereich Digital Grid -----------------------------------------------------------------](https://www.netzwoche.ch/news/2024-05-29/schneider-electric-ernennt-neuen-ceo-fuer-den-bereich-digital-grid) - -[ Transparenz, Verantwortung und Sicherheit Kalifornien beschliesst rechtlichen Rahmen für KI-Giganten ---------------------------------------------------------- 02.10.2025 - 11:00 Uhr](https://www.netzwoche.ch/news/2025-10-02/kalifornien-beschliesst-rechtlichen-rahmen-fuer-ki-giganten)[ European Cyber Security Month BACS gibt Tipps für Berufstätige, wie sie der Phishing-Falle entgehen --------------------------------------------------------------------- 02.10.2025 - 12:54 Uhr](https://www.netzwoche.ch/news/2025-10-02/bacs-gibt-tipps-fuer-berufstaetige-wie-sie-der-phishing-falle-entgehen)[ Zwischen Antivirenschutz und Wiederherstellungsdienst Google-Drive entwickelt neuen KI-gestützten Ransomware-Schutz ------------------------------------------------------------- 02.10.2025 - 12:37 Uhr](https://www.netzwoche.ch/news/2025-10-02/google-drive-entwickelt-neuen-ki-gestuetzten-ransomware-schutz)[ 35 Finalisten unter 136 Einreichungen Die Shortlist für Best of Swiss Apps 2025 steht fest ---------------------------------------------------- 02.10.2025 - 11:23 Uhr](https://www.netzwoche.ch/news/2025-10-02/die-shortlist-fuer-best-of-swiss-apps-2025-steht-fest)[ VMware und Speicher Warum Zürich fast 40 Millionen Franken für Informatik ausgibt ------------------------------------------------------------- 02.10.2025 - 12:24 Uhr](https://www.netzwoche.ch/news/2025-10-02/warum-zuerich-fast-40-millionen-franken-fuer-informatik-ausgibt)[ Wachstum in Nischensegmenten Projektormarkt sinkt im zweiten Quartal erneut ---------------------------------------------- 02.10.2025 - 12:12 Uhr](https://www.netzwoche.ch/news/2025-10-02/projektormarkt-sinkt-im-zweiten-quartal-erneut)[ SMS-Phishing Phisher ködern mit Migros-Cumulus-Punkten ----------------------------------------- 02.10.2025 - 15:12 Uhr](https://www.netzwoche.ch/news/2025-10-02/phisher-koedern-mit-migros-cumulus-punkten)[ Rote Panzer statt Reifenwechsel Hamilton, Verstappen und Co. beim Pilz-Cup ------------------------------------------ 02.10.2025 - 12:03 Uhr](https://www.netzwoche.ch/netzwitzig/2025-10-02/hamilton-verstappen-und-co-beim-pilz-cup)[ Registrieren, orchestrieren, kontrollieren Salesforce lanciert "Mulesoft Agent Fabric" zur Koordination von KI-Agenten --------------------------------------------------------------------------- 02.10.2025 - 17:17 Uhr](https://www.netzwoche.ch/news/2025-10-02/salesforce-lanciert-mulesoft-agent-fabric-zur-koordination-von-ki-agenten)[ Partner-Post Kaiko.ai entwickelt den klinischen KI-Assistenten ------------------------------------------------- 29.09.2025 - 08:00 Uhr](https://www.netzwoche.ch/news/2025-09-29/kaikoai-entwickelt-den-klinischen-ki-assistenten) - -Tags - -[Führung](https://www.netzwoche.ch/tags/fuehrung) - -[People](https://www.netzwoche.ch/tags/people) - -[ceo](https://www.netzwoche.ch/tags/ceo) - -[Köpfe](https://www.netzwoche.ch/tags/koepfe) - -Webcode - -U5Wh68hz - -Meist gelesen -------------- - -[» Mehr News](https://www.netzwoche.ch/news) - -1[ VMware und Speicher Warum Zürich fast 40 Millionen Franken für Informatik ausgibt ------------------------------------------------------------- 02.10.2025 - 12:24 Uhr](https://www.netzwoche.ch/news/2025-10-02/warum-zuerich-fast-40-millionen-franken-fuer-informatik-ausgibt) - -2[ 35 Finalisten unter 136 Einreichungen Die Shortlist für Best of Swiss Apps 2025 steht fest ---------------------------------------------------- 02.10.2025 - 11:23 Uhr](https://www.netzwoche.ch/news/2025-10-02/die-shortlist-fuer-best-of-swiss-apps-2025-steht-fest) - -3[ Daniel Anders Schaffhauser Kantonalbank findet neuen Leiter Operations & IT ------------------------------------------------------------- 02.10.2025 - 10:14 Uhr](https://www.netzwoche.ch/news/2025-10-02/schaffhauser-kantonalbank-findet-neuen-leiter-operations-it) - -* * * - -Events ------- - -[» Mehr Events](https://www.netzwoche.ch/events) - -[Online-Infoanlass MAS Software Engineering ------------------------------------------ 12. November 2025 - 18:15 bis 19:15 Online Premium Event](https://www.netzwoche.ch/node/104293) - -[Studerus Technology Forum 2025 ------------------------------ 13. November 2025 - 8:30 bis 18:00 Mövenpick Hotel Zürich-Regensdorf Premium Event](https://www.netzwoche.ch/node/104438) - -[Swiss Payment Forum ------------------- 17. November 2025 - 18. November 2025 8:00 bis 17:00 Zürich Premium Event](https://www.netzwoche.ch/node/103794) - -[Smart Energy Pary ----------------- 23. Oktober 2025 - 7:00 bis 23:00 Umwelt Arena Spreitenbach Premium Event](https://www.netzwoche.ch/node/104435) - -[Service Management Forum Schweiz, SMFS -------------------------------------- 30. Oktober 2025 - 8:00 bis 18:30 Hotel Radisson Blu, Zürich Flughafen Premium Event](https://www.netzwoche.ch/node/103381) - -[Bechtle Xperience ----------------- 30. Oktober 2025 - 12:00 bis 21:00 AHA Aarau Premium Event](https://www.netzwoche.ch/node/103922) - -[Data Community Conference 2025 ------------------------------ 05. November 2025 - 8:30 bis 18:30 Bern Premium Event](https://www.netzwoche.ch/node/104286) - -[Online-Infoanlass MAS Software Engineering ------------------------------------------ 12. November 2025 - 18:15 bis 19:15 Online Premium Event](https://www.netzwoche.ch/node/104293) - -[Studerus Technology Forum 2025 ------------------------------ 13. November 2025 - 8:30 bis 18:00 Mövenpick Hotel Zürich-Regensdorf Premium Event](https://www.netzwoche.ch/node/104438) - -[Swiss Payment Forum ------------------- 17. November 2025 - 18. November 2025 8:00 bis 17:00 Zürich Premium Event](https://www.netzwoche.ch/node/103794) - -[Smart Energy Pary ----------------- 23. Oktober 2025 - 7:00 bis 23:00 Umwelt Arena Spreitenbach Premium Event](https://www.netzwoche.ch/node/104435) - -[Service Management Forum Schweiz, SMFS -------------------------------------- 30. Oktober 2025 - 8:00 bis 18:30 Hotel Radisson Blu, Zürich Flughafen Premium Event](https://www.netzwoche.ch/node/103381) - -[Bechtle Xperience ----------------- 30. Oktober 2025 - 12:00 bis 21:00 AHA Aarau Premium Event](https://www.netzwoche.ch/node/103922) - -[Data Community Conference 2025 ------------------------------ 05. November 2025 - 8:30 bis 18:30 Bern Premium Event](https://www.netzwoche.ch/node/104286) - -[Online-Infoanlass MAS Software Engineering ------------------------------------------ 12. November 2025 - 18:15 bis 19:15 Online Premium Event](https://www.netzwoche.ch/node/104293) - -[Studerus Technology Forum 2025 ------------------------------ 13. November 2025 - 8:30 bis 18:00 Mövenpick Hotel Zürich-Regensdorf Premium Event](https://www.netzwoche.ch/node/104438) - -[Swiss Payment Forum ------------------- 17. November 2025 - 18. November 2025 8:00 bis 17:00 Zürich Premium Event](https://www.netzwoche.ch/node/103794) - -* 1 -* 2 -* 3 - -Previous Next - -* * * - -Dossiers --------- - -[» Mehr Dossiers](https://www.netzwoche.ch/dossiers) - -[ Dossier Fintech, Insurtech & Digital Banking ------------------------------------ 24.09.2025 - 09:24 Uhr](https://www.netzwoche.ch/dossier/fintech-insurtech-digital-banking) - -[ Dossier DevOps ------ 24.06.2025 - 11:15 Uhr](https://www.netzwoche.ch/dossier/dossier-devops) - -[ Dossier SAP S/4 Hana - Was bis 2027 zu tun ist -------------------------------------- 21.05.2025 - 10:55 Uhr](https://www.netzwoche.ch/dossier/sap-s4-hana-was-bis-2025-zu-tun-ist) - -Aktuelle Ausgabe ----------------- - -[Business-Software und KI in der Psychotherapie Netzwoche Nr. 10/2025 ---------------------](https://www.netzwoche.ch/dossier/netzwoche-nr-102025) - -[](https://www.netzwoche.ch/dossier/netzwoche-nr-102025) - -[](https://www.netzwoche.ch/news/2025-09-24/die-neue-netzwoche-und-das-it-for-health-sind-da) - -[Die neue Netzwoche und das IT for Health sind da](https://www.netzwoche.ch/news/2025-09-24/die-neue-netzwoche-und-das-it-for-health-sind-da) - -[](https://www.netzwoche.ch/news/2025-09-24/mit-weniger-vorankommen) - -[Mit weniger vorankommen](https://www.netzwoche.ch/news/2025-09-24/mit-weniger-vorankommen) - -[](https://www.netzwoche.ch/news/2025-09-24/ki-im-schweizer-erp-markt-automatisieren-assistieren-vorhersagen) - -[KI im Schweizer ERP-Markt – automatisieren, assistieren, vorhersagen](https://www.netzwoche.ch/news/2025-09-24/ki-im-schweizer-erp-markt-automatisieren-assistieren-vorhersagen) - -[» Mehr Beiträge](https://www.netzwoche.ch/dossier/netzwoche-nr-102025) - -Direkt in Ihren Briefkasten CHF 139.-[» Magazin Abonnieren](https://www.netzwoche.ch/abo)[» Zum shop](https://www.netzmedien.ch/de/shop/)[» Newsletter](https://www.netzwoche.ch/newsletteranmeldung) - -[](https://www.facebook.com/netzwoche)[](https://www.linkedin.com/company/18519911/)[](https://twitter.com/Netzwoche)[](https://www.xing.com/news/pages/netzwoche-919) - -Netzwoche ---------- - -* [Mediadaten](https://www.netzmedien.ch/de/mediadaten/) -* [Magazin](https://www.netzwoche.ch/magazin) -* [Abo](https://www.netzwoche.ch/abo) -* [Shop](https://www.netzwoche.ch/shop "Netzwoche Shop") - -Services --------- - -* [E-Paper Login](https://epaper.netzwoche.ch/) -* [Kontakt](https://www.netzwoche.ch/contact) -* [Event-Plus-Eintrag](https://www.netzwoche.ch/event-plus) -* [Login](https://www.netzwoche.ch/user/login) - -Partner-Websites ----------------- - -* [ICTjournal](http://www.ictjournal.ch/) -* [IT-Markt.ch](http://www.it-markt.ch/) -* [netzmedien.ch](http://www.netzmedien.ch/) -* [Swisscybersecurity.net](https://www.swisscybersecurity.net/) - -© Netzmedien AG 2025 --------------------- - -* [Impressum](https://www.netzwoche.ch/impressum) -* [AGB](https://www.netzwoche.ch/AGB) -* [Nutzungsbestimmungen](https://www.netzwoche.ch/nutzungsbestimmungen) -* [Datenschutzerklärung](https://www.netzwoche.ch/datenschutzerklaerung "Datenschutzerklärung") - -[Back to top](https://www.netzwoche.ch/news/2024-06-10/neuer-ceo-fuer-valueon#top) - -Diese Website verwendet Cookies und Analysetools, um die Nutzerfreundlichkeit der Website zu verbessern und die Werbung von Netzmedien und Werbepartnern zu personalisieren. Weitere Infos: [Datenschutzerklärung](https://www.netzwoche.ch/datenschutzerklaerung) - -Ich stimme zu \ No newline at end of file diff --git a/test_web_content_20251002_205603/main_url_013_www.valueon.ch_.txt b/test_web_content_20251002_205603/main_url_013_www.valueon.ch_.txt deleted file mode 100644 index 39603ff0..00000000 --- a/test_web_content_20251002_205603/main_url_013_www.valueon.ch_.txt +++ /dev/null @@ -1,107 +0,0 @@ -Title: https://www.valueon.ch/ -URL: https://www.valueon.ch/ -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -# Power für deinendigitalen Erfolg - -Vertrauen von führenden Unternehmen - -## Unsere Expertise - -Von digitaler Transformation bis zu künstlicher Intelligenz – wir begleiten Sie auf Ihrem Weg in die Zukunft. - -### Digitale Strategie entwickeln - -Ihre Richtung im digitalen Wandel. - -Gemeinsames Zielbild & Roadmap, abgestimmt auf Ihr Geschäft und leiten konkrete Handlungsempfehlungen ab. - -Orientierung & Handlungssicherheit - -### Transformation gezielt optimieren - -Lücken aufdecken. Stärken nutzen. - -Systematischer Blick auf Prozesse, Systeme & Potenziale und leiten konkrete Handlungsempfehlungen ab. - -Relevanz statt Aktionismus - -### Change Management etablieren - -Menschen mitnehmen. Wandel gestalten. - -Strukturierte Begleitung der Mitarbeiter durch den digitalen Wandel mit gezielten Schulungskonzepten. - -Akzeptanz & Erfolg sichern - -### Prozesse digital automatisieren - -Effizienz steigern. Kosten senken. - -Identifikation und Umsetzung von Automatisierungspotenzialen für nachhaltige Produktivitätssteigerung. - -Messbare Effizienzgewinne - -## Erfolgreiche Projekte & Transformationen - -Unter dem Motto «Unsere Kunden stehen im Mittelpunkt» haben wir für Sie eine Auswahl an Kundenreferenzen und Business Cases zusammengestellt. - -Als KMU sind wir es eigentlich nicht gewohnt, einen so grossen Aufwand wie bei der Evaluation des richtigen Partners für die Entwicklung und Realisierung unseres neuen Kernsystems zu betreiben. Doch i... - -Markus Berther - -Geschäftsführer, Schaden Service Schweiz AG - -ValueOn hat uns durch den gesamten Prozess der Digitalen Business Transformation mit grossem Einsatz und Engagement begleitet – von der ersten IT-Standortanalyse und Sourcing Analyse über digitales Zi... - -Stefan Wolf - -Präsident, FC Luzern - -In diesem businesskritischen IT-Programm waren insgesamt vier Experten von ValueOn (ehem. Project Competence) involviert, als Projektleiter und Koordinator, Cut-Over-Manager bis hin zur Gesamt-Program... - -Roland Bosshard - -CIO / Mitglied der GL, KPT - -In time, in quality, under budget: Andreas Friedli von ValueOn (ehem. Project Competence) hat in seiner Co-Leitungsfunktion in diesem IT-Projekt ganz massgeblich dazu beigetragen, dass wir dieses trot... - -Thomas Sturzenegger - -Divisional IT Lead, RUAG Real Estate AG - -Die erfolgreiche Realisierung dieses Vorhabens ist ein wichtiger Meilenstein für die strategische Neuausrichtung der WWZ. Die Projektberater der ValueOn AG (ehem. Project Competence AG) haben dabei da... - -Thomas Reber - -Leiter Telekom & IT Services, WWZ AG - -Um die Zukunftsausrichtung unserer IT-Strategie und -Organisation möglichst optimal auf unsere Business-Anforderungen auszurichten, haben wir ValueOn (ehem. Project Competence) als Sparringpartner ... - -Andreas Guglielmo - -CFO, CHRIS sports AG - -Wir danken den externen Projektberatern der ValueOn (ehem. Project Competence), die uns kompetent und mit ebenso hohem Arbeitseinsatz durch dieses Projekt und die Verhandlungen unter schwierigen Be... - -Michael Kohlbacher - -Generalsekretär, AGZ - -Dank ValueOn konnten wir unser komplexes IT-Infrastrukturprojekt termingerecht und im Budget abschliessen. Die strukturierte Herangehensweise war ausschlaggebend. - -Peter Keller - -Projektleiter, InnovaCorp - -ValueOn hat uns sowohl fachlich als auch menschlich auf höchstem Niveau beraten. Die Experten begleiteten uns kompetent bei der Modernisierung unserer IT-Infrastruktur und der reibungslosen Ablösung u... - -Silvan Wildhaber - -CEO, Filtex Group AG - -← Wischen Sie für weitere Testimonials → - -Auto-Scroll aktiv \ No newline at end of file diff --git a/test_web_content_20251002_205603/main_url_014_www.valueon.ch_about.txt b/test_web_content_20251002_205603/main_url_014_www.valueon.ch_about.txt deleted file mode 100644 index 72468485..00000000 --- a/test_web_content_20251002_205603/main_url_014_www.valueon.ch_about.txt +++ /dev/null @@ -1,639 +0,0 @@ -Title: https://www.valueon.ch/about -URL: https://www.valueon.ch/about -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unser Team -========== - -Seit über 25 Jahren stehen wir für Innovation, Qualität und nachhaltigen Erfolg. Erfahren Sie mehr über unsere Geschichte, unsere Werte und die Menschen, die ValueON zu dem machen, was es heute ist. - -Alle Kernteam Geschäftsführende Partner Externe Zertifizierte Partner - - - -Mehr erfahren - -### Dominic Largo - -CEO - - - -Dominic führt das Unternehmen mit einer klaren Vision für digitale Innovation und strategisches Wachstum in der Beratung. - -### Dominic Largo - -CEO - - - -Zum Vergrößern klicken - -#### Schwerpunkte - -* Sicherstellen der besten Projekt- & Tranformationsmanager für unsere Kunden und unsere Vorhaben -* Reviews von komplexen und erfolgskritischen Vorhaben -* Advisor & Einsitz in Steering Boards -* Sparringpartner für Führungskräfte und Gremien - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Handel / eCommerce Tourismus Konsumgüter Luxusgüter Industrie - -#### Berufliche Stationen - -* BottleButler AG (Founder & CEO) -* Arosa Lenzerheide (Marken- und Digital Leader) -* Mitgründer mehrerer Startups (Co-CEO & VR) -* Porsche Design Group (Country Manager & GCC) -* HAWAS & Jung von Matt (Markenstratege) - -#### Und ganz nebenbei... - -...ist Dominic Largo mit grosser Passion Langstreckenläufer, Kulinariker und Game Challenger. Er geniesst explizit die Berge und seine Familienzeit. - - - -Mehr erfahren - -### Andreas Friedli - -Managing Partner - - - -Mit über 25 Jahren Erfahrung in der digitalen Transformation leitet Andreas als Partner erfolgreich strategische Grossprojekte. - -### Andreas Friedli - -Managing Partner - -#### Schwerpunkte - -* Health-Check von Projekten und Programmen -* Advisor digitaler Transformationen -* Führung von Digitalisierungsprojekten und -programmen -* Emergency- und Recoveryprojekte -* Risiko- und Quality-Assurance bei digitalen Transformationen -* Advisor digitaler Neuausrichtungen -* Leadership-Coaching Projekt und Programm Manager - -#### Im Team seit - -2004 - -#### Branchenerfahrungen - -Finanzen / Banken Versicherungen / Krankenkassen Detailhandel Verwaltung Militär Automobile IT / Telekommunikation Immobilien - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of Complex Projects -* HP GmbH, Senior Project Manager -* Compaq Computer GmbH, Senior Project Manager -* Volkswirtschaftsdep. St. Gallen, Informatikverantwortlicher - -#### Und ganz nebenbei... - -…spielt Andreas Friedli gerne Golf, liebt feines Essen und guten Wein und verbringt viel Zeit mit seiner Familie – ganz nach dem Motto «Geniesse den Moment!». - - - -Mehr erfahren - -### Patrick Motsch - -Managing Partner - - - -Patrick leitet als Partner erfolgreich komplexe IT-Implementierungsprojekte. - -### Patrick Motsch - -Managing Partner - -#### Schwerpunkte - -* Health Check von Projekten -* Führen von geschäftskritischen Projekten und Programmen -* Führen und Begleiten von Emergency und Recovery Projekten -* Führen und Begleiten von DC Moves und ICT Konsolidierungsprojekten -* Advisor für Auftraggeber - -#### Im Team seit - -2001 - -#### Branchenerfahrungen - -Baubranche IT / Telekommunikation / Data Center Industrie Sport Verteidigung Verwaltung Airspace Management Versicherungen Handel - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG) -* Vater und Pionier des TimeWinner Führungssystems -* CIO einer IT Consulting Organisation - -#### Und ganz nebenbei... - -…liebt Patrick Motsch den Garten, das Tanzen, wandert gerne, taucht so oft es geht und lernt gerne fremde Länder kennen. Sein persönliches Motto: «Wer will, der kann». - - - -Mehr erfahren - -### Richard Salvisberg - -Managing Partner - - - -Richard bringt als Partner strategische Beratungsexpertise und Führungskompetenz ein. - -### Richard Salvisberg - -Managing Partner - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Führen von geschäftskritischen Programmen und Transformationen -* Aufbau und Führen von Projektportfolio-Managementsystemen -* Sparringpartner und Advisor - -#### Im Team seit - -2006 - -#### Branchenerfahrungen - -Gesundheitswesen & (Kranken-)Versicherung Militär Verwaltung Beschaffungswesen & Transport Informatik & Telekommunikation Bau Sport Energie - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of PPM -* T-Systems Schweiz AG, Chief Information Officer -* Orange Communications SA, IT Account Manager -* Swisscom AG Bern, Head Management Support -* Swisscom AG Bern, Programm Manager Charging & Billing - -#### Und ganz nebenbei... - -…liebt Richard Salvisberg das Tanzen, lernt gerne fremde Kulturen kennen, hat Freude an schönen Autos und geniesst ein Buch bei einem guten Schluck Wein. In klaren Nächten beobachtet er interessiert den Kosmos. Sein persönliches Motto lautet «Auf innovativen Wegen nachhaltige Erfolge erzielen». - - - -Mehr erfahren - -### Stephan Schellworth - -Experte - - - -Stephan verbindet strategisches Denken mit praxisnaher Projektsteuerung und gestaltet digitale Projekte - -### Stephan Schellworth - -Experte - -#### Schwerpunkte - -* Projekt- und Teamführung -* Datenanalyse und Optimierung -* Agiles Projektmanagement - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Automatisierungstechnik Digitalisierung - -#### Berufliche Stationen - -* 2023 - 2024: Testmanager im Energiebordnetz, BMW Group -* 2021 - 2023: Gesamtfahrzeugspezialist in der E/E, BMW Group -* 2018 - 2021: Prüfstandsspezialist im BMW Prototypen-Motorenwerk, Academic Work -* 2016 - 2018: Entwicklungsingenieur, EDAG Engineering Group - -#### Und ganz nebenbei... - -…sammelt und pflegt Stephan Young- und Oldtimern, treibt Sport wie Squash und besucht regelmässig das Fitnessstudio. Er geht gern mit seinem Hund spazieren oder wandert in der Natur. Ausserdem programmiert er kleinere SmartHome-Anwendungen mit dem Raspberry Pi, Apps und erstellt 3D-Visualisierungen von Innen- und Aussenräumen. - - - -Mehr erfahren - -### Mats Rudolf - -Experte - - - -Mats berät Unternehmen zu digitalen Transformationsprojekten und Systemimplementierungen. - -### Mats Rudolf - -Experte - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Advisor digitaler Transformation -* Advisor Systems Engineering -* Projekt- und Teamführung -* Agiles Projektmanagement - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Sensortechnik Luft- und Raumfahrttechnik Maschinen- und Anlagenbau Transport und Logistik - -#### Berufliche Stationen - -* 2019 - 2024: Management Consultant Innovation und Transformation, UNITY Schweiz AG -* 2018: Industrial Solution Consulting Intern, Brütsch Rüegger Werkzeuge -* 2015 - 2016: Sensor Research and Development Intern, Sensirion AG - -#### Und ganz nebenbei... - -…zieht es Mats Rudolf im Winter für Skitouren und rasante Abfahrten auf die frisch verschneiten Berge. Wenn der Sommer kommt, tauscht er seine Ski gegen ein Surfbrett und geniesst die Wellen im Meer. Zudem schwingt er gerne den Schläger auf dem Tennisplatz und bastelt an seinen Smart-Device-Projekten. - - - -Mehr erfahren - -### Ida Dittrich - -AI Specialist - -Ida verbindet ihr wissenschaftliches Know-how mit praktischer IT-Erfahrung und bringt innovative Ansätze in technische Projekte ein. - -### Ida Dittrich - -AI Specialist - -#### Schwerpunkte - -* Product Architect and Software Engineer PowerOn Platform - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Luft- und Raumfahrtindustrie Kommunikation und Interessenvertretung Medien - -#### Berufliche Stationen - -* Forschungsprojekt zur Modellierung des inneren Aufbaus terrestrischer Exoplaneten (ETH Zürich) -* Recovery Engineer und Systems Engineer bei verschiedenen Projekten der Akademischen Raumfahrtinitiative der Schweiz (ARIS) - -#### Und ganz nebenbei... - -… spielt Ida Dittrich leidenschaftlich gern Computerspiele und bastelt an handwerklichen Projekten wie Nähen, Häkeln oder Stricken. Sie ist regelmäßig sportlich aktiv – sei es beim Joggen an der frischen Luft, im Fitnessstudio oder bei einer entspannenden Yoga-Einheit. - - - -Mehr erfahren - -### Nick Melloh - -AI-Specialist - -Nick macht künstliche Intelligenz für Unternehmen greifbar – in Projekten, Strategien und praxisnahen Schulungen. - -### Nick Melloh - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Digitale Transformation & Business Innovation -* Advisor für Künstliche Intelligenz & Wissensvermittlung -* Advisor für Strategisches Projekt- und Prozessmanagement -* Trainer für KI-Schulungen und Weiterbildung - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Digitalisierung Consulting Hospitality Event- und Innovationsmanagement KI-Anwendungen - -#### Berufliche Stationen - -* 2023–heute: Master in Business Innovation, Universität St. Gallen – Schwerpunkt Digitale Transformation & KI -* 2023–heute: Event Manager SQUARE, Universität St. Gallen – Gestaltung innovativer Lern- und Austauschformate -* 2022–2023: VP Sales, Contler AG – SaaS-Lösungen & Prozessautomatisierung im Hospitality-Sektor - -#### Und ganz nebenbei... - -…hat Nick eine Schwäche für Reisen, gutes Essen und Bücher – um neue Denkanstöße zu gewinnen und frische Perspektiven einzunehmen. Energie findet er beim Sport, in den Bergen oder bei langen Gesprächen mit Freunden – die besten Momente für ihn sind die, in denen die Uhr keine Rolle spielt. - - - -Mehr erfahren - -### Yannick Althaus - -AI-Specialist - -Yannick berät Unternehmen, indem er Strategiekompetenz mit unternehmerischer DNA verbindet. - -### Yannick Althaus - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Strategisches Management und Unternehmensführung -* Advisor für Künstliche Intelligenz und digitale Transformation -* Advisor für Produktion und Supply Chain Management - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Industrie Digitalisierung Supply Chain Management Consulting - -#### Berufliche Stationen - -* 2025: M.A. HSG in Unternehmensführung - Masterarbeit zum Einsatz von generativer KI in der Strategieentwicklung von CEOs -* 2022: B.Sc. Wirtschaftsingenieurwesen -* 2019–2025: Diverse Consulting-Praktika & Projekte in Supply Chain Management, Digitalisierung und strategischem Management sowie Mitarbeit im Familienunternehmen (neben dem Studium) -* 2013–2017: Automatiker EFZ bei Bystronic - -#### Und ganz nebenbei... - -…wenn er nicht an Strategien feilt, zieht es Yannick aufs Eis – Eishockey ist sein Adrenalinschub. Auch sonst bleibt er regelmässig in Bewegung: Skifahren im Winter, Joggen zwischendurch und Golf im Sommer. Ausserdem hat er eine Schwäche für schnelle Autos und reist gerne – am liebsten ans Meer. - - - -### Philipp Dick - -Certified Partner - -"KI wird Manager nicht ersetzen, aber Manager, die KI einsetzen, werden die ersetzen, die es nicht tun." - - - -### Romano Caviezel - -Certified Partner - -"Innovation bedeutet, bestehende Dinge zu hinterfragen und neue Wege zu entdecken." - - - -### Dawid Puzik - -Certified Partner - -"Manche sehen, was möglich ist – andere verändern, was möglich ist." - - - -### Holger Ridinger - -Certified Partner - -"Transformation braucht Struktur, Leidenschaft und Ausdauer." - - - -### Alain Kappeler - -Certified Partner - -"Wenn es dich nicht herausfordert, verändert es dich nicht." - - - -### Andreas Wyss - -Certified Partner - -Andreas verbindet strategisches Denken mit menschlichem Feingefuehl in Transformationsprozessen. - - - -### Alfredo Mercurio - -Certified Partner - -"Eine klare Vision ist der Anfang von allem." - - - -### Bernd Nagel - -Certified Partner - -"Wer will, findet Wege. Wer nicht will, findet Gründe." - - - -### Daniel Sengstag - -Certified Partner - -"Wer nicht mit der Zeit geht, geht mit der Zeit." - - - -### Daniel Lochmatter - -Certified Partner - -"Neues und bisher Unbekanntes kann man nur explorativ erfahren, erspüren, erlernen – und danach zum eigenen Nutzen einsetzen." - - - -### Michael Hermann - -Certified Partner - -"Auch beim Projekt gilt: Ende gut, alles gut." - - - -### Heinz Ruffieux - -Certified Partner - -"C'est le ton qui fait la musique." - - - -### Sven Fassbender - -Certified Partner - -"Mein Ziel ist es, Cybersicherheit verständlich und greifbar zu machen – für jeden zugänglich und praktikabel." - - - -### Raffael Santchi - -Certified Partner - -"Wer Prozesse versteht, kann Systeme formen – nicht umgekehrt." - - - -### Stephanie Kieninger - -Certified Partner - -Stephanie konzentriert sich mit ihrer Beratung auf die Menschen im Veraenderungsprozess. - - - -### Christoph Merle - -Certified Partner - -Christoph engagiert sich mit seiner langjährigen Führungserfahrung in der Industrie und mit seinem Hintergrund in strategischer und operativer Beratung für den Erfolg unserer Kunden. - -Previous slide Next slide - -Über ValueOn ------------- - -Wir schaffen digitale Transformation mit Leidenschaft und Expertise - -### Unsere Mission - -Durch exzellente Beratung schaffen wir digitale Transformation erfolgreich zu meistern. - -### Unser Versprechen - -Höchste Qualität, agile Ansätze und Passion für gemeinsamen Wirken - -25+ - -Jahre Erfahrung - -100+ - -Projekte - -98% - -Weiterempfehlung - -60% - -Schneller zum Ziel - -Unsere Geschichte ------------------ - -Eine Reise der Innovation - -Heute - -Heute und Morgen - -Als führendes Beratungsunternehmen gestalten wir aktiv die Zukunft der digitalen Transformation mit innovativen KI-Lösungen und nachhaltigen Strategien. - -KI-Ära - -KI-Revolution - -Die Einführung von KI-Systemen veränderte unsere Beratungsleistung grundlegend und ermöglichte es uns, unseren Kunden noch innovativere Lösungen anzubieten. - -Digital - -Digitale Transformation - -Mit neuen digitalen Lösungen begleiteten wir unsere Kunden in der Transformation und etablierten uns als führender Partner für digitale Innovation. - -Aufbau - -Etablierung am Markt - -Wir etablierten uns am Markt mit innovativen IT-Strategien und nachhaltiger Umsetzung, wodurch wir eine solide Basis für weiteres Wachstum schufen. - -2000 - -Gründung von ValueON - -ValueON wurde mit der Vision gegründet, Unternehmen bei der digitalen Transformation zu unterstützen und nachhaltigen Erfolg zu schaffen. - -Unsere Werte ------------- - -Was uns antreibt - -### Exzellenz - -Höchste Qualität in allem, was wir tun. Von der ersten Beratung bis zur finalen Umsetzung setzen wir auf höchste Standards. - -### Partnerschaft - -Wir sehen uns als langfristige Partner unserer Kunden und arbeiten gemeinsam an nachhaltigen Lösungen. - -### Integrität - -Ehrlichkeit, Transparenz und Vertrauen bilden das Fundament aller unserer Geschäftsbeziehungen. - -### Effektivität - -Zielgerichtete Lösungen, die messbare Ergebnisse liefern und nachhaltigen Geschäftserfolg schaffen. - -Karriere bei ValueOn --------------------- - -Werde Teil unseres Teams - -### Product-Architekt/in für KI-Plattformen - -Zürich, Schweiz M/W, 50-100% - -Details ansehen - -Keine passende Stelle gefunden? - -[Initiativbewerbung senden](mailto:office@valueon.ch) - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_205603/main_url_015_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt b/test_web_content_20251002_205603/main_url_015_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt deleted file mode 100644 index 3837989e..00000000 --- a/test_web_content_20251002_205603/main_url_015_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt +++ /dev/null @@ -1,364 +0,0 @@ -Title: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](#)[Save + Exit](#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - -[Startseite](/de/) [>](javascript:void(0)) [Unternehmen](/de/search?q=ValueOn AG) [>](javascript:void(0)) ValueOn AG - -# ValueOn AG - -ZH - -aktiv - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) -[Zur Timeline](/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -Handelsregister-Nr.: CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](/de/company/valueon-ag-4663161481/messages) - -[Sie möchten eine Änderung der Firmendaten vornehmen? Wir unterstützen Sie hierbei gerne.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Alter der Firma - -18 Jahre - -#### Umsatz in CHF - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Kapital in CHF - -200'000 - -#### Mitarbeiter - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Aktive Marken - -0 - -c/o Westhive AG -Am Stadtrand 11 -8600 Dübendorf -[Nachbarschaft](/de/company/valueon-ag-4663161481/network#neighbourhood) - -[Sie möchten Ihre Adresse anpassen? -Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -[News aus der Region Uster](/de/region/uster/uebersicht) - -## Auskünfte zu ValueOn AG - -\*angezeigte Auskünfte sind Beispiele - -#### Bonitätsauskunft - -Einschätzung der Bonität mit einer Ampel als Risikoindikator und weiteren hilfreichen Firmeninformationen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -#### Wirtschaftsauskunft - -Umfassende Auskunft über die wirtschaftliche Situation der Firma. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#commercial-report) - -#### Zahlungsverhalten - -Beurteilung der Zahlungsmoral aufgrund vergangener Rechnungen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-mode-report) - -#### Betreibungsauskunft - -Übersicht über aktuelle und vergangene Betreibungsverfahren. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-collection-report) - -#### Beteiligungsauskunft - -Erfahren Sie, an welchen nationalen und internationalen Firmen die Aktiengesellschaft, für die Sie sich interessieren, noch beteiligt ist. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#wow-report) - -#### Firmendossier als PDF - -Kontaktinformationen, Veränderungen, Umsatz- und Mitarbeiterzahlen, Management, Besitzverhältnisse, Beteiligungsstruktur und weitere Firmendaten. -[Jetzt kostenlos abrufen](/de/company/valueon-ag-4663161481/reports#firmendossier-report) - -## Über ValueOn AG - -* ValueOn AG hat den Sitz in Dübendorf, ist aktiv und im Bereich «Erbringen von IT-Dienstleistungen» tätig. - - - -* Das [Management](valueon-ag-4663161481/management) der Firma ValueOn AG besteht aus 5 Personen. - - - -* Unter [Meldungen](valueon-ag-4663161481/messages) finden Sie alle Handelsregisteränderung, die letzte erfolgte am 27.08.2025. - - - -* Die Firma ist im Handelsregister des Kantons ZH unter der UID CHE-113.416.882 eingetragen. - - - -* Unternehmen mit derselben Adresse wie ValueOn AG: [Black Projects GmbH](black-projects-gmbh-3958227961), [Bluespace Ventures AG](bluespace-ventures-ag-20038582721), [Cyberfy Consulting AG](cyberfy-consulting-ag-5194156221). - -## Management (5) - -#### neueste Verwaltungsräte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901) - -#### neuste Zeichnungsberechtigte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -#### Geschäftsleitung - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -Quelle: [SHAB](/de/datasources) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -## Netzwerk - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -## Handelsregisterinformationen - -Quelle: [SHAB](/de/datasources) - -#### Eintrag ins Handelsregister - -02.02.2007 - -#### Rechtsform - -Aktiengesellschaft - -#### Rechtssitz der Firma - -Dübendorf - -#### Handelsregisteramt - -ZH - -#### Handelsregister-Nummer - -CH-020.3.030.651-3 - -#### UID/MWST - -CHE-113.416.882 - -#### Branche - -Erbringen von IT-Dienstleistungen - -#### Firmenzweck - -Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -[Passen Sie den Firmenzweck mit wenigen Klicks an.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Revisionsstelle - -Quelle: [SHAB](/de/datasources) - -#### Aktive Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [TBO Revisions AG](/de/company/tbo-revisions-ag-20607789301) | | Zürich | 18.03.2015 | | - -[Möchten Sie die Revisionsstelle anpassen? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Frühere Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [Trevisca AG](/de/company/trevisca-ag-20628390611) | | Baar | 08.02.2007 | 17.03.2015 | - -## Weitere Firmennamen - -Quelle: [SHAB](/de/datasources) - -#### Frühere und übersetzte Firmennamen - -* Project Competence AG - -[Möchten Sie den Firmennamen aktualisieren? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Zweigniederlassungen (0) - -## Besitzverhältnisse - -Es liegen uns keine Angaben zu den Besitzverhältnissen vor. - -## Beteiligungen - -Es liegen uns keine Angaben zu den Beteiligungen vor. - - - - - - - - - -## Neueste SHAB-Meldungen: ValueOn AG - -SHAB 250827/2025 - 27.08.2025 - -**Kategorien:** Änderung des Firmenzwecks, Änderung der Firmenadresse - -Publikationsnummer: [HR02-1006417690](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006417690 "Download SHAB Publikation der ValueOn AG vom 27.08.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 133 vom 14.07.2025, Publ. 1006383218). - -**Statutenänderung:** - 18.08.2025. - -**Sitz neu:** - Dübendorf. - -**Domizil neu:** - c/o Westhive AG, Am Stadtrand 11, 8600 Dübendorf. - -**Zweck neu:** - Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -**Mitteilungen neu:** - Mitteilungen an die Aktionäre erfolgen per Brief oder E-Mail an die im Aktienbuch verzeichneten Adressen. - -SHAB 250714/2025 - 14.07.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006383218](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006383218 "Download SHAB Publikation der ValueOn AG vom 14.07.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 101 vom 27.05.2025, Publ. 1006341693). - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Einzelunterschrift [*bisher: Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]. - -SHAB 250527/2025 - 27.05.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006341693](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006341693 "Download SHAB Publikation der ValueOn AG vom 27.05.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 222 vom 14.11.2024, Publ. 1006178101). - -**Ausgeschiedene Personen und erloschene Unterschriften:** - Hamburger, Marc Eric, von St. Gallen, in Mörschwil, Präsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Egloff, Reto](/de/person/egloff-reto-101763781201), von Oberrohrdorf, in Bern, Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Mühlemann, Markus](/de/person/muehlemann-markus-142196879901), von Seeberg, in Uster, Delegierter des Verwaltungsrates, mit Einzelunterschrift. - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien [*bisher: Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]; - [Althaus, Walter](/de/person/althaus-jun-walter-205367807901), von Affoltern im Emmental, in Aarwangen, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Wyss, Andreas](/de/person/wyss-andreas-129476912501), von Dietikon, in Dietikon, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien. - -[Alle SHAB-Meldungen ansehen](/de/company/valueon-ag-4663161481/messages) - -## Trefferliste - -Hier finden Sie eine Verlinkung des Managements auf eine Trefferliste zu Personen mit dem gleichen Namen, die im Handelsregister eingetragen sind. - -[Dominic Pascal Largo](/de/list/person/largo-dominic-pascal) - -[Andreas Wyss](/de/list/person/wyss-andreas) - -[Walter Althaus Jun.](/de/list/person/althaus-jun-walter) - -[Andreas Friedli](/de/list/person/friedli-andreas) - -[Richard Salvisberg](/de/list/person/salvisberg-richard) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](/de/terms)[Datenschutz |](/de/privacy)[Impressum](/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](/de/overview) - - - - - - -[Übersicht](/de/company/valueon-ag-4663161481) - -[Auskünfte](/de/company/valueon-ag-4663161481/reports) - -[Management](/de/company/valueon-ag-4663161481/management) - -[Netzwerk](/de/company/valueon-ag-4663161481/network) - -[Timeline](/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](/de/company/valueon-ag-4663161481/shares) - -[Meldungen](/de/company/valueon-ag-4663161481/messages) - -[Marken](/de/company/valueon-ag-4663161481/brands) - -[Jobs](/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_205603/main_url_016_www.valueon.ch_.txt b/test_web_content_20251002_205603/main_url_016_www.valueon.ch_.txt deleted file mode 100644 index 39603ff0..00000000 --- a/test_web_content_20251002_205603/main_url_016_www.valueon.ch_.txt +++ /dev/null @@ -1,107 +0,0 @@ -Title: https://www.valueon.ch/ -URL: https://www.valueon.ch/ -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -# Power für deinendigitalen Erfolg - -Vertrauen von führenden Unternehmen - -## Unsere Expertise - -Von digitaler Transformation bis zu künstlicher Intelligenz – wir begleiten Sie auf Ihrem Weg in die Zukunft. - -### Digitale Strategie entwickeln - -Ihre Richtung im digitalen Wandel. - -Gemeinsames Zielbild & Roadmap, abgestimmt auf Ihr Geschäft und leiten konkrete Handlungsempfehlungen ab. - -Orientierung & Handlungssicherheit - -### Transformation gezielt optimieren - -Lücken aufdecken. Stärken nutzen. - -Systematischer Blick auf Prozesse, Systeme & Potenziale und leiten konkrete Handlungsempfehlungen ab. - -Relevanz statt Aktionismus - -### Change Management etablieren - -Menschen mitnehmen. Wandel gestalten. - -Strukturierte Begleitung der Mitarbeiter durch den digitalen Wandel mit gezielten Schulungskonzepten. - -Akzeptanz & Erfolg sichern - -### Prozesse digital automatisieren - -Effizienz steigern. Kosten senken. - -Identifikation und Umsetzung von Automatisierungspotenzialen für nachhaltige Produktivitätssteigerung. - -Messbare Effizienzgewinne - -## Erfolgreiche Projekte & Transformationen - -Unter dem Motto «Unsere Kunden stehen im Mittelpunkt» haben wir für Sie eine Auswahl an Kundenreferenzen und Business Cases zusammengestellt. - -Als KMU sind wir es eigentlich nicht gewohnt, einen so grossen Aufwand wie bei der Evaluation des richtigen Partners für die Entwicklung und Realisierung unseres neuen Kernsystems zu betreiben. Doch i... - -Markus Berther - -Geschäftsführer, Schaden Service Schweiz AG - -ValueOn hat uns durch den gesamten Prozess der Digitalen Business Transformation mit grossem Einsatz und Engagement begleitet – von der ersten IT-Standortanalyse und Sourcing Analyse über digitales Zi... - -Stefan Wolf - -Präsident, FC Luzern - -In diesem businesskritischen IT-Programm waren insgesamt vier Experten von ValueOn (ehem. Project Competence) involviert, als Projektleiter und Koordinator, Cut-Over-Manager bis hin zur Gesamt-Program... - -Roland Bosshard - -CIO / Mitglied der GL, KPT - -In time, in quality, under budget: Andreas Friedli von ValueOn (ehem. Project Competence) hat in seiner Co-Leitungsfunktion in diesem IT-Projekt ganz massgeblich dazu beigetragen, dass wir dieses trot... - -Thomas Sturzenegger - -Divisional IT Lead, RUAG Real Estate AG - -Die erfolgreiche Realisierung dieses Vorhabens ist ein wichtiger Meilenstein für die strategische Neuausrichtung der WWZ. Die Projektberater der ValueOn AG (ehem. Project Competence AG) haben dabei da... - -Thomas Reber - -Leiter Telekom & IT Services, WWZ AG - -Um die Zukunftsausrichtung unserer IT-Strategie und -Organisation möglichst optimal auf unsere Business-Anforderungen auszurichten, haben wir ValueOn (ehem. Project Competence) als Sparringpartner ... - -Andreas Guglielmo - -CFO, CHRIS sports AG - -Wir danken den externen Projektberatern der ValueOn (ehem. Project Competence), die uns kompetent und mit ebenso hohem Arbeitseinsatz durch dieses Projekt und die Verhandlungen unter schwierigen Be... - -Michael Kohlbacher - -Generalsekretär, AGZ - -Dank ValueOn konnten wir unser komplexes IT-Infrastrukturprojekt termingerecht und im Budget abschliessen. Die strukturierte Herangehensweise war ausschlaggebend. - -Peter Keller - -Projektleiter, InnovaCorp - -ValueOn hat uns sowohl fachlich als auch menschlich auf höchstem Niveau beraten. Die Experten begleiteten uns kompetent bei der Modernisierung unserer IT-Infrastruktur und der reibungslosen Ablösung u... - -Silvan Wildhaber - -CEO, Filtex Group AG - -← Wischen Sie für weitere Testimonials → - -Auto-Scroll aktiv \ No newline at end of file diff --git a/test_web_content_20251002_205603/main_url_017_www.valueon.ch_about.txt b/test_web_content_20251002_205603/main_url_017_www.valueon.ch_about.txt deleted file mode 100644 index 72468485..00000000 --- a/test_web_content_20251002_205603/main_url_017_www.valueon.ch_about.txt +++ /dev/null @@ -1,639 +0,0 @@ -Title: https://www.valueon.ch/about -URL: https://www.valueon.ch/about -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unser Team -========== - -Seit über 25 Jahren stehen wir für Innovation, Qualität und nachhaltigen Erfolg. Erfahren Sie mehr über unsere Geschichte, unsere Werte und die Menschen, die ValueON zu dem machen, was es heute ist. - -Alle Kernteam Geschäftsführende Partner Externe Zertifizierte Partner - - - -Mehr erfahren - -### Dominic Largo - -CEO - - - -Dominic führt das Unternehmen mit einer klaren Vision für digitale Innovation und strategisches Wachstum in der Beratung. - -### Dominic Largo - -CEO - - - -Zum Vergrößern klicken - -#### Schwerpunkte - -* Sicherstellen der besten Projekt- & Tranformationsmanager für unsere Kunden und unsere Vorhaben -* Reviews von komplexen und erfolgskritischen Vorhaben -* Advisor & Einsitz in Steering Boards -* Sparringpartner für Führungskräfte und Gremien - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Handel / eCommerce Tourismus Konsumgüter Luxusgüter Industrie - -#### Berufliche Stationen - -* BottleButler AG (Founder & CEO) -* Arosa Lenzerheide (Marken- und Digital Leader) -* Mitgründer mehrerer Startups (Co-CEO & VR) -* Porsche Design Group (Country Manager & GCC) -* HAWAS & Jung von Matt (Markenstratege) - -#### Und ganz nebenbei... - -...ist Dominic Largo mit grosser Passion Langstreckenläufer, Kulinariker und Game Challenger. Er geniesst explizit die Berge und seine Familienzeit. - - - -Mehr erfahren - -### Andreas Friedli - -Managing Partner - - - -Mit über 25 Jahren Erfahrung in der digitalen Transformation leitet Andreas als Partner erfolgreich strategische Grossprojekte. - -### Andreas Friedli - -Managing Partner - -#### Schwerpunkte - -* Health-Check von Projekten und Programmen -* Advisor digitaler Transformationen -* Führung von Digitalisierungsprojekten und -programmen -* Emergency- und Recoveryprojekte -* Risiko- und Quality-Assurance bei digitalen Transformationen -* Advisor digitaler Neuausrichtungen -* Leadership-Coaching Projekt und Programm Manager - -#### Im Team seit - -2004 - -#### Branchenerfahrungen - -Finanzen / Banken Versicherungen / Krankenkassen Detailhandel Verwaltung Militär Automobile IT / Telekommunikation Immobilien - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of Complex Projects -* HP GmbH, Senior Project Manager -* Compaq Computer GmbH, Senior Project Manager -* Volkswirtschaftsdep. St. Gallen, Informatikverantwortlicher - -#### Und ganz nebenbei... - -…spielt Andreas Friedli gerne Golf, liebt feines Essen und guten Wein und verbringt viel Zeit mit seiner Familie – ganz nach dem Motto «Geniesse den Moment!». - - - -Mehr erfahren - -### Patrick Motsch - -Managing Partner - - - -Patrick leitet als Partner erfolgreich komplexe IT-Implementierungsprojekte. - -### Patrick Motsch - -Managing Partner - -#### Schwerpunkte - -* Health Check von Projekten -* Führen von geschäftskritischen Projekten und Programmen -* Führen und Begleiten von Emergency und Recovery Projekten -* Führen und Begleiten von DC Moves und ICT Konsolidierungsprojekten -* Advisor für Auftraggeber - -#### Im Team seit - -2001 - -#### Branchenerfahrungen - -Baubranche IT / Telekommunikation / Data Center Industrie Sport Verteidigung Verwaltung Airspace Management Versicherungen Handel - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG) -* Vater und Pionier des TimeWinner Führungssystems -* CIO einer IT Consulting Organisation - -#### Und ganz nebenbei... - -…liebt Patrick Motsch den Garten, das Tanzen, wandert gerne, taucht so oft es geht und lernt gerne fremde Länder kennen. Sein persönliches Motto: «Wer will, der kann». - - - -Mehr erfahren - -### Richard Salvisberg - -Managing Partner - - - -Richard bringt als Partner strategische Beratungsexpertise und Führungskompetenz ein. - -### Richard Salvisberg - -Managing Partner - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Führen von geschäftskritischen Programmen und Transformationen -* Aufbau und Führen von Projektportfolio-Managementsystemen -* Sparringpartner und Advisor - -#### Im Team seit - -2006 - -#### Branchenerfahrungen - -Gesundheitswesen & (Kranken-)Versicherung Militär Verwaltung Beschaffungswesen & Transport Informatik & Telekommunikation Bau Sport Energie - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of PPM -* T-Systems Schweiz AG, Chief Information Officer -* Orange Communications SA, IT Account Manager -* Swisscom AG Bern, Head Management Support -* Swisscom AG Bern, Programm Manager Charging & Billing - -#### Und ganz nebenbei... - -…liebt Richard Salvisberg das Tanzen, lernt gerne fremde Kulturen kennen, hat Freude an schönen Autos und geniesst ein Buch bei einem guten Schluck Wein. In klaren Nächten beobachtet er interessiert den Kosmos. Sein persönliches Motto lautet «Auf innovativen Wegen nachhaltige Erfolge erzielen». - - - -Mehr erfahren - -### Stephan Schellworth - -Experte - - - -Stephan verbindet strategisches Denken mit praxisnaher Projektsteuerung und gestaltet digitale Projekte - -### Stephan Schellworth - -Experte - -#### Schwerpunkte - -* Projekt- und Teamführung -* Datenanalyse und Optimierung -* Agiles Projektmanagement - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Automatisierungstechnik Digitalisierung - -#### Berufliche Stationen - -* 2023 - 2024: Testmanager im Energiebordnetz, BMW Group -* 2021 - 2023: Gesamtfahrzeugspezialist in der E/E, BMW Group -* 2018 - 2021: Prüfstandsspezialist im BMW Prototypen-Motorenwerk, Academic Work -* 2016 - 2018: Entwicklungsingenieur, EDAG Engineering Group - -#### Und ganz nebenbei... - -…sammelt und pflegt Stephan Young- und Oldtimern, treibt Sport wie Squash und besucht regelmässig das Fitnessstudio. Er geht gern mit seinem Hund spazieren oder wandert in der Natur. Ausserdem programmiert er kleinere SmartHome-Anwendungen mit dem Raspberry Pi, Apps und erstellt 3D-Visualisierungen von Innen- und Aussenräumen. - - - -Mehr erfahren - -### Mats Rudolf - -Experte - - - -Mats berät Unternehmen zu digitalen Transformationsprojekten und Systemimplementierungen. - -### Mats Rudolf - -Experte - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Advisor digitaler Transformation -* Advisor Systems Engineering -* Projekt- und Teamführung -* Agiles Projektmanagement - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Sensortechnik Luft- und Raumfahrttechnik Maschinen- und Anlagenbau Transport und Logistik - -#### Berufliche Stationen - -* 2019 - 2024: Management Consultant Innovation und Transformation, UNITY Schweiz AG -* 2018: Industrial Solution Consulting Intern, Brütsch Rüegger Werkzeuge -* 2015 - 2016: Sensor Research and Development Intern, Sensirion AG - -#### Und ganz nebenbei... - -…zieht es Mats Rudolf im Winter für Skitouren und rasante Abfahrten auf die frisch verschneiten Berge. Wenn der Sommer kommt, tauscht er seine Ski gegen ein Surfbrett und geniesst die Wellen im Meer. Zudem schwingt er gerne den Schläger auf dem Tennisplatz und bastelt an seinen Smart-Device-Projekten. - - - -Mehr erfahren - -### Ida Dittrich - -AI Specialist - -Ida verbindet ihr wissenschaftliches Know-how mit praktischer IT-Erfahrung und bringt innovative Ansätze in technische Projekte ein. - -### Ida Dittrich - -AI Specialist - -#### Schwerpunkte - -* Product Architect and Software Engineer PowerOn Platform - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Luft- und Raumfahrtindustrie Kommunikation und Interessenvertretung Medien - -#### Berufliche Stationen - -* Forschungsprojekt zur Modellierung des inneren Aufbaus terrestrischer Exoplaneten (ETH Zürich) -* Recovery Engineer und Systems Engineer bei verschiedenen Projekten der Akademischen Raumfahrtinitiative der Schweiz (ARIS) - -#### Und ganz nebenbei... - -… spielt Ida Dittrich leidenschaftlich gern Computerspiele und bastelt an handwerklichen Projekten wie Nähen, Häkeln oder Stricken. Sie ist regelmäßig sportlich aktiv – sei es beim Joggen an der frischen Luft, im Fitnessstudio oder bei einer entspannenden Yoga-Einheit. - - - -Mehr erfahren - -### Nick Melloh - -AI-Specialist - -Nick macht künstliche Intelligenz für Unternehmen greifbar – in Projekten, Strategien und praxisnahen Schulungen. - -### Nick Melloh - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Digitale Transformation & Business Innovation -* Advisor für Künstliche Intelligenz & Wissensvermittlung -* Advisor für Strategisches Projekt- und Prozessmanagement -* Trainer für KI-Schulungen und Weiterbildung - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Digitalisierung Consulting Hospitality Event- und Innovationsmanagement KI-Anwendungen - -#### Berufliche Stationen - -* 2023–heute: Master in Business Innovation, Universität St. Gallen – Schwerpunkt Digitale Transformation & KI -* 2023–heute: Event Manager SQUARE, Universität St. Gallen – Gestaltung innovativer Lern- und Austauschformate -* 2022–2023: VP Sales, Contler AG – SaaS-Lösungen & Prozessautomatisierung im Hospitality-Sektor - -#### Und ganz nebenbei... - -…hat Nick eine Schwäche für Reisen, gutes Essen und Bücher – um neue Denkanstöße zu gewinnen und frische Perspektiven einzunehmen. Energie findet er beim Sport, in den Bergen oder bei langen Gesprächen mit Freunden – die besten Momente für ihn sind die, in denen die Uhr keine Rolle spielt. - - - -Mehr erfahren - -### Yannick Althaus - -AI-Specialist - -Yannick berät Unternehmen, indem er Strategiekompetenz mit unternehmerischer DNA verbindet. - -### Yannick Althaus - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Strategisches Management und Unternehmensführung -* Advisor für Künstliche Intelligenz und digitale Transformation -* Advisor für Produktion und Supply Chain Management - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Industrie Digitalisierung Supply Chain Management Consulting - -#### Berufliche Stationen - -* 2025: M.A. HSG in Unternehmensführung - Masterarbeit zum Einsatz von generativer KI in der Strategieentwicklung von CEOs -* 2022: B.Sc. Wirtschaftsingenieurwesen -* 2019–2025: Diverse Consulting-Praktika & Projekte in Supply Chain Management, Digitalisierung und strategischem Management sowie Mitarbeit im Familienunternehmen (neben dem Studium) -* 2013–2017: Automatiker EFZ bei Bystronic - -#### Und ganz nebenbei... - -…wenn er nicht an Strategien feilt, zieht es Yannick aufs Eis – Eishockey ist sein Adrenalinschub. Auch sonst bleibt er regelmässig in Bewegung: Skifahren im Winter, Joggen zwischendurch und Golf im Sommer. Ausserdem hat er eine Schwäche für schnelle Autos und reist gerne – am liebsten ans Meer. - - - -### Philipp Dick - -Certified Partner - -"KI wird Manager nicht ersetzen, aber Manager, die KI einsetzen, werden die ersetzen, die es nicht tun." - - - -### Romano Caviezel - -Certified Partner - -"Innovation bedeutet, bestehende Dinge zu hinterfragen und neue Wege zu entdecken." - - - -### Dawid Puzik - -Certified Partner - -"Manche sehen, was möglich ist – andere verändern, was möglich ist." - - - -### Holger Ridinger - -Certified Partner - -"Transformation braucht Struktur, Leidenschaft und Ausdauer." - - - -### Alain Kappeler - -Certified Partner - -"Wenn es dich nicht herausfordert, verändert es dich nicht." - - - -### Andreas Wyss - -Certified Partner - -Andreas verbindet strategisches Denken mit menschlichem Feingefuehl in Transformationsprozessen. - - - -### Alfredo Mercurio - -Certified Partner - -"Eine klare Vision ist der Anfang von allem." - - - -### Bernd Nagel - -Certified Partner - -"Wer will, findet Wege. Wer nicht will, findet Gründe." - - - -### Daniel Sengstag - -Certified Partner - -"Wer nicht mit der Zeit geht, geht mit der Zeit." - - - -### Daniel Lochmatter - -Certified Partner - -"Neues und bisher Unbekanntes kann man nur explorativ erfahren, erspüren, erlernen – und danach zum eigenen Nutzen einsetzen." - - - -### Michael Hermann - -Certified Partner - -"Auch beim Projekt gilt: Ende gut, alles gut." - - - -### Heinz Ruffieux - -Certified Partner - -"C'est le ton qui fait la musique." - - - -### Sven Fassbender - -Certified Partner - -"Mein Ziel ist es, Cybersicherheit verständlich und greifbar zu machen – für jeden zugänglich und praktikabel." - - - -### Raffael Santchi - -Certified Partner - -"Wer Prozesse versteht, kann Systeme formen – nicht umgekehrt." - - - -### Stephanie Kieninger - -Certified Partner - -Stephanie konzentriert sich mit ihrer Beratung auf die Menschen im Veraenderungsprozess. - - - -### Christoph Merle - -Certified Partner - -Christoph engagiert sich mit seiner langjährigen Führungserfahrung in der Industrie und mit seinem Hintergrund in strategischer und operativer Beratung für den Erfolg unserer Kunden. - -Previous slide Next slide - -Über ValueOn ------------- - -Wir schaffen digitale Transformation mit Leidenschaft und Expertise - -### Unsere Mission - -Durch exzellente Beratung schaffen wir digitale Transformation erfolgreich zu meistern. - -### Unser Versprechen - -Höchste Qualität, agile Ansätze und Passion für gemeinsamen Wirken - -25+ - -Jahre Erfahrung - -100+ - -Projekte - -98% - -Weiterempfehlung - -60% - -Schneller zum Ziel - -Unsere Geschichte ------------------ - -Eine Reise der Innovation - -Heute - -Heute und Morgen - -Als führendes Beratungsunternehmen gestalten wir aktiv die Zukunft der digitalen Transformation mit innovativen KI-Lösungen und nachhaltigen Strategien. - -KI-Ära - -KI-Revolution - -Die Einführung von KI-Systemen veränderte unsere Beratungsleistung grundlegend und ermöglichte es uns, unseren Kunden noch innovativere Lösungen anzubieten. - -Digital - -Digitale Transformation - -Mit neuen digitalen Lösungen begleiteten wir unsere Kunden in der Transformation und etablierten uns als führender Partner für digitale Innovation. - -Aufbau - -Etablierung am Markt - -Wir etablierten uns am Markt mit innovativen IT-Strategien und nachhaltiger Umsetzung, wodurch wir eine solide Basis für weiteres Wachstum schufen. - -2000 - -Gründung von ValueON - -ValueON wurde mit der Vision gegründet, Unternehmen bei der digitalen Transformation zu unterstützen und nachhaltigen Erfolg zu schaffen. - -Unsere Werte ------------- - -Was uns antreibt - -### Exzellenz - -Höchste Qualität in allem, was wir tun. Von der ersten Beratung bis zur finalen Umsetzung setzen wir auf höchste Standards. - -### Partnerschaft - -Wir sehen uns als langfristige Partner unserer Kunden und arbeiten gemeinsam an nachhaltigen Lösungen. - -### Integrität - -Ehrlichkeit, Transparenz und Vertrauen bilden das Fundament aller unserer Geschäftsbeziehungen. - -### Effektivität - -Zielgerichtete Lösungen, die messbare Ergebnisse liefern und nachhaltigen Geschäftserfolg schaffen. - -Karriere bei ValueOn --------------------- - -Werde Teil unseres Teams - -### Product-Architekt/in für KI-Plattformen - -Zürich, Schweiz M/W, 50-100% - -Details ansehen - -Keine passende Stelle gefunden? - -[Initiativbewerbung senden](mailto:office@valueon.ch) - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_205603/main_url_018_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt b/test_web_content_20251002_205603/main_url_018_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt deleted file mode 100644 index 3837989e..00000000 --- a/test_web_content_20251002_205603/main_url_018_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt +++ /dev/null @@ -1,364 +0,0 @@ -Title: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 -Type: Main URL -Extracted: 2025-10-02 20:56:03 -================================================================================ - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](#)[Save + Exit](#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - -[Startseite](/de/) [>](javascript:void(0)) [Unternehmen](/de/search?q=ValueOn AG) [>](javascript:void(0)) ValueOn AG - -# ValueOn AG - -ZH - -aktiv - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) -[Zur Timeline](/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -Handelsregister-Nr.: CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](/de/company/valueon-ag-4663161481/messages) - -[Sie möchten eine Änderung der Firmendaten vornehmen? Wir unterstützen Sie hierbei gerne.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Alter der Firma - -18 Jahre - -#### Umsatz in CHF - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Kapital in CHF - -200'000 - -#### Mitarbeiter - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Aktive Marken - -0 - -c/o Westhive AG -Am Stadtrand 11 -8600 Dübendorf -[Nachbarschaft](/de/company/valueon-ag-4663161481/network#neighbourhood) - -[Sie möchten Ihre Adresse anpassen? -Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -[News aus der Region Uster](/de/region/uster/uebersicht) - -## Auskünfte zu ValueOn AG - -\*angezeigte Auskünfte sind Beispiele - -#### Bonitätsauskunft - -Einschätzung der Bonität mit einer Ampel als Risikoindikator und weiteren hilfreichen Firmeninformationen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -#### Wirtschaftsauskunft - -Umfassende Auskunft über die wirtschaftliche Situation der Firma. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#commercial-report) - -#### Zahlungsverhalten - -Beurteilung der Zahlungsmoral aufgrund vergangener Rechnungen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-mode-report) - -#### Betreibungsauskunft - -Übersicht über aktuelle und vergangene Betreibungsverfahren. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-collection-report) - -#### Beteiligungsauskunft - -Erfahren Sie, an welchen nationalen und internationalen Firmen die Aktiengesellschaft, für die Sie sich interessieren, noch beteiligt ist. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#wow-report) - -#### Firmendossier als PDF - -Kontaktinformationen, Veränderungen, Umsatz- und Mitarbeiterzahlen, Management, Besitzverhältnisse, Beteiligungsstruktur und weitere Firmendaten. -[Jetzt kostenlos abrufen](/de/company/valueon-ag-4663161481/reports#firmendossier-report) - -## Über ValueOn AG - -* ValueOn AG hat den Sitz in Dübendorf, ist aktiv und im Bereich «Erbringen von IT-Dienstleistungen» tätig. - - - -* Das [Management](valueon-ag-4663161481/management) der Firma ValueOn AG besteht aus 5 Personen. - - - -* Unter [Meldungen](valueon-ag-4663161481/messages) finden Sie alle Handelsregisteränderung, die letzte erfolgte am 27.08.2025. - - - -* Die Firma ist im Handelsregister des Kantons ZH unter der UID CHE-113.416.882 eingetragen. - - - -* Unternehmen mit derselben Adresse wie ValueOn AG: [Black Projects GmbH](black-projects-gmbh-3958227961), [Bluespace Ventures AG](bluespace-ventures-ag-20038582721), [Cyberfy Consulting AG](cyberfy-consulting-ag-5194156221). - -## Management (5) - -#### neueste Verwaltungsräte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901) - -#### neuste Zeichnungsberechtigte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -#### Geschäftsleitung - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -Quelle: [SHAB](/de/datasources) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -## Netzwerk - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -## Handelsregisterinformationen - -Quelle: [SHAB](/de/datasources) - -#### Eintrag ins Handelsregister - -02.02.2007 - -#### Rechtsform - -Aktiengesellschaft - -#### Rechtssitz der Firma - -Dübendorf - -#### Handelsregisteramt - -ZH - -#### Handelsregister-Nummer - -CH-020.3.030.651-3 - -#### UID/MWST - -CHE-113.416.882 - -#### Branche - -Erbringen von IT-Dienstleistungen - -#### Firmenzweck - -Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -[Passen Sie den Firmenzweck mit wenigen Klicks an.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Revisionsstelle - -Quelle: [SHAB](/de/datasources) - -#### Aktive Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [TBO Revisions AG](/de/company/tbo-revisions-ag-20607789301) | | Zürich | 18.03.2015 | | - -[Möchten Sie die Revisionsstelle anpassen? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Frühere Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [Trevisca AG](/de/company/trevisca-ag-20628390611) | | Baar | 08.02.2007 | 17.03.2015 | - -## Weitere Firmennamen - -Quelle: [SHAB](/de/datasources) - -#### Frühere und übersetzte Firmennamen - -* Project Competence AG - -[Möchten Sie den Firmennamen aktualisieren? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Zweigniederlassungen (0) - -## Besitzverhältnisse - -Es liegen uns keine Angaben zu den Besitzverhältnissen vor. - -## Beteiligungen - -Es liegen uns keine Angaben zu den Beteiligungen vor. - - - - - - - - - -## Neueste SHAB-Meldungen: ValueOn AG - -SHAB 250827/2025 - 27.08.2025 - -**Kategorien:** Änderung des Firmenzwecks, Änderung der Firmenadresse - -Publikationsnummer: [HR02-1006417690](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006417690 "Download SHAB Publikation der ValueOn AG vom 27.08.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 133 vom 14.07.2025, Publ. 1006383218). - -**Statutenänderung:** - 18.08.2025. - -**Sitz neu:** - Dübendorf. - -**Domizil neu:** - c/o Westhive AG, Am Stadtrand 11, 8600 Dübendorf. - -**Zweck neu:** - Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -**Mitteilungen neu:** - Mitteilungen an die Aktionäre erfolgen per Brief oder E-Mail an die im Aktienbuch verzeichneten Adressen. - -SHAB 250714/2025 - 14.07.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006383218](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006383218 "Download SHAB Publikation der ValueOn AG vom 14.07.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 101 vom 27.05.2025, Publ. 1006341693). - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Einzelunterschrift [*bisher: Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]. - -SHAB 250527/2025 - 27.05.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006341693](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006341693 "Download SHAB Publikation der ValueOn AG vom 27.05.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 222 vom 14.11.2024, Publ. 1006178101). - -**Ausgeschiedene Personen und erloschene Unterschriften:** - Hamburger, Marc Eric, von St. Gallen, in Mörschwil, Präsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Egloff, Reto](/de/person/egloff-reto-101763781201), von Oberrohrdorf, in Bern, Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Mühlemann, Markus](/de/person/muehlemann-markus-142196879901), von Seeberg, in Uster, Delegierter des Verwaltungsrates, mit Einzelunterschrift. - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien [*bisher: Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]; - [Althaus, Walter](/de/person/althaus-jun-walter-205367807901), von Affoltern im Emmental, in Aarwangen, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Wyss, Andreas](/de/person/wyss-andreas-129476912501), von Dietikon, in Dietikon, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien. - -[Alle SHAB-Meldungen ansehen](/de/company/valueon-ag-4663161481/messages) - -## Trefferliste - -Hier finden Sie eine Verlinkung des Managements auf eine Trefferliste zu Personen mit dem gleichen Namen, die im Handelsregister eingetragen sind. - -[Dominic Pascal Largo](/de/list/person/largo-dominic-pascal) - -[Andreas Wyss](/de/list/person/wyss-andreas) - -[Walter Althaus Jun.](/de/list/person/althaus-jun-walter) - -[Andreas Friedli](/de/list/person/friedli-andreas) - -[Richard Salvisberg](/de/list/person/salvisberg-richard) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](/de/terms)[Datenschutz |](/de/privacy)[Impressum](/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](/de/overview) - - - - - - -[Übersicht](/de/company/valueon-ag-4663161481) - -[Auskünfte](/de/company/valueon-ag-4663161481/reports) - -[Management](/de/company/valueon-ag-4663161481/management) - -[Netzwerk](/de/company/valueon-ag-4663161481/network) - -[Timeline](/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](/de/company/valueon-ag-4663161481/shares) - -[Meldungen](/de/company/valueon-ag-4663161481/messages) - -[Marken](/de/company/valueon-ag-4663161481/brands) - -[Jobs](/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_212142/additional_link_001_www.valueon.ch_services.txt b/test_web_content_20251002_212142/additional_link_001_www.valueon.ch_services.txt deleted file mode 100644 index 7fe76a15..00000000 --- a/test_web_content_20251002_212142/additional_link_001_www.valueon.ch_services.txt +++ /dev/null @@ -1,110 +0,0 @@ -URL: https://www.valueon.ch/services -Type: Additional Link -Extracted: 2025-10-02 21:21:42 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unsere Leistungen -================= - -Von der digitalen Transformation bis zur KI-Integration – wir begleiten Sie bei jedem Schritt zu nachhaltigem Erfolg, messbaren Ergebnissen und langfristiger Wertschöpfung. - -Digitale Transformation Künstliche Intelligenz IT- & Digitalprojekte - -Digitale Transformation ------------------------ - -Wir begleiten Sie bei jedem Schritt – von der Strategie bis zur erfolgreichen Umsetzung. - -### Zukunft gestalten mit klarem Zielbild - -IHRE RICHTUNG IM DIGITALEN WANDEL - -Zielbild & Roadmap für digitale Transformation – zugeschnitten auf Ihr Geschäft. - -Orientierung & Handlungssicherheit - -### Transformation analysieren & optimieren - -LÜCKEN AUFDECKEN. NUTZEN SCHÄRFEN - -Fit-Gap-Analyse und Review Ihrer Prozesse, Tools & Struktur. - -Systematische Bewertung statt Aktionismus - -### IT, Business & Digitalstrategie vereinen - -SCHNITTSTELLEN AUFLÖSEN. STRATEGIE VERBINDEN - -Abgleich Ihrer Digital- und Businessstrategie – für nachhaltige Wirkung. - -Strategische Klarheit gewinnen - -### CIO/CDO ad interim einsetzen - -FÜHRUNG SICHERN. KOMPETENZ EINBRINGEN - -Temporäre Führungsstärke, wenn Verantwortung gebraucht wird. - -Sofort einsatzbereit & erfahrungssicher - -### Zukunft gestalten mit klarem Zielbild - -IHRE RICHTUNG IM DIGITALEN WANDEL - -Zielbild & Roadmap für digitale Transformation – zugeschnitten auf Ihr Geschäft. - -Orientierung & Handlungssicherheit - -### Transformation analysieren & optimieren - -LÜCKEN AUFDECKEN. NUTZEN SCHÄRFEN - -Fit-Gap-Analyse und Review Ihrer Prozesse, Tools & Struktur. - -Systematische Bewertung statt Aktionismus - -### IT, Business & Digitalstrategie vereinen - -SCHNITTSTELLEN AUFLÖSEN. STRATEGIE VERBINDEN - -Abgleich Ihrer Digital- und Businessstrategie – für nachhaltige Wirkung. - -Strategische Klarheit gewinnen - -### CIO/CDO ad interim einsetzen - -FÜHRUNG SICHERN. KOMPETENZ EINBRINGEN - -Temporäre Führungsstärke, wenn Verantwortung gebraucht wird. - -Sofort einsatzbereit & erfahrungssicher - -### Bereit für den ersten Schritt? - -Ob Strategie, Analyse oder Interim – wir zeigen Ihnen den passenden Einstieg. - -Kostenfrei Strategiegespräch vereinbaren - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_212142/additional_link_002_www.valueon.ch_projects.txt b/test_web_content_20251002_212142/additional_link_002_www.valueon.ch_projects.txt deleted file mode 100644 index 7a44c732..00000000 --- a/test_web_content_20251002_212142/additional_link_002_www.valueon.ch_projects.txt +++ /dev/null @@ -1,354 +0,0 @@ -URL: https://www.valueon.ch/projects -Type: Additional Link -Extracted: 2025-10-02 21:21:42 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unsere Erfolgsprojekte -====================== - -Entdecken Sie, wie wir Unternehmen dabei helfen, ihre digitale Transformation erfolgreich umzusetzen und nachhaltige Werte zu schaffen. - -50+ - -Erfolgreiche Projekte - -100% - -Kundenzufriedenheit - -25% - -Ø Kostenoptimierung - -60% - -schneller Integriert - -Referenzprojekte & Success Stories ----------------------------------- - -Jedes Projekt ist einzigartig. Entdecken Sie, wie wir mit massgeschneiderten Lösungen echte Mehrwerte für unsere Kunden schaffen. - - - -Digitale Transformation - -KPT • 18 Monate - -### Digitale Transformation der KPT - -Komplette Modernisierung der IT-Infrastruktur mit 24% Kostenoptimierung und deutlich mehr Leistung, Flexibilität und Sicherheit. - -#### Technologien: - -Cloud Migration Prozessoptimierung Change Management - -#### Ergebnisse: - -* 24% Kostenoptimierung -* Erhöhte Flexibilität -* Verbesserte Sicherheit - - - -Künstliche Intelligenz - -WWZ • 12 Monate - -### KI-gestützte Prozessoptimierung WWZ - -Implementierung einer KI-Lösung zur Automatisierung von Geschäftsprozessen und Entscheidungsfindung. - -#### Technologien: - -Machine Learning Process Mining Automation - -#### Ergebnisse: - -* 40% Zeitersparnis -* Verbesserte Genauigkeit -* Datenbasierte Entscheidungen - - - -IT-Infrastruktur - -FC Luzern • 8 Monate - -### Businesskritische IT-Infrastruktur FC Luzern - -Aufbau einer hochverfügbaren IT-Infrastruktur für geschäftskritische Anwendungen mit 99.9% Uptime. - -#### Technologien: - -High Availability Disaster Recovery Security - -#### Ergebnisse: - -* 99.9% Verfügbarkeit -* Null Datenverlust -* Compliance erreicht - - - -Cloud Transformation - -TechStart AG • 10 Monate - -### Cloud-First Strategie TechStart AG - -Vollständige Migration zur Cloud mit Fokus auf Skalierbarkeit und Kosteneffizienz. - -#### Technologien: - -AWS Kubernetes DevOps - -#### Ergebnisse: - -* 60% Kosteneinsparung -* Bessere Skalierbarkeit -* Schnellere Deployments - - - -Change Management - -InnovaCorp • 15 Monate - -### Agile Transformation InnovaCorp - -Einführung agiler Arbeitsweisen und Kulturwandel für verbesserte Projekteffizienz. - -#### Technologien: - -Scrum Kanban Team Coaching - -#### Ergebnisse: - -* 50% kürzere Time-to-Market -* Höhere Mitarbeiterzufriedenheit -* Verbesserte Qualität - - - -Strategieberatung - -Swiss Enterprise • 24 Monate - -### Digital Excellence Program - -Entwicklung einer umfassenden Digitalisierungsstrategie für nachhaltiges Wachstum. - -#### Technologien: - -Strategy Design Digital Roadmap KPI Framework - -#### Ergebnisse: - -* 30% Umsatzsteigerung -* Neue Geschäftsmodelle -* Marktführerschaft - - - -Digitale Transformation - -Filtex Textil • 14 Monate - -### Digital Transformation der Filtex Textil - -Komplette Analyse und Erneuerung der gesamten IT-/Datenarchitektur mit massiven Kostenreduktion, 100% Sales Flexibilität und Sicherheit. - -#### Technologien: - -Cloud Migration Prozessoptimierung KPI-Dashboard Security - -#### Ergebnisse: - -* 99.9% Verfügbarkeit -* Maximale Kundenorientierung -* Zeit- und Ressourcenersparnis -* Planungssicherheit - - - -Digitale Transformation - -Häny Pumpen • 16 Monate - -### Digital Transformation der Häny Pumpen - -Analyse und Erneuerung der gesamten IT-/Datenarchitektur mit Kostenreduktion, Sales Flexibilität, ERP-Standardisierung und Sicherheit. - -#### Technologien: - -Cloud Migration Prozessoptimierung ERP-Technologie KPI-Dashboard Security - -#### Ergebnisse: - -* Komplette ERP-Systemmigration -* Maximale Kundenorientierung -* Risikominimierung -* Zeit- und Ressourcenersparnis -* Verbesserte Sicherheit - - - -Digitale Transformation - -Swiss Ice Hockey Federation • 20 Monate - -### Digital Transformation der Swiss Ice Hockey Federation - -Analyse und Erneuerung der gesamten IT-/Datenarchitektur, Kostenreduktion, Prozesslandschafts- und Kollaborationsplattform, ERP- und Datensicherheit. - -#### Technologien: - -Cloud Migration Prozessoptimierung ERP-Technologie Security - -#### Ergebnisse: - -* Komplette ERP-Systemmigration -* Anspruchsgruppen-Fokus -* Risikominimierung -* Zeit- und Ressourcenersparnis -* Verbesserte Sicherheit - - - -Strategieberatung - -Swiss Olympic • 12 Monate - -### Digitalisierungsstrategie für Swiss Olympic - -Analyse der gesamten IT-/Datenarchitektur, Prozesslandschafts- und Kollaborationsplattform, ERP- und Datensicherheit. - -#### Technologien: - -ERP-Technologie Security Kollaborations-Technologie - -#### Ergebnisse: - -* Komplette Roadmap mit Handlungsfeldern -* Anspruchsgruppen-Fokus -* Risiko-Management -* Vorbereitung Aufbau PPM -* Zeit- und Ressourcenersparnis -* Verbesserte Sicherheit - - - -Künstliche Intelligenz - -LayerFinance • 18 Monate - -### KI-Transformation für LayerFinance - -Analyse der gesamten Datenarchitektur, Prozesslandschaft, Datensicherheit, KI-Anwendungen. - -#### Technologien: - -KI-Technologie Deal-closing AI-Plattform - -#### Ergebnisse: - -* Continuation in Enabling KI based Deal Closing Plattform -* Zeit- und Ressourcenersparnis -* Verbesserte Sicherheit - - - -Strategieberatung - -Steuerverwaltung Bern • 7 Monate - -### Technologiewechsel-Programm Steuerverwaltung Bern - -Umfassende Analyse des Technologiewechsel-Programms zur Identifikation kritischer Erfolgsfaktoren und zur Definition konkreter Massnahmen für den Abschluss. Erstellung einer integrierten Gesamtplanung mit Abhängigkeitsmanagement sowie Etablierung eines konsistenten Change- und Risikomanagements. - -#### Technologien: - -Prozessoptimierung Strategy Design Roadmap Management - -#### Ergebnisse: - -* Einheitliche, steuerbare Prozesse -* Vollständige Transparenz über Programmverlauf -* Hohe Planungs- und Umsetzungssicherheit -* Frühzeitige Risikokontrolle und Eskalationsfähigkeit -* Stärkung der Steuerungsfähigkeit auf Gesamtprogrammebene - - - -Digitale Transformation - -Schadenservice Schweiz • 24 Monate - -### Von der Analyse zur Umsetzung – ERP-Projekt Schadenservice Schweiz - -Begleitung eines ERP-Erneuerungsprojekts von der initialen Bedarfsanalyse über die Evaluation bis zur vollständigen Umsetzung. Nach dem Entscheid zur Eigenentwicklung übernahm ein externer Anbieter die technische Realisierung, während wir die Kundenseite als unabhängige Vertretung begleiteten. - -#### Technologien: - -Bedarfsanalyse Evaluation & Auswahlprozess Projektleitung auf Kundenseite Change Management - -#### Ergebnisse: - -* Massgeschneiderte ERP-Lösung auf Basis individueller Anforderungen -* Strukturierte Zusammenarbeit zwischen Entwicklung, Fachbereichen und Betrieb -* Einführung standardisierter Prozesse und digitaler Abläufe -* Hohe Akzeptanz bei den Nutzerinnen und Nutzern -* Erfolgreiche Verankerung der neuen Lösung im Tagesgeschäft - - - -Strategieberatung - -Sunrise TDC Switzerland AG • 3 Monate - -### PMO-Aufbau Sunrise TDC Switzerland AG - -Aufbau eines voll funktionsfähigen Project Management Office (PMO) für Customer Care und Effizienzsteigerung der PMIO-Organisation innerhalb von 3 Monaten. - -#### Technologien: - -Situationsanalyse PMO-Strukturierung Change Management Prozessoptimierung - -#### Ergebnisse: - -* Funnel- und Steuerungsausschussstrukturen etabliert -* Bewertungskriterien für Priorisierung definiert -* Standardisierter Funnel- und Steuerungsbericht -* Konstruktiver und offener Management Buy-in -* Termingerechte PMO-Kompetenz realisiert - -> "Das PMO-Setup war ein voller Erfolg. Termingerecht und mit konstruktivem Management Buy-in haben wir ein funktionsfähiges System etabliert." - -— Dr. Marc Furrer, CEO Sunrise TDC Switzerland AG - -Previous slide Next slide - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_212142/additional_link_003_www.valueon.ch_vernissage.txt b/test_web_content_20251002_212142/additional_link_003_www.valueon.ch_vernissage.txt deleted file mode 100644 index 33a6af47..00000000 --- a/test_web_content_20251002_212142/additional_link_003_www.valueon.ch_vernissage.txt +++ /dev/null @@ -1,68 +0,0 @@ -URL: https://www.valueon.ch/vernissage -Type: Additional Link -Extracted: 2025-10-02 21:21:42 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Beyond AI -========= - -Wo KI auf Führung trifft ------------------------- - -Künstliche Intelligenz ist nicht nur ein Werkzeug – sie ist ein transformativer Treiber, der grundlegend verändert, wie wir führen, arbeiten und Wert schaffen. - -PeaqPartners und ValueOn laden Sie herzlich zur AI Vernissage ein – einem exklusiven Abend für ausgewählte Partner:innen und Führungspersönlichkeiten. Freuen Sie sich auf Impulse, Gespräche und kreative Erlebnisse rund um den strategischen Einsatz von KI. - -### Event-Details - -Datum:Dienstag, 16. September 2025 - -Ort:Le Bijou, Lintheschergasse 18, 8001 Zürich (3 min von ZHB) - -Zeit:17:30 – 19:30 Uhr - -Teilnahmegebühr:CHF 100.- - -Sprache:Deutsch - -Zielgruppe:Führungskräfte & strategische Entscheider:innen - -### Anmeldung - -Anrede * Bitte wählen - -Vorname * - -Nachname * - -Firma * - -Industrie * - -E-Mail * - -Anmeldung senden - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_212142/additional_link_004_www.valueon.ch_self-check.txt b/test_web_content_20251002_212142/additional_link_004_www.valueon.ch_self-check.txt deleted file mode 100644 index bce586fd..00000000 --- a/test_web_content_20251002_212142/additional_link_004_www.valueon.ch_self-check.txt +++ /dev/null @@ -1,58 +0,0 @@ -URL: https://www.valueon.ch/self-check -Type: Additional Link -Extracted: 2025-10-02 21:21:42 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Digital Readiness Check - -Wie digital ist dein - -Unternehmen wirklich? -=========================================== - -In nur 7 Fragen erfährst du, wie zukunftsfit dein Unternehmen ist – inkl. individueller Einschätzung & konkreter Handlungsempfehlungen. - -Jetzt kostenlos testen - -Dauert nur 3 Minuten - -Frage 1 von 7 14% abgeschlossen - -STRATEGIE - -Wie werden in eurem Unternehmen aktuell Entscheidungen getroffen? ------------------------------------------------------------------ - -Intuitiv und erfahrungsbasiert - -Teilweise datenbasiert, aber oft ohne Systematik - -Wir nutzen regelmäßig Datenanalysen zur Entscheidungsfindung - -Unsere Entscheidungen basieren fast ausschließlich auf KPIs & Datenmodellen - -Zurück Weiter - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_212142/additional_link_005_www.valueon.ch_contact.txt b/test_web_content_20251002_212142/additional_link_005_www.valueon.ch_contact.txt deleted file mode 100644 index 0f813f23..00000000 --- a/test_web_content_20251002_212142/additional_link_005_www.valueon.ch_contact.txt +++ /dev/null @@ -1,89 +0,0 @@ -URL: https://www.valueon.ch/contact -Type: Additional Link -Extracted: 2025-10-02 21:21:42 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unser Kontakt -============= - -Lassen Sie uns gemeinsam Ihre digitale Transformation vorantreiben. - -Lassen Sie uns ins Gespräch kommen ----------------------------------- - -Sie haben Fragen zu unseren Dienstleistungen oder möchten mehr über unsere Expertise erfahren? Nutzen Sie das Kontaktformular oder kontaktieren Sie uns direkt – wir sind für Sie da. - -### Telefon - -[+41 44 943 70 40](tel:+41449437040) - -### E-Mail - -[office@valueon.ch](mailto:office@valueon.ch) - -### Adresse - -ValueOn AG - -Am Stadtrand 11 - -8600 Dübendorf - -Schweiz - -### Folgen Sie uns - -[](https://www.linkedin.com/company/valueon) - -Name * - -E-Mail * - -Telefon - -Unternehmen - -Nachricht * - -Nachricht senden - -* Pflichtfelder - -So finden Sie uns ------------------ - -Unser Büro befindet sich in Dübendorf, nur wenige Minuten von Zürich entfernt. - -### Anreise - -#### Mit dem Auto - -Ausreichend Parkplätze stehen direkt vor dem Gebäude zur Verfügung. - -#### Mit öffentlichen Verkehrsmitteln - -Vom Bahnhof Dübendorf erreichen Sie unser Büro bequem zu Fuß in ca. 10 Minuten oder mit dem Bus. - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_212142/additional_link_006_www.valueon.ch_privacy.txt b/test_web_content_20251002_212142/additional_link_006_www.valueon.ch_privacy.txt deleted file mode 100644 index 9534609d..00000000 --- a/test_web_content_20251002_212142/additional_link_006_www.valueon.ch_privacy.txt +++ /dev/null @@ -1,103 +0,0 @@ -URL: https://www.valueon.ch/privacy -Type: Additional Link -Extracted: 2025-10-02 21:21:42 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Datenschutzerklärung -==================== - -Die Betreiber dieser Seiten nehmen den Schutz Ihrer persönlichen Daten sehr ernst. Wir behandeln Ihre personenbezogenen Daten vertraulich und entsprechend den gesetzlichen Datenschutzvorschriften sowie dieser Datenschutzerklärung. - -Wenn Sie diese Website benutzen, werden verschiedene personenbezogene Daten erhoben. Personenbezogene Daten sind Daten, mit denen Sie persönlich identifiziert werden können. Die vorliegende Datenschutzerklärung erläutert, welche Daten wir erheben und wofür wir sie nutzen. Sie erläutert auch, wie und zu welchem Zweck das geschieht. - -**Wichtiger Hinweis:** Wir weisen darauf hin, dass die Datenübertragung im Internet (z. B. bei der Kommunikation per E-Mail) Sicherheitslücken aufweisen kann. Ein lückenloser Schutz der Daten vor dem Zugriff durch Dritte ist nicht möglich. - -Grundlegende Informationen --------------------------- - -### Verantwortliche Stelle - -Die verantwortliche Stelle für die Datenverarbeitung auf dieser Website ist: ValueOn AG, Am Stadtrand 11, 8600 Dübendorf, Schweiz, T +41 44 943 70 40, E-Mail: info@valueon.ch. Verantwortliche Stelle ist die natürliche oder juristische Person, die allein oder gemeinsam mit anderen über die Zwecke und Mittel der Verarbeitung von personenbezogenen Daten (z. B. Namen, E-Mail-Adressen o. Ä.) entscheidet. - -### Speicherdauer - -Löschersuchen geltend machen oder eine Einwilligung zur Datenverarbeitung widerrufen, werden Ihre Daten gelöscht, sofern wir keine anderen rechtlich zulässigen Gründe für die Speicherung Ihrer personenbezogenen Daten haben (z. B. steuer- oder handelsrechtliche Aufbewahrungsfristen); im letztgenannten Fall erfolgt die Löschung nach Fortfall dieser Gründe. - -### Auskunft, Löschung, Sperrung - -Sie haben jederzeit das Recht auf unentgeltliche Auskunft über Ihre gespeicherten personenbezogenen Daten, deren Herkunft und Empfänger und den Zweck der Datenverarbeitung sowie ein Recht auf Berichtigung, Sperrung oder Löschung dieser Daten. Hierzu sowie zu weiteren Fragen zum Thema personenbezogene Daten können Sie sich jederzeit unter der im Impressum angegebenen Adresse bzw. an die in der Datenschutzerklärung genannte verantwortliche Person an uns wenden. - -### Widerspruch gegen Werbe-E-Mails - -Der Nutzung von im Rahmen der Impressumspflicht veröffentlichten Kontaktdaten zur Übersendung von nicht ausdrücklich angeforderter Werbung und Informationsmaterialien wird hiermit widersprochen. Die Betreiber der Seiten behalten sich ausdrücklich rechtliche Schritte im Falle der unverlangten Zusendung von Werbeinformationen, etwa durch Spam-E-Mails, vor. - -Technische Datenverarbeitung ----------------------------- - -### Cookies - -Unsere Internetseiten verwenden so genannte "Cookies". Cookies sind kleine Textdateien und richten auf Ihrem Endgerät keinen Schaden an. Sie werden entweder vorübergehend für die Dauer einer Sitzung (Session-Cookies) oder dauerhaft (permanente Cookies) auf Ihrem Endgerät gespeichert. Session-Cookies werden nach Ende Ihres Besuchs automatisch gelöscht. Permanente Cookies bleiben auf Ihrem Endgerät gespeichert, bis Sie diese selbst löschen oder eine automatische Löschung durch Ihren Webbrowser erfolgt. - -### Server-Log-Dateien - -Der Provider der Seiten erhebt und speichert automatisch Informationen in so genannten Server-Log-Dateien, die Ihr Browser automatisch an uns übermittelt. Dies sind: Browsertyp und Browserversion, verwendetes Betriebssystem, Referrer URL, Hostname des zugreifenden Rechners, Uhrzeit der Serveranfrage, IP-Adresse. Eine Zusammenführung dieser Daten mit anderen Datenquellen wird nicht vorgenommen. - -### Anmelde- und Kontaktformulare - -Wenn Sie uns per Kontaktformular Anfragen zukommen lassen oder sich mit dem Anmeldeformular für unsere Veranstaltungen anmelden, werden Ihre Angaben aus den Formularen inklusive der von Ihnen dort angegebenen Kontaktdaten und Informationen zwecks Bearbeitung der Anfrage und für den Fall von Anschlussfragen bei uns gespeichert. Diese Daten geben wir nicht ohne Ihre Einwilligung weiter. - -### Newsletter-Daten - -Die Verarbeitung der in das Newsletteranmeldeformular eingegebenen Daten erfolgt ausschließlich auf Grundlage Ihrer Einwilligung (Art. 6 Abs. 1 lit. a DSGVO). Die erteilte Einwilligung zur Speicherung der Daten, der E-Mail-Adresse sowie deren Nutzung zum Versand des Newsletters können Sie jederzeit widerrufen, etwa über den "Austragen"-Link im Newsletter. - -Externe Dienste ---------------- - -### Hinweis zur Datenweitergabe in die USA und sonstige Drittstaaten - -Wir weisen darauf hin, dass in diesen Ländern kein mit der EU oder der Schweiz vergleichbares Datenschutzniveau garantiert werden kann. Beispielsweise sind US-Unternehmen dazu verpflichtet, personenbezogene Daten an Sicherheitsbehörden herauszugeben, ohne dass Sie als Betroffener hiergegen gerichtlich vorgehen könnten. - -### Nutzung von HubSpot CRM - -Wir nutzen Hubspot CRM auf dieser Website. Anbieter ist Hubspot Inc. 25 Street, Cambridge, MA 02141 USA. Hubspot CRM ermöglicht es uns unter anderem, bestehende und potenzielle Kunden sowie Kundenkontakte zu verwalten. Die Verwendung von Hubspot CRM erfolgt auf Grundlage von Art. 6 Abs. 1 lit. f DSGVO. - -### LinkedIn - -Diese Website nutzt Elemente des Netzwerks LinkedIn. Anbieter ist die LinkedIn Ireland Unlimited Company, Wilton Plaza, Wilton Place, Dublin 2, Irland. Bei jedem Abruf einer Seite dieser Website, die Elemente von LinkedIn enthält, wird eine Verbindung zu Servern von LinkedIn aufgebaut. - -### Google Analytics - -Diese Website nutzt Funktionen des Webanalysedienstes Google Analytics. Anbieter ist die Google Inc. 1600 Amphitheatre Parkway Mountain View, CA 94043, USA. Google Analytics verwendet sog. "Cookies". Das sind Textdateien, die auf Ihrem Computer gespeichert werden und die eine Analyse der Benutzung der Website durch Sie ermöglichen. - -### Leadinfo - -Diese Website nutzt den Service des Anbieters Leadinfo B.V. mit Sitz in Rotterdam. Dieser Service zeigt uns auf Grundlage von IP-Adressen öffentlich zugängliche Unternehmensdaten an, wie z.B. Firmennamen und -adressen. Die Erkennung von Unternehmen basiert einzig und allein auf IP-Adressen. - -Fragen zum Datenschutz? ------------------------ - -Bei Fragen zum Datenschutz oder zur Verarbeitung Ihrer Daten kontaktieren Sie uns gerne. - -ValueOn AG - -Am Stadtrand 11, 8600 Dübendorf, Schweiz - -T +41 44 943 70 40 - -info@valueon.ch diff --git a/test_web_content_20251002_212142/additional_link_007_www.valueon.ch_imprint.txt b/test_web_content_20251002_212142/additional_link_007_www.valueon.ch_imprint.txt deleted file mode 100644 index 5315ac0c..00000000 --- a/test_web_content_20251002_212142/additional_link_007_www.valueon.ch_imprint.txt +++ /dev/null @@ -1,62 +0,0 @@ -URL: https://www.valueon.ch/imprint -Type: Additional Link -Extracted: 2025-10-02 21:21:42 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Impressum -========= - -Angaben gemäß den gesetzlichen Bestimmungen - -Inhaber der Website und verantwortlich für den Inhalt ------------------------------------------------------ - -### Unternehmen - -ValueOn AG - -Dominic Largo - -### Kontakt - -Am Stadtrand 11 - -8600 Dübendorf - -+41 44 943 70 40 - -[info@valueon.ch](mailto:info@valueon.ch) - -### Rechtliche Hinweise - -Alle Inhalte dieser Website sind urheberrechtlich geschützt. Jede Verwendung, Vervielfältigung oder Weiterverbreitung bedarf der ausdrücklichen schriftlichen Genehmigung der ValueOn AG. - -### Haftungsausschluss - -Die Inhalte unserer Seiten wurden mit größter Sorgfalt erstellt. Für die Richtigkeit, Vollständigkeit und Aktualität der Inhalte können wir jedoch keine Gewähr übernehmen. - -### Externe Links - -Unser Angebot enthält Links zu externen Webseiten Dritter, auf deren Inhalte wir keinen Einfluss haben. Deshalb können wir für diese fremden Inhalte auch keine Gewähr übernehmen. - -### Haben Sie Fragen? - -Bei rechtlichen Fragen oder Anliegen kontaktieren Sie uns gerne direkt. - -[Kontakt aufnehmen](mailto:info@valueon.ch) diff --git a/test_web_content_20251002_212142/additional_link_008_www.moneyhouse.ch_de_terms.txt b/test_web_content_20251002_212142/additional_link_008_www.moneyhouse.ch_de_terms.txt deleted file mode 100644 index 2966ed61..00000000 --- a/test_web_content_20251002_212142/additional_link_008_www.moneyhouse.ch_de_terms.txt +++ /dev/null @@ -1,96 +0,0 @@ -URL: https://www.moneyhouse.ch/de/terms -Type: Additional Link -Extracted: 2025-10-02 21:21:42 -================================================================================ - -Version gültig ab 1. Januar 2020 bis Widerruf - -Die vorliegenden Nutzungsbedingungen regeln die Geschäftsbeziehungen zwischen der Neue Zürcher Zeitung AG bezogen auf ihr Produkt Moneyhouse (nachfolgend «Moneyhouse» genannt) und dem Kunden (nachfolgend «Kunde» genannt). Diese Bestimmungen sind für alle Plattformen von Moneyhouse gültig, insbesondere für moneyhouse.ch. Abweichende AGB des Kunden finden keine Anwendung, auch wenn Moneyhouse nicht ausdrücklich widerspricht. - -**1. Grundlage der Geschäftsbeziehung** - -Ein Vertrag über eine der unterschiedlichen Dienstleistungen von Moneyhouse berechtigt den Kunden – nach Leistung des vereinbarten Entgelts – zur Inanspruchnahme der offerierten Leistungen. Dabei gelangen die jeweils gültigen Tarife und Konditionen sowie die vorliegenden Nutzungsbedingungen sowie allenfalls weitere, besondere Geschäftsbedingungen und Vertragsgrundlagen zur Anwendung. - -**2. Vertragsinhalt** - -Gegenstand der Leistungserbringung von Moneyhouse und deren Partnern sind Informationsdienstleistungen. Sie beinhalten in keinem Falle irgendwelche Rechte an Software, Lizenzrechte oder sonstige Immaterialgüterrechte. - -**3. Vertragsdauer und Verlängerung** - -Die Online-Dienstleistungen wie beispielsweise (keine abschliessende Aufzählung) die Premium-Mitgliedschaft oder das Bonitäts-Abo können ab Abschluss des Vertrags in Anspruch genommen werden und gelten für die jeweils abgeschlossene Vertragsdauer. - -Die Verträge betreffend die Dienstleistungen von moneyhouse.ch erneuern sich bei Ablauf stillschweigend um die vereinbarte Vertragsdauer, sofern nicht eine Partei einen Tag vor Ablauf der Vertragsdauer den Vertrag wie unter «Mein Konto» beschrieben kündigt. Davon ausgeschlossen sind etwaige Probe-Abonnements, welche sich auf die beim Abschluss definierte Dauer und zum vorab kommunizierten Preis verlängern. - -Sollte sich der Kunde mit Zahlungen im Verzug befinden oder gegen die vorliegenden AGB verstossen, ist Moneyhouse zur sofortigen Auflösung des Vertragsverhältnisses berechtigt. - -Wird der Vertrag erneuert, so gilt automatisch die allfällig neue Preisliste, welche dem Kunden auf Anfrage zur Verfügung gestellt wird. Der vorausbezahlte Abonnementpreis ist für den Zeitraum der Vorauszahlung garantiert und kann nicht erhöht werden. Abonnementpreiserhöhungen werden vor ihrer Wirksamkeit auf den jeweiligen Websites von Moneyhouse angekündigt. Einzelbenachrichtigungen erfolgen nicht. Entsprechend kann bei Nichtakzeptieren der Preiserhöhung der Vertrag zu den bisherigen Konditionen auf Ende der Laufzeit unter Einhaltung der Kündigungsfristen gekündigt werden. Alle von Moneyhouse genannten oder in etwaigen Tariflisten aufgeführten Preise sind Nettopreise ohne Mehrwertsteuer in Schweizer Franken. - -**4. Nutzungsbedingungen** - -**4.1. Nutzungsumfang** - -Die Produkte dienen ausschliesslich der persönlichen, nicht kommerziellen Nutzung durch natürliche und juristische Personen – eine weitergehende oder abweichende Nutzung und deren Verbreitung in anderen Systemen ist nur mit ausdrücklicher Zustimmung von Moneyhouse gestattet und kann jederzeit widerrufen werden. - -**4.2. Registrierung** - -Die Registrierung eines Benutzerkontos erfordert unter anderem einen Vor- und Nachnamen, eine Adresse sowie weitere Informationen, abhängig von der Art der gewünschten Nutzung (privat oder geschäftlich). Das automatisierte Anlegen von Benutzerkonten ist nicht gestattet. Der Kunde verpflichtet sich, seine Zugangsdaten vertragskonform zu verwenden und diese ohne schriftliche Zustimmung von Moneyhouse keinem Dritten zugänglich zu machen. Der Nutzer ist für den Schutz seiner Zugangsdaten verantwortlich. - -**4.3. Leistungen Moneyhouse** - -Inhalt und Umfang der dem Nutzer zur Verfügung gestellten Produkte bestimmen sich nach der jeweiligen Nutzungsform (zum Beispiel: registrierter oder nicht registrierter Kunde, kostenlose oder kostenpflichtige Nutzung etc.), einem allfällig bestehenden Vertragsverhältnis und den vorliegenden Nutzungsbedingungen und der Datenschutzerklärung. - -Die Online-Dienste sind in der Regel an 7 Tagen während 24 Stunden verfügbar. Moneyhouse behält sich das Recht vor, diese Betriebszeiten einzuschränken und/oder aus technischen Gründen vorübergehend auszusetzen sowie die Produkte jederzeit zu modifizieren. Die Produkte unterliegen laufenden Änderungen und Anpassungen. Auch können Software-Updates oder technische Weiterentwicklungen Inhalt und Umfang der Produkte jederzeit ausbauen. - -**4.4. Fälligkeit, Zahlungsverzug und Zahlungsarten** - -Die von Moneyhouse gestellten Rechnungen sind, sofern keine Zahlungsfrist vermerkt ist und nichts anderes vereinbart wurde, sofort fällig. Ist der Kunde mit seiner Zahlung in Verzug, treten die gesetzlichen Verzugsfolgen ein und mit der zweiten Mahnung Mahnkosten von CHF 20.–. Darüber hinaus hat Moneyhouse das Recht, externe Partner zur Bearbeitung des Inkassos hinzuzuziehen. Ausserdem trägt der Kunde alle weiteren Kosten, die durch seinen Zahlungsverzug entstehen. - -Es werden die folgenden Zahlungsarten bei kostenpflichtigen Produkten angeboten: Kreditkarte oder per Rechnung. Moneyhouse behält sich das Recht vor, die verschiedenen Zahlungsmittel nach eigenem Ermessen zu ändern, zu ergänzen oder zu streichen. Es besteht kein Anspruch auf Bezahlung mit einem bestimmten Zahlungsmittel. Die Rechnung per E-Mail kann via E-Banking beglichen werden. Der Vertrag zwischen Moneyhouse und dem Kunden kommt entweder mit der Bestellung durch den Kunden über einen Verkaufsmitarbeiter oder aber mit der Auftrags-, der Bestellungs- sowie/oder der Zahlungsbestätigung durch Moneyhouse zustande. - -**4.5. Haftung von Moneyhouse** - -Moneyhouse ist bemüht, den eigenen Datenbestand sowie jenen von Partnern zu pflegen. Der Kunde nimmt zur Kenntnis, dass Daten und Informationen bis zu einem gewissen Masse trotzdem Fehler enthalten können. Vorbehaltlich gesetzlicher Vorgaben bzw. einer anderweitigen schriftlichen Vereinbarung schliessen Moneyhouse und deren Partner jegliche Garantie und Gewährleistung, insbesondere für Vollständigkeit, Aktualität, Richtigkeit, Verwertbarkeit oder Eignung der Daten zu einem bestimmten Zweck, aus. Empfehlungen und Erfahrungswerte wie Ratings, Einteilung in Risikoklassen und Scorewerte sind ausnahmslos unverbindlich, womit auch dafür jede Gewähr ausgeschlossen ist. - -Moneyhouse haftet nur für Verzögerungen und für Fehler, sofern ihr ein vorsätzliches oder grobfahrlässiges Handeln nachgewiesen werden kann. Sie haftet insbesondere nicht für Verfehlungen und Versäumnisse Dritter. Für Schäden, die dem Kunden durch die Nutzung der Produkte entstehen, haftet Moneyhouse nur, falls ihr grobfahrlässiges oder vorsätzliches Verhalten nachgewiesen werden kann. Soweit gesetzlich zulässig, ist die Haftung von Moneyhouse in jedem Fall auf denjenigen Betrag beschränkt, welcher dem Kunden für das entsprechende Produkt in Rechnung gestellt wurde. In keinem Fall haftet Moneyhouse für Folgeschäden oder entgangenen Gewinn. - -Moneyhouse haftet nicht für schadhafte Technik und für durch Computerviren, Spionageprogramme und/oder andere schädliche Computerprogramme (Malware, Spyware) bewirkte Schäden. Es besteht auch keine Haftung für die Folgen von Betriebsunterbrüchen, die durch Störungen aller Art entstehen oder die der Störungsbehebung, der Wartung und der Einführung neuer Technologien dienen. - -Dieselben Haftungsbeschränkungen gelten auch für die Mitarbeiter, Vertreter und Erfüllungsgehilfen von Moneyhouse. - -**4.6. Sorgfaltspflicht und Haftung des Kunden** - -Alle Informationen, Auskünfte und Berichte von Moneyhouse sind streng vertraulich zu behandeln. Benutzung und Verwendung dieser Informationen sind nur dem Kunden und dessen allfälligen Angestellten für deren eigene Zwecke gestattet. Der Kunde verpflichtet sich, sein Benutzerkonto und im Speziellen seine Zugangsdaten (Passwort) nicht anderen Personen – auch nicht im gleichen Unternehmen – zur Verfügung zu stellen, sie zu schützen und vor Zugriffen Dritter sicher aufzubewahren, seine Kontaktinformationen und sonstigen Angaben bei der Registrierung wahrheitsgetreu auszufüllen und seinen Zugang nicht missbräuchlich oder übermässig zu nutzen. - -Der Kunde verpflichtet sich sodann, die gesetzlichen Datenschutzvorschriften sowie die Vorschriften gemäss Datenschutzerklärung von Moneyhouse einzuhalten. Der Kunde ist für jeden Schaden verantwortlich, der aus einer Nichtbeachtung seiner Sorgfaltspflichten oder einem Verstoss gegen Urheberrechte entsteht, und zwar sowohl gegenüber Moneyhouse als auch deren Partnern. - -**4.7. Auskünfte und Identifikation** - -Der Kunde nimmt zur Kenntnis, dass er sich und damit sein persönliches Kundenkonto für das Aufrufen von Profilen zu Privatpersonen und die Abfrage von Bonitätsauskünften, Zahlungsverhaltenauskünften und Wirtschaftsauskünften mittels eines Identitätsnachweises (ID, Reisepass, Führerschein) einmalig verifizieren muss. Zudem dürfen die zuvor genannten Auskünfte nur abgefragt werden, wenn ein berechtigtes Interesse vorliegt. Das Vorliegen einer solchen Berechtigung kann nachträglich durch Moneyhouse überprüft werden. Der Kunde muss Moneyhouse innerhalb von 10 Tagen nach Erhalt der Aufforderung das Vorliegen einer entsprechenden Berechtigung nachweisen. Für Betreibungsauskünfte muss durch den Kunden grundsätzlich ein den vom jeweiligen Betreibungsamt vorgegebenen Bedingungen entsprechender Interessensnachweis übermittelt werden. Alle rechtlichen und vertraglichen Konsequenzen, die durch die Nichtübermittlung, einen nicht ausreichenden oder nicht vorhandenen Interessensnachweises resultieren, trägt der Kunde.Bei Zuwiderhandlung gegen diese Vorschrift ist Moneyhouse berechtigt, die Vertragsbeziehung zum Kunden unmittelbar und entschädigungslos zu beenden. - -Weitere Informationen hierzu können jederzeit[hier](https://www.moneyhouse.ch/de/howto/reports) eingesehen werden. - -**4.8. Urheber- und weitere immaterielle Rechte** - -Moneyhouse behält sich bezüglich der Produkte inklusive Layout, Software und deren Inhalten sämtliche Urheber- und sonstigen Schutzrechte vor. Es ist untersagt, die Webseiten von Moneyhouse oder deren Inhalte ganz oder teilweise mittels technischer Hilfsmittel darzustellen (z.B. „Framing“). - -Eigentums- und Urheberrechte an allen zur Verfügung gestellten Daten und Dienstleistungen verbleiben bei Moneyhouse. Nutzungsrechte werden dem Kunden nur in dem Ausmass eingeräumt, als dies zur Erfüllung des Vertragszweckes zwingend notwendig ist. Im Zweifel werden nur Nutzungsrechte und keine Urheber- und Eigentumsrechte übertragen. Der Kunde ist zur Weitergabe der Daten an Dritte nicht berechtigt. - -**4.9. Vertretungsberechtigung** - -Für die Leistungserbringung und insbesondere die Abwicklung im Rahmen einer Premium-Mitgliedschaft oder anderen spezifischen Leistungen gilt gegenüber Moneyhouse, unabhängig von der im Handelsregister eingetragenen Zeichnungsberechtigung, der oder die Mitarbeiter/in des Kunden als zur Vertretung befugt und ermächtigt, welche/r mit Moneyhouse mündlich, telefonisch oder schriftlich (durch Brief, Fax oder E-Mail) kommunizierte. Der Kunde trägt das Risiko für ungenügende Vertretungsberechtigung oder fehlende Legitimation seiner Mitarbeiter. - -**4.10. API** - -Moneyhouse stellt dem Kunden eine Schnittstelle (API) zur Kommunikation mit Software von Drittanbietern zur Verfügung. Sofern nicht schriftlich anders vereinbart, hat Moneyhouse in jedem Fall das Recht, den Zugriff auf diese Schnittstelle aus wichtigem Grund jederzeit teilweise oder ganz einzuschränken. Ein wichtiger Grund liegt insbesondere vor, wenn Mitbewerber von Moneyhouse zum Schaden von Moneyhouse über die Schnittstelle Daten migrieren oder die Infrastruktur über Anfragen über diese Schnittstelle zu stark belastet wird. Der Kunde verpflichtet sich, alle von Moneyhouse gelieferten Daten innert 10 Tagen nach Beendigung des Vertrages zu löschen und die Löschung Moneyhouse schriftlich zu bestätigen. - -**4.11. Kommunikationsmittel und Übermittlungsfehler** - -Moneyhouse ist berechtigt, alle Mitteilungen an den Kunden an die auf dem Vertrag aufgeführte und vom Kunden angegebene Zustell- oder E-Mail-Adresse, Telefon- und/oder Faxnummer zu richten. Änderungen sind Moneyhouse vom Kunden rechtzeitig und schriftlich (durch Brief, Fax oder E-Mail oder mittels Änderung im persönlichen Bereich „Mein Konto“ auf moneyhouse.ch) mitzuteilen. Der Kunde trägt das Risiko für Schäden aus der Benutzung von Kommunikations- und/oder Transportmitteln einschliesslich Verlust, Verspätung oder falsche Übermittlung. - -**4.12.Gerichtsstand und anwendbares Recht** - -Der Gerichtsstand befindet sich am Sitz der Neue Zürcher Zeitung AG in Zürich ZH. Es gilt Schweizer Recht. Die Neue Zürcher Zeitung AG hat das Recht, den Kunden bei einem anderen zuständigen Gericht einzuklagen. - -**4.13. Anpassungen** - -Wir behalten uns ausdrücklich das Recht vor, die vorliegenden Nutzungsbedingungen jederzeit zu ändern. Werden derartige Anpassungen vorgenommen, veröffentlichen wir diese umgehend auf unserer Webseite. Es liegt in Ihrer Verantwortung, sich über die aktuell geltende Fassung der Datenschutzerklärung auf unserer Webseite zu informieren. Wir empfehlen Ihnen daher, diese Datenschutzerklärung und die Nutzungsbedingungen regelmässig zu konsultieren. \ No newline at end of file diff --git a/test_web_content_20251002_212142/additional_link_009_www.moneyhouse.ch_de_imprint.txt b/test_web_content_20251002_212142/additional_link_009_www.moneyhouse.ch_de_imprint.txt deleted file mode 100644 index 94679d57..00000000 --- a/test_web_content_20251002_212142/additional_link_009_www.moneyhouse.ch_de_imprint.txt +++ /dev/null @@ -1,401 +0,0 @@ -URL: https://www.moneyhouse.ch/de/imprint -Type: Additional Link -Extracted: 2025-10-02 21:21:42 -================================================================================ - -Impressum - Moneyhouse - - - - - - - -[](/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](/de/register?redirectUrl=%2Fimprint) - -[Anmelden](/de/login?redirectUrl=%2Fimprint) - -[Erweiterte Suche](/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](/de/overview)[Voller Datenzugriff](/de/membership)[Public API](/de/apiintegration)[Corporate-Angebote](/de/enterprise)[Firmenlisten](/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](/de/businessreports)[Bonitätsauskunft](/de/creditrating)[Zahlungsverhalten](/de/paymentbehaviour)[Wirtschaftsauskunft](/de/economicinformation)[Beteiligungsauskunft](/de/shareholderinformation)[Betreibungsauskunft](/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](/de/commercialregister/foundation)[Firma liquidieren](/de/commercialregister/liquidation)[Änderung Eintrag](/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](/de/datasources)[Kontakt](/de/contact) - -- [KMU\_today](https://www.kmutoday.ch/) -[Regio-News](/de/region)[Hilfebereich](/de/howto) - -[AGB](/de/terms)[Datenschutz](/de/privacy)[Impressum](/de/imprint) - -[](/de/) - -[Kostenlos registrieren](/de/register?redirectUrl=%2Fimprint) - -[Regio-News](/de/region)[KMU\_today](https://www.kmutoday.ch/) - -[Anmelden](/de/login?redirectUrl=%2Fimprint)[Hilfe](/de/howto) - -DE - -- [Deutsch](javascript:void(0)) -- [Français](javascript:void(0)) -- [Italiano](javascript:void(0)) -- [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](/de/advancedsearch) - -**Datenzugriff** - -- [Übersicht Mitgliedschaften](/de/overview) -- [Voller Datenzugriff](/de/membership) -- [Public API](/de/apiintegration) -- [Corporate-Angebote](/de/enterprise) -- [Firmenlisten](/de/companieslists) -- [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -- [Übersicht](/de/businessreports) -- [Bonitätsauskunft](/de/creditrating) -- [Zahlungsverhalten](/de/paymentbehaviour) -- [Wirtschaftsauskunft](/de/economicinformation) -- [Beteiligungsauskunft](/de/shareholderinformation) -- [Betreibungsauskunft](/de/paymentcollection) - -**Handelsregister** - -- [Firma gründen](/de/commercialregister/foundation) -- [Firma liquidieren](/de/commercialregister/liquidation) -- [Änderung Eintrag](/de/commercialregister/services) - -**Unternehmen** - -- [Über uns](/de/about) -- [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -- [Datenquellen](/de/datasources) -- [Kontakt](/de/contact) - -- [Anmelden](/de/login?redirectUrl=%2Fimprint) -- [Hilfebereich](/de/howto) - -- [Sprache wechseln](javascript:void(0)) -- [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -- [KMU\_today](https://www.kmutoday.ch/) -- [Regio-News](/de/region) - - - -# Impressum - -**Moneyhouse** -Neue Zürcher Zeitung AG -Falkenstrasse 11 -CH-8008 Zürich - -[Kontaktieren Sie uns](https://www.moneyhouse.ch/de/contact/contactform) - -Sitz: Zürich -UID: CHE-106.838.812 -Handelsregisteramt: Kanton Zürich - -**Datenzugriff** - -- [Übersicht Mitgliedschaften](/de/overview) -- [Voller Datenzugriff](/de/membership) -- [Public API](/de/apiintegration) -- [Corporate-Angebote](/de/enterprise) -- [Firmenlisten](/de/companieslists) -- [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -- [Übersicht](/de/businessreports) -- [Bonitätsauskunft](/de/creditrating) -- [Zahlungsverhalten](/de/paymentbehaviour) -- [Wirtschaftsauskunft](/de/economicinformation) -- [Beteiligungsauskunft](/de/shareholderinformation) -- [Betreibungsauskunft](/de/paymentcollection) - -**Handelsregister** - -- [Firma gründen](/de/commercialregister/foundation) -- [Firma liquidieren](/de/commercialregister/liquidation) -- [Änderung Eintrag](/de/commercialregister/services) - -**Unternehmen** - -- [Über uns](/de/about) -- [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -- [Datenquellen](/de/datasources) -- [Kontakt](/de/contact) - -- [Anmelden](/de/login?redirectUrl=%2Fimprint) -- [Hilfebereich](/de/howto) - -- [Sprache wechseln](javascript:void(0)) -- [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -- [KMU\_today](https://www.kmutoday.ch/) -- [Regio-News](/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](/de/companydirectory/ag/a/a_) - -[AI](/de/companydirectory/ai/a/a_) - -[AR](/de/companydirectory/ar/a/a_) - -[BL](/de/companydirectory/bl/a/a_) - -[BS](/de/companydirectory/bs/a/a_) - -[BE](/de/companydirectory/be/a/a_) - -[FR](/de/companydirectory/fr/a/a_) - -[GE](/de/companydirectory/ge/a/a_) - -[GL](/de/companydirectory/gl/a/a_) - -[GR](/de/companydirectory/gr/a/a_) - -[JU](/de/companydirectory/ju/a/a_) - -[LU](/de/companydirectory/lu/a/a_) - -[NE](/de/companydirectory/ne/a/a_) - -[NW](/de/companydirectory/nw/a/a_) - -[OW](/de/companydirectory/ow/a/a_) - -[SH](/de/companydirectory/sh/a/a_) - -[SZ](/de/companydirectory/sz/a/a_) - -[SO](/de/companydirectory/so/a/a_) - -[SG](/de/companydirectory/sg/a/a_) - -[TI](/de/companydirectory/ti/a/a_) - -[TG](/de/companydirectory/tg/a/a_) - -[UR](/de/companydirectory/ur/a/a_) - -[VD](/de/companydirectory/vd/a/a_) - -[VS](/de/companydirectory/vs/a/a_) - -[ZG](/de/companydirectory/zg/a/a_) - -[ZH](/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](/de/persondirectory/a/aa) - -[B](/de/persondirectory/b/ba) - -[C](/de/persondirectory/c/ca) - -[D](/de/persondirectory/d/da) - -[E](/de/persondirectory/e/ea) - -[F](/de/persondirectory/f/fa) - -[G](/de/persondirectory/g/ga) - -[H](/de/persondirectory/h/ha) - -[I](/de/persondirectory/i/ia) - -[J](/de/persondirectory/j/ja) - -[K](/de/persondirectory/k/ka) - -[L](/de/persondirectory/l/la) - -[M](/de/persondirectory/m/ma) - -[N](/de/persondirectory/n/na) - -[O](/de/persondirectory/o/oa) - -[P](/de/persondirectory/p/pa) - -[Q](/de/persondirectory/q/qa) - -[R](/de/persondirectory/r/ra) - -[S](/de/persondirectory/s/sa) - -[T](/de/persondirectory/t/ta) - -[U](/de/persondirectory/u/ua) - -[V](/de/persondirectory/v/va) - -[W](/de/persondirectory/w/wa) - -[X](/de/persondirectory/x/xa) - -[Y](/de/persondirectory/y/ya) - -[Z](/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](/de/terms)[Datenschutz |](/de/privacy)[Impressum](/de/imprint) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU\_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/imprint) - -[Startseite](/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/imprint) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -[Premium-Mitglied werden](/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/imprint)[Anmelden](/de/login?redirectUrl=%2Fimprint) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/imprint)[Anmelden](/de/login?redirectUrl=%2Fimprint) - - - - - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Sonstige - -Kantone hinzufügen oder löschen: - -Kanton -Aargau -Appenzell I. Rh. -Appenzell A. Rh. -Bern -Basel-Landschaft -Basel-Stadt -Freiburg -Genf -Glarus -Graubünden -Jura -Luzern -Neuenburg -Nidwalden -Obwalden -St. Gallen -Schaffhausen -Solothurn -Schwyz -Thurgau -Tessin -Uri -Waadt -Wallis -Zug -Zürich - -[Bestätigen](javascript:void(0)) \ No newline at end of file diff --git a/test_web_content_20251002_212142/additional_link_010_www.moneyhouse.ch_de_.txt b/test_web_content_20251002_212142/additional_link_010_www.moneyhouse.ch_de_.txt deleted file mode 100644 index c83c0de3..00000000 --- a/test_web_content_20251002_212142/additional_link_010_www.moneyhouse.ch_de_.txt +++ /dev/null @@ -1,642 +0,0 @@ -URL: https://www.moneyhouse.ch/de/ -Type: Additional Link -Extracted: 2025-10-02 21:21:42 -================================================================================ - -Moneyhouse - Handelsregister- & Wirtschaftsinformationen - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/#)[Save + Exit](https://www.moneyhouse.ch/de/#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2F) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2F) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -Smart Data für KMU -================== - -Schweizer Handelsregister- und Wirtschaftsinformationen. - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -749'770 - -aktive Firmen - -288'251 - -Verwaltungsräte - -292'760 - -Geschäftsführer - -141 - -neue Firmen pro Tag - -Voller Zugriff - -Voller Zugriff auf alle Funktionen und Informationen zu Firmen und Personen - -* Kontaktdetails, Firmenkennzahlen und Management -* Zugang zu Bonitätsauskünften (1 Auskunft inklusive) -* Unbegrenzt Firmen, Personen und Themen folgen -* Verbindungen zwischen Firmen und Personen im Netzwerk erkennen -* Erweiterte Suchfunktion zu Firmen, Personen, Marken und Jobs in der gesamten Datenbank -* Unbegrenzt Firmen- und Personendossiers, druckfertig als PDF -* Keine Werbung - -ab - -CHF 79.00 - -[Jetzt entdecken](https://www.moneyhouse.ch/de/membership) - -Beschränkter Zugriff - -Beschränkter Zugriff auf Funktionen und Informationen zu Firmen und Personen - -* 2 Firmen oder Personen folgen mit E-Mail-Benachrichtigung -* 2 kostenlose Firmen- oder Personendossiers, druckfertig als PDF -* Alle Markeneinträge von Firmen ansehen -* Aktuelles Management -* Adresse, Hauptsitz und Standorte -* Handelsregister-Nummer, Firmenzweck und Kapital -* Das neueste aus Ihrer Region als Newsletter - -kostenlos - -[Jetzt entdecken](https://www.moneyhouse.ch/de/register?redirectUrl=%2F) - -[Hier alle Details zu den Mitgliedschaften vergleichen](https://www.moneyhouse.ch/de/overview) - - - - - -[](https://www.moneyhouse.ch/de/kmuplus) - - - -[](https://www.moneyhouse.ch/de/kmuplus) - -Umfassende Auskünfte --------------------- - -Schützen Sie sich vor finanziellen Schäden und erhalten Sie Klarheit über Ihre Kunden und Geschäftspartner. - -* Einschätzung der Bonität mit Ampel -* Zahlungsverhalten der letzten Rechnungen -* Umfassende Auskunft über die wirtschaftliche Situation einer Firma -* Übersicht über aktuelle und vergangene Betreibungsverfahren - -[Mehr Informationen](https://www.moneyhouse.ch/de/businessreports) - - - - - -Umfassende Auskünfte --------------------- - -Schützen Sie sich vor finanziellen Schäden und erhalten Sie Klarheit über Ihre Kunden und Geschäftspartner. - -* Einschätzung der Bonität mit Ampel -* Zahlungsverhalten der letzten Rechnungen -* Umfassende Auskunft über die wirtschaftliche Situation einer Firma -* Übersicht über aktuelle und vergangene Betreibungsverfahren - -[Mehr Informationen](https://www.moneyhouse.ch/de/businessreports) - - - -Public API ----------- - -Geben Sie Ihren Entwicklern über die API von Moneyhouse den Zugang zu unserer Datenbank und integrieren Sie unsere Wirtschaftsinformationen direkt in Ihre IT-Umgebung. - -[Mehr erfahren](https://www.moneyhouse.ch/de/apiintegration) - - - -Handelsregister ---------------- - -Neuer Verwaltungsrat, neue Adresse? Was immer Sie im Handelsregister ändern müssen, wir sorgen für den korrekten Eintrag. Schnell und einfach mit unserem Online-Tool. - -[Mehr erfahren](https://handelsregister.moneyhouse.ch/de/?itm_campaign=traderegister&itm_content=link-homepage&itm_medium=referral&itm_source=moneyhouse.ch) - - - -Regio-News ----------- - -Was immer in Ihrer Region auch passiert: Hier erfahren Sie es zuerst. Sehen Sie täglich alle Neuigkeiten aus Ihrer Region oder lesen Sie im Newsletter die Zusammenfassung. - -[Mehr erfahren](https://www.moneyhouse.ch/de/region) - -Neue Schweizer Firmen vom 01.10.2025 ------------------------------------- - -[duTalent SA](https://www.moneyhouse.ch/de/company/dutalent-sa-18003554041) - -Place du Casino 2 | 1110 Morges -[Gilomen Treuhand GmbH](https://www.moneyhouse.ch/de/company/gilomen-treuhand-gmbh-8989359371) - -Fuchsiastrasse 10 | 8048 Zürich - -[Kelkom GmbH](https://www.moneyhouse.ch/de/company/kelkom-gmbh-4110413891) - -Räbmatt 4 | 6403 Küssnacht am Rigi -[Schneiderei Epting](https://www.moneyhouse.ch/de/company/schneiderei-epting-13684386591) - -Industriestrasse 11b | 8627 Grüningen - -[mehr anzeigen](javascript:void(0))[weniger anzeigen](javascript:void(0)) - -[mehr anzeigen](https://www.moneyhouse.ch/de/newcompanieslist) - -Konkurs- und Liquidationsmeldungen vom 01.10.2025 -------------------------------------------------- - -[Ayser Taxi, Inhaber Kilic](https://www.moneyhouse.ch/de/company/ayser-taxi-inhaber-kilic-10707383481) - -Hermikonstrasse 100 | 8600 Dübendorf -[Palade SA in liquidazione](https://www.moneyhouse.ch/de/company/palade-sa-12850863581) - -Via Valdani 2 | 6830 Chiasso - -[RMT Holding AG in Liquidation](https://www.moneyhouse.ch/de/company/rmt-holding-ag-6498121101) - -Blegistrasse 5 | 6340 Baar -[Silikon Service König](https://www.moneyhouse.ch/de/company/silikon-service-koenig-21268819451) - -Norimatt 1 | 4242 Laufen - -[mehr anzeigen](javascript:void(0))[weniger anzeigen](javascript:void(0)) - -[mehr anzeigen](https://www.moneyhouse.ch/de/bankruptcieslist) - -Aktuelle News aus Ihrer Region ------------------------------- - -Dies sind aktuell die Top-Regionen: - -* [Zürich](https://www.moneyhouse.ch/de/region/zuerich/uebersicht) -* [Region Zürich](https://www.moneyhouse.ch/de/region/zuerich/uebersicht) -* [Bern-Mittelland](https://www.moneyhouse.ch/de/region/bern-mittelland/uebersicht) -* [Region Bern-Mittelland](https://www.moneyhouse.ch/de/region/bern-mittelland/uebersicht) -* [Baden](https://www.moneyhouse.ch/de/region/baden/uebersicht) -* [Region Baden](https://www.moneyhouse.ch/de/region/baden/uebersicht) -* [Winterthur](https://www.moneyhouse.ch/de/region/winterthur/uebersicht) -* [Region Winterthur](https://www.moneyhouse.ch/de/region/winterthur/uebersicht) -* [Basel-Stadt](https://www.moneyhouse.ch/de/region/basel-stadt/uebersicht) -* [Region Basel-Stadt](https://www.moneyhouse.ch/de/region/basel-stadt/uebersicht) -* [Horgen](https://www.moneyhouse.ch/de/region/horgen/uebersicht) -* [Region Horgen](https://www.moneyhouse.ch/de/region/horgen/uebersicht) -* [Arlesheim](https://www.moneyhouse.ch/de/region/arlesheim/uebersicht) -* [Region Arlesheim](https://www.moneyhouse.ch/de/region/arlesheim/uebersicht) -* [Oberaargau](https://www.moneyhouse.ch/de/region/oberaargau/uebersicht) -* [Region Oberaargau](https://www.moneyhouse.ch/de/region/oberaargau/uebersicht) -* [St. Gallen](https://www.moneyhouse.ch/de/region/stgallen/uebersicht) -* [Region St. Gallen](https://www.moneyhouse.ch/de/region/stgallen/uebersicht) - -* [Meilen](https://www.moneyhouse.ch/de/region/meilen/uebersicht) -* [Region Meilen](https://www.moneyhouse.ch/de/region/meilen/uebersicht) -* [Dielsdorf](https://www.moneyhouse.ch/de/region/dielsdorf/uebersicht) -* [Region Dielsdorf](https://www.moneyhouse.ch/de/region/dielsdorf/uebersicht) -* [Bülach](https://www.moneyhouse.ch/de/region/buelach/uebersicht) -* [Region Bülach](https://www.moneyhouse.ch/de/region/buelach/uebersicht) -* [Hinwil](https://www.moneyhouse.ch/de/region/hinwil/uebersicht) -* [Region Hinwil](https://www.moneyhouse.ch/de/region/hinwil/uebersicht) -* [Luzern-Stadt](https://www.moneyhouse.ch/de/region/luzern-stadt/uebersicht) -* [Region Luzern-Stadt](https://www.moneyhouse.ch/de/region/luzern-stadt/uebersicht) -* [Rheintal](https://www.moneyhouse.ch/de/region/rheintal/uebersicht) -* [Region Rheintal](https://www.moneyhouse.ch/de/region/rheintal/uebersicht) -* [Sursee](https://www.moneyhouse.ch/de/region/sursee/uebersicht) -* [Region Sursee](https://www.moneyhouse.ch/de/region/sursee/uebersicht) -* [Uster](https://www.moneyhouse.ch/de/region/uster/uebersicht) -* [Region Uster](https://www.moneyhouse.ch/de/region/uster/uebersicht) -* [Luzern-Land](https://www.moneyhouse.ch/de/region/luzern-land/uebersicht) -* [Region Luzern-Land](https://www.moneyhouse.ch/de/region/luzern-land/uebersicht) - -* [Bremgarten](https://www.moneyhouse.ch/de/region/bremgarten/uebersicht) -* [Region Bremgarten](https://www.moneyhouse.ch/de/region/bremgarten/uebersicht) -* [Hochdorf](https://www.moneyhouse.ch/de/region/hochdorf/uebersicht) -* [Region Hochdorf](https://www.moneyhouse.ch/de/region/hochdorf/uebersicht) -* [Zofingen](https://www.moneyhouse.ch/de/region/zofingen/uebersicht) -* [Region Zofingen](https://www.moneyhouse.ch/de/region/zofingen/uebersicht) -* [Aarau](https://www.moneyhouse.ch/de/region/aarau/uebersicht) -* [Region Aarau](https://www.moneyhouse.ch/de/region/aarau/uebersicht) -* [Thun](https://www.moneyhouse.ch/de/region/thun/uebersicht) -* [Region Thun](https://www.moneyhouse.ch/de/region/thun/uebersicht) -* [Frauenfeld](https://www.moneyhouse.ch/de/region/frauenfeld/uebersicht) -* [Region Frauenfeld](https://www.moneyhouse.ch/de/region/frauenfeld/uebersicht) -* [Lenzburg](https://www.moneyhouse.ch/de/region/lenzburg/uebersicht) -* [Region Lenzburg](https://www.moneyhouse.ch/de/region/lenzburg/uebersicht) -* [Zug](https://www.moneyhouse.ch/de/region/zug/uebersicht) -* [Region Zug](https://www.moneyhouse.ch/de/region/zug/uebersicht) -* [Dietikon](https://www.moneyhouse.ch/de/region/dietikon/uebersicht) -* [Region Dietikon](https://www.moneyhouse.ch/de/region/dietikon/uebersicht) - -* [See-Gaster](https://www.moneyhouse.ch/de/region/see-gaster/uebersicht) -* [Region See-Gaster](https://www.moneyhouse.ch/de/region/see-gaster/uebersicht) -* [Olten](https://www.moneyhouse.ch/de/region/olten/uebersicht) -* [Region Olten](https://www.moneyhouse.ch/de/region/olten/uebersicht) -* [Willisau](https://www.moneyhouse.ch/de/region/willisau/uebersicht) -* [Region Willisau](https://www.moneyhouse.ch/de/region/willisau/uebersicht) -* [Kreuzlingen](https://www.moneyhouse.ch/de/region/kreuzlingen/uebersicht) -* [Region Kreuzlingen](https://www.moneyhouse.ch/de/region/kreuzlingen/uebersicht) -* [Wil](https://www.moneyhouse.ch/de/region/wil/uebersicht) -* [Region Wil](https://www.moneyhouse.ch/de/region/wil/uebersicht) -* [Brugg](https://www.moneyhouse.ch/de/region/brugg/uebersicht) -* [Region Brugg](https://www.moneyhouse.ch/de/region/brugg/uebersicht) -* [Biel](https://www.moneyhouse.ch/de/region/biel-bienne/uebersicht) -* [Region Biel](https://www.moneyhouse.ch/de/region/biel-bienne/uebersicht) -* [Emmental](https://www.moneyhouse.ch/de/region/emmental/uebersicht) -* [Region Emmental](https://www.moneyhouse.ch/de/region/emmental/uebersicht) -* [Meine Region suchen](https://www.moneyhouse.ch/de/region) -* [Region suchen](https://www.moneyhouse.ch/de/region) - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) \ No newline at end of file diff --git a/test_web_content_20251002_212142/additional_link_011_www.moneyhouse.ch_de_company_valueon-ag-4663161481_reportscreditworthiness-report.txt b/test_web_content_20251002_212142/additional_link_011_www.moneyhouse.ch_de_company_valueon-ag-4663161481_reportscreditworthiness-report.txt deleted file mode 100644 index ca29691e..00000000 --- a/test_web_content_20251002_212142/additional_link_011_www.moneyhouse.ch_de_company_valueon-ag-4663161481_reportscreditworthiness-report.txt +++ /dev/null @@ -1,643 +0,0 @@ -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report -Type: Additional Link -Extracted: 2025-10-02 21:21:42 -================================================================================ - -ValueOn AG in Dübendorf - Bonitätsauskunft, Zahlungsverhalten, Betreibungsauskunft und Kreditwürdigkeit - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#)[Save + Exit](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -[ValueOn AG](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Bonitätsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -[Zahlungsverhalten](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#payment-mode-report) - -[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#commercial-report) - -[Beteiligungsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#wow-report) - -[Betreibungsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#payment-collection-report) - -[Firmendossier](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#firmendossier-report) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -[Startseite](https://www.moneyhouse.ch/de/)[>](javascript:void(0))[Unternehmen](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG)[>](javascript:void(0))ValueOn AG - -ValueOn AG -========== - -ZH - -aktiv - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Zur Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -Handelsregister-Nr.:CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Bonitätsauskunft ----------------- - -Einschätzung der Bonität mit einer Ampel als Risikoindikator und weiteren hilfreichen Firmeninformationen. - -* Einschätzung der Bonität mit einer Ampel -* Weitere Hinweise -* Firmeninformationen aus dem Handelsregister -* Aktuelle Zahlungsdetails (als Zusatzabfrage) - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:09f387aa-7faa-4b0d-8eea-c619aed45506) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:09f387aa-7faa-4b0d-8eea-c619aed45506) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen Premium-Mitgliedschaft mit Bonitäts-Paket ab CHF 99.00](https://www.moneyhouse.ch/de/service/purchase/creditrating?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D1) - -[Jetzt bestellen Premium-Mitglied werden (1 Abfrage inkl.)jede weitere für CHF 19.00](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D1) - -[Jetzt bestellen Einzelabfrage ohne Premium-Mitgliedschaft für CHF 24.00](https://www.moneyhouse.ch/de/service/purchase/creditratingsingle?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D1) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -Zahlungsverhalten ------------------ - -Beurteilung der Zahlungsmoral aufgrund vergangener Rechnungen. - -* Zahlungsverhalten der letzten Rechnungen -* Durchschnittliches Zahlungsverhalten -* Anteil aller bekannten, pünktlich bezahlten Rechnungen - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:9acd118e-dc76-4a33-ab7c-ebaec52c619a) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:9acd118e-dc76-4a33-ab7c-ebaec52c619a) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen Premium-Mitgliedschaft mit Zahlungsverhalten-Paket ab CHF 99.00](https://www.moneyhouse.ch/de/service/purchase/paymentbehaviour?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D2) - -[Jetzt bestellen Premium-Mitglied werden 1 Abfrage für CHF 19.00](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D2) - -[Jetzt bestellen Einzelabfrage ohne Premium-Mitgliedschaft für CHF 24.00](https://www.moneyhouse.ch/de/service/purchase/paymentbehavioursingle?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D2) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -Wirtschaftsauskunft -------------------- - -Umfassende Auskunft über die wirtschaftliche Situation der Firma. - -* Einschätzung der Bonität mit einer Ampel -* Zahlungsverhalten der letzten Rechnungen -* Risikobewertung im Branchenvergleich -* Meldung von Inkassobüros und Betreibungsämtern -* Firmeninformationen aus dem Handelsregister - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:e9d3178c-3e96-4218-ac8d-39baffee2871) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:e9d3178c-3e96-4218-ac8d-39baffee2871) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen CHF 49.00 pro Abfrage](https://www.moneyhouse.ch/de/service/purchase/economicinformation?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D3) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -Beteiligungsauskunft --------------------- - -Auflistung aller Firmenbeteiligungen einer Aktiengesellschaft. - -* Manuell recherchierte Beteiligungen -* Informationen zu im Handelsregister eingetragenen Beteiligungen -* Firmeninformationen aus dem Handelsregister -* Umsatz- und Mitarbeiterzahlen - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:f1e0a255-5d6e-4ac5-be21-6f90d7b20a17) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:f1e0a255-5d6e-4ac5-be21-6f90d7b20a17) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen CHF 19.00 pro Abfrage](https://www.moneyhouse.ch/de/service/purchase/shareholderinformation?companyName=valueon-ag-4663161481&returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D8) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -Betreibungsauskunft -------------------- - -Übersicht über aktuelle und vergangene Betreibungsverfahren. - -* Amtlicher Betreibungsauszug -* Aktuelle Betreibungsverfahren -* Alle Betreibungen der letzten zwei Jahren - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:a1b45e6a-5cba-4063-8d4f-aa20378a1852) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:a1b45e6a-5cba-4063-8d4f-aa20378a1852) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen CHF 26.00 pro Abfrage](https://www.moneyhouse.ch/de/service/purchase/paymentcollection?companyName=valueon-ag-4663161481&returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fupload%3FcompanyName%3Dvalueon-ag-4663161481%26chNr%3DCH02030306513) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -Firmendossier -------------- - -Alle Firmeninformationen kompakt in einem Dokument. - -* Kontaktinformationen -* Firmeninformationen aus dem Handelsregister -* Unternehmensführung und Zeichnungsberechtigte -* Umsatz- und Mitarbeiterzahlen - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:62e110dc-83ed-4738-b49f-7a9799183287) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:62e110dc-83ed-4738-b49f-7a9799183287) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Kostenlos registrieren 2 Firmendossiers kostenlos verfügbar](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren 2 Firmendossiers kostenlos verfügbar](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Bonitätsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -[Zahlungsverhalten](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#payment-mode-report) - -[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#commercial-report) - -[Beteiligungsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#wow-report) - -[Betreibungsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#payment-collection-report) - -[Firmendossier](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#firmendossier-report) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_212142/additional_link_012_www.moneyhouse.ch_de_company_valueon-ag-4663161481_timeline.txt b/test_web_content_20251002_212142/additional_link_012_www.moneyhouse.ch_de_company_valueon-ag-4663161481_timeline.txt deleted file mode 100644 index 55a310a7..00000000 --- a/test_web_content_20251002_212142/additional_link_012_www.moneyhouse.ch_de_company_valueon-ag-4663161481_timeline.txt +++ /dev/null @@ -1,515 +0,0 @@ -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline -Type: Additional Link -Extracted: 2025-10-02 21:21:42 -================================================================================ - -Timeline ValueOn AG - Dübendorf - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline#)[Save + Exit](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -[ValueOn AG](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -[Startseite](https://www.moneyhouse.ch/de/)[>](javascript:void(0))[Unternehmen](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG)[>](javascript:void(0))ValueOn AG - -ValueOn AG -========== - -ZH - -aktiv - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Zur Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -Handelsregister-Nr.:CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Timeline --------- - -2025 - -[Um die Einträge zu sehen, benötigen Sie eine Premium-Mitgliedschaft.](https://www.moneyhouse.ch/membership) - -2024 - -[Um die Einträge zu sehen, benötigen Sie eine Premium-Mitgliedschaft.](https://www.moneyhouse.ch/membership) - -2023 - -[Um die Einträge zu sehen, benötigen Sie eine Premium-Mitgliedschaft.](https://www.moneyhouse.ch/membership) - -2022 - -[Um die Einträge zu sehen, benötigen Sie eine Premium-Mitgliedschaft.](https://www.moneyhouse.ch/membership) - -2007 - -[Um die Einträge zu sehen, benötigen Sie eine Premium-Mitgliedschaft.](https://www.moneyhouse.ch/membership) - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_212142/additional_link_013_www.moneyhouse.ch_de_company_valueon-ag-4663161481_messages.txt b/test_web_content_20251002_212142/additional_link_013_www.moneyhouse.ch_de_company_valueon-ag-4663161481_messages.txt deleted file mode 100644 index 054434eb..00000000 --- a/test_web_content_20251002_212142/additional_link_013_www.moneyhouse.ch_de_company_valueon-ag-4663161481_messages.txt +++ /dev/null @@ -1,625 +0,0 @@ -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages -Type: Additional Link -Extracted: 2025-10-02 21:21:42 -================================================================================ - -Meldungen ValueOn AG - Dübendorf - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages#)[Save + Exit](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -[ValueOn AG](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -[Startseite](https://www.moneyhouse.ch/de/)[>](javascript:void(0))[Unternehmen](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG)[>](javascript:void(0))ValueOn AG - -ValueOn AG -========== - -ZH - -aktiv - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Zur Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -Handelsregister-Nr.:CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Meldungen ---------- - -SHAB 250827/2025 - 27.08.2025 - -**Kategorien:** Änderung des Firmenzwecks, Änderung der Firmenadresse - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006417690 "Download SHAB Publikation der ValueOn AG vom 27.08.2025") - -Publikationsnummer: [HR02-1006417690](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006417690 "Download SHAB Publikation der ValueOn AG vom 27.08.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 133 vom 14.07.2025, Publ. 1006383218). - -**Statutenänderung:** - - 18.08.2025. - -**Sitz neu:** - - Dübendorf. - -**Domizil neu:** - - c/o Westhive AG, Am Stadtrand 11, 8600 Dübendorf. - -**Zweck neu:** - - Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -**Mitteilungen neu:** - - Mitteilungen an die Aktionäre erfolgen per Brief oder E-Mail an die im Aktienbuch verzeichneten Adressen. - -SHAB 250714/2025 - 14.07.2025 - -**Kategorien:** Änderung im Management - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006383218 "Download SHAB Publikation der ValueOn AG vom 14.07.2025") - -Publikationsnummer: [HR02-1006383218](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006383218 "Download SHAB Publikation der ValueOn AG vom 14.07.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 101 vom 27.05.2025, Publ. 1006341693). - -**Eingetragene Personen neu oder mutierend:** - -[Largo, Dominic](https://www.moneyhouse.ch/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Einzelunterschrift [_bisher: Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien_]. - -SHAB 250527/2025 - 27.05.2025 - -**Kategorien:** Änderung im Management - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006341693 "Download SHAB Publikation der ValueOn AG vom 27.05.2025") - -Publikationsnummer: [HR02-1006341693](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006341693 "Download SHAB Publikation der ValueOn AG vom 27.05.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 222 vom 14.11.2024, Publ. 1006178101). - -**Ausgeschiedene Personen und erloschene Unterschriften:** - - Hamburger, Marc Eric, von St. Gallen, in Mörschwil, Präsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - -[Egloff, Reto](https://www.moneyhouse.ch/de/person/egloff-reto-101763781201), von Oberrohrdorf, in Bern, Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - -[Mühlemann, Markus](https://www.moneyhouse.ch/de/person/muehlemann-markus-142196879901), von Seeberg, in Uster, Delegierter des Verwaltungsrates, mit Einzelunterschrift. - -**Eingetragene Personen neu oder mutierend:** - -[Largo, Dominic](https://www.moneyhouse.ch/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien [_bisher: Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien_]; - -[Althaus, Walter](https://www.moneyhouse.ch/de/person/althaus-jun-walter-205367807901), von Affoltern im Emmental, in Aarwangen, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - -[Wyss, Andreas](https://www.moneyhouse.ch/de/person/wyss-andreas-129476912501), von Dietikon, in Dietikon, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien. - -SHAB 241114/2024 - 14.11.2024 - -**Kategorien:** Änderung im Management - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006178101 "Download SHAB Publikation der ValueOn AG vom 14.11.2024") - -Publikationsnummer: [HR02-1006178101](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006178101 "Download SHAB Publikation der ValueOn AG vom 14.11.2024"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 134 vom 13.07.2023, Publ. 1005794339). - -**Eingetragene Personen neu oder mutierend:** - -[Largo, Dominic](https://www.moneyhouse.ch/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien. - -SHAB 230713/2023 - 13.07.2023 - -**Kategorien:** Änderung im Management - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1005794339 "Download SHAB Publikation der ValueOn AG vom 13.07.2023") - -Publikationsnummer: [HR02-1005794339](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1005794339 "Download SHAB Publikation der ValueOn AG vom 13.07.2023"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 207 vom 25.10.2022, Publ. 1005590007). - -**Ausgeschiedene Personen und erloschene Unterschriften:** - -[Wechsler, Beat](https://www.moneyhouse.ch/de/person/wechsler-beat-61329453301), von Willisau, in Küssnacht (SZ), Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - -[Trentini, Stefano Enrico](https://www.moneyhouse.ch/de/person/trentini-stefano-52560044101), von Mendrisio, in Stäfa, Geschäftsführer, mit Kollektivunterschrift zu zweien. - -**Eingetragene Personen neu oder mutierend:** - -[Egloff, Reto](https://www.moneyhouse.ch/de/person/egloff-reto-101763781201), von Oberrohrdorf, in Bern, Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien. - -SHAB 221025/2022 - 25.10.2022 - -**Kategorien:** Änderung des Firmennamens, Änderung des Firmenzwecks - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1005590007 "Download SHAB Publikation der ValueOn AG vom 25.10.2022") - -Publikationsnummer: [HR02-1005590007](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1005590007 "Download SHAB Publikation der ValueOn AG vom 25.10.2022"), Handelsregister-Amt Zürich, (20) - -**Project Competence AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 123 vom 28.06.2022, Publ. 1005505965). - -**Statutenänderung:** - - 07.10.2022. - -**Firma neu:** - -**ValueOn AG**. - -**Zweck neu:** - - Der Zweck der Gesellschaft ist die Erbringung von Dienstleistungen für Unternehmen, im Besonderen Beratung für Unternehmensentwicklung, Digitale Business Transformation und Projekt Management sowie Handel mit Waren aller Art. Die Gesellschaft kann sich an anderen Unternehmungen des In- und Auslandes beteiligen sowie alle Geschäfte eingehen und Verträge abschliessen, die geeignet sind, ihren Zweck zu fördern oder die direkt oder indirekt damit im Zusammenhang stehen. Sie kann ferner im In- und Ausland Zweigniederlassungen errichten, Liegenschaften, Unternehmen, Immaterialgüterrechte und Wertschriften im In- und Ausland im Rahmen des Gesetzes erwerben bzw. errichten, verwalten und verkaufen. - -**Mitteilungen neu:** - - Mitteilungen an die Aktionäre erfolgen per Brief, Telefax oder E-Mail an die im Aktienbuch verzeichneten Adressen. - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_212142/additional_link_014_www.moneyhouse.ch_de_commercialregister_overviewchnrCH02030306513uidCHE113416882.txt b/test_web_content_20251002_212142/additional_link_014_www.moneyhouse.ch_de_commercialregister_overviewchnrCH02030306513uidCHE113416882.txt deleted file mode 100644 index b75fbfd6..00000000 --- a/test_web_content_20251002_212142/additional_link_014_www.moneyhouse.ch_de_commercialregister_overviewchnrCH02030306513uidCHE113416882.txt +++ /dev/null @@ -1,593 +0,0 @@ -URL: https://www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882 -Type: Additional Link -Extracted: 2025-10-02 21:21:42 -================================================================================ - -Analoge und digitale Handelsregisteränderungen - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882#)[Save + Exit](https://www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) - -[Änderung Firmenname](https://www.moneyhouse.ch/de/commercialregister/services/company-name) - -[Personenmutation](https://www.moneyhouse.ch/de/commercialregister/services/person) - -[Änderung Sitz & Domizil](https://www.moneyhouse.ch/de/commercialregister/services/address) - -[Änderung Statuten](https://www.moneyhouse.ch/de/commercialregister/services/statutes) - -[Anpassung Zweck](https://www.moneyhouse.ch/de/commercialregister/services/company-purpose) - -[Liquidation](https://www.moneyhouse.ch/de/commercialregister/liquidation) - -[Weitere Services](https://www.moneyhouse.ch/de/commercialregister/services/other-services) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -Handelsregisteränderung: digital oder analog -============================================ - -Wir unterstützen Sie bei der Anpassung Ihrer Handelsregisterdaten, egal welchen Weg Sie bevorzugen. - -**Die digitale Lösung: schneller, einfacher, modern** - - Erledigen Sie Ihre Mutation komplett digital innerhalb wenigen Tagen – ohne Papier, Postweg oder Notartermin. Sie erhalten die Dokumente automatisch zugestellt, können sie bequem per Smartphone unterzeichnen und sofort einreichen. Profitieren dabei Sie von diesen Vorteilen: - -* **Schnell:**Erledigung in Tagen statt Wochen. - -* **Einfach:**Schritt-für-Schritt-Anleitung ohne Fehlerrisiko. - -* **Flexibel:**Von überall aus durchführbar, auch im Ausland. - -* **Rechtssicher:**E-Signatur (QES) ist schweizweit anerkannt. - -* **Nachhaltig:**Vollständig digital und papierfrei. - -_Hinweis: Der digitale Service wird laufend erweitert; einzelne Mutationen sind ggf. noch nicht verfügbar._ - -**Sie möchten die Mutation ohne Smartphone durchführen?** - - Kein Problem: Nutzen Sie hierzu einfach unser Mutationsformular. Sie erhalten die Unterlagen innerhalb eines Arbeitstages per E-Mail zur Unterzeichnung zugestellt. Diese müssen dann per Post retourniert werden. - -Bestseller -Digitale Mutation ------------------ - -in CHF (exkl. MWST)Analoge Mutation ----------------- - -in CHF (exkl. MWST) -### ab CHF 130.00 - -Erledigen Sie Ihre Handelsregisteränderung direkt über Ihr Smartphone.### ab CHF 150.00 - -Sie möchten die Änderung ohne Smartphone durchführen? Wir unterstützen Sie hierbei selbstverständlich gerne. -[Jetzt digitale Mutation starten](https://app.hoop.deepcloud.swiss/fiduciary?partnerUUID=eaa32e4c-d75d-4474-af03-2cc835a02802&companyUID=CHE113416882) - -[Sie wünschen eine kostenlose Erstberatung? Jetzt Termin buchen.](https://calendly.com/moneyhouse-hr-service/beratung-gruendung)[Jetzt Handelsregistereintrag kostenlos prüfen](https://handelsregister.moneyhouse.ch/de/mutation/CH02030306513?itm_campaign=traderegister&itm_medium=referral&itm_source=moneyhouse.ch&itm_content=link-traderegister-company_banner) - -[Sie wünschen eine kostenlose Erstberatung? Jetzt Termin buchen.](https://calendly.com/moneyhouse-hr-service/beratung-gruendung) - -#### Ihre Handelsregisteränderung – einfach und sofort digital erledigt - -Digitale Mutation ------------------ - -in CHF (exkl. MWST) - -### ab CHF 130.00 - -Erledigen Sie Ihre Handelsregisteränderung direkt über Ihr Smartphone. - -[Jetzt digitale Mutation starten](https://app.hoop.deepcloud.swiss/fiduciary?partnerUUID=eaa32e4c-d75d-4474-af03-2cc835a02802&companyUID=CHE113416882) - -[Sie wünschen eine kostenlose Erstberatung? Jetzt Termin buchen.](https://calendly.com/moneyhouse-hr-service/beratung-gruendung) - -Analoge Mutation ----------------- - -in CHF (exkl. MWST) - -### ab CHF 150.00 - -Sie möchten die Änderung ohne Smartphone durchführen? Wir unterstützen Sie hierbei selbstverständlich gerne. - -[Jetzt Handelsregistereintrag kostenlos prüfen](https://handelsregister.moneyhouse.ch/de/mutation/CH02030306513?itm_campaign=traderegister&itm_medium=referral&itm_source=moneyhouse.ch&itm_content=link-traderegister-company_banner) - -[Sie wünschen eine kostenlose Erstberatung? Jetzt Termin buchen.](https://calendly.com/moneyhouse-hr-service/beratung-gruendung) - -Ablauf digitaler Prozess ------------------------- - -### Deepcloud und Datenerfassung - - -Registrieren Sie sich bei deepcloud und erfassen Sie die Mutation direkt online. - -### Registrierung DeepID - - -Laden Sie die DeepID-App aus dem App Store herunter und registrieren Sie sich. Mehr Informationen dazu finden Sie [hier](https://www.deepid.swiss/de/digitale-identifizierung/). - -### Digitale Unterzeichnung - - -Unterzeichen Sie alle Dokumente gemäss der Aufforderung in DeepSign. - -### Einreichung der Unterlagen - - -Reichen Sie die digital unterzeichneten Dokumente mit wenigen Klicks direkt beim zuständigen Handelsregisteramt ein. - -Ablauf analoger Prozess ------------------------ - -### Erfassung Daten - - -Wir erfassen die Änderungen in unserem System gemäss Ihrer Angaben. - -### Dokumente - - -Wir erstellen die Dokumente und senden Ihnen diese per Mail zu. Von unserer Seite her dauert dieser Schritt maximal zwei Arbeitstage. - -### Rücksendung - - -Schauen Sie sich die Unterlagen durch und senden Sie uns alle Dokumente unterschieben zurück. Vergessen Sie die Ausweiskopien nicht. - -### Publikation - - -Nach Erhalt der Unterlagen prüfen wir diese und senden sie (wenn nötig) an unseren Notar oder direkt weiter ans Handelsregisteramt. Das Handelsregisteramt benötigt etwa zwei Wochen. - - - -Service Umfang --------------- - -* digitale oder analoge Erstellung der Unterlagen -* Alle Notariatskosten (falls notwendig) -* Beurkundungen(falls notwendig) -* Vorprüfung der Unterlagen (analoger Prozess) -* Kommunikation mit dem Handelsregisteramt -* Falls nötig, Publikation Schuldenrufe - -Bitte beachten Sie, dass alle amtlichen Gebühren des Handelsregisters in beiden Formen des Prozesses (digital und analog) sowie die Kosten für allfällige Beglaubigungen von Unterschriften im analogen Prozess nicht enthalten sind. - -[](https://www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -Preise und Prozessdauer ------------------------ - -Digitaler Prozess Analoger Prozess -Kosten ab CHF 150.00 Kosten ab CHF 150.00 -Dauer: 3 - 4 Tage ab Einreichung bei Handelsregister Dauer: ca. 2 Wochen (ohne Beurkundung) bis 3 Wochen (mit Beurkundung) - -Alle Unternehmensformen -Digitaler - - Prozess Kosten ab CHF 150.00 -Analoger - - Prozess Kosten ab CHF 150.00 - -Prozessdauer -Digitaler - - Prozess 3 - 4 Tage ab Einreichung bei Handelsregister -Analoger - - Prozess ca. 2 Wochen (ohne Beurkundung) bis 3 Wochen (mit Beurkundung) - - - -Wie können wir Ihnen helfen? ----------------------------- - -Haben Sie Fragen oder wünschen Sie weitere Informationen? - - Vereinbaren Sie direkt online einen [kostenlosen Beratungstermin](http://calendly.com/moneyhouse-hr-service/beratung-gruendung) oder kontaktieren Sie uns: - -Telefon: +41 44 258 28 88 oder per E-Mail:[crs@moneyhouse.ch](mailto:crs@moneyhouse.ch) - - Montag-Freitag: 8.30 - 11.00 Uhr und 13.30 - 16.00 Uhr - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Änderung Firmenname](https://www.moneyhouse.ch/de/commercialregister/services/company-name) - -[Personenmutation](https://www.moneyhouse.ch/de/commercialregister/services/person) - -[Änderung Sitz & Domizil](https://www.moneyhouse.ch/de/commercialregister/services/address) - -[Änderung Statuten](https://www.moneyhouse.ch/de/commercialregister/services/statutes) - -[Anpassung Zweck](https://www.moneyhouse.ch/de/commercialregister/services/company-purpose) - -[Liquidation](https://www.moneyhouse.ch/de/commercialregister/liquidation) - -[Weitere Services](https://www.moneyhouse.ch/de/commercialregister/services/other-services) \ No newline at end of file diff --git a/test_web_content_20251002_212142/additional_link_015_www.moneyhouse.ch_de_company_valueon-ag-4663161481_revenue.txt b/test_web_content_20251002_212142/additional_link_015_www.moneyhouse.ch_de_company_valueon-ag-4663161481_revenue.txt deleted file mode 100644 index 37696a50..00000000 --- a/test_web_content_20251002_212142/additional_link_015_www.moneyhouse.ch_de_company_valueon-ag-4663161481_revenue.txt +++ /dev/null @@ -1,565 +0,0 @@ -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue -Type: Additional Link -Extracted: 2025-10-02 21:21:42 -================================================================================ - -Kennzahlen ValueOn AG - Dübendorf - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue#)[Save + Exit](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -[ValueOn AG](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -[Startseite](https://www.moneyhouse.ch/de/)[>](javascript:void(0))[Unternehmen](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG)[>](javascript:void(0))ValueOn AG - -ValueOn AG -========== - -ZH - -aktiv - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Zur Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -Handelsregister-Nr.:CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Umsatz ------- - -[Exklusiv für Premium-Mitglieder](https://www.moneyhouse.ch/membership) - -Mitarbeiter ------------ - -[Exklusiv für Premium-Mitglieder](https://www.moneyhouse.ch/membership) - -Kapital -------- - -#### Aktienkapital - -CHF 200'000 (vollständig liberiert) - -#### Aktien-Stückelung - -(Aktienkapital) - -[Exklusiv für Premium-Mitglieder](https://www.moneyhouse.ch/membership) - -#### Anzahl Kapitalveränderungen - -(Datum letzte Änderung) - -[Exklusiv für Premium-Mitglieder](https://www.moneyhouse.ch/membership) - -Alter der Firma ---------------- - -18 Jahre 8 Monate -#### Eintrag ins Handelsregister - -02.02.2007 - -Premium-Mitglied werden ------------------------ - -**Uneingeschränkter** Zugriff auf alle Hintergrundinformationen und auf Umsatz- & Mitarbeiterzahlen der ValueOn AG - -[Premium-Mitglied werden](https://www.moneyhouse.ch/membership) - -Hinweis: Die Informationen zu Mitarbeiter- und Umsatzzahlen sind in den meisten Fällen statistisch berechnete Werte und werden in vordefinierten Ranges angezeigt (Bsp. 4-9, 10-19). - -Liegen Ihnen genauere Angaben zu den Mitarbeiter- und Umsatzzahlen vor?[Kontaktieren Sie uns](https://www.moneyhouse.ch/de/contact/contactform) - -Möchten Sie mehr Details zur ValueOn AG? - -Dann empfehlen wir Ihnen die Wirtschaftsauskunft! - -Wirtschaftsauskunft -------------------- - -Umfassende Auskunft über die wirtschaftliche Situation der Firma. - -* Einschätzung der Bonität mit einer Ampel -* Zahlungsverhalten der letzten Rechnungen -* Risikobewertung im Branchenvergleich -* Meldung von Inkassobüros und Betreibungsämtern -* Firmeninformationen aus dem Handelsregister - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:e9d3178c-3e96-4218-ac8d-39baffee2871) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:e9d3178c-3e96-4218-ac8d-39baffee2871) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen CHF 49.00 pro Abfrage](https://www.moneyhouse.ch/de/service/purchase/economicinformation?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D3) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Jetzt bestellen CHF 49.00 pro Abfrage](https://www.moneyhouse.ch/de/service/purchase/economicinformation?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D3) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_212142/additional_link_016_www.moneyhouse.ch_de_company_valueon-ag-4663161481_networkneighbourhood.txt b/test_web_content_20251002_212142/additional_link_016_www.moneyhouse.ch_de_company_valueon-ag-4663161481_networkneighbourhood.txt deleted file mode 100644 index 2bf7335c..00000000 --- a/test_web_content_20251002_212142/additional_link_016_www.moneyhouse.ch_de_company_valueon-ag-4663161481_networkneighbourhood.txt +++ /dev/null @@ -1,743 +0,0 @@ -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network#neighbourhood -Type: Additional Link -Extracted: 2025-10-02 21:21:42 -================================================================================ - -Netzwerk ValueOn AG - Dübendorf - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network#)[Save + Exit](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -[ValueOn AG](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -[Startseite](https://www.moneyhouse.ch/de/)[>](javascript:void(0))[Unternehmen](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG)[>](javascript:void(0))ValueOn AG - -ValueOn AG -========== - -ZH - -aktiv - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Zur Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -Handelsregister-Nr.:CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Netzwerk --------- - -Netzwerk: Alle Verbindungen im Überblick ----------------------------------------- - -Mit dem Netzwerk sehen Sie auf einen Blick alle Verbindungen von Firmen und Personen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/membership) - -Es können maximal die 250 neuesten aktiven und 50 inaktive Verbindungen angezeigt werden. - -**Status** - -- [x] aktive Verbindungen - -- [x] inaktive Verbindungen - -**Management** - -- [x] oberstes Management - -- [x] Geschäftsführung - -- [x] andere Funktionen - -- [x] Zeichnungsberechtigte - -**Verbindungen** - -- [x] zu Firmen - -- [x] zu Personen - -**Revisionsstellen** - -- [x] Revisionsstellen - -[Zurücksetzen](javascript:void(0)) - -[](javascript:void(0))[](javascript:void(0))[+](javascript:void(0))[-](javascript:void(0)) - -* * * - -Aktive Firmen in der Nachbarschaft ----------------------------------- - -Quelle: [SHAB](https://www.moneyhouse.ch/de/datasources) - -#### 8 aktive Firmen mit gleichem Domizil: Am Stadtrand 11, 8600 Dübendorf - -[Black Projects GmbH](https://www.moneyhouse.ch/de/company/black-projects-gmbh-3958227961) -[Bluespace Ventures AG](https://www.moneyhouse.ch/de/company/bluespace-ventures-ag-20038582721) -[Cyberfy Consulting AG](https://www.moneyhouse.ch/de/company/cyberfy-consulting-ag-5194156221) -[FICHTNER MANAGEMENT CONSULTING AG SCHWEIZ](https://www.moneyhouse.ch/de/company/fichtner-management-consulting-ag-10801938741) -[Gex Immo Consult AG](https://www.moneyhouse.ch/de/company/gex-immo-consult-ag-12703377601) -[Gracher Kredit- und Kautionsmakler GmbH & Co.KG, Trier, Zweigniederlassung Dübendorf](https://www.moneyhouse.ch/de/company/gracher-kredit-und-kautionsmakler-gmbh-co-kg--5397627361) -[SIP Switzerland AG](https://www.moneyhouse.ch/de/company/sip-switzerland-ag-12346588291) -[WonderWave GmbH](https://www.moneyhouse.ch/de/company/wonderwave-gmbh-19889373591) - -[Alle anzeigen](javascript:void(0)) - -[Weniger anzeigen](javascript:void(0)) - -#### 60 aktive Firmen an der gleichen Strasse: Am Stadtrand, 8600 Dübendorf - -[Fibre Pharma AG](https://www.moneyhouse.ch/de/company/fibre-pharma-ag-4088828381) - -Am Stadtrand 1 -[NetEducation GmbH](https://www.moneyhouse.ch/de/company/neteducation-gmbh-12921962361) - -Am Stadtrand 1 -[NetIT-Services GmbH](https://www.moneyhouse.ch/de/company/netit-services-gmbh-13663579741) - -Am Stadtrand 1 -[Top Nails and Beauty GmbH](https://www.moneyhouse.ch/de/company/top-nails-and-beauty-gmbh-7371788851) - -Am Stadtrand 1 -[Frauenpraxis Stettbach Mitte Dr. med. Gunther Kaindl](https://www.moneyhouse.ch/de/company/frauenpraxis-stettbach-mitte-dr-med-gunther-4154277041) - -Am Stadtrand 3 -[PhysiOsteo Montagna GmbH](https://www.moneyhouse.ch/de/company/physiosteo-montagna-gmbh-13903303071) - -Am Stadtrand 3 -[TwoMoons AG](https://www.moneyhouse.ch/de/company/twomoons-ag-5574859691) - -Am Stadtrand 3 -[CITYDENTAL Group AG](https://www.moneyhouse.ch/de/company/citydental-group-ag-14551629461) - -Am Stadtrand 5 -[CITYDENTAL Stettbach AG](https://www.moneyhouse.ch/de/company/citydental-stettbach-ag-19365176231) - -Am Stadtrand 5 -[PlusMAT Instrumentenhandel Seefeld](https://www.moneyhouse.ch/de/company/plusmat-instrumentenhandel-seefeld-15313160081) - -Am Stadtrand 5 -[Praxis am Stadtrand AG](https://www.moneyhouse.ch/de/company/praxis-am-stadtrand-ag-5244050981) - -Am Stadtrand 5 -[Questline KLG](https://www.moneyhouse.ch/de/company/questline-klg-20237845361) - -Am Stadtrand 13 -[berg & kunz KLG](https://www.moneyhouse.ch/de/company/berg-kunz-klg-14260698371) - -Am Stadtrand 23 -[Virtumate Manuela Erhart](https://www.moneyhouse.ch/de/company/virtumate-manuela-erhart-4697950761) - -Am Stadtrand 23 -[Vollmann AgileXcellence](https://www.moneyhouse.ch/de/company/vollmann-agilexcellence-3128545151) - -Am Stadtrand 23 -[Getfitbylina, Rada Cardozo](https://www.moneyhouse.ch/de/company/getfitbylina-rada-cardozo-15072677181) - -Am Stadtrand 25 -[Oni GmbH](https://www.moneyhouse.ch/de/company/oni-gmbh-6702936421) - -Am Stadtrand 29 -[Malina BB Vidan Stepanovic](https://www.moneyhouse.ch/de/company/malina-bb-vidan-stepanovic-694882931) - -Am Stadtrand 31 -[Konoha Holding AG](https://www.moneyhouse.ch/de/company/konoha-holding-ag-5681159481) - -Am Stadtrand 43 -[LAU](https://www.moneyhouse.ch/de/company/lau-10678515661) - -Am Stadtrand 43 -[Michael Bjeski IT Engineering](https://www.moneyhouse.ch/de/company/michael-bjeski-it-engineering-6411005861) - -Am Stadtrand 43 -[MMACIAS, Inh. Macias Speissegger](https://www.moneyhouse.ch/de/company/mmacias-inh-macias-speissegger-18447240901) - -Am Stadtrand 43 -[Ryser Living Solutions GmbH](https://www.moneyhouse.ch/de/company/ryser-living-solutions-gmbh-1491545501) - -Am Stadtrand 43 -[Physiotherapie Stettbach GmbH](https://www.moneyhouse.ch/de/company/physiotherapie-stettbach-gmbh-14832629151) - -Am Stadtrand 46 -[SGA Swiss AG](https://www.moneyhouse.ch/de/company/sga-swiss-ag-11969999171) - -Am Stadtrand 46 -[Sport-Fitness-Center Schumacher AG](https://www.moneyhouse.ch/de/company/sport-fitness-center-schumacher-ag-3417231251) - -Am Stadtrand 46 -[ESTETICA STUDIO Nadine Suter](https://www.moneyhouse.ch/de/company/estetica-studio-nadine-suter-13756684561) - -Am Stadtrand 49b -[Nacer, Ximena Silva](https://www.moneyhouse.ch/de/company/nacer-ximena-silva-13292556001) - -Am Stadtrand 49a -[Compliance Powerhouse AG](https://www.moneyhouse.ch/de/company/compliance-powerhouse-ag-4177952931) - -Am Stadtrand 51b -[LogicStar AG](https://www.moneyhouse.ch/de/company/logicstar-ag-5246816641) - -Am Stadtrand 51a -[MAISON DE LA ROCHEMACÉ](https://www.moneyhouse.ch/de/company/maison-de-la-rochemace-15044423081) - -Am Stadtrand 51a -[SWiss tO cuRe Dipg](https://www.moneyhouse.ch/de/company/swiss-to-cure-dipg-14331095251) - -Am Stadtrand 51a -[Triple-X by Werner Blättler](https://www.moneyhouse.ch/de/company/triple-x-by-werner-blaettler-20046122301) - -Am Stadtrand 51a -[Vinitaly GmbH](https://www.moneyhouse.ch/de/company/vinitaly-gmbh-20529542651) - -Am Stadtrand 51B -[Beyond Patterns GmbH](https://www.moneyhouse.ch/de/company/beyond-patterns-gmbh-12342874101) - -Am Stadtrand 53a -[Biasi Immobilien AG](https://www.moneyhouse.ch/de/company/biasi-immobilien-ag-6021309661) - -Am Stadtrand 53b -[Cucina Alpina GmbH](https://www.moneyhouse.ch/de/company/cucina-alpina-gmbh-3852911181) - -Am Stadtrand 53b -[curlA Engineering GmbH](https://www.moneyhouse.ch/de/company/curla-engineering-gmbh-14759700611) - -Am Stadtrand 53a -[Kriztle Bath & Wellness GmbH](https://www.moneyhouse.ch/de/company/kriztle-bath-wellness-gmbh-15976831551) - -Am Stadtrand 53b -[Talent Sutra von Agarwal](https://www.moneyhouse.ch/de/company/talent-sutra-von-agarwal-7057294151) - -Am Stadtrand 53a -[AI Swiss Knife, Inh. Brunner](https://www.moneyhouse.ch/de/company/ai-swiss-knife-inh-brunner-5180921761) - -Am Stadtrand 56 -[Amalia GmbH](https://www.moneyhouse.ch/de/company/amalia-gmbh-4465184331) - -Am Stadtrand 56 -[Blütentanz Heidi Kummer](https://www.moneyhouse.ch/de/company/bluetentanz-heidi-kummer-91594131) - -Am Stadtrand 56 -[Chronos Web Solutions KlG](https://www.moneyhouse.ch/de/company/chronos-web-solutions-klg-21410964941) - -Am Stadtrand 56 -[CorePiece GmbH](https://www.moneyhouse.ch/de/company/corepiece-gmbh-3996687461) - -Am Stadtrand 56 -[Doppel A KlG](https://www.moneyhouse.ch/de/company/doppel-a-klg-4715173231) - -Am Stadtrand 56 -[DPC Academy GmbH](https://www.moneyhouse.ch/de/company/dpc-academy-gmbh-5425938371) - -Am Stadtrand 56 -[Exec. Express GmbH](https://www.moneyhouse.ch/de/company/exec-express-gmbh-4270000211) - -Am Stadtrand 56 -[Immoservice-Solutions GmbH](https://www.moneyhouse.ch/de/company/immoservice-solutions-gmbh-5695654661) - -Am Stadtrand 56 -[J.F. Schulz & Company AG](https://www.moneyhouse.ch/de/company/j-f-schulz-company-ag-12183475011) - -Am Stadtrand 56 -[mags.porcelain by Marilei Genther](https://www.moneyhouse.ch/de/company/mags-porcelain-by-marilei-genther-19680925581) - -Am Stadtrand 56 -[Marijana Mionic Ebersold](https://www.moneyhouse.ch/de/company/marijana-mionic-ebersold-4251659421) - -Am Stadtrand 56 -[Milo Finanz AG](https://www.moneyhouse.ch/de/company/milo-finanz-ag-19873157631) - -Am Stadtrand 56 -[Reimer Life Journey Coaching und Beratung](https://www.moneyhouse.ch/de/company/reimer-life-journey-coaching-und-15986689981) - -Am Stadtrand 56 -[RUPOVA VENTURES](https://www.moneyhouse.ch/de/company/rupova-ventures-4042215861) - -Am Stadtrand 56 -[S. Reiser](https://www.moneyhouse.ch/de/company/s-reiser-18805059631) - -Am Stadtrand 56 -[Tipp Topp Cakes by Sophie Hogg](https://www.moneyhouse.ch/de/company/tipp-topp-cakes-by-sophie-hogg-12878277641) - -Am Stadtrand 56 -[Vögeli Flowers](https://www.moneyhouse.ch/de/company/voegeli-flowers-13556974501) - -Am Stadtrand 56 -[Wismer Marketing](https://www.moneyhouse.ch/de/company/wismer-marketing-2108420601) - -Am Stadtrand 56 -[Kita Zwerglinge GmbH](https://www.moneyhouse.ch/de/company/kita-zwerglinge-gmbh-14370068251) - -Am Stadtrand 58a - -[Alle anzeigen](javascript:void(0)) - -[Weniger anzeigen](javascript:void(0)) - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/network)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/network)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_212142/main_url_001_www.valueon.ch_.txt b/test_web_content_20251002_212142/main_url_001_www.valueon.ch_.txt deleted file mode 100644 index 221227f6..00000000 --- a/test_web_content_20251002_212142/main_url_001_www.valueon.ch_.txt +++ /dev/null @@ -1,107 +0,0 @@ -Title: https://www.valueon.ch/ -URL: https://www.valueon.ch/ -Type: Main URL -Extracted: 2025-10-02 21:21:42 -================================================================================ - -# Power für deinendigitalen Erfolg - -Vertrauen von führenden Unternehmen - -## Unsere Expertise - -Von digitaler Transformation bis zu künstlicher Intelligenz – wir begleiten Sie auf Ihrem Weg in die Zukunft. - -### Digitale Strategie entwickeln - -Ihre Richtung im digitalen Wandel. - -Gemeinsames Zielbild & Roadmap, abgestimmt auf Ihr Geschäft und leiten konkrete Handlungsempfehlungen ab. - -Orientierung & Handlungssicherheit - -### Transformation gezielt optimieren - -Lücken aufdecken. Stärken nutzen. - -Systematischer Blick auf Prozesse, Systeme & Potenziale und leiten konkrete Handlungsempfehlungen ab. - -Relevanz statt Aktionismus - -### Change Management etablieren - -Menschen mitnehmen. Wandel gestalten. - -Strukturierte Begleitung der Mitarbeiter durch den digitalen Wandel mit gezielten Schulungskonzepten. - -Akzeptanz & Erfolg sichern - -### Prozesse digital automatisieren - -Effizienz steigern. Kosten senken. - -Identifikation und Umsetzung von Automatisierungspotenzialen für nachhaltige Produktivitätssteigerung. - -Messbare Effizienzgewinne - -## Erfolgreiche Projekte & Transformationen - -Unter dem Motto «Unsere Kunden stehen im Mittelpunkt» haben wir für Sie eine Auswahl an Kundenreferenzen und Business Cases zusammengestellt. - -Als KMU sind wir es eigentlich nicht gewohnt, einen so grossen Aufwand wie bei der Evaluation des richtigen Partners für die Entwicklung und Realisierung unseres neuen Kernsystems zu betreiben. Doch i... - -Markus Berther - -Geschäftsführer, Schaden Service Schweiz AG - -ValueOn hat uns durch den gesamten Prozess der Digitalen Business Transformation mit grossem Einsatz und Engagement begleitet – von der ersten IT-Standortanalyse und Sourcing Analyse über digitales Zi... - -Stefan Wolf - -Präsident, FC Luzern - -In diesem businesskritischen IT-Programm waren insgesamt vier Experten von ValueOn (ehem. Project Competence) involviert, als Projektleiter und Koordinator, Cut-Over-Manager bis hin zur Gesamt-Program... - -Roland Bosshard - -CIO / Mitglied der GL, KPT - -In time, in quality, under budget: Andreas Friedli von ValueOn (ehem. Project Competence) hat in seiner Co-Leitungsfunktion in diesem IT-Projekt ganz massgeblich dazu beigetragen, dass wir dieses trot... - -Thomas Sturzenegger - -Divisional IT Lead, RUAG Real Estate AG - -Die erfolgreiche Realisierung dieses Vorhabens ist ein wichtiger Meilenstein für die strategische Neuausrichtung der WWZ. Die Projektberater der ValueOn AG (ehem. Project Competence AG) haben dabei da... - -Thomas Reber - -Leiter Telekom & IT Services, WWZ AG - -Um die Zukunftsausrichtung unserer IT-Strategie und -Organisation möglichst optimal auf unsere Business-Anforderungen auszurichten, haben wir ValueOn (ehem. Project Competence) als Sparringpartner ... - -Andreas Guglielmo - -CFO, CHRIS sports AG - -Wir danken den externen Projektberatern der ValueOn (ehem. Project Competence), die uns kompetent und mit ebenso hohem Arbeitseinsatz durch dieses Projekt und die Verhandlungen unter schwierigen Be... - -Michael Kohlbacher - -Generalsekretär, AGZ - -Dank ValueOn konnten wir unser komplexes IT-Infrastrukturprojekt termingerecht und im Budget abschliessen. Die strukturierte Herangehensweise war ausschlaggebend. - -Peter Keller - -Projektleiter, InnovaCorp - -ValueOn hat uns sowohl fachlich als auch menschlich auf höchstem Niveau beraten. Die Experten begleiteten uns kompetent bei der Modernisierung unserer IT-Infrastruktur und der reibungslosen Ablösung u... - -Silvan Wildhaber - -CEO, Filtex Group AG - -← Wischen Sie für weitere Testimonials → - -Auto-Scroll aktiv \ No newline at end of file diff --git a/test_web_content_20251002_212142/main_url_002_www.valueon.ch_about.txt b/test_web_content_20251002_212142/main_url_002_www.valueon.ch_about.txt deleted file mode 100644 index 1c5a4742..00000000 --- a/test_web_content_20251002_212142/main_url_002_www.valueon.ch_about.txt +++ /dev/null @@ -1,639 +0,0 @@ -Title: https://www.valueon.ch/about -URL: https://www.valueon.ch/about -Type: Main URL -Extracted: 2025-10-02 21:21:42 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unser Team -========== - -Seit über 25 Jahren stehen wir für Innovation, Qualität und nachhaltigen Erfolg. Erfahren Sie mehr über unsere Geschichte, unsere Werte und die Menschen, die ValueON zu dem machen, was es heute ist. - -Alle Kernteam Geschäftsführende Partner Externe Zertifizierte Partner - - - -Mehr erfahren - -### Dominic Largo - -CEO - - - -Dominic führt das Unternehmen mit einer klaren Vision für digitale Innovation und strategisches Wachstum in der Beratung. - -### Dominic Largo - -CEO - - - -Zum Vergrößern klicken - -#### Schwerpunkte - -* Sicherstellen der besten Projekt- & Tranformationsmanager für unsere Kunden und unsere Vorhaben -* Reviews von komplexen und erfolgskritischen Vorhaben -* Advisor & Einsitz in Steering Boards -* Sparringpartner für Führungskräfte und Gremien - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Handel / eCommerce Tourismus Konsumgüter Luxusgüter Industrie - -#### Berufliche Stationen - -* BottleButler AG (Founder & CEO) -* Arosa Lenzerheide (Marken- und Digital Leader) -* Mitgründer mehrerer Startups (Co-CEO & VR) -* Porsche Design Group (Country Manager & GCC) -* HAWAS & Jung von Matt (Markenstratege) - -#### Und ganz nebenbei... - -...ist Dominic Largo mit grosser Passion Langstreckenläufer, Kulinariker und Game Challenger. Er geniesst explizit die Berge und seine Familienzeit. - - - -Mehr erfahren - -### Andreas Friedli - -Managing Partner - - - -Mit über 25 Jahren Erfahrung in der digitalen Transformation leitet Andreas als Partner erfolgreich strategische Grossprojekte. - -### Andreas Friedli - -Managing Partner - -#### Schwerpunkte - -* Health-Check von Projekten und Programmen -* Advisor digitaler Transformationen -* Führung von Digitalisierungsprojekten und -programmen -* Emergency- und Recoveryprojekte -* Risiko- und Quality-Assurance bei digitalen Transformationen -* Advisor digitaler Neuausrichtungen -* Leadership-Coaching Projekt und Programm Manager - -#### Im Team seit - -2004 - -#### Branchenerfahrungen - -Finanzen / Banken Versicherungen / Krankenkassen Detailhandel Verwaltung Militär Automobile IT / Telekommunikation Immobilien - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of Complex Projects -* HP GmbH, Senior Project Manager -* Compaq Computer GmbH, Senior Project Manager -* Volkswirtschaftsdep. St. Gallen, Informatikverantwortlicher - -#### Und ganz nebenbei... - -…spielt Andreas Friedli gerne Golf, liebt feines Essen und guten Wein und verbringt viel Zeit mit seiner Familie – ganz nach dem Motto «Geniesse den Moment!». - - - -Mehr erfahren - -### Patrick Motsch - -Managing Partner - - - -Patrick leitet als Partner erfolgreich komplexe IT-Implementierungsprojekte. - -### Patrick Motsch - -Managing Partner - -#### Schwerpunkte - -* Health Check von Projekten -* Führen von geschäftskritischen Projekten und Programmen -* Führen und Begleiten von Emergency und Recovery Projekten -* Führen und Begleiten von DC Moves und ICT Konsolidierungsprojekten -* Advisor für Auftraggeber - -#### Im Team seit - -2001 - -#### Branchenerfahrungen - -Baubranche IT / Telekommunikation / Data Center Industrie Sport Verteidigung Verwaltung Airspace Management Versicherungen Handel - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG) -* Vater und Pionier des TimeWinner Führungssystems -* CIO einer IT Consulting Organisation - -#### Und ganz nebenbei... - -…liebt Patrick Motsch den Garten, das Tanzen, wandert gerne, taucht so oft es geht und lernt gerne fremde Länder kennen. Sein persönliches Motto: «Wer will, der kann». - - - -Mehr erfahren - -### Richard Salvisberg - -Managing Partner - - - -Richard bringt als Partner strategische Beratungsexpertise und Führungskompetenz ein. - -### Richard Salvisberg - -Managing Partner - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Führen von geschäftskritischen Programmen und Transformationen -* Aufbau und Führen von Projektportfolio-Managementsystemen -* Sparringpartner und Advisor - -#### Im Team seit - -2006 - -#### Branchenerfahrungen - -Gesundheitswesen & (Kranken-)Versicherung Militär Verwaltung Beschaffungswesen & Transport Informatik & Telekommunikation Bau Sport Energie - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of PPM -* T-Systems Schweiz AG, Chief Information Officer -* Orange Communications SA, IT Account Manager -* Swisscom AG Bern, Head Management Support -* Swisscom AG Bern, Programm Manager Charging & Billing - -#### Und ganz nebenbei... - -…liebt Richard Salvisberg das Tanzen, lernt gerne fremde Kulturen kennen, hat Freude an schönen Autos und geniesst ein Buch bei einem guten Schluck Wein. In klaren Nächten beobachtet er interessiert den Kosmos. Sein persönliches Motto lautet «Auf innovativen Wegen nachhaltige Erfolge erzielen». - - - -Mehr erfahren - -### Stephan Schellworth - -Experte - - - -Stephan verbindet strategisches Denken mit praxisnaher Projektsteuerung und gestaltet digitale Projekte - -### Stephan Schellworth - -Experte - -#### Schwerpunkte - -* Projekt- und Teamführung -* Datenanalyse und Optimierung -* Agiles Projektmanagement - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Automatisierungstechnik Digitalisierung - -#### Berufliche Stationen - -* 2023 - 2024: Testmanager im Energiebordnetz, BMW Group -* 2021 - 2023: Gesamtfahrzeugspezialist in der E/E, BMW Group -* 2018 - 2021: Prüfstandsspezialist im BMW Prototypen-Motorenwerk, Academic Work -* 2016 - 2018: Entwicklungsingenieur, EDAG Engineering Group - -#### Und ganz nebenbei... - -…sammelt und pflegt Stephan Young- und Oldtimern, treibt Sport wie Squash und besucht regelmässig das Fitnessstudio. Er geht gern mit seinem Hund spazieren oder wandert in der Natur. Ausserdem programmiert er kleinere SmartHome-Anwendungen mit dem Raspberry Pi, Apps und erstellt 3D-Visualisierungen von Innen- und Aussenräumen. - - - -Mehr erfahren - -### Mats Rudolf - -Experte - - - -Mats berät Unternehmen zu digitalen Transformationsprojekten und Systemimplementierungen. - -### Mats Rudolf - -Experte - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Advisor digitaler Transformation -* Advisor Systems Engineering -* Projekt- und Teamführung -* Agiles Projektmanagement - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Sensortechnik Luft- und Raumfahrttechnik Maschinen- und Anlagenbau Transport und Logistik - -#### Berufliche Stationen - -* 2019 - 2024: Management Consultant Innovation und Transformation, UNITY Schweiz AG -* 2018: Industrial Solution Consulting Intern, Brütsch Rüegger Werkzeuge -* 2015 - 2016: Sensor Research and Development Intern, Sensirion AG - -#### Und ganz nebenbei... - -…zieht es Mats Rudolf im Winter für Skitouren und rasante Abfahrten auf die frisch verschneiten Berge. Wenn der Sommer kommt, tauscht er seine Ski gegen ein Surfbrett und geniesst die Wellen im Meer. Zudem schwingt er gerne den Schläger auf dem Tennisplatz und bastelt an seinen Smart-Device-Projekten. - - - -Mehr erfahren - -### Ida Dittrich - -AI Specialist - -Ida verbindet ihr wissenschaftliches Know-how mit praktischer IT-Erfahrung und bringt innovative Ansätze in technische Projekte ein. - -### Ida Dittrich - -AI Specialist - -#### Schwerpunkte - -* Product Architect and Software Engineer PowerOn Platform - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Luft- und Raumfahrtindustrie Kommunikation und Interessenvertretung Medien - -#### Berufliche Stationen - -* Forschungsprojekt zur Modellierung des inneren Aufbaus terrestrischer Exoplaneten (ETH Zürich) -* Recovery Engineer und Systems Engineer bei verschiedenen Projekten der Akademischen Raumfahrtinitiative der Schweiz (ARIS) - -#### Und ganz nebenbei... - -… spielt Ida Dittrich leidenschaftlich gern Computerspiele und bastelt an handwerklichen Projekten wie Nähen, Häkeln oder Stricken. Sie ist regelmäßig sportlich aktiv – sei es beim Joggen an der frischen Luft, im Fitnessstudio oder bei einer entspannenden Yoga-Einheit. - - - -Mehr erfahren - -### Nick Melloh - -AI-Specialist - -Nick macht künstliche Intelligenz für Unternehmen greifbar – in Projekten, Strategien und praxisnahen Schulungen. - -### Nick Melloh - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Digitale Transformation & Business Innovation -* Advisor für Künstliche Intelligenz & Wissensvermittlung -* Advisor für Strategisches Projekt- und Prozessmanagement -* Trainer für KI-Schulungen und Weiterbildung - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Digitalisierung Consulting Hospitality Event- und Innovationsmanagement KI-Anwendungen - -#### Berufliche Stationen - -* 2023–heute: Master in Business Innovation, Universität St. Gallen – Schwerpunkt Digitale Transformation & KI -* 2023–heute: Event Manager SQUARE, Universität St. Gallen – Gestaltung innovativer Lern- und Austauschformate -* 2022–2023: VP Sales, Contler AG – SaaS-Lösungen & Prozessautomatisierung im Hospitality-Sektor - -#### Und ganz nebenbei... - -…hat Nick eine Schwäche für Reisen, gutes Essen und Bücher – um neue Denkanstöße zu gewinnen und frische Perspektiven einzunehmen. Energie findet er beim Sport, in den Bergen oder bei langen Gesprächen mit Freunden – die besten Momente für ihn sind die, in denen die Uhr keine Rolle spielt. - - - -Mehr erfahren - -### Yannick Althaus - -AI-Specialist - -Yannick berät Unternehmen, indem er Strategiekompetenz mit unternehmerischer DNA verbindet. - -### Yannick Althaus - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Strategisches Management und Unternehmensführung -* Advisor für Künstliche Intelligenz und digitale Transformation -* Advisor für Produktion und Supply Chain Management - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Industrie Digitalisierung Supply Chain Management Consulting - -#### Berufliche Stationen - -* 2025: M.A. HSG in Unternehmensführung - Masterarbeit zum Einsatz von generativer KI in der Strategieentwicklung von CEOs -* 2022: B.Sc. Wirtschaftsingenieurwesen -* 2019–2025: Diverse Consulting-Praktika & Projekte in Supply Chain Management, Digitalisierung und strategischem Management sowie Mitarbeit im Familienunternehmen (neben dem Studium) -* 2013–2017: Automatiker EFZ bei Bystronic - -#### Und ganz nebenbei... - -…wenn er nicht an Strategien feilt, zieht es Yannick aufs Eis – Eishockey ist sein Adrenalinschub. Auch sonst bleibt er regelmässig in Bewegung: Skifahren im Winter, Joggen zwischendurch und Golf im Sommer. Ausserdem hat er eine Schwäche für schnelle Autos und reist gerne – am liebsten ans Meer. - - - -### Philipp Dick - -Certified Partner - -"KI wird Manager nicht ersetzen, aber Manager, die KI einsetzen, werden die ersetzen, die es nicht tun." - - - -### Romano Caviezel - -Certified Partner - -"Innovation bedeutet, bestehende Dinge zu hinterfragen und neue Wege zu entdecken." - - - -### Dawid Puzik - -Certified Partner - -"Manche sehen, was möglich ist – andere verändern, was möglich ist." - - - -### Holger Ridinger - -Certified Partner - -"Transformation braucht Struktur, Leidenschaft und Ausdauer." - - - -### Alain Kappeler - -Certified Partner - -"Wenn es dich nicht herausfordert, verändert es dich nicht." - - - -### Andreas Wyss - -Certified Partner - -Andreas verbindet strategisches Denken mit menschlichem Feingefuehl in Transformationsprozessen. - - - -### Alfredo Mercurio - -Certified Partner - -"Eine klare Vision ist der Anfang von allem." - - - -### Bernd Nagel - -Certified Partner - -"Wer will, findet Wege. Wer nicht will, findet Gründe." - - - -### Daniel Sengstag - -Certified Partner - -"Wer nicht mit der Zeit geht, geht mit der Zeit." - - - -### Daniel Lochmatter - -Certified Partner - -"Neues und bisher Unbekanntes kann man nur explorativ erfahren, erspüren, erlernen – und danach zum eigenen Nutzen einsetzen." - - - -### Michael Hermann - -Certified Partner - -"Auch beim Projekt gilt: Ende gut, alles gut." - - - -### Heinz Ruffieux - -Certified Partner - -"C'est le ton qui fait la musique." - - - -### Sven Fassbender - -Certified Partner - -"Mein Ziel ist es, Cybersicherheit verständlich und greifbar zu machen – für jeden zugänglich und praktikabel." - - - -### Raffael Santchi - -Certified Partner - -"Wer Prozesse versteht, kann Systeme formen – nicht umgekehrt." - - - -### Stephanie Kieninger - -Certified Partner - -Stephanie konzentriert sich mit ihrer Beratung auf die Menschen im Veraenderungsprozess. - - - -### Christoph Merle - -Certified Partner - -Christoph engagiert sich mit seiner langjährigen Führungserfahrung in der Industrie und mit seinem Hintergrund in strategischer und operativer Beratung für den Erfolg unserer Kunden. - -Previous slide Next slide - -Über ValueOn ------------- - -Wir schaffen digitale Transformation mit Leidenschaft und Expertise - -### Unsere Mission - -Durch exzellente Beratung schaffen wir digitale Transformation erfolgreich zu meistern. - -### Unser Versprechen - -Höchste Qualität, agile Ansätze und Passion für gemeinsamen Wirken - -25+ - -Jahre Erfahrung - -100+ - -Projekte - -98% - -Weiterempfehlung - -60% - -Schneller zum Ziel - -Unsere Geschichte ------------------ - -Eine Reise der Innovation - -Heute - -Heute und Morgen - -Als führendes Beratungsunternehmen gestalten wir aktiv die Zukunft der digitalen Transformation mit innovativen KI-Lösungen und nachhaltigen Strategien. - -KI-Ära - -KI-Revolution - -Die Einführung von KI-Systemen veränderte unsere Beratungsleistung grundlegend und ermöglichte es uns, unseren Kunden noch innovativere Lösungen anzubieten. - -Digital - -Digitale Transformation - -Mit neuen digitalen Lösungen begleiteten wir unsere Kunden in der Transformation und etablierten uns als führender Partner für digitale Innovation. - -Aufbau - -Etablierung am Markt - -Wir etablierten uns am Markt mit innovativen IT-Strategien und nachhaltiger Umsetzung, wodurch wir eine solide Basis für weiteres Wachstum schufen. - -2000 - -Gründung von ValueON - -ValueON wurde mit der Vision gegründet, Unternehmen bei der digitalen Transformation zu unterstützen und nachhaltigen Erfolg zu schaffen. - -Unsere Werte ------------- - -Was uns antreibt - -### Exzellenz - -Höchste Qualität in allem, was wir tun. Von der ersten Beratung bis zur finalen Umsetzung setzen wir auf höchste Standards. - -### Partnerschaft - -Wir sehen uns als langfristige Partner unserer Kunden und arbeiten gemeinsam an nachhaltigen Lösungen. - -### Integrität - -Ehrlichkeit, Transparenz und Vertrauen bilden das Fundament aller unserer Geschäftsbeziehungen. - -### Effektivität - -Zielgerichtete Lösungen, die messbare Ergebnisse liefern und nachhaltigen Geschäftserfolg schaffen. - -Karriere bei ValueOn --------------------- - -Werde Teil unseres Teams - -### Product-Architekt/in für KI-Plattformen - -Zürich, Schweiz M/W, 50-100% - -Details ansehen - -Keine passende Stelle gefunden? - -[Initiativbewerbung senden](mailto:office@valueon.ch) - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_212142/main_url_003_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt b/test_web_content_20251002_212142/main_url_003_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt deleted file mode 100644 index ed62b3d4..00000000 --- a/test_web_content_20251002_212142/main_url_003_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt +++ /dev/null @@ -1,364 +0,0 @@ -Title: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 -Type: Main URL -Extracted: 2025-10-02 21:21:42 -================================================================================ - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](#)[Save + Exit](#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - -[Startseite](/de/) [>](javascript:void(0)) [Unternehmen](/de/search?q=ValueOn AG) [>](javascript:void(0)) ValueOn AG - -# ValueOn AG - -ZH - -aktiv - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) -[Zur Timeline](/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -Handelsregister-Nr.: CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](/de/company/valueon-ag-4663161481/messages) - -[Sie möchten eine Änderung der Firmendaten vornehmen? Wir unterstützen Sie hierbei gerne.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Alter der Firma - -18 Jahre - -#### Umsatz in CHF - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Kapital in CHF - -200'000 - -#### Mitarbeiter - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Aktive Marken - -0 - -c/o Westhive AG -Am Stadtrand 11 -8600 Dübendorf -[Nachbarschaft](/de/company/valueon-ag-4663161481/network#neighbourhood) - -[Sie möchten Ihre Adresse anpassen? -Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -[News aus der Region Uster](/de/region/uster/uebersicht) - -## Auskünfte zu ValueOn AG - -\*angezeigte Auskünfte sind Beispiele - -#### Bonitätsauskunft - -Einschätzung der Bonität mit einer Ampel als Risikoindikator und weiteren hilfreichen Firmeninformationen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -#### Wirtschaftsauskunft - -Umfassende Auskunft über die wirtschaftliche Situation der Firma. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#commercial-report) - -#### Zahlungsverhalten - -Beurteilung der Zahlungsmoral aufgrund vergangener Rechnungen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-mode-report) - -#### Betreibungsauskunft - -Übersicht über aktuelle und vergangene Betreibungsverfahren. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-collection-report) - -#### Beteiligungsauskunft - -Erfahren Sie, an welchen nationalen und internationalen Firmen die Aktiengesellschaft, für die Sie sich interessieren, noch beteiligt ist. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#wow-report) - -#### Firmendossier als PDF - -Kontaktinformationen, Veränderungen, Umsatz- und Mitarbeiterzahlen, Management, Besitzverhältnisse, Beteiligungsstruktur und weitere Firmendaten. -[Jetzt kostenlos abrufen](/de/company/valueon-ag-4663161481/reports#firmendossier-report) - -## Über ValueOn AG - -* ValueOn AG hat den Sitz in Dübendorf, ist aktiv und im Bereich «Erbringen von IT-Dienstleistungen» tätig. - - - -* Das [Management](valueon-ag-4663161481/management) der Firma ValueOn AG besteht aus 5 Personen. - - - -* Unter [Meldungen](valueon-ag-4663161481/messages) finden Sie alle Handelsregisteränderung, die letzte erfolgte am 27.08.2025. - - - -* Die Firma ist im Handelsregister des Kantons ZH unter der UID CHE-113.416.882 eingetragen. - - - -* Unternehmen mit derselben Adresse wie ValueOn AG: [Black Projects GmbH](black-projects-gmbh-3958227961), [Bluespace Ventures AG](bluespace-ventures-ag-20038582721), [Cyberfy Consulting AG](cyberfy-consulting-ag-5194156221). - -## Management (5) - -#### neueste Verwaltungsräte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901) - -#### neuste Zeichnungsberechtigte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -#### Geschäftsleitung - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -Quelle: [SHAB](/de/datasources) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -## Netzwerk - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -## Handelsregisterinformationen - -Quelle: [SHAB](/de/datasources) - -#### Eintrag ins Handelsregister - -02.02.2007 - -#### Rechtsform - -Aktiengesellschaft - -#### Rechtssitz der Firma - -Dübendorf - -#### Handelsregisteramt - -ZH - -#### Handelsregister-Nummer - -CH-020.3.030.651-3 - -#### UID/MWST - -CHE-113.416.882 - -#### Branche - -Erbringen von IT-Dienstleistungen - -#### Firmenzweck - -Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -[Passen Sie den Firmenzweck mit wenigen Klicks an.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Revisionsstelle - -Quelle: [SHAB](/de/datasources) - -#### Aktive Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [TBO Revisions AG](/de/company/tbo-revisions-ag-20607789301) | | Zürich | 18.03.2015 | | - -[Möchten Sie die Revisionsstelle anpassen? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Frühere Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [Trevisca AG](/de/company/trevisca-ag-20628390611) | | Baar | 08.02.2007 | 17.03.2015 | - -## Weitere Firmennamen - -Quelle: [SHAB](/de/datasources) - -#### Frühere und übersetzte Firmennamen - -* Project Competence AG - -[Möchten Sie den Firmennamen aktualisieren? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Zweigniederlassungen (0) - -## Besitzverhältnisse - -Es liegen uns keine Angaben zu den Besitzverhältnissen vor. - -## Beteiligungen - -Es liegen uns keine Angaben zu den Beteiligungen vor. - - - - - - - - - -## Neueste SHAB-Meldungen: ValueOn AG - -SHAB 250827/2025 - 27.08.2025 - -**Kategorien:** Änderung des Firmenzwecks, Änderung der Firmenadresse - -Publikationsnummer: [HR02-1006417690](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006417690 "Download SHAB Publikation der ValueOn AG vom 27.08.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 133 vom 14.07.2025, Publ. 1006383218). - -**Statutenänderung:** - 18.08.2025. - -**Sitz neu:** - Dübendorf. - -**Domizil neu:** - c/o Westhive AG, Am Stadtrand 11, 8600 Dübendorf. - -**Zweck neu:** - Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -**Mitteilungen neu:** - Mitteilungen an die Aktionäre erfolgen per Brief oder E-Mail an die im Aktienbuch verzeichneten Adressen. - -SHAB 250714/2025 - 14.07.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006383218](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006383218 "Download SHAB Publikation der ValueOn AG vom 14.07.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 101 vom 27.05.2025, Publ. 1006341693). - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Einzelunterschrift [*bisher: Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]. - -SHAB 250527/2025 - 27.05.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006341693](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006341693 "Download SHAB Publikation der ValueOn AG vom 27.05.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 222 vom 14.11.2024, Publ. 1006178101). - -**Ausgeschiedene Personen und erloschene Unterschriften:** - Hamburger, Marc Eric, von St. Gallen, in Mörschwil, Präsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Egloff, Reto](/de/person/egloff-reto-101763781201), von Oberrohrdorf, in Bern, Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Mühlemann, Markus](/de/person/muehlemann-markus-142196879901), von Seeberg, in Uster, Delegierter des Verwaltungsrates, mit Einzelunterschrift. - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien [*bisher: Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]; - [Althaus, Walter](/de/person/althaus-jun-walter-205367807901), von Affoltern im Emmental, in Aarwangen, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Wyss, Andreas](/de/person/wyss-andreas-129476912501), von Dietikon, in Dietikon, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien. - -[Alle SHAB-Meldungen ansehen](/de/company/valueon-ag-4663161481/messages) - -## Trefferliste - -Hier finden Sie eine Verlinkung des Managements auf eine Trefferliste zu Personen mit dem gleichen Namen, die im Handelsregister eingetragen sind. - -[Dominic Pascal Largo](/de/list/person/largo-dominic-pascal) - -[Andreas Wyss](/de/list/person/wyss-andreas) - -[Walter Althaus Jun.](/de/list/person/althaus-jun-walter) - -[Andreas Friedli](/de/list/person/friedli-andreas) - -[Richard Salvisberg](/de/list/person/salvisberg-richard) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](/de/terms)[Datenschutz |](/de/privacy)[Impressum](/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](/de/overview) - - - - - - -[Übersicht](/de/company/valueon-ag-4663161481) - -[Auskünfte](/de/company/valueon-ag-4663161481/reports) - -[Management](/de/company/valueon-ag-4663161481/management) - -[Netzwerk](/de/company/valueon-ag-4663161481/network) - -[Timeline](/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](/de/company/valueon-ag-4663161481/shares) - -[Meldungen](/de/company/valueon-ag-4663161481/messages) - -[Marken](/de/company/valueon-ag-4663161481/brands) - -[Jobs](/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_212142/main_url_004_www.valueon.ch_.txt b/test_web_content_20251002_212142/main_url_004_www.valueon.ch_.txt deleted file mode 100644 index 221227f6..00000000 --- a/test_web_content_20251002_212142/main_url_004_www.valueon.ch_.txt +++ /dev/null @@ -1,107 +0,0 @@ -Title: https://www.valueon.ch/ -URL: https://www.valueon.ch/ -Type: Main URL -Extracted: 2025-10-02 21:21:42 -================================================================================ - -# Power für deinendigitalen Erfolg - -Vertrauen von führenden Unternehmen - -## Unsere Expertise - -Von digitaler Transformation bis zu künstlicher Intelligenz – wir begleiten Sie auf Ihrem Weg in die Zukunft. - -### Digitale Strategie entwickeln - -Ihre Richtung im digitalen Wandel. - -Gemeinsames Zielbild & Roadmap, abgestimmt auf Ihr Geschäft und leiten konkrete Handlungsempfehlungen ab. - -Orientierung & Handlungssicherheit - -### Transformation gezielt optimieren - -Lücken aufdecken. Stärken nutzen. - -Systematischer Blick auf Prozesse, Systeme & Potenziale und leiten konkrete Handlungsempfehlungen ab. - -Relevanz statt Aktionismus - -### Change Management etablieren - -Menschen mitnehmen. Wandel gestalten. - -Strukturierte Begleitung der Mitarbeiter durch den digitalen Wandel mit gezielten Schulungskonzepten. - -Akzeptanz & Erfolg sichern - -### Prozesse digital automatisieren - -Effizienz steigern. Kosten senken. - -Identifikation und Umsetzung von Automatisierungspotenzialen für nachhaltige Produktivitätssteigerung. - -Messbare Effizienzgewinne - -## Erfolgreiche Projekte & Transformationen - -Unter dem Motto «Unsere Kunden stehen im Mittelpunkt» haben wir für Sie eine Auswahl an Kundenreferenzen und Business Cases zusammengestellt. - -Als KMU sind wir es eigentlich nicht gewohnt, einen so grossen Aufwand wie bei der Evaluation des richtigen Partners für die Entwicklung und Realisierung unseres neuen Kernsystems zu betreiben. Doch i... - -Markus Berther - -Geschäftsführer, Schaden Service Schweiz AG - -ValueOn hat uns durch den gesamten Prozess der Digitalen Business Transformation mit grossem Einsatz und Engagement begleitet – von der ersten IT-Standortanalyse und Sourcing Analyse über digitales Zi... - -Stefan Wolf - -Präsident, FC Luzern - -In diesem businesskritischen IT-Programm waren insgesamt vier Experten von ValueOn (ehem. Project Competence) involviert, als Projektleiter und Koordinator, Cut-Over-Manager bis hin zur Gesamt-Program... - -Roland Bosshard - -CIO / Mitglied der GL, KPT - -In time, in quality, under budget: Andreas Friedli von ValueOn (ehem. Project Competence) hat in seiner Co-Leitungsfunktion in diesem IT-Projekt ganz massgeblich dazu beigetragen, dass wir dieses trot... - -Thomas Sturzenegger - -Divisional IT Lead, RUAG Real Estate AG - -Die erfolgreiche Realisierung dieses Vorhabens ist ein wichtiger Meilenstein für die strategische Neuausrichtung der WWZ. Die Projektberater der ValueOn AG (ehem. Project Competence AG) haben dabei da... - -Thomas Reber - -Leiter Telekom & IT Services, WWZ AG - -Um die Zukunftsausrichtung unserer IT-Strategie und -Organisation möglichst optimal auf unsere Business-Anforderungen auszurichten, haben wir ValueOn (ehem. Project Competence) als Sparringpartner ... - -Andreas Guglielmo - -CFO, CHRIS sports AG - -Wir danken den externen Projektberatern der ValueOn (ehem. Project Competence), die uns kompetent und mit ebenso hohem Arbeitseinsatz durch dieses Projekt und die Verhandlungen unter schwierigen Be... - -Michael Kohlbacher - -Generalsekretär, AGZ - -Dank ValueOn konnten wir unser komplexes IT-Infrastrukturprojekt termingerecht und im Budget abschliessen. Die strukturierte Herangehensweise war ausschlaggebend. - -Peter Keller - -Projektleiter, InnovaCorp - -ValueOn hat uns sowohl fachlich als auch menschlich auf höchstem Niveau beraten. Die Experten begleiteten uns kompetent bei der Modernisierung unserer IT-Infrastruktur und der reibungslosen Ablösung u... - -Silvan Wildhaber - -CEO, Filtex Group AG - -← Wischen Sie für weitere Testimonials → - -Auto-Scroll aktiv \ No newline at end of file diff --git a/test_web_content_20251002_212142/main_url_005_www.valueon.ch_about.txt b/test_web_content_20251002_212142/main_url_005_www.valueon.ch_about.txt deleted file mode 100644 index 1c5a4742..00000000 --- a/test_web_content_20251002_212142/main_url_005_www.valueon.ch_about.txt +++ /dev/null @@ -1,639 +0,0 @@ -Title: https://www.valueon.ch/about -URL: https://www.valueon.ch/about -Type: Main URL -Extracted: 2025-10-02 21:21:42 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unser Team -========== - -Seit über 25 Jahren stehen wir für Innovation, Qualität und nachhaltigen Erfolg. Erfahren Sie mehr über unsere Geschichte, unsere Werte und die Menschen, die ValueON zu dem machen, was es heute ist. - -Alle Kernteam Geschäftsführende Partner Externe Zertifizierte Partner - - - -Mehr erfahren - -### Dominic Largo - -CEO - - - -Dominic führt das Unternehmen mit einer klaren Vision für digitale Innovation und strategisches Wachstum in der Beratung. - -### Dominic Largo - -CEO - - - -Zum Vergrößern klicken - -#### Schwerpunkte - -* Sicherstellen der besten Projekt- & Tranformationsmanager für unsere Kunden und unsere Vorhaben -* Reviews von komplexen und erfolgskritischen Vorhaben -* Advisor & Einsitz in Steering Boards -* Sparringpartner für Führungskräfte und Gremien - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Handel / eCommerce Tourismus Konsumgüter Luxusgüter Industrie - -#### Berufliche Stationen - -* BottleButler AG (Founder & CEO) -* Arosa Lenzerheide (Marken- und Digital Leader) -* Mitgründer mehrerer Startups (Co-CEO & VR) -* Porsche Design Group (Country Manager & GCC) -* HAWAS & Jung von Matt (Markenstratege) - -#### Und ganz nebenbei... - -...ist Dominic Largo mit grosser Passion Langstreckenläufer, Kulinariker und Game Challenger. Er geniesst explizit die Berge und seine Familienzeit. - - - -Mehr erfahren - -### Andreas Friedli - -Managing Partner - - - -Mit über 25 Jahren Erfahrung in der digitalen Transformation leitet Andreas als Partner erfolgreich strategische Grossprojekte. - -### Andreas Friedli - -Managing Partner - -#### Schwerpunkte - -* Health-Check von Projekten und Programmen -* Advisor digitaler Transformationen -* Führung von Digitalisierungsprojekten und -programmen -* Emergency- und Recoveryprojekte -* Risiko- und Quality-Assurance bei digitalen Transformationen -* Advisor digitaler Neuausrichtungen -* Leadership-Coaching Projekt und Programm Manager - -#### Im Team seit - -2004 - -#### Branchenerfahrungen - -Finanzen / Banken Versicherungen / Krankenkassen Detailhandel Verwaltung Militär Automobile IT / Telekommunikation Immobilien - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of Complex Projects -* HP GmbH, Senior Project Manager -* Compaq Computer GmbH, Senior Project Manager -* Volkswirtschaftsdep. St. Gallen, Informatikverantwortlicher - -#### Und ganz nebenbei... - -…spielt Andreas Friedli gerne Golf, liebt feines Essen und guten Wein und verbringt viel Zeit mit seiner Familie – ganz nach dem Motto «Geniesse den Moment!». - - - -Mehr erfahren - -### Patrick Motsch - -Managing Partner - - - -Patrick leitet als Partner erfolgreich komplexe IT-Implementierungsprojekte. - -### Patrick Motsch - -Managing Partner - -#### Schwerpunkte - -* Health Check von Projekten -* Führen von geschäftskritischen Projekten und Programmen -* Führen und Begleiten von Emergency und Recovery Projekten -* Führen und Begleiten von DC Moves und ICT Konsolidierungsprojekten -* Advisor für Auftraggeber - -#### Im Team seit - -2001 - -#### Branchenerfahrungen - -Baubranche IT / Telekommunikation / Data Center Industrie Sport Verteidigung Verwaltung Airspace Management Versicherungen Handel - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG) -* Vater und Pionier des TimeWinner Führungssystems -* CIO einer IT Consulting Organisation - -#### Und ganz nebenbei... - -…liebt Patrick Motsch den Garten, das Tanzen, wandert gerne, taucht so oft es geht und lernt gerne fremde Länder kennen. Sein persönliches Motto: «Wer will, der kann». - - - -Mehr erfahren - -### Richard Salvisberg - -Managing Partner - - - -Richard bringt als Partner strategische Beratungsexpertise und Führungskompetenz ein. - -### Richard Salvisberg - -Managing Partner - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Führen von geschäftskritischen Programmen und Transformationen -* Aufbau und Führen von Projektportfolio-Managementsystemen -* Sparringpartner und Advisor - -#### Im Team seit - -2006 - -#### Branchenerfahrungen - -Gesundheitswesen & (Kranken-)Versicherung Militär Verwaltung Beschaffungswesen & Transport Informatik & Telekommunikation Bau Sport Energie - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of PPM -* T-Systems Schweiz AG, Chief Information Officer -* Orange Communications SA, IT Account Manager -* Swisscom AG Bern, Head Management Support -* Swisscom AG Bern, Programm Manager Charging & Billing - -#### Und ganz nebenbei... - -…liebt Richard Salvisberg das Tanzen, lernt gerne fremde Kulturen kennen, hat Freude an schönen Autos und geniesst ein Buch bei einem guten Schluck Wein. In klaren Nächten beobachtet er interessiert den Kosmos. Sein persönliches Motto lautet «Auf innovativen Wegen nachhaltige Erfolge erzielen». - - - -Mehr erfahren - -### Stephan Schellworth - -Experte - - - -Stephan verbindet strategisches Denken mit praxisnaher Projektsteuerung und gestaltet digitale Projekte - -### Stephan Schellworth - -Experte - -#### Schwerpunkte - -* Projekt- und Teamführung -* Datenanalyse und Optimierung -* Agiles Projektmanagement - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Automatisierungstechnik Digitalisierung - -#### Berufliche Stationen - -* 2023 - 2024: Testmanager im Energiebordnetz, BMW Group -* 2021 - 2023: Gesamtfahrzeugspezialist in der E/E, BMW Group -* 2018 - 2021: Prüfstandsspezialist im BMW Prototypen-Motorenwerk, Academic Work -* 2016 - 2018: Entwicklungsingenieur, EDAG Engineering Group - -#### Und ganz nebenbei... - -…sammelt und pflegt Stephan Young- und Oldtimern, treibt Sport wie Squash und besucht regelmässig das Fitnessstudio. Er geht gern mit seinem Hund spazieren oder wandert in der Natur. Ausserdem programmiert er kleinere SmartHome-Anwendungen mit dem Raspberry Pi, Apps und erstellt 3D-Visualisierungen von Innen- und Aussenräumen. - - - -Mehr erfahren - -### Mats Rudolf - -Experte - - - -Mats berät Unternehmen zu digitalen Transformationsprojekten und Systemimplementierungen. - -### Mats Rudolf - -Experte - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Advisor digitaler Transformation -* Advisor Systems Engineering -* Projekt- und Teamführung -* Agiles Projektmanagement - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Sensortechnik Luft- und Raumfahrttechnik Maschinen- und Anlagenbau Transport und Logistik - -#### Berufliche Stationen - -* 2019 - 2024: Management Consultant Innovation und Transformation, UNITY Schweiz AG -* 2018: Industrial Solution Consulting Intern, Brütsch Rüegger Werkzeuge -* 2015 - 2016: Sensor Research and Development Intern, Sensirion AG - -#### Und ganz nebenbei... - -…zieht es Mats Rudolf im Winter für Skitouren und rasante Abfahrten auf die frisch verschneiten Berge. Wenn der Sommer kommt, tauscht er seine Ski gegen ein Surfbrett und geniesst die Wellen im Meer. Zudem schwingt er gerne den Schläger auf dem Tennisplatz und bastelt an seinen Smart-Device-Projekten. - - - -Mehr erfahren - -### Ida Dittrich - -AI Specialist - -Ida verbindet ihr wissenschaftliches Know-how mit praktischer IT-Erfahrung und bringt innovative Ansätze in technische Projekte ein. - -### Ida Dittrich - -AI Specialist - -#### Schwerpunkte - -* Product Architect and Software Engineer PowerOn Platform - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Luft- und Raumfahrtindustrie Kommunikation und Interessenvertretung Medien - -#### Berufliche Stationen - -* Forschungsprojekt zur Modellierung des inneren Aufbaus terrestrischer Exoplaneten (ETH Zürich) -* Recovery Engineer und Systems Engineer bei verschiedenen Projekten der Akademischen Raumfahrtinitiative der Schweiz (ARIS) - -#### Und ganz nebenbei... - -… spielt Ida Dittrich leidenschaftlich gern Computerspiele und bastelt an handwerklichen Projekten wie Nähen, Häkeln oder Stricken. Sie ist regelmäßig sportlich aktiv – sei es beim Joggen an der frischen Luft, im Fitnessstudio oder bei einer entspannenden Yoga-Einheit. - - - -Mehr erfahren - -### Nick Melloh - -AI-Specialist - -Nick macht künstliche Intelligenz für Unternehmen greifbar – in Projekten, Strategien und praxisnahen Schulungen. - -### Nick Melloh - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Digitale Transformation & Business Innovation -* Advisor für Künstliche Intelligenz & Wissensvermittlung -* Advisor für Strategisches Projekt- und Prozessmanagement -* Trainer für KI-Schulungen und Weiterbildung - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Digitalisierung Consulting Hospitality Event- und Innovationsmanagement KI-Anwendungen - -#### Berufliche Stationen - -* 2023–heute: Master in Business Innovation, Universität St. Gallen – Schwerpunkt Digitale Transformation & KI -* 2023–heute: Event Manager SQUARE, Universität St. Gallen – Gestaltung innovativer Lern- und Austauschformate -* 2022–2023: VP Sales, Contler AG – SaaS-Lösungen & Prozessautomatisierung im Hospitality-Sektor - -#### Und ganz nebenbei... - -…hat Nick eine Schwäche für Reisen, gutes Essen und Bücher – um neue Denkanstöße zu gewinnen und frische Perspektiven einzunehmen. Energie findet er beim Sport, in den Bergen oder bei langen Gesprächen mit Freunden – die besten Momente für ihn sind die, in denen die Uhr keine Rolle spielt. - - - -Mehr erfahren - -### Yannick Althaus - -AI-Specialist - -Yannick berät Unternehmen, indem er Strategiekompetenz mit unternehmerischer DNA verbindet. - -### Yannick Althaus - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Strategisches Management und Unternehmensführung -* Advisor für Künstliche Intelligenz und digitale Transformation -* Advisor für Produktion und Supply Chain Management - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Industrie Digitalisierung Supply Chain Management Consulting - -#### Berufliche Stationen - -* 2025: M.A. HSG in Unternehmensführung - Masterarbeit zum Einsatz von generativer KI in der Strategieentwicklung von CEOs -* 2022: B.Sc. Wirtschaftsingenieurwesen -* 2019–2025: Diverse Consulting-Praktika & Projekte in Supply Chain Management, Digitalisierung und strategischem Management sowie Mitarbeit im Familienunternehmen (neben dem Studium) -* 2013–2017: Automatiker EFZ bei Bystronic - -#### Und ganz nebenbei... - -…wenn er nicht an Strategien feilt, zieht es Yannick aufs Eis – Eishockey ist sein Adrenalinschub. Auch sonst bleibt er regelmässig in Bewegung: Skifahren im Winter, Joggen zwischendurch und Golf im Sommer. Ausserdem hat er eine Schwäche für schnelle Autos und reist gerne – am liebsten ans Meer. - - - -### Philipp Dick - -Certified Partner - -"KI wird Manager nicht ersetzen, aber Manager, die KI einsetzen, werden die ersetzen, die es nicht tun." - - - -### Romano Caviezel - -Certified Partner - -"Innovation bedeutet, bestehende Dinge zu hinterfragen und neue Wege zu entdecken." - - - -### Dawid Puzik - -Certified Partner - -"Manche sehen, was möglich ist – andere verändern, was möglich ist." - - - -### Holger Ridinger - -Certified Partner - -"Transformation braucht Struktur, Leidenschaft und Ausdauer." - - - -### Alain Kappeler - -Certified Partner - -"Wenn es dich nicht herausfordert, verändert es dich nicht." - - - -### Andreas Wyss - -Certified Partner - -Andreas verbindet strategisches Denken mit menschlichem Feingefuehl in Transformationsprozessen. - - - -### Alfredo Mercurio - -Certified Partner - -"Eine klare Vision ist der Anfang von allem." - - - -### Bernd Nagel - -Certified Partner - -"Wer will, findet Wege. Wer nicht will, findet Gründe." - - - -### Daniel Sengstag - -Certified Partner - -"Wer nicht mit der Zeit geht, geht mit der Zeit." - - - -### Daniel Lochmatter - -Certified Partner - -"Neues und bisher Unbekanntes kann man nur explorativ erfahren, erspüren, erlernen – und danach zum eigenen Nutzen einsetzen." - - - -### Michael Hermann - -Certified Partner - -"Auch beim Projekt gilt: Ende gut, alles gut." - - - -### Heinz Ruffieux - -Certified Partner - -"C'est le ton qui fait la musique." - - - -### Sven Fassbender - -Certified Partner - -"Mein Ziel ist es, Cybersicherheit verständlich und greifbar zu machen – für jeden zugänglich und praktikabel." - - - -### Raffael Santchi - -Certified Partner - -"Wer Prozesse versteht, kann Systeme formen – nicht umgekehrt." - - - -### Stephanie Kieninger - -Certified Partner - -Stephanie konzentriert sich mit ihrer Beratung auf die Menschen im Veraenderungsprozess. - - - -### Christoph Merle - -Certified Partner - -Christoph engagiert sich mit seiner langjährigen Führungserfahrung in der Industrie und mit seinem Hintergrund in strategischer und operativer Beratung für den Erfolg unserer Kunden. - -Previous slide Next slide - -Über ValueOn ------------- - -Wir schaffen digitale Transformation mit Leidenschaft und Expertise - -### Unsere Mission - -Durch exzellente Beratung schaffen wir digitale Transformation erfolgreich zu meistern. - -### Unser Versprechen - -Höchste Qualität, agile Ansätze und Passion für gemeinsamen Wirken - -25+ - -Jahre Erfahrung - -100+ - -Projekte - -98% - -Weiterempfehlung - -60% - -Schneller zum Ziel - -Unsere Geschichte ------------------ - -Eine Reise der Innovation - -Heute - -Heute und Morgen - -Als führendes Beratungsunternehmen gestalten wir aktiv die Zukunft der digitalen Transformation mit innovativen KI-Lösungen und nachhaltigen Strategien. - -KI-Ära - -KI-Revolution - -Die Einführung von KI-Systemen veränderte unsere Beratungsleistung grundlegend und ermöglichte es uns, unseren Kunden noch innovativere Lösungen anzubieten. - -Digital - -Digitale Transformation - -Mit neuen digitalen Lösungen begleiteten wir unsere Kunden in der Transformation und etablierten uns als führender Partner für digitale Innovation. - -Aufbau - -Etablierung am Markt - -Wir etablierten uns am Markt mit innovativen IT-Strategien und nachhaltiger Umsetzung, wodurch wir eine solide Basis für weiteres Wachstum schufen. - -2000 - -Gründung von ValueON - -ValueON wurde mit der Vision gegründet, Unternehmen bei der digitalen Transformation zu unterstützen und nachhaltigen Erfolg zu schaffen. - -Unsere Werte ------------- - -Was uns antreibt - -### Exzellenz - -Höchste Qualität in allem, was wir tun. Von der ersten Beratung bis zur finalen Umsetzung setzen wir auf höchste Standards. - -### Partnerschaft - -Wir sehen uns als langfristige Partner unserer Kunden und arbeiten gemeinsam an nachhaltigen Lösungen. - -### Integrität - -Ehrlichkeit, Transparenz und Vertrauen bilden das Fundament aller unserer Geschäftsbeziehungen. - -### Effektivität - -Zielgerichtete Lösungen, die messbare Ergebnisse liefern und nachhaltigen Geschäftserfolg schaffen. - -Karriere bei ValueOn --------------------- - -Werde Teil unseres Teams - -### Product-Architekt/in für KI-Plattformen - -Zürich, Schweiz M/W, 50-100% - -Details ansehen - -Keine passende Stelle gefunden? - -[Initiativbewerbung senden](mailto:office@valueon.ch) - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_212142/main_url_006_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt b/test_web_content_20251002_212142/main_url_006_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt deleted file mode 100644 index ed62b3d4..00000000 --- a/test_web_content_20251002_212142/main_url_006_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt +++ /dev/null @@ -1,364 +0,0 @@ -Title: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 -Type: Main URL -Extracted: 2025-10-02 21:21:42 -================================================================================ - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](#)[Save + Exit](#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - -[Startseite](/de/) [>](javascript:void(0)) [Unternehmen](/de/search?q=ValueOn AG) [>](javascript:void(0)) ValueOn AG - -# ValueOn AG - -ZH - -aktiv - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) -[Zur Timeline](/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -Handelsregister-Nr.: CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](/de/company/valueon-ag-4663161481/messages) - -[Sie möchten eine Änderung der Firmendaten vornehmen? Wir unterstützen Sie hierbei gerne.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Alter der Firma - -18 Jahre - -#### Umsatz in CHF - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Kapital in CHF - -200'000 - -#### Mitarbeiter - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Aktive Marken - -0 - -c/o Westhive AG -Am Stadtrand 11 -8600 Dübendorf -[Nachbarschaft](/de/company/valueon-ag-4663161481/network#neighbourhood) - -[Sie möchten Ihre Adresse anpassen? -Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -[News aus der Region Uster](/de/region/uster/uebersicht) - -## Auskünfte zu ValueOn AG - -\*angezeigte Auskünfte sind Beispiele - -#### Bonitätsauskunft - -Einschätzung der Bonität mit einer Ampel als Risikoindikator und weiteren hilfreichen Firmeninformationen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -#### Wirtschaftsauskunft - -Umfassende Auskunft über die wirtschaftliche Situation der Firma. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#commercial-report) - -#### Zahlungsverhalten - -Beurteilung der Zahlungsmoral aufgrund vergangener Rechnungen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-mode-report) - -#### Betreibungsauskunft - -Übersicht über aktuelle und vergangene Betreibungsverfahren. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-collection-report) - -#### Beteiligungsauskunft - -Erfahren Sie, an welchen nationalen und internationalen Firmen die Aktiengesellschaft, für die Sie sich interessieren, noch beteiligt ist. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#wow-report) - -#### Firmendossier als PDF - -Kontaktinformationen, Veränderungen, Umsatz- und Mitarbeiterzahlen, Management, Besitzverhältnisse, Beteiligungsstruktur und weitere Firmendaten. -[Jetzt kostenlos abrufen](/de/company/valueon-ag-4663161481/reports#firmendossier-report) - -## Über ValueOn AG - -* ValueOn AG hat den Sitz in Dübendorf, ist aktiv und im Bereich «Erbringen von IT-Dienstleistungen» tätig. - - - -* Das [Management](valueon-ag-4663161481/management) der Firma ValueOn AG besteht aus 5 Personen. - - - -* Unter [Meldungen](valueon-ag-4663161481/messages) finden Sie alle Handelsregisteränderung, die letzte erfolgte am 27.08.2025. - - - -* Die Firma ist im Handelsregister des Kantons ZH unter der UID CHE-113.416.882 eingetragen. - - - -* Unternehmen mit derselben Adresse wie ValueOn AG: [Black Projects GmbH](black-projects-gmbh-3958227961), [Bluespace Ventures AG](bluespace-ventures-ag-20038582721), [Cyberfy Consulting AG](cyberfy-consulting-ag-5194156221). - -## Management (5) - -#### neueste Verwaltungsräte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901) - -#### neuste Zeichnungsberechtigte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -#### Geschäftsleitung - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -Quelle: [SHAB](/de/datasources) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -## Netzwerk - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -## Handelsregisterinformationen - -Quelle: [SHAB](/de/datasources) - -#### Eintrag ins Handelsregister - -02.02.2007 - -#### Rechtsform - -Aktiengesellschaft - -#### Rechtssitz der Firma - -Dübendorf - -#### Handelsregisteramt - -ZH - -#### Handelsregister-Nummer - -CH-020.3.030.651-3 - -#### UID/MWST - -CHE-113.416.882 - -#### Branche - -Erbringen von IT-Dienstleistungen - -#### Firmenzweck - -Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -[Passen Sie den Firmenzweck mit wenigen Klicks an.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Revisionsstelle - -Quelle: [SHAB](/de/datasources) - -#### Aktive Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [TBO Revisions AG](/de/company/tbo-revisions-ag-20607789301) | | Zürich | 18.03.2015 | | - -[Möchten Sie die Revisionsstelle anpassen? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Frühere Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [Trevisca AG](/de/company/trevisca-ag-20628390611) | | Baar | 08.02.2007 | 17.03.2015 | - -## Weitere Firmennamen - -Quelle: [SHAB](/de/datasources) - -#### Frühere und übersetzte Firmennamen - -* Project Competence AG - -[Möchten Sie den Firmennamen aktualisieren? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Zweigniederlassungen (0) - -## Besitzverhältnisse - -Es liegen uns keine Angaben zu den Besitzverhältnissen vor. - -## Beteiligungen - -Es liegen uns keine Angaben zu den Beteiligungen vor. - - - - - - - - - -## Neueste SHAB-Meldungen: ValueOn AG - -SHAB 250827/2025 - 27.08.2025 - -**Kategorien:** Änderung des Firmenzwecks, Änderung der Firmenadresse - -Publikationsnummer: [HR02-1006417690](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006417690 "Download SHAB Publikation der ValueOn AG vom 27.08.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 133 vom 14.07.2025, Publ. 1006383218). - -**Statutenänderung:** - 18.08.2025. - -**Sitz neu:** - Dübendorf. - -**Domizil neu:** - c/o Westhive AG, Am Stadtrand 11, 8600 Dübendorf. - -**Zweck neu:** - Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -**Mitteilungen neu:** - Mitteilungen an die Aktionäre erfolgen per Brief oder E-Mail an die im Aktienbuch verzeichneten Adressen. - -SHAB 250714/2025 - 14.07.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006383218](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006383218 "Download SHAB Publikation der ValueOn AG vom 14.07.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 101 vom 27.05.2025, Publ. 1006341693). - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Einzelunterschrift [*bisher: Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]. - -SHAB 250527/2025 - 27.05.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006341693](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006341693 "Download SHAB Publikation der ValueOn AG vom 27.05.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 222 vom 14.11.2024, Publ. 1006178101). - -**Ausgeschiedene Personen und erloschene Unterschriften:** - Hamburger, Marc Eric, von St. Gallen, in Mörschwil, Präsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Egloff, Reto](/de/person/egloff-reto-101763781201), von Oberrohrdorf, in Bern, Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Mühlemann, Markus](/de/person/muehlemann-markus-142196879901), von Seeberg, in Uster, Delegierter des Verwaltungsrates, mit Einzelunterschrift. - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien [*bisher: Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]; - [Althaus, Walter](/de/person/althaus-jun-walter-205367807901), von Affoltern im Emmental, in Aarwangen, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Wyss, Andreas](/de/person/wyss-andreas-129476912501), von Dietikon, in Dietikon, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien. - -[Alle SHAB-Meldungen ansehen](/de/company/valueon-ag-4663161481/messages) - -## Trefferliste - -Hier finden Sie eine Verlinkung des Managements auf eine Trefferliste zu Personen mit dem gleichen Namen, die im Handelsregister eingetragen sind. - -[Dominic Pascal Largo](/de/list/person/largo-dominic-pascal) - -[Andreas Wyss](/de/list/person/wyss-andreas) - -[Walter Althaus Jun.](/de/list/person/althaus-jun-walter) - -[Andreas Friedli](/de/list/person/friedli-andreas) - -[Richard Salvisberg](/de/list/person/salvisberg-richard) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](/de/terms)[Datenschutz |](/de/privacy)[Impressum](/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](/de/overview) - - - - - - -[Übersicht](/de/company/valueon-ag-4663161481) - -[Auskünfte](/de/company/valueon-ag-4663161481/reports) - -[Management](/de/company/valueon-ag-4663161481/management) - -[Netzwerk](/de/company/valueon-ag-4663161481/network) - -[Timeline](/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](/de/company/valueon-ag-4663161481/shares) - -[Meldungen](/de/company/valueon-ag-4663161481/messages) - -[Marken](/de/company/valueon-ag-4663161481/brands) - -[Jobs](/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_001_www.valueon.ch_services.txt b/test_web_content_20251002_212426/additional_link_001_www.valueon.ch_services.txt deleted file mode 100644 index 56b695c9..00000000 --- a/test_web_content_20251002_212426/additional_link_001_www.valueon.ch_services.txt +++ /dev/null @@ -1,110 +0,0 @@ -URL: https://www.valueon.ch/services -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unsere Leistungen -================= - -Von der digitalen Transformation bis zur KI-Integration – wir begleiten Sie bei jedem Schritt zu nachhaltigem Erfolg, messbaren Ergebnissen und langfristiger Wertschöpfung. - -Digitale Transformation Künstliche Intelligenz IT- & Digitalprojekte - -Digitale Transformation ------------------------ - -Wir begleiten Sie bei jedem Schritt – von der Strategie bis zur erfolgreichen Umsetzung. - -### Zukunft gestalten mit klarem Zielbild - -IHRE RICHTUNG IM DIGITALEN WANDEL - -Zielbild & Roadmap für digitale Transformation – zugeschnitten auf Ihr Geschäft. - -Orientierung & Handlungssicherheit - -### Transformation analysieren & optimieren - -LÜCKEN AUFDECKEN. NUTZEN SCHÄRFEN - -Fit-Gap-Analyse und Review Ihrer Prozesse, Tools & Struktur. - -Systematische Bewertung statt Aktionismus - -### IT, Business & Digitalstrategie vereinen - -SCHNITTSTELLEN AUFLÖSEN. STRATEGIE VERBINDEN - -Abgleich Ihrer Digital- und Businessstrategie – für nachhaltige Wirkung. - -Strategische Klarheit gewinnen - -### CIO/CDO ad interim einsetzen - -FÜHRUNG SICHERN. KOMPETENZ EINBRINGEN - -Temporäre Führungsstärke, wenn Verantwortung gebraucht wird. - -Sofort einsatzbereit & erfahrungssicher - -### Zukunft gestalten mit klarem Zielbild - -IHRE RICHTUNG IM DIGITALEN WANDEL - -Zielbild & Roadmap für digitale Transformation – zugeschnitten auf Ihr Geschäft. - -Orientierung & Handlungssicherheit - -### Transformation analysieren & optimieren - -LÜCKEN AUFDECKEN. NUTZEN SCHÄRFEN - -Fit-Gap-Analyse und Review Ihrer Prozesse, Tools & Struktur. - -Systematische Bewertung statt Aktionismus - -### IT, Business & Digitalstrategie vereinen - -SCHNITTSTELLEN AUFLÖSEN. STRATEGIE VERBINDEN - -Abgleich Ihrer Digital- und Businessstrategie – für nachhaltige Wirkung. - -Strategische Klarheit gewinnen - -### CIO/CDO ad interim einsetzen - -FÜHRUNG SICHERN. KOMPETENZ EINBRINGEN - -Temporäre Führungsstärke, wenn Verantwortung gebraucht wird. - -Sofort einsatzbereit & erfahrungssicher - -### Bereit für den ersten Schritt? - -Ob Strategie, Analyse oder Interim – wir zeigen Ihnen den passenden Einstieg. - -Kostenfrei Strategiegespräch vereinbaren - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_212426/additional_link_002_www.valueon.ch_projects.txt b/test_web_content_20251002_212426/additional_link_002_www.valueon.ch_projects.txt deleted file mode 100644 index 5b229a5f..00000000 --- a/test_web_content_20251002_212426/additional_link_002_www.valueon.ch_projects.txt +++ /dev/null @@ -1,354 +0,0 @@ -URL: https://www.valueon.ch/projects -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unsere Erfolgsprojekte -====================== - -Entdecken Sie, wie wir Unternehmen dabei helfen, ihre digitale Transformation erfolgreich umzusetzen und nachhaltige Werte zu schaffen. - -50+ - -Erfolgreiche Projekte - -100% - -Kundenzufriedenheit - -25% - -Ø Kostenoptimierung - -60% - -schneller Integriert - -Referenzprojekte & Success Stories ----------------------------------- - -Jedes Projekt ist einzigartig. Entdecken Sie, wie wir mit massgeschneiderten Lösungen echte Mehrwerte für unsere Kunden schaffen. - - - -Digitale Transformation - -KPT • 18 Monate - -### Digitale Transformation der KPT - -Komplette Modernisierung der IT-Infrastruktur mit 24% Kostenoptimierung und deutlich mehr Leistung, Flexibilität und Sicherheit. - -#### Technologien: - -Cloud Migration Prozessoptimierung Change Management - -#### Ergebnisse: - -* 24% Kostenoptimierung -* Erhöhte Flexibilität -* Verbesserte Sicherheit - - - -Künstliche Intelligenz - -WWZ • 12 Monate - -### KI-gestützte Prozessoptimierung WWZ - -Implementierung einer KI-Lösung zur Automatisierung von Geschäftsprozessen und Entscheidungsfindung. - -#### Technologien: - -Machine Learning Process Mining Automation - -#### Ergebnisse: - -* 40% Zeitersparnis -* Verbesserte Genauigkeit -* Datenbasierte Entscheidungen - - - -IT-Infrastruktur - -FC Luzern • 8 Monate - -### Businesskritische IT-Infrastruktur FC Luzern - -Aufbau einer hochverfügbaren IT-Infrastruktur für geschäftskritische Anwendungen mit 99.9% Uptime. - -#### Technologien: - -High Availability Disaster Recovery Security - -#### Ergebnisse: - -* 99.9% Verfügbarkeit -* Null Datenverlust -* Compliance erreicht - - - -Cloud Transformation - -TechStart AG • 10 Monate - -### Cloud-First Strategie TechStart AG - -Vollständige Migration zur Cloud mit Fokus auf Skalierbarkeit und Kosteneffizienz. - -#### Technologien: - -AWS Kubernetes DevOps - -#### Ergebnisse: - -* 60% Kosteneinsparung -* Bessere Skalierbarkeit -* Schnellere Deployments - - - -Change Management - -InnovaCorp • 15 Monate - -### Agile Transformation InnovaCorp - -Einführung agiler Arbeitsweisen und Kulturwandel für verbesserte Projekteffizienz. - -#### Technologien: - -Scrum Kanban Team Coaching - -#### Ergebnisse: - -* 50% kürzere Time-to-Market -* Höhere Mitarbeiterzufriedenheit -* Verbesserte Qualität - - - -Strategieberatung - -Swiss Enterprise • 24 Monate - -### Digital Excellence Program - -Entwicklung einer umfassenden Digitalisierungsstrategie für nachhaltiges Wachstum. - -#### Technologien: - -Strategy Design Digital Roadmap KPI Framework - -#### Ergebnisse: - -* 30% Umsatzsteigerung -* Neue Geschäftsmodelle -* Marktführerschaft - - - -Digitale Transformation - -Filtex Textil • 14 Monate - -### Digital Transformation der Filtex Textil - -Komplette Analyse und Erneuerung der gesamten IT-/Datenarchitektur mit massiven Kostenreduktion, 100% Sales Flexibilität und Sicherheit. - -#### Technologien: - -Cloud Migration Prozessoptimierung KPI-Dashboard Security - -#### Ergebnisse: - -* 99.9% Verfügbarkeit -* Maximale Kundenorientierung -* Zeit- und Ressourcenersparnis -* Planungssicherheit - - - -Digitale Transformation - -Häny Pumpen • 16 Monate - -### Digital Transformation der Häny Pumpen - -Analyse und Erneuerung der gesamten IT-/Datenarchitektur mit Kostenreduktion, Sales Flexibilität, ERP-Standardisierung und Sicherheit. - -#### Technologien: - -Cloud Migration Prozessoptimierung ERP-Technologie KPI-Dashboard Security - -#### Ergebnisse: - -* Komplette ERP-Systemmigration -* Maximale Kundenorientierung -* Risikominimierung -* Zeit- und Ressourcenersparnis -* Verbesserte Sicherheit - - - -Digitale Transformation - -Swiss Ice Hockey Federation • 20 Monate - -### Digital Transformation der Swiss Ice Hockey Federation - -Analyse und Erneuerung der gesamten IT-/Datenarchitektur, Kostenreduktion, Prozesslandschafts- und Kollaborationsplattform, ERP- und Datensicherheit. - -#### Technologien: - -Cloud Migration Prozessoptimierung ERP-Technologie Security - -#### Ergebnisse: - -* Komplette ERP-Systemmigration -* Anspruchsgruppen-Fokus -* Risikominimierung -* Zeit- und Ressourcenersparnis -* Verbesserte Sicherheit - - - -Strategieberatung - -Swiss Olympic • 12 Monate - -### Digitalisierungsstrategie für Swiss Olympic - -Analyse der gesamten IT-/Datenarchitektur, Prozesslandschafts- und Kollaborationsplattform, ERP- und Datensicherheit. - -#### Technologien: - -ERP-Technologie Security Kollaborations-Technologie - -#### Ergebnisse: - -* Komplette Roadmap mit Handlungsfeldern -* Anspruchsgruppen-Fokus -* Risiko-Management -* Vorbereitung Aufbau PPM -* Zeit- und Ressourcenersparnis -* Verbesserte Sicherheit - - - -Künstliche Intelligenz - -LayerFinance • 18 Monate - -### KI-Transformation für LayerFinance - -Analyse der gesamten Datenarchitektur, Prozesslandschaft, Datensicherheit, KI-Anwendungen. - -#### Technologien: - -KI-Technologie Deal-closing AI-Plattform - -#### Ergebnisse: - -* Continuation in Enabling KI based Deal Closing Plattform -* Zeit- und Ressourcenersparnis -* Verbesserte Sicherheit - - - -Strategieberatung - -Steuerverwaltung Bern • 7 Monate - -### Technologiewechsel-Programm Steuerverwaltung Bern - -Umfassende Analyse des Technologiewechsel-Programms zur Identifikation kritischer Erfolgsfaktoren und zur Definition konkreter Massnahmen für den Abschluss. Erstellung einer integrierten Gesamtplanung mit Abhängigkeitsmanagement sowie Etablierung eines konsistenten Change- und Risikomanagements. - -#### Technologien: - -Prozessoptimierung Strategy Design Roadmap Management - -#### Ergebnisse: - -* Einheitliche, steuerbare Prozesse -* Vollständige Transparenz über Programmverlauf -* Hohe Planungs- und Umsetzungssicherheit -* Frühzeitige Risikokontrolle und Eskalationsfähigkeit -* Stärkung der Steuerungsfähigkeit auf Gesamtprogrammebene - - - -Digitale Transformation - -Schadenservice Schweiz • 24 Monate - -### Von der Analyse zur Umsetzung – ERP-Projekt Schadenservice Schweiz - -Begleitung eines ERP-Erneuerungsprojekts von der initialen Bedarfsanalyse über die Evaluation bis zur vollständigen Umsetzung. Nach dem Entscheid zur Eigenentwicklung übernahm ein externer Anbieter die technische Realisierung, während wir die Kundenseite als unabhängige Vertretung begleiteten. - -#### Technologien: - -Bedarfsanalyse Evaluation & Auswahlprozess Projektleitung auf Kundenseite Change Management - -#### Ergebnisse: - -* Massgeschneiderte ERP-Lösung auf Basis individueller Anforderungen -* Strukturierte Zusammenarbeit zwischen Entwicklung, Fachbereichen und Betrieb -* Einführung standardisierter Prozesse und digitaler Abläufe -* Hohe Akzeptanz bei den Nutzerinnen und Nutzern -* Erfolgreiche Verankerung der neuen Lösung im Tagesgeschäft - - - -Strategieberatung - -Sunrise TDC Switzerland AG • 3 Monate - -### PMO-Aufbau Sunrise TDC Switzerland AG - -Aufbau eines voll funktionsfähigen Project Management Office (PMO) für Customer Care und Effizienzsteigerung der PMIO-Organisation innerhalb von 3 Monaten. - -#### Technologien: - -Situationsanalyse PMO-Strukturierung Change Management Prozessoptimierung - -#### Ergebnisse: - -* Funnel- und Steuerungsausschussstrukturen etabliert -* Bewertungskriterien für Priorisierung definiert -* Standardisierter Funnel- und Steuerungsbericht -* Konstruktiver und offener Management Buy-in -* Termingerechte PMO-Kompetenz realisiert - -> "Das PMO-Setup war ein voller Erfolg. Termingerecht und mit konstruktivem Management Buy-in haben wir ein funktionsfähiges System etabliert." - -— Dr. Marc Furrer, CEO Sunrise TDC Switzerland AG - -Previous slide Next slide - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_212426/additional_link_003_www.valueon.ch_vernissage.txt b/test_web_content_20251002_212426/additional_link_003_www.valueon.ch_vernissage.txt deleted file mode 100644 index aae65313..00000000 --- a/test_web_content_20251002_212426/additional_link_003_www.valueon.ch_vernissage.txt +++ /dev/null @@ -1,68 +0,0 @@ -URL: https://www.valueon.ch/vernissage -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Beyond AI -========= - -Wo KI auf Führung trifft ------------------------- - -Künstliche Intelligenz ist nicht nur ein Werkzeug – sie ist ein transformativer Treiber, der grundlegend verändert, wie wir führen, arbeiten und Wert schaffen. - -PeaqPartners und ValueOn laden Sie herzlich zur AI Vernissage ein – einem exklusiven Abend für ausgewählte Partner:innen und Führungspersönlichkeiten. Freuen Sie sich auf Impulse, Gespräche und kreative Erlebnisse rund um den strategischen Einsatz von KI. - -### Event-Details - -Datum:Dienstag, 16. September 2025 - -Ort:Le Bijou, Lintheschergasse 18, 8001 Zürich (3 min von ZHB) - -Zeit:17:30 – 19:30 Uhr - -Teilnahmegebühr:CHF 100.- - -Sprache:Deutsch - -Zielgruppe:Führungskräfte & strategische Entscheider:innen - -### Anmeldung - -Anrede * Bitte wählen - -Vorname * - -Nachname * - -Firma * - -Industrie * - -E-Mail * - -Anmeldung senden - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_212426/additional_link_004_www.valueon.ch_self-check.txt b/test_web_content_20251002_212426/additional_link_004_www.valueon.ch_self-check.txt deleted file mode 100644 index 7227c933..00000000 --- a/test_web_content_20251002_212426/additional_link_004_www.valueon.ch_self-check.txt +++ /dev/null @@ -1,58 +0,0 @@ -URL: https://www.valueon.ch/self-check -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Digital Readiness Check - -Wie digital ist dein - -Unternehmen wirklich? -=========================================== - -In nur 7 Fragen erfährst du, wie zukunftsfit dein Unternehmen ist – inkl. individueller Einschätzung & konkreter Handlungsempfehlungen. - -Jetzt kostenlos testen - -Dauert nur 3 Minuten - -Frage 1 von 7 14% abgeschlossen - -STRATEGIE - -Wie werden in eurem Unternehmen aktuell Entscheidungen getroffen? ------------------------------------------------------------------ - -Intuitiv und erfahrungsbasiert - -Teilweise datenbasiert, aber oft ohne Systematik - -Wir nutzen regelmäßig Datenanalysen zur Entscheidungsfindung - -Unsere Entscheidungen basieren fast ausschließlich auf KPIs & Datenmodellen - -Zurück Weiter - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_212426/additional_link_005_www.valueon.ch_contact.txt b/test_web_content_20251002_212426/additional_link_005_www.valueon.ch_contact.txt deleted file mode 100644 index bdfecfcf..00000000 --- a/test_web_content_20251002_212426/additional_link_005_www.valueon.ch_contact.txt +++ /dev/null @@ -1,89 +0,0 @@ -URL: https://www.valueon.ch/contact -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unser Kontakt -============= - -Lassen Sie uns gemeinsam Ihre digitale Transformation vorantreiben. - -Lassen Sie uns ins Gespräch kommen ----------------------------------- - -Sie haben Fragen zu unseren Dienstleistungen oder möchten mehr über unsere Expertise erfahren? Nutzen Sie das Kontaktformular oder kontaktieren Sie uns direkt – wir sind für Sie da. - -### Telefon - -[+41 44 943 70 40](tel:+41449437040) - -### E-Mail - -[office@valueon.ch](mailto:office@valueon.ch) - -### Adresse - -ValueOn AG - -Am Stadtrand 11 - -8600 Dübendorf - -Schweiz - -### Folgen Sie uns - -[](https://www.linkedin.com/company/valueon) - -Name * - -E-Mail * - -Telefon - -Unternehmen - -Nachricht * - -Nachricht senden - -* Pflichtfelder - -So finden Sie uns ------------------ - -Unser Büro befindet sich in Dübendorf, nur wenige Minuten von Zürich entfernt. - -### Anreise - -#### Mit dem Auto - -Ausreichend Parkplätze stehen direkt vor dem Gebäude zur Verfügung. - -#### Mit öffentlichen Verkehrsmitteln - -Vom Bahnhof Dübendorf erreichen Sie unser Büro bequem zu Fuß in ca. 10 Minuten oder mit dem Bus. - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_212426/additional_link_006_www.valueon.ch_privacy.txt b/test_web_content_20251002_212426/additional_link_006_www.valueon.ch_privacy.txt deleted file mode 100644 index 60988795..00000000 --- a/test_web_content_20251002_212426/additional_link_006_www.valueon.ch_privacy.txt +++ /dev/null @@ -1,103 +0,0 @@ -URL: https://www.valueon.ch/privacy -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Datenschutzerklärung -==================== - -Die Betreiber dieser Seiten nehmen den Schutz Ihrer persönlichen Daten sehr ernst. Wir behandeln Ihre personenbezogenen Daten vertraulich und entsprechend den gesetzlichen Datenschutzvorschriften sowie dieser Datenschutzerklärung. - -Wenn Sie diese Website benutzen, werden verschiedene personenbezogene Daten erhoben. Personenbezogene Daten sind Daten, mit denen Sie persönlich identifiziert werden können. Die vorliegende Datenschutzerklärung erläutert, welche Daten wir erheben und wofür wir sie nutzen. Sie erläutert auch, wie und zu welchem Zweck das geschieht. - -**Wichtiger Hinweis:** Wir weisen darauf hin, dass die Datenübertragung im Internet (z. B. bei der Kommunikation per E-Mail) Sicherheitslücken aufweisen kann. Ein lückenloser Schutz der Daten vor dem Zugriff durch Dritte ist nicht möglich. - -Grundlegende Informationen --------------------------- - -### Verantwortliche Stelle - -Die verantwortliche Stelle für die Datenverarbeitung auf dieser Website ist: ValueOn AG, Am Stadtrand 11, 8600 Dübendorf, Schweiz, T +41 44 943 70 40, E-Mail: info@valueon.ch. Verantwortliche Stelle ist die natürliche oder juristische Person, die allein oder gemeinsam mit anderen über die Zwecke und Mittel der Verarbeitung von personenbezogenen Daten (z. B. Namen, E-Mail-Adressen o. Ä.) entscheidet. - -### Speicherdauer - -Löschersuchen geltend machen oder eine Einwilligung zur Datenverarbeitung widerrufen, werden Ihre Daten gelöscht, sofern wir keine anderen rechtlich zulässigen Gründe für die Speicherung Ihrer personenbezogenen Daten haben (z. B. steuer- oder handelsrechtliche Aufbewahrungsfristen); im letztgenannten Fall erfolgt die Löschung nach Fortfall dieser Gründe. - -### Auskunft, Löschung, Sperrung - -Sie haben jederzeit das Recht auf unentgeltliche Auskunft über Ihre gespeicherten personenbezogenen Daten, deren Herkunft und Empfänger und den Zweck der Datenverarbeitung sowie ein Recht auf Berichtigung, Sperrung oder Löschung dieser Daten. Hierzu sowie zu weiteren Fragen zum Thema personenbezogene Daten können Sie sich jederzeit unter der im Impressum angegebenen Adresse bzw. an die in der Datenschutzerklärung genannte verantwortliche Person an uns wenden. - -### Widerspruch gegen Werbe-E-Mails - -Der Nutzung von im Rahmen der Impressumspflicht veröffentlichten Kontaktdaten zur Übersendung von nicht ausdrücklich angeforderter Werbung und Informationsmaterialien wird hiermit widersprochen. Die Betreiber der Seiten behalten sich ausdrücklich rechtliche Schritte im Falle der unverlangten Zusendung von Werbeinformationen, etwa durch Spam-E-Mails, vor. - -Technische Datenverarbeitung ----------------------------- - -### Cookies - -Unsere Internetseiten verwenden so genannte "Cookies". Cookies sind kleine Textdateien und richten auf Ihrem Endgerät keinen Schaden an. Sie werden entweder vorübergehend für die Dauer einer Sitzung (Session-Cookies) oder dauerhaft (permanente Cookies) auf Ihrem Endgerät gespeichert. Session-Cookies werden nach Ende Ihres Besuchs automatisch gelöscht. Permanente Cookies bleiben auf Ihrem Endgerät gespeichert, bis Sie diese selbst löschen oder eine automatische Löschung durch Ihren Webbrowser erfolgt. - -### Server-Log-Dateien - -Der Provider der Seiten erhebt und speichert automatisch Informationen in so genannten Server-Log-Dateien, die Ihr Browser automatisch an uns übermittelt. Dies sind: Browsertyp und Browserversion, verwendetes Betriebssystem, Referrer URL, Hostname des zugreifenden Rechners, Uhrzeit der Serveranfrage, IP-Adresse. Eine Zusammenführung dieser Daten mit anderen Datenquellen wird nicht vorgenommen. - -### Anmelde- und Kontaktformulare - -Wenn Sie uns per Kontaktformular Anfragen zukommen lassen oder sich mit dem Anmeldeformular für unsere Veranstaltungen anmelden, werden Ihre Angaben aus den Formularen inklusive der von Ihnen dort angegebenen Kontaktdaten und Informationen zwecks Bearbeitung der Anfrage und für den Fall von Anschlussfragen bei uns gespeichert. Diese Daten geben wir nicht ohne Ihre Einwilligung weiter. - -### Newsletter-Daten - -Die Verarbeitung der in das Newsletteranmeldeformular eingegebenen Daten erfolgt ausschließlich auf Grundlage Ihrer Einwilligung (Art. 6 Abs. 1 lit. a DSGVO). Die erteilte Einwilligung zur Speicherung der Daten, der E-Mail-Adresse sowie deren Nutzung zum Versand des Newsletters können Sie jederzeit widerrufen, etwa über den "Austragen"-Link im Newsletter. - -Externe Dienste ---------------- - -### Hinweis zur Datenweitergabe in die USA und sonstige Drittstaaten - -Wir weisen darauf hin, dass in diesen Ländern kein mit der EU oder der Schweiz vergleichbares Datenschutzniveau garantiert werden kann. Beispielsweise sind US-Unternehmen dazu verpflichtet, personenbezogene Daten an Sicherheitsbehörden herauszugeben, ohne dass Sie als Betroffener hiergegen gerichtlich vorgehen könnten. - -### Nutzung von HubSpot CRM - -Wir nutzen Hubspot CRM auf dieser Website. Anbieter ist Hubspot Inc. 25 Street, Cambridge, MA 02141 USA. Hubspot CRM ermöglicht es uns unter anderem, bestehende und potenzielle Kunden sowie Kundenkontakte zu verwalten. Die Verwendung von Hubspot CRM erfolgt auf Grundlage von Art. 6 Abs. 1 lit. f DSGVO. - -### LinkedIn - -Diese Website nutzt Elemente des Netzwerks LinkedIn. Anbieter ist die LinkedIn Ireland Unlimited Company, Wilton Plaza, Wilton Place, Dublin 2, Irland. Bei jedem Abruf einer Seite dieser Website, die Elemente von LinkedIn enthält, wird eine Verbindung zu Servern von LinkedIn aufgebaut. - -### Google Analytics - -Diese Website nutzt Funktionen des Webanalysedienstes Google Analytics. Anbieter ist die Google Inc. 1600 Amphitheatre Parkway Mountain View, CA 94043, USA. Google Analytics verwendet sog. "Cookies". Das sind Textdateien, die auf Ihrem Computer gespeichert werden und die eine Analyse der Benutzung der Website durch Sie ermöglichen. - -### Leadinfo - -Diese Website nutzt den Service des Anbieters Leadinfo B.V. mit Sitz in Rotterdam. Dieser Service zeigt uns auf Grundlage von IP-Adressen öffentlich zugängliche Unternehmensdaten an, wie z.B. Firmennamen und -adressen. Die Erkennung von Unternehmen basiert einzig und allein auf IP-Adressen. - -Fragen zum Datenschutz? ------------------------ - -Bei Fragen zum Datenschutz oder zur Verarbeitung Ihrer Daten kontaktieren Sie uns gerne. - -ValueOn AG - -Am Stadtrand 11, 8600 Dübendorf, Schweiz - -T +41 44 943 70 40 - -info@valueon.ch diff --git a/test_web_content_20251002_212426/additional_link_007_www.valueon.ch_imprint.txt b/test_web_content_20251002_212426/additional_link_007_www.valueon.ch_imprint.txt deleted file mode 100644 index c125ba43..00000000 --- a/test_web_content_20251002_212426/additional_link_007_www.valueon.ch_imprint.txt +++ /dev/null @@ -1,62 +0,0 @@ -URL: https://www.valueon.ch/imprint -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Impressum -========= - -Angaben gemäß den gesetzlichen Bestimmungen - -Inhaber der Website und verantwortlich für den Inhalt ------------------------------------------------------ - -### Unternehmen - -ValueOn AG - -Dominic Largo - -### Kontakt - -Am Stadtrand 11 - -8600 Dübendorf - -+41 44 943 70 40 - -[info@valueon.ch](mailto:info@valueon.ch) - -### Rechtliche Hinweise - -Alle Inhalte dieser Website sind urheberrechtlich geschützt. Jede Verwendung, Vervielfältigung oder Weiterverbreitung bedarf der ausdrücklichen schriftlichen Genehmigung der ValueOn AG. - -### Haftungsausschluss - -Die Inhalte unserer Seiten wurden mit größter Sorgfalt erstellt. Für die Richtigkeit, Vollständigkeit und Aktualität der Inhalte können wir jedoch keine Gewähr übernehmen. - -### Externe Links - -Unser Angebot enthält Links zu externen Webseiten Dritter, auf deren Inhalte wir keinen Einfluss haben. Deshalb können wir für diese fremden Inhalte auch keine Gewähr übernehmen. - -### Haben Sie Fragen? - -Bei rechtlichen Fragen oder Anliegen kontaktieren Sie uns gerne direkt. - -[Kontakt aufnehmen](mailto:info@valueon.ch) diff --git a/test_web_content_20251002_212426/additional_link_008_www.moneyhouse.ch_de_terms.txt b/test_web_content_20251002_212426/additional_link_008_www.moneyhouse.ch_de_terms.txt deleted file mode 100644 index 90fe6805..00000000 --- a/test_web_content_20251002_212426/additional_link_008_www.moneyhouse.ch_de_terms.txt +++ /dev/null @@ -1,96 +0,0 @@ -URL: https://www.moneyhouse.ch/de/terms -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Version gültig ab 1. Januar 2020 bis Widerruf - -Die vorliegenden Nutzungsbedingungen regeln die Geschäftsbeziehungen zwischen der Neue Zürcher Zeitung AG bezogen auf ihr Produkt Moneyhouse (nachfolgend «Moneyhouse» genannt) und dem Kunden (nachfolgend «Kunde» genannt). Diese Bestimmungen sind für alle Plattformen von Moneyhouse gültig, insbesondere für moneyhouse.ch. Abweichende AGB des Kunden finden keine Anwendung, auch wenn Moneyhouse nicht ausdrücklich widerspricht. - -**1. Grundlage der Geschäftsbeziehung** - -Ein Vertrag über eine der unterschiedlichen Dienstleistungen von Moneyhouse berechtigt den Kunden – nach Leistung des vereinbarten Entgelts – zur Inanspruchnahme der offerierten Leistungen. Dabei gelangen die jeweils gültigen Tarife und Konditionen sowie die vorliegenden Nutzungsbedingungen sowie allenfalls weitere, besondere Geschäftsbedingungen und Vertragsgrundlagen zur Anwendung. - -**2. Vertragsinhalt** - -Gegenstand der Leistungserbringung von Moneyhouse und deren Partnern sind Informationsdienstleistungen. Sie beinhalten in keinem Falle irgendwelche Rechte an Software, Lizenzrechte oder sonstige Immaterialgüterrechte. - -**3. Vertragsdauer und Verlängerung** - -Die Online-Dienstleistungen wie beispielsweise (keine abschliessende Aufzählung) die Premium-Mitgliedschaft oder das Bonitäts-Abo können ab Abschluss des Vertrags in Anspruch genommen werden und gelten für die jeweils abgeschlossene Vertragsdauer. - -Die Verträge betreffend die Dienstleistungen von moneyhouse.ch erneuern sich bei Ablauf stillschweigend um die vereinbarte Vertragsdauer, sofern nicht eine Partei einen Tag vor Ablauf der Vertragsdauer den Vertrag wie unter «Mein Konto» beschrieben kündigt. Davon ausgeschlossen sind etwaige Probe-Abonnements, welche sich auf die beim Abschluss definierte Dauer und zum vorab kommunizierten Preis verlängern. - -Sollte sich der Kunde mit Zahlungen im Verzug befinden oder gegen die vorliegenden AGB verstossen, ist Moneyhouse zur sofortigen Auflösung des Vertragsverhältnisses berechtigt. - -Wird der Vertrag erneuert, so gilt automatisch die allfällig neue Preisliste, welche dem Kunden auf Anfrage zur Verfügung gestellt wird. Der vorausbezahlte Abonnementpreis ist für den Zeitraum der Vorauszahlung garantiert und kann nicht erhöht werden. Abonnementpreiserhöhungen werden vor ihrer Wirksamkeit auf den jeweiligen Websites von Moneyhouse angekündigt. Einzelbenachrichtigungen erfolgen nicht. Entsprechend kann bei Nichtakzeptieren der Preiserhöhung der Vertrag zu den bisherigen Konditionen auf Ende der Laufzeit unter Einhaltung der Kündigungsfristen gekündigt werden. Alle von Moneyhouse genannten oder in etwaigen Tariflisten aufgeführten Preise sind Nettopreise ohne Mehrwertsteuer in Schweizer Franken. - -**4. Nutzungsbedingungen** - -**4.1. Nutzungsumfang** - -Die Produkte dienen ausschliesslich der persönlichen, nicht kommerziellen Nutzung durch natürliche und juristische Personen – eine weitergehende oder abweichende Nutzung und deren Verbreitung in anderen Systemen ist nur mit ausdrücklicher Zustimmung von Moneyhouse gestattet und kann jederzeit widerrufen werden. - -**4.2. Registrierung** - -Die Registrierung eines Benutzerkontos erfordert unter anderem einen Vor- und Nachnamen, eine Adresse sowie weitere Informationen, abhängig von der Art der gewünschten Nutzung (privat oder geschäftlich). Das automatisierte Anlegen von Benutzerkonten ist nicht gestattet. Der Kunde verpflichtet sich, seine Zugangsdaten vertragskonform zu verwenden und diese ohne schriftliche Zustimmung von Moneyhouse keinem Dritten zugänglich zu machen. Der Nutzer ist für den Schutz seiner Zugangsdaten verantwortlich. - -**4.3. Leistungen Moneyhouse** - -Inhalt und Umfang der dem Nutzer zur Verfügung gestellten Produkte bestimmen sich nach der jeweiligen Nutzungsform (zum Beispiel: registrierter oder nicht registrierter Kunde, kostenlose oder kostenpflichtige Nutzung etc.), einem allfällig bestehenden Vertragsverhältnis und den vorliegenden Nutzungsbedingungen und der Datenschutzerklärung. - -Die Online-Dienste sind in der Regel an 7 Tagen während 24 Stunden verfügbar. Moneyhouse behält sich das Recht vor, diese Betriebszeiten einzuschränken und/oder aus technischen Gründen vorübergehend auszusetzen sowie die Produkte jederzeit zu modifizieren. Die Produkte unterliegen laufenden Änderungen und Anpassungen. Auch können Software-Updates oder technische Weiterentwicklungen Inhalt und Umfang der Produkte jederzeit ausbauen. - -**4.4. Fälligkeit, Zahlungsverzug und Zahlungsarten** - -Die von Moneyhouse gestellten Rechnungen sind, sofern keine Zahlungsfrist vermerkt ist und nichts anderes vereinbart wurde, sofort fällig. Ist der Kunde mit seiner Zahlung in Verzug, treten die gesetzlichen Verzugsfolgen ein und mit der zweiten Mahnung Mahnkosten von CHF 20.–. Darüber hinaus hat Moneyhouse das Recht, externe Partner zur Bearbeitung des Inkassos hinzuzuziehen. Ausserdem trägt der Kunde alle weiteren Kosten, die durch seinen Zahlungsverzug entstehen. - -Es werden die folgenden Zahlungsarten bei kostenpflichtigen Produkten angeboten: Kreditkarte oder per Rechnung. Moneyhouse behält sich das Recht vor, die verschiedenen Zahlungsmittel nach eigenem Ermessen zu ändern, zu ergänzen oder zu streichen. Es besteht kein Anspruch auf Bezahlung mit einem bestimmten Zahlungsmittel. Die Rechnung per E-Mail kann via E-Banking beglichen werden. Der Vertrag zwischen Moneyhouse und dem Kunden kommt entweder mit der Bestellung durch den Kunden über einen Verkaufsmitarbeiter oder aber mit der Auftrags-, der Bestellungs- sowie/oder der Zahlungsbestätigung durch Moneyhouse zustande. - -**4.5. Haftung von Moneyhouse** - -Moneyhouse ist bemüht, den eigenen Datenbestand sowie jenen von Partnern zu pflegen. Der Kunde nimmt zur Kenntnis, dass Daten und Informationen bis zu einem gewissen Masse trotzdem Fehler enthalten können. Vorbehaltlich gesetzlicher Vorgaben bzw. einer anderweitigen schriftlichen Vereinbarung schliessen Moneyhouse und deren Partner jegliche Garantie und Gewährleistung, insbesondere für Vollständigkeit, Aktualität, Richtigkeit, Verwertbarkeit oder Eignung der Daten zu einem bestimmten Zweck, aus. Empfehlungen und Erfahrungswerte wie Ratings, Einteilung in Risikoklassen und Scorewerte sind ausnahmslos unverbindlich, womit auch dafür jede Gewähr ausgeschlossen ist. - -Moneyhouse haftet nur für Verzögerungen und für Fehler, sofern ihr ein vorsätzliches oder grobfahrlässiges Handeln nachgewiesen werden kann. Sie haftet insbesondere nicht für Verfehlungen und Versäumnisse Dritter. Für Schäden, die dem Kunden durch die Nutzung der Produkte entstehen, haftet Moneyhouse nur, falls ihr grobfahrlässiges oder vorsätzliches Verhalten nachgewiesen werden kann. Soweit gesetzlich zulässig, ist die Haftung von Moneyhouse in jedem Fall auf denjenigen Betrag beschränkt, welcher dem Kunden für das entsprechende Produkt in Rechnung gestellt wurde. In keinem Fall haftet Moneyhouse für Folgeschäden oder entgangenen Gewinn. - -Moneyhouse haftet nicht für schadhafte Technik und für durch Computerviren, Spionageprogramme und/oder andere schädliche Computerprogramme (Malware, Spyware) bewirkte Schäden. Es besteht auch keine Haftung für die Folgen von Betriebsunterbrüchen, die durch Störungen aller Art entstehen oder die der Störungsbehebung, der Wartung und der Einführung neuer Technologien dienen. - -Dieselben Haftungsbeschränkungen gelten auch für die Mitarbeiter, Vertreter und Erfüllungsgehilfen von Moneyhouse. - -**4.6. Sorgfaltspflicht und Haftung des Kunden** - -Alle Informationen, Auskünfte und Berichte von Moneyhouse sind streng vertraulich zu behandeln. Benutzung und Verwendung dieser Informationen sind nur dem Kunden und dessen allfälligen Angestellten für deren eigene Zwecke gestattet. Der Kunde verpflichtet sich, sein Benutzerkonto und im Speziellen seine Zugangsdaten (Passwort) nicht anderen Personen – auch nicht im gleichen Unternehmen – zur Verfügung zu stellen, sie zu schützen und vor Zugriffen Dritter sicher aufzubewahren, seine Kontaktinformationen und sonstigen Angaben bei der Registrierung wahrheitsgetreu auszufüllen und seinen Zugang nicht missbräuchlich oder übermässig zu nutzen. - -Der Kunde verpflichtet sich sodann, die gesetzlichen Datenschutzvorschriften sowie die Vorschriften gemäss Datenschutzerklärung von Moneyhouse einzuhalten. Der Kunde ist für jeden Schaden verantwortlich, der aus einer Nichtbeachtung seiner Sorgfaltspflichten oder einem Verstoss gegen Urheberrechte entsteht, und zwar sowohl gegenüber Moneyhouse als auch deren Partnern. - -**4.7. Auskünfte und Identifikation** - -Der Kunde nimmt zur Kenntnis, dass er sich und damit sein persönliches Kundenkonto für das Aufrufen von Profilen zu Privatpersonen und die Abfrage von Bonitätsauskünften, Zahlungsverhaltenauskünften und Wirtschaftsauskünften mittels eines Identitätsnachweises (ID, Reisepass, Führerschein) einmalig verifizieren muss. Zudem dürfen die zuvor genannten Auskünfte nur abgefragt werden, wenn ein berechtigtes Interesse vorliegt. Das Vorliegen einer solchen Berechtigung kann nachträglich durch Moneyhouse überprüft werden. Der Kunde muss Moneyhouse innerhalb von 10 Tagen nach Erhalt der Aufforderung das Vorliegen einer entsprechenden Berechtigung nachweisen. Für Betreibungsauskünfte muss durch den Kunden grundsätzlich ein den vom jeweiligen Betreibungsamt vorgegebenen Bedingungen entsprechender Interessensnachweis übermittelt werden. Alle rechtlichen und vertraglichen Konsequenzen, die durch die Nichtübermittlung, einen nicht ausreichenden oder nicht vorhandenen Interessensnachweises resultieren, trägt der Kunde.Bei Zuwiderhandlung gegen diese Vorschrift ist Moneyhouse berechtigt, die Vertragsbeziehung zum Kunden unmittelbar und entschädigungslos zu beenden. - -Weitere Informationen hierzu können jederzeit[hier](https://www.moneyhouse.ch/de/howto/reports) eingesehen werden. - -**4.8. Urheber- und weitere immaterielle Rechte** - -Moneyhouse behält sich bezüglich der Produkte inklusive Layout, Software und deren Inhalten sämtliche Urheber- und sonstigen Schutzrechte vor. Es ist untersagt, die Webseiten von Moneyhouse oder deren Inhalte ganz oder teilweise mittels technischer Hilfsmittel darzustellen (z.B. „Framing“). - -Eigentums- und Urheberrechte an allen zur Verfügung gestellten Daten und Dienstleistungen verbleiben bei Moneyhouse. Nutzungsrechte werden dem Kunden nur in dem Ausmass eingeräumt, als dies zur Erfüllung des Vertragszweckes zwingend notwendig ist. Im Zweifel werden nur Nutzungsrechte und keine Urheber- und Eigentumsrechte übertragen. Der Kunde ist zur Weitergabe der Daten an Dritte nicht berechtigt. - -**4.9. Vertretungsberechtigung** - -Für die Leistungserbringung und insbesondere die Abwicklung im Rahmen einer Premium-Mitgliedschaft oder anderen spezifischen Leistungen gilt gegenüber Moneyhouse, unabhängig von der im Handelsregister eingetragenen Zeichnungsberechtigung, der oder die Mitarbeiter/in des Kunden als zur Vertretung befugt und ermächtigt, welche/r mit Moneyhouse mündlich, telefonisch oder schriftlich (durch Brief, Fax oder E-Mail) kommunizierte. Der Kunde trägt das Risiko für ungenügende Vertretungsberechtigung oder fehlende Legitimation seiner Mitarbeiter. - -**4.10. API** - -Moneyhouse stellt dem Kunden eine Schnittstelle (API) zur Kommunikation mit Software von Drittanbietern zur Verfügung. Sofern nicht schriftlich anders vereinbart, hat Moneyhouse in jedem Fall das Recht, den Zugriff auf diese Schnittstelle aus wichtigem Grund jederzeit teilweise oder ganz einzuschränken. Ein wichtiger Grund liegt insbesondere vor, wenn Mitbewerber von Moneyhouse zum Schaden von Moneyhouse über die Schnittstelle Daten migrieren oder die Infrastruktur über Anfragen über diese Schnittstelle zu stark belastet wird. Der Kunde verpflichtet sich, alle von Moneyhouse gelieferten Daten innert 10 Tagen nach Beendigung des Vertrages zu löschen und die Löschung Moneyhouse schriftlich zu bestätigen. - -**4.11. Kommunikationsmittel und Übermittlungsfehler** - -Moneyhouse ist berechtigt, alle Mitteilungen an den Kunden an die auf dem Vertrag aufgeführte und vom Kunden angegebene Zustell- oder E-Mail-Adresse, Telefon- und/oder Faxnummer zu richten. Änderungen sind Moneyhouse vom Kunden rechtzeitig und schriftlich (durch Brief, Fax oder E-Mail oder mittels Änderung im persönlichen Bereich „Mein Konto“ auf moneyhouse.ch) mitzuteilen. Der Kunde trägt das Risiko für Schäden aus der Benutzung von Kommunikations- und/oder Transportmitteln einschliesslich Verlust, Verspätung oder falsche Übermittlung. - -**4.12.Gerichtsstand und anwendbares Recht** - -Der Gerichtsstand befindet sich am Sitz der Neue Zürcher Zeitung AG in Zürich ZH. Es gilt Schweizer Recht. Die Neue Zürcher Zeitung AG hat das Recht, den Kunden bei einem anderen zuständigen Gericht einzuklagen. - -**4.13. Anpassungen** - -Wir behalten uns ausdrücklich das Recht vor, die vorliegenden Nutzungsbedingungen jederzeit zu ändern. Werden derartige Anpassungen vorgenommen, veröffentlichen wir diese umgehend auf unserer Webseite. Es liegt in Ihrer Verantwortung, sich über die aktuell geltende Fassung der Datenschutzerklärung auf unserer Webseite zu informieren. Wir empfehlen Ihnen daher, diese Datenschutzerklärung und die Nutzungsbedingungen regelmässig zu konsultieren. \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_009_www.moneyhouse.ch_de_imprint.txt b/test_web_content_20251002_212426/additional_link_009_www.moneyhouse.ch_de_imprint.txt deleted file mode 100644 index 227e3490..00000000 --- a/test_web_content_20251002_212426/additional_link_009_www.moneyhouse.ch_de_imprint.txt +++ /dev/null @@ -1,401 +0,0 @@ -URL: https://www.moneyhouse.ch/de/imprint -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Impressum - Moneyhouse - - - - - - - -[](/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](/de/register?redirectUrl=%2Fimprint) - -[Anmelden](/de/login?redirectUrl=%2Fimprint) - -[Erweiterte Suche](/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](/de/overview)[Voller Datenzugriff](/de/membership)[Public API](/de/apiintegration)[Corporate-Angebote](/de/enterprise)[Firmenlisten](/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](/de/businessreports)[Bonitätsauskunft](/de/creditrating)[Zahlungsverhalten](/de/paymentbehaviour)[Wirtschaftsauskunft](/de/economicinformation)[Beteiligungsauskunft](/de/shareholderinformation)[Betreibungsauskunft](/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](/de/commercialregister/foundation)[Firma liquidieren](/de/commercialregister/liquidation)[Änderung Eintrag](/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](/de/datasources)[Kontakt](/de/contact) - -- [KMU\_today](https://www.kmutoday.ch/) -[Regio-News](/de/region)[Hilfebereich](/de/howto) - -[AGB](/de/terms)[Datenschutz](/de/privacy)[Impressum](/de/imprint) - -[](/de/) - -[Kostenlos registrieren](/de/register?redirectUrl=%2Fimprint) - -[Regio-News](/de/region)[KMU\_today](https://www.kmutoday.ch/) - -[Anmelden](/de/login?redirectUrl=%2Fimprint)[Hilfe](/de/howto) - -DE - -- [Deutsch](javascript:void(0)) -- [Français](javascript:void(0)) -- [Italiano](javascript:void(0)) -- [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](/de/advancedsearch) - -**Datenzugriff** - -- [Übersicht Mitgliedschaften](/de/overview) -- [Voller Datenzugriff](/de/membership) -- [Public API](/de/apiintegration) -- [Corporate-Angebote](/de/enterprise) -- [Firmenlisten](/de/companieslists) -- [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -- [Übersicht](/de/businessreports) -- [Bonitätsauskunft](/de/creditrating) -- [Zahlungsverhalten](/de/paymentbehaviour) -- [Wirtschaftsauskunft](/de/economicinformation) -- [Beteiligungsauskunft](/de/shareholderinformation) -- [Betreibungsauskunft](/de/paymentcollection) - -**Handelsregister** - -- [Firma gründen](/de/commercialregister/foundation) -- [Firma liquidieren](/de/commercialregister/liquidation) -- [Änderung Eintrag](/de/commercialregister/services) - -**Unternehmen** - -- [Über uns](/de/about) -- [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -- [Datenquellen](/de/datasources) -- [Kontakt](/de/contact) - -- [Anmelden](/de/login?redirectUrl=%2Fimprint) -- [Hilfebereich](/de/howto) - -- [Sprache wechseln](javascript:void(0)) -- [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -- [KMU\_today](https://www.kmutoday.ch/) -- [Regio-News](/de/region) - - - -# Impressum - -**Moneyhouse** -Neue Zürcher Zeitung AG -Falkenstrasse 11 -CH-8008 Zürich - -[Kontaktieren Sie uns](https://www.moneyhouse.ch/de/contact/contactform) - -Sitz: Zürich -UID: CHE-106.838.812 -Handelsregisteramt: Kanton Zürich - -**Datenzugriff** - -- [Übersicht Mitgliedschaften](/de/overview) -- [Voller Datenzugriff](/de/membership) -- [Public API](/de/apiintegration) -- [Corporate-Angebote](/de/enterprise) -- [Firmenlisten](/de/companieslists) -- [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -- [Übersicht](/de/businessreports) -- [Bonitätsauskunft](/de/creditrating) -- [Zahlungsverhalten](/de/paymentbehaviour) -- [Wirtschaftsauskunft](/de/economicinformation) -- [Beteiligungsauskunft](/de/shareholderinformation) -- [Betreibungsauskunft](/de/paymentcollection) - -**Handelsregister** - -- [Firma gründen](/de/commercialregister/foundation) -- [Firma liquidieren](/de/commercialregister/liquidation) -- [Änderung Eintrag](/de/commercialregister/services) - -**Unternehmen** - -- [Über uns](/de/about) -- [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -- [Datenquellen](/de/datasources) -- [Kontakt](/de/contact) - -- [Anmelden](/de/login?redirectUrl=%2Fimprint) -- [Hilfebereich](/de/howto) - -- [Sprache wechseln](javascript:void(0)) -- [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -- [KMU\_today](https://www.kmutoday.ch/) -- [Regio-News](/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](/de/companydirectory/ag/a/a_) - -[AI](/de/companydirectory/ai/a/a_) - -[AR](/de/companydirectory/ar/a/a_) - -[BL](/de/companydirectory/bl/a/a_) - -[BS](/de/companydirectory/bs/a/a_) - -[BE](/de/companydirectory/be/a/a_) - -[FR](/de/companydirectory/fr/a/a_) - -[GE](/de/companydirectory/ge/a/a_) - -[GL](/de/companydirectory/gl/a/a_) - -[GR](/de/companydirectory/gr/a/a_) - -[JU](/de/companydirectory/ju/a/a_) - -[LU](/de/companydirectory/lu/a/a_) - -[NE](/de/companydirectory/ne/a/a_) - -[NW](/de/companydirectory/nw/a/a_) - -[OW](/de/companydirectory/ow/a/a_) - -[SH](/de/companydirectory/sh/a/a_) - -[SZ](/de/companydirectory/sz/a/a_) - -[SO](/de/companydirectory/so/a/a_) - -[SG](/de/companydirectory/sg/a/a_) - -[TI](/de/companydirectory/ti/a/a_) - -[TG](/de/companydirectory/tg/a/a_) - -[UR](/de/companydirectory/ur/a/a_) - -[VD](/de/companydirectory/vd/a/a_) - -[VS](/de/companydirectory/vs/a/a_) - -[ZG](/de/companydirectory/zg/a/a_) - -[ZH](/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](/de/persondirectory/a/aa) - -[B](/de/persondirectory/b/ba) - -[C](/de/persondirectory/c/ca) - -[D](/de/persondirectory/d/da) - -[E](/de/persondirectory/e/ea) - -[F](/de/persondirectory/f/fa) - -[G](/de/persondirectory/g/ga) - -[H](/de/persondirectory/h/ha) - -[I](/de/persondirectory/i/ia) - -[J](/de/persondirectory/j/ja) - -[K](/de/persondirectory/k/ka) - -[L](/de/persondirectory/l/la) - -[M](/de/persondirectory/m/ma) - -[N](/de/persondirectory/n/na) - -[O](/de/persondirectory/o/oa) - -[P](/de/persondirectory/p/pa) - -[Q](/de/persondirectory/q/qa) - -[R](/de/persondirectory/r/ra) - -[S](/de/persondirectory/s/sa) - -[T](/de/persondirectory/t/ta) - -[U](/de/persondirectory/u/ua) - -[V](/de/persondirectory/v/va) - -[W](/de/persondirectory/w/wa) - -[X](/de/persondirectory/x/xa) - -[Y](/de/persondirectory/y/ya) - -[Z](/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](/de/terms)[Datenschutz |](/de/privacy)[Impressum](/de/imprint) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU\_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/imprint) - -[Startseite](/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/imprint) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -[Premium-Mitglied werden](/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/imprint)[Anmelden](/de/login?redirectUrl=%2Fimprint) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/imprint)[Anmelden](/de/login?redirectUrl=%2Fimprint) - - - - - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Sonstige - -Kantone hinzufügen oder löschen: - -Kanton -Aargau -Appenzell I. Rh. -Appenzell A. Rh. -Bern -Basel-Landschaft -Basel-Stadt -Freiburg -Genf -Glarus -Graubünden -Jura -Luzern -Neuenburg -Nidwalden -Obwalden -St. Gallen -Schaffhausen -Solothurn -Schwyz -Thurgau -Tessin -Uri -Waadt -Wallis -Zug -Zürich - -[Bestätigen](javascript:void(0)) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_010_www.moneyhouse.ch_de_.txt b/test_web_content_20251002_212426/additional_link_010_www.moneyhouse.ch_de_.txt deleted file mode 100644 index 40c260e8..00000000 --- a/test_web_content_20251002_212426/additional_link_010_www.moneyhouse.ch_de_.txt +++ /dev/null @@ -1,642 +0,0 @@ -URL: https://www.moneyhouse.ch/de/ -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Moneyhouse - Handelsregister- & Wirtschaftsinformationen - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/#)[Save + Exit](https://www.moneyhouse.ch/de/#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2F) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2F) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -Smart Data für KMU -================== - -Schweizer Handelsregister- und Wirtschaftsinformationen. - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -749'770 - -aktive Firmen - -288'251 - -Verwaltungsräte - -292'760 - -Geschäftsführer - -141 - -neue Firmen pro Tag - -Voller Zugriff - -Voller Zugriff auf alle Funktionen und Informationen zu Firmen und Personen - -* Kontaktdetails, Firmenkennzahlen und Management -* Zugang zu Bonitätsauskünften (1 Auskunft inklusive) -* Unbegrenzt Firmen, Personen und Themen folgen -* Verbindungen zwischen Firmen und Personen im Netzwerk erkennen -* Erweiterte Suchfunktion zu Firmen, Personen, Marken und Jobs in der gesamten Datenbank -* Unbegrenzt Firmen- und Personendossiers, druckfertig als PDF -* Keine Werbung - -ab - -CHF 79.00 - -[Jetzt entdecken](https://www.moneyhouse.ch/de/membership) - -Beschränkter Zugriff - -Beschränkter Zugriff auf Funktionen und Informationen zu Firmen und Personen - -* 2 Firmen oder Personen folgen mit E-Mail-Benachrichtigung -* 2 kostenlose Firmen- oder Personendossiers, druckfertig als PDF -* Alle Markeneinträge von Firmen ansehen -* Aktuelles Management -* Adresse, Hauptsitz und Standorte -* Handelsregister-Nummer, Firmenzweck und Kapital -* Das neueste aus Ihrer Region als Newsletter - -kostenlos - -[Jetzt entdecken](https://www.moneyhouse.ch/de/register?redirectUrl=%2F) - -[Hier alle Details zu den Mitgliedschaften vergleichen](https://www.moneyhouse.ch/de/overview) - - - - - -[](https://www.moneyhouse.ch/de/kmuplus) - - - -[](https://www.moneyhouse.ch/de/kmuplus) - -Umfassende Auskünfte --------------------- - -Schützen Sie sich vor finanziellen Schäden und erhalten Sie Klarheit über Ihre Kunden und Geschäftspartner. - -* Einschätzung der Bonität mit Ampel -* Zahlungsverhalten der letzten Rechnungen -* Umfassende Auskunft über die wirtschaftliche Situation einer Firma -* Übersicht über aktuelle und vergangene Betreibungsverfahren - -[Mehr Informationen](https://www.moneyhouse.ch/de/businessreports) - - - - - -Umfassende Auskünfte --------------------- - -Schützen Sie sich vor finanziellen Schäden und erhalten Sie Klarheit über Ihre Kunden und Geschäftspartner. - -* Einschätzung der Bonität mit Ampel -* Zahlungsverhalten der letzten Rechnungen -* Umfassende Auskunft über die wirtschaftliche Situation einer Firma -* Übersicht über aktuelle und vergangene Betreibungsverfahren - -[Mehr Informationen](https://www.moneyhouse.ch/de/businessreports) - - - -Public API ----------- - -Geben Sie Ihren Entwicklern über die API von Moneyhouse den Zugang zu unserer Datenbank und integrieren Sie unsere Wirtschaftsinformationen direkt in Ihre IT-Umgebung. - -[Mehr erfahren](https://www.moneyhouse.ch/de/apiintegration) - - - -Handelsregister ---------------- - -Neuer Verwaltungsrat, neue Adresse? Was immer Sie im Handelsregister ändern müssen, wir sorgen für den korrekten Eintrag. Schnell und einfach mit unserem Online-Tool. - -[Mehr erfahren](https://handelsregister.moneyhouse.ch/de/?itm_campaign=traderegister&itm_content=link-homepage&itm_medium=referral&itm_source=moneyhouse.ch) - - - -Regio-News ----------- - -Was immer in Ihrer Region auch passiert: Hier erfahren Sie es zuerst. Sehen Sie täglich alle Neuigkeiten aus Ihrer Region oder lesen Sie im Newsletter die Zusammenfassung. - -[Mehr erfahren](https://www.moneyhouse.ch/de/region) - -Neue Schweizer Firmen vom 01.10.2025 ------------------------------------- - -[Eren Gastro und Handels GmbH](https://www.moneyhouse.ch/de/company/eren-gastro-und-handels-gmbh-1844900481) - -Hohengasse 12 | 3400 Burgdorf -[Nemain SA](https://www.moneyhouse.ch/de/company/nemain-sa-5769974371) - -Via al Ruscello 11 | 6962 Viganello - -[OptimalPSI AG](https://www.moneyhouse.ch/de/company/optimalpsi-ag-20446796181) - -Picassoplatz 4 | 4052 Basel -[VIRA Communication AG](https://www.moneyhouse.ch/de/company/vira-communication-ag-4933540921) - -Piazzetta San Carlo 2 | 6900 Lugano - -[mehr anzeigen](javascript:void(0))[weniger anzeigen](javascript:void(0)) - -[mehr anzeigen](https://www.moneyhouse.ch/de/newcompanieslist) - -Konkurs- und Liquidationsmeldungen vom 01.10.2025 -------------------------------------------------- - -[Andro-Data AG in Liquidation](https://www.moneyhouse.ch/de/company/andro-data-ag-21156000641) - -Lindenfeldstrasse 10 | 6006 Luzern -[Huddle Makers Sàrl en liquidation](https://www.moneyhouse.ch/de/company/huddle-makers-sarl-12625588561) - -Avenue Charles-Dickens 2 | 1006 Lausanne - -[Immeubles P. Luder SA en liquidation](https://www.moneyhouse.ch/de/company/immeubles-p-luder-sa-5434200431) - -Coin des Bois 6 | 2733 Pontenet -[LE LABO traiteur, Nguele Evina](https://www.moneyhouse.ch/de/company/le-labo-traiteur-nguele-evina-6298641) - -Route d'Yvonand 22a | 1522 Lucens - -[mehr anzeigen](javascript:void(0))[weniger anzeigen](javascript:void(0)) - -[mehr anzeigen](https://www.moneyhouse.ch/de/bankruptcieslist) - -Aktuelle News aus Ihrer Region ------------------------------- - -Dies sind aktuell die Top-Regionen: - -* [Zürich](https://www.moneyhouse.ch/de/region/zuerich/uebersicht) -* [Region Zürich](https://www.moneyhouse.ch/de/region/zuerich/uebersicht) -* [Bern-Mittelland](https://www.moneyhouse.ch/de/region/bern-mittelland/uebersicht) -* [Region Bern-Mittelland](https://www.moneyhouse.ch/de/region/bern-mittelland/uebersicht) -* [Baden](https://www.moneyhouse.ch/de/region/baden/uebersicht) -* [Region Baden](https://www.moneyhouse.ch/de/region/baden/uebersicht) -* [Winterthur](https://www.moneyhouse.ch/de/region/winterthur/uebersicht) -* [Region Winterthur](https://www.moneyhouse.ch/de/region/winterthur/uebersicht) -* [Basel-Stadt](https://www.moneyhouse.ch/de/region/basel-stadt/uebersicht) -* [Region Basel-Stadt](https://www.moneyhouse.ch/de/region/basel-stadt/uebersicht) -* [Horgen](https://www.moneyhouse.ch/de/region/horgen/uebersicht) -* [Region Horgen](https://www.moneyhouse.ch/de/region/horgen/uebersicht) -* [Arlesheim](https://www.moneyhouse.ch/de/region/arlesheim/uebersicht) -* [Region Arlesheim](https://www.moneyhouse.ch/de/region/arlesheim/uebersicht) -* [Oberaargau](https://www.moneyhouse.ch/de/region/oberaargau/uebersicht) -* [Region Oberaargau](https://www.moneyhouse.ch/de/region/oberaargau/uebersicht) -* [St. Gallen](https://www.moneyhouse.ch/de/region/stgallen/uebersicht) -* [Region St. Gallen](https://www.moneyhouse.ch/de/region/stgallen/uebersicht) - -* [Meilen](https://www.moneyhouse.ch/de/region/meilen/uebersicht) -* [Region Meilen](https://www.moneyhouse.ch/de/region/meilen/uebersicht) -* [Dielsdorf](https://www.moneyhouse.ch/de/region/dielsdorf/uebersicht) -* [Region Dielsdorf](https://www.moneyhouse.ch/de/region/dielsdorf/uebersicht) -* [Bülach](https://www.moneyhouse.ch/de/region/buelach/uebersicht) -* [Region Bülach](https://www.moneyhouse.ch/de/region/buelach/uebersicht) -* [Hinwil](https://www.moneyhouse.ch/de/region/hinwil/uebersicht) -* [Region Hinwil](https://www.moneyhouse.ch/de/region/hinwil/uebersicht) -* [Luzern-Stadt](https://www.moneyhouse.ch/de/region/luzern-stadt/uebersicht) -* [Region Luzern-Stadt](https://www.moneyhouse.ch/de/region/luzern-stadt/uebersicht) -* [Rheintal](https://www.moneyhouse.ch/de/region/rheintal/uebersicht) -* [Region Rheintal](https://www.moneyhouse.ch/de/region/rheintal/uebersicht) -* [Sursee](https://www.moneyhouse.ch/de/region/sursee/uebersicht) -* [Region Sursee](https://www.moneyhouse.ch/de/region/sursee/uebersicht) -* [Uster](https://www.moneyhouse.ch/de/region/uster/uebersicht) -* [Region Uster](https://www.moneyhouse.ch/de/region/uster/uebersicht) -* [Luzern-Land](https://www.moneyhouse.ch/de/region/luzern-land/uebersicht) -* [Region Luzern-Land](https://www.moneyhouse.ch/de/region/luzern-land/uebersicht) - -* [Bremgarten](https://www.moneyhouse.ch/de/region/bremgarten/uebersicht) -* [Region Bremgarten](https://www.moneyhouse.ch/de/region/bremgarten/uebersicht) -* [Hochdorf](https://www.moneyhouse.ch/de/region/hochdorf/uebersicht) -* [Region Hochdorf](https://www.moneyhouse.ch/de/region/hochdorf/uebersicht) -* [Zofingen](https://www.moneyhouse.ch/de/region/zofingen/uebersicht) -* [Region Zofingen](https://www.moneyhouse.ch/de/region/zofingen/uebersicht) -* [Aarau](https://www.moneyhouse.ch/de/region/aarau/uebersicht) -* [Region Aarau](https://www.moneyhouse.ch/de/region/aarau/uebersicht) -* [Thun](https://www.moneyhouse.ch/de/region/thun/uebersicht) -* [Region Thun](https://www.moneyhouse.ch/de/region/thun/uebersicht) -* [Frauenfeld](https://www.moneyhouse.ch/de/region/frauenfeld/uebersicht) -* [Region Frauenfeld](https://www.moneyhouse.ch/de/region/frauenfeld/uebersicht) -* [Lenzburg](https://www.moneyhouse.ch/de/region/lenzburg/uebersicht) -* [Region Lenzburg](https://www.moneyhouse.ch/de/region/lenzburg/uebersicht) -* [Zug](https://www.moneyhouse.ch/de/region/zug/uebersicht) -* [Region Zug](https://www.moneyhouse.ch/de/region/zug/uebersicht) -* [Dietikon](https://www.moneyhouse.ch/de/region/dietikon/uebersicht) -* [Region Dietikon](https://www.moneyhouse.ch/de/region/dietikon/uebersicht) - -* [See-Gaster](https://www.moneyhouse.ch/de/region/see-gaster/uebersicht) -* [Region See-Gaster](https://www.moneyhouse.ch/de/region/see-gaster/uebersicht) -* [Olten](https://www.moneyhouse.ch/de/region/olten/uebersicht) -* [Region Olten](https://www.moneyhouse.ch/de/region/olten/uebersicht) -* [Willisau](https://www.moneyhouse.ch/de/region/willisau/uebersicht) -* [Region Willisau](https://www.moneyhouse.ch/de/region/willisau/uebersicht) -* [Kreuzlingen](https://www.moneyhouse.ch/de/region/kreuzlingen/uebersicht) -* [Region Kreuzlingen](https://www.moneyhouse.ch/de/region/kreuzlingen/uebersicht) -* [Wil](https://www.moneyhouse.ch/de/region/wil/uebersicht) -* [Region Wil](https://www.moneyhouse.ch/de/region/wil/uebersicht) -* [Brugg](https://www.moneyhouse.ch/de/region/brugg/uebersicht) -* [Region Brugg](https://www.moneyhouse.ch/de/region/brugg/uebersicht) -* [Biel](https://www.moneyhouse.ch/de/region/biel-bienne/uebersicht) -* [Region Biel](https://www.moneyhouse.ch/de/region/biel-bienne/uebersicht) -* [Emmental](https://www.moneyhouse.ch/de/region/emmental/uebersicht) -* [Region Emmental](https://www.moneyhouse.ch/de/region/emmental/uebersicht) -* [Meine Region suchen](https://www.moneyhouse.ch/de/region) -* [Region suchen](https://www.moneyhouse.ch/de/region) - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_011_www.moneyhouse.ch_de_company_valueon-ag-4663161481_reportscreditworthiness-report.txt b/test_web_content_20251002_212426/additional_link_011_www.moneyhouse.ch_de_company_valueon-ag-4663161481_reportscreditworthiness-report.txt deleted file mode 100644 index efa57d9e..00000000 --- a/test_web_content_20251002_212426/additional_link_011_www.moneyhouse.ch_de_company_valueon-ag-4663161481_reportscreditworthiness-report.txt +++ /dev/null @@ -1,623 +0,0 @@ -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -ValueOn AG in Dübendorf - Bonitätsauskunft, Zahlungsverhalten, Betreibungsauskunft und Kreditwürdigkeit - -=============== - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -[ValueOn AG](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Bonitätsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -[Zahlungsverhalten](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#payment-mode-report) - -[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#commercial-report) - -[Beteiligungsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#wow-report) - -[Betreibungsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#payment-collection-report) - -[Firmendossier](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#firmendossier-report) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -[Startseite](https://www.moneyhouse.ch/de/)[>](javascript:void(0))[Unternehmen](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG)[>](javascript:void(0))ValueOn AG - -ValueOn AG -========== - -ZH - -aktiv - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Zur Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -Handelsregister-Nr.:CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Bonitätsauskunft ----------------- - -Einschätzung der Bonität mit einer Ampel als Risikoindikator und weiteren hilfreichen Firmeninformationen. - -* Einschätzung der Bonität mit einer Ampel -* Weitere Hinweise -* Firmeninformationen aus dem Handelsregister -* Aktuelle Zahlungsdetails (als Zusatzabfrage) - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:09f387aa-7faa-4b0d-8eea-c619aed45506) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:09f387aa-7faa-4b0d-8eea-c619aed45506) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen Premium-Mitgliedschaft mit Bonitäts-Paket ab CHF 99.00](https://www.moneyhouse.ch/de/service/purchase/creditrating?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D1) - -[Jetzt bestellen Premium-Mitglied werden (1 Abfrage inkl.)jede weitere für CHF 19.00](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D1) - -[Jetzt bestellen Einzelabfrage ohne Premium-Mitgliedschaft für CHF 24.00](https://www.moneyhouse.ch/de/service/purchase/creditratingsingle?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D1) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -Zahlungsverhalten ------------------ - -Beurteilung der Zahlungsmoral aufgrund vergangener Rechnungen. - -* Zahlungsverhalten der letzten Rechnungen -* Durchschnittliches Zahlungsverhalten -* Anteil aller bekannten, pünktlich bezahlten Rechnungen - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:9acd118e-dc76-4a33-ab7c-ebaec52c619a) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:9acd118e-dc76-4a33-ab7c-ebaec52c619a) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen Premium-Mitgliedschaft mit Zahlungsverhalten-Paket ab CHF 99.00](https://www.moneyhouse.ch/de/service/purchase/paymentbehaviour?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D2) - -[Jetzt bestellen Premium-Mitglied werden 1 Abfrage für CHF 19.00](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D2) - -[Jetzt bestellen Einzelabfrage ohne Premium-Mitgliedschaft für CHF 24.00](https://www.moneyhouse.ch/de/service/purchase/paymentbehavioursingle?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D2) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -Wirtschaftsauskunft -------------------- - -Umfassende Auskunft über die wirtschaftliche Situation der Firma. - -* Einschätzung der Bonität mit einer Ampel -* Zahlungsverhalten der letzten Rechnungen -* Risikobewertung im Branchenvergleich -* Meldung von Inkassobüros und Betreibungsämtern -* Firmeninformationen aus dem Handelsregister - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:e9d3178c-3e96-4218-ac8d-39baffee2871) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:e9d3178c-3e96-4218-ac8d-39baffee2871) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen CHF 49.00 pro Abfrage](https://www.moneyhouse.ch/de/service/purchase/economicinformation?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D3) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -Beteiligungsauskunft --------------------- - -Auflistung aller Firmenbeteiligungen einer Aktiengesellschaft. - -* Manuell recherchierte Beteiligungen -* Informationen zu im Handelsregister eingetragenen Beteiligungen -* Firmeninformationen aus dem Handelsregister -* Umsatz- und Mitarbeiterzahlen - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:f1e0a255-5d6e-4ac5-be21-6f90d7b20a17) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:f1e0a255-5d6e-4ac5-be21-6f90d7b20a17) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen CHF 19.00 pro Abfrage](https://www.moneyhouse.ch/de/service/purchase/shareholderinformation?companyName=valueon-ag-4663161481&returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D8) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -Betreibungsauskunft -------------------- - -Übersicht über aktuelle und vergangene Betreibungsverfahren. - -* Amtlicher Betreibungsauszug -* Aktuelle Betreibungsverfahren -* Alle Betreibungen der letzten zwei Jahren - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:a1b45e6a-5cba-4063-8d4f-aa20378a1852) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:a1b45e6a-5cba-4063-8d4f-aa20378a1852) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen CHF 26.00 pro Abfrage](https://www.moneyhouse.ch/de/service/purchase/paymentcollection?companyName=valueon-ag-4663161481&returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fupload%3FcompanyName%3Dvalueon-ag-4663161481%26chNr%3DCH02030306513) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -Firmendossier -------------- - -Alle Firmeninformationen kompakt in einem Dokument. - -* Kontaktinformationen -* Firmeninformationen aus dem Handelsregister -* Unternehmensführung und Zeichnungsberechtigte -* Umsatz- und Mitarbeiterzahlen - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:62e110dc-83ed-4738-b49f-7a9799183287) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:62e110dc-83ed-4738-b49f-7a9799183287) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Kostenlos registrieren 2 Firmendossiers kostenlos verfügbar](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren 2 Firmendossiers kostenlos verfügbar](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Bonitätsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -[Zahlungsverhalten](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#payment-mode-report) - -[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#commercial-report) - -[Beteiligungsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#wow-report) - -[Betreibungsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#payment-collection-report) - -[Firmendossier](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#firmendossier-report) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_012_www.moneyhouse.ch_de_company_valueon-ag-4663161481_timeline.txt b/test_web_content_20251002_212426/additional_link_012_www.moneyhouse.ch_de_company_valueon-ag-4663161481_timeline.txt deleted file mode 100644 index cb9aa3ac..00000000 --- a/test_web_content_20251002_212426/additional_link_012_www.moneyhouse.ch_de_company_valueon-ag-4663161481_timeline.txt +++ /dev/null @@ -1,515 +0,0 @@ -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Timeline ValueOn AG - Dübendorf - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline#)[Save + Exit](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -[ValueOn AG](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -[Startseite](https://www.moneyhouse.ch/de/)[>](javascript:void(0))[Unternehmen](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG)[>](javascript:void(0))ValueOn AG - -ValueOn AG -========== - -ZH - -aktiv - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Zur Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -Handelsregister-Nr.:CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Timeline --------- - -2025 - -[Um die Einträge zu sehen, benötigen Sie eine Premium-Mitgliedschaft.](https://www.moneyhouse.ch/membership) - -2024 - -[Um die Einträge zu sehen, benötigen Sie eine Premium-Mitgliedschaft.](https://www.moneyhouse.ch/membership) - -2023 - -[Um die Einträge zu sehen, benötigen Sie eine Premium-Mitgliedschaft.](https://www.moneyhouse.ch/membership) - -2022 - -[Um die Einträge zu sehen, benötigen Sie eine Premium-Mitgliedschaft.](https://www.moneyhouse.ch/membership) - -2007 - -[Um die Einträge zu sehen, benötigen Sie eine Premium-Mitgliedschaft.](https://www.moneyhouse.ch/membership) - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_013_www.moneyhouse.ch_de_company_valueon-ag-4663161481_messages.txt b/test_web_content_20251002_212426/additional_link_013_www.moneyhouse.ch_de_company_valueon-ag-4663161481_messages.txt deleted file mode 100644 index 681b40ea..00000000 --- a/test_web_content_20251002_212426/additional_link_013_www.moneyhouse.ch_de_company_valueon-ag-4663161481_messages.txt +++ /dev/null @@ -1,625 +0,0 @@ -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Meldungen ValueOn AG - Dübendorf - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages#)[Save + Exit](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -[ValueOn AG](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -[Startseite](https://www.moneyhouse.ch/de/)[>](javascript:void(0))[Unternehmen](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG)[>](javascript:void(0))ValueOn AG - -ValueOn AG -========== - -ZH - -aktiv - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Zur Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -Handelsregister-Nr.:CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Meldungen ---------- - -SHAB 250827/2025 - 27.08.2025 - -**Kategorien:** Änderung des Firmenzwecks, Änderung der Firmenadresse - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006417690 "Download SHAB Publikation der ValueOn AG vom 27.08.2025") - -Publikationsnummer: [HR02-1006417690](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006417690 "Download SHAB Publikation der ValueOn AG vom 27.08.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 133 vom 14.07.2025, Publ. 1006383218). - -**Statutenänderung:** - - 18.08.2025. - -**Sitz neu:** - - Dübendorf. - -**Domizil neu:** - - c/o Westhive AG, Am Stadtrand 11, 8600 Dübendorf. - -**Zweck neu:** - - Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -**Mitteilungen neu:** - - Mitteilungen an die Aktionäre erfolgen per Brief oder E-Mail an die im Aktienbuch verzeichneten Adressen. - -SHAB 250714/2025 - 14.07.2025 - -**Kategorien:** Änderung im Management - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006383218 "Download SHAB Publikation der ValueOn AG vom 14.07.2025") - -Publikationsnummer: [HR02-1006383218](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006383218 "Download SHAB Publikation der ValueOn AG vom 14.07.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 101 vom 27.05.2025, Publ. 1006341693). - -**Eingetragene Personen neu oder mutierend:** - -[Largo, Dominic](https://www.moneyhouse.ch/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Einzelunterschrift [_bisher: Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien_]. - -SHAB 250527/2025 - 27.05.2025 - -**Kategorien:** Änderung im Management - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006341693 "Download SHAB Publikation der ValueOn AG vom 27.05.2025") - -Publikationsnummer: [HR02-1006341693](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006341693 "Download SHAB Publikation der ValueOn AG vom 27.05.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 222 vom 14.11.2024, Publ. 1006178101). - -**Ausgeschiedene Personen und erloschene Unterschriften:** - - Hamburger, Marc Eric, von St. Gallen, in Mörschwil, Präsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - -[Egloff, Reto](https://www.moneyhouse.ch/de/person/egloff-reto-101763781201), von Oberrohrdorf, in Bern, Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - -[Mühlemann, Markus](https://www.moneyhouse.ch/de/person/muehlemann-markus-142196879901), von Seeberg, in Uster, Delegierter des Verwaltungsrates, mit Einzelunterschrift. - -**Eingetragene Personen neu oder mutierend:** - -[Largo, Dominic](https://www.moneyhouse.ch/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien [_bisher: Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien_]; - -[Althaus, Walter](https://www.moneyhouse.ch/de/person/althaus-jun-walter-205367807901), von Affoltern im Emmental, in Aarwangen, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - -[Wyss, Andreas](https://www.moneyhouse.ch/de/person/wyss-andreas-129476912501), von Dietikon, in Dietikon, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien. - -SHAB 241114/2024 - 14.11.2024 - -**Kategorien:** Änderung im Management - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006178101 "Download SHAB Publikation der ValueOn AG vom 14.11.2024") - -Publikationsnummer: [HR02-1006178101](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006178101 "Download SHAB Publikation der ValueOn AG vom 14.11.2024"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 134 vom 13.07.2023, Publ. 1005794339). - -**Eingetragene Personen neu oder mutierend:** - -[Largo, Dominic](https://www.moneyhouse.ch/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien. - -SHAB 230713/2023 - 13.07.2023 - -**Kategorien:** Änderung im Management - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1005794339 "Download SHAB Publikation der ValueOn AG vom 13.07.2023") - -Publikationsnummer: [HR02-1005794339](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1005794339 "Download SHAB Publikation der ValueOn AG vom 13.07.2023"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 207 vom 25.10.2022, Publ. 1005590007). - -**Ausgeschiedene Personen und erloschene Unterschriften:** - -[Wechsler, Beat](https://www.moneyhouse.ch/de/person/wechsler-beat-61329453301), von Willisau, in Küssnacht (SZ), Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - -[Trentini, Stefano Enrico](https://www.moneyhouse.ch/de/person/trentini-stefano-52560044101), von Mendrisio, in Stäfa, Geschäftsführer, mit Kollektivunterschrift zu zweien. - -**Eingetragene Personen neu oder mutierend:** - -[Egloff, Reto](https://www.moneyhouse.ch/de/person/egloff-reto-101763781201), von Oberrohrdorf, in Bern, Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien. - -SHAB 221025/2022 - 25.10.2022 - -**Kategorien:** Änderung des Firmennamens, Änderung des Firmenzwecks - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1005590007 "Download SHAB Publikation der ValueOn AG vom 25.10.2022") - -Publikationsnummer: [HR02-1005590007](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1005590007 "Download SHAB Publikation der ValueOn AG vom 25.10.2022"), Handelsregister-Amt Zürich, (20) - -**Project Competence AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 123 vom 28.06.2022, Publ. 1005505965). - -**Statutenänderung:** - - 07.10.2022. - -**Firma neu:** - -**ValueOn AG**. - -**Zweck neu:** - - Der Zweck der Gesellschaft ist die Erbringung von Dienstleistungen für Unternehmen, im Besonderen Beratung für Unternehmensentwicklung, Digitale Business Transformation und Projekt Management sowie Handel mit Waren aller Art. Die Gesellschaft kann sich an anderen Unternehmungen des In- und Auslandes beteiligen sowie alle Geschäfte eingehen und Verträge abschliessen, die geeignet sind, ihren Zweck zu fördern oder die direkt oder indirekt damit im Zusammenhang stehen. Sie kann ferner im In- und Ausland Zweigniederlassungen errichten, Liegenschaften, Unternehmen, Immaterialgüterrechte und Wertschriften im In- und Ausland im Rahmen des Gesetzes erwerben bzw. errichten, verwalten und verkaufen. - -**Mitteilungen neu:** - - Mitteilungen an die Aktionäre erfolgen per Brief, Telefax oder E-Mail an die im Aktienbuch verzeichneten Adressen. - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_014_www.moneyhouse.ch_de_commercialregister_overviewchnrCH02030306513uidCHE113416882.txt b/test_web_content_20251002_212426/additional_link_014_www.moneyhouse.ch_de_commercialregister_overviewchnrCH02030306513uidCHE113416882.txt deleted file mode 100644 index f0a91106..00000000 --- a/test_web_content_20251002_212426/additional_link_014_www.moneyhouse.ch_de_commercialregister_overviewchnrCH02030306513uidCHE113416882.txt +++ /dev/null @@ -1,593 +0,0 @@ -URL: https://www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882 -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Analoge und digitale Handelsregisteränderungen - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882#)[Save + Exit](https://www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) - -[Änderung Firmenname](https://www.moneyhouse.ch/de/commercialregister/services/company-name) - -[Personenmutation](https://www.moneyhouse.ch/de/commercialregister/services/person) - -[Änderung Sitz & Domizil](https://www.moneyhouse.ch/de/commercialregister/services/address) - -[Änderung Statuten](https://www.moneyhouse.ch/de/commercialregister/services/statutes) - -[Anpassung Zweck](https://www.moneyhouse.ch/de/commercialregister/services/company-purpose) - -[Liquidation](https://www.moneyhouse.ch/de/commercialregister/liquidation) - -[Weitere Services](https://www.moneyhouse.ch/de/commercialregister/services/other-services) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -Handelsregisteränderung: digital oder analog -============================================ - -Wir unterstützen Sie bei der Anpassung Ihrer Handelsregisterdaten, egal welchen Weg Sie bevorzugen. - -**Die digitale Lösung: schneller, einfacher, modern** - - Erledigen Sie Ihre Mutation komplett digital innerhalb wenigen Tagen – ohne Papier, Postweg oder Notartermin. Sie erhalten die Dokumente automatisch zugestellt, können sie bequem per Smartphone unterzeichnen und sofort einreichen. Profitieren dabei Sie von diesen Vorteilen: - -* **Schnell:**Erledigung in Tagen statt Wochen. - -* **Einfach:**Schritt-für-Schritt-Anleitung ohne Fehlerrisiko. - -* **Flexibel:**Von überall aus durchführbar, auch im Ausland. - -* **Rechtssicher:**E-Signatur (QES) ist schweizweit anerkannt. - -* **Nachhaltig:**Vollständig digital und papierfrei. - -_Hinweis: Der digitale Service wird laufend erweitert; einzelne Mutationen sind ggf. noch nicht verfügbar._ - -**Sie möchten die Mutation ohne Smartphone durchführen?** - - Kein Problem: Nutzen Sie hierzu einfach unser Mutationsformular. Sie erhalten die Unterlagen innerhalb eines Arbeitstages per E-Mail zur Unterzeichnung zugestellt. Diese müssen dann per Post retourniert werden. - -Bestseller -Digitale Mutation ------------------ - -in CHF (exkl. MWST)Analoge Mutation ----------------- - -in CHF (exkl. MWST) -### ab CHF 130.00 - -Erledigen Sie Ihre Handelsregisteränderung direkt über Ihr Smartphone.### ab CHF 150.00 - -Sie möchten die Änderung ohne Smartphone durchführen? Wir unterstützen Sie hierbei selbstverständlich gerne. -[Jetzt digitale Mutation starten](https://app.hoop.deepcloud.swiss/fiduciary?partnerUUID=eaa32e4c-d75d-4474-af03-2cc835a02802&companyUID=CHE113416882) - -[Sie wünschen eine kostenlose Erstberatung? Jetzt Termin buchen.](https://calendly.com/moneyhouse-hr-service/beratung-gruendung)[Jetzt Handelsregistereintrag kostenlos prüfen](https://handelsregister.moneyhouse.ch/de/mutation/CH02030306513?itm_campaign=traderegister&itm_medium=referral&itm_source=moneyhouse.ch&itm_content=link-traderegister-company_banner) - -[Sie wünschen eine kostenlose Erstberatung? Jetzt Termin buchen.](https://calendly.com/moneyhouse-hr-service/beratung-gruendung) - -#### Ihre Handelsregisteränderung – einfach und sofort digital erledigt - -Digitale Mutation ------------------ - -in CHF (exkl. MWST) - -### ab CHF 130.00 - -Erledigen Sie Ihre Handelsregisteränderung direkt über Ihr Smartphone. - -[Jetzt digitale Mutation starten](https://app.hoop.deepcloud.swiss/fiduciary?partnerUUID=eaa32e4c-d75d-4474-af03-2cc835a02802&companyUID=CHE113416882) - -[Sie wünschen eine kostenlose Erstberatung? Jetzt Termin buchen.](https://calendly.com/moneyhouse-hr-service/beratung-gruendung) - -Analoge Mutation ----------------- - -in CHF (exkl. MWST) - -### ab CHF 150.00 - -Sie möchten die Änderung ohne Smartphone durchführen? Wir unterstützen Sie hierbei selbstverständlich gerne. - -[Jetzt Handelsregistereintrag kostenlos prüfen](https://handelsregister.moneyhouse.ch/de/mutation/CH02030306513?itm_campaign=traderegister&itm_medium=referral&itm_source=moneyhouse.ch&itm_content=link-traderegister-company_banner) - -[Sie wünschen eine kostenlose Erstberatung? Jetzt Termin buchen.](https://calendly.com/moneyhouse-hr-service/beratung-gruendung) - -Ablauf digitaler Prozess ------------------------- - -### Deepcloud und Datenerfassung - - -Registrieren Sie sich bei deepcloud und erfassen Sie die Mutation direkt online. - -### Registrierung DeepID - - -Laden Sie die DeepID-App aus dem App Store herunter und registrieren Sie sich. Mehr Informationen dazu finden Sie [hier](https://www.deepid.swiss/de/digitale-identifizierung/). - -### Digitale Unterzeichnung - - -Unterzeichen Sie alle Dokumente gemäss der Aufforderung in DeepSign. - -### Einreichung der Unterlagen - - -Reichen Sie die digital unterzeichneten Dokumente mit wenigen Klicks direkt beim zuständigen Handelsregisteramt ein. - -Ablauf analoger Prozess ------------------------ - -### Erfassung Daten - - -Wir erfassen die Änderungen in unserem System gemäss Ihrer Angaben. - -### Dokumente - - -Wir erstellen die Dokumente und senden Ihnen diese per Mail zu. Von unserer Seite her dauert dieser Schritt maximal zwei Arbeitstage. - -### Rücksendung - - -Schauen Sie sich die Unterlagen durch und senden Sie uns alle Dokumente unterschieben zurück. Vergessen Sie die Ausweiskopien nicht. - -### Publikation - - -Nach Erhalt der Unterlagen prüfen wir diese und senden sie (wenn nötig) an unseren Notar oder direkt weiter ans Handelsregisteramt. Das Handelsregisteramt benötigt etwa zwei Wochen. - - - -Service Umfang --------------- - -* digitale oder analoge Erstellung der Unterlagen -* Alle Notariatskosten (falls notwendig) -* Beurkundungen(falls notwendig) -* Vorprüfung der Unterlagen (analoger Prozess) -* Kommunikation mit dem Handelsregisteramt -* Falls nötig, Publikation Schuldenrufe - -Bitte beachten Sie, dass alle amtlichen Gebühren des Handelsregisters in beiden Formen des Prozesses (digital und analog) sowie die Kosten für allfällige Beglaubigungen von Unterschriften im analogen Prozess nicht enthalten sind. - -[](https://www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -Preise und Prozessdauer ------------------------ - -Digitaler Prozess Analoger Prozess -Kosten ab CHF 150.00 Kosten ab CHF 150.00 -Dauer: 3 - 4 Tage ab Einreichung bei Handelsregister Dauer: ca. 2 Wochen (ohne Beurkundung) bis 3 Wochen (mit Beurkundung) - -Alle Unternehmensformen -Digitaler - - Prozess Kosten ab CHF 150.00 -Analoger - - Prozess Kosten ab CHF 150.00 - -Prozessdauer -Digitaler - - Prozess 3 - 4 Tage ab Einreichung bei Handelsregister -Analoger - - Prozess ca. 2 Wochen (ohne Beurkundung) bis 3 Wochen (mit Beurkundung) - - - -Wie können wir Ihnen helfen? ----------------------------- - -Haben Sie Fragen oder wünschen Sie weitere Informationen? - - Vereinbaren Sie direkt online einen [kostenlosen Beratungstermin](http://calendly.com/moneyhouse-hr-service/beratung-gruendung) oder kontaktieren Sie uns: - -Telefon: +41 44 258 28 88 oder per E-Mail:[crs@moneyhouse.ch](mailto:crs@moneyhouse.ch) - - Montag-Freitag: 8.30 - 11.00 Uhr und 13.30 - 16.00 Uhr - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Änderung Firmenname](https://www.moneyhouse.ch/de/commercialregister/services/company-name) - -[Personenmutation](https://www.moneyhouse.ch/de/commercialregister/services/person) - -[Änderung Sitz & Domizil](https://www.moneyhouse.ch/de/commercialregister/services/address) - -[Änderung Statuten](https://www.moneyhouse.ch/de/commercialregister/services/statutes) - -[Anpassung Zweck](https://www.moneyhouse.ch/de/commercialregister/services/company-purpose) - -[Liquidation](https://www.moneyhouse.ch/de/commercialregister/liquidation) - -[Weitere Services](https://www.moneyhouse.ch/de/commercialregister/services/other-services) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_015_www.moneyhouse.ch_de_company_valueon-ag-4663161481_revenue.txt b/test_web_content_20251002_212426/additional_link_015_www.moneyhouse.ch_de_company_valueon-ag-4663161481_revenue.txt deleted file mode 100644 index 4e143aad..00000000 --- a/test_web_content_20251002_212426/additional_link_015_www.moneyhouse.ch_de_company_valueon-ag-4663161481_revenue.txt +++ /dev/null @@ -1,565 +0,0 @@ -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Kennzahlen ValueOn AG - Dübendorf - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue#)[Save + Exit](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -[ValueOn AG](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -[Startseite](https://www.moneyhouse.ch/de/)[>](javascript:void(0))[Unternehmen](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG)[>](javascript:void(0))ValueOn AG - -ValueOn AG -========== - -ZH - -aktiv - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Zur Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -Handelsregister-Nr.:CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Umsatz ------- - -[Exklusiv für Premium-Mitglieder](https://www.moneyhouse.ch/membership) - -Mitarbeiter ------------ - -[Exklusiv für Premium-Mitglieder](https://www.moneyhouse.ch/membership) - -Kapital -------- - -#### Aktienkapital - -CHF 200'000 (vollständig liberiert) - -#### Aktien-Stückelung - -(Aktienkapital) - -[Exklusiv für Premium-Mitglieder](https://www.moneyhouse.ch/membership) - -#### Anzahl Kapitalveränderungen - -(Datum letzte Änderung) - -[Exklusiv für Premium-Mitglieder](https://www.moneyhouse.ch/membership) - -Alter der Firma ---------------- - -18 Jahre 8 Monate -#### Eintrag ins Handelsregister - -02.02.2007 - -Premium-Mitglied werden ------------------------ - -**Uneingeschränkter** Zugriff auf alle Hintergrundinformationen und auf Umsatz- & Mitarbeiterzahlen der ValueOn AG - -[Premium-Mitglied werden](https://www.moneyhouse.ch/membership) - -Hinweis: Die Informationen zu Mitarbeiter- und Umsatzzahlen sind in den meisten Fällen statistisch berechnete Werte und werden in vordefinierten Ranges angezeigt (Bsp. 4-9, 10-19). - -Liegen Ihnen genauere Angaben zu den Mitarbeiter- und Umsatzzahlen vor?[Kontaktieren Sie uns](https://www.moneyhouse.ch/de/contact/contactform) - -Möchten Sie mehr Details zur ValueOn AG? - -Dann empfehlen wir Ihnen die Wirtschaftsauskunft! - -Wirtschaftsauskunft -------------------- - -Umfassende Auskunft über die wirtschaftliche Situation der Firma. - -* Einschätzung der Bonität mit einer Ampel -* Zahlungsverhalten der letzten Rechnungen -* Risikobewertung im Branchenvergleich -* Meldung von Inkassobüros und Betreibungsämtern -* Firmeninformationen aus dem Handelsregister - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:e9d3178c-3e96-4218-ac8d-39baffee2871) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:e9d3178c-3e96-4218-ac8d-39baffee2871) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen CHF 49.00 pro Abfrage](https://www.moneyhouse.ch/de/service/purchase/economicinformation?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D3) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Jetzt bestellen CHF 49.00 pro Abfrage](https://www.moneyhouse.ch/de/service/purchase/economicinformation?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D3) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_016_www.moneyhouse.ch_de_company_valueon-ag-4663161481_networkneighbourhood.txt b/test_web_content_20251002_212426/additional_link_016_www.moneyhouse.ch_de_company_valueon-ag-4663161481_networkneighbourhood.txt deleted file mode 100644 index 51cb56a4..00000000 --- a/test_web_content_20251002_212426/additional_link_016_www.moneyhouse.ch_de_company_valueon-ag-4663161481_networkneighbourhood.txt +++ /dev/null @@ -1,743 +0,0 @@ -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network#neighbourhood -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Netzwerk ValueOn AG - Dübendorf - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network#)[Save + Exit](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -[ValueOn AG](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -[Startseite](https://www.moneyhouse.ch/de/)[>](javascript:void(0))[Unternehmen](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG)[>](javascript:void(0))ValueOn AG - -ValueOn AG -========== - -ZH - -aktiv - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Zur Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -Handelsregister-Nr.:CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Netzwerk --------- - -Netzwerk: Alle Verbindungen im Überblick ----------------------------------------- - -Mit dem Netzwerk sehen Sie auf einen Blick alle Verbindungen von Firmen und Personen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/membership) - -Es können maximal die 250 neuesten aktiven und 50 inaktive Verbindungen angezeigt werden. - -**Status** - -- [x] aktive Verbindungen - -- [x] inaktive Verbindungen - -**Management** - -- [x] oberstes Management - -- [x] Geschäftsführung - -- [x] andere Funktionen - -- [x] Zeichnungsberechtigte - -**Verbindungen** - -- [x] zu Firmen - -- [x] zu Personen - -**Revisionsstellen** - -- [x] Revisionsstellen - -[Zurücksetzen](javascript:void(0)) - -[](javascript:void(0))[](javascript:void(0))[+](javascript:void(0))[-](javascript:void(0)) - -* * * - -Aktive Firmen in der Nachbarschaft ----------------------------------- - -Quelle: [SHAB](https://www.moneyhouse.ch/de/datasources) - -#### 8 aktive Firmen mit gleichem Domizil: Am Stadtrand 11, 8600 Dübendorf - -[Black Projects GmbH](https://www.moneyhouse.ch/de/company/black-projects-gmbh-3958227961) -[Bluespace Ventures AG](https://www.moneyhouse.ch/de/company/bluespace-ventures-ag-20038582721) -[Cyberfy Consulting AG](https://www.moneyhouse.ch/de/company/cyberfy-consulting-ag-5194156221) -[FICHTNER MANAGEMENT CONSULTING AG SCHWEIZ](https://www.moneyhouse.ch/de/company/fichtner-management-consulting-ag-10801938741) -[Gex Immo Consult AG](https://www.moneyhouse.ch/de/company/gex-immo-consult-ag-12703377601) -[Gracher Kredit- und Kautionsmakler GmbH & Co.KG, Trier, Zweigniederlassung Dübendorf](https://www.moneyhouse.ch/de/company/gracher-kredit-und-kautionsmakler-gmbh-co-kg--5397627361) -[SIP Switzerland AG](https://www.moneyhouse.ch/de/company/sip-switzerland-ag-12346588291) -[WonderWave GmbH](https://www.moneyhouse.ch/de/company/wonderwave-gmbh-19889373591) - -[Alle anzeigen](javascript:void(0)) - -[Weniger anzeigen](javascript:void(0)) - -#### 60 aktive Firmen an der gleichen Strasse: Am Stadtrand, 8600 Dübendorf - -[Fibre Pharma AG](https://www.moneyhouse.ch/de/company/fibre-pharma-ag-4088828381) - -Am Stadtrand 1 -[NetEducation GmbH](https://www.moneyhouse.ch/de/company/neteducation-gmbh-12921962361) - -Am Stadtrand 1 -[NetIT-Services GmbH](https://www.moneyhouse.ch/de/company/netit-services-gmbh-13663579741) - -Am Stadtrand 1 -[Top Nails and Beauty GmbH](https://www.moneyhouse.ch/de/company/top-nails-and-beauty-gmbh-7371788851) - -Am Stadtrand 1 -[Frauenpraxis Stettbach Mitte Dr. med. Gunther Kaindl](https://www.moneyhouse.ch/de/company/frauenpraxis-stettbach-mitte-dr-med-gunther-4154277041) - -Am Stadtrand 3 -[PhysiOsteo Montagna GmbH](https://www.moneyhouse.ch/de/company/physiosteo-montagna-gmbh-13903303071) - -Am Stadtrand 3 -[TwoMoons AG](https://www.moneyhouse.ch/de/company/twomoons-ag-5574859691) - -Am Stadtrand 3 -[CITYDENTAL Group AG](https://www.moneyhouse.ch/de/company/citydental-group-ag-14551629461) - -Am Stadtrand 5 -[CITYDENTAL Stettbach AG](https://www.moneyhouse.ch/de/company/citydental-stettbach-ag-19365176231) - -Am Stadtrand 5 -[PlusMAT Instrumentenhandel Seefeld](https://www.moneyhouse.ch/de/company/plusmat-instrumentenhandel-seefeld-15313160081) - -Am Stadtrand 5 -[Praxis am Stadtrand AG](https://www.moneyhouse.ch/de/company/praxis-am-stadtrand-ag-5244050981) - -Am Stadtrand 5 -[Questline KLG](https://www.moneyhouse.ch/de/company/questline-klg-20237845361) - -Am Stadtrand 13 -[berg & kunz KLG](https://www.moneyhouse.ch/de/company/berg-kunz-klg-14260698371) - -Am Stadtrand 23 -[Virtumate Manuela Erhart](https://www.moneyhouse.ch/de/company/virtumate-manuela-erhart-4697950761) - -Am Stadtrand 23 -[Vollmann AgileXcellence](https://www.moneyhouse.ch/de/company/vollmann-agilexcellence-3128545151) - -Am Stadtrand 23 -[Getfitbylina, Rada Cardozo](https://www.moneyhouse.ch/de/company/getfitbylina-rada-cardozo-15072677181) - -Am Stadtrand 25 -[Oni GmbH](https://www.moneyhouse.ch/de/company/oni-gmbh-6702936421) - -Am Stadtrand 29 -[Malina BB Vidan Stepanovic](https://www.moneyhouse.ch/de/company/malina-bb-vidan-stepanovic-694882931) - -Am Stadtrand 31 -[Konoha Holding AG](https://www.moneyhouse.ch/de/company/konoha-holding-ag-5681159481) - -Am Stadtrand 43 -[LAU](https://www.moneyhouse.ch/de/company/lau-10678515661) - -Am Stadtrand 43 -[Michael Bjeski IT Engineering](https://www.moneyhouse.ch/de/company/michael-bjeski-it-engineering-6411005861) - -Am Stadtrand 43 -[MMACIAS, Inh. Macias Speissegger](https://www.moneyhouse.ch/de/company/mmacias-inh-macias-speissegger-18447240901) - -Am Stadtrand 43 -[Ryser Living Solutions GmbH](https://www.moneyhouse.ch/de/company/ryser-living-solutions-gmbh-1491545501) - -Am Stadtrand 43 -[Physiotherapie Stettbach GmbH](https://www.moneyhouse.ch/de/company/physiotherapie-stettbach-gmbh-14832629151) - -Am Stadtrand 46 -[SGA Swiss AG](https://www.moneyhouse.ch/de/company/sga-swiss-ag-11969999171) - -Am Stadtrand 46 -[Sport-Fitness-Center Schumacher AG](https://www.moneyhouse.ch/de/company/sport-fitness-center-schumacher-ag-3417231251) - -Am Stadtrand 46 -[ESTETICA STUDIO Nadine Suter](https://www.moneyhouse.ch/de/company/estetica-studio-nadine-suter-13756684561) - -Am Stadtrand 49b -[Nacer, Ximena Silva](https://www.moneyhouse.ch/de/company/nacer-ximena-silva-13292556001) - -Am Stadtrand 49a -[Compliance Powerhouse AG](https://www.moneyhouse.ch/de/company/compliance-powerhouse-ag-4177952931) - -Am Stadtrand 51b -[LogicStar AG](https://www.moneyhouse.ch/de/company/logicstar-ag-5246816641) - -Am Stadtrand 51a -[MAISON DE LA ROCHEMACÉ](https://www.moneyhouse.ch/de/company/maison-de-la-rochemace-15044423081) - -Am Stadtrand 51a -[SWiss tO cuRe Dipg](https://www.moneyhouse.ch/de/company/swiss-to-cure-dipg-14331095251) - -Am Stadtrand 51a -[Triple-X by Werner Blättler](https://www.moneyhouse.ch/de/company/triple-x-by-werner-blaettler-20046122301) - -Am Stadtrand 51a -[Vinitaly GmbH](https://www.moneyhouse.ch/de/company/vinitaly-gmbh-20529542651) - -Am Stadtrand 51B -[Beyond Patterns GmbH](https://www.moneyhouse.ch/de/company/beyond-patterns-gmbh-12342874101) - -Am Stadtrand 53a -[Biasi Immobilien AG](https://www.moneyhouse.ch/de/company/biasi-immobilien-ag-6021309661) - -Am Stadtrand 53b -[Cucina Alpina GmbH](https://www.moneyhouse.ch/de/company/cucina-alpina-gmbh-3852911181) - -Am Stadtrand 53b -[curlA Engineering GmbH](https://www.moneyhouse.ch/de/company/curla-engineering-gmbh-14759700611) - -Am Stadtrand 53a -[Kriztle Bath & Wellness GmbH](https://www.moneyhouse.ch/de/company/kriztle-bath-wellness-gmbh-15976831551) - -Am Stadtrand 53b -[Talent Sutra von Agarwal](https://www.moneyhouse.ch/de/company/talent-sutra-von-agarwal-7057294151) - -Am Stadtrand 53a -[AI Swiss Knife, Inh. Brunner](https://www.moneyhouse.ch/de/company/ai-swiss-knife-inh-brunner-5180921761) - -Am Stadtrand 56 -[Amalia GmbH](https://www.moneyhouse.ch/de/company/amalia-gmbh-4465184331) - -Am Stadtrand 56 -[Blütentanz Heidi Kummer](https://www.moneyhouse.ch/de/company/bluetentanz-heidi-kummer-91594131) - -Am Stadtrand 56 -[Chronos Web Solutions KlG](https://www.moneyhouse.ch/de/company/chronos-web-solutions-klg-21410964941) - -Am Stadtrand 56 -[CorePiece GmbH](https://www.moneyhouse.ch/de/company/corepiece-gmbh-3996687461) - -Am Stadtrand 56 -[Doppel A KlG](https://www.moneyhouse.ch/de/company/doppel-a-klg-4715173231) - -Am Stadtrand 56 -[DPC Academy GmbH](https://www.moneyhouse.ch/de/company/dpc-academy-gmbh-5425938371) - -Am Stadtrand 56 -[Exec. Express GmbH](https://www.moneyhouse.ch/de/company/exec-express-gmbh-4270000211) - -Am Stadtrand 56 -[Immoservice-Solutions GmbH](https://www.moneyhouse.ch/de/company/immoservice-solutions-gmbh-5695654661) - -Am Stadtrand 56 -[J.F. Schulz & Company AG](https://www.moneyhouse.ch/de/company/j-f-schulz-company-ag-12183475011) - -Am Stadtrand 56 -[mags.porcelain by Marilei Genther](https://www.moneyhouse.ch/de/company/mags-porcelain-by-marilei-genther-19680925581) - -Am Stadtrand 56 -[Marijana Mionic Ebersold](https://www.moneyhouse.ch/de/company/marijana-mionic-ebersold-4251659421) - -Am Stadtrand 56 -[Milo Finanz AG](https://www.moneyhouse.ch/de/company/milo-finanz-ag-19873157631) - -Am Stadtrand 56 -[Reimer Life Journey Coaching und Beratung](https://www.moneyhouse.ch/de/company/reimer-life-journey-coaching-und-15986689981) - -Am Stadtrand 56 -[RUPOVA VENTURES](https://www.moneyhouse.ch/de/company/rupova-ventures-4042215861) - -Am Stadtrand 56 -[S. Reiser](https://www.moneyhouse.ch/de/company/s-reiser-18805059631) - -Am Stadtrand 56 -[Tipp Topp Cakes by Sophie Hogg](https://www.moneyhouse.ch/de/company/tipp-topp-cakes-by-sophie-hogg-12878277641) - -Am Stadtrand 56 -[Vögeli Flowers](https://www.moneyhouse.ch/de/company/voegeli-flowers-13556974501) - -Am Stadtrand 56 -[Wismer Marketing](https://www.moneyhouse.ch/de/company/wismer-marketing-2108420601) - -Am Stadtrand 56 -[Kita Zwerglinge GmbH](https://www.moneyhouse.ch/de/company/kita-zwerglinge-gmbh-14370068251) - -Am Stadtrand 58a - -[Alle anzeigen](javascript:void(0)) - -[Weniger anzeigen](javascript:void(0)) - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/network)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/network)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_017_www.itreseller.ch_media.txt b/test_web_content_20251002_212426/additional_link_017_www.itreseller.ch_media.txt deleted file mode 100644 index 826001bc..00000000 --- a/test_web_content_20251002_212426/additional_link_017_www.itreseller.ch_media.txt +++ /dev/null @@ -1,203 +0,0 @@ -URL: https://www.itreseller.ch/media -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Inserieren in IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Inserieren in IT Reseller -========================= - - IT Reseller ist seit 1998 die führende Fachzeitschrift für die Schweizer IT-Industrie. - - Die Print-Ausgabe erscheint monatlich in einer Auflage von 2500 Exemplaren und erreicht persönlich adressiert den Schweizer ICT-Channel. - - Online erreicht IT Reseller monatlich 32'000 Besucher (Unique Clients) und erzielt bis zu 92'000 Page Impressions. -Print-Anzeigen --------------- - - Gültig ab 1. Januar 2025 -Anzeigen -Format Satzspiegel - -B x H in mm Randabfallend * - -B x H in mm Preis in CHF - -exkl. MwSt -2/1 Seiten Panorama 385 x 265 420 x 297 6600.– -1/1 Seite 175 x 265 210 x 297 4000.– -1/2 Seite quer 175 x 130 210 x 145 3000.– -1/2 Seite hoch 85 x 265 103 x 297 3000.– -1/3 Seite quer 175 x 85 210 x 95 2800.– -1/3 Seite hoch 55 x 265 67 x 297 2800.– -2. oder 4. Umschlagsseite 175 x 265 210 x 297 4800.– -Advertorial -2/1 Seite 385 x 265 420 x 297 4950.– -1/1 Seite 175 x 265 210 x 297 3000.– -3er-Kombi ** -3x 1/1 Seite 175 x 265 210 x 297 6000.– -3x 1/2 Seite quer 175 x 130 210 x 145 4500.– -3x 1/2 Seite hoch 85 x 265 103 x 297 4500.– -Jahresangebot ** -10x 1/1 Seite 175 x 265 210 x 297 12'000.– -10x 1/2 Seite quer 175 x 130 210 x 145 9000.– -10x 1/2 Seite hoch 85 x 265 103 x 297 9000.– -Coverlasche (Flappe) -Coverlasche Vorderseite-auf Anfrage 5'400.– -Coverlasche Rückseite mit 4. Umschlagseite-auf Anfrage 5'400.– -Coverlasche im 5er Kombi-auf Anfrage 4000.– -Veranstaltungskalender -Eintrag mit Datum, Titel, Tagline und URL + Online-Publikation (s. unten)180.– - -* 3 mm Beschnitt pro Aussenrand hinzufügen - - ** Fixpreis für 3 resp. 10 aufeinanderfolgende Ausgaben, Vorauszahlung, nicht Rabatt- oder BK-berechtigt, ohne redaktionellen Anschluss, keine Platzierungswünsche möglich, Verwendung des alten Sujets bei Nichtlieferung eines neuen Sujets bis Inserateschluss. - -Online-Anzeigen ---------------- - - Gültig ab 1. Januar 2025 -TKP-Buchungen -Werbemittel Platzierung Preis in CHF pro 1000 Impressions Format BxH - -(max. 50 KB)Datenformate -Maxiboard Run-of-Site 55.–994 x 118 Pixel JPEG, GIF, HTML5 -Leaderboard Run-of-Site 55.–728 x 90 Pixel JPEG, GIF, HTML5 -Wideskyscraper Run-of-Site 55.–160 x 600 Pixel JPEG, GIF, HTML5 -Half Page Run-of-Site 55.–300 x 600 Pixel JPEG, GIF, HTML5 -Rectangle Run-of-Site 55.–300 x 250 Pixel JPEG, GIF, HTML5 -Mindestbuchungsvolumen: CHF 1100.– -Buchungen mit Fixplatzierung -Werbemittel Platzierung Preis pro Woche Format (max. 50 KB)Datenformate -Maxiboard Run-of-Site 1290.–994 x 118 Pixel JPEG, GIF, HTML5 -Leaderboard Run-of-Site 1290.–728 x 90 Pixel JPEG, GIF, HTML5 -Wideskyscraper Run-of-Site 1290.–160 x 600 Pixel JPEG, GIF, HTML5 -Half Page Run-of-Site 1290.–300 x 600 Pixel JPEG, GIF, HTML5 -Rectangle Run-of-Site 1490.–300 x 250 Pixel JPEG, GIF, HTML5 -Advertorial -Advertorial Homepage & Newsletter 1200.–Titel, max. 4000 Zeichen Text, Bild - -Newsletter-Anzeigen -------------------- - -Fixplatzierung -Werbemittel Preis pro Woche Format (max. 50 KB)Datenformate -Banner 600.–468 x 60 Pixel JPEG, GIF -Skyscraper 825.–160 x 600 Pixel JPEG, GIF -Rectangle 825.–300 x 250 Pixel JPEG, GIF -Textanzeige 825.–n/a JPEG, GIF - -Veranstaltungen ---------------- - -Grundeintrag im Veranstaltungskalender -Werbemittel Preis in CHF exkl. MWST -Eintrag mit Titel, Datum und URL kostenlos -Premium-Eintrag im Veranstaltungskalender -Eintrag mit Titel, Datum und URL 180.- -+ Eintrag mit farblicher Hervorhebung, Logo, Beschreibung -+ Tägliche Veröffentlichung im Newsletter (Start: 3 Monate vor Beginn) -+ Veröffentlichung im Veranstaltungskalender der Print-Ausgabe - -SALES KONTAKT - - - - Sie möchten Werbung schalten oder wünschen eine kompetente Beratung? - -**Unsere Verkaufsleiterin Tanja Zesiger freut sich auf Ihre Kontaktaufnahme!** - -#### ✆ +41 (0) 44 723 50 05 - -#### [tzesiger@swissitmedia.ch](mailto:tzesiger@swissitmedia.ch) - -MEDIADATEN - -[ ##### Download Mediadaten 2025](https://www.itreseller.ch/media/tarife/ITR_Mediadaten_2025_DE.pdf) - -MEDIA ALERT - - Abonnieren Sie unseren monatlichen Media Alert mit der Themenvorschau auf die kommenden Ausgaben von IT Reseller. - -AUSGABEN & TERMINE - -**IT Reseller 2025/ 11** -Erscheint am:3. November 2025 -Anzeigenschluss:24. Oktober 2025 - -**IT Reseller 2025/ 12** -Erscheint am:8. Dezember 2025 -Anzeigenschluss:28. November 2025 - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_018_www.itreseller.ch_abo.txt b/test_web_content_20251002_212426/additional_link_018_www.itreseller.ch_abo.txt deleted file mode 100644 index 7473762d..00000000 --- a/test_web_content_20251002_212426/additional_link_018_www.itreseller.ch_abo.txt +++ /dev/null @@ -1,157 +0,0 @@ -URL: https://www.itreseller.ch/abo -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Abonnement - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Abonnement-Bestellung -===================== - - IT Reseller wird ausschliesslich im **Controlled-Circulation-Modell** vertrieben und ist damit nur für Unternehmensmitarbeiter im IT- oder Consumer-Electronics-Markt erhältlich. - - Um sicherzustellen, dass nur qualifizierte Personen den IT Reseller erhalten, bitten wir Sie, bei Ihrer Bestellung **alle mit (*) gekennzeichneten Felder auszufüllen**, damit wir Ihre Angaben prüfen können. - -**1-Jahres-Abonnement** - - Ich abonniere IT Reseller inkl. Swiss IT Magazine für ein Jahr zum Preis von Fr. 95.– - -(Ausland Europa Fr. 190.-). -**2-Jahres-Abonnement** - - Ich abonniere IT Reseller inkl. Swiss IT Magazine für 2 Jahre zum Preis von Fr. 150.– - -(Ausland Europa Fr. 300.-). -**Online-Abonnement** - - Ich abonniere die digitale Ausgabe von IT Reseller und erhalte damit für 1 Jahr Zugriff auf die Online-Archive von [IT Reseller](https://www.itreseller.ch/Heftarchiv/) und [Swiss IT Magazine](http://www.itmagazine.ch/heftarchiv) zum Preis von Fr. 75.– -**Probe-Abonnement** - - Ich möchte drei Ausgaben kostenlos zur Probe. (Kein Ausland-Versand) -**Das Abo startet mit der Ausgabe** -- [x]Ich möchte auch den täglichen Newsletter von IT Reseller abonnieren! - -**Firma*** -**Anrede** -**Vorname*** -**Nachname*** -**Abteilung** -**Position** -**Branche*** -**Strasse*** -**PLZ/Ort*** -**Land** -**Telefon*** -**E-Mail*** -* Angabe obligatorisch -Dies ist meine Geschäftsadresse -Dies ist meine Privatadresse -- [x]IT Reseller darf mich für Meinungsumfragen - -und Recherchen kontaktieren. - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_019_www.itreseller.ch_newsletter.txt b/test_web_content_20251002_212426/additional_link_019_www.itreseller.ch_newsletter.txt deleted file mode 100644 index 576def79..00000000 --- a/test_web_content_20251002_212426/additional_link_019_www.itreseller.ch_newsletter.txt +++ /dev/null @@ -1,119 +0,0 @@ -URL: https://www.itreseller.ch/newsletter -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Newsletter - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Newsletter abonnieren -===================== - - Um die Newsletter von IT Reseller zu abonnieren, geben Sie bitte Ihre E-Mail-Adresse in das folgende Feld ein und klicken Sie auf den Anmelden-Button. - - Um den Newsletter abzubestellen, klicken Sie bitte auf den Link am Ende jedes Newsletters. - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_020_www.itreseller.ch_rubriken_165_people.html.txt b/test_web_content_20251002_212426/additional_link_020_www.itreseller.ch_rubriken_165_people.html.txt deleted file mode 100644 index 00198363..00000000 --- a/test_web_content_20251002_212426/additional_link_020_www.itreseller.ch_rubriken_165_people.html.txt +++ /dev/null @@ -1,195 +0,0 @@ -URL: https://www.itreseller.ch/rubriken/165/people.html -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -People - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -PEOPLE ------- - -[](https://www.itreseller.ch/Artikel/104096/Daniele_Palazzo_verlaesst_Lake_Solutions.html) - -[Daniele Palazzo verlässt Lake Solutions =======================================](https://www.itreseller.ch/Artikel/104096/Daniele_Palazzo_verlaesst_Lake_Solutions.html) - -[Lake Solutions verkleinert die Geschäftsleitung. Daniele Palazzo verlässt das Unternehmen nach mehr als 20 Jahren, seine Aufgaben werden im Rahmen einer Reorganisation an die drei verbleibenden GL-Mitglieder verteilt.](https://www.itreseller.ch/Artikel/104096/Daniele_Palazzo_verlaesst_Lake_Solutions.html) - - 2. Oktober 2025 - -Meistgelesen in People - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -[](https://www.itreseller.ch/Artikel/104097/Torsten_Boettjer_ist_Head_of_Cloud_Services_bei_Inventx.html) - -[### Torsten Böttjer ist Head of Cloud Services bei Inventx Mit der neu geschaffenen Position des Head of Cloud Services will Inventx die Weiterentwicklung seiner Hybrid-Cloud-Strategie weiterentwickeln. Besetzt wurde die Position mit Torsten Böttjer. 2. Oktober 2025](https://www.itreseller.ch/Artikel/104097/Torsten_Boettjer_ist_Head_of_Cloud_Services_bei_Inventx.html) - -[](https://www.itreseller.ch/Artikel/104100/Hohmann_verlaesst_Thomas-Krenn_Meier_und_Frei_bilden_Doppelspitze.html) - -[### Hohmann verlässt Thomas-Krenn, Meier und Frei bilden Doppelspitze Beim Server- und Storage-Spezialisten Thomas-Krenn verkleinert sich der Vorstand wieder. Ralf Hohmann scheidet aus, CEO Christoph Maier und COO Thomas Frei übernehmen fortan zu zweit die Aufgaben des Vorstands. 2. Oktober 2025](https://www.itreseller.ch/Artikel/104100/Hohmann_verlaesst_Thomas-Krenn_Meier_und_Frei_bilden_Doppelspitze.html) - -[](https://www.itreseller.ch/Artikel/104094/NTT_Data_stellt_Michael_Seiger_als_neuen_DACH-Chef_vor.html) - -[### NTT Data stellt Michael Seiger als neuen DACH-Chef vor NTT Data ernennt Michael Seiger zum Executive Managing Director für Deutschland, Österreich und die Schweiz. Er folgt auf Stefan Hansen. 2. Oktober 2025](https://www.itreseller.ch/Artikel/104094/NTT_Data_stellt_Michael_Seiger_als_neuen_DACH-Chef_vor.html) - -[](https://www.itreseller.ch/Artikel/104095/Sonepar_Schweiz_ernennt_Raphael_Maier_zum_neuen_CEO.html) - -[### Sonepar Schweiz ernennt Raphael Maier zum neuen CEO David von Ow ist nach 30 Jahren in den Ruhestand getreten. Für ihn übernimmt nun Raphael Maier die Rolle als CEO von Sonepar in der Schweiz. 1. Oktober 2025](https://www.itreseller.ch/Artikel/104095/Sonepar_Schweiz_ernennt_Raphael_Maier_zum_neuen_CEO.html) - -[](https://www.itreseller.ch/Artikel/104090/AWS_ernennt_Stphane_Isral_zum_Leiter_der_Sovereign_Cloud.html) - -[### AWS ernennt Stéphane Israël zum Leiter der Sovereign Cloud AWS gibt mit Stéphane Israël einen zweiten Leiter der European Sovereign Cloud bekannt. Zusammen mit Kathrin Renz soll er das Geschäft mit souveränen Cloud-Strukturen leiten. 1. Oktober 2025](https://www.itreseller.ch/Artikel/104090/AWS_ernennt_Stphane_Isral_zum_Leiter_der_Sovereign_Cloud.html) - -[](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html) - -[### Paessler bekommt mit Jason Teichman neuen CEO](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html) - -[IT- und OT-Monitoring-Anbieter Paessler stellt mit Jason Teichman seinen neuen CEO vor. Mit der Personalie unterstreicht das Unternehmen seine globale Expansionsstrategie.](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html)1. Oktober 2025 - -[](https://www.itreseller.ch/Artikel/104086/Connect-Test_Schweizer_Internet-Provider_sind_ueberragend.html) - -[### Connect-Test: Schweizer Internet-Provider sind überragend](https://www.itreseller.ch/Artikel/104086/Connect-Test_Schweizer_Internet-Provider_sind_ueberragend.html) - -[Während Swisscom und Sunrise im grossen Festnetztest Schweiz 2025 von "Connect" beinahe gleichauf liegen, sind die Unterschiede bei den regionalen Anbietern etwas grösser. Klar ist aber: Die Schweizer Internet-Provider sind durchs Band top.](https://www.itreseller.ch/Artikel/104086/Connect-Test_Schweizer_Internet-Provider_sind_ueberragend.html)1. Oktober 2025 - -[](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) - -[Mit Renato Petrillo (Bild, Mitte) hat Baggenstos einen neuen CEO gefunden. Er folgt auf Michael Kistler (Bild, links), der dem Unternehmen in verschiedenen Rollen erhalten bleibt.](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html)30. September 2025 - -[](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) - -[Dennis Monner (Bild, rechts) folgt bei Open Systems als CEO auf Daniel Neuhaus (Bild, links), der 2020 mit der Übernahme seines Unternehmens Sqooba zum Unternehmen stiess.](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html)30. September 2025 - -[](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) - -[Mit Marco Pierro hat Check Point Software Technologies einen neuen Country Manager für die Schweiz ernannt. Er übernimmt die Funktion per 1. Oktober 2025 und folgt auf Alvaro Amato, der zum Director Globals für EMEA & Asien befördert wurde.](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html)30. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_021_www.itreseller.ch_rubriken_163_business.html.txt b/test_web_content_20251002_212426/additional_link_021_www.itreseller.ch_rubriken_163_business.html.txt deleted file mode 100644 index 02be0858..00000000 --- a/test_web_content_20251002_212426/additional_link_021_www.itreseller.ch_rubriken_163_business.html.txt +++ /dev/null @@ -1,195 +0,0 @@ -URL: https://www.itreseller.ch/rubriken/163/business.html -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Business - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -BUSINESS --------- - -[](https://www.itreseller.ch/Artikel/104102/Matrix42_kauft_SaaS-Management-Spezialisten_Viio.html) - -[Matrix42 kauft SaaS-Management-Spezialisten Viio ================================================](https://www.itreseller.ch/Artikel/104102/Matrix42_kauft_SaaS-Management-Spezialisten_Viio.html) - -[Mit dem Zukauf des dänischen SaaS-Management-Spezialisten will Matrix42 die eigenen Fähigkeiten im Bereich Software Asset Management und Enterprise Service Management verbessern. Die Übernahme soll noch dieses Jahr abgeschlossen werden.](https://www.itreseller.ch/Artikel/104102/Matrix42_kauft_SaaS-Management-Spezialisten_Viio.html) - - 2. Oktober 2025 - -Meistgelesen in Business - -[### Nutanix Cloud Platform unterstützt neu Dell PowerStore](https://www.itreseller.ch/Artikel/104070/Nutanix_Cloud_Platform_unterstuetzt_neu_Dell_PowerStore.html) 26. September 2025 - -[### Intel wirbt auch bei Apple um Investitionen](https://www.itreseller.ch/Artikel/104063/Intel_wirbt_auch_bei_Apple_um_Investitionen.html) 25. September 2025 - -[### AWS und SAP stellen gemeinsam "souveräne Cloud" auf die Beine](https://www.itreseller.ch/Artikel/104060/AWS_und_SAP_stellen_gemeinsam_souveraene_Cloud_auf_die_Beine.html) 25. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) 23. September 2025 - -[](https://www.itreseller.ch/Artikel/104099/Fritz_startet_mit_eigenem_Online-Shop_in_der_Schweiz_.html) - -[### Fritz startet mit eigenem Online-Shop in der Schweiz Netzwerkspezialist Fritz öffnet einen eigenen Online-Shop in der Schweiz. Dieser soll spätestens Mitte Oktober bereitstehen und die gewohnten Zusatzservices bieten. 2. Oktober 2025](https://www.itreseller.ch/Artikel/104099/Fritz_startet_mit_eigenem_Online-Shop_in_der_Schweiz_.html) - -[](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - -[### Swico ICT Index zeigt abermals Knick für das vierte Quartal Der Swico ICT Index geht im vierten Quartal 2025 um 2 Punkte zurück. Noch sind viele Segmente im Wachstumsbereich, allerdings zeigen Unsicherheiten, Zölle und Wettbewerb Effekte. 1. Oktober 2025](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - -[](https://www.itreseller.ch/Artikel/104091/Arrow_vertreibt_Thales-Plattform_in_der_Schweiz.html) - -[### Arrow vertreibt Thales-Plattform in der Schweiz Arrow hat das bestehende Distributionsabkommen mit Thales erweitert und bietet die Imperva Application Security-Plattform auch in der Schweiz sowie in Österreich und Italien an. 1. Oktober 2025](https://www.itreseller.ch/Artikel/104091/Arrow_vertreibt_Thales-Plattform_in_der_Schweiz.html) - -[](https://www.itreseller.ch/Artikel/104084/Infinigate_vertreibt_neu_Thales_in_der_Schweiz.html) - -[### Infinigate vertreibt neu Thales in der Schweiz Schweizer Channel-Partner können neu das gesamte Security-Portfolio von Thales über Infinigate beziehen und erhalten beim VAD den dazugehörigen Support. 30. September 2025](https://www.itreseller.ch/Artikel/104084/Infinigate_vertreibt_neu_Thales_in_der_Schweiz.html) - -[](https://www.itreseller.ch/Artikel/104082/NTT_Data_streicht_Ivanti_aus_Sicherheitsgruenden_aus_Portfolio_.html) - -[### NTT Data streicht Ivanti aus Sicherheitsgründen aus Portfolio NTT Data vertreibt keine Produkte mehr von Ivanti. Laut dem IT-Dienstleister stellen diese ein zu hohes Sicherheitsrisiko dar. 30. September 2025](https://www.itreseller.ch/Artikel/104082/NTT_Data_streicht_Ivanti_aus_Sicherheitsgruenden_aus_Portfolio_.html) - -[](https://www.itreseller.ch/Artikel/104077/Microsoft_startet_neuen_Marketplace_fuer_Cloud-_und_KI-Loesungen.html) - -[### Microsoft startet neuen Marketplace für Cloud- und KI-Lösungen](https://www.itreseller.ch/Artikel/104077/Microsoft_startet_neuen_Marketplace_fuer_Cloud-_und_KI-Loesungen.html) - -[Microsoft startet einen einheitlichen Marketplace, der Azure Marketplace und AppSource bündelt und Unternehmen Cloud-Lösungen sowie KI-Apps und Agenten zentral finden, testen, kaufen und direkt in ihrer Microsoft-Umgebung bereitstellen lässt.](https://www.itreseller.ch/Artikel/104077/Microsoft_startet_neuen_Marketplace_fuer_Cloud-_und_KI-Loesungen.html)29. September 2025 - -[](https://www.itreseller.ch/Artikel/104075/ADN_setzt_verstaerkt_auf_das_Dell-Geschaeft.html) - -[### ADN setzt verstärkt auf das Dell-Geschäft](https://www.itreseller.ch/Artikel/104075/ADN_setzt_verstaerkt_auf_das_Dell-Geschaeft.html) - -[ADN baut personell mit den drei neuen Channel-Experten Ronny Pilgram (Bild), Thomas Kroll und Christof Sokolowski aus und bekräftigt damit seinen Anspruch als strategischer Value-Added-Distributor für Dell Technologies.](https://www.itreseller.ch/Artikel/104075/ADN_setzt_verstaerkt_auf_das_Dell-Geschaeft.html)29. September 2025 - -[](https://www.itreseller.ch/Artikel/104070/Nutanix_Cloud_Platform_unterstuetzt_neu_Dell_PowerStore.html) - -[### Nutanix Cloud Platform unterstützt neu Dell PowerStore](https://www.itreseller.ch/Artikel/104070/Nutanix_Cloud_Platform_unterstuetzt_neu_Dell_PowerStore.html) - -[Mit der Unterstützung der All-Flash-Storage-Plattform Dell PowerStore in der Nutanix Cloud Platform vertiefen die beiden Technologieunternehmen ihre strategische Partnerschaft.](https://www.itreseller.ch/Artikel/104070/Nutanix_Cloud_Platform_unterstuetzt_neu_Dell_PowerStore.html)26. September 2025 - -[](https://www.itreseller.ch/Artikel/104066/Motorola_startet_in_der_Schweiz_eigenen_Online-Shop.html) - -[### Motorola startet in der Schweiz eigenen Online-Shop](https://www.itreseller.ch/Artikel/104066/Motorola_startet_in_der_Schweiz_eigenen_Online-Shop.html) - -[Motorola baut das Direktgeschäft in der Schweiz aus und startet einen eigenen Online-Shop für Privat- und Geschäftskunden. So will der Hersteller die Präsenz hierzulande stärken.](https://www.itreseller.ch/Artikel/104066/Motorola_startet_in_der_Schweiz_eigenen_Online-Shop.html)26. September 2025 - -[](https://www.itreseller.ch/Artikel/104064/Crayon_ist_neuer_Zendesk-Distributor_.html) - -[### Crayon ist neuer Zendesk-Distributor](https://www.itreseller.ch/Artikel/104064/Crayon_ist_neuer_Zendesk-Distributor_.html) - -[Crayon tritt in mehr als 70 Ländern als neuer Distributor für Zendesk auf. Die Partnerschaft umfasst das gesamte Portfolio des Anbieters von CX-Lösungen.](https://www.itreseller.ch/Artikel/104064/Crayon_ist_neuer_Zendesk-Distributor_.html)26. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_022_www.itreseller.ch_rubriken_166_finance.html.txt b/test_web_content_20251002_212426/additional_link_022_www.itreseller.ch_rubriken_166_finance.html.txt deleted file mode 100644 index a8838cd9..00000000 --- a/test_web_content_20251002_212426/additional_link_022_www.itreseller.ch_rubriken_166_finance.html.txt +++ /dev/null @@ -1,173 +0,0 @@ -URL: https://www.itreseller.ch/rubriken/166/finance.html -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Finance - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -FINANCE -------- - -[](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -[OpenAI knackt 500-Milliarden-Marke ==================================](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -[Die KI-Blase wächst weiter: Nach einem grossen Aktienverkauf durch OpenAI-Mitarbeiter an Investoren liegt der Unternehmenswert nun erstmals bei einer halben Billion US-Dollar.](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - - 2. Oktober 2025 - -Meistgelesen in Finance - -[### Adobe-Zahlen übertreffen die Markterwartungen](https://www.itreseller.ch/Artikel/103962/Adobe-Zahlen_uebertreffen_die_Markterwartungen.html) 12. September 2025 - -[### Aveniq setzt auf Fokussierung und einheitliche Strukturen](https://www.itreseller.ch/Artikel/103935/Aveniq_setzt_auf_Fokussierung_und_einheitliche_Strukturen.html) 9. September 2025 - -[### ASML wird Hauptaktionär von Mistral AI](https://www.itreseller.ch/Artikel/103933/ASML_wird_Hauptaktionaer_von_Mistral_AI.html) 8. September 2025 - -[### HPE übertrifft Markterwartungen mit Rekordumsatz](https://www.itreseller.ch/Artikel/103920/HPE_uebertrifft_Markterwartungen_mit_Rekordumsatz_.html) 5. September 2025 - -[](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -[### Accenture mit mehr Umsatz und weniger Gewinn Accenture steigerte im jüngsten Quartal die Einnahmen um 7 Prozent auf 17,6 Milliarden Dollar. Hingegen mussten beim Gewinn zweistellige Einbussen in Kauf genommen werden. 26. September 2025](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -[](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab TD Synnex übertraf im abgelaufenen Quartal die Markterwartungen sowohl beim Gewinn, als auch beim Umsatz deutlich. Obwohl auch der Ausblick die Analystenschätzungen übertraf, konnte die Aktie nicht profitieren. 26. September 2025](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -[](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -[### Schweizer KI-Start-up Giotto sucht Finanzierung Giotto mit Sitz in Lausanne sucht mit Unterstützung einer Investmentbank Investoren für eine weitere Finanzierung im Umfang von über 200 Millionen US-Dollar. Das Unternehmen ist im Bereich künstliche allgemeine Intelligenz (AGI) tätig. 23. September 2025](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -[](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -[### Nvidia will kräftig in OpenAI investieren OpenAI will seine KI-Infrastruktur ab nächstem Jahr stark ausbauen und dazu Nvidia-Systeme der neuesten Generation einsetzen. Nvidia sichert zu, mindestens 100 Millionen Dollar in OpenAI zu investieren. 23. September 2025](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -[](https://www.itreseller.ch/Artikel/104009/Oracle_vor_20-Milliarden-Deal_mit_Meta.html) - -[### Oracle vor 20-Milliarden-Deal mit Meta Nach dem 300-Milliarden-Dollar-Vertrag mit OpenAI plant Oracle ein weiteres Abkommen zum Bezug von Cloud-Dienstleistungen mit Meta. In den kommenden Monaten sollen noch mehr ähnliche Deals folgen. 22. September 2025](https://www.itreseller.ch/Artikel/104009/Oracle_vor_20-Milliarden-Deal_mit_Meta.html) - -[](https://www.itreseller.ch/Artikel/103975/Alphabet_ist_erstmals_3_Billionen_Dollar_Wert.html) - -[### Alphabet ist erstmals 3 Billionen Dollar Wert](https://www.itreseller.ch/Artikel/103975/Alphabet_ist_erstmals_3_Billionen_Dollar_Wert.html) - -[Nach einem erneuten Anstieg des Aktienkurses um über 3 Prozent hat die Börsenbewertung der Google-Mutter Alphabet nun zum ersten Mal die Schwelle von 3 Billionen US-Dollar überschritten.](https://www.itreseller.ch/Artikel/103975/Alphabet_ist_erstmals_3_Billionen_Dollar_Wert.html)16. September 2025 - -[](https://www.itreseller.ch/Artikel/103962/Adobe-Zahlen_uebertreffen_die_Markterwartungen.html) - -[### Adobe-Zahlen übertreffen die Markterwartungen](https://www.itreseller.ch/Artikel/103962/Adobe-Zahlen_uebertreffen_die_Markterwartungen.html) - -[Im jüngsten Quartal konnte Adobe beim Umsatz wie auch beim Gewinn zulegen. Da das Management auch die Umsatzprognose fürs gesamte Geschäftsjahr nach oben angepasst hat, konnte auch die Aktie profitieren.](https://www.itreseller.ch/Artikel/103962/Adobe-Zahlen_uebertreffen_die_Markterwartungen.html)12. September 2025 - -[](https://www.itreseller.ch/Artikel/103950/Oracles_IaaS-Umsaetze_gehen_durch_die_Decke.html) - -[### Oracles IaaS-Umsätze gehen durch die Decke](https://www.itreseller.ch/Artikel/103950/Oracles_IaaS-Umsaetze_gehen_durch_die_Decke.html) - -[Oracle kann starke Zahlen für das erste Quartal des Geschäftsjahres 2026 vorlegen. Vor allem das Cloud-Infrastruktur-Business boomt.](https://www.itreseller.ch/Artikel/103950/Oracles_IaaS-Umsaetze_gehen_durch_die_Decke.html)11. September 2025 - -[](https://www.itreseller.ch/Artikel/103946/Computacenter_meldet_Umsatzsprung_-_aber_nicht_fuer_Westeuropa.html) - -[### Computacenter meldet Umsatzsprung - aber nicht für Westeuropa](https://www.itreseller.ch/Artikel/103946/Computacenter_meldet_Umsatzsprung_-_aber_nicht_fuer_Westeuropa.html) - -[Computacenter kann für das erste Halbjahr 2025 beachtliche Zahlen vorlegen. Die westeuropäischen Märkte (exklusive UK) haben dazu jedoch nur bedingt beigetragen.](https://www.itreseller.ch/Artikel/103946/Computacenter_meldet_Umsatzsprung_-_aber_nicht_fuer_Westeuropa.html)10. September 2025 - -[](https://www.itreseller.ch/Artikel/103935/Aveniq_setzt_auf_Fokussierung_und_einheitliche_Strukturen.html) - -[### Aveniq setzt auf Fokussierung und einheitliche Strukturen](https://www.itreseller.ch/Artikel/103935/Aveniq_setzt_auf_Fokussierung_und_einheitliche_Strukturen.html) - -[Aveniq hat in Baden Anfang September den Business Summit 2025 veranstaltet. In diesem Rahmen gab Head of Sales & Marketing Walter Lienhard Einblick in den strategischen Status quo des IT-Dienstleisters.](https://www.itreseller.ch/Artikel/103935/Aveniq_setzt_auf_Fokussierung_und_einheitliche_Strukturen.html)9. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_023_www.itreseller.ch_rubriken_122_research.html.txt b/test_web_content_20251002_212426/additional_link_023_www.itreseller.ch_rubriken_122_research.html.txt deleted file mode 100644 index 87fc821e..00000000 --- a/test_web_content_20251002_212426/additional_link_023_www.itreseller.ch_rubriken_122_research.html.txt +++ /dev/null @@ -1,195 +0,0 @@ -URL: https://www.itreseller.ch/rubriken/122/research.html -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Research - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -RESEARCH --------- - -[](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - -[Swico ICT Index zeigt abermals Knick für das vierte Quartal ===========================================================](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - -[Der Swico ICT Index geht im vierten Quartal 2025 um 2 Punkte zurück. Noch sind viele Segmente im Wachstumsbereich, allerdings zeigen Unsicherheiten, Zölle und Wettbewerb Effekte.](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - - 1. Oktober 2025 - -Meistgelesen in Research - -[### Drucker-Firmware wird zu selten aktualisiert](https://www.itreseller.ch/Artikel/103970/Drucker-Firmware_wird_zu_selten_aktualisiert.html) 15. September 2025 - -[### Globaler Ethernet-Switch-Markt mit 42 Prozent Wachstum](https://www.itreseller.ch/Artikel/103966/Globaler_Ethernet-Switch-Markt_mit_42_Prozent_Wachstum.html) 15. September 2025 - -[### Huawei überholt Apple im Smartwatch-Markt](https://www.itreseller.ch/Artikel/103938/Huawei_ueberholt_Apple_im_Smartwatch-Markt.html) 9. September 2025 - -[### Europas Markt für Large Format Displays erleidet Einbussen](https://www.itreseller.ch/Artikel/103926/Europas_Markt_fuer_Large_Format_Displays_erleidet_Einbussen.html) 8. September 2025 - -[](https://www.itreseller.ch/Artikel/104059/Smartphone-Durchschnittspreise_steigen.html) - -[### Smartphone-Durchschnittspreise steigen Der durchschnittliche Preis, der für ein Smartphone bezahlt wird, soll von 370 Dollar in diesem Jahr auf 412 Dollar im Jahr 2029 steigen. 25. September 2025](https://www.itreseller.ch/Artikel/104059/Smartphone-Durchschnittspreise_steigen.html) - -[](https://www.itreseller.ch/Artikel/104026/Ausgaben_der_Hyperscaler_gehen_durch_die_Decke.html) - -[### Ausgaben der Hyperscaler gehen durch die Decke Die Hyperscaler investieren immer mehr in ihre Infrastruktur und hier vor allem in KI-Rechenzentren. Damit befeuern sie laut Analysten ihr "aggressives Wachstum". 24. September 2025](https://www.itreseller.ch/Artikel/104026/Ausgaben_der_Hyperscaler_gehen_durch_die_Decke.html) - -[](https://www.itreseller.ch/Artikel/104003/Globaler_Notebook-Markt_auf_Erholungskurs.html) - -[### Globaler Notebook-Markt auf Erholungskurs Fürs laufende Jahr prognostiziert Trendforce für den globalen Notebook-Markt ein Absatzplus von 2,2 Prozent. Das Wachstum gibt im Jahresverlauf allerdings kontinuierlich nach, um dann im Q4 in den negativen Bereich zu kippen. 22. September 2025](https://www.itreseller.ch/Artikel/104003/Globaler_Notebook-Markt_auf_Erholungskurs.html) - -[](https://www.itreseller.ch/Artikel/103990/KI-Ausgaben_sollen_sich_2025_auf_15_Billionen_Dollar_belaufen.html) - -[### KI-Ausgaben sollen sich 2025 auf 1,5 Billionen Dollar belaufen 2025 sollen die weltweiten Ausgaben für Künstliche Intelligenz knapp 1,5 Billionen US-Dollar ausmachen. Für das kommende Jahr prognostizieren Gartner-Analysten dann den Sprung über die 2-Milliarden-Marke. 18. September 2025](https://www.itreseller.ch/Artikel/103990/KI-Ausgaben_sollen_sich_2025_auf_15_Billionen_Dollar_belaufen.html) - -[](https://www.itreseller.ch/Artikel/103974/Europaeischer_PC-Markt_legt_im_dritten_Quartal_deutlich_zu.html) - -[### Europäischer PC-Markt legt im dritten Quartal deutlich zu Im Juli und August 2025 hat die europäische Distribution bei Desktop-PCs ein Umsatzplus von über 30 Prozent erreicht, während Notebooks um über 11 Prozent zulegten. 15. September 2025](https://www.itreseller.ch/Artikel/103974/Europaeischer_PC-Markt_legt_im_dritten_Quartal_deutlich_zu.html) - -[](https://www.itreseller.ch/Artikel/103970/Drucker-Firmware_wird_zu_selten_aktualisiert.html) - -[### Drucker-Firmware wird zu selten aktualisiert](https://www.itreseller.ch/Artikel/103970/Drucker-Firmware_wird_zu_selten_aktualisiert.html) - -[Mit Updates der Drucker-Firmware hapert es in vielen Unternehmen. Sicherheitsprobleme bestehen jedoch nicht nur im Betrieb, sie treten von der Beschaffung bis zur Entsorgung auf.](https://www.itreseller.ch/Artikel/103970/Drucker-Firmware_wird_zu_selten_aktualisiert.html)15. September 2025 - -[](https://www.itreseller.ch/Artikel/103967/Enterprise-WLAN-Markt_im_Q2_2025_deutlich_im_Plus.html) - -[### Enterprise-WLAN-Markt im Q2 2025 deutlich im Plus](https://www.itreseller.ch/Artikel/103967/Enterprise-WLAN-Markt_im_Q2_2025_deutlich_im_Plus.html) - -[Im zweiten Quartal 2025 legte der weltweite Enterprise-WLAN-Markt gegenüber der Vorjahresperiode um 13,2 Prozent zu. Marktführer ist Cisco, gefolgt vom HPE Aruba, Ubiquiti, Huawei und Juniper Networks.](https://www.itreseller.ch/Artikel/103967/Enterprise-WLAN-Markt_im_Q2_2025_deutlich_im_Plus.html)15. September 2025 - -[](https://www.itreseller.ch/Artikel/103966/Globaler_Ethernet-Switch-Markt_mit_42_Prozent_Wachstum.html) - -[### Globaler Ethernet-Switch-Markt mit 42 Prozent Wachstum](https://www.itreseller.ch/Artikel/103966/Globaler_Ethernet-Switch-Markt_mit_42_Prozent_Wachstum.html) - -[Der wachsende Bedarf der Hyperscaler sorgt im Markt für Ethernet Switches für einen aussergewöhnlichen Umsatzanstieg von über 42 Prozent auf 14,5 Milliarden Dollar.](https://www.itreseller.ch/Artikel/103966/Globaler_Ethernet-Switch-Markt_mit_42_Prozent_Wachstum.html)15. September 2025 - -[](https://www.itreseller.ch/Artikel/103939/_Weltweiter_Halbleitermarkt_waechst_2025_um_176_Prozent.html) - -[### Weltweiter Halbleitermarkt wächst 2025 um 17,6 Prozent](https://www.itreseller.ch/Artikel/103939/_Weltweiter_Halbleitermarkt_waechst_2025_um_176_Prozent.html) - -[Angetrieben durch die hohe Nachfrage nach KI-Infrastruktur und Rechenzentrums-Technologien wächst der weltweite Halbleitermarkt 2025 laut IDC um 17,6 Prozent auf 800 Milliarden US-Dollar. 2028 könnte eine Billion erreicht werden.](https://www.itreseller.ch/Artikel/103939/_Weltweiter_Halbleitermarkt_waechst_2025_um_176_Prozent.html)9. September 2025 - -[](https://www.itreseller.ch/Artikel/103938/Huawei_ueberholt_Apple_im_Smartwatch-Markt.html) - -[### Huawei überholt Apple im Smartwatch-Markt](https://www.itreseller.ch/Artikel/103938/Huawei_ueberholt_Apple_im_Smartwatch-Markt.html) - -[Huawei hat Apple als führenden Anbieter im globalen Smartwatch-Markt abgelöst, so Zahlen von Counterpoint. Apple-Kunden würden auf neue Modelle warten, diese werden wohl heute noch vorgestellt.](https://www.itreseller.ch/Artikel/103938/Huawei_ueberholt_Apple_im_Smartwatch-Markt.html)9. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_024_www.itreseller.ch_veranstaltungen.txt b/test_web_content_20251002_212426/additional_link_024_www.itreseller.ch_veranstaltungen.txt deleted file mode 100644 index 75566f89..00000000 --- a/test_web_content_20251002_212426/additional_link_024_www.itreseller.ch_veranstaltungen.txt +++ /dev/null @@ -1,151 +0,0 @@ -URL: https://www.itreseller.ch/veranstaltungen -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Veranstaltungen - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Veranstaltungen -=============== - -[### SCION Day 2025 Kongress/Konferenz Zürich • 21. Oktober 2025](https://www.itreseller.ch/veranstaltungen/2324/SCION_Day_2025.html) - -[### Global Cyber Conference 2025 Zürich • 22./23. Oktober 2025](https://www.itreseller.ch/veranstaltungen/2331/Global_Cyber_Conference_2025.html) - -[### Swiss Cyber Storm 2025 Resilience in a mad, mad world Bern • 28. Oktober 2025](https://www.itreseller.ch/veranstaltungen/2373/Swiss_Cyber_Storm_2025.html) - -[### Data Community Conference 2025 Kongress/Konferenz Bern • 5. November 2025](https://www.itreseller.ch/veranstaltungen/2376/Data_Community_Conference_2025.html) - - - -[### TEFO 2025 Studerus Technology Forum Regensdorf • 13. November 2025](https://www.itreseller.ch/veranstaltungen/2357/TEFO_2025.html) - -[### Digital Economy Award Zürich-Oerlikon • 13. November 2025](https://www.itreseller.ch/veranstaltungen/2374/Digital_Economy_Award.html) - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_025_www.itreseller.ch_jobs.txt b/test_web_content_20251002_212426/additional_link_025_www.itreseller.ch_jobs.txt deleted file mode 100644 index 977b450e..00000000 --- a/test_web_content_20251002_212426/additional_link_025_www.itreseller.ch_jobs.txt +++ /dev/null @@ -1,327 +0,0 @@ -URL: https://www.itreseller.ch/jobs -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -ICT-Stellenangebote - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Aktuelle ICT-Stellenangebote -============================ - -In Zusammenarbeit mit - -[](https://www.jobchannel.ch/inserieren/?utm_medium=affiliate&utm_source=Swiss%20IT%20Media%20GmbH&utm_campaign=PublishLink) - -Top Jobs der Woche ------------------- - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=&pbl=2&src=site_ict&nlc2=) - -[#### Senior .NET Softwareentwickler and Power Platform Engineer (m/w/d) 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187711&pbl=2&src=site_ict&nlc2=) - - Winterthur - -Ambit Schweiz AG (26. September 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=&pbl=2&src=site_ict&nlc2=) - -[#### System Engineer Microsoft (80–100%)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187693&pbl=2&src=site_ict&nlc2=) - - Dübendorf - -ITIVITY AG (25. September 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=&pbl=2&src=site_ict&nlc2=) - -[#### SAP Application Engineer Finance & Controlling | 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187611&pbl=2&src=site_ict&nlc2=) - - Burgdorf - -Ypsomed Diabetes Care AG (24. September 2025) - -Neueste IT-Jobs ---------------- - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187855&pbl=2&src=site_ict&nlc2=) - -[#### Azure Spezialist (axelion ag)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187855&pbl=2&src=site_ict&nlc2=) - - Zug - -Avalect HR-Executive Consulting (2. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187849&pbl=2&src=site_ict&nlc2=) - -[#### ICT-Koordination – spannende Stelle mit Entwicklungspotential 80%–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187849&pbl=2&src=site_ict&nlc2=) - - Zürich - -Meier-Kopp Gruppe (2. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187842&pbl=2&src=site_ict&nlc2=) - -[#### Software Developer – Professional/Senior 80-100% (a)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187842&pbl=2&src=site_ict&nlc2=) - - Altishofen - -Galliker Transport AG (2. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187836&pbl=2&src=site_ict&nlc2=) - -[#### ICT-Projektleiter/-in 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187836&pbl=2&src=site_ict&nlc2=) - - Bern - -Kanton Bern (2. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187816&pbl=2&src=site_ict&nlc2=) - -[#### Senior AI Business Consultant 70–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187816&pbl=2&src=site_ict&nlc2=) - - Bern - -Post CH AG (2. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187831&pbl=2&src=site_ict&nlc2=) - -[#### (Senior) IT Audit Managerin oder Manager Interne Revision (80%–100%)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187831&pbl=2&src=site_ict&nlc2=) - - Zürich - -Schweizerische Nationalbank (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187826&pbl=2&src=site_ict&nlc2=) - -[#### IT Security Spezialist/-in 100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187826&pbl=2&src=site_ict&nlc2=) - - Zürich - -Kanton Zürich (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187821&pbl=2&src=site_ict&nlc2=) - -[#### Enterprise Architect für digitale Steuerlösungen 100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187821&pbl=2&src=site_ict&nlc2=) - - Zürich - -Kanton Zürich (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187810&pbl=2&src=site_ict&nlc2=) - -[#### IT-Support & Helpdesk Manager:in](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187810&pbl=2&src=site_ict&nlc2=) - - Aarau - -Leoba GmbH (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187804&pbl=2&src=site_ict&nlc2=) - -[#### Mitarbeiter/in Informatik Systemtechnik (100%)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187804&pbl=2&src=site_ict&nlc2=) - - Münsingen - -Gemeinde Münsingen (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187798&pbl=2&src=site_ict&nlc2=) - -[#### Applikationsmanager:in (mit Erfahrung in Softwareentwicklung) 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187798&pbl=2&src=site_ict&nlc2=) - - Winterthur - -ZHAW (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187793&pbl=2&src=site_ict&nlc2=) - -[#### Requirements to Deployment Manager Customer Touchpoints 70–100% (oder im Jobsharing)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187793&pbl=2&src=site_ict&nlc2=) - - Bern - -Post CH AG (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187537&pbl=2&src=site_ict&nlc2=) - -[#### Head of Sales + Marketing 80–100% (w/m/d)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187537&pbl=2&src=site_ict&nlc2=) - - Bern - -SmartIT Services AG (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187777&pbl=2&src=site_ict&nlc2=) - -[#### IT-Fachapplikationsspezialist/-in 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187777&pbl=2&src=site_ict&nlc2=) - - Zürich - -Kanton Zürich (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187771&pbl=2&src=site_ict&nlc2=) - -[#### Praktikum Content Creation 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187771&pbl=2&src=site_ict&nlc2=) - - Aarau - -Kanton Aargau (1. Oktober 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187787&pbl=2&src=site_ict&nlc2=) - -[#### Head of Application Services | 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187787&pbl=2&src=site_ict&nlc2=) - - Burgdorf - -Ypsomed AG (30. September 2025) - -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187782&pbl=2&src=site_ict&nlc2=) - -[#### SAP Application Engineer Supply Chain Management | 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187782&pbl=2&src=site_ict&nlc2=) - - Burgdorf - -Ypsomed AG (30. September 2025) - -[.jpg)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187749&pbl=2&src=site_ict&nlc2=) - -[#### Senior .NET Engineer, 80–100% (w/m/d)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187749&pbl=2&src=site_ict&nlc2=) - - Zürich - -Swiss Life (Schweiz) AG (30. September 2025) - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -People - -[### Sonepar Schweiz ernennt Raphael Maier zum neuen CEO 1. Oktober 2025](https://www.itreseller.ch/Artikel/104095/Sonepar_Schweiz_ernennt_Raphael_Maier_zum_neuen_CEO.html) - -[### AWS ernennt Stéphane Israël zum Leiter der Sovereign Cloud 1. Oktober 2025](https://www.itreseller.ch/Artikel/104090/AWS_ernennt_Stphane_Isral_zum_Leiter_der_Sovereign_Cloud.html) - -[### Paessler bekommt mit Jason Teichman neuen CEO 1. Oktober 2025](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html) - -[### Renato Petrillo wird CEO von Baggenstos 30. September 2025](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab 30. September 2025](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_212426/additional_link_026_www.itreseller.ch_heftarchiv_2025.txt b/test_web_content_20251002_212426/additional_link_026_www.itreseller.ch_heftarchiv_2025.txt deleted file mode 100644 index 0ceb6db6..00000000 --- a/test_web_content_20251002_212426/additional_link_026_www.itreseller.ch_heftarchiv_2025.txt +++ /dev/null @@ -1,194 +0,0 @@ -URL: https://www.itreseller.ch/heftarchiv/2025 -Type: Additional Link -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Heftarchiv 2025 - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Heftarchiv 2025 -=============== - -< - -[2025](https://www.itreseller.ch/heftarchiv/2025)[2024](https://www.itreseller.ch/heftarchiv/2024)[2023](https://www.itreseller.ch/heftarchiv/2023)[2022](https://www.itreseller.ch/heftarchiv/2022)[2021](https://www.itreseller.ch/heftarchiv/2021)[2020](https://www.itreseller.ch/heftarchiv/2020)[2019](https://www.itreseller.ch/heftarchiv/2019)[2018](https://www.itreseller.ch/heftarchiv/2018)[2017](https://www.itreseller.ch/heftarchiv/2017)[2016](https://www.itreseller.ch/heftarchiv/2016)[2015](https://www.itreseller.ch/heftarchiv/2015)[2014](https://www.itreseller.ch/heftarchiv/2014)[2013](https://www.itreseller.ch/heftarchiv/2013)[2012](https://www.itreseller.ch/heftarchiv/2012)[2011](https://www.itreseller.ch/heftarchiv/2011)[2010](https://www.itreseller.ch/heftarchiv/2010)[2009](https://www.itreseller.ch/heftarchiv/2009) - -> - -X - -Heftarchiv-Premium-Zugriff --------------------------- - - Der Zugriff auf das Heftarchiv von "IT Reseller" wird exklusiv den Abonnenten der Print-Ausgabe zur Verfügung gestellt. - - Um eine beliebige Ausgabe herunterzuladen, geben Sie bitte den Premium-Zugangscode ein, den Sie auf der Editorial-Seite der aktuellen Ausgabe finden, und klicken Sie auf den Download-PDF-Button. - -**Premium-Zugangscode** - -Ausgabe 2025/10 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202510_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202510/inhaltsverzeichnis.html) - -Ausgabe 2025/09 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202509_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202509/inhaltsverzeichnis.html) - -Ausgabe 2025/7-8 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202507_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202507/inhaltsverzeichnis.html) - -Ausgabe 2025/06 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202506_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202506/inhaltsverzeichnis.html) - -Ausgabe 2025/05 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202505_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202505/inhaltsverzeichnis.html) - -Ausgabe 2025/04 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202504_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202504/inhaltsverzeichnis.html) - -Ausgabe 2025/03 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202503_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202503/inhaltsverzeichnis.html) - -Ausgabe 2025/1-2 - -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202501_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202501/inhaltsverzeichnis.html) - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) - - - -[](https://www.itreseller.ch/heftarchiv/2025)[](https://www.itreseller.ch/heftarchiv/2025) - -[](https://www.itreseller.ch/heftarchiv/2025) - -[](https://www.itreseller.ch/heftarchiv/2025) \ No newline at end of file diff --git a/test_web_content_20251002_212426/main_url_001_www.valueon.ch_.txt b/test_web_content_20251002_212426/main_url_001_www.valueon.ch_.txt deleted file mode 100644 index d5290b1f..00000000 --- a/test_web_content_20251002_212426/main_url_001_www.valueon.ch_.txt +++ /dev/null @@ -1,107 +0,0 @@ -Title: https://www.valueon.ch/ -URL: https://www.valueon.ch/ -Type: Main URL -Extracted: 2025-10-02 21:24:26 -================================================================================ - -# Power für deinendigitalen Erfolg - -Vertrauen von führenden Unternehmen - -## Unsere Expertise - -Von digitaler Transformation bis zu künstlicher Intelligenz – wir begleiten Sie auf Ihrem Weg in die Zukunft. - -### Digitale Strategie entwickeln - -Ihre Richtung im digitalen Wandel. - -Gemeinsames Zielbild & Roadmap, abgestimmt auf Ihr Geschäft und leiten konkrete Handlungsempfehlungen ab. - -Orientierung & Handlungssicherheit - -### Transformation gezielt optimieren - -Lücken aufdecken. Stärken nutzen. - -Systematischer Blick auf Prozesse, Systeme & Potenziale und leiten konkrete Handlungsempfehlungen ab. - -Relevanz statt Aktionismus - -### Change Management etablieren - -Menschen mitnehmen. Wandel gestalten. - -Strukturierte Begleitung der Mitarbeiter durch den digitalen Wandel mit gezielten Schulungskonzepten. - -Akzeptanz & Erfolg sichern - -### Prozesse digital automatisieren - -Effizienz steigern. Kosten senken. - -Identifikation und Umsetzung von Automatisierungspotenzialen für nachhaltige Produktivitätssteigerung. - -Messbare Effizienzgewinne - -## Erfolgreiche Projekte & Transformationen - -Unter dem Motto «Unsere Kunden stehen im Mittelpunkt» haben wir für Sie eine Auswahl an Kundenreferenzen und Business Cases zusammengestellt. - -Als KMU sind wir es eigentlich nicht gewohnt, einen so grossen Aufwand wie bei der Evaluation des richtigen Partners für die Entwicklung und Realisierung unseres neuen Kernsystems zu betreiben. Doch i... - -Markus Berther - -Geschäftsführer, Schaden Service Schweiz AG - -ValueOn hat uns durch den gesamten Prozess der Digitalen Business Transformation mit grossem Einsatz und Engagement begleitet – von der ersten IT-Standortanalyse und Sourcing Analyse über digitales Zi... - -Stefan Wolf - -Präsident, FC Luzern - -In diesem businesskritischen IT-Programm waren insgesamt vier Experten von ValueOn (ehem. Project Competence) involviert, als Projektleiter und Koordinator, Cut-Over-Manager bis hin zur Gesamt-Program... - -Roland Bosshard - -CIO / Mitglied der GL, KPT - -In time, in quality, under budget: Andreas Friedli von ValueOn (ehem. Project Competence) hat in seiner Co-Leitungsfunktion in diesem IT-Projekt ganz massgeblich dazu beigetragen, dass wir dieses trot... - -Thomas Sturzenegger - -Divisional IT Lead, RUAG Real Estate AG - -Die erfolgreiche Realisierung dieses Vorhabens ist ein wichtiger Meilenstein für die strategische Neuausrichtung der WWZ. Die Projektberater der ValueOn AG (ehem. Project Competence AG) haben dabei da... - -Thomas Reber - -Leiter Telekom & IT Services, WWZ AG - -Um die Zukunftsausrichtung unserer IT-Strategie und -Organisation möglichst optimal auf unsere Business-Anforderungen auszurichten, haben wir ValueOn (ehem. Project Competence) als Sparringpartner ... - -Andreas Guglielmo - -CFO, CHRIS sports AG - -Wir danken den externen Projektberatern der ValueOn (ehem. Project Competence), die uns kompetent und mit ebenso hohem Arbeitseinsatz durch dieses Projekt und die Verhandlungen unter schwierigen Be... - -Michael Kohlbacher - -Generalsekretär, AGZ - -Dank ValueOn konnten wir unser komplexes IT-Infrastrukturprojekt termingerecht und im Budget abschliessen. Die strukturierte Herangehensweise war ausschlaggebend. - -Peter Keller - -Projektleiter, InnovaCorp - -ValueOn hat uns sowohl fachlich als auch menschlich auf höchstem Niveau beraten. Die Experten begleiteten uns kompetent bei der Modernisierung unserer IT-Infrastruktur und der reibungslosen Ablösung u... - -Silvan Wildhaber - -CEO, Filtex Group AG - -← Wischen Sie für weitere Testimonials → - -Auto-Scroll aktiv \ No newline at end of file diff --git a/test_web_content_20251002_212426/main_url_002_www.valueon.ch_about.txt b/test_web_content_20251002_212426/main_url_002_www.valueon.ch_about.txt deleted file mode 100644 index 448c339d..00000000 --- a/test_web_content_20251002_212426/main_url_002_www.valueon.ch_about.txt +++ /dev/null @@ -1,639 +0,0 @@ -Title: https://www.valueon.ch/about -URL: https://www.valueon.ch/about -Type: Main URL -Extracted: 2025-10-02 21:24:26 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unser Team -========== - -Seit über 25 Jahren stehen wir für Innovation, Qualität und nachhaltigen Erfolg. Erfahren Sie mehr über unsere Geschichte, unsere Werte und die Menschen, die ValueON zu dem machen, was es heute ist. - -Alle Kernteam Geschäftsführende Partner Externe Zertifizierte Partner - - - -Mehr erfahren - -### Dominic Largo - -CEO - - - -Dominic führt das Unternehmen mit einer klaren Vision für digitale Innovation und strategisches Wachstum in der Beratung. - -### Dominic Largo - -CEO - - - -Zum Vergrößern klicken - -#### Schwerpunkte - -* Sicherstellen der besten Projekt- & Tranformationsmanager für unsere Kunden und unsere Vorhaben -* Reviews von komplexen und erfolgskritischen Vorhaben -* Advisor & Einsitz in Steering Boards -* Sparringpartner für Führungskräfte und Gremien - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Handel / eCommerce Tourismus Konsumgüter Luxusgüter Industrie - -#### Berufliche Stationen - -* BottleButler AG (Founder & CEO) -* Arosa Lenzerheide (Marken- und Digital Leader) -* Mitgründer mehrerer Startups (Co-CEO & VR) -* Porsche Design Group (Country Manager & GCC) -* HAWAS & Jung von Matt (Markenstratege) - -#### Und ganz nebenbei... - -...ist Dominic Largo mit grosser Passion Langstreckenläufer, Kulinariker und Game Challenger. Er geniesst explizit die Berge und seine Familienzeit. - - - -Mehr erfahren - -### Andreas Friedli - -Managing Partner - - - -Mit über 25 Jahren Erfahrung in der digitalen Transformation leitet Andreas als Partner erfolgreich strategische Grossprojekte. - -### Andreas Friedli - -Managing Partner - -#### Schwerpunkte - -* Health-Check von Projekten und Programmen -* Advisor digitaler Transformationen -* Führung von Digitalisierungsprojekten und -programmen -* Emergency- und Recoveryprojekte -* Risiko- und Quality-Assurance bei digitalen Transformationen -* Advisor digitaler Neuausrichtungen -* Leadership-Coaching Projekt und Programm Manager - -#### Im Team seit - -2004 - -#### Branchenerfahrungen - -Finanzen / Banken Versicherungen / Krankenkassen Detailhandel Verwaltung Militär Automobile IT / Telekommunikation Immobilien - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of Complex Projects -* HP GmbH, Senior Project Manager -* Compaq Computer GmbH, Senior Project Manager -* Volkswirtschaftsdep. St. Gallen, Informatikverantwortlicher - -#### Und ganz nebenbei... - -…spielt Andreas Friedli gerne Golf, liebt feines Essen und guten Wein und verbringt viel Zeit mit seiner Familie – ganz nach dem Motto «Geniesse den Moment!». - - - -Mehr erfahren - -### Patrick Motsch - -Managing Partner - - - -Patrick leitet als Partner erfolgreich komplexe IT-Implementierungsprojekte. - -### Patrick Motsch - -Managing Partner - -#### Schwerpunkte - -* Health Check von Projekten -* Führen von geschäftskritischen Projekten und Programmen -* Führen und Begleiten von Emergency und Recovery Projekten -* Führen und Begleiten von DC Moves und ICT Konsolidierungsprojekten -* Advisor für Auftraggeber - -#### Im Team seit - -2001 - -#### Branchenerfahrungen - -Baubranche IT / Telekommunikation / Data Center Industrie Sport Verteidigung Verwaltung Airspace Management Versicherungen Handel - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG) -* Vater und Pionier des TimeWinner Führungssystems -* CIO einer IT Consulting Organisation - -#### Und ganz nebenbei... - -…liebt Patrick Motsch den Garten, das Tanzen, wandert gerne, taucht so oft es geht und lernt gerne fremde Länder kennen. Sein persönliches Motto: «Wer will, der kann». - - - -Mehr erfahren - -### Richard Salvisberg - -Managing Partner - - - -Richard bringt als Partner strategische Beratungsexpertise und Führungskompetenz ein. - -### Richard Salvisberg - -Managing Partner - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Führen von geschäftskritischen Programmen und Transformationen -* Aufbau und Führen von Projektportfolio-Managementsystemen -* Sparringpartner und Advisor - -#### Im Team seit - -2006 - -#### Branchenerfahrungen - -Gesundheitswesen & (Kranken-)Versicherung Militär Verwaltung Beschaffungswesen & Transport Informatik & Telekommunikation Bau Sport Energie - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of PPM -* T-Systems Schweiz AG, Chief Information Officer -* Orange Communications SA, IT Account Manager -* Swisscom AG Bern, Head Management Support -* Swisscom AG Bern, Programm Manager Charging & Billing - -#### Und ganz nebenbei... - -…liebt Richard Salvisberg das Tanzen, lernt gerne fremde Kulturen kennen, hat Freude an schönen Autos und geniesst ein Buch bei einem guten Schluck Wein. In klaren Nächten beobachtet er interessiert den Kosmos. Sein persönliches Motto lautet «Auf innovativen Wegen nachhaltige Erfolge erzielen». - - - -Mehr erfahren - -### Stephan Schellworth - -Experte - - - -Stephan verbindet strategisches Denken mit praxisnaher Projektsteuerung und gestaltet digitale Projekte - -### Stephan Schellworth - -Experte - -#### Schwerpunkte - -* Projekt- und Teamführung -* Datenanalyse und Optimierung -* Agiles Projektmanagement - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Automatisierungstechnik Digitalisierung - -#### Berufliche Stationen - -* 2023 - 2024: Testmanager im Energiebordnetz, BMW Group -* 2021 - 2023: Gesamtfahrzeugspezialist in der E/E, BMW Group -* 2018 - 2021: Prüfstandsspezialist im BMW Prototypen-Motorenwerk, Academic Work -* 2016 - 2018: Entwicklungsingenieur, EDAG Engineering Group - -#### Und ganz nebenbei... - -…sammelt und pflegt Stephan Young- und Oldtimern, treibt Sport wie Squash und besucht regelmässig das Fitnessstudio. Er geht gern mit seinem Hund spazieren oder wandert in der Natur. Ausserdem programmiert er kleinere SmartHome-Anwendungen mit dem Raspberry Pi, Apps und erstellt 3D-Visualisierungen von Innen- und Aussenräumen. - - - -Mehr erfahren - -### Mats Rudolf - -Experte - - - -Mats berät Unternehmen zu digitalen Transformationsprojekten und Systemimplementierungen. - -### Mats Rudolf - -Experte - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Advisor digitaler Transformation -* Advisor Systems Engineering -* Projekt- und Teamführung -* Agiles Projektmanagement - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Sensortechnik Luft- und Raumfahrttechnik Maschinen- und Anlagenbau Transport und Logistik - -#### Berufliche Stationen - -* 2019 - 2024: Management Consultant Innovation und Transformation, UNITY Schweiz AG -* 2018: Industrial Solution Consulting Intern, Brütsch Rüegger Werkzeuge -* 2015 - 2016: Sensor Research and Development Intern, Sensirion AG - -#### Und ganz nebenbei... - -…zieht es Mats Rudolf im Winter für Skitouren und rasante Abfahrten auf die frisch verschneiten Berge. Wenn der Sommer kommt, tauscht er seine Ski gegen ein Surfbrett und geniesst die Wellen im Meer. Zudem schwingt er gerne den Schläger auf dem Tennisplatz und bastelt an seinen Smart-Device-Projekten. - - - -Mehr erfahren - -### Ida Dittrich - -AI Specialist - -Ida verbindet ihr wissenschaftliches Know-how mit praktischer IT-Erfahrung und bringt innovative Ansätze in technische Projekte ein. - -### Ida Dittrich - -AI Specialist - -#### Schwerpunkte - -* Product Architect and Software Engineer PowerOn Platform - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Luft- und Raumfahrtindustrie Kommunikation und Interessenvertretung Medien - -#### Berufliche Stationen - -* Forschungsprojekt zur Modellierung des inneren Aufbaus terrestrischer Exoplaneten (ETH Zürich) -* Recovery Engineer und Systems Engineer bei verschiedenen Projekten der Akademischen Raumfahrtinitiative der Schweiz (ARIS) - -#### Und ganz nebenbei... - -… spielt Ida Dittrich leidenschaftlich gern Computerspiele und bastelt an handwerklichen Projekten wie Nähen, Häkeln oder Stricken. Sie ist regelmäßig sportlich aktiv – sei es beim Joggen an der frischen Luft, im Fitnessstudio oder bei einer entspannenden Yoga-Einheit. - - - -Mehr erfahren - -### Nick Melloh - -AI-Specialist - -Nick macht künstliche Intelligenz für Unternehmen greifbar – in Projekten, Strategien und praxisnahen Schulungen. - -### Nick Melloh - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Digitale Transformation & Business Innovation -* Advisor für Künstliche Intelligenz & Wissensvermittlung -* Advisor für Strategisches Projekt- und Prozessmanagement -* Trainer für KI-Schulungen und Weiterbildung - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Digitalisierung Consulting Hospitality Event- und Innovationsmanagement KI-Anwendungen - -#### Berufliche Stationen - -* 2023–heute: Master in Business Innovation, Universität St. Gallen – Schwerpunkt Digitale Transformation & KI -* 2023–heute: Event Manager SQUARE, Universität St. Gallen – Gestaltung innovativer Lern- und Austauschformate -* 2022–2023: VP Sales, Contler AG – SaaS-Lösungen & Prozessautomatisierung im Hospitality-Sektor - -#### Und ganz nebenbei... - -…hat Nick eine Schwäche für Reisen, gutes Essen und Bücher – um neue Denkanstöße zu gewinnen und frische Perspektiven einzunehmen. Energie findet er beim Sport, in den Bergen oder bei langen Gesprächen mit Freunden – die besten Momente für ihn sind die, in denen die Uhr keine Rolle spielt. - - - -Mehr erfahren - -### Yannick Althaus - -AI-Specialist - -Yannick berät Unternehmen, indem er Strategiekompetenz mit unternehmerischer DNA verbindet. - -### Yannick Althaus - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Strategisches Management und Unternehmensführung -* Advisor für Künstliche Intelligenz und digitale Transformation -* Advisor für Produktion und Supply Chain Management - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Industrie Digitalisierung Supply Chain Management Consulting - -#### Berufliche Stationen - -* 2025: M.A. HSG in Unternehmensführung - Masterarbeit zum Einsatz von generativer KI in der Strategieentwicklung von CEOs -* 2022: B.Sc. Wirtschaftsingenieurwesen -* 2019–2025: Diverse Consulting-Praktika & Projekte in Supply Chain Management, Digitalisierung und strategischem Management sowie Mitarbeit im Familienunternehmen (neben dem Studium) -* 2013–2017: Automatiker EFZ bei Bystronic - -#### Und ganz nebenbei... - -…wenn er nicht an Strategien feilt, zieht es Yannick aufs Eis – Eishockey ist sein Adrenalinschub. Auch sonst bleibt er regelmässig in Bewegung: Skifahren im Winter, Joggen zwischendurch und Golf im Sommer. Ausserdem hat er eine Schwäche für schnelle Autos und reist gerne – am liebsten ans Meer. - - - -### Philipp Dick - -Certified Partner - -"KI wird Manager nicht ersetzen, aber Manager, die KI einsetzen, werden die ersetzen, die es nicht tun." - - - -### Romano Caviezel - -Certified Partner - -"Innovation bedeutet, bestehende Dinge zu hinterfragen und neue Wege zu entdecken." - - - -### Dawid Puzik - -Certified Partner - -"Manche sehen, was möglich ist – andere verändern, was möglich ist." - - - -### Holger Ridinger - -Certified Partner - -"Transformation braucht Struktur, Leidenschaft und Ausdauer." - - - -### Alain Kappeler - -Certified Partner - -"Wenn es dich nicht herausfordert, verändert es dich nicht." - - - -### Andreas Wyss - -Certified Partner - -Andreas verbindet strategisches Denken mit menschlichem Feingefuehl in Transformationsprozessen. - - - -### Alfredo Mercurio - -Certified Partner - -"Eine klare Vision ist der Anfang von allem." - - - -### Bernd Nagel - -Certified Partner - -"Wer will, findet Wege. Wer nicht will, findet Gründe." - - - -### Daniel Sengstag - -Certified Partner - -"Wer nicht mit der Zeit geht, geht mit der Zeit." - - - -### Daniel Lochmatter - -Certified Partner - -"Neues und bisher Unbekanntes kann man nur explorativ erfahren, erspüren, erlernen – und danach zum eigenen Nutzen einsetzen." - - - -### Michael Hermann - -Certified Partner - -"Auch beim Projekt gilt: Ende gut, alles gut." - - - -### Heinz Ruffieux - -Certified Partner - -"C'est le ton qui fait la musique." - - - -### Sven Fassbender - -Certified Partner - -"Mein Ziel ist es, Cybersicherheit verständlich und greifbar zu machen – für jeden zugänglich und praktikabel." - - - -### Raffael Santchi - -Certified Partner - -"Wer Prozesse versteht, kann Systeme formen – nicht umgekehrt." - - - -### Stephanie Kieninger - -Certified Partner - -Stephanie konzentriert sich mit ihrer Beratung auf die Menschen im Veraenderungsprozess. - - - -### Christoph Merle - -Certified Partner - -Christoph engagiert sich mit seiner langjährigen Führungserfahrung in der Industrie und mit seinem Hintergrund in strategischer und operativer Beratung für den Erfolg unserer Kunden. - -Previous slide Next slide - -Über ValueOn ------------- - -Wir schaffen digitale Transformation mit Leidenschaft und Expertise - -### Unsere Mission - -Durch exzellente Beratung schaffen wir digitale Transformation erfolgreich zu meistern. - -### Unser Versprechen - -Höchste Qualität, agile Ansätze und Passion für gemeinsamen Wirken - -25+ - -Jahre Erfahrung - -100+ - -Projekte - -98% - -Weiterempfehlung - -60% - -Schneller zum Ziel - -Unsere Geschichte ------------------ - -Eine Reise der Innovation - -Heute - -Heute und Morgen - -Als führendes Beratungsunternehmen gestalten wir aktiv die Zukunft der digitalen Transformation mit innovativen KI-Lösungen und nachhaltigen Strategien. - -KI-Ära - -KI-Revolution - -Die Einführung von KI-Systemen veränderte unsere Beratungsleistung grundlegend und ermöglichte es uns, unseren Kunden noch innovativere Lösungen anzubieten. - -Digital - -Digitale Transformation - -Mit neuen digitalen Lösungen begleiteten wir unsere Kunden in der Transformation und etablierten uns als führender Partner für digitale Innovation. - -Aufbau - -Etablierung am Markt - -Wir etablierten uns am Markt mit innovativen IT-Strategien und nachhaltiger Umsetzung, wodurch wir eine solide Basis für weiteres Wachstum schufen. - -2000 - -Gründung von ValueON - -ValueON wurde mit der Vision gegründet, Unternehmen bei der digitalen Transformation zu unterstützen und nachhaltigen Erfolg zu schaffen. - -Unsere Werte ------------- - -Was uns antreibt - -### Exzellenz - -Höchste Qualität in allem, was wir tun. Von der ersten Beratung bis zur finalen Umsetzung setzen wir auf höchste Standards. - -### Partnerschaft - -Wir sehen uns als langfristige Partner unserer Kunden und arbeiten gemeinsam an nachhaltigen Lösungen. - -### Integrität - -Ehrlichkeit, Transparenz und Vertrauen bilden das Fundament aller unserer Geschäftsbeziehungen. - -### Effektivität - -Zielgerichtete Lösungen, die messbare Ergebnisse liefern und nachhaltigen Geschäftserfolg schaffen. - -Karriere bei ValueOn --------------------- - -Werde Teil unseres Teams - -### Product-Architekt/in für KI-Plattformen - -Zürich, Schweiz M/W, 50-100% - -Details ansehen - -Keine passende Stelle gefunden? - -[Initiativbewerbung senden](mailto:office@valueon.ch) - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_212426/main_url_003_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt b/test_web_content_20251002_212426/main_url_003_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt deleted file mode 100644 index 9f8265ed..00000000 --- a/test_web_content_20251002_212426/main_url_003_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt +++ /dev/null @@ -1,364 +0,0 @@ -Title: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 -Type: Main URL -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](#)[Save + Exit](#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - -[Startseite](/de/) [>](javascript:void(0)) [Unternehmen](/de/search?q=ValueOn AG) [>](javascript:void(0)) ValueOn AG - -# ValueOn AG - -ZH - -aktiv - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) -[Zur Timeline](/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -Handelsregister-Nr.: CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](/de/company/valueon-ag-4663161481/messages) - -[Sie möchten eine Änderung der Firmendaten vornehmen? Wir unterstützen Sie hierbei gerne.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Alter der Firma - -18 Jahre - -#### Umsatz in CHF - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Kapital in CHF - -200'000 - -#### Mitarbeiter - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Aktive Marken - -0 - -c/o Westhive AG -Am Stadtrand 11 -8600 Dübendorf -[Nachbarschaft](/de/company/valueon-ag-4663161481/network#neighbourhood) - -[Sie möchten Ihre Adresse anpassen? -Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -[News aus der Region Uster](/de/region/uster/uebersicht) - -## Auskünfte zu ValueOn AG - -\*angezeigte Auskünfte sind Beispiele - -#### Bonitätsauskunft - -Einschätzung der Bonität mit einer Ampel als Risikoindikator und weiteren hilfreichen Firmeninformationen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -#### Wirtschaftsauskunft - -Umfassende Auskunft über die wirtschaftliche Situation der Firma. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#commercial-report) - -#### Zahlungsverhalten - -Beurteilung der Zahlungsmoral aufgrund vergangener Rechnungen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-mode-report) - -#### Betreibungsauskunft - -Übersicht über aktuelle und vergangene Betreibungsverfahren. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-collection-report) - -#### Beteiligungsauskunft - -Erfahren Sie, an welchen nationalen und internationalen Firmen die Aktiengesellschaft, für die Sie sich interessieren, noch beteiligt ist. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#wow-report) - -#### Firmendossier als PDF - -Kontaktinformationen, Veränderungen, Umsatz- und Mitarbeiterzahlen, Management, Besitzverhältnisse, Beteiligungsstruktur und weitere Firmendaten. -[Jetzt kostenlos abrufen](/de/company/valueon-ag-4663161481/reports#firmendossier-report) - -## Über ValueOn AG - -* ValueOn AG hat den Sitz in Dübendorf, ist aktiv und im Bereich «Erbringen von IT-Dienstleistungen» tätig. - - - -* Das [Management](valueon-ag-4663161481/management) der Firma ValueOn AG besteht aus 5 Personen. - - - -* Unter [Meldungen](valueon-ag-4663161481/messages) finden Sie alle Handelsregisteränderung, die letzte erfolgte am 27.08.2025. - - - -* Die Firma ist im Handelsregister des Kantons ZH unter der UID CHE-113.416.882 eingetragen. - - - -* Unternehmen mit derselben Adresse wie ValueOn AG: [Black Projects GmbH](black-projects-gmbh-3958227961), [Bluespace Ventures AG](bluespace-ventures-ag-20038582721), [Cyberfy Consulting AG](cyberfy-consulting-ag-5194156221). - -## Management (5) - -#### neueste Verwaltungsräte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901) - -#### neuste Zeichnungsberechtigte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -#### Geschäftsleitung - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -Quelle: [SHAB](/de/datasources) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -## Netzwerk - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -## Handelsregisterinformationen - -Quelle: [SHAB](/de/datasources) - -#### Eintrag ins Handelsregister - -02.02.2007 - -#### Rechtsform - -Aktiengesellschaft - -#### Rechtssitz der Firma - -Dübendorf - -#### Handelsregisteramt - -ZH - -#### Handelsregister-Nummer - -CH-020.3.030.651-3 - -#### UID/MWST - -CHE-113.416.882 - -#### Branche - -Erbringen von IT-Dienstleistungen - -#### Firmenzweck - -Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -[Passen Sie den Firmenzweck mit wenigen Klicks an.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Revisionsstelle - -Quelle: [SHAB](/de/datasources) - -#### Aktive Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [TBO Revisions AG](/de/company/tbo-revisions-ag-20607789301) | | Zürich | 18.03.2015 | | - -[Möchten Sie die Revisionsstelle anpassen? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Frühere Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [Trevisca AG](/de/company/trevisca-ag-20628390611) | | Baar | 08.02.2007 | 17.03.2015 | - -## Weitere Firmennamen - -Quelle: [SHAB](/de/datasources) - -#### Frühere und übersetzte Firmennamen - -* Project Competence AG - -[Möchten Sie den Firmennamen aktualisieren? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Zweigniederlassungen (0) - -## Besitzverhältnisse - -Es liegen uns keine Angaben zu den Besitzverhältnissen vor. - -## Beteiligungen - -Es liegen uns keine Angaben zu den Beteiligungen vor. - - - - - - - - - -## Neueste SHAB-Meldungen: ValueOn AG - -SHAB 250827/2025 - 27.08.2025 - -**Kategorien:** Änderung des Firmenzwecks, Änderung der Firmenadresse - -Publikationsnummer: [HR02-1006417690](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006417690 "Download SHAB Publikation der ValueOn AG vom 27.08.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 133 vom 14.07.2025, Publ. 1006383218). - -**Statutenänderung:** - 18.08.2025. - -**Sitz neu:** - Dübendorf. - -**Domizil neu:** - c/o Westhive AG, Am Stadtrand 11, 8600 Dübendorf. - -**Zweck neu:** - Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -**Mitteilungen neu:** - Mitteilungen an die Aktionäre erfolgen per Brief oder E-Mail an die im Aktienbuch verzeichneten Adressen. - -SHAB 250714/2025 - 14.07.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006383218](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006383218 "Download SHAB Publikation der ValueOn AG vom 14.07.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 101 vom 27.05.2025, Publ. 1006341693). - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Einzelunterschrift [*bisher: Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]. - -SHAB 250527/2025 - 27.05.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006341693](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006341693 "Download SHAB Publikation der ValueOn AG vom 27.05.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 222 vom 14.11.2024, Publ. 1006178101). - -**Ausgeschiedene Personen und erloschene Unterschriften:** - Hamburger, Marc Eric, von St. Gallen, in Mörschwil, Präsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Egloff, Reto](/de/person/egloff-reto-101763781201), von Oberrohrdorf, in Bern, Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Mühlemann, Markus](/de/person/muehlemann-markus-142196879901), von Seeberg, in Uster, Delegierter des Verwaltungsrates, mit Einzelunterschrift. - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien [*bisher: Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]; - [Althaus, Walter](/de/person/althaus-jun-walter-205367807901), von Affoltern im Emmental, in Aarwangen, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Wyss, Andreas](/de/person/wyss-andreas-129476912501), von Dietikon, in Dietikon, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien. - -[Alle SHAB-Meldungen ansehen](/de/company/valueon-ag-4663161481/messages) - -## Trefferliste - -Hier finden Sie eine Verlinkung des Managements auf eine Trefferliste zu Personen mit dem gleichen Namen, die im Handelsregister eingetragen sind. - -[Dominic Pascal Largo](/de/list/person/largo-dominic-pascal) - -[Andreas Wyss](/de/list/person/wyss-andreas) - -[Walter Althaus Jun.](/de/list/person/althaus-jun-walter) - -[Andreas Friedli](/de/list/person/friedli-andreas) - -[Richard Salvisberg](/de/list/person/salvisberg-richard) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](/de/terms)[Datenschutz |](/de/privacy)[Impressum](/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](/de/overview) - - - - - - -[Übersicht](/de/company/valueon-ag-4663161481) - -[Auskünfte](/de/company/valueon-ag-4663161481/reports) - -[Management](/de/company/valueon-ag-4663161481/management) - -[Netzwerk](/de/company/valueon-ag-4663161481/network) - -[Timeline](/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](/de/company/valueon-ag-4663161481/shares) - -[Meldungen](/de/company/valueon-ag-4663161481/messages) - -[Marken](/de/company/valueon-ag-4663161481/brands) - -[Jobs](/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_212426/main_url_004_www.valueon.ch_about.txt b/test_web_content_20251002_212426/main_url_004_www.valueon.ch_about.txt deleted file mode 100644 index 448c339d..00000000 --- a/test_web_content_20251002_212426/main_url_004_www.valueon.ch_about.txt +++ /dev/null @@ -1,639 +0,0 @@ -Title: https://www.valueon.ch/about -URL: https://www.valueon.ch/about -Type: Main URL -Extracted: 2025-10-02 21:24:26 -================================================================================ - -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unser Team -========== - -Seit über 25 Jahren stehen wir für Innovation, Qualität und nachhaltigen Erfolg. Erfahren Sie mehr über unsere Geschichte, unsere Werte und die Menschen, die ValueON zu dem machen, was es heute ist. - -Alle Kernteam Geschäftsführende Partner Externe Zertifizierte Partner - - - -Mehr erfahren - -### Dominic Largo - -CEO - - - -Dominic führt das Unternehmen mit einer klaren Vision für digitale Innovation und strategisches Wachstum in der Beratung. - -### Dominic Largo - -CEO - - - -Zum Vergrößern klicken - -#### Schwerpunkte - -* Sicherstellen der besten Projekt- & Tranformationsmanager für unsere Kunden und unsere Vorhaben -* Reviews von komplexen und erfolgskritischen Vorhaben -* Advisor & Einsitz in Steering Boards -* Sparringpartner für Führungskräfte und Gremien - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Handel / eCommerce Tourismus Konsumgüter Luxusgüter Industrie - -#### Berufliche Stationen - -* BottleButler AG (Founder & CEO) -* Arosa Lenzerheide (Marken- und Digital Leader) -* Mitgründer mehrerer Startups (Co-CEO & VR) -* Porsche Design Group (Country Manager & GCC) -* HAWAS & Jung von Matt (Markenstratege) - -#### Und ganz nebenbei... - -...ist Dominic Largo mit grosser Passion Langstreckenläufer, Kulinariker und Game Challenger. Er geniesst explizit die Berge und seine Familienzeit. - - - -Mehr erfahren - -### Andreas Friedli - -Managing Partner - - - -Mit über 25 Jahren Erfahrung in der digitalen Transformation leitet Andreas als Partner erfolgreich strategische Grossprojekte. - -### Andreas Friedli - -Managing Partner - -#### Schwerpunkte - -* Health-Check von Projekten und Programmen -* Advisor digitaler Transformationen -* Führung von Digitalisierungsprojekten und -programmen -* Emergency- und Recoveryprojekte -* Risiko- und Quality-Assurance bei digitalen Transformationen -* Advisor digitaler Neuausrichtungen -* Leadership-Coaching Projekt und Programm Manager - -#### Im Team seit - -2004 - -#### Branchenerfahrungen - -Finanzen / Banken Versicherungen / Krankenkassen Detailhandel Verwaltung Militär Automobile IT / Telekommunikation Immobilien - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of Complex Projects -* HP GmbH, Senior Project Manager -* Compaq Computer GmbH, Senior Project Manager -* Volkswirtschaftsdep. St. Gallen, Informatikverantwortlicher - -#### Und ganz nebenbei... - -…spielt Andreas Friedli gerne Golf, liebt feines Essen und guten Wein und verbringt viel Zeit mit seiner Familie – ganz nach dem Motto «Geniesse den Moment!». - - - -Mehr erfahren - -### Patrick Motsch - -Managing Partner - - - -Patrick leitet als Partner erfolgreich komplexe IT-Implementierungsprojekte. - -### Patrick Motsch - -Managing Partner - -#### Schwerpunkte - -* Health Check von Projekten -* Führen von geschäftskritischen Projekten und Programmen -* Führen und Begleiten von Emergency und Recovery Projekten -* Führen und Begleiten von DC Moves und ICT Konsolidierungsprojekten -* Advisor für Auftraggeber - -#### Im Team seit - -2001 - -#### Branchenerfahrungen - -Baubranche IT / Telekommunikation / Data Center Industrie Sport Verteidigung Verwaltung Airspace Management Versicherungen Handel - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG) -* Vater und Pionier des TimeWinner Führungssystems -* CIO einer IT Consulting Organisation - -#### Und ganz nebenbei... - -…liebt Patrick Motsch den Garten, das Tanzen, wandert gerne, taucht so oft es geht und lernt gerne fremde Länder kennen. Sein persönliches Motto: «Wer will, der kann». - - - -Mehr erfahren - -### Richard Salvisberg - -Managing Partner - - - -Richard bringt als Partner strategische Beratungsexpertise und Führungskompetenz ein. - -### Richard Salvisberg - -Managing Partner - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Führen von geschäftskritischen Programmen und Transformationen -* Aufbau und Führen von Projektportfolio-Managementsystemen -* Sparringpartner und Advisor - -#### Im Team seit - -2006 - -#### Branchenerfahrungen - -Gesundheitswesen & (Kranken-)Versicherung Militär Verwaltung Beschaffungswesen & Transport Informatik & Telekommunikation Bau Sport Energie - -#### Berufliche Stationen - -* ValueOn AG (ehem. Project Competence AG), Head of PPM -* T-Systems Schweiz AG, Chief Information Officer -* Orange Communications SA, IT Account Manager -* Swisscom AG Bern, Head Management Support -* Swisscom AG Bern, Programm Manager Charging & Billing - -#### Und ganz nebenbei... - -…liebt Richard Salvisberg das Tanzen, lernt gerne fremde Kulturen kennen, hat Freude an schönen Autos und geniesst ein Buch bei einem guten Schluck Wein. In klaren Nächten beobachtet er interessiert den Kosmos. Sein persönliches Motto lautet «Auf innovativen Wegen nachhaltige Erfolge erzielen». - - - -Mehr erfahren - -### Stephan Schellworth - -Experte - - - -Stephan verbindet strategisches Denken mit praxisnaher Projektsteuerung und gestaltet digitale Projekte - -### Stephan Schellworth - -Experte - -#### Schwerpunkte - -* Projekt- und Teamführung -* Datenanalyse und Optimierung -* Agiles Projektmanagement - -#### Im Team seit - -2024 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Automatisierungstechnik Digitalisierung - -#### Berufliche Stationen - -* 2023 - 2024: Testmanager im Energiebordnetz, BMW Group -* 2021 - 2023: Gesamtfahrzeugspezialist in der E/E, BMW Group -* 2018 - 2021: Prüfstandsspezialist im BMW Prototypen-Motorenwerk, Academic Work -* 2016 - 2018: Entwicklungsingenieur, EDAG Engineering Group - -#### Und ganz nebenbei... - -…sammelt und pflegt Stephan Young- und Oldtimern, treibt Sport wie Squash und besucht regelmässig das Fitnessstudio. Er geht gern mit seinem Hund spazieren oder wandert in der Natur. Ausserdem programmiert er kleinere SmartHome-Anwendungen mit dem Raspberry Pi, Apps und erstellt 3D-Visualisierungen von Innen- und Aussenräumen. - - - -Mehr erfahren - -### Mats Rudolf - -Experte - - - -Mats berät Unternehmen zu digitalen Transformationsprojekten und Systemimplementierungen. - -### Mats Rudolf - -Experte - -#### Schwerpunkte - -* Analysen von Strategien und Umsetzungsinitiativen -* Advisor digitaler Transformation -* Advisor Systems Engineering -* Projekt- und Teamführung -* Agiles Projektmanagement - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Elektromobilität Automobilindustrie Sensortechnik Luft- und Raumfahrttechnik Maschinen- und Anlagenbau Transport und Logistik - -#### Berufliche Stationen - -* 2019 - 2024: Management Consultant Innovation und Transformation, UNITY Schweiz AG -* 2018: Industrial Solution Consulting Intern, Brütsch Rüegger Werkzeuge -* 2015 - 2016: Sensor Research and Development Intern, Sensirion AG - -#### Und ganz nebenbei... - -…zieht es Mats Rudolf im Winter für Skitouren und rasante Abfahrten auf die frisch verschneiten Berge. Wenn der Sommer kommt, tauscht er seine Ski gegen ein Surfbrett und geniesst die Wellen im Meer. Zudem schwingt er gerne den Schläger auf dem Tennisplatz und bastelt an seinen Smart-Device-Projekten. - - - -Mehr erfahren - -### Ida Dittrich - -AI Specialist - -Ida verbindet ihr wissenschaftliches Know-how mit praktischer IT-Erfahrung und bringt innovative Ansätze in technische Projekte ein. - -### Ida Dittrich - -AI Specialist - -#### Schwerpunkte - -* Product Architect and Software Engineer PowerOn Platform - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Luft- und Raumfahrtindustrie Kommunikation und Interessenvertretung Medien - -#### Berufliche Stationen - -* Forschungsprojekt zur Modellierung des inneren Aufbaus terrestrischer Exoplaneten (ETH Zürich) -* Recovery Engineer und Systems Engineer bei verschiedenen Projekten der Akademischen Raumfahrtinitiative der Schweiz (ARIS) - -#### Und ganz nebenbei... - -… spielt Ida Dittrich leidenschaftlich gern Computerspiele und bastelt an handwerklichen Projekten wie Nähen, Häkeln oder Stricken. Sie ist regelmäßig sportlich aktiv – sei es beim Joggen an der frischen Luft, im Fitnessstudio oder bei einer entspannenden Yoga-Einheit. - - - -Mehr erfahren - -### Nick Melloh - -AI-Specialist - -Nick macht künstliche Intelligenz für Unternehmen greifbar – in Projekten, Strategien und praxisnahen Schulungen. - -### Nick Melloh - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Digitale Transformation & Business Innovation -* Advisor für Künstliche Intelligenz & Wissensvermittlung -* Advisor für Strategisches Projekt- und Prozessmanagement -* Trainer für KI-Schulungen und Weiterbildung - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Digitalisierung Consulting Hospitality Event- und Innovationsmanagement KI-Anwendungen - -#### Berufliche Stationen - -* 2023–heute: Master in Business Innovation, Universität St. Gallen – Schwerpunkt Digitale Transformation & KI -* 2023–heute: Event Manager SQUARE, Universität St. Gallen – Gestaltung innovativer Lern- und Austauschformate -* 2022–2023: VP Sales, Contler AG – SaaS-Lösungen & Prozessautomatisierung im Hospitality-Sektor - -#### Und ganz nebenbei... - -…hat Nick eine Schwäche für Reisen, gutes Essen und Bücher – um neue Denkanstöße zu gewinnen und frische Perspektiven einzunehmen. Energie findet er beim Sport, in den Bergen oder bei langen Gesprächen mit Freunden – die besten Momente für ihn sind die, in denen die Uhr keine Rolle spielt. - - - -Mehr erfahren - -### Yannick Althaus - -AI-Specialist - -Yannick berät Unternehmen, indem er Strategiekompetenz mit unternehmerischer DNA verbindet. - -### Yannick Althaus - -AI-Specialist - -#### Schwerpunkte - -* Advisor für Strategisches Management und Unternehmensführung -* Advisor für Künstliche Intelligenz und digitale Transformation -* Advisor für Produktion und Supply Chain Management - -#### Im Team seit - -2025 - -#### Branchenerfahrungen - -Automatisierungstechnik Industrie Digitalisierung Supply Chain Management Consulting - -#### Berufliche Stationen - -* 2025: M.A. HSG in Unternehmensführung - Masterarbeit zum Einsatz von generativer KI in der Strategieentwicklung von CEOs -* 2022: B.Sc. Wirtschaftsingenieurwesen -* 2019–2025: Diverse Consulting-Praktika & Projekte in Supply Chain Management, Digitalisierung und strategischem Management sowie Mitarbeit im Familienunternehmen (neben dem Studium) -* 2013–2017: Automatiker EFZ bei Bystronic - -#### Und ganz nebenbei... - -…wenn er nicht an Strategien feilt, zieht es Yannick aufs Eis – Eishockey ist sein Adrenalinschub. Auch sonst bleibt er regelmässig in Bewegung: Skifahren im Winter, Joggen zwischendurch und Golf im Sommer. Ausserdem hat er eine Schwäche für schnelle Autos und reist gerne – am liebsten ans Meer. - - - -### Philipp Dick - -Certified Partner - -"KI wird Manager nicht ersetzen, aber Manager, die KI einsetzen, werden die ersetzen, die es nicht tun." - - - -### Romano Caviezel - -Certified Partner - -"Innovation bedeutet, bestehende Dinge zu hinterfragen und neue Wege zu entdecken." - - - -### Dawid Puzik - -Certified Partner - -"Manche sehen, was möglich ist – andere verändern, was möglich ist." - - - -### Holger Ridinger - -Certified Partner - -"Transformation braucht Struktur, Leidenschaft und Ausdauer." - - - -### Alain Kappeler - -Certified Partner - -"Wenn es dich nicht herausfordert, verändert es dich nicht." - - - -### Andreas Wyss - -Certified Partner - -Andreas verbindet strategisches Denken mit menschlichem Feingefuehl in Transformationsprozessen. - - - -### Alfredo Mercurio - -Certified Partner - -"Eine klare Vision ist der Anfang von allem." - - - -### Bernd Nagel - -Certified Partner - -"Wer will, findet Wege. Wer nicht will, findet Gründe." - - - -### Daniel Sengstag - -Certified Partner - -"Wer nicht mit der Zeit geht, geht mit der Zeit." - - - -### Daniel Lochmatter - -Certified Partner - -"Neues und bisher Unbekanntes kann man nur explorativ erfahren, erspüren, erlernen – und danach zum eigenen Nutzen einsetzen." - - - -### Michael Hermann - -Certified Partner - -"Auch beim Projekt gilt: Ende gut, alles gut." - - - -### Heinz Ruffieux - -Certified Partner - -"C'est le ton qui fait la musique." - - - -### Sven Fassbender - -Certified Partner - -"Mein Ziel ist es, Cybersicherheit verständlich und greifbar zu machen – für jeden zugänglich und praktikabel." - - - -### Raffael Santchi - -Certified Partner - -"Wer Prozesse versteht, kann Systeme formen – nicht umgekehrt." - - - -### Stephanie Kieninger - -Certified Partner - -Stephanie konzentriert sich mit ihrer Beratung auf die Menschen im Veraenderungsprozess. - - - -### Christoph Merle - -Certified Partner - -Christoph engagiert sich mit seiner langjährigen Führungserfahrung in der Industrie und mit seinem Hintergrund in strategischer und operativer Beratung für den Erfolg unserer Kunden. - -Previous slide Next slide - -Über ValueOn ------------- - -Wir schaffen digitale Transformation mit Leidenschaft und Expertise - -### Unsere Mission - -Durch exzellente Beratung schaffen wir digitale Transformation erfolgreich zu meistern. - -### Unser Versprechen - -Höchste Qualität, agile Ansätze und Passion für gemeinsamen Wirken - -25+ - -Jahre Erfahrung - -100+ - -Projekte - -98% - -Weiterempfehlung - -60% - -Schneller zum Ziel - -Unsere Geschichte ------------------ - -Eine Reise der Innovation - -Heute - -Heute und Morgen - -Als führendes Beratungsunternehmen gestalten wir aktiv die Zukunft der digitalen Transformation mit innovativen KI-Lösungen und nachhaltigen Strategien. - -KI-Ära - -KI-Revolution - -Die Einführung von KI-Systemen veränderte unsere Beratungsleistung grundlegend und ermöglichte es uns, unseren Kunden noch innovativere Lösungen anzubieten. - -Digital - -Digitale Transformation - -Mit neuen digitalen Lösungen begleiteten wir unsere Kunden in der Transformation und etablierten uns als führender Partner für digitale Innovation. - -Aufbau - -Etablierung am Markt - -Wir etablierten uns am Markt mit innovativen IT-Strategien und nachhaltiger Umsetzung, wodurch wir eine solide Basis für weiteres Wachstum schufen. - -2000 - -Gründung von ValueON - -ValueON wurde mit der Vision gegründet, Unternehmen bei der digitalen Transformation zu unterstützen und nachhaltigen Erfolg zu schaffen. - -Unsere Werte ------------- - -Was uns antreibt - -### Exzellenz - -Höchste Qualität in allem, was wir tun. Von der ersten Beratung bis zur finalen Umsetzung setzen wir auf höchste Standards. - -### Partnerschaft - -Wir sehen uns als langfristige Partner unserer Kunden und arbeiten gemeinsam an nachhaltigen Lösungen. - -### Integrität - -Ehrlichkeit, Transparenz und Vertrauen bilden das Fundament aller unserer Geschäftsbeziehungen. - -### Effektivität - -Zielgerichtete Lösungen, die messbare Ergebnisse liefern und nachhaltigen Geschäftserfolg schaffen. - -Karriere bei ValueOn --------------------- - -Werde Teil unseres Teams - -### Product-Architekt/in für KI-Plattformen - -Zürich, Schweiz M/W, 50-100% - -Details ansehen - -Keine passende Stelle gefunden? - -[Initiativbewerbung senden](mailto:office@valueon.ch) - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) diff --git a/test_web_content_20251002_212426/main_url_005_www.itreseller.ch_unternehmen_6046_Valueon.html.txt b/test_web_content_20251002_212426/main_url_005_www.itreseller.ch_unternehmen_6046_Valueon.html.txt deleted file mode 100644 index b3599ff5..00000000 --- a/test_web_content_20251002_212426/main_url_005_www.itreseller.ch_unternehmen_6046_Valueon.html.txt +++ /dev/null @@ -1,124 +0,0 @@ -Title: https://www.itreseller.ch/unternehmen/6046/Valueon.html -URL: https://www.itreseller.ch/unternehmen/6046/Valueon.html -Type: Main URL -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Valueon - Unternehmensverzeichnis IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Valueon in den News von -======================= - - - -[](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html) - -[### Valueon vollzieht Führungswechsel](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html) - -[Generationen- und Führungswechsel bei Valueon: Gründer Markus Mühlemann (Bild, links) übergibt das Zepter an Dominic Largo (Bild, rechts).](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html)7. Juni 2024 - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) \ No newline at end of file diff --git a/test_web_content_20251002_212426/main_url_006_www.valueon.ch_.txt b/test_web_content_20251002_212426/main_url_006_www.valueon.ch_.txt deleted file mode 100644 index d5290b1f..00000000 --- a/test_web_content_20251002_212426/main_url_006_www.valueon.ch_.txt +++ /dev/null @@ -1,107 +0,0 @@ -Title: https://www.valueon.ch/ -URL: https://www.valueon.ch/ -Type: Main URL -Extracted: 2025-10-02 21:24:26 -================================================================================ - -# Power für deinendigitalen Erfolg - -Vertrauen von führenden Unternehmen - -## Unsere Expertise - -Von digitaler Transformation bis zu künstlicher Intelligenz – wir begleiten Sie auf Ihrem Weg in die Zukunft. - -### Digitale Strategie entwickeln - -Ihre Richtung im digitalen Wandel. - -Gemeinsames Zielbild & Roadmap, abgestimmt auf Ihr Geschäft und leiten konkrete Handlungsempfehlungen ab. - -Orientierung & Handlungssicherheit - -### Transformation gezielt optimieren - -Lücken aufdecken. Stärken nutzen. - -Systematischer Blick auf Prozesse, Systeme & Potenziale und leiten konkrete Handlungsempfehlungen ab. - -Relevanz statt Aktionismus - -### Change Management etablieren - -Menschen mitnehmen. Wandel gestalten. - -Strukturierte Begleitung der Mitarbeiter durch den digitalen Wandel mit gezielten Schulungskonzepten. - -Akzeptanz & Erfolg sichern - -### Prozesse digital automatisieren - -Effizienz steigern. Kosten senken. - -Identifikation und Umsetzung von Automatisierungspotenzialen für nachhaltige Produktivitätssteigerung. - -Messbare Effizienzgewinne - -## Erfolgreiche Projekte & Transformationen - -Unter dem Motto «Unsere Kunden stehen im Mittelpunkt» haben wir für Sie eine Auswahl an Kundenreferenzen und Business Cases zusammengestellt. - -Als KMU sind wir es eigentlich nicht gewohnt, einen so grossen Aufwand wie bei der Evaluation des richtigen Partners für die Entwicklung und Realisierung unseres neuen Kernsystems zu betreiben. Doch i... - -Markus Berther - -Geschäftsführer, Schaden Service Schweiz AG - -ValueOn hat uns durch den gesamten Prozess der Digitalen Business Transformation mit grossem Einsatz und Engagement begleitet – von der ersten IT-Standortanalyse und Sourcing Analyse über digitales Zi... - -Stefan Wolf - -Präsident, FC Luzern - -In diesem businesskritischen IT-Programm waren insgesamt vier Experten von ValueOn (ehem. Project Competence) involviert, als Projektleiter und Koordinator, Cut-Over-Manager bis hin zur Gesamt-Program... - -Roland Bosshard - -CIO / Mitglied der GL, KPT - -In time, in quality, under budget: Andreas Friedli von ValueOn (ehem. Project Competence) hat in seiner Co-Leitungsfunktion in diesem IT-Projekt ganz massgeblich dazu beigetragen, dass wir dieses trot... - -Thomas Sturzenegger - -Divisional IT Lead, RUAG Real Estate AG - -Die erfolgreiche Realisierung dieses Vorhabens ist ein wichtiger Meilenstein für die strategische Neuausrichtung der WWZ. Die Projektberater der ValueOn AG (ehem. Project Competence AG) haben dabei da... - -Thomas Reber - -Leiter Telekom & IT Services, WWZ AG - -Um die Zukunftsausrichtung unserer IT-Strategie und -Organisation möglichst optimal auf unsere Business-Anforderungen auszurichten, haben wir ValueOn (ehem. Project Competence) als Sparringpartner ... - -Andreas Guglielmo - -CFO, CHRIS sports AG - -Wir danken den externen Projektberatern der ValueOn (ehem. Project Competence), die uns kompetent und mit ebenso hohem Arbeitseinsatz durch dieses Projekt und die Verhandlungen unter schwierigen Be... - -Michael Kohlbacher - -Generalsekretär, AGZ - -Dank ValueOn konnten wir unser komplexes IT-Infrastrukturprojekt termingerecht und im Budget abschliessen. Die strukturierte Herangehensweise war ausschlaggebend. - -Peter Keller - -Projektleiter, InnovaCorp - -ValueOn hat uns sowohl fachlich als auch menschlich auf höchstem Niveau beraten. Die Experten begleiteten uns kompetent bei der Modernisierung unserer IT-Infrastruktur und der reibungslosen Ablösung u... - -Silvan Wildhaber - -CEO, Filtex Group AG - -← Wischen Sie für weitere Testimonials → - -Auto-Scroll aktiv \ No newline at end of file diff --git a/test_web_content_20251002_212426/main_url_007_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt b/test_web_content_20251002_212426/main_url_007_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt deleted file mode 100644 index 9f8265ed..00000000 --- a/test_web_content_20251002_212426/main_url_007_www.moneyhouse.ch_de_company_valueon-ag-4663161481.txt +++ /dev/null @@ -1,364 +0,0 @@ -Title: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 -URL: https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 -Type: Main URL -Extracted: 2025-10-02 21:24:26 -================================================================================ - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](#)[Save + Exit](#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - -[Startseite](/de/) [>](javascript:void(0)) [Unternehmen](/de/search?q=ValueOn AG) [>](javascript:void(0)) ValueOn AG - -# ValueOn AG - -ZH - -aktiv - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) -[Zur Timeline](/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -Handelsregister-Nr.: CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](/de/company/valueon-ag-4663161481/messages) - -[Sie möchten eine Änderung der Firmendaten vornehmen? Wir unterstützen Sie hierbei gerne.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Alter der Firma - -18 Jahre - -#### Umsatz in CHF - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Kapital in CHF - -200'000 - -#### Mitarbeiter - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Aktive Marken - -0 - -c/o Westhive AG -Am Stadtrand 11 -8600 Dübendorf -[Nachbarschaft](/de/company/valueon-ag-4663161481/network#neighbourhood) - -[Sie möchten Ihre Adresse anpassen? -Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -[News aus der Region Uster](/de/region/uster/uebersicht) - -## Auskünfte zu ValueOn AG - -\*angezeigte Auskünfte sind Beispiele - -#### Bonitätsauskunft - -Einschätzung der Bonität mit einer Ampel als Risikoindikator und weiteren hilfreichen Firmeninformationen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -#### Wirtschaftsauskunft - -Umfassende Auskunft über die wirtschaftliche Situation der Firma. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#commercial-report) - -#### Zahlungsverhalten - -Beurteilung der Zahlungsmoral aufgrund vergangener Rechnungen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-mode-report) - -#### Betreibungsauskunft - -Übersicht über aktuelle und vergangene Betreibungsverfahren. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-collection-report) - -#### Beteiligungsauskunft - -Erfahren Sie, an welchen nationalen und internationalen Firmen die Aktiengesellschaft, für die Sie sich interessieren, noch beteiligt ist. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#wow-report) - -#### Firmendossier als PDF - -Kontaktinformationen, Veränderungen, Umsatz- und Mitarbeiterzahlen, Management, Besitzverhältnisse, Beteiligungsstruktur und weitere Firmendaten. -[Jetzt kostenlos abrufen](/de/company/valueon-ag-4663161481/reports#firmendossier-report) - -## Über ValueOn AG - -* ValueOn AG hat den Sitz in Dübendorf, ist aktiv und im Bereich «Erbringen von IT-Dienstleistungen» tätig. - - - -* Das [Management](valueon-ag-4663161481/management) der Firma ValueOn AG besteht aus 5 Personen. - - - -* Unter [Meldungen](valueon-ag-4663161481/messages) finden Sie alle Handelsregisteränderung, die letzte erfolgte am 27.08.2025. - - - -* Die Firma ist im Handelsregister des Kantons ZH unter der UID CHE-113.416.882 eingetragen. - - - -* Unternehmen mit derselben Adresse wie ValueOn AG: [Black Projects GmbH](black-projects-gmbh-3958227961), [Bluespace Ventures AG](bluespace-ventures-ag-20038582721), [Cyberfy Consulting AG](cyberfy-consulting-ag-5194156221). - -## Management (5) - -#### neueste Verwaltungsräte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901) - -#### neuste Zeichnungsberechtigte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -#### Geschäftsleitung - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -Quelle: [SHAB](/de/datasources) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -## Netzwerk - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -## Handelsregisterinformationen - -Quelle: [SHAB](/de/datasources) - -#### Eintrag ins Handelsregister - -02.02.2007 - -#### Rechtsform - -Aktiengesellschaft - -#### Rechtssitz der Firma - -Dübendorf - -#### Handelsregisteramt - -ZH - -#### Handelsregister-Nummer - -CH-020.3.030.651-3 - -#### UID/MWST - -CHE-113.416.882 - -#### Branche - -Erbringen von IT-Dienstleistungen - -#### Firmenzweck - -Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -[Passen Sie den Firmenzweck mit wenigen Klicks an.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Revisionsstelle - -Quelle: [SHAB](/de/datasources) - -#### Aktive Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [TBO Revisions AG](/de/company/tbo-revisions-ag-20607789301) | | Zürich | 18.03.2015 | | - -[Möchten Sie die Revisionsstelle anpassen? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Frühere Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [Trevisca AG](/de/company/trevisca-ag-20628390611) | | Baar | 08.02.2007 | 17.03.2015 | - -## Weitere Firmennamen - -Quelle: [SHAB](/de/datasources) - -#### Frühere und übersetzte Firmennamen - -* Project Competence AG - -[Möchten Sie den Firmennamen aktualisieren? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Zweigniederlassungen (0) - -## Besitzverhältnisse - -Es liegen uns keine Angaben zu den Besitzverhältnissen vor. - -## Beteiligungen - -Es liegen uns keine Angaben zu den Beteiligungen vor. - - - - - - - - - -## Neueste SHAB-Meldungen: ValueOn AG - -SHAB 250827/2025 - 27.08.2025 - -**Kategorien:** Änderung des Firmenzwecks, Änderung der Firmenadresse - -Publikationsnummer: [HR02-1006417690](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006417690 "Download SHAB Publikation der ValueOn AG vom 27.08.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 133 vom 14.07.2025, Publ. 1006383218). - -**Statutenänderung:** - 18.08.2025. - -**Sitz neu:** - Dübendorf. - -**Domizil neu:** - c/o Westhive AG, Am Stadtrand 11, 8600 Dübendorf. - -**Zweck neu:** - Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -**Mitteilungen neu:** - Mitteilungen an die Aktionäre erfolgen per Brief oder E-Mail an die im Aktienbuch verzeichneten Adressen. - -SHAB 250714/2025 - 14.07.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006383218](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006383218 "Download SHAB Publikation der ValueOn AG vom 14.07.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 101 vom 27.05.2025, Publ. 1006341693). - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Einzelunterschrift [*bisher: Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]. - -SHAB 250527/2025 - 27.05.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006341693](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006341693 "Download SHAB Publikation der ValueOn AG vom 27.05.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 222 vom 14.11.2024, Publ. 1006178101). - -**Ausgeschiedene Personen und erloschene Unterschriften:** - Hamburger, Marc Eric, von St. Gallen, in Mörschwil, Präsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Egloff, Reto](/de/person/egloff-reto-101763781201), von Oberrohrdorf, in Bern, Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Mühlemann, Markus](/de/person/muehlemann-markus-142196879901), von Seeberg, in Uster, Delegierter des Verwaltungsrates, mit Einzelunterschrift. - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien [*bisher: Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]; - [Althaus, Walter](/de/person/althaus-jun-walter-205367807901), von Affoltern im Emmental, in Aarwangen, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Wyss, Andreas](/de/person/wyss-andreas-129476912501), von Dietikon, in Dietikon, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien. - -[Alle SHAB-Meldungen ansehen](/de/company/valueon-ag-4663161481/messages) - -## Trefferliste - -Hier finden Sie eine Verlinkung des Managements auf eine Trefferliste zu Personen mit dem gleichen Namen, die im Handelsregister eingetragen sind. - -[Dominic Pascal Largo](/de/list/person/largo-dominic-pascal) - -[Andreas Wyss](/de/list/person/wyss-andreas) - -[Walter Althaus Jun.](/de/list/person/althaus-jun-walter) - -[Andreas Friedli](/de/list/person/friedli-andreas) - -[Richard Salvisberg](/de/list/person/salvisberg-richard) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](/de/terms)[Datenschutz |](/de/privacy)[Impressum](/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](/de/overview) - - - - - - -[Übersicht](/de/company/valueon-ag-4663161481) - -[Auskünfte](/de/company/valueon-ag-4663161481/reports) - -[Management](/de/company/valueon-ag-4663161481/management) - -[Netzwerk](/de/company/valueon-ag-4663161481/network) - -[Timeline](/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](/de/company/valueon-ag-4663161481/shares) - -[Meldungen](/de/company/valueon-ag-4663161481/messages) - -[Marken](/de/company/valueon-ag-4663161481/brands) - -[Jobs](/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](/de/company/valueon-ag-4663161481/buildingproject) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_001_www.immoscout24.ch_fr_terrain_acheter_canton-zurich.txt b/test_web_content_20251002_215219/additional_link_001_www.immoscout24.ch_fr_terrain_acheter_canton-zurich.txt new file mode 100644 index 00000000..a13203fc --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_001_www.immoscout24.ch_fr_terrain_acheter_canton-zurich.txt @@ -0,0 +1,437 @@ +URL: https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +70 Terrain à bâtir à vendre: Canton Zurich | ImmoScout24 + +=============== + +[](https://www.immoscout24.ch/fr) +* [Chercher](https://www.immoscout24.ch/fr "Chercher") +* [Services](https://www.immoscout24.ch/c/fr/hypotheques "Services") + +[Créer une annonce](https://www.immoscout24.ch/fr/insertion/publier-soi-meme-en-ligne "Créer une annonce") + +[Favoris](https://www.immoscout24.ch/favoris "Favoris") + +[Mon Compte](https://www.immoscout24.ch/fr/account-overview "Mon Compte") + +Menu + +[](https://www.immoscout24.ch/fr) +* [Chercher](https://www.immoscout24.ch/fr "Chercher") +* [Services](https://www.immoscout24.ch/c/fr/hypotheques "Services") +* [Estimer](https://www.immoscout24.ch/fr/estimation "Estimer") +* [Magazine](https://www.immoscout24.ch/c/fr/magazine-immobilier "Magazine") + +[Créer une annonce](https://www.immoscout24.ch/fr/insertion/publier-soi-meme-en-ligne "Créer une annonce") + +[Favoris](https://www.immoscout24.ch/favoris "Favoris") + +[Mon Compte](https://www.immoscout24.ch/fr/account-overview "Mon Compte") + +Menu + +FR +* [DE](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich) +* [FR](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich) +* [IT](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo) +* [EN](https://www.immoscout24.ch/en/plot/buy/canton-zurich) + +1. [](https://www.immoscout24.ch/fr) +2. [Terrain à bâtir à vendre](https://www.immoscout24.ch/fr/terrain/acheter) +3. [Canton Zurich](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich) + +Où? + + Canton Zurich + + Canton Zurich + + CHF à + + + + Filtres + + 70 objets + +70 résultats - Terrain à bâtir à vendre: Canton Zurich +====================================================== + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 16    **360m²**, CHF 2’563’760.– Top Luegetenstrasse 11, 8489 Wildberg Votre nouvelle maison avec potentiel - Maison de campagne idyllique avec réserve de terrain constructible Votre nouvelle maison Bienvenue dans votre futur domicile de rêve - une maison de campagne spacieuse et indépendante dans un endroit calme et idyllique avec vue sur le pittoresque Wildberg. Ici, l'idylle rurale, la vie privée et la rare opportunité de créer ou d'agrandir un espace de vie selon vos propres idées se rencontrent.Que ce soit comme un refuge familial charmant avec un grand jardin ou comme un objet d'investissement avec un potentiel de développement - cette propriété unique vous offre les deux options. Sur le terrain de 1339m², vous avez non seulement beaucoup d'espace pour vivre, mais aussi une réserve de terrain constructible précieuse, qui vous ouvre des possibilités de conception variées. Les investigations initiales montrent : Il existe la possibilité de réaliser une maison à plusieurs familles avec jusqu'à cinq unités de logement - une véritable plus-value pour les acheteurs visionnaires.Plongez dans une oasis verte avec une vue lointaine - un endroit qui vous donne la paix et vous inspire.Points forts en un coup d'œil • Endroit idyllique et calme avec une grande valeur de loisirs • Grand terrain avec 1339m², idéal pour une utilisation personnelle et/ou pour le développement d'un nouveau bâtiment • Réserve de terrain constructible : Potentiel de développement attractif - selon les estimations initiales, il existe la possibilité de réaliser, en plus de la maison unifamiliale existante, une maison à plusieurs familles avec jusqu'à cinq unités de logement (non contraignant, sans garantie) • Jardin en fleurs avec différents espaces de séjour, pergola avec cheminée extérieure, maisons de jardin, population d'arbres bien entretenue et vastes espaces verts • Substance de construction solide avec maçonnerie à double paroi • Concept de pièces spacieux avec environ 220m² d'espace de vie et environ 96m² d'espace de stockage supplémentaire au sous-sol. Surface totale d'environ 360m². • Espace de vie spacieux avec poêle à tuiles confortable - un endroit pour arriver et se sentir bien • Cuisine de vie pratique avec salle à manger intégrée - idéale pour les heures sociales • 4 chambres lumineuses - idéales pour les familles ou le télétravail • 2 cellules humides avec lumière du jour • Grenier aménagé pour un espace supplémentaire ou des possibilités d'utilisation créative • Chauffage au moyen d'un stockage électrique et d'un chauffage par le sol à eau • Garage avec porte électrique et possibilités de stationnement supplémentaires sur la propriété • Avec une modernisation élégante, vous pouvez transformer cette maison en un véritable joyau Prix de vente : CHF 1'870'000.-Avec notre visite virtuelle à 360 degrés, vous pouvez déjà avoir les premières impressions de cette grande propriété. Nous serions ravis de vous montrer cette propriété directement sur place et nous attendons avec impatience votre contact.Autres données clésAnnée de construction de la maison : 1984, année de construction de la dépendance : 1986, volume de la maison (GVZ) : 936m³, volume de la dépendance (GVZ) : 40m³, feuillet de registre foncier : n° 437, numéro de cadastre : 249, 1/4 de propriété subjective-réelle de la feuille 444, cadastre 249. Surface habitable nette : environ 220m², surface habitable brute : environ 360m², surface du terrain : 1'339m².Construction solide, maçonnerie à double paroi, fenêtres en bois et métal presque neuves (EgoKiefer) avec vitrage triple et meneaux & volets en bois. Chauffage électrique à stockage, chauffage par le sol à eau, chaudière électrique 300 litres.Ascenseur, garage avec ouverture de porte électrique. Cuisine de style maison de campagne avec couverture en granit, lave-vaisselle, cuisinière à induction et réfrigérateur avec compartiment congélateur.Revêtements de solRez-de-chaussée : Entrée, corridor, douche, cuisine, salle à manger avec sol en plaques.Étage : Chambres et avant-cour avec stratifié en optic bois. Salle de bains avec plaques.  Durée du trajet Nouveau 28 min.Station: Rämismühle-Zell](https://www.immoscout24.ch/acheter/4002491909) + +[*  *  *  *  *  *  *  *  1 / 4 Prix sur demande Top Lüss, 8542 Wiesendangen À remettre en droit de construction : 14’770 m2 de terrain à bâtir dans un excellent emplacement à Wiesendangen, avantageux en termes d'impôts À remettre en droit de construction :14’770 m2 de terrain à bâtir dans un excellent emplacement à Wiesendangen, avantageux en termes d'impôtsPropriété WD4674 – Lüss WiesendangenTous les détails sur la propriété, le contrat de droit de construction et les critères d'attribution se trouvent dans le dossier joint.Les offres fermes pour la reprise du contrat de droit de construction, y compris la preuve de financement, doivent être soumises à :Commune de WiesendangenÀ l'attention de Martin SchindlerSchulstrasse 208542 Wiesendangen Veuillez utiliser le formulaire en annexe pour la soumission de l'offre.Date limite de soumission : lundi 20 octobre 2025, 11h00 Durée du trajet Nouveau 9 min.Station: Wiesendangen](https://www.immoscout24.ch/acheter/4002510601) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 12    CHF 2’323’840.– Hürstringstrasse 37, 8046 Zürich Terrain avec maison unifamiliale existante et grand potentiel Nous serons ravis de vous présenter ce terrain avec grand potentiel et de nombreuses possibilités.Après consultation, nous vendons un terrain avec une maison unifamiliale existante dans un endroit calme à Zurich. Ce qui est intéressant dans cette propriété, cependant, c'est que lors de l'achat, vous disposez déjà de l'autorisation de construire associée, qui vous permet d'agrandir et de rénover l'espace de vie sur cette parcelle selon vos souhaits.Non loin de la gare principale de Zurich, derrière le Käferberg, le terrain spacieux est situé dans un quartier résidentiel calme avec une zone 30.À pied, vous pouvez rejoindre un arrêt de bus, ainsi que la petite forêt, qui est idéale pour des promenades plus courtes.Les informations les plus importantes en bref: • Terrain avec maison unifamiliale et autorisation de construire pour agrandir la surface habitable • Année de construction 1934 • Superficie du terrain de 410 m2 • Possibilité de projet 1 : Agrandissement en maison multifamiliale avec deux appartements en propriété ou en location • Possibilité de projet 2 : Agrandissement en maison à plusieurs générations Découvrez l'atmosphère calme et la proximité simultanée avec le centre-ville lors d'une visite personnelle!Pour plus d'informations sur la propriété ou pour planifier une visite, n'hésitez pas à nous contacter à tout moment.  Durée du trajet Nouveau 22 min.Station: Zürich Seebach](https://www.immoscout24.ch/acheter/4002349882) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 11    CHF 3’290’400.– Luzernerstrasse 57, 8903 Birmensdorf (ZH) Emplacement ensoleillé avec vue Au nom de notre client, nous vendons un terrain à bâtir dans un emplacement ensoleillé avec vue de 1'228 m² de surface foncière (zone résidentielle W2).La propriété existante se présente dans un état entretenu conforme à son âge.Prix de vente cible : CHF 2'400'000Nous avons éveillé votre intérêt ? Nous serons ravis de vous envoyer l'exposé détaillé de cette offre intéressante.  Durée du trajet Nouveau 19 min.Station: Birmensdorf](https://www.immoscout24.ch/acheter/4002566208) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13 CHF 4’044’440.– Mühlemattstrasse 12, 8135 Langnau am Albis Terrain à bâtir ou maison unifamiliale existante à vendre ! La maison convainc par son apparence inimitable. Les murs en briques à l'intérieur donnent à l'espace de vie une atmosphère chaude et naturelle, tandis que la cheminée dans le salon assure le confort les jours plus froids. Le plan d'étage est ouvert et accueillant, complété par de grandes façades de fenêtres qui amènent la lumière et la nature dans la maison.Un point fort est la terrasse spacieuse avec une vue merveilleuse – idéale pour des heures agréables à l'extérieur. Le jardin est vaste et offre beaucoup d'espace pour une conception individuelle. Avec un peu d'attention, un paradis vert merveilleux peut être créé ici – que ce soit comme jardin familial, refuge ou pour des projets créatifs à l'extérieur.Grâce à la taille de la propriété et à son emplacement, la propriété ouvre également des perspectives intéressantes pour un éventuel nouveau bâtiment de remplacement - comme une maison unifamiliale moderne ou une maison multifamiliale.Nous serons ravis de vous fournir des informations supplémentaires ou de convenir d'un rendez-vous de visite personnel. Découvrez le potentiel et l'atmosphère unique de cet endroit. Dans la documentation de vente, vous trouverez toutes les informations importantes.  Durée du trajet Nouveau 12 min.Station: Langnau-Gattikon](https://www.immoscout24.ch/acheter/4002406229) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13    CHF 1’302’440.– Kanalweg 2, 8714 Feldbach Terrain pour une maison unifamiliale projetée Dans le village pittoresque de Feldbach, au bord du lac de Zurich, ce terrain avec une grange existante, construite sur un seul côté, est à vendre. Le prix d'achat inclut un projet préliminaire réalisable pour une maison unifamiliale en remplacement de la grange.L'objet vous offre la possibilité unique de réaliser votre rêve de propriété dans un lieu idyllique. Il offre suffisamment d'espace pour une famille, et une combinaison de "vie et travail" est également possible.En 30 minutes, vous pouvez rejoindre Zurich en S-Bahn, et la garderie et l'école primaire sont également à proximité. Des possibilités de shopping sont disponibles à Hombrechtikon, Stäfa et Rapperswil. En été, une piscine voisine dans la charmante Seebadi Feldbach vous invite à vous rafraîchir.Il existe un devis de coût actuel pour la maison (construction en éléments de bois) y compris les environs, les coûts de construction et les coûts accessoires d'un montant de Fr. 1'380'000.--.Nous avons piqué votre intérêt ? Alors appelez-nous. Nous serons ravis de répondre à vos questions ou de vous fournir notre documentation de vente pour étude. La propriété peut, bien sûr, également être visitée. Nous nous réjouissons de votre appel.  Durée du trajet Nouveau 6 min.Station: Feldbach](https://www.immoscout24.ch/acheter/4002434745) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13    **5.5 pièces**, CHF 4’111’620.– Schaffhauserstrasse 226b, 8057 Zürich Mehr Raum fürs Leben: Reihenhaus mit Potenzial Attraktive Stadtliegenschaft mit ausgearbeitetem ProjektIm Zürcher Kreis 11 veräussern wir ein hübsches Reiheneinfamilien-Eckhaus mit grosszügigem Umschwung. Die Liegenschaft und das Grundstück verfügen über viel Ausnützungspotenzial und ermöglicht so die Realisation spannender Projekte sowohl im Umbau als auch Neubau.Diese Liegenschaft überzeugt durch viele Besonderheiten: • grosszügiger Umschwung mit viel Potenzial • Blick ins Grüne von nahezu allen Fenstern • Schwedenofen im Wohnbereich • viel Stauraum durch Wandschränke und Estrich • Altbaucharme in modernem Quartier • zentrale und familienfreundliche Lage • sonnenverwöhnter Standort Haben wir Ihr Interesse geweckt? Bestellen Sie noch heute unsere ausführliche Verkaufsdokumentation mittels Kontaktformular und Sie erhalten weitere spannende Informationen zur Immobilie. Wir freuen uns über Ihre Kontaktaufnahme!Une oasis de verdure dans la ville de Zurich avec un projet élaboréDans le quartier 11 de Zurich, nous vendons une jolie maison mitoyenne en angle avec de vastes alentours. L'immeuble et le terrain disposent d'un grand potentiel d'exploitation et permettent ainsi la réalisation de projets passionnants, tant en transformation qu'en construction neuve.Cette propriété convainc par ses nombreuses particularités : • Un vaste terrain avec beaucoup de potentiel • Une vue sur la verdure depuis presque toutes les fenêtres • Un poêle suédois dans le séjour • beaucoup d'espace de rangement grâce aux armoires murales et au grenier • Le charme d'un ancien bâtiment dans un quartier moderne • Un emplacement central et favorable aux familles • Un emplacement ensoleillé Nous avons éveillé votre intérêt ? Commandez dès aujourd'hui notre documentation de vente détaillée au moyen du formulaire de contact et vous recevrez d'autres informations passionnantes sur le bien immobilier. Nous nous réjouissons de votre prise de contact!A green oasis in the city of Zurich with an elaborate projectIn Zurich's Kreis 11 district, we are selling a pretty terraced single-family corner house with spacious grounds. The property and the plot have a lot of utilization potential and thus enable the realization of exciting projects both in conversion and new construction.This property boasts many special features: • spacious grounds with lots of potential • view of the countryside from almost all windows • Swedish stove in the living area • lots of storage space thanks to wall cupboards and attic • old building charm in a modern district • central and family-friendly location • sun-drenched location Have we piqued your interest? Order our detailed sales documentation today using the contact form and you will receive further exciting information about the property. We look forward to hearing from you!  Durée du trajet Nouveau 4 min.Station: Berninaplatz](https://www.immoscout24.ch/acheter/4002346061) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 12 Prix sur demande Überlandstrasse 23, 8340 Hinwil Parcelle de terrain industriel et de construction à un emplacement attractif dans le Zürcher-Oberland Dans la zone industrielle animée de Hinwil, nous vendons un terrain de construction industriel à un emplacement très fréquenté, directement sur l'axe principal de Rapperswil, Wetzikon, et Pfäffikon ZH. La parcelle de terrain à bâtir est située à la limite de la zone industrielle et borde la zone résidentielle de Hinwil ZH.Données clés :- Surface totale du terrain 4 246 m2- Zone de construction industrielle/commerciale IG/7 - Facteur de volume de construction 7 m3/m2- Hauteur de bâtiment maximale 21,5 m- Longueur de bâtiment maximale ouverte- Grande distance de limite à la route nationale- Distance de bâtiment tout autour 3,5 m- Volume de construction possible maximal environ 30 000 m3- Surface brute de plancher environ 9 500 m2Le terrain de construction est actuellement encore utilisé avec deux unités de logement, un atelier de réparation auto avec un showroom séparé, et une station-service. Autour de la propriété, de grandes surfaces pavées sont disponibles pour une utilisation.  Durée du trajet Nouveau 10 min.Station: Hinwil](https://www.immoscout24.ch/acheter/4002417917) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 10 CHF 2’947’650.– Trottenrain 14, 8474 Dinhard Projet de construction approuvé dans le Dinhard-Welsikon avantageux en termes d'impôts Le terrain à bâtir avec un entrepôt est situé dans une zone centrale à Welsikon, à la périphérie de la commune de Dinhard, dans la zone centrale. L'utilisation élevée obtenue permet la construction de nouveaux bâtiments attractifs dans un emplacement central. Les visualisations et les plans d'étage du projet de construction approuvé peuvent être trouvés dans la documentation. L'entrepôt est inscrit à l'inventaire communal des bâtiments protégés. Par conséquent, un accord de protection a été élaboré en consultation avec la protection du patrimoine et la commune de Dinhard, qui permet une conversion extraordinaire en un loft moderne.Points forts : • projet de construction approuvé et planification des appels d'offres pour les nouveaux bâtiments • accord de protection • excellente situation à Welsikon • havre fiscal (taux d'impôt communal 83 %) • parcelle de terrain à bâtir bien proportionnée • bonne connexion aux transports en commun (gare à 170 m) Réalisation :L'association des propriétaires de Winterthur vous soutient, si nécessaire, en étroite collaboration avec Kästle Architekten dans la réalisation de votre projet de nouveau bâtiment.De la planification à la vente/location du nouveau bâtiment terminé – l'association des propriétaires de Winterthur vous offre tous les services d'une seule source. Il n'y a pas d'obligation architecturale.Les parties intéressées sont cordialement invitées à nous contacter.Appelez notre équipe de vente au 052 209 01 68 si vous souhaitez recevoir des informations supplémentaires ou une visite. Nous nous réjouissons de vous entendre.Votre équipe de vente HEVImportant : Nous sommes exclusivement chargés de la vente. Le contact direct avec les propriétaires entraînera l'exclusion de la liste des parties intéressées. S.E.&.O.  Durée du trajet Nouveau 5 min.Station: Dinhard](https://www.immoscout24.ch/acheter/4002188905) + +[ 1 / 1 CHF 2’399’240.– In der Gass 2, 8627 Grüningen Terrain avec permis de construire pour vente Mis en vente, un terrain avec un projet de nouvelle construction approuvé. Bâtiment C de l'Enssamble au Binzikerstrasse 21 / In der Gass 2, 8627 Grüningen. Les garages actuellement existants peuvent être démolis et remplacés par un nouveau bâtiment avec 8 appartements de tailles différentes avec des espaces extérieurs attractifs. En outre, la construction conjointe d'un garage souterrain pour 11 places de parking avec accès via la rue "In der Gass" a été approuvée.  Durée du trajet Nouveau 54 min.Station: Esslingen](https://www.immoscout24.ch/acheter/3003479026) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 2’604’890.– Im Königstal 2, 8487 Zell Durée du trajet Nouveau 22 min.Station: Rämismühle-Zell](https://www.immoscout24.ch/acheter/4002279293) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 4’112’990.– Im Königstal 3, 8487 Zell ZH Durée du trajet Nouveau 22 min.Station: Rämismühle-Zell](https://www.immoscout24.ch/acheter/4002279266) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 6’717’900.– Im Königstal 3, 8487 Zell ZH Durée du trajet Nouveau 22 min.Station: Rämismühle-Zell](https://www.immoscout24.ch/acheter/4002279259) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    CHF 2’879’100.– Rotweg 20, 8820 Wädenswil Votre nouveau projet avec vue sur le lac Au nom de notre client, nous vendons un quartier résidentiel préféré, surélevé et calme avec une belle vue sur le lac et la lointaine, 706 m² de terrain constructible avec un objet de démolition.Prix de vente cible : CHF 2'100'000.00Est-ce que nous avons éveillé votre intérêt ? Nous serons ravis de vous envoyer l'exposé détaillé de cette offre intéressante.  Durée du trajet Nouveau 12 min.Station: Wädenswil](https://www.immoscout24.ch/acheter/4002559578) + +[*  *  *  *  *  *  *  *  *  *  *  1 / 7    CHF 651’220.– Auf Anfrage 1, 8195 Wasterkingen Terrain à bâtir attractif dans un environnement calme et rural Bienvenue à Wasterkingen, une communauté idyllique et calme du Zurich Unterland, connue pour sa haute qualité de vie, sa tranquillité rurale et sa bonne accessibilité. Exactement ici, un terrain à bâtir attractif vous attend - la base idéale pour votre futur domicile.Le terrain est entièrement viabilisé et est situé en zone centrale B, ce qui vous offre de nombreuses options de conception. Que ce soit une maison unifamiliale moderne, un domicile classique au caractère de village ou un projet architectural individuel - ici, vous pouvez réaliser vos rêves de vie exactement selon vos idées.La communauté charmante de Wasterkingen impressionne par son emplacement calme au milieu des champs, des vignes et de la nature.Cette offre ImmoSky propose les avantages suivants *Plus de performance*:+ Entièrement viabilisé+ Communauté calme+ Taille idéale pour la flexibilité (650m²)+ Zone centrale B+ Coefficient d'occupation des sols pour bâtiment principal 30%Ce terrain vous offre la rare opportunité de combiner l'idylle rurale avec la proximité urbaine - un endroit où vous pouvez vous reposer et être parfaitement connecté.Réaliserez-vous ici votre rêve de propriété et concevrez-vous votre refuge personnel à Wasterkingen.Nous avons-vous convaincu avec cette offre? Alors n'hésitez pas à nous contacter pour plus de questions ou un rendez-vous de visite!(Le dossier de vente vous sera envoyé dans un délai maximum de 24 heures. Veuillez également vérifier votre dossier SPAM.)  Durée du trajet -](https://www.immoscout24.ch/acheter/4002537208) + +[*  *  *  *  *  *  *  *  *  *  *  1 / 7    CHF 7’540’490.– Staldernstrasse 13, 8158 Regensberg Terrain à développer dans un excellent emplacement en zone centrale 2 Dans la commune très demandée de Regensberg (ZH), un terrain très bien situé est en vente, qui convient idéalement aux investisseurs, entrepreneurs généraux ou totaux. Le parcelle de 2 557 m², no 949, est située en zone centrale 2, qui permet une variété de possibilités de développement liées à la construction et à l'utilisation, en particulier pour des projets résidentiels ou à usage mixte.Actuellement, un bâtiment non préservable se trouve sur la propriété, qui peut être démolit dans le cadre d'un nouveau développement. Aucune demande de construction ou de permis n'est disponible, il y a donc une totale liberté de conception dans le cadre des règlements de construction et d'urbanisme applicables.Les calculs montrent qu'une attente de revenu locatif durable de l'ordre de CHF 485 600 par an semble réaliste - en supposant une utilisation d'environ 1 664 m² d'espace utilisable principal (HNF) et 28 places de parking souterraines. Le taux de capitalisation déterminé est de 4,20 %.Chiffres clés d'évaluation :Valeur marchande (valeur foncière actualisée) : CHF 5 505 000Valeur de revenu dans un état renouvelé : CHF 11 556 795Valeur réelle (hypothétique) : CHF 12 485 000Revenu potentiel de vente : CHF 16 190 000Rendement brut (valeur locative) : 4,20 %Le développement hypothétique prévoit deux maisons multifamiliales avec une surface totale de plancher brut (BGF) de 2 080 m² - correspondant à un facteur d'utilisation des sols de 0,81, entièrement dans le cadre de la réglementation d'urbanisme. Les coûts de construction calculés (BKP 2-5) s'élèvent à environ CHF 8,74 millions. La valeur foncière actualisée par m² est de CHF 2 155, ce qui souligne encore le potentiel économique.La zone centrale 2 permet également des utilisations mixtes, telles que des offres commerciales au rez-de-chaussée, en plus de l'utilisation résidentielle pure. C'est un avantage supplémentaire pour des concepts de développement flexibles et adaptés au lieu. L'emplacement à Regensberg offre une qualité de vie résidentielle calme à proximité de l'agglomération de Zurich et est intégré dans un environnement historique attractif.En conclusion : le terrain offre la rare opportunité d'acquérir un terrain développeable dans un excellent emplacement avec un objet de démolition existant et de le construire selon ses propres idées. Grâce aux possibilités d'utilisation flexibles et à l'emplacement attractif, cet investissement représente un excellent point de départ pour des développements de projets à rendement élevé.Pour des informations détaillées, nous sommes à votre disposition.  Durée du trajet Nouveau 23 min.Station: Steinmaur](https://www.immoscout24.ch/acheter/4002529588) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    CHF 3’633’140.– Riedwiesenstrasse 20, 8305 Dietlikon RÉSERVÉ - Parcelle de construction industrielle dans un emplacement central à Dietlikon ZH Nous sommes ravis de vous présenter une parcelle de construction unique et extrêmement rare dans un emplacement central à Dietlikon ZH – une opportunité exceptionnelle avec des propriétés excellentes, particulièrement adaptée aux investisseurs.Emplacement central : La parcelle est située dans un quartier très demandé avec d'excellentes connexions : l'aéroport de Zurich est accessible en 10 minutes en voiture, et la ville de Zurich est accessible en 12 minutes en voiture • Visibilité : Votre entreprise sera parfaitement visible de l'autoroute, offrant des opportunités publicitaires optimales (environ 500 m2 de façade pour la publicité). • Densité de construction : Bénéficiez de la haute densité de construction de 10,0, qui permet une flexibilité et une efficacité maximales. • Droits de construction voisins : La parcelle a des droits de construction voisins à droite et à gauche. À l'arrière, un droit de construction voisin peut être obtenu de la ville de Zurich • Environ 3 500 m2 de surface brute possible • Parking souterrain / sous-sol jusqu'à environ 800 m2 peut être réalisé • Hauteur totale maximale 20 m. 7 étages avec 500 m2 de surface brute et 2,85 m de hauteur de pièce (brute) possibles • Parcelle : La surface plane de la parcelle simplifie la planification et l'exécution de la construction. • Forme : La parcelle a une forme idéale, permettant des possibilités de construction polyvalentes. • Jonction autoroutière : Brüttiseller Kreuz, situé directement à l'un des principaux carrefours autoroutiers de Suisse, offre à la parcelle une excellente accessibilité et des avantages logistiques • Commerce gênant : L'emplacement est également adapté au commerce qui peut être potentiellement gênant. • Les centres culturels et les activités hôtelières sont également possibles. Maintenant ou jamais – votre chance pour un excellent investissement :Une telle parcelle de construction industrielle dans cet emplacement est extrêmement rare sur le marché – depuis quelque temps, il n'y a pas eu d'offre comparable dans ce quartier très demandé. Sécurisez cette propriété unique maintenant, idéale pour les entrepreneurs visionnaires et les investisseurs qui comptent sur un emplacement stratégiquement optimal.Avez-vous été intéressé ? Alors contactez-nous aujourd'hui. Nous serons ravis de vous envoyer le dossier de vente détaillé, y compris une étude de faisabilité – exclusivement et sans engagement.  Durée du trajet Nouveau 14 min.Station: Dietlikon](https://www.immoscout24.ch/acheter/4002331523) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    Prix sur demande Kaffeestrasse, 8180 Bülach Votre bâtiment industriel directement à Bülach DescriptionNous serions ravis de développer et de réaliser un projet sur mesure répondant à vos besoins, qui vous sera mis à disposition à titre de location ou de propriété.Intéressé ou avez-vous des questions ? N'hésitez pas à nous contacter !Le terrain n'est pas celui qui convient à vos exigences ? Pas de problème ! Visitez notre site web et trouvez d'autres offres sur : gewerbeland-schweiz.ch  Durée du trajet Nouveau 20 min.Station: Bülach](https://www.immoscout24.ch/acheter/4001788654) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    Prix sur demande Kaffeestrasse, 8180 Bülach Votre bâtiment industriel directement à Bülach DescriptionNous serions ravis de développer et de réaliser un projet sur mesure répondant à vos besoins, qui vous sera mis à disposition à titre de location ou de propriété.Intéressé ou avez-vous des questions ? N'hésitez pas à nous contacter !Le terrain n'est pas celui qui convient à vos exigences ? Pas de problème ! Visitez notre site web et trouvez d'autres offres sur : gewerbeland-schweiz.ch  Durée du trajet Nouveau 20 min.Station: Bülach](https://www.immoscout24.ch/acheter/4001788644) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    * Quartier calme CHF 3’358’950.– 8192 Glattfelden TERRAIN À CONSTRUIRE SANS OBSTACLES À ZWEIDLEN Dans le populaire Zweidlen, nous vendons un terrain à construire attractif de 1'226 m² avec un objet existant. Notre étude de projet montre un potentiel élevé pour la construction d'une maison multifamiliale. • Surface brute au sol possible de jusqu'à 940 m² (projet 789 m²) • Zone résidentielle et commerciale WG 2.3 • Aucune protection du patrimoine pour l'objet existant • La frontière allemande à Kaiserstuhl est à seulement 8 minutes en voiture • L'aéroport de Zurich est accessible en seulement 19 minutes en voiture Intéressé ? Pour plus d'informations, des photos et une visite virtuelle de la propriété, ainsi que des options de visite, consultez : https://www.propertyowner.ch/de/immobilien/25-12278 Numéro de référence : 25-12278 Devenez membre gratuit de la Grundeigentümer Verband Schweiz aujourd'hui et profitez de nombreux avantages pour les membres : www.propertyowner.ch - Les membres de l'association peuvent financer la propriété en question ou d'autres propriétés avec le soutien de notre département de financement. - Les membres de l'association ont accès à notre service juridique (consultation téléphonique initiale gratuite de 30 minutes). - Évaluation professionnelle gratuite de la propriété - Consultation et calcul gratuits de l'impôt sur les gains immobiliers Êtes-vous devenu curieux ? En savoir plus sur notre site https://www.propertyowner.ch/immobilien/ et laissez-vous inspirer par nos offres. Nous nous réjouissons de la possibilité de vous rencontrer personnellement et de réaliser vos rêves immobiliers ! * Quartier calme  Durée du trajet -](https://www.immoscout24.ch/acheter/4002558181) + +[1](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich)[2](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich?pn=2)[...4](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich?pn=4)[](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich?pn=2) + +Sauvegarder la recherche Voir carte + +Propriétés suggérées sur base des résultats de ta recherche +----------------------------------------------------------- + +Autres objets intéressants +-------------------------- + +Localités - Canton Zurich + +* [Zurich](https://www.immoscout24.ch/fr/terrain/acheter/lieu-zuerich) + +Districts dans le canton de Canton Zurich + +* [District Affoltern](https://www.immoscout24.ch/fr/terrain/acheter/region-affoltern) +* [District Andelfingen](https://www.immoscout24.ch/fr/terrain/acheter/region-andelfingen) +* [District Bülach](https://www.immoscout24.ch/fr/terrain/acheter/region-buelach) +* [District Dielsdorf](https://www.immoscout24.ch/fr/terrain/acheter/region-dielsdorf) +* [District Dietikon](https://www.immoscout24.ch/fr/terrain/acheter/region-dietikon) +* [District Hinwil](https://www.immoscout24.ch/fr/terrain/acheter/region-hinwil) +* [District Horgen](https://www.immoscout24.ch/fr/terrain/acheter/region-horgen) +* [District Meilen](https://www.immoscout24.ch/fr/terrain/acheter/region-meilen) +* [District Pfäffikon](https://www.immoscout24.ch/fr/terrain/acheter/region-pfaeffikon) +* [District Uster](https://www.immoscout24.ch/fr/terrain/acheter/region-uster) +* [District Winterthur](https://www.immoscout24.ch/fr/terrain/acheter/region-winterthour) + +Cantons - Suisse (Switzerland) + +* [Canton Argovie](https://www.immoscout24.ch/fr/terrain/acheter/canton-argovie) +* [Canton Appenzell R.E.](https://www.immoscout24.ch/fr/terrain/acheter/canton-appenzell-re) +* [Canton Appenzell R.I.](https://www.immoscout24.ch/fr/terrain/acheter/canton-appenzell-ri) +* [Canton Bâle-Campagne](https://www.immoscout24.ch/fr/terrain/acheter/canton-bale-campagne) +* [Canton Bâle-Ville](https://www.immoscout24.ch/fr/terrain/acheter/canton-bale-ville) +* [Canton Berne](https://www.immoscout24.ch/fr/terrain/acheter/canton-berne) +* [Canton Fribourg](https://www.immoscout24.ch/fr/terrain/acheter/canton-fribourg) +* [Canton Genève](https://www.immoscout24.ch/fr/terrain/acheter/canton-geneve) +* [Canton Glaris](https://www.immoscout24.ch/fr/terrain/acheter/canton-glaris) +* [Canton Grisons](https://www.immoscout24.ch/fr/terrain/acheter/canton-grisons) +* [Canton Jura](https://www.immoscout24.ch/fr/terrain/acheter/canton-jura) +* [Canton Lucerne](https://www.immoscout24.ch/fr/terrain/acheter/canton-lucerne) +* [Canton Neuchâtel](https://www.immoscout24.ch/fr/terrain/acheter/canton-neuchatel) +* [Canton Nidwald](https://www.immoscout24.ch/fr/terrain/acheter/canton-nidwald) +* [Canton Obwald](https://www.immoscout24.ch/fr/terrain/acheter/canton-obwald) +* [Canton Schaffhouse](https://www.immoscout24.ch/fr/terrain/acheter/canton-schaffhouse) +* [Canton Schwyz](https://www.immoscout24.ch/fr/terrain/acheter/canton-schwyz) +* [Canton Soleure](https://www.immoscout24.ch/fr/terrain/acheter/canton-soleure) +* [Canton St. Gall](https://www.immoscout24.ch/fr/terrain/acheter/canton-st-gall) +* [Canton Thurgovie](https://www.immoscout24.ch/fr/terrain/acheter/canton-turgovie) +* [Canton Tessin](https://www.immoscout24.ch/fr/terrain/acheter/canton-tessin) +* [Canton Uri](https://www.immoscout24.ch/fr/terrain/acheter/canton-uri) +* [Canton Valais](https://www.immoscout24.ch/fr/terrain/acheter/canton-valais) +* [Canton Vaud](https://www.immoscout24.ch/fr/terrain/acheter/canton-vaud) +* [Canton Zoug](https://www.immoscout24.ch/fr/terrain/acheter/canton-zoug) + +### ImmoScout24 + +* [Créer une annonce](https://www.immoscout24.ch/fr/insertion/publier-soi-meme-en-ligne) +* [Publicité](https://swissmarketplace.group/fr/publicite/) +* [Réseau de publication](https://www.immoscout24.ch/c/fr/tout-sur-nous/reseau-de-publication) + +### À propos de nous + +* [Contact](https://www.immoscout24.ch/c/fr/tout-sur-nous/contact) +* [Portrait](https://swissmarketplace.group/fr/portfolio/real-estate/) +* [Jobs](https://swissmarketplace.group/fr/carrieres/) +* [Faits et chiffres](https://swissmarketplace.group/fr/portfolio/real-estate/) +* [Médias](https://swissmarketplace.group/fr/actualites/) +* [Newsletter](https://www.immoscout24.ch/c/fr/tout-sur-nous/newsletter-abonnement) +* [Service de médiation](https://konsum.ch/fr/service-de-mediation-pour-les-plateformes-immobilieres/) + +### Aspects légaux + +* [Protection des données](https://privacy.swissmarketplace.group/fr/) +* [Règles d’insertion](https://www.immoscout24.ch/c/fr/tout-sur-nous/regles-d-insertion-d-annonces) +* [Conseils de sécurité](https://www.immoscout24.ch/c/fr/tout-sur-nous/consignes-de-securite) +* [Impressum](https://www.immoscout24.ch/c/fr/tout-sur-nous/impressum) +* [CG](https://www.immoscout24.ch/c/fr/tout-sur-nous/conditions-generales) +* [Description des prestations](https://www.immoscout24.ch/c/fr/tout-sur-nous/dispositions-pour-les-membres-et-cg-supplementaires) +* [Signaler un problème de sécurité](https://swissmarketplace.group/fr/vulnerability-disclosure-program) +* Paramètres de confidentialité + +### Services + +* [Extrait du registre des poursuites](https://www.immoscout24.ch/fr/extrait-du-registre-des-poursuites?source=footer) +* [Aide au déménagement](https://www.immoscout24.ch/c/fr/demenagement) +* [Conseil en assurances](https://www.immoscout24.ch/c/fr/lp/conseil-en-assurances) +* [Liste agences](https://www.immoscout24.ch/liste-agences) +* [Calculateur hypothécaire](https://www.immoscout24.ch/fr/financement/calculateur-hypotheque) +* [Estimation immobilière](https://www.immoscout24.ch/fr/estimation) + +### Télécharger l’app + +[](https://7o11.app.link/IS24_Web_Footer_iOS?%243p=a_custom_358665 "iOS App")[](https://7o11.app.link/IS24_Web_Footer_GP?%243p=a_custom_358665 "Android App") + +### Notre partenaire + +[](https://www.swisstennis.ch/fr/?utm_source=website-immoscout24&utm_medium=footer) + +* [Deutsch](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich) +* [Français](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich) +* [Italiano](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo) +* [English](https://www.immoscout24.ch/en/plot/buy/canton-zurich) + +### Suivez-nous + +[](https://www.facebook.com/immoscout24.ch "Facebook")[](https://www.instagram.com/immoscout24ch/ "Instagram")[](https://twitter.com/ImmoScout24ch "Twitter")[](https://www.youtube.com/user/ImmoScout24Schweiz "YouTube")[](https://www.linkedin.com/company/immoscout24-schweiz/ "LinkedIn") + +[SMG Swiss Marketplace Group](https://swissmarketplace.group/fr/)[AutoScout24](https://www.autoscout24.ch/fr)[FinanceScout24](https://www.financescout24.ch/fr?utm_source=immoscout24.ch&utm_medium=web&utm_campaign=footer_bottom)[MotoScout24](https://www.motoscout24.ch/fr)[anibis.ch](https://www.anibis.ch/fr) + +© Copyright 2025 by SMG Swiss Marketplace Group SA. Tous droits réservés.La duplication et l’appropriation des annonces par des tiers, en particulier des photos et des données personnelles qu’elles contiennent, portent atteinte aux droits associés et sont strictement interdites. + +We Care About Your Privacy +-------------------------- + +We and our 455 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data.[Imprint](https://www.immoscout24.ch/en/info/impressum/3530) + +### We and our partners process data to provide: + +Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. List of Partners (vendors) + +I Accept No consent Show Purposes + + + +About Your Privacy +------------------ + +We process your data to deliver content or advertisements and measure the delivery of such content or advertisements to extract insights about our website. We share this information with our partners on the basis of consent. You may exercise your right to consent, based on a specific purpose below or at a partner level in the link under each purpose. These choices will be signaled to our vendors participating in the Transparency and Consent Framework. + +[Privacy Policy](https://www.immoscout24.ch/c/en/about-us/privacy-policy) + +Allow All +### Manage Consent Preferences + +#### Functional Cookies + +- [x] Functional Cookies + +These cookies enable the website to provide enhanced functionality and personalisation. They may be set by us or by third party providers whose services we have added to our pages. If you do not allow these cookies then some or all of these services may not function properly. + +Cookies Details + +#### Strictly Necessary Cookies + +Always Active + +These cookies are necessary for the website to function and cannot be switched off in our systems. They are usually only set in response to actions made by you which amount to a request for services, such as setting your privacy preferences, logging in or filling in forms. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. These cookies do not store any personally identifiable information. + +Cookies Details + +#### Targeting Cookies + +- [x] Targeting Cookies + +These cookies may be set on our website by our advertising partners. They can be used by these companies to build a profile of your interests and to control which advertisements you see on other websites. If you do not allow these cookies, you will still see advertisements, but they will no longer be tailored to you. Your master and usage data will also be made available to the other brands of the SMG Group for analysis, for the management of personalized advertising display, and for personalized marketing communication. The latter means that you may be contacted in a personalized manner for marketing purposes not only by this brand but also by all other brands of the SMG Group. The brands of the SMG Group are ImmoScout24, Homegate, Immostreet.ch, home.ch, Publimmo, Acheter-Louer.ch, CASASOFT, IAZI, AutoScout24, MotoScout24, anibis.ch, tutti.ch, Ricardo, FinanceScout24, Flatfox, and Moneyland. We use Enhanced Conversion that may transmit pseudonymised (e.g. hashed) email addresses to third parties such as Google or publishers (e.g. TX Group or Ringier AG) to improve campaign performance and measurement and/or to create audience segments. Personal identification is not possible unless you are logged in with the same email address and associated with an account of these third parties. Your personal data will be processed either jointly with these third parties, in accordance with their respective privacy notices, or independently by SMG as controller. Please note that your personal data may also be transferred to insecure third countries, where local authorities may access them without protection equivalent to European data protection law. If the level of data protection in a country does not match that of Switzerland, we ensure contractually that the protection of your personal data always corresponds to the level in Switzerland. + +Cookies Details + +#### Performance Cookies + +- [x] Performance Cookies + +These cookies allow us to count visits and traffic sources so we can measure and improve the performance of our site. They help us to know which pages are the most and least popular and see how visitors move around the site. All information these cookies collect is aggregated and therefore anonymous. If you do not allow these cookies we will not know when you have visited our site, and will not be able to monitor its performance. + +Cookies Details + +#### Store and/or access information on a device 365 partners can use this purpose + +- [x] Store and/or access information on a device + +Cookies, device or similar online identifiers (e.g. login-based identifiers, randomly assigned identifiers, network based identifiers) together with other information (e.g. browser type and information, language, screen size, supported technologies etc.) can be stored or read on your device to recognise it each time it connects to an app or to a website, for one or several of the purposes presented here. + +List of IAB Vendors|View Illustrations + +#### Personalised advertising and content, advertising and content measurement, audience research and services development 438 partners can use this purpose + +- [x] Personalised advertising and content, advertising and content measurement, audience research and services development + +* ##### Use limited data to select advertising 359 partners can use this purpose + +- [x] Switch Label +Advertising presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type or which content you are (or have been) interacting with (for example, to limit the number of times an ad is presented to you). + +View Illustrations + +* ##### Create profiles for personalised advertising 283 partners can use this purpose + +- [x] Switch Label +Information about your activity on this service (such as forms you submit, content you look at) can be stored and combined with other information about you (for example, information from your previous activity on this service and other websites or apps) or similar users. This is then used to build or improve a profile about you (that might include possible interests and personal aspects). Your profile can be used (also later) to present advertising that appears more relevant based on your possible interests by this and other entities. + +View Illustrations + +* ##### Use profiles to select personalised advertising 281 partners can use this purpose + +- [x] Switch Label +Advertising presented to you on this service can be based on your advertising profiles, which can reflect your activity on this service or other websites or apps (like the forms you submit, content you look at), possible interests and personal aspects. + +View Illustrations + +* ##### Create profiles to personalise content 103 partners can use this purpose + +- [x] Switch Label +Information about your activity on this service (for instance, forms you submit, non-advertising content you look at) can be stored and combined with other information about you (such as your previous activity on this service or other websites or apps) or similar users. This is then used to build or improve a profile about you (which might for example include possible interests and personal aspects). Your profile can be used (also later) to present content that appears more relevant based on your possible interests, such as by adapting the order in which content is shown to you, so that it is even easier for you to find content that matches your interests. + +View Illustrations + +* ##### Use profiles to select personalised content 92 partners can use this purpose + +- [x] Switch Label +Content presented to you on this service can be based on your content personalisation profiles, which can reflect your activity on this or other services (for instance, the forms you submit, content you look at), possible interests and personal aspects. This can for example be used to adapt the order in which content is shown to you, so that it is even easier for you to find (non-advertising) content that matches your interests. + +View Illustrations + +* ##### Measure advertising performance 404 partners can use this purpose + +- [x] Switch Label +Information regarding which advertising is presented to you and how you interact with it can be used to determine how well an advert has worked for you or other users and whether the goals of the advertising were reached. For instance, whether you saw an ad, whether you clicked on it, whether it led you to buy a product or visit a website, etc. This is very helpful to understand the relevance of advertising campaigns. + +View Illustrations + +* ##### Measure content performance 171 partners can use this purpose + +- [x] Switch Label +Information regarding which content is presented to you and how you interact with it can be used to determine whether the (non-advertising) content e.g. reached its intended audience and matched your interests. For instance, whether you read an article, watch a video, listen to a podcast or look at a product description, how long you spent on this service and the web pages you visit etc. This is very helpful to understand the relevance of (non-advertising) content that is shown to you. + +View Illustrations + +* ##### Understand audiences through statistics or combinations of data from different sources 253 partners can use this purpose + +- [x] Switch Label +Reports can be generated based on the combination of data sets (like user profiles, statistics, market research, analytics data) regarding your interactions and those of other users with advertising or (non-advertising) content to identify common characteristics (for instance, to determine which target audiences are more receptive to an ad campaign or to certain contents). + +View Illustrations + +* ##### Develop and improve services 300 partners can use this purpose + +- [x] Switch Label +Information about your activity on this service, such as your interaction with ads or content, can be very helpful to improve products and services and to build new products and services based on user interactions, the type of audience, etc. This specific purpose does not include the development or improvement of user profiles and identifiers. + +View Illustrations + +* ##### Use limited data to select content 83 partners can use this purpose + +- [x] Switch Label +Content presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type, or which content you are (or have been) interacting with (for example, to limit the number of times a video or an article is presented to you). + +View Illustrations + +List of IAB Vendors + +#### Use precise geolocation data 132 partners can use this special feature + +- [x] Use precise geolocation data + +With your acceptance, your precise location (within a radius of less than 500 metres) may be used in support of the purposes explained in this notice. + +List of IAB Vendors + +#### Actively scan device characteristics for identification 71 partners can use this special feature + +- [x] Actively scan device characteristics for identification + +With your acceptance, certain characteristics specific to your device might be requested and used to distinguish it from other devices (such as the installed fonts or plugins, the resolution of your screen) in support of the purposes explained in this notice. + +List of IAB Vendors + +#### Ensure security, prevent and detect fraud, and fix errors 290 partners can use this special purpose + +Always Active + +Your data can be used to monitor for and prevent unusual and possibly fraudulent activity (for example, regarding advertising, ad clicks by bots), and ensure systems and processes work properly and securely. It can also be used to correct any problems you, the publisher or the advertiser may encounter in the delivery of content and ads and in your interaction with them. + +List of IAB Vendors|View Illustrations + +#### Deliver and present advertising and content 286 partners can use this special purpose + +Always Active + +Certain information (like an IP address or device capabilities) is used to ensure the technical compatibility of the content or advertising, and to facilitate the transmission of the content or ad to your device. + +List of IAB Vendors|View Illustrations + +#### Match and combine data from other data sources 214 partners can use this feature + +Always Active + +Information about your activity on this service may be matched and combined with other information relating to you and originating from various sources (for instance your activity on a separate online service, your use of a loyalty card in-store, or your answers to a survey), in support of the purposes explained in this notice. + +List of IAB Vendors + +#### Link different devices 172 partners can use this feature + +Always Active + +In support of the purposes explained in this notice, your device might be considered as likely linked to other devices that belong to you or your household (for instance because you are logged in to the same service on both your phone and your computer, or because you may use the same Internet connection on both devices). + +List of IAB Vendors + +#### Identify devices based on information transmitted automatically 265 partners can use this feature + +Always Active + +Your device might be distinguished from other devices based on information it automatically sends when accessing the Internet (for instance, the IP address of your Internet connection or the type of browser you are using) in support of the purposes exposed in this notice. + +List of IAB Vendors + +#### Save and communicate privacy choices 245 partners can use this special purpose + +Always Active + +The choices you make regarding the purposes and entities listed in this notice are saved and made available to those entities in the form of digital signals (such as a string of characters). This is necessary in order to enable both this service and those entities to respect such choices. + +List of IAB Vendors|View Illustrations + +### Cookie List + +Clear + +- [x] checkbox label label + +Apply Cancel + +Consent Leg.Interest + +- [x] checkbox label label + +- [x] checkbox label label + +- [x] checkbox label label + +No consent Confirm My Choices + +[](https://www.onetrust.com/products/cookie-consent/) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_002_www.immoscout24.ch_it_terreno_acquistare_cantone-zurigo.txt b/test_web_content_20251002_215219/additional_link_002_www.immoscout24.ch_it_terreno_acquistare_cantone-zurigo.txt new file mode 100644 index 00000000..5a6af40e --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_002_www.immoscout24.ch_it_terreno_acquistare_cantone-zurigo.txt @@ -0,0 +1,437 @@ +URL: https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +70 Terreno edificabile in vendita: Cantone Zurigo | ImmoScout24 + +=============== + +[](https://www.immoscout24.ch/it) +* [Cercare](https://www.immoscout24.ch/it "Cercare") +* [Servizi](https://www.immoscout24.ch/c/it/ipoteche "Servizi") + +[Creare un annuncio](https://www.immoscout24.ch/it/insertion/inserire-in-linea "Creare un annuncio") + +[Preferiti](https://www.immoscout24.ch/favoriti "Preferiti") + +[Il Mio Conto](https://www.immoscout24.ch/it/account-overview "Il Mio Conto") + +Menu + +[](https://www.immoscout24.ch/it) +* [Cercare](https://www.immoscout24.ch/it "Cercare") +* [Servizi](https://www.immoscout24.ch/c/it/ipoteche "Servizi") +* [Stimare](https://www.immoscout24.ch/it/valutazione "Stimare") +* [Rubrica](https://www.immoscout24.ch/c/it/rubrica-immobiliare "Rubrica") + +[Creare un annuncio](https://www.immoscout24.ch/it/insertion/inserire-in-linea "Creare un annuncio") + +[Preferiti](https://www.immoscout24.ch/favoriti "Preferiti") + +[Il Mio Conto](https://www.immoscout24.ch/it/account-overview "Il Mio Conto") + +Menu + +IT +* [DE](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich) +* [FR](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich) +* [IT](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo) +* [EN](https://www.immoscout24.ch/en/plot/buy/canton-zurich) + +1. [](https://www.immoscout24.ch/it) +2. [Terreno edificabile in vendita](https://www.immoscout24.ch/it/terreno/acquistare) +3. [Cantone Zurigo](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo) + +Dove? + + Cantone Zurigo + + Cantone Zurigo + + CHF a + + + + Filtri + + 70 oggetti + +70 risultati - Terreno edificabile in vendita: Cantone Zurigo +============================================================= + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 16    **360m²**, CHF 2’563’760.– Top Luegetenstrasse 11, 8489 Wildberg La tua nuova casa con potenziale - Casa di campagna idillica con riserva di terreno edificabile La tua nuova casa Benvenuti nella vostra futura casa dei sogni - una spaziosa e indipendente casa di campagna in un luogo tranquillo e idillico con vista sul pittoresco Wildberg. Qui, l'idillio rurale, la privacy e la rara opportunità di creare o ampliare uno spazio di vita secondo le vostre idee si incontrano.Se come un rifugio familiare affascinante con un grande giardino o come un oggetto di investimento con potenziale di sviluppo - questa proprietà unica vi offre entrambe le opzioni. Sul terreno di 1339m², avete non solo molto spazio per vivere, ma anche una riserva di terreno edificabile preziosa, che vi apre varie possibilità di progettazione. Le indagini iniziali mostrano: Esiste la possibilità di realizzare una casa a più famiglie con fino a cinque unità abitative - un vero e proprio valore aggiunto per gli acquirenti visionari.Immergetevi in un'oasi verde con una vista lontana - un luogo che vi dà la pace e vi ispira.Punti salienti in un colpo d'occhio • Luogo idillico e tranquillo con alta valenza ricreativa • Ampio terreno con 1339m², ideale per l'uso personale e/o per lo sviluppo di un nuovo edificio • Riserva di terreno edificabile: Potenziale di sviluppo attraente - secondo le stime iniziali, esiste la possibilità di realizzare, in aggiunta alla casa unifamiliare esistente, una casa a più famiglie con fino a cinque unità abitative (non vincolante, senza garanzia) • Giardino fiorito con diversi spazi di soggiorno, pergola con camino esterno, case di giardino, popolazione di alberi ben curata e vasti spazi verdi • Sostanza di costruzione solida con muratura a doppia parete • Concept di spazi ampi con circa 220m² di spazio di vita e circa 96m² di spazio di stoccaggio supplementare nel seminterrato. Superficie totale di circa 360m². • Ampio spazio di vita con stufa a mattoni confortevole - un luogo per arrivare e sentirsi bene • Cucina di vita pratica con sala da pranzo integrata - ideale per le ore sociali • 4 camere luminose - ideali per le famiglie o il telelavoro • 2 celle umide con luce diurna • Sottotetto ampiato per uno spazio supplementare o possibilità di utilizzo creativo • Riscaldamento mediante accumulo elettrico e riscaldamento a pavimento ad acqua • Garage con porta elettrica e possibilità di parcheggio supplementari sulla proprietà • Con una modernizzazione elegante, potete trasformare questa casa in un vero e proprio gioiello Prezzo di vendita: CHF 1'870'000.-Con il nostro tour virtuale a 360 gradi, potete già avere le prime impressioni di questa grande proprietà. Saremmo felici di mostrarvi questa proprietà direttamente sul posto e attendiamo con ansia il vostro contatto.Altri dati chiaveAnno di costruzione della casa: 1984, anno di costruzione della dépendance: 1986, volume della casa (GVZ): 936m³, volume della dépendance (GVZ): 40m³, foglio di registro fondiario: n. 437, numero di catasto: 249, 1/4 di proprietà soggettiva-reale del foglio 444, catasto 249. Superficie abitabile netta: circa 220m², superficie abitabile lorda: circa 360m², superficie del terreno: 1'339m².Costruzione solida, muratura a doppia parete, finestre in legno e metallo quasi nuove (EgoKiefer) con vetratura tripla e meneaux & volets in legno. Riscaldamento elettrico ad accumulo, riscaldamento a pavimento ad acqua, caldaia elettrica 300 litri.Ascensore, garage con apertura di porta elettrica. Cucina di stile casa di campagna con copertura in granito, lavastoviglie, cucina a induzione e frigorifero con compartimento congelatore.Rivestimenti di pavimentoPiano terra: Ingresso, corridoio, doccia, cucina, sala da pranzo con pavimento in piastrelle.Piano superiore: Camere e avant-corpo con pavimento in legno. Bagno con piastrelle.  Tempo di percorrenza Nuovo 28 min.Stazione: Rämismühle-Zell](https://www.immoscout24.ch/acquistare/4002491909) + +[*  *  *  *  *  *  *  *  1 / 4 Prezzo su richiesta Top Lüss, 8542 Wiesendangen Da consegnare in diritto di costruzione: 14’770 m2 di terreno edificabile nella migliore posizione a Wiesendangen, vantaggiosa in termini di tasse Da consegnare in diritto di costruzione :14’770 m2 di terreno edificabile nella migliore posizione a Wiesendangen, vantaggiosa in termini di tasseProprietà WD4674 – Lüss WiesendangenTutti i dettagli sulla proprietà, il contratto di diritto di costruzione e i criteri di assegnazione si trovano nel dossier allegato.Le offerte vincolanti per la ripresa del contratto di diritto di costruzione, compresa la prova di finanziamento, devono essere presentate a:Comune di WiesendangenAl signor Martin SchindlerSchulstrasse 208542 Wiesendangen Si prega di utilizzare il modulo in allegato per la presentazione dell'offerta.Scadenza per la presentazione : lunedì 20 ottobre 2025, ore 11:00 Tempo di percorrenza Nuovo 9 min.Stazione: Wiesendangen](https://www.immoscout24.ch/acquistare/4002510601) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 12    CHF 2’323’840.– Hürstringstrasse 37, 8046 Zürich Terreno con casa unifamiliare esistente e grande potenziale Saremmo felici di presentarvi questo terreno con grande potenziale e molte possibilità.Dopo consultazione, vendiamo un terreno con una casa unifamiliare esistente in una posizione tranquilla a Zurigo. Ciò che è interessante in questa proprietà, tuttavia, è che quando si acquista, si dispone già dell'autorizzazione di costruzione associata, che consente di ampliare e ristrutturare lo spazio abitativo in questa parcelle secondo le proprie esigenze.Non lontano dalla stazione principale di Zurigo, dietro il Käferberg, il terreno spazioso è situato in un quartiere residenziale tranquillo con zona a 30 km/h.A piedi, si può raggiungere una fermata dell'autobus, nonché la piccola foresta, che è ideale per brevi passeggiate.Le informazioni più importanti in breve: • Terreno con casa unifamiliare e autorizzazione di costruzione per ampliare la superficie abitabile • Anno di costruzione 1934 • Superficie del terreno di 410 m2 • Possibilità di progetto 1: Ampliamento in casa multifamiliare con due appartamenti in proprietà o in affitto • Possibilità di progetto 2: Ampliamento in casa a più generazioni Sperimentate l'atmosfera tranquilla e la simultanea vicinanza al centro città durante una visita personale!Per ulteriori informazioni sulla proprietà o per pianificare una visita, non esitate a contattarci in qualsiasi momento.  Tempo di percorrenza Nuovo 22 min.Stazione: Zürich Seebach](https://www.immoscout24.ch/acquistare/4002349882) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 11    CHF 3’290’400.– Luzernerstrasse 57, 8903 Birmensdorf (ZH) Posizione soleggiata con vista Per conto del nostro cliente, vendiamo un terreno edificabile in una posizione soleggiata con vista di 1'228 m² di superficie fondiaria (zona residenziale W2).La proprietà esistente si presenta in uno stato di manutenzione corrispondente alla sua età.Prezzo di vendita target: CHF 2'400'000Abbiamo suscitato il tuo interesse? Saremmo felici di inviarti l'esposé dettagliato di questa offerta interessante.  Tempo di percorrenza Nuovo 19 min.Stazione: Birmensdorf](https://www.immoscout24.ch/acquistare/4002566208) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13 CHF 4’044’440.– Mühlemattstrasse 12, 8135 Langnau am Albis Terreno edificabile o casa unifamiliare esistente in vendita! Questa casa unifamiliare indipendente si trova in una zona tranquilla e offre una rara combinazione di carattere architettonico, ambiente generoso e potenziale di sviluppo ispirante. Immersa in una grande quantità di verde e circondata da alberi, potrete godere di privacy, pace e una bellissima vista.La casa convince per la sua inconfondibile apparenza. I muri in mattoni all'interno danno allo spazio abitativo un'atmosfera calda e naturale, mentre il caminetto nel soggiorno assicura il comfort nei giorni più freddi. Il piano è aperto e accogliente, completato da ampie facciate di finestre che portano luce e natura nella casa.Un punto di forza è la spaziosa terrazza con una vista meravigliosa – ideale per ore piacevoli all'aperto. Il giardino è vasto e offre molto spazio per una progettazione individuale. Con un po' di attenzione, si può creare qui un meraviglioso paradiso verde – che sia come giardino familiare, rifugio o per progetti creativi all'aperto.Grazie alle dimensioni della proprietà e alla sua posizione, la proprietà apre anche prospettive interessanti per un eventuale nuovo edificio di sostituzione - come una casa unifamiliare moderna o una casa multifamiliare.Saremmo felici di fornirvi ulteriori informazioni o di concordare un appuntamento di visita personale. Scoprite il potenziale e l'atmosfera unica di questo posto. Nella documentazione di vendita, troverete tutte le informazioni importanti.  Tempo di percorrenza Nuovo 12 min.Stazione: Langnau-Gattikon](https://www.immoscout24.ch/acquistare/4002406229) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13    CHF 1’302’440.– Kanalweg 2, 8714 Feldbach Terreno per una casa unifamiliare progettata Nel tranquillo villaggio di Feldbach, sul lago di Zurigo, questo terreno con una fattoria esistente, costruita su un solo lato, è in vendita. Il prezzo di acquisto include un progetto preliminare realizzabile per una casa unifamiliare in sostituzione della fattoria.L'oggetto offre la possibilità unica di realizzare il vostro sogno di proprietà in un luogo idilliaco. Offre abbastanza spazio per una famiglia, e una combinazione di "vita e lavoro" è anche possibile.Entro 30 minuti, si può raggiungere Zurigo con la S-Bahn, e l'asilo nido e la scuola primaria sono anche vicine. Ci sono opportunità di shopping a Hombrechtikon, Stäfa e Rapperswil. In estate, una piscina vicina nella charmante Seebadi Feldbach invita a rinfrescarsi.Esiste una stima dei costi attuale per la casa (costruzione in elementi di legno) compresi i dintorni, i costi di costruzione e i costi accessori di Fr. 1'380'000.--.Abbiamo suscitato il vostro interesse? Allora chiamateci. Saremo felici di rispondere alle vostre domande o di fornirvi la nostra documentazione di vendita per studio. La proprietà può, naturalmente, essere visitata. Ci aspettiamo della vostra chiamata.  Tempo di percorrenza Nuovo 6 min.Stazione: Feldbach](https://www.immoscout24.ch/acquistare/4002434745) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13    **5.5 locali**, CHF 4’111’620.– Schaffhauserstrasse 226b, 8057 Zürich Mehr Raum fürs Leben: Reihenhaus mit Potenzial Attraktive Stadtliegenschaft mit ausgearbeitetem ProjektIm Zürcher Kreis 11 veräussern wir ein hübsches Reiheneinfamilien-Eckhaus mit grosszügigem Umschwung. Die Liegenschaft und das Grundstück verfügen über viel Ausnützungspotenzial und ermöglicht so die Realisation spannender Projekte sowohl im Umbau als auch Neubau.Diese Liegenschaft überzeugt durch viele Besonderheiten: • grosszügiger Umschwung mit viel Potenzial • Blick ins Grüne von nahezu allen Fenstern • Schwedenofen im Wohnbereich • viel Stauraum durch Wandschränke und Estrich • Altbaucharme in modernem Quartier • zentrale und familienfreundliche Lage • sonnenverwöhnter Standort Haben wir Ihr Interesse geweckt? Bestellen Sie noch heute unsere ausführliche Verkaufsdokumentation mittels Kontaktformular und Sie erhalten weitere spannende Informationen zur Immobilie. Wir freuen uns über Ihre Kontaktaufnahme!Une oasis de verdure dans la ville de Zurich avec un projet élaboréDans le quartier 11 de Zurich, nous vendons une jolie maison mitoyenne en angle avec de vastes alentours. L'immeuble et le terrain disposent d'un grand potentiel d'exploitation et permettent ainsi la réalisation de projets passionnants, tant en transformation qu'en construction neuve.Cette propriété convainc par ses nombreuses particularités : • Un vaste terrain avec beaucoup de potentiel • Une vue sur la verdure depuis presque toutes les fenêtres • Un poêle suédois dans le séjour • beaucoup d'espace de rangement grâce aux armoires murales et au grenier • Le charme d'un ancien bâtiment dans un quartier moderne • Un emplacement central et favorable aux familles • Un emplacement ensoleillé Nous avons éveillé votre intérêt ? Commandez dès aujourd'hui notre documentation de vente détaillée au moyen du formulaire de contact et vous recevrez d'autres informations passionnantes sur le bien immobilier. Nous nous réjouissons de votre prise de contact!A green oasis in the city of Zurich with an elaborate projectIn Zurich's Kreis 11 district, we are selling a pretty terraced single-family corner house with spacious grounds. The property and the plot have a lot of utilization potential and thus enable the realization of exciting projects both in conversion and new construction.This property boasts many special features: • spacious grounds with lots of potential • view of the countryside from almost all windows • Swedish stove in the living area • lots of storage space thanks to wall cupboards and attic • old building charm in a modern district • central and family-friendly location • sun-drenched location Have we piqued your interest? Order our detailed sales documentation today using the contact form and you will receive further exciting information about the property. We look forward to hearing from you!  Tempo di percorrenza Nuovo 4 min.Stazione: Berninaplatz](https://www.immoscout24.ch/acquistare/4002346061) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 12 Prezzo su richiesta Überlandstrasse 23, 8340 Hinwil Parcelle di terra industriale e di costruzione in una posizione attraente nel Zürcher-Oberland Nella zona industriale vivace di Hinwil, vendiamo un terreno di costruzione industriale in una posizione molto frequentata, direttamente sull'asse principale di Rapperswil, Wetzikon, e Pfäffikon ZH. La parcelle di terra da costruire è situata ai margini della zona industriale e confina con la zona residenziale di Hinwil ZH.Dati chiave:- Superficie totale del terreno 4.246 m2- Zona di costruzione industriale/commerciale IG/7 - Fattore di volume di costruzione 7 m3/m2- Altezza massima dell'edificio 21,5 m- Lunghezza massima dell'edificio aperta- Grande distanza di confine alla strada nazionale- Distanza di edificio tutto intorno 3,5 m- Volume di costruzione possibile massimo circa 30.000 m3- Superficie lorda di piano circa 9.500 m2Il terreno di costruzione è attualmente ancora utilizzato con due unità abitative, un'officina di riparazione auto con un showroom separato, e una stazione di servizio. Intorno alla proprietà, ci sono grandi aree pavimentate disponibili per l'uso.  Tempo di percorrenza Nuovo 10 min.Stazione: Hinwil](https://www.immoscout24.ch/acquistare/4002417917) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 10 CHF 2’947’650.– Trottenrain 14, 8474 Dinhard Progetto di costruzione approvato a Dinhard-Welsikon con vantaggi fiscali Il terreno edificabile con un magazzino si trova in una zona centrale a Welsikon, alla periferia del comune di Dinhard, nella zona centrale. L'elevata utilizzazione ottenuta consente la costruzione di nuovi edifici attraenti in una posizione centrale. Le visualizzazioni e i piani del progetto di costruzione approvato possono essere trovati nella documentazione. Il magazzino è elencato nell'inventario comunale degli edifici protetti. Pertanto, è stato elaborato un accordo di protezione in consultazione con la protezione del patrimonio e il comune di Dinhard, che consente una conversione straordinaria in un loft moderno.Punti salienti: • progetto di costruzione approvato e pianificazione degli appalti per i nuovi edifici • accordo di protezione • eccellente posizione a Welsikon • paradiso fiscale (tasso di imposta comunale 83%) • parcelle di terreno edificabile ben proporzionata • buona connessione ai trasporti pubblici (stazione a 170 m) Realizzazione:L'associazione dei proprietari di Winterthur sostiene, se necessario, in stretta collaborazione con Kästle Architekten nella realizzazione del vostro progetto di nuovo edificio.Dalla pianificazione alla vendita/affitto del nuovo edificio terminato – l'associazione dei proprietari di Winterthur offre tutti i servizi da una sola fonte. Non c'è obbligo architettonico.Le parti interessate sono cordialmente invitate a contattarci.Chiamate il nostro team di vendita al 052 209 01 68 se desiderate ricevere informazioni aggiuntive o una visita. Ci rallegriamo di sentirvi.Il vostro team di vendita HEVImportante: Siamo esclusivamente incaricati della vendita. Il contatto diretto con i proprietari porterà all'esclusione dall'elenco delle parti interessate. S.E.&.O.  Tempo di percorrenza Nuovo 5 min.Stazione: Dinhard](https://www.immoscout24.ch/acquistare/4002188905) + +[ 1 / 1 CHF 2’399’240.– In der Gass 2, 8627 Grüningen Terreno con permesso di costruire in vendita In vendita, un terreno con un progetto di nuova costruzione approvato. Edificio C dell'Enssamble in Binzikerstrasse 21 / In der Gass 2, 8627 Grüningen. I garage attualmente esistenti possono essere demoliti e sostituiti da un nuovo edificio con 8 appartamenti di dimensioni diverse con aree esterne attraenti. Inoltre, la costruzione congiunta di un garage sotterraneo per 11 posti auto con accesso via la strada "In der Gass" è stata approvata.  Tempo di percorrenza Nuovo 54 min.Stazione: Esslingen](https://www.immoscout24.ch/acquistare/3003479026) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 2’604’890.– Im Königstal 2, 8487 Zell Tempo di percorrenza Nuovo 22 min.Stazione: Rämismühle-Zell](https://www.immoscout24.ch/acquistare/4002279293) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 4’112’990.– Im Königstal 3, 8487 Zell ZH Tempo di percorrenza Nuovo 22 min.Stazione: Rämismühle-Zell](https://www.immoscout24.ch/acquistare/4002279266) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 6’717’900.– Im Königstal 3, 8487 Zell ZH Tempo di percorrenza Nuovo 22 min.Stazione: Rämismühle-Zell](https://www.immoscout24.ch/acquistare/4002279259) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    CHF 2’879’100.– Rotweg 20, 8820 Wädenswil Il tuo nuovo progetto con vista sul lago Per conto del nostro cliente, vendiamo un'area residenziale preferita, elevata e tranquilla con una bella vista sul lago e sulla distanza, 706 m² di terreno edificabile con un oggetto di demolizione.Prezzo di vendita target: CHF 2'100'000.00Abbiamo suscitato il tuo interesse? Saremmo felici di inviarti l'esposé dettagliato di questa offerta interessante.  Tempo di percorrenza Nuovo 12 min.Stazione: Wädenswil](https://www.immoscout24.ch/acquistare/4002559578) + +[*  *  *  *  *  *  *  *  *  *  *  1 / 7    CHF 651’220.– Auf Anfrage 1, 8195 Wasterkingen Terreno edificabile attraente in un ambiente rurale e tranquillo Benvenuti a Wasterkingen, una comunità idillica e tranquilla del Zurich Unterland, nota per la sua alta qualità della vita, la tranquillità rurale e la buona accessibilità. Esattamente qui, un terreno edificabile attraente vi aspetta - la base ideale per la vostra futura casa.Il terreno è completamente urbanizzato e si trova nella zona centrale B, il che vi offre numerose opzioni di progettazione. Che si tratti di una casa unifamiliare moderna, di una casa classica con carattere di villaggio o di un progetto architettonico individuale - qui potete realizzare i vostri sogni di vita esattamente secondo le vostre idee.La comunità affascinante di Wasterkingen colpisce per la sua posizione tranquilla in mezzo ai campi, alle vigne e alla natura.Questa offerta ImmoSky propone i seguenti vantaggi *Prestazioni aggiuntive*:+ Completamente urbanizzato+ Comunità tranquilla+ Dimensione ideale per la flessibilità (650m²)+ Zona centrale B+ Coefficiente di occupazione del suolo per edificio principale 30%Questo terreno vi offre la rara opportunità di combinare l'idillio rurale con la vicinanza urbana - un luogo dove potete riposare e essere perfettamente connessi.Realizzerete qui il vostro sogno di proprietà e progetterete il vostro rifugio personale a Wasterkingen.Vi abbiamo convinto con questa offerta? Allora non esitate a contattarci per ulteriori domande o un appuntamento di visita!(La documentazione di vendita vi sarà inviata entro un massimo di 24 ore. Verificate anche la vostra cartella SPAM.)  Tempo di percorrenza -](https://www.immoscout24.ch/acquistare/4002537208) + +[*  *  *  *  *  *  *  *  *  *  *  1 / 7    CHF 7’540’490.– Staldernstrasse 13, 8158 Regensberg Terreno da sviluppare in una posizione eccellente nella zona centrale 2 Nel comune molto richiesto di Regensberg (ZH), un terreno molto ben situato è in vendita, che si adatta ideale agli investitori, imprenditori generali o totali. La parcella di 2 557 m², n. 949, si trova nella zona centrale 2, che consente una varietà di possibilità di sviluppo legate alla costruzione e all'uso, in particolare per progetti residenziali o a uso misto.Attualmente, un edificio non preservabile si trova sulla proprietà, che può essere demolito nel quadro di un nuovo sviluppo. Nessuna richiesta di costruzione o permesso è disponibile, quindi c'è una totale libertà di progettazione nel quadro delle norme di costruzione e urbanistica applicabili.I calcoli mostrano che un'attesa di reddito locativo sostenibile di circa CHF 485 600 all'anno sembra realistica - supponendo un utilizzo di circa 1 664 m² di spazio utilizzabile principale (HNF) e 28 posti auto sotterranei. Il tasso di capitalizzazione determinato è del 4,20 %.Cifre chiave di valutazione:Valore di mercato (valore fondiario attualizzato): CHF 5 505 000Valore di reddito in uno stato rinnovato: CHF 11 556 795Valore reale (ipotetico): CHF 12 485 000Reddito potenziale di vendita: CHF 16 190 000Rendita lorda (valore locativo): 4,20 %Lo sviluppo ipotetico prevede due case multifamiliari con una superficie totale di pavimento lordo (BGF) di 2 080 m² - corrispondente a un fattore di utilizzo del suolo di 0,81, interamente nel quadro della normativa urbanistica. I costi di costruzione calcolati (BKP 2-5) ammontano a circa CHF 8,74 milioni. Il valore fondiario attualizzato per m² è di CHF 2 155, il che sottolinea ulteriormente il potenziale economico.La zona centrale 2 consente anche utilizzi misti, come ad esempio offerte commerciali al piano terra, in aggiunta all'uso residenziale puro. Ciò è un vantaggio supplementare per concetti di sviluppo flessibili e adattati al luogo. La posizione a Regensberg offre una qualità della vita residenziale calma vicino all'agglomerazione di Zurigo e è integrata in un ambiente storico attraente.In conclusione: il terreno offre la rara opportunità di acquisire un terreno sviluppabile in una posizione eccellente con un oggetto di demolizione esistente e di costruirlo secondo le proprie idee. Grazie alle possibilità di utilizzo flessibili e alla posizione attraente, questo investimento rappresenta un ottimo punto di partenza per sviluppi di progetti a rendimento elevato.Per informazioni dettagliate, siamo a vostra disposizione.  Tempo di percorrenza Nuovo 23 min.Stazione: Steinmaur](https://www.immoscout24.ch/acquistare/4002529588) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    CHF 3’633’140.– Riedwiesenstrasse 20, 8305 Dietlikon RISERVATO - Lotto edificabile industriale in posizione centrale a Dietlikon ZH Siamo lieti di presentarvi un lotto edificabile unico e estremamente raro in una posizione centrale a Dietlikon ZH – un'opportunità eccezionale con proprietà eccellenti, particolarmente adatta agli investitori.Posizione centrale: Il lotto si trova in un quartiere molto richiesto con ottime connessioni: l'aeroporto di Zurigo è raggiungibile in 10 minuti in auto, e la città di Zurigo è raggiungibile in 12 minuti in auto • Visibilità: La vostra azienda sarà perfettamente visibile dall'autostrada, offrendo opportunità pubblicitarie ottimali (circa 500 m2 di facciata per la pubblicità). • Densità di costruzione: Beneficiate della alta densità di costruzione di 10,0, che consente una flessibilità e un'efficienza massime. • Diritti di costruzione vicini: Il lotto ha diritti di costruzione vicini a destra e a sinistra. Sul retro, un diritto di costruzione vicino può essere ottenuto dalla città di Zurigo • Circa 3.500 m2 di superficie lorda possibile • Parcheggio sotterraneo / seminterrato fino a circa 800 m2 può essere realizzato • Altezza totale massima 20 m. 7 piani con 500 m2 di superficie lorda e 2,85 m di altezza di stanza (lorda) possibili • Lotto: La superficie piana del lotto semplifica la pianificazione e l'esecuzione della costruzione. • Forma: Il lotto ha una forma ideale, che consente possibilità di costruzione polivalenti. • Incrocio autostradale: Brüttiseller Kreuz, situato direttamente a uno degli incroci autostradali più importanti della Svizzera, offre al lotto un'ottima accessibilità e vantaggi logistici • Commercio fastidioso: La posizione è anche adatta al commercio che può essere potenzialmente fastidioso. • I centri culturali e le attività alberghiere sono anche possibili. Adesso o mai – la vostra chance per un ottimo investimento:Un tale lotto edificabile industriale in questa posizione è estremamente raro sul mercato – da qualche tempo, non c'è stata un'offerta comparabile in questo quartiere molto richiesto. Assicuratevi questa proprietà unica adesso, ideale per gli imprenditori visionari e gli investitori che contano su una posizione strategicamente ottimale.Vi abbiamo interessato? Allora contattateci oggi. Saremo lieti di inviarvi il dossier di vendita dettagliato, compresa uno studio di fattibilità – esclusivamente e senza impegno.  Tempo di percorrenza Nuovo 14 min.Stazione: Dietlikon](https://www.immoscout24.ch/acquistare/4002331523) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    Prezzo su richiesta Kaffeestrasse, 8180 Bülach Il vostro edificio industriale direttamente a Bülach DescriptionSaremmo felici di sviluppare e realizzare un progetto su misura per le vostre esigenze, che sarà a vostra disposizione per l'affitto o la proprietà.Interessati o avete domande? Non esitate a contattarci!Il terreno non è quello giusto per le vostre esigenze? Nessun problema! Visita il nostro sito web e trova altre offerte su: gewerbeland-schweiz.ch  Tempo di percorrenza Nuovo 20 min.Stazione: Bülach](https://www.immoscout24.ch/acquistare/4001788654) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    Prezzo su richiesta Kaffeestrasse, 8180 Bülach Il tuo edificio industriale direttamente a Bülach DescriptionSaremmo felici di sviluppare e realizzare un progetto su misura per le tue esigenze, che sarà a tua disposizione per l'affitto o la proprietà.Interessato o hai domande? Contattaci!Il terreno non è quello giusto per le tue esigenze? Nessun problema! Visita il nostro sito web e trova altre offerte su: gewerbeland-schweiz.ch  Tempo di percorrenza Nuovo 20 min.Stazione: Bülach](https://www.immoscout24.ch/acquistare/4001788644) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    * Quartiere tranquillo CHF 3’358’950.– 8192 Glattfelden TERRENO EDIFICABILE SENZA OSTACOLI A ZWEIDLEN Nel popolare Zweidlen, vendiamo un terreno edificabile attraente di 1'226 m² con un oggetto esistente. Il nostro studio di progetto mostra un potenziale elevato per la costruzione di una casa multifamiliare. • Superficie lorda possibile di fino a 940 m² (progetto 789 m²) • Zona residenziale e commerciale WG 2.3 • Nessuna protezione del patrimonio per l'oggetto esistente • Il confine tedesco a Kaiserstuhl è a soli 8 minuti in auto • L'aeroporto di Zurigo è raggiungibile in soli 19 minuti in auto Interessato? Per ulteriori informazioni, foto e una visita virtuale della proprietà, nonché opzioni di visita, visitate: https://www.propertyowner.ch/de/immobilien/25-12278 Numero di riferimento: 25-12278 Diventate membro gratuito della Grundeigentümer Verband Schweiz oggi e beneficiate di numerosi vantaggi per i membri: www.propertyowner.ch - I membri dell'associazione possono finanziare la proprietà in questione o altre proprietà con il sostegno del nostro dipartimento di finanziamento. - I membri dell'associazione hanno accesso al nostro servizio legale (consultazione telefonica iniziale gratuita di 30 minuti). - Valutazione professionale gratuita della proprietà - Consultazione e calcolo gratuiti dell'imposta sulle plusvalenze immobiliari Siete diventati curiosi? Scoprite di più sul nostro sito https://www.propertyowner.ch/immobilien/ e lasciatevi ispirare dalle nostre offerte. Ci rallegriamo della possibilità di conoscerVi personalmente e di realizzare i Vostri sogni immobiliari! * Quartiere tranquillo  Tempo di percorrenza -](https://www.immoscout24.ch/acquistare/4002558181) + +[1](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo)[2](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo?pn=2)[...4](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo?pn=4)[](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo?pn=2) + +Salvare la ricerca Vista mappa + +Proprietà suggerite sulla base dei risultati della tua ricerca +-------------------------------------------------------------- + +Altri oggetti interessanti +-------------------------- + +Località - Cantone Zurigo + +* [Zurigo](https://www.immoscout24.ch/it/terreno/acquistare/luogo-zuerich) + +Distretti nel cantone di Cantone Zurigo + +* [Distretto Affoltern](https://www.immoscout24.ch/it/terreno/acquistare/regione-affoltern) +* [Distretto Andelfingen](https://www.immoscout24.ch/it/terreno/acquistare/regione-andelfingen) +* [Distretto Bülach](https://www.immoscout24.ch/it/terreno/acquistare/regione-buelach) +* [Distretto Dielsdorf](https://www.immoscout24.ch/it/terreno/acquistare/regione-dielsdorf) +* [Distretto Dietikon](https://www.immoscout24.ch/it/terreno/acquistare/regione-dietikon) +* [Distretto Hinwil](https://www.immoscout24.ch/it/terreno/acquistare/regione-hinwil) +* [Distretto Horgen](https://www.immoscout24.ch/it/terreno/acquistare/regione-horgen) +* [Distretto Meilen](https://www.immoscout24.ch/it/terreno/acquistare/regione-meilen) +* [Distretto Pfäffikon](https://www.immoscout24.ch/it/terreno/acquistare/regione-pfaeffikon) +* [Distretto Uster](https://www.immoscout24.ch/it/terreno/acquistare/regione-uster) +* [Distretto Winterthur](https://www.immoscout24.ch/it/terreno/acquistare/regione-winterthur) + +Cantoni - Svizzera (Switzerland) + +* [Cantone Argovia](https://www.immoscout24.ch/it/terreno/acquistare/cantone-argovia) +* [Cantone Appenzello esterno](https://www.immoscout24.ch/it/terreno/acquistare/cantone-appenzello-esterno) +* [Cantone Appenzello interno](https://www.immoscout24.ch/it/terreno/acquistare/cantone-appenzello-interno) +* [Cantone Basilea-campagna](https://www.immoscout24.ch/it/terreno/acquistare/cantone-basilea-campagna) +* [Cantone Basilea-città](https://www.immoscout24.ch/it/terreno/acquistare/cantone-basilea-citta) +* [Cantone Berna](https://www.immoscout24.ch/it/terreno/acquistare/cantone-berna) +* [Cantone Friborgo](https://www.immoscout24.ch/it/terreno/acquistare/cantone-friborgo) +* [Cantone Ginevra](https://www.immoscout24.ch/it/terreno/acquistare/cantone-ginevra) +* [Cantone Glarona](https://www.immoscout24.ch/it/terreno/acquistare/cantone-glarona) +* [Cantone Grigioni](https://www.immoscout24.ch/it/terreno/acquistare/cantone-grigioni) +* [Cantone Giura](https://www.immoscout24.ch/it/terreno/acquistare/cantone-giura) +* [Cantone Lucerna](https://www.immoscout24.ch/it/terreno/acquistare/cantone-lucerna) +* [Cantone Neuchatel](https://www.immoscout24.ch/it/terreno/acquistare/cantone-neuchatel) +* [Cantone Nidvaldo](https://www.immoscout24.ch/it/terreno/acquistare/cantone-nidvaldo) +* [Cantone Obvaldo](https://www.immoscout24.ch/it/terreno/acquistare/cantone-obvaldo) +* [Cantone Sciaffusa](https://www.immoscout24.ch/it/terreno/acquistare/cantone-sciaffusa) +* [Cantone Svitto](https://www.immoscout24.ch/it/terreno/acquistare/cantone-svitto) +* [Cantone Soletta](https://www.immoscout24.ch/it/terreno/acquistare/cantone-soletta) +* [Cantone San Gallo](https://www.immoscout24.ch/it/terreno/acquistare/cantone-san-gallo) +* [Cantone Turgovia](https://www.immoscout24.ch/it/terreno/acquistare/cantone-turgovia) +* [Cantone Ticino](https://www.immoscout24.ch/it/terreno/acquistare/cantone-ticino) +* [Cantone Uri](https://www.immoscout24.ch/it/terreno/acquistare/cantone-uri) +* [Cantone Vallese](https://www.immoscout24.ch/it/terreno/acquistare/cantone-vallese) +* [Cantone Vaud](https://www.immoscout24.ch/it/terreno/acquistare/cantone-vaud) +* [Cantone Zugo](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zugo) + +### ImmoScout24 + +* [Creare un annuncio](https://www.immoscout24.ch/it/insertion/inserire-in-linea) +* [Pubblicità](https://swissmarketplace.group/advertising/) +* [Rete di pubblicazione](https://www.immoscout24.ch/c/it/chi-siamo/rete-pubblicazioni) + +### Su di noi + +* [Contatto](https://www.immoscout24.ch/c/it/chi-siamo/contatto) +* [Ritratto](https://swissmarketplace.group/portfolio/real-estate/) +* [Impiego](https://swissmarketplace.group/career/) +* [Fatti e cifre](https://swissmarketplace.group/portfolio/real-estate/) +* [Media](https://swissmarketplace.group/media/) +* [Newsletter](https://www.immoscout24.ch/c/it/chi-siamo/newsletter-abbonamento) +* [Ufficio del mediatore](https://konsum.ch/it/ufficio-del-mediatore-per-le-piattaforme-immobiliari/) + +### Aspetti legali + +* [Protezione dei dati](https://privacy.swissmarketplace.group/it/) +* [Regole di inserzione](https://www.immoscout24.ch/c/it/chi-siamo/regole-d-inserzione-immoScout24) +* [Consigli di sicurezza](https://www.immoscout24.ch/c/it/chi-siamo/avviso-di-sicurezza) +* [Impressum](https://www.immoscout24.ch/c/it/chi-siamo/impressum) +* [CG](https://www.immoscout24.ch/c/it/chi-siamo/cgc) +* [Descrizione delle prestazioni](https://www.immoscout24.ch/c/it/chi-siamo/disposizioni-per-i-membri-e-cg-supplementari) +* [Segnala un problema di sicurezza](https://swissmarketplace.group/vulnerability-disclosure-program) +* Impostazioni sulla privacy + +### Services + +* [Estratto del registro delle esecuzioni](https://www.immoscout24.ch/it/certificato-di-solvibilita?source=footer) +* [Assistenza trasloco](https://www.immoscout24.ch/c/it/traslocare) +* [Consulenza assicurativa](https://www.immoscout24.ch/c/it/lp/consulenza-assicurativa) +* [Elenco agenzie](https://www.immoscout24.ch/elenco-agenzie) +* [Calcolatore di ipoteca](https://www.immoscout24.ch/it/finanziamento/calcolo-ipoteca) +* [Valutazione immobiliare](https://www.immoscout24.ch/it/valutazione) + +### Scaricare l’app + +[](https://7o11.app.link/IS24_Web_Footer_iOS?%243p=a_custom_358665 "iOS App")[](https://7o11.app.link/IS24_Web_Footer_GP?%243p=a_custom_358665 "Android App") + +### Il nostro partner + +[](https://www.swisstennis.ch/de/?utm_source=website-immoscout24&utm_medium=footer) + +* [Deutsch](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich) +* [Français](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich) +* [Italiano](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo) +* [English](https://www.immoscout24.ch/en/plot/buy/canton-zurich) + +### Ci segua + +[](https://www.facebook.com/immoscout24.ch "Facebook")[](https://www.instagram.com/immoscout24ch/ "Instagram")[](https://twitter.com/ImmoScout24ch "Twitter")[](https://www.youtube.com/user/ImmoScout24Schweiz "YouTube")[](https://www.linkedin.com/company/immoscout24-schweiz/ "LinkedIn") + +[SMG Swiss Marketplace Group](https://swissmarketplace.group/)[AutoScout24](https://www.autoscout24.ch/it)[FinanceScout24](https://www.financescout24.ch/it?utm_source=immoscout24.ch&utm_medium=web&utm_campaign=footer_bottom)[MotoScout24](https://www.motoscout24.ch/it)[anibis.ch](https://www.anibis.ch/it) + +© Copyright 2025 by SMG Swiss Marketplace Group SA. Tutti i diritti riservati.La duplicazione e la ripresa degli annunci da parte di terzi, in particolare di foto e dati personali in essi contenuti, viola i diritti ad essi associati ed è espressamente vietate. + +We Care About Your Privacy +-------------------------- + +We and our 455 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data.[Imprint](https://www.immoscout24.ch/en/info/impressum/3530) + +### We and our partners process data to provide: + +Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. List of Partners (vendors) + +I Accept No consent Show Purposes + + + +About Your Privacy +------------------ + +We process your data to deliver content or advertisements and measure the delivery of such content or advertisements to extract insights about our website. We share this information with our partners on the basis of consent. You may exercise your right to consent, based on a specific purpose below or at a partner level in the link under each purpose. These choices will be signaled to our vendors participating in the Transparency and Consent Framework. + +[Privacy Policy](https://www.immoscout24.ch/c/en/about-us/privacy-policy) + +Allow All +### Manage Consent Preferences + +#### Functional Cookies + +- [x] Functional Cookies + +These cookies enable the website to provide enhanced functionality and personalisation. They may be set by us or by third party providers whose services we have added to our pages. If you do not allow these cookies then some or all of these services may not function properly. + +Cookies Details + +#### Strictly Necessary Cookies + +Always Active + +These cookies are necessary for the website to function and cannot be switched off in our systems. They are usually only set in response to actions made by you which amount to a request for services, such as setting your privacy preferences, logging in or filling in forms. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. These cookies do not store any personally identifiable information. + +Cookies Details + +#### Targeting Cookies + +- [x] Targeting Cookies + +These cookies may be set on our website by our advertising partners. They can be used by these companies to build a profile of your interests and to control which advertisements you see on other websites. If you do not allow these cookies, you will still see advertisements, but they will no longer be tailored to you. Your master and usage data will also be made available to the other brands of the SMG Group for analysis, for the management of personalized advertising display, and for personalized marketing communication. The latter means that you may be contacted in a personalized manner for marketing purposes not only by this brand but also by all other brands of the SMG Group. The brands of the SMG Group are ImmoScout24, Homegate, Immostreet.ch, home.ch, Publimmo, Acheter-Louer.ch, CASASOFT, IAZI, AutoScout24, MotoScout24, anibis.ch, tutti.ch, Ricardo, FinanceScout24, Flatfox, and Moneyland. We use Enhanced Conversion that may transmit pseudonymised (e.g. hashed) email addresses to third parties such as Google or publishers (e.g. TX Group or Ringier AG) to improve campaign performance and measurement and/or to create audience segments. Personal identification is not possible unless you are logged in with the same email address and associated with an account of these third parties. Your personal data will be processed either jointly with these third parties, in accordance with their respective privacy notices, or independently by SMG as controller. Please note that your personal data may also be transferred to insecure third countries, where local authorities may access them without protection equivalent to European data protection law. If the level of data protection in a country does not match that of Switzerland, we ensure contractually that the protection of your personal data always corresponds to the level in Switzerland. + +Cookies Details + +#### Performance Cookies + +- [x] Performance Cookies + +These cookies allow us to count visits and traffic sources so we can measure and improve the performance of our site. They help us to know which pages are the most and least popular and see how visitors move around the site. All information these cookies collect is aggregated and therefore anonymous. If you do not allow these cookies we will not know when you have visited our site, and will not be able to monitor its performance. + +Cookies Details + +#### Store and/or access information on a device 365 partners can use this purpose + +- [x] Store and/or access information on a device + +Cookies, device or similar online identifiers (e.g. login-based identifiers, randomly assigned identifiers, network based identifiers) together with other information (e.g. browser type and information, language, screen size, supported technologies etc.) can be stored or read on your device to recognise it each time it connects to an app or to a website, for one or several of the purposes presented here. + +List of IAB Vendors|View Illustrations + +#### Personalised advertising and content, advertising and content measurement, audience research and services development 438 partners can use this purpose + +- [x] Personalised advertising and content, advertising and content measurement, audience research and services development + +* ##### Use limited data to select advertising 359 partners can use this purpose + +- [x] Switch Label +Advertising presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type or which content you are (or have been) interacting with (for example, to limit the number of times an ad is presented to you). + +View Illustrations + +* ##### Create profiles for personalised advertising 283 partners can use this purpose + +- [x] Switch Label +Information about your activity on this service (such as forms you submit, content you look at) can be stored and combined with other information about you (for example, information from your previous activity on this service and other websites or apps) or similar users. This is then used to build or improve a profile about you (that might include possible interests and personal aspects). Your profile can be used (also later) to present advertising that appears more relevant based on your possible interests by this and other entities. + +View Illustrations + +* ##### Use profiles to select personalised advertising 281 partners can use this purpose + +- [x] Switch Label +Advertising presented to you on this service can be based on your advertising profiles, which can reflect your activity on this service or other websites or apps (like the forms you submit, content you look at), possible interests and personal aspects. + +View Illustrations + +* ##### Create profiles to personalise content 103 partners can use this purpose + +- [x] Switch Label +Information about your activity on this service (for instance, forms you submit, non-advertising content you look at) can be stored and combined with other information about you (such as your previous activity on this service or other websites or apps) or similar users. This is then used to build or improve a profile about you (which might for example include possible interests and personal aspects). Your profile can be used (also later) to present content that appears more relevant based on your possible interests, such as by adapting the order in which content is shown to you, so that it is even easier for you to find content that matches your interests. + +View Illustrations + +* ##### Use profiles to select personalised content 92 partners can use this purpose + +- [x] Switch Label +Content presented to you on this service can be based on your content personalisation profiles, which can reflect your activity on this or other services (for instance, the forms you submit, content you look at), possible interests and personal aspects. This can for example be used to adapt the order in which content is shown to you, so that it is even easier for you to find (non-advertising) content that matches your interests. + +View Illustrations + +* ##### Measure advertising performance 404 partners can use this purpose + +- [x] Switch Label +Information regarding which advertising is presented to you and how you interact with it can be used to determine how well an advert has worked for you or other users and whether the goals of the advertising were reached. For instance, whether you saw an ad, whether you clicked on it, whether it led you to buy a product or visit a website, etc. This is very helpful to understand the relevance of advertising campaigns. + +View Illustrations + +* ##### Measure content performance 171 partners can use this purpose + +- [x] Switch Label +Information regarding which content is presented to you and how you interact with it can be used to determine whether the (non-advertising) content e.g. reached its intended audience and matched your interests. For instance, whether you read an article, watch a video, listen to a podcast or look at a product description, how long you spent on this service and the web pages you visit etc. This is very helpful to understand the relevance of (non-advertising) content that is shown to you. + +View Illustrations + +* ##### Understand audiences through statistics or combinations of data from different sources 253 partners can use this purpose + +- [x] Switch Label +Reports can be generated based on the combination of data sets (like user profiles, statistics, market research, analytics data) regarding your interactions and those of other users with advertising or (non-advertising) content to identify common characteristics (for instance, to determine which target audiences are more receptive to an ad campaign or to certain contents). + +View Illustrations + +* ##### Develop and improve services 300 partners can use this purpose + +- [x] Switch Label +Information about your activity on this service, such as your interaction with ads or content, can be very helpful to improve products and services and to build new products and services based on user interactions, the type of audience, etc. This specific purpose does not include the development or improvement of user profiles and identifiers. + +View Illustrations + +* ##### Use limited data to select content 83 partners can use this purpose + +- [x] Switch Label +Content presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type, or which content you are (or have been) interacting with (for example, to limit the number of times a video or an article is presented to you). + +View Illustrations + +List of IAB Vendors + +#### Use precise geolocation data 132 partners can use this special feature + +- [x] Use precise geolocation data + +With your acceptance, your precise location (within a radius of less than 500 metres) may be used in support of the purposes explained in this notice. + +List of IAB Vendors + +#### Actively scan device characteristics for identification 71 partners can use this special feature + +- [x] Actively scan device characteristics for identification + +With your acceptance, certain characteristics specific to your device might be requested and used to distinguish it from other devices (such as the installed fonts or plugins, the resolution of your screen) in support of the purposes explained in this notice. + +List of IAB Vendors + +#### Ensure security, prevent and detect fraud, and fix errors 290 partners can use this special purpose + +Always Active + +Your data can be used to monitor for and prevent unusual and possibly fraudulent activity (for example, regarding advertising, ad clicks by bots), and ensure systems and processes work properly and securely. It can also be used to correct any problems you, the publisher or the advertiser may encounter in the delivery of content and ads and in your interaction with them. + +List of IAB Vendors|View Illustrations + +#### Deliver and present advertising and content 286 partners can use this special purpose + +Always Active + +Certain information (like an IP address or device capabilities) is used to ensure the technical compatibility of the content or advertising, and to facilitate the transmission of the content or ad to your device. + +List of IAB Vendors|View Illustrations + +#### Match and combine data from other data sources 214 partners can use this feature + +Always Active + +Information about your activity on this service may be matched and combined with other information relating to you and originating from various sources (for instance your activity on a separate online service, your use of a loyalty card in-store, or your answers to a survey), in support of the purposes explained in this notice. + +List of IAB Vendors + +#### Link different devices 172 partners can use this feature + +Always Active + +In support of the purposes explained in this notice, your device might be considered as likely linked to other devices that belong to you or your household (for instance because you are logged in to the same service on both your phone and your computer, or because you may use the same Internet connection on both devices). + +List of IAB Vendors + +#### Identify devices based on information transmitted automatically 265 partners can use this feature + +Always Active + +Your device might be distinguished from other devices based on information it automatically sends when accessing the Internet (for instance, the IP address of your Internet connection or the type of browser you are using) in support of the purposes exposed in this notice. + +List of IAB Vendors + +#### Save and communicate privacy choices 245 partners can use this special purpose + +Always Active + +The choices you make regarding the purposes and entities listed in this notice are saved and made available to those entities in the form of digital signals (such as a string of characters). This is necessary in order to enable both this service and those entities to respect such choices. + +List of IAB Vendors|View Illustrations + +### Cookie List + +Clear + +- [x] checkbox label label + +Apply Cancel + +Consent Leg.Interest + +- [x] checkbox label label + +- [x] checkbox label label + +- [x] checkbox label label + +No consent Confirm My Choices + +[](https://www.onetrust.com/products/cookie-consent/) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_003_www.comparis.ch_versicherung.txt b/test_web_content_20251002_215219/additional_link_003_www.comparis.ch_versicherung.txt new file mode 100644 index 00000000..2a636054 --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_003_www.comparis.ch_versicherung.txt @@ -0,0 +1,487 @@ +URL: https://www.comparis.ch/versicherung +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Versicherungen Schweiz: informieren & vergleichen + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/versicherung)[IT](https://it.comparis.ch/versicherung)[EN](https://en.comparis.ch/versicherung) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/versicherung)[FR](https://fr.comparis.ch/versicherung)[IT](https://it.comparis.ch/versicherung)[EN](https://en.comparis.ch/versicherung) + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. Versicherungen + +Versicherungen der Schweiz im Vergleich +======================================= + +Schützen Sie sich, Ihre Familie und Ihr Eigentum. Bei Comparis finden Sie verschiedene Vergleiche und umfangreiche Informationen rund um das Thema Versicherung in der Schweiz. + +[Person versichern](https://www.comparis.ch/versicherung#content-2)[Fahrzeug versichern](https://www.comparis.ch/versicherung#content-3)[Eigentum versichern](https://www.comparis.ch/versicherung#content-4) + + + +Umfassend + +Bei uns finden Sie umfangreiche Versicherungsvergleiche für verschiedene Lebenssituationen. + + + +Hohes Sparpotenzial + +Wir zeigen Ihnen übersichtlich und unverbindlich, wo Sie Geld sparen können. + + + +Einfach und schnell + +Mit nur wenigen Angaben können Sie sofort vergleichen. + + + +Umfassend + +Bei uns finden Sie umfangreiche Versicherungsvergleiche für verschiedene Lebenssituationen. + + + +Hohes Sparpotenzial + +Wir zeigen Ihnen übersichtlich und unverbindlich, wo Sie Geld sparen können. + + + +Einfach und schnell + +Mit nur wenigen Angaben können Sie sofort vergleichen. + +Person versichern +----------------- + +Schützen Sie sich und Ihre Liebsten. Comparis bietet Ihnen verschiedene Vergleiche und umfangreiche Informationen zu den Themen Gesundheit und Leben. + +[](https://www.comparis.ch/krankenkassen/default) + +[### Krankenkasse Erfahren Sie das Wichtigste zum Thema Krankenkasse in der Schweiz. Unsere Tipps helfen dabei, die passende Grund- und Zusatzversicherung zu finden.](https://www.comparis.ch/krankenkassen/default) + +[Krankenkassen vergleichen](https://www.comparis.ch/krankenkassen/input) + +[](https://www.comparis.ch/lebensversicherung/default) + +[### Lebensversicherung Eine Lebensversicherung lohnt sich für jeden. Aber welche Varianten gibt es? Bei Comparis finden Sie die relevanten Informationen.](https://www.comparis.ch/lebensversicherung/default) + +[Unverbindlich beraten lassen](https://www.comparis.ch/altersvorsorge/beratung?origin=vle) + +[](https://www.comparis.ch/rechtsschutz/default) + +[### Rechtsschutz Anwaltshonorare und Gerichtskosten sind teuer. Schützen Sie sich mit einer Rechtsschutzversicherung und vergleichen Sie die Prämien.](https://www.comparis.ch/rechtsschutz/default) + +[Rechtsschutz Prämien vergleichen](https://www.comparis.ch/rechtsschutz/input) + +[](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +[### Reiseversicherung Können Sie Ihre Reise z. B. aufgrund eines unerwarteten Ereignisses nicht antreten? Mit unseren Tipps sind Sie günstig und optimal versichert.](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +Fahrzeug versichern +------------------- + +Mit unseren Versicherungsvergleichen, Services und Informationen rund um Töff und Auto finden Sie das passende Angebot und sparen Prämien. + +[](https://www.comparis.ch/autoversicherung/default) + +[### Autoversicherung Vollkasko? Oder doch nur Teilkasko? Welche Versicherung ist für mich geeignet? Auf Comparis finden Sie Antworten zu diesen und vielen weiteren Fragen rund um das Thema Auto.](https://www.comparis.ch/autoversicherung/default) + +[Autoversicherung berechnen](https://www.comparis.ch/autoversicherung/berechnen) + +[](https://www.comparis.ch/motorradversicherung/default) + +[### Motorradversicherung Damit Sie sorglos fahren können, halten wir Sie mit unseren Versicherungsvergleichen, Infos und Tipps auf dem Laufenden.](https://www.comparis.ch/motorradversicherung/default) + +[Motorradversicherung vergleichen](https://www.comparis.ch/motorradversicherung/vergleich/fahrzeug) + +Eigentum versichern +------------------- + +Vorsicht ist besser als Nachsicht. Mit der optimalen Versicherung schützen Sie sich vor finanziellen Einbussen und sparen unnötige Kosten aufgrund von Überversicherung. + +[](https://www.comparis.ch/hausrat-versicherung/default) + +[### Hausrat und Privathaftpflicht Die Hausratversicherung deckt Schäden an Ihrem Hab und Gut durch etwa Feuer, Wasser oder Diebstahl. Die Privathaftpflicht schützt Sie, wenn Sie anderen ungewollt Schaden zufügen. Comparis klärt Sie über die Details auf.](https://www.comparis.ch/hausrat-versicherung/default) + +[Hausrat und Privathaftpflicht vergleichen](https://www.comparis.ch/hausrat-versicherung/comparison/input?insuranceType=3) + +[](https://www.comparis.ch/tierversicherung/default) + +[### Tierversicherung Auch unsere Vierbeiner wollen gut versichert sein. Denn schnell ist was passiert und die Arztrechnung für Hund und Katze hoch. Vergleichen Sie Tierversicherungen und nutzen Sie unsere Services rund um Ihre Fellnasen.](https://www.comparis.ch/tierversicherung/default) + +[Tierversicherungen vergleichen](https://www.comparis.ch/tierversicherung/vergleichen?insuranceType=1) + +Aktuelle Tipps und Informationen zum Thema Versicherungen +--------------------------------------------------------- + +Unsere Tipps helfen Ihnen, beim Thema Versicherungen die richtigen Entscheidungen zu treffen. + +[ ### Schlüssel verloren Schweiz: Was tun und wer zahlt? 15.11.2023](https://www.comparis.ch/hausrat-versicherung/schaden/schluessel-verloren)[ ### Krankenkasse wechseln und kündigen: Fristen und Vorgehen 12.09.2024](https://www.comparis.ch/krankenkassen/system/kassenwechsel)[ ### Autoversicherung kündigen in der Schweiz: So geht's 27.08.2025](https://www.comparis.ch/autoversicherung/vertrag/kuendigungsfristen) + +Häufig gestellte Versicherungsfragen +------------------------------------ + +Hier finden Sie die häufigsten Fragen unserer Nutzerinnen und Nutzer. + +### Wie kann ich meine Versicherung kündigen? + +Jede Versicherung hat ihre eigenen Kündigungsrechte und -fristen, die Sie bei einer einseitigen Vertragsauflösung beachten müssen. Die genaue Handhabung ist von Vertrag und Anbieter abhängig und in den allgemeinen Versicherungsbedingungen festgelegt. + +Kündigt man einen Versicherungsvertrag wie oben genannt, handelt es sich um eine **ordentliche Kündigung**. + +In verschiedenen Situationen kennen Versicherungsverträge zudem **ausserordentliche Kündigungsgründe**. Darunter versteht man beispielsweise eine allgemeine Prämienerhöhung der Krankenkasse oder einen gedeckten Schadensfall in der Autoversicherung. + +Die Kündigung muss generell schriftlich bei der Versicherung eingehen. Massgebend ist dabei der Posteingang bei der Versicherung und nicht der Poststempel. Wir empfehlen Ihnen, den Kündigungsbrief frühzeitig per Einschreiben zu versenden. + +Hier finden Sie detaillierte Kündigungsinformationen zu den jeweiligen Versicherungen: + +[Krankenkasse](https://www.comparis.ch/krankenkassen/system/kassenwechsel) + +[Auto- und Motorradversicherung](https://www.comparis.ch/autoversicherung/vertrag/kuendigungsfristen) + +[Hausrat- und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/wechseln/kuendigung) + +[Rechtsschutz](https://www.comparis.ch/rechtsschutz/deckung-leistung/wichtige-begriffe) + +### Wie kann ich zu einer anderen Versicherung wechseln? + +Wir zeigen Ihnen, wie Sie Ihre aktuelle Versicherung in nur vier Schritten ganz leicht kündigen und zu einer anderen Gesellschaft wechseln können. + +1. **Prämien vergleichen** + +Die Höhe der Prämien kann je nach Anbieter stark variieren, zudem kommen laufend neue Produkte auf den Markt. Ein Vergleich verschiedener Angebote und ein Versicherungswechsel können sich somit lohnen. + +2. **Offerten einholen** + +Holen Sie eine oder mehrere Versicherungsofferten ein, vergleichen Sie die Leistungen und finden Sie das beste Angebot. + +3. **Versicherung rechtzeitig kündigen** + +Informieren Sie sich über Ihre Kündigungsrechte und welche Fristen Sie dabei einhalten müssen. Ziehen Sie dazu die allgemeinen Versicherungsbedingungen Ihres Vertrages bei. + +4. **Neue Versicherung abschliessen** + +Die zuvor gewählte Offerte können Sie nun annehmen und von der optimierten Leistung profitieren. + +Beachten Sie: Bei einer [Krankenkassen-Zusatzversicherung](https://www.comparis.ch/krankenkassen/zusatzversicherungen) sollten Sie diesen Schritt der Kündigung vorziehen und abwarten, bis Sie die Aufnahmebestätigung der neuen Krankenkasse erhalten haben. + +### Welche Versicherungen kann ich bei Comparis vergleichen? + +Bei Comparis können Sie folgende Versicherungen vergleichen: + +[Krankenkasse](https://www.comparis.ch/krankenkassen/default) + +[Autoversicherung](https://www.comparis.ch/autoversicherung/berechnen) + +[Hausrat- und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/comparison/input) + +[Motorradversicherung](https://www.comparis.ch/motorradversicherung/vergleich/fahrzeug) + +[Privat- und Verkehrsrechtsschutz](https://www.comparis.ch/rechtsschutz/input) + +[Tierversicherung](https://www.comparis.ch/tierversicherung/vergleichen?insuranceType=1) + +Für folgende Versicherungen können Sie eine unverbindliche und kostenlose Beratung anfordern: + +[Lebensversicherung](https://www.comparis.ch/altersvorsorge/beratung?origin=vle) + +[Reiseversicherung](https://calendly.com/optimatis-vorsorge/reiseversicherung?month=2022-01) + +### Welche Versicherungen sind in der Schweiz obligatorisch? + +In der Schweiz sind einige Versicherungen obligatorisch, das heisst, dass Sie gesetzlich dazu verpflichtet sind, diese Versicherungen abzuschliessen. + +Dies gilt vor allem für die [Krankenkasse](https://www.comparis.ch/krankenkassen/default). Die obligatorische Unfallversicherung (UVG) besitzen Sie automatisch, wenn Sie mehr als 8 Stunden in der Woche beim selben Arbeitgeber angestellt sind. Ist Ihr Pensum geringer, müssen Sie diese Unfalldeckung privat über die Krankenversicherung abschliessen. + +Falls Sie ein [Auto](https://www.comparis.ch/autoversicherung/berechnen) oder [Motorrad](https://www.comparis.ch/motorradversicherung/vergleich/fahrzeug) besitzen, ist mindestens die Haftpflicht Pflicht. Diese deckt Schäden an fremden Fahrzeugen, Sachen oder Personen. + +Die Teilkasko- oder Vollkaskoversicherungen sind freiwillig, lohnen sich aber vor allem bei neueren oder teureren Fahrzeugen schnell. + +Weitere Versicherungen, die nicht obligatorisch sind, aber jeder haben sollte: + +* [Privathaftpflichtversicherung](https://www.comparis.ch/hausrat-versicherung/comparison/input?insuranceType=2) + +* [Hausratversicherung](https://www.comparis.ch/hausrat-versicherung/comparison/input?insuranceType=1) + +* [Rechtsschutzversicherung](https://www.comparis.ch/rechtsschutz/input) + +* Private Vorsorge im Rahmen einer [Lebensversicherung](https://www.comparis.ch/altersvorsorge/beratung?origin=vle) oder [3. Säule](https://www.comparis.ch/altersvorsorge/saeule3a) + +### Kann ich bei Comparis eine Versicherung auch direkt abschliessen? + +Ja! [Hausrat- und Privathaftpflichtversicherungen](https://www.comparis.ch/hausrat-versicherung/comparison/input) gewisser Anbieter können Sie bei Comparis direkt online abschliessen. + +Das Netzwerk unserer Direkt-Abschluss-Partner bauen wir stetig aus. + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_004_www.comparis.ch_finanzen.txt b/test_web_content_20251002_215219/additional_link_004_www.comparis.ch_finanzen.txt new file mode 100644 index 00000000..e342ef57 --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_004_www.comparis.ch_finanzen.txt @@ -0,0 +1,408 @@ +URL: https://www.comparis.ch/finanzen +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Wichtiges über Finanzen in der Schweiz + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/finanzen)[IT](https://it.comparis.ch/finanzen)[EN](https://en.comparis.ch/finanzen) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/finanzen)[FR](https://fr.comparis.ch/finanzen)[IT](https://it.comparis.ch/finanzen)[EN](https://en.comparis.ch/finanzen) + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. Finanzen + +Wichtiges über Finanzen in der Schweiz +====================================== + +Ob Privatkredit, Hypothek oder Bonitätsauskunft: Mit unseren Vergleichen und Services finden Sie die passende Finanzierungslösung für sich. + +[Geld aufnehmen](https://www.comparis.ch/finanzen#content-2)[Immobilie finanzieren](https://www.comparis.ch/finanzen#content-3)[Altersvorsorge planen](https://www.comparis.ch/finanzen#content-4)[Steuern vergleichen](https://www.comparis.ch/finanzen#content-5)[Fahrzeug finanzieren](https://www.comparis.ch/finanzen#content-6)[Wirtschaftsinfos einholen](https://www.comparis.ch/finanzen#content-7) + + + +Überblick verschaffen + +Bei uns finden Sie umfangreiche Vergleiche und Informationen zu verschiedenen Finanzprodukten. + + + +Unabhängigkeit + +HypoPlus ist der Hypothekenpartner von Comparis. HypoPlus unterstützt Sie bei der Suche nach der passenden Hypothek und dem besten Zinssatz. + + + +Zufriedene Kunden + +Die Kundinnen und Kunden von HypoPlus schätzen die professionelle Beratung und die hilfreichen Services rund um das Thema Finanzen. + + + +Überblick verschaffen + +Bei uns finden Sie umfangreiche Vergleiche und Informationen zu verschiedenen Finanzprodukten. + + + +Unabhängigkeit + +HypoPlus ist der Hypothekenpartner von Comparis. HypoPlus unterstützt Sie bei der Suche nach der passenden Hypothek und dem besten Zinssatz. + + + +Zufriedene Kunden + +Die Kundinnen und Kunden von HypoPlus schätzen die professionelle Beratung und die hilfreichen Services rund um das Thema Finanzen. + +Geld aufnehmen +-------------- + +Manchmal ändern sich die Lebensumstände und Sie müssen einen finanziellen Engpass überbrücken oder eine ungeplante Anschaffung machen. Comparis klärt auf, worauf Sie bei einem Kredit achten sollten. + +[](https://www.comparis.ch/privatkredit/default) + +[### Privatkredit Wir informieren Sie zum Thema Privatkredit und unterstützen Sie von der ersten Anfrage bis zum erfolgreichen Abschluss.](https://www.comparis.ch/privatkredit/default) + +[Zum Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + +[](https://www.comparis.ch/privatkredit/kreditvergleich) + +[### Kreditvergleich Finden Sie heraus, wie hoch die monatlichen Raten und Kosten für die im Markt angebotenen Zinssätze ausfallen.](https://www.comparis.ch/privatkredit/kreditvergleich) + +Immobilie finanzieren +--------------------- + +Hypotheken und Zinsen sind entscheidend für Ihre Immobilienfinanzierung. Comparis bietet Ihnen einen Überblick, damit Sie fundierte Entscheidungen treffen können. + +[](https://www.comparis.ch/hypotheken/default) + +[### Hypotheken Ob Hypothekarzinsen vergleichen, individuelle Zinsen berechnen oder zum Thema Hypotheken auf dem Laufenden bleiben: Zusammen mit unserem Hypothekenpartner HypoPlus unterstützen wir Sie unabhängig und persönlich.](https://www.comparis.ch/hypotheken/default) + +[Persönliche Zinsen berechnen](https://www.comparis.ch/hypotheken/angaben) + +[](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +[### Zinsentwicklung Mit unserem interaktiven Hypotheken-Chart vergleichen Sie die Historie von Laufzeiten und unterschiedlichen Anbietern.](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +[Zinssätze vergleichen](https://www.comparis.ch/hypotheken/zinssatz) + +Altersvorsorge planen +--------------------- + +Mit einer optimierten Altersvorsorge können Sie eine Vorsorgelücke verhindern. Comparis berät Sie neutral und unabhängig und versorgt Sie mit wichtigen Informationen. + +[](https://www.comparis.ch/altersvorsorge/default) + +[### Altersvorsorge Für eine optimale Altersvorsorge ist es wichtig, das Schweizer Vorsorgesystem und die eigene finanzielle Lage zu kennen. Comparis informiert und begleitet Sie.](https://www.comparis.ch/altersvorsorge/default) + +[Zur Vorsorgeberatung](https://www.comparis.ch/altersvorsorge/beratung) + +[](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +[### Pensionsplanung Vom Berechnen von Vorsorgelücken bis zur 3a-Auszahlung: Hier finden Sie wichtige Informationen und Tipps zur Planung Ihrer Pensionierung.](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +Steuern vergleichen +------------------- + +Mit dem Steuerrechner von Comparis können Sie berechnen, wie sich Ihre Steuern verändern bei einem Umzug und welche Steuerentlastung eine Einzahlung in die 2. oder 3. Säule mit sich bringt. + +[](https://www.comparis.ch/steuern/steuervergleich/default) + +[### Steuervergleich Welche Gemeinde in der Schweiz hat die tiefsten Steuern? Unser Steuervergleich unterstützt Sie bei der Suche nach einem steuergünstigen Wohnort.](https://www.comparis.ch/steuern/steuervergleich/default) + +[Zum Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +[](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +[### Quellensteuer Vergleichen Sie mit wenigen Angaben, wie hoch Ihre Quellensteuer in den verschiedenen Kantonen ausfällt.](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +Fahrzeug finanzieren +-------------------- + +Der Autokauf ist einer der häufigsten Gründe für einen Kredit. Comparis informiert Sie über die verschiedenen Möglichkeiten der Autofinanzierung und darüber, worauf Sie achten sollten. + +[](https://www.comparis.ch/leasing/default) + +[### Leasing und Autofinanzierung Suchen Sie nach einer passenden Autofinanzierung? Erfahren Sie mehr über die Möglichkeiten hier.](https://www.comparis.ch/leasing/default) + +[Zum Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + +Wirtschaftsinfos einholen +------------------------- + +Erkunden Sie die Wirtschaftswelt mit Schwerpunkt auf Konjunkturzyklen, Inflation, Einkommen und Löhnen. + +[](https://www.comparis.ch/finanzen/wirtschaft) + +[### Finanzen und Wirtschaft Wie entwickeln sich die Preise in der Schweiz? Wie hoch sind die Löhne? Informieren Sie sich hier.](https://www.comparis.ch/finanzen/wirtschaft) + +[Zum Kurzarbeit-Lohnrechner](https://www.comparis.ch/finanzen/wirtschaft/einkommen/kurzarbeit-lohnrechner) + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_005_www.comparis.ch_wohnen.txt b/test_web_content_20251002_215219/additional_link_005_www.comparis.ch_wohnen.txt new file mode 100644 index 00000000..844777fc --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_005_www.comparis.ch_wohnen.txt @@ -0,0 +1,423 @@ +URL: https://www.comparis.ch/wohnen +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Schöner und günstiger Wohnen mit Comparis + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/wohnen)[IT](https://it.comparis.ch/wohnen)[EN](https://en.comparis.ch/wohnen) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/wohnen)[FR](https://fr.comparis.ch/wohnen)[IT](https://it.comparis.ch/wohnen)[EN](https://en.comparis.ch/wohnen) + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. Wohnen + +Wohnen in der Schweiz mit Comparis +================================== + +Ob Sie eine Wohnung oder ein Haus mieten, kaufen, verkaufen oder bewerten lassen wollen: Bei Comparis finden Sie Inserate verschiedener Immobilienmärkte der Schweiz. Zudem erhalten Sie Tipps rund um die Themen Umzug und Immobilien. + +[Immobilie finden](https://www.comparis.ch/wohnen#content-2)[Immobilie finanzieren](https://www.comparis.ch/wohnen#content-3)[Immobilie bewerten](https://www.comparis.ch/wohnen#content-4)[Immobilie inserieren](https://www.comparis.ch/wohnen#content-5)[Umzug planen](https://www.comparis.ch/wohnen#content-6)[Hausrat versichern](https://www.comparis.ch/wohnen#content-7) + + + +Umfassendes Angebot + +Bei Comparis finden Sie Inserate verschiedener Online-Marktplätze für Immobilien in der Schweiz. + + + +Online suchen und bewerten + +In wenigen Schritten erstellen Sie ein Inserat oder ein Suchabo oder führen eine Immobilienbewertung durch. + + + +Umfassend informiert + +Vergleichen Sie Steuern, lassen Sie Ihre Immobilie bewerten, nutzen Sie unseren Umzugsratgeber oder weitere Services. + + + +Umfassendes Angebot + +Bei Comparis finden Sie Inserate verschiedener Online-Marktplätze für Immobilien in der Schweiz. + + + +Online suchen und bewerten + +In wenigen Schritten erstellen Sie ein Inserat oder ein Suchabo oder führen eine Immobilienbewertung durch. + + + +Umfassend informiert + +Vergleichen Sie Steuern, lassen Sie Ihre Immobilie bewerten, nutzen Sie unseren Umzugsratgeber oder weitere Services. + +Immobilie finden +---------------- + +Ob Wohnung oder Haus: Comparis vereinigt verschiedene Online-Marktplätze der Schweiz. So erhalten Sie eine umfangreiche Auswahl an Immobilieninseraten. + +[](https://www.comparis.ch/immobilien/default) + +[### Immobilienmarkt Hier finden Sie die Inserate verschiedener Immobilienmarktplätze der Schweiz auf einer Plattform.](https://www.comparis.ch/immobilien/default) + +[](https://www.comparis.ch/steuern/steuervergleich/default) + +[### Steuervergleich Welche Gemeinde in der Schweiz hat die tiefsten Steuern? Unser Steuervergleich unterstützt Sie bei der Suche nach einem steuergünstigen Wohnort.](https://www.comparis.ch/steuern/steuervergleich/default) + +[Zum Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +Immobilie finanzieren +--------------------- + +Wie möchten Sie Ihre Wohnung oder Ihr Haus finanzieren? Bei Comparis finden Sie zahlreiche Tipps und Tools rund um das Thema Immobilienfinanzierung. + +[](https://www.comparis.ch/hypotheken/default) + +[### Hypotheken Ob Hypothekarzinsen vergleichen, individuelle Zinsen berechnen oder zum Thema Hypotheken auf dem Laufenden bleiben: Zusammen mit unserem Hypothekenpartner HypoPlus unterstützen wir Sie unabhängig und persönlich.](https://www.comparis.ch/hypotheken/default) + +[Persönliche Zinsen berechnen](https://www.comparis.ch/hypotheken/angaben) + +[](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +[### Zinsentwicklung Mit unserem interaktiven Hypotheken-Chart vergleichen Sie die Historie von Laufzeiten und unterschiedlichen Anbietern.](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +[Zinssätze vergleichen](https://www.comparis.ch/hypotheken/zinssatz) + +Immobilie bewerten & verkaufen +------------------------------ + +Mit Comparis finden Sie schnell und effizient einen Käufer für Ihre Immobilie und erhalten Unterstützung von der Bewertung bis zum Verkauf. + +[](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + +[### Immobilienbewertung Erfahren Sie kostenlos den Wert Ihrer Immobilie und verkaufen Sie zu einem marktgerechten Preis.](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + +[](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + +[### Immobilienbewertung Plus Erhalten Sie eine detaillierte Bewertung Ihrer Immobilie inkl. Einblicke in Markttrends, Nachfrage und Lagequalität.](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + +[](https://www.comparis.ch/immobilien/verkaufen) + +[### Immobilienverkauf Comparis unterstützt Sie von der Planung bis zum Verkauf sowohl digital als auch persönlich.](https://www.comparis.ch/immobilien/verkaufen) + +[](https://www.comparis.ch/immobilien/verkaufen/immobilienpreise) + +[### Preisentwicklung Immobilienmarkt Sie wollen wissen, wie sich die Kaufpreise von Immobilien in der Schweiz entwickelt haben? Nutzen Sie dafür unsere interaktive Karte.](https://www.comparis.ch/immobilien/verkaufen/immobilienpreise) + +Immobilie kostenlos inserieren +------------------------------ + +Egal ob Nachmieterin oder Käufer: Mit Comparis finden Sie den passenden Interessenten für Ihre Immobilie. + +[](https://www.comparis.ch/immobilien/inserieren/default) + +[Inserieren, wo die Schweiz sucht: Auf Comparis suchen jeden Monat über eine Million Personen ihre Traumwohnung.](https://www.comparis.ch/immobilien/inserieren/default) + +Umzug planen +------------ + +Ein Umzug kann stressig sein. Gut, wenn man vorher alles durchgeplant und bedacht hat. Comparis hilft Ihnen dabei. + +[](https://www.comparis.ch/immobilien/umzug/default) + +[### Umzugsservice Alles, was Sie für Ihren Umzug wissen müssen, inklusive Vergleich von Umzugs- und Reinigungsfirmen.](https://www.comparis.ch/immobilien/umzug/default) + +Direkt Offerten anfordern + +[](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + +[### Umzugskostenrechner Wie viel wird Ihr Umzug ungefähr kosten? Der Umzugkostenrechner sagt es Ihnen.](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + +[](https://www.comparis.ch/neu-in-der-schweiz/default) + +[### Umzug in die Schweiz Beim Umzug vom Ausland in die Schweiz gibt es einiges zu beachten. Comparis informiert Sie über alle Schritte.](https://www.comparis.ch/neu-in-der-schweiz/default) + +Hausrat versichern +------------------ + +Vergleichen Sie mehrere Anbieter von Hausratversicherungen und verschaffen Sie sich einen Überblick über die Prämien. + +[](https://www.comparis.ch/hausrat-versicherung/default) + +[### Hausrat und Privathaftpflicht Die Hausratversicherung deckt Schäden an Ihrem Hab und Gut durch etwa Feuer, Wasser oder Diebstahl. Die Privathaftpflicht schützt Sie, wenn Sie anderen ungewollt Schaden zufügen. Comparis klärt Sie über die Details auf.](https://www.comparis.ch/hausrat-versicherung/default) + +[Hausrat und Privathaftpflicht vergleichen](https://www.comparis.ch/hausrat-versicherung/comparison/input?insuranceType=3) + +Aktuelle Tipps und Informationen zu den Themen Immobilien und Wohnen +-------------------------------------------------------------------- + +Wir versorgen Sie mit spannenden Neuigkeiten aus der Welt der Immobilien. + +[ ### Adressänderung beim Umzug– die grosse Checkliste 04.06.2025](https://www.comparis.ch/immobilien/umzug/nach-dem-umzug/umzug-adressaenderung)[ ### Grundstückgewinnsteuer in der Schweiz: Wie wird sie berechnet? 26.11.2021](https://www.comparis.ch/immobilien/verkaufen/vertragsabschlussphase/grundstueckgewinnsteuer)[ ### Nebenkostenabrechnung Schweiz: Diese Nebenkosten sind erlaubt 27.03.2025](https://www.comparis.ch/immobilien/mietrecht/mietnebenkosten) + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_006_www.comparis.ch_mobilitaet.txt b/test_web_content_20251002_215219/additional_link_006_www.comparis.ch_mobilitaet.txt new file mode 100644 index 00000000..c0088b4e --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_006_www.comparis.ch_mobilitaet.txt @@ -0,0 +1,407 @@ +URL: https://www.comparis.ch/mobilitaet +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Verkehr und Mobilität in der Schweiz + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/mobilitaet)[IT](https://it.comparis.ch/mobilitaet)[EN](https://en.comparis.ch/mobilitaet) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/mobilitaet)[FR](https://fr.comparis.ch/mobilitaet)[IT](https://it.comparis.ch/mobilitaet)[EN](https://en.comparis.ch/mobilitaet) + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. Mobilität + +Verkehr und Mobilität in der Schweiz +==================================== + +Informationen zu Mobilität und Reisen: Kaufen oder verkaufen Sie Ihr Auto, vergleichen Sie Versicherungen und planen Sie Ihre Reise mit unseren Tipps. + +[Fahrzeug kaufen und verkaufen](https://www.comparis.ch/mobilitaet#content-2)[Fahrzeug finanzieren](https://www.comparis.ch/mobilitaet#content-3)[Fahrzeug versichern](https://www.comparis.ch/mobilitaet#content-4)[Autofahren lernen](https://www.comparis.ch/mobilitaet#content-5)[Elektroautos kennenlernen](https://www.comparis.ch/mobilitaet#content-6)[Entspannter reisen](https://www.comparis.ch/mobilitaet#content-7) + + + +Mehrere Schweizer Automärkte + +Ob kaufen oder verkaufen: Comparis vereint die Anzeigen verschiedener Automarktplätze der Schweiz. + + + +Online vergleichen + +Mit wenigen Klicks kaufen oder verkaufen Sie Ihr Auto oder schliessen eine Versicherung ab. + + + +Umfassend informiert + +Mit Comparis bleiben Sie stets umfassend rund um verschiedene Themen der Mobilität informiert – vom Auto bis zur Fernreise. + + + +Mehrere Schweizer Automärkte + +Ob kaufen oder verkaufen: Comparis vereint die Anzeigen verschiedener Automarktplätze der Schweiz. + + + +Online vergleichen + +Mit wenigen Klicks kaufen oder verkaufen Sie Ihr Auto oder schliessen eine Versicherung ab. + + + +Umfassend informiert + +Mit Comparis bleiben Sie stets umfassend rund um verschiedene Themen der Mobilität informiert – vom Auto bis zur Fernreise. + +Auto kaufen und verkaufen +------------------------- + +Bei Comparis ganz einfach Autos online kaufen, verkaufen und bewerten lassen. Ob Occasion oder Neuwagen: Finden Sie Ihr neues Auto – und verkaufen Sie Ihr altes Fahrzeug unkompliziert. + +[](https://www.comparis.ch/carfinder/default) + +[### Automarkt Finden Sie Angebote der grossen Automarktplätze der Schweiz.](https://www.comparis.ch/carfinder/default) + +[](https://www.comparis.ch/carfinder/bewertung) + +[### Fahrzeug bewerten Bewerten Sie kostenlos Ihren Personenwagen und ermitteln Sie den aktuellen Marktwert Ihres Autos.](https://www.comparis.ch/carfinder/bewertung) + +[](https://www.comparis.ch/carfinder/inserieren/default) + +[### Fahrzeug inserieren Inserieren Sie Ihr Auto online und finden Sie eine Käuferin oder einen Käufer.](https://www.comparis.ch/carfinder/inserieren/default) + +Fahrzeug finanzieren +-------------------- + +Jede zweite Person in der Schweiz nutzt zum Autokauf nicht das eigene Geld. Ob Kredit oder Leasing: Comparis informiert Sie über die verschiedenen Möglichkeiten der Autofinanzierung und darüber, worauf Sie achten sollten. + +[](https://www.comparis.ch/leasing/default) + +[### Leasing und Privatkredit Suchen Sie nach einer passenden Autofinanzierung? Erfahren Sie hier mehr über die Möglichkeiten.](https://www.comparis.ch/leasing/default) + +[Zum Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + +Fahrzeug versichern +------------------- + +Mit unseren Versicherungsvergleichen, Services und Informationen rund um Töff und Auto finden Sie das passende Angebot und sparen Prämien. + +[](https://www.comparis.ch/autoversicherung/default) + +[### Autoversicherung Vollkasko oder nur Teilkasko? Welche Versicherung ist für mich geeignet? Bei Comparis finden Sie Antworten zu diesen und vielen weiteren Fragen rund um das Thema Autoversicherung.](https://www.comparis.ch/autoversicherung/default) + +[Autoversicherung berechnen](https://www.comparis.ch/autoversicherung/berechnen) + +[](https://www.comparis.ch/motorradversicherung/default) + +[### Motorradversicherung Geniessen Sie die Freiheit auf zwei Rädern: Comparis versorgt Sie mit Versicherungsvergleichen, Infos und Tipps rund ums Motorrad.](https://www.comparis.ch/motorradversicherung/default) + +[Motorradversicherungen vergleichen](https://www.comparis.ch/motorradversicherung/vergleich/fahrzeug) + +Fahrzeug nutzen +--------------- + +Besitzen Sie ein Fahrzeug, möchten Sie es auch nutzen. Aber auch ohne eigenes Auto gibt es Möglichkeiten. Was Sie zur Nutzung meist brauchen: Benzin und einen Führerausweis. + +[](https://www.comparis.ch/benzin-preise) + +[### Benzinpreise Finden Sie mit unserer interaktiven Karte die günstigste Tankstelle in Ihrer Nähe.](https://www.comparis.ch/benzin-preise) + +[](https://www.comparis.ch/life/auto) + +[### Autoprüfung Hier gibt es alle wichtigen Informationen rund um den Führerschein und das Fahrenlernen in der Schweiz.](https://www.comparis.ch/life/auto) + +Elektroautos kennenlernen +------------------------- + +Elektroautos gewinnen zunehmend an Beliebtheit. Doch was sollten Sie wissen über die Elektromobilität? Hier erfahren Sie alles Wichtige rund um E-Autos. + +[](https://www.comparis.ch/elektromobilitaet/default) + +[### Elektromobilität Informationen zu Vorteilen und Herausforderungen der E-Mobilität.](https://www.comparis.ch/elektromobilitaet/default) + +Entspannter reisen +------------------ + +Ferien bedeuten oft Entspannung – wenn nichts schiefgeht. Comparis gibt Ihnen Tipps für eine sorgenfreie Reise und verrät, wie Sie Geld sparen können. + +[](https://www.comparis.ch/mobilitaet/reisen) + +[### Reisen Informationen und Tipps für entspannte Ferienreisen.](https://www.comparis.ch/mobilitaet/reisen) + +Aktuelle Tipps und Informationen rund um das Thema Mobilität +------------------------------------------------------------ + +Mit Comparis bleiben Sie in der Welt der Mobilität auf dem neuesten Stand. + +[ ### Auto-Occasionen: Tipps für den Kauf eines Gebrauchtwagens 29.11.2023](https://www.comparis.ch/carfinder/autokaufen/gute-occasionen)[ ### Welche Autoversicherung brauche ich? 08.09.2025](https://www.comparis.ch/autoversicherung/deckung/autoversicherung-uebersicht)[ ### Vier Motorradtouren in der Schweiz: Töfftouren & Ausflugsziele 06.06.2023](https://www.comparis.ch/motorradversicherung/motorrad-fahren/motorradtouren)[ ### Theorieprüfung fürs Auto in der Schweiz 14.08.2024](https://www.comparis.ch/life/auto/theoriepruefung)[ ### Reichweite Elektroautos: Wie weit fahren sie? 09.12.2024](https://www.comparis.ch/elektromobilitaet/elektroauto/reichweite)[ ### Reiseversicherung in der Schweiz: Was ist versichert? 03.07.2025](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_007_www.comparis.ch_gesundheit.txt b/test_web_content_20251002_215219/additional_link_007_www.comparis.ch_gesundheit.txt new file mode 100644 index 00000000..c6cc051d --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_007_www.comparis.ch_gesundheit.txt @@ -0,0 +1,362 @@ +URL: https://www.comparis.ch/gesundheit +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Gesundheit + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/gesundheit)[IT](https://it.comparis.ch/gesundheit)[EN](https://en.comparis.ch/gesundheit) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/gesundheit)[FR](https://fr.comparis.ch/gesundheit)[IT](https://it.comparis.ch/gesundheit)[EN](https://en.comparis.ch/gesundheit) + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. Gesundheit + +Gesundheit und Pflege in der Schweiz +==================================== + +Die Themen Gesundheit und Pflege betreffen alle Schweizerinnen und Schweizer. Comparis unterstützt Sie mit Informationen dabei, kompetente Entscheidungen bei der Wahl Ihres Arztes, Ihrer Psychotherapie oder Ihrer Vorsorgelösungen wie Spitex zu treffen. + +[Arzt finden und Behandlungen](https://www.comparis.ch/gesundheit#content-2)[Leben im Alter und Spitex](https://www.comparis.ch/gesundheit#content-3)[Psychotherapie](https://www.comparis.ch/gesundheit#content-4)[Krankenkasse](https://www.comparis.ch/gesundheit#content-2) + + + +Umfassender Krankenkassen-Vergleich + +Auf comparis.ch einfach mehrere Offerten unverbindlich bestellen und die passendste auswählen. + + + +Praktische Spitex-Suche + +Vergleichen Sie Spitex-Anbieter und informieren Sie sich über Leistungen, anfallende Kosten und vieles mehr. + + + +Die richtigen Ärztinnen und Ärzte finden + +Bei Comparis suchen Sie einfach und schnell die passenden Fachleute, die geeignete Praxis oder das richtige Spital. + + + +Umfassender Krankenkassen-Vergleich + +Auf comparis.ch einfach mehrere Offerten unverbindlich bestellen und die passendste auswählen. + + + +Praktische Spitex-Suche + +Vergleichen Sie Spitex-Anbieter und informieren Sie sich über Leistungen, anfallende Kosten und vieles mehr. + + + +Die richtigen Ärztinnen und Ärzte finden + +Bei Comparis suchen Sie einfach und schnell die passenden Fachleute, die geeignete Praxis oder das richtige Spital. + +Arzt finden und Behandlungen +---------------------------- + +Bei Comparis suchen Sie einfach und schnell die passenden medizinischen Fachleute, die geeignete Praxis oder das richtige Spital. + +[](https://www.comparis.ch/gesundheit/arzt/default) + +[### Arzt finden Das unabhängige Ärzte-Verzeichnis umfasst über 40’000 praktizierende Ärztinnen und Ärzte in der Schweiz. So finden Sie die passenden Fachleute auch in Ihrer Nähe.](https://www.comparis.ch/gesundheit/arzt/default) + +Leben im Alter und Spitex +------------------------- + +[](https://www.comparis.ch/gesundheit/leben-im-alter/default) + +[### Spitex finden Finden Sie eine passende Spitex-Organisation und berechnen Sie die maximalen Kosten für Pflegeleistungen, welche Sie jährlich selbst tragen müssen.](https://www.comparis.ch/gesundheit/leben-im-alter/default) + +Psychotherapie +-------------- + +Hier finden Sie alles Wichtige zum Thema Psychotherapie + +[](https://www.comparis.ch/gesundheit) + +[### Ratgeber Psychotherapie Wie finde ich die passende Therapie? Was kostet eine Psychotherapie und was übernimmt die Krankenkasse? Hier finden Sie alle wichtigen Informationen.](https://www.comparis.ch/gesundheit) + +[Jetzt Psychiater finden](https://www.comparis.ch/gesundheit/arzt/psychiater) + +Krankenkasse +------------ + +Finden Sie mit Comparis die passende Krankenkasse für sich und Ihre Familie. + +[](https://www.comparis.ch/krankenkassen/default) + +[### Krankenkasse Erfahren Sie das Wichtigste zum Thema Krankenkasse in der Schweiz. Unsere Tipps helfen dabei, die passende Grund- und Zusatzversicherung zu finden.](https://www.comparis.ch/krankenkassen/default) + +[Krankenkassen vergleichen](https://www.comparis.ch/krankenkassen/default) + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_008_www.comparis.ch_telecom.txt b/test_web_content_20251002_215219/additional_link_008_www.comparis.ch_telecom.txt new file mode 100644 index 00000000..f329432d --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_008_www.comparis.ch_telecom.txt @@ -0,0 +1,353 @@ +URL: https://www.comparis.ch/telecom +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Internet-, TV-, Festnetz- & Handy-Abos vergleichen mit Comparis + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/telecom)[IT](https://it.comparis.ch/telecom)[EN](https://en.comparis.ch/telecom) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/telecom)[FR](https://fr.comparis.ch/telecom)[IT](https://it.comparis.ch/telecom)[EN](https://en.comparis.ch/telecom) + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. Telecom + +Telecom +======= + +Ob für zuhause oder unterwegs: Finden Sie mit Comparis das passende Abo für Internet, TV, Festnetz und Handy. + +[Mobile](https://www.comparis.ch/telecom#content-2)[Internet & TV zuhause](https://www.comparis.ch/telecom#content-3) + + + +Abos vergleichen + +Ob Internet, TV, Festnetz oder Handy: Verschiedene Abos auf einen Blick. + + + +Wechseln und sparen + +Finden Sie das für Sie passende Abo und sparen Sie mit aktuellen Aktionen. + + + +Informiert bleiben + +Bleiben Sie mit Comparis in Sachen Telekom auf dem neuesten Stand. + + + +Abos vergleichen + +Ob Internet, TV, Festnetz oder Handy: Verschiedene Abos auf einen Blick. + + + +Wechseln und sparen + +Finden Sie das für Sie passende Abo und sparen Sie mit aktuellen Aktionen. + + + +Informiert bleiben + +Bleiben Sie mit Comparis in Sachen Telekom auf dem neuesten Stand. + +Mobile +------ + +Bleiben Sie auch unterwegs online. Dazu benötigen Sie nicht unbedingt das teuerste Abo. + +[](https://www.comparis.ch/telecom/mobile/default) + +[### Handy-Abo Ob Sie wenig telefonieren oder viel surfen: Comparis unterstützt Sie bei der Suche nach dem passenden Abo.](https://www.comparis.ch/telecom/mobile/default) + +[Handy-Abos vergleichen](https://www.comparis.ch/telecom/mobile/angebote/alle-handyabos) + +Internet & TV zuhause +--------------------- + +Anschluss für zuhause: Mit Comparis finden Sie das passende Angebot. + +[](https://www.comparis.ch/telecom/zuhause/default) + +[### Internet, TV & Festnetz Vergleichen Sie die Kosten der Anbieter für Internet, TV und Festnetz hier.](https://www.comparis.ch/telecom/zuhause/default) + +[Internet-Abos vergleichen](https://www.comparis.ch/telecom/zuhause/angebote/internet-tv-festnetz-abo) + +Tipps und Informationen zu den Themen Internet, TV und Festnetz +--------------------------------------------------------------- + +Ratgeber für Ihren Anschluss: Comparis versorgt Sie mit Neuigkeiten und Tipps in Sachen Telekom. + +[ ### 5G-Abdeckung in der Schweiz: Netzanbieter im Vergleich 30.07.2025](https://www.comparis.ch/telecom/mobile/handy-abo/mobilfunknetz)[ ### Streaming-Dienste in der Schweiz: Welche gibt es & was bieten sie? 13.01.2025](https://www.comparis.ch/telecom/zuhause/streaming/streaming)[ ### Speedtest Internet: Wie schnell surfe ich? 06.02.2025](https://www.comparis.ch/telecom/zuhause/internet-tv-festnetz-abo/internetgeschwindigkeit-speedtest) + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_009_www.comparis.ch_neu-in-der-schweiz_default.txt b/test_web_content_20251002_215219/additional_link_009_www.comparis.ch_neu-in-der-schweiz_default.txt new file mode 100644 index 00000000..281d8147 --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_009_www.comparis.ch_neu-in-der-schweiz_default.txt @@ -0,0 +1,434 @@ +URL: https://www.comparis.ch/neu-in-der-schweiz/default +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Umzug in die Schweiz: Entspannt in die Schweiz umziehen + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/neu-in-der-schweiz/default)[IT](https://it.comparis.ch/neu-in-der-schweiz/default)[EN](https://en.comparis.ch/neu-in-der-schweiz/default) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/neu-in-der-schweiz/default)[FR](https://fr.comparis.ch/neu-in-der-schweiz/default)[IT](https://it.comparis.ch/neu-in-der-schweiz/default)[EN](https://en.comparis.ch/neu-in-der-schweiz/default) + + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. [Wohnen](https://www.comparis.ch/wohnen "Wohnen") +3. Neu in der Schweiz + +Neu in der Schweiz +================== + +Willkommen in der Schweiz: Ihre interaktive Checkliste für einen reibungslosen Umzug in die Schweiz. Schritt für Schritt durch alle wichtigen Themen – von der Vorbereitung bis zum erfolgreichen Ankommen. + +[Zur Checkliste](https://www.comparis.ch/neu-in-der-schweiz/w2ch) + +Hilfreiche Services +------------------- + +Finden Sie hier die wichtigsten Comparis-Services, die Ihnen den Umzug in die Schweiz erleichtern. + +[### Quellensteuer  Quellensteuer berechnen und sparen.](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer)[### Immobilienmarkt  Das grösste Online-Immobilienangebot der Schweiz auf einen Blick.](https://www.comparis.ch/immobilien/default)[### Krankenkasse  Mit wenigen Klicks Angebote vergleichen und sparen.](https://www.comparis.ch/krankenkassen/default)[### Internet, TV, Festnetz  Tarife von Anbietern vergleichen und das passende Abo für Ihr Zuhause finden.](https://www.comparis.ch/telecom/zuhause/default)[### Hausrat- und Haftpflichtversicherung  Die passende Versicherung finden und Prämien sparen.](https://www.comparis.ch/hausrat-versicherung/default)[### Autoversicherung  Prämien wichtiger Anbieter in der Schweiz vergleichen. ](https://www.comparis.ch/autoversicherung/default)[### Motorradversicherung  Die passende Motorradversicherung finden und Prämien sparen.](https://www.comparis.ch/motorradversicherung/default)[### Hypotheken  Schnell und einfach eine günstige Hypothek finden.](https://www.comparis.ch/hypotheken/default) + +Diese 4 Schritte machen Ihren Umzug in die Schweiz einfacher +------------------------------------------------------------ + +### Überblick verschaffen + +Was müssen Sie bei einem Umzug in die Schweiz beachten? Was sind mögliche Herausforderungen? Ist dieser Schritt für Sie und Ihre Familie der richtige? Bei Comparis finden Sie umfassende Informationen: + +* Welche [Einreisebestimmungen](https://www.comparis.ch/neu-in-der-schweiz/auswandern/zollbestimmungen) gelten für die Schweiz? + +* Was kostet das [Wohnen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung)? + +* Was gilt es bezüglich [Niederlassungs- und Arbeitsbewilligungen](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) zu beachten? + +* Gibt es zusätzliche Besonderheiten bei einem Umzug in die Schweiz? + +### Umzug vorbereiten + +Ihre Entscheidung steht fest: Sie wollen in der Schweiz leben. Nun beginnt die Umzugsplanung. Comparis bietet Ihnen neben Informationen auch Dienstleistungen, die Ihnen den Umzug erleichtern: + +* Welche To-dos gilt es zu erledigen? [Unsere umfangreiche Umzugscheckliste](https://www.comparis.ch/neu-in-der-schweiz/auswandern/checkliste) + +* Ihr [neues Zuhause](https://www.comparis.ch/immobilien/default) finden auf dem grössten [Online-Immobilienmarkt](https://www.comparis.ch/immobilien/default) der Schweiz + +* Was muss ich bei der [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) berücksichtigen? + +### In die Schweiz umziehen + +Es ist so weit: Der Umzug steht an. Mit Comparis vergessen Sie keine wichtigen Schritte. + +* Welche Aufgaben muss ich fristgerecht bei den Behörden erledigen? + +* Wie [melde ich mich in der Schweiz an](https://www.comparis.ch/neu-in-der-schweiz/leben/anmeldung)? + +* [Welche Versicherungen](https://www.comparis.ch/neu-in-der-schweiz/leben) sollte ich zuerst abschliessen? + +### Einrichten und einleben + +Sie sind angekommen: Herzlich willkommen in der Schweiz! Nun wollen Sie Ihr neues Zuhause möglichst rasch einrichten und sich einleben. Comparis hilft Ihnen dabei mit Dienstleistungsvergleichen für viele Lebensbereiche. Zudem geben wir Ihnen Einblicke in die Kultur und Eigenheiten der Schweiz: + +* Lesen Sie mehr über [Besonderheiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +* Informieren Sie sich zur [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +* Vergleichen Sie [Handy- und Internet-Abos](https://www.comparis.ch/neu-in-der-schweiz/leben/handy-abo) + +So hilft Ihnen Comparis beim Umzug in die Schweiz +------------------------------------------------- + +Beim Umzug ist optimale Vorbereitung alles. Comparis hilft Ihnen dabei mit viel Wissen an einem Ort. Darüber hinaus finden Sie über unsere Seite auch Ihre neue Wohnung oder Ihr neues Haus – und Vergleiche für Lebensbereiche wie Versicherungen, Finanzen, Mobilität, Gesundheit oder Telekommunikation. + + + +Wichtiges Know-how + +Unsere Inhalte, Tipps und Vergleiche stehen Ihnen kostenlos zur Verfügung. + + + +Umfangreiche Produktvergleiche + +Finden Sie die für Sie passenden Dienstleistungen und Produkte im Vergleich. + + + +Unabhängig & neutral + +An Comparis ist weder der Staat noch ein anderes Unternehmen beteiligt. Comparis ist unabhängig und neutral. + + + +Wichtiges Know-how + +Unsere Inhalte, Tipps und Vergleiche stehen Ihnen kostenlos zur Verfügung. + + + +Umfangreiche Produktvergleiche + +Finden Sie die für Sie passenden Dienstleistungen und Produkte im Vergleich. + + + +Unabhängig & neutral + +An Comparis ist weder der Staat noch ein anderes Unternehmen beteiligt. Comparis ist unabhängig und neutral. + +Vom 1. Umzugsgedanken bis zum Leben in der Schweiz +-------------------------------------------------- + +Ob Sie erst mit dem Gedanken spielen, kurz davor sind oder bereits in die Schweiz umgezogen sind: Bei uns finden Sie Tipps für die damit verbundenen Herausforderungen. + +[ ### Umziehen in die Schweiz Welche Formalitäten bei Behörden gilt es zu erledigen, welche Dokumente und Kontakte sind relevant?](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + +[ ### Arbeiten in der Schweiz Sie sind neu in der Schweiz und möchten hier arbeiten? Lesen Sie Tipps für die Stellensuche, Infos zum Gehalt und mehr.](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + +[ ### Leben neu organisieren Jetzt stellen sich viele Fragen: Wie komme ich an ein passendes Mobilabo? Wie lasse ich mein Fahrzeug zu? Wir geben Ihnen Antworten.](https://www.comparis.ch/neu-in-der-schweiz/leben) + +[ ### Finanzen in der Schweiz Ob Steuern oder Lebenshaltungskosten: Wir zeigen, was Sie zum Thema Finanzen in der Schweiz wissen sollten.](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + +Praktisches Wissen für Ihren Umzug in die Schweiz +------------------------------------------------- + +Es ist ein grosser Schritt, in ein fremdes Land zu ziehen. Diese praktischen Tipps helfen Ihnen vor und während des Umzugs in die Schweiz. + +[### Das kostet eine Wohnung Sie möchten wissen, wie viel eine Wohnung in der Schweiz kostet? Gibt es regionale Unterschiede? Comparis bringt Licht ins Dunkel.](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung)[### Den passenden Job finden Erfahren Sie, wo Sie einen passenden Job finden. Comparis erklärt zudem das Wichtigste zu den Arbeitsbedingungen in der Schweiz.](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + +[### Formalitäten bei der Einreise Bei der Einreise in die Schweiz müssen Sie schon vorgängig an einiges denken. Mit Comparis vergessen Sie nichts Wichtiges.](https://www.comparis.ch/neu-in-der-schweiz/auswandern/checkliste)[### Fahrzeug einführen Beim Umzug mit einem Fahrzeug gibt es von der Deklaration bis zur Zulassung einiges zu beachten. Hier finden Sie die Übersicht.](https://www.comparis.ch/neu-in-der-schweiz/auswandern/auto-einfuhr) + +Häufig gestellte Fragen zum Umzug in die Schweiz +------------------------------------------------ + +### Was ist die Voraussetzung für einen Aufenthalt (bis zu 5 Jahren) in der Schweiz? + +Das ist von verschiedenen Faktoren abhängig. Sind Sie Bürger eines EU- oder Efta-Landes, können Sie sich drei Monate in der Schweiz aufhalten, um eine Arbeitsstelle zu finden. Danach sind Sie zum Aufenthalt berechtigt. Kommen Sie hingegen aus einem sogenannten Drittstaat, benötigen Sie bereits einen Arbeitsvertrag inklusive einer entsprechenden Arbeitsbewilligung bzw. einen Studienplatz. Übrigens: Angehörige ausländischer Personen dürfen sich unter Einhaltung gewisser Bedingungen ebenfalls in der Schweiz niederlassen. Als Angehörige gelten: Ehepartner, Kinder unter 21 Jahren und Angehörige, für die die eingewanderte Person ein Sorge- oder Pflegerecht hat. Weitere Informationen zu den Aufenthaltsbewilligungen in der Schweiz finden Sie [hier](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung). + +### Was ist der Unterschied zwischen der Aufenthaltsbewilligung (B-Ausweis) und der Niederlassungsbewilligung (C-Ausweis)? + +* Eine**Aufenthaltsbewilligung (B-Ausweis)**erhalten EU-/Efta-Staatsangehörige, wenn sie sich in einem unbefristeten oder mindestens 12 Monate dauernden Arbeitsverhältnis befinden. Diese Bewilligung ist 5 Jahre gültig sowie verlängerbar und kann zur Erhebung der[Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) genutzt werden. + +* Die unbeschränkt gültige **Niederlassungsbewilligung (C-Ausweis)** erhalten ausländische Erwerbstätige aus EU-/Efta-Staaten dann nach 5 Jahren. Sie haben damit mit der Ausnahme des Stimm- und Wahlrechts die gleichen Rechte und Pflichten wie Schweizer. + +Detaillierte Informationen finden Sie in diesem [Comparis-Artikel](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung). + +### Wie viel Steuern muss ich bezahlen? + +Die Höhe des Steuerbetrags ist in der Schweiz von Kanton zu Kanton unterschiedlich und abhängig von verschiedenen Kenngrössen. Am besten nutzen Sie den Comparis-[Quellensteuer-Rechner](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer), um die für Sie zu erwartenden Steuern schnell und unkompliziert zu berechnen. Unser Rechner lässt Sie zudem Steuern über alle Kantone vergleichen. + +### Wie schreibe ich meinen Führerschein in der Schweiz um? + +Der ausländische Führerschein (auch oft Führerausweis genannt) ist während der ersten 12 Monate in der Schweiz gültig. Melden Sie sich innerhalb dieser Zeit bei Ihrem [kantonalen Strassenverkehrsamt](https://asa.ch/strassenverkehrsaemter/adressen/). Weiterführende Informationen sowie die für die Umschreibung benötigten Dokumente finden Sie [in diesem Artikel](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben). Weitere Informationen zur Einfuhr und Zulassung Ihres Autos haben wir Ihnen [hier](https://www.comparis.ch/neu-in-der-schweiz/auswandern/auto-einfuhr) zusammengestellt. + +### Was sind die wichtigsten Schweizerdeutsch-Wörter? + +Grundsätzlich ist es nicht notwendig, Schweizerdeutsch zu verstehen, da die Menschen in der Deutschschweiz auch Deutsch sprechen und alles in Deutsch angeschrieben steht. Alternativ freuen sich die Deutschschweizer, wenn Sie ein paar wenige schweizerdeutsche Wörter kennen. Wir haben Ihnen dafür ein [kleines Wörterbuch](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) zusammengestellt. Wenn Sie die Sprache lernen möchten, besuchen Sie doch z.B. einen preislich attraktiven Kurs in der [Migros Klubschule](https://www.klubschule.ch/sprachen/deutschkurse/schweizerdeutsch/). + +Wichtig: Deutsch wird lediglich in der grössten Region gesprochen. Es gibt ebenfalls Französisch, Italienisch und Rätoromanisch. + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_010_www.comparis.ch_krankenkassen_default.txt b/test_web_content_20251002_215219/additional_link_010_www.comparis.ch_krankenkassen_default.txt new file mode 100644 index 00000000..f35c11cb --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_010_www.comparis.ch_krankenkassen_default.txt @@ -0,0 +1,253 @@ +URL: https://www.comparis.ch/krankenkassen/default +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Suchassistent + +[Login](/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +[Newsletter](/comparis/newsletter/subscribe) + +[Login](/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/krankenkassen/default) +[FR](https://fr.comparis.ch/krankenkassen/default) +[IT](https://it.comparis.ch/krankenkassen/default) +[EN](https://en.comparis.ch/krankenkassen/default) + +# Krankenkassenvergleich 2025 + +Mit dem grossen Krankenkassenvergleich der Schweiz Prämien berechnen und sparen. Vergleichen Sie bei Comparis die Krankenkassenprämien 2025. + +Umfassend vergleichen + +Vergleichen Sie Leistungen, Prämien und Kundenzufriedenheit. + +Einfach sparen + +Finden Sie in wenigen Minuten eine preiswerte Krankenkasse. + +Unkompliziert abschliessen + +Bestellen Sie mehrere Offerten – kostenlos und unverbindlich. + +Umfassend vergleichen + +Vergleichen Sie Leistungen, Prämien und Kundenzufriedenheit. + +Einfach sparen + +Finden Sie in wenigen Minuten eine preiswerte Krankenkasse. + +Unkompliziert abschliessen + +Bestellen Sie mehrere Offerten – kostenlos und unverbindlich. + +## In drei Schritten zur Krankenversicherung + +Wählen Sie: Möchten Sie die [Grundversicherung](/krankenkassen/grundversicherungen), die [Zusatzversicherung](/krankenkassen/zusatzversicherungen) oder beides zusammen vergleichen? + +Geben Sie Ihre Personalien und Bedürfnisse an. + +Vergleichen Sie die Ergebnisse des Prämienrechners in Ihrer persönlichen Resultatliste. + +Speichern Sie Ihre Favoriten (bis zu drei Angebote) und bestellen Sie unverbindliche Offerten. + +So finden Sie die Versicherung, die zu Ihnen passt. + +## Krankenkasse wechseln und über 35’000 Franken sparen + +Durch das Wechseln Ihrer Krankenkasse können Sie in zehn Jahren **Prämien in Höhe eines Kleinwagens sparen.** Eine [Comparis-Analyse](https://res.cloudinary.com/comparis-cms/image/upload/v1754920631/press/de/2025/08/20250812_MM_KK_10_Jahre_Sparpotenzial_DE_vfkigz.pdf) zeigt: Hätten Sie 2015 von der teuersten zur günstigsten Krankenkasse gewechselt, hätten Sie bis heute **über 35’000 Franken sparen** können – ohne weiteren Wechsel. + +Wechseln Sie die Krankenkasse **jährlich**, ist Ihr [Sparpotenzial](/krankenkassen/praemien/sparen) noch höher. Deswegen lohnt sich ein Vergleich der Krankenkassenprämien, besonders langfristig. + +[Jetzt Krankenkassenprämien berechnen](/krankenkassen/input) + +## Beste Krankenkasse 2025 + +Im Rahmen des [Comparis-Siegels](/info/siegel) haben wir die Schweizer Bevölkerung zu ihrer Zufriedenheit mit ihrer Krankenkasse befragt. Die Ergebnisse sehen Sie als Comparis-Note direkt im Krankenkassenvergleich – und auf der [Übersichtsseite zu den besten Krankenkassen](/krankenkassen/beste-krankenkasse). + +## Die Krankenversicherungen in unserem Vergleich + +[5.0/6](/krankenkassen/anbieter/agrisano) + +[4.9/6](/krankenkassen/anbieter/kpt-versicherung) + +[5.0/6](/krankenkassen/anbieter/concordia-versicherung) + +[5.1/6](/krankenkassen/anbieter/swica-versicherung) + +[5.0/6](/krankenkassen/anbieter/visana-assurance) + +[5.1/6](/krankenkassen/anbieter/helsana-versicherung) + +[5.1/6](/krankenkassen/anbieter/oekk-versicherung) + +[5.1/6](/krankenkassen/anbieter/aquilana-versicherung) + +[Weitere Krankenkassen](/krankenkassen/beste-krankenkasse) + +Der Grundversicherungsvergleich enthält Produkte (Prämien) von Anbietern (Krankenversicherern), die vom Bundesamt für Gesundheit (BAG) genehmigt worden sind. + +Der Zusatzversicherungsvergleich enthält Produkte von Anbietern, die Offert-/Kontaktanfragen von [Optimatis](/altersvorsorge/vorsorgesystem/ueber-optimatis +) entgegennehmen, und/oder Produkte von Anbietern, die keine Offert-/Kontaktanfragen von Optimatis entgegennehmen. Die Anbieter in diesem Vergleich nutzen die von Optimatis angebotene Schnittstelle. + +In der «Standard-Ansicht» zeigt Comparis Produkte von Anbietern, die Offert-/Kontaktanfragen von [Optimatis](/altersvorsorge/vorsorgesystem/ueber-optimatis +) entgegennehmen, sowie das günstigste und teuerste Produkt. In der «Erweiterten Ansicht» zeigt Comparis alle vom BAG genehmigten Produkte (Grundversicherungsvergleich) respektive alle Prämien von Anbietern, die die von Optimatis angebotene Schnittstelle nutzen (Zusatzversicherungsvergleich). + +Die Rangierung der Suchresultate erfolgt nach objektiv messbaren Kriterien gemäss gewähltem Filter. Von diesem Sachverhalt ausgeschlossene Angebote sind deutlich als «Anzeige» ausgewiesen. + +Die Angaben zur Verfügbarkeit von Hausärztinnen und Hausärzten basieren auf den Daten von medswissnet, dem Schweizer Dachverband der Ärztenetzwerke. Sie enthalten nur dem Verband angeschlossene Ärztinnen und Ärzte und können vom Hausarztverzeichnis der Krankenkassen abweichen. + +## Das Wichtigste zum Thema Krankenversicherung + +[### Krankenkasse wechseln + +Antworten auf die wichtigsten Fragen zum Krankenkassenwechsel.](/krankenkassen/system/kassenwechsel) +[### Zusatzversicherung + +Zusatzversicherungen ergänzen wertvolle Leistungen der Grundversicherung. Beispiele dafür sind: Zähne, Brille, Ausland, Fitness, halbprivate oder private Spitaldeckung.](/krankenkassen/zusatzversicherungen) +[### Krankenkassenprämien + +Finden Sie alle Neuigkeiten zu den Krankenkassenprämien.](/krankenkassen/praemien) + +[### Franchise + +Die Franchise definiert mit dem Selbstbehalt die Kostenbeteiligung der versicherten Person. Finden Sie heraus, welche für Sie geeignet ist.](/krankenkassen/grundversicherungen/franchise) +[### Selbstbehalt + +Bei jeder Behandlung oder bezogenen Leistung aus der Grundversicherung müssen Sie einen Selbstbehalt übernehmen. Dieser beträgt 10 Prozent.](/krankenkassen/grundversicherungen/selbstbehalt) +[COMPARIS-SERVICE + +Kündigungsbrief für die Grundversicherung](/krankenkassen/system/vorlage-kuendigungsschreiben) + +## Unser Krankenkassen-Ratgeber + +[### Unfallversicherung in der Schweiz + +Die Unfallversicherung trägt die finanziellen Folgen von Unfällen und Berufskrankheiten. Sie ist in der Schweiz obligatorisch. Erfahren Sie, wie Sie sich am besten vor unerwarteten Behandlungskosten schützen können.](/krankenkassen/unfallversicherung) + +[### Familienkrankenkasse: Krankenversicherung für die ganze Familie + +Die Grundversicherung ist für jede in der Schweiz wohnhafte Person obligatorisch. Dies gilt für Erwachsene und Kinder. Finden Sie die passende Krankenversicherung für Ihre gesamte Familie.](/krankenkassen/familie) + +[### Grundversicherung – obligatorische Krankenkasse + +Wer in der Schweiz wohnt oder arbeitet, muss eine Grundversicherung abschliessen. Die Grundversicherung kommt zum Tragen, wenn Sie krank werden oder verunfallen.](/krankenkassen/grundversicherungen) + +[### Leistungen der Krankenkasse + +Von Alternativmedizin bis Zahnarzt: Lesen Sie hier, welche Behandlungen, Medikamente und Hilfsmittel die Grundversicherung übernimmt und wo sich eine Zusatzversicherung lohnt.](/krankenkassen/leistungen) + +[### Das Krankenkassensystem in der Schweiz + +Wer bestimmt eigentlich, welche Leistungen die Grundversicherung bezahlt? Was muss ich beim Krankenkassenwechsel beachten? Und welchen Einfluss haben die Prämien auf meine Steuern?](/krankenkassen/system) + +[### Krankenkassenprämien in der Schweiz + +In der Grundversicherung bezahlen Sie Prämien. Was sind Prämien und wie können Sie Prämienkosten gering halten? Comparis gibt Tipps und Tricks rund um Krankenkassenprämien.](/krankenkassen/praemien) + +[### Zusatzversicherungen vergleichen + +Finden Sie mit einem Vergleich der Zusatzversicherungen in der Schweiz die passende Deckung für Sie. Comparis hilft Ihnen dabei.](/krankenkassen/zusatzversicherungen) + +## Prämien-Benachrichtigung + +Das Bundesamt für Gesundheit BAG veröffentlicht die Prämien für das nächste Jahr immer im September. Melden Sie sich für die Benachrichtigung an. So können Sie die neuen Prämien rechtzeitig vergleichen und im neuen Jahr sparen. + +Mit der Anmeldung stimme ich der Bearbeitung meiner Daten entsprechend der [Datenschutzerklärung](/comparis/info/privacy) von comparis.ch zu. + +## Beliebte Krankenkassen-Artikel + +[### Kündigung der Krankenkasse: Vorlage fürs Kündigungsschreiben + +06.11.2024](/krankenkassen/system/vorlage-kuendigungsschreiben) +[### Prognose der Krankenkassenprämien 2026: 4 Prozent teurer + +22.05.2025](/krankenkassen/praemien/prognose-trend) +[### Krankenwagen-Kosten in der Schweiz: Wer zahlt? + +09.03.2023](/krankenkassen/leistungen/krankenwagen-ambulanz) +[### Gewichtsverlust durch Abnehmspritzen: Zahlt die Krankenkasse? + +27.03.2025](/krankenkassen/leistungen/abnehmspritze) +[### Krankenkassen und Fitness-Abos: Welche Krankenkasse zahlt das Fitnessstudio? + +23.12.2024](/krankenkassen/leistungen/fitnessabo) +[### Steuererklärung: Kann ich Krankenkassen-Kosten abziehen? + +05.02.2025](/krankenkassen/system/steuererklaerung) + +## Häufige Fragen zum Thema Krankenkassenvergleich + +Die Krankenkassenprämien sind je nach Wohnort, Krankenversicherung, Modell, Franchise und Alter unterschiedlich. Vergleichen Sie die Grundversicherungsprämien gemäss Ihrer Situation und finden Sie so die günstigste Krankenkasse. + +[Krankenkassenprämien vergleichen](/krankenkassen/input) + +#### Obligatorische Krankenversicherung + +Die **Grundversicherung** können Sie in der Regel jährlich wechseln. Stichtag für den [Krankenkassenwechsel](/krankenkassen/system/kassenwechsel) bzw. die Kündigung ist der **30. November**. **Wichtig:** Fällt der 30. November auf das Wochenende, muss die Kündigung am Freitag davor bei der Krankenkasse eintreffen. + +Krankenkassen müssen neue Versicherte unabhängig von ihrer gesundheitlichen Situation aufnehmen. Darum müssen Sie keine Auskunft geben zu Vorerkrankungen. + +#### Zusatzversicherung + +Für die **Zusatzversicherung** ist in der Regel die Beantwortung eines [Gesundheitsfragebogens](/krankenkassen/zusatzversicherungen/gesundheitsfragen) erforderlich. Eine Vorerkrankung bedeutet nicht zwingend eine Ablehnung. Allenfalls wird die Vorerkrankung aus der Deckung ausgeschlossen. + +**Wichtig:** Kündigen Sie bei einem Wechsel die alte Zusatzversicherung erst, wenn Sie die Aufnahmebestätigung der neuen Krankenkasse erhalten haben. + +Weitere Infos finden Sie im Artikel zum Thema [Zusatzversicherung abschliessen](/krankenkassen/zusatzversicherungen/versicherung-abschliessen). + +Die Krankenkassenprämien für die Grundversicherung stiegen 2025 im Durchschnitt [um sechs Prozent](/krankenkassen/praemien/prognose-trend). Das war bereits die dritte grosse Prämienerhöhung in Folge. + +Mit der Wahl der Krankenkasse, der [Franchise](/krankenkassen/grundversicherungen/franchise) und des Versicherungsmodells können Sie den Kostenanstieg bestmöglich abfedern. + +Darum ist es wichtig, dass Sie Ihr [Sparpotenzial](/krankenkassen/praemien/sparen) ausschöpfen und einen [Krankenkassenvergleich](/krankenkassen/input) vornehmen. + +Die monatliche Prämie 2025 beträgt im Durchschnitt **378.70 Franken**. + +Die mittlere Prämie ergibt sich aus der Summe aller gezahlten Prämien in der Schweiz – geteilt durch die Anzahl der Versicherten. + +Die tatsächlichen Prämien unterscheiden sich allerdings je nach Alter, Wohnort, Franchise und Versicherungsmodell teils stark. + +[Krankenkassenprämien vergleichen](/krankenkassen/input) + +Am höchsten sind die Prämien 2025 im Durchschnitt in den Kantonen Genf, Tessin und Basel-Stadt. + +Am tiefsten sind die mittleren Prämien 2025 in den Kantonen Appenzell Innerrhoden, Uri und Obwalden. + +Die Antwort auf die Frage nach der besten Krankenkasse hängt von Ihren **persönlichen Bedürfnissen** ab. Denn: Krankenversicherungen bieten unterschiedliche Leistungsmerkmale. Die Leistungen der Krankenkassen sind in der Grundversicherung aber überall gleich. + +#### Comparis-Siegel zeigt Kundenzufriedenheit + +Einen wichtigen Hinweis zur Kundenzufriedenheit liefert das [Comparis-Siegel](/krankenkassen/beste-krankenkasse). In diesem Zusammenhang befragen wir jährlich 4’500 Krankenversicherte zu ihrer Zufriedenheit mit ihrer Krankenkasse. + +Bewertet werden diese **Leistungsmerkmale**: + +* Preis/Leistung +* Touchpoints und Kontakt +* Qualität und Service +* Information und Transparenz + +Die Teilnehmenden der Befragung vergeben dann **Noten je Merkmal**. Daraus wird eine **Gesamtnote** berechnet. Die laut der Umfrage besten Krankenkassen werden mit einem Siegel ausgezeichnet. + +Zum **Ergebnis** der Kundenzufriedenheits-Umfrage für die Grundversicherung: [Beste Krankenkasse](/krankenkassen/beste-krankenkasse) + +In der Schweiz ist die **Unfallversicherung obligatorisch**. Aber: Sind Sie mindestens acht Stunden pro Woche bei einem einzigen Arbeitgeber angestellt oder beim RAV angemeldet, sind Sie gemäss [Unfallversicherungsgesetz (UVG)](/krankenkassen/unfallversicherung/unfallversicherungsgesetz-uvg) automatisch gegen [Unfall](/krankenkassen/unfallversicherung) versichert. Alle anderen Versicherten müssen die Unfalldeckung in ihrer Grundversicherung einschliessen. Für Selbstständige gibt es auch alternative Lösungen. + +Eine zusätzliche Unfalldeckung über die [Zusatzversicherung](/krankenkassen/zusatzversicherungen) kann je nach Bedürfnissen sinnvoll sein – auch bei bestehender Unfallversicherung durch den Arbeitgeber. + +Die stationären Behandlungen und Untersuchungen in Spitälern sind in der Grundversicherung bei allen Krankenkassen **in der allgemeinen Abteilung im Wohnkanton** gedeckt. Möchten Sie aber in ein Spital ausserhalb des Wohnkantons gehen oder wünschen Sie etwas mehr Qualität und Komfort? Dann können Sie eine Spitalzusatzversicherung abschliessen. Hier finden Sie weitere Informationen zur [Spitalzusatzversicherung](/krankenkassen/zusatzversicherungen/spitalzusatzversicherung). + +Die Grund- und Zusatzversicherung müssen Sie **nicht zwingend bei der gleichen Krankenkasse** abschliessen. Trennen Sie die beiden Versicherungen, fallen in der Zusatzversicherung aber unter Umständen Administrationskosten an. + +Ebenso kann es bei einer Trennung zu einem **Verlust von Vergünstigungen** kommen, z. B. Familien- oder Kollektivrabatt. Hier finden Sie weitere Tipps zur [Trennung von Grund- und Zusatzversicherung](/krankenkassen/system/trennung-grundversicherung-zusatzversicherung). + +Die günstigste Krankenkassenprämie finden Sie durch einen **Vergleich verschiedener Anbieter.** Dazu können Sie zum Beispiel den Krankenkassenvergleich von Comparis nutzen. + +Sie können aber auch durch Anpassungen bei Ihrer Krankenkasse sparen. Wählen Sie ein [alternatives Versicherungsmodell](/krankenkassen/grundversicherungen/krankenkassenmodelle) und eine hohe [Franchise](/krankenkassen/grundversicherungen/franchise), zahlen Sie monatlich weniger. + +[Krankenkassenprämien vergleichen](/krankenkassen/input) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_011_www.comparis.ch_lebensversicherung_default.txt b/test_web_content_20251002_215219/additional_link_011_www.comparis.ch_lebensversicherung_default.txt new file mode 100644 index 00000000..16892f41 --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_011_www.comparis.ch_lebensversicherung_default.txt @@ -0,0 +1,589 @@ +URL: https://www.comparis.ch/lebensversicherung/default +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Lebensversicherungs-Vergleich für die Schweiz: So finden Sie die passende Versicherung | Comparis + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/lebensversicherung/default)[IT](https://it.comparis.ch/lebensversicherung/default)[EN](https://en.comparis.ch/lebensversicherung/default) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/lebensversicherung/default)[FR](https://fr.comparis.ch/lebensversicherung/default)[IT](https://it.comparis.ch/lebensversicherung/default)[EN](https://en.comparis.ch/lebensversicherung/default) + + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. [Versicherungen](https://www.comparis.ch/versicherung "Versicherungen") +3. Lebensversicherung + +Lebensversicherungen vergleichen in der Schweiz +=============================================== + +Mit Comparis finden Sie die passende Lebensversicherung. Vergleichen Ihre Möglichkeiten – unverbindlich und transparent. + +[Beratung anfordern](https://www.comparis.ch/altersvorsorge/beratung?origin=vle) + +[So funktioniert's](https://www.comparis.ch/lebensversicherung/default#content-5) + +Was ist eine Lebensversicherung? +-------------------------------- + +Die Lebensversicherung schützt Ihre Angehörigen und sichert den gewohnten Lebensstandard im Falle von Invalidität oder Tod. Sie können sie gleichzeitig zum Kapitalaufbau Ihrer privaten Altersvorsorge (3. Säule) nutzen. Erfahren Sie, welche Modelle es gibt und worauf Sie achten sollten. + +[ ### Modelle der Lebensversicherung Ob Risikolebensversicherung, Todesfallversicherung oder Erwerbsunfähigkeitsversicherung: Wir klären Sie über die verschiedenen Modelle auf.](https://www.comparis.ch/lebensversicherung/modelle) + +[ ### Finanzielle Absicherung Familie absichern, fürs Alter vorsorgen, Steuern sparen, Einkommen bei Erwerbsausfall sichern – die Vorteile einer Lebensversicherung sind zahlreich. Doch welche Lösung eignet sich für welches Ziel? Comparis zeigt Ihnen die Möglichkeiten.](https://www.comparis.ch/lebensversicherung/finanzielle-absicherung) + +[ ### Für wen ist eine Lebensversicherung sinnvoll? Es gibt verschiedene Gründe für den Abschluss einer Lebensversicherung. Sie ist besonders sinnvoll, wenn Sie Familie oder Wohneigentum haben. Auch für Selbstständige kann eine solche Versicherung Sinn ergeben. Erfahren Sie, warum.](https://www.comparis.ch/lebensversicherung/finanzielle-absicherung/wann-brauche-ich-eine-lebensversicherung) + +Wichtiges zum Thema Lebensversicherung +-------------------------------------- + +Comparis bietet Ihnen wichtige Informationen über die Lebensversicherung und hilfreiche Tools zur Veranschaulichung Ihrer finanziellen Situation. + +[### Todesfallversicherung Im Todesfall werden Ihre Angehörigen durch Todesfallkapital und Prämienzahlung vor den finanziellen Folgen geschützt.](https://www.comparis.ch/lebensversicherung/modelle/todesfallversicherung)[### Vorsorgelücken-Rechner Wie gross ist Ihre finanzielle Lücke bei Invalidität und Tod? Berechnen Sie Ihr Risiko.](https://www.comparis.ch/altersvorsorge/vorsorgesystem/vorsorgeluecke) + +[### Erwerbsunfähigkeitsversicherung Bei Erwerbsunfähigkeit wegen Krankheit oder Unfall werden ihre finanziellen Lücken bis zur Pensionierung gedeckt.](https://www.comparis.ch/lebensversicherung/modelle/erwerbsunfaehigkeitsversicherung)[### Beratung zur Lebensversicherung Lassen Sie sich neutral und unverbindlich beraten und vergleichen Sie die Angebote, die für Sie am besten passen.](https://www.comparis.ch/altersvorsorge/beratung?origin=vle) + +Warum eine Lebensversicherung? +------------------------------ + +Die Beraterinnen und Berater von Optimatis, dem Brokerage-Partner von Comparis, und seine Vertragsfirmen sind für Sie da. + + + +Risiken erkennen + +Fachpersonen beraten Sie, damit Sie im Falle von Invalidität, Tod und Pensionierung optimal abgesichert sind. + + + +Individueller Schutz + +Entscheiden Sie, wie hoch die Rente bei Erwerbsunfähigkeit bzw. die Höhe des Todesfallkapitals sein soll. + + + +Sparen und Rendite optimieren + +Die Expertinnen und Experten zeigen Ihnen, wie Sie Ihre Rendite auf Basis der 3. Säule optimieren und dabei Steuern sparen können. + + + +Risiken erkennen + +Fachpersonen beraten Sie, damit Sie im Falle von Invalidität, Tod und Pensionierung optimal abgesichert sind. + + + +Individueller Schutz + +Entscheiden Sie, wie hoch die Rente bei Erwerbsunfähigkeit bzw. die Höhe des Todesfallkapitals sein soll. + + + +Sparen und Rendite optimieren + +Die Expertinnen und Experten zeigen Ihnen, wie Sie Ihre Rendite auf Basis der 3. Säule optimieren und dabei Steuern sparen können. + +In drei Schritten zur passenden Lebensversicherung +-------------------------------------------------- + + + +### Überblick verschaffen + +Machen Sie sich im Detail mit dem Thema Lebensversicherung und Ihrer finanziellen Lage vertraut: + +* [Grösstes Risiko berechnen](https://www.comparis.ch/altersvorsorge/vorsorgerechner) + +* [Lebensversicherungen verstehen](https://www.comparis.ch/lebensversicherung/modelle/was-ist-eine-lebensversicherung) + +* [Absicherung der Familie](https://www.comparis.ch/altersvorsorge/vorsorgesystem/familie)mit einbeziehen + + + +### Beratungstermin anfragen + +Fachpersonen klären Ihre Anliegen und vergleichen unterschiedliche Anbieter von Lebensversicherungen. Sie analysieren, welche Angebote am besten zu Ihren Bedürfnissen passen. + + + +### Lebensversicherungen vergleichen und abschliessen + +Sie erhalten verschiedene Angebote vorgeschlagen. Jetzt können Sie die passende Versicherung auswählen. + +Das sagen Kundinnen und Kunden von Optimatis +-------------------------------------------- + +Google-Rating + +5/5 + +(283 Bewertungen) + +Herr Aladzic hat mich gut und ehrlich beraten.Vielen Dank für die tolle Beratung! + +C. + +06.05.2025 + +Google-Rating + +5/5 + +(283 Bewertungen) + +Sehr gute Beratung und Unterstützung von Herr Redzepi. + +M. + +01.02.2025 + +Google-Rating + +5/5 + +(283 Bewertungen) + +Floriana Kryeziu, vielen, vielen Dank für das angenehme und umsorgende Gespräch. Sie haben mir sehr (schnell!) weitergeholfen. + +M.I. + +03.12.2024 + +Google-Rating + +5/5 + +(283 Bewertungen) + +Herr Aladzic hat mich gut und ehrlich beraten.Vielen Dank für die tolle Beratung! + +C. + +06.05.2025 + +Google-Rating + +5/5 + +(283 Bewertungen) + +Sehr gute Beratung und Unterstützung von Herr Redzepi. + +M. + +01.02.2025 + +Google-Rating + +5/5 + +(283 Bewertungen) + +Floriana Kryeziu, vielen, vielen Dank für das angenehme und umsorgende Gespräch. Sie haben mir sehr (schnell!) weitergeholfen. + +M.I. + +03.12.2024 + +[Zu den Google-Bewertungen](https://www.google.com/search?q=optimatis+ag&rlz=1C1GCEU_deCH966CH966&oq=optimatis+ag&aqs=chrome.0.0i355i512j46i175i199i512j0i22i30.2026j0j7&sourceid=chrome&ie=UTF-8#lrd=0x47900b67716b40ef:0x5dc901562e27afb3,1,,,) + +Häufige Fragen zur Lebensversicherung +------------------------------------- + +### Was ist eine Lebensversicherung? + +Lebensversicherungen sind Versicherungen, die Risiken wie Tod oder Invalidität absichern – sogenannte reine Risikolebensversicherungen. Daneben gibt es noch die Versicherungen, die primär der privaten Altersvorsorge dienen. Diese heissen kapitalbildende Lebensversicherungen. Beide Versicherungsvarianten zählen zur 3. Säule in der Schweiz und damit zu Ihrer privaten Vorsorge. + +### Was sind die Hauptunterschiede zwischen den verschiedenen Lebensversicherungen? + +Es gibt zum einen reine Risikolebensversicherungen, zum anderen gemischte Lebensversicherungen. Beide sollen das finanzielle Risiko einer Erwerbsunfähigkeit durch Unfall oder Krankheit abdecken. Die gemischte Lebensversicherung dient zusätzlich dazu, dass sie das finanzielle Risiko eines Todesfalls abdeckt. Zudem beinhaltet sie einen Sparteil, den man bis zum Renteneintritt in einen Fonds investieren kann. + +### Welche Lebensversicherung ist die beste für mich? + +Welche Lebensversicherung für Sie die beste ist, kann man pauschal so nicht beantworten. Denn individuelle Lebenssituationen benötigen individuelle Lösungen. Wir raten Ihnen daher zu einer professionellen Beratung. Darin wird Ihre finanzielle Situation im Fall einer Erwerbsunfähigkeit analysiert und geschaut, wie Ihre Familie im Todesfall geschützt ist und ob eine Lücke in Ihrer Altersvorsorge besteht. So wissen Sie schnell und zuverlässig, welche Vorsorgeversicherung Sie benötigen. + +### Wie teuer ist eine Lebensversicherung im Monat? + +Ihre Vorsorge wird individuell auf Ihre persönlichen Bedürfnisse angepasst. Daher sind auch die Kosten für eine Lebensversicherung unterschiedlich. Wie hoch die Prämie für Ihre Vorsorgeversicherung ist, hängt ganz von Ihrer Lebenssituation ab. Pauschal kann man aber sagen, dass eine kapitalbildende Versicherung schon ab rund CHF 100 pro Monat möglich ist. + +### Muss ich eine Gesundheitsprüfung machen? + +Beim Abschluss einer Lebensversicherung ist Ihr Gesundheitszustand wichtig. Daher ist eine **_Gesundheitsprüfung_****oder****_Risikoprüfung_** üblich. + +In den meisten Fällen müssen Sie für die Gesundheitsprüfung einen Fragebogen ausfüllen. Bei hohen Versicherungssummen oder bekannten gesundheitlichen Problemen kann die Prüfung auch durch einen Arzt oder eine Ärztin erfolgen. + +### Gibt es eine Altersbeschränkung für den Abschluss einer Lebensversicherung? + +Das Eintrittsalter ist das Alter der versicherten Person bei Beginn der Versicherungspolice. Bei den Lebensversicherungen gibt es meistens Altersbeschränkungen für den Eintritt. + +Häufig gilt ein maximales Eintrittsalter von beispielsweise 60 oder 65 Jahren. Oft ist das Eintrittsalter auch nach unten eingeschränkt. Für Lebensversicherungen der [Säule 3a](https://www.comparis.ch/altersvorsorge/saeule3a) gelten die Bestimmungen der Säule 3a. Das heisst, Sie dürfen **ab dem 1. Januar nach Ihrem 17. Geburtstag**einzahlen. + +### Wie lange läuft eine Lebensversicherung? + +Eine Lebensversicherung ist eine langfristige Vorsorgelösung. Da sie oft mit der Säule 3a kombiniert wird, läuft diese meist bis zur Pensionierung. Bitte beachten Sie: Die Auszahlung ist frühestens 5 Jahre vor oder spätestens 5 Jahre nach Erreichen des ordentlichen Rentenalters möglich. + +### Kann ich meine Lebensversicherung vorzeitig auszahlen lassen? + +In der Säule 3a haben Sie unter gewissen Umständen die Möglichkeit, sich Ihre Lebensversicherung vorzeitig auszahlen zu lassen. Bei einer vorzeitigen Auflösung erhalten Sie den Rückkaufswert der Versicherung. + +### Gibt es Steuervorteile für Lebensversicherungen? + +In der Säule 3a können Sie die Beiträge der Lebensversicherung von den Steuern abziehen. Dabei gibt es jedoch einen gesetzlichen Maximalwert. Sollten Sie sich Ihre Lebensversicherung auszahlen lassen, gilt ein reduzierter Steuersatz. + +### Lebensversicherungs-Vertrag: Worauf sollte ich achten? + +Diese Punkte sind wichtig im Vertrag zur Lebensversicherung: + +### **Barwert** + +Der Barwert bedeutet: So viel Geld müssten Sie heute zu einem konstanten Zinssatz anlegen, um damit alle künftigen Prämien zahlen zu können. Er **macht die verschiedenen Versicherungsprodukte vergleichbar**. + +### Begünstigte + +Begünstigte sind die Personen, die bei Eintreten des versicherten Ereignisses **Anspruch auf die Versicherungsleistung** haben. + +### **Deckungskapital** + +Deckungskapital nennt man die **Rückstellungen für laufende Versicherungsverträge**. Dieses Kapital braucht die Versicherung zur Erfüllung der künftigen Verpflichtungen. + +### **Deckungsumfang** + +Der Deckungsumfang beschreibt die **Leistungen**, die Sie durch die Versicherung beziehen können. + +### **Garantierte Versicherungssumme** + +Die Summe, die im Todesfall **mindestens ausgezahlt**wird. Die garantierte Versicherungssumme ist unabhängig vom finanziellen Erfolg der Versicherungsgesellschaft oder anderen Faktoren. + +### **Prämiengarantie** + +Das bedeutet: Die bei Vertragsbeginn vereinbarte Prämienhöhe **ändert sich über die gesamte Vertragslaufzeit nicht**. Diese Garantie der Versicherung ist unabhängig vom finanziellen Erfolg der Versicherungsgesellschaft. + +### **Risikoausschluss** + +Der Risikoausschluss ist die **Herausnahme eines Gefahrenumstandes aus dem Versicherungsschutz**. Ein Beispiel: Bei Todesfallversicherungen wird meist das Risiko der Selbsttötung für eine bestimmte Zeitdauer vom Versicherungsschutz ausgenommen. Bei Selbsttötung besteht somit in dieser Zeitdauer keine Deckung und die Versicherungssumme wird nicht ausbezahlt. + +### **Versicherungssumme** + +Die Versicherungssumme ist im Versicherungsvertrag festgelegt. Sie bezeichnet den **vereinbarten Höchstbetrag**der Leistung des Versicherers. + +### **Vertragsdauer oder Vertragslaufzeit** + +Die Vertragsdauer oder -laufzeit beschreibt die **Zeitspanne, in der der Versicherungsschutz gewährleistet ist**. Bei den meisten Lebensversicherungen können Sie die Laufzeit innerhalb bestimmter Grenzen frei wählen. + +### **Todesfall** + +Versicherungstechnisch bedeutet der Todesfall, dass die versicherte Person innerhalb der Versicherungslaufzeit stirbt. + +### Was bedeutet Prämienbefreiung bei der Lebensversicherung? + +Prämienbefreiung bedeutet: Sie müssen keine Versicherungsprämien zahlen, wenn bestimmte im Vertrag festgelegte Ereignisse eintreten. Typischer Grund für eine Prämienbefreiung ist die [Erwerbsunfähigkeit](https://www.comparis.ch/lebensversicherung/modelle/erwerbsunfaehigkeitsversicherung). + +### Was ist das Widerrufsrecht? + +Widerrufsrecht bedeutet: Sie können innerhalb einer bestimmten Frist **von einem Vertrag zurücktreten**. Die [gesetzliche Widerrufsfrist](https://www.fedlex.admin.ch/eli/cc/24/719_735_717/de#art_2_a) beträgt 14 Tage. + +Die Frist beginnt, sobald Sie den Vertrag beantragt oder angenommen haben. Spätestens am letzten Tag der Widerrufsfrist müssen Sie Ihren Widerruf der Versicherung mitteilen oder Ihre Widerrufserklärung der Post übergeben. + +Ein **Beispiel**: Sie unterzeichnen am 4. Januar 2025 einen Versicherungsantrag. Dann können Sie diesen Vertrag bis zum 18. Januar 2025 widerrufen. + +### Was bedeutet das Rating von Versicherungen? + +Das Rating ist die **Einschätzung der Bonität eines Unternehmens**. Es wird durch eine unabhängige private oder staatliche Einrichtung durchgeführt. + +Das Rating gibt auch Hinweis auf die Ausfallwahrscheinlichkeit bzw. die Zahlungsunfähigkeit eines Unternehmens an. + +Wichtig ist unter anderem die Ratingagentur Standard and Poor's. Ihre Abstufungen reichen von **AAA (höchste Bonität / geringes Ausfallrisiko) bis D (Zahlungsausfall)**. + +### Was muss ich bei einem Todesfall machen? + +#### **Was muss ich bei einem Todesfall machen?** + +Im Todesfall einer versicherten Person muss der Versicherer **unverzüglich benachrichtigt** werden. Üblicherweise wird ein amtlicher Todesschein und ein Zeugnis über die Todesursache verlangt. Bei einem Unfalltod kann ein Polizeirapport zur Klärung beitragen. + +Der Versicherer klärt dann die Anspruchsberechtigung ab. Das kann bei mehreren Begünstigten zu Verzögerungen bei der Auszahlung führen. + +Liegen alle erforderlichen Unterlagen vor, muss das Versicherungsunternehmen**innert vier Wochen die vereinbarte Leistung erbringen** ([VVG Art. 41](https://www.fedlex.admin.ch/eli/cc/24/719_735_717/de#art_41)). Häufig erfolgt die Auszahlung aber wesentlich schneller. + +Kontakt Optimatis, der Brokerage-Partner von Comparis +----------------------------------------------------- + +Haben Sie Fragen zum Thema Vorsorge und Lebensversicherung? Möchten Sie von Expertinnen und Experten beraten werden? Dann vereinbaren Sie einen unverbindlichen Termin [via Kontaktformular](https://www.comparis.ch/altersvorsorge/beratung?origin=vle). + +[+41 44 559 54 00](https://www.comparis.ch/) + +[info@optimatis.ch](mailto:info@optimatis.ch) + +**MO – FR** + +08.00 – 12.00 Uhr + +13.30 – 17.00 Uhr + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_012_www.comparis.ch_rechtsschutz_default.txt b/test_web_content_20251002_215219/additional_link_012_www.comparis.ch_rechtsschutz_default.txt new file mode 100644 index 00000000..9ede9eb9 --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_012_www.comparis.ch_rechtsschutz_default.txt @@ -0,0 +1,496 @@ +URL: https://www.comparis.ch/rechtsschutz/default +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Rechtsschutzversicherungen in der Schweiz vergleichen | Comparis + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/rechtsschutz/default)[IT](https://it.comparis.ch/rechtsschutz/default)[EN](https://en.comparis.ch/rechtsschutz/default) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/rechtsschutz/default)[FR](https://fr.comparis.ch/rechtsschutz/default)[IT](https://it.comparis.ch/rechtsschutz/default)[EN](https://en.comparis.ch/rechtsschutz/default) + + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. [Versicherungen](https://www.comparis.ch/versicherung "Versicherungen") +3. Rechtsschutz + +Rechtsschutz: Versicherungen vergleichen in der Schweiz +======================================================= + +Vergleichen Sie bei Comparis verschiedene Schweizer Rechtsschutzversicherungen. Finden Sie online den passenden Anbieter. + +Versicherungsart + +Versicherungsart Kombi-Rechtsschutz (Privat und Verkehr) + +Prämien vergleichen + +[So funktioniert’s](https://www.comparis.ch/rechtsschutz/default#content-4) + +Vorteile des Rechtsschutz-Versicherungsvergleichs auf Comparis +-------------------------------------------------------------- + + + +Verschiedene Anbieter + +Profitieren Sie von einem umfassenden Rechtsschutz-Versicherungsvergleich. + + + +Hohes Sparpotenzial + +Verschaffen Sie sich einen Überblick über die aktuellsten Prämien und sparen Sie bares Geld. + + + +Online-Offerte + +Mit wenigen Klicks finden Sie die passenden Offerten – unverbindlich. + + + +Verschiedene Anbieter + +Profitieren Sie von einem umfassenden Rechtsschutz-Versicherungsvergleich. + + + +Hohes Sparpotenzial + +Verschaffen Sie sich einen Überblick über die aktuellsten Prämien und sparen Sie bares Geld. + + + +Online-Offerte + +Mit wenigen Klicks finden Sie die passenden Offerten – unverbindlich. + +Wichtiges über die Rechtsschutzversicherung +------------------------------------------- + +[ ### Deckungen und Leistungen Erfahren Sie, was eine Rechtsschutzversicherung deckt und welche Leistungen Ihnen zustehen.](https://www.comparis.ch/rechtsschutz/deckung-leistung) + +[ ### Privatrechtsschutz Verschaffen Sie sich einen Überblick: Wichtiges über die Privatrechtsschutz-Versicherung.](https://www.comparis.ch/rechtsschutz/privatrechtsschutz) + +[ ### Verkehrsrechtsschutz In welchen Fällen hilft der Verkehrsrechtsschutz und für wen ist die Versicherung sinnvoll?](https://www.comparis.ch/rechtsschutz/verkehrsrechtsschutz) + +In 4 Schritten zur Rechtsschutz-Versicherung +-------------------------------------------- + + + +### Versicherung wählen + +Im 1. Schritt haben Sie die Wahl zwischen folgenden Versicherungen: + +* Privatrechtsschutz + +* Verkehrsrechtsschutz + +* Privat- und Verkehrsrechtsschutz in einer Police + +Weiter entscheiden Sie, ob Sie die Prämien einer **Einzel-** oder **Mehrpersonenversicherung** vergleichen möchten. Zu guter Letzt benötigen die Versicherungen zur Berechnung der individuellen Prämie Ihr Geburtsjahr. + + + +### Prämien vergleichen + +In Ihrer persönlichen Resultatliste zeigen wir Ihnen alle Angebote mit passender Deckung. + + + +### Kostenlose Offerte bestellen + +Treffen Sie Ihre Auswahl und bestellen Sie mit einem Klick Ihre Offerten. Diese erhalten Sie unverbindlich per E-Mail und können so in Ruhe vergleichen. + + + +### So funktioniert der Comparis-Rechtsschutz-Versicherungsvergleich + +Dieser Vergleich enthält Produkte von Anbietern, die Offert-/Kontaktanfragen von [Optimatis](https://www.comparis.ch/altersvorsorge/vorsorgesystem/ueber-optimatis) entgegennehmen, und Produkte von Anbietern, die keine Offert-/Kontaktanfragen von Optimatis entgegennehmen. Die Anbieter in diesem Vergleich nutzen die von Comparis angebotene Schnittstelle. Die Rangierung der Suchresultate erfolgt nach objektiv messbaren Kriterien gemäss gewähltem Filter. Von diesem Sachverhalt ausgeschlossene Angebote sind deutlich als «Anzeige» ausgewiesen. + +Hilfreiche Informationen rund um das Thema Rechtsschutz-Versicherung +-------------------------------------------------------------------- + +[### Verkehrsrechtsschutz Braucht es das?](https://www.comparis.ch/rechtsschutz/verkehrsrechtsschutz/verkehrsrechtsschutz-sinnvoll)[### Familienrecht Scheidung oder Erbstreit? Das müssen Sie wissen.](https://www.comparis.ch/rechtsschutz/privatrechtsschutz/scheidung-familienrecht) + +[### Kündigungserinnerung Keinen Kündigungstermin mehr verpassen? Mit der Kündigungserinnerung über MyComparis erhalten Sie rechtzeitig vor Ablauf der Kündigungsfrist eine Erinnerungsmail.](https://account.mycomparis.ch/account/login) + +Häufige Fragen zur Rechtsschutz-Versicherung +-------------------------------------------- + +### Ab wann gilt der Rechtsschutz? + +Generell gilt: Die **Ursache**, d.h. das auslösende Ereignis, darf erst nach dem Vertragsabschluss entstanden sein. + +Zudem behalten sich einige Versicherungen eine Wartefrist von 3 Monaten für bestimmte Rechtsbereiche vor, die in dieser Zeit nicht versichert sind. + +Die**Wartefristen** sind je nach Anbieter verschieden und in den allgemeinen Versicherungsbedingungen geregelt. + +### Wann kann ich meine Rechtsschutz-Versicherung kündigen? + +In den folgenden Fällen können Sie Ihre Rechtsschutz-Versicherung kündigen: + +* **Bei Ablauf der vereinbarten Vertragsdauer** + +Achten Sie dabei auf die Kündigungsfrist, in der Regel muss das Kündigungsschreiben 3 Monate vor Ablauf beim Versicherer eintreffen, ansonsten wird die Police stillschweigend um 1 Jahr verlängert.**Tipp:** Möchten Sie die Kündigungsfrist Ihrer Rechtsschutzversicherung nicht mehr verpassen? Mit der **Kündigungserinnerung von Comparis** erhalten Sie rechtzeitig vor Ablauf der Kündigungsfrist eine Erinnerungsmail. [Loggen Sie sich dazu in MyComparis ein](https://account.mycomparis.ch/account/login)und erstellen Sie die gewünschte Erinnerung. + +* **Im Schadensfall** + +Bei einem gedeckten Schadensfall und innerhalb von 14 Tagen kann nach Kenntnis der letzten Zahlung gekündigt werden. + +* **Wegzug ins Ausland** + +Schweizer Recht findet bei Wegzug ins Ausland keine Anwendung mehr, daher kann gegen Vorlage einer Abmeldebestätigung der Schweizer Wohngemeinde die Versicherung gekündigt werden. + +### Was deckt eine Rechtsschutz-Versicherung? + +Die Rechtsschutz-Versicherung schützt Sie vor finanziellen Risiken infolge Rechtsstreitigkeiten. Allgemein gedeckt sind folgende Kosten: + +* Anwaltshonorare + +* Gutachten + +* Gerichtsgebühren + +* Prozessentschädigung an Gegenpartei + +* Strafkautionen (Vorschuss) + +Die **Privatrechtsschutz-Versicherung** deckt Rechtsstreitigkeiten im Privatrecht, zum Beispiel im Mietrecht, Konsumentenrecht oder Arbeitsrecht. + +Die **Verkehrsrechtsschutz-Versicherung** bietet finanziellen Schutz bei rechtlichen Auseinandersetzungen im Strassenverkehr. So zum Beispiel bei Rechtsfällen nach einem Verkehrsunfall oder Streitigkeiten bei Kauf, Leasing oder einer unsachgemässen Reparatur eines Fahrzeuges. + +**Wichtig:** Die Leistungen der verschiedenen Versicherungen können variieren. Es lohnt sich, verschiedene Angebote zu vergleichen – das günstigste ist nicht immer das beste. + +### Was deckt eine Rechtsschutz-Versicherung nicht? + +In der Deckung grundsätzlich ausgeschlossen sind: + +* Geldstrafen und Bussen + +* Vorsätzlich begangene Taten + +* Eigene Vergehen + +* Ereignisse, die vor Versicherungsbeginn eingetreten sind oder absehbar waren + +Familienrechtliche Streitigkeiten (Unterhalts-, Eheschutz- und Scheidungsverfahren), Erbstreitigkeiten, Bauprozesse, Steuerverfahren und die meisten Strafverfahren sind nicht oder nur im Rahmen einer juristischen Beratung gedeckt. + +### Wie ist die Deckung in den Bereichen Familien-, Scheidungs- und Erbrecht? + +Streitigkeiten im Familien-, Scheidungs- und Erbrecht sind in der Regel nicht versichert. + +Das bedeutet: Die Versicherung übernimmt im Normalfall weder Anwalts- noch Prozesskosten, wenn es sich um eine familiäre Angelegenheit handelt. + +Einige Versicherungen bieten jedoch mit der Rechtsschutzversicherung eine Rechtsberatung bei internen Anwälten für Personen-, Familien- und Erbrecht. Achten Sie darauf, ob das Familienrecht (inkl. Scheidung) in der Rechtsberatung inbegriffen ist. + +Rechtsschutz-Versicherungen im Vergleich +---------------------------------------- + +[](https://www.comparis.ch/rechtsschutz/anbieter/emilia) + +[](https://www.comparis.ch/rechtsschutz/anbieter/cap) + +[](https://www.comparis.ch/rechtsschutz/anbieter/vcs) + +[](https://www.comparis.ch/rechtsschutz/anbieter/baloisedirect) + +[](https://www.comparis.ch/rechtsschutz/anbieter/groupe-mutuel) + +[](https://www.comparis.ch/rechtsschutz/anbieter/k-tipp) + +[](https://www.comparis.ch/rechtsschutz/anbieter/smile-direct) + +[](https://www.comparis.ch/rechtsschutz/anbieter/coop-rechtsschutz) + +[](https://www.comparis.ch/rechtsschutz/anbieter/generali) + +[](https://www.comparis.ch/rechtsschutz/anbieter/elvia) + +[](https://www.comparis.ch/rechtsschutz/anbieter/dextra-rechtsschutz) + +[](https://www.comparis.ch/rechtsschutz/anbieter/axa-arag) + +[](https://www.comparis.ch/rechtsschutz/anbieter/justis%20rechtsschutz) + +[](https://www.comparis.ch/rechtsschutz/anbieter/css) + +[](https://www.comparis.ch/rechtsschutz/anbieter/helsana) + +[](https://www.comparis.ch/rechtsschutz/anbieter/protekta) + +[](https://www.comparis.ch/rechtsschutz/anbieter/visana) + +[](https://www.comparis.ch/rechtsschutz/anbieter/assista-tcs) + +Alle anzeigen + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_013_www.homegate.ch_c_de_hypothekenintlinkh_MortgagesServices.txt b/test_web_content_20251002_215219/additional_link_013_www.homegate.ch_c_de_hypothekenintlinkh_MortgagesServices.txt new file mode 100644 index 00000000..71bc9e73 --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_013_www.homegate.ch_c_de_hypothekenintlinkh_MortgagesServices.txt @@ -0,0 +1,255 @@ +URL: https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages "Services" +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Alles rund um Hypotheken und Eigenheimfinanzierung | Homegate.ch + +=============== + +[https://www.homegate.ch](https://www.homegate.ch/) + +* [Suchen](https://www.homegate.ch/c/de/suchen) +* [Services](https://www.homegate.ch/c/de/hypotheken) +* [Schätzen](https://www.homegate.ch/c/de/schaetzen) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Inserieren Ab CHF 0](https://www.homegate.ch/c/de/inserieren) + + DE +* [DE](https://www.homegate.ch/c/de/hypotheken) +* [FR](https://www.homegate.ch/c/fr/hypotheques) +* [IT](https://www.homegate.ch/c/it/ipoteche) +* [EN](https://www.homegate.ch/c/en/mortgages) + +[](https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages%20%22Services%22#) + +[https://www.homegate.ch](https://www.homegate.ch/) + +* [Suchen](https://www.homegate.ch/c/de/suchen) +* [Services](https://www.homegate.ch/c/de/hypotheken) +* [Schätzen](https://www.homegate.ch/c/de/schaetzen) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Inserieren Ab CHF 0](https://www.homegate.ch/c/de/inserieren) + +* [DE](https://www.homegate.ch/c/de/hypotheken) +* [FR](https://www.homegate.ch/c/fr/hypotheques) +* [IT](https://www.homegate.ch/c/it/ipoteche) +* [EN](https://www.homegate.ch/c/en/mortgages) + + + + + +Eigenheim finanzieren und versichern +==================================== + +Jederzeit persönlich für dich da +-------------------------------- + +Eigenheim finanzieren und versichern +------------------------------------ + +[Jetzt loslegen](https://www.homegate.ch/de/finanzieren/hypotheken-beratung?source=CMS_content) + +Finanzierungsangebote +--------------------- + +Träumst auch du von deinen eigenen vier Wänden? Oder hast du deine Wunschimmobilie vielleicht bereits im Blick und bist noch auf der Suche nach der passenden Finanzierung? An welchem Punkt du auch gerade stehst: Mit unseren Angeboten, Tipps und Tools rund ums Finanzieren von Wohneigentum bist du optimal gerüstet, um deine nächste Entscheidung zu treffen. + +[](https://www.homegate.ch/c/de/hypotheken/hypothek-verlaengern) + +#### Hypothek verlängern + +Suchst du nach einer passenden Hypothek für die anstehende Verlängerung? Wir helfen dir, die Hypothek zu finden, die am besten zu dir passt. + +[Mehr erfahren](https://www.homegate.ch/c/de/hypotheken/hypothek-verlaengern) + +[](https://www.homegate.ch/de/finanzieren/hypotheken-beratung?source=CMS_content) + +#### Hypothekarberatung + +Hier kannst du dich kostenlos und unverbindlich zu sämtlichen Möglichkeiten für die Finanzierung deiner Immobilie beraten lassen. + +[Mehr erfahren](https://www.homegate.ch/de/finanzieren/hypotheken-beratung?source=CMS_content) + +[](https://www.homegate.ch/c/de/ueber-uns/newsletter-anmeldung) + +#### Newsletter abonnieren + +Mit unserem kostenlosen Newsletter erhältst du regelmässig Infos und Tipps rund um die Themen Immobilien, Finanzieren und Versichern. + +[Mehr erfahren](https://www.homegate.ch/c/de/ueber-uns/newsletter-anmeldung) + +Versicherungsangebote +--------------------- + +Es ist sehr wichtig, ab und an die eigene Versicherungssituation zu überprüfen: Entdecke die Angebote unserer Partnerin Mobiliar und lass dich unverbindlich beraten. + +[](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/versicherungen/hausrat) + +#### Hausratversicherung + +Werden deine Möbel, Elektrogeräte oder Kleidung zum Beispiel bei einem Brand zerstört, bist du mit einer Hausratversicherung vor den finanziellen Schäden geschützt. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/versicherungen/hausrat) + +[](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/versicherungen/rechtsschutz) + +#### Rechtsschutzversicherung + +Wenn ein Streit mit den Nachbarn, der Baubehörde oder der Steuerverwaltung eskaliert, erhältst du dank einer Rechtsschutzversicherung anwaltschaftlichen Beistand. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/versicherungen/rechtsschutz) + +[](https://www.homegate.ch/c/de/lp/versicherungsberatung) + +#### Versicherungsberatung + +Wann hast du zum letzten Mal deine Versicherungs- und Vorsorgesituation überprüfen lassen? Vereinbare jetzt eine kostenlose Beratung mit unserer Partnerin Mobiliar. + +[Mehr erfahren](https://www.homegate.ch/c/de/lp/versicherungsberatung) + +Tools und Services +------------------ + +[](https://www.homegate.ch/de/finanzieren/hypothekenrechner) + +#### Hypothekenrechner + +Unser kostenloser Hypothekenrechner ermöglicht es dir, diverse Finanzierungsszenarien durchzuspielen und du siehst sofort, was für dich möglich ist. + +[Mehr erfahren](https://www.homegate.ch/de/finanzieren/hypothekenrechner) + +[](https://www.homegate.ch/c/de/ratgeber/umziehen/umzugstipps/steuerrechner) + +#### Steuerrechner + +Planst du einen Immobilienerwerb in einer anderen Gemeinde? Berechne den Steuerunterschied zwischen deinem jetzigen und dem neuen Wohnort. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/umziehen/umzugstipps/steuerrechner) + +Immobilienbewertung und Immobilienverkauf +----------------------------------------- + +[](https://microsites.ubs.com/price-checker/de/form/init/?provider=homegate&campID=DS-HOMEGATEKOOP-CH-DEU-LINK-HOMEGATE-JOURNEYHOMEGATE-DIRECT-IMMOCHECKLIGHT-HTML-DESKTOP) + +#### Kostenlose Immobilienbewertung + +Hier erhältst du innert weniger Minuten eine kostenlose Ersteinschätzung zum Marktwert deiner Immobilie. + +[Mehr erfahren](https://microsites.ubs.com/price-checker/de/form/init/?provider=homegate&campID=DS-HOMEGATEKOOP-CH-DEU-LINK-HOMEGATE-JOURNEYHOMEGATE-DIRECT-IMMOCHECKLIGHT-HTML-DESKTOP) + +[](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/wohneigentum-schaetzen/online-schaetzung/jetzt-wohneigentum-bewerten) + +#### Professionelle Immobilienbewertung + +Lass deine Immobilie professionell durch unseren Partner IAZI bewerten und profitiere von einem Homegate-Rabatt. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/wohneigentum-schaetzen/online-schaetzung/jetzt-wohneigentum-bewerten) + +[](https://www.xperthome.ch/module/a-zustands-analyse-bau-und-sanierungskosten) + +#### Zustandsanalyse deiner Immobilie + +Bei unserem Partner XpertHome erhältst eine professionelle Zustandsanalyse inklusive Sanierungsplan für deine Immobilie. + +[Mehr erfahren](https://www.xperthome.ch/module/a-zustands-analyse-bau-und-sanierungskosten) + +Weitere Informationen rund ums Finanzieren +------------------------------------------ + +[](https://www.homegate.ch/c/de/hypotheken/hypothekarmodelle) + +#### Hypothekarmodelle + +Die verschiedenen Hypothekarmodelle unterscheiden sich in der Höhe und Fixierung des Zinssatzes und in der Laufzeit. Daraus ergeben sich Vor- und Nachteile. + +[Mehr erfahren](https://www.homegate.ch/c/de/hypotheken/hypothekarmodelle) + +[](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/hypothek/eigenheimbudget) + +#### Eigenkapital und Tragbarkeit + +Wir verraten dir die wichtigsten Informationen zur Eigenheimfinanzierung und zeigen dir, wie du richtig budgetierst, bevor du eine Immobilie kaufst. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/hypothek/eigenheimbudget) + +[](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/steuern/immobilie-steuererklaerung-fehler) + +#### Mit Immobilien Steuern sparen + +Hier erfährst du, wie du deine Immobilie korrekt versteuerst und welche Ausgaben du in Abzug bringen kannst, um Steuern zu sparen. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/steuern/immobilie-steuererklaerung-fehler) + +### Newsletter abonnieren + +Möchtest du regelmässig über Immobilien- und Finanzierungsthemen informiert werden? Mit unserem kostenlosen Newsletter bleibst du stets auf dem Laufenden und erhältst wertvolle Tipps und Tricks. + +[Jetzt abonnieren](https://www.homegate.ch/c/de/ueber-uns/newsletter) + +### Homegate + +* [Über uns](https://swissmarketplace.group/de/portfolio/real-estate/) +* [Kontakt & Hilfe](https://www.homegate.ch/c/de/ueber-uns/kontakt) +* [Geschäftskunde werden](https://swissmarketplace.group/real-estate/de/kunde-werden/) +* [Newsletter abonnieren](https://www.homegate.ch/c/de/ueber-uns/newsletter-anmeldung) +* [Medien](https://swissmarketplace.group/de/media/) +* [Karriere](https://swissmarketplace.group/de/karriere) +* [Ombudsstelle](https://konsum.ch/de/ombudsstelle-immobilienplattformen/) +* [Sitemap](https://www.homegate.ch/c/de/ueber-uns/sitemap) + +### Immobilien + +* [Inserieren](https://www.homegate.ch/c/de/inserieren) +* [Mieten](https://www.homegate.ch/mieten/immobilie-suchen) +* [Kaufen](https://www.homegate.ch/kaufen/immobilie-suchen) +* [Vermieten](https://www.homegate.ch/c/de/inserieren/immobilien/wohnung/vermieten) +* [Verkaufen](https://www.homegate.ch/c/de/ratgeber/inserieren/immobilien-verkaufen) +* [Finanzieren](https://www.homegate.ch/c/de/hypotheken) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Kategorien](https://www.homegate.ch/kategorien-de) + +### Rechtliches + +* [Datenschutz](https://privacy.swissmarketplace.group/de/) +* [Leistungsbeschrieb](https://www.homegate.ch/c/de/ueber-uns/rechtliches/leistungsbeschrieb) +* [Sicherheitstipps](https://www.homegate.ch/c/de/ratgeber/news/vorsicht-betrug-mit-gefaelschten-inseraten) +* [Impressum](https://www.homegate.ch/c/de/ueber-uns/rechtliches) +* [AGB](https://www.homegate.ch/c/de/ueber-uns/rechtliches/agb) +* [Sicherheitsproblem melden](https://swissmarketplace.group/de/vulnerability-disclosure-program) + +### Services + +* [Suchabo anlegen](https://www.homegate.ch/c/de/ratgeber/mieten/wohnung-finden/suchabo) +* [Finanzierungsrechner](https://www.homegate.ch/de/finanzieren/hypothekenrechner) +* [Steuerrechner](https://www.homegate.ch/c/de/ratgeber/umziehen/umzugstipps/steuerrechner) +* [Betreibungsauszug](https://www.homegate.ch/de/betreibungsauszug) +* [Gemeinderatgeber](https://www.homegate.ch/c/de/ratgeber/umziehen/gemeinderatgeber) +* [Mietkaution](https://www.homegate.ch/c/de/ratgeber/umziehen/mietzinskaution) +* [Umzugshilfe](https://www.homegate.ch/de/umziehen/movu) +* [Wohneigentum schätzen](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/wohneigentum-schaetzen/online-schaetzung/jetzt-wohneigentum-bewerten) + +### App herunterladen + +* [](https://apps.apple.com/de/app/homegate-ch/id326131004) + +* Deutsch +* [Français](https://www.homegate.ch/c/fr/hypotheques) +* [Italiano](https://www.homegate.ch/c/it/ipoteche) +* [English](https://www.homegate.ch/c/en/mortgages) + +### Social Media + +* [](https://www.facebook.com/homegate.ch "https://www.facebook.com/homegate.ch") +* [](https://www.youtube.com/user/homegate "https://www.youtube.com/user/homegate") +* [](https://ch.linkedin.com/company/smg-real-estate "https://ch.linkedin.com/company/smg-real-estate") +* [](https://twitter.com/homegate_Deu "https://twitter.com/homegate_Deu") + +* [**SMG Swiss Marketplace Group**](https://swissmarketplace.group/) +* [ImmoScout24](https://www.immoscout24.ch/de) +* [Alle Immobilien](https://www.alle-immobilien.ch/) +* [home.ch](https://www.home.ch/) +* [immostreet.ch](https://www.immostreet.ch/) + +© Copyright 2025 by SMG Swiss Marketplace Group AG. Alle Rechte vorbehalten. \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_014_www.homegate.ch_c_de_ratgeberintlinkh_AdvisorRatgeber.txt b/test_web_content_20251002_215219/additional_link_014_www.homegate.ch_c_de_ratgeberintlinkh_AdvisorRatgeber.txt new file mode 100644 index 00000000..3efc997f --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_014_www.homegate.ch_c_de_ratgeberintlinkh_AdvisorRatgeber.txt @@ -0,0 +1,215 @@ +URL: https://www.homegate.ch/c/de/ratgeber?intlink=h_Advisor "Ratgeber" +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Ratgeber | Homegate.ch + +=============== + +[https://www.homegate.ch](https://www.homegate.ch/) + +* [Suchen](https://www.homegate.ch/c/de/suchen) +* [Services](https://www.homegate.ch/c/de/hypotheken) +* [Schätzen](https://www.homegate.ch/c/de/schaetzen) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Inserieren Ab CHF 0](https://www.homegate.ch/c/de/inserieren) + + DE +* [DE](https://www.homegate.ch/c/de/ratgeber) +* [FR](https://www.homegate.ch/c/fr/guide) +* [IT](https://www.homegate.ch/c/it/guida) +* [EN](https://www.homegate.ch/c/en/advisor) + +[](https://www.homegate.ch/c/de/ratgeber?intlink=h_Advisor%20%22Ratgeber%22#) + +[https://www.homegate.ch](https://www.homegate.ch/) + +* [Suchen](https://www.homegate.ch/c/de/suchen) +* [Services](https://www.homegate.ch/c/de/hypotheken) +* [Schätzen](https://www.homegate.ch/c/de/schaetzen) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Inserieren Ab CHF 0](https://www.homegate.ch/c/de/inserieren) + +* [DE](https://www.homegate.ch/c/de/ratgeber) +* [FR](https://www.homegate.ch/c/fr/guide) +* [IT](https://www.homegate.ch/c/it/guida) +* [EN](https://www.homegate.ch/c/en/advisor) + +* Ratgeber + +Ratgeber +======== + +[](https://www.homegate.ch/c/de/ratgeber/meistgelesene-artikel) + +#### Meistgelesene Artikel + +Was unsere Nutzerinnen und Nutzer zurzeit am meisten interessiert: Dies sind die beliebtesten Beiträge in unserem Ratgeber. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/meistgelesene-artikel) + +[](https://www.homegate.ch/c/de/ratgeber/news) + +#### News + +Hier findest du spannende Neuigkeiten von Homegate. Bleibe immer auf dem Laufenden über neue Produkte und erfahre, was hinter den Kulissen passiert. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/news) + +[](https://www.homegate.ch/c/de/ratgeber/mieten) + +#### Mieten + +Lebst du in einer Mietwohnung? Hier findest du alle wichtigen Informationen rund ums Thema Mieten. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/mieten) + +[](https://www.homegate.ch/c/de/ratgeber/kaufen) + +#### Kaufen + +Alles rund ums Thema Immobilien kaufen. Erfahre, worauf du beim Kauf eines Hauses oder einer Wohnung achten solltest. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/kaufen) + +[](https://www.homegate.ch/c/de/ratgeber/umziehen) + +#### Umziehen + +Der Umzug in eine neue Wohnung kann sich als Herausforderung heraustellen. Mit unseren Tipps zum Thema Umziehen gelingt dir das Zügeln einwandfrei. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/umziehen) + +[](https://www.homegate.ch/c/de/ratgeber/bauen-und-renovieren) + +#### Bauen und Renovieren + +Hier erfährst du alles über das Bauen und Renovieren deines Wohneigentums. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/bauen-und-renovieren) + +[](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern) + +#### Finanzieren und Versichern + +So finanzierst du das Traumhaus: Hier erfährst du alles über die Finanzierung deiner Immobilie, Hypotheken und Versicherungen. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern) + +[](https://www.homegate.ch/c/de/ratgeber/verkaufen) + +#### Verkaufen + +Bevor du deine Immobilie verkaufen kannst, müssen verschiedene Vorbereitungen getroffen werden. Wir zeigen dir, worauf es ankommt. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/verkaufen) + +[](https://www.homegate.ch/c/de/ratgeber/wohnen-und-einrichten) + +#### Wohnen und Einrichten + +Hier findest du alles rund ums Wohnen und Einrichten. Wir zeigen dir, welche Trends gerade aktuell sind und wie du dein Zuhause verschönern kannst. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/wohnen-und-einrichten) + +[](https://www.homegate.ch/c/de/ratgeber/inserieren) + +#### Inserieren + +Du suchst einen Mieter oder Käufer für deine Immobilie? Hier findest du wertvolle Tipps und Tricks zum erfolgreichen Inserieren. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/inserieren) + +[](https://www.homegate.ch/c/de/ratgeber/nachhaltigkeit) + +#### Nachhaltigkeit + +Möchtest du nachhaltiger wohnen? Wir verraten dir, wie du dabei am besten vorgehst. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/nachhaltigkeit) + +[](https://www.homegate.ch/c/de/ratgeber/funktionen) + +#### Homegate-Funktionen + +Hier findest du detaillierte Anleitungen und Erklärungen zu den verschiedenen Features auf Homegate. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/funktionen) + +### Homegate + +* [Über uns](https://swissmarketplace.group/de/portfolio/real-estate/) +* [Kontakt & Hilfe](https://www.homegate.ch/c/de/ueber-uns/kontakt) +* [Geschäftskunde werden](https://swissmarketplace.group/real-estate/de/kunde-werden/) +* [Newsletter abonnieren](https://www.homegate.ch/c/de/ueber-uns/newsletter-anmeldung) +* [Medien](https://swissmarketplace.group/de/media/) +* [Karriere](https://swissmarketplace.group/de/karriere) +* [Ombudsstelle](https://konsum.ch/de/ombudsstelle-immobilienplattformen/) +* [Sitemap](https://www.homegate.ch/c/de/ueber-uns/sitemap) + +### Immobilien + +* [Inserieren](https://www.homegate.ch/c/de/inserieren) +* [Mieten](https://www.homegate.ch/mieten/immobilie-suchen) +* [Kaufen](https://www.homegate.ch/kaufen/immobilie-suchen) +* [Vermieten](https://www.homegate.ch/c/de/inserieren/immobilien/wohnung/vermieten) +* [Verkaufen](https://www.homegate.ch/c/de/ratgeber/inserieren/immobilien-verkaufen) +* [Finanzieren](https://www.homegate.ch/c/de/hypotheken) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Kategorien](https://www.homegate.ch/kategorien-de) + +### Rechtliches + +* [Datenschutz](https://privacy.swissmarketplace.group/de/) +* [Leistungsbeschrieb](https://www.homegate.ch/c/de/ueber-uns/rechtliches/leistungsbeschrieb) +* [Sicherheitstipps](https://www.homegate.ch/c/de/ratgeber/news/vorsicht-betrug-mit-gefaelschten-inseraten) +* [Impressum](https://www.homegate.ch/c/de/ueber-uns/rechtliches) +* [AGB](https://www.homegate.ch/c/de/ueber-uns/rechtliches/agb) +* [Sicherheitsproblem melden](https://swissmarketplace.group/de/vulnerability-disclosure-program) + +### Services + +* [Suchabo anlegen](https://www.homegate.ch/c/de/ratgeber/mieten/wohnung-finden/suchabo) +* [Finanzierungsrechner](https://www.homegate.ch/de/finanzieren/hypothekenrechner) +* [Steuerrechner](https://www.homegate.ch/c/de/ratgeber/umziehen/umzugstipps/steuerrechner) +* [Betreibungsauszug](https://www.homegate.ch/de/betreibungsauszug) +* [Gemeinderatgeber](https://www.homegate.ch/c/de/ratgeber/umziehen/gemeinderatgeber) +* [Mietkaution](https://www.homegate.ch/c/de/ratgeber/umziehen/mietzinskaution) +* [Umzugshilfe](https://www.homegate.ch/de/umziehen/movu) +* [Wohneigentum schätzen](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/wohneigentum-schaetzen/online-schaetzung/jetzt-wohneigentum-bewerten) + +### App herunterladen + +* [](https://apps.apple.com/de/app/homegate-ch/id326131004) + +* Deutsch +* [Français](https://www.homegate.ch/c/fr/guide) +* [Italiano](https://www.homegate.ch/c/it/guida) +* [English](https://www.homegate.ch/c/en/advisor) + +### Social Media + +* [](https://www.facebook.com/homegate.ch "https://www.facebook.com/homegate.ch") +* [](https://www.youtube.com/user/homegate "https://www.youtube.com/user/homegate") +* [](https://ch.linkedin.com/company/smg-real-estate "https://ch.linkedin.com/company/smg-real-estate") +* [](https://twitter.com/homegate_Deu "https://twitter.com/homegate_Deu") + +* [**SMG Swiss Marketplace Group**](https://swissmarketplace.group/) +* [ImmoScout24](https://www.immoscout24.ch/de) +* [Alle Immobilien](https://www.alle-immobilien.ch/) +* [home.ch](https://www.home.ch/) +* [immostreet.ch](https://www.immostreet.ch/) + +© Copyright 2025 by SMG Swiss Marketplace Group AG. Alle Rechte vorbehalten. + +We Care About Your Privacy +-------------------------- + +We and our 459 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below, including your right to object where legitimate interest is used, or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data. + +### We and our partners process data to provide: + +Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. List of Partners (vendors) + +I Accept No consent Show Purposes \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_015_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferlisteep2.txt b/test_web_content_20251002_215219/additional_link_015_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferlisteep2.txt new file mode 100644 index 00000000..f971769c --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_015_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferlisteep2.txt @@ -0,0 +1,214 @@ +URL: https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=2 +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Seite 2 - Bauland kaufen in Kanton Zürich | homegate.ch + +=============== + +[](https://www.homegate.ch/de) +* [Suchen](https://www.homegate.ch/de "Suchen") +* [Services](https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages "Services") + +[Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen "Inserieren") + +[Favoriten](https://www.homegate.ch/favoriten "Favoriten") + +[Mein Konto](https://www.homegate.ch/de/overview "Mein Konto") + +Menü + +[](https://www.homegate.ch/de) +* [Suchen](https://www.homegate.ch/de "Suchen") +* [Services](https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages "Services") +* [Schätzen](https://www.homegate.ch/de/immobilienbewertung "Schätzen") +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber?intlink=h_Advisor "Ratgeber") + +[Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen "Inserieren") + +[Favoriten](https://www.homegate.ch/favoriten "Favoriten") + +[Mein Konto](https://www.homegate.ch/de/overview "Mein Konto") + +DE +* [DE](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=2) +* [FR](https://www.homegate.ch/acheter/terrain/canton-zurich/liste-annonces?ep=2) +* [IT](https://www.homegate.ch/acquistare/terreno/cantone-zurigo/lista-annunci?ep=2) +* [EN](https://www.homegate.ch/buy/plot/canton-zurich/matching-list?ep=2) + +Ort + + Kanton Zürich + + Kanton Zürich + + Preis bis + + + + Weitere Filter + + 73 Treffer + +73 Treffer - Bauland kaufen in Kanton Zürich +============================================ + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 10 CHF 2’150’000.– Trottenrain 14, 8474 Dinhard Bewilligtes Bauprojekt im steuergünstigen Dinhard-Welsikon Das Bauland mit Magazingebäude befindet sich an zentraler Lage in Welsikon am Rande der Gemeinde Dinhard in der Kernzone. Die erreichte hohe Ausnutzung ermöglicht attraktive Neubauten an zentraler Lage. Visualisierungen und Grundrisse des bewilligten Bauprojekts finden Sie in der Dokumentation. Das Magazingebäude steht im kommunalen Inventar der schutzwürdigen Bauten. Es wurde deshalb in Absprache mit dem Heimatschutz und der Gemeinde Dinhard ein Schutzvertrag erarbeitet, der einen aussergewöhnlichen Umbau zu einem modernen Loft gestattet.Highlights: • bewilligtes Bauprojekt und Ausschreibungsplanung der Neubauten • Schutzvertrag • ausgezeichnete Lage in Welsikon • Steueroase (Gemeindesteuerfuss 83 %) • gut geschnittene Baulandparzelle • Gute ÖV-Anbindung (Bahnhof 170 m) Realisierung:Der Hauseigentümerverband Winterthur unterstützt Sie bei Bedarf gerne in enger Zusammenarbeit mit Kästle Architekten bei der Realisierung Ihres Neubauprojekts.Von der Planung bis hin zum Verkauf/Vermietung des fertigen Neubaus ? der Hauseigentümerverband Winterthur bietet Ihnen alle Dienstleistungen aus einer Hand. Es besteht keine Architekturverpflichtung.Interessenten sind herzlich eingeladen, mit uns Kontakt aufzunehmen.Rufen Sie unser Verkaufsteam über Telefon 052 209 01 68 an, wenn Sie zusätzliche Informationen oder eine Besichtigung wünschen. Wir freuen uns auf Sie.Ihr HEV-VerkaufsteamWichtig: Wir sind exklusiv mit dem Verkauf beauftragt. Direkte Eigentümerkontakte führen zu einem Interessentenausschluss. S.E.&.O.  Wegzeit Neu 5 min.Station: Dinhard](https://www.homegate.ch/kaufen/4002188905) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    Preis auf Anfrage Kaffeestrasse, 8180 Bülach Ihr Industriebau direkt in Bülach BeschreibungGerne entwickeln und realisieren wir ein auf ihre Bedürfnisse massgeschneidertes Projekt, welches Ihnen zur Miete oder im Eigentum zur Verfügung stehen wird.Interesse oder Fragen? Nehmen Sie Kontakt mit uns auf!Die Parzelle ist nicht das Richtige für Ihre Anforderungen? Kein Problem! Besuchen Sie unsere Homepage und finden Sie weitere Angebote unter: gewerbeland-schweiz.ch  Wegzeit Neu 20 min.Station: Bülach](https://www.homegate.ch/kaufen/4001788654) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    Preis auf Anfrage Kaffeestrasse, 8180 Bülach Ihr Industriebau direkt in Bülach BeschreibungGerne entwickeln und realisieren wir ein auf ihre Bedürfnisse massgeschneidertes Projekt, welches Ihnen zur Miete oder im Eigentum zur Verfügung stehen wird.Interesse oder Fragen? Nehmen Sie Kontakt mit uns auf!Die Parzelle ist nicht das Richtige für Ihre Anforderungen? Kein Problem! Besuchen Sie unsere Homepage und finden Sie weitere Angebote unter: gewerbeland-schweiz.ch  Wegzeit Neu 20 min.Station: Bülach](https://www.homegate.ch/kaufen/4001788644) + +[*  *  *  *  *  *  *  *  *  *  *  *  1 / 8    Preis auf Anfrage 8605 Gutenswil OPPORTUNITÄT IM GLATTTAL: 6'093 m² WOHNBAULAND In Gutenswil (Gemeinde Volketswil) verkaufen wir im Zentrum eine attraktive Baulandparzelle mit 6'093 m². Die Projektstudie (ab Seite 6) zeigt das grosse Potenzial der Parzelle auf. In der Maximalvariante ist ein ansprechender Mix mit verschiedener Haus- und Wohnungstypen für einen Neubau von vier Gebäuden mit einer Hauptnutzfläche von insgesamt 3'357 m² vorgesehen. • Heutige Bebauung: Ein Bauernhaus und ein zusätzliches Ökonomiegebäude • Aufteilung Bauzonen:3'965 m² in der Kernzone 1, 2'128 m² in der Kernzone 2 • Ortsbildschutzgebiet - besondere architektonische Rücksichtnahme erforderlich • Je zwei Vollgeschosse+ zwei Dachgeschosse möglich • Total realisierbare Hauptnutzfläche gemäss Studie von 3'357 m² Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: https://www.propertyowner.ch/de/immobilien/25-12302 Referenznummer: 25-12302Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website https://www.propertyowner.ch/immobilien/ und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen!  Wegzeit -](https://www.homegate.ch/kaufen/4002533580) + +Dein Immobilienexperte vor Ort +------------------------------ + +[ Stöhr Immobilien GmbH berät dich persönlich zur optimalen Verkaufsstrategie für deine Immobilie.](https://homegate.ch/anbieter/n023/stohr-immobilien-gmb-h) + +[*  *  *  *  *  *  *  *  *  1 / 5    CHF 1’700’000.– Lägernstrasse 8, 8153 Rümlang Attraktives Grundstück mit Altliegenschaft - Ideal für Ihr Bauprojekt Inmitten der beliebten Zürcher Gemeinde Rümlang befindet sich dieses vielseitige Baugrundstück mit bestehender Altliegenschaft. Die ruhige Lage kombiniert mit einer ausgezeichneten Infrastruktur sowie der Nähe zur Stadt Zürich und zum Flughafen macht das Objekt besonders attraktiv. Dank der optimalen Anbindung an den öffentlichen Verkehr, vielfältigen Einkaufsmöglichkeiten, Schulen und Naherholungsgebieten ist dieser Standort sowohl für Familien als auch für Investoren interessant.Die aussichtsreiche Parzelle umfasst 736 m² in der Bauzone W 1.2 und bietet ein hervorragendes Entwicklungspotenzial. Das erschlossene Bauland eignet sich sowohl für den Neubau eines modernen Einfamilienhauses als auch für die Realisierung von zwei Doppelhäusern oder eines kleinen Bauprojekts.Die bestehende Liegenschaft eröffnet zusätzliche Möglichkeiten, sei es durch eine umfassende Sanierung oder als Ausgangspunkt für einen individuellen Neubau ganz nach Ihren Vorstellungen. Dieses Angebot ist eine seltene Gelegenheit in Rümlang und lädt dazu ein, eigene Wohnträume oder ein spannendes Bauprojekt zu verwirklichen.Kontaktieren Sie uns bei Interesse für weitere Informationen. Wir freuen uns auf Ihren Anruf.  Wegzeit Neu 8 min.Station: Rümlang](https://www.homegate.ch/kaufen/4002530739) + +[*  *  *  *  *  *  *  *  *  1 / 5    CHF 995’000.– Sonnenbühlstrasse 12, 8181 Höri Weitblick an der Landwirtschaftszone Im Auftrag unseres Kunden verkaufen wir eine Baulandparzelle mit 696 m² Grundstücksfläche in der Wohnzone E2. Ein Projekt wurde bereits gepfüt und bewilligt. Verkaufsrichtpreis: CHF 995'000.--Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot.  Wegzeit Neu 32 min.Station: Niederglatt](https://www.homegate.ch/kaufen/4002529781) + +[ 1 / 1 CHF 2’065’000.– **240m²** Nutzfläche 8105 Regensdorf Zentrale Liegenschaft mit Potenzial in Regensdorf Attraktives Entwicklungsgrundstück mit eingereichtem Baugesuch in Regensdorf Im Zentrum von Regensdorf bietet sich eine seltene Gelegenheit: Zum Verkauf steht ein Grundstück mit bestehender Liegenschaft, welche stark sanierungs- bzw. entwicklungsbedürftig ist. Der grosse Vorteil: Für dieses Areal liegt bereits ein konkretes Neubauprojekt vor - mit Baugesuch, das bei der Gemeinde eingereicht ist.Geplant ist der Ersatzneubau eines Mehrfamilienhauses mit neun Wohneinheiten. Das Projekt umfasst einen attraktiven Wohnungsmix von 2.5 bis 4.5 Zimmer-Wohnungen, darunter auch zwei grosszügige Maisonette-Wohnungen. Die Gesamtwohnfläche beläuft sich auf ca. 658 m² und deckt damit ein breites Spektrum an Wohnbedürfnissen ab.Die Grundrisse sind hell, modern und auf heutige Ansprüche zugeschnitten. Balkone, Terrassen und offene Wohn-/Essbereiche schaffen hohen Wohnkomfort. Eine Tiefgarage mit Autolift, Veloraum und Kellerabteilen rundet das Projekt ab und garantiert eine optimale Nutzung.Damit eignet sich dieses Objekt sowohl für Investoren, die ein Projekt mit hohem Wertsteigerungspotenzial suchen, als auch für Bauträger, die direkt in die Realisierung einsteigen möchten.Folgende Highlights bietet Ihnen diese Liegenschaft: • Eingereichtes Baugesuch für einen Ersatzneubau mit 9 Wohnungen • Wohnungsmix von 2.5 bis 4.5 Zimmer inkl. Maisonettes • Gesamtwohnfläche: ca. 658 m² • Tiefgarage mit Autolift, Veloraum und Kellerabteilen • Sehr sonnige, zentrale Lage im Zentrum von Regensdorf • Kurze Distanzen nach Zürich-City und zum Flughafen Kloten • Attraktives Investitionsobjekt mit nachhaltigem Wertsteigerungspotenzial Ergreifen Sie diese seltene Gelegenheit und lassen Sie sich bei einer persönlichen Besichtigung von der Einzigartigkeit und dem Potenzial dieser aussergewöhnlichen Liegenschaft in Regensdorf überzeugen.  Wegzeit -](https://www.homegate.ch/kaufen/4002528704) + +[ 1 / 1 Preis auf Anfrage 8910 Affoltern am Albis Flexibles Bauland in W4 ? vom Eigenheim bis zum Mehrfamilienhaus Am Ende einer ruhigen Sackgasse gelegen, überzeugt diese Parzelle in der Zone W4 mit vielseitigen Möglichkeiten für Ihr Bauvorhaben. Ob ein modernes Einfamilienhaus mit rund 200 m² Wohnfläche oder ein Mehrfamilienhaus mit drei Vollgeschossen ? hier haben Sie die Wahl. Dank der guten Erschliessung sowie kurzen Wegen zu Schulen, Einkaufsmöglichkeiten und öffentlichem Verkehr eignet sich das Grundstück sowohl für private Bauherren als auch für Investoren. Eine seltene Gelegenheit, sich in einem gefragten Wohnquartier zu verwirklichen.Auf einen Blick:+ W4-ZONENPLANUNG: Ausnutzungsziffer 74 %+ EINFAMILIENHAUS: ca. 200 m² Wohnfläche + Dach/Attika möglich+ MEHRFAMILIENHAUS: mit 3 Vollgeschossen realisierbar+ GRUNDSTÜCKSFLÄCHE: 250?400 m² (flexibel wählbar)+ ATTRAKTIVE LAGE: Ruhige 30er-Zone, mit schneller Anbindung nach Zürich, Zug und Luzern+ INFRASTRUKTUR: Einkauf, Schulen, Freizeitangebot in unmittelbarer NäheBei Interesse senden wir Ihnen gerne einen ausführlichen Objektbeschrieb inklusive sämtlichen Informationen und freuen uns, Sie persönlich an einem Besichtigungstermin beraten zu dürfen.WENET AG Immobilien der KI Group AG since 1974.  Wegzeit -](https://www.homegate.ch/kaufen/4002527536) + +[*  *  *  *  *  *  *  *  1 / 4    CHF 1’600’000.– Grundbuch Blatt 50514, Kataster 720, Breiten, 8459 Volken Hervorragende Gelegenheit an idyllischer Lage Das Bauland in Volken bietet eine hervorragende Gelegenheit für die Errichtung eines individuellen Wohnprojekts. Die Kombination aus idyllischer Lage, einer wohltuenden und unverbaubaren Sicht ins Grüne, hervorragender Infrastruktur und vielfältigen Freizeitmöglichkeiten macht dieses Grundstück zu einer aussergewöhnlichen Investition in eine Lebensqualität der Extraklasse. Die Käufer geniessen im Rahmen der Bau- und Zonenordnung freie Gestaltungswahl, ob für den Bau von Doppeleinfamilienhäusern, Einfamilienhäusern oder anderen Projekten. Haben wir Ihre Neugier geweckt? Wir freuen uns auf Ihre Kontaktaufnahme!  Wegzeit -](https://www.homegate.ch/kaufen/4002526342) + +[ 1 / 1 CHF 3’750’000.– 8953 Dietikon Wo jeder Quadratzentimeter nach Ihnen ruft Dieses attraktive Grundstück mit einer stattlichen Grösse von 1'094 m² bietet erhebliches Potenzial für eine Neubebauung im wunderschönen Dietikon im Kanton Zürich. Auf dem Grundstück können bis zu zwei Vollgeschosse errichtet werden, was eine bebaubare Bruttogeschossfläche von fast 330 m² ermöglicht.Das erstklassige Angebot ist ideal für weitsichtige Investoren oder Bauherren, die unmittelbar mit der Bauplanung beginnen möchten. Welch aussergewöhnliche Investitionsmöglichkeit! Auf einen Blick:+ NEUBAUMÖGLICHKEIT: 1 grosszügiges EFH sowie ein MFH mit zwei Vollgeschossen + BRUTTOGESCHOSSFLÄCHE: 330 m2 sind zulässig+ BAUZONE: W2 mit einer Ausnützungsziffer von 0,30+ PRIVATSPHÄRE: Villenquartier, uneingeschränkte Rückzugsoase in allen Belangen + ZUSTAND: ausbaufähiges, bestehendes Einfamilienhaus (1967) mit 6.5 Zimmern+ LAGE: ruhige Quartierstrasse, leichte Hanglage, ganztägige Besonnung, Panorama Fernsicht + RENDITEOBJEKT: spannende und interessante Anlage Bei Interesse senden wir Ihnen gerne einen ausführlichen Objektbeschrieb inklusive sämtlichen Informationen und freuen uns, Sie persönlich an einem Besichtigungstermin beraten zu dürfen. WENET AG ? Immobilien der KI Group AG since 1974.  Wegzeit -](https://www.homegate.ch/kaufen/4002349481) + +[ 1 / 1 * Ruhige Lage CHF 1’700’000.– 8910 Affoltern am Albis Attraktive Entwicklungsparzelle mit Machbarkeitsstudie - 7 EH möglich Share Deal - Entwickeln Sie Ihr nächstes Erfolgsprojekt! Diese attraktive Parzelle in Affoltern am Albis bietet eine einmalige Investitionsmöglichkeit. Der Altbestand auf dem Grundstück muss abgerissen werden, um Platz für ein zukunftsorientiertes Neubauprojekt zu schaffen. Die bereits vorliegende Machbarkeitsstudie und die vollständige Erschliessung des Grundstücks erleichtern den Entwicklungsprozess und bieten ein grosses Potenzial.Folgende Highlights bietet Ihnen diese Immobilie: • Machbarkeitsstudie für 7 EH vorhanden • Zentrale Lage in Affoltern am Albis • Grundstücksfläche ca: 702 m² • Zone: W3 / Kernzone • Gute Verkehrsanbindung an die ÖV • Hervorragende Infrastruktur (Einkaufsmöglichkeiten, Schulen, Freizeit) • Geringes Risiko durch Machbarkeitsstudie und klare Projektplanung • Netto-Geschossfläche (NGF): ca. 400 m² • Voll erschlossen • Ruhige und grüne Umgebung • Nähe zu städtischen Zentren (Zürcher Oberland) • Hohe Lebensqualität • 30er Zone • Dealstruktur: Share - Deal (Firma exkl.) • Wert der zugehörigen Firma: Ca. CHF 500'000 zzgl. Lassen Sie sich diese einmalige Gelegenheit nicht entgehen und melden Sie sich heute noch für weitere Informationen! * Ruhige Lage  Wegzeit -](https://www.homegate.ch/kaufen/4002105351) + +[ 1 / 1 CHF 1’070’000.– Auf Anfrage 1, 8340 Hinwil Hier beginnt Ihre Zukunft Dieses attraktive Grundstück befindet sich an ruhiger und familienfreundlicher Lage in Hinwil. Mit einer Gesamtfläche von über 1’070 m² bietet es vielfältige Nutzungsmöglichkeiten und eignet sich hervorragend für die Realisierung mehrerer Reihenfamilienhäuser. Dank der Möglichkeit zur Abparzellierung kann auch nur ein Teil des Landes – beispielsweise ideal für ein Einfamilienhaus – erworben werden. Das Grundstück liegt in der Kernzone und eröffnet dadurch grossen Gestaltungsspielraum für individuelle Bauprojekte.Dieses ImmoSky Angebot bietet folgende *MEHR LEISTUNG*:+ Kernzone+ 2 Vollgeschosse, 1 Dachgeschoss+ 4m Grenzabstand+ 7.5m FassadenhöheDas Grundstück ist baureif und erschlossen, die Quartierplankosten von CHF 150.00/m² werden zum Verkaufspreis dazugerechnet.Aktuell befinden sich alte Holzschuppen auf dem Grundstück. Diese können abgerissen werden, um Platz für neue Ideen zu schaffen. Eine seltene Gelegenheit, Wohnen mit hoher Lebensqualität im Zürcher Oberland zu verwirklichen. Gerne stehe ich Ihnen bei Fragen zur Verfügung – Ihr Daniel Arigoni.(Das Verkaufsdossier wird in der Regel innert maximal 24 Stunden an Sie versendet, bitte prüfen Sie auch Ihren SPAM-Ordner.)  Wegzeit -](https://www.homegate.ch/kaufen/4002554241) + +[*  *  *  *  *  *  *  *  1 / 4    CHF 3’300’000.– Sonnenhalde, 8602 Wangen-Brüttisetten Exklusives Bauland: letzte Chance in Toplage Dieses seltene Angebot bietet Ihnen die Möglichkeit, sich ein exklusives Stück Land in einer der begehrtesten Lagen von Wangen-Brüttisellen zu sichern.- Unbebautes Grundstück in erhöhter Lage- 1666 m², Wohnzone 2 (30%)- Viel Sonne, Ruhe und Privatsphäre- Maximal realisierbare Wohnfläche: ca. 600 m² (gemäss Machbarkeitsstudie)Die ideale Ausrichtung und die leicht erhöhte Position garantieren eine optimale Besonnung und ein Wohnerlebnis auf höchstem Niveau. Ob exklusive Einfamilienhäuser oder repräsentative Villa - hier können Sie Ihre Wohnträume verwirklichen.Die detaillierte Machbarkeitsstudie stellen wir Ihnen auf Wunsch gerne zur Verfügung.Hier geht's zum Teaser Video: https://show.tours/v/CGdKtCx  Wegzeit -](https://www.homegate.ch/kaufen/4002543522) + +[*  *  *  *  *  *  *  *  1 / 4 CHF 750’000.– Sonnhalde 8, 8421 Dättlikon Grundstück 563 m2, sonnige Lage, einmalige Aussicht! Wir bieten an sonniger und ruhiger Lage ein einmaliges Grundstück (563m2) mit einer unverbaubaren Weitsicht an!Details entnehmen Sie der Verkaufsdokumentation im Anhang.Wegen seiner Hanglage ist eine ideale Besonnung sowie eine unverbaubare Aussicht garantiert.Gerne zeigen wir Ihnen dieses Wohnbauland an bester Lage oder Sie fahren mal vorbei und geniessen den Moment!Lassen Sie sich diese Gelegenheit nicht entgehen. Nehmen Sie Kontakt mit uns auf.Zögern Sie nicht, wir freuen uns auf Ihren Anruf  Wegzeit Neu 36 min.Station: Pfungen](https://www.homegate.ch/kaufen/4002470802) + +[*  *  *  *  *  *  *  *  *  1 / 5    CHF 1’300’000.– Leisibüel, 8484 Weisslingen Attraktives Grundstück an ruhiger und sonniger Lage Verwirklichen Sie Ihren Wohntraum im Zürcher OberlandIm exklusiven und begehrten Quartier Leisibüel in der Gemeinde Weisslingen steht eine der letzten unbebauten Baulandparzellen zum Verkauf. Diese seltene Gelegenheit bietet Ihnen die Möglichkeit, Ihr individuelles Einfamilien- oder Doppeleinfamilienhaus in einer Quartiererhaltungszone zu realisieren.Grundstücksdaten: • Lage: Quartier Leisibüel, Weisslingen ZH • Zone: Quartiererhaltungszone Leisibüel • Bebaubarkeit: Einfamilienhaus oder Doppeleinfamilienhaus • Ausrichtung: Südwest, mit optimaler Besonnung • Topografie: Hanglage mit herrlicher Aussicht Besondere Merkmale: • Ruhige, sonnige und erhöhte Lage mit viel Privatsphäre • Unverbaubare Fernsicht in die umliegende Natur und Berge • Umgeben von gepflegter Nachbarschaft mit hochwertigen Liegenschaften • Ideale Voraussetzungen für naturnahes und zugleich stilvolles Wohnen  Wegzeit -](https://www.homegate.ch/kaufen/4002403830) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 1’900’000.– Im Königstal 2, 8487 Zell Wegzeit Neu 22 min.Station: Rämismühle-Zell](https://www.homegate.ch/kaufen/4002279293) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 3’000’000.– Im Königstal 3, 8487 Zell ZH Wegzeit Neu 22 min.Station: Rämismühle-Zell](https://www.homegate.ch/kaufen/4002279266) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 4’900’000.– Im Königstal 3, 8487 Zell ZH Wegzeit Neu 22 min.Station: Rämismühle-Zell](https://www.homegate.ch/kaufen/4002279259) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  1 / 9    CHF 1’590’000.– 8912 Obfelden Attraktives Baugrundstück am Hang in Obfelden! Attraktives Baugrundstück mit Weitblick in Obfelden!In der Gemeinde Obfelden bietet sich Ihnen eine exklusive Möglichkeit: Ein 925 m² grosses Grundstück in bevorzugter Lage wartet auf eine neue Vision. Ob als grosszügiges Einfamilienhaus, als Doppelhaus oder als modernes Mehrfamilienprojekt mit bis zu vier Wohneinheiten - die Parzelle eröffnet vielfältige Gestaltungsmöglichkeiten für private oder gewerbliche Bauherren.Eckdaten zum Grundstück: • mit bestehendem, nicht bewohntem Gebäude • Grundstücksfläche: 925 m², Bauzone W2E • Zulässige Grundfläche Hauptbau: ca. 195 m² • Maximal erlaubte Geschosszahl: 4 • Realisierbare Hauptnutzfläche: über 550 m² • Baureife: Umfangreiche Vorabklärungen und Unterlagen bereits vorhanden Highlights: • Südlich ausgerichtete Hanglage mit freiem Blick in die Ferne • Ruhige Wohnsituation dank bevorstehender Verkehrsberuhigung der Dorfstrasse • Optimale Infrastruktur: Schule, Kindergarten und öffentliche Verkehrsmittel nur wenige Schritte entfernt • Hervorragende Anbindung: Nur 2 Fahrminuten zur Autobahn (Affoltern am Albis) • Vielversprechendes Potenzial für Investoren, Projektentwickler oder anspruchsvolle Eigenheimbauer Dieses Grundstück kombiniert Lagequalität mit Entwicklungspotenzial - eine seltene Gelegenheit in einem aufstrebenden Wohnumfeld. Nutzen Sie die Chance, hier ein zukunftsorientiertes Projekt zu realisieren.Für weitere Informationen oder zur Vereinbarung eines Besichtigungstermins stehen wir Ihnen gerne persönlich zur Verfügung.Zögern Sie nicht, uns zu kontaktieren - wir freuen uns auf Ihre Anfrage.  Wegzeit -](https://www.homegate.ch/kaufen/4002115081) + +[*  *  *  *  *  *  *  *  1 / 4 CHF 1’169’200.– Bergstrasse 56, 8424 Embrach attraktive Baulandparzelle für grosszügiges Einfamilienhaus Die angebotene Baulandparzelle befindet sich an einer begehrten und privilegierten Wohnlage am Rande des Einfamilienhausquartiers „Im Haller“ in Embrach. Diese idyllische Umgebung bietet eine harmonische Kombination aus naturnaher Erholung und einer hervorragenden Anbindungen an den Flughafen Kloten sowie an die nahegelegenen Städte Zürich und Winterthur.Zum Verkauf steht noch eine attraktives Grundstück:Baulandparzelle „54“ (im Situationsplan rot gekennzeichnet):Diese Parzelle umfasst 614m² (zzgl. 1/3 Miteigentum an Erschliessung 126 m²) und eignet sich perfekt für die Realisierung eines grosszügigen freistehenden Einfamilienhauses.Baulandparzelle „60“ ist bereits verkauft.Die Baulandparzelle „56“ ist bereits verkauft.Diese Grundstücke bieten die seltene Gelegenheit, Ihre Wohnträume an einer der schönsten Adressen in Embrach zu verwirklichen.ArchitekturDie Grundeigentümerin hat das ganze Areal dem Architekturbüro RWPA GmbH, Lagerplatz 6, 8400 Winterthur, für eine Projektentwicklung zur Verfügung gestellt. Die Bauparzellen werden mit Architekturverpflichtung zu Gunsten der RWPA GmbH, Lagerplatz 6, 8400 Winterthur, veräussert. Die Architekten stehen Interessenten für eine Projektstudie jederzeit gerne zur Verfügung.BesichtigungenGerne laden wir Sie zu einer Besichtigung vor Ort ein.VerkaufspreisDer Verkaufspreis beträgt CHF 1'169'200.00, wobei das Objekt voraussichtlich an den Meistbietenden veräussert wird. Ein allfälliges Kaufangebot möchten Sie uns bitte schriftlich (per Mail oder per Post) zukommen lassen.Wir freuen uns auf Ihre Kontaktaufnahme. Gerne stellen wir Ihnen die Verkaufsdokumentation zur Verfügung.  Wegzeit Neu 38 min.Station: Embrach-Rorbas](https://www.homegate.ch/kaufen/4001792418) + +[](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste)[1](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste)[2](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=2)[3](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=3)[4](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=4)[](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=3) + +Suche speichern Karte + +Vorschläge basierend auf deinen Suchresultaten +---------------------------------------------- + +* [ CHF 2’500’000.– 8442 Hettlingen](https://www.homegate.ch/kaufen/4002438548) +* [ Preis auf Anfrage 8424 Embrach](https://www.homegate.ch/kaufen/4002492324) +* [ CHF 2’980’000.– Klosterstrasse 29, 8962 Bergdietikon](https://www.homegate.ch/kaufen/4002485540) +* [ CHF 3’600’000.– 8330 Pfäffikon ZH](https://www.homegate.ch/kaufen/4002531588) +* [ Preis auf Anfrage Industriestrasse 34, 8117 Fällanden](https://www.homegate.ch/kaufen/4002549837) +* [ CHF 3’440’000.– Weiacherstrasse 85, 8427 Rorbas](https://www.homegate.ch/kaufen/4002277619) +* [ CHF 85’000.– Klosterrebenstrasse 41 / 43 / 45, 8918 Unterlunkhofen](https://www.homegate.ch/kaufen/3000765189) +* [ CHF 4’900’000.– **2’595m²** Wohnfläche 8506 Herdern](https://www.homegate.ch/kaufen/4002529753) +* [ CHF 1’750’000.– In der Gass 2, 8627 Grüningen](https://www.homegate.ch/kaufen/3003479026) +* [ Preis auf Anfrage Nüsatzstrasse, 8463 Benken ZH](https://www.homegate.ch/kaufen/4002355750) +* [ CHF 510’000.– 8194 Hüntwangen](https://www.homegate.ch/kaufen/4002469116) +* [ Preis auf Anfrage Auf Anfrage 1, 8505 Pfyn](https://www.homegate.ch/kaufen/4002546900) +* [ Preis auf Anfrage 8570 Weinfelden](https://www.homegate.ch/kaufen/4002486406) +* [ CHF 1’870’000.– **5.5** Zimmer **173m²** Wohnfläche Luegetenstrasse 11, 8489 Wildberg](https://www.homegate.ch/kaufen/4002491909) +* [ CHF 2’200’000.– Götzen, 8197 Rafz](https://www.homegate.ch/kaufen/4002297853) +* [ CHF 1’900’000.– Wehntalerstrasse 28, 8181 Höri](https://www.homegate.ch/kaufen/4002530816) +* [ CHF 5’400’000.– Feldstrasse 2, 8805 Richterswil](https://www.homegate.ch/kaufen/4002526347) +* [ Preis auf Anfrage 8157 Dielsdorf](https://www.homegate.ch/kaufen/4001788652) +* [ Preis auf Anfrage 8618 Oetwil am See](https://www.homegate.ch/kaufen/4002510045) +* [ CHF 1’310’000.– Steig, 8535 Herdern](https://www.homegate.ch/kaufen/4002230356) + +1. [Startseite](https://www.homegate.ch/de) +2. [Kaufen](https://www.homegate.ch/kaufen/immobilie-suchen) +3. [Bauland zum Kaufen](https://www.homegate.ch/kaufen/bauland/trefferliste) +4. [Schweiz](https://www.homegate.ch/kaufen/bauland/land-schweiz/trefferliste) + +Bezirke im Kanton Kanton Zürich + +[Bauland kaufen Bezirk Affoltern](https://www.homegate.ch/kaufen/bauland/region-affoltern/trefferliste)|[Bauland kaufen Bezirk Andelfingen](https://www.homegate.ch/kaufen/bauland/region-andelfingen/trefferliste)|[Bauland kaufen Bezirk Bülach](https://www.homegate.ch/kaufen/bauland/region-buelach/trefferliste)|[Bauland kaufen Bezirk Dielsdorf](https://www.homegate.ch/kaufen/bauland/region-dielsdorf/trefferliste)|[Bauland kaufen Bezirk Hinwil](https://www.homegate.ch/kaufen/bauland/region-hinwil/trefferliste)|[Bauland kaufen Bezirk Horgen](https://www.homegate.ch/kaufen/bauland/region-horgen/trefferliste)|[Bauland kaufen Bezirk Meilen](https://www.homegate.ch/kaufen/bauland/region-meilen/trefferliste)|[Bauland kaufen Bezirk Pfäffikon](https://www.homegate.ch/kaufen/bauland/region-pfaeffikon/trefferliste)|[Bauland kaufen Bezirk Uster](https://www.homegate.ch/kaufen/bauland/region-uster/trefferliste)|[Bauland kaufen Bezirk Winterthur](https://www.homegate.ch/kaufen/bauland/region-winterthur/trefferliste)|[Bauland kaufen Bezirk Dietikon](https://www.homegate.ch/kaufen/bauland/region-dietikon/trefferliste)|[Bauland kaufen Zürich](https://www.homegate.ch/kaufen/bauland/ort-zuerich/trefferliste) + +Weitere Immobiliensuchen in Kanton Zürich + +[Immobilien mieten Kanton Zürich](https://www.homegate.ch/mieten/immobilien/kanton-zuerich/trefferliste)|[Wohnung mieten Kanton Zürich](https://www.homegate.ch/mieten/wohnung/kanton-zuerich/trefferliste)|[Haus mieten Kanton Zürich](https://www.homegate.ch/mieten/haus/kanton-zuerich/trefferliste)|[Möbliertes Wohnobjekt mieten Kanton Zürich](https://www.homegate.ch/mieten/moebliertes-wohnobjekt/kanton-zuerich/trefferliste)|[Parkplatz, Garage mieten Kanton Zürich](https://www.homegate.ch/mieten/parkplatz-garage/kanton-zuerich/trefferliste)|[Büro mieten Kanton Zürich](https://www.homegate.ch/mieten/buero/kanton-zuerich/trefferliste)|[Gewerbe mieten Kanton Zürich](https://www.homegate.ch/mieten/gewerbeobjekt/kanton-zuerich/trefferliste)|[Neubau zum Mieten Kanton Zürich](https://www.homegate.ch/mieten/immobilien/kanton-zuerich/trefferliste?an=G)|[Wohnung kaufen Kanton Zürich](https://www.homegate.ch/kaufen/wohnung/kanton-zuerich/trefferliste)|[Haus kaufen Kanton Zürich](https://www.homegate.ch/kaufen/haus/kanton-zuerich/trefferliste)|[Immobilien kaufen Kanton Zürich](https://www.homegate.ch/kaufen/immobilien/kanton-zuerich/trefferliste)|[Mehrfamilienhaus kaufen Kanton Zürich](https://www.homegate.ch/kaufen/mehrfamilienhaus/kanton-zuerich/trefferliste)|[Parkplatz, Garage kaufen Kanton Zürich](https://www.homegate.ch/kaufen/parkplatz-garage/kanton-zuerich/trefferliste)|[Gewerbe, Büro, Lager kaufen Kanton Zürich](https://www.homegate.ch/kaufen/gewerbeobjekt/kanton-zuerich/trefferliste)|[Neubau zum Kaufen Kanton Zürich](https://www.homegate.ch/kaufen/immobilien/kanton-zuerich/trefferliste?an=G) + +### Homegate + +* [Über uns](https://swissmarketplace.group/de/portfolio/real-estate/) +* [Kontakt & Hilfe](https://www.homegate.ch/c/de/ueber-uns/kontakt) +* [Geschäftskunde werden](https://swissmarketplace.group/real-estate/de/kunde-werden/) +* [Newsletter abonnieren](https://www.homegate.ch/c/de/ueber-uns/newsletter-anmeldung) +* [Medien](https://swissmarketplace.group/de/media/) +* [Karriere](https://swissmarketplace.group/de/karriere/) +* [Ombudsstelle](https://konsum.ch/de/ombudsstelle-immobilienplattformen/) +* [Werbung auf Homegate](https://swissmarketplace.group/de/werbung/) +* [Sitemap](https://www.homegate.ch/c/de/ueber-uns/sitemap) + +### Immobilien + +* [Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen) +* [Mieten](https://www.homegate.ch/mieten/immobilie-suchen) +* [Kaufen](https://www.homegate.ch/kaufen/immobilie-suchen) +* [Vermieten](https://www.homegate.ch/c/de/inserieren/immobilien/wohnung/vermieten) +* [Verkaufen](https://www.homegate.ch/c/de/ratgeber/inserieren/immobilien-verkaufen) +* [Finanzieren](https://www.homegate.ch/c/de/hypotheken) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Kategorien](https://www.homegate.ch/kategorien-de) + +### Rechtliches + +* [Datenschutz](https://privacy.swissmarketplace.group/de/) +* [Leistungsbeschrieb](https://www.homegate.ch/c/de/ueber-uns/rechtliches/leistungsbeschrieb) +* [Sicherheitstipps](https://www.homegate.ch/c/de/ratgeber/news/vorsicht-betrug-mit-gefaelschten-inseraten) +* [Impressum](https://www.homegate.ch/c/de/ueber-uns/rechtliches) +* [AGB](https://www.homegate.ch/c/de/ueber-uns/rechtliches/agb) +* [Sicherheitsproblem melden](https://swissmarketplace.group/de/vulnerability-disclosure-program) +* Privatsphäre-Einstellungen + +### Services + +* [Suchabo anlegen](https://www.homegate.ch/c/de/ratgeber/mieten/wohnung-finden/suchabo) +* [Finanzierungsrechner](https://www.homegate.ch/de/finanzieren/hypothekenrechner) +* [Steuerrechner](https://www.homegate.ch/c/de/ratgeber/umziehen/umzugstipps/steuerrechner) +* [Betreibungsauszug](https://www.homegate.ch/de/betreibungsauszug) +* [Gemeinderatgeber](https://www.homegate.ch/c/de/ratgeber/umziehen/gemeinderatgeber) +* [Mietkaution](https://www.homegate.ch/c/de/ratgeber/umziehen/mietzinskaution) +* [Umzugshilfe](https://www.homegate.ch/c/de/umziehen) +* [Wohneigentum schätzen](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/wohneigentum-schaetzen/online-schaetzung/jetzt-wohneigentum-bewerten) +* [Agenturverzeichnis](https://www.homegate.ch/agenturverzeichnis) + +### App herunterladen + +[](https://itunes.apple.com/de/app/homegate.ch/id326131004 "iOS App")[](https://play.google.com/store/apps/details?id=ch.homegate.mobile&hl=de "Android App") + +* [Deutsch](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=2) +* [Français](https://www.homegate.ch/acheter/terrain/canton-zurich/liste-annonces?ep=2) +* [Italiano](https://www.homegate.ch/acquistare/terreno/cantone-zurigo/lista-annunci?ep=2) +* [English](https://www.homegate.ch/buy/plot/canton-zurich/matching-list?ep=2) + +### Social Media + +[](https://www.facebook.com/homegate.ch "Facebook")[](https://www.youtube.com/user/homegateeng "YouTube")[](https://ch.linkedin.com/company/homegate-ch-ag "LinkedIn")[](https://twitter.com/homegate_Deu "Twitter") + +[SMG Swiss Marketplace Group](https://swissmarketplace.group/)[ImmoScout24](https://www.immoscout24.ch/de)[Alle Immobilien](https://www.alle-immobilien.ch/)[home.ch](https://www.home.ch/)[immostreet.ch](https://www.immostreet.ch/) + +© Copyright 2025 by SMG Swiss Marketplace Group AG. Alle Rechte vorbehalten.Die Vervielfältigung und Übernahme von Inseraten durch Dritte, insbesondere von Fotos und persönlichen Daten in diesen Inseraten, verletzt die damit verbundenen Rechte und ist ausdrücklich verboten. + +We Care About Your Privacy +-------------------------- + +We and our 459 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below, including your right to object where legitimate interest is used, or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data. + +### We and our partners process data to provide: + +Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. List of Partners (vendors) + +I Accept No consent Show Purposes \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_016_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferlisteep4.txt b/test_web_content_20251002_215219/additional_link_016_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferlisteep4.txt new file mode 100644 index 00000000..ddc3b21e --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_016_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferlisteep4.txt @@ -0,0 +1,200 @@ +URL: https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=4 +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Seite 4 - Bauland kaufen in Kanton Zürich | homegate.ch + +=============== + +[](https://www.homegate.ch/de) +* [Suchen](https://www.homegate.ch/de "Suchen") +* [Services](https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages "Services") + +[Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen "Inserieren") + +[Favoriten](https://www.homegate.ch/favoriten "Favoriten") + +[Mein Konto](https://www.homegate.ch/de/overview "Mein Konto") + +Menü + +[](https://www.homegate.ch/de) +* [Suchen](https://www.homegate.ch/de "Suchen") +* [Services](https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages "Services") +* [Schätzen](https://www.homegate.ch/de/immobilienbewertung "Schätzen") +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber?intlink=h_Advisor "Ratgeber") + +[Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen "Inserieren") + +[Favoriten](https://www.homegate.ch/favoriten "Favoriten") + +[Mein Konto](https://www.homegate.ch/de/overview "Mein Konto") + +DE +* [DE](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=4) +* [FR](https://www.homegate.ch/acheter/terrain/canton-zurich/liste-annonces?ep=4) +* [IT](https://www.homegate.ch/acquistare/terreno/cantone-zurigo/lista-annunci?ep=4) +* [EN](https://www.homegate.ch/buy/plot/canton-zurich/matching-list?ep=4) + +Ort + + Kanton Zürich + + Kanton Zürich + + Preis bis + + + + Weitere Filter + + 73 Treffer + +73 Treffer - Bauland kaufen in Kanton Zürich +============================================ + +[*  *  *  *  *  *  *  1 / 3 CHF 3’564’590.– 8820 Wädenswil Verwirklichen Sie hier Ihren Wohntraum Das Grundstück liegt leicht erhöht an einer Sackgasse, eingebettet in einem ruhigen, familienfreundlichen Wohnquartier in Wädenswil, der beliebten Kleinstadt mit Charme. Eine Bushaltestelle befindet sich in kurzer Gehdistanz. Kindergarten, Schule, Einkauf und der See sind von hier bequem zu Fuss erreichbar. Die attraktive Baulandparzelle umfasst eine Fläche von 607 m2und befindet sich in der Wohnzone 2/30, was gemäss Bau-und Zonenordnung der Stadt Wädenswil eine Ausnutzungsziffer von 30% und somit eine mögliche Wohnfläche von ca. 182 m2 bedeutet. Damit bietet die Parzelle vielseitige Möglichkeiten grosszügiges Wohnen mit einem schönen und lauschigen Aussenraum zu verbinden.Ein paar der Highlights: • Ruhige, sonnige und familienfreundliche Lage in einer Sackgasse • Schönes Wohnquartier • Möglichkeit für die Verwirklichung Ihres Wohntraums ganz nach Ihren Vorstellungen • Wohnzone 2/30 mit einer Ausnutzungsziffer von 30% • Bushaltestelle in unmittelbarer Nähe (Distanz ca. 140 m) • Einkauf, Kindergarten, Schule und See in Gehdistanz  Wegzeit -](https://www.homegate.ch/kaufen/4002446172) + +[*  *  *  *  *  *  *  *  *  *  *  1 / 7 CHF 3’701’690.– Bergstrasse 7a, 8155 Niederhasli Wegzeit Neu 30 min.Station: Niederhasli](https://www.homegate.ch/kaufen/4002208545) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 10 CHF 1’343’580.– Baumgarten, 8914 Aeugst am Albis Wegzeit Neu 35 min.Station: Affoltern am Albis](https://www.homegate.ch/kaufen/4001969725) + +[*  *  *  *  *  *  *  1 / 3 Preis auf Anfrage **3’880m²** Nutzfläche Industriestrasse 34, 8117 Fällanden Wegzeit Neu 19 min.Station: Schwerzenbach](https://www.homegate.ch/kaufen/4002549837) + +Dein Immobilienexperte vor Ort +------------------------------ + +[ Property One Partners AG berät dich persönlich zur optimalen Verkaufsstrategie für deine Immobilie.](https://homegate.ch/anbieter/h239/property-one-partners-ag) + +[ 1 / 1 CHF 4’935’590.– 8330 Pfäffikon ZH Ihre Chance: Off-Market Grundstück in Pfäffikon ZH an familienfreundlicher Lage Pfäffikon ZH In Pfäffikon ZH wartet ein grosszügiges Grundstück auf neue Besitzer. Es besticht durch seine traumhafte, ruhige und familienfreundliche Lage sowie die Nähe zur Natur - eine seltene Gelegenheit für Investoren oder private Bauherren mit Weitblick.Auf einen Blick: • Erschlossene Grundstücksfläche: ca. 2'000-2'200 m², Wohnzone W1.25 • Traumhafte, ruhige Lage, ideal für Familien • Nähe zur Natur • Bei einem Neubau realisierbare Nettowohnfläche von ca. 900-920 m² • Preis: CHF 3'600'000 Off-Market-Vermarktung, kein BieterverfahrenBei Interesse bitten wir Sie um Kontaktaufnahme. Nach Unterzeichnung einer Vertraulichkeitserklärung (NDA) senden wir Ihnen gerne weiterführende Informationen zu.IMROT vermarktet jährlich 50 bis 100 Off-Market-Grundstücke an bevorzugten Lagen.Suchen Sie Bauland im Kanton Zürich? Wir sind Ihr Ansprechpartner.  Wegzeit -](https://www.homegate.ch/kaufen/4002531588) + +[ 1 / 1 CHF 12’476’100.– 8703 Erlenbach ZH Seltene Gelegenheit: Off-Market Grundstück an Toplage in Erlenbach ZH Erlenbach In Erlenbach ZH steht ein grosszügiges Grundstück zum Verkauf, das Lagequalität, Seesicht und Wertsteigerungspotenzial vereint - eine seltene Gelegenheit für anspruchsvolle Investoren oder private Bauherren.Auf einen Blick: • Erschlossene Grundstücksfläche: ca. 1'100-1'300 m², Wohnzone W2/30 • Ruhige, bevorzugte Lage mit Seesicht • Bestandsimmobilie mit Mietwohnungen und ausbaubaren Mieterträgen • Bei einem Neubau realisierbare Nettowohnfläche von 560-580 m² und einer Bruttorendite von 16-20% • Hanglage vorhanden (Hanggeschosse möglich) • Preis: CHF 9'100'000 • Off-Market-Vermarktung, kein Bieterverfahren Bei Interesse bitten wir Sie um Kontaktaufnahme. Nach Unterzeichnung einer Vertraulichkeitserklärung (NDA) senden wir Ihnen gerne weiterführende Informationen zu.IMROT vermarktet jährlich 50 bis 100 Off-Market-Grundstücke an bevorzugten Lagen.Suchen Sie Bauland im Kanton Zürich? Wir sind Ihr Ansprechpartner.  Wegzeit -](https://www.homegate.ch/kaufen/4002505102) + +[ 1 / 1 CHF 3’153’300.– **240m²** Nutzfläche 8172 Niederglatt 8½-Zimmer-Bauernhaus mit Charme und Potenzial in Niederglatt ALLE FOTOS und weitere Informationen sind auf unserer Homepage REMAX.chzu finden: https://www.remax.ch/de/118641003-168Suchen Sie ein aussergewöhnliches Zuhause mit Charakter, Geschichte und vielseitigen Nutzungsmöglichkeiten? Dieses charmante Bauernhaus im idyllischen Niederglatt bietet all das und noch mehr.Das historische Gebäude wurde im Jahr 1680 erbaut und seither laufend renoviert. Heute präsentiert es sich in einem sehr guten baulichen Zustand und verbindet gekonnt den traditionellen Stil mit zeitgemässem Wohnkomfort.Eckdaten: 8½ Zimmer auf 4 Etagen Ca. 240 m² Wohnfläche Gebäudevolumen: 1500 m³ GVA Grundstücksfläche: 881 m² Bauland Ausgebautes Dachgeschoss mit 3½-Zimmer-Wohnung im 2. Obergeschoss 2 Küchen, 3 Badezimmer Grosses unausgebautes Dachgeschoss mit weiterem Ausbaupotenzial Angebaute Scheune vielseitig ausbaubar nach Ihren Vorstellungen Parkmöglichkeiten direkt vor dem Haus Haus unterliegt Ortsbildschutz Die Liegenschaft liegt in einer ruhigen, familienfreundlichen Umgebung perfekt für alle, die das Landleben geniessen und dennoch nicht auf eine gute Anbindung verzichten möchten. Der charmante Garten und die grosszügigen Aussenflächen laden zum Verweilen und Spielen ein.Das Grundstück befindet sich in der Bauzone und unterliegt lediglich dem sogenannten Ortsbildschutz einem sanften Schutz, der Ihnen viele Freiheiten für bauliche Erweiterungen lässt.Ob Sie sich ein gemütliches Zuhause für die Familie wünschen, ein Generationenprojekt planen oder Wohnen und Arbeiten unter einem Dach kombinieren möchten dieses Bauernhaus bietet zahlreiche Möglichkeiten für Ihre individuellen Wohnträume.Nutzen Sie diese seltene Gelegenheit, Eigentümer eines solch einzigartigen Objekts im Zürcher Unterland zu werden. Lassen Sie sich vom Charme dieser Immobilie verzaubern ein Ort, an dem Geschichte auf Zukunft trifft.-Are you looking for an exceptional home with character, history and versatile utilisation options? This charming farmhouse in idyllic Niederglatt offers all of this - and more.The historic building was built in 1680 and has been continuously renovated since then. Today it is in very good structural condition and skilfully combines traditional style with contemporary living comfort.Key data:- 8½ rooms on 4 floors- Approx. 240 m² living space- Building volume: 1,500 m³ GVA- Plot area: 881 m² building land- Developed attic with 3½-room flat on the 2nd floor- 2 kitchens, 3 bathrooms- Large unfinished attic with further expansion potential- Attached barn - can be converted in many ways according to your ideas- Parking directly in front of the house- The house is subject to conservation ordersThe property is located in a quiet, family-friendly neighbourhood - perfect for anyone who enjoys country life but doesn't want to miss out on good transport links. The charming garden and spacious outdoor areas invite you to linger and play.The property is located in the building zone and is only subject to what is known as townscape protection - a gentle protection that gives you plenty of freedom for structural extensions.Whether you are looking for a cosy home for the family, planning a generational project or want to combine living and working under one roof - this farmhouse offers numerous possibilities for your individual dream home.Take advantage of this rare opportunity to become the owner of such a unique property in the Zurich Unterland. Let yourself be enchanted by the charm of this property - a place where history meets the future.-Vous cherchez une maison exceptionnelle avec du caractère, de l'histoire et de multiples possibilités d'utilisation ? Cette charmante ferme située dans le village idyllique de Niederglatt offre tout cela - et bien plus encore.Le bâtiment historique a été construit en 1680 et a été régulièrement rénové depuis. Aujourd'hui, elle se présente dans un très bon état de construction et allie habilement le style  Wegzeit -](https://www.homegate.ch/kaufen/4002418234) + +[*  *  *  *  *  *  *  *  1 / 4 CHF 27’419’990.– Bergstrasse Kat. Nr. 9259, 9261, 8706 Meilen Wegzeit -](https://www.homegate.ch/kaufen/4001884044) + +[*  *  * 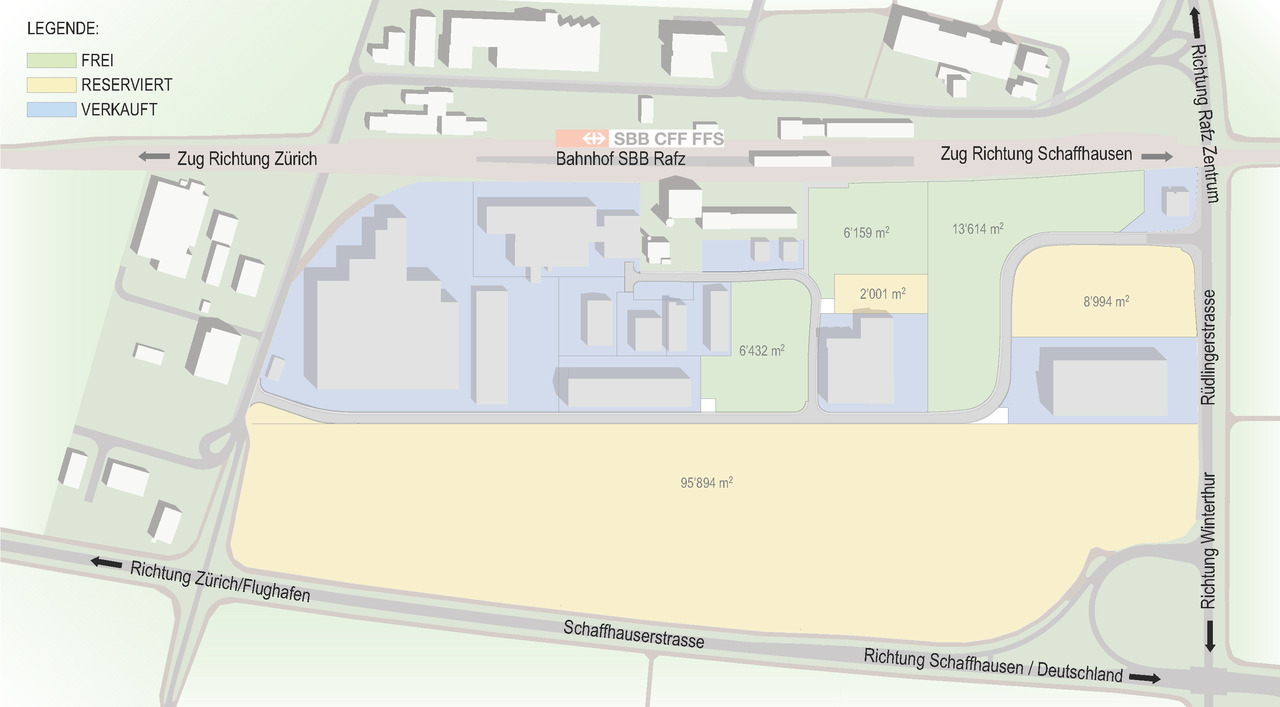 *  *  *  *  *  *  *  *  *  *  *  *  1 / 11 Preis auf Anfrage 8197 Rafz Wegzeit -](https://www.homegate.ch/kaufen/3003046952) + +[*  *  *  *  *  *  *  *  *  *  1 / 6 CHF 2’604’890.– 8468 Waltalingen Wegzeit -](https://www.homegate.ch/kaufen/4002364568) + +[*  *  *  *  *  *  *  *  1 / 4 CHF 3’016’200.– **1’820m²** Nutzfläche Götzen, 8197 Rafz Wegzeit -](https://www.homegate.ch/kaufen/4002297853) + +[*  *  *  *  *  *  *  1 / 3 Preis auf Anfrage 8162 Steinmaur Wegzeit -](https://www.homegate.ch/kaufen/4002558306) + +[ 1 / 1 CHF 3’427’490.– 8442 Hettlingen Wegzeit -](https://www.homegate.ch/kaufen/4002438548) + +[](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=3)[1...](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste)[3](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=3)[4](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=4) + +Suche speichern Karte + +Vorschläge basierend auf deinen Suchresultaten +---------------------------------------------- + +* [ CHF 3’440’000.– Weiacherstrasse 85, 8427 Rorbas](https://www.homegate.ch/kaufen/4002277619) +* [ CHF 1’600’000.– Grundbuch Blatt 50514, Kataster 720, Breiten, 8459 Volken](https://www.homegate.ch/kaufen/4002526342) +* [ CHF 1’750’000.– In der Gass 2, 8627 Grüningen](https://www.homegate.ch/kaufen/3003479026) +* [ CHF 3’300’000.– Sonnenhalde, 8602 Wangen-Brüttisetten](https://www.homegate.ch/kaufen/4002543522) +* [ Preis auf Anfrage 8570 Weinfelden](https://www.homegate.ch/kaufen/4002486406) +* [ CHF 1’550’000.– 8267 Berlingen](https://www.homegate.ch/kaufen/4001272290) +* [ CHF 26’000’000.– 8050 Zürich](https://www.homegate.ch/kaufen/4002553821) +* [ Preis auf Anfrage 8605 Gutenswil](https://www.homegate.ch/kaufen/4002533580) +* [ CHF 1’400’000.– 8187 Weiach](https://www.homegate.ch/kaufen/4001410555) +* [ CHF 8’400’000.– Rütiwiese, 8704 Herrliberg](https://www.homegate.ch/kaufen/4002487028) +* [ CHF 5’400’000.– Feldstrasse 2, 8805 Richterswil](https://www.homegate.ch/kaufen/4002526347) +* [ Preis auf Anfrage 8424 Embrach](https://www.homegate.ch/kaufen/4002492324) +* [ CHF 900’000.– Geissliäcker, 5623 Boswil](https://www.homegate.ch/kaufen/4001984963) +* [ Preis auf Anfrage Schoeckstrasse 2, 9008 St. Gallen](https://www.homegate.ch/kaufen/4002500928) +* [ CHF 4’900’000.– **2’595m²** Wohnfläche 8506 Herdern](https://www.homegate.ch/kaufen/4002529753) +* [ CHF 1’310’000.– Steig, 8535 Herdern](https://www.homegate.ch/kaufen/4002230356) +* [ Preis auf Anfrage Auf Anfrage 1, 8505 Pfyn](https://www.homegate.ch/kaufen/4002546900) +* [ Preis auf Anfrage Büntlistrasse 1, 8174 Stadel](https://www.homegate.ch/kaufen/4000669374) +* [ CHF 1’700’000.– 8910 Affoltern am Albis](https://www.homegate.ch/kaufen/4002105351) +* [ CHF 1’230’000.– 8187 Weiach](https://www.homegate.ch/kaufen/4002404604) + +1. [Startseite](https://www.homegate.ch/de) +2. [Kaufen](https://www.homegate.ch/kaufen/immobilie-suchen) +3. [Bauland zum Kaufen](https://www.homegate.ch/kaufen/bauland/trefferliste) +4. [Schweiz](https://www.homegate.ch/kaufen/bauland/land-schweiz/trefferliste) + +Bezirke im Kanton Kanton Zürich + +[Bauland kaufen Bezirk Affoltern](https://www.homegate.ch/kaufen/bauland/region-affoltern/trefferliste)|[Bauland kaufen Bezirk Andelfingen](https://www.homegate.ch/kaufen/bauland/region-andelfingen/trefferliste)|[Bauland kaufen Bezirk Bülach](https://www.homegate.ch/kaufen/bauland/region-buelach/trefferliste)|[Bauland kaufen Bezirk Dielsdorf](https://www.homegate.ch/kaufen/bauland/region-dielsdorf/trefferliste)|[Bauland kaufen Bezirk Hinwil](https://www.homegate.ch/kaufen/bauland/region-hinwil/trefferliste)|[Bauland kaufen Bezirk Horgen](https://www.homegate.ch/kaufen/bauland/region-horgen/trefferliste)|[Bauland kaufen Bezirk Meilen](https://www.homegate.ch/kaufen/bauland/region-meilen/trefferliste)|[Bauland kaufen Bezirk Pfäffikon](https://www.homegate.ch/kaufen/bauland/region-pfaeffikon/trefferliste)|[Bauland kaufen Bezirk Uster](https://www.homegate.ch/kaufen/bauland/region-uster/trefferliste)|[Bauland kaufen Bezirk Winterthur](https://www.homegate.ch/kaufen/bauland/region-winterthur/trefferliste)|[Bauland kaufen Bezirk Dietikon](https://www.homegate.ch/kaufen/bauland/region-dietikon/trefferliste)|[Bauland kaufen Zürich](https://www.homegate.ch/kaufen/bauland/ort-zuerich/trefferliste) + +Weitere Immobiliensuchen in Kanton Zürich + +[Immobilien mieten Kanton Zürich](https://www.homegate.ch/mieten/immobilien/kanton-zuerich/trefferliste)|[Wohnung mieten Kanton Zürich](https://www.homegate.ch/mieten/wohnung/kanton-zuerich/trefferliste)|[Haus mieten Kanton Zürich](https://www.homegate.ch/mieten/haus/kanton-zuerich/trefferliste)|[Möbliertes Wohnobjekt mieten Kanton Zürich](https://www.homegate.ch/mieten/moebliertes-wohnobjekt/kanton-zuerich/trefferliste)|[Parkplatz, Garage mieten Kanton Zürich](https://www.homegate.ch/mieten/parkplatz-garage/kanton-zuerich/trefferliste)|[Büro mieten Kanton Zürich](https://www.homegate.ch/mieten/buero/kanton-zuerich/trefferliste)|[Gewerbe mieten Kanton Zürich](https://www.homegate.ch/mieten/gewerbeobjekt/kanton-zuerich/trefferliste)|[Neubau zum Mieten Kanton Zürich](https://www.homegate.ch/mieten/immobilien/kanton-zuerich/trefferliste?an=G)|[Wohnung kaufen Kanton Zürich](https://www.homegate.ch/kaufen/wohnung/kanton-zuerich/trefferliste)|[Haus kaufen Kanton Zürich](https://www.homegate.ch/kaufen/haus/kanton-zuerich/trefferliste)|[Immobilien kaufen Kanton Zürich](https://www.homegate.ch/kaufen/immobilien/kanton-zuerich/trefferliste)|[Mehrfamilienhaus kaufen Kanton Zürich](https://www.homegate.ch/kaufen/mehrfamilienhaus/kanton-zuerich/trefferliste)|[Parkplatz, Garage kaufen Kanton Zürich](https://www.homegate.ch/kaufen/parkplatz-garage/kanton-zuerich/trefferliste)|[Gewerbe, Büro, Lager kaufen Kanton Zürich](https://www.homegate.ch/kaufen/gewerbeobjekt/kanton-zuerich/trefferliste)|[Neubau zum Kaufen Kanton Zürich](https://www.homegate.ch/kaufen/immobilien/kanton-zuerich/trefferliste?an=G) + +### Homegate + +* [Über uns](https://swissmarketplace.group/de/portfolio/real-estate/) +* [Kontakt & Hilfe](https://www.homegate.ch/c/de/ueber-uns/kontakt) +* [Geschäftskunde werden](https://swissmarketplace.group/real-estate/de/kunde-werden/) +* [Newsletter abonnieren](https://www.homegate.ch/c/de/ueber-uns/newsletter-anmeldung) +* [Medien](https://swissmarketplace.group/de/media/) +* [Karriere](https://swissmarketplace.group/de/karriere/) +* [Ombudsstelle](https://konsum.ch/de/ombudsstelle-immobilienplattformen/) +* [Werbung auf Homegate](https://swissmarketplace.group/de/werbung/) +* [Sitemap](https://www.homegate.ch/c/de/ueber-uns/sitemap) + +### Immobilien + +* [Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen) +* [Mieten](https://www.homegate.ch/mieten/immobilie-suchen) +* [Kaufen](https://www.homegate.ch/kaufen/immobilie-suchen) +* [Vermieten](https://www.homegate.ch/c/de/inserieren/immobilien/wohnung/vermieten) +* [Verkaufen](https://www.homegate.ch/c/de/ratgeber/inserieren/immobilien-verkaufen) +* [Finanzieren](https://www.homegate.ch/c/de/hypotheken) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Kategorien](https://www.homegate.ch/kategorien-de) + +### Rechtliches + +* [Datenschutz](https://privacy.swissmarketplace.group/de/) +* [Leistungsbeschrieb](https://www.homegate.ch/c/de/ueber-uns/rechtliches/leistungsbeschrieb) +* [Sicherheitstipps](https://www.homegate.ch/c/de/ratgeber/news/vorsicht-betrug-mit-gefaelschten-inseraten) +* [Impressum](https://www.homegate.ch/c/de/ueber-uns/rechtliches) +* [AGB](https://www.homegate.ch/c/de/ueber-uns/rechtliches/agb) +* [Sicherheitsproblem melden](https://swissmarketplace.group/de/vulnerability-disclosure-program) +* Privatsphäre-Einstellungen + +### Services + +* [Suchabo anlegen](https://www.homegate.ch/c/de/ratgeber/mieten/wohnung-finden/suchabo) +* [Finanzierungsrechner](https://www.homegate.ch/de/finanzieren/hypothekenrechner) +* [Steuerrechner](https://www.homegate.ch/c/de/ratgeber/umziehen/umzugstipps/steuerrechner) +* [Betreibungsauszug](https://www.homegate.ch/de/betreibungsauszug) +* [Gemeinderatgeber](https://www.homegate.ch/c/de/ratgeber/umziehen/gemeinderatgeber) +* [Mietkaution](https://www.homegate.ch/c/de/ratgeber/umziehen/mietzinskaution) +* [Umzugshilfe](https://www.homegate.ch/c/de/umziehen) +* [Wohneigentum schätzen](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/wohneigentum-schaetzen/online-schaetzung/jetzt-wohneigentum-bewerten) +* [Agenturverzeichnis](https://www.homegate.ch/agenturverzeichnis) + +### App herunterladen + +[](https://itunes.apple.com/de/app/homegate.ch/id326131004 "iOS App")[](https://play.google.com/store/apps/details?id=ch.homegate.mobile&hl=de "Android App") + +* [Deutsch](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=4) +* [Français](https://www.homegate.ch/acheter/terrain/canton-zurich/liste-annonces?ep=4) +* [Italiano](https://www.homegate.ch/acquistare/terreno/cantone-zurigo/lista-annunci?ep=4) +* [English](https://www.homegate.ch/buy/plot/canton-zurich/matching-list?ep=4) + +### Social Media + +[](https://www.facebook.com/homegate.ch "Facebook")[](https://www.youtube.com/user/homegateeng "YouTube")[](https://ch.linkedin.com/company/homegate-ch-ag "LinkedIn")[](https://twitter.com/homegate_Deu "Twitter") + +[SMG Swiss Marketplace Group](https://swissmarketplace.group/)[ImmoScout24](https://www.immoscout24.ch/de)[Alle Immobilien](https://www.alle-immobilien.ch/)[home.ch](https://www.home.ch/)[immostreet.ch](https://www.immostreet.ch/) + +© Copyright 2025 by SMG Swiss Marketplace Group AG. Alle Rechte vorbehalten.Die Vervielfältigung und Übernahme von Inseraten durch Dritte, insbesondere von Fotos und persönlichen Daten in diesen Inseraten, verletzt die damit verbundenen Rechte und ist ausdrücklich verboten. + +We Care About Your Privacy +-------------------------- + +We and our 459 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below, including your right to object where legitimate interest is used, or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data. + +### We and our partners process data to provide: + +Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. List of Partners (vendors) + +I Accept No consent Show Purposes \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_017_www.homegate.ch_de.txt b/test_web_content_20251002_215219/additional_link_017_www.homegate.ch_de.txt new file mode 100644 index 00000000..18713093 --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_017_www.homegate.ch_de.txt @@ -0,0 +1,165 @@ +URL: https://www.homegate.ch/de +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +# Die cleverste Immobiliensuche der Schweiz + +* [Mieten](javascript:) +* [Kaufen](javascript:) + +Orte, Regionen, PLZ, Land + +[Objekt inserieren](/de/insertion/inserat-online-erfassen)oder[Objekt schätzen](/de/immobilienbewertung) + +#### Gratis Nachmieter finden + +Erstelle ein kostenloses Inserat auf Homegate und finde in kürzester Zeit den perfekten Nachmieter für deine Wohnung. + +[Jetzt inserieren](https://www.homegate.ch/c/de/inserieren/immobilien/nachmieter-suchen?intlink=t2t_intbanner_hp) + +#### MieterPlus: Zugang zu exklusiven Inseraten + +Exklusive Möglichkeit, Inserenten von MieterPlus-Anzeigen zu kontaktieren. + +[Vorteile ansehen](https://www.homegate.ch/de/mieterplus) + +* [Bewerten & Finanzieren](javascript:) +* [Mieten](javascript:) +* [Kaufen](javascript:) + +## Services + +## Deine Immobilie ist bei uns an der richtigen Adresse + +Mit einem Inserat auf Homegate erreichst du ein grosses Publikum und qualifizierte Bewerber. Wähle aus unseren Inseratspaketen und setze dein Angebot perfekt in Szene. + +[Inserat erfassen](/de/insertion/inserat-online-erfassen) + +## Umziehen oder zügeln? + +Egal wie du’s nennst – vergleiche die besten Umzugsunternehmen und halte die Zügel in der Hand. + +CHF935.– + +Wohnortwechsel + +2 Zimmer + +* 1.5 Zimmer +* 2 Zimmer +* 2.5 Zimmer +* 3 Zimmer +* 3.5 Zimmer +* 4 Zimmer +* 4.5 Zimmer +* 5 Zimmer +* 5.5 Zimmer +* 6 Zimmer +* 6+ Zimmer + +10 km Entfernung + +* 10 km Entfernung +* 20 km Entfernung +* 30 km Entfernung +* 40 km Entfernung +* 50 km Entfernung +* 60 km Entfernung +* 70 km Entfernung +* 70+ km Entfernung + +[Offerten anfordern](https://www.homegate.ch/de/umziehen/movu) + +## Mit der Homegate-App bist du vorne dabei + +Schnell gesucht, eingezeichnet, als Suchabo und Favorit gespeichert, bei Treffern umgehend benachrichtigt: Neues Zuhause gefunden mit der Homegate-App. + +## Immobilien zum Mieten + +* [Immobilien mieten](https://www.homegate.ch/mieten/immobilien/trefferliste) +* [Wohnung mieten](https://www.homegate.ch/mieten/wohnung/trefferliste) +* [Haus mieten](https://www.homegate.ch/mieten/haus/trefferliste) +* [Parkplatz, Garage mieten](https://www.homegate.ch/mieten/parkplatz-garage/trefferliste) +* [Möbliertes Wohnobjekt mieten](https://www.homegate.ch/mieten/moebliertes-wohnobjekt/trefferliste) +* [Büro mieten](https://www.homegate.ch/mieten/buero/trefferliste) +* [Gewerbe mieten](https://www.homegate.ch/mieten/gewerbeobjekt/trefferliste) +* [Lager mieten](https://www.homegate.ch/mieten/lager/trefferliste) +* [Neubau mieten](https://www.homegate.ch/mieten/immobilien/trefferliste?an=G) + +## Immobilien zum Kaufen + +* [Immobilien kaufen](https://www.homegate.ch/kaufen/immobilien/trefferliste) +* [Wohnung kaufen](https://www.homegate.ch/kaufen/wohnung/trefferliste) +* [Haus kaufen](https://www.homegate.ch/kaufen/haus/trefferliste) +* [Parkplatz, Garage kaufen](https://www.homegate.ch/kaufen/parkplatz-garage/trefferliste) +* [Bauland kaufen](https://www.homegate.ch/kaufen/bauland/trefferliste) +* [Mehrfamilienhaus kaufen](https://www.homegate.ch/kaufen/mehrfamilienhaus/trefferliste) +* [Wohn- / Geschäftshaus kaufen](https://www.homegate.ch/kaufen/wohn-geschaeftshaus/trefferliste) +* [Gewerbe, Büro, Lager kaufen](https://www.homegate.ch/kaufen/gewerbeobjekt/trefferliste) +* [Neubau kaufen](https://www.homegate.ch/kaufen/immobilien/trefferliste?an=G) + +## Wohnung mieten in + +* [Zürich](https://www.homegate.ch/mieten/wohnung/ort-zuerich/trefferliste "wohnung mieten zürich") +* [Luzern](https://www.homegate.ch/mieten/wohnung/ort-luzern/trefferliste "wohnung mieten luzern") +* [Bern](https://www.homegate.ch/mieten/wohnung/ort-bern/trefferliste "wohnung mieten bern") +* [Winterthur](https://www.homegate.ch/mieten/wohnung/ort-winterthur/trefferliste "wohnung mieten winterthur") +* [St. Gallen](https://www.homegate.ch/mieten/wohnung/ort-st-gallen/trefferliste "wohnung mieten st. gallen") +* [Basel](https://www.homegate.ch/mieten/wohnung/ort-basel/trefferliste "wohnung mieten basel") +* [Chur](https://www.homegate.ch/mieten/wohnung/ort-chur/trefferliste "wohnung mieten chur") +* [Thun](https://www.homegate.ch/mieten/wohnung/ort-thun/trefferliste "wohnung mieten thun") +* [Aargau](https://www.homegate.ch/mieten/wohnung/kanton-aargau/trefferliste "wohnung mieten aargau") +* [Waadt](https://www.homegate.ch/mieten/wohnung/kanton-waadt/trefferliste "wohnung mieten waadt") +* [Graubünden](https://www.homegate.ch/mieten/wohnung/kanton-graubuenden/trefferliste "wohnung mieten graubünden") + +## Haus mieten in + +* [Zürich](https://www.homegate.ch/mieten/haus/ort-zuerich/trefferliste "haus mieten zürich") +* [Aargau](https://www.homegate.ch/mieten/haus/kanton-aargau/trefferliste "haus mieten aargau") +* [Thurgau](https://www.homegate.ch/mieten/haus/kanton-thurgau/trefferliste "haus mieten thurgau") +* [Baselland](https://www.homegate.ch/mieten/haus/kanton-baselland/trefferliste "haus mieten baselland") +* [Bern](https://www.homegate.ch/mieten/haus/ort-bern/trefferliste "haus mieten bern") +* [Schweiz](https://www.homegate.ch/mieten/haus/land-schweiz/trefferliste "haus mieten schweiz") +* [Kanton Bern](https://www.homegate.ch/mieten/haus/kanton-bern/trefferliste "haus mieten kanton bern") +* [Luzern](https://www.homegate.ch/mieten/haus/ort-luzern/trefferliste "haus mieten luzern") +* [Basel](https://www.homegate.ch/mieten/haus/ort-basel/trefferliste "haus mieten basel") +* [Waadt](https://www.homegate.ch/mieten/haus/kanton-waadt/trefferliste "haus mieten waadt") +* [St. Gallen](https://www.homegate.ch/mieten/haus/ort-st-gallen/trefferliste "haus mieten st. gallen") +* [Graubünden](https://www.homegate.ch/mieten/haus/kanton-graubuenden/trefferliste "haus mieten graubünden") + +## Wohnung kaufen in + +* [Zürich](https://www.homegate.ch/kaufen/wohnung/ort-zuerich/trefferliste "wohnung kaufen zürich") +* [Bern](https://www.homegate.ch/kaufen/wohnung/ort-bern/trefferliste "wohnung kaufen bern") +* [Basel](https://www.homegate.ch/kaufen/wohnung/ort-basel/trefferliste "wohnung kaufen basel") +* [Luzern](https://www.homegate.ch/kaufen/wohnung/ort-luzern/trefferliste "wohnung kaufen luzern") +* [St. Gallen](https://www.homegate.ch/kaufen/wohnung/ort-st-gallen/trefferliste "wohnung kaufen st. gallen") +* [Thun](https://www.homegate.ch/kaufen/wohnung/ort-thun/trefferliste "wohnung kaufen thun") +* [Winterthur](https://www.homegate.ch/kaufen/wohnung/ort-winterthur/trefferliste "wohnung kaufen winterthur") +* [Aargau](https://www.homegate.ch/kaufen/wohnung/kanton-aargau/trefferliste "wohnung kaufen aargau") +* [Baselland](https://www.homegate.ch/kaufen/wohnung/kanton-baselland/trefferliste "wohnung kaufen baselland") +* [Waadt](https://www.homegate.ch/kaufen/wohnung/kanton-waadt/trefferliste "wohnung kaufen waadt") +* [Graubünden](https://www.homegate.ch/kaufen/wohnung/kanton-graubuenden/trefferliste "wohnung kaufen graubünden") + +## Haus kaufen in + +* [Schweiz](https://www.homegate.ch/kaufen/haus/land-schweiz/trefferliste "haus kaufen schweiz") +* [Bern](https://www.homegate.ch/kaufen/haus/ort-bern/trefferliste "haus kaufen bern") +* [Aargau](https://www.homegate.ch/kaufen/haus/kanton-aargau/trefferliste "haus kaufen aargau") +* [Baselland](https://www.homegate.ch/kaufen/haus/kanton-baselland/trefferliste "haus kaufen baselland") +* [Thurgau](https://www.homegate.ch/kaufen/haus/kanton-thurgau/trefferliste "haus kaufen thurgau") +* [Zürich](https://www.homegate.ch/kaufen/haus/ort-zuerich/trefferliste "haus kaufen zürich") +* [Luzern](https://www.homegate.ch/kaufen/haus/ort-luzern/trefferliste "haus kaufen luzern") +* [Winterthur](https://www.homegate.ch/kaufen/haus/ort-winterthur/trefferliste "haus kaufen winterthur") +* [Waadt](https://www.homegate.ch/kaufen/haus/kanton-waadt/trefferliste "haus kaufen waadt") +* [St. Gallen](https://www.homegate.ch/kaufen/haus/ort-st-gallen/trefferliste "haus kaufen st. gallen") +* [Graubünden](https://www.homegate.ch/kaufen/haus/kanton-graubuenden/trefferliste "haus kaufen graubünden") + +## We Care About Your Privacy + +We and our 453 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below, including your right to object where legitimate interest is used, or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data. + +### We and our partners process data to provide: + +Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_018_realadvisor.ch_de_immobilien-kaufen.txt b/test_web_content_20251002_215219/additional_link_018_realadvisor.ch_de_immobilien-kaufen.txt new file mode 100644 index 00000000..ea8c2ce2 --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_018_realadvisor.ch_de_immobilien-kaufen.txt @@ -0,0 +1,250 @@ +URL: https://realadvisor.ch/de/immobilien-kaufen +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Wohnung, Haus, Immobilien kaufen in der Schweiz | RealAdvisor + +=============== + +[](https://realadvisor.ch/de) + +* [Bewerten](https://realadvisor.ch/de/immobilien-kaufen) + * [Immobilienbewertung](https://realadvisor.ch/de/online-immobilienbewertung) + * [Renditeliegenschaft bewerten](https://realadvisor.ch/de/renditeliegenschaft-bewerten-online) + * [Immobilienpreise](https://realadvisor.ch/de/immobilienpreise-pro-m2) + +* [Kaufen](https://realadvisor.ch/de/immobilien-kaufen) +* [Mieten](https://realadvisor.ch/de/immobilien-mieten) +* [Verkaufen](https://realadvisor.ch/de/haus-verkaufen) +* [Makler finden](https://realadvisor.ch/de/makler-finden) +* [Mein Konto](https://realadvisor.ch/de/profile) + +* [DE](https://realadvisor.ch/de/immobilien-kaufen#) + * [FR](https://realadvisor.ch/fr/immobilier-a-vendre) + * [IT](https://realadvisor.ch/it/vendita-immobile) + * [EN](https://realadvisor.ch/en/property-for-sale) + +Die grösste Immobilien-Suchmaschine der Schweiz + +Über 40'000 Inserate für Immobilien zum Kauf +============================================ + +[](https://de.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + + + +Alle Inserate in einer App +-------------------------- + +Mit RealAdvisor suchen Sie auf allen Schweizer Immobilienportalen gleichzeitig. Verpassen Sie nie wieder ein Angebot! + +Verwenden Sie professionelle Filter, zeichnen Sie Ihren Suchbereich auf einer Karte und erhalten Sie sofort Benachrichtigungen zu neuen Inseraten, die Ihren Kriterien entsprechen. + +[](https://play.google.com/store/apps/details?id=com.realadvisor.app)[](https://apps.apple.com/ch/app/realadvisor/id6504883593?l=de-DE) + + + + + +Über 40'000 Inserate für Kaufimmobilien +--------------------------------------- + +Immobilien aller Art zum Verkauf in der Schweiz + +RealAdvisor zentralisiert die Inserate von zum Verkauf stehenden Häusern und Wohnungen aller wichtigen Schweizer Immobilienplattformen, sodass Sie keine kostbare Zeit mit der Suche auf verschiedenen Seiten verlieren. Wir sondieren den gesamten Markt, um Ihnen die beste Übersicht aller verfügbaren Liegenschaften, passenden Immobilien, Objekte mit guter Verkehrsanbindung und Häuser in der Nähe zu bieten. + +Alle zum Verkauf stehenden Immobilien in der Schweiz +---------------------------------------------------- + +Ob Villa, Wohnhaus und Grundstück zum Verkauf. Penthouse, Wohnung, Gewerbe oder Studio zu verkaufen. Immobilien kaufen in der Nähe bei RealAdvisor. + +[Genf](https://realadvisor.ch/de/kaufen/stadt-genf/wohnung) + +[Lausanne](https://realadvisor.ch/de/kaufen/stadt-lausanne/wohnung) + +[Zurich](https://realadvisor.ch/de/kaufen/stadt-zurich/wohnung) + +[Basel](https://realadvisor.ch/de/kaufen/stadt-basel/wohnung) + +[Bern](https://realadvisor.ch/de/kaufen/stadt-bern/wohnung) + +### Erweiterte Suchfilter + +Als Immobilienexperten verstehen wir den Wert von relevanten Informationen bei der Suche nach einer Immobilie zum Kauf in CH. Ob Sie Ihr nächstes Zuhause oder eine günstige Investitionsmöglichkeit in der Schweiz suchen, mit RealAdvisor können Sie Inserate nach m2-Preis, geschätzten jährlichen Mieteinnahmen, dem Einstellungsdatum im Internet und noch vielem mehr filtern! + + + + + +### Immobilien-Suchabo + +Speichern Sie Ihre Immobiliensuche als Abo mit zwei Klicks und werden Sie per E-Mail benachrichtigt, wenn neue Liegenschaften oder Immobilien in der Nähe, die Ihren Suchkriterien entsprechen, inseriert werden. Ein Immobilien-Suchabo bei uns ist alles, was Sie benötigen, um alle Inserate der Schweizer Immobilienportale im Auge zu behalten. + +[Liegenschaften zum Verkauf](https://realadvisor.ch/de/kaufen) + +Wohnungen zum Verkauf, in jedem Kanton der Schweiz +-------------------------------------------------- + +Studieren Sie alle Immobilien-Angebote, sortiert nach Schweizer Kanton. Finden Sie alle zum Verkauf stehenden Wohnungen, ob in Genf, Waadt, Basel, Zürich oder jedem anderen CH-Kanton. + +[Kanton Zurich](https://realadvisor.ch/de/kaufen/kanton-zurich/wohnung) + +[Kanton Bern](https://realadvisor.ch/de/kaufen/kanton-bern/wohnung) + +[Kanton Waadt](https://realadvisor.ch/de/kaufen/kanton-waadt/wohnung) + +[Kanton Aargau](https://realadvisor.ch/de/kaufen/kanton-aargau/wohnung) + +[Kanton St-Gallen](https://realadvisor.ch/de/kaufen/kanton-st-gallen/wohnung) + +[Kanton Genf](https://realadvisor.ch/de/kaufen/kanton-genf/wohnung) + +[Kanton Luzern](https://realadvisor.ch/de/kaufen/kanton-luzern/wohnung) + +[Kanton Tessin](https://realadvisor.ch/de/kaufen/kanton-tessin/wohnung) + +[Kanton Wallis](https://realadvisor.ch/de/kaufen/kanton-wallis/wohnung) + +[Kanton Freiburg](https://realadvisor.ch/de/kaufen/kanton-freiburg/wohnung) + +[Kanton Basel-Landschaft](https://realadvisor.ch/de/kaufen/kanton-basel-landschaft/wohnung) + +[Kanton Thurgau](https://realadvisor.ch/de/kaufen/kanton-thurgau/wohnung) + +[Kanton Solothurn](https://realadvisor.ch/de/kaufen/kanton-solothurn/wohnung) + +[Kanton Graubunden](https://realadvisor.ch/de/kaufen/kanton-graubunden/wohnung) + +[Kanton Basel-Stadt](https://realadvisor.ch/de/kaufen/kanton-basel-stadt/wohnung) + +[Kanton Neuenburg](https://realadvisor.ch/de/kaufen/kanton-neuenburg/wohnung) + +[Kanton Schwyz](https://realadvisor.ch/de/kaufen/kanton-schwyz/wohnung) + +[Kanton Zug](https://realadvisor.ch/de/kaufen/kanton-zug/wohnung) + +[Kanton Schaffhausen](https://realadvisor.ch/de/kaufen/kanton-schaffhausen/wohnung) + +[Kanton Jura](https://realadvisor.ch/de/kaufen/kanton-jura/wohnung) + +[Kanton Appenzell-Ausserrhoden](https://realadvisor.ch/de/kaufen/kanton-appenzell-ausserrhoden/wohnung) + +[Kanton Nidwalden](https://realadvisor.ch/de/kaufen/kanton-nidwalden/wohnung) + +[Kanton Glarus](https://realadvisor.ch/de/kaufen/kanton-glarus/wohnung) + +[Kanton Obwalden](https://realadvisor.ch/de/kaufen/kanton-obwalden/wohnung) + +[Kanton Uri](https://realadvisor.ch/de/kaufen/kanton-uri/wohnung) + +[Kanton Appenzell-Innerrhoden](https://realadvisor.ch/de/kaufen/kanton-appenzell-innerrhoden/wohnung) + + + +Neubauten zum Verkauf +--------------------- + +Typischerweise werden die besten Neubauten verkauft, ohne jemals online inseriert zu werden, da Vermarkter und Entwickler dafür auf ihre private Kundendatenbank von potenziellen Interessenten zurückgreifen. + +RealAdvisor ermöglicht es Kaufinteressenten, sich in die direkte Kundendatenbank unserer Partner einzuschreiben und so neue Immobilien in der Nähe oder auch in der gesamten Schweiz zu erwerben. + +Einmal eingeschrieben, werden Sie vorrangig über unsere jüngsten Neubauprojekte und privaten Investitionsmöglichkeiten benachrichtigt. + +[Für Neubauprojekte registrieren](https://realadvisor.ch/de/neubauprojekte) + + + +Immobilienpreise in der Schweiz +------------------------------- + +Erkundigen Sie sich über die mittleren Verkaufspreise für Häuser und Wohnungen nach Kanton oder Gemeinde. Diese basieren auf der Echtzeit-Datenerfassung aller wichtigen Immobilienplattformen der Schweiz. + +[Preise ansehen](https://realadvisor.ch/de/immobilienpreise-pro-m2) + +Wohnungen kaufen in der Schweiz +------------------------------- + +[* Wohnungen kaufen in Freiburg](https://realadvisor.ch/de/kaufen/stadt-freiburg/wohnung)[* Wohnungen kaufen in Genf](https://realadvisor.ch/de/kaufen/stadt-genf/wohnung)[* Wohnungen kaufen in St. Gallen](https://realadvisor.ch/de/kaufen/stadt-st-gallen/wohnung)[* Wohnungen kaufen in Biel](https://realadvisor.ch/de/kaufen/stadt-biel/wohnung)[* Wohnungen kaufen in Aarau](https://realadvisor.ch/de/kaufen/stadt-aarau/wohnung) + +[* Wohnungen kaufen in Basel](https://realadvisor.ch/de/kaufen/stadt-basel/wohnung)[* Wohnungen kaufen in Winterthur](https://realadvisor.ch/de/kaufen/stadt-winterthur/wohnung)[* Wohnungen kaufen in Luzern](https://realadvisor.ch/de/kaufen/stadt-luzern/wohnung)[* Wohnungen kaufen in Chur](https://realadvisor.ch/de/kaufen/7000-chur/wohnung)[* Wohnungen kaufen in Rapperswil-Jona](https://realadvisor.ch/de/kaufen/stadt-rapperswil-jona/wohnung) + +[* Wohnungen kaufen in Thun](https://realadvisor.ch/de/kaufen/stadt-thun/wohnung)[* Wohnungen kaufen in Arosa](https://realadvisor.ch/de/kaufen/gemeinde-arosa/wohnung)[* Wohnungen kaufen in Visp](https://realadvisor.ch/de/kaufen/gemeinde-visp/wohnung)[* Wohnungen kaufen in Bern](https://realadvisor.ch/de/kaufen/stadt-bern/wohnung)[* Wohnungen kaufen in Wettingen](https://realadvisor.ch/de/kaufen/5430-wettingen/wohnung) + +[* Wohnungen kaufen in Uster](https://realadvisor.ch/de/kaufen/stadt-uster/wohnung)[* Wohnungen kaufen in Reinach BL](https://realadvisor.ch/de/kaufen/4153-reinach-bl/wohnung)[* Wohnungen kaufen in Wil (SG)](https://realadvisor.ch/de/kaufen/stadt-wil-sg/wohnung)[* Wohnungen kaufen in Emmen](https://realadvisor.ch/de/kaufen/stadt-emmen/wohnung)[* Wohnungen kaufen in Köniz](https://realadvisor.ch/de/kaufen/stadt-koniz/wohnung) + +Häuser kaufen in der Schweiz +---------------------------- + +[* Häuser kaufen in Zürich](https://realadvisor.ch/de/kaufen/stadt-zurich/haus)[* Häuser kaufen in Winterthur](https://realadvisor.ch/de/kaufen/stadt-winterthur/haus)[* Häuser kaufen in St. Gallen](https://realadvisor.ch/de/kaufen/stadt-st-gallen/haus)[* Häuser kaufen in Wohlen](https://realadvisor.ch/de/kaufen/stadt-wohlen-ag/haus)[* Häuser kaufen in Riehen](https://realadvisor.ch/de/kaufen/4125-riehen/haus) + +[* Häuser kaufen in Rothrist](https://realadvisor.ch/de/kaufen/4852-rothrist/haus)[* Häuser kaufen in Luzern](https://realadvisor.ch/de/kaufen/stadt-luzern/haus)[* Häuser kaufen in Muttenz](https://realadvisor.ch/de/kaufen/4132-muttenz/haus)[* Häuser kaufen in Allschwil](https://realadvisor.ch/de/kaufen/4123-allschwil/haus)[* Häuser kaufen in Rapperswil-Jona](https://realadvisor.ch/de/kaufen/stadt-rapperswil-jona/haus) + +[* Häuser kaufen in Langenthal](https://realadvisor.ch/de/kaufen/stadt-langenthal/haus)[* Häuser kaufen in Biel](https://realadvisor.ch/de/kaufen/stadt-biel/haus)[* Häuser kaufen in Wil (SG)](https://realadvisor.ch/de/kaufen/stadt-wil-sg/haus)[* Häuser kaufen in Bern](https://realadvisor.ch/de/kaufen/stadt-bern/haus)[* Häuser kaufen in Burgdorf](https://realadvisor.ch/de/kaufen/3400-burgdorf/haus) + +[* Häuser kaufen in Aarau](https://realadvisor.ch/de/kaufen/stadt-aarau/haus)[* Häuser kaufen in Solothurn](https://realadvisor.ch/de/kaufen/4500-solothurn/haus)[* Häuser kaufen in Wildhaus-Alt St. Johann](https://realadvisor.ch/de/kaufen/gemeinde-wildhaus-alt-st-johann/haus)[* Häuser kaufen in Lausen](https://realadvisor.ch/de/kaufen/4415-lausen/haus)[* Häuser kaufen in Reinach BL](https://realadvisor.ch/de/kaufen/4153-reinach-bl/haus) + +FAQ +--- + +### Werden Immobilienpreise in der Schweiz sinken? + +Die Schweiz hat traditionell einen stabilen Immobilienmarkt, aber auch hier können Preise je nach wirtschaftlicher Lage, Zinssätzen und Immobilien-Angeboten variieren. Lokale Marktanalysen können aktuellere und genauere Einschätzungen bieten.Am besten bleiben Sie stets am Ball und informieren sich auf unserer Seite regelmäßig zu den jeweils[aktuellsten Quadratmeterpreisen in der Schweiz](https://realadvisor.ch/de/immobilienpreise-pro-m2). + +### Wie berechnet man die Rendite eines Mietshauses? + +Der beste Zeitpunkt zum Kauf einer Immobilie hängt von Ihren persönlichen finanziellen Umständen, Marktbedingungen und individuellen Zielen ab. Eine umfassende Marktanalyse und Beratung durch einen Fachmann können hierbei unterstützend wirken. Überprüfen Sie unser[Immobilienagentur-Verzeichnis](https://realadvisor.ch/de/makler-finden)und wenden Sie sich an die erfahrensten Makler in Ihrer Umgebung, um über Ihr Projekt zu sprechen. + +### Wo sollte man Immobilien kaufen? + +Die Entscheidung, wo man Immobilien kaufen sollte, hängt von Faktoren wie Lebensstil, Arbeitsort, Infrastruktur, Bildungsangeboten und persönlichen Präferenzen ab. Bei RealAdvisor haben Sie den Vorteil, praktisch [alle Immobilienanzeigen der Schweiz](https://realadvisor.ch/de/kaufen) gebündelt an einer Stelle zu haben. Auf diese Weise haben Sie Zugriff auf rund 180.000 Anzeigen auf einen Blick. Schauen Sie doch mal rein. + +[](https://realadvisor.ch/de)[](https://ch.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + +Verkaufen + +* [Immobilienbewertung](https://realadvisor.ch/de/online-immobilienbewertung) +* [Renditeliegenschaft bewerten](https://realadvisor.ch/de/renditeliegenschaft-bewerten-online) +* [Immobilienpreise](https://realadvisor.ch/de/immobilienpreise-pro-m2) +* [Makler finden](https://realadvisor.ch/de/makler-finden) +* [Immobilien-Glossar](https://realadvisor.ch/de/immobilien-glossar) +* [Immobilien-Blog](https://realadvisor.ch/de/blog) + +Kaufen / Mieten + +* [Immobilien Kaufen](https://realadvisor.ch/de/immobilien-kaufen) +* [Immobilien Mieten](https://realadvisor.ch/de/immobilien-mieten) +* [Neubauprojekte](https://realadvisor.ch/de/neubauprojekte) +* [Immobilienfinanzierung](https://realadvisor.ch/de/finanzierung) + +Für Makler + +* [Partner werden](https://realadvisor.ch/de/pro) +* [Blog Pro](https://realadvisor.ch/de/pro/blog) + +Unternehmen + +* [Über uns](https://realadvisor.ch/de/uber-uns) +* [Presseraum](https://realadvisor.ch/de/presseraum) +* [Offene Stellen](https://realadvisor.welcomekit.co/) +* [Allgemeine Geschäftsbedingungen](https://realadvisor.ch/de/begriffe) +* [Datenschutzerklärung](https://realadvisor.ch/de/datenschutzerklarung) +* [Impressum](https://realadvisor.ch/de/impressum) +* [Alle Immobilien](https://realadvisor.ch/de/sitemap) + +* [France (FR)](https://realadvisor.fr/fr) +* [España (ES)](https://realadvisor.es/es) +* [Italia (IT)](https://realadvisor.it/it) +* [Deutschland (DE)](https://realadvisor.de/de) +* [Great Britain (EN)](https://realadvisor.co.uk/en) +* [Belgique (FR)](https://realadvisor.be/fr) +* [België (NL)](https://realadvisor.be/nl) +* [Nederland (NL)](https://realadvisor.nl/nl) +* [Polska (PL)](https://realadvisor.pl/pl) +* [Czech (CZ)](https://realadvisor.cz/cs) + +[](https://apps.apple.com/ch/app/realadvisor/id6504883593)[](https://play.google.com/store/apps/details?id=com.realadvisor.app) + +© RealAdvisor 2024. All Rights Reserved. + +[](https://ch.linkedin.com/company/realadvisor)[](https://www.facebook.com/realadvisorcom)[](https://twitter.com/RealAdvisor)[](https://www.instagram.com/realadvisorcom/)[](https://www.youtube.com/channel/UCsEDTDlmxBpyxLXYhWT769Q) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_019_realadvisor.ch_de_immobilien-mieten.txt b/test_web_content_20251002_215219/additional_link_019_realadvisor.ch_de_immobilien-mieten.txt new file mode 100644 index 00000000..c8d689b3 --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_019_realadvisor.ch_de_immobilien-mieten.txt @@ -0,0 +1,235 @@ +URL: https://realadvisor.ch/de/immobilien-mieten +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Immobilien mieten in der Schweiz (Wohnung, Haus) | RealAdvisor + +=============== + +[](https://realadvisor.ch/de) + +* [Bewerten](https://realadvisor.ch/de/immobilien-mieten) + * [Immobilienbewertung](https://realadvisor.ch/de/online-immobilienbewertung) + * [Renditeliegenschaft bewerten](https://realadvisor.ch/de/renditeliegenschaft-bewerten-online) + * [Immobilienpreise](https://realadvisor.ch/de/immobilienpreise-pro-m2) + +* [Kaufen](https://realadvisor.ch/de/immobilien-kaufen) +* [Mieten](https://realadvisor.ch/de/immobilien-mieten) +* [Verkaufen](https://realadvisor.ch/de/haus-verkaufen) +* [Makler finden](https://realadvisor.ch/de/makler-finden) +* [Mein Konto](https://realadvisor.ch/de/profile) + +* [DE](https://realadvisor.ch/de/immobilien-mieten#) + * [FR](https://realadvisor.ch/fr/immobilier-a-louer) + * [IT](https://realadvisor.ch/it/immobili-in-affitto) + * [EN](https://realadvisor.ch/en/property-for-rent) + +Die grösste Immobilien-Suchmaschine der Schweiz + +Über 50'000 Inserate für Immobilien zur Miete in der Schweiz +============================================================ + +[](https://de.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + + + +Alle Inserate in einer App +-------------------------- + +Mit RealAdvisor suchen Sie auf allen Schweizer Immobilienportalen gleichzeitig.Verpassen Sie nie wieder ein Angebot! + +Verwenden Sie professionelle Filter, zeichnen Sie Ihren Suchbereich auf einer Karte und erhalten Sie sofort Benachrichtigungen zu neuen Inseraten, die Ihren Kriterien entsprechen. + +[](https://play.google.com/store/apps/details?id=com.realadvisor.app)[](https://apps.apple.com/ch/app/realadvisor/id6504883593?l=de-DE) + + + + + +Alle Immobilien zur Miete in der Schweiz, ob Zug, Luzern, Thurgau oder anderen Orten +------------------------------------------------------------------------------------ + +Wir zentralisieren Anzeigen von Zimmern, Wohnungen, Häusern und Gewerbeobjekten zur Miete der wichtigsten Schweizer Immobilienplattformen. Verlieren Sie keine Zeit mit der Suche auf zahlreichen Seiten und Duplikaten. Mit uns haben Sie sofort den Gesamtüberblick des Markts. + +Alle Wohnungen zur Miete in der Schweiz +--------------------------------------- + +Haus mieten Schweiz. Wohnungssuche Schweiz. Alle Immobilien in CH bei uns vereint. + +[Genf](https://realadvisor.ch/de/mieten/stadt-genf/wohnung) + +[Lausanne](https://realadvisor.ch/de/mieten/stadt-lausanne/wohnung) + +[Zurich](https://realadvisor.ch/de/mieten/stadt-zurich/wohnung) + +[Basel](https://realadvisor.ch/de/mieten/stadt-basel/wohnung) + +[Bern](https://realadvisor.ch/de/mieten/stadt-bern/wohnung) + +### Das beste Suchergebnis + +Geniessen Sie blitzschnelle Ladezeiten, suchen Sie nach mehreren Postleitzahlen oder Nachbarschaften gleichzeitig, nutzen Sie erweiterte Suchfilter wie Preis pro Zimmer pro Monat, um Ihre Suche zu präzisieren oder speichern Sie Ihre Favoriten mit einem Klick, um sie später schnell und einfach erneut zu studieren. + + + + + +### Suchabo + +Wir haben stetig ein Auge auf den Markt und benachrichtigen Sie, sobald eine neue, Ihren Kriterien entsprechende Anzeige auf den massgebenden Schweizer Portalen geschaltet wird. Speichern Sie einfach Ihre Suche und sorgen Sie sich nicht mehr um verpasste Gelegenheiten. + +[Suche nach Mietobjekten](https://realadvisor.ch/de/mieten) + +Mietwohnungen in jedem Schweizer Kanton +--------------------------------------- + +Suchen Sie wie ein Profi durch alle Anzeigen in jedem Schweizer Kanton. Finden Sie alle Mietwohnungen, ob in Genf, Waadt, Basel oder Zürich. + +[Kanton Zurich](https://realadvisor.ch/de/mieten/kanton-zurich/wohnung) + +[Kanton Bern](https://realadvisor.ch/de/mieten/kanton-bern/wohnung) + +[Kanton Waadt](https://realadvisor.ch/de/mieten/kanton-waadt/wohnung) + +[Kanton Aargau](https://realadvisor.ch/de/mieten/kanton-aargau/wohnung) + +[Kanton St-Gallen](https://realadvisor.ch/de/mieten/kanton-st-gallen/wohnung) + +[Kanton Genf](https://realadvisor.ch/de/mieten/kanton-genf/wohnung) + +[Kanton Luzern](https://realadvisor.ch/de/mieten/kanton-luzern/wohnung) + +[Kanton Tessin](https://realadvisor.ch/de/mieten/kanton-tessin/wohnung) + +[Kanton Wallis](https://realadvisor.ch/de/mieten/kanton-wallis/wohnung) + +[Kanton Freiburg](https://realadvisor.ch/de/mieten/kanton-freiburg/wohnung) + +[Kanton Basel-Landschaft](https://realadvisor.ch/de/mieten/kanton-basel-landschaft/wohnung) + +[Kanton Thurgau](https://realadvisor.ch/de/mieten/kanton-thurgau/wohnung) + +[Kanton Solothurn](https://realadvisor.ch/de/mieten/kanton-solothurn/wohnung) + +[Kanton Graubunden](https://realadvisor.ch/de/mieten/kanton-graubunden/wohnung) + +[Kanton Basel-Stadt](https://realadvisor.ch/de/mieten/kanton-basel-stadt/wohnung) + +[Kanton Neuenburg](https://realadvisor.ch/de/mieten/kanton-neuenburg/wohnung) + +[Kanton Schwyz](https://realadvisor.ch/de/mieten/kanton-schwyz/wohnung) + +[Kanton Zug](https://realadvisor.ch/de/mieten/kanton-zug/wohnung) + +[Kanton Schaffhausen](https://realadvisor.ch/de/mieten/kanton-schaffhausen/wohnung) + +[Kanton Jura](https://realadvisor.ch/de/mieten/kanton-jura/wohnung) + +[Kanton Appenzell-Ausserrhoden](https://realadvisor.ch/de/mieten/kanton-appenzell-ausserrhoden/wohnung) + +[Kanton Nidwalden](https://realadvisor.ch/de/mieten/kanton-nidwalden/wohnung) + +[Kanton Glarus](https://realadvisor.ch/de/mieten/kanton-glarus/wohnung) + +[Kanton Obwalden](https://realadvisor.ch/de/mieten/kanton-obwalden/wohnung) + +[Kanton Uri](https://realadvisor.ch/de/mieten/kanton-uri/wohnung) + +[Kanton Appenzell-Innerrhoden](https://realadvisor.ch/de/mieten/kanton-appenzell-innerrhoden/wohnung) + + + +Mietpreise in der Schweiz +------------------------- + +Informieren Sie sich über mittlere monatliche Mietpreise für Wohnungen und Häuser nach Kanton oder Gemeinde. Diese basieren auf der Echtzeit-Datenerfassung in allen wichtigen Immobilienplattformen der Schweiz. + +[Mietpreise ansehen](https://realadvisor.ch/de/immobilienpreise-pro-m2) + +Wohnungen mieten in der Schweiz +------------------------------- + +[* Wohnungen mieten in Zürich](https://realadvisor.ch/de/mieten/stadt-zurich/wohnung)[* Wohnungen mieten in Bern](https://realadvisor.ch/de/mieten/stadt-bern/wohnung)[* Wohnungen mieten in St. Gallen](https://realadvisor.ch/de/mieten/stadt-st-gallen/wohnung)[* Wohnungen mieten in Biel](https://realadvisor.ch/de/mieten/stadt-biel/wohnung)[* Wohnungen mieten in Luzern](https://realadvisor.ch/de/mieten/stadt-luzern/wohnung) + +[* Wohnungen mieten in Winterthur](https://realadvisor.ch/de/mieten/stadt-winterthur/wohnung)[* Wohnungen mieten in Schaffhausen](https://realadvisor.ch/de/mieten/stadt-schaffhausen/wohnung)[* Wohnungen mieten in Dübendorf](https://realadvisor.ch/de/mieten/stadt-dubendorf/wohnung)[* Wohnungen mieten in Olten](https://realadvisor.ch/de/mieten/4600-olten/wohnung)[* Wohnungen mieten in Gossau SG](https://realadvisor.ch/de/mieten/9200-gossau-sg/wohnung) + +[* Wohnungen mieten in Rapperswil-Jona](https://realadvisor.ch/de/mieten/stadt-rapperswil-jona/wohnung)[* Wohnungen mieten in Aarau](https://realadvisor.ch/de/mieten/stadt-aarau/wohnung)[* Wohnungen mieten in Wil (SG)](https://realadvisor.ch/de/mieten/stadt-wil-sg/wohnung)[* Wohnungen mieten in Kriens](https://realadvisor.ch/de/mieten/stadt-kriens/wohnung)[* Wohnungen mieten in Chur](https://realadvisor.ch/de/mieten/7000-chur/wohnung) + +[* Wohnungen mieten in Kloten](https://realadvisor.ch/de/mieten/8302-kloten/wohnung)[* Wohnungen mieten in Baden](https://realadvisor.ch/de/mieten/stadt-baden/wohnung)[* Wohnungen mieten in Bülach](https://realadvisor.ch/de/mieten/8180-bulach/wohnung)[* Wohnungen mieten in Kreuzlingen](https://realadvisor.ch/de/mieten/8280-kreuzlingen/wohnung)[* Wohnungen mieten in Dietikon](https://realadvisor.ch/de/mieten/8953-dietikon/wohnung) + +Häuser mieten in der Schweiz +---------------------------- + +[* Häuser mieten in Zürich](https://realadvisor.ch/de/mieten/stadt-zurich/haus)[* Häuser mieten in Winterthur](https://realadvisor.ch/de/mieten/stadt-winterthur/haus)[* Häuser mieten in Bern](https://realadvisor.ch/de/mieten/stadt-bern/haus) + +[* Häuser mieten in St. Gallen](https://realadvisor.ch/de/mieten/stadt-st-gallen/haus)[* Häuser mieten in Buchs SG](https://realadvisor.ch/de/mieten/9470-buchs-sg/haus)[* Häuser mieten in Allschwil](https://realadvisor.ch/de/mieten/4123-allschwil/haus) + +[* Häuser mieten in Luzern](https://realadvisor.ch/de/mieten/stadt-luzern/haus)[* Häuser mieten in Langenthal](https://realadvisor.ch/de/mieten/stadt-langenthal/haus)[* Häuser mieten in Widnau](https://realadvisor.ch/de/mieten/9443-widnau/haus) + +[* Häuser mieten in Reinach BL](https://realadvisor.ch/de/mieten/4153-reinach-bl/haus)[* Häuser mieten in Frauenfeld](https://realadvisor.ch/de/mieten/stadt-frauenfeld/haus)[* Häuser mieten in Hausen am Albis](https://realadvisor.ch/de/mieten/gemeinde-hausen-am-albis/haus) + +FAQ +--- + +### Ist es schwer, in der Schweiz eine Wohnung zu finden? + +Die Wohnungssuche in der Schweiz kann sich je nach Region und Zeitpunkt unterscheiden. In Grossstädten wie Zürich, Genf und Basel ist der Markt oft dynamisch, was die Suche erschweren kann. Unsere Seite bietet eine zentrale Übersicht über Angebote von den wichtigsten Immobilienplattformen der Schweiz, um Ihnen einen umfassenden Marktüberblick zu verschaffen. Das Ziel ist es, Ihre Suche nach einem neuen Zuhause so einfach und effizient wie möglich zu gestalten. + +### Was ist die durchschnittliche Miete in der Schweiz? + +Die Mietpreise in der Schweiz variieren erheblich und hängen von der Region und dem Wohnort ab. In grösseren Städten liegen die Mieten in der Regel höher als in ländlicheren Gebieten. Für aktuelle Daten zu den durchschnittlichen Mietpreisen nach Stadt, Postleitzahl und Nachbarschaft empfehlen wir, unsere Seite mit den Mietpreisinformationen zu besuchen:[Aktuelle Mietpreise in der Schweiz](https://realadvisor.ch/de/immobilienpreise-pro-m2). Hier finden Sie umfassende Informationen, die auf Echtzeit-Datenerfassungen basieren. + +### Wo kann man in der Schweiz am billigsten wohnen? + +Die kostengünstigsten Wohnmöglichkeiten finden sich oft in weniger dicht besiedelten Gebieten oder kleineren Städten. Regionen wie der Kanton Jura, Glarus und Neuenburg bieten im Vergleich zu Grossstädten oftmals niedrigere Mieten. Unsere Plattform ermöglicht eine gezielte Suche, um passende und preiswerte Wohnoptionen in Ihrer gewünschten Region zu finden. Nutzen Sie unsere Ressourcen für eine effiziente Wohnungssuche. + +[](https://realadvisor.ch/de)[](https://ch.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + +Verkaufen + +* [Immobilienbewertung](https://realadvisor.ch/de/online-immobilienbewertung) +* [Renditeliegenschaft bewerten](https://realadvisor.ch/de/renditeliegenschaft-bewerten-online) +* [Immobilienpreise](https://realadvisor.ch/de/immobilienpreise-pro-m2) +* [Makler finden](https://realadvisor.ch/de/makler-finden) +* [Immobilien-Glossar](https://realadvisor.ch/de/immobilien-glossar) +* [Immobilien-Blog](https://realadvisor.ch/de/blog) + +Kaufen / Mieten + +* [Immobilien Kaufen](https://realadvisor.ch/de/immobilien-kaufen) +* [Immobilien Mieten](https://realadvisor.ch/de/immobilien-mieten) +* [Neubauprojekte](https://realadvisor.ch/de/neubauprojekte) +* [Immobilienfinanzierung](https://realadvisor.ch/de/finanzierung) + +Für Makler + +* [Partner werden](https://realadvisor.ch/de/pro) +* [Blog Pro](https://realadvisor.ch/de/pro/blog) + +Unternehmen + +* [Über uns](https://realadvisor.ch/de/uber-uns) +* [Presseraum](https://realadvisor.ch/de/presseraum) +* [Offene Stellen](https://realadvisor.welcomekit.co/) +* [Allgemeine Geschäftsbedingungen](https://realadvisor.ch/de/begriffe) +* [Datenschutzerklärung](https://realadvisor.ch/de/datenschutzerklarung) +* [Impressum](https://realadvisor.ch/de/impressum) +* [Alle Immobilien](https://realadvisor.ch/de/sitemap) + +* [France (FR)](https://realadvisor.fr/fr) +* [España (ES)](https://realadvisor.es/es) +* [Italia (IT)](https://realadvisor.it/it) +* [Deutschland (DE)](https://realadvisor.de/de) +* [Great Britain (EN)](https://realadvisor.co.uk/en) +* [Belgique (FR)](https://realadvisor.be/fr) +* [België (NL)](https://realadvisor.be/nl) +* [Nederland (NL)](https://realadvisor.nl/nl) +* [Polska (PL)](https://realadvisor.pl/pl) +* [Czech (CZ)](https://realadvisor.cz/cs) + +[](https://apps.apple.com/ch/app/realadvisor/id6504883593)[](https://play.google.com/store/apps/details?id=com.realadvisor.app) + +© RealAdvisor 2024. All Rights Reserved. + +[](https://ch.linkedin.com/company/realadvisor)[](https://www.facebook.com/realadvisorcom)[](https://twitter.com/RealAdvisor)[](https://www.instagram.com/realadvisorcom/)[](https://www.youtube.com/channel/UCsEDTDlmxBpyxLXYhWT769Q) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_020_realadvisor.ch_it_comprare_canton-zurigo_trama.txt b/test_web_content_20251002_215219/additional_link_020_realadvisor.ch_it_comprare_canton-zurigo_trama.txt new file mode 100644 index 00000000..ac98b61c --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_020_realadvisor.ch_it_comprare_canton-zurigo_trama.txt @@ -0,0 +1,356 @@ +URL: https://realadvisor.ch/it/comprare/canton-zurigo/trama +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Terreno in vendita nel Canton Zurigo - 75 annunci + +=============== +[](https://realadvisor.ch/it/vendita-immobile) + +Valuta + +[Compra](https://realadvisor.ch/it/vendita-immobile)[Affitta](https://realadvisor.ch/it/immobili-in-affitto)[Vendi](https://realadvisor.ch/it/vendi-casa)[Agenzie immobiliari](https://realadvisor.ch/it/trova-una-agenzia) + +IT Mostra menu di navigazione + + + +Terreno in vendita nel Canton Zurigo +==================================== + +[Compra](https://realadvisor.ch/it/comprare/canton-zurigo/trama)[Affitto](https://realadvisor.ch/it/affitto/canton-zurigo) + +Località + +Tipo di immobile + +Cerca + +1. [](https://realadvisor.ch/it) +2. [Compra](https://realadvisor.ch/it/comprare) +3. [Terreno](https://realadvisor.ch/it/comprare/trama) +4. Canton Zurigo + +Canton Zurigo - 75 terreni in vendita +------------------------------------- + +Sfoglia tutti gli annunci di parcelle, terreni edificabili o agricoli in vendita nel Canton Zurigo, e perfeziona la tua ricerca tra 75 offerte. + +Mostra immobili sulla mappa Mostra immobili sulla mappa + +Prezzo + +- [x] Fino a CHF 200’000 + +- [x] CHF 200’000 - CHF 400’000 + +- [x] CHF 400’000 - CHF 600’000 + +- [x] CHF 600’000 - CHF 1’000’000 + +- [x] CHF 1’000’000 - CHF 2’000’000 + +- [x] CHF 2’000’000 - CHF 3’000’000 + +- [x] CHF 3’000’000+ + +Superficie terreno + +- [x] Fino a 500 m² + +- [x] 500 - 1000 m² + +- [x] 1000 - 2000 m² + +- [x] 2000 - 5000 m² + +- [x] 5000 - 10000 m² + +- [x] 10000 - 20000 m² + +- [x] 20000+ m² + +Raccomandato Più recente Prezzo più basso Prezzo più alto + +[3 giorni fa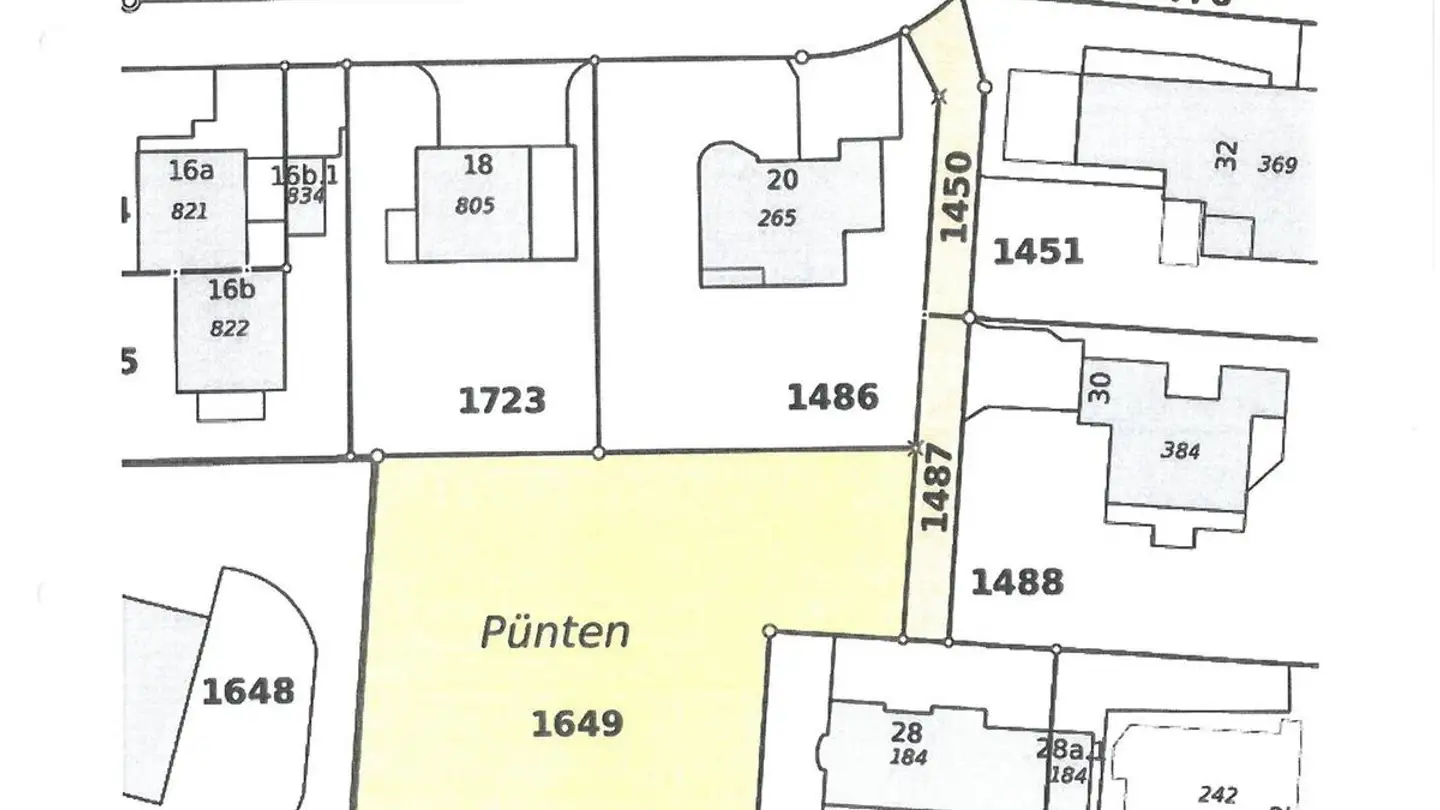 get living 1452 m² Plot • Terreno edificabile 8162 Steinmaur * Terreno pianeggiante e edificabile * Posizione tranquilla e soleggiata * Ottimo accesso ai trasporti pubblici * * * Prezzo su richiesta - ](https://realadvisor.ch/it/comprare/trama/8162-steinmaur-B62R-PZDJ) + +[6 giorni fa ImmoSky AG - Standort Dübendorf ZH (Zentrale) 1070 m² Plot • Terreno edificabile 8340 Hinwil * Oltre 1.070 m² di area * Opzioni di suddivisione flessibili * Ideale per case familiari * * * CHF 1’070’000 CHF 1’000 m² ](https://realadvisor.ch/it/comprare/trama/8340-hinwil-LDX9-L6M2) + +[7 giorni fa PREMIUM HOMES AG 1940 m² Plot • Terreno edificabile 8633 Wolfhausen * Terreno generoso di 1'940m² * Posizione adatta alle famiglie * Opzioni di design flessibili * * * CHF 4’074’000 CHF 2’100 m² ](https://realadvisor.ch/it/comprare/trama/8633-wolfhausen-YB6N-VRVP) + +[9 giorni fa Moser Anlageimmobilien AG 1666 m² Plot • Terreno edificabile Sonnhalde, 8602 Wangen b. Dübendorf * 1666 m² di terreno esclusivo * Ottima esposizione al sole * Privacy in zona tranquilla * * * CHF 3’300’000 CHF 1’981 m² ](https://realadvisor.ch/it/comprare/trama/sonnhalde-8602-wangen-b.-dubendorf-83JW-X5X3) + +[11 giorni fa Centrum Immo Terreno edificabile 8000 Zürich * Ideale per sviluppo * Vicino ai trasporti pubblici * Vista panoramica sulla città * * * Prezzo su richiesta - ](https://realadvisor.ch/it/comprare/trama/8000-zurich-NAG4-JV4R) + +[13 giorni fa ImmoSky AG - Standort Dübendorf ZH (Zentrale) 650 m² Plot • Terreno edificabile 8195 Wasterkingen * Terreno completamente servito * Comunità rurale tranquilla * Opzioni di design flessibili * * * CHF 475’000 CHF 731 m² ](https://realadvisor.ch/it/comprare/trama/8195-wasterkingen-7JPL-7X5M) + +[21 giorni fa Swiss Residence Group AG 1622 m² Plot • Terreno edificabile 8618 Oetwil am See * Terreno soleggiato di 1'622 m² * Zonizzazione flessibile per progetti * Vista montagna non edificabile * * * Prezzo su richiesta - ](https://realadvisor.ch/it/comprare/trama/8618-oetwil-am-see-8OOG-PWB5) + +[22 giorni fa PREMIUM HOMES AG 850 m² Plot • Terreno edificabile 8617 Mönchaltorf * Alto potenziale di sviluppo * Posizione tranquilla e soleggiata * Opzioni di utilizzo flessibili * * * Prezzo su richiesta - ](https://realadvisor.ch/it/comprare/trama/8617-monchaltorf-KRNG-WO9R) + +[26 giorni fa Schiblis Immobilien GmbH 507 m² Plot • Terreno edificabile Güeterstalstrasse, 8133 Esslingen * Posizione centrale a Esslingen * Nessun obbligo architettonico * Nessuna contaminazione presente * * * CHF 600’000 CHF 1’183 m² ](https://realadvisor.ch/it/comprare/trama/gueterstalstrasse-8133-esslingen-YMXG-R3MR) + +[28 giorni fa Grundeigentümer Verband Schweiz 1226 m² Plot • Terreno edificabile 8192 Zweidlen * Superficie totale di 1'226 m² * Superficie utile max. 940 m² * Opzioni di sviluppo flessibili * * * CHF 2’450’000 CHF 1’998 m²](https://realadvisor.ch/it/comprare/trama/8192-zweidlen-6ZMD-4WE3) + +[29 giorni fa PREMIUM HOMES AG 1670 m² Plot • Terreno edificabile 8424 Embrach * Posizione adatta alle famiglie * Luce abbondante tutto il giorno * Opzioni di costruzione flessibili * * * Prezzo su richiesta - ](https://realadvisor.ch/it/comprare/trama/8424-embrach-8WRG-NEGR) + +[29 giorni fa SH Immo GmbH 854 m² Plot • Terreno edificabile Berghalde 10, 8332 Russikon * Ampio terreno di 854 m2 * Posizione collinare soleggiata * Potenziale per nuova costruzione * * * CHF 1’500’000 CHF 1’756 m² ](https://realadvisor.ch/it/comprare/trama/10-berghalde-8332-russikon-6ZMD-432O) + +[un mese fa Moos & Partner Immobilien GmbH 694 m² Plot • Terreno edificabile 8134 Adliswil * Posizione centrale con potenziale * Zona W3 ad alta utilizzazione * Ideale per investitori e sviluppatori * * * CHF 3’600’000 CHF 5’187 m² ](https://realadvisor.ch/it/comprare/trama/8134-adliswil-Y7J5-W36M) + +[2 mesi fa RE/MAX Immobilien in Rapperswil-Jona 4246 m² Plot • Terreno edificabile Überlandstrasse 23, 8340 Hinwil * Posizione privilegiata vicino a strade * Ampia area per sviluppo * Opzioni di altezza edificio flessibili * * * Prezzo su richiesta - ](https://realadvisor.ch/it/comprare/trama/23-uberlandstrasse-8340-hinwil-YB69-VB7M) + +[2 mesi fa RE/MAX Immobilien in Winterthur 877 m² Plot • Terreno edificabile Winzerstrasse 20, 8353 Elgg * Ideale per case familiari * Opportunità di investimento * Adiacente a casa esistente * * * CHF 1’140’000 CHF 1’300 m² ](https://realadvisor.ch/it/comprare/trama/20-winzerstrasse-8353-elgg-KRNL-ZPNR) + +[3 mesi fa RE/MAX Immobilien in Meilen 2838 m² • 1706 m² Plot • Terreno edificabile Industriestrasse 34, 8117 Fällanden * Progetto commerciale approvato * Utilizzo commerciale flessibile * 37 posti auto disponibili * * * Prezzo su richiesta - ](https://realadvisor.ch/it/comprare/trama/34-industriestrasse-8117-fallanden-YJDX-JXRR) + +[4 mesi fa PREMIUM HOMES AG 3460 m² Plot • Terreno edificabile 8630 Rüti ZH * Zona residenziale tranquilla * Tasso di utilizzo del 30% * Bonus per spazio extra * * * Prezzo su richiesta - ](https://realadvisor.ch/it/comprare/trama/8630-ruti-zh-84E9-Z65G) + +[16 giorni fa Swisslife 2557 m² Plot • Terreno edificabile Staldernstrasse 13, 8158 Regensberg * Zonizzazione flessibile per uso misto * Alto potenziale di rendimento locativo * Posizione tranquilla vicino a Zurigo * * * CHF 5’500’000 CHF 2’151 m² dreamo.ch](https://realadvisor.ch/it/comprare/trama/13-staldernstrasse-8158-regensberg-YJDX-XWMO) + +[2 mesi fa Orgnet Immobilien AG 844 m² Plot • Terreno edificabile Leisibüel, 8484 Weisslingen * Vista mozzafiato sulle montagne * Orientamento sud-ovest soleggiato * Quartiere tranquillo e privato * * * CHF 1’300’000 CHF 1’540 m² dreamo.ch](https://realadvisor.ch/it/comprare/trama/leisibuel-8484-weisslingen-8OO2-753X) + +[3 mesi fa TREVAG Treuhand und Verwaltungs AG 2295 m² Plot • Terreno edificabile Weiacherstrasse 85, 8427 Rorbas * Terreno spazioso di 2'295 m2 * Edificio a uso misto * Contratti di affitto esistenti * * * CHF 3’440’000 CHF 1’499 m² dreamo.ch](https://realadvisor.ch/it/comprare/trama/85-weiacherstrasse-8427-rorbas-YJD9-MVWW) + +[3 mesi fa TREVAG Treuhand und Verwaltungs AG 1742 m² Plot • Terreno edificabile Bergstrasse 7a, 8155 Nassenwil * Ampia superficie di terreno * Posizione tranquilla * Vicino a Dielsdorf * * * CHF 2’700’000 CHF 1’550 m² dreamo.ch](https://realadvisor.ch/it/comprare/trama/7a-bergstrasse-8155-nassenwil-YB69-GEB6) + +[3 mesi fa TREVAG Treuhand und Verwaltungs AG 1340 m² • 1340 m² Plot • Terreno edificabile Götze, 8197 Rafz * Vista libera * Ideale per sviluppo * Posizione privilegiata * * * CHF 2’200’000 CHF 1’642 m² dreamo.ch](https://realadvisor.ch/it/comprare/trama/gotze-8197-rafz-Y6ZW-VB6G) + +[3 mesi fa VZ VermögensZentrum 4.5 stanze • 114 m² • 480 m² Plot • Terreno edificabile Schaffhauserstrasse 226b, 8057 Zürich * Ampio spazio esterno * Vista verde dalle finestre * Stufa svedese accogliente * * * CHF 2’999’000 CHF 26’307 m² dreamo.ch](https://realadvisor.ch/it/comprare/trama/226b-schaffhauserstrasse-8057-zurich-KRNL-A6J7) + +[7 ore fa 829 m² Plot • Terreno edificabile Haldenstrasse 10, 8134 Adliswil * Posizione tranquilla con vista * Vicino ai mezzi pubblici * Disponibilità immediata * * * CHF 3’300’000 CHF 3’981 m² homegate.ch](https://realadvisor.ch/it/comprare/canton-zurigo/trama#) + +Mostra tutti i 75 annunci + +### Altri immobili in vendita nel Canton Zurigo + +[Appartamenti in vendita](https://realadvisor.ch/it/comprare/canton-zurigo/appartamento) + +[Case in vendita](https://realadvisor.ch/it/comprare/canton-zurigo/casa) + +[Terreni in vendita](https://realadvisor.ch/it/comprare/canton-zurigo/trama) + +[Edifici in vendita](https://realadvisor.ch/it/comprare/canton-zurigo/edificio) + +[Immobili commerciali in vendita](https://realadvisor.ch/it/comprare/canton-zurigo/commerciale) + +[Hotel & ristoranti in vendita](https://realadvisor.ch/it/comprare/canton-zurigo/ospitalita) + +Comprare un terreno nel Canton Zurigo +------------------------------------- + +### Terreni in vendita nel Canton Zurigo + +* [Terreni in vendita a Zurigo](https://realadvisor.ch/it/comprare/citta-zurigo/trama) +* [Terreni in vendita a Winterthur](https://realadvisor.ch/it/comprare/citta-winterthur/trama) +* [Terreni in vendita a Uster](https://realadvisor.ch/it/comprare/citta-uster/trama) +* [Terreni in vendita a Dübendorf](https://realadvisor.ch/it/comprare/citta-dubendorf/trama) +* [Terreni in vendita a Dietikon (8953)](https://realadvisor.ch/it/comprare/8953-dietikon/trama) +* [Terreni in vendita a Wädenswil](https://realadvisor.ch/it/comprare/citta-wadenswil/trama) +* [Terreni in vendita a Wetzikon (ZH)](https://realadvisor.ch/it/comprare/citta-wetzikon-zh/trama) +* [Terreni in vendita a Horgen](https://realadvisor.ch/it/comprare/citta-horgen/trama) +* [Terreni in vendita a Opfikon](https://realadvisor.ch/it/comprare/citta-opfikon/trama) +* [Terreni in vendita a Bülach (8180)](https://realadvisor.ch/it/comprare/8180-bulach/trama) +* [Terreni in vendita a Kloten (8302)](https://realadvisor.ch/it/comprare/8302-kloten/trama) +* [Terreni in vendita a Adliswil (8134)](https://realadvisor.ch/it/comprare/8134-adliswil/trama) +* [Terreni in vendita a Schlieren (8952)](https://realadvisor.ch/it/comprare/8952-schlieren/trama) +* [Terreni in vendita a Volketswil](https://realadvisor.ch/it/comprare/citta-volketswil/trama) +* [Terreni in vendita a Regensdorf](https://realadvisor.ch/it/comprare/citta-regensdorf/trama) +* [Terreni in vendita a Thalwil](https://realadvisor.ch/it/comprare/citta-thalwil/trama) +* [Terreni in vendita a Illnau-Effretikon](https://realadvisor.ch/it/comprare/citta-illnau-effretikon/trama) +* [Terreni in vendita a Wallisellen (8304)](https://realadvisor.ch/it/comprare/8304-wallisellen/trama) +* [Terreni in vendita a Stäfa](https://realadvisor.ch/it/comprare/citta-stafa/trama) +* [Terreni in vendita a Küsnacht (ZH)](https://realadvisor.ch/it/comprare/citta-kusnacht-zh/trama) +* [Terreni in vendita a Meilen (8706)](https://realadvisor.ch/it/comprare/8706-meilen/trama) +* [Terreni in vendita a Richterswil](https://realadvisor.ch/it/comprare/citta-richterswil/trama) +* [Terreni in vendita a Zollikon](https://realadvisor.ch/it/comprare/citta-zollikon/trama) +* [Terreni in vendita a Rüti ZH (8630)](https://realadvisor.ch/it/comprare/8630-ruti-zh/trama) +* [Terreni in vendita a Affoltern am Albis](https://realadvisor.ch/it/comprare/citta-affoltern-am-albis/trama) +* [Terreni in vendita a Pfäffikon](https://realadvisor.ch/it/comprare/citta-pfaffikon/trama) +* [Terreni in vendita a Bassersdorf (8303)](https://realadvisor.ch/it/comprare/8303-bassersdorf/trama) +* [Terreni in vendita a Hinwil](https://realadvisor.ch/it/comprare/citta-hinwil/trama) +* [Terreni in vendita a Männedorf (8708)](https://realadvisor.ch/it/comprare/8708-mannedorf/trama) +* [Terreni in vendita a Maur](https://realadvisor.ch/it/comprare/citta-maur/trama) +* [Terreni in vendita a Gossau (ZH)](https://realadvisor.ch/it/comprare/comune-gossau-zh/trama) +* [Terreni in vendita a Wald (ZH)](https://realadvisor.ch/it/comprare/comune-wald-zh/trama) +* [Terreni in vendita a Urdorf (8902)](https://realadvisor.ch/it/comprare/8902-urdorf/trama) +* [Terreni in vendita a Embrach (8424)](https://realadvisor.ch/it/comprare/8424-embrach/trama) +* [Terreni in vendita a Niederhasli](https://realadvisor.ch/it/comprare/comune-niederhasli/trama) +* [Terreni in vendita a Hombrechtikon](https://realadvisor.ch/it/comprare/comune-hombrechtikon/trama) +* [Terreni in vendita a Fällanden](https://realadvisor.ch/it/comprare/comune-fallanden/trama) +* [Terreni in vendita a Kilchberg ZH (8802)](https://realadvisor.ch/it/comprare/8802-kilchberg-zh/trama) +* [Terreni in vendita a Egg](https://realadvisor.ch/it/comprare/comune-egg/trama) +* [Terreni in vendita a Rümlang (8153)](https://realadvisor.ch/it/comprare/8153-rumlang/trama) +* [Terreni in vendita a Wangen-Brüttisellen](https://realadvisor.ch/it/comprare/comune-wangen-bruttisellen/trama) +* [Terreni in vendita a Dietlikon (8305)](https://realadvisor.ch/it/comprare/8305-dietlikon/trama) +* [Terreni in vendita a Dürnten](https://realadvisor.ch/it/comprare/comune-durnten/trama) +* [Terreni in vendita a Langnau am Albis (8135)](https://realadvisor.ch/it/comprare/8135-langnau-am-albis/trama) +* [Terreni in vendita a Seuzach (8472)](https://realadvisor.ch/it/comprare/8472-seuzach/trama) +* [Terreni in vendita a Bubikon](https://realadvisor.ch/it/comprare/comune-bubikon/trama) +* [Terreni in vendita a Oberglatt ZH (8154)](https://realadvisor.ch/it/comprare/8154-oberglatt-zh/trama) +* [Terreni in vendita a Oberengstringen (8102)](https://realadvisor.ch/it/comprare/8102-oberengstringen/trama) +* [Terreni in vendita a Fehraltorf (8320)](https://realadvisor.ch/it/comprare/8320-fehraltorf/trama) +* [Terreni in vendita a Birmensdorf ZH (8903)](https://realadvisor.ch/it/comprare/8903-birmensdorf-zh/trama) +* [Terreni in vendita a Wiesendangen](https://realadvisor.ch/it/comprare/comune-wiesendangen/trama) +* [Terreni in vendita a Buchs ZH (8107)](https://realadvisor.ch/it/comprare/8107-buchs-zh/trama) +* [Terreni in vendita a Herrliberg (8704)](https://realadvisor.ch/it/comprare/8704-herrliberg/trama) +* [Terreni in vendita a Uetikon am See (8707)](https://realadvisor.ch/it/comprare/8707-uetikon-am-see/trama) +* [Terreni in vendita a Dielsdorf (8157)](https://realadvisor.ch/it/comprare/8157-dielsdorf/trama) +* [Terreni in vendita a Zell (ZH)](https://realadvisor.ch/it/comprare/comune-zell-zh/trama) +* [Terreni in vendita a Rüschlikon (8803)](https://realadvisor.ch/it/comprare/8803-ruschlikon/trama) +* [Terreni in vendita a Lindau](https://realadvisor.ch/it/comprare/comune-lindau/trama) +* [Terreni in vendita a Nürensdorf (8309)](https://realadvisor.ch/it/comprare/8309-nurensdorf/trama) +* [Terreni in vendita a Erlenbach ZH (8703)](https://realadvisor.ch/it/comprare/8703-erlenbach-zh/trama) +* [Terreni in vendita a Neftenbach](https://realadvisor.ch/it/comprare/comune-neftenbach/trama) +* [Terreni in vendita a Bonstetten (8906)](https://realadvisor.ch/it/comprare/8906-bonstetten/trama) +* [Terreni in vendita a Obfelden (8912)](https://realadvisor.ch/it/comprare/8912-obfelden/trama) +* [Terreni in vendita a Greifensee (8606)](https://realadvisor.ch/it/comprare/8606-greifensee/trama) +* [Terreni in vendita a Glattfelden](https://realadvisor.ch/it/comprare/comune-glattfelden/trama) +* [Terreni in vendita a Eglisau (8193)](https://realadvisor.ch/it/comprare/8193-eglisau/trama) +* [Terreni in vendita a Zumikon (8126)](https://realadvisor.ch/it/comprare/8126-zumikon/trama) +* [Terreni in vendita a Wettswil (8907)](https://realadvisor.ch/it/comprare/8907-wettswil/trama) +* [Terreni in vendita a Schwerzenbach (8603)](https://realadvisor.ch/it/comprare/8603-schwerzenbach/trama) +* [Terreni in vendita a Oberrieden (8942)](https://realadvisor.ch/it/comprare/8942-oberrieden/trama) +* [Terreni in vendita a Bäretswil](https://realadvisor.ch/it/comprare/comune-baretswil/trama) +* [Terreni in vendita a Niederglatt ZH (8172)](https://realadvisor.ch/it/comprare/8172-niederglatt-zh/trama) +* [Terreni in vendita a Geroldswil](https://realadvisor.ch/it/comprare/comune-geroldswil/trama) +* [Terreni in vendita a Bauma](https://realadvisor.ch/it/comprare/comune-bauma/trama) +* [Terreni in vendita a Elgg](https://realadvisor.ch/it/comprare/comune-elgg/trama) +* [Terreni in vendita a Mettmenstetten (8932)](https://realadvisor.ch/it/comprare/8932-mettmenstetten/trama) +* [Terreni in vendita a Weiningen ZH (8104)](https://realadvisor.ch/it/comprare/8104-weiningen-zh/trama) +* [Terreni in vendita a Oetwil am See (8618)](https://realadvisor.ch/it/comprare/8618-oetwil-am-see/trama) +* [Terreni in vendita a Turbenthal](https://realadvisor.ch/it/comprare/comune-turbenthal/trama) +* [Terreni in vendita a Winkel (8185)](https://realadvisor.ch/it/comprare/8185-winkel/trama) +* [Terreni in vendita a Rafz (8197)](https://realadvisor.ch/it/comprare/8197-rafz/trama) +* [Terreni in vendita a Russikon](https://realadvisor.ch/it/comprare/comune-russikon/trama) +* [Terreni in vendita a Uitikon Waldegg (8142)](https://realadvisor.ch/it/comprare/8142-uitikon-waldegg/trama) +* [Terreni in vendita a Dällikon (8108)](https://realadvisor.ch/it/comprare/8108-dallikon/trama) +* [Terreni in vendita a Bachenbülach (8184)](https://realadvisor.ch/it/comprare/8184-bachenbulach/trama) +* [Terreni in vendita a Pfungen (8422)](https://realadvisor.ch/it/comprare/8422-pfungen/trama) +* [Terreni in vendita a Unterengstringen (8103)](https://realadvisor.ch/it/comprare/8103-unterengstringen/trama) +* [Terreni in vendita a Mönchaltorf (8617)](https://realadvisor.ch/it/comprare/8617-monchaltorf/trama) +* [Terreni in vendita a Stallikon](https://realadvisor.ch/it/comprare/comune-stallikon/trama) +* [Terreni in vendita a Hedingen (8908)](https://realadvisor.ch/it/comprare/8908-hedingen/trama) +* [Terreni in vendita a Hausen am Albis](https://realadvisor.ch/it/comprare/comune-hausen-am-albis/trama) +* [Terreni in vendita a Feuerthalen](https://realadvisor.ch/it/comprare/comune-feuerthalen/trama) +* [Terreni in vendita a Hittnau (8335)](https://realadvisor.ch/it/comprare/8335-hittnau/trama) +* [Terreni in vendita a Elsau (8352)](https://realadvisor.ch/it/comprare/8352-elsau/trama) +* [Terreni in vendita a Steinmaur](https://realadvisor.ch/it/comprare/comune-steinmaur/trama) +* [Terreni in vendita a Grüningen (8627)](https://realadvisor.ch/it/comprare/8627-gruningen/trama) +* [Terreni in vendita a Weisslingen](https://realadvisor.ch/it/comprare/comune-weisslingen/trama) +* [Terreni in vendita a Hettlingen (8442)](https://realadvisor.ch/it/comprare/8442-hettlingen/trama) +* [Terreni in vendita a Neerach (8173)](https://realadvisor.ch/it/comprare/8173-neerach/trama) +* [Terreni in vendita a Niederweningen (8166)](https://realadvisor.ch/it/comprare/8166-niederweningen/trama) +* [Terreni in vendita a Otelfingen (8112)](https://realadvisor.ch/it/comprare/8112-otelfingen/trama) +* [Terreni in vendita a Rorbas (8427)](https://realadvisor.ch/it/comprare/8427-rorbas/trama) +* [Terreni in vendita a Stammheim](https://realadvisor.ch/it/comprare/comune-stammheim/trama) +* [Terreni in vendita a Höri (8181)](https://realadvisor.ch/it/comprare/8181-hori/trama) +* [Terreni in vendita a Rickenbach (ZH)](https://realadvisor.ch/it/comprare/comune-rickenbach-zh/trama) +* [Terreni in vendita a Ottenbach (8913)](https://realadvisor.ch/it/comprare/8913-ottenbach/trama) +* [Terreni in vendita a Fischenthal](https://realadvisor.ch/it/comprare/comune-fischenthal/trama) +* [Terreni in vendita a Oetwil an der Limmat (8955)](https://realadvisor.ch/it/comprare/8955-oetwil-an-der-limmat/trama) +* [Terreni in vendita a Lufingen (8426)](https://realadvisor.ch/it/comprare/8426-lufingen/trama) +* [Terreni in vendita a Freienstein-Teufen](https://realadvisor.ch/it/comprare/comune-freienstein-teufen/trama) +* [Terreni in vendita a Knonau (8934)](https://realadvisor.ch/it/comprare/8934-knonau/trama) +* [Terreni in vendita a Stadel](https://realadvisor.ch/it/comprare/comune-stadel/trama) +* [Terreni in vendita a Henggart (8444)](https://realadvisor.ch/it/comprare/8444-henggart/trama) +* [Terreni in vendita a Andelfingen (8450)](https://realadvisor.ch/it/comprare/8450-andelfingen/trama) +* [Terreni in vendita a Kleinandelfingen](https://realadvisor.ch/it/comprare/comune-kleinandelfingen/trama) +* [Terreni in vendita a Brütten (8311)](https://realadvisor.ch/it/comprare/8311-brutten/trama) +* [Terreni in vendita a Wila (8492)](https://realadvisor.ch/it/comprare/8492-wila/trama) +* [Terreni in vendita a Marthalen](https://realadvisor.ch/it/comprare/comune-marthalen/trama) +* [Terreni in vendita a Aeugst am Albis](https://realadvisor.ch/it/comprare/comune-aeugst-am-albis/trama) +* [Terreni in vendita a Dachsen (8447)](https://realadvisor.ch/it/comprare/8447-dachsen/trama) +* [Terreni in vendita a Hochfelden (8182)](https://realadvisor.ch/it/comprare/8182-hochfelden/trama) +* [Terreni in vendita a Dänikon ZH (8114)](https://realadvisor.ch/it/comprare/8114-danikon-zh/trama) +* [Terreni in vendita a Oberweningen (8165)](https://realadvisor.ch/it/comprare/8165-oberweningen/trama) +* [Terreni in vendita a Weiach (8187)](https://realadvisor.ch/it/comprare/8187-weiach/trama) +* [Terreni in vendita a Laufen-Uhwiesen](https://realadvisor.ch/it/comprare/comune-laufen-uhwiesen/trama) +* [Terreni in vendita a Ossingen (8475)](https://realadvisor.ch/it/comprare/8475-ossingen/trama) +* [Terreni in vendita a Dinhard (8474)](https://realadvisor.ch/it/comprare/8474-dinhard/trama) +* [Terreni in vendita a Seegräben](https://realadvisor.ch/it/comprare/comune-seegraben/trama) +* [Terreni in vendita a Flurlingen (8247)](https://realadvisor.ch/it/comprare/8247-flurlingen/trama) +* [Terreni in vendita a Wil ZH (8196)](https://realadvisor.ch/it/comprare/8196-wil-zh/trama) +* [Terreni in vendita a Schöfflisdorf (8165)](https://realadvisor.ch/it/comprare/8165-schofflisdorf/trama) +* [Terreni in vendita a Flaach (8416)](https://realadvisor.ch/it/comprare/8416-flaach/trama) +* [Terreni in vendita a Boppelsen (8113)](https://realadvisor.ch/it/comprare/8113-boppelsen/trama) +* [Terreni in vendita a Aesch ZH (8904)](https://realadvisor.ch/it/comprare/8904-aesch-zh/trama) +* [Terreni in vendita a Rheinau (8462)](https://realadvisor.ch/it/comprare/8462-rheinau/trama) +* [Terreni in vendita a Kappel am Albis](https://realadvisor.ch/it/comprare/comune-kappel-am-albis/trama) +* [Terreni in vendita a Hagenbuch ZH (8523)](https://realadvisor.ch/it/comprare/8523-hagenbuch-zh/trama) +* [Terreni in vendita a Rifferswil (8911)](https://realadvisor.ch/it/comprare/8911-rifferswil/trama) +* [Terreni in vendita a Trüllikon](https://realadvisor.ch/it/comprare/comune-trullikon/trama) +* [Terreni in vendita a Oberembrach (8425)](https://realadvisor.ch/it/comprare/8425-oberembrach/trama) +* [Terreni in vendita a Hüntwangen (8194)](https://realadvisor.ch/it/comprare/8194-huntwangen/trama) +* [Terreni in vendita a Dägerlen](https://realadvisor.ch/it/comprare/comune-dagerlen/trama) +* [Terreni in vendita a Wildberg](https://realadvisor.ch/it/comprare/comune-wildberg/trama) +* [Terreni in vendita a Buch am Irchel (8414)](https://realadvisor.ch/it/comprare/8414-buch-am-irchel/trama) +* [Terreni in vendita a Hüttikon (8115)](https://realadvisor.ch/it/comprare/8115-huttikon/trama) +* [Terreni in vendita a Thalheim an der Thur (8478)](https://realadvisor.ch/it/comprare/8478-thalheim-an-der-thur/trama) +* [Terreni in vendita a Ellikon an der Thur (8548)](https://realadvisor.ch/it/comprare/8548-ellikon-an-der-thur/trama) +* [Terreni in vendita a Benken ZH (8463)](https://realadvisor.ch/it/comprare/8463-benken-zh/trama) +* [Terreni in vendita a Dättlikon (8421)](https://realadvisor.ch/it/comprare/8421-dattlikon/trama) +* [Terreni in vendita a Schleinikon (8165)](https://realadvisor.ch/it/comprare/8165-schleinikon/trama) +* [Terreni in vendita a Schlatt ZH (8418)](https://realadvisor.ch/it/comprare/8418-schlatt-zh/trama) +* [Terreni in vendita a Dorf (8458)](https://realadvisor.ch/it/comprare/8458-dorf/trama) +* [Terreni in vendita a Altikon (8479)](https://realadvisor.ch/it/comprare/8479-altikon/trama) +* [Terreni in vendita a Adlikon b. Andelfingen (8452)](https://realadvisor.ch/it/comprare/8452-adlikon-b-andelfingen/trama) +* [Terreni in vendita a Maschwanden (8933)](https://realadvisor.ch/it/comprare/8933-maschwanden/trama) +* [Terreni in vendita a Bachs (8164)](https://realadvisor.ch/it/comprare/8164-bachs/trama) +* [Terreni in vendita a Wasterkingen (8195)](https://realadvisor.ch/it/comprare/8195-wasterkingen/trama) +* [Terreni in vendita a Berg am Irchel](https://realadvisor.ch/it/comprare/comune-berg-am-irchel/trama) +* [Terreni in vendita a Humlikon (8457)](https://realadvisor.ch/it/comprare/8457-humlikon/trama) +* [Terreni in vendita a Truttikon (8467)](https://realadvisor.ch/it/comprare/8467-truttikon/trama) +* [Terreni in vendita a Regensberg (8158)](https://realadvisor.ch/it/comprare/8158-regensberg/trama) +* [Terreni in vendita a Volken (8459)](https://realadvisor.ch/it/comprare/8459-volken/trama) +* Mostra 144 altri + +Quanto vale la mia casa? + +[Ottieni subito una valutazione online](https://realadvisor.ch/it/valutazione-immobile-gratuita) + +Qual è il prezzo medio degli immobili? + +[Scopri i prezzi al m² aggiornati nel Canton Zurigo](https://realadvisor.ch/it/prezzi-immobili/canton-zurigo) + +Cerchi un esperto immobiliare di fiducia? + +[Trova la migliore agenzia nel Canton Zurigo](https://realadvisor.ch/it/agenzie-immobiliari/canton-zurigo) + +[](https://realadvisor.ch/it) + +[](https://it.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + +Vendere + +* [Valutazione immobiliare](https://realadvisor.ch/it/valutazione-immobile-gratuita) +* [Valutazione degli Immobili a reddito](https://realadvisor.ch/it/valutazione-immobili-a-reddito) +* [Prezzo degli immobili](https://realadvisor.ch/it/prezzi-immobili) +* [Agenzie immobiliari](https://realadvisor.ch/it/trova-una-agenzia) +* [Blog immobiliare](https://realadvisor.ch/it/blog) + +Comprare / Affittare + +* [Immobili in vendita](https://realadvisor.ch/it/vendita-immobile) +* [Immobili in affitto](https://realadvisor.ch/it/immobili-in-affitto) +* [Promozioni immobiliari](https://realadvisor.ch/it/nuove-costruzioni) +* [Finanziamento immobiliare](https://realadvisor.ch/it/finanziamento) + +Professionisti + +* [Diventare partner](https://realadvisor.ch/it/pro) + +La Società + +* [Chi siamo](https://realadvisor.ch/it/chi-siamo) +* [Press](https://realadvisor.ch/it/press) +* [Offerte di lavoro](https://realadvisor.welcomekit.co/) +* [Termini e condizioni](https://realadvisor.ch/it/termin-e-condizioni) +* [Informativa sulla privacy](https://realadvisor.ch/it/protezione-dati) +* [Informazioni legali](https://realadvisor.ch/it/informazioni-legali) +* [Tutti gli immobili](https://realadvisor.ch/it/sitemap) + +© Realadvisor 2025. All Rights Reserved. + +[](https://ch.linkedin.com/company/realadvisor)[](https://www.facebook.com/realadvisorcom)[](https://twitter.com/RealAdvisor)[](https://www.instagram.com/realadvisorcom/)[](https://www.youtube.com/channel/UCsEDTDlmxBpyxLXYhWT769Q) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_021_realadvisor.ch_fr_acheter_canton-zurich_terrain.txt b/test_web_content_20251002_215219/additional_link_021_realadvisor.ch_fr_acheter_canton-zurich_terrain.txt new file mode 100644 index 00000000..2e9a67eb --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_021_realadvisor.ch_fr_acheter_canton-zurich_terrain.txt @@ -0,0 +1,436 @@ +URL: https://realadvisor.ch/fr/acheter/canton-zurich/terrain +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +75 Terrains à vendre dans le canton de Zurich - octobre 2025 + +=============== + +[](https://realadvisor.ch/fr/immobilier-a-vendre) + ++1 plus + +Canton de Zurich + + + +Estimer + +[Acheter](https://realadvisor.ch/fr/immobilier-a-vendre)[Louer](https://realadvisor.ch/fr/immobilier-a-louer) + +Connexion + +FR + +[Italiano](https://realadvisor.ch/it/comprare/canton-zurigo/trama)[Deutsch](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck)[English](https://realadvisor.ch/en/buy/canton-zurich/plot) + +Créer une alerte + ++1 plus + +Canton de Zurich + + + +Acheter Louer + +Acheter Louer + +Terrain + +Prix + +Modifier la recherche + +Surface du terrain + +Autre filtres + +Créer une alerte + +- [x] Carte + +←Move left +→Move right +↑Move up +↓Move down ++Zoom in +-Zoom out +Home Jump left by 75% +End Jump right by 75% +Page Up Jump up by 75% +Page Down Jump down by 75% + + + + + + + + + + + + + + + + + + + + + + + + + +9 + +9 + +5 + +5 + +3 + +3 + +6 + +6 + +17 + +17 + +7 + +7 + +4 + +4 + +2 + +2 + +2 + +2 + +14 + +14 + +5 + +5 + +1 + +1 + + + +Map +* Map +* Satellite +* Terrain +* Labels + + + + + +*  +*  +*  +*  +*  +*  + +[](https://maps.google.com/maps?ll=47.421441,8.671322&z=9&t=m&hl=en-US&gl=US&mapclient=apiv3 "Open this area in Google Maps (opens a new window)") + +Keyboard shortcuts + +Map Data Map data ©2025 GeoBasis-DE/BKG (©2009), Google + +Map data ©2025 GeoBasis-DE/BKG (©2009), Google + +10 km + +Click to toggle between metric and imperial units + +[Terms](https://www.google.com/intl/en-US_US/help/terms_maps.html) + +[Report a map error](https://www.google.com/maps/@47.421441,8.6713222,9z/data=!10m1!1e1!12b1?source=apiv3&rapsrc=apiv3 "Report errors in the road map or imagery to Google") + +1. [](https://realadvisor.ch/fr) + +3. [Acheter](https://realadvisor.ch/fr/acheter) + +5. [Terrain](https://realadvisor.ch/fr/acheter/terrain) + +7. Canton de Zurich + +Terrains à vendre dans le canton de Zurich +========================================== + +75 Résultats + +Nos suggestions + +[](https://realadvisor.ch/fr/acheter/terrain/8162-steinmaur-B62R-PZDJ) + +il y a 3 jours + +- [x] + +[get living 1’452 m² Terrain • Terrain constructible 8162 Steinmaur * Terrain plat et constructible * Emplacement calme et ensoleillé * Accès facile aux transports publics ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Sur demande —](https://realadvisor.ch/fr/acheter/terrain/8162-steinmaur-B62R-PZDJ) + +[](https://realadvisor.ch/fr/acheter/terrain/8340-hinwil-LDX9-L6M2) + +il y a 6 jours + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 1’070 m² Terrain • Terrain constructible 8340 Hinwil * Plus de 1 070 m² * Options de subdivision flexibles * Idéal pour maisons familiales ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’070’000.- CHF 1’000 / m²](https://realadvisor.ch/fr/acheter/terrain/8340-hinwil-LDX9-L6M2) + +[](https://realadvisor.ch/fr/acheter/terrain/8633-wolfhausen-YB6N-VRVP) + +il y a 7 jours + +- [x] + +[PREMIUM HOMES AG 1’940 m² Terrain • Terrain constructible 8633 Wolfhausen * Terrain généreux de 1'940m² * Emplacement familial * Options de conception flexibles ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 4’074’000.- CHF 2’100 / m²](https://realadvisor.ch/fr/acheter/terrain/8633-wolfhausen-YB6N-VRVP) + +[](https://realadvisor.ch/fr/acheter/terrain/sonnhalde-8602-wangen-b.-dubendorf-83JW-X5X3) + +il y a 9 jours + +- [x] + +[Moser Anlageimmobilien AG 1’666 m² Terrain • Terrain constructible Sonnhalde, 8602 Wangen b. Dübendorf * 1666 m² de terrain privilégié * Exposition optimale au soleil * Intimité dans un quartier calme ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3’300’000.- CHF 1’981 / m²](https://realadvisor.ch/fr/acheter/terrain/sonnhalde-8602-wangen-b.-dubendorf-83JW-X5X3) + +[](https://realadvisor.ch/fr/acheter/terrain/8000-zurich-NAG4-JV4R) + +il y a 11 jours + +- [x] + +[Centrum Immo Terrain constructible 8000 Zürich * Idéal pour le développement * Proche des transports publics * Vues pittoresques sur la ville ------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Sur demande —](https://realadvisor.ch/fr/acheter/terrain/8000-zurich-NAG4-JV4R) + +[](https://realadvisor.ch/fr/acheter/terrain/8195-wasterkingen-7JPL-7X5M) + +il y a 13 jours + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 650 m² Terrain • Terrain constructible 8195 Wasterkingen * Terrain entièrement viabilisé * Communauté rurale calme * Options de conception flexibles ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 475’000.- CHF 731 / m²](https://realadvisor.ch/fr/acheter/terrain/8195-wasterkingen-7JPL-7X5M) + +[](https://realadvisor.ch/fr/acheter/terrain/8618-oetwil-am-see-8OOG-PWB5) + +il y a 21 jours + +- [x] + +[Swiss Residence Group AG 1’622 m² Terrain • Terrain constructible 8618 Oetwil am See * Terrain ensoleillé de 1'622 m² * Zonage flexible pour projets * Vue imprenable sur les montagnes ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Sur demande —](https://realadvisor.ch/fr/acheter/terrain/8618-oetwil-am-see-8OOG-PWB5) + +[](https://realadvisor.ch/fr/acheter/terrain/8617-monchaltorf-KRNG-WO9R) + +il y a 22 jours + +- [x] + +[PREMIUM HOMES AG 850 m² Terrain • Terrain constructible 8617 Mönchaltorf * Fort potentiel de développement * Emplacement calme et ensoleillé * Options d'utilisation flexibles --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Sur demande —](https://realadvisor.ch/fr/acheter/terrain/8617-monchaltorf-KRNG-WO9R) + +[](https://realadvisor.ch/fr/acheter/terrain/gueterstalstrasse-8133-esslingen-YMXG-R3MR) + +il y a 26 jours + +- [x] + +[Schiblis Immobilien GmbH 507 m² Terrain • Terrain constructible Güeterstalstrasse, 8133 Esslingen * Emplacement central à Esslingen * Pas d'obligation architecturale * Aucune contamination présente -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 600’000.- CHF 1’183 / m²](https://realadvisor.ch/fr/acheter/terrain/gueterstalstrasse-8133-esslingen-YMXG-R3MR) + +[](https://realadvisor.ch/fr/acheter/terrain/8192-zweidlen-6ZMD-4WE3) + +il y a 28 jours + +- [x] + +[Grundeigentümer Verband Schweiz 1’226 m² Terrain • Terrain constructible 8192 Zweidlen * Superficie totale de 1'226 m² * Surface utile max. 940 m² * Options de développement flexibles ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 2’450’000.- CHF 1’998 / m²](https://realadvisor.ch/fr/acheter/terrain/8192-zweidlen-6ZMD-4WE3) + +[](https://realadvisor.ch/fr/acheter/terrain/8424-embrach-8WRG-NEGR) + +il y a 29 jours + +- [x] + +[PREMIUM HOMES AG 1’670 m² Terrain • Terrain constructible 8424 Embrach * Emplacement familial * Lumière abondante toute la journée * Options de construction flexibles ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Sur demande —](https://realadvisor.ch/fr/acheter/terrain/8424-embrach-8WRG-NEGR) + +[](https://realadvisor.ch/fr/acheter/terrain/10-berghalde-8332-russikon-6ZMD-432O) + +il y a 29 jours + +- [x] + +[SH Immo GmbH 854 m² Terrain • Terrain constructible Berghalde 10, 8332 Russikon * Terrain spacieux de 854 m2 * Emplacement ensoleillé idéal * Potentiel pour nouvelle construction ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’500’000.- CHF 1’756 / m²](https://realadvisor.ch/fr/acheter/terrain/10-berghalde-8332-russikon-6ZMD-432O) + +[](https://realadvisor.ch/fr/acheter/terrain/8134-adliswil-Y7J5-W36M) + +il y a 1 mois + +- [x] + +[Moos & Partner Immobilien GmbH 694 m² Terrain • Terrain constructible 8134 Adliswil * Emplacement central avec potentiel * Zone W3 à haute utilisation * Idéal pour investisseurs & développeurs --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3’600’000.- CHF 5’187 / m²](https://realadvisor.ch/fr/acheter/terrain/8134-adliswil-Y7J5-W36M) + +[](https://realadvisor.ch/fr/acheter/terrain/23-uberlandstrasse-8340-hinwil-YB69-VB7M) + +il y a 2 mois + +- [x] + +[RE/MAX Immobilien in Rapperswil-Jona 4’246 m² Terrain • Terrain constructible Überlandstrasse 23, 8340 Hinwil * Emplacement privilégié près des routes * Grande surface à développer * Options de hauteur de bâtiment flexibles ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Sur demande —](https://realadvisor.ch/fr/acheter/terrain/23-uberlandstrasse-8340-hinwil-YB69-VB7M) + +[](https://realadvisor.ch/fr/acheter/terrain/20-winzerstrasse-8353-elgg-KRNL-ZPNR) + +il y a 2 mois + +- [x] + +[RE/MAX Immobilien in Winterthur 877 m² Terrain • Terrain constructible Winzerstrasse 20, 8353 Elgg * Idéal pour maisons familiales * Opportunité d'investissement * Adjacent à une maison existante ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 1’140’000.- CHF 1’300 / m²](https://realadvisor.ch/fr/acheter/terrain/20-winzerstrasse-8353-elgg-KRNL-ZPNR) + +[](https://realadvisor.ch/fr/acheter/terrain/34-industriestrasse-8117-fallanden-YJDX-JXRR) + +il y a 3 mois + +- [x] + +[RE/MAX Immobilien in Meilen 2’838 m² • 1’706 m² Terrain • Terrain constructible Industriestrasse 34, 8117 Fällanden * Projet commercial approuvé * Utilisation commerciale flexible * 37 places de parking disponibles ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Sur demande —](https://realadvisor.ch/fr/acheter/terrain/34-industriestrasse-8117-fallanden-YJDX-JXRR) + +[](https://realadvisor.ch/fr/acheter/terrain/8630-ruti-zh-84E9-Z65G) + +il y a 4 mois + +- [x] + +[PREMIUM HOMES AG 3’460 m² Terrain • Terrain constructible 8630 Rüti ZH * Zone résidentielle calme * Taux d'utilisation de 30% * Bonus pour espace supplémentaire ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Sur demande —](https://realadvisor.ch/fr/acheter/terrain/8630-ruti-zh-84E9-Z65G) + +[](https://realadvisor.ch/fr/acheter/terrain/13-staldernstrasse-8158-regensberg-YJDX-XWMO) + +il y a 16 jours + +- [x] + +[Swisslife 2’557 m² Terrain • Terrain constructible Staldernstrasse 13, 8158 Regensberg * Zonage flexible pour usage mixte * Fort potentiel de rendement locatif * Emplacement calme près de Zurich ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 5’500’000.- CHF 2’151 / m² dreamo.ch](https://realadvisor.ch/fr/acheter/terrain/13-staldernstrasse-8158-regensberg-YJDX-XWMO) + +[](https://realadvisor.ch/fr/acheter/terrain/leisibuel-8484-weisslingen-8OO2-753X) + +il y a 2 mois + +- [x] + +[Orgnet Immobilien AG 844 m² Terrain • Terrain constructible Leisibüel, 8484 Weisslingen * Vue imprenable sur les montagnes * Orientation sud-ouest ensoleillée * Quartier calme et privé ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’300’000.- CHF 1’540 / m² dreamo.ch](https://realadvisor.ch/fr/acheter/terrain/leisibuel-8484-weisslingen-8OO2-753X) + +[](https://realadvisor.ch/fr/acheter/terrain/85-weiacherstrasse-8427-rorbas-YJD9-MVWW) + +il y a 3 mois + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 2’295 m² Terrain • Terrain constructible Weiacherstrasse 85, 8427 Rorbas * Terrain spacieux de 2'295 m2 * Bâtiment à usage mixte * Baux existants --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3’440’000.- CHF 1’499 / m² dreamo.ch](https://realadvisor.ch/fr/acheter/terrain/85-weiacherstrasse-8427-rorbas-YJD9-MVWW) + +[](https://realadvisor.ch/fr/acheter/terrain/7a-bergstrasse-8155-nassenwil-YB69-GEB6) + +il y a 3 mois + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 1’742 m² Terrain • Terrain constructible Bergstrasse 7a, 8155 Nassenwil * Grande superficie de terrain * Emplacement paisible * Proche de Dielsdorf ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2’700’000.- CHF 1’550 / m² dreamo.ch](https://realadvisor.ch/fr/acheter/terrain/7a-bergstrasse-8155-nassenwil-YB69-GEB6) + +[](https://realadvisor.ch/fr/acheter/terrain/gotze-8197-rafz-Y6ZW-VB6G) + +il y a 3 mois + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 1’340 m² • 1’340 m² Terrain • Terrain constructible Götze, 8197 Rafz * Vues dégagées * Idéal pour développement * Emplacement privilégié ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 2’200’000.- CHF 1’642 / m² dreamo.ch](https://realadvisor.ch/fr/acheter/terrain/gotze-8197-rafz-Y6ZW-VB6G) + +[](https://realadvisor.ch/fr/acheter/terrain/226b-schaffhauserstrasse-8057-zurich-KRNL-A6J7) + +il y a 3 mois + +- [x] + +[VZ VermögensZentrum 4.5 pces • 114 m² • 480 m² Terrain • Terrain constructible Schaffhauserstrasse 226b, 8057 Zürich * Grand espace extérieur * Vue sur la verdure * Poêle suédois chaleureux ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 2’999’000.- CHF 26’307 / m² dreamo.ch](https://realadvisor.ch/fr/acheter/terrain/226b-schaffhauserstrasse-8057-zurich-KRNL-A6J7) + +[](https://realadvisor.ch/fr/acheter/canton-zurich/terrain#) + +il y a 7 heures + +- [x] + +[— 829 m² Terrain • Terrain constructible Haldenstrasse 10, 8134 Adliswil * Emplacement calme avec vue * Proche des transports publics * Disponibilité immédiate ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 3’300’000.- CHF 3’981 / m² homegate.ch](https://realadvisor.ch/fr/acheter/canton-zurich/terrain#) + +[1](https://realadvisor.ch/fr/acheter/canton-zurich/terrain) + +[2](https://realadvisor.ch/fr/acheter/canton-zurich/terrain/page-2) + +[3](https://realadvisor.ch/fr/acheter/canton-zurich/terrain/page-3) + +[4](https://realadvisor.ch/fr/acheter/canton-zurich/terrain/page-4) + +[](https://realadvisor.ch/fr/acheter/canton-zurich/terrain/page-2) + +1 - 24 de 75 Résultats + +Acheter un terrain dans le canton de Zurich +------------------------------------------- + +[Voir les prix de l’immobilier pour Canton de Zurich](https://realadvisor.ch/fr/prix-m2-immobilier/canton-zurich) + +### Terrain à vendre dans le canton de Zurich + +[Terrain à vendre à Zurich](https://realadvisor.ch/fr/acheter/ville-zurich/terrain)[Terrain à vendre à Winterthour](https://realadvisor.ch/fr/acheter/ville-winterthour/terrain)[Terrain à vendre à Uster](https://realadvisor.ch/fr/acheter/ville-uster/terrain)[Terrain à vendre à Dübendorf](https://realadvisor.ch/fr/acheter/ville-dubendorf/terrain)[Terrain à vendre à Dietikon (8953)](https://realadvisor.ch/fr/acheter/8953-dietikon/terrain)[Terrain à vendre à Wädenswil](https://realadvisor.ch/fr/acheter/ville-wadenswil/terrain)[Terrain à vendre à Wetzikon (ZH)](https://realadvisor.ch/fr/acheter/ville-wetzikon-zh/terrain)[Terrain à vendre à Horgen](https://realadvisor.ch/fr/acheter/ville-horgen/terrain)[Terrain à vendre à Opfikon](https://realadvisor.ch/fr/acheter/ville-opfikon/terrain)[Terrain à vendre à Bülach (8180)](https://realadvisor.ch/fr/acheter/8180-bulach/terrain)[Terrain à vendre à Kloten (8302)](https://realadvisor.ch/fr/acheter/8302-kloten/terrain)[Terrain à vendre à Adliswil (8134)](https://realadvisor.ch/fr/acheter/8134-adliswil/terrain)[Terrain à vendre à Schlieren (8952)](https://realadvisor.ch/fr/acheter/8952-schlieren/terrain)[Terrain à vendre à Volketswil](https://realadvisor.ch/fr/acheter/ville-volketswil/terrain)[Terrain à vendre à Regensdorf](https://realadvisor.ch/fr/acheter/ville-regensdorf/terrain)[Terrain à vendre à Thalwil](https://realadvisor.ch/fr/acheter/ville-thalwil/terrain)[Terrain à vendre à Illnau-Effretikon](https://realadvisor.ch/fr/acheter/ville-illnau-effretikon/terrain)[Terrain à vendre à Wallisellen (8304)](https://realadvisor.ch/fr/acheter/8304-wallisellen/terrain)[Terrain à vendre à Stäfa](https://realadvisor.ch/fr/acheter/ville-stafa/terrain)[Terrain à vendre à Küsnacht (ZH)](https://realadvisor.ch/fr/acheter/ville-kusnacht-zh/terrain)[Terrain à vendre à Meilen (8706)](https://realadvisor.ch/fr/acheter/8706-meilen/terrain)[Terrain à vendre à Richterswil](https://realadvisor.ch/fr/acheter/ville-richterswil/terrain)[Terrain à vendre à Zollikon](https://realadvisor.ch/fr/acheter/ville-zollikon/terrain)[Terrain à vendre à Rüti ZH (8630)](https://realadvisor.ch/fr/acheter/8630-ruti-zh/terrain)[Terrain à vendre à Affoltern am Albis](https://realadvisor.ch/fr/acheter/ville-affoltern-am-albis/terrain)[Terrain à vendre à Pfäffikon](https://realadvisor.ch/fr/acheter/ville-pfaffikon/terrain)[Terrain à vendre à Bassersdorf (8303)](https://realadvisor.ch/fr/acheter/8303-bassersdorf/terrain)[Terrain à vendre à Hinwil](https://realadvisor.ch/fr/acheter/ville-hinwil/terrain)[Terrain à vendre à Männedorf (8708)](https://realadvisor.ch/fr/acheter/8708-mannedorf/terrain)[Terrain à vendre à Maur](https://realadvisor.ch/fr/acheter/ville-maur/terrain)[Terrain à vendre à Gossau (ZH)](https://realadvisor.ch/fr/acheter/commune-gossau-zh/terrain)[Terrain à vendre à Wald (ZH)](https://realadvisor.ch/fr/acheter/commune-wald-zh/terrain)[Terrain à vendre à Urdorf (8902)](https://realadvisor.ch/fr/acheter/8902-urdorf/terrain)[Terrain à vendre à Embrach (8424)](https://realadvisor.ch/fr/acheter/8424-embrach/terrain)[Terrain à vendre à Niederhasli](https://realadvisor.ch/fr/acheter/commune-niederhasli/terrain)[Terrain à vendre à Hombrechtikon](https://realadvisor.ch/fr/acheter/commune-hombrechtikon/terrain)[Terrain à vendre à Fällanden](https://realadvisor.ch/fr/acheter/commune-fallanden/terrain)[Terrain à vendre à Kilchberg ZH (8802)](https://realadvisor.ch/fr/acheter/8802-kilchberg-zh/terrain)[Terrain à vendre à Egg](https://realadvisor.ch/fr/acheter/commune-egg/terrain)[Terrain à vendre à Rümlang (8153)](https://realadvisor.ch/fr/acheter/8153-rumlang/terrain)[Terrain à vendre à Wangen-Brüttisellen](https://realadvisor.ch/fr/acheter/commune-wangen-bruttisellen/terrain)[Terrain à vendre à Dietlikon (8305)](https://realadvisor.ch/fr/acheter/8305-dietlikon/terrain)[Terrain à vendre à Dürnten](https://realadvisor.ch/fr/acheter/commune-durnten/terrain)[Terrain à vendre à Langnau am Albis (8135)](https://realadvisor.ch/fr/acheter/8135-langnau-am-albis/terrain)[Terrain à vendre à Seuzach (8472)](https://realadvisor.ch/fr/acheter/8472-seuzach/terrain)[Terrain à vendre à Bubikon](https://realadvisor.ch/fr/acheter/commune-bubikon/terrain)[Terrain à vendre à Oberglatt ZH (8154)](https://realadvisor.ch/fr/acheter/8154-oberglatt-zh/terrain)[Terrain à vendre à Oberengstringen (8102)](https://realadvisor.ch/fr/acheter/8102-oberengstringen/terrain)[Terrain à vendre à Fehraltorf (8320)](https://realadvisor.ch/fr/acheter/8320-fehraltorf/terrain)[Terrain à vendre à Birmensdorf ZH (8903)](https://realadvisor.ch/fr/acheter/8903-birmensdorf-zh/terrain)[Terrain à vendre à Wiesendangen](https://realadvisor.ch/fr/acheter/commune-wiesendangen/terrain)[Terrain à vendre à Buchs ZH (8107)](https://realadvisor.ch/fr/acheter/8107-buchs-zh/terrain)[Terrain à vendre à Herrliberg (8704)](https://realadvisor.ch/fr/acheter/8704-herrliberg/terrain)[Terrain à vendre à Uetikon am See (8707)](https://realadvisor.ch/fr/acheter/8707-uetikon-am-see/terrain)[Terrain à vendre à Dielsdorf (8157)](https://realadvisor.ch/fr/acheter/8157-dielsdorf/terrain)[Terrain à vendre à Zell (ZH)](https://realadvisor.ch/fr/acheter/commune-zell-zh/terrain)[Terrain à vendre à Rüschlikon (8803)](https://realadvisor.ch/fr/acheter/8803-ruschlikon/terrain)[Terrain à vendre à Lindau](https://realadvisor.ch/fr/acheter/commune-lindau/terrain)[Terrain à vendre à Nürensdorf (8309)](https://realadvisor.ch/fr/acheter/8309-nurensdorf/terrain)[Terrain à vendre à Erlenbach ZH (8703)](https://realadvisor.ch/fr/acheter/8703-erlenbach-zh/terrain)[Terrain à vendre à Neftenbach](https://realadvisor.ch/fr/acheter/commune-neftenbach/terrain)[Terrain à vendre à Bonstetten (8906)](https://realadvisor.ch/fr/acheter/8906-bonstetten/terrain)[Terrain à vendre à Obfelden (8912)](https://realadvisor.ch/fr/acheter/8912-obfelden/terrain)[Terrain à vendre à Greifensee (8606)](https://realadvisor.ch/fr/acheter/8606-greifensee/terrain)[Terrain à vendre à Glattfelden](https://realadvisor.ch/fr/acheter/commune-glattfelden/terrain)[Terrain à vendre à Eglisau (8193)](https://realadvisor.ch/fr/acheter/8193-eglisau/terrain)[Terrain à vendre à Zumikon (8126)](https://realadvisor.ch/fr/acheter/8126-zumikon/terrain)[Terrain à vendre à Wettswil (8907)](https://realadvisor.ch/fr/acheter/8907-wettswil/terrain)[Terrain à vendre à Schwerzenbach (8603)](https://realadvisor.ch/fr/acheter/8603-schwerzenbach/terrain)[Terrain à vendre à Oberrieden (8942)](https://realadvisor.ch/fr/acheter/8942-oberrieden/terrain)[Terrain à vendre à Bäretswil](https://realadvisor.ch/fr/acheter/commune-baretswil/terrain)[Terrain à vendre à Niederglatt ZH (8172)](https://realadvisor.ch/fr/acheter/8172-niederglatt-zh/terrain)[Terrain à vendre à Geroldswil](https://realadvisor.ch/fr/acheter/commune-geroldswil/terrain)[Terrain à vendre à Bauma](https://realadvisor.ch/fr/acheter/commune-bauma/terrain)[Terrain à vendre à Elgg](https://realadvisor.ch/fr/acheter/commune-elgg/terrain)[Terrain à vendre à Mettmenstetten (8932)](https://realadvisor.ch/fr/acheter/8932-mettmenstetten/terrain)[Terrain à vendre à Weiningen ZH (8104)](https://realadvisor.ch/fr/acheter/8104-weiningen-zh/terrain)[Terrain à vendre à Oetwil am See (8618)](https://realadvisor.ch/fr/acheter/8618-oetwil-am-see/terrain)[Terrain à vendre à Turbenthal](https://realadvisor.ch/fr/acheter/commune-turbenthal/terrain)[Terrain à vendre à Winkel (8185)](https://realadvisor.ch/fr/acheter/8185-winkel/terrain)[Terrain à vendre à Rafz (8197)](https://realadvisor.ch/fr/acheter/8197-rafz/terrain)[Terrain à vendre à Russikon](https://realadvisor.ch/fr/acheter/commune-russikon/terrain)[Terrain à vendre à Uitikon Waldegg (8142)](https://realadvisor.ch/fr/acheter/8142-uitikon-waldegg/terrain)[Terrain à vendre à Dällikon (8108)](https://realadvisor.ch/fr/acheter/8108-dallikon/terrain)[Terrain à vendre à Bachenbülach (8184)](https://realadvisor.ch/fr/acheter/8184-bachenbulach/terrain)[Terrain à vendre à Pfungen (8422)](https://realadvisor.ch/fr/acheter/8422-pfungen/terrain)[Terrain à vendre à Unterengstringen (8103)](https://realadvisor.ch/fr/acheter/8103-unterengstringen/terrain)[Terrain à vendre à Mönchaltorf (8617)](https://realadvisor.ch/fr/acheter/8617-monchaltorf/terrain)[Terrain à vendre à Stallikon](https://realadvisor.ch/fr/acheter/commune-stallikon/terrain)[Terrain à vendre à Hedingen (8908)](https://realadvisor.ch/fr/acheter/8908-hedingen/terrain)[Terrain à vendre à Hausen am Albis](https://realadvisor.ch/fr/acheter/commune-hausen-am-albis/terrain)[Terrain à vendre à Feuerthalen](https://realadvisor.ch/fr/acheter/commune-feuerthalen/terrain)[Terrain à vendre à Hittnau (8335)](https://realadvisor.ch/fr/acheter/8335-hittnau/terrain)[Terrain à vendre à Elsau (8352)](https://realadvisor.ch/fr/acheter/8352-elsau/terrain)[Terrain à vendre à Steinmaur](https://realadvisor.ch/fr/acheter/commune-steinmaur/terrain)[Terrain à vendre à Grüningen (8627)](https://realadvisor.ch/fr/acheter/8627-gruningen/terrain)[Terrain à vendre à Weisslingen](https://realadvisor.ch/fr/acheter/commune-weisslingen/terrain)[Terrain à vendre à Hettlingen (8442)](https://realadvisor.ch/fr/acheter/8442-hettlingen/terrain)[Terrain à vendre à Neerach (8173)](https://realadvisor.ch/fr/acheter/8173-neerach/terrain)[Terrain à vendre à Niederweningen (8166)](https://realadvisor.ch/fr/acheter/8166-niederweningen/terrain)[Terrain à vendre à Otelfingen (8112)](https://realadvisor.ch/fr/acheter/8112-otelfingen/terrain)[Terrain à vendre à Rorbas (8427)](https://realadvisor.ch/fr/acheter/8427-rorbas/terrain)[Terrain à vendre à Stammheim](https://realadvisor.ch/fr/acheter/commune-stammheim/terrain)[Terrain à vendre à Höri (8181)](https://realadvisor.ch/fr/acheter/8181-hori/terrain)[Terrain à vendre à Rickenbach (ZH)](https://realadvisor.ch/fr/acheter/commune-rickenbach-zh/terrain)[Terrain à vendre à Ottenbach (8913)](https://realadvisor.ch/fr/acheter/8913-ottenbach/terrain)[Terrain à vendre à Fischenthal](https://realadvisor.ch/fr/acheter/commune-fischenthal/terrain)[Terrain à vendre à Oetwil an der Limmat (8955)](https://realadvisor.ch/fr/acheter/8955-oetwil-an-der-limmat/terrain)[Terrain à vendre à Lufingen (8426)](https://realadvisor.ch/fr/acheter/8426-lufingen/terrain)[Terrain à vendre à Freienstein-Teufen](https://realadvisor.ch/fr/acheter/commune-freienstein-teufen/terrain)[Terrain à vendre à Knonau (8934)](https://realadvisor.ch/fr/acheter/8934-knonau/terrain)[Terrain à vendre à Stadel](https://realadvisor.ch/fr/acheter/commune-stadel/terrain)[Terrain à vendre à Henggart (8444)](https://realadvisor.ch/fr/acheter/8444-henggart/terrain)[Terrain à vendre à Andelfingen (8450)](https://realadvisor.ch/fr/acheter/8450-andelfingen/terrain)[Terrain à vendre à Kleinandelfingen](https://realadvisor.ch/fr/acheter/commune-kleinandelfingen/terrain)[Terrain à vendre à Brütten (8311)](https://realadvisor.ch/fr/acheter/8311-brutten/terrain)[Terrain à vendre à Wila (8492)](https://realadvisor.ch/fr/acheter/8492-wila/terrain)[Terrain à vendre à Marthalen](https://realadvisor.ch/fr/acheter/commune-marthalen/terrain)[Terrain à vendre à Aeugst am Albis](https://realadvisor.ch/fr/acheter/commune-aeugst-am-albis/terrain)[Terrain à vendre à Dachsen (8447)](https://realadvisor.ch/fr/acheter/8447-dachsen/terrain)[Terrain à vendre à Hochfelden (8182)](https://realadvisor.ch/fr/acheter/8182-hochfelden/terrain)[Terrain à vendre à Dänikon ZH (8114)](https://realadvisor.ch/fr/acheter/8114-danikon-zh/terrain)[Terrain à vendre à Oberweningen (8165)](https://realadvisor.ch/fr/acheter/8165-oberweningen/terrain)[Terrain à vendre à Weiach (8187)](https://realadvisor.ch/fr/acheter/8187-weiach/terrain)[Terrain à vendre à Laufen-Uhwiesen](https://realadvisor.ch/fr/acheter/commune-laufen-uhwiesen/terrain)[Terrain à vendre à Ossingen (8475)](https://realadvisor.ch/fr/acheter/8475-ossingen/terrain)[Terrain à vendre à Dinhard (8474)](https://realadvisor.ch/fr/acheter/8474-dinhard/terrain)[Terrain à vendre à Seegräben](https://realadvisor.ch/fr/acheter/commune-seegraben/terrain)[Terrain à vendre à Flurlingen (8247)](https://realadvisor.ch/fr/acheter/8247-flurlingen/terrain)[Terrain à vendre à Wil ZH (8196)](https://realadvisor.ch/fr/acheter/8196-wil-zh/terrain)[Terrain à vendre à Schöfflisdorf (8165)](https://realadvisor.ch/fr/acheter/8165-schofflisdorf/terrain)[Terrain à vendre à Flaach (8416)](https://realadvisor.ch/fr/acheter/8416-flaach/terrain)[Terrain à vendre à Boppelsen (8113)](https://realadvisor.ch/fr/acheter/8113-boppelsen/terrain)[Terrain à vendre à Aesch ZH (8904)](https://realadvisor.ch/fr/acheter/8904-aesch-zh/terrain)[Terrain à vendre à Rheinau (8462)](https://realadvisor.ch/fr/acheter/8462-rheinau/terrain)[Terrain à vendre à Kappel am Albis](https://realadvisor.ch/fr/acheter/commune-kappel-am-albis/terrain)[Terrain à vendre à Hagenbuch ZH (8523)](https://realadvisor.ch/fr/acheter/8523-hagenbuch-zh/terrain)[Terrain à vendre à Rifferswil (8911)](https://realadvisor.ch/fr/acheter/8911-rifferswil/terrain)[Terrain à vendre à Trüllikon](https://realadvisor.ch/fr/acheter/commune-trullikon/terrain)[Terrain à vendre à Oberembrach (8425)](https://realadvisor.ch/fr/acheter/8425-oberembrach/terrain)[Terrain à vendre à Hüntwangen (8194)](https://realadvisor.ch/fr/acheter/8194-huntwangen/terrain)[Terrain à vendre à Dägerlen](https://realadvisor.ch/fr/acheter/commune-dagerlen/terrain)[Terrain à vendre à Wildberg](https://realadvisor.ch/fr/acheter/commune-wildberg/terrain)[Terrain à vendre à Buch am Irchel (8414)](https://realadvisor.ch/fr/acheter/8414-buch-am-irchel/terrain)[Terrain à vendre à Hüttikon (8115)](https://realadvisor.ch/fr/acheter/8115-huttikon/terrain)[Terrain à vendre à Thalheim an der Thur (8478)](https://realadvisor.ch/fr/acheter/8478-thalheim-an-der-thur/terrain)[Terrain à vendre à Ellikon an der Thur (8548)](https://realadvisor.ch/fr/acheter/8548-ellikon-an-der-thur/terrain)[Terrain à vendre à Benken ZH (8463)](https://realadvisor.ch/fr/acheter/8463-benken-zh/terrain)[Terrain à vendre à Dättlikon (8421)](https://realadvisor.ch/fr/acheter/8421-dattlikon/terrain)[Terrain à vendre à Schleinikon (8165)](https://realadvisor.ch/fr/acheter/8165-schleinikon/terrain)[Terrain à vendre à Schlatt ZH (8418)](https://realadvisor.ch/fr/acheter/8418-schlatt-zh/terrain)[Terrain à vendre à Dorf (8458)](https://realadvisor.ch/fr/acheter/8458-dorf/terrain)[Terrain à vendre à Altikon (8479)](https://realadvisor.ch/fr/acheter/8479-altikon/terrain)[Terrain à vendre à Adlikon b. Andelfingen (8452)](https://realadvisor.ch/fr/acheter/8452-adlikon-b-andelfingen/terrain)[Terrain à vendre à Maschwanden (8933)](https://realadvisor.ch/fr/acheter/8933-maschwanden/terrain)[Terrain à vendre à Bachs (8164)](https://realadvisor.ch/fr/acheter/8164-bachs/terrain)[Terrain à vendre à Wasterkingen (8195)](https://realadvisor.ch/fr/acheter/8195-wasterkingen/terrain)[Terrain à vendre à Berg am Irchel](https://realadvisor.ch/fr/acheter/commune-berg-am-irchel/terrain)[Terrain à vendre à Humlikon (8457)](https://realadvisor.ch/fr/acheter/8457-humlikon/terrain)[Terrain à vendre à Truttikon (8467)](https://realadvisor.ch/fr/acheter/8467-truttikon/terrain)[Terrain à vendre à Regensberg (8158)](https://realadvisor.ch/fr/acheter/8158-regensberg/terrain)[Terrain à vendre à Volken (8459)](https://realadvisor.ch/fr/acheter/8459-volken/terrain) + +Voir plus + +### Autres types de bien dans le canton de Zurich + +[Maison à vendre dans le canton de Zurich](https://realadvisor.ch/fr/acheter/canton-zurich/maison)[Appartement à vendre dans le canton de Zurich](https://realadvisor.ch/fr/acheter/canton-zurich/appartement)[Immeuble à vendre dans le canton de Zurich](https://realadvisor.ch/fr/acheter/canton-zurich/immeuble)[Local commercial à vendre dans le canton de Zurich](https://realadvisor.ch/fr/acheter/canton-zurich/commercial)[Hôtel, Restaurant à vendre dans le canton de Zurich](https://realadvisor.ch/fr/acheter/canton-zurich/hotellerie) + +### Recherches populaires dans le canton de Zurich + +[Studios à vendre dans le Canton de Zürich](https://realadvisor.ch/fr/recherches-populaires/studio-a-vendre-canton-zurich) + +[](https://fr.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + +Vendre + +[Estimation immobilière en ligne](https://realadvisor.ch/fr/estimation-bien-immobilier)[Estimation immeuble de rendement](https://realadvisor.ch/fr/estimation-immeuble-de-rendement-gratuite)[Prix Immobilier](https://realadvisor.ch/fr/prix-m2-immobilier)[Agences immobilières](https://realadvisor.ch/fr/trouver-une-agence)[Glossaire Immobilier](https://realadvisor.ch/fr/glossaire-immobilier)[Blog Immobilier](https://realadvisor.ch/fr/blog) + +Acheter / Louer + +[Biens immobiliers à vendre](https://realadvisor.ch/fr/immobilier-a-vendre)[Biens immobiliers à louer](https://realadvisor.ch/fr/immobilier-a-louer)[Promotions immobilières](https://realadvisor.ch/fr/promotions)[Financement Immobilier](https://realadvisor-finance.ch/) + +Professionnels + +[Devenir Partenaire](https://realadvisor.ch/fr/pro)[Blog Pro](https://realadvisor.ch/fr/pro/blog) + +À propos + +[À propos de nous](https://realadvisor.ch/fr/a-propos)[Espace presse](https://realadvisor.ch/fr/espace-presse)[Jobs](https://realadvisor.welcomekit.co/)[Conditions générales](https://realadvisor.ch/fr/conditions-generales)[Politique de confidentialité](https://realadvisor.ch/fr/politique-de-confidentialite)[Mentions légales](https://realadvisor.ch/fr/mentions-legales)[Tout l'immobilier](https://realadvisor.ch/fr/sitemap) + +© RealAdvisor 2025. All Rights Reserved. v.e89072f + +[](https://ch.linkedin.com/company/realadvisor)[](https://www.facebook.com/realadvisorcom)[](https://twitter.com/realadvisor)[](https://www.instagram.com/realadvisorcom)[](https://www.youtube.com/channel/UCsEDTDlmxBpyxLXYhWT769Q) + +Carte + +BESbswy + + \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_022_realadvisor.ch_en_buy_canton-zurich_plot.txt b/test_web_content_20251002_215219/additional_link_022_realadvisor.ch_en_buy_canton-zurich_plot.txt new file mode 100644 index 00000000..d947f07d --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_022_realadvisor.ch_en_buy_canton-zurich_plot.txt @@ -0,0 +1,430 @@ +URL: https://realadvisor.ch/en/buy/canton-zurich/plot +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +75 Plots For Sale in Canton of Zurich - October 2025 + +=============== + +[](https://realadvisor.ch/en/property-for-sale) + ++1 more + +Canton of Zurich + + + +Valuation + +[Buy](https://realadvisor.ch/en/property-for-sale)[Rent](https://realadvisor.ch/en/property-for-rent) + +Login + +EN + +[Italiano](https://realadvisor.ch/it/comprare/canton-zurigo/trama)[Français](https://realadvisor.ch/fr/acheter/canton-zurich/terrain)[Deutsch](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck) + +Create an alert + ++1 more + +Canton of Zurich + + + +Buy Rent + +Buy Rent + +Plot + +Price + +Modify search + +Land surface + +Other Filters + +Create an alert + +- [x] Show map + +←Move left +→Move right +↑Move up +↓Move down ++Zoom in +-Zoom out +Home Jump left by 75% +End Jump right by 75% +Page Up Jump up by 75% +Page Down Jump down by 75% + + + + + + + + + + + + + + + + + + + + + + + + + +9 + +9 + +5 + +5 + +3 + +3 + +6 + +6 + +17 + +17 + +7 + +7 + +4 + +4 + +2 + +2 + +2 + +2 + +14 + +14 + +5 + +5 + +1 + +1 + + + +Map +* Map +* Satellite +* Terrain +* Labels + + + + + +*  +*  +*  +*  +*  +*  + +[](https://maps.google.com/maps?ll=47.421441,8.671322&z=9&t=m&hl=en-US&gl=US&mapclient=apiv3 "Open this area in Google Maps (opens a new window)") + +Keyboard shortcuts + +Map Data Map data ©2025 GeoBasis-DE/BKG (©2009), Google + +Map data ©2025 GeoBasis-DE/BKG (©2009), Google + +10 km + +Click to toggle between metric and imperial units + +[Terms](https://www.google.com/intl/en-US_US/help/terms_maps.html) + +[Report a map error](https://www.google.com/maps/@47.421441,8.6713222,9z/data=!10m1!1e1!12b1?source=apiv3&rapsrc=apiv3 "Report errors in the road map or imagery to Google") + +1. [](https://realadvisor.ch/en) + +3. [Buy](https://realadvisor.ch/en/buy) + +5. [Plot](https://realadvisor.ch/en/buy/plot) + +7. Canton of Zurich + +Plots For Sale in Canton of Zurich +================================== + +75 Results + +Our recommendations + +[](https://realadvisor.ch/en/buy/plot/8162-steinmaur-B62R-PZDJ) + +3 days ago + +- [x] + +[get living 1,452 m² Plot • Constructible plot 8162 Steinmaur * Flat, buildable land * Quiet, sunny location * Excellent public transport access -------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * On request —](https://realadvisor.ch/en/buy/plot/8162-steinmaur-B62R-PZDJ) + +[](https://realadvisor.ch/en/buy/plot/8340-hinwil-LDX9-L6M2) + +6 days ago + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 1,070 m² Plot • Constructible plot 8340 Hinwil * Over 1,070 m² area * Flexible subdivision options * Ideal for family homes ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1,070,000.- CHF 1,000 / m²](https://realadvisor.ch/en/buy/plot/8340-hinwil-LDX9-L6M2) + +[](https://realadvisor.ch/en/buy/plot/8633-wolfhausen-YB6N-VRVP) + +7 days ago + +- [x] + +[PREMIUM HOMES AG 1,940 m² Plot • Constructible plot 8633 Wolfhausen * Generous 1,940m² plot * Family-friendly location * Flexible design options --------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 4,074,000.- CHF 2,100 / m²](https://realadvisor.ch/en/buy/plot/8633-wolfhausen-YB6N-VRVP) + +[](https://realadvisor.ch/en/buy/plot/sonnhalde-8602-wangen-b.-dubendorf-83JW-X5X3) + +9 days ago + +- [x] + +[Moser Anlageimmobilien AG 1,666 m² Plot • Constructible plot Sonnhalde, 8602 Wangen b. Dübendorf * 1666 m² of prime land * Optimal sun exposure * Privacy in a quiet area ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3,300,000.- CHF 1,981 / m²](https://realadvisor.ch/en/buy/plot/sonnhalde-8602-wangen-b.-dubendorf-83JW-X5X3) + +[](https://realadvisor.ch/en/buy/plot/8000-zurich-NAG4-JV4R) + +11 days ago + +- [x] + +[Centrum Immo Constructible plot 8000 Zürich * Ideal for development * Close to public transport * Scenic views of the city ----------------------------------------------------------------------------------------------------------------------------------------- * * * On request —](https://realadvisor.ch/en/buy/plot/8000-zurich-NAG4-JV4R) + +[](https://realadvisor.ch/en/buy/plot/8195-wasterkingen-7JPL-7X5M) + +13 days ago + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 650 m² Plot • Constructible plot 8195 Wasterkingen * Fully serviced land * Quiet rural community * Flexible design options --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 475,000.- CHF 731 / m²](https://realadvisor.ch/en/buy/plot/8195-wasterkingen-7JPL-7X5M) + +[](https://realadvisor.ch/en/buy/plot/8618-oetwil-am-see-8OOG-PWB5) + +21 days ago + +- [x] + +[Swiss Residence Group AG 1,622 m² Plot • Constructible plot 8618 Oetwil am See * 1'622 m² sunny plot * Flexible zoning for projects * Unobstructed mountain views -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * On request —](https://realadvisor.ch/en/buy/plot/8618-oetwil-am-see-8OOG-PWB5) + +[](https://realadvisor.ch/en/buy/plot/8617-monchaltorf-KRNG-WO9R) + +22 days ago + +- [x] + +[PREMIUM HOMES AG 850 m² Plot • Constructible plot 8617 Mönchaltorf * High development potential * Quiet, sunny location * Flexible usage options --------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * On request —](https://realadvisor.ch/en/buy/plot/8617-monchaltorf-KRNG-WO9R) + +[](https://realadvisor.ch/en/buy/plot/gueterstalstrasse-8133-esslingen-YMXG-R3MR) + +26 days ago + +- [x] + +[Schiblis Immobilien GmbH 507 m² Plot • Constructible plot Güeterstalstrasse, 8133 Esslingen * Central location in Esslingen * No architectural obligation * No contamination issues -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 600,000.- CHF 1,183 / m²](https://realadvisor.ch/en/buy/plot/gueterstalstrasse-8133-esslingen-YMXG-R3MR) + +[](https://realadvisor.ch/en/buy/plot/8192-zweidlen-6ZMD-4WE3) + +28 days ago + +- [x] + +[Grundeigentümer Verband Schweiz 1,226 m² Plot • Constructible plot 8192 Zweidlen * Total area of 1,226 m² * Max. usable area 940 m² * Flexible development options --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2,450,000.- CHF 1,998 / m²](https://realadvisor.ch/en/buy/plot/8192-zweidlen-6ZMD-4WE3) + +[](https://realadvisor.ch/en/buy/plot/8424-embrach-8WRG-NEGR) + +29 days ago + +- [x] + +[PREMIUM HOMES AG 1,670 m² Plot • Constructible plot 8424 Embrach * Family-friendly location * Abundant sunlight all day * Flexible building options ------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * On request —](https://realadvisor.ch/en/buy/plot/8424-embrach-8WRG-NEGR) + +[](https://realadvisor.ch/en/buy/plot/10-berghalde-8332-russikon-6ZMD-432O) + +29 days ago + +- [x] + +[SH Immo GmbH 854 m² Plot • Constructible plot Berghalde 10, 8332 Russikon * Spacious 854 m2 plot * Ideal sunny hillside location * Potential for new construction -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1,500,000.- CHF 1,756 / m²](https://realadvisor.ch/en/buy/plot/10-berghalde-8332-russikon-6ZMD-432O) + +[](https://realadvisor.ch/en/buy/plot/8134-adliswil-Y7J5-W36M) + +1 month ago + +- [x] + +[Moos & Partner Immobilien GmbH 694 m² Plot • Constructible plot 8134 Adliswil * Central location with potential * High utilization zone W3 * Ideal for investors & developers -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3,600,000.- CHF 5,187 / m²](https://realadvisor.ch/en/buy/plot/8134-adliswil-Y7J5-W36M) + +[](https://realadvisor.ch/en/buy/plot/23-uberlandstrasse-8340-hinwil-YB69-VB7M) + +2 months ago + +- [x] + +[RE/MAX Immobilien in Rapperswil-Jona 4,246 m² Plot • Constructible plot Überlandstrasse 23, 8340 Hinwil * Prime location near main roads * Large area for development * Flexible building height options ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * On request —](https://realadvisor.ch/en/buy/plot/23-uberlandstrasse-8340-hinwil-YB69-VB7M) + +[](https://realadvisor.ch/en/buy/plot/20-winzerstrasse-8353-elgg-KRNL-ZPNR) + +2 months ago + +- [x] + +[RE/MAX Immobilien in Winterthur 877 m² Plot • Constructible plot Winzerstrasse 20, 8353 Elgg * Ideal for family homes * Investment opportunity * Adjacent to existing house ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 1,140,000.- CHF 1,300 / m²](https://realadvisor.ch/en/buy/plot/20-winzerstrasse-8353-elgg-KRNL-ZPNR) + +[](https://realadvisor.ch/en/buy/plot/34-industriestrasse-8117-fallanden-YJDX-JXRR) + +3 months ago + +- [x] + +[RE/MAX Immobilien in Meilen 2,838 m² • 1,706 m² Plot • Constructible plot Industriestrasse 34, 8117 Fällanden * Approved commercial project * Flexible commercial use * 37 parking spaces available ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * On request —](https://realadvisor.ch/en/buy/plot/34-industriestrasse-8117-fallanden-YJDX-JXRR) + +[](https://realadvisor.ch/en/buy/plot/8630-ruti-zh-84E9-Z65G) + +4 months ago + +- [x] + +[PREMIUM HOMES AG 3,460 m² Plot • Constructible plot 8630 Rüti ZH * Quiet residential area * 30% utilization rate * Bonus for extra space ------------------------------------------------------------------------------------------------------------------------------------------------------- * * * On request —](https://realadvisor.ch/en/buy/plot/8630-ruti-zh-84E9-Z65G) + +[](https://realadvisor.ch/en/buy/plot/13-staldernstrasse-8158-regensberg-YJDX-XWMO) + +16 days ago + +- [x] + +[Swisslife 2,557 m² Plot • Constructible plot Staldernstrasse 13, 8158 Regensberg * Flexible zoning for mixed use * High rental yield potential * Quiet location near Zurich ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 5,500,000.- CHF 2,151 / m² dreamo.ch](https://realadvisor.ch/en/buy/plot/13-staldernstrasse-8158-regensberg-YJDX-XWMO) + +[](https://realadvisor.ch/en/buy/plot/leisibuel-8484-weisslingen-8OO2-753X) + +2 months ago + +- [x] + +[Orgnet Immobilien AG 844 m² Plot • Constructible plot Leisibüel, 8484 Weisslingen * Stunning mountain views * Sunny southwest orientation * Quiet, private neighborhood -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1,300,000.- CHF 1,540 / m² dreamo.ch](https://realadvisor.ch/en/buy/plot/leisibuel-8484-weisslingen-8OO2-753X) + +[](https://realadvisor.ch/en/buy/plot/85-weiacherstrasse-8427-rorbas-YJD9-MVWW) + +3 months ago + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 2,295 m² Plot • Constructible plot Weiacherstrasse 85, 8427 Rorbas * Spacious 2,295 m2 plot * Mixed-use building available * Existing rental agreements --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3,440,000.- CHF 1,499 / m² dreamo.ch](https://realadvisor.ch/en/buy/plot/85-weiacherstrasse-8427-rorbas-YJD9-MVWW) + +[](https://realadvisor.ch/en/buy/plot/7a-bergstrasse-8155-nassenwil-YB69-GEB6) + +3 months ago + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 1,742 m² Plot • Constructible plot Bergstrasse 7a, 8155 Nassenwil * Spacious land area * Quiet scenic location * Close to Dielsdorf ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2,700,000.- CHF 1,550 / m² dreamo.ch](https://realadvisor.ch/en/buy/plot/7a-bergstrasse-8155-nassenwil-YB69-GEB6) + +[](https://realadvisor.ch/en/buy/plot/gotze-8197-rafz-Y6ZW-VB6G) + +3 months ago + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 1,340 m² • 1,340 m² Plot • Constructible plot Götze, 8197 Rafz * Unobstructed views * Ideal for development * Prime location ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 2,200,000.- CHF 1,642 / m² dreamo.ch](https://realadvisor.ch/en/buy/plot/gotze-8197-rafz-Y6ZW-VB6G) + +[](https://realadvisor.ch/en/buy/plot/226b-schaffhauserstrasse-8057-zurich-KRNL-A6J7) + +3 months ago + +- [x] + +[VZ VermögensZentrum 4.5 rooms • 114 m² • 480 m² Plot • Constructible plot Schaffhauserstrasse 226b, 8057 Zürich * Spacious outdoor area * Green views from windows * Cozy Swedish stove ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 2,999,000.- CHF 26,307 / m² dreamo.ch](https://realadvisor.ch/en/buy/plot/226b-schaffhauserstrasse-8057-zurich-KRNL-A6J7) + +[](https://realadvisor.ch/en/buy/canton-zurich/plot#) + +7 hours ago + +- [x] + +[— 829 m² Plot • Constructible plot Haldenstrasse 10, 8134 Adliswil * Quiet location with views * Close to public transport * Immediate availability ------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 3,300,000.- CHF 3,981 / m² homegate.ch](https://realadvisor.ch/en/buy/canton-zurich/plot#) + +[1](https://realadvisor.ch/en/buy/canton-zurich/plot) + +[2](https://realadvisor.ch/en/buy/canton-zurich/plot/page-2) + +[3](https://realadvisor.ch/en/buy/canton-zurich/plot/page-3) + +[4](https://realadvisor.ch/en/buy/canton-zurich/plot/page-4) + +[](https://realadvisor.ch/en/buy/canton-zurich/plot/page-2) + +1-24 of 75 Results + +Buy a plot in Canton of Zurich +------------------------------ + +[View property prices Canton of Zurich](https://realadvisor.ch/en/property-prices/canton-zurich) + +### Plot For Sale in Canton of Zurich + +[Plot For Sale in Zurich](https://realadvisor.ch/en/buy/city-zurich/plot)[Plot For Sale in Winterthur](https://realadvisor.ch/en/buy/city-winterthur/plot)[Plot For Sale in Uster](https://realadvisor.ch/en/buy/city-uster/plot)[Plot For Sale in Dübendorf](https://realadvisor.ch/en/buy/city-dubendorf/plot)[Plot For Sale in Dietikon (8953)](https://realadvisor.ch/en/buy/8953-dietikon/plot)[Plot For Sale in Wädenswil](https://realadvisor.ch/en/buy/city-wadenswil/plot)[Plot For Sale in Wetzikon (ZH)](https://realadvisor.ch/en/buy/city-wetzikon-zh/plot)[Plot For Sale in Horgen](https://realadvisor.ch/en/buy/city-horgen/plot)[Plot For Sale in Opfikon](https://realadvisor.ch/en/buy/city-opfikon/plot)[Plot For Sale in Bülach (8180)](https://realadvisor.ch/en/buy/8180-bulach/plot)[Plot For Sale in Kloten (8302)](https://realadvisor.ch/en/buy/8302-kloten/plot)[Plot For Sale in Adliswil (8134)](https://realadvisor.ch/en/buy/8134-adliswil/plot)[Plot For Sale in Schlieren (8952)](https://realadvisor.ch/en/buy/8952-schlieren/plot)[Plot For Sale in Volketswil](https://realadvisor.ch/en/buy/city-volketswil/plot)[Plot For Sale in Regensdorf](https://realadvisor.ch/en/buy/city-regensdorf/plot)[Plot For Sale in Thalwil](https://realadvisor.ch/en/buy/city-thalwil/plot)[Plot For Sale in Illnau-Effretikon](https://realadvisor.ch/en/buy/city-illnau-effretikon/plot)[Plot For Sale in Wallisellen (8304)](https://realadvisor.ch/en/buy/8304-wallisellen/plot)[Plot For Sale in Stäfa](https://realadvisor.ch/en/buy/city-stafa/plot)[Plot For Sale in Küsnacht (ZH)](https://realadvisor.ch/en/buy/city-kusnacht-zh/plot)[Plot For Sale in Meilen (8706)](https://realadvisor.ch/en/buy/8706-meilen/plot)[Plot For Sale in Richterswil](https://realadvisor.ch/en/buy/city-richterswil/plot)[Plot For Sale in Zollikon](https://realadvisor.ch/en/buy/city-zollikon/plot)[Plot For Sale in Rüti ZH (8630)](https://realadvisor.ch/en/buy/8630-ruti-zh/plot)[Plot For Sale in Affoltern am Albis](https://realadvisor.ch/en/buy/city-affoltern-am-albis/plot)[Plot For Sale in Pfäffikon](https://realadvisor.ch/en/buy/city-pfaffikon/plot)[Plot For Sale in Bassersdorf (8303)](https://realadvisor.ch/en/buy/8303-bassersdorf/plot)[Plot For Sale in Hinwil](https://realadvisor.ch/en/buy/city-hinwil/plot)[Plot For Sale in Männedorf (8708)](https://realadvisor.ch/en/buy/8708-mannedorf/plot)[Plot For Sale in Maur](https://realadvisor.ch/en/buy/city-maur/plot)[Plot For Sale in Gossau (ZH)](https://realadvisor.ch/en/buy/town-gossau-zh/plot)[Plot For Sale in Wald (ZH)](https://realadvisor.ch/en/buy/town-wald-zh/plot)[Plot For Sale in Urdorf (8902)](https://realadvisor.ch/en/buy/8902-urdorf/plot)[Plot For Sale in Embrach (8424)](https://realadvisor.ch/en/buy/8424-embrach/plot)[Plot For Sale in Niederhasli](https://realadvisor.ch/en/buy/town-niederhasli/plot)[Plot For Sale in Hombrechtikon](https://realadvisor.ch/en/buy/town-hombrechtikon/plot)[Plot For Sale in Fällanden](https://realadvisor.ch/en/buy/town-fallanden/plot)[Plot For Sale in Kilchberg ZH (8802)](https://realadvisor.ch/en/buy/8802-kilchberg-zh/plot)[Plot For Sale in Egg](https://realadvisor.ch/en/buy/town-egg/plot)[Plot For Sale in Rümlang (8153)](https://realadvisor.ch/en/buy/8153-rumlang/plot)[Plot For Sale in Wangen-Brüttisellen](https://realadvisor.ch/en/buy/town-wangen-bruttisellen/plot)[Plot For Sale in Dietlikon (8305)](https://realadvisor.ch/en/buy/8305-dietlikon/plot)[Plot For Sale in Dürnten](https://realadvisor.ch/en/buy/town-durnten/plot)[Plot For Sale in Langnau am Albis (8135)](https://realadvisor.ch/en/buy/8135-langnau-am-albis/plot)[Plot For Sale in Seuzach (8472)](https://realadvisor.ch/en/buy/8472-seuzach/plot)[Plot For Sale in Bubikon](https://realadvisor.ch/en/buy/town-bubikon/plot)[Plot For Sale in Oberglatt ZH (8154)](https://realadvisor.ch/en/buy/8154-oberglatt-zh/plot)[Plot For Sale in Oberengstringen (8102)](https://realadvisor.ch/en/buy/8102-oberengstringen/plot)[Plot For Sale in Fehraltorf (8320)](https://realadvisor.ch/en/buy/8320-fehraltorf/plot)[Plot For Sale in Birmensdorf ZH (8903)](https://realadvisor.ch/en/buy/8903-birmensdorf-zh/plot)[Plot For Sale in Wiesendangen](https://realadvisor.ch/en/buy/town-wiesendangen/plot)[Plot For Sale in Buchs ZH (8107)](https://realadvisor.ch/en/buy/8107-buchs-zh/plot)[Plot For Sale in Herrliberg (8704)](https://realadvisor.ch/en/buy/8704-herrliberg/plot)[Plot For Sale in Uetikon am See (8707)](https://realadvisor.ch/en/buy/8707-uetikon-am-see/plot)[Plot For Sale in Dielsdorf (8157)](https://realadvisor.ch/en/buy/8157-dielsdorf/plot)[Plot For Sale in Zell (ZH)](https://realadvisor.ch/en/buy/town-zell-zh/plot)[Plot For Sale in Rüschlikon (8803)](https://realadvisor.ch/en/buy/8803-ruschlikon/plot)[Plot For Sale in Lindau](https://realadvisor.ch/en/buy/town-lindau/plot)[Plot For Sale in Nürensdorf (8309)](https://realadvisor.ch/en/buy/8309-nurensdorf/plot)[Plot For Sale in Erlenbach ZH (8703)](https://realadvisor.ch/en/buy/8703-erlenbach-zh/plot)[Plot For Sale in Neftenbach](https://realadvisor.ch/en/buy/town-neftenbach/plot)[Plot For Sale in Bonstetten (8906)](https://realadvisor.ch/en/buy/8906-bonstetten/plot)[Plot For Sale in Obfelden (8912)](https://realadvisor.ch/en/buy/8912-obfelden/plot)[Plot For Sale in Greifensee (8606)](https://realadvisor.ch/en/buy/8606-greifensee/plot)[Plot For Sale in Glattfelden](https://realadvisor.ch/en/buy/town-glattfelden/plot)[Plot For Sale in Eglisau (8193)](https://realadvisor.ch/en/buy/8193-eglisau/plot)[Plot For Sale in Zumikon (8126)](https://realadvisor.ch/en/buy/8126-zumikon/plot)[Plot For Sale in Wettswil (8907)](https://realadvisor.ch/en/buy/8907-wettswil/plot)[Plot For Sale in Schwerzenbach (8603)](https://realadvisor.ch/en/buy/8603-schwerzenbach/plot)[Plot For Sale in Oberrieden (8942)](https://realadvisor.ch/en/buy/8942-oberrieden/plot)[Plot For Sale in Bäretswil](https://realadvisor.ch/en/buy/town-baretswil/plot)[Plot For Sale in Niederglatt ZH (8172)](https://realadvisor.ch/en/buy/8172-niederglatt-zh/plot)[Plot For Sale in Geroldswil](https://realadvisor.ch/en/buy/town-geroldswil/plot)[Plot For Sale in Bauma](https://realadvisor.ch/en/buy/town-bauma/plot)[Plot For Sale in Elgg](https://realadvisor.ch/en/buy/town-elgg/plot)[Plot For Sale in Mettmenstetten (8932)](https://realadvisor.ch/en/buy/8932-mettmenstetten/plot)[Plot For Sale in Weiningen ZH (8104)](https://realadvisor.ch/en/buy/8104-weiningen-zh/plot)[Plot For Sale in Oetwil am See (8618)](https://realadvisor.ch/en/buy/8618-oetwil-am-see/plot)[Plot For Sale in Turbenthal](https://realadvisor.ch/en/buy/town-turbenthal/plot)[Plot For Sale in Winkel (8185)](https://realadvisor.ch/en/buy/8185-winkel/plot)[Plot For Sale in Rafz (8197)](https://realadvisor.ch/en/buy/8197-rafz/plot)[Plot For Sale in Russikon](https://realadvisor.ch/en/buy/town-russikon/plot)[Plot For Sale in Uitikon Waldegg (8142)](https://realadvisor.ch/en/buy/8142-uitikon-waldegg/plot)[Plot For Sale in Dällikon (8108)](https://realadvisor.ch/en/buy/8108-dallikon/plot)[Plot For Sale in Bachenbülach (8184)](https://realadvisor.ch/en/buy/8184-bachenbulach/plot)[Plot For Sale in Pfungen (8422)](https://realadvisor.ch/en/buy/8422-pfungen/plot)[Plot For Sale in Unterengstringen (8103)](https://realadvisor.ch/en/buy/8103-unterengstringen/plot)[Plot For Sale in Mönchaltorf (8617)](https://realadvisor.ch/en/buy/8617-monchaltorf/plot)[Plot For Sale in Stallikon](https://realadvisor.ch/en/buy/town-stallikon/plot)[Plot For Sale in Hedingen (8908)](https://realadvisor.ch/en/buy/8908-hedingen/plot)[Plot For Sale in Hausen am Albis](https://realadvisor.ch/en/buy/town-hausen-am-albis/plot)[Plot For Sale in Feuerthalen](https://realadvisor.ch/en/buy/town-feuerthalen/plot)[Plot For Sale in Hittnau (8335)](https://realadvisor.ch/en/buy/8335-hittnau/plot)[Plot For Sale in Elsau (8352)](https://realadvisor.ch/en/buy/8352-elsau/plot)[Plot For Sale in Steinmaur](https://realadvisor.ch/en/buy/town-steinmaur/plot)[Plot For Sale in Grüningen (8627)](https://realadvisor.ch/en/buy/8627-gruningen/plot)[Plot For Sale in Weisslingen](https://realadvisor.ch/en/buy/town-weisslingen/plot)[Plot For Sale in Hettlingen (8442)](https://realadvisor.ch/en/buy/8442-hettlingen/plot)[Plot For Sale in Neerach (8173)](https://realadvisor.ch/en/buy/8173-neerach/plot)[Plot For Sale in Niederweningen (8166)](https://realadvisor.ch/en/buy/8166-niederweningen/plot)[Plot For Sale in Otelfingen (8112)](https://realadvisor.ch/en/buy/8112-otelfingen/plot)[Plot For Sale in Rorbas (8427)](https://realadvisor.ch/en/buy/8427-rorbas/plot)[Plot For Sale in Stammheim](https://realadvisor.ch/en/buy/town-stammheim/plot)[Plot For Sale in Höri (8181)](https://realadvisor.ch/en/buy/8181-hori/plot)[Plot For Sale in Rickenbach (ZH)](https://realadvisor.ch/en/buy/town-rickenbach-zh/plot)[Plot For Sale in Ottenbach (8913)](https://realadvisor.ch/en/buy/8913-ottenbach/plot)[Plot For Sale in Fischenthal](https://realadvisor.ch/en/buy/town-fischenthal/plot)[Plot For Sale in Oetwil an der Limmat (8955)](https://realadvisor.ch/en/buy/8955-oetwil-an-der-limmat/plot)[Plot For Sale in Lufingen (8426)](https://realadvisor.ch/en/buy/8426-lufingen/plot)[Plot For Sale in Freienstein-Teufen](https://realadvisor.ch/en/buy/town-freienstein-teufen/plot)[Plot For Sale in Knonau (8934)](https://realadvisor.ch/en/buy/8934-knonau/plot)[Plot For Sale in Stadel](https://realadvisor.ch/en/buy/town-stadel/plot)[Plot For Sale in Henggart (8444)](https://realadvisor.ch/en/buy/8444-henggart/plot)[Plot For Sale in Andelfingen (8450)](https://realadvisor.ch/en/buy/8450-andelfingen/plot)[Plot For Sale in Kleinandelfingen](https://realadvisor.ch/en/buy/town-kleinandelfingen/plot)[Plot For Sale in Brütten (8311)](https://realadvisor.ch/en/buy/8311-brutten/plot)[Plot For Sale in Wila (8492)](https://realadvisor.ch/en/buy/8492-wila/plot)[Plot For Sale in Marthalen](https://realadvisor.ch/en/buy/town-marthalen/plot)[Plot For Sale in Aeugst am Albis](https://realadvisor.ch/en/buy/town-aeugst-am-albis/plot)[Plot For Sale in Dachsen (8447)](https://realadvisor.ch/en/buy/8447-dachsen/plot)[Plot For Sale in Hochfelden (8182)](https://realadvisor.ch/en/buy/8182-hochfelden/plot)[Plot For Sale in Dänikon ZH (8114)](https://realadvisor.ch/en/buy/8114-danikon-zh/plot)[Plot For Sale in Oberweningen (8165)](https://realadvisor.ch/en/buy/8165-oberweningen/plot)[Plot For Sale in Weiach (8187)](https://realadvisor.ch/en/buy/8187-weiach/plot)[Plot For Sale in Laufen-Uhwiesen](https://realadvisor.ch/en/buy/town-laufen-uhwiesen/plot)[Plot For Sale in Ossingen (8475)](https://realadvisor.ch/en/buy/8475-ossingen/plot)[Plot For Sale in Dinhard (8474)](https://realadvisor.ch/en/buy/8474-dinhard/plot)[Plot For Sale in Seegräben](https://realadvisor.ch/en/buy/town-seegraben/plot)[Plot For Sale in Flurlingen (8247)](https://realadvisor.ch/en/buy/8247-flurlingen/plot)[Plot For Sale in Wil ZH (8196)](https://realadvisor.ch/en/buy/8196-wil-zh/plot)[Plot For Sale in Schöfflisdorf (8165)](https://realadvisor.ch/en/buy/8165-schofflisdorf/plot)[Plot For Sale in Flaach (8416)](https://realadvisor.ch/en/buy/8416-flaach/plot)[Plot For Sale in Boppelsen (8113)](https://realadvisor.ch/en/buy/8113-boppelsen/plot)[Plot For Sale in Aesch ZH (8904)](https://realadvisor.ch/en/buy/8904-aesch-zh/plot)[Plot For Sale in Rheinau (8462)](https://realadvisor.ch/en/buy/8462-rheinau/plot)[Plot For Sale in Kappel am Albis](https://realadvisor.ch/en/buy/town-kappel-am-albis/plot)[Plot For Sale in Hagenbuch ZH (8523)](https://realadvisor.ch/en/buy/8523-hagenbuch-zh/plot)[Plot For Sale in Rifferswil (8911)](https://realadvisor.ch/en/buy/8911-rifferswil/plot)[Plot For Sale in Trüllikon](https://realadvisor.ch/en/buy/town-trullikon/plot)[Plot For Sale in Oberembrach (8425)](https://realadvisor.ch/en/buy/8425-oberembrach/plot)[Plot For Sale in Hüntwangen (8194)](https://realadvisor.ch/en/buy/8194-huntwangen/plot)[Plot For Sale in Dägerlen](https://realadvisor.ch/en/buy/town-dagerlen/plot)[Plot For Sale in Wildberg](https://realadvisor.ch/en/buy/town-wildberg/plot)[Plot For Sale in Buch am Irchel (8414)](https://realadvisor.ch/en/buy/8414-buch-am-irchel/plot)[Plot For Sale in Hüttikon (8115)](https://realadvisor.ch/en/buy/8115-huttikon/plot)[Plot For Sale in Thalheim an der Thur (8478)](https://realadvisor.ch/en/buy/8478-thalheim-an-der-thur/plot)[Plot For Sale in Ellikon an der Thur (8548)](https://realadvisor.ch/en/buy/8548-ellikon-an-der-thur/plot)[Plot For Sale in Benken ZH (8463)](https://realadvisor.ch/en/buy/8463-benken-zh/plot)[Plot For Sale in Dättlikon (8421)](https://realadvisor.ch/en/buy/8421-dattlikon/plot)[Plot For Sale in Schleinikon (8165)](https://realadvisor.ch/en/buy/8165-schleinikon/plot)[Plot For Sale in Schlatt ZH (8418)](https://realadvisor.ch/en/buy/8418-schlatt-zh/plot)[Plot For Sale in Dorf (8458)](https://realadvisor.ch/en/buy/8458-dorf/plot)[Plot For Sale in Altikon (8479)](https://realadvisor.ch/en/buy/8479-altikon/plot)[Plot For Sale in Adlikon b. Andelfingen (8452)](https://realadvisor.ch/en/buy/8452-adlikon-b-andelfingen/plot)[Plot For Sale in Maschwanden (8933)](https://realadvisor.ch/en/buy/8933-maschwanden/plot)[Plot For Sale in Bachs (8164)](https://realadvisor.ch/en/buy/8164-bachs/plot)[Plot For Sale in Wasterkingen (8195)](https://realadvisor.ch/en/buy/8195-wasterkingen/plot)[Plot For Sale in Berg am Irchel](https://realadvisor.ch/en/buy/town-berg-am-irchel/plot)[Plot For Sale in Humlikon (8457)](https://realadvisor.ch/en/buy/8457-humlikon/plot)[Plot For Sale in Truttikon (8467)](https://realadvisor.ch/en/buy/8467-truttikon/plot)[Plot For Sale in Regensberg (8158)](https://realadvisor.ch/en/buy/8158-regensberg/plot)[Plot For Sale in Volken (8459)](https://realadvisor.ch/en/buy/8459-volken/plot) + +Show more + +### Other property types in Canton of Zurich + +[House For Sale in Canton of Zurich](https://realadvisor.ch/en/buy/canton-zurich/house)[Apartment For Sale in Canton of Zurich](https://realadvisor.ch/en/buy/canton-zurich/apartment)[Building For Sale in Canton of Zurich](https://realadvisor.ch/en/buy/canton-zurich/building)[Commercial property For Sale in Canton of Zurich](https://realadvisor.ch/en/buy/canton-zurich/commercial)[Hotel, Restaurant For Sale in Canton of Zurich](https://realadvisor.ch/en/buy/canton-zurich/hospitality) + +[](https://www.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + +Sell + +[House valuation](https://realadvisor.ch/en/online-property-valuation)[Investment property valuation](https://realadvisor.ch/en/investment-rental-property-valuation)[House Prices](https://realadvisor.ch/en/property-prices)[Find an agent](https://realadvisor.ch/en/find-agent) + +Buy / Rent + +[New developments](https://realadvisor.ch/en/developments)[Real estate financing](https://realadvisor.ch/en/financing) + +Professionals + +[Become a partner](https://realadvisor.ch/en/pro) + +About + +[About us](https://realadvisor.ch/en/about-us)[Press area](https://realadvisor.ch/en/press-area)[Jobs](https://realadvisor.welcomekit.co/)[Terms and conditions](https://realadvisor.ch/en/terms)[Privacy policy](https://realadvisor.ch/en/privacy)[Legal Information](https://realadvisor.ch/en/legal-information)[All real estate](https://realadvisor.ch/en/sitemap) + +© RealAdvisor 2025. All Rights Reserved. v.e89072f + +[](https://ch.linkedin.com/company/realadvisor)[](https://www.facebook.com/realadvisorcom)[](https://twitter.com/realadvisor)[](https://www.instagram.com/realadvisorcom)[](https://www.youtube.com/channel/UCsEDTDlmxBpyxLXYhWT769Q) + +Show map + +BESbswy \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_023_realadvisor.ch_de_kaufen.txt b/test_web_content_20251002_215219/additional_link_023_realadvisor.ch_de_kaufen.txt new file mode 100644 index 00000000..4b3134d3 --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_023_realadvisor.ch_de_kaufen.txt @@ -0,0 +1,417 @@ +URL: https://realadvisor.ch/de/kaufen +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Immobilie kaufen Schweiz - 48’581 Angebote im Oktober 2025 + +=============== + +[](https://realadvisor.ch/de/immobilien-kaufen) + + + +Bewerten + +[Kaufen](https://realadvisor.ch/de/immobilien-kaufen)[Mieten](https://realadvisor.ch/de/immobilien-mieten) + +Anmelden + +DE + +[Italiano](https://realadvisor.ch/it/comprare)[Français](https://realadvisor.ch/fr/acheter)[English](https://realadvisor.ch/en/buy) + +Suchabo erstellen + + + +Kaufen Mieten + +Kaufen Mieten + +Art der Immobilie + +Preis + +Suche ändern + +Wohnfläche + +Andere Filter + +Suchabo erstellen + +- [x] Karte + +←Move left +→Move right +↑Move up +↓Move down ++Zoom in +-Zoom out +Home Jump left by 75% +End Jump right by 75% +Page Up Jump up by 75% +Page Down Jump down by 75% + + + + + + + + + + + + + + + + + + + + + + + + + +3 + +3 + +19k + +19k + +13k + +13k + +11k + +11k + +5.6k + +5.6k + +207 + +207 + +Map +* Map +* Satellite +* Terrain +* Labels + + + + + +*  +*  +*  +*  +*  +*  + +[](https://maps.google.com/maps?ll=46.113069,8.441516&z=6&t=m&hl=en-US&gl=US&mapclient=apiv3 "Open this area in Google Maps (opens a new window)") + +Keyboard shortcuts + +Map Data Map data ©2025 GeoBasis-DE/BKG (©2009), Google, Inst. Geogr. Nacional + +Map data ©2025 GeoBasis-DE/BKG (©2009), Google, Inst. Geogr. Nacional + +100 km + +Click to toggle between metric and imperial units + +[Terms](https://www.google.com/intl/en-US_US/help/terms_maps.html) + +[Report a map error](https://www.google.com/maps/@46.1130688,8.4415156,6z/data=!10m1!1e1!12b1?source=apiv3&rapsrc=apiv3 "Report errors in the road map or imagery to Google") + +1. [](https://realadvisor.ch/de) + +3. Kaufen + +Immobilien kaufen Schweiz +========================= + +48’581 Ergebnisse + +Unseren Empfehlungen + +[](https://realadvisor.ch/de/kaufen/wohnung/1206-geneve-B62R-PBJ6) + +vor 28 Minuten + +- [x] + +[Naef | Projets neufs – Genève 4 Zi. • 112 m² • Wohnung 1206 Genève * Helle Südwestlage * Zwei schöne Balkone * In der Nähe von Parks und Geschäften ------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 1’850’000.- CHF 15’077 / m²](https://realadvisor.ch/de/kaufen/wohnung/1206-geneve-B62R-PBJ6) + +[](https://realadvisor.ch/de/kaufen/wohnung/5-altbrunnenweg-4410-liestal-ZZ74-V4OL) + +vor 46 Minuten + +- [x] + +[Newtak Immobilien GmbH 3.5 Zi. • 68 m² • Wohnung Altbrunnenweg 5, 4410 Liestal * Elegante Stuckdecken * Sonniger Balkon mit Aussicht * Moderne Küche mit Granit ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 590’000.- CHF 8’676 / m²](https://realadvisor.ch/de/kaufen/wohnung/5-altbrunnenweg-4410-liestal-ZZ74-V4OL) + +[](https://realadvisor.ch/de/kaufen/haus/1865-les-diablerets-VBG4-X4V9) + +vor 2 Stunden + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 4.5 Zi. • 99 m² • 300 m² Grundstück • Einfamilienhaus 1865 Les Diablerets * Atemberaubende Panoramablicke * Sonniger Garten mit 300 m² * Seltene Garage Box inklusive ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 980’000.- CHF 9’899 / m²](https://realadvisor.ch/de/kaufen/haus/1865-les-diablerets-VBG4-X4V9) + +[](https://realadvisor.ch/de/kaufen/wohnung/1018-lausanne-RNG4-9LQB) + +vor 2 Stunden + +- [x] + +[Naef Immobilier Lausanne - Vente 4.5 Zi. • 90 m² • Wohnung 1018 Lausanne * Moderne Ausstattungen überall * Geräumige Balkone bis 53m² * Ruhige Wohngegend ------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 1’110’000.- CHF 11’684 / m²](https://realadvisor.ch/de/kaufen/wohnung/1018-lausanne-RNG4-9LQB) + +[](https://realadvisor.ch/de/kaufen/wohnung/1018-lausanne-7JPL-7R6W) + +vor 2 Stunden + +- [x] + +[Naef Immobilier Lausanne - Vente 4.5 Zi. • 90 m² • Wohnung 1018 Lausanne * Zeitgenössisches Design überall * Geräumige Balkone bis 53 m² * Nahe an öffentlichen Verkehrsmitteln ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’090’000.- CHF 11’474 / m²](https://realadvisor.ch/de/kaufen/wohnung/1018-lausanne-7JPL-7R6W) + +[](https://realadvisor.ch/de/kaufen/wohnung/1018-lausanne-ELXJ-E9D6) + +vor 2 Stunden + +- [x] + +[Naef Immobilier Lausanne - Vente 4.5 Zi. • 90 m² • Wohnung 1018 Lausanne * Moderne Ausstattungen und Materialien * Geräumige Balkone bis 53 m² * Ruhige Wohngegend mit Zugang -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 915’000.- CHF 9’632 / m²](https://realadvisor.ch/de/kaufen/wohnung/1018-lausanne-ELXJ-E9D6) + +[](https://realadvisor.ch/de/kaufen/wohnung/1207-geneve-XEG4-74WW) + +vor 2 Stunden + +- [x] + +[Naef Prestige | Knight Frank – Genève 8 Zi. • 416 m² • Penthouse 1207 Genève * Außergewöhnliche Lage auf dem Dach * Atemberaubende Ausblicke auf Wahrzeichen * Geräumige, lichtdurchflutete Wohnbereiche ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/wohnung/1207-geneve-XEG4-74WW) + +[](https://realadvisor.ch/de/kaufen/haus/1820-montreux-4E56-LOJ5) + +vor 3 Stunden + +- [x] + +[Switzerland | Sotheby's International Realty 8 Zi. • 220 m² • 1’883 m² Grundstück • Einfamilienhaus 1820 Montreux * Ruhige grüne Umgebung * Geräumige Räume mit Charakter * Schneller Zugang zu Montreux ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2’985’000.- CHF 11’940 / m²](https://realadvisor.ch/de/kaufen/haus/1820-montreux-4E56-LOJ5) + +[](https://realadvisor.ch/de/kaufen/wohnung/1003-lausanne-XEG4-3E43) + +vor 3 Stunden + +- [x] + +[Switzerland | Sotheby's International Realty 3.5 Zi. • 96 m² • Wohnung 1003 Lausanne * Spektakulärer Blick auf Lausanne * Charaktervolles Gebäude aus dem 19. Jh. * Private Loggia für den Außenbereich ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/wohnung/1003-lausanne-XEG4-3E43) + +[](https://realadvisor.ch/de/kaufen/wohnung/30-grand-rue-1180-rolle-Y7JP-MPL4) + +vor 3 Stunden + +- [x] + +[L3 Properties 5.5 Zi. • 172 m² • Duplex Grand-Rue 30, 1180 Rolle * Zentrale Lage, alle Annehmlichkeiten * Geräumig mit großzügigen Flächen * Unverbaute Sicht auf See & Alpen -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’290’000.- CHF 7’500 / m²](https://realadvisor.ch/de/kaufen/wohnung/30-grand-rue-1180-rolle-Y7JP-MPL4) + +[](https://realadvisor.ch/de/kaufen/haus/1091-grandvaux-Y23Z-VZJW) + +vor 3 Stunden + +- [x] + +[Kreal Immobilier SA 4.5 Zi. • 220 m² • Einfamilienhaus 1091 Grandvaux * Atemberaubender Seeblick * Geräumige Gartenterrasse * Funktionaler Keller mit Garage --------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’650’000.- CHF 7’500 / m²](https://realadvisor.ch/de/kaufen/haus/1091-grandvaux-Y23Z-VZJW) + +[](https://realadvisor.ch/de/kaufen/wohnung/1815-clarens-YMXG-PG4A) + +vor 3 Stunden + +- [x] + +[G-Diffusion Sàrl 3.5 Zi. • 79 m² • Wohnung 1815 Clarens * 14 m² Balkon mit Seeblick * Vollständig renoviertes Design * Nah an Geschäften und Verkehrsmitteln --------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 750’000.- CHF 9’494 / m²](https://realadvisor.ch/de/kaufen/wohnung/1815-clarens-YMXG-PG4A) + +[](https://realadvisor.ch/de/kaufen/wohnung/1607-palezieux-village-8PMG-EG2D) + +vor 3 Stunden + +- [x] + +[G-Diffusion Sàrl 2.5 Zi. • 60 m² • Wohnung 1607 Palézieux-Village * Helle Wohnfläche mit Balkon * Hochwertige Ausstattungen * Ruhige Wohngegend -------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 480’000.- CHF 8’000 / m²](https://realadvisor.ch/de/kaufen/wohnung/1607-palezieux-village-8PMG-EG2D) + +[](https://realadvisor.ch/de/kaufen/wohnung/route-du-simplon-1957-ardon-KXEG-XG2X) + +vor 3 Stunden + +- [x] + +[C-Service Promotions Sàrl 4.5 Zi. • 124 m² • Wohnung Route Du Simplon, 1957 Ardon * Sonnige Terrasse mit Rasen * 2730 m² Grünfläche * Solarzellen installiert ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 575’000.- CHF 4’637 / m²](https://realadvisor.ch/de/kaufen/wohnung/route-du-simplon-1957-ardon-KXEG-XG2X) + +[](https://realadvisor.ch/de/kaufen/haus/1302-vufflens-la-ville-8VBG-DG9Q) + +vor 3 Stunden + +- [x] + +[M Home 7.5 Zi. • 180 m² • Villa 1302 Vufflens-la-Ville * Mittelmeer-Garten-Oase * Beheizter Salzwasserpool * Unabhängiger Büroraum ------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2’380’000.- CHF 13’222 / m²](https://realadvisor.ch/de/kaufen/haus/1302-vufflens-la-ville-8VBG-DG9Q) + +[](https://realadvisor.ch/de/kaufen/haus/7-bielengasse-3948-oberems-8OOG-RG75) + +vor 3 Stunden + +- [x] + +[PROVIVA Immobilien AG 6 Zi. • 138 m² • Einfamilienhaus Bielengasse 7, 3948 Oberems * Atemberaubende Panoramaaussicht * Geräumiges Grundstück von 1'331 m² * Vielseitiger Keller mit Annehmlichkeiten ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 600’000.- CHF 4’348 / m²](https://realadvisor.ch/de/kaufen/haus/7-bielengasse-3948-oberems-8OOG-RG75) + +[](https://realadvisor.ch/de/kaufen/wohnung/19-acherestrasse-3718-kandersteg-YMXG-PG7O) + +vor 3 Stunden + +- [x] + +[RE/MAX Immobilien in Belp 3.5 Zi. • 66 m² • Wohnung Acherestrasse 19, 3718 Kandersteg * Moderne Küche mit V-Zug-Geräten * Gemütliche Terrasse mit Bergblick * Nachhaltige Heizung mit Bodenwärme --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 590’000.- CHF 8’939 / m²](https://realadvisor.ch/de/kaufen/wohnung/19-acherestrasse-3718-kandersteg-YMXG-PG7O) + +[](https://realadvisor.ch/de/kaufen/wohnung/46-im-sihlhof-8134-adliswil-KXEG-XG9X) + +vor 3 Stunden + +- [x] + +[RE/MAX Immobilien in Eglisau 4.5 Zi. • 117 m² • Penthouse Im Sihlhof 46, 8134 Adliswil * Grosse Terrasse mit Grünsicht * Helle Küche mit viel Stauraum * Zwei moderne Badezimmer für Komfort ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’595’000.- CHF 13’632 / m²](https://realadvisor.ch/de/kaufen/wohnung/46-im-sihlhof-8134-adliswil-KXEG-XG9X) + +[](https://realadvisor.ch/de/kaufen/wohnung/8-dorfstrasse-3703-aeschi-b.-spiez-KGGX-VXXW) + +vor 3 Stunden + +- [x] + +[RE/MAX Immobilien in Wallisellen 1.5 Zi. • 27 m² • Wohnung Dorfstrasse 8, 3703 Aeschi b. Spiez * Atemberaubender Bergblick * Heller, geräumiger Wohnbereich * Möglichkeit zur Mieteinnahme --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 220’000.- CHF 8’148 / m²](https://realadvisor.ch/de/kaufen/wohnung/8-dorfstrasse-3703-aeschi-b.-spiez-KGGX-VXXW) + +[](https://realadvisor.ch/de/kaufen/wohnung/7-fohrlibuckstrasse-8304-wallisellen-83JW-ZWW3) + +vor 3 Stunden + +- [x] + +[RE/MAX Immobilien in Wallisellen 3.5 Zi. • 83 m² • Wohnung Föhrlibuckstrasse 7, 8304 Wallisellen * Geräumige Terrasse zum Entspannen * Helle Räume mit großen Fenstern * Zentrale und ruhige Lage ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’135’000.- CHF 13’675 / m²](https://realadvisor.ch/de/kaufen/wohnung/7-fohrlibuckstrasse-8304-wallisellen-83JW-ZWW3) + +[](https://realadvisor.ch/de/kaufen/parkplatz/3910-saas-grund-84E5-W55A) + +vor 3 Stunden + +- [x] + +[RE/MAX Immobilien in Saas-Fee Aussenplatz 3910 Saas-Grund * Ideal für Eigenbedarf * Möglichkeit zur Vermietung * Kauf mit angrenzendem Grundstück ---------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/parkplatz/3910-saas-grund-84E5-W55A) + +[](https://realadvisor.ch/de/kaufen/grundstuck/3952-susten-Y23Z-VZZB) + +vor 3 Stunden + +- [x] + +[RE/MAX Immobilien in Susten 1’641 m² • Bauland 3952 Susten * Genehmigtes Projekt für 2 Häuser * Ruhige Lage in der Natur * Ferienhauszone verfügbar ------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/3952-susten-Y23Z-VZZB) + +[](https://realadvisor.ch/de/kaufen/haus/1260-nyon-YNAG-NGGQ) + +vor 3 Stunden + +- [x] + +[DronEstate SA Einfamilienhaus 1260 Nyon * Atemberaubender See- und Mont-Blanc-Blick * Luxuriöser Wellnessbereich mit Spa * Privater Bootshaus und Hafen ---------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 31’000’000.- —](https://realadvisor.ch/de/kaufen/haus/1260-nyon-YNAG-NGGQ) + +[](https://realadvisor.ch/de/kaufen/wohnung/87-route-de-lully-1470-lully-fr-Y23Z-VZAB) + +vor 3 Stunden + +- [x] + +[Lombard Immobilier SA 2.5 Zi. • 62 m² • Wohnung Route De Lully 87, 1470 Lully FR * Geräumige 8 m² Terrasse * Hochwertige Materialien * Tiefgaragenstellplatz inklusive ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/wohnung/87-route-de-lully-1470-lully-fr-Y23Z-VZAB) + +[1](https://realadvisor.ch/de/kaufen) + +[2](https://realadvisor.ch/de/kaufen/seite-2) + +[3](https://realadvisor.ch/de/kaufen/seite-3) + +[4](https://realadvisor.ch/de/kaufen/seite-4) + +[5](https://realadvisor.ch/de/kaufen/seite-5) + +[6](https://realadvisor.ch/de/kaufen/seite-6) + +[7](https://realadvisor.ch/de/kaufen/seite-7) + +[](https://realadvisor.ch/de/kaufen/seite-2) + +1-24 von 48’581 Ergebnisse + +Der Immobilienmarkt Schweiz +--------------------------- + +### 💰 Wie viel kostet eine Immobilie zum Verkauf Schweiz? + +Der mittlere Kaufpreis für eine Immobilie beträgt aktuell **CHF 1’333’703**. Der Kaufpreis für 80% der Immobilien liegt zwischen **CHF 580’553** und **CHF 3’451’937**. Der Durchschnittspreis pro m² Schweiz beträgt **CHF 8’749/m²**. + +### Wo kann ich Schweiz kostengünstig eine Immobilie kaufen? + +Für Immobilien zum Verkauf Schweiz sind die preisgünstigsten Gemeinden: [Fahy](https://realadvisor.ch/de/kaufen/2916-fahy) mit einem mittleren Preis pro m² von **CHF 2’494**, [Simplon](https://realadvisor.ch/de/kaufen/gemeinde-simplon) mit **CHF 2’636**/m² und [Bonfol](https://realadvisor.ch/de/kaufen/2944-bonfol) mit **CHF 2’652**/m². + +### Welche Gemeinden Schweiz sind die teuersten um Immobilien zu kaufen? + +Für Immobilien zum Verkauf Schweiz sind die teuersten Gemeinden: [St. Moritz](https://realadvisor.ch/de/kaufen/7500-st-moritz) mit einem mittleren Preis pro m² von **CHF 21’069**, [Vandoeuvres](https://realadvisor.ch/de/kaufen/1253-vandoeuvres) mit **CHF 19’954**/m² und [Cologny](https://realadvisor.ch/de/kaufen/1223-cologny) mit **CHF 19’578**/m². + +Immobilie kaufen Schweiz +------------------------ + +[Immobilienpreise in Schweiz](https://realadvisor.ch/de/immobilienpreise-pro-m2) + +### Immobilie kaufen Schweiz + +[Immobilie kaufen im Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich)[Immobilie kaufen im Kanton Bern](https://realadvisor.ch/de/kaufen/kanton-bern)[Immobilie kaufen im Kanton Waadt](https://realadvisor.ch/de/kaufen/kanton-waadt)[Immobilie kaufen im Kanton Aargau](https://realadvisor.ch/de/kaufen/kanton-aargau)[Immobilie kaufen im Kanton St. Gallen](https://realadvisor.ch/de/kaufen/kanton-st-gallen)[Immobilie kaufen im Kanton Genf](https://realadvisor.ch/de/kaufen/kanton-genf)[Immobilie kaufen im Kanton Luzern](https://realadvisor.ch/de/kaufen/kanton-luzern)[Immobilie kaufen im Kanton Tessin](https://realadvisor.ch/de/kaufen/kanton-tessin)[Immobilie kaufen im Kanton Wallis](https://realadvisor.ch/de/kaufen/kanton-wallis)[Immobilie kaufen im Kanton Freiburg](https://realadvisor.ch/de/kaufen/kanton-freiburg)[Immobilie kaufen im Kanton Basel-Landschaft](https://realadvisor.ch/de/kaufen/kanton-basel-landschaft)[Immobilie kaufen im Kanton Thurgau](https://realadvisor.ch/de/kaufen/kanton-thurgau)[Immobilie kaufen im Kanton Solothurn](https://realadvisor.ch/de/kaufen/kanton-solothurn)[Immobilie kaufen im Kanton Graubünden](https://realadvisor.ch/de/kaufen/kanton-graubunden)[Immobilie kaufen im Kanton Basel-Stadt](https://realadvisor.ch/de/kaufen/kanton-basel-stadt)[Immobilie kaufen im Kanton Neuenburg](https://realadvisor.ch/de/kaufen/kanton-neuenburg)[Immobilie kaufen im Kanton Schwyz](https://realadvisor.ch/de/kaufen/kanton-schwyz)[Immobilie kaufen im Kanton Zug](https://realadvisor.ch/de/kaufen/kanton-zug)[Immobilie kaufen im Kanton Schaffhausen](https://realadvisor.ch/de/kaufen/kanton-schaffhausen)[Immobilie kaufen im Kanton Jura](https://realadvisor.ch/de/kaufen/kanton-jura)[Immobilie kaufen im Kanton Appenzell Ausserrhoden](https://realadvisor.ch/de/kaufen/kanton-appenzell-ausserrhoden)[Immobilie kaufen im Kanton Nidwalden](https://realadvisor.ch/de/kaufen/kanton-nidwalden)[Immobilie kaufen im Kanton Glarus](https://realadvisor.ch/de/kaufen/kanton-glarus)[Immobilie kaufen im Liechtenstein](https://realadvisor.ch/de/kaufen/liechtenstein)[Immobilie kaufen im Kanton Obwalden](https://realadvisor.ch/de/kaufen/kanton-obwalden)[Immobilie kaufen im Kanton Uri](https://realadvisor.ch/de/kaufen/kanton-uri)[Immobilie kaufen im Kanton Appenzell Innerrhoden](https://realadvisor.ch/de/kaufen/kanton-appenzell-innerrhoden) + +Mehr + +### Andere Immobilienarten Schweiz + +[Haus kaufen Schweiz](https://realadvisor.ch/de/kaufen/haus)[Wohnung kaufen Schweiz](https://realadvisor.ch/de/kaufen/wohnung)[Grundstück kaufen Schweiz](https://realadvisor.ch/de/kaufen/grundstuck)[Mehrfamilienhaus kaufen Schweiz](https://realadvisor.ch/de/kaufen/gebaude)[Gewerberaum kaufen Schweiz](https://realadvisor.ch/de/kaufen/gewerbe)[Hotel, Restaurant kaufen Schweiz](https://realadvisor.ch/de/kaufen/gastfreundschaft) + +### Beliebte Suchen Schweiz + +[Neubauprojekte in der Schweiz](https://realadvisor.ch/de/beliebte-suchen/neubauprojekte-schweiz)[Neubauten kaufen in der Schweiz](https://realadvisor.ch/de/beliebte-suchen/neubauten-kaufen-schweiz)[Neubauwohnungen kaufen in der Schweiz](https://realadvisor.ch/de/beliebte-suchen/neubauwohnung-kaufen-schweiz) + +[](https://ch.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + +Verkaufen + +[Immobilienbewertung](https://realadvisor.ch/de/online-immobilienbewertung)[Renditeliegenschaft bewerten](https://realadvisor.ch/de/renditeliegenschaft-bewerten-online)[Immobilienpreise](https://realadvisor.ch/de/immobilienpreise-pro-m2)[Makler finden](https://realadvisor.ch/de/makler-finden)[Immobilien-Glossar](https://realadvisor.ch/de/immobilien-glossar)[Immobilien-Blog](https://realadvisor.ch/de/blog) + +Kaufen / Mieten + +[Immobilien kaufen](https://realadvisor.ch/de/immobilien-kaufen)[Immobilien mieten](https://realadvisor.ch/de/immobilien-mieten)[Neubauprojekte](https://realadvisor.ch/de/neubauprojekte)[Immobilienfinanzierung](https://realadvisor.ch/de/finanzierung) + +Für Makler + +[Partner werden](https://realadvisor.ch/de/pro)[Blog Pro](https://realadvisor.ch/de/pro/blog) + +Unternehmen + +[Über uns](https://realadvisor.ch/de/uber-uns)[Presseraum](https://realadvisor.ch/de/presseraum)[Offene Stellen](https://realadvisor.welcomekit.co/)[Allgemeine Geschäftsbedingungen](https://realadvisor.ch/de/begriffe)[Datenschutzerklärung](https://realadvisor.ch/de/datenschutzerklarung)[Impressum](https://realadvisor.ch/de/impressum)[Alle Immobilien](https://realadvisor.ch/de/sitemap) + +© RealAdvisor 2025. All Rights Reserved. v.e89072f + +[](https://ch.linkedin.com/company/realadvisor)[](https://www.facebook.com/realadvisorcom)[](https://twitter.com/realadvisor)[](https://www.instagram.com/realadvisorcom)[](https://www.youtube.com/channel/UCsEDTDlmxBpyxLXYhWT769Q) + +Karte + +BESbswy \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_024_realadvisor.ch_de_kaufen_grundstuck.txt b/test_web_content_20251002_215219/additional_link_024_realadvisor.ch_de_kaufen_grundstuck.txt new file mode 100644 index 00000000..9fb32676 --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_024_realadvisor.ch_de_kaufen_grundstuck.txt @@ -0,0 +1,398 @@ +URL: https://realadvisor.ch/de/kaufen/grundstuck +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Grundstück kaufen Schweiz - 2’266 Angebote im Oktober 2025 + +=============== + +[](https://realadvisor.ch/de/immobilien-kaufen) + + + +Bewerten + +[Kaufen](https://realadvisor.ch/de/immobilien-kaufen)[Mieten](https://realadvisor.ch/de/immobilien-mieten) + +Anmelden + +DE + +[Italiano](https://realadvisor.ch/it/comprare/trama)[Français](https://realadvisor.ch/fr/acheter/terrain)[English](https://realadvisor.ch/en/buy/plot) + +Suchabo erstellen + + + +Kaufen Mieten + +Kaufen Mieten + +Grundstück + +Preis + +Suche ändern + +Grundstücksfläche + +Andere Filter + +Suchabo erstellen + +- [x] Karte + +←Move left +→Move right +↑Move up +↓Move down ++Zoom in +-Zoom out +Home Jump left by 75% +End Jump right by 75% +Page Up Jump up by 75% +Page Down Jump down by 75% + + + + + + + + + + + + + + + + + + + + + + + + + +701 + +701 + +618 + +618 + +711 + +711 + +234 + +234 + +2 + +2 + +Map +* Map +* Satellite +* Terrain +* Labels + + + + + +*  +*  +*  +*  +*  +*  + +[](https://maps.google.com/maps?ll=46.113069,8.441516&z=6&t=m&hl=en-US&gl=US&mapclient=apiv3 "Open this area in Google Maps (opens a new window)") + +Keyboard shortcuts + +Map Data Map data ©2025 GeoBasis-DE/BKG (©2009), Google, Inst. Geogr. Nacional + +Map data ©2025 GeoBasis-DE/BKG (©2009), Google, Inst. Geogr. Nacional + +100 km + +Click to toggle between metric and imperial units + +[Terms](https://www.google.com/intl/en-US_US/help/terms_maps.html) + +[Report a map error](https://www.google.com/maps/@46.1130688,8.4415156,6z/data=!10m1!1e1!12b1?source=apiv3&rapsrc=apiv3 "Report errors in the road map or imagery to Google") + +1. [](https://realadvisor.ch/de) + +3. [Kaufen](https://realadvisor.ch/de/kaufen) + +5. Grundstück + +Grundstücke kaufen Schweiz +========================== + +2’266 Ergebnisse + +Unseren Empfehlungen + +[](https://realadvisor.ch/de/kaufen/grundstuck/3952-susten-Y23Z-VZZB) + +vor 3 Stunden + +- [x] + +[RE/MAX Immobilien in Susten 1’641 m² • Bauland 3952 Susten * Genehmigtes Projekt für 2 Häuser * Ruhige Lage in der Natur * Ferienhauszone verfügbar ------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/3952-susten-Y23Z-VZZB) + +[](https://realadvisor.ch/de/kaufen/grundstuck/2802-develier-YZZ7-B5M3) + +vor 3 Stunden + +- [x] + +[Neuschwander Immobilier Sàrl 1’444 m² • Bauland 2802 Develier * Voll erschlossenes 1'444 m² * Ideal für 6 Wohnungen Projekt * Nahe an Annehmlichkeiten & Verkehr ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/2802-develier-YZZ7-B5M3) + +[](https://realadvisor.ch/de/kaufen/grundstuck/grenzstrasse-8280-kreuzlingen-YJDX-5ML4) + +vor 7 Stunden + +- [x] + +[Retronova Immobilien AG 462 m² Grundstück • Bauland Grenzstrasse, 8280 Kreuzlingen * Ideal für Mehrfamilienhäuser * Bis zu 557m² bebaubare Fläche * Top Lage nahe Stadtzentrum --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’150’000.- CHF 2’489 / m²](https://realadvisor.ch/de/kaufen/grundstuck/grenzstrasse-8280-kreuzlingen-YJDX-5ML4) + +[](https://realadvisor.ch/de/kaufen/grundstuck/incella-6614-brissago-84E5-WV2G) + +vor 7 Stunden + +- [x] + +[Pura Immobiliare Bauland Incella, 6614 Brissago * Einzigartiger Zugang über Treppen * Atemberaubende Seesicht * Ideal für Luxusvillen ---------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’060’000.- —](https://realadvisor.ch/de/kaufen/grundstuck/incella-6614-brissago-84E5-WV2G) + +[](https://realadvisor.ch/de/kaufen/grundstuck/1509-vucherens-B62R-PRGJ) + +vor 11 Stunden + +- [x] + +[Froidevaux Immobilier SA 1’368 m² Grundstück • Bauland 1509 Vucherens * Ideal für Ihr Traumhaus * 1368m2 prime Land * Verfügbar mit Baugenehmigung ----------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/1509-vucherens-B62R-PRGJ) + +[](https://realadvisor.ch/de/kaufen/grundstuck/2854-bassecourt-8WR9-EAMB) + +vor 12 Stunden + +- [x] + +[MAGICimmo SA Bauland 2854 Bassecourt * 893 m2 Baufläche * Ruhige grüne Umgebung * Keine Baugrenze ---------------------------------------------------------------------------------------------------------------- * * * CHF 267’900.- —](https://realadvisor.ch/de/kaufen/grundstuck/2854-bassecourt-8WR9-EAMB) + +[](https://realadvisor.ch/de/kaufen/grundstuck/2854-bassecourt-YB6N-5O7J) + +vor 12 Stunden + +- [x] + +[MAGICimmo SA Bauland 2854 Bassecourt * Lage in Wohngebiet * Flexible Bauoptionen * Mindestkoeffizient 0.35 ------------------------------------------------------------------------------------------------------------------------- * * * CHF 250.- —](https://realadvisor.ch/de/kaufen/grundstuck/2854-bassecourt-YB6N-5O7J) + +[Keine Fotos](https://realadvisor.ch/de/kaufen/grundstuck/1012-lausanne-85VO-BOPA) + +vor 12 Stunden + +- [x] + +[AD Immob Sàrl 920 m² Grundstück • Bauland 1012 Lausanne * Geräumiges Grundstück von 920 m2 * Befreit von Bauvorschriften * Perfekt für Familienhäuser -------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’540’000.- CHF 1’674 / m²](https://realadvisor.ch/de/kaufen/grundstuck/1012-lausanne-85VO-BOPA) + +[](https://realadvisor.ch/de/kaufen/grundstuck/2829-vermes-KRNG-JN9B) + +vor 13 Stunden + +- [x] + +[Neuschwander Immobilier Sàrl 6’062 m² Grundstück • Bauland 2829 Vermes * Großes Grundstück von 6'062 m² * Bebaubare Fläche von 3'580 m² * Ruhige Lage in der Natur --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 400’000.- CHF 66 / m²](https://realadvisor.ch/de/kaufen/grundstuck/2829-vermes-KRNG-JN9B) + +[](https://realadvisor.ch/de/kaufen/grundstuck/11-l-eiron-6523-preonzo-8VBG-DWXW) + +vor 13 Stunden + +- [x] + +[Immobiliare Ascolux Sagl 400 m² Grundstück • Bauland L Eirón 11, 6523 Preonzo * Ruhige Wohnlage * 200m zur Bushaltestelle * In der Nähe von Grundschulen ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 200’000.- CHF 500 / m²](https://realadvisor.ch/de/kaufen/grundstuck/11-l-eiron-6523-preonzo-8VBG-DWXW) + +[](https://realadvisor.ch/de/kaufen/grundstuck/2025-chez-le-bart-8LDP-7JZ4) + +vor 22 Stunden + +- [x] + +[Diatimis Sàrl 2’310 m² • 2’310 m² Grundstück • Bauland 2025 Chez-le-Bart * Grosszügige Fläche von 2310 m² * Bevorzugte Lage am See * Aussergewöhnliche Lebensqualität ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 1’500’000.- CHF 649 / m²](https://realadvisor.ch/de/kaufen/grundstuck/2025-chez-le-bart-8LDP-7JZ4) + +[Keine Fotos](https://realadvisor.ch/de/kaufen/grundstuck/1700-fribourg-KEL9-P4MP) + +vor 1 Tag + +- [x] + +[JG Immobilier 5’776 m² • 5’776 m² Grundstück • Bauland 1700 Fribourg * Bemerkenswertes Baupotenzial * Optimales Licht und Ausblick * Ideal für Luxusprojekte --------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3’100’000.- CHF 537 / m²](https://realadvisor.ch/de/kaufen/grundstuck/1700-fribourg-KEL9-P4MP) + +[Keine Fotos](https://realadvisor.ch/de/kaufen/grundstuck/1012-lausanne-KGGX-5A6Q) + +vor 1 Tag + +- [x] + +[AD Immob Sàrl 920 m² • 920 m² Grundstück • Bauland 1012 Lausanne * 920 m2 Grundstücksfläche * Bau frei von Einschränkungen * Ideal für Familienhäuser -------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’540’000.- CHF 1’674 / m²](https://realadvisor.ch/de/kaufen/grundstuck/1012-lausanne-KGGX-5A6Q) + +[](https://realadvisor.ch/de/kaufen/grundstuck/7134-obersaxen-JDXL-ALVL) + +vor 1 Tag + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 732 m² Grundstück • Bauland 7134 Obersaxen * Atemberaubende Panoramasicht * Skizugang bis zur Haustür * Vollständig ausgearbeitetes Bauprojekt ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 270’000.- CHF 369 / m²](https://realadvisor.ch/de/kaufen/grundstuck/7134-obersaxen-JDXL-ALVL) + +[](https://realadvisor.ch/de/kaufen/grundstuck/2000-neuchatel-YMXG-PB5O) + +vor 1 Tag + +- [x] + +[Wolf Output SA 443 m² Grundstück • Bauland 2000 Neuchâtel * Seltene Gelegenheit in der Stadt * Ideal für Wohnprojekte * Attraktive Preise verfügbar ------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 110’000.- CHF 248 / m²](https://realadvisor.ch/de/kaufen/grundstuck/2000-neuchatel-YMXG-PB5O) + +[](https://realadvisor.ch/de/kaufen/grundstuck/guttet-3956-guttet-feschel-YA69-QV5X) + +vor 1 Tag + +- [x] + +[valvida 585 m² • 585 m² Grundstück • Bauland Guttet, 3956 Guttet-Feschel * Unverbaubare Talansicht * Ruhige und sonnige Lage * Einfacher Zugang zum Dorfzentrum ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 129’000.- CHF 221 / m²](https://realadvisor.ch/de/kaufen/grundstuck/guttet-3956-guttet-feschel-YA69-QV5X) + +[](https://realadvisor.ch/de/kaufen/grundstuck/1918-la-tzoumaz-84RP-QZN5) + +vor 1 Tag + +- [x] + +[4vallees4saisons.com 5 Zi. • 1’287 m² Grundstück • Bauland 1918 La Tzoumaz * Atemberaubende Panoramaaussicht * Bebaubar für Chalets * Steuervorteile Lex Webber ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 295’000.- CHF 229 / m²](https://realadvisor.ch/de/kaufen/grundstuck/1918-la-tzoumaz-84RP-QZN5) + +[](https://realadvisor.ch/de/kaufen/grundstuck/3954-leukerbad-Y23B-64EB) + +vor 1 Tag + +- [x] + +[Fast Home AG 2’842 m² • 2’842 m² Grundstück • Bauland 3954 Leukerbad * Atemberaubende Alpenblicke * Thermalquellen in der Nähe * Ganzjährige Outdoor-Aktivitäten ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 998’000.- CHF 351 / m²](https://realadvisor.ch/de/kaufen/grundstuck/3954-leukerbad-Y23B-64EB) + +[](https://realadvisor.ch/de/kaufen/grundstuck/1854-leysin-KEL4-DRAM) + +vor 1 Tag + +- [x] + +[VON POLL REAL ESTATE BASEL 1’010 m² Grundstück • Bauland 1854 Leysin * Atemberaubende Panoramasicht * Ruhige Lage, gute Erreichbarkeit * Bauzone Chalet A ------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/1854-leysin-KEL4-DRAM) + +[](https://realadvisor.ch/de/kaufen/grundstuck/3900-brig-KQND-2967) + +vor 1 Tag + +- [x] + +[Fast Home AG 12’841 m² Grundstück • Bauland 3900 Brig * 12.000 m² für Ihr Projekt * Flexible Bauoptionen * Ausgezeichnete Verkehrsanbindung ---------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/3900-brig-KQND-2967) + +[Keine Fotos](https://realadvisor.ch/de/kaufen/grundstuck/1012-lausanne-Y6ZM-BQM3) + +vor 1 Tag + +- [x] + +[AD Immob Sàrl 920 m² Grundstück • Bauland 1012 Lausanne * 920 m2 erstklassiges Land * Keine bestehenden Bauwerke * Perfekt für Familienhäuser ------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 1’540’000.- CHF 1’674 / m²](https://realadvisor.ch/de/kaufen/grundstuck/1012-lausanne-Y6ZM-BQM3) + +[](https://realadvisor.ch/de/kaufen/grundstuck/3472-wynigen-YA6X-NGBV) + +vor 1 Tag + +- [x] + +[Agentur Wyss AG 10 Zi. • 223 m² • 249’992 m² Grundstück • Industriebauland 3472 Wynigen * Atemberaubende Aussicht auf Wynigen * Zwei separate moderne Wohnungen * Ideal für Pferdesportaktivitäten ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’140’000.- CHF 518 / m²](https://realadvisor.ch/de/kaufen/grundstuck/3472-wynigen-YA6X-NGBV) + +[](https://realadvisor.ch/de/kaufen/grundstuck/5057-reitnau-YZZ7-RDOJ) + +vor 1 Tag + +- [x] + +[BAY & PARTNER IMMOBILIEN GmbH 3’031 m² Grundstück • Bauland 5057 Reitnau * 3031 m2 flaches Land * Neu errichtete Erschliessungsstrasse * Keine Architekturverpflichtung -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’268’000.- CHF 418 / m²](https://realadvisor.ch/de/kaufen/grundstuck/5057-reitnau-YZZ7-RDOJ) + +[](https://realadvisor.ch/de/kaufen/grundstuck/7134-obersaxen-VBG4-X5JW) + +vor 1 Tag + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 1’414 m² Grundstück • Bauland 7134 Obersaxen * Spektakuläre Bergsicht * Ruhige, sonnige Lage * Ausgezeichnete Verkehrsanbindung -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/7134-obersaxen-VBG4-X5JW) + +[1](https://realadvisor.ch/de/kaufen/grundstuck) + +[2](https://realadvisor.ch/de/kaufen/grundstuck/seite-2) + +[3](https://realadvisor.ch/de/kaufen/grundstuck/seite-3) + +[4](https://realadvisor.ch/de/kaufen/grundstuck/seite-4) + +[5](https://realadvisor.ch/de/kaufen/grundstuck/seite-5) + +[6](https://realadvisor.ch/de/kaufen/grundstuck/seite-6) + +[7](https://realadvisor.ch/de/kaufen/grundstuck/seite-7) + +[](https://realadvisor.ch/de/kaufen/grundstuck/seite-2) + +1-24 von 2’266 Ergebnisse + +Grundstück kaufen Schweiz +------------------------- + +[Immobilienpreise in Schweiz](https://realadvisor.ch/de/immobilienpreise-pro-m2) + +### Grundstück kaufen Schweiz + +[Grundstück kaufen im Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck)[Grundstück kaufen im Kanton Bern](https://realadvisor.ch/de/kaufen/kanton-bern/grundstuck)[Grundstück kaufen im Kanton Waadt](https://realadvisor.ch/de/kaufen/kanton-waadt/grundstuck)[Grundstück kaufen im Kanton Aargau](https://realadvisor.ch/de/kaufen/kanton-aargau/grundstuck)[Grundstück kaufen im Kanton St. Gallen](https://realadvisor.ch/de/kaufen/kanton-st-gallen/grundstuck)[Grundstück kaufen im Kanton Genf](https://realadvisor.ch/de/kaufen/kanton-genf/grundstuck)[Grundstück kaufen im Kanton Luzern](https://realadvisor.ch/de/kaufen/kanton-luzern/grundstuck)[Grundstück kaufen im Kanton Tessin](https://realadvisor.ch/de/kaufen/kanton-tessin/grundstuck)[Grundstück kaufen im Kanton Wallis](https://realadvisor.ch/de/kaufen/kanton-wallis/grundstuck)[Grundstück kaufen im Kanton Freiburg](https://realadvisor.ch/de/kaufen/kanton-freiburg/grundstuck)[Grundstück kaufen im Kanton Basel-Landschaft](https://realadvisor.ch/de/kaufen/kanton-basel-landschaft/grundstuck)[Grundstück kaufen im Kanton Thurgau](https://realadvisor.ch/de/kaufen/kanton-thurgau/grundstuck)[Grundstück kaufen im Kanton Solothurn](https://realadvisor.ch/de/kaufen/kanton-solothurn/grundstuck)[Grundstück kaufen im Kanton Graubünden](https://realadvisor.ch/de/kaufen/kanton-graubunden/grundstuck)[Grundstück kaufen im Kanton Basel-Stadt](https://realadvisor.ch/de/kaufen/kanton-basel-stadt/grundstuck)[Grundstück kaufen im Kanton Neuenburg](https://realadvisor.ch/de/kaufen/kanton-neuenburg/grundstuck)[Grundstück kaufen im Kanton Schwyz](https://realadvisor.ch/de/kaufen/kanton-schwyz/grundstuck)[Grundstück kaufen im Kanton Zug](https://realadvisor.ch/de/kaufen/kanton-zug/grundstuck)[Grundstück kaufen im Kanton Schaffhausen](https://realadvisor.ch/de/kaufen/kanton-schaffhausen/grundstuck)[Grundstück kaufen im Kanton Jura](https://realadvisor.ch/de/kaufen/kanton-jura/grundstuck)[Grundstück kaufen im Kanton Appenzell Ausserrhoden](https://realadvisor.ch/de/kaufen/kanton-appenzell-ausserrhoden/grundstuck)[Grundstück kaufen im Kanton Nidwalden](https://realadvisor.ch/de/kaufen/kanton-nidwalden/grundstuck)[Grundstück kaufen im Kanton Glarus](https://realadvisor.ch/de/kaufen/kanton-glarus/grundstuck)[Grundstück kaufen im Liechtenstein](https://realadvisor.ch/de/kaufen/liechtenstein/grundstuck)[Grundstück kaufen im Kanton Obwalden](https://realadvisor.ch/de/kaufen/kanton-obwalden/grundstuck)[Grundstück kaufen im Kanton Uri](https://realadvisor.ch/de/kaufen/kanton-uri/grundstuck)[Grundstück kaufen im Kanton Appenzell Innerrhoden](https://realadvisor.ch/de/kaufen/kanton-appenzell-innerrhoden/grundstuck) + +Mehr + +### Andere Immobilienarten Schweiz + +[Haus kaufen Schweiz](https://realadvisor.ch/de/kaufen/haus)[Wohnung kaufen Schweiz](https://realadvisor.ch/de/kaufen/wohnung)[Mehrfamilienhaus kaufen Schweiz](https://realadvisor.ch/de/kaufen/gebaude)[Gewerberaum kaufen Schweiz](https://realadvisor.ch/de/kaufen/gewerbe)[Hotel, Restaurant kaufen Schweiz](https://realadvisor.ch/de/kaufen/gastfreundschaft) + +### Beliebte Suchen Schweiz + +[Neubauprojekte in der Schweiz](https://realadvisor.ch/de/beliebte-suchen/neubauprojekte-schweiz)[Neubauten kaufen in der Schweiz](https://realadvisor.ch/de/beliebte-suchen/neubauten-kaufen-schweiz)[Neubauwohnungen kaufen in der Schweiz](https://realadvisor.ch/de/beliebte-suchen/neubauwohnung-kaufen-schweiz) + +[](https://ch.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + +Verkaufen + +[Immobilienbewertung](https://realadvisor.ch/de/online-immobilienbewertung)[Renditeliegenschaft bewerten](https://realadvisor.ch/de/renditeliegenschaft-bewerten-online)[Immobilienpreise](https://realadvisor.ch/de/immobilienpreise-pro-m2)[Makler finden](https://realadvisor.ch/de/makler-finden)[Immobilien-Glossar](https://realadvisor.ch/de/immobilien-glossar)[Immobilien-Blog](https://realadvisor.ch/de/blog) + +Kaufen / Mieten + +[Immobilien kaufen](https://realadvisor.ch/de/immobilien-kaufen)[Immobilien mieten](https://realadvisor.ch/de/immobilien-mieten)[Neubauprojekte](https://realadvisor.ch/de/neubauprojekte)[Immobilienfinanzierung](https://realadvisor.ch/de/finanzierung) + +Für Makler + +[Partner werden](https://realadvisor.ch/de/pro)[Blog Pro](https://realadvisor.ch/de/pro/blog) + +Unternehmen + +[Über uns](https://realadvisor.ch/de/uber-uns)[Presseraum](https://realadvisor.ch/de/presseraum)[Offene Stellen](https://realadvisor.welcomekit.co/)[Allgemeine Geschäftsbedingungen](https://realadvisor.ch/de/begriffe)[Datenschutzerklärung](https://realadvisor.ch/de/datenschutzerklarung)[Impressum](https://realadvisor.ch/de/impressum)[Alle Immobilien](https://realadvisor.ch/de/sitemap) + +© RealAdvisor 2025. All Rights Reserved. v.e89072f + +[](https://ch.linkedin.com/company/realadvisor)[](https://www.facebook.com/realadvisorcom)[](https://twitter.com/realadvisor)[](https://www.instagram.com/realadvisorcom)[](https://www.youtube.com/channel/UCsEDTDlmxBpyxLXYhWT769Q) + +Karte \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_025_realadvisor.ch_de_kaufen_grundstuck_8162-steinmaur-B62R-PZDJ.txt b/test_web_content_20251002_215219/additional_link_025_realadvisor.ch_de_kaufen_grundstuck_8162-steinmaur-B62R-PZDJ.txt new file mode 100644 index 00000000..7e4ed101 --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_025_realadvisor.ch_de_kaufen_grundstuck_8162-steinmaur-B62R-PZDJ.txt @@ -0,0 +1,237 @@ +URL: https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Bauland zu verkaufen - 8162 Steinmaur - | RealAdvisor + +=============== + +[](https://realadvisor.ch/de) + +Bewerten + +[Kaufen](https://realadvisor.ch/de/immobilien-kaufen)[Mieten](https://realadvisor.ch/de/immobilien-mieten) + +Anmelden + +DE + +[Français](https://realadvisor.ch/fr/acheter/terrain/8162-steinmaur-B62R-PZDJ)[Italiano](https://realadvisor.ch/it/comprare/trama/8162-steinmaur-B62R-PZDJ)[English](https://realadvisor.ch/en/buy/plot/8162-steinmaur-B62R-PZDJ) + +[Alle Inserate anzeigen](https://realadvisor.ch/de/kaufen/gemeinde-steinmaur/grundstuck) + + + + + + + + + + + + + +- [x] + +Speichern + +- [x] + +Bauland zu verkaufen - 8162 Steinmaur +===================================== + +Auf Anfrage + +* * * + +Grundstück + +Beschreibung + +BAULAND AN TRAUMHAFTER LAGE AM FISCHBACH +---------------------------------------- + +Wir bieten ein idyllisch gelegenes, flaches Grundstück zum Verkauf an, perfekt für Ihr Bauvorhaben! + +Derzeit könnten auf dem Grundstück **ein Mehrfamilienhaus (MFH) oder zwei freistehende Einfamilienhäuser (EFH) realisiert werden**. Die Gemeinde bzw. der Kanton plant jedoch eine Verlegung des Baches. Dadurch könnten zukünftig **zwei Doppel-EFHs oder alternativ drei Reihen-EFHs sowie ein Doppel-EFH umgesetzt werden**. Das Bauland liegt in der Bauzone W2, die Ausnützungsziffer beträgt 40 %. + +Dieses Grundstück bietet eine ruhige, naturnahe Atmosphäre, kombiniert mit einer hervorragenden Anbindung an den öffentlichen Verkehr. + +Dieses Grundstück bietet Ihnen alle Möglichkeiten, Ihr Projekt an einer ruhigen und naturnahen Umgebung zu realisieren. Profitieren Sie von der sonnigen Lage, dem Ausblick auf die Natur und der gut durchdachten Infrastruktur. + +**Grundstückdetails:** + +* **Grösse:** 1'452 m² +* **Bauvorschriften / Zone:** Zone: Wohnzone W2 Ausnützungsziffer: 40 +* **Lage:** Ruhiges, sonniges Wohnquartier nahe dem Zentrum von Niedersteinmaur +* **Bahnhof:** In 10 Minuten zu Fuss erreichbar +* **Bushaltestelle:** Nur 370 m entfernt +* **Besonderheiten:** Flaches, gut bebaubares Grundstück mit Bachanstoss, angrenzend an Landwirtschaftszone, Quartierschliessung ohne Durchgangsverkehr + +**Gemeinde Steinmaur:** + +* Einwohner: Ca. 3'750 +* Steuerfuss: 112% + +**Infrastruktur:** + +* **Einkauf:** Volg und Hofläden im Ort, grösseres Angebot in Dielsdorf und Bülach +* **Naherholung:** Umgeben von Natur und idealen Möglichkeiten für Spaziergänge und Erholung + +**TRAUMHAFTE LAGE INMITTEN DER NATUR** + +Wir bieten Ihnen ein einmaliges, ruhig gelegenes Bauland in Steinmaur, direkt am idyllischen Fischbach. Das flache Grundstück eignet sich perfekt für Ihr zukünftiges Bauvorhaben und bietet einen unverbaubaren Blick auf die angrenzende Landwirtschaftszone. + +**Lage und Umgebung:** Steinmaur ist eine familienfreundliche Gemeinde mit etwa 3'750 Einwohnern und einem attraktiven Steuerfuss von 112%. Hier finden Sie die perfekte Balance zwischen ländlicher Ruhe und einer guten Anbindung an die Städte Zürich, Bülach und Dielsdorf. + +Einkaufsmöglichkeiten: Im Ort gibt es einen Volg sowie diverse Hofläden mit frischen, lokalen Produkten. Weitere Einkaufsmöglichkeiten finden Sie in den nahegelegenen Zentren von Dielsdorf und Bülach. + +**Naherholung:** Die Umgebung von Steinmaur bietet zahlreiche Naherholungsgebiete, die zu ausgedehnten Spaziergängen, Radtouren und Naturerkundungen einladen. Der Fischbach verleiht dem Grundstück eine besondere Idylle und sorgt für eine entspannte Atmosphäre direkt vor Ihrer Haustür. + +**Verkehrsanbindung:** Das Bauland besticht durch seine hervorragende Anbindung an den öffentlichen Verkehr. Der Bahnhof Steinmaur ist in 10 Minuten zu Fuss erreichbar, und die Bushaltestelle befindet sich nur 370 m vom Grundstück entfernt. So sind Sie schnell und bequem in den umliegenden Städten und Gemeinden unterwegs + +### Angaben zur Immobilie + +Verfügbar ab + +Nach Vereinbarung + +* * * + +Grundstücksfläche + +1’452.0 m² + +* * * + +Agentur +------- + + + +get living + +4.9 + +(39 Bewertungen) + +[Agenturprofil anzeigen](https://realadvisor.ch/de/immobilienagenturen/agentur-get-living-gmbh) +Sadegh Karkhaneh + +[Nummer anzeigen](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ) + +Ref. VKXW-42L8-590 + +Energy diagnostics +------------------ + +Energy consumption + +No data + +Greenhouse gas emmissions + +No data + +Ort +--- + +8162 Steinmaur(ZH) + +Nicht was Sie suchen? + +Entdecken Sie 0 ähnliche Angebote in Steinmaur + +[Inserate ansehen](https://realadvisor.ch/de/kaufen/gemeinde-steinmaur/grundstuck) + +1. [](https://realadvisor.ch/de) + +3. [Kaufen](https://realadvisor.ch/de/kaufen) + +5. [Grundstück](https://realadvisor.ch/de/kaufen/grundstuck) + +7. [Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck) + +9. [Bezirk Dielsdorf](https://realadvisor.ch/de/kaufen/bezirk-dielsdorf/grundstuck) + +11. [Steinmaur](https://realadvisor.ch/de/kaufen/gemeinde-steinmaur/grundstuck) + +13. [8162 Steinmaur](https://realadvisor.ch/de/kaufen/8162-steinmaur/grundstuck) + +15. Bauland zu verkaufen - 8162 Steinmaur + +Preis auf Anfrage + +CHF - / m² + +* * * + + + +get living + +4.9 + +(39 Bewertungen) + +[Agenturprofil anzeigen](https://realadvisor.ch/de/immobilienagenturen/agentur-get-living-gmbh) + +Ref. VKXW-42L8-590 + +[Nummer anzeigen](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ) + +* * * + +Anbieter kontaktieren + +Vorname * + +Nachname * + +E-Mail-Adresse * + +Telefonnummer * + +69/3000 + +Anfrage abschicken + +Ähnliche Inserate + +[](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ#) + +vor 14 Tagen + +- [x] + +[— 752 m² Grundstück • Bauland Wehntalerstrasse 28, 8181 Höri * Inklusive Baubewilligung * Geologisches Gutachten enthalten * 9 Tiefgaragenplätze * * * CHF 1’900’000.- CHF 2’527 / m² homegate.ch](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ#) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ#) + +vor 28 Tagen + +- [x] + +[Losinger Marazzi Industriebauland Kaffeestrasse, 8180 Bülach * Anpassbare Projektoptionen * Flexible Miete oder Eigentum * Weitere Grundstücksangebote erkunden * * * Auf Anfrage — immoscout24.ch](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ#) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ#) + +vor 28 Tagen + +- [x] + +[Losinger Marazzi 17’582 m² Grundstück • Bauland 8157 Dielsdorf * Ideal für individuelle Projekte * Ausgezeichnete Verkehrsanbindung * Geräumiges Grundstück von 17'582 m² * * * Auf Anfrage — immoscout24.ch](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ#) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8172-niederglatt-zh-YMX9-JZX5) + +vor 2 Monaten + +- [x] + +[RE/MAX Immobilien in Bülach 9 Zi. • 180 m² • 891 m² Grundstück • Bauland 8172 Niederglatt ZH * Historischer Charme seit 1680 * Geräumiger Garten zum Entspannen * Vielseitige Scheune für Erweiterung * * * CHF 2’300’000.- CHF 12’778 / m² immobilier.ch](https://realadvisor.ch/de/kaufen/grundstuck/8172-niederglatt-zh-YMX9-JZX5) + +* * * + +Anfrage abschicken \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_026_realadvisor.ch_de_kaufen_grundstuck_8340-hinwil-LDX9-L6M2.txt b/test_web_content_20251002_215219/additional_link_026_realadvisor.ch_de_kaufen_grundstuck_8340-hinwil-LDX9-L6M2.txt new file mode 100644 index 00000000..00eac79e --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_026_realadvisor.ch_de_kaufen_grundstuck_8340-hinwil-LDX9-L6M2.txt @@ -0,0 +1,216 @@ +URL: https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2 +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Bauland zu verkaufen - 8340 Hinwil - | RealAdvisor + +=============== + +[](https://realadvisor.ch/de) + +Bewerten + +[Kaufen](https://realadvisor.ch/de/immobilien-kaufen)[Mieten](https://realadvisor.ch/de/immobilien-mieten) + +Anmelden + +DE + +[Français](https://realadvisor.ch/fr/acheter/terrain/8340-hinwil-LDX9-L6M2)[Italiano](https://realadvisor.ch/it/comprare/trama/8340-hinwil-LDX9-L6M2)[English](https://realadvisor.ch/en/buy/plot/8340-hinwil-LDX9-L6M2) + +[Alle Inserate anzeigen](https://realadvisor.ch/de/kaufen/stadt-hinwil/grundstuck) + + + + + + + + + +- [x] + +Speichern + +- [x] + +Bauland zu verkaufen - 8340 Hinwil +================================== + +CHF 1’070’000.- + +CHF 1’000 / m² + +* * * + +Grundstück + +Beschreibung + +Hier beginnt Ihre Zukunft +------------------------- + +Dieses attraktive Grundstück befindet sich an ruhiger und familienfreundlicher Lage in Hinwil. Mit einer Gesamtfläche von über 1070 m² bietet es vielfältige Nutzungsmöglichkeiten und eignet sich hervorragend für die Realisierung mehrerer Reihenfamilienhäuser. Dank der Möglichkeit zur Abparzellierung kann auch nur ein Teil des Landes beispielsweise ideal für ein Einfamilienhaus erworben werden. Das Grundstück liegt in der Kernzone und eröffnet dadurch grossen Gestaltungsspielraum für individuelle Bauprojekte. + +Dieses ImmoSky Angebot bietet folgende _MEHR LEISTUNG_: + ++ Kernzone + ++ 2 Vollgeschosse, 1 Dachgeschoss + ++ 4m Grenzabstand + ++ 7.5m Fassadenhöhe + +Das Grundstück ist baureif und erschlossen, die Quartierplankosten von CHF 150.00/m² werden zum Verkaufspreis dazugerechnet. + +Aktuell befinden sich alte Holzschuppen auf dem Grundstück. Diese können abgerissen werden, um Platz für neue Ideen zu schaffen. Eine seltene Gelegenheit, Wohnen mit hoher Lebensqualität im Zürcher Oberland zu verwirklichen. Gerne stehe ich Ihnen bei Fragen zur Verfügung Ihr Daniel Arigoni. + +(Das Verkaufsdossier wird in der Regel innert maximal 24 Stunden an Sie versendet, bitte prüfen Sie auch Ihren SPAM-Ordner.) + +### Angaben zur Immobilie + +Verfügbar ab + +Nach Vereinbarung + +* * * + +Grundstücksfläche + +1’070.0 m² + +* * * + +Agentur +------- + + + +ImmoSky AG - Standort Dübendorf ZH (Zentrale) + +4.1 + +(308 Bewertungen) + +[Agenturprofil anzeigen](https://realadvisor.ch/de/immobilienagenturen/agentur-immosky-ag) +Daniel Arigoni + +[Nummer anzeigen](https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2) + +[Nummer anzeigen](https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2) + +Ref. 6650102 + +Energy diagnostics +------------------ + +Energy consumption + +No data + +Greenhouse gas emmissions + +No data + +Ort +--- + +8340 Hinwil(ZH) + +Nicht was Sie suchen? + +Entdecken Sie 0 ähnliche Angebote in Hinwil + +[Inserate ansehen](https://realadvisor.ch/de/kaufen/stadt-hinwil/grundstuck) + +1. [](https://realadvisor.ch/de) + +3. [Kaufen](https://realadvisor.ch/de/kaufen) + +5. [Grundstück](https://realadvisor.ch/de/kaufen/grundstuck) + +7. [Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck) + +9. [Bezirk Hinwil](https://realadvisor.ch/de/kaufen/bezirk-hinwil/grundstuck) + +11. [Hinwil](https://realadvisor.ch/de/kaufen/stadt-hinwil/grundstuck) + +13. [8340 Hinwil](https://realadvisor.ch/de/kaufen/8340-hinwil/grundstuck) + +15. Bauland zu verkaufen - 8340 Hinwil + +CHF 1’070’000.- + +CHF 1’000 / m² + +* * * + + + +ImmoSky AG - Standort Dübendorf ZH (Zentrale) + +4.1 + +(308 Bewertungen) + +[Agenturprofil anzeigen](https://realadvisor.ch/de/immobilienagenturen/agentur-immosky-ag) + +Ref. 6650102 + +[Nummer anzeigen](https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2) + +* * * + +Anbieter kontaktieren + +Vorname * + +Nachname * + +E-Mail-Adresse * + +Telefonnummer * + +69/3000 + +Anfrage abschicken + +Ähnliche Inserate + +[](https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2#) + +vor 28 Tagen + +- [x] + +[Goda Verwaltung AG 380 m² Grundstück • Bauland In Der Gass 2, 8627 Grüningen * Genehmigtes Neubauprojekt * Geplante 8 Wohnungen * Tiefgarage für 11 Autos * * * CHF 1’750’000.- CHF 4’605 / m² immoscout24.ch](https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2#) + +[](https://realadvisor.ch/de/kaufen/grundstuck/23-uberlandstrasse-8340-hinwil-YB69-VB7M) + +vor 2 Monaten + +- [x] + +[RE/MAX Immobilien in Rapperswil-Jona 4’246 m² Grundstück • Bauland Überlandstrasse 23, 8340 Hinwil * Top Lage an Hauptstrassen * Grosse Fläche für Entwicklung * Flexible Gebäudehöhen möglich * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/23-uberlandstrasse-8340-hinwil-YB69-VB7M) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8630-ruti-zh-84E9-Z65G) + +vor 4 Monaten + +- [x] + +[PREMIUM HOMES AG 3’460 m² Grundstück • Bauland 8630 Rüti ZH * Ruhige Wohnzone * Ausnützungsziffer 30% * Bonus für zusätzlichen Raum * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/8630-ruti-zh-84E9-Z65G) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8633-wolfhausen-YB6N-VRVP) + +vor 7 Tagen + +- [x] + +[PREMIUM HOMES AG 1’940 m² Grundstück • Bauland 8633 Wolfhausen * Grosszügige 1'940m² Parzelle * Familienfreundliche Lage * Flexible Gestaltungsmöglichkeiten * * * CHF 4’074’000.- CHF 2’100 / m²](https://realadvisor.ch/de/kaufen/grundstuck/8633-wolfhausen-YB6N-VRVP) + +* * * + +Anfrage abschicken \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_027_www.immoyou.ch_.txt b/test_web_content_20251002_215219/additional_link_027_www.immoyou.ch_.txt new file mode 100644 index 00000000..fb455843 --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_027_www.immoyou.ch_.txt @@ -0,0 +1,199 @@ +URL: https://www.immoyou.ch/ +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +ImmoYou: Das grösste Immobilienportal der Deutschschweiz 🏘 + +=============== +[Skip to content](https://www.immoyou.ch/#content) + +[](https://www.immoyou.ch/) + +* [Kaufen](https://www.immoyou.ch/#) + * [Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz) + * [Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + * [Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz) + +* [Mieten](https://www.immoyou.ch/#) + * [Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz) + * [Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + * [Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz) + +Menu + +* [Kaufen](https://www.immoyou.ch/#) + * [Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz) + * [Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + * [Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz) + +* [Mieten](https://www.immoyou.ch/#) + * [Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz) + * [Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + * [Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz) + +Alle Immobilieninserate der Deutschschweiz auf einer Seite +========================================================== + +[Immobilie kaufen](https://www.immoyou.ch/kaufen-schweiz) + +[Immobilie mieten](https://www.immoyou.ch/mieten-schweiz) + +Ihr Immobilienprojekt +--------------------- + +Ob Kauf- oder Verkaufsplan, ImmoYou hat für Sie die aktuell 30.000 online verfügbaren Immobilieninserate in der Westschweiz ausgewählt. + +Finden Sie das Haus Ihrer Träume, die ideale Wohnung, einen Parkplatz oder**wahllose Räumlichkeiten**zur Miete oder zum Kauf auf ImmoYou, alles in nur wenigen Klicks! + +Immobilien zur Miete in der Deutschschweiz + +[](https://www.immoyou.ch/mieten-kanton-zurich) + +[](https://www.immoyou.ch/mieten-kanton-thurgau) + +[](https://www.immoyou.ch/mieten-kanton-zug) + +Immobilien zum Verkauf in der Deutschschweiz + +[](https://www.immoyou.ch/kaufen-kanton-schaffhausen) + +[](https://www.immoyou.ch/kaufen-kanton-bern) + +[](https://www.immoyou.ch/kaufen-kanton-luzern) + +Immobilienangebote nach Kanton +------------------------------ + +**Häuser zur Miete in der Schweiz nach Kanton** + +[Haus mieten im Kanton Aargau](https://www.immoyou.ch/haus-mieten-kanton-aargau) + +[Haus mieten im Kanton Thurgau](https://www.immoyou.ch/haus-mieten-kanton-thurgau) + +[Haus mieten im Kanton Bern](https://www.immoyou.ch/haus-mieten-kanton-bern) + +[Haus mieten im Kanton Zürich](https://www.immoyou.ch/haus-mieten-kanton-zurich) + +[Haus mieten im Kanton Basel-Landschaft](https://www.immoyou.ch/haus-mieten-kanton-basel-landschaft) + +[Haus mieten im Kanton Luzern](https://www.immoyou.ch/haus-mieten-kanton-luzern) + +**Häuser zum Verkauf in der Schweiz nach Kanton** + +[Haus kaufen im Kanton Aargau](https://www.immoyou.ch/haus-kaufen-kanton-aargau) + +[Haus kaufen im Kanton Thurgau](https://www.immoyou.ch/haus-kaufen-kanton-thurgau) + +[Haus kaufen im Kanton Bern](https://www.immoyou.ch/haus-kaufen-kanton-bern) + +[Haus kaufen im Kanton Zürich](https://www.immoyou.ch/haus-kaufen-kanton-zurich) + +[Haus kaufen im Kanton Basel-Landschaft](https://www.immoyou.ch/haus-kaufen-kanton-basel-landschaft) + +[Haus kaufen im Kanton Luzern](https://www.immoyou.ch/haus-kaufen-kanton-luzern) + +**Wohnungen zur Miete in der Schweiz nach Kanton** + +[Wohnung mieten im Kanton Zürich](https://www.immoyou.ch/wohnung-mieten-kanton-zurich) + +[Wohnung mieten im Kanton Luzern](https://www.immoyou.ch/wohnung-mieten-kanton-luzern) + +[Wohnung mieten im Kanton Bern](https://www.immoyou.ch/wohnung-mieten-kanton-bern) + +[Wohnung mieten im Kanton Basel-Landschaft](https://www.immoyou.ch/wohnung-mieten-kanton-basel-landschaft) + +[Wohnung mieten im Kanton St. Gallen](https://www.immoyou.ch/wohnung-mieten-kanton-st-gallen) + +[Wohnung mieten im Kanton Schaffhausen](https://www.immoyou.ch/wohnung-mieten-kanton-schaffhausen) + +**Wohnungen zum Verkauf in der Schweiz nach Kanton** + +[Wohnung kaufen im Kanton Zürich](https://www.immoyou.ch/wohnung-kaufen-kanton-zurich) + +[Wohnung kaufen im Kanton Luzern](https://www.immoyou.ch/wohnung-kaufen-kanton-luzern) + +[Wohnung kaufen im Kanton Bern](https://www.immoyou.ch/wohnung-kaufen-kanton-bern) + +[Wohnung kaufen im Kanton Basel-Landschaft](https://www.immoyou.ch/wohnung-kaufen-kanton-basel-landschaft) + +[Wohnung kaufen im Kanton St.Gallen](https://www.immoyou.ch/wohnung-kaufen-kanton-st-gallen) + +[Wohnung kaufen in Kanton Aargau](https://www.immoyou.ch/wohnung-kaufen-kanton-aargau) + +Beliebte Suchanfragen in der Deutschschweiz +------------------------------------------- + +**Häuser zur Miete in Schweiz nach Stadt** + +[Haus mieten in Bern](https://www.immoyou.ch/haus-mieten-stadt-bern) | [Haus mieten in Zürich](https://www.immoyou.ch/haus-mieten-stadt-zurich) | [Haus mieten Basel](https://www.immoyou.ch/haus-mieten-stadt-basel) | [Haus mieten in Winterthur](https://www.immoyou.ch/haus-mieten-stadt-winterthur) | [Haus mieten Luzern](https://www.immoyou.ch/haus-mieten-stadt-luzern) | [Haus mieten in Solothurn](https://www.immoyou.ch/haus-mieten-stadt-solothurn) | [Haus mieten in St. Gallen](https://www.immoyou.ch/haus-mieten-stadt-st-gallen) + +**Häuser zum Verkauf in Schweiz nach Stadt** + +[Haus kaufen in Bern](https://www.immoyou.ch/haus-kaufen-stadt-bern) | [Haus kaufen in Zürich](https://www.immoyou.ch/haus-kaufen-stadt-zurich) | [Haus kaufen Basel](https://www.immoyou.ch/haus-kaufen-stadt-basel) | [Haus kaufen in Winterthur](https://www.immoyou.ch/haus-kaufen-stadt-winterthur) | [Haus kaufen Luzern](https://www.immoyou.ch/haus-kaufen-stadt-luzern) | [Haus kaufen in Solothurn](https://www.immoyou.ch/haus-kaufen-stadt-solothurn) | [Haus kaufen in Schaffhausen](https://www.immoyou.ch/haus-kaufen-stadt-schaffhausen) + +**Wohnungen zur Miete in Schweiz nach Städten** + +[Wohnung mieten in Bern](https://www.immoyou.ch/wohnung-mieten-stadt-bern) | [Wohnung mieten in Zürich](https://www.immoyou.ch/wohnung-mieten-stadt-zurich) | [Wohnung mieten Luzern](https://www.immoyou.ch/wohnung-mieten-stadt-luzern) | [Wohnung mieten in Chur](https://www.immoyou.ch/wohnung-mieten-stadt-chur) | [Wohnung mieten St. Gallen](https://www.immoyou.ch/wohnung-mieten-stadt-st-gallen) | [Wohnung mieten in Basel](https://www.immoyou.ch/wohnung-mieten-stadt-basel) | [Wohnung mieten in Winterthur](https://www.immoyou.ch/wohnung-mieten-stadt-winterthur) + +**Wohnungen zum Verkauf in Schweiz nach Stadt** + +[Wohnung kaufen in Bern](https://www.immoyou.ch/wohnung-kaufen-stadt-bern) | [Wohnung kaufen in Zürich](https://www.immoyou.ch/wohnung-kaufen-stadt-zurich) | [Wohnung kaufen Luzern](https://www.immoyou.ch/wohnung-kaufen-stadt-luzern) | [Wohnung kaufen in Chur](https://www.immoyou.ch/wohnung-kaufen-stadt-chur) | [Wohnung kaufen St. Gallen](https://www.immoyou.ch/wohnung-kaufen-stadt-st-gallen) | [Wohnung kaufen in Basel](https://www.immoyou.ch/wohnung-kaufen-stadt-basel) | [Wohnung kaufen in Winterthur](https://www.immoyou.ch/wohnung-kaufen-stadt-winterthur) + + + +c/o AI Partners SA + + Avenue Louis-Casaï 86A + + 1216 Cointrin + + Suisse + +**Immobilien zum Verkauf** + +[Haus kaufen in Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + +[Wohung kaufen in Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz) + +[Wohung kaufen in Zürich](https://www.immoyou.ch/wohnung-kaufen-stadt-zurich) + +[Wohung kaufen in Bern](https://www.immoyou.ch/wohnung-kaufen-stadt-bern) + +[Wohnung kaufen in Luzern](https://www.immoyou.ch/wohnung-kaufen-stadt-luzern) + +[Haus kaufen in Zürich](https://www.immoyou.ch/haus-kaufen-stadt-zurich) + +[Haus kaufen in Bern](https://www.immoyou.ch/haus-kaufen-stadt-bern) + +[Haus kaufen in Thurgau](https://www.immoyou.ch/haus-kaufen-kanton-thurgau) + +[Haus kaufen in Aargau](https://www.immoyou.ch/haus-kaufen-kanton-aargau) + +**Immobilien zur Miete** + +[Haus mieten in Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + +[Wohung mieten in Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz) + +[Wohnung mieten in Zürich](https://www.immoyou.ch/wohnung-mieten-stadt-zurich) + +[Wohnung mieten in Luzern](https://www.immoyou.ch/wohnung-mieten-stadt-luzern) + +[Wohnung mieten in Bern](https://www.immoyou.ch/wohnung-mieten-stadt-bern) + +[Wohnung mieten in Winterthur](https://www.immoyou.ch/wohnung-mieten-stadt-winterthur) + +[Wohnung mieten in St. Gallen](https://www.immoyou.ch/wohnung-mieten-stadt-st-gallen) + +[Wohnung mieten in Chur](https://www.immoyou.ch/wohnung-mieten-stadt-chur) + +[Wohnung mieten in Thun](https://www.immoyou.ch/wohnung-mieten-stadt-thun) + +**Über uns** + +[Wer sind wir?](https://www.immoyou.ch/uber-uns) + +[Datenschutzerklärung](https://www.immoyou.ch/datenschutzerklarung) + +[Allgemeine Geschäftsbedingungen](https://www.immoyou.ch/allgemeine-geschaftsbedingungen) \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_028_www.immoyou.ch_kaufen-schweiz.txt b/test_web_content_20251002_215219/additional_link_028_www.immoyou.ch_kaufen-schweiz.txt new file mode 100644 index 00000000..5aa1ce1f --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_028_www.immoyou.ch_kaufen-schweiz.txt @@ -0,0 +1,423 @@ +URL: https://www.immoyou.ch/kaufen-schweiz +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +🏠 59’403 Immobilien kaufen in der Schweiz | ImmoYou + +=============== + +[ImmoYou](https://www.immoyou.ch/) + +Kaufen + +[Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + +Mieten + +[Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + + Ändern Sie die Suche + +[](https://www.immoyou.ch/)[Kaufen](https://www.immoyou.ch/kaufen-schweiz)[Schweiz](https://www.immoyou.ch/kaufen-schweiz) + +Immobilien kaufen in der Schweiz +================================ + +Ort + + Schweiz + + Zürich + + Genf + + Typ + +- [x] Haus + +- [x] Wohnung + +- [x] Zimmer + +- [x] Parkplatz + +- [x] Büro & Gewerbe + +- [x] Wohnhaus + +- [x] Grundstück + + Verkaufspreis + + - + + Zimmer + + - + + Wohnfläche (m²) + + - + + Grundstücksfläche (m²) + + - + + Ausstattung & Eigenschaften + +- [x] Neubauprojekte + +- [x] Balkon + +- [x] Garten + +- [x] Parkplatz + +- [x] Lift + +- [x] Freie Aussicht + +- [x] Cheminée + +- [x] Garage + +- [x] Kinderfreundlich + +- [x] Rollstuhlgängig + +- [x] Möbliert + +Ordnen + + 59’403 Ergebnisse + + + + vor 2 Tagen + +Haus zu verkaufen + +1512 Chavannes-sur-Moudon • 7.5 Zimmer • 291 m² +------------------------------------------------------------------ + +Magnifique maison avec vue sur la campagne située à 5min de Moudon Environnement idéal pour cette villa qui offre un cadre de vie très agréable grâce à de généreux volumes distribués sur 3 étages, dont une vaste pièce à vivre avec cheminée, une grande cuisine ouverte moderne, 6 belles chambres, 3 salles d'eau, un wc visiteurs, un studio indépendant très pratique, un grand sous-sol aménagé avec Sauna qui offre diverses possibilités d'aménagements. L'espace extérieur offre une très belle terrasse ensoleillée avec brasero et un grand jardin avec piscine.Adresse exacte disponible sur demande .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1512-22-1 Superb house with view on the countryside located at 5min from Moudon Ideal environment for this villa which offers a very pleasant living environment thanks to generous volumes distributed on 3 floors, including a large living room with fireplace, a large modern open kitchen, 6 beautiful bedrooms, 3 bathrooms, a guest toilet, a very practical independent studio, a large basement with sauna which offers various development possibilities. The outside space offers a beautiful sunny terrace with brazier and a large garden with swimming pool.Exact address available on request .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/1512-22-1 + +CHF 5’668 / m² + +CHF 1’649’500 + + + + vor 2 Tagen + +Haus zu verkaufen + +8335 Hittnau • 3.5 Zimmer • 162 m² +----------------------------------------------------- + +Helles 3.5-Zimmer Einfamilienhaus mit erstklassiger Gartenanlage Dieses einzigartige Angebot überzeugt sowohl durch die qualitative Bausubstanz als auch durch die unmittelbare Nähe zu Schulen, öffentlichen Verkehrsmitteln und Einkaufsmöglichkeiten. Der offene Wohn-/Essbereich mit elegantem Cheminée, das helle Wohnambiente und die hochwertige Küche mit Frühstückbar versprechen ein hervorragendes Wohnerlebnis. Weitere Highlights sind das Hauptschlafzimmer mit En-Suite Bad sowie die atemberaubende Gartenanlage mit diversen Sitzplätzen, Bächlein und Teich.Genaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/8335-23-1 + +CHF 10’185 / m² + +CHF 1’650’000 + + vor 2 Tagen + +Haus zu verkaufen + +1000 Lausanne 27 • 5.5 Zimmer • 301 m² +--------------------------------------------------------- + +Magnificent building with adjoining barn to renovate Beautiful character house with a plot of more than 1'300m2 with trees offering a nice clearance on the lake. This property is ideally located in a peaceful environment while being close to all amenities (schools, shops and public transport). The housing part is currently spread over two levels and the barn-workshop part offers generous volumes. Great opportunity for transformation with a very good potential for interior space planning.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1000-22-1 + +CHF 4’153 / m² + +CHF 1’250’000 + + vor 2 Tagen + +Haus zu verkaufen + +1038 Bercher • 3.5 Zimmer • 110 m² +----------------------------------------------------- + +A haven of peace full of charm, village house near the Are you looking for a village house full of charm and ideally located? Look no further, this rare pearl is made for you Nestled in a quiet area and a PPE of two lots, it is perfectly maintained. Kitchen open to the dining room, large living room equipped with a wood stove, this village house offers all the comfort and authenticity you are looking for. Enjoy 2 bedrooms, a reduced, a bathroom and a guest toilet for your comfort. Close to the.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1038-22-2 + +CHF 5’909 / m² + +CHF 650’000 + + vor 2 Tagen + +Haus zu verkaufen + +1003 Lausanne • 8.5 Zimmer • 340 m² +------------------------------------------------------ + +Magnifique maison des années 30 entièrement rénovée à Lausanne Située en plein c?ur de Lausanne, cette splendide maison du début des années 30 offre un cachet remarquable et des prestations hors du commun. Les espaces sont spacieux et ouverts, créant une atmosphère chaleureuse et accueillante dès l'entrée. Les matériaux utilisés sont de qualité supérieure, avec des finitions soignées qui ajoutent une touche de standing à chaque détail. Cette maison entièrement rénovée au long de ces dix dernières années est idéale pour les familles, offrant des espaces de vie adaptés à toutes les générations. Les chambres sont spacieuses et confortables, tandis que les espaces de vie communs sont accueillants et conviviaux. L' aménagement paysager remarquable du jardin est une véritable ode à la nature, vous offrant une oasis de paix et de sérénité. Vous profiterez de moments de détente et de convivialité avec vos proches et vos amis dans cet espace extérieur exceptionnel. Enfin, ce bien d'exception vous permettra de profiter d'un espace fitness avec salle de bain et sauna, d'une cave à vin digne de ce nom et d'un garage souterrain de pas moins de 200m² . Si vous cherchez une maison de prestige à Lausanne, ne manquez pas cette opportunité rare. Contactez-nous dès maintenant pour organiser une visite et découvrir cette demeure exceptionnelle de vos propres yeux.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1012-23-3 Magnificent house of the 30s entirely renovated in Lausanne Located in the heart of Lausanne, this splendid house dating from the early 1930s offers a remarkable cachet and outstanding amenities. The spaces are spacious and open, creating a warm and welcoming atmosphere from the moment you enter. The materials used are of the highest quality, with meticulous finishing that adds a touch of luxury to every detail. This house has been completely renovated over the last ten years and is ideal for families, offering living spaces suitable for all generations. The bedrooms are spacious and comfortable, while the communal living areas are welcoming and friendly. The outstanding landscaping of the garden is a true ode to nature, offering you an oasis of peace and serenity. You will enjoy moments of relaxation and conviviality with your family and friends in this exceptional outdoor space. Finally, this exceptional property will allow you to enjoy a fitness area with bathroom and sauna, a wine cellar worthy of the name and an underground garage of no less than 200m². If you are looking for a prestigious house in Lausanne, do not miss this rare opportunity. Contact us now to arrange a visit and discover this exceptional home with your own eyes.Exact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/1012-23-3 + +CHF 15’294 / m² + +CHF 5’200’000 + + vor 2 Tagen + +Haus zu verkaufen + +1814 La Tour-de-Peilz • 6.5 Zimmer • 177 m² +-------------------------------------------------------------- + +Exclusive: Semi-detached villa with panoramic views of the lake & the Alps This villa consists of a 4.5-room triplex and an independent duplex, which can easily be combined into a single family home. Enjoy a breathtaking panoramic view of the lake and the Alps, all in a quiet and bright situation. With its magnificent west-facing terrace, this place is ideal for relaxing moments with the family. Do not miss the opportunity to live in this exceptional living environment. Contact us for a visitExact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1814-23-1 + +CHF 7’627 / m² + +CHF 1’350’000 + + vor 2 Tagen + +Haus zu verkaufen + +1344 L'Abbaye • 7.5 Zimmer • 220 m² +------------------------------------------------------ + +Coup de coeur pour cette magnifique demeure avec jardin bucolique Magnifique maison villageoise transformée et entièrement rénovée entre 1997 et 2019. Elle jouit d'une belle terrasse et d'un jardin bucolique entièrement clôturé en bordure de rivière. Elle est distribuée sur 3 étages et elle est excavée (cave voutée). Ce bien est en parfait état d'entretien général et ne nécessite d'aucuns travaux. Possibilité de créer une pièce habitable dans les combles. Une place de parc extérieure complète ce bien et diverses places de parc se trouvent à proximité.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1344-21-1 + +CHF 4’773 / m² + +CHF 1’050’000 + + vor 2 Tagen + +Wohnhaus zu verkaufen + +8153 Rümlang +----------------------------------- + +Seltene Gelegenheit - Mehrfamilienhaus an Toplage Diese charmante Liegenschaft an zentraler Wohnlage in Rümlang verfügt über drei Wohneinheiten, ein Studio und zahlreiche Parkmöglichkeiten. Das interessante Raumangebot mit zwei 3-Zimmer-Wohnungen und einer 5-Zimmer-Wohnung, der gute Zustand dank laufend vorgenommenen Renovationen sowie das vorhandene Ausbaupotenzial versprechen eine attraktive Investitionsmöglichkeit. Das Mehrfamilienhaus ist zurzeit vollständig vermietet und erzielt eine Bruttorendite von ca. 3%.Genaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/8153-23-1 + +- + +CHF 2’195’000 + + vor 2 Tagen + +Haus zu verkaufen + +1003 Lausanne • 18 Zimmer • 683 m² +----------------------------------------------------- + +Magnifique maison de Maître dans les beaux quartiers Lausannois Située dans un quartier résidentiel Lausannois, cette propriété de charme de 683m2 utiles, bordée par 1'359 m2 de jardin paysagé dispose d'un fort potentiel d'extension et bénéficie de nombreuses possibilités d'aménagement (logements/commercial, mixte). Idéal pour ceux qui exercent une profession libérale comme médecin, avocat, notaire, architecte... Construite en 1927 avec son architecture classique, elle se développe sur cinq niveaux. Actuellement, les deux premiers étages sont à usage commercial et les deux derniers offrent deux appartements. Entièrement excavé, le sous-sol de 203 m2 dispose lui aussi de nombreuses possibilités d'aménagement. Cette bâtisse offre une grande flexibilité d'utilisation, pouvant être réaménagée en une seule ou plusieurs habitations familiales. A voir absolumentAdresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1012-22-2 Magnificent house in the beautiful districts of Lausanne Located in a residential area of Lausanne, this charming property of 683m2, bordered by 1'359 m2 of landscaped garden has a strong potential for extension and have many development possibilities (residential/commercial, mixed). Ideal for a liberal profession such as doctor, lawyer, notary, architect... Built in 1927 with a classical architecture, this house is on five levels. Currently, the first two floors are used for commercial purposes and the last tow floors are 2 apartments. The basement of 203 m2 offers numerous possibilities for development. This building offers a great flexibility of use, being able to be reorganized into one or several family dwellings. A must seeExact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/1012-22-2 Wunderschöne Immobilie in den schönen Vierteln von Lausanne In einem Wohnviertel von Lausanne gelegen, verfügt diese charmante Immobilie mit 683m2 Nutzfläche, die von 1'359 m2 angelegtem Garten begrenzt wird, über ein hohes Ausbaupotenzial und profitiert von zahlreichen Gestaltungsmöglichkeiten (Wohnen/Gewerbe, gemischt). Ideal für Personen, die einen freien Beruf wie Arzt, Anwalt, Notar, Architekt usw. ausüben. Das 1927 erbaute Gebäude mit seiner klassischen Architektur erstreckt sich über fünf Stockwerke. Derzeit werden die ersten beiden Stockwerke gewerblich genutzt und die letzten beiden bieten zwei Wohnungen. Das vollständig ausgehobene Untergeschoss mit 203 m2 verfügt ebenfalls über zahlreiche Gestaltungsmöglichkeiten. Dieses Gebäude bietet eine hohe Nutzungsflexibilität und kann in eine einzige oder mehrere Familienwohnungen umgewandelt werden. Unbedingt ansehenGenaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/1012-22-2 + +CHF 9’854 / m² + +CHF 6’730’000 + + vor 2 Tagen + +Haus zu verkaufen + +1854 Leysin • 6 Zimmer • 190 m² +-------------------------------------------------- + +DIRECTIMMO OFFERS YOU AN INDIVIDUAL CHALET A superb chalet with stunning panoramic views of the Alps. This cottage is intended for the main residence. Quality finishes at the discretion of the lessee. This project is subject to obtaining the building permit. It is possible to modify the interior distribution according to your wishes. Distribution (editable): Lower ground floor: A garage and 3 outdoor parking spaces A cellar and a technical room (laundry possible) An entrance hall A studio of 35m2 with an independent entrance, a cellar and a reduced Upper ground floor: A clearance A bathroom An equipped kitchen open to a dining area and a living room (fireplace or stove possible) A large terrace of about 80m2 Floor: A clearance Three bedrooms One bathroom, shower A balcony of about 11m2 Technical: Underfloor heating with a heat pump Comfortable finishing budgets (CHF 25'000.- for the kitchen, CHF 18'000.- for the sanitary facilities, CHF 60.- per m2 for the tiles, CHF 80.- per m2 for the parquet floors...) Windows with triple glazingIf you need to sell a property for the purchase of your new property, we offer you more than 20 years of experience in the field of sales. During these years, we have developed an unprecedented presentation with our Virtual-Tours of properties, our strengthened presence on real estate portals as well as unbeatable brokerage fees make us an ideal partner. Information and visit to Mirko Gysin at 079 574 33 39 WWW.DIRECTIMMO.CH + +CHF 6’737 / m² + +CHF 1’280’000 + + vor 2 Tagen + +Büro & Gewerbe zu verkaufen + +1800 Vevey +--------------------------------------- + +Hairdressing salon to put back, active for more than 40 years with an excellent location in the center of the old town of Vevey. The show is to be resumed with a clientele both loyal and passing through, women, men, children. The equipment and stock would remain at your disposal. You also have the option to keep some of the current employees. You have the opportunity to have an independent nail stylist who could occupy a small part of the premises. His rent would be collected by the hair salon. The rental income of the latter can be a plus. This commercial premises of about 70m2 which was renovated in 2019, benefits from large windows and has 6 workstations and 2 washing bins. Private washing machine and dryer remain available to the buyer. The resumption of trade, stock of products, equipment, furniture, etc. is CHF 99'000.-. Monthly rent CHF 2'420.00 charges included. Turnover 2019 - 2020 - 2021 available if real interest during a face-to-face meeting. Date of resumption to be agreed. We are at your disposal for further information as well as a possible site visit. The information is elaborated from the data provided by the seller, it has an informative character. Non-contractual document This property remains subject to change in price, availability and withdrawal of sale without notice. WWW.EDEN-IMMOBILIER.CH©copyright All rights reserved CP 414 - Rue d'Octodure 15 - 1920 Martigny - info@eden-immobilier.ch - www.eden-immobilier.ch + +- + +CHF 99’000 + + vor 2 Tagen + +Haus zu verkaufen + +1800 Vevey • 5.5 Zimmer • 160 m² +--------------------------------------------------- + +Detached villa of 5.5 roomsOn a beautiful plot of more than 1500m²Hallway and viewTerraces and gardenOutdoor parking spacesMost sought-after neighborhoodQuiet and residentialClose to transport and the lake File on request + +- + +Auf Anfrage + + vor 2 Tagen + +Wohnhaus zu verkaufen + +1844 Villeneuve VD +----------------------------------------- + +Modular, innovative construction and storage complex, an activity accelerator for small and medium-sized entrepreneurs. It is a modern industrial building comprising production, design and craft workshops, commercial offices, storage spaces, warehouses and apartment for rent for you and your business. Information and visit: François Volet+41 79 831 44 52 IMPORTANT: Confidential file, for any additional requests, please send us your full contact details. Privacy and Data Protection Agreement. This file is delivered to the attention and exclusive use of the recipient. It must not be disclosed to third parties without our written consent. All other information is on request from our agency. + +- + +CHF 16’000’000 + + vor 2 Tagen + +Wohnhaus zu verkaufen + +1847 Rennaz +---------------------------------- + +Beautiful commercial building completely renovated in 2018/2019, with a volume of 3,138 m³ on a plot of 2,052 m². This property is ideally located in the center of Rennaz, close to highways, amenities, shops and the Riviera Chablais Vaud Valais hospital. It enjoys a magnificent clearance on the mountains and the surrounding nature as well as an optimal brightness and sunshine throughout the day by its south-east orientation. A rental statement of CHF 235'000.- for a gross yield of more than 6%. Great opportunity to seize + +- + +Auf Anfrage + + vor 2 Tagen + +Haus zu verkaufen + +1071 Chexbres • 270 m² +----------------------------------------- + +Video of the panoramic view on www.chiffelle-immobilier.ch (under multimedia files) Located in the most exclusive area of Chexbres, this exceptional plot offers a panoramic view of the entire Lake Geneva basin, it is sold with a building permit in force for a luxurious contemporary villa of about 270 m2 of living space (three levels), 7.5 rooms, sauna, and outdoor pool facing the lake with removable deck. Allow about two million for the construction of the villa, in addition to the sale price of the plot. Complete plans available upon request. Video der Panoramaaussicht auf www.chiffelle-immobilier.ch (unter Multimedia-Dateien) Dieses aussergewöhnliche Grundstück im erlesensten Quartier von Chexbres bietet eine Panoramasicht auf das gesamte Genferseebecken und wird mit a Baugenehmigung für eine luxuriöse, moderne Villa mit ca. 270 m2 Wohnfläche (drei Ebenen), 7,5 Zimmern, Sauna und Außenpool mit Seeblick und abnehmbarer Terrasse. Stellen Sie zusätzlich zum Verkaufspreis des Grundstücks etwa zwei Millionen für den Bau der Villa bereit. Vollständige Pläne auf Anfrage erhältlich. Video of the panoramic view on www.chiffelle-immobilier.ch (under multimedia files) Located in the most select district of Chexbres, this exceptional plot offers a panoramic view of the entire Lake Geneva basin, it is sold with a building permit in force for a luxurious contemporary villa of approximately 270 m2 of living space (three levels), 7.5 rooms, sauna, and outdoor swimming pool facing the lake with removable deck. Provide about two million for the construction of the villa, in addition to the sale price of the plot. Complete plans available on request. + +CHF 9’259 / m² + +CHF 2’500’000 + + vor 2 Tagen + +Grundstück zu verkaufen + +1071 Chexbres • 270 m² +----------------------------------------------- + +Vidéo de la vue panoramique sur www.chiffelle-immobilier.ch (sous fichiers multimedia) Située dans le quartier le plus select de Chexbres, cette parcelle exceptionnelle offre une vue panoramique sur tout le bassin lémanique, elle est vendue avec un permis de construire en force pour une luxueuse villa contemporaine d'environ 270 m2 habitables (trois niveaux), 7.5 pièces, sauna, et piscine extérieure face au lac avec deck amovible. Prévoir environ deux millions pour la construction de la villa, en sus du prix de vente de la parcelle. Plans complets disponibles sur demande. Video der Panoramaaussicht auf www.chiffelle-immobilier.ch (unter Multimedia-Dateien) Dieses aussergewöhnliche Grundstück im erlesensten Quartier von Chexbres bietet eine Panoramasicht auf das gesamte Genferseebecken und wird mit a Baugenehmigung für eine luxuriöse, moderne Villa mit ca. 270 m2 Wohnfläche (drei Ebenen), 7,5 Zimmern, Sauna und Außenpool mit Seeblick und abnehmbarer Terrasse. Stellen Sie zusätzlich zum Verkaufspreis des Grundstücks etwa zwei Millionen für den Bau der Villa bereit. Vollständige Pläne auf Anfrage erhältlich. Video of the panoramic view on www.chiffelle-immobilier.ch (under multimedia files) Located in the most select district of Chexbres, this exceptional plot offers a panoramic view of the entire Lake Geneva basin, it is sold with a building permit in force for a luxurious contemporary villa of approximately 270 m2 of living space (three levels), 7.5 rooms, sauna, and outdoor swimming pool facing the lake with removable deck. Provide about two million for the construction of the villa, in addition to the sale price of the plot. Complete plans available on request. + +CHF 9’259 / m² + +CHF 2’500’000 + + vor 2 Tagen + +Haus zu verkaufen + +1297 Founex • 8 Zimmer • 180 m² +-------------------------------------------------- + +Located in the commune of Founex, this charming individual villa offers a living space of 180 sqm (250 sqm useful) and is composed of 8 rooms including 4 bedrooms. Built on a plot of more than 1'300 sqm, it offers a comfortable and bright living space and is distributed over two levels plus basement. Thanks to its privileged location, in the heart of an exclusive residential area, it meets all the criteria for a quiet family life in an idyllic setting. The private schools La Châtaigneraie (-5 minutes) and Le Collège du Léman (-10 minutes) are located nearby. Carefully maintained and renovated, it benefits from quality services and finishes, including solid wood flooring, recessed LED spotlights, plenty of storage space, mosaic tiles in the bathrooms, wooden shutters, double-glazed windows, and a fully equipped and furnished kitchen. The second floor is characterized by generous volumes thanks to a beautiful height under ceiling. Outside, a large wooden pergola protects the terrace. The living space is composed of an entrance hall, a kitchen with a central island of 12 sqm, a living/dining room with a fireplace of about 45 sqm and a living room/office of about 15 sqm, all opening onto the terrace. The second floor is dedicated to the night area, with a master bedroom of 21 sqm with its own shower room, 3 other bedrooms and a shower room with double sink. The basement, entirely excavated, offers two large multipurpose rooms of respectively 23 and 28 sqm, a laundry room, the technical rooms and a fallout shelter. The villa is distributed as follows : First floor :- Entrance hall with storage space- Kitchen with central island- Living/dining room with access to the terrace and the garden- Multipurpose room (living room, office, etc.) First floor :- Master bedroom of 20 m2 with its adjoining shower room with WC- Three bedrooms of about 15 sqm- Shower room with WC Basement :- Multipurpose room of 23 sqm- Multipurpose room of about 28 sqm- Laundry room and fallout shelter- Technical rooms Outside :- Large terrace covered by a pergola- Garden with trees and fenced- Garden shed- Box for two cars- Outdoor parking spaces The exterior spaces consist of a large fenced garden with trees, a large terrace with pergola and a garden shed. The access to the property is secured by a gate. A double garage and several outdoor parking spaces located at the entrance complete this property. Its location close to all amenities and road axes gives it a quick access to Nyon (-15 minutes), to the center of Geneva and to the international airport of Geneva (- 20 minutes). + +CHF 16’389 / m² + +CHF 2’950’000 + + vor 2 Tagen + +Haus zu verkaufen + +1145 Bière • 4.5 Zimmer • 110 m² +--------------------------------------------------- + +Detached house built in 1964 on a beautiful plot of more than 1'000m2 ideally located in Bière. This house is habitable in the state but requires renovation to be updated to the tastes of the day. The plot has an interesting potential for expansion. To visit without delay Contact us directly at 079 276 89 94 or by email at l.bolay@atix-immobilier.ch for any further information or to arrange a visit on site. + +CHF 8’455 / m² + +CHF 930’000 + + vor 2 Tagen + +Büro & Gewerbe zu verkaufen + +1343 Les Charbonnières • 296 m² +------------------------------------------------------------ + +It is a disused former pigsty, built in 1988, having undergone major renovations in 2002 is located in the small village Les Charbonnières which is at the end of Lake Joux. Many shops and amenities are located in the city of Vallorbe, at a distance of about 10km or Yverdon-les-Bains about 35km away. The plot is 250m from the village which makes it extremely well located. Built on a plot of 1,376 m2, this building is located in an agricultural area, not subject to the LDFR. Pig walkways have been set up on the east and west sides of the building. At the front, a large asphalted space allows the parking of light vehicles as well as access for trucks delivery or transport of animals. The plot also has two circular metal silos, for the storage of pig food and a capacity of about 8 tons each, they are located at the southeast corner of the building.Construction information: The building is not excavated. Its debarer/paving is reinforced concrete, built on piles, due to the wet nature of the land. The supporting walls are made of masonry and the facades of cement brick covered with ribbed panels. The frame is made of wood. The roof is covered with ribbed steel panels assembled around an expanded polyurethane foam. The kelps and downspouts are made of stainless steel. The building is not connected to the sewer. Waste water from the sanitary facilities is discharged into the slurry pit. Heat production is provided by an oil boiler (2,000-litre cistern). As for the distribution of heat, it is carried out by radiators in the technical room and the toilet, by coils in the soil and in the fattening cells.Major rehabilitation or transformation work is to be expected. + +CHF 845 / m² + +CHF 250’000 + + vor 2 Tagen + +Büro & Gewerbe zu verkaufen + +1530 Payerne +----------------------------------------- + +Land in village area with three tobacco sheds. Located in a quiet area, the land is flat and enjoys a magnificent view of the Alps. The hangars are electrified and have a water supply. The connection to clear water/wastewater is pending at the plot boundary. This property is quite suitable for yield but can also become a building plot, as soon as the building restriction is lifted, for twin villas. + +- + +CHF 650’000 + + vor 2 Tagen + +Haus zu verkaufen + +1342 Le Pont • 4.5 Zimmer • 180 m² +----------------------------------------------------- + +Who has never dreamed of a house close to the lake and nature? This property is for you. You will just have to push the doors of this property to immediately fall under the spell. This house consisting of 2 dwellings will offer you great flexibility. Located between the lake and nature you will reside in a quiet residential area. A real idyll You will have understood this property will not remain available for long. So do not hesitate and contact us. Our real estate agents will be happy to open the doors of this little paradise. + +CHF 10’000 / m² + +CHF 1’800’000 + + vor 2 Tagen + +Haus zu verkaufen + +1815 Clarens • 10 Zimmer • 400 m² +---------------------------------------------------- + +DIRECTIMMO VOUS PROPOSE UNE SOMPTUEUSE VILLA DUBOCHET DE 10 PIECES PROCHE DU LAC Les Villas Dubochet situées à Clarens dans le canton de Vaud en Suisse forment un exceptionnel ensemble de demeures résidentielles (1874-1879), destinées à la villégiature d'hôtes fortunés souhaitant éviter la promiscuité des hôtels. Il y en a très exactement 21. Situées à Clarens, elles sont toutes différentes. Nous vous proposons l'une d'entre elles à la vente. L'entier de son charme et de son raffinement ont été conservés lors de sa complète rénovation en 2011. Pour ce faire, des matériaux de grande qualité et des normes historique de rénovation ont été respectées. Sa proximité avec le lac (200m), son grand jardin arborisé, ses terrasses qui pour certaine vous offre une superbe vue sur le lac et les Alpes, ses grands volumes intérieurs sont autant d'arguments qui vous donnerons le sentiment de privilège et d'authenticité. Cette Villa de 9 pièces est construite sur une parcelle de 1'662m2. Sur 4 niveaux, elle dispose d'une surface habitable d'environ 400m2 et de 1'546m2 de jardin. Elle est distribuée comme suit :Rez inférieur (également accessible par une entrée indépendante) : Une chambre Une salle de bain/WC Une bibliothèque Une cave à vin Une buanderie Rez-de-chaussée : Grande pièce de réception s'ouvrant sur une terrasse Une cuisine entièrement agencée Un WC visiteur 1erétage : Trois belles chambres dont deux avec terrasse Deux salles de bain/WC dont une privative 2èmeétage : Une somptueuse chambre parentale avec terrasse et vue sur le lac Une salle de bain privative Un grand dressing Autres informations : Construite en 1874 Complètement rénovée en 2011 La surface de la parcelle de 1'662m2 La surface habitable est de 400m2 Le volume est d'environ 1'835m3m3 5 places de parc extérieures Chauffage au gaz Distribution du chauffage par radiateurs Commodités : Commodité à 500 mètres Bus à 50 mètres Lac & port de Clarens à 200 mètres Accès autoroute à 2.5km Montreux centre à 5 minutes Lausanne à 20 minutes Genève Aéroport à 1h15 Présentation des alentours et de la région : Clarens-Montreux ou Clarens est une localité de la commune de Montreux en Suisse située sur la Riviera vaudoise, au bord du lac Léman et sur les contreforts des Préalpes fribourgeoises. Avec la salle omnisports du Pierrier sur son sol, Clarens accueille des compétitions d'importance nationale et internationale à l'image des Montreux Volley Masters, de la coupe de nations de Rink hockey ou encore des finales de la coupe de la ligue de basket. Clarens, c'est aussi le lac et les sports d'eau. Les amateurs de baignade trouveront leur bonheur au bord du lac à la plage du Pierrier ou aux bains de Clarens. Pour ceux qui préfèrent la piscine, la Maladaire les accueille été comme hivers ; deux bassins extérieurs et deux bassins intérieurs sont à disposition. Si vous devez vendre un bien pour l'achat de votre nouvelle propriété, nous vous proposons plus de 20 ans d'expérience dans le domaine de la vente. Durant ces années, nous avons développé une présentation inédite avec nos Virtual-Tours des biens, notre présence renforcée sur les portails immobiliers ainsi que des frais de courtages défiant toute concurrence font de nous un partenaire idéal. Renseignements et visite auprès de Thierry Lenoir au 079 476 08 11.WWW.DIRECTIMMO.CH + +CHF 17’250 / m² + +CHF 6’900’000 + + vor 2 Tagen + +Haus zu verkaufen + +1000 Lausanne 26 • 10 Zimmer • 270 m² +-------------------------------------------------------- + +BARNES Lausanne a la plaisir de vous présenter cette charmante maison de caractère située sur les hauteurs de Lausanne. Au coeur d'un quartier calme et dans un environnement verdoyant, la propriété se trouve à seulement quelques pas des transports en commun vous permettant d'accéder au centre de Lausanne. Les axes autoroutiers se trouvent à 3 minutes en voiture. Implantée sur une parcelle de plus de 1'600 m², cette bâtisse de ce début du XXe siècle a été entièrement rénovée entre 2004 et 2008 et a de plus été agrandie avec la construction de deux grandes extensions au Nord et à l'Ouest et a su allié le confort à l'authenticité. Distribuée de manière harmonieuse et lumineuse, elle se compose notamment de 6 chambres, de 4 salles d'eau, d'un WC séparé, d'un spacieux séjour donnant accès aux extérieurs, d'une salle à manger et d'une cuisine équipée donnant également accès à la terrasse et au jardin, le tout reparti sur une surface d'environ 270 m² utiles. Grâce à ces nombreuses ouvertures donnant sur la forêt et son vaste jardin arboré et clos, la maison vous promet un cadre de vie agréable et apaisant. A noter qu'il est possible d'y construire une piscine. Pour compléter ce bien, une cave, un garage double et 6 places de parc extérieures sont à disposition. + +CHF 8’852 / m² + +CHF 2’390’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1052 Le Mont-sur-Lausanne • 4.5 Zimmer +------------------------------------------------------------ + +Located in a green and family area, this apartment is away from traffic while being only 200 m from the first stop of the TL and all amenities. Large apartment of 4.5 rooms of approx. 112 m2 of living space in perfect condition, made with sober and quality materials. These large spaces perfectly distributed as well as its large windows offer perfect brightness throughout the day. The apartment consists of an entrance with fitted wardrobes, which serves 3 bedrooms, a bathroom and a bathroom. The open and equipped kitchen overlooks a spacious living room, a bright veranda and the garden. An indoor parking space in addition, a motorcycle space and a large cellar complete this rare property on the market. Apartment price: 1'190'000.- Parking space: 35'000.- Motorcycle space: 5'000.- + +- + +CHF 1’190’000 + +[1](https://www.immoyou.ch/kaufen-schweiz)234567 + + 1 - 24 von 59’403 Ergebnisse + +### Immobilie kaufen in der Schweiz + +[Immobilie kaufen im Kanton Zürich](https://www.immoyou.ch/kaufen-kanton-zurich)[Immobilie kaufen im Kanton Bern](https://www.immoyou.ch/kaufen-kanton-bern)[Immobilie kaufen im Kanton Aargau](https://www.immoyou.ch/kaufen-kanton-aargau)[Immobilie kaufen im Kanton St. Gallen](https://www.immoyou.ch/kaufen-kanton-st-gallen)[Immobilie kaufen im Kanton Luzern](https://www.immoyou.ch/kaufen-kanton-luzern)[Immobilie kaufen im Kanton Basel-Landschaft](https://www.immoyou.ch/kaufen-kanton-basel-landschaft)[Immobilie kaufen im Kanton Thurgau](https://www.immoyou.ch/kaufen-kanton-thurgau)[Immobilie kaufen im Kanton Solothurn](https://www.immoyou.ch/kaufen-kanton-solothurn)[Immobilie kaufen im Kanton Graubünden](https://www.immoyou.ch/kaufen-kanton-graubunden)[Immobilie kaufen im Kanton Basel-Stadt](https://www.immoyou.ch/kaufen-kanton-basel-stadt)[Immobilie kaufen im Kanton Schwyz](https://www.immoyou.ch/kaufen-kanton-schwyz)[Immobilie kaufen im Kanton Zug](https://www.immoyou.ch/kaufen-kanton-zug) + +### Andere Immobilienarten in der Schweiz + +[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Zimmer kaufen in der Schweiz](https://www.immoyou.ch/wg-zimmer-kaufen-schweiz)[Parkplatz kaufen in der Schweiz](https://www.immoyou.ch/parkplatz-kaufen-schweiz)[Büro & Gewerbe kaufen in der Schweiz](https://www.immoyou.ch/buro-gewerbe-kaufen-schweiz)[Wohnhaus kaufen in der Schweiz](https://www.immoyou.ch/wohnhaus-kaufen-schweiz)[Grundstück kaufen in der Schweiz](https://www.immoyou.ch/grundstuck-kaufen-schweiz) + + All rights reserved. v.541ff84 \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_029_www.immoyou.ch_wohnung-kaufen-schweiz.txt b/test_web_content_20251002_215219/additional_link_029_www.immoyou.ch_wohnung-kaufen-schweiz.txt new file mode 100644 index 00000000..31055224 --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_029_www.immoyou.ch_wohnung-kaufen-schweiz.txt @@ -0,0 +1,423 @@ +URL: https://www.immoyou.ch/wohnung-kaufen-schweiz +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +🏢 29’844 Wohnungen kaufen in der Schweiz | ImmoYou + +=============== + +[ImmoYou](https://www.immoyou.ch/) + +Kaufen + +[Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + +Mieten + +[Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + + Ändern Sie die Suche + +[](https://www.immoyou.ch/)[Kaufen](https://www.immoyou.ch/kaufen-schweiz)[Wohnungen](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz) + +Wohnung kaufen in der Schweiz +============================= + +Ort + + Schweiz + + Zürich + + Genf + + Typ + +- [x] Haus + +- [x] Wohnung + +- [x] Zimmer + +- [x] Parkplatz + +- [x] Büro & Gewerbe + +- [x] Wohnhaus + +- [x] Grundstück + + Verkaufspreis + + - + + Zimmer + + - + + Wohnfläche (m²) + + - + + Grundstücksfläche (m²) + + - + + Ausstattung & Eigenschaften + +- [x] Neubauprojekte + +- [x] Balkon + +- [x] Garten + +- [x] Parkplatz + +- [x] Lift + +- [x] Freie Aussicht + +- [x] Cheminée + +- [x] Garage + +- [x] Kinderfreundlich + +- [x] Rollstuhlgängig + +- [x] Möbliert + +Ordnen + + 29’844 Ergebnisse + + + + vor 2 Tagen + +Wohnung zu verkaufen + +1052 Le Mont-sur-Lausanne • 4.5 Zimmer +------------------------------------------------------------ + +Located in a green and family area, this apartment is away from traffic while being only 200 m from the first stop of the TL and all amenities. Large apartment of 4.5 rooms of approx. 112 m2 of living space in perfect condition, made with sober and quality materials. These large spaces perfectly distributed as well as its large windows offer perfect brightness throughout the day. The apartment consists of an entrance with fitted wardrobes, which serves 3 bedrooms, a bathroom and a bathroom. The open and equipped kitchen overlooks a spacious living room, a bright veranda and the garden. An indoor parking space in addition, a motorcycle space and a large cellar complete this rare property on the market. Apartment price: 1'190'000.- Parking space: 35'000.- Motorcycle space: 5'000.- + +- + +CHF 1’190’000 + + + + vor 2 Tagen + +Wohnung zu verkaufen + +1865 Les Diablerets • 4.5 Zimmer • 148 m² +--------------------------------------------------------------- + +Tucked away admits the Swiss Alps just 20 kilometers away from the prestigious Gstaad ski resort. You will be able to rub the eternal snows of the Glacier 3000 and taste the simple charms of an authentic mountain village. The duplex apartment consists of a kitchen fully equipped with branded appliances, open to the dining room. Its intelligent design brings a user-friendly appearance and comfort of use. The balcony offers panoramic views of the Diablerets mountain range. Each apartment is fitted with an array of built-in oak wardrobes that go beautifully with the natural oiled oak flooring for an elegant effect. A vast well-being area has been set up in the Cristal de Roche Residence for the owners exclusive use. Accessible by day and night, it enjoys natural light, jacuzzi, Turkish bath, sauna and relaxation room. At the Diablerets, ski, hike and paragliding all year round. Discover a region steeped in living history and spectacular natural surroundings. Underground parking space available in the condominium. + +CHF 6’926 / m² + +CHF 1’025’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1865 Les Diablerets • 2.5 Zimmer • 74 m² +-------------------------------------------------------------- + +Tucked away admits the Swiss Alps just 20 kilometers away from the prestigious Gstaad ski resort. You will be able to rub the eternal snows of the Glacier 3000 and taste the simple charms of an authentic mountain village. The duplex apartment consists of a kitchen fully equipped with branded appliances, open to the dining room. Its intelligent design brings a user-friendly appearance and comfort of use. The balcony offers panoramic views of the Diablerets mountain range. Each apartment is fitted with an array of built-in oak wardrobes that go beautifully with the natural oiled oak flooring for an elegant effect. A vast well-being area has been set up in the Cristal de Roche Residence for the owners exclusive use. Accessible by day and night, it enjoys natural light, jacuzzi, Turkish bath, sauna and relaxation room. At the Diablerets, ski, hike and paragliding all year round. Discover a region steeped in living history and spectacular natural surroundings. Underground parking space available in the condominium. + +CHF 6’689 / m² + +CHF 495’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +3954 Leukerbad • 1 Zimmer • 29 m² +------------------------------------------------------- + +Located less than 5 minutes walk from the departure of the gondola, this bright studio, which enjoys a magnificent view of the mountains will seduce you. Located on the upper ground floor of a small building of 14 apartments, it enjoys easy access, also for people with reduced mobility. The south-facing balcony brings you plenty of sun and light. It is composed as follows: Entrance: A wardrobe A bathroom with bath - WC and sink The living space: A spacious living room with access to a south-facing balcony. A large wardrobe bed (2 people) A sofa bed A table for 4 people integrated into the kitchen A cellar completes this property The common areas of the PPE include a ski storage room and a laundry room. Don't wait to ask for a visit + +CHF 5’828 / m² + +CHF 169’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +8965 Berikon • 3.5 Zimmer • 94 m² +------------------------------------------------------- + +Moderne 3.5-Zimmer Attikawohnung an attraktiver Lage Diese hochwertige Wohnung befindet sich an ruhiger und zentraler Lage unweit von Wald- und Spazierwegen. Der hochwertige Innenausbau, der durchdachte Grundriss und die farblich abgestimmten Materialien vermitteln ein Wohngefühl der Extraklasse. Ein Einstellplatz in der Tiefgarage kann für CHF 35'000.? dazugekauft werden. Besuchen Sie den virtuellen Rundgang und überzeugen Sie sich selbst. Wir freuen uns auf Ihre Anfrage.Genaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/8965-23-1 + +CHF 10’213 / m² + +CHF 960’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1669 Les Sciernes-d'Albeuve • 4.5 Zimmer • 78 m² +---------------------------------------------------------------------- + +Exclusive: Penthouse with 2 balconies & enjoying a quiet location Beautiful apartment on the top floor of a small building of 6 lots, offering two balconies, one of which is accessible from the master bedroom. This property has a beautiful unobstructed view of the Pre-Alps, without any vis-à-vis, all with a quiet location. A large cellar & a spacious attic of 77 m2 are part of this lot. In addition, a garage-box and two outdoor spaces complete this property, in addition to CHF 45,000 each. Possibility to acquire an additional garage-box if desired.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1669-23-1 + +CHF 5’064 / m² + +CHF 395’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1450 Le Château-de-Ste-Croix • 5.5 Zimmer • 144 m² +------------------------------------------------------------------------ + +Beaucoup de cachet pour cet appartement/triplex rénové avec jardin Dans une ancienne maison de village, sis ce joli appartement rénové avec beaucoup de cachet distribué sur 3 niveaux avec jardin et accès indépendant. Il se situe au centre du village, sans aucune nuisance. L'immeuble a été entièrement transformé en 1991. L'appartement a été bien entretenu et des travaux d'amélioration ont été effectués. Idéal pour une famille, il saura séduire les amateurs de bien atypique. Parcelle de 113 m2 à proximité vendue également avec ce bien.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1450-23-1 + +CHF 3’819 / m² + +CHF 550’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1003 Lausanne • 2.5 Zimmer • 71 m² +-------------------------------------------------------- + +Large 2.5-room apartment on the ground floor in Lausanne In the heights of Lausanne, in the immediate vicinity of amenities, this beautiful apartment of 60m² of net living space is an opportunity to seize The large living room is spacious and bright thanks to its large openings that overlook a beautiful terrace and a very nice little garden. The fully equipped kitchen is open to the dining area and living room. In the night part, a beautiful bedroom, a bathroom, a guest toilet and storage. A parking space extra. See also Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1010-22-2 Large 2.5 room apartment on garden level in Lausanne In the heights of Lausanne, close to all amenities, this beautiful apartment of 60m² of net living space is an opportunity to seize The large living room is spacious and luminous thanks to its large openings which give onto a beautiful terrace and a very nice little garden. The fully equipped kitchen is open to the dining area and the living room. In the night part, a beautiful bedroom, a bathroom, a guest toilet and storage. One parking space in addition. A must see Exact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST: https://neho.ch/o/1010-22-2 + +CHF 10’352 / m² + +CHF 735’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1820 Veytaux • 4.5 Zimmer • 126 m² +-------------------------------------------------------- + +Magnificent apartment with panoramic views of Lake Geneva This beautiful apartment has been completely renovated recently and consists of an entrance hall with wardrobes, a spacious living room with access to the south-facing balcony and an incredible view, a large open kitchen fully equipped, 3 pleasant bedrooms as well as two bathrooms and a guest toilet. A cellar and a garage space complete this property. Privileged location because very well connected to public transport and close to all the amenities of Montreux and its city center.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1820-22-4 + +CHF 10’278 / m² + +CHF 1’295’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1462 Yvonand • 2.5 Zimmer • 49 m² +------------------------------------------------------- + +Appartement avec grand balcon à Yvonand Joli appartement de 2,5 pces d'une surface de 49.50 m2 habitables + un balcon de 21.25 m2. Sis au 1er étage d'une PPE de 8 lots, avec ascenseur. Des travaux de rafraichissement ont été effectués en novembre 2022. L'immeuble est équipé de panneaux solaires. Il se situe au centre du village, proche de toutes commodités (commerces, transports, écoles, plages, etc.) Une cave, une buanderie commune ainsi qu'une place de parc extérieure complètent ce bien. L'appartement est libre de tout bail.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1462-22-3 + +CHF 8’878 / m² + +CHF 435’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1009 Pully • 3.5 Zimmer • 84 m² +----------------------------------------------------- + +Beautiful 3.5 room apartment with stunning lake views in Pully This large apartment of 88m ² of PPE surface is an opportunity to seize. With its southern orientation, it enjoys abundant natural light that illuminates every room of the apartment, creating a warm atmosphere. A living room with fireplace very friendly, a dining room and a large kitchen make up the day part. In the night part, two beautiful bedrooms, a bathroom and a guest toilet. Always well maintained, it is in good general condition. A must see Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1009-23-2 Beautiful 3.5 room flat with breathtaking view of the lake in Pully This large flat with 88m² of living space is an opportunity to be seized. With its southern orientation, it enjoys an abundance of natural light which illuminates each room of the flat, creating a warm atmosphere. A living room with a very convivial fireplace, a dining room and a large kitchen make up the day part. In the night area there are two beautiful bedrooms, a bathroom and a guest toilet. Always well maintained, it is in excellent general condition. A must seeExact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST: https://neho.ch/o/1009-23-2 + +CHF 10’119 / m² + +CHF 850’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1162 St-Prex • 2.5 Zimmer • 70 m² +------------------------------------------------------- + +Large and bright apartment 2.5p ideally located in St-Prex Charming apartment very well maintained and located close to all amenities and a few steps from schools which offers optimal comfort to its future occupants. In addition, it is also a short distance from Lake Geneva. Beautiful pleasant living space with a generous living room that overlooks a sunny balcony, a large and comfortable bedroom with custom dressing room. The bathroom and separate toilet were renovated in 2022. A cellar and a parking space complete this property.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1162-23-1 + +CHF 9’786 / m² + +CHF 685’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1163 Etoy • 3.5 Zimmer • 111 m² +----------------------------------------------------- + +Résidence La Romanèche Cet appartement charmant vous offrira un cadre de vie idéal Avec son jardin clôturé et les espaces de jeux extérieurs, vous pourrez profiter de moments de détente en plein air. Il dispose d'une grande pièce à vivre avec accès à la terrasse couverte. Vous serez également séduit par sa proximité avec toutes les commodités pour faciliter votre quotidien. Et cerise sur le gâteau, vous pourrez créer une pièce supplémentaire selon vos besoins Hypothèque à taux préférentiel à reprendre.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1163-23-2 La Romanèche residence This charming apartment will offer you an ideal living environment With its garden and outdoor play areas, you will be able to enjoy relaxing moments in the open air. The optimization of space has been thought out for your comfort, in order to create a convivial living space, with a large living room. You will also be seduced by its proximity to all amenities to facilitate your daily life. And to top it all off, you can create an extra room according to your needsExact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/1163-23-2 + +CHF 11’532 / m² + +CHF 1’280’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1166 Perroy • 2.5 Zimmer • 56 m² +------------------------------------------------------ + +Appartement 2.5p neuf spacieux et très lumineux Superbe appartement neuf situé dans un quartier résidentiel paisible, il est très agréable de par ses généreux volumes, des matériaux de qualité et il bénéficie d'une belle luminosité. Il offre tout le confort moderne avec un beau séjour avec cuisine ouverte, une grande chambre, une belle salle de douche et le magnifique balcon avec espace de rangement. Pour terminer cet appartement dispose de deux places de parc, dont une couverte avec un local de rangement.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1166-23-1 + +CHF 11’875 / m² + +CHF 665’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +2532 Magglingen/Macolin • 4.5 Zimmer • 139 m² +------------------------------------------------------------------- + +Einmalige und exklusive 4½ Zimmer Attikawohnung mit Alpen-Panorama Diese wunderschöne Wohnung mit einem aussergewöhnlichen Ausbaustandard der oberen Klasse wird Sie begeistern. Das helle und luftige Wohnambiente, in Kombination mit einem abwechslungsreichen Grundriss machen diese Liegenschaft sehr spannend und einzigartig. Geniessen Sie hier eine spektakuläre Aussicht und viel Komfort. Ein Bastelraum mit Bad und Sauna, drei Einstellhallenplätze und ein Aussenparkplatz gehören zur Wohnung dazu. Der grosszügige Aussenbereich rundet das attraktive Angebot ab.Genaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/2532-23-1 + +CHF 7’122 / m² + +CHF 990’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1817 Brent • 3.5 Zimmer • 76 m² +----------------------------------------------------- + +Exclusif: Charmant appartement traversant avec vue sur les Alpes A deux pas de la gare du MOB de Fontanivent, cet appartement traversant bénéficie d'une bonne luminosité. Il offre une vue dégagée sur les Alpes avec un petit dégagement sur le lac. Il se compose d'un hall d'entrée avec armoires, d'un séjour avec accès au balcon habitable orienté sud, d'une cuisine ouverte, de deux chambres ainsi que d'une salle de bain. Jouissance possible d'un grand jardin commun de la copropriété. Une cave ainsi qu'une place de parc en souterrain complètent ce bien.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1817-22-2 + +CHF 7’697 / m² + +CHF 585’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1950 Sion • 5.5 Zimmer • 164 m² +----------------------------------------------------- + +Spacious apartment in downtown Sion Beautiful apartment on the 1st floor of a building located in the heart of the city of Sion, in a quiet area and close to all amenities. It enjoys a beautiful exposure from its balconies, and a good brightness from East to West. It has 4 bedrooms, 2 bathrooms, a large and warm living room with fireplace, a closed kitchen, a heated galetas and a cellar. A space in the underground car park is available for rent for CHF 1000 per year.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1950-22-8 + +CHF 4’695 / m² + +CHF 770’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +3968 Veyras • 6.5 Zimmer • 184 m² +------------------------------------------------------- + +Spacious attic duplex currently rented in Veyras Spacious penthouse duplex in a small building of 4 apartments, located in a quiet area, a few minutes by transport from the center of Sierre. Regularly maintained and ideal for families, it has 5 bedrooms, 3 bathrooms with shower or bath, a warm living room with a fireplace and a well-appointed open kitchen. Two balconies, one facing south, a large garage in addition and a private carnotzet complete this property.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/3968-22-1 + +CHF 3’995 / m² + +CHF 735’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1283 La Plaine • 4.5 Zimmer • 137 m² +---------------------------------------------------------- + +A stone's throw from the train station With direct access by lift, this beautiful apartment has a spacious south-facing terrace. Out of nuisance, while being close to the station, it has a large living room, closed kitchen, 2 bedrooms and a bathroom. Individual boiler in the apartment. Possibility to make a third bedroom instead of the office area. Building of 8 apartments.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1283-22-1 Close to the train station With a direct access by the elevator, this beautiful apartment has a spacious terrace facing South. Out of the nuisances, while being close to the station, it has a large living room, an equipped closed kitchen, 2 bedrooms and a bathroom. Individual boiler in the apartment. Possibility to arrange a third bedroom instead of the office corner. 8 apartments building.Exact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST: https://neho.ch/o/1283-22-1 + +CHF 9’270 / m² + +CHF 1’270’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +3963 Crans-Montana • 3.5 Zimmer • 80 m² +------------------------------------------------------------- + +Lumineux appartement au pied du domaine skiable de Crans-Monatana Bel appartement idéalement situé à quelques pas des remontées mécaniques de Crans-Montana. Il bénéficie d'une orientation d'Est en Ouest avec vue panoramique, et d'un ensoleillement optimal depuis son balcon au Sud-Ouest. Bien entretenu, il dispose de 2 chambres, d'une salle de douche, d'une chaleureuse pièce à vivre avec cuisine ouverte et poêle à bois, d'une cave et d'un casier à ski. Des places de parking extérieures appartiennent à la copropriété et sont à disposition.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/3963-23-1 Bright flat at the foot of the Crans-Monatana ski area Beautiful flat ideally located a few steps from the ski lifts of Crans-Montana. It benefits from a beautiful orientation from East to West with a panoramic view, and an optimal sunshine from its balcony on the South-West. Well maintained, it has 2 bedrooms, a shower room, a cosy living room with open kitchen and wood stove, a cellar and a ski locker. Outside parking spaces belong to the co-ownership and are available.Exact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/3963-23-1 + +CHF 8’063 / m² + +CHF 645’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1205 Genève • 4.5 Zimmer • 85 m² +------------------------------------------------------ + +A 5-minute walk to the old town In a beautiful building close to the HUG and very well maintained, crossing apartment with high ceilings, moldings and old parquet, composed of a beautiful living room, a bedroom, a bedroom and a bathroom, a closed kitchen as well as a separate toilet and a reduced. The rooms overlook a quiet courtyard The façade is in good condition. Free of any occupant. A cellar completes this property.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1205-22-1 5 minutes walk from the old town In a beautiful building close to the hospital and very well maintained, crossing apartment with high ceilings and old parquet, composed of a beautiful living room, 2 bedrooms and a bathroom, as well as a kitchen. The apartment overlooks a quiet courtyard Surface PPE 85 m². The facade has been recently redone. Free of any occupant. A cellar.Exact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST: https://neho.ch/o/1205-22-1 + +CHF 14’000 / m² + +CHF 1’190’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1283 La Plaine • 6 Zimmer • 114 m² +-------------------------------------------------------- + +Duplex en combles, au calme, idéal pour une famille. Bel appartement en duplex d'env. 125m2 utiles, idéalement situé à proximité immédiate du Rhône et de la gare de La Plaine. Rénové avec soins entre 2020 et 2022 pour près de CHF 100'000.- (cuisine, poêle, sol, fenêtres, sdb et wc, radiateurs, peintures). 1er niveau: Salon, cuisine, balcon, 3 chambres, 1 salle de bain douche et double vasque, 1 wc. Combles: Chambre ouverte, 1 pièce de rangement, espace salle de bain baignoire, buanderie. 1 place de parc INT complète ce bien. A visiterAdresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1283-23-1 + +CHF 8’728 / m² + +CHF 995’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1958 St-Léonard • 4.5 Zimmer • 103 m² +----------------------------------------------------------- + +Beautiful well maintained 4.5 room apartment in St-Léonard Beautiful apartment in a building of 6 apartments located in St-Léonard, in a quiet area close to all amenities. It enjoys a beautiful view of the mountains from its balconies to the south and north. Well maintained over the years, it has 3 bedrooms, a bathroom with shower and bath, a separate toilet, an open living room, a kitchen, a large galetas under the eaves, a cellar, a garage in addition and outdoor places.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1958-22-2 + +CHF 3’544 / m² + +CHF 365’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1260 Nyon • 5.5 Zimmer • 101 m² +----------------------------------------------------- + +Boiron District Located close to all the amenities of Nyon and its city center in a quiet environment, this crossing apartment has 4 bedrooms, 2 bathrooms, 1 toilet and a large living room with a spacious open-end Miele kitchen that gives access to the balcony - unobstructed view of the park and the mountains in the background. Completely renovated between 2015/16, including windows and radiators. Complete home automation system. A closed garage box outside and a cellar - To visitExact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1260-22-9 Boiron neighbourhood Located close to all the shops and schools of Nyon and its city center in a quiet environment, this apartment has 4 bedrooms, 2 bathrooms, 1 WC and a large living room with an open kitchen that gives access to the balcony - unobstructed view of the park and the mountains in the background. Fully renovated between 2015 and 2016, including windows and radiators. A garage outside and a cellar are available with the apartment.Exact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST: https://neho.ch/o/1260-22-9 + +CHF 11’089 / m² + +CHF 1’120’000 + +[1](https://www.immoyou.ch/wohnung-kaufen-schweiz)234567 + + 1 - 24 von 29’844 Ergebnisse + +### Wohnung kaufen in der Schweiz + +[Wohnung kaufen im Kanton Zürich](https://www.immoyou.ch/wohnung-kaufen-kanton-zurich)[Wohnung kaufen im Kanton Bern](https://www.immoyou.ch/wohnung-kaufen-kanton-bern)[Wohnung kaufen im Kanton Aargau](https://www.immoyou.ch/wohnung-kaufen-kanton-aargau)[Wohnung kaufen im Kanton St. Gallen](https://www.immoyou.ch/wohnung-kaufen-kanton-st-gallen)[Wohnung kaufen im Kanton Luzern](https://www.immoyou.ch/wohnung-kaufen-kanton-luzern)[Wohnung kaufen im Kanton Basel-Landschaft](https://www.immoyou.ch/wohnung-kaufen-kanton-basel-landschaft)[Wohnung kaufen im Kanton Thurgau](https://www.immoyou.ch/wohnung-kaufen-kanton-thurgau)[Wohnung kaufen im Kanton Solothurn](https://www.immoyou.ch/wohnung-kaufen-kanton-solothurn)[Wohnung kaufen im Kanton Graubünden](https://www.immoyou.ch/wohnung-kaufen-kanton-graubunden)[Wohnung kaufen im Kanton Basel-Stadt](https://www.immoyou.ch/wohnung-kaufen-kanton-basel-stadt)[Wohnung kaufen im Kanton Schwyz](https://www.immoyou.ch/wohnung-kaufen-kanton-schwyz)[Wohnung kaufen im Kanton Zug](https://www.immoyou.ch/wohnung-kaufen-kanton-zug) + +### Andere Immobilienarten in der Schweiz + +[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz)[Zimmer kaufen in der Schweiz](https://www.immoyou.ch/wg-zimmer-kaufen-schweiz)[Parkplatz kaufen in der Schweiz](https://www.immoyou.ch/parkplatz-kaufen-schweiz)[Büro & Gewerbe kaufen in der Schweiz](https://www.immoyou.ch/buro-gewerbe-kaufen-schweiz)[Wohnhaus kaufen in der Schweiz](https://www.immoyou.ch/wohnhaus-kaufen-schweiz)[Grundstück kaufen in der Schweiz](https://www.immoyou.ch/grundstuck-kaufen-schweiz) + + All rights reserved. v.541ff84 \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_030_www.immoyou.ch_haus-kaufen-schweiz.txt b/test_web_content_20251002_215219/additional_link_030_www.immoyou.ch_haus-kaufen-schweiz.txt new file mode 100644 index 00000000..ce85a0d0 --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_030_www.immoyou.ch_haus-kaufen-schweiz.txt @@ -0,0 +1,423 @@ +URL: https://www.immoyou.ch/haus-kaufen-schweiz +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +🏠 20’071 Häuser kaufen in der Schweiz | ImmoYou + +=============== + +[ImmoYou](https://www.immoyou.ch/) + +Kaufen + +[Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + +Mieten + +[Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + + Ändern Sie die Suche + +[](https://www.immoyou.ch/)[Kaufen](https://www.immoyou.ch/kaufen-schweiz)[Häuser](https://www.immoyou.ch/haus-kaufen-schweiz)[Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + +Haus kaufen in der Schweiz +========================== + +Ort + + Schweiz + + Zürich + + Genf + + Typ + +- [x] Haus + +- [x] Wohnung + +- [x] Zimmer + +- [x] Parkplatz + +- [x] Büro & Gewerbe + +- [x] Wohnhaus + +- [x] Grundstück + + Verkaufspreis + + - + + Zimmer + + - + + Wohnfläche (m²) + + - + + Grundstücksfläche (m²) + + - + + Ausstattung & Eigenschaften + +- [x] Neubauprojekte + +- [x] Balkon + +- [x] Garten + +- [x] Parkplatz + +- [x] Lift + +- [x] Freie Aussicht + +- [x] Cheminée + +- [x] Garage + +- [x] Kinderfreundlich + +- [x] Rollstuhlgängig + +- [x] Möbliert + +Ordnen + + 20’071 Ergebnisse + + + + vor 2 Tagen + +Haus zu verkaufen + +1512 Chavannes-sur-Moudon • 7.5 Zimmer • 291 m² +------------------------------------------------------------------ + +Magnifique maison avec vue sur la campagne située à 5min de Moudon Environnement idéal pour cette villa qui offre un cadre de vie très agréable grâce à de généreux volumes distribués sur 3 étages, dont une vaste pièce à vivre avec cheminée, une grande cuisine ouverte moderne, 6 belles chambres, 3 salles d'eau, un wc visiteurs, un studio indépendant très pratique, un grand sous-sol aménagé avec Sauna qui offre diverses possibilités d'aménagements. L'espace extérieur offre une très belle terrasse ensoleillée avec brasero et un grand jardin avec piscine.Adresse exacte disponible sur demande .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1512-22-1 Superb house with view on the countryside located at 5min from Moudon Ideal environment for this villa which offers a very pleasant living environment thanks to generous volumes distributed on 3 floors, including a large living room with fireplace, a large modern open kitchen, 6 beautiful bedrooms, 3 bathrooms, a guest toilet, a very practical independent studio, a large basement with sauna which offers various development possibilities. The outside space offers a beautiful sunny terrace with brazier and a large garden with swimming pool.Exact address available on request .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/1512-22-1 + +CHF 5’668 / m² + +CHF 1’649’500 + + + + vor 2 Tagen + +Haus zu verkaufen + +8335 Hittnau • 3.5 Zimmer • 162 m² +----------------------------------------------------- + +Helles 3.5-Zimmer Einfamilienhaus mit erstklassiger Gartenanlage Dieses einzigartige Angebot überzeugt sowohl durch die qualitative Bausubstanz als auch durch die unmittelbare Nähe zu Schulen, öffentlichen Verkehrsmitteln und Einkaufsmöglichkeiten. Der offene Wohn-/Essbereich mit elegantem Cheminée, das helle Wohnambiente und die hochwertige Küche mit Frühstückbar versprechen ein hervorragendes Wohnerlebnis. Weitere Highlights sind das Hauptschlafzimmer mit En-Suite Bad sowie die atemberaubende Gartenanlage mit diversen Sitzplätzen, Bächlein und Teich.Genaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/8335-23-1 + +CHF 10’185 / m² + +CHF 1’650’000 + + vor 2 Tagen + +Haus zu verkaufen + +1000 Lausanne 27 • 5.5 Zimmer • 301 m² +--------------------------------------------------------- + +Magnificent building with adjoining barn to renovate Beautiful character house with a plot of more than 1'300m2 with trees offering a nice clearance on the lake. This property is ideally located in a peaceful environment while being close to all amenities (schools, shops and public transport). The housing part is currently spread over two levels and the barn-workshop part offers generous volumes. Great opportunity for transformation with a very good potential for interior space planning.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1000-22-1 + +CHF 4’153 / m² + +CHF 1’250’000 + + vor 2 Tagen + +Haus zu verkaufen + +1038 Bercher • 3.5 Zimmer • 110 m² +----------------------------------------------------- + +A haven of peace full of charm, village house near the Are you looking for a village house full of charm and ideally located? Look no further, this rare pearl is made for you Nestled in a quiet area and a PPE of two lots, it is perfectly maintained. Kitchen open to the dining room, large living room equipped with a wood stove, this village house offers all the comfort and authenticity you are looking for. Enjoy 2 bedrooms, a reduced, a bathroom and a guest toilet for your comfort. Close to the.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1038-22-2 + +CHF 5’909 / m² + +CHF 650’000 + + vor 2 Tagen + +Haus zu verkaufen + +1003 Lausanne • 8.5 Zimmer • 340 m² +------------------------------------------------------ + +Magnifique maison des années 30 entièrement rénovée à Lausanne Située en plein c?ur de Lausanne, cette splendide maison du début des années 30 offre un cachet remarquable et des prestations hors du commun. Les espaces sont spacieux et ouverts, créant une atmosphère chaleureuse et accueillante dès l'entrée. Les matériaux utilisés sont de qualité supérieure, avec des finitions soignées qui ajoutent une touche de standing à chaque détail. Cette maison entièrement rénovée au long de ces dix dernières années est idéale pour les familles, offrant des espaces de vie adaptés à toutes les générations. Les chambres sont spacieuses et confortables, tandis que les espaces de vie communs sont accueillants et conviviaux. L' aménagement paysager remarquable du jardin est une véritable ode à la nature, vous offrant une oasis de paix et de sérénité. Vous profiterez de moments de détente et de convivialité avec vos proches et vos amis dans cet espace extérieur exceptionnel. Enfin, ce bien d'exception vous permettra de profiter d'un espace fitness avec salle de bain et sauna, d'une cave à vin digne de ce nom et d'un garage souterrain de pas moins de 200m² . Si vous cherchez une maison de prestige à Lausanne, ne manquez pas cette opportunité rare. Contactez-nous dès maintenant pour organiser une visite et découvrir cette demeure exceptionnelle de vos propres yeux.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1012-23-3 Magnificent house of the 30s entirely renovated in Lausanne Located in the heart of Lausanne, this splendid house dating from the early 1930s offers a remarkable cachet and outstanding amenities. The spaces are spacious and open, creating a warm and welcoming atmosphere from the moment you enter. The materials used are of the highest quality, with meticulous finishing that adds a touch of luxury to every detail. This house has been completely renovated over the last ten years and is ideal for families, offering living spaces suitable for all generations. The bedrooms are spacious and comfortable, while the communal living areas are welcoming and friendly. The outstanding landscaping of the garden is a true ode to nature, offering you an oasis of peace and serenity. You will enjoy moments of relaxation and conviviality with your family and friends in this exceptional outdoor space. Finally, this exceptional property will allow you to enjoy a fitness area with bathroom and sauna, a wine cellar worthy of the name and an underground garage of no less than 200m². If you are looking for a prestigious house in Lausanne, do not miss this rare opportunity. Contact us now to arrange a visit and discover this exceptional home with your own eyes.Exact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/1012-23-3 + +CHF 15’294 / m² + +CHF 5’200’000 + + vor 2 Tagen + +Haus zu verkaufen + +1814 La Tour-de-Peilz • 6.5 Zimmer • 177 m² +-------------------------------------------------------------- + +Exclusive: Semi-detached villa with panoramic views of the lake & the Alps This villa consists of a 4.5-room triplex and an independent duplex, which can easily be combined into a single family home. Enjoy a breathtaking panoramic view of the lake and the Alps, all in a quiet and bright situation. With its magnificent west-facing terrace, this place is ideal for relaxing moments with the family. Do not miss the opportunity to live in this exceptional living environment. Contact us for a visitExact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1814-23-1 + +CHF 7’627 / m² + +CHF 1’350’000 + + vor 2 Tagen + +Haus zu verkaufen + +1344 L'Abbaye • 7.5 Zimmer • 220 m² +------------------------------------------------------ + +Coup de coeur pour cette magnifique demeure avec jardin bucolique Magnifique maison villageoise transformée et entièrement rénovée entre 1997 et 2019. Elle jouit d'une belle terrasse et d'un jardin bucolique entièrement clôturé en bordure de rivière. Elle est distribuée sur 3 étages et elle est excavée (cave voutée). Ce bien est en parfait état d'entretien général et ne nécessite d'aucuns travaux. Possibilité de créer une pièce habitable dans les combles. Une place de parc extérieure complète ce bien et diverses places de parc se trouvent à proximité.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1344-21-1 + +CHF 4’773 / m² + +CHF 1’050’000 + + vor 2 Tagen + +Haus zu verkaufen + +1003 Lausanne • 18 Zimmer • 683 m² +----------------------------------------------------- + +Magnifique maison de Maître dans les beaux quartiers Lausannois Située dans un quartier résidentiel Lausannois, cette propriété de charme de 683m2 utiles, bordée par 1'359 m2 de jardin paysagé dispose d'un fort potentiel d'extension et bénéficie de nombreuses possibilités d'aménagement (logements/commercial, mixte). Idéal pour ceux qui exercent une profession libérale comme médecin, avocat, notaire, architecte... Construite en 1927 avec son architecture classique, elle se développe sur cinq niveaux. Actuellement, les deux premiers étages sont à usage commercial et les deux derniers offrent deux appartements. Entièrement excavé, le sous-sol de 203 m2 dispose lui aussi de nombreuses possibilités d'aménagement. Cette bâtisse offre une grande flexibilité d'utilisation, pouvant être réaménagée en une seule ou plusieurs habitations familiales. A voir absolumentAdresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1012-22-2 Magnificent house in the beautiful districts of Lausanne Located in a residential area of Lausanne, this charming property of 683m2, bordered by 1'359 m2 of landscaped garden has a strong potential for extension and have many development possibilities (residential/commercial, mixed). Ideal for a liberal profession such as doctor, lawyer, notary, architect... Built in 1927 with a classical architecture, this house is on five levels. Currently, the first two floors are used for commercial purposes and the last tow floors are 2 apartments. The basement of 203 m2 offers numerous possibilities for development. This building offers a great flexibility of use, being able to be reorganized into one or several family dwellings. A must seeExact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/1012-22-2 Wunderschöne Immobilie in den schönen Vierteln von Lausanne In einem Wohnviertel von Lausanne gelegen, verfügt diese charmante Immobilie mit 683m2 Nutzfläche, die von 1'359 m2 angelegtem Garten begrenzt wird, über ein hohes Ausbaupotenzial und profitiert von zahlreichen Gestaltungsmöglichkeiten (Wohnen/Gewerbe, gemischt). Ideal für Personen, die einen freien Beruf wie Arzt, Anwalt, Notar, Architekt usw. ausüben. Das 1927 erbaute Gebäude mit seiner klassischen Architektur erstreckt sich über fünf Stockwerke. Derzeit werden die ersten beiden Stockwerke gewerblich genutzt und die letzten beiden bieten zwei Wohnungen. Das vollständig ausgehobene Untergeschoss mit 203 m2 verfügt ebenfalls über zahlreiche Gestaltungsmöglichkeiten. Dieses Gebäude bietet eine hohe Nutzungsflexibilität und kann in eine einzige oder mehrere Familienwohnungen umgewandelt werden. Unbedingt ansehenGenaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/1012-22-2 + +CHF 9’854 / m² + +CHF 6’730’000 + + vor 2 Tagen + +Haus zu verkaufen + +1854 Leysin • 6 Zimmer • 190 m² +-------------------------------------------------- + +DIRECTIMMO OFFERS YOU AN INDIVIDUAL CHALET A superb chalet with stunning panoramic views of the Alps. This cottage is intended for the main residence. Quality finishes at the discretion of the lessee. This project is subject to obtaining the building permit. It is possible to modify the interior distribution according to your wishes. Distribution (editable): Lower ground floor: A garage and 3 outdoor parking spaces A cellar and a technical room (laundry possible) An entrance hall A studio of 35m2 with an independent entrance, a cellar and a reduced Upper ground floor: A clearance A bathroom An equipped kitchen open to a dining area and a living room (fireplace or stove possible) A large terrace of about 80m2 Floor: A clearance Three bedrooms One bathroom, shower A balcony of about 11m2 Technical: Underfloor heating with a heat pump Comfortable finishing budgets (CHF 25'000.- for the kitchen, CHF 18'000.- for the sanitary facilities, CHF 60.- per m2 for the tiles, CHF 80.- per m2 for the parquet floors...) Windows with triple glazingIf you need to sell a property for the purchase of your new property, we offer you more than 20 years of experience in the field of sales. During these years, we have developed an unprecedented presentation with our Virtual-Tours of properties, our strengthened presence on real estate portals as well as unbeatable brokerage fees make us an ideal partner. Information and visit to Mirko Gysin at 079 574 33 39 WWW.DIRECTIMMO.CH + +CHF 6’737 / m² + +CHF 1’280’000 + + vor 2 Tagen + +Haus zu verkaufen + +1800 Vevey • 5.5 Zimmer • 160 m² +--------------------------------------------------- + +Detached villa of 5.5 roomsOn a beautiful plot of more than 1500m²Hallway and viewTerraces and gardenOutdoor parking spacesMost sought-after neighborhoodQuiet and residentialClose to transport and the lake File on request + +- + +Auf Anfrage + + vor 2 Tagen + +Haus zu verkaufen + +1071 Chexbres • 270 m² +----------------------------------------- + +Video of the panoramic view on www.chiffelle-immobilier.ch (under multimedia files) Located in the most exclusive area of Chexbres, this exceptional plot offers a panoramic view of the entire Lake Geneva basin, it is sold with a building permit in force for a luxurious contemporary villa of about 270 m2 of living space (three levels), 7.5 rooms, sauna, and outdoor pool facing the lake with removable deck. Allow about two million for the construction of the villa, in addition to the sale price of the plot. Complete plans available upon request. Video der Panoramaaussicht auf www.chiffelle-immobilier.ch (unter Multimedia-Dateien) Dieses aussergewöhnliche Grundstück im erlesensten Quartier von Chexbres bietet eine Panoramasicht auf das gesamte Genferseebecken und wird mit a Baugenehmigung für eine luxuriöse, moderne Villa mit ca. 270 m2 Wohnfläche (drei Ebenen), 7,5 Zimmern, Sauna und Außenpool mit Seeblick und abnehmbarer Terrasse. Stellen Sie zusätzlich zum Verkaufspreis des Grundstücks etwa zwei Millionen für den Bau der Villa bereit. Vollständige Pläne auf Anfrage erhältlich. Video of the panoramic view on www.chiffelle-immobilier.ch (under multimedia files) Located in the most select district of Chexbres, this exceptional plot offers a panoramic view of the entire Lake Geneva basin, it is sold with a building permit in force for a luxurious contemporary villa of approximately 270 m2 of living space (three levels), 7.5 rooms, sauna, and outdoor swimming pool facing the lake with removable deck. Provide about two million for the construction of the villa, in addition to the sale price of the plot. Complete plans available on request. + +CHF 9’259 / m² + +CHF 2’500’000 + + vor 2 Tagen + +Haus zu verkaufen + +1297 Founex • 8 Zimmer • 180 m² +-------------------------------------------------- + +Located in the commune of Founex, this charming individual villa offers a living space of 180 sqm (250 sqm useful) and is composed of 8 rooms including 4 bedrooms. Built on a plot of more than 1'300 sqm, it offers a comfortable and bright living space and is distributed over two levels plus basement. Thanks to its privileged location, in the heart of an exclusive residential area, it meets all the criteria for a quiet family life in an idyllic setting. The private schools La Châtaigneraie (-5 minutes) and Le Collège du Léman (-10 minutes) are located nearby. Carefully maintained and renovated, it benefits from quality services and finishes, including solid wood flooring, recessed LED spotlights, plenty of storage space, mosaic tiles in the bathrooms, wooden shutters, double-glazed windows, and a fully equipped and furnished kitchen. The second floor is characterized by generous volumes thanks to a beautiful height under ceiling. Outside, a large wooden pergola protects the terrace. The living space is composed of an entrance hall, a kitchen with a central island of 12 sqm, a living/dining room with a fireplace of about 45 sqm and a living room/office of about 15 sqm, all opening onto the terrace. The second floor is dedicated to the night area, with a master bedroom of 21 sqm with its own shower room, 3 other bedrooms and a shower room with double sink. The basement, entirely excavated, offers two large multipurpose rooms of respectively 23 and 28 sqm, a laundry room, the technical rooms and a fallout shelter. The villa is distributed as follows : First floor :- Entrance hall with storage space- Kitchen with central island- Living/dining room with access to the terrace and the garden- Multipurpose room (living room, office, etc.) First floor :- Master bedroom of 20 m2 with its adjoining shower room with WC- Three bedrooms of about 15 sqm- Shower room with WC Basement :- Multipurpose room of 23 sqm- Multipurpose room of about 28 sqm- Laundry room and fallout shelter- Technical rooms Outside :- Large terrace covered by a pergola- Garden with trees and fenced- Garden shed- Box for two cars- Outdoor parking spaces The exterior spaces consist of a large fenced garden with trees, a large terrace with pergola and a garden shed. The access to the property is secured by a gate. A double garage and several outdoor parking spaces located at the entrance complete this property. Its location close to all amenities and road axes gives it a quick access to Nyon (-15 minutes), to the center of Geneva and to the international airport of Geneva (- 20 minutes). + +CHF 16’389 / m² + +CHF 2’950’000 + + vor 2 Tagen + +Haus zu verkaufen + +1145 Bière • 4.5 Zimmer • 110 m² +--------------------------------------------------- + +Detached house built in 1964 on a beautiful plot of more than 1'000m2 ideally located in Bière. This house is habitable in the state but requires renovation to be updated to the tastes of the day. The plot has an interesting potential for expansion. To visit without delay Contact us directly at 079 276 89 94 or by email at l.bolay@atix-immobilier.ch for any further information or to arrange a visit on site. + +CHF 8’455 / m² + +CHF 930’000 + + vor 2 Tagen + +Haus zu verkaufen + +1342 Le Pont • 4.5 Zimmer • 180 m² +----------------------------------------------------- + +Who has never dreamed of a house close to the lake and nature? This property is for you. You will just have to push the doors of this property to immediately fall under the spell. This house consisting of 2 dwellings will offer you great flexibility. Located between the lake and nature you will reside in a quiet residential area. A real idyll You will have understood this property will not remain available for long. So do not hesitate and contact us. Our real estate agents will be happy to open the doors of this little paradise. + +CHF 10’000 / m² + +CHF 1’800’000 + + vor 2 Tagen + +Haus zu verkaufen + +1815 Clarens • 10 Zimmer • 400 m² +---------------------------------------------------- + +DIRECTIMMO VOUS PROPOSE UNE SOMPTUEUSE VILLA DUBOCHET DE 10 PIECES PROCHE DU LAC Les Villas Dubochet situées à Clarens dans le canton de Vaud en Suisse forment un exceptionnel ensemble de demeures résidentielles (1874-1879), destinées à la villégiature d'hôtes fortunés souhaitant éviter la promiscuité des hôtels. Il y en a très exactement 21. Situées à Clarens, elles sont toutes différentes. Nous vous proposons l'une d'entre elles à la vente. L'entier de son charme et de son raffinement ont été conservés lors de sa complète rénovation en 2011. Pour ce faire, des matériaux de grande qualité et des normes historique de rénovation ont été respectées. Sa proximité avec le lac (200m), son grand jardin arborisé, ses terrasses qui pour certaine vous offre une superbe vue sur le lac et les Alpes, ses grands volumes intérieurs sont autant d'arguments qui vous donnerons le sentiment de privilège et d'authenticité. Cette Villa de 9 pièces est construite sur une parcelle de 1'662m2. Sur 4 niveaux, elle dispose d'une surface habitable d'environ 400m2 et de 1'546m2 de jardin. Elle est distribuée comme suit :Rez inférieur (également accessible par une entrée indépendante) : Une chambre Une salle de bain/WC Une bibliothèque Une cave à vin Une buanderie Rez-de-chaussée : Grande pièce de réception s'ouvrant sur une terrasse Une cuisine entièrement agencée Un WC visiteur 1erétage : Trois belles chambres dont deux avec terrasse Deux salles de bain/WC dont une privative 2èmeétage : Une somptueuse chambre parentale avec terrasse et vue sur le lac Une salle de bain privative Un grand dressing Autres informations : Construite en 1874 Complètement rénovée en 2011 La surface de la parcelle de 1'662m2 La surface habitable est de 400m2 Le volume est d'environ 1'835m3m3 5 places de parc extérieures Chauffage au gaz Distribution du chauffage par radiateurs Commodités : Commodité à 500 mètres Bus à 50 mètres Lac & port de Clarens à 200 mètres Accès autoroute à 2.5km Montreux centre à 5 minutes Lausanne à 20 minutes Genève Aéroport à 1h15 Présentation des alentours et de la région : Clarens-Montreux ou Clarens est une localité de la commune de Montreux en Suisse située sur la Riviera vaudoise, au bord du lac Léman et sur les contreforts des Préalpes fribourgeoises. Avec la salle omnisports du Pierrier sur son sol, Clarens accueille des compétitions d'importance nationale et internationale à l'image des Montreux Volley Masters, de la coupe de nations de Rink hockey ou encore des finales de la coupe de la ligue de basket. Clarens, c'est aussi le lac et les sports d'eau. Les amateurs de baignade trouveront leur bonheur au bord du lac à la plage du Pierrier ou aux bains de Clarens. Pour ceux qui préfèrent la piscine, la Maladaire les accueille été comme hivers ; deux bassins extérieurs et deux bassins intérieurs sont à disposition. Si vous devez vendre un bien pour l'achat de votre nouvelle propriété, nous vous proposons plus de 20 ans d'expérience dans le domaine de la vente. Durant ces années, nous avons développé une présentation inédite avec nos Virtual-Tours des biens, notre présence renforcée sur les portails immobiliers ainsi que des frais de courtages défiant toute concurrence font de nous un partenaire idéal. Renseignements et visite auprès de Thierry Lenoir au 079 476 08 11.WWW.DIRECTIMMO.CH + +CHF 17’250 / m² + +CHF 6’900’000 + + vor 2 Tagen + +Haus zu verkaufen + +1000 Lausanne 26 • 10 Zimmer • 270 m² +-------------------------------------------------------- + +BARNES Lausanne a la plaisir de vous présenter cette charmante maison de caractère située sur les hauteurs de Lausanne. Au coeur d'un quartier calme et dans un environnement verdoyant, la propriété se trouve à seulement quelques pas des transports en commun vous permettant d'accéder au centre de Lausanne. Les axes autoroutiers se trouvent à 3 minutes en voiture. Implantée sur une parcelle de plus de 1'600 m², cette bâtisse de ce début du XXe siècle a été entièrement rénovée entre 2004 et 2008 et a de plus été agrandie avec la construction de deux grandes extensions au Nord et à l'Ouest et a su allié le confort à l'authenticité. Distribuée de manière harmonieuse et lumineuse, elle se compose notamment de 6 chambres, de 4 salles d'eau, d'un WC séparé, d'un spacieux séjour donnant accès aux extérieurs, d'une salle à manger et d'une cuisine équipée donnant également accès à la terrasse et au jardin, le tout reparti sur une surface d'environ 270 m² utiles. Grâce à ces nombreuses ouvertures donnant sur la forêt et son vaste jardin arboré et clos, la maison vous promet un cadre de vie agréable et apaisant. A noter qu'il est possible d'y construire une piscine. Pour compléter ce bien, une cave, un garage double et 6 places de parc extérieures sont à disposition. + +CHF 8’852 / m² + +CHF 2’390’000 + + vor 2 Tagen + +Haus zu verkaufen + +6832 Pedrinate • 7 Zimmer • 260 m² +----------------------------------------------------- + +A Pedrinate, vendiamo questa casa unifamiliare di dimensioni molto generose. È ideale per famiglie numerose e offre anche la possibilità di suddividere l'abitazione in eventuali due appartamenti. Al piano terra troviamo un ampio atrio e le cantine con un locale hobby. Salendo le scale al piano rialzato si trova la cucina abitabile, la sala da pranzo, il soggiorno, un sevizio e una camera da letto. Al primo piano troviamo quattro camere di cui la camera padronale con il bagno in camera e un altro servizio completo. Questa offerta di BETTERHOMES è messa in risalto per i seguenti vantaggi: - struttura massiccia- portico - locali ampi- 2 posti auto in garage- 3/4 posti auto esterni- locale hobby- giardino con porticato- ecc., ecc., ecc. Interessati? Contattateci per una visita senza impegno Non estato trovato nessun oggetto corrispondente? Piu di 2'200 offerte su: www.betterhomes.ch Lo specialista svizzero per le intermediazioni immobiliari Avete un immobile da vendere? Approfittate del nostro know-how: https://www.betterhomes.ch/it/profittare Vorreste sapere quanto vale il vostro immobile? Scoprite subito il suo valore con la nostra stima gratuita, immediatamente e senza impegno https://www.betterhomes.ch/it/knowledge/estimation Oltre dati Posizione: buona Condizione dell'oggetto: buone Bagni / Docce: 3 (1 x bagno / lavabo / bidet / WC, 2 x lavabo / doccia / WC / bidet) Riscaldamento: gasolio Trasporti pubblici: bus, 50 m / FFS, 2,5 km Scuole: asilo / elementari / superiori, 4 km Negozi: Migros / Denner / Coop, 2,5 km + +CHF 5’769 / m² + +CHF 1’500’000 + + vor 2 Tagen + +Haus zu verkaufen + +1272 Genolier • 6.5 Zimmer • 200 m² +------------------------------------------------------ + +Splendid property in Sus-Châtel on 3 levels. Very nice property, quietly located in the popular villa district of Sus-Châtel. Bright, quality materials, perfectly maintained and enjoying beautiful outdoor spaces. 5 bedrooms including a master suite, 3 full bathrooms (3 showers, a bath, double sinks), a balcony an excavated basement with many usable spaces. Pergola in the extension of the terrace. 2 levels of garden on a swimming pool. Double garage and 2 main parking spaces. Ideally connected to the amenities of La Côte, the town of Genolier is located 10 minutes from the motorway access of Nyon or Gland. It is served at high frequency by the NStCM railway line. It enjoys an active local life thanks to its shops, restaurants, schools and sports clubs. A unique property to visit now.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1272-22-1 + +CHF 12’750 / m² + +CHF 2’550’000 + + vor 2 Tagen + +Haus zu verkaufen + +1762 Givisiez • 5.5 Zimmer • 163 m² +------------------------------------------------------ + +Exclusive: Semi-detached triplex villa with heated pool Pretty semi-detached villa, ideally located in a residential area and offering a beautiful open view, without vis-à-vis. Built on three levels, it benefits from generous surfaces as well as a large south-facing terrace, with a pretty heated 4x8m swimming pool (heat pump). Quiet location, close to all amenities. Conditions for the repossession of the existing mortgage loan at an attractive rate (1.21% over the remaining 7 years). A garage-box and 2 parking spaces included.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1762-23-1 + +CHF 5’890 / m² + +CHF 960’000 + + vor 2 Tagen + +Haus zu verkaufen + +5072 Oeschgen • 4.5 Zimmer • 115 m² +------------------------------------------------------ + +Charmantes 4.5-Zimmer Doppeleinfamilienhaus an zentraler Lage Das Bauernhaus an zentraler Lage eignet sich ideal für Paare oder eine kleine Familie. Die Highlights sind der geräumige Wohn-Essbereich mit Kachelofen sowie die Küche mit Tiba Herd. Das Obergeschoss verfügt über 3 Schlafzimmer und das Badezimmer mit Badewanne und Dusche. Weiteres Ausbaupotential bietet das geräumige Dachgeschoss, das aktuell mit einer Sauna ausgestattet ist. Der pflegeleichte Gartensitzplatz rundet das Angebot optimal ab. Wir freuen uns au Ihre AnfrageGenaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/5072-23-1 + +CHF 5’478 / m² + +CHF 630’000 + + vor 2 Tagen + +Haus zu verkaufen + +3963 Crans-Montana • 3.5 Zimmer • 87 m² +---------------------------------------------------------- + +Succumb to the charm of this sumptuous triplex with views in Montana Village Located in a peaceful area and nestled in a charming house of 2 units with character, you will enjoy a sunny balcony for moments of relaxation. Heated by a heat pump for maximum energy efficiency, this wellness setting offers 2 bedrooms, 1 shower room, 1 separate toilet, 1 bright living room with open kitchen, a laundry room and a covered parking space. And why not consider acquiring the entire house?Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/3963-23-4 + +CHF 7’989 / m² + +CHF 695’000 + + vor 2 Tagen + +Haus zu verkaufen + +1712 Tafers • 7.5 Zimmer • 329 m² +---------------------------------------------------- + +Wunderschöne Luxusvilla mit großer Terrasse und Außenpool Ideal gelegen in einer sehr ruhigen Gegend, genießt diese herrliche Luxusvilla eine schöne Aussicht. Der große Garten mit überdachter Terrasse und Außenpool, die Helligkeit des Hauses und seine großen Flächen, die zahlreichen Schlafzimmer, die offene Küche mit Kochinsel, das Soundsystem oder der ausgezeichnete Pflegezustand sind alles Argumente, die Sie begeistern werden. Die untere Etage lässt sich außerdem problemlos in ein Studio umwandeln.Genaue Address verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/1712-22-1 Splendid luxury villa with large terrace and outdoor pool Ideally located in a very quiet area, this splendid luxury villa enjoys a beautiful view. The large garden with covered terrace and outdoor pool, the brightness of the house and its large surfaces, the many bedrooms, the open kitchen with cooking island, the sound system or the excellent state of maintenance are all arguments that will seduce you. The lower floor is also easily convertible into a studio.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1712-22-1 Splendid luxury villa with large terrace and outdoor pool Ideally located in a very quiet area, this splendid luxury villa enjoys a beautiful view. The large garden with covered terrace and outdoor swimming pool, the brightness of the house and its large surfaces, the numerous bedrooms, the open kitchen with cooking island, the sound system or the excellent state of maintenance are all arguments that will seduce you. The lower floor can also be easily converted into a studio.Exact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST: https://neho.ch/o/1712-22-1 + +- + +Auf Anfrage + + vor 2 Tagen + +Haus zu verkaufen + +1008 Jouxtens-Mézery • 7.5 Zimmer • 242 m² +------------------------------------------------------------- + +Spacieuse villa mitoyenne avec logement indépendant Idéalement située et dotée de nombreux atouts pour vous offrir un cadre de vie exceptionnel Cette spacieuse villa bénéficie d'un logement indépendant supplémentaire, parfait pour recevoir vos invités ou pour générer des revenus locatifs supplémentaires. Vous pourrez également profiter d'un jardin verdoyant, idéal pour des moments de détente en famille ou entre amis. Proche de toutes les commodités nécessaires au quotidien : commerces, écoles, transports en commun... tout est à portée de main Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1008-22-4 Spacious semi-detached villa with separate accommodation Ideally located and with many assets to offer you an exceptional living environment This spacious villa benefits from an additional independent dwelling, perfect for entertaining your guests or for generating additional rental income. You will also be able to enjoy a green garden, ideal for relaxing with family or friends. Close to all the amenities needed for daily life: shops, schools, public transport... everything is within easy reachExact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/1008-22-4 + +CHF 8’471 / m² + +CHF 2’050’000 + + vor 2 Tagen + +Haus zu verkaufen + +3232 Ins • 4.5 Zimmer • 124 m² +------------------------------------------------- + +Gepflegtes 4½ Zimmer Reihenmittelhaus in ländlicher Umgebung Ansprechendes Reihenmittelhaus, welches für Sie und Ihre Familie zu einem heimeligen und gemütlichen Zuhause werden kann. Es bietet einen spannenden und grosszügigen Grundriss an. Die lichtdurchfluteten Wohnbereiche mit Dachschrägen verleihen dem Haus ein luftiges Ambiente. Die schöne und gedeckte Pergola lädt dazu ein, unzähligen Sonnenstunden zu geniessen. Die ländliche Umgebung sowie die zentrale Lage, machen das Wohnen hier für Familien noch attraktiver.Genaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/3232-23-1 + +CHF 5’403 / m² + +CHF 670’000 + +[1](https://www.immoyou.ch/haus-kaufen-schweiz)234567 + + 1 - 24 von 20’071 Ergebnisse + +### Haus kaufen in der Schweiz + +[Haus kaufen im Kanton Zürich](https://www.immoyou.ch/haus-kaufen-kanton-zurich)[Haus kaufen im Kanton Bern](https://www.immoyou.ch/haus-kaufen-kanton-bern)[Haus kaufen im Kanton Aargau](https://www.immoyou.ch/haus-kaufen-kanton-aargau)[Haus kaufen im Kanton St. Gallen](https://www.immoyou.ch/haus-kaufen-kanton-st-gallen)[Haus kaufen im Kanton Luzern](https://www.immoyou.ch/haus-kaufen-kanton-luzern)[Haus kaufen im Kanton Basel-Landschaft](https://www.immoyou.ch/haus-kaufen-kanton-basel-landschaft)[Haus kaufen im Kanton Thurgau](https://www.immoyou.ch/haus-kaufen-kanton-thurgau)[Haus kaufen im Kanton Solothurn](https://www.immoyou.ch/haus-kaufen-kanton-solothurn)[Haus kaufen im Kanton Graubünden](https://www.immoyou.ch/haus-kaufen-kanton-graubunden)[Haus kaufen im Kanton Basel-Stadt](https://www.immoyou.ch/haus-kaufen-kanton-basel-stadt)[Haus kaufen im Kanton Schwyz](https://www.immoyou.ch/haus-kaufen-kanton-schwyz)[Haus kaufen im Kanton Zug](https://www.immoyou.ch/haus-kaufen-kanton-zug) + +### Andere Immobilienarten in der Schweiz + +[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Zimmer kaufen in der Schweiz](https://www.immoyou.ch/wg-zimmer-kaufen-schweiz)[Parkplatz kaufen in der Schweiz](https://www.immoyou.ch/parkplatz-kaufen-schweiz)[Büro & Gewerbe kaufen in der Schweiz](https://www.immoyou.ch/buro-gewerbe-kaufen-schweiz)[Wohnhaus kaufen in der Schweiz](https://www.immoyou.ch/wohnhaus-kaufen-schweiz)[Grundstück kaufen in der Schweiz](https://www.immoyou.ch/grundstuck-kaufen-schweiz) + + All rights reserved. v.541ff84 \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_031_www.immoyou.ch_mieten-schweiz.txt b/test_web_content_20251002_215219/additional_link_031_www.immoyou.ch_mieten-schweiz.txt new file mode 100644 index 00000000..2020191d --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_031_www.immoyou.ch_mieten-schweiz.txt @@ -0,0 +1,403 @@ +URL: https://www.immoyou.ch/mieten-schweiz +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +🏠 114’440 Immobilien mieten in der Schweiz | ImmoYou + +=============== + +[ImmoYou](https://www.immoyou.ch/) + +Kaufen + +[Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + +Mieten + +[Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + + Ändern Sie die Suche + +[](https://www.immoyou.ch/)[Mieten](https://www.immoyou.ch/mieten-schweiz)[Schweiz](https://www.immoyou.ch/mieten-schweiz) + +Immobilien mieten in der Schweiz +================================ + +Ort + + Schweiz + + Zürich + + Genf + + Typ + +- [x] Haus + +- [x] Wohnung + +- [x] Zimmer + +- [x] Parkplatz + +- [x] Büro & Gewerbe + +- [x] Wohnhaus + +- [x] Grundstück + + Miete + + - + + Zimmer + + - + + Wohnfläche (m²) + + - + + Grundstücksfläche (m²) + + - + + Ausstattung & Eigenschaften + +- [x] Neubauprojekte + +- [x] Balkon + +- [x] Garten + +- [x] Parkplatz + +- [x] Lift + +- [x] Freie Aussicht + +- [x] Cheminée + +- [x] Garage + +- [x] Kinderfreundlich + +- [x] Rollstuhlgängig + +- [x] Möbliert + +Ordnen + + 114’440 Ergebnisse + + + + vor 2 Wochen + +Wohnung zu vermieten + +4052 Basel • 3 Zimmer • 64 m² +--------------------------------------------------- + +Emplacement Votre nouvelle maison dans le quartier populaire de Breite n'est qu'à deux pas du centre-ville et de la gare CFF. Divers commerces et centres de remise en forme sont accessibles en quelques minutes à pied. La bonne connexion des transports en commun, à travers la ligne de tramway 3 et la ligne de bus 36, vous emmène confortablement à votre destination, même les jours de pluie. Sur les rives voisines du Rhin, vous pouvez échapper au stress de la vie quotidienne en vous promenant tranquillement et en reconstituant vos réserves de vitamine D. Une visite de votre appartement Le plan d'étage généreux vous permet de laisser libre cours à votre imagination lors de l'ameublement. Le parquet dans tous les espaces de vie donne aux chambres leur caractère de bien-être. Les grandes fenêtres offrent un cadre de vie lumineux et confortable. En outre, l'appartement impressionne avec les points suivants: Cuisine lumineuse avec lave-vaisselle et plaque vitrocéramique Salle de bain avec baignoire et armoire miroir Salon spacieux Ascenseur disponible Détails Une place de parking extérieure peut être louée sur demande pour 80.- CHF par mois.Call.View.Rent. Aimeriez-vous vivre plus près de la ville? Ensuite, nous sommes impatients d'avoir de vos nouvelles. Laura Weick 058 280 22 02 laura.weick@helvetia.ch Les photos publiées sont des appartements du même type / type. Des écarts par rapport à l'offre réelle sont donc possibles. En tant que locataire d'Helvetia, vous bénéficiez d'une réduction de 50% sur votre première prime annuelle pour certains produits d'assurance Helvetia D'autres propriétés locatives intéressantes peuvent être trouvées à: www.helvetia.ch/immobilien + +CHF 263 / m² / Jahr + +CHF 1’400 + + Keine Bilder + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +5033 Buchs AG +------------------------------------------ + +- + +Auf Anfrage + + vor 2 Wochen + +Wohnung zu vermieten + +2540 Grenchen • 2.5 Zimmer • 56 m² +-------------------------------------------------------- + +CHF 270 / m² / Jahr + +CHF 1’260 + + vor 2 Wochen + +Parkplatz zu vermieten + +2504 Biel/Bienne +---------------------------------------- + +CHF 50 / m² / Jahr + +CHF 25 + + vor 2 Wochen + +Wohnung zu vermieten + +3612 Steffisburg • 3.5 Zimmer • 83 m² +----------------------------------------------------------- + +Emplacement Le développement Erlenmatte est un quartier adapté aux enfants dans un cadre idyllique et bien entretenu. En plus de nombreuses aires de jeux, les locataires amateurs de football ont leur propre terrain de football privé en bordure du développement à leur disposition. Tout pour vos besoins quotidiens peut être fait dans la Coop ou dans le Landi dans le village. L'arrêt de bus est à seulement 2 minutes, en bus, vous pouvez rejoindre la ville de Thoune en environ 10 minutes. En plus de l'Aar populaire et du lido de Thoune, vous trouverez de nombreux commerces et restaurants. Depuis la gare de Thoune, la ville de Berne est accessible en train en 40 minutes environ. Le jardin d'enfants est à 12 minutes, l'école primaire à 8 minutes et le lycée à 15 minutes à pied.Visite de votre appartement Le point culminant de l'appartement est clairement le balcon, qui devient un espace de vie supplémentaire dans les mois chauds. La cuisine indépendante et pratique dispose d'une fenêtre et d'un accès au balcon. Le coin salon-repas est doté de parquet en chêne. La salle de bain est pourvue d'une baignoire. Les toilettes sont séparées. Cuisine séparée Vitrocéramique, lave-vaisselle Combinaison réfrigérateur avec sep. Congélateur Salon 2 chambres Salle de bain avec baignoire WC séparé Armoires Balcon Compartiment cave Ascenseur disponible Détails Un garage peut également être loué. + +CHF 227 / m² / Jahr + +CHF 1’570 + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +5502 Hunzenschwil +---------------------------------------------- + +CHF 241 / m² / Jahr + +CHF 2’210 + + Keine Bilder + + vor 2 Wochen + +Haus zu vermieten + +8311 Brütten • 4.5 Zimmer • 130 m² +----------------------------------------------------- + +Nous louons cette grande maison jumelée dans la belle campagne de Brütten. La maison s'étend sur trois étages avec des chambres grandes et lumineuses et est située dans un endroit calme mais central. Idéal pour les amoureux de la nature qui aiment profiter du soleil pendant la journée et terminer la soirée dans le magnifique jardin. La maison offre, entre autres, beaucoup d'espace, d'espace de rangement, une grande cuisine, deux salles de bain et bien plus encore. Cette offre BETTERHOMES se caractérise par les avantages suivants :- Ancienne bâtisse de charme avec grand poêle en faïence dans le salon - grande cuisine avec beaucoup d'espace de rangement - récemment rénové en 2022- grand jardin bien entretenu- belle vue sur le loin, le jardin et la nature- Machine à laver disponible dans la maison - Famille et animaux acceptés- Place de parking dans la box garage et places de parking extérieures incluses dans le prix de location- et, et, et... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Situation: centrale et proche de la nature, à la campagne Condition: bien, récemment rénové (2022) Salles de bains / salles d'eau: 2 (1 x douche / WC / lavabo, 1 x baignoire / WC / lavabo) Système de chauffage: Chauffage par le sol Transports publics suivants: Bus, 400m Ecoles: école maternelle / primaire, 900m Commerces: Volg, 900m + +CHF 277 / m² / Jahr + +CHF 3’000 + + vor 2 Wochen + +Restaurant zu vermieten + +8630 Rüti ZH • 3 Zimmer +------------------------------------------------ + +Dans un emplacement central au milieu de Rüti ZH, un nouvel opérateur est recherché pour ce bar avec un espace extérieur généreusement couvert. Le restaurant bien équipé dispose également d'un bar, de plusieurs coins salons et d'un fumoir. Il y a aussi une bonne ventilation et une pièce séparée avec permission pour une petite cuisine. Un permis de plats à emporter est également disponible. Juste à côté de la localité, il y a aussi un parking souterrain, qui offre à vos invités de nombreuses possibilités de stationnement. Là, vous avez accès pendant 24 heures. Cette offre BETTERHOMES se caractérise par les avantages suivants :- Inventaire CHF 70'000.-- fumoir généreux avec une bonne ventilation- Permis de plats à emporter disponible-Espace de stockage-Sanitaires- beaucoup de places de parking à proximité immédiate- et, et, et ... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Emplacement: central Condition: bon Salles de bains / salles de bains: 3 (3 x WC / lavabo) Système de chauffage: chauffage central Transports publics les plus proches: Bus, 100 m Ecoles: école primaire, 580 m / école secondaire, 500 m Commerces : commerces divers, à proximité immédiate + +- + +CHF 4’380 + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +5436 Würenlos • 1 Zimmer +----------------------------------------------------- + +- + +Auf Anfrage + + Keine Bilder + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +6020 Emmenbrücke +--------------------------------------------- + +CHF 199 / m² / Jahr + +CHF 1’660 + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +4414 Füllinsdorf • 3 Zimmer +-------------------------------------------------------- + +Nous louons cette salle de stockage spacieuse et bien équipée dans un emplacement central du centre Schönthal à Füllinsdorf. La propriété se caractérise par ses locaux spacieux et facilement utilisables. La propriété dispose également de 2 chambres froides (environ 8 - 10 m²) et d'une salle d'eau avec 2 toilettes et un lavabo. Un monte-charge d'une capacité allant jusqu'à 2000 kg complète l'offre. Cette offre BETTERHOMES se caractérise par les avantages suivants :- spacieux et facile à utiliser-centré- 3 chambres- 2 chambres froides supplémentaires (environ 8 -10 m²)- 2 WC avec lavabo- Monte-charge (jusqu'à 2000 kg)- et, et, et ... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Lieu: dans le Schönthal-Zentrum à Füllinsdorf Condition: bon Salles de bain / salles de bains: 1 (lavabo / 2 x WC) Transports publics les plus proches : bus n° 75/80, 15 m / gare de Frenkendorf-Füllinsdorf, 550 m Ecoles: Schulhaus Schönthal, 600 m / Sekundarschule Frenkendorf, 800 m Commerces: Supermarché Migros, 50 m / Denner Discount, 95 m + +CHF 65 / m² / Jahr + +CHF 2’650 + + vor 2 Wochen + +Wohnung zu vermieten + +4414 Füllinsdorf • 3.5 Zimmer • 70 m² +----------------------------------------------------------- + +CHF 271 / m² / Jahr + +CHF 1’580 + + vor 2 Wochen + +Wohnung zu vermieten + +6020 Emmenbrücke • 7.5 Zimmer • 168 m² +------------------------------------------------------------ + +CHF 183 / m² / Jahr + +CHF 2’560 + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +6423 Seewen SZ • 1 Zimmer +------------------------------------------------------ + +CHF 126 / m² / Jahr + +CHF 735 + + vor 2 Wochen + +Restaurant zu vermieten + +8604 Volketswil • 3 Zimmer +--------------------------------------------------- + +Ce restaurant est situé dans un emplacement privilégié à Volketswil, sur une route très fréquentée. Une belle boutique avec une terrasse accueillante, plus la salle à manger. Comme un bel ajout, qui peut être utilisé comme un plat à emporter ou un courrier de pizza. Les toilettes invités sont situées au rez-de-chaussée, ainsi que la cuisine, qui est très bien équipée, four à pizza double, deux entrepôts de congélation, grande cuisinière à gaz, etc. En outre, il y a deux salles de stockage. Cette offre BETTERHOMES se caractérise par les avantages suivants :- entièrement équipé- Restaurant 50 couverts- Terrasse jusqu'à 20 places- Système de point de vente- Ventilation / air d'alimentation et air évacué- Transfert d'inventaire CHF 125000.-- et, et, et... Intéressé? Contactez-nous pour une visite sans engagement également possible de visualisation en ligne Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Emplacement: bon Condition: bon Salles de bain / salles d'eau: 2 (2 x lavabo / WC) Transports publics suivants: train, 500m Ecoles: Ecole primaire, 500m Commerces: Volkiland 200m + +CHF 216 / m² / Jahr + +CHF 4’500 + + Keine Bilder + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +4900 Langenthal • 1 Zimmer +------------------------------------------------------- + +CHF 259 / m² / Jahr + +CHF 625 + + vor 2 Wochen + +Wohnung zu vermieten + +3286 Muntelier • 2.5 Zimmer • 80 m² +--------------------------------------------------------- + +Vous cherchez une maison confortable dans un quartier calme avec vue sur le lac de Morat? L'appartement mansardé offre un salon spacieux et lumineux avec une cuisine ouverte et une grande chambre. Vous avez également accès à la grande terrasse, où vous pourrez vous détendre avec vos amis et votre famille en été après avoir nagé dans le lac. Cette offre BETTERHOMES se caractérise par les avantages suivants :- chambres inondées de lumière- Vue sur le magnifique lac de Morat- grande salle de bain avec baignoire- Screed avec beaucoup d'espace de rangement- cuisine ouverte entièrement équipée- Une place de parking peut être louée pour CHF 50.-- et, et, et ... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Situation: dans un quartier très calme, avec vue sur le lac de Morat Condition: bon Salles de bain / salles d'eau: 1 (1 x douche / baignoire / double vasque / WC) Système de chauffage: Chauffage au mazout Transports en commun : gare de Muntelier, env. 400 m Ecoles: Ecole primaire à Morat, 1,5 km Commerces: magasin de village, env. 500 m / magasins divers à Morat, env. 1,5 km + +CHF 245 / m² / Jahr + +CHF 1’630 + + vor 2 Wochen + +Wohnung zu vermieten + +8592 Uttwil • 4.5 Zimmer • 136 m² +------------------------------------------------------- + +Vous cherchez un appartement qui ne laisse rien à désirer? Alors votre recherche est terminée. Ce bel appartement en duplex offre tout ce dont vous avez toujours rêvé et bien plus encore. Vous y trouverez de très grandes chambres lumineuses, 2 salles de bains luxueuses qui vous invitent à la détente, une cuisine moderne équipée des derniers appareils Siemens, un balcon, une grande terrasse avec son propre poêle et un chauffage au sol luxueux dans toutes les chambres. Cette offre BETTERHOMES se caractérise par les avantages suivants :- chauffage au sol luxueux dans toutes les chambres- grand balcon- grande terrasse avec son propre poêle, avec vue magnifique sur le lac- grandes pièces inondées de lumière- cuisine moderne, équipée des meilleurs appareils- 2 salles de bains luxueuses- et, et, et ... Intéressé? Contactez-nous pour une visite sans engagement également possible de visualisation en ligne Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Situation: bel emplacement avec vue sur le lac Condition: très bon Salles de bain / Salles de bain: 2 (1 x baignoire / double vasque / WC, 1 x WC / lavabo / douche) Système de chauffage: chauffage au mazout / chauffage au sol Transports publics les plus proches: Uttwil train station, 750 m Ecoles: Ecole primaire Schulhaus Gries, 650 m Commerces: Volg Uttwil, 550 m / Centre commercial Hubzelg, 3.3 km + +CHF 203 / m² / Jahr + +CHF 2’300 + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +4900 Langenthal • 1 Zimmer +------------------------------------------------------- + +CHF 253 / m² / Jahr + +CHF 2’130 + + vor 2 Wochen + +Wohnung zu vermieten + +9470 Werdenberg • 4.5 Zimmer • 88 m² +---------------------------------------------------------- + +Cet appartement récemment rénové impressionne par ses chambres inondées de lumière et sa cuisine ouverte. Grâce au vitrage 3 plis, l'appartement est très calme. Beaucoup de bois et de parquet créent une ambiance chaleureuse. Sur le balcon ou dans le jardin avec la vue magnifique sur le château, vous pourrez profiter des heures de soleil. Tous les centres commerciaux et l'école sont accessibles à pied, et le bus est presque à côté. Cette offre BETTERHOMES se caractérise par les avantages suivants :- récemment rénové- cuisine ouverte-Parquet-Lave-vaisselle-centré- balcon privé et jardin à usage commun-Cave- et, et, et ... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Emplacement: central Condition: très bon Salles de bain / Salles de bain: 1 (1 x douche / lavabo / WC / bidet) Système de chauffage : pompe à chaleur air-eau Transports publics les plus proches: Bus, 50 m / train, 1,5 km Ecoles: école primaire / maternelle, 800 m Commerces: Coop / Migros, 950 m + +CHF 252 / m² / Jahr + +CHF 1’850 + + vor 2 Wochen + +Wohnung zu vermieten + +2544 Bettlach • 5 Zimmer • 217 m² +------------------------------------------------------- + +CHF 170 / m² / Jahr + +CHF 3’080 + + vor 2 Wochen + +Wohnung zu vermieten + +4410 Liestal • 6 Zimmer • 144 m² +------------------------------------------------------ + +CHF 233 / m² / Jahr + +CHF 2’800 + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +4104 Oberwil BL • 2 Zimmer +------------------------------------------------------- + +Ce salon entièrement équipé et bien entretenu offre à votre clientèle la plus haute qualité. Le lavage, la coupe, le brushing, la teinture et le coiffage pour les femmes, les hommes et les enfants sont les activités quotidiennes. Le salon dispose de quatre chaises de barbier et d'une station de lavage, d'une toilette client, de sa propre machine à laver et d'un gobelet. La clientèle régulière est énorme. Grâce à l'emplacement central, il y a beaucoup de clients spontanés. Transfert d'inventaire pour CHF 50'000.-. Cette offre BETTERHOMES se caractérise par les avantages suivants :- emplacement idéal- grand cercle de clients réguliers- beaucoup de clients sans rendez-vous- entièrement équipé- Machine à laver et sèche-linge- Transfert d'inventaire- et, et, et ... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Emplacement: très bien Condition: bon Salles de bain / Salles de bain: 1 (1 x WC / Lavabo) Transports publics: Bus, 210 m / Tram, 290 mÉcoles: École secondaire, 160 m Commerces: Coop, 120 m + +CHF 421 / m² / Jahr + +CHF 2’000 + + Keine Bilder + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +4900 Langenthal • 1 Zimmer +------------------------------------------------------- + +CHF 253 / m² / Jahr + +CHF 4’260 + +[1](https://www.immoyou.ch/mieten-schweiz)234567 + + 1 - 24 von 114’440 Ergebnisse + +### Immobilie mieten in der Schweiz + +[Immobilie mieten im Kanton Zürich](https://www.immoyou.ch/mieten-kanton-zurich)[Immobilie mieten im Kanton Bern](https://www.immoyou.ch/mieten-kanton-bern)[Immobilie mieten im Kanton Aargau](https://www.immoyou.ch/mieten-kanton-aargau)[Immobilie mieten im Kanton St. Gallen](https://www.immoyou.ch/mieten-kanton-st-gallen)[Immobilie mieten im Kanton Luzern](https://www.immoyou.ch/mieten-kanton-luzern)[Immobilie mieten im Kanton Basel-Landschaft](https://www.immoyou.ch/mieten-kanton-basel-landschaft)[Immobilie mieten im Kanton Thurgau](https://www.immoyou.ch/mieten-kanton-thurgau)[Immobilie mieten im Kanton Solothurn](https://www.immoyou.ch/mieten-kanton-solothurn)[Immobilie mieten im Kanton Graubünden](https://www.immoyou.ch/mieten-kanton-graubunden)[Immobilie mieten im Kanton Basel-Stadt](https://www.immoyou.ch/mieten-kanton-basel-stadt)[Immobilie mieten im Kanton Schwyz](https://www.immoyou.ch/mieten-kanton-schwyz)[Immobilie mieten im Kanton Zug](https://www.immoyou.ch/mieten-kanton-zug) + +### Andere Immobilienarten in der Schweiz + +[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Zimmer mieten in der Schweiz](https://www.immoyou.ch/wg-zimmer-mieten-schweiz)[Parkplatz mieten in der Schweiz](https://www.immoyou.ch/parkplatz-mieten-schweiz)[Büro & Gewerbe mieten in der Schweiz](https://www.immoyou.ch/buro-gewerbe-mieten-schweiz)[Wohnhaus mieten in der Schweiz](https://www.immoyou.ch/wohnhaus-mieten-schweiz)[Grundstück mieten in der Schweiz](https://www.immoyou.ch/grundstuck-mieten-schweiz) + + All rights reserved. v.541ff84 \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_032_www.immoyou.ch_wohnung-mieten-schweiz.txt b/test_web_content_20251002_215219/additional_link_032_www.immoyou.ch_wohnung-mieten-schweiz.txt new file mode 100644 index 00000000..02f9258e --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_032_www.immoyou.ch_wohnung-mieten-schweiz.txt @@ -0,0 +1,423 @@ +URL: https://www.immoyou.ch/wohnung-mieten-schweiz +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +🏢 53’252 Wohnungen mieten in der Schweiz | ImmoYou + +=============== + +[ImmoYou](https://www.immoyou.ch/) + +Kaufen + +[Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + +Mieten + +[Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + + Ändern Sie die Suche + +[](https://www.immoyou.ch/)[Mieten](https://www.immoyou.ch/mieten-schweiz)[Wohnungen](https://www.immoyou.ch/wohnung-mieten-schweiz)[Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz) + +Wohnung mieten in der Schweiz +============================= + +Ort + + Schweiz + + Zürich + + Genf + + Typ + +- [x] Haus + +- [x] Wohnung + +- [x] Zimmer + +- [x] Parkplatz + +- [x] Büro & Gewerbe + +- [x] Wohnhaus + +- [x] Grundstück + + Miete + + - + + Zimmer + + - + + Wohnfläche (m²) + + - + + Grundstücksfläche (m²) + + - + + Ausstattung & Eigenschaften + +- [x] Neubauprojekte + +- [x] Balkon + +- [x] Garten + +- [x] Parkplatz + +- [x] Lift + +- [x] Freie Aussicht + +- [x] Cheminée + +- [x] Garage + +- [x] Kinderfreundlich + +- [x] Rollstuhlgängig + +- [x] Möbliert + +Ordnen + + 53’252 Ergebnisse + + + + vor 2 Tagen + +Wohnung zu vermieten + +8706 Meilen • 1 Zimmer +-------------------------------------------- + +Ich vermiete 1 Zimmer in einer 4.5 Zimmerwhg im wunderschönen und steuergünstigen Feldmeilen (Zürisee) Die Whg verfügt über: 1 Wohnzimmer mit Cheminée & Essecke 1 Büro 1 Schlafzimmer 1 andere Schlafzimmer 1 Küche 1 WC 1 Badeszimmer 1 Balkon mit Grill Parkplatz aussen vorhanden See 10 Min zu Fuss Bushaltestelle 2 Min zu Fuss Bahnhof / Coop 10 Min zu Fuss Die Wohnung liegt an sehr ruhige Lage und nah vom Naturgebiet. Ideal für Spaziergänge oder Joggen Internetanschluss / Elektrizität / Wasche inkl. in der Miete Ich suche eine positive, sorgfältige, unkomplizierte und kommunikative Person (1) als MitbewohnerIn per sofort. Nicht RaucherIn gewünscht Fühlst Du Dich angesprochen? Dann melde Dich jetzt für eine Besichtigungstermin an + +- + +CHF 1’200 + + + + vor 2 Tagen + +Wohnung zu vermieten + +8636 Wald ZH • 2.5 Zimmer • 150 m² +-------------------------------------------------------- + +Modernes Wohnen in bester Lage Erleben Sie ein helles und geräumiges Zuhause in unserer 2.5-Zimmerwohnung in Wald. Der offene Wohnbereich mit vielen Fenstern bietet viel natürliches Licht und eine tolle Atmosphäre. Bei Bedarf kann der Raum mit Schienen unterteilt werden, um noch mehr Flexibilität zu schaffen. Die grosszügige und neuwertige Küche ist mit einem Steamer und einem Induktionskochfeld ausgestattet. Hier macht das Kochen richtig Spass Das Badezimmer ist geräumig und bietet eine Dusche und eine Badewanne. Eine separate Toilette mit Waschturm rundet das Angebot ab. Die Wohnung verfügt über 2 Gemeinschaftsgärten und einen Spielraum, in denen Sie sich entspannen und Ihre Freizeit geniessen können. Ein Aussenparkplatz ist im Preis inbegriffen, sodass Sie Ihr Auto immer sicher abstellen können. Einkaufsmöglichkeiten und Restaurants sind in wenigen Gehminuten erreichbar, der Bahnhof in nur 15 Minuten. Diese Wohnung bietet Ihnen alles, was Sie brauchen, um sich rundum wohlzufühlen. Überzeugen Sie sich selbst und vereinbaren Sie einen BesichtigungsterminDieses properti-Angebot zeichnet sich durch folgende Vorteile aus: Offener Wohnbereich Viele Fenster, lichtdurchflutet Schienen zur Raumteilung 153m² Wohnfläche Modern ausgestattet Grosszügige, neuwertige Küche mit Steamer und Induktionskochfeld Grosses Badezimmer mit Dusche und Badewanne Separate Toilette mit Waschturm 2 Gemeinschaftsgärten und Spielraum Inklusive Aussenparkplatz Geräumiges Kellerabteil Einkaufsmöglichkeiten und Restaurants in Gehweite Bahnhof in 15 Minuten zu Fuss erreichbar Ruhige, sonnige und zentrale Lage Interessiert? Kontaktieren Sie uns für ein unverbindliches Gespräch Selbst eine Immobilie zu vermarkten? Wir überzeugen mit fairen und transparenten Konditionen + +CHF 186 / m² / Jahr + +CHF 2’330 + + vor 2 Tagen + +Wohnung zu vermieten + +8004 Zürich • 1 Zimmer +-------------------------------------------- + +Hi As of July 1st I will have a free room in my beautiful apartment situated on the corner of the Bäckeranlage park. The area around is beautiful and lively but not noisy at night. The room will come fully furnished at a reasonable price. The flat is very well connected. It is 2 min to the tram stop for the 8, 5 min from the tram stop for lines 2 and 3, and 8 min from Bahnhof Wiedikon. We are also close to the main station as well as Helvetiaplatz. The room available is the largest in the flat and is not on the street-side of the building which makes its extra quiet. I will stay in the smaller room as Im already set up in there. We have a bright living room, a bathroom with a tub, a kitchen, and a rooftop terrace we have shared access to. The flat is recently renovated as you can probably see in the photos. The washer and dryer are located in the flat which is considered a huge bonus in Zurich. To share a little about myself, my name is Chandler. I grew up in Florida but I moved to Germany when I was 15 to join a professional dance school and have been living in Europe working as a professional dancer ever since then. Ive been in Zurich for nearly five years now. I speak German very well and of course English which is my mother tongue. Im also familiar with quite a few swear-words in several other languages. I love music, especially any kind of underground electronic. I even DJ on the side some when I can catch a gig. Im looking for someone I think will be a good match as a roommate for me. Ideally that would probably be a young professional who works a lot like me. Probably age 30 or under (Im 24) who is somewhat creative and and easygoing. Id love to have someone I could have fun with as well as someone who is respectful of personal space and quiet time/nights. It would be nice to be able to cook together and play some cards with friends here some nights as well. I can also appreciate a good night out when I can. Send me a message if youre interested and think wed be a good fit :)-Chandler + +- + +CHF 1’495 + + vor 2 Tagen + +Wohnung zu vermieten + +8600 Dübendorf • 2.5 Zimmer • 79 m² +--------------------------------------------------------- + +Ich suche per sofort oder nach Vereinbarung einen Nachmieter für meine grosszügige 2.5-Zimmerwohnung in Dübendorf. - grosser Wohn-/ Essbereich- mit Schiebetür abtrennbare Küche- grosszügiges Schlafzimmer- Badezimmer mit Doppelwaschtisch, Badewanne und Duschkabine- 3 Doppeltürige Wandschränke- 1 Reduit für zusätzlichen Stauraum- Parkett in Wohn-/Schlafbereich- Sonnige Terasse mit Zugang zur Wiese, teils überdachtt- Parkplatz in Tiefgarage kann für 130.- übernommen werden, muss aber nicht.- Teils Möbel können nach Wunsch und Preiseinigung übernommen werden.- Kellerabteil ca. 10m2 mit Stromanschluss gehört ebenfalls zur Wohnung. Die Wohnung liegt in einem ruhigen Quartier, abgelegen von Hauptsrassen. Die Bushaltestelle ist 2 Gehminuten entfernt. Bahnhöfe Stettbach und Dübendorf sind zu Fuss in 15 Minuten oder 5 Minuten per Bus zu 3 erreichen. Ebenfalls in 3 Minuten ist die Tramhaltestelle der Glattalbahn in Richtung Flughafen zu erreichen. die Fassade des Gebäudes wurde vor ca. 1.5 Jahren erneuert. Ebenfalls wurden kürzlich der Kühlschrank, die Gegensprechanlage und die Heizungsregler erneuert. Haustiere in Absprache mit der Verwaltung. + +CHF 266 / m² / Jahr + +CHF 1’750 + + vor 2 Tagen + +Wohnung zu vermieten + +6340 Baar • 3 Zimmer • 68 m² +-------------------------------------------------- + +Da ich sehr viel unterwegs bin, untervermiete ich meine Wohnung flexibel, jederzeit ab dem 20 März 2023 oder nach Vereinbarung. Dauer der Untermiete: nach Vereinbarung, auch längerfristig möglich . Verbringe deine Tage in einer ruhigen, vollmöblierten, schön eingerichtete Wohnung, nur 5 Minuten zu Fuß vom Bahnhof, Einkaufmöglichkeiten (Coop, Migro, Aldi, Denner), Geschäften, Restaurants, Bäckereien und Baar-Stadtzentrum entfernt. Oder eine kurze Radtour zum Zugersee (12 Minuten / 3 km). Diese gemütliche Wohnung im 2. Stockwerk bietet alles, was Sie für ein angenehmes Zuhause benötigen, einschließlich geräumiger Zimmer, moderner Ausstattung und einer heimeligen Atmosphäre. Verpassen Sie nicht die Chance, diese einzigartige Wohnmöglichkeit zu erleben. Kontaktieren Sie mich heute, um einen Besichtigungstermin zu vereinbaren. Die Wohnung besteht aus einem Schlafzimmer ausgestattet mit einem Queensize-Bett (Breite 180 cm x Länge 220 cm) und einem geräumigen Kleiderschrank, einem Gästezimmer/Arbeitszimmer (Austattung als Home Office und Gästezimmer - Bett mit Futonmatratze 140 cm x 200 cm), einem Badezimmer (mit Badewanne), einer schönen Küche und einem Wohnzimmer. Vom Wohnzimmer aus haben Sie Zugang zu einem schönen, kleinen Balkon. Zu den Annehmlichkeiten zählen TV set, Arbeitsplatz für work from home (Arbeitstisch aus Massivholz und ergonomischer Bürostuhl). Die Waschmaschine und der Trockner befinden sich im Keller. Zu Verfügung steht auch ein Kellerraum, ein Abstellraum für Fahrräder und auf Anfrage zusätzlicher Abstellraum auf dem Dachboden. Direktverbindung zum Flughafen Kloten mit dem Zug: 45 Minuten (54 Minuten Tür zu Tür) und nach Luzern.Miete (inkl. Nebenkosten): 1900,00 CHF pro Monat . Extrakosten für Internet, TV, Festnetz und SERAFE (Radio & Fernsehergebühr). + +CHF 335 / m² / Jahr + +CHF 1’900 + + vor 2 Tagen + +Wohnung zu vermieten + +8600 Dübendorf • 2 Zimmer • 53 m² +------------------------------------------------------- + +Perfekte 2-Zimmer- Wohnung an top Lage Diese moderne Wohnung liegt an einer verkehrsberuhigten Lage und ist nach Vereinbarung Verfügbar: 2-Zimmer-Wohnung- 1x Bad- 1x Schlaffzimmer- Wohnzimmer- Möbel sind zum Verkaufen Konditionen (CHF 1290 + CHF 150 NK) Dübendorf ist eine Stadt zum Wohlfühlen. Wer hier wohnt findet alles, was zum Alltag gehört. Sie hat ein lebendiges Zentrum mit einer optimalen Mischung zwischen Stadt und Land. Sie profitieren von einem breitgefächerten Angebot an Geschäften, Restaurants, Schulen und Kindergarten, so-wie der Nähe zum Lycée Française (Gockhausen), der Int. School Zürich North ISZN (Wallisellen) und Inter Community School ICS (Zumikon). + +CHF 326 / m² / Jahr + +CHF 1’440 + + vor 2 Tagen + +Wohnung zu vermieten + +8105 Watt • 2 Zimmer • 45 m² +-------------------------------------------------- + +Suche ab 15.5.2023 einen Nachmieter für diese gemütliche Wohnung in Watt. Die Wohnung wurde 2019 komplett renoviert und hat folgendes zu bieten:- Fußbodenheizung- modernes Bad- moderne Küche mit Geschirrspüler Backofen und Waschmaschine- geräumiger Kellerabteil- Parkplatz- Raum für Velo Es sind 2 Zimmer und 45 Quadratmeter in einem gepflegten ruhigen Mehrfamilienhaus Mit ÖV ist man in ca. 25 Minuten am Züricher Hauptbahnhof. SB Haltestelle Regensdorf-Watt 18 Minuten mit der S6 Trotzdem ergibt sich am Abend die Möglichkeit einen Rundgang in die natur zu machen. + +CHF 400 / m² / Jahr + +CHF 1’500 + + vor 2 Tagen + +Wohnung zu vermieten + +8048 Zürich • 4.5 Zimmer +---------------------------------------------- + +We are leaving this renovated, spacious and bright 4.5 room attic apartment in Altstetten since 1st May 2023 and looking for the new tennants. The apartment can offer the following:- Open plan kitchen with granite bar. Glass ceramic, dishwasher, extractor fan and microwave.- 3 separate spacious rooms + large living room with fireplace.- 2 bathrooms: toilet/bath and toilet/shower.- Large terrace/balcony.- Generous built-in closets in the corridor.- Own washing machine in a separate laundry room within the apartment.- Entire apartment freshly painted and new laminate flooring.- Shops (including big Migros, Co-op and Denner) and public transport at Lindenplatz in 3 minutes walk.- 9 minutes walk to Zürich Altstetten train station and 3 minutes walk to tram 2 station.- Big public swimming pool in 7 minutes walk and various sport clubs and parks in walking distance.- Separate storage included in the contract cost. Cost is 3250 CHF per month (+3 months deposit) Parking is available at 180 CHF per month + +- + +CHF 3’250 + + vor 2 Tagen + +Wohnung zu vermieten + +8400 Winterthur • 2 Zimmer • 55 m² +-------------------------------------------------------- + +Um eine allfällige Wohnungsbesichtigungen möglichst effizient zu halten, werden ausschliesslich ernsthafte Interessenten zugelassen. Dafür finden Sie hier auf der Website ausreichend Bild- und Textmaterial sowie einen Grundrissplan, sodass Sie die Wohnung vorab virtuell sehr detailliert einschätzen können. Wenn Sie, nach ausreichendem Studium der Unterlagen, mehrheitlich überzeugt sind, können Sie in einem 2. Schritt im Kontaktfenster (auf der Website rechts bei Inserent kontaktieren) im Textfeld eine persönlich formulierte Anfrage oder ein Motivationsschreiben an die Verwaltung richten - und werden daraufhin zur Terminabsprache via email für eine Besichtigung an die derzeitige Mieterin verwiesen. Das Interesse für solche Wohnungen nähe Altstadt ist gross. Minimalistische Anfragen (erkennbar an der Verwendung des standardisierten Textbausteins im Kontaktfenster) werden kommentarlos gelöscht Nähe Altstadt und Hauptbahnhof (700m), unmittelbar neben der Bushaltestelle Hinterwiesli (20m Luftlinie) gelegen, mit vielseitigen Einkaufsmöglichkeiten in Gehdistanz (Bäckerei, Migros, Denner, Gemüse Markt, Kiosk, Apotheke) und diversen Restaurants im Umkreis, findet sich das kleine Mehrfamilienhaus mit 8 Single-Wohnungen an sehr ruhiger Wohnlage (trotz Zentrumsnähe) in schönem und gepflegtem Quartier. Es herrscht eine angenehme und kollegiale Atmosphäre im Haus, dank der niveauvollen Bewohnerschaft bestehend aus vorwiegend jüngeren Einzelhaushalten. Die Altbauliegenschaft ist gut unterhalten und wird von einem Privatvermieter angeboten. Die lichtdurchflutete Wohnung im Dachgeschoss links (ohne Lift) zeichnet sich durch ein Ambiente von Gemütlichkeit und Ruhe aus, wozu die dicken Mauern in Kombination mit der überdurchschnittlichen Raumhöhe von 2.57m als spezielles Stilmittel besonders beitragen. Der schöne Bodenbelag in Parkettoptik schafft eine behagliche Atmosphäre und lässt kreativen Leuten viel Spielraum zur individuellen Einrichtung. Die Forster-Küche ist zweckmässig und mit einem Putzschrank ausgestattet. Sie bietet ausreichend Platz für einen kleinen Esstisch in der Ecke. Die Nasszelle mit Wanne lädt zum gemütlichen Baden ein. Zur Wohnung gehören ein eigenes Estrich- und ein Kellerabteil . Zur allgemeinen Mitbenutzung stehen die Waschküche mit WM/Tumbler und separatem Trockenraum im Keller, ein Veloeinstellraum auf dem Hof sowie eine Dachterrasse mit einmaliger Aussicht über das Quartier zur Verfügung. Ausreichend Parkiermöglichkeiten finden sich entlang der Quartierstrasse in der blauen Zone. Die Liegenschaft ist ans Glasfasernetz angeschlossen. Die Nebenkosten sind ohne monatliche Antennengebühr berechnet. + +CHF 277 / m² / Jahr + +CHF 1’270 + + vor 2 Tagen + +Wohnung zu vermieten + +8180 Bülach • 4 Zimmer • 68 m² +---------------------------------------------------- + +Die 68 Quadratmeter grosse 4 Zimmer-Wohnung im zweiten Obergeschoss verfügt über ein grosses, lichtdurchflutetes Schlafzimmer mit Parkettboden. Der Wohn- und Essbereich bietet Platz für einen Esstisch und eine wohnliche Couch. Die moderne Küche wurde ebenfalls 2021 Jahren umgebaut und verfügt über einen Backofen, einen Glaskeramikherd und eine Abwaschmaschine. Vom Wohnbereich gelangst du auf einen kleinen Balkon. Parkplätze können dazu gemietet werden. + +CHF 314 / m² / Jahr + +CHF 1’780 + + vor 2 Tagen + +Wohnung zu vermieten + +8038 Zürich • 2 Zimmer +-------------------------------------------- + +An der Kurfirstenstr. 84 auf ruhiger grüner Strasse vermieten wir per 1. Mai 2023 eine helle 2 Zimmer Wohnung im 2.OG mit Balkon. Die Wohnung hat in im Wohnzimmer und Schlafzimmer Parkett und Bad/WC mit Bodenplatten, geschlossene Küche.Besichtigung: Montag 20.032023 um 18.30-19.00 Uhr 2023, WHG Winkelmann + +- + +CHF 2’190 + + vor 2 Tagen + +Wohnung zu vermieten + +8180 Bülach • 4.5 Zimmer • 135 m² +------------------------------------------------------- + +Garagenparplatz kann für 120.- dazgemietet werden. Ab 01.06.24 kann ein zusätzlicher Parkplatz bei Bedarf dazugemietet werden. + +CHF 227 / m² / Jahr + +CHF 2’550 + + vor 2 Tagen + +Wohnung zu vermieten + +8004 Zürich • 3 Zimmer +-------------------------------------------- + +Untermieter/in für Wohnung im Kreis 4 gesucht Für unsere schöne Altbauwohnung an der Wengistrasse in Zürich, mitten im Kreis 4, suchen wir ab Mitte April einen Untermieter für voraussichtlich 2 Monate . Die Wohnung befindet sich im 4. Stock, hat 3 Zimmer und einen Balkon. Es handelt sich um eine renovierte, moderne Wohnung in einem Altbau. Verfügbar ab: ca. 15 April bis ca. 11 Juni (nach Vereinbarung) Die Wohnung wird voll möbliert vermietet - vom Fernseher über den Staubsaugerroboter bis zum Smoothie-Maker ist alles dabei. Ausstattung:- Aufzug- Kellerabteil- Küche mit Geschirrspüler- Eigene Waschmaschine & Tumbler Nachbarschaft:- Direkt an der Langstrasse- Migros & Denner auf der anderen Strassenseite, 24-Stunden-Laden 100 Meter entfernt- Tram & Bushaltestelle direkt nebenan Die Miete beträgt CHF 2500 (inkl. Möbel & NK). Stromkosten & Internet sind nicht inbegriffen. ---------------------------- For our beautiful apartment on Wengistrasse in Zurich, in the middle of district 4, we are looking for a subtenant from mid-April for probably 2 months. The apartment is on the 4th floor, has 3 rooms and a balcony. It is a renovated, modern apartment in an old building. Available from: approx. 15 April to approx. 11 June (by agreement). The apartment is rented fully furnished - from TV to vacuum cleaner robot to smoothie maker, everything is included. Facilities:- elevator- cellar compartment- Kitchen with dishwasher- Own washing machine & tumble dryer Neighborhood:- Directly on Langstrasse- Migros & Denner on the other side of the street, 24-hour store 100 meters away- Streetcar & bus stop right next door The rent is CHF 2500 (incl. furniture & NK). Electricity costs & internet are not included. + +- + +CHF 2’500 + + vor 2 Tagen + +Wohnung zu vermieten + +8057 Zürich • 3 Zimmer • 80 m² +---------------------------------------------------- + +Ich suche per 1.4. (oder erste April Woche) Nachmieter für meine Wohnung. Die Wohnung ist im obersten Geschoss in einem Altbau in der Nähe vom Irchelpark und den Tramhaltestellen Universität Irchel und Langmauerstrasse ist 80m2 gross und 2.5m hoch und bietet:- Wohnzimmer 34m2 (momentan mit Holzwand in 2 Zimmer von 18m2 & 16m2 aufgeteilt, kann übernommen werden, muss nicht)- Mit Wohnzimmer verbundener Vorplatz mit Putzschrank 4.5m2- Zimmer 14m2- Zimmer mit Einbauschrank 11m2- Küche mit 3.5m3 Nutzfläche mit Backofen, Kühlschrank mit Gefrierfach, Geschirrspühler (alles 2 jährig)- Dusche 3.5m2 (vor 1 Jahr teilrenoviert)- Vorplatz im Treppenhaus zur Nutzung 5m2 Die Zimmer sind mit Laminat ausgelegt. Zur Wohnung gehört ein geräumiges trockenes Kellerabteil. Waschmaschine und Tumbler werden nur mit der Wohnung unterhalb geteilt. Grosse Dachterrasse zur Mitbenutzung. Gedeckter Veloplatz vor dem Eingang. Miete ohne Kaution. Als Mieter kommen in Frage: Singles, Paare, WG mit zwei Personen, Alleinstehende mit Kind(ern) im Primarschulalter. Besichtigungstermine werden an valable Interessenten vergeben. Bitte mit kurzer Vorstellung der interessierten Mietpartei(en). Bei grossen Andrang, entschuldigen sie bitte, falls sie keine Antwort erhalten. --------------------------------- I'm looking for 1.4. (or first week of April) Subsequent tenants for my apartment. The apartment is on the top floor in an old building near Irchelpark and tram stops Universität Irchel and Langmauerstrasse, is 80m2 and 2.5m high and offers:- Living room 34m2 (currently divided into 2 rooms of 18m2 & 16m2 with a wooden wall, can be taken over, does not have to)- Forecourt connected to living room with cleaning cupboard 4.5m2- Room 14m2- Room with built-in wardrobe 11m2- Kitchen with 3.5m3 usable area with oven, refrigerator with freezer compartment, dishwasher (everything 2 years old)- Shower 3.5m2 (partially renovated 1 year ago)- Forecourt in the stairwell for use 5m2 The rooms are laid out with laminate. The apartment has a spacious dry basement compartment. Washing machine and dryer are only shared with the apartment below. Large roof terrace for shared use. Covered bicycle space in front of the entrance. Rent without deposit. Possible tenants are: singles, couples, flat shares with two people, single people with child(ren) of primary school age. Viewing appointments are given to valid interested parties. Please provide a brief introduction to the interested tenant(s). If there is a large rush, please excuse me if you do not receive an answer. + +CHF 360 / m² / Jahr + +CHF 2’400 + + vor 2 Tagen + +Wohnung zu vermieten + +8906 Bonstetten • 2.5 Zimmer • 55 m² +---------------------------------------------------------- + +Ganz nah zur Stadt Zürich und trotzdem mitten in der grünen Lunge Knonaueramt. Baujahr 2016 im Minergie-Standard Naturnah und doch zentral (2 Minuten zur S-Bahn & Busbahnhof): Mit S5 ist man in 22 Minuten in Zürich HB bzw in 25 Minuten in Zug Wohnfläche ca. 55 qm (plus 12 qm gedeckte Loggia) Eigenes Kellerabteil, separates kleines Reduit in der Wohnung Waschturm, Waschmaschine & Tumbler (V-Zug) in der Wohnung Stellplatz in der Tiefgarage mit direktem Hauszugang für CHF 170.- Fussbodenheizung Komplett barrierefrei und rollstuhlgängig Durch die Ausrichtung der Wohnung geniessen Sie die Sonne auf der geschützten grossen Loggias Die hier gezeigten Fotos wurden vor dem Einzug aufgenommen und gehören zu einer Beispielwohnung, d.h. sie können leicht von der Realität abweichen. Das (kostenpflichtige) bonacasa Konzept unterstützt Sie in vielen Alltagsarbeiten, so z.B. Wohnungsreinigung, Ferienabwesenheitsdienst, Schlüsseltresor für Notfälle, Wäscheservice , u.v.m. Video-Impressionen: https://www.youtube.com/watch?v=ivHXe0FTWFw&t=50s + +CHF 362 / m² / Jahr + +CHF 1’660 + + vor 2 Tagen + +Wohnung zu vermieten + +8610 Uster • 3.5 Zimmer • 63 m² +----------------------------------------------------- + +Geräumige und sonnige Wohnung im DG mit Dachschrägen. Vom Wohnzimmer aus hat man Aussicht auf die Alpen, den Greifensee und die Egger Hügellandschaft. Auf der gegenüberliegenden Seite blickt man auf den Wald jenseits der Autobahn A15 (einfache Zufahrt in beide Richtungen). In der Nähe befinden sich ein Restaurant, zwei Höfe, der Panoramapunkt Känzeli und die Sportanlage Buchholz. Spacious and sunny apartment on the last floor with a slopped ceiling. View from the living room is on the Alps, Greifensee and Eggs hills. The opposite sides view is on the forest beyond the A15 highway (easy entrance in both direction). In the neighbourhood are a local restaurant, two hofs, panorama point Känzeli and Buchholz sports complex. + +CHF 305 / m² / Jahr + +CHF 1’600 + + vor 2 Tagen + +Wohnung zu vermieten + +5035 Unterentfelden • 3.5 Zimmer • 98 m² +-------------------------------------------------------------- + +In der der naturnahen und exklusiven Neubau Wohnsiedlung Im Erlifeld Unterentfelden sucht diese wunderschöne, helle 3.5 Zimmerwohnung im 2 OG per sofort einen neuen Mieter. Die Wohnung verfügt über einen sehr grossen Balkon mit Privatsphäre. Die hochwertig ausgebaute Küche, die gute Aufteilung der Räumlichkeiten sowie der lichtdurchflutete offene Wohn- und Essbereich laden zu einem wuderschönen Wohngefühl ein. Die Wohnung hat Ihnen folgendes zu bieten:- Obere Etage unter der Attikawohnung- Eingangsbereich mit Einbauschränken- Lichtdurchfluteter offener Wohn- und Essbereich- Hochwertige Küche- Hochwertige Garnituren- Grosse Balkon mit Aussicht ins Grüne 17m2- Morgen- und Abendsonne- 1 Bad mit grosser Dusche direkt mit dem Schlafzimmer verbunden- 1 Bad mir Badewanne- Grosszügiges Reduit- Eigener Waschturm (Waschmaschine & Tumbler)- Grosse Zimmer- Wohnfläche ca. 98m2- Grosser Tiefgaragenplatz 130.-/Monat (Platz für ein Auto und ein Motorrad)- Grosszügiger Keller- Familiäres Wohngefühl- Hautiere erlaubt- super nahe ÖV Verbindung, 2 min zu Fuss zum Bahnhof- Autobahneinfahrt auf die A1, ca. 4min Netto: 1582.- Nebenkosten: 280.- Brutto pro Monat: 1862.- CHF Verfügbar ab 01.04.2023 Adresse: Neufeldstrasse 16, 5035 Unterentfelden Für eine gemeinsame Besichtigung dürfen Sie sich gerne mir uns in Verbindung setzen. + +CHF 228 / m² / Jahr + +CHF 1’862 + + vor 2 Tagen + +Wohnung zu vermieten + +1205 Genève • 1.5 Zimmer • 25 m² +------------------------------------------------------ + +The Boulevard des Philosophes is ideally located in the Plainpalais district on the left bank of Geneva. Tram stop 12,14,15,17,18, Rond-Point is 150 metres away. The city centre can be reached within a 10-minute walk. The plain of Plainpalais and its markets is 50 meters from the property. Amenities are in the immediate vicinity (schools, restaurants, Plainpalais shopping center, shops, post office, bank, theater, Bastion Park, communal hall, neighborhood house, police station, HUG). This 2-room apartment of 30m2 on the 3rd floor of a secure building with elevator is composed as follows:- Fitted and equipped kitchen- Living room- Bathroom- Linked cellar The building has a laundry room, bicycle storage and is connected to fiber optics Here are the documents required for your application:- Swiss identity document/residence permit- A certificate of non-prosecution of less than 3 months- A recent certificate from your employer mentioning the date of entry into employment, the salary and the type of your current contract- The last 3 payslips To apply, please use the following link: https://rentalapplication.zimmermannimmobilier.ch/?ref=5790-304 + +CHF 686 / m² / Jahr + +CHF 1’430 + + vor 2 Tagen + +Wohnung zu vermieten + +5000 Aarau • 3 Zimmer • 70 m² +--------------------------------------------------- + +Sind Sie auf der Suche nach einer Wohnung mit Charakter und einer Seele? Dann werden Sie von dieser charmanten Dachwohnung in Aarau begeistert sein. Die vielen Fenster lassen das Sonnenlicht in die Räume strömen und schenken der Wohnung eine warme und einladende Atmosphäre. Die zentrale Lage an der Buchserstrasse bietet eine bequeme Anbindung an öffentliche Verkehrsmittel, Restaurants und Einkaufsmöglichkeiten, was Ihnen ein unkompliziertes Leben in der Stadt ermöglicht. Diese zauberhafte Wohnung ist perfekt für Singles oder Paare, die das Leben in vollen Zügen geniessen möchten. Wenn Sie sich selbst davon überzeugen möchten, kommen Sie vorbei und lassen Sie sich verzaubern Bitte beachten Sie, dass die Wohnung keinen Balkon hat, aber Sie haben ein eigenes Kellerabteil und einen eigenen Waschturm. Die Nebenkosten sind im Mietpreis enthalten und Sie haben auch die Möglichkeit, einen Aussenparkplatz für CHF 80.00 pro Monat zu mieten.Dieses properti-Angebot zeichnet sich durch folgende Vorteile aus: Wohnung mit Charakter Helle Zimmer Gute Lage Kein Balkon vorhanden Eigenes Kellerabteil Eigener Waschturm Nebenkosten sind inklusive Aussenparkplatz für CHF 80.00 / Monat zumietbar Interessiert? Kontaktieren Sie uns für ein unverbindliches Gespräch Selbst eine Immobilie zu vermarkten? Wir überzeugen mit fairen und transparenten Konditionen + +CHF 240 / m² / Jahr + +CHF 1’400 + + vor 2 Tagen + +Wohnung zu vermieten + +5079 Zeihen • 3.5 Zimmer • 97 m² +------------------------------------------------------ + +3,5 Zimmerwohnung im Minergie-Standard mit kontrollierter Wohnungsbelüftung; hoher Ausbaustandard; offene und moderne Küche; grosses, helles Wohnzimmer; begehbare Dusche; praktische Einbauschränke; grosser, überdachter Balkon mit Sicht ins Grüne; geräumiges Kellerabteil. Ruhige Lage, Lift vorhanden. Waschküche mit Tumbler zur gemeinsamen Benützung im Keller vorhanden. Bushaltestelle direkt vor dem Haus. Einkaufsmöglichkeiten im Dorf vorhanden. Parkplatz in der Einstellhalle kann für monatlich CHF 110.-- dazu gemietet werden. + +CHF 207 / m² / Jahr + +CHF 1’670 + + vor 2 Tagen + +Wohnung zu vermieten + +3974 Mollens VS • 1 Zimmer +------------------------------------------------ + +Furnished studio, parking spaces nearby, wood stove, electric underfloor heating. Large room Kitchenette Bathroom To rent at least 3 months. Ideal for single person Free of charge / CHF 750.-/month + deposit charges, CHF 80.-/month: 830.-/month www.immo-trading.com info@immo-trading.com BT Building Technology Sàrl+41 79 259 57 81 At your service for any question or possible visit on site. + +- + +CHF 750 + + vor 2 Tagen + +Wohnung zu vermieten + +1965 Savièse • 3.5 Zimmer +----------------------------------------------- + +For rent in a small building of 6 apartments in Granois / Savièse (without elevator): Charming app. 3.5 rooms on the ground floor with terrace-lawn: - entrance with built-in wardrobe- living / dining room with access to the terrace- fully equipped open kitchen (large fridge, oven, dishwasher)- 1 parents bedroom with built-in wardrobe- 1 small bedroom- baths / WC- 1 cellar- 1 outdoor parking space- solid terrace (approx. 8 m2) + lawn (approx. 40 m2) with fireplace for grills Fr. 1'280.- / month, charges and place included Information and visits: 027 322 02 89 We are at your disposal for any further information at the 027 322 02 89 (Monday - Thursday 8:00 - 12:00 / 13:30 - 17:00) + +- + +CHF 1’280 + + vor 2 Tagen + +Wohnung zu vermieten + +1950 Sion • 4.5 Zimmer +-------------------------------------------- + +For rent from April 15, 2023 or to be agreed, at rue des Aubépines 15, near the Place du Midi, shops, schools and public transport, in a quiet area (30 km / h zone): Beautiful 4.5 room apartment on the 3rd floor with balcony is: Large entrance hall with fitted wardrobes separate kitchen with exit to the balcony large living/dining room with exit to the balcony hallway with fitted wardrobes Parent room with small west balcony 2 children's bedrooms baths / WC with double washbasin shower / WC with connection for washing machine and dryer balcony 1 cellar. Fr. 1'770.- / month, charges included Possibility to rent an indoor parking space: Fr. 100.- / month We are at your disposal for any further information at the 027 322 02 89 (Monday - Thursday 8:00 - 12:00 / 13:30 - 17:00) + +- + +CHF 1’770 + + vor 2 Tagen + +Wohnung zu vermieten + +2610 St-Imier • 3.5 Zimmer +------------------------------------------------ + +Description Magnificent spacious apartment of 3.5 rooms located in the center of the locality, close to shops and schools. Description of the apartment: Large kitchen arranged habitable with dishwasher and a large fridge Access to the private terrace Living room Bathroom with walk-in shower Large office space Room with possibility of arranging a dressing room Granary + +- + +CHF 1’100 + +[1](https://www.immoyou.ch/wohnung-mieten-schweiz)234567 + + 1 - 24 von 53’252 Ergebnisse + +### Wohnung mieten in der Schweiz + +[Wohnung mieten im Kanton Zürich](https://www.immoyou.ch/wohnung-mieten-kanton-zurich)[Wohnung mieten im Kanton Bern](https://www.immoyou.ch/wohnung-mieten-kanton-bern)[Wohnung mieten im Kanton Aargau](https://www.immoyou.ch/wohnung-mieten-kanton-aargau)[Wohnung mieten im Kanton St. Gallen](https://www.immoyou.ch/wohnung-mieten-kanton-st-gallen)[Wohnung mieten im Kanton Luzern](https://www.immoyou.ch/wohnung-mieten-kanton-luzern)[Wohnung mieten im Kanton Basel-Landschaft](https://www.immoyou.ch/wohnung-mieten-kanton-basel-landschaft)[Wohnung mieten im Kanton Thurgau](https://www.immoyou.ch/wohnung-mieten-kanton-thurgau)[Wohnung mieten im Kanton Solothurn](https://www.immoyou.ch/wohnung-mieten-kanton-solothurn)[Wohnung mieten im Kanton Graubünden](https://www.immoyou.ch/wohnung-mieten-kanton-graubunden)[Wohnung mieten im Kanton Basel-Stadt](https://www.immoyou.ch/wohnung-mieten-kanton-basel-stadt)[Wohnung mieten im Kanton Schwyz](https://www.immoyou.ch/wohnung-mieten-kanton-schwyz)[Wohnung mieten im Kanton Zug](https://www.immoyou.ch/wohnung-mieten-kanton-zug) + +### Andere Immobilienarten in der Schweiz + +[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz)[Zimmer mieten in der Schweiz](https://www.immoyou.ch/wg-zimmer-mieten-schweiz)[Parkplatz mieten in der Schweiz](https://www.immoyou.ch/parkplatz-mieten-schweiz)[Büro & Gewerbe mieten in der Schweiz](https://www.immoyou.ch/buro-gewerbe-mieten-schweiz)[Wohnhaus mieten in der Schweiz](https://www.immoyou.ch/wohnhaus-mieten-schweiz)[Grundstück mieten in der Schweiz](https://www.immoyou.ch/grundstuck-mieten-schweiz) + + All rights reserved. v.541ff84 \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_033_www.immoyou.ch_haus-mieten-schweiz.txt b/test_web_content_20251002_215219/additional_link_033_www.immoyou.ch_haus-mieten-schweiz.txt new file mode 100644 index 00000000..55bf880d --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_033_www.immoyou.ch_haus-mieten-schweiz.txt @@ -0,0 +1,419 @@ +URL: https://www.immoyou.ch/haus-mieten-schweiz +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +🏠 3’577 Häuser mieten in der Schweiz | ImmoYou + +=============== + +[ImmoYou](https://www.immoyou.ch/) + +Kaufen + +[Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + +Mieten + +[Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + + Ändern Sie die Suche + +[](https://www.immoyou.ch/)[Mieten](https://www.immoyou.ch/mieten-schweiz)[Häuser](https://www.immoyou.ch/haus-mieten-schweiz)[Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + +Haus mieten in der Schweiz +========================== + +Ort + + Schweiz + + Zürich + + Genf + + Typ + +- [x] Haus + +- [x] Wohnung + +- [x] Zimmer + +- [x] Parkplatz + +- [x] Büro & Gewerbe + +- [x] Wohnhaus + +- [x] Grundstück + + Miete + + - + + Zimmer + + - + + Wohnfläche (m²) + + - + + Grundstücksfläche (m²) + + - + + Ausstattung & Eigenschaften + +- [x] Neubauprojekte + +- [x] Balkon + +- [x] Garten + +- [x] Parkplatz + +- [x] Lift + +- [x] Freie Aussicht + +- [x] Cheminée + +- [x] Garage + +- [x] Kinderfreundlich + +- [x] Rollstuhlgängig + +- [x] Möbliert + +Ordnen + + 3’577 Ergebnisse + + + + vor 2 Tagen + +Haus zu vermieten + +1292 Chambésy • 7 Zimmer • 200 m² +---------------------------------------------------- + +Belle villa jumelle de grand standing Discrètement située au fond d'un chemin privé à l'abri des regards, villa à l'architecture forte et originale offrant des finitions de premier choix. D'une surface habitable de 200 m2 env. + un sous-sol complet, elle comprend au rez un hall d'entrée avec vestiaires, un living, une cuisine ouverte luxueusement équipée ouverte sur un coin à manger, un bureau, toilettes. L'étage présente de beaux volumes et abrite 3 chambres-à-coucher avec 3 salles-de-bain en suite dont une vaste master suite avec son walk-in dressing et prolongée d'une belle terrasse.Sous-sol complet incluant une grande salle-de-jeux, caves, chaufferie-buanderie. Charmant jardin et belle terrasse. Couvert à voiture + 2 parkings extérieurs. DISPONIBLE AU 1er JUILLET 2023Loyer mensuel : Frs 7'700.- + +CHF 462 / m² / Jahr + +CHF 7’700 + + + + vor 2 Tagen + +Haus zu vermieten + +5070 Frick • 4.5 Zimmer • 118 m² +--------------------------------------------------- + +Lage Das Dorf liegt im Tal der Sissle. Die lebendige Dorfgemeinschaft Frick, wird Sie dank dem vielfältigen Angebot an Vereinen, kulturellen Events sowie Restaurants auf Anhieb wohlfühlen lassen. Hier wohnen Sie in einem familienfreundlichen Quartier, mit kurzen Gehdistanzen zu Einkaufsmöglichkeiten. In der Freizeit ist ein Besuch im Sauriermuseum ein muss und für Sportfans hat Frick eine eigene Nordic Walking Route mit diversen Schwierigkeitsrouten.Ein Rundgang durch Ihre Wohnung Der grosszügige Grundriss ermöglicht es Ihnen, sich auf den 117m2 individuell einzurichten. Die Dachschrägen und Holzelemente verleihen den Räumen ihren Charme. Die Parkett- und Plattenboden in allen Wohnräumen sorgen zusätzlich für eine heimelige Atmosphäre. Desweiteren überzeugt die Attikawohnung mit folgenden Vorzügen: UG: Kellerabteil EG: moderne Küche, Wohnzimmer und Gäste-WC OG: 2 Schlafzimmer, Bad/WC mit Waschturm OG: 1 Schlafzimmer mit Dusche/WC Parkett- und Steinböden Bodenheizung Sitzplatz und Gartenanteil Details Ein Autoeinstellplatz kann für 130.- CHF / monatlich dazugemietet werden. + +CHF 223 / m² / Jahr + +CHF 2’190 + + vor 2 Tagen + +Haus zu vermieten + +1025 St-Sulpice VD • 6 Zimmer • 200 m² +--------------------------------------------------------- + +Very beautiful beautiful bright house very close to the lake quiet offers on 200m2: Superb large living room open to kitchen of very Highscale. 3 large bedrooms 3 bathrooms Beautiful outbuilding of 30 m2 office or studio separated 4 parking spaces (electric vehicle charging possible) Nice enclosed garden of 600m2 available to be agreed + +CHF 450 / m² / Jahr + +CHF 7’500 + + vor 2 Tagen + +Haus zu vermieten + +1814 La Tour-de-Peilz • 6.5 Zimmer • 230 m² +-------------------------------------------------------------- + +EXCLUSIVE Magnificent detached house of 6.5 rooms offering a surface of about 230 m2 with terrace and garden. Distribution: Ground floor: an entrance with built-in wardrobes, a guest toilet, a small office room or storage, a fully equipped kitchen, a dining room, a living room, a terrace, a garden 1st floor: a large bedroom with en-suite shower room, two bedrooms, a bathroom with toilet and washing machine connection. 2nd floor: a large bedroom with terrace, a shower room with toilet. Basement: a laundry room, a large furnished room, a large cellar. A covered garage for two cars Garden maintenance contract: 400 Frs extra (mandatory) For visits: Pascaline Pottier - 079 836 99 04 + +CHF 287 / m² / Jahr + +CHF 5’500 + + vor 3 Tagen + +Haus zu vermieten + +1196 Gland • 4 Zimmer +---------------------------------------- + +Magnifique espace commerciale, composé deux belles vitrines avec la possibilité de deux entrées indépendantes. Possibilité de lier plusieurs professions indépendantes. Vitrine 1: Actuellement un salon de coiffure entièrement équipé, composé d'une grande pièce avec réception, onglerie et d'une pièce agréable équipée pour les soins esthétiques. Vitrine 2: Grande pièce vitrine et deux pièces supplémentaires complètent l'espace à disposition. Cette offre de BETTERHOMES se caractérise par les avantages suivants: - spacieux, lumineux et fonctionnel- locaux séparés avec accès indépendants- modulable et polyvalent- idéale pour un pool de professionnels indépendants- emplacement favorable- accès facile- parking à disposition pour les clients- loyer très attractif- charges en sus CHF 200.- par mois- etc., etc., etc... Intéressé? Contactez-nous pour une visite sans engagement - visite en ligne également possible Rien qui correspond? Vous trouverez plus de 2'200 autres objets sur: www.betterhomes.ch - Le spécialiste suisse des transactions immobilières. Vous avez un bien immobilier à commercialiser? Profitez de notre savoir-faire: https://www.betterhomes.ch/fr/profiter Vous souhaitez connaître la valeur de votre bien immobilier? Découvrez sa valeur dès maintenant grâce à notre estimation gratuite, immédiate et sans engagement https://www.betterhomes.ch/fr/knowledge/estimation Plus détails Situation: situé idéalement dans le complexe urbain de Gland, sur les principaux axes routiers Etat du bâtiment: moyen Salles de bain: 2 (1 x WC / lavabo, 1 x douche / WC / lavabo) Système de chauffage: Mazout Transport publics: bus à proximité Ecole: école primaire, 400 m Commerces: Migros / Coop, 500 m + +CHF 265 / m² / Jahr + +CHF 2’300 + + vor 3 Tagen + +Haus zu vermieten + +8906 Bonstetten • 6.5 Zimmer • 160 m² +-------------------------------------------------------- + +Das Haus hat einen gehobenen Ausbaustandard. Es ist sehr zentral und ruhig gelegen am sudwestlichen Dorfrand von Bonstetten. Der Kindergarten ist 300m entfernt, die Bushaltestelle Dorfplatz ebenso. Einkaufsmoglichkeiten gibt es in Fussdistanz. Im Erdgeschosses das Wohn-/Esszimmer mit Chemineeofen und offener Kuche sowie Gaste WC, ca. 52m2. Im Obergeschoss sind drei (Kinder-)Zimmer 2 x 12.5m2, einmal 10.5, WC/Bad und Balkon. Im Dachgeschoss ist das 4m hohe Elternschlafzimmer von 20 m2 mit zwei begehbaren Ankleiden und Dusche/WC (2016 neu). Das Untergeschoss enthalt als 6. Zimmer einen ausgebauten Hobbyraum, der mit Parkett ausgestattet ist und als TV-/Bugel-/Gastezimmer verwendet wird. Die Waschkuche ist mit einem Waschturm ausgestattet und hat einen eigenen Warmepumpen Oekoboiler. Daneben finden sich ein Vorratskeller und ein weiterer Kellerraum mit direktem Zugang zur Tiefgarage, wo zwei Parkplatze zur Verfugung stehen. Neben dem Hauseingang ist ein kleiner Schopf/Schuppen fur die Gartengerate vorhanden. 2019 wurden alle Fenster ersetzt durch 3fach-Verglasung, das Wohnzimmer mit Parkett und Sideboard erneuert. Das ganze Haus ist mit Parkett belegt. Das Haus ist an die Erdsondenheizung der Siedlung angeschlossen. Das Haus wird innen frisch gestrichen, die Boden renoviert. Haustiere sind nicht erlaubt. Auf Anfrage eine Katze, doch muss ein Katzenturli selber installiert werden. Wir wollen, dass nicht im Haus geraucht wird. + +CHF 308 / m² / Jahr + +CHF 4’100 + + vor 3 Tagen + +Haus zu vermieten + +1634 La Roche FR • 5.5 Zimmer • 150 m² +--------------------------------------------------------- + +Nous avons le plaisir de vous présenter cette magnifique villa de 150 m2, située dans le charmant village de La Roche, au cur de la Gruyère. Située dans un quartier tranquille et agréable, cette propriété offre une vue magnifique sur la campagne et le Moléson. Elle est proche des écoles, des commerces, des restaurants, arrêt de bus et vous pourrez facilement accéder aux pistes de ski de la Berra en 10 minutes en voiture, ainsi qu'au bord du lac de la Gruyère en seulement 5 minutes. Cette maison de qualité se compose comme suit : Au rez-de-chaussée : une entrée avec des placards encastrés, un WC visiteur, une cuisine équipée ouverte sur le séjour et deux terrasses avec stores électriques. À l'étage : deux chambres avec placards encastrés, une salle d'eau avec douche et une chambre parentale avec salle de bain privative (baignoire). Au rez-inférieur : une cave, une buanderie équipée d'un lave-linge et d'un sèche-linge MIELE, ainsi qu'un espace de rangement et de séchage. Il y a également un local technique avec une pompe à chaleur AIR-EAU. À l'extérieur, vous pourrez profiter d'un couvert à voiture et de 2 places de stationnement extérieures goudronnées. Ainsi que d'une belle parcelle aménagée avec 2 terrasses bénéficiant d'un ensoleillement optimal et d'un store électrique avec luminaire intégré. La performance de l'isolation du bâtiment est très élevée, ce qui permet de maintenir une température agréablement fraîche en été et de réduire considérablement la nécessité de chauffer la maison en hiver. Le loyer net s'élève à CHF 2'750.00, auxquels s'ajoutent les charges raisonnables, qui seront payées directement par le locataire selon son utilisation. Veuillez noter qu'un studio avec une entrée indépendante fait partie de la maison, mais n'est pas inclus dans la location. N'hésitez pas à nous contacter pour organiser une visite de cette magnifique propriété. C'est une occasion unique à ne pas manquer + +CHF 220 / m² / Jahr + +CHF 2’750 + + vor 3 Tagen + +Haus zu vermieten + +1218 Le Grand-Saconnex • 7 Zimmer +---------------------------------------------------- + +Twin villa of 7.5 rooms Located in a quiet environment, this beautiful villa offers a living area of 170 m2 approx. + a complete basement. It includes an entrance hall, a large living room with a fireplace with access to the terrace and garden, a fully equipped closed kitchen, a bedroom, a bathroom-wc. Upstairs, 3 beautiful bedrooms, bathroom. Full basement including a games room with access to the garden, a bedroom,1 shower room, a laundry room, a cellar-shelter. Covered parking and outdoor parking space.Available July 1, 2023Monthly rent: Frs 5'600.- + +- + +CHF 5’600 + + vor 3 Tagen + +Haus zu vermieten + +6828 Balerna • 5 Zimmer • 160 m² +--------------------------------------------------- + +A Balerna, in zona collinare, verde e moltro tranquilla, lontano dal traffico ma a poca distanza dalle via dalle vie di comunicazioni, AFFITTASI AMPIA PORZIONE DI CASA DI 5,5 LOCALI di 160mq. disposta su 3 livelli oltre piano interrato e cosi' composta: Ingresso; Soggiorno; Cucina abitabile; 4 camere da letto; 2 bagni; Lavanderia; Cantina; Canone mensile di richiesta CHF 1.800 libero subito!!A disposizione per chf 80 mensili un posto auto coperto e chf 40 per posto auto scoperto. Per informazioni potete anche contattarci ai seguenti recapiti: BERNASCONI MARCOReal estate consultantnatel: +41 76 221 56 45 + +CHF 135 / m² / Jahr + +CHF 1’800 + + vor 3 Tagen + +Haus zu vermieten + +1222 Vésenaz • 8 Zimmer • 230 m² +--------------------------------------------------- + +Parfaitement intégré dans son environnement, cette magnifique villa sera disponible dès l'été 2023. Elle se située sur la commune de Vésenaz, à l'abri des nuisances et à quelques minutes à pied du centre-ville. Cette maison de 8 pièces totalise une superficie d'environ 230m² habitables répartie sur 2 niveaux ainsi qu'un sous-sol. Elle se veut généreuse par ses espaces de vie, lumineuse grâce à ses nombreuses ouvertures sur le jardin et fonctionnelle de part la qualité de son aménagement intérieur. Elle se compose comme suit : Rez-de-chaussée :- Hall d'entrée avec armoires encastrées- Cuisine spacieuse entièrement équipée avec son espace repas, accès terrasse- Bel espace de vie d'environ 50m² ouvert sur une terrasse dallée et la piscine- Suite parentale avec sa salle de douche (douche à l'italienne, lavabo, WC) et son dressing attenant- Bureau aménagé baigné de lumière et accès terrasse- Salon d'été ou salle de sport- WC visiteurs Premier étage :- Chambre spacieuse d'environ 20m2 et son dressing- Deux chambres de taille confortable avec armoires encastrées- Salle de bains/douche (douche à l'italienne, baignoire, double vasque, WC)- Salle de bains (baignoire, lavabo, WC) Sous-sol :- Grande pièce pouvant être aménagée au gré du preneur avec sa salle de douche (douche, lavabo, WC)- Buanderie / local technique- Cave, abri et nombreux espaces de rangement Un jardin arboré et clôturé ainsi qu'une piscine viennent s'ajouter aux nombreux atouts de ce bien d'exception. Un garage box pour une voiture ainsi que deux places de stationnement extérieures sont disponibles. CONDITION DE LOCATION :- Loyer : CHF 9'000.- (incluant l'entretien de la piscine et autres frais d'entretien)- Charges individuelles : en supplément- Jardin : à la charge du locataire (taille des haies et entretien pelouse) + +CHF 470 / m² / Jahr + +CHF 9’000 + + vor 4 Tagen + +Haus zu vermieten + +8500 Frauenfeld • 6.5 Zimmer • 130 m² +-------------------------------------------------------- + +Für dieses tolle 6.5 Zimmer Reiheneinfamilienhaus (Eckhaus) wird ein Nachmieter gesucht. Heller Wohn- Essbereich mit direktem Zugang zum Sitzplatz und Garten. Offene Küche mit Backofen & Steamer Cheminée im Erdgeschoss. 5 Schlafzimmer mit Parkettfussboden davon eines mit Dachterrasse. Badezimmer mit Dusche und Badewanne im 1. OG. Separates Gäste WC im Erdgeschoss. Schöner, pflegeleichter Garten. Wasseranschluss im Garten. Komplett Eingezäunt mit direktem Zugang zum Kellergeschoss. Praktischer Veloschopf und Unterstand vor dem Haus. Sauna und Waschküche (Mit Waschmaschine und Tumbler) im Untergeschoss. Es gehören zwei Tiefgaragenplätze zu je 120 CHF/Monat zum Haus. Nebenkosten (Strom, Wasser usw. )werden nach Verbrauch direkt von der Stadt verrechnet. Top Lage in Frauenfeld. Schule und Kindergärten in ca. 300 Meter erreichbar. Einkaufsmöglichkeiten (Denner) ca. 200 Meter entfernt. Zwei Spielplätze in der Überbauung. Grosser Robinson Spielplatz im Burgerholzwald schnell zu Fuss erreichbar.ÖV und Autobahnanschluss wenige Minuten entfernt. Eine Besichtigung lohnt sich auf jeden Fall. + +CHF 263 / m² / Jahr + +CHF 2’850 + + vor 4 Tagen + +Haus zu vermieten + +1292 Chambésy • 7 Zimmer • 200 m² +---------------------------------------------------- + +Agency: Millenium Properties SA Ref : LM/KM 1471 Located in the heart of the town of Chambésy in a residential area, this spacious twin villa of 7 rooms has recently benefited from a complete renovation with quality materials. Distribution: Ground floor: Entrance hall, beautiful living room with dining room and fireplace, kitchen closed by sliding door, guest toilet, a cloakroom. Floor: Beautiful master bedroom with private bathroom (bath and shower), 2 beautiful bedrooms and a bathroom. Attic: A large multipurpose room, a shower room and a small room. Basement: A multipurpose room (games room / fitness room / etc ...) a bottle cellar, a laundry room and a cellar. Outside: Garage box, parking spaces, garden shed. Heating type: Heat pump Heating installation: Radiators To visit without delay Rent: CHF 7'500 Contact: Kari Marill-Hernandez+41 79 572 19 97 km@milleniumproperties.ch + +CHF 450 / m² / Jahr + +CHF 7’500 + + vor 4 Tagen + +Haus zu vermieten + +4463 Buus • 5.5 Zimmer • 170 m² +-------------------------------------------------- + +Dieses wunderschöne und moderne Einfamilienhaus wird Sie in jeder Hinsicht überzeugen. Das Objekt und auch der grosszügige Gartensitzplatz liegen etwas erhöht und bieten eine unverbaubare Sicht auf die Nachbarschaft. Die vielen Fenster lassen sehr viel Licht in die Räume. Ausserdem haben Sie einen Balkon mit Panorama. Die moderne Küche verfügt über viele moderne Geräte. Kommen Sie vorbei und lassen Sie sich diese einmalige Chance nicht entgehen Dieses BETTERHOMES-Angebot zeichnet sich durch folgende Vorteile aus:- verglaste Terrasse und Gartensitzplatz- Doppelgarage mit Zugang- unverbaubare Aussicht- kinderfreundliche Lage (Sackgasse)- Cheminée - Minergie-Bauweise- und, und, und ... Interessiert? Kontaktieren Sie uns für eine unverbindliche Besichtigung Nichts Passendes gefunden? Über 2'200 weitere Angebote unter: www.betterhomes.ch - der Immobilienfairmittler® Selber eine Immobilie zu vermarkten? Profitieren Sie von unserem Know-how: https://www.betterhomes.ch/de/profitieren Sie möchten eine Immobilie schätzen lassen? Erfahren Sie jetzt ihren Wert über unsere Gratis-Schätzung, sofort und unverbindlich https://www.betterhomes.ch/de/knowledge/estimation Mehr Details Lage: sonnig, ruhig Zustand: gut Bäder / Nasszellen: 2 (1 x Badewanne / Dusche / WC / Lavabo, 1 x WC / Lavabo) Heizsystem: Oelheizung Verteilung über BodenheizungÖffentliche Verkehrsmittel: Bus, 200 m Schulen: Primarschule / Kindergarten, in Gehdistanz Geschäfte: Volg, in Gehdistanz + +CHF 247 / m² / Jahr + +CHF 3’500 + + vor 4 Tagen + +Haus zu vermieten + +8712 Stäfa • 3.5 Zimmer • 55 m² +-------------------------------------------------- + +Zimmer: 3.5 Baujahr: 1979 Quadratmeter: 55 Installation: Entsprechen dem Standard aus der Erstellungszeit S-Bahn: 2min zu Fuss Einkaufsmöglichkeiten: 2min zu Fuss Charmante Gartenlaube Gartensitzplatz mit Cheminée Grosser Garten Parkplätze können dazu gemietet werdenBefristet bis 01.06.24 + +CHF 316 / m² / Jahr + +CHF 1’450 + + vor 5 Tagen + +Haus zu vermieten + +1630 Bulle • 7.5 Zimmer • 260 m² +--------------------------------------------------- + +Villa de 7½ pièces sise sur 3 niveaux avec un grand espace extérieur. Ce bien se compose de la manière suivante : Rez :- Hall de distribution avec armoires murales- Cuisine entièrement agencée, habitable et donnant accès à la terrasse- Grand et lumineux séjour avec cheminée et accès à la terrasse- 1 WC séparé 1er étage :- Hall de distribution avec réduit- 1 grande chambre parentale avec parquet, équipée d'armoires murales et donnant accès direct à la salle de bains et au balcon- 4 chambres avec parquet équipées d'armoires murales et donnant toutes accès au balcon- 1 salle de douche/WC- 1 salle d'eau avec lavabo double Sous-sol :- Abri PC- Petit local avec étagères- Grande cave- Buanderie avec colonne de lavage/séchage- Local technique Extérieurs :- Grande surface engazonnée- Petit étang- 1 garage box individuel- 1 place de parc extérieure Les charges sont à payer par les locataires (chauffage à distance + entretien de la haie et des arbustes). Cette opportunité se situe à deux pas du centre ville de Bulle ainsi qu'à quelques minutes à pied de forêt de Bouleyres. Ce bien profite d'une situation idéale à proximité de toutes les commodités (école primaire, école secondaires, commerces, ...) ainsi que des axes routiers. Si vous désirez de plus amples informations, n'hésitez pas à nous contacter + +CHF 166 / m² / Jahr + +CHF 3’600 + + vor 5 Tagen + +Haus zu vermieten + +3185 Schmitten FR • 3 Zimmer +----------------------------------------------- + +Moderne Praxis- oder Büroräumlichkeiten im Parterre mit breiter Fensterfront. Die Lokalität besteht aus einem grossen Raum und zwei kleineren Räumen, inklusive einer gut ausgestatteten Küche und WC/Dusche. Für eine optimale Raumaufteilung besteht die Möglichkeit, Trennwände zu entfernen. Dieses BETTERHOMES-Angebot zeichnet sich durch folgende Vorteile aus:- zwei Eingänge bieten sehr variable Einrichtungsmöglichkeiten- Raumeinteilung sehr flexibel gestaltbar (Trockenwände entfernbar)- Schaufenster möglich- mehrere Wasseranschlüsse für Lavabos vorhanden- 2 Aussenparkplätze zu je CHF 60.- zur Verfügung- grosszügige Küche- und, und, und ... Interessiert? Kontaktieren Sie uns für eine unverbindliche Besichtigung Nichts Passendes gefunden? Über 2'200 weitere Angebote unter: www.betterhomes.ch - der Immobilienfairmittler® Selber eine Immobilie zu vermarkten? Profitieren Sie von unserem Know-how: https://www.betterhomes.ch/de/profitieren Sie möchten eine Immobilie schätzen lassen? Erfahren Sie jetzt ihren Wert über unsere Gratis-Schätzung, sofort und unverbindlich https://www.betterhomes.ch/de/knowledge/estimation Mehr Details Lage: gut Zustand: gut Bäder / Nasszellen: 1 (1 x Duschkabine / WC / Lavabo) Heizsystem: BodenheizungÖffentliche Verkehrsmittel: Bahn, 600 m / Bus, 150 m Geschäfte: Denner, 650 m / Coop, 800 m / Restaurant, 650 m + +CHF 225 / m² / Jahr + +CHF 1’500 + + vor 5 Tagen + +Haus zu vermieten + +1260 Nyon • 3.5 Zimmer • 88 m² +------------------------------------------------- + +Magnificent adjoining villa, refreshed at the end of 2022, 3.5 rooms in a quiet residential area. It offers an access hall, two bedrooms and access to the garden. The kitchen is fully fitted and is open to a living room with a very large terrace. The house also has storage cabinets, a bathroom with shower and toilet and a washing and drying column. Attics with a usable area of 50 m² complete this accommodation. Two outdoor parking spaces are included in this property. This offer of BETTERHOMES is characterized by the following advantages: - two bedrooms- fully fitted kitchen- residential area, quiet- monthly charges of 200.-- available quickly- etc., etc., etc. Interested? Contact us for a visit without obligation - online visit also possible Nothing that matches? You will find more than 2'200 other objects at: www.betterhomes.ch - The Swiss specialist in real estate transactions. Do you have a property to market? Take advantage of our know-how: https://www.betterhomes.ch/fr/profiter Do you want to know the value of your property? Discover its value now with our free, immediate and non-binding estimate https://www.betterhomes.ch/fr/knowledge/estimation More details Location: good Condition of the building: good Bathrooms: 1 (1 x WC/washbasin/shower) Public transport: train, 700 m School: primary/secondary schools, 500 m Shops: Coop / Migros, 700 m + +CHF 402 / m² / Jahr + +CHF 2’950 + + vor 5 Tagen + +Haus zu vermieten + +7482 Preda • 1.5 Zimmer +------------------------------------------ + +Vermiete im traumhaften Preda am Albulapass GR, mein urchiges Ferienhaus im bündnerstil. Sehr ruhige und abgelegene Lage aber trotzdem 5 min. Zum Bhf.Preda/ 15 min. Bergün /30min.St.Moritz + +- + +CHF 850 + + vor 6 Tagen + +Haus zu vermieten + +8332 Russikon • 6.5 Zimmer • 202 m² +------------------------------------------------------ + +Eine seltene Gelegenheit - nach umfassender Renovation vermieten wir diese grosszüge Villa in einer ruhigen Nachbarschaft auf der Sonnenseite des Zürcher Oberlandes. Das malerische Dorf Russikon bietet eine zeitgemässe Infrastruktur und Einkaufsmöglichkeiten für den täglichen Bedarf. Eingebettet in eine schöne Landschaft mit vielen Naherholungsgebieten liegt die Gemeinde oberhalb der Nebelgrenze mit Sicht auf den Pfäffikersee und die Alpen. Mit 25 Minuten Fahrzeit nach Zürich, Winterthur oder zum Flughafen sind Sie abseits des Lärms und doch nah genug an den kulturellen Hotspots von Downtown Switzerland. Zur Liegenschaft gehört ein schöner, pflegeleichter Garten sowie eine 65m2 grosse Terrasse. Neben dem Haus stehen ein Doppel-Carport mit Stromanschluss, ein Gästeparkplatz sowie eine abschliessbare Box für Fahrräder, Kickboards & Co. für rund CHF 250.00 pro Monat zur Verfügung.Dieses properti-Angebot zeichnet sich durch folgende Vorteile aus: Einzigartige Panoramaaussicht Sonnige und ruhige Lage Gepflegte Wohnumgebung Ausgeklügeltes Raumkonzept Cheminée Lichtdurchflutete Räumlichkeiten Mehrere Aussenbereiche Doppel-Carport, Gästeparkplatz und Fahrradbox für CHF 250.00 zumietbar Interessiert? Kontaktieren Sie uns für ein unverbindliches Gespräch Selbst eine Immobilie zu vermarkten? Wir überzeugen mit fairen und transparenten Konditionen + +CHF 347 / m² / Jahr + +CHF 5’845 + + vor 6 Tagen + +Haus zu vermieten + +4424 Arboldswil • 5 Zimmer • 110 m² +------------------------------------------------------ + +Wunderschönes Reihenhaus im Dorfkern von Arboldswil, das sich für Familien und Paare eignet, die gerne in einer ruhigen und natürlichen Umgebung leben möchten. Das Haus verfügt über 5 geräumige Zimmer, die nach und nach renoviert und modernisiert wurden, eine Küche und ein Bad. Zum Haus gehört ein grosszügiger Garten, in dem Sie die Sonne geniessen können. Dieses BETTERHOMES-Angebot zeichnet sich durch folgende Vorteile aus:- mitten im Dorfkern- gemütliches Cheminée- sonniger Garten- nachhaltiges Heizen mit Wärmepumpe- modernes Bad und Küche- inklusive Parkplatz- und, und, und ... Interessiert? Kontaktieren Sie uns für eine unverbindliche Besichtigung Nichts Passendes gefunden? Über 2'200 weitere Angebote unter: www.betterhomes.ch - der Immobilienfairmittler® Selber eine Immobilie zu vermarkten? Profitieren Sie von unserem Know-how: https://www.betterhomes.ch/de/profitieren Sie möchten eine Immobilie schätzen lassen? Erfahren Sie jetzt ihren Wert über unsere Gratis-Schätzung, sofort und unverbindlich https://www.betterhomes.ch/de/knowledge/estimation Mehr Details Lage: zentral Zustand: sehr gepflegt Bäder / Nasszellen: 3 (1 x Duschkabine / WC / Lavabo, 1 x Badewanne / Lavabo, 1 x WC / Lavabo) Heizsystem: WärmepumpeÖffentliche Verkehrsmittel: Bus, 100 m Schulen: Primarschule, 550 m Geschäfte: Dorfladen, 300 m + +CHF 207 / m² / Jahr + +CHF 1’900 + + vor 6 Tagen + +Haus zu vermieten + +1030 Bussigny • 1 Zimmer • 15 m² +--------------------------------------------------- + +CHF 952 / m² / Jahr + +CHF 1’190 + + vor 6 Tagen + +Haus zu vermieten + +9478 Azmoos • 4.5 Zimmer • 140 m² +---------------------------------------------------- + +CHF 150 / m² / Jahr + +CHF 1’750 + + vor 6 Tagen + +Haus zu vermieten + +1204 Genève • 9 Zimmer • 255 m² +-------------------------------------------------- + +Close to all amenities (Balexert, public transport) in the Petit-Saconnex district, this three-level villa with a large basement, was built in the 1930s and was renovated in 2021. It is located in a beautiful green garden of 1'478 m2 facing south. It consists of 9 rooms including 5 bedrooms and 3 bathrooms, 1 office, 1 kitchen, 1 large living room, 1 dining room and 2 terraces, 1 on the first floor accessible from the bedrooms. Beautiful interior amenities: parquet floors, high ceilings and large windows in the living room allowing exceptional brightness. A must see + +CHF 461 / m² / Jahr + +CHF 9’800 + + vor 6 Tagen + +Haus zu vermieten + +1806 St-Légier-La Chiésaz • 6 Zimmer • 257 m² +---------------------------------------------------------------- + +Cette somptueuse demeure est située à St-Légier, dans un environnement calme et résidentiel. Elle se trouve à proximité immédiate des villes de Vevey et Montreux ainsi que de l'entrée d'autoroute. Sa position dominante lui permet de bénéficier d'une vue sur le lac et les Alpes. Elle se compose comme suit :- grand garage double pour 2 voitures- wc visiteurs- local buanderie- hall avec armoires murales- salon/salle à manger- terrasse/jardin- cuisine avec coin à manger 1er étage:- salon- chambre parentale avec armoires murales et salle de bains/douches/wc attenante- chambre à coucher avec salle de douches attenante- chambre à coucher avec mezzanine- chambre à coucher/bureau- salle de bains/douches/wc- balcon sous-sol:- pièce aménagée- cave- local technique/cave Annexes: Piscine intérieure chauffée avec sauna, douche SPA disponible pour l'ensemble du domaine de Jolimont Portail électrique à l'entrée du domaine fermé le soir 3 places de parc extérieures comprises Loyer net : CHF 7'200.- jardin compris + charges individuelles gaz + +CHF 336 / m² / Jahr + +CHF 7’200 + +[1](https://www.immoyou.ch/haus-mieten-schweiz)234567 + + 1 - 24 von 3’577 Ergebnisse + +### Haus mieten in der Schweiz + +[Haus mieten im Kanton Zürich](https://www.immoyou.ch/haus-mieten-kanton-zurich)[Haus mieten im Kanton Bern](https://www.immoyou.ch/haus-mieten-kanton-bern)[Haus mieten im Kanton Aargau](https://www.immoyou.ch/haus-mieten-kanton-aargau)[Haus mieten im Kanton St. Gallen](https://www.immoyou.ch/haus-mieten-kanton-st-gallen)[Haus mieten im Kanton Luzern](https://www.immoyou.ch/haus-mieten-kanton-luzern)[Haus mieten im Kanton Basel-Landschaft](https://www.immoyou.ch/haus-mieten-kanton-basel-landschaft)[Haus mieten im Kanton Thurgau](https://www.immoyou.ch/haus-mieten-kanton-thurgau)[Haus mieten im Kanton Solothurn](https://www.immoyou.ch/haus-mieten-kanton-solothurn)[Haus mieten im Kanton Graubünden](https://www.immoyou.ch/haus-mieten-kanton-graubunden)[Haus mieten im Kanton Basel-Stadt](https://www.immoyou.ch/haus-mieten-kanton-basel-stadt)[Haus mieten im Kanton Schwyz](https://www.immoyou.ch/haus-mieten-kanton-schwyz)[Haus mieten im Kanton Zug](https://www.immoyou.ch/haus-mieten-kanton-zug) + +### Andere Immobilienarten in der Schweiz + +[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Zimmer mieten in der Schweiz](https://www.immoyou.ch/wg-zimmer-mieten-schweiz)[Parkplatz mieten in der Schweiz](https://www.immoyou.ch/parkplatz-mieten-schweiz)[Büro & Gewerbe mieten in der Schweiz](https://www.immoyou.ch/buro-gewerbe-mieten-schweiz)[Wohnhaus mieten in der Schweiz](https://www.immoyou.ch/wohnhaus-mieten-schweiz)[Grundstück mieten in der Schweiz](https://www.immoyou.ch/grundstuck-mieten-schweiz) + + All rights reserved. v.541ff84 \ No newline at end of file diff --git a/test_web_content_20251002_215219/additional_link_034_www.immoyou.ch_grundstuck-kaufen-schweiz.txt b/test_web_content_20251002_215219/additional_link_034_www.immoyou.ch_grundstuck-kaufen-schweiz.txt new file mode 100644 index 00000000..dd068ade --- /dev/null +++ b/test_web_content_20251002_215219/additional_link_034_www.immoyou.ch_grundstuck-kaufen-schweiz.txt @@ -0,0 +1,399 @@ +URL: https://www.immoyou.ch/grundstuck-kaufen-schweiz +Type: Additional Link +Extracted: 2025-10-02 21:52:19 +================================================================================ + +🌳 3’123 Grundstücke kaufen in der Schweiz | ImmoYou + +=============== + +[ImmoYou](https://www.immoyou.ch/) + +Kaufen + +[Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + +Mieten + +[Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + + Ändern Sie die Suche + +[](https://www.immoyou.ch/)[Kaufen](https://www.immoyou.ch/kaufen-schweiz)[Grundstücke](https://www.immoyou.ch/grundstuck-kaufen-schweiz)[Schweiz](https://www.immoyou.ch/grundstuck-kaufen-schweiz) + +Grundstück kaufen in der Schweiz +================================ + +Ort + + Schweiz + + Zürich + + Genf + + Typ + +- [x] Haus + +- [x] Wohnung + +- [x] Zimmer + +- [x] Parkplatz + +- [x] Büro & Gewerbe + +- [x] Wohnhaus + +- [x] Grundstück + + Verkaufspreis + + - + + Zimmer + + - + + Wohnfläche (m²) + + - + + Grundstücksfläche (m²) + + - + + Ausstattung & Eigenschaften + +- [x] Neubauprojekte + +- [x] Balkon + +- [x] Garten + +- [x] Parkplatz + +- [x] Lift + +- [x] Freie Aussicht + +- [x] Cheminée + +- [x] Garage + +- [x] Kinderfreundlich + +- [x] Rollstuhlgängig + +- [x] Möbliert + +Ordnen + + 3’123 Ergebnisse + + + + vor 2 Wochen + +Grundstück zu verkaufen + +3963 Crans-Montana +------------------------------------------- + +Descriptif Opportunité à ne pas ne pas manquer Terrain à vendre avec un permis de construire en force pour un chalet de 2 logements. Cette parcelle bénéficie d'un emplacement idéal proche des pistes de ski et est libre de mandat de construction et/ou d'architecte. Si nécessaire il est possible de demander un projet de mandat de construction. Résidence principale uniquement Sous-sol 1 grand garage (3 voitures) 2 local à ski 1 local technique Rez-de-chaussée Appartement 1 de 4.5 pces 1 hall d'entrée 1 cuisine ouvert sur un séjour et salle à manger 1 salle de bain (lavabo, WC, baignoire, tour de lavage) 2 chambres 1 suite parentale avec dressing et salle de douche (lavabo double, WC, douche) 1 couloir avec armoires murales 1 balcon 1er niveau Appartement 2 de 4.5 pces avec mezzanine 1 hall d'entrée 1 cuisine ouvert sur un séjour et salle à manger 1 salle de bain (lavabo, WC, baignoire, tour de lavage) 2 chambres 1 suite parentale avec dressing et salle de douche (lavabo double, WC, douche) 1 couloir avec armoires murales 1 balcon Combles 1 grande mezzanine A disposition pour tout renseignement complémentaire à info@roquimmo.ch ou au 027 565 09 69 (en cas d'absence au bureau l'appel est dévié sur le portable) + +- + +Auf Anfrage + + + + vor 2 Wochen + +Grundstück zu verkaufen + +6674 Riveo +----------------------------------- + +À Riveo in Vallemaggia, nous proposons un terrain à bâtir dans la zone R3 dans une position centrale et ensoleillée avec un accès direct depuis la route cantonale. La parcelle se compose de 421 m² de surface constructible et de 9 900 m² de forêt. Le prix comprend également un projet de construction d'un immeuble avec 3 appartements et des places de parking. Cette offre de BETTERHOMES est mise en évidence pour les avantages suivants: - central et ensoleillé- forêt 9'900 m²- avec projet inclus dans le prix- zone R3- etc., etc., etc. ... Intéressé? Contactez-nous pour une visite sans engagement Aucun objet correspondant n'a été trouvé ? Plus de 2'200 offres sur: www.betterhomes.ch Le spécialiste suisse du courtage immobilier Avez-vous une propriété à vendre? Profitez de notre savoir-faire : https://www.betterhomes.ch/it/profittare Voulez-vous savoir combien vaut votre propriété? Découvrez sa valeur dès maintenant avec notre évaluation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/it/knowledge/estimation Au-delà des données Position: ensoleilléÉtat de l'article: - Toilettes / Douches: - Chauffage:-- Transports en commun: arrêt de bus, 300 m Ecoles: collège à Cevio, 3 km Commerces: Coop / restaurant / bar / kiosque à Cevio, 3 km + +- + +CHF 190’000 + + vor 2 Wochen + +Grundstück zu verkaufen + +3925 Grächen +------------------------------------- + +Située à l'entrée de Grächen, cette propriété offre une vue imprenable sur les belles montagnes. Cette offre BETTERHOMES se caractérise par les avantages suivants :- vue dégagée- très ensoleillé et central- facilement accessible- développé- et, et, et... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur : www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser une propriété vous-même? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Souhaitez-vous avoir une propriété évaluée? Découvrez votre valeur dès maintenant via notre devis gratuit, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Situation: Grächen est situé à 1 619 m d'altitude sur une terrasse au-dessus du village voisin de St. Niklaus. Ce village original offre beaucoup de paix, un grand domaine skiable et diverses possibilités de randonnée. Transports en commun: à proximitéÉcoles: à proximité Commerces: à proximité + +- + +CHF 119 + + vor 2 Wochen + +Grundstück zu verkaufen + +3929 Täsch +----------------------------------- + +L'emplacement ensoleillé et l'accès de part et d'autre par une route rendent cette parcelle idéale pour la construction de chalets. La vue dégagée complète parfaitement ce bien. Il est situé au pied de la célèbre station balnéaire de Zermatt. Cette offre BETTERHOMES se caractérise par les avantages suivants :-tranquille-ensoleillé- vue dégagée-développé- Près de Zermatt- Zone de construction pour chalets- Salle d'utilisation 0,3- et, et, et... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Emplacement: central Transports publics: gare de Zermatt-Brigue, 10 min. en voiture Ecoles: Toutes les écoles à Täsch, 10 min. en voiture Commerces: Coop, banque et bureau de poste, 10 min. en voiture + +- + +CHF 160 + + vor 2 Wochen + +Grundstück zu verkaufen + +1996 Baar (Nendaz) • 1 Zimmer +------------------------------------------------------ + +- + +CHF 315 + + vor 2 Wochen + +Grundstück zu verkaufen + +3922 Stalden VS +---------------------------------------- + +Stalden est connue pour son climat doux et sec. C'est l'un des endroits les plus secs de Suisse (500 - 600 mm par an). Surtout les mois d'été ont de faibles précipitations. Dans le même temps, les températures sont souvent carrément tropicales. Les mois d'hiver sont généralement de courte durée. Cette offre BETTERHOMES se caractérise par les avantages suivants :- Grande prévoyance- Porte d'entrée des vallées de la Matière et du Saas- vue imprenable sur une colline- Zone W2, AZ 0.5-développé- Route d'accès prévue- et, et, et... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Situation: Le joli village de Stalden est situé à 810 m d'altitude, à seulement 7 km au sud de Viège et est la porte d'entrée des vallées de Matter et de Saas. Transports en commun: gare, bus 7 min. à pied Ecoles: maternelle, collèges et lycées, 300 m Commerces: boulangerie, boucherie, épicerie, 300 m + +- + +CHF 70 + + Keine Bilder + + vor 2 Wochen + +Grundstück zu verkaufen + +8572 Guntershausen b. Berg +--------------------------------------------------- + +- + +CHF 640’000 + + vor 2 Wochen + +Grundstück zu verkaufen + +3960 Sierre +------------------------------------ + +- + +CHF 915’000 + + vor 2 Wochen + +Grundstück zu verkaufen + +1978 Lens +---------------------------------- + +Belle parcelle de 1'395 m2 avec projet en force, située à Trionna/Lens, dans un quartier bucolique à 5min en voiture de la station de Crans-Montana. Le projet offre une surface de 532.9m2 sur 3 niveaux avec espace SPA, ascenseur, garage et 349m2 de surface habitable. Habitez... vivez votre rêve + +- + +CHF 1’050’000 + + vor 2 Wochen + +Grundstück zu verkaufen + +1896 Miex +---------------------------------- + +Au centre même du village de Vouvry, grange à rénover pour création de logements et/ou commerces. Caractéristiques de la grange existante : * Cubage : environ 1 600 m3 * Surface au sol : 150 m2 * Hauteurs : - Sablière : 9,4 m - Au faîte : 12,7 m * Surface de plancher constructible : environ 450 m2 + combles Le bien-fonds de 190 m2 est situé en zone village, les caractéristiques principales de la zone sont les suivantes : * Destination : habitations individuelles et collectives, commerces * Densité , IBUS : sans limite * Hauteur : selon existant Le bien-fonds ne permet pas la création de places de parc, la zone village prévoit des dérogations à cet effet. Equipements sur le bien-fonds ou en limite : * Electricité * Eau potable * Evacuation * Téléphone * Gaz + +- + +CHF 340’000 + + vor 2 Wochen + +Grundstück zu verkaufen + +3961 Grimentz +-------------------------------------- + +Libre de mandat Pour résidence principale Vue panoramique sur le val d'Anniviers et sa couronne alpine A quelques pas de l'arrêt des transports publics Terrain situé à Grimentz, au coeur du Valais, dans le val d'Anniviers et à 1'572 mètres d'altitude. Ce beau village bénéficie d'un climat agréable et propose une atmosphère de calme et de convivialité. Particularités : Pour résidence principale Libre de mandat Position dominante, vue panoramique, ensoleillement généreux A quelques pas de l'arrêt des transports publics Route d'accès Equipements à proximité Densité 0.5 Zone habitations collectives Hauteur maximale 10 mètres CHF 180.- / m2 Remarques Dossier PDF complet et plan de situation sur demande Visite uniquement en présence et avec l'accord préalable de Swiss-Immobilier.ch Aucun document ne peut être transmis à des tiers sans autorisation www.swiss-immobilier.ch - Réf. 10225406 Copyright © 2023. Tous droits réservés. + +- + +CHF 491’940 + + vor 2 Wochen + +Grundstück zu verkaufen + +3955 Albinen +------------------------------------- + +Libre de mandat Pour résidence principale Position dominante, magnifique panorama et ensoleillement parfait Importante offre financière aux personnes s'installant sur la commune Terrain situé à Albinen. Ce charmant et authentique village valaisan se trouve sur le versant ensoleillé de la vallée du Rhône. Son emplacement est absolument exceptionnel et lui offre un panorama époustouflant sur la plaine et les Alpes. Tout au long de l'année, Albinen baigne dans les rayons du soleil. Les villes et villages des environs offrent toute une palette d'activités sportives et culturelles. La situation géographique d'Albinen est particulièrement intéressante : 8 minutes de la station thermale et de ski de Leukerbad 20 minutes de Sierre (cité du Soleil) 20 minutes de Steg (route menant au Lötschberg) 30 minutes de Sion (capitale valaisanne) 40 minutes de Brig (au pied du col du Simplon et carrefour de voies de communication internationales) Particularités En bordure d'une route secondaire sans issue Accès dégagé durant la saison hivernale Equipements à proximité Densité 0.3 CHF 150.- / m2 La commune offre jusqu'à CHF 75'000.- pour un projet immobilier (voir conditions sur le site de la commune) Remarques Dossier PDF complet et plan de situation sur demande Visite uniquement en présence et avec l'accord préalable de Swiss-Immobilier.ch Aucun document ne peut être transmis à des tiers sans autorisation www.swiss-immobilier.ch - Réf. 10235410 Copyright © 2023. Tous droits réservés. + +- + +CHF 104’700 + + vor 3 Wochen + +Grundstück zu verkaufen + +3970 Salgesch • 3 Zimmer +------------------------------------------------- + +Ce joli chalet de camping comble vos rêves de camping. Il est situé sur un emplacement calme non loin d'un petit lac de baignade à SwissPlage Salgesch. Le salon ouvert avec table à manger pour 4 personnes et un canapé avec table basse se connecte à la cuisine ouverte avec cuisinière à gaz et réfrigérateur. Une chambre double et une chambre séparée pour 2 personnes peuvent accueillir jusqu'à 4 personnes. L'espace extérieur dispose d'un patio et de deux hangars à outils pour vos meubles de jardin et ustensiles nécessaires. Le parking correspondant est situé directement au chalet. Pendant les chaudes journées d'été, le lac de baignade voisin vous offre un rafraîchissement et une détente frais. Cette offre BETTERHOMES se caractérise par les avantages suivants :-spacieux- confortablement meublé- 2 chambres-Siège- Hangar à outils et à meubles- Loyer annuel d'environ CHF 3500.-- Parking directement au chalet- Restaurant à l'entrée- Utilisation d'avril à octobre- et, et, et... Intéressé? Contactez-nous pour une visite sans engagement également possible de visualisation en ligne Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Emplacement: bon Condition: bon Salles de bain / Salles de bain: 1 (1 x douche / WC / lavabo) Transports publics suivants: Bus, 200m Ecoles: école primaire de Salgesch, 2km Commerces: Coop Pronto, 2km + +- + +CHF 46’000 + + Keine Bilder + + vor 3 Wochen + +Grundstück zu verkaufen + +1400 Cheseaux-Noréaz +--------------------------------------------- + +Pour agriculteurs ou investisseurs !Surplombant le lac de Neuchâtel, cette exploitation agricole bénéficie d'un excellent climat pour les cultures maraîchères.Elle est répartie comme suit :Parcelle lot 1 : 2'027 m2 : Cour, chemins et bâtiments Zone villageoise, terrain à bâtir Bâtiment d'env. 8'794 m3 comprenant 3 parties : grange, anciens appartements des employés et nouveaux appartements destinés au personnel.Nouvelle partie : rénovation effectuée en 2014. Cuisine commune, 7 chambres individuelles meublées et 2 salles d'eau communes. Idéal pour le personnel. Possibilité de rénover 1-2 nouveaux appartements dans la grange pour l'exploitant et pour la location.Parcelle lot 2 : 1.87 ha : Cour, bâtiments et chemins Zone agricole Immeuble halle fruitière :construite en 2001, cette halle fruitière de 6'332 m3 comprend 1 bureau, une halle de préparation chauffée, 1 entrepôt frigorifique pour 80 tonnes et un deuxièmeentrepôt frigorifique pour 15 tonnes. Place pour 3 camions devant la rampe. Immeuble entrepôt:pour machines et matériel, 705 m3Parcelle lot 3 (regroupement de 8 parcelles) 18 ha : Prairie et terrain agricole Cultures : 5.5 ha pommes, 4.3 ha cerises, 3.2 ha prunes, 1.0 ha poires, 0.8 ha abricots et 1.0 ha baies Tonnages : abricots : 10-15 tonnes, cerises : 42 tonnes, pruneaux : 65-75tonnes, pommes et poires : 200 tonnes, petits fruits : 4 tonnesA noter : Tout le matériel et les véhicules liés à l'exploitation peuvent être achetés en sus ou loués.Contactez-moi pour une visite sans plus attendre ! +41 76 581 74 25 Manuela Deguara + +- + +Auf Anfrage + + vor 3 Wochen + +Grundstück zu verkaufen + +8532 Warth +----------------------------------- + +- + +CHF 2’100’000 + + vor 3 Wochen + +Grundstück zu verkaufen + +3974 Mollens VS +---------------------------------------- + +- + +CHF 180 + + vor 3 Wochen + +Grundstück zu verkaufen + +3903 Mund +---------------------------------- + +- + +CHF 175 + + vor 3 Wochen + +Grundstück zu verkaufen + +8596 Scherzingen +----------------------------------------- + +- + +CHF 1’100’000 + + vor 3 Wochen + +Grundstück zu verkaufen + +9428 Walzenhausen +------------------------------------------ + +- + +CHF 895’000 + + vor 3 Wochen + +Grundstück zu verkaufen + +6955 Oggio +----------------------------------- + +- + +CHF 1’300’000 + + vor 3 Wochen + +Grundstück zu verkaufen + +6945 Origlio +------------------------------------- + +- + +CHF 170’000 + + vor 3 Wochen + +Grundstück zu verkaufen + +1907 Saxon +----------------------------------- + +Du raisin, des abricots, et même des tournesols…. Beaucoup de soleil, une nature omniprésente et nos belles montagnes en toile de fond… Bienvenue dans le joli village de Saxon Dans un quartier très tranquille en zone village, belle parcelle dominante de 3674m2, avec vue plongeante et imprenable sur la vallée et toute la chaîne montagneuse. Un très bel endroit pour y faire votre lieu de vie…Lécole est tout près, ainsi que toutes les commodités de services. Cette parcelle est constructible, libre de mandat, et les équipements sont en limite de propriété. Prix : CHF 300.-/m2 Situé au cur du massif rocheux des Alpes, dans la plaine luxuriante du Rhône, Saxon est un village alliant goût de l'authenticité et diversité des cultures; il bénéficie d'un artisanat et d'un commerce florissant et se trouve à proximité des centres urbains et des stations touristiques. Au niveau fiscal, Saxon est une des communes les plus avantageuses du Valais, avec 1.2 de coefficient et 160% d'indexation communale. Les écoles enfantines et primaires se trouvent sur place et le cycle d'orientation, à Fully. Au niveau des transports publics, la gare dessert les trains régionaux de la ligne ferroviaire Martigny-Sion-Martigny. Quant aux commerces, on y trouve tout… de lalimentaire, au médecin, en passant par la poste ou la banque, en sarrêtant plus que raisonnablement aux cafés-restaurants ou aux caves, après un détour à travers les jardins du Casino… Saxon est une commune où il y fait bon vivre. + +- + +CHF 300 + + vor 3 Wochen + +Grundstück zu verkaufen + +1966 Botyre (Ayent) +-------------------------------------------- + +Belle parcelle d'environ 500 m2 en limite de zone agricole à seulement 10 minutes de Sion et 15 minutes de Crans-Montana. Elle bénéficie d'une vue dégagée et l'ensoleillement est optimal. Ce terrain n'est pas libre de mandat. En tant que bureau d'architecture, nous pouvons vous créer un projet sur-mesure. Sovalco, entreprise de construction valaisanne fondée en 1983, notre réputation n'est plus à faire. Nous mettons tout en oeuvre pour vous garantir un travail de qualité dans le respect des budgets. Votre rêve...notre réalité Un exemple de construction a déjà été élaboré sur ce terrain - rendez-vous sur https://www.sovalco.ch/avendre + +- + +CHF 155’000 + + vor 3 Wochen + +Grundstück zu verkaufen + +1965 Savièse +------------------------------------- + +Belle parcelle d'environ 500 m2 à seulement 3 minutes de Sion.. Elle bénéficie d'une vue dégagée et l'ensoleillement est optimal. Ce terrain n'est pas libre de mandat. En tant que bureau d'architecture, nous pouvons vous créer un projet sur-mesure. Sovalco, entreprise de construction valaisanne fondée en 1983, notre réputation n'est plus à faire. Nous mettons tout en oeuvre pour vous garantir un travail de qualité dans le respect des budgets. Votre rêve...notre réalité Un exemple de construction a déjà été élaboré sur ce terrain - rendez-vous sur https://www.sovalco.ch/avendre + +- + +CHF 270’000 + +[1](https://www.immoyou.ch/grundstuck-kaufen-schweiz)234567 + + 1 - 24 von 3’123 Ergebnisse + + All rights reserved. v.541ff84 \ No newline at end of file diff --git a/test_web_content_20251002_215219/main_url_001_www.immoscout24.ch_de_grundstueck_kaufen_kanton-zuerich.txt b/test_web_content_20251002_215219/main_url_001_www.immoscout24.ch_de_grundstueck_kaufen_kanton-zuerich.txt new file mode 100644 index 00000000..999d23d7 --- /dev/null +++ b/test_web_content_20251002_215219/main_url_001_www.immoscout24.ch_de_grundstueck_kaufen_kanton-zuerich.txt @@ -0,0 +1,443 @@ +Title: https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich +URL: https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich +Type: Main URL +Extracted: 2025-10-02 21:52:19 +================================================================================ + +70 Bauland zum Kaufen: Kanton Zürich | ImmoScout24 + +=============== + +[](https://www.immoscout24.ch/de) +* [Suchen](https://www.immoscout24.ch/de "Suchen") +* [Services](https://www.immoscout24.ch/c/de/hypotheken "Services") + +[Inserat erstellen](https://www.immoscout24.ch/de/insertion/inserat-online-erfassen "Inserat erstellen") + +[Favoriten](https://www.immoscout24.ch/favoriten "Favoriten") + +[Mein Konto](https://www.immoscout24.ch/de/account-overview "Mein Konto") + +Menü + +[](https://www.immoscout24.ch/de) +* [Suchen](https://www.immoscout24.ch/de "Suchen") +* [Services](https://www.immoscout24.ch/c/de/hypotheken "Services") +* [Bewerten](https://www.immoscout24.ch/de/immobilienbewertung "Bewerten") +* [Magazin](https://www.immoscout24.ch/c/de/immobilien-magazin "Magazin") + +[Inserat erstellen](https://www.immoscout24.ch/de/insertion/inserat-online-erfassen "Inserat erstellen") + +[Favoriten](https://www.immoscout24.ch/favoriten "Favoriten") + +[Mein Konto](https://www.immoscout24.ch/de/account-overview "Mein Konto") + +Menü + +DE +* [DE](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich) +* [FR](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich) +* [IT](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo) +* [EN](https://www.immoscout24.ch/en/plot/buy/canton-zurich) + +1. [](https://www.immoscout24.ch/de) +2. [Bauland zum Kaufen](https://www.immoscout24.ch/de/grundstueck/kaufen) +3. [Kanton Zürich](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich) + +Wo? + + Kanton Zürich + + Kanton Zürich + + CHF bis + + + + Filter + + 70 Objekte + +70 Treffer - Bauland zum Kaufen: Kanton Zürich +============================================== + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 16    **360m²**, CHF 2’563’760.– Top Luegetenstrasse 11, 8489 Wildberg Ihr neues Zuhause mit Potenzial - Idyllisches Landhaus mit Baulandreserve Ihr neues Zuhause Willkommen in Ihrem zukünftigen Traumdomizil - ein grosszügiges, freistehendes Landhaus an ruhiger und idyllischer Aussichtslage im malerischen Wildberg. Hier vereinen sich ländliche Idylle, Privatsphäre und die seltene Möglichkeit, Wohnraum nach eigenen Vorstellungen zu schaffen oder zu erweitern.Ob als charmantes Familienrefugium mit grossem Garten oder als Investitionsobjekt mit Entwicklungspotenzial - dieses einzigartige Anwesen bietet Ihnen beide Optionen. Auf dem 1339m² grossen Grundstück geniessen Sie nicht nur viel Platz zum Leben, sondern verfügen auch über eine wertvolle Baulandreserve, die Ihnen vielfältige Gestaltungsmöglichkeiten eröffnet. Erste Abklärungen zeigen: Es besteht die Möglichkeit, ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren - ein echter Mehrwert für visionäre Käufer.Tauchen Sie ein in eine grüne Oase mit Weitblick - ein Ort, der Ruhe schenkt und inspiriert.Highlights auf einen Blick • Idyllische, ruhige Aussichtslage mit hohem Erholungswert • Grosszügiges Grundstück mit 1339m², ideal zur Eigennutzung und/oder für die Entwicklung eines Neubaus • Baulandreserve: Attraktives Entwicklungspotenzial - gemäss erster Einschätzung besteht die Möglichkeit, zusätzlich zum bestehenden Einfamilienhaus ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren (unverbindlich, ohne Gewähr) • Blühender Garten mit verschiedenen Sitzplätzen, Pergola mit Aussencheminée, Gartenhäusern, gepflegtem Baumbestand und weitläufigen Grünflächen • Solide Bausubstanz mit Doppelschalenmauerwerk • Grosszügiges Raumkonzept mit ca. 220m² Wohnfläche und ca. 96m² zusätzlichem Stauraum im Untergeschoss. Total ca. 360m² Bruttofläche. • Geräumiger Wohnbereich mit gemütlichem Kachelofen - ein Ort zum Ankommen und Wohlfühlen • Praktische Wohnküche mit integriertem Essbereich - ideal für gesellige Stunden • 4 helle Schlafzimmer - ideal für Familien oder Homeoffice • 2 Nasszellen mit Tageslicht • Ausgebauter Estrich für zusätzlichen Raum oder kreative Nutzungsmöglichkeiten • Beheizt durch Elektrospeicher und wassergeführte Fussbodenheizung • Garage mit elektrischem Tor und weitere Parkmöglichkeiten auf dem Grundstück • Mit einer stilvollen Modernisierung verwandeln Sie dieses Haus in ein wahres Schmuckstück Verkaufspreis: CHF 1'870'000.-Mit unserer virtuellen 360-Grad-Tour können Sie bereits die ersten Eindrücke dieser tollen Liegenschaft gewinnen. Sehr gerne zeigen wir Ihnen diese Liegenschaft direkt vor Ort und freuen uns auf Ihre Kontaktaufnahme.Weitere EckdatenBaujahr Haus: 1984, Baujahr Gerätehaus: 1986, Kubatur Haus (GVZ): 936m³, Kubatur Gerätehaus (GVZ): 40m³, Grundbuchblatt: Nr. 437, Kataster-Nr.: 249, 1/4 subjektiv-dingliches Miteigentum an Blatt 444, Kataster 249. Nettowohnfläche: ca. 220m², Bruttowohnfläche: ca. 360m², Grundstücksfläche: 1'339m².Massivbauweise, Doppelschalenmauerwerk, neuwertige Holzmetallfenster (EgoKiefer) mit dreifacher Verglasung und Sprossen & Holzläden. Elektrospeicherofen, wassergeführte Fussbodenheizung, Elektroboiler 300 Liter.Treppenlift, Garage mit elektrischem Torantrieb. Küche im Landhausstil mit Granitabdeckung, Geschirrspüler, Induktions-Kochherd und Kühlschrank mit Gefrierfach.BodenbelägeEG: Entrée, Gang, Dusche, Küche, Essen mit Plattenboden.OG: Zimmer und Vorplatz mit Laminat in Holzoptik. Bad mit Platten.  Wegzeit Neu 28 min.Station: Rämismühle-Zell](https://www.immoscout24.ch/kaufen/4002491909) + +[*  *  *  *  *  *  *  *  1 / 4 Preis auf Anfrage Top Lüss, 8542 Wiesendangen Im Baurecht abzugeben: 14’770 m2 Bauland an bester Lage im steuergünstigen Wiesendangen Im Baurecht abzugeben:14’770 m2 Bauland an bester Lage im steuergünstigen WiesendangenGrundstück WD4674 – Lüss WiesendangenAlle Details zum Grundstück, zum Baurechtsvertrag sowie zu den Vergabekriterien finden sie im angefügten Dossier.Verbindliche Angebote für eine Übernahme des Baurechtsvertrages inklusive Finanzierungsnachweis sind einzureichen an:Gemeinde Wiesendangenz. Hd. Martin SchindlerSchulstrasse 208542 Wiesendangen Bitte verwenden Sie für die Angebotseingabe das Formular im Anhang.Eingabeschluss: Montag, 20. Oktober 2025, 11.00 Uhr Wegzeit Neu 9 min.Station: Wiesendangen](https://www.immoscout24.ch/kaufen/4002510601) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 12    CHF 2’323’840.– Hürstringstrasse 37, 8046 Zürich Grundstück mit bestehendem EFH und grossem Potenzial Gerne stellen wir Ihnen das Grundstück mit grossem Potenzial und vielen Möglichkeiten vor.Nach Absprache verkaufen wir an ruhiger Lage in Zürich ein Grundstück mit bestehendem Einfamilienhaus. Interessant an diesem Objekt ist jedoch, dass Sie beim Kauf bereits über die zugehörige Baubewilligung verfügen, welche es Ihnen erlaubt, den Wohnraum auf dieser Parzelle nach Ihren Wünschen zu vergrössern und zu sanieren.Nicht weit vom Zürcher Hauptbahnhof entfernt, hinter dem Käferberg liegt die grosszügige Parzelle mitten in einem ruhigen Wohnquartier mit 30er-Zone.Zu Fuss erreichen Sie eine Bushaltestelle, sowie auch den kleinen Wald, der sich ideal für kürzere Spaziergänge eignet.Die wichtigsten Infos in Kürze: • Landparzelle inkl. Einfamilienhaus und Baubewilligung zum Ausbau der Wohnfläche • Baujahr 1934 • Grundstückfläche von 410 m2 • Projektmöglichkeit 1: Ausbau zum Mehrfamilienhaus mit zwei Eigentums- oder Mietwohnungen • Projektmöglichkeit 2: Ausbau zum Generationenhaus Erleben Sie die ruhige Atmosphäre und gleichzeitige Nähe zum Stadtzentrum bei einem persönlichen Besuch!Für nähere Informationen zum Objekt oder einen Besichtigungstermin dürfen Sie sich gerne jederzeit bei uns melden.  Wegzeit Neu 22 min.Station: Zürich Seebach](https://www.immoscout24.ch/kaufen/4002349882) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 11    CHF 3’290’400.– Luzernerstrasse 57, 8903 Birmensdorf (ZH) Sonnige Aussichtslage Im Auftrag unseres Kunden verkaufen wir ein Bauland an sonniger Aussichtlage mit 1'228 m² Grundstücksfläche (Wohnzone W2).Die bestehende Liegenschaft präsentiert sich in einem dem Alter entsprechend gut unterhaltenen Zustand.Verkaufsrichtpreis: CHF 2'400'000Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot.  Wegzeit Neu 19 min.Station: Birmensdorf](https://www.immoscout24.ch/kaufen/4002566208) + +Dein Immobilienexperte vor Ort +------------------------------ + +[ Stöhr Immobilien GmbH berät dich persönlich zur optimalen Verkaufsstrategie für deine Immobilie.](https://immoscout24.ch/anbieter/n023/stohr-immobilien-gmb-h) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13 CHF 4’044’440.– Mühlemattstrasse 12, 8135 Langnau am Albis Bauland oder bestehendes Einfamilienhaus zum Verkauf! Dieses freistehende Einfamilienhaus befindet sich an ruhiger Lage und bietet eine seltene Kombination aus architektonischem Charakter, grosszügigem Umschwung und inspirierendem Entwicklungspotenzial. Eingebettet in viel Grün und umgeben von Bäumen geniessen Sie hier Privatsphäre, Ruhe – und eine wunderschöne Weitsicht.Das Haus überzeugt durch eine unverwechselbare Ausstrahlung. Die Backsteinwände im Innenbereich verleihen dem Wohnraum eine warme, natürliche Atmosphäre, während das Cheminée im Wohnzimmer für Behaglichkeit an kühleren Tagen sorgt. Der Grundriss ist offen und einladend, ergänzt durch grosse Fensterfronten, die Licht und Natur ins Haus holen.Ein Highlight ist die grosszügige Terrasse mit herrlichem Ausblick – ideal für gemütliche Stunden im Freien. Der Garten ist weitläufig und bietet viel Platz für individuelle Gestaltung. Mit etwas Aufmerksamkeit lässt sich hier ein wunderbares grünes Paradies schaffen – ob als Familiengarten, Rückzugsort oder für kreative Projekte im Freien.Dank der Grundstücksgrösse und der Lage eröffnet die Liegenschaft auch interessante Perspektiven für einen möglichen Ersatzneubau - wie ein modernes Einfamilienhaus oder ein Mehrfamilienhaus.Gerne stellen wir Ihnen weitere Informationen zur Verfügung oder vereinbaren einen persönlichen Besichtigungstermin. Entdecken Sie das Potenzial und die besondere Atmosphäre dieses einzigartigen Ortes. In der Verkaufsdokumentation finden Sie alle wichtigen Informationen.  Wegzeit Neu 12 min.Station: Langnau-Gattikon](https://www.immoscout24.ch/kaufen/4002406229) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13    CHF 1’302’440.– Kanalweg 2, 8714 Feldbach Bauland für projektiertes Einfamilienhaus Im beschaulichen Dorf Feldbach am Zürichsee ist dieses Grundstück mit einer bestehenden, einseitig angebauten Scheune zu verkaufen. Im Kaufpreis inbegriffen ist ein bewilligungsfähiges Vorprojekt für ein Einfamilienhaus als Ersatzbau der Scheune.Das Objekt bietet Ihnen die einmalige Möglichkeit, Ihren Traum vom Eigenheim an idyllischer Lage zu verwirklichen. Es bietet genügend Platz für eine Familie, auch eine Kombination von "Wohnen und Arbeiten" ist denkbar.Innert 30 Minuten sind Sie mit der S-Bahn in Zürich, auch Kindergarten und Primarschule sind nah. Einkaufsmöglichkeiten bestehen in Hombrechtikon, Stäfa und Rapperswil. Im Sommer lockt in unmittelbarer Nähe eine Abkühlung in der schmucken Seebadi Feldbach.Es besteht ein aktueller Kostenvoranschlag für das Haus (Holzelementbauweise) inkl. Umgebung, Bau- und Nebenkosten in der Höhe von Fr. 1'380'000.--.Haben wir Sie neugierig gemacht? Dann rufen Sie uns an. Gerne beantworten wir Ihre Fragen oder stellen Ihnen unsere Verkaufsdokumentation zum Studium zu. Die Liegenschaft kann selbstverständlich auch besichtigt werden. Wir freuen uns auf Ihren Anruf.  Wegzeit Neu 6 min.Station: Feldbach](https://www.immoscout24.ch/kaufen/4002434745) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13    **5.5 Zimmer**, CHF 4’111’620.– Schaffhauserstrasse 226b, 8057 Zürich Mehr Raum fürs Leben: Reihenhaus mit Potenzial Attraktive Stadtliegenschaft mit ausgearbeitetem ProjektIm Zürcher Kreis 11 veräussern wir ein hübsches Reiheneinfamilien-Eckhaus mit grosszügigem Umschwung. Die Liegenschaft und das Grundstück verfügen über viel Ausnützungspotenzial und ermöglicht so die Realisation spannender Projekte sowohl im Umbau als auch Neubau.Diese Liegenschaft überzeugt durch viele Besonderheiten: • grosszügiger Umschwung mit viel Potenzial • Blick ins Grüne von nahezu allen Fenstern • Schwedenofen im Wohnbereich • viel Stauraum durch Wandschränke und Estrich • Altbaucharme in modernem Quartier • zentrale und familienfreundliche Lage • sonnenverwöhnter Standort Haben wir Ihr Interesse geweckt? Bestellen Sie noch heute unsere ausführliche Verkaufsdokumentation mittels Kontaktformular und Sie erhalten weitere spannende Informationen zur Immobilie. Wir freuen uns über Ihre Kontaktaufnahme!Une oasis de verdure dans la ville de Zurich avec un projet élaboréDans le quartier 11 de Zurich, nous vendons une jolie maison mitoyenne en angle avec de vastes alentours. L'immeuble et le terrain disposent d'un grand potentiel d'exploitation et permettent ainsi la réalisation de projets passionnants, tant en transformation qu'en construction neuve.Cette propriété convainc par ses nombreuses particularités : • Un vaste terrain avec beaucoup de potentiel • Une vue sur la verdure depuis presque toutes les fenêtres • Un poêle suédois dans le séjour • beaucoup d'espace de rangement grâce aux armoires murales et au grenier • Le charme d'un ancien bâtiment dans un quartier moderne • Un emplacement central et favorable aux familles • Un emplacement ensoleillé Nous avons éveillé votre intérêt ? Commandez dès aujourd'hui notre documentation de vente détaillée au moyen du formulaire de contact et vous recevrez d'autres informations passionnantes sur le bien immobilier. Nous nous réjouissons de votre prise de contact!A green oasis in the city of Zurich with an elaborate projectIn Zurich's Kreis 11 district, we are selling a pretty terraced single-family corner house with spacious grounds. The property and the plot have a lot of utilization potential and thus enable the realization of exciting projects both in conversion and new construction.This property boasts many special features: • spacious grounds with lots of potential • view of the countryside from almost all windows • Swedish stove in the living area • lots of storage space thanks to wall cupboards and attic • old building charm in a modern district • central and family-friendly location • sun-drenched location Have we piqued your interest? Order our detailed sales documentation today using the contact form and you will receive further exciting information about the property. We look forward to hearing from you!  Wegzeit Neu 4 min.Station: Berninaplatz](https://www.immoscout24.ch/kaufen/4002346061) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 12 Preis auf Anfrage Überlandstrasse 23, 8340 Hinwil Industrie- und Baulandparzelle an attraktivem Standort im Zürcher-Oberland Im pulsierenden Industriegebiet von Hinwil verkaufen wir ein Industriebaugrundstück an einer top frequentierter Lage, direkt an der Hauptachse in Rapperswil Wetzikon Pfäffikon ZH. Die Baulandparzelle befindet sich am Rand der Industriezone und grenzt an die Wohnzone zu Hinwil ZH.Eckdaten:- Grundstück-Fläche total 4'246 m2- Bauzone Industrie/Gewerbe IG/7 - Baumassenziffer 7 m3/m2- Gebäudehöhe maximal 21.5 m- Gebäudelänge maximal offen- Grosser Grenzabstand Nationalstrasse- Allseitiger Gebäudeabstand 3.5 m1- Maximal mögliche Baumasse ca. 30'000 m3- Bruttogeschossfläche ca. 9'500 m2Das Baugrundstück wird derzeit noch mit zwei Wohneinheiten, der Autowerkstatt mit separatem Showroom und einer Tankstelle genutzt. Rund um die Liegenschaft bieten sich grosse, befestigte Flächen zur Nutzung an.  Wegzeit Neu 10 min.Station: Hinwil](https://www.immoscout24.ch/kaufen/4002417917) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 10 CHF 2’947’650.– Trottenrain 14, 8474 Dinhard Bewilligtes Bauprojekt im steuergünstigen Dinhard-Welsikon Das Bauland mit Magazingebäude befindet sich an zentraler Lage in Welsikon am Rande der Gemeinde Dinhard in der Kernzone. Die erreichte hohe Ausnutzung ermöglicht attraktive Neubauten an zentraler Lage. Visualisierungen und Grundrisse des bewilligten Bauprojekts finden Sie in der Dokumentation. Das Magazingebäude steht im kommunalen Inventar der schutzwürdigen Bauten. Es wurde deshalb in Absprache mit dem Heimatschutz und der Gemeinde Dinhard ein Schutzvertrag erarbeitet, der einen aussergewöhnlichen Umbau zu einem modernen Loft gestattet.Highlights: • bewilligtes Bauprojekt und Ausschreibungsplanung der Neubauten • Schutzvertrag • ausgezeichnete Lage in Welsikon • Steueroase (Gemeindesteuerfuss 83 %) • gut geschnittene Baulandparzelle • Gute ÖV-Anbindung (Bahnhof 170 m) Realisierung:Der Hauseigentümerverband Winterthur unterstützt Sie bei Bedarf gerne in enger Zusammenarbeit mit Kästle Architekten bei der Realisierung Ihres Neubauprojekts.Von der Planung bis hin zum Verkauf/Vermietung des fertigen Neubaus ? der Hauseigentümerverband Winterthur bietet Ihnen alle Dienstleistungen aus einer Hand. Es besteht keine Architekturverpflichtung.Interessenten sind herzlich eingeladen, mit uns Kontakt aufzunehmen.Rufen Sie unser Verkaufsteam über Telefon 052 209 01 68 an, wenn Sie zusätzliche Informationen oder eine Besichtigung wünschen. Wir freuen uns auf Sie.Ihr HEV-VerkaufsteamWichtig: Wir sind exklusiv mit dem Verkauf beauftragt. Direkte Eigentümerkontakte führen zu einem Interessentenausschluss. S.E.&.O.  Wegzeit Neu 5 min.Station: Dinhard](https://www.immoscout24.ch/kaufen/4002188905) + +[ 1 / 1 CHF 2’399’240.– In der Gass 2, 8627 Grüningen Grundstück mit Baubewilligung für MFH zu verkaufen Zum Verkauf steht ein Grundstück mit bewilligtem Neubauprojekt. Gebäude C des Enssamble an der Binzikerstrasse 21 / In der Gass 2, 8627 Grüningen. Die aktuell bestehenden Garagen können abgebrochen werden und durch einen Neubau mit 8 Wohnungen unterschiedlicher Grösse mit attraktiven Aussenbereich ersetzt werden. Zusätzlich wurde der gemeinsame Bau einer Tiefgarage für 11 Parkplätze mit der Zufahrt über die Strasse "In der Gass" bewilligt.  Wegzeit Neu 54 min.Station: Esslingen](https://www.immoscout24.ch/kaufen/3003479026) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 2’604’890.– Im Königstal 2, 8487 Zell Wegzeit Neu 22 min.Station: Rämismühle-Zell](https://www.immoscout24.ch/kaufen/4002279293) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 4’112’990.– Im Königstal 3, 8487 Zell ZH Wegzeit Neu 22 min.Station: Rämismühle-Zell](https://www.immoscout24.ch/kaufen/4002279266) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 6’717’900.– Im Königstal 3, 8487 Zell ZH Wegzeit Neu 22 min.Station: Rämismühle-Zell](https://www.immoscout24.ch/kaufen/4002279259) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    CHF 2’879’100.– Rotweg 20, 8820 Wädenswil Ihr neues Projekt mit Seesicht Im Auftrag unseres Kunden verkaufen wir an bevorzugter, erhöhter und ruhiger Wohnquartierlage mit schöner See- und Fernsicht, 706 m² Bauland mit Rückbauobjekt.Verkaufsrichtpreis: CHF 2'100'000.00Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot.  Wegzeit Neu 12 min.Station: Wädenswil](https://www.immoscout24.ch/kaufen/4002559578) + +[*  *  *  *  *  *  *  *  *  *  *  1 / 7    CHF 651’220.– Auf Anfrage 1, 8195 Wasterkingen Attraktives Baugrundstück in ruhiger, ländlicher Umgebung Willkommen in Wasterkingen, einer idyllischen und ruhigen Gemeinde im Zürcher Unterland, die für ihre hohe Lebensqualität, ländliche Gelassenheit und dennoch gute Erreichbarkeit bekannt ist. Genau hier wartet ein attraktives Baugrundstück auf Sie – die ideale Basis für Ihr zukünftiges Zuhause.Das Grundstück ist voll erschlossen und liegt in der Kernzone B, was Ihnen zahlreiche Gestaltungsmöglichkeiten eröffnet. Ob ein modernes Einfamilienhaus, ein klassisches Zuhause im Dorfcharakter oder ein individuelles Architektenprojekt – hier können Sie Ihre Wohnträume ganz nach Ihren Vorstellungen verwirklichen.Die charmante Gemeinde Wasterkingen besticht durch ihre ruhige Lage inmitten von Feldern, Reben und Natur.Dieses ImmoSky-Angebot bietet folgende *Mehr Leistung*:+ Voll erschlossen+ Ruhige Gemeinde+ Ideale Grösse für flexibilität (650m²)+ Kernzone B+Überbauungsziffer für Hauptgebäude 30%Dieses Grundstück bietet Ihnen die seltene Gelegenheit, ländliche Idylle mit urbaner Nähe zu vereinen – ein Ort, an dem Sie zur Ruhe kommen und dennoch bestens angebunden sind.Erfüllen Sie sich hier den Traum vom Eigenheim und gestalten Sie Ihr persönliches Refugium in Wasterkingen.Haben wir Sie mit diesem Angebot überzeugt? Dann zögern Sie nicht und kontaktieren Sie uns für weitere Fragen oder einen Besichtigungstermin!(Das Verkaufsdossier wird in der Regel innerhalb von maximal 24 Stunden an Sie versendet. Bitte überprüfen Sie auch Ihren SPAM-Ordner.)  Wegzeit -](https://www.immoscout24.ch/kaufen/4002537208) + +[*  *  *  *  *  *  *  *  *  *  *  1 / 7    CHF 7’540’490.– Staldernstrasse 13, 8158 Regensberg Entwicklungsgrundstück an top Lage in der Kernzone 2 In der gefragten Gemeinde Regensberg (ZH) steht ein hervorragend gelegenes Grundstück zum Verkauf, das sich ideal für Investoren, General- oder Totalunternehmer eignet. Die 2.557 m² grosse Parzelle Nr. 949 befindet sich in der Kernzone 2, die vielfältige bauliche und nutzungsbezogene Entwicklungsmöglichkeiten zulässt, insbesondere für Wohn- oder gemischt genutzte Projekte.Aktuell steht auf dem Grundstück ein nicht erhaltenswertes Gebäude, das im Rahmen einer Neuentwicklung rückgebaut werden kann. Eine Baueingabe oder Bewilligung liegt nicht vor, sodass volle gestalterische Freiheit innerhalb der geltenden bau- und zonenrechtlichen Rahmenbedingungen besteht.Berechnungen zeigen, dass eine nachhaltige Mietertragserwartung von rund CHF 485'600 pro Jahr realistisch erscheint - unter der Annahme einer Ausnutzung mit rund 1 664 m² Hauptnutzfläche (HNF) und 28 Tiefgaragenplätzen. Der ermittelte Kapitalisierungssatz liegt bei 4.20 %.Wesentliche Bewertungskennzahlen:Verkehrswert (diskontierter Landwert): CHF 5'505'000Ertragswert im erneuerten Zustand: CHF 11'556'795Realwert (hypothetisch): CHF 12'485'000Potenzieller Verkaufserlös: CHF 16'190'000Bruttorendite (Mietwert): 4.20%Die hypothetische Bebauung sieht zwei Mehrfamilienhäuser mit einer Bruttogeschossfläche (BGF) von insgesamt 2'080 m² vor - entsprechend einer Ausnützungsziffer von 0.81, voll im Rahmen der Zonenordnung. Die kalkulierten Baukosten (BKP 2-5) belaufen sich auf ca. CHF 8.74 Mio. Der diskontierte Landwert pro m² liegt bei CHF 2'155, was das wirtschaftliche Potenzial zusätzlich unterstreicht.Die Kernzone 2 erlaubt neben der reinen Wohnnutzung auch Mischnutzungen, beispielsweise mit gewerblichen Angeboten im Erdgeschoss. Dies ist ein zusätzlicher Vorteil für flexible, standortgerechte Entwicklungskonzepte. Die Lage in Regensberg bietet ruhige Wohnqualität in der Nähe der Agglomeration Zürich und ist in eine attraktive historische Umgebung eingebettet.Fazit: Das Grundstück bietet die seltene Gelegenheit, ein entwicklungsfähiges Grundstück an bester Lage mit bestehendem Abbruchobjekt zu akquirieren und nach eigenen Vorstellungen zu bebauen. Dank der flexiblen Nutzungsmöglichkeiten und des attraktiven Standorts stellt diese Investition eine hervorragende Ausgangslage für renditestarke Projektentwicklungen dar.Für detaillierte Informationen stehen wir Ihnen gerne zur Verfügung.  Wegzeit Neu 23 min.Station: Steinmaur](https://www.immoscout24.ch/kaufen/4002529588) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    CHF 3’633’140.– Riedwiesenstrasse 20, 8305 Dietlikon RESERVIERT - Industrie-Baulandparzelle an zentraler Lage in Dietlikon ZH Mit Freude präsentieren wir Ihnen eine einzigartige und äusserst seltene Baulandparzelle an zentraler Lage in Dietlikon ZH – eine aussergewöhnliche Gelegenheit mit hervorragenden Eigenschaften, die sich besonders für Investoren eignet.Zentrale Lage: Die Parzelle befindet sich in einer äusserst gefragten Gegend mit hervorragender Anbindung: Flughafen Zürich erreichbar in 10 Fahrminuten Stadt Zürich erreichbar in 12 Fahrminuten • Visibilität: Ihr Unternehmen wird von der Autobahn aus perfekt sichtbar sein, was optimale Werbemöglichkeiten bietet (ca. 500 m2 Fassade für Werbung). • Baumassenziffer: Profitieren Sie von der hohen Baumassenziffer 10.0, die maximale Flexibilität und Nutzungseffizienz ermöglicht. • Näherbaurechte: Die Parzelle verfügt über Näherbaurechte rechts und links. Auf der Rückseite kann ein Näherbaurecht von der Stadt Zürich eingeholt werden • ca. 3'500 m2 Bruttogeschossfläche möglich • Tiefgarage / Untergeschoss bis zu ca. 800 m2 gross realisierbar • Maximale Gesamthöhe 20 m. 7 Stockwerke à 500 m2 Bruttogeschossfläche und 2.85 m Raumhöhe (brutto) möglich • Parzelle: Die ebene Fläche der Parzelle erleichtert die Bauplanung und Ausführung. • Form: Die Parzelle hat eine ideale Form, die vielseitige Bebauungsmöglichkeiten erlaubt. • Autobahnknotenpunkt: Brüttiseller Kreuz, direkt an einem der wichtigsten Autobahnknotenpunkt der Schweiz gelegen, bietet die Parzelle hervorragende Erreichbarkeit und Logistikvorteile • Störendes Gewerbe: Die Lage ist auch für Gewerbe geeignet, das potenziell störend sein kann. • Kulturzentren sowie Hotelbetriebe auch möglich. Jetzt oder nie – Ihre Chance auf ein grossartiges Investment:Solch eine Industrie-Baulandparzelle in dieser Lage kommt äusserst selten auf den Markt – seit geraumer Zeit gab es in dieser gefragten Gegend kein vergleichbares Angebot. Sichern Sie sich jetzt dieses einmalige Grundstück, ideal für visionäre Unternehmer und Investoren, die auf einen strategisch optimalen Standort setzen.Haben wir Ihr Interesse geweckt? Dann nehmen Sie noch heute Kontakt mit uns auf. Gerne lassen wir Ihnen das detaillierte Verkaufsdossier inklusive Machbarkeitsstudie zukommen – exklusiv und unverbindlich.  Wegzeit Neu 14 min.Station: Dietlikon](https://www.immoscout24.ch/kaufen/4002331523) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    Preis auf Anfrage Kaffeestrasse, 8180 Bülach Ihr Industriebau direkt in Bülach BeschreibungGerne entwickeln und realisieren wir ein auf ihre Bedürfnisse massgeschneidertes Projekt, welches Ihnen zur Miete oder im Eigentum zur Verfügung stehen wird.Interesse oder Fragen? Nehmen Sie Kontakt mit uns auf!Die Parzelle ist nicht das Richtige für Ihre Anforderungen? Kein Problem! Besuchen Sie unsere Homepage und finden Sie weitere Angebote unter: gewerbeland-schweiz.ch  Wegzeit Neu 20 min.Station: Bülach](https://www.immoscout24.ch/kaufen/4001788654) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    Preis auf Anfrage Kaffeestrasse, 8180 Bülach Ihr Industriebau direkt in Bülach BeschreibungGerne entwickeln und realisieren wir ein auf ihre Bedürfnisse massgeschneidertes Projekt, welches Ihnen zur Miete oder im Eigentum zur Verfügung stehen wird.Interesse oder Fragen? Nehmen Sie Kontakt mit uns auf!Die Parzelle ist nicht das Richtige für Ihre Anforderungen? Kein Problem! Besuchen Sie unsere Homepage und finden Sie weitere Angebote unter: gewerbeland-schweiz.ch  Wegzeit Neu 20 min.Station: Bülach](https://www.immoscout24.ch/kaufen/4001788644) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    * Ruhige Lage CHF 3’358’950.– 8192 Glattfelden ZWEIFELSFREIES BAULAND IN ZWEIDLEN Im beliebten Zweidlen verkaufen wir ein eine attraktive, 1'226 m² grosse Baulandparzelle mit Bestandesobjekt.Unsere Projektstudie zeigt eine hohe Ausnutzung für die Erstellung eines Mehrfamilienhauses. • Anrechenbare mögliche Bruttogeschossfläche von max. 940 m² (Projekt 789 m²) • Wohn- und Gewerbezone WG 2.3 • Kein Denkmalschutz beim Bestandesobjekt • Die Deutsche Grenze in Kaiserstuhl ist nur 8 Autominuten entfernt • Der Flughafen Zürich ist in nur 19 Autominuten erreichbar Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: https://www.propertyowner.ch/de/immobilien/25-12278 Referenznummer: 25-12278Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website https://www.propertyowner.ch/immobilien/ und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen! * Ruhige Lage  Wegzeit -](https://www.immoscout24.ch/kaufen/4002558181) + +[1](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich)[2](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich?pn=2)[...4](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich?pn=4)[](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich?pn=2) + +Suche speichern Kartenansicht + +Vorschläge basierend auf deinen Suchresultaten +---------------------------------------------- + +Weitere interessante Objekte +---------------------------- + +Orte von Kanton Zürich + +* [Zürich](https://www.immoscout24.ch/de/grundstueck/kaufen/ort-zuerich) + +Bezirke im Kanton Kanton Zürich + +* [Bezirk Affoltern](https://www.immoscout24.ch/de/grundstueck/kaufen/region-affoltern) +* [Bezirk Andelfingen](https://www.immoscout24.ch/de/grundstueck/kaufen/region-andelfingen) +* [Bezirk Bülach](https://www.immoscout24.ch/de/grundstueck/kaufen/region-buelach) +* [Bezirk Dielsdorf](https://www.immoscout24.ch/de/grundstueck/kaufen/region-dielsdorf) +* [Bezirk Dietikon](https://www.immoscout24.ch/de/grundstueck/kaufen/region-dietikon) +* [Bezirk Hinwil](https://www.immoscout24.ch/de/grundstueck/kaufen/region-hinwil) +* [Bezirk Horgen](https://www.immoscout24.ch/de/grundstueck/kaufen/region-horgen) +* [Bezirk Meilen](https://www.immoscout24.ch/de/grundstueck/kaufen/region-meilen) +* [Bezirk Pfäffikon](https://www.immoscout24.ch/de/grundstueck/kaufen/region-pfaeffikon) +* [Bezirk Uster](https://www.immoscout24.ch/de/grundstueck/kaufen/region-uster) +* [Bezirk Winterthur](https://www.immoscout24.ch/de/grundstueck/kaufen/region-winterthur) + +Kantone der Schweiz + +* [Kanton Aargau](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-aargau) +* [Kanton Appenzell Ausserrhoden](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-appenzell-ar) +* [Kanton Appenzell Innerrhoden](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-appenzell-ai) +* [Kanton Basel-Landschaft](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-basel-landschaft) +* [Kanton Basel-Stadt](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-basel-stadt) +* [Kanton Bern](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-bern) +* [Kanton Freiburg](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-freiburg) +* [Kanton Genf](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-genf) +* [Kanton Glarus](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-glarus) +* [Kanton Graubünden](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-graubuenden) +* [Kanton Jura](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-jura) +* [Kanton Luzern](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-luzern) +* [Kanton Neuenburg](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-neuenburg) +* [Kanton Nidwalden](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-nidwalden) +* [Kanton Obwalden](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-obwalden) +* [Kanton Schaffhausen](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-schaffhausen) +* [Kanton Schwyz](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-schwyz) +* [Kanton Solothurn](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-solothurn) +* [Kanton St. Gallen](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-st-gallen) +* [Kanton Thurgau](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-thurgau) +* [Kanton Tessin](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-tessin) +* [Kanton Uri](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-uri) +* [Kanton Wallis](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-wallis) +* [Kanton Waadt](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-waadt) +* [Kanton Zug](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zug) + +### ImmoScout24 + +* [Inserat erstellen](https://www.immoscout24.ch/de/insertion/inserat-online-erfassen) +* [Werbung](https://swissmarketplace.group/de/werbung/) +* [Publikationsnetzwerk](https://www.immoscout24.ch/c/de/ueber-uns/publikationsnetzwerk) + +### Über uns + +* [Kontakt](https://www.immoscout24.ch/c/de/ueber-uns/kontakt) +* [Porträt](https://swissmarketplace.group/de/portfolio/real-estate/) +* [Jobs](https://swissmarketplace.group/de/karriere/) +* [Fakten und Zahlen](https://swissmarketplace.group/de/portfolio/real-estate/) +* [Medien](https://swissmarketplace.group/de/media/) +* [Newsletter](https://www.immoscout24.ch/c/de/ueber-uns/newsletter-anmeldung) +* [Ombudsstelle](https://konsum.ch/de/ombudsstelle-immobilienplattformen/) + +### Rechtliches + +* [Datenschutz](https://privacy.swissmarketplace.group/de/) +* [Insertionsregeln](https://www.immoscout24.ch/c/de/ueber-uns/insertionsregeln) +* [Sicherheitstipps](https://www.immoscout24.ch/c/de/ueber-uns/sicherheitshinweise) +* [Impressum](https://www.immoscout24.ch/c/de/ueber-uns/impressum) +* [AGB](https://www.immoscout24.ch/c/de/ueber-uns/agb) +* [Leistungsbeschrieb](https://www.immoscout24.ch/c/de/ueber-uns/member-bestimmungen-zusatz-agb) +* [Sicherheitsproblem melden](https://swissmarketplace.group/de/vulnerability-disclosure-program) +* Privatsphäre-Einstellungen + +### Services + +* [Betreibungsauszug](https://www.immoscout24.ch/de/betreibungsauszug?source=footer) +* [Umzugshilfe](https://www.immoscout24.ch/c/de/umzug) +* [Versicherungsberatung](https://www.immoscout24.ch/c/de/lp/versicherungsberatung) +* [Agenturverzeichnis](https://www.immoscout24.ch/agenturverzeichnis) +* [Hypothekenrechner](https://www.immoscout24.ch/de/finanzieren/hypothekenrechner) +* [Immobilienbewertung](https://www.immoscout24.ch/de/immobilienbewertung) + +### App herunterladen + +[](https://7o11.app.link/IS24_Web_Footer_iOS?%243p=a_custom_358665 "iOS App")[](https://7o11.app.link/IS24_Web_Footer_GP?%243p=a_custom_358665 "Android App") + +### Unser Partner + +[](https://www.swisstennis.ch/de/?utm_source=website-immoscout24&utm_medium=footer) + +* [Deutsch](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich) +* [Français](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich) +* [Italiano](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo) +* [English](https://www.immoscout24.ch/en/plot/buy/canton-zurich) + +### Folgen Sie uns + +[](https://www.facebook.com/immoscout24.ch "Facebook")[](https://www.instagram.com/immoscout24ch/ "Instagram")[](https://twitter.com/ImmoScout24ch "Twitter")[](https://www.youtube.com/user/ImmoScout24Schweiz "YouTube")[](https://www.linkedin.com/company/immoscout24-schweiz/ "LinkedIn") + +[SMG Swiss Marketplace Group](https://swissmarketplace.group/de/)[AutoScout24](https://www.autoscout24.ch/de)[FinanceScout24](https://www.financescout24.ch/de?utm_source=immoscout24.ch&utm_medium=web&utm_campaign=footer_bottom)[MotoScout24](https://www.motoscout24.ch/de)[anibis.ch](https://www.anibis.ch/de) + +© Copyright 2025 by SMG Swiss Marketplace Group AG . Alle Rechte vorbehalten.Die Vervielfältigung und Übernahme von Inseraten durch Dritte, insbesondere von Fotos und persönlichen Daten in diesen Inseraten, verletzt die damit verbundenen Rechte und ist ausdrücklich verboten. + +We Care About Your Privacy +-------------------------- + +We and our 455 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data.[Imprint](https://www.immoscout24.ch/en/info/impressum/3530) + +### We and our partners process data to provide: + +Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. List of Partners (vendors) + +I Accept No consent Show Purposes + + + +About Your Privacy +------------------ + +We process your data to deliver content or advertisements and measure the delivery of such content or advertisements to extract insights about our website. We share this information with our partners on the basis of consent. You may exercise your right to consent, based on a specific purpose below or at a partner level in the link under each purpose. These choices will be signaled to our vendors participating in the Transparency and Consent Framework. + +[Privacy Policy](https://www.immoscout24.ch/c/en/about-us/privacy-policy) + +Allow All +### Manage Consent Preferences + +#### Functional Cookies + +- [x] Functional Cookies + +These cookies enable the website to provide enhanced functionality and personalisation. They may be set by us or by third party providers whose services we have added to our pages. If you do not allow these cookies then some or all of these services may not function properly. + +Cookies Details + +#### Strictly Necessary Cookies + +Always Active + +These cookies are necessary for the website to function and cannot be switched off in our systems. They are usually only set in response to actions made by you which amount to a request for services, such as setting your privacy preferences, logging in or filling in forms. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. These cookies do not store any personally identifiable information. + +Cookies Details + +#### Targeting Cookies + +- [x] Targeting Cookies + +These cookies may be set on our website by our advertising partners. They can be used by these companies to build a profile of your interests and to control which advertisements you see on other websites. If you do not allow these cookies, you will still see advertisements, but they will no longer be tailored to you. Your master and usage data will also be made available to the other brands of the SMG Group for analysis, for the management of personalized advertising display, and for personalized marketing communication. The latter means that you may be contacted in a personalized manner for marketing purposes not only by this brand but also by all other brands of the SMG Group. The brands of the SMG Group are ImmoScout24, Homegate, Immostreet.ch, home.ch, Publimmo, Acheter-Louer.ch, CASASOFT, IAZI, AutoScout24, MotoScout24, anibis.ch, tutti.ch, Ricardo, FinanceScout24, Flatfox, and Moneyland. We use Enhanced Conversion that may transmit pseudonymised (e.g. hashed) email addresses to third parties such as Google or publishers (e.g. TX Group or Ringier AG) to improve campaign performance and measurement and/or to create audience segments. Personal identification is not possible unless you are logged in with the same email address and associated with an account of these third parties. Your personal data will be processed either jointly with these third parties, in accordance with their respective privacy notices, or independently by SMG as controller. Please note that your personal data may also be transferred to insecure third countries, where local authorities may access them without protection equivalent to European data protection law. If the level of data protection in a country does not match that of Switzerland, we ensure contractually that the protection of your personal data always corresponds to the level in Switzerland. + +Cookies Details + +#### Performance Cookies + +- [x] Performance Cookies + +These cookies allow us to count visits and traffic sources so we can measure and improve the performance of our site. They help us to know which pages are the most and least popular and see how visitors move around the site. All information these cookies collect is aggregated and therefore anonymous. If you do not allow these cookies we will not know when you have visited our site, and will not be able to monitor its performance. + +Cookies Details + +#### Store and/or access information on a device 365 partners can use this purpose + +- [x] Store and/or access information on a device + +Cookies, device or similar online identifiers (e.g. login-based identifiers, randomly assigned identifiers, network based identifiers) together with other information (e.g. browser type and information, language, screen size, supported technologies etc.) can be stored or read on your device to recognise it each time it connects to an app or to a website, for one or several of the purposes presented here. + +List of IAB Vendors|View Illustrations + +#### Personalised advertising and content, advertising and content measurement, audience research and services development 438 partners can use this purpose + +- [x] Personalised advertising and content, advertising and content measurement, audience research and services development + +* ##### Use limited data to select advertising 359 partners can use this purpose + +- [x] Switch Label +Advertising presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type or which content you are (or have been) interacting with (for example, to limit the number of times an ad is presented to you). + +View Illustrations + +* ##### Create profiles for personalised advertising 283 partners can use this purpose + +- [x] Switch Label +Information about your activity on this service (such as forms you submit, content you look at) can be stored and combined with other information about you (for example, information from your previous activity on this service and other websites or apps) or similar users. This is then used to build or improve a profile about you (that might include possible interests and personal aspects). Your profile can be used (also later) to present advertising that appears more relevant based on your possible interests by this and other entities. + +View Illustrations + +* ##### Use profiles to select personalised advertising 281 partners can use this purpose + +- [x] Switch Label +Advertising presented to you on this service can be based on your advertising profiles, which can reflect your activity on this service or other websites or apps (like the forms you submit, content you look at), possible interests and personal aspects. + +View Illustrations + +* ##### Create profiles to personalise content 103 partners can use this purpose + +- [x] Switch Label +Information about your activity on this service (for instance, forms you submit, non-advertising content you look at) can be stored and combined with other information about you (such as your previous activity on this service or other websites or apps) or similar users. This is then used to build or improve a profile about you (which might for example include possible interests and personal aspects). Your profile can be used (also later) to present content that appears more relevant based on your possible interests, such as by adapting the order in which content is shown to you, so that it is even easier for you to find content that matches your interests. + +View Illustrations + +* ##### Use profiles to select personalised content 92 partners can use this purpose + +- [x] Switch Label +Content presented to you on this service can be based on your content personalisation profiles, which can reflect your activity on this or other services (for instance, the forms you submit, content you look at), possible interests and personal aspects. This can for example be used to adapt the order in which content is shown to you, so that it is even easier for you to find (non-advertising) content that matches your interests. + +View Illustrations + +* ##### Measure advertising performance 404 partners can use this purpose + +- [x] Switch Label +Information regarding which advertising is presented to you and how you interact with it can be used to determine how well an advert has worked for you or other users and whether the goals of the advertising were reached. For instance, whether you saw an ad, whether you clicked on it, whether it led you to buy a product or visit a website, etc. This is very helpful to understand the relevance of advertising campaigns. + +View Illustrations + +* ##### Measure content performance 171 partners can use this purpose + +- [x] Switch Label +Information regarding which content is presented to you and how you interact with it can be used to determine whether the (non-advertising) content e.g. reached its intended audience and matched your interests. For instance, whether you read an article, watch a video, listen to a podcast or look at a product description, how long you spent on this service and the web pages you visit etc. This is very helpful to understand the relevance of (non-advertising) content that is shown to you. + +View Illustrations + +* ##### Understand audiences through statistics or combinations of data from different sources 253 partners can use this purpose + +- [x] Switch Label +Reports can be generated based on the combination of data sets (like user profiles, statistics, market research, analytics data) regarding your interactions and those of other users with advertising or (non-advertising) content to identify common characteristics (for instance, to determine which target audiences are more receptive to an ad campaign or to certain contents). + +View Illustrations + +* ##### Develop and improve services 300 partners can use this purpose + +- [x] Switch Label +Information about your activity on this service, such as your interaction with ads or content, can be very helpful to improve products and services and to build new products and services based on user interactions, the type of audience, etc. This specific purpose does not include the development or improvement of user profiles and identifiers. + +View Illustrations + +* ##### Use limited data to select content 83 partners can use this purpose + +- [x] Switch Label +Content presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type, or which content you are (or have been) interacting with (for example, to limit the number of times a video or an article is presented to you). + +View Illustrations + +List of IAB Vendors + +#### Use precise geolocation data 132 partners can use this special feature + +- [x] Use precise geolocation data + +With your acceptance, your precise location (within a radius of less than 500 metres) may be used in support of the purposes explained in this notice. + +List of IAB Vendors + +#### Actively scan device characteristics for identification 71 partners can use this special feature + +- [x] Actively scan device characteristics for identification + +With your acceptance, certain characteristics specific to your device might be requested and used to distinguish it from other devices (such as the installed fonts or plugins, the resolution of your screen) in support of the purposes explained in this notice. + +List of IAB Vendors + +#### Ensure security, prevent and detect fraud, and fix errors 290 partners can use this special purpose + +Always Active + +Your data can be used to monitor for and prevent unusual and possibly fraudulent activity (for example, regarding advertising, ad clicks by bots), and ensure systems and processes work properly and securely. It can also be used to correct any problems you, the publisher or the advertiser may encounter in the delivery of content and ads and in your interaction with them. + +List of IAB Vendors|View Illustrations + +#### Deliver and present advertising and content 286 partners can use this special purpose + +Always Active + +Certain information (like an IP address or device capabilities) is used to ensure the technical compatibility of the content or advertising, and to facilitate the transmission of the content or ad to your device. + +List of IAB Vendors|View Illustrations + +#### Match and combine data from other data sources 214 partners can use this feature + +Always Active + +Information about your activity on this service may be matched and combined with other information relating to you and originating from various sources (for instance your activity on a separate online service, your use of a loyalty card in-store, or your answers to a survey), in support of the purposes explained in this notice. + +List of IAB Vendors + +#### Link different devices 172 partners can use this feature + +Always Active + +In support of the purposes explained in this notice, your device might be considered as likely linked to other devices that belong to you or your household (for instance because you are logged in to the same service on both your phone and your computer, or because you may use the same Internet connection on both devices). + +List of IAB Vendors + +#### Identify devices based on information transmitted automatically 265 partners can use this feature + +Always Active + +Your device might be distinguished from other devices based on information it automatically sends when accessing the Internet (for instance, the IP address of your Internet connection or the type of browser you are using) in support of the purposes exposed in this notice. + +List of IAB Vendors + +#### Save and communicate privacy choices 245 partners can use this special purpose + +Always Active + +The choices you make regarding the purposes and entities listed in this notice are saved and made available to those entities in the form of digital signals (such as a string of characters). This is necessary in order to enable both this service and those entities to respect such choices. + +List of IAB Vendors|View Illustrations + +### Cookie List + +Clear + +- [x] checkbox label label + +Apply Cancel + +Consent Leg.Interest + +- [x] checkbox label label + +- [x] checkbox label label + +- [x] checkbox label label + +No consent Confirm My Choices + +[](https://www.onetrust.com/products/cookie-consent/) \ No newline at end of file diff --git a/test_web_content_20251002_215219/main_url_002_www.comparis.ch_immobilien_marktplatz_kanton_zuerich_grundstueck_kaufen.txt b/test_web_content_20251002_215219/main_url_002_www.comparis.ch_immobilien_marktplatz_kanton_zuerich_grundstueck_kaufen.txt new file mode 100644 index 00000000..5e1eacac --- /dev/null +++ b/test_web_content_20251002_215219/main_url_002_www.comparis.ch_immobilien_marktplatz_kanton_zuerich_grundstueck_kaufen.txt @@ -0,0 +1,516 @@ +Title: https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen +URL: https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen +Type: Main URL +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Grundstück in Kanton Zürich kaufen - Vergleiche 72 Inserate mit comparis.ch + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zu Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +DE + +[FR](https://fr.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen)[IT](https://it.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen)[EN](https://en.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen) + +[Login](https://www.comparis.ch/bff/login) + +[Login](https://www.comparis.ch/bff/login) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/newsletter) + +[Login](https://www.comparis.ch/bff/login) + +[DE](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen)[FR](https://fr.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen)[IT](https://it.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen)[EN](https://en.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen) + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. [Wohnen](https://www.comparis.ch/wohnen "Wohnen") +3. [Immobilien](https://www.comparis.ch/immobilien/default "Immobilien") +4. [Bauland kaufen](https://www.comparis.ch/immobilien/marktplatz/grundstueck/kaufen "Bauland kaufen") +5. Grundstück in Kanton Zürich kaufen + +[Favoriten (0)](https://www.comparis.ch/immobilien/result/favoritelist) + +Grundstück in Kanton Zürich kaufen: 72 Resultate +================================================ + +Filter (4)[Suchabo anlegen Suchabo](https://www.comparis.ch/immobilien/searchsubscription/add?requestobject=%7B%22DealType%22%3A20%2C%22SwapProperty%22%3A0%2C%22SiteId%22%3A0%2C%22RootPropertyTypes%22%3A%5B9%5D%2C%22PropertyTypes%22%3A%5B%5D%2C%22RoomsFrom%22%3Anull%2C%22RoomsTo%22%3Anull%2C%22FloorSearchType%22%3A0%2C%22LivingSpaceFrom%22%3Anull%2C%22LivingSpaceTo%22%3Anull%2C%22PriceFrom%22%3Anull%2C%22PriceTo%22%3Anull%2C%22ComparisPointsMin%22%3A0%2C%22AdAgeMax%22%3A0%2C%22AdAgeInHoursMax%22%3Anull%2C%22Keyword%22%3A%22%22%2C%22WithImagesOnly%22%3Anull%2C%22WithPointsOnly%22%3Anull%2C%22Radius%22%3Anull%2C%22MinAvailableDate%22%3A%221753-01-01T00%3A00%3A00%22%2C%22MinChangeDate%22%3A%221753-01-01T00%3A00%3A00%22%2C%22LocationSearchString%22%3A%22Kanton%20Z%C3%BCrich%22%2C%22Sort%22%3A3%2C%22HasBalcony%22%3Afalse%2C%22HasTerrace%22%3Afalse%2C%22HasFireplace%22%3Afalse%2C%22HasDishwasher%22%3Afalse%2C%22HasWashingMachine%22%3Afalse%2C%22HasLift%22%3Afalse%2C%22HasParking%22%3Afalse%2C%22PetsAllowed%22%3Afalse%2C%22MinergieCertified%22%3Afalse%2C%22WheelchairAccessible%22%3Afalse%2C%22LowerLeftLatitude%22%3Anull%2C%22LowerLeftLongitude%22%3Anull%2C%22UpperRightLatitude%22%3Anull%2C%22UpperRightLongitude%22%3Anull%2C%22ShowComparisPoints%22%3Afalse%7D) + +Kein neues Inserat verpassen! +* Umgehende Benachrichtigung +* Jederzeit anpassbar +* Kostenlos + +Infobox schliessen + +* * * + +Sortieren nach: + +Sortieren nach:Erstmals gefunden am + +Sortieren + +[Bauland Online seit einem Tag 706 m² ------ «Ihr neues Projekt mit Seesicht» 8820 Wädenswil Rotweg 20 CHF 2'100'000 Kaufpreis Merken Merken CHF 2'100'000 Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35829556) + +[Gewerbegrundstück Online seit 3 Tagen Gewerbegrundstück ----------------- «*Bauernhof mit mehreren landwirtschaftlichen Parzellen*» 8460 Marthalen Talackerberg, Im Türni CHF 1'020'000 Kaufpreis Merken Merken CHF 1'020'000 Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35821879) + +[Bauland Online seit 3 Tagen Bauland ------- «BAULAND AN TRAUMHAFTER LAGE AM FISCHBACH» 8162 Steinmaur auf Anfrage Kaufpreis Merken Merken auf Anfrage Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35819533) + +[Bauland Online seit 4 Tagen 1285 m² ------- «Windlach: Grundstück mit Potenzial für Wohnraumentwicklung» 8175 Windlach CHF 800'000 Kaufpreis Merken Merken CHF 800'000 Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35816133) + +[Bauland Online seit 5 Tagen 3166 m² ------- «Attraktives Entwicklungsareal an zentraler Lage mit 3?166 m²» 8050 Zürich CHF 26'000'000 Kaufpreis Merken Merken CHF 26'000'000 Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35813836) + +[Grundstück Online seit 5 Tagen  Grundstück ---------- «Hier beginnt Ihre Zukunft» 8340 Hinwil CHF 1'070'000 Kaufpreis Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken CHF 1'070'000 Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35812529) + +[Bauland Online seit einer Woche  9175 m² ------- «Vergabe der Gewerbefläche GB Nr. 74, Neuhausen am Rheinfall» 8212 Neuhausen am Rheinfall CHF 343 Kaufpreis pro m² Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken CHF 343 Kaufpreis pro m²](https://www.comparis.ch/immobilien/marktplatz/details/show/35789351) + +[Bauland Online seit einer Woche Bauland ------- «Zürich» 8000 Zürich auf Anfrage Kaufpreis Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken auf Anfrage Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35782427) + +[Grundstück Online seit einer Woche Grundstück ---------- «Zürich» 8001 Zürich auf Anfrage Kaufpreis Merken Merken auf Anfrage Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35778374) + +[Grundstück Online seit einer Woche  Grundstück ---------- «Attraktives Baugrundstück in ruhiger, ländlicher Umgebung» 8195 Wasterkingen CHF 475'000 Kaufpreis Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken CHF 475'000 Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35770932) + +* 1 +* [2](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen?page=1) +* [3](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen?page=2) +* [4](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen?page=3) +* [5](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen?page=4) +* [6](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen?page=5) +* [8](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen?page=7) +* [](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen?page=1) + +Gemeinden in diesem Kanton +-------------------------- + +[A](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#A) + +[B](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#B) + +[C](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#C) + +[D](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#D) + +[E](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#E) + +[F](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#F) + +[G](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#G) + +[H](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#H) + +[I](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#I) + +[J](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#J) + +[K](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#K) + +[L](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#L) + +[M](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#M) + +[N](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#N) + +[O](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#O) + +[P](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#P) + +[Q](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#Q) + +[R](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#R) + +[S](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#S) + +[T](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#T) + +[U](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#U) + +[V](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#V) + +[W](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#W) + +[X](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#X) + +[Y](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#Y) + +[Z](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#Z) + +### A + +[Adliswil](https://www.comparis.ch/immobilien/marktplatz/adliswil/grundstueck/kaufen) + +[Aeugst am Albis](https://www.comparis.ch/immobilien/marktplatz/aeugst-am-albis/grundstueck/kaufen) + +[Affoltern am Albis](https://www.comparis.ch/immobilien/marktplatz/affoltern-am-albis/grundstueck/kaufen) + +### B + +[Benken (ZH)](https://www.comparis.ch/immobilien/marktplatz/benken-zh/grundstueck/kaufen) + +[Bülach](https://www.comparis.ch/immobilien/marktplatz/buelach/grundstueck/kaufen) + +### D + +[Dättlikon](https://www.comparis.ch/immobilien/marktplatz/daettlikon/grundstueck/kaufen) + +[Dielsdorf](https://www.comparis.ch/immobilien/marktplatz/dielsdorf/grundstueck/kaufen) + +[Dietikon](https://www.comparis.ch/immobilien/marktplatz/dietikon/grundstueck/kaufen) + +[Dietlikon](https://www.comparis.ch/immobilien/marktplatz/dietlikon/grundstueck/kaufen) + +[Dinhard](https://www.comparis.ch/immobilien/marktplatz/dinhard/grundstueck/kaufen) + +[Dorf](https://www.comparis.ch/immobilien/marktplatz/dorf/grundstueck/kaufen) + +### E + +[Elgg](https://www.comparis.ch/immobilien/marktplatz/elgg/grundstueck/kaufen) + +[Embrach](https://www.comparis.ch/immobilien/marktplatz/embrach/grundstueck/kaufen) + +[Erlenbach (ZH)](https://www.comparis.ch/immobilien/marktplatz/erlenbach-zh/grundstueck/kaufen) + +### F + +[Fällanden](https://www.comparis.ch/immobilien/marktplatz/faellanden/grundstueck/kaufen) + +### H + +[Herrliberg](https://www.comparis.ch/immobilien/marktplatz/herrliberg/grundstueck/kaufen) + +[Hettlingen](https://www.comparis.ch/immobilien/marktplatz/hettlingen/grundstueck/kaufen) + +[Hinwil](https://www.comparis.ch/immobilien/marktplatz/hinwil/grundstueck/kaufen) + +[Höri](https://www.comparis.ch/immobilien/marktplatz/hoeri/grundstueck/kaufen) + +[Hüntwangen](https://www.comparis.ch/immobilien/marktplatz/huentwangen/grundstueck/kaufen) + +### M + +[Marthalen](https://www.comparis.ch/immobilien/marktplatz/marthalen/grundstueck/kaufen) + +[Mönchaltorf](https://www.comparis.ch/immobilien/marktplatz/moenchaltorf/grundstueck/kaufen) + +### N + +[Niederglatt](https://www.comparis.ch/immobilien/marktplatz/niederglatt/grundstueck/kaufen) + +[Niederhasli](https://www.comparis.ch/immobilien/marktplatz/niederhasli/grundstueck/kaufen) + +### O + +[Oetwil am See](https://www.comparis.ch/immobilien/marktplatz/oetwil-am-see/grundstueck/kaufen) + +### P + +[Pfäffikon](https://www.comparis.ch/immobilien/marktplatz/pfaeffikon/grundstueck/kaufen) + +### R + +[Rafz](https://www.comparis.ch/immobilien/marktplatz/rafz/grundstueck/kaufen) + +[Regensberg](https://www.comparis.ch/immobilien/marktplatz/regensberg/grundstueck/kaufen) + +[Regensdorf](https://www.comparis.ch/immobilien/marktplatz/regensdorf/grundstueck/kaufen) + +[Richterswil](https://www.comparis.ch/immobilien/marktplatz/richterswil/grundstueck/kaufen) + +[Rifferswil](https://www.comparis.ch/immobilien/marktplatz/rifferswil/grundstueck/kaufen) + +[Rümlang](https://www.comparis.ch/immobilien/marktplatz/ruemlang/grundstueck/kaufen) + +[Russikon](https://www.comparis.ch/immobilien/marktplatz/russikon/grundstueck/kaufen) + +[Rüti (ZH)](https://www.comparis.ch/immobilien/marktplatz/rueti-zh/grundstueck/kaufen) + +### S + +[Steinmaur](https://www.comparis.ch/immobilien/marktplatz/steinmaur/grundstueck/kaufen) + +### V + +[Volken](https://www.comparis.ch/immobilien/marktplatz/volken/grundstueck/kaufen) + +### W + +[Wädenswil](https://www.comparis.ch/immobilien/marktplatz/waedenswil/grundstueck/kaufen) + +[Wasterkingen](https://www.comparis.ch/immobilien/marktplatz/wasterkingen/grundstueck/kaufen) + +[Weisslingen](https://www.comparis.ch/immobilien/marktplatz/weisslingen/grundstueck/kaufen) + +[Wildberg](https://www.comparis.ch/immobilien/marktplatz/wildberg/grundstueck/kaufen) + +### Z + +[Zell (ZH)](https://www.comparis.ch/immobilien/marktplatz/zell-zh/grundstueck/kaufen) + +[Zürich](https://www.comparis.ch/immobilien/marktplatz/zuerich/grundstueck/kaufen) + +Das könnte Sie interessieren +---------------------------- + +### Weitere Comparis Services + +[Was zahlt die Nachbarschaft?](https://www.comparis.ch/immobilien/mashup/show)[Umzugsfirma Zürich](https://www.comparis.ch/immobilien/umzug/anbieter/zuerich)[Inserieren](https://www.comparis.ch/immobilien/inserieren/default) + +### Weitere Kaufobjekte in Kanton Zürich + +[Wohnung kaufen Kanton Zürich (1500)](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/wohnung/kaufen)[Haus kaufen Kanton Zürich (642)](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/haus/kaufen)[Mehrfamilienhaus kaufen Kanton Zürich (70)](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/mehrfamilienhaus/kaufen) + +[ZU DEN FAVORITEN](https://www.comparis.ch/immobilien/result/favoritelist) + +Filter (4) + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/newsletter) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) + + \ No newline at end of file diff --git a/test_web_content_20251002_215219/main_url_003_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferliste.txt b/test_web_content_20251002_215219/main_url_003_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferliste.txt new file mode 100644 index 00000000..716ced49 --- /dev/null +++ b/test_web_content_20251002_215219/main_url_003_www.homegate.ch_kaufen_bauland_kanton-zuerich_trefferliste.txt @@ -0,0 +1,174 @@ +Title: https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste +URL: https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste +Type: Main URL +Extracted: 2025-10-02 21:52:19 +================================================================================ + +73 Bauland kaufen in Kanton Zürich | homegate.ch + +=============== + +[](https://www.homegate.ch/de) +* [Suchen](https://www.homegate.ch/de "Suchen") +* [Services](https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages "Services") + +[Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen "Inserieren") + +[Mein Konto](https://www.homegate.ch/de/overview "Mein Konto") + +Menü + +[](https://www.homegate.ch/de) +* [Suchen](https://www.homegate.ch/de "Suchen") +* [Services](https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages "Services") +* [Schätzen](https://www.homegate.ch/de/immobilienbewertung "Schätzen") +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber?intlink=h_Advisor "Ratgeber") + +[Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen "Inserieren") + +[Mein Konto](https://www.homegate.ch/de/overview "Mein Konto") + +DE +* [DE](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste) +* [FR](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste) +* [IT](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste) +* [EN](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste) + +Ort + + Kanton Zürich + + Kanton Zürich + + Preis bis + + + + Weitere Filter + + 73 Treffer + +73 Treffer - Bauland kaufen in Kanton Zürich +============================================ + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 16    CHF 2’563’760.– Top **360m²** Nutzfläche Luegetenstrasse 11, 8489 Wildberg Ihr neues Zuhause mit Potenzial - Idyllisches Landhaus mit Baulandreserve Ihr neues Zuhause Willkommen in Ihrem zukünftigen Traumdomizil - ein grosszügiges, freistehendes Landhaus an ruhiger und idyllischer Aussichtslage im malerischen Wildberg. Hier vereinen sich ländliche Idylle, Privatsphäre und die seltene Möglichkeit, Wohnraum nach eigenen Vorstellungen zu schaffen oder zu erweitern.Ob als charmantes Familienrefugium mit grossem Garten oder als Investitionsobjekt mit Entwicklungspotenzial - dieses einzigartige Anwesen bietet Ihnen beide Optionen. Auf dem 1339m² grossen Grundstück geniessen Sie nicht nur viel Platz zum Leben, sondern verfügen auch über eine wertvolle Baulandreserve, die Ihnen vielfältige Gestaltungsmöglichkeiten eröffnet. Erste Abklärungen zeigen: Es besteht die Möglichkeit, ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren - ein echter Mehrwert für visionäre Käufer.Tauchen Sie ein in eine grüne Oase mit Weitblick - ein Ort, der Ruhe schenkt und inspiriert.Highlights auf einen Blick • Idyllische, ruhige Aussichtslage mit hohem Erholungswert • Grosszügiges Grundstück mit 1339m², ideal zur Eigennutzung und/oder für die Entwicklung eines Neubaus • Baulandreserve: Attraktives Entwicklungspotenzial - gemäss erster Einschätzung besteht die Möglichkeit, zusätzlich zum bestehenden Einfamilienhaus ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren (unverbindlich, ohne Gewähr) • Blühender Garten mit verschiedenen Sitzplätzen, Pergola mit Aussencheminée, Gartenhäusern, gepflegtem Baumbestand und weitläufigen Grünflächen • Solide Bausubstanz mit Doppelschalenmauerwerk • Grosszügiges Raumkonzept mit ca. 220m² Wohnfläche und ca. 96m² zusätzlichem Stauraum im Untergeschoss. Total ca. 360m² Bruttofläche. • Geräumiger Wohnbereich mit gemütlichem Kachelofen - ein Ort zum Ankommen und Wohlfühlen • Praktische Wohnküche mit integriertem Essbereich - ideal für gesellige Stunden • 4 helle Schlafzimmer - ideal für Familien oder Homeoffice • 2 Nasszellen mit Tageslicht • Ausgebauter Estrich für zusätzlichen Raum oder kreative Nutzungsmöglichkeiten • Beheizt durch Elektrospeicher und wassergeführte Fussbodenheizung • Garage mit elektrischem Tor und weitere Parkmöglichkeiten auf dem Grundstück • Mit einer stilvollen Modernisierung verwandeln Sie dieses Haus in ein wahres Schmuckstück Verkaufspreis: CHF 1'870'000.-Mit unserer virtuellen 360-Grad-Tour können Sie bereits die ersten Eindrücke dieser tollen Liegenschaft gewinnen. Sehr gerne zeigen wir Ihnen diese Liegenschaft direkt vor Ort und freuen uns auf Ihre Kontaktaufnahme.Weitere EckdatenBaujahr Haus: 1984, Baujahr Gerätehaus: 1986, Kubatur Haus (GVZ): 936m³, Kubatur Gerätehaus (GVZ): 40m³, Grundbuchblatt: Nr. 437, Kataster-Nr.: 249, 1/4 subjektiv-dingliches Miteigentum an Blatt 444, Kataster 249. Nettowohnfläche: ca. 220m², Bruttowohnfläche: ca. 360m², Grundstücksfläche: 1'339m².Massivbauweise, Doppelschalenmauerwerk, neuwertige Holzmetallfenster (EgoKiefer) mit dreifacher Verglasung und Sprossen & Holzläden. Elektrospeicherofen, wassergeführte Fussbodenheizung, Elektroboiler 300 Liter.Treppenlift, Garage mit elektrischem Torantrieb. Küche im Landhausstil mit Granitabdeckung, Geschirrspüler, Induktions-Kochherd und Kühlschrank mit Gefrierfach.BodenbelägeEG: Entrée, Gang, Dusche, Küche, Essen mit Plattenboden.OG: Zimmer und Vorplatz mit Laminat in Holzoptik. Bad mit Platten.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002491909) + +[*  *  *  *  *  *  *  *  1 / 8 CHF 2’604’890.– Top Wehntalerstrasse 28, 8181 Höri Grundstück mit Baubewilligung für ein Mehrfamilienhaus mit 6 Einheiten Das Grundstück ist derzeit mit einem Einfamilienhaus bebaut (Baujahr 1960)Nach dem Rückbau kann, gemäss Bewilligung ein Mehrfamilienhaus mit 6 Wohnungen (3 Wohnungen 4½ Zimmer und 3 Wohnungen 2½ Zimmer) mit 9 Tiefgaragen, 1 Tiefgaragen Behinderten Parkplatz sowie 2 Besucher Aussenparkplätze realisiert werden. (Siehe Pläne)Im Kaufpreis enthalten: • Baubewilligung • Bewilligungsgebühren • Projektpläne in PDF, DWG und Step Dateien • Lärmschutznachweis Strasse / Lärmschutznachweis Fluglärm • Geologisches Gutachten (Meldeblatt zu Bodenverschiebung) Parzelle nicht belastet! • Private Kontrolle bei Rückbau- und Umbau. (2 Asbestproben wurden positiv auf Asbest getestet) • Amtlich Beglaubigter Katasterplan • Farb- und Materialkonzept Verkaufspreis für Liegenschaft inkl. Vorbeschriebenen Leistungen: CHF 1'900'000.-Wir hoffen Ihr Interesse geweckt zu haben. Gerne stellen wir Ihnen die Verkaufsdokumente und Projektunterlagen, mit ausführlichen Informationen, per E-Mail zu.Es werden keine Makleranfragen berücksichtigt.Die zugestellten Informationen sind Eigentum von Bujar Bunjaku. Veröffentlichung, kopieren sind nicht gestattet.Kaufabwicklung:CHF 72'000.-- fällig bei Unterzeichnung der Kaufzusage; CHF 150'000.-- fällig bei Unterzeichnung und notarieller Beurkundung des Kaufvertrages; Restzahlung des Verkaufspreises fällig bei der Eigentumsübertragung.Notariats- und Grundbuchgebühren: Je zur Hälfte zu Lasten Käufer / Verkäufer.Anbieter:Bujar BunjakuWehntalerstrasse 288181 Höri Wegzeit Neu -](https://www.homegate.ch/kaufen/4002530816) + +[*  *  *  *  1 / 4 CHF 1’096’790.– Top Bahnhofstrasse 41, 8496 Steg im Tösstal 1’111 m² attraktives Bauland in Steg Dieses 1'111 m² grosse Bauland liegt im schönen Tösstal, einer der sonnigsten Regionen der Ostschweiz. Die ruhige Lage direkt am Waldrand bietet viel Natur, frische Luft und Privatsphäre.Ein idealer Ort für Naturliebhaber und Ruhesuchende, die dennoch Wert auf eine gute Erreichbarkeit legen. Hier lassen sich Wohnträume verwirklichen.Besichtigungen sind jederzeit frei möglich.Neugierig geworden? Alle weiteren Details entnehmen Sie bitte der oben angehängten Verkaufsdokumentation.Isler-Consolis AG, Technikumstrasse 73, 8401 Winterthur, Tel. 052 267 81 00, Dorentina Bytyqi Wegzeit Neu -](https://www.homegate.ch/kaufen/4002331120) + +[*  *  *  *  1 / 4 Preis auf Anfrage Top Lüss, 8542 Wiesendangen Im Baurecht abzugeben: 14’770 m2 Bauland an bester Lage im steuergünstigen Wiesendangen Im Baurecht abzugeben:14’770 m2 Bauland an bester Lage im steuergünstigen WiesendangenGrundstück WD4674 – Lüss WiesendangenAlle Details zum Grundstück, zum Baurechtsvertrag sowie zu den Vergabekriterien finden sie im angefügten Dossier.Verbindliche Angebote für eine Übernahme des Baurechtsvertrages inklusive Finanzierungsnachweis sind einzureichen an:Gemeinde Wiesendangenz. Hd. Martin SchindlerSchulstrasse 208542 Wiesendangen Bitte verwenden Sie für die Angebotseingabe das Formular im Anhang.Eingabeschluss: Montag, 20. Oktober 2025, 11.00 Uhr Wegzeit Neu -](https://www.homegate.ch/kaufen/4002510601) + +[ 1 / 1 Preis auf Anfrage Top Büntlistrasse 1, 8174 Stadel Bauland in Stadel b. Niederglatt Die Primarschule Stadel hat zwei Landparzellen zu verkaufen. Nummber 305 & 306. 305 ist unbebaut, hingegen 306 hat ein Gebäude, welches als Kindergarten und Mietwohnungen genutzt wurde. Wir möchten die beiden Landparzellen zusammen verkaufen. Der Kontakt für die erste Anlaufstelle ist Rolf Schindelholz einer unserer Mitarbeiter in der Schulverwaltung. Geleitet wird das Projekt von Patrick Heusser dem Finanzvorstand der Primarschulpflege Stadel. Wegzeit Neu -](https://www.homegate.ch/kaufen/4000669374) + +[*  *  *  *  *  *  *  *  *  *  *  *  1 / 12    CHF 2’323’840.– Hürstringstrasse 37, 8046 Zürich Grundstück mit bestehendem EFH und grossem Potenzial Gerne stellen wir Ihnen das Grundstück mit grossem Potenzial und vielen Möglichkeiten vor.Nach Absprache verkaufen wir an ruhiger Lage in Zürich ein Grundstück mit bestehendem Einfamilienhaus. Interessant an diesem Objekt ist jedoch, dass Sie beim Kauf bereits über die zugehörige Baubewilligung verfügen, welche es Ihnen erlaubt, den Wohnraum auf dieser Parzelle nach Ihren Wünschen zu vergrössern und zu sanieren.Nicht weit vom Zürcher Hauptbahnhof entfernt, hinter dem Käferberg liegt die grosszügige Parzelle mitten in einem ruhigen Wohnquartier mit 30er-Zone.Zu Fuss erreichen Sie eine Bushaltestelle, sowie auch den kleinen Wald, der sich ideal für kürzere Spaziergänge eignet.Die wichtigsten Infos in Kürze: • Landparzelle inkl. Einfamilienhaus und Baubewilligung zum Ausbau der Wohnfläche • Baujahr 1934 • Grundstückfläche von 410 m2 • Projektmöglichkeit 1: Ausbau zum Mehrfamilienhaus mit zwei Eigentums- oder Mietwohnungen • Projektmöglichkeit 2: Ausbau zum Generationenhaus Erleben Sie die ruhige Atmosphäre und gleichzeitige Nähe zum Stadtzentrum bei einem persönlichen Besuch!Für nähere Informationen zum Objekt oder einen Besichtigungstermin dürfen Sie sich gerne jederzeit bei uns melden.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002349882) + +[*  *  *  *  *  *  *  *  *  *  *  1 / 11    CHF 3’290’400.– Luzernerstrasse 57, 8903 Birmensdorf (ZH) Sonnige Aussichtslage Im Auftrag unseres Kunden verkaufen wir ein Bauland an sonniger Aussichtlage mit 1'228 m² Grundstücksfläche (Wohnzone W2).Die bestehende Liegenschaft präsentiert sich in einem dem Alter entsprechend gut unterhaltenen Zustand.Verkaufsrichtpreis: CHF 2'400'000Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002566208) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13    CHF 1’302’440.– Kanalweg 2, 8714 Feldbach Bauland für projektiertes Einfamilienhaus Im beschaulichen Dorf Feldbach am Zürichsee ist dieses Grundstück mit einer bestehenden, einseitig angebauten Scheune zu verkaufen. Im Kaufpreis inbegriffen ist ein bewilligungsfähiges Vorprojekt für ein Einfamilienhaus als Ersatzbau der Scheune.Das Objekt bietet Ihnen die einmalige Möglichkeit, Ihren Traum vom Eigenheim an idyllischer Lage zu verwirklichen. Es bietet genügend Platz für eine Familie, auch eine Kombination von "Wohnen und Arbeiten" ist denkbar.Innert 30 Minuten sind Sie mit der S-Bahn in Zürich, auch Kindergarten und Primarschule sind nah. Einkaufsmöglichkeiten bestehen in Hombrechtikon, Stäfa und Rapperswil. Im Sommer lockt in unmittelbarer Nähe eine Abkühlung in der schmucken Seebadi Feldbach.Es besteht ein aktueller Kostenvoranschlag für das Haus (Holzelementbauweise) inkl. Umgebung, Bau- und Nebenkosten in der Höhe von Fr. 1'380'000.--.Haben wir Sie neugierig gemacht? Dann rufen Sie uns an. Gerne beantworten wir Ihre Fragen oder stellen Ihnen unsere Verkaufsdokumentation zum Studium zu. Die Liegenschaft kann selbstverständlich auch besichtigt werden. Wir freuen uns auf Ihren Anruf.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002434745) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13    CHF 4’111’620.– **5.5** Zimmer Schaffhauserstrasse 226b, 8057 Zürich Mehr Raum fürs Leben: Reihenhaus mit Potenzial Attraktive Stadtliegenschaft mit ausgearbeitetem ProjektIm Zürcher Kreis 11 veräussern wir ein hübsches Reiheneinfamilien-Eckhaus mit grosszügigem Umschwung. Die Liegenschaft und das Grundstück verfügen über viel Ausnützungspotenzial und ermöglicht so die Realisation spannender Projekte sowohl im Umbau als auch Neubau.Diese Liegenschaft überzeugt durch viele Besonderheiten: • grosszügiger Umschwung mit viel Potenzial • Blick ins Grüne von nahezu allen Fenstern • Schwedenofen im Wohnbereich • viel Stauraum durch Wandschränke und Estrich • Altbaucharme in modernem Quartier • zentrale und familienfreundliche Lage • sonnenverwöhnter Standort Haben wir Ihr Interesse geweckt? Bestellen Sie noch heute unsere ausführliche Verkaufsdokumentation mittels Kontaktformular und Sie erhalten weitere spannende Informationen zur Immobilie. Wir freuen uns über Ihre Kontaktaufnahme!Une oasis de verdure dans la ville de Zurich avec un projet élaboréDans le quartier 11 de Zurich, nous vendons une jolie maison mitoyenne en angle avec de vastes alentours. L'immeuble et le terrain disposent d'un grand potentiel d'exploitation et permettent ainsi la réalisation de projets passionnants, tant en transformation qu'en construction neuve.Cette propriété convainc par ses nombreuses particularités : • Un vaste terrain avec beaucoup de potentiel • Une vue sur la verdure depuis presque toutes les fenêtres • Un poêle suédois dans le séjour • beaucoup d'espace de rangement grâce aux armoires murales et au grenier • Le charme d'un ancien bâtiment dans un quartier moderne • Un emplacement central et favorable aux familles • Un emplacement ensoleillé Nous avons éveillé votre intérêt ? Commandez dès aujourd'hui notre documentation de vente détaillée au moyen du formulaire de contact et vous recevrez d'autres informations passionnantes sur le bien immobilier. Nous nous réjouissons de votre prise de contact!A green oasis in the city of Zurich with an elaborate projectIn Zurich's Kreis 11 district, we are selling a pretty terraced single-family corner house with spacious grounds. The property and the plot have a lot of utilization potential and thus enable the realization of exciting projects both in conversion and new construction.This property boasts many special features: • spacious grounds with lots of potential • view of the countryside from almost all windows • Swedish stove in the living area • lots of storage space thanks to wall cupboards and attic • old building charm in a modern district • central and family-friendly location • sun-drenched location Have we piqued your interest? Order our detailed sales documentation today using the contact form and you will receive further exciting information about the property. We look forward to hearing from you!  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002346061) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13 CHF 4’044’440.– Mühlemattstrasse 12, 8135 Langnau am Albis Bauland oder bestehendes Einfamilienhaus zum Verkauf! Dieses freistehende Einfamilienhaus befindet sich an ruhiger Lage und bietet eine seltene Kombination aus architektonischem Charakter, grosszügigem Umschwung und inspirierendem Entwicklungspotenzial. Eingebettet in viel Grün und umgeben von Bäumen geniessen Sie hier Privatsphäre, Ruhe – und eine wunderschöne Weitsicht.Das Haus überzeugt durch eine unverwechselbare Ausstrahlung. Die Backsteinwände im Innenbereich verleihen dem Wohnraum eine warme, natürliche Atmosphäre, während das Cheminée im Wohnzimmer für Behaglichkeit an kühleren Tagen sorgt. Der Grundriss ist offen und einladend, ergänzt durch grosse Fensterfronten, die Licht und Natur ins Haus holen.Ein Highlight ist die grosszügige Terrasse mit herrlichem Ausblick – ideal für gemütliche Stunden im Freien. Der Garten ist weitläufig und bietet viel Platz für individuelle Gestaltung. Mit etwas Aufmerksamkeit lässt sich hier ein wunderbares grünes Paradies schaffen – ob als Familiengarten, Rückzugsort oder für kreative Projekte im Freien.Dank der Grundstücksgrösse und der Lage eröffnet die Liegenschaft auch interessante Perspektiven für einen möglichen Ersatzneubau - wie ein modernes Einfamilienhaus oder ein Mehrfamilienhaus.Gerne stellen wir Ihnen weitere Informationen zur Verfügung oder vereinbaren einen persönlichen Besichtigungstermin. Entdecken Sie das Potenzial und die besondere Atmosphäre dieses einzigartigen Ortes. In der Verkaufsdokumentation finden Sie alle wichtigen Informationen.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002406229) + +[*  *  *  *  *  *  1 / 6    * Ruhige Lage CHF 3’358’950.– 8192 Glattfelden ZWEIFELSFREIES BAULAND IN ZWEIDLEN Im beliebten Zweidlen verkaufen wir ein eine attraktive, 1'226 m² grosse Baulandparzelle mit Bestandesobjekt.Unsere Projektstudie zeigt eine hohe Ausnutzung für die Erstellung eines Mehrfamilienhauses. • Anrechenbare mögliche Bruttogeschossfläche von max. 940 m² (Projekt 789 m²) • Wohn- und Gewerbezone WG 2.3 • Kein Denkmalschutz beim Bestandesobjekt • Die Deutsche Grenze in Kaiserstuhl ist nur 8 Autominuten entfernt • Der Flughafen Zürich ist in nur 19 Autominuten erreichbar Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: https://www.propertyowner.ch/de/immobilien/25-12278 Referenznummer: 25-12278Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website https://www.propertyowner.ch/immobilien/ und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen! * Ruhige Lage  Wegzeit -](https://www.homegate.ch/kaufen/4002558181) + +[*  *  *  *  *  *  *  *  *  *  *  *  1 / 12 Preis auf Anfrage Überlandstrasse 23, 8340 Hinwil Industrie- und Baulandparzelle an attraktivem Standort im Zürcher-Oberland Im pulsierenden Industriegebiet von Hinwil verkaufen wir ein Industriebaugrundstück an einer top frequentierter Lage, direkt an der Hauptachse in Rapperswil Wetzikon Pfäffikon ZH. Die Baulandparzelle befindet sich am Rand der Industriezone und grenzt an die Wohnzone zu Hinwil ZH.Eckdaten:- Grundstück-Fläche total 4'246 m2- Bauzone Industrie/Gewerbe IG/7 - Baumassenziffer 7 m3/m2- Gebäudehöhe maximal 21.5 m- Gebäudelänge maximal offen- Grosser Grenzabstand Nationalstrasse- Allseitiger Gebäudeabstand 3.5 m1- Maximal mögliche Baumasse ca. 30'000 m3- Bruttogeschossfläche ca. 9'500 m2Das Baugrundstück wird derzeit noch mit zwei Wohneinheiten, der Autowerkstatt mit separatem Showroom und einer Tankstelle genutzt. Rund um die Liegenschaft bieten sich grosse, befestigte Flächen zur Nutzung an.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002417917) + +[*  *  *  *  *  *  *  1 / 7    CHF 5’484’000.– 8156 Oberhasli ATTRAKTIVE INVESTITION IN FLUGHAFENNÄHE Unweit des Flughafens Kloten bieten wir ein attraktives Gewerbebauland für ein Neubauprojekt im strategisch ideal gelegenen Oberhasli zum Verkauf an. • Parzellenfläche: 2'010 m² • Zone: Gewerbezone • Optionen für Investoren: Neubau einer Gewerbeimmobilie mit bis zu 5'000 m² Geschossfläche (Verkauf oder Vermietung) • Optionen für Selbstnutzer: Neubau einer für die Selbstnutzung konzipierten Gewerbeimmobilie mit bis zu 5'000 m² Geschossfläche • Es besteht die Möglichkeit, die derzeit vermietete Gewerbeliegenschaft weiterzuführen. Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: https://www.propertyowner.ch/immobilien/24-101578/ Referenznummer: 24-101578Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website https://www.propertyowner.ch/immobilien/ und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen!  Wegzeit -](https://www.homegate.ch/kaufen/4001472412) + +[*  *  *  *  *  *  1 / 6    CHF 1’919’390.– 8187 Weiach WILLKOMMENE WERTSCHÖPFUNG IN WEIACH Im steuergünstigen Weiach bieten wir an ruhiger Ortskernlage eine wohldimensionierte, unbebaute Baulandparzelle zum Verkauf an. Unsere Baulandstudie sieht die Erstellung von zwei attraktiven Doppeleinfamilienhäusern mit 4 Wohneinheiten vor. • 1'157 m² Parzellenfläche mit bestehender Zufahrt im Wegrecht • Unser Projekt sieht die Erstellung von zwei Doppeleinfamilienhäusern mit je zwei Vollgeschossen vor • Total erstellbare Bruttogeschossfläche von 648 m² • Maximal erstellbare Gebäudelänge von 25 Metern • Der Flughafen Zürich ist in nur 20 Minuten zu erreichen, die Stadt Zürich ist nur rund 30 Km entfernt Interessiert? Weitere Informationen und Bilder zum Grundstück sowie Besichtigungsmöglichkeiten unter: https://www.propertyowner.ch/immobilien/24-99121/ Referenznummer: 24-99121Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch- Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website https://www.propertyowner.ch/immobilien/ und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen!  Wegzeit -](https://www.homegate.ch/kaufen/4001410555) + +[ 1 / 1 CHF 2’399’240.– In der Gass 2, 8627 Grüningen Grundstück mit Baubewilligung für MFH zu verkaufen Zum Verkauf steht ein Grundstück mit bewilligtem Neubauprojekt. Gebäude C des Enssamble an der Binzikerstrasse 21 / In der Gass 2, 8627 Grüningen. Die aktuell bestehenden Garagen können abgebrochen werden und durch einen Neubau mit 8 Wohnungen unterschiedlicher Grösse mit attraktiven Aussenbereich ersetzt werden. Zusätzlich wurde der gemeinsame Bau einer Tiefgarage für 11 Parkplätze mit der Zufahrt über die Strasse "In der Gass" bewilligt.  Wegzeit Neu -](https://www.homegate.ch/kaufen/3003479026) + +[*  *  *  *  *  *  1 / 6    CHF 2’879’100.– Rotweg 20, 8820 Wädenswil Ihr neues Projekt mit Seesicht Im Auftrag unseres Kunden verkaufen wir an bevorzugter, erhöhter und ruhiger Wohnquartierlage mit schöner See- und Fernsicht, 706 m² Bauland mit Rückbauobjekt.Verkaufsrichtpreis: CHF 2'100'000.00Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002559578) + +[*  *  *  *  *  *  *  1 / 7    CHF 651’220.– Auf Anfrage 1, 8195 Wasterkingen Attraktives Baugrundstück in ruhiger, ländlicher Umgebung Willkommen in Wasterkingen, einer idyllischen und ruhigen Gemeinde im Zürcher Unterland, die für ihre hohe Lebensqualität, ländliche Gelassenheit und dennoch gute Erreichbarkeit bekannt ist. Genau hier wartet ein attraktives Baugrundstück auf Sie – die ideale Basis für Ihr zukünftiges Zuhause.Das Grundstück ist voll erschlossen und liegt in der Kernzone B, was Ihnen zahlreiche Gestaltungsmöglichkeiten eröffnet. Ob ein modernes Einfamilienhaus, ein klassisches Zuhause im Dorfcharakter oder ein individuelles Architektenprojekt – hier können Sie Ihre Wohnträume ganz nach Ihren Vorstellungen verwirklichen.Die charmante Gemeinde Wasterkingen besticht durch ihre ruhige Lage inmitten von Feldern, Reben und Natur.Dieses ImmoSky-Angebot bietet folgende *Mehr Leistung*:+ Voll erschlossen+ Ruhige Gemeinde+ Ideale Grösse für flexibilität (650m²)+ Kernzone B+Überbauungsziffer für Hauptgebäude 30%Dieses Grundstück bietet Ihnen die seltene Gelegenheit, ländliche Idylle mit urbaner Nähe zu vereinen – ein Ort, an dem Sie zur Ruhe kommen und dennoch bestens angebunden sind.Erfüllen Sie sich hier den Traum vom Eigenheim und gestalten Sie Ihr persönliches Refugium in Wasterkingen.Haben wir Sie mit diesem Angebot überzeugt? Dann zögern Sie nicht und kontaktieren Sie uns für weitere Fragen oder einen Besichtigungstermin!(Das Verkaufsdossier wird in der Regel innerhalb von maximal 24 Stunden an Sie versendet. Bitte überprüfen Sie auch Ihren SPAM-Ordner.)  Wegzeit -](https://www.homegate.ch/kaufen/4002537208) + +[*  *  *  *  *  *  *  1 / 7    CHF 7’540’490.– Staldernstrasse 13, 8158 Regensberg Entwicklungsgrundstück an top Lage in der Kernzone 2 In der gefragten Gemeinde Regensberg (ZH) steht ein hervorragend gelegenes Grundstück zum Verkauf, das sich ideal für Investoren, General- oder Totalunternehmer eignet. Die 2.557 m² grosse Parzelle Nr. 949 befindet sich in der Kernzone 2, die vielfältige bauliche und nutzungsbezogene Entwicklungsmöglichkeiten zulässt, insbesondere für Wohn- oder gemischt genutzte Projekte.Aktuell steht auf dem Grundstück ein nicht erhaltenswertes Gebäude, das im Rahmen einer Neuentwicklung rückgebaut werden kann. Eine Baueingabe oder Bewilligung liegt nicht vor, sodass volle gestalterische Freiheit innerhalb der geltenden bau- und zonenrechtlichen Rahmenbedingungen besteht.Berechnungen zeigen, dass eine nachhaltige Mietertragserwartung von rund CHF 485'600 pro Jahr realistisch erscheint - unter der Annahme einer Ausnutzung mit rund 1 664 m² Hauptnutzfläche (HNF) und 28 Tiefgaragenplätzen. Der ermittelte Kapitalisierungssatz liegt bei 4.20 %.Wesentliche Bewertungskennzahlen:Verkehrswert (diskontierter Landwert): CHF 5'505'000Ertragswert im erneuerten Zustand: CHF 11'556'795Realwert (hypothetisch): CHF 12'485'000Potenzieller Verkaufserlös: CHF 16'190'000Bruttorendite (Mietwert): 4.20%Die hypothetische Bebauung sieht zwei Mehrfamilienhäuser mit einer Bruttogeschossfläche (BGF) von insgesamt 2'080 m² vor - entsprechend einer Ausnützungsziffer von 0.81, voll im Rahmen der Zonenordnung. Die kalkulierten Baukosten (BKP 2-5) belaufen sich auf ca. CHF 8.74 Mio. Der diskontierte Landwert pro m² liegt bei CHF 2'155, was das wirtschaftliche Potenzial zusätzlich unterstreicht.Die Kernzone 2 erlaubt neben der reinen Wohnnutzung auch Mischnutzungen, beispielsweise mit gewerblichen Angeboten im Erdgeschoss. Dies ist ein zusätzlicher Vorteil für flexible, standortgerechte Entwicklungskonzepte. Die Lage in Regensberg bietet ruhige Wohnqualität in der Nähe der Agglomeration Zürich und ist in eine attraktive historische Umgebung eingebettet.Fazit: Das Grundstück bietet die seltene Gelegenheit, ein entwicklungsfähiges Grundstück an bester Lage mit bestehendem Abbruchobjekt zu akquirieren und nach eigenen Vorstellungen zu bebauen. Dank der flexiblen Nutzungsmöglichkeiten und des attraktiven Standorts stellt diese Investition eine hervorragende Ausgangslage für renditestarke Projektentwicklungen dar.Für detaillierte Informationen stehen wir Ihnen gerne zur Verfügung.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002529588) + +[*  *  *  1 / 3   CHF 1’686’330.– 8187 Weiach Ihr Bauland in Weiach ZH zum Schnäppchenpreis! Ihre Chance auf ein vielversprechendes Bauprojekt In der beliebten Gemeinde Weiach, eingebettet in eine ruhige und dennoch gut erreichbare Lage, erwartet Sie die Parzelle 1602. Das Grundstück in der Kernzone (K) bietet ideale Rahmenbedingungen für Investoren und Bauherren, die von Flexibilität und klar definierten Bauvorgaben profitieren möchten.Die Parzelle ermöglicht eine Bebauung mit bis zu 2 Vollgeschosse, einem anrechenbaren Dachgeschoss sowie einem Untergeschoss. Die maximale Gebäudehöhe von 7.50 m und die erlaubte Gebäudelänge von bis zu 30 m eröffnen vielseitige Bau- und Gestaltungsmöglichkeiten. Mit grosszügigen Grenzabständen von mindestens 6 m (grosser Grenzabstand) und 4 m (kleiner Grenzabstand) bietet das Grundstück genügend Raum für ansprechende Projekte mit Privatsphäre.Dieses Bauland ist die perfekte Gelegenheit, um ein individuelles Projekt in einer aufstrebenden Region zu realisieren. Egal, ob Sie Wohnraum schaffen oder ein Mischprojekt umsetzen möchten - die Parzelle hält alle Optionen offen.Ihre Vorteile auf einen Blick: • Vorhandene Machbarkeitsstudie • Bebaubare Fläche 1026 m² • Landwirtschaftszone 479 m² (CHF 60'000.- exkl.) • Kernzone (K) mit klar definierten Bauvorgaben • Maximal 2 Vollgeschosse, 1 anrechenbares Dach- und Untergeschoss • Gebäudehöhe bis zu 7.50 m • Maximale Gebäudelänge: 30 m • Grenzabstände: mind. 6 m und 4 m • Optimale Voraussetzungen für vielseitige Bauprojekte Nutzen Sie diese Gelegenheit, um ein nachhaltiges und gewinnbringendes Projekt in einer gefragten Region zu realisieren!  Wegzeit -](https://www.homegate.ch/kaufen/4002404604) + +[*  *  *  *  *  *  1 / 6    CHF 3’633’140.– Riedwiesenstrasse 20, 8305 Dietlikon RESERVIERT - Industrie-Baulandparzelle an zentraler Lage in Dietlikon ZH Mit Freude präsentieren wir Ihnen eine einzigartige und äusserst seltene Baulandparzelle an zentraler Lage in Dietlikon ZH – eine aussergewöhnliche Gelegenheit mit hervorragenden Eigenschaften, die sich besonders für Investoren eignet.Zentrale Lage: Die Parzelle befindet sich in einer äusserst gefragten Gegend mit hervorragender Anbindung: Flughafen Zürich erreichbar in 10 Fahrminuten Stadt Zürich erreichbar in 12 Fahrminuten • Visibilität: Ihr Unternehmen wird von der Autobahn aus perfekt sichtbar sein, was optimale Werbemöglichkeiten bietet (ca. 500 m2 Fassade für Werbung). • Baumassenziffer: Profitieren Sie von der hohen Baumassenziffer 10.0, die maximale Flexibilität und Nutzungseffizienz ermöglicht. • Näherbaurechte: Die Parzelle verfügt über Näherbaurechte rechts und links. Auf der Rückseite kann ein Näherbaurecht von der Stadt Zürich eingeholt werden • ca. 3'500 m2 Bruttogeschossfläche möglich • Tiefgarage / Untergeschoss bis zu ca. 800 m2 gross realisierbar • Maximale Gesamthöhe 20 m. 7 Stockwerke à 500 m2 Bruttogeschossfläche und 2.85 m Raumhöhe (brutto) möglich • Parzelle: Die ebene Fläche der Parzelle erleichtert die Bauplanung und Ausführung. • Form: Die Parzelle hat eine ideale Form, die vielseitige Bebauungsmöglichkeiten erlaubt. • Autobahnknotenpunkt: Brüttiseller Kreuz, direkt an einem der wichtigsten Autobahnknotenpunkt der Schweiz gelegen, bietet die Parzelle hervorragende Erreichbarkeit und Logistikvorteile • Störendes Gewerbe: Die Lage ist auch für Gewerbe geeignet, das potenziell störend sein kann. • Kulturzentren sowie Hotelbetriebe auch möglich. Jetzt oder nie – Ihre Chance auf ein grossartiges Investment:Solch eine Industrie-Baulandparzelle in dieser Lage kommt äusserst selten auf den Markt – seit geraumer Zeit gab es in dieser gefragten Gegend kein vergleichbares Angebot. Sichern Sie sich jetzt dieses einmalige Grundstück, ideal für visionäre Unternehmer und Investoren, die auf einen strategisch optimalen Standort setzen.Haben wir Ihr Interesse geweckt? Dann nehmen Sie noch heute Kontakt mit uns auf. Gerne lassen wir Ihnen das detaillierte Verkaufsdossier inklusive Machbarkeitsstudie zukommen – exklusiv und unverbindlich.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002331523) + +[1](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste)[2](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=2)[...4](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=4)[](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=2) + +Suche speichern Karte + +Vorschläge basierend auf deinen Suchresultaten +---------------------------------------------- + +1. [Startseite](https://www.homegate.ch/de) +2. [Kaufen](https://www.homegate.ch/kaufen/immobilie-suchen) +3. [Bauland zum Kaufen](https://www.homegate.ch/kaufen/bauland/trefferliste) +4. [Schweiz](https://www.homegate.ch/kaufen/bauland/land-schweiz/trefferliste) + +Bezirke im Kanton Kanton Zürich + +[Bauland kaufen Bezirk Affoltern](https://www.homegate.ch/kaufen/bauland/region-affoltern/trefferliste)|[Bauland kaufen Bezirk Andelfingen](https://www.homegate.ch/kaufen/bauland/region-andelfingen/trefferliste)|[Bauland kaufen Bezirk Bülach](https://www.homegate.ch/kaufen/bauland/region-buelach/trefferliste)|[Bauland kaufen Bezirk Dielsdorf](https://www.homegate.ch/kaufen/bauland/region-dielsdorf/trefferliste)|[Bauland kaufen Bezirk Hinwil](https://www.homegate.ch/kaufen/bauland/region-hinwil/trefferliste)|[Bauland kaufen Bezirk Horgen](https://www.homegate.ch/kaufen/bauland/region-horgen/trefferliste)|[Bauland kaufen Bezirk Meilen](https://www.homegate.ch/kaufen/bauland/region-meilen/trefferliste)|[Bauland kaufen Bezirk Pfäffikon](https://www.homegate.ch/kaufen/bauland/region-pfaeffikon/trefferliste)|[Bauland kaufen Bezirk Uster](https://www.homegate.ch/kaufen/bauland/region-uster/trefferliste)|[Bauland kaufen Bezirk Winterthur](https://www.homegate.ch/kaufen/bauland/region-winterthur/trefferliste)|[Bauland kaufen Bezirk Dietikon](https://www.homegate.ch/kaufen/bauland/region-dietikon/trefferliste)|[Bauland kaufen Zürich](https://www.homegate.ch/kaufen/bauland/ort-zuerich/trefferliste) + +Weitere Immobiliensuchen in Kanton Zürich + +[Immobilien mieten Kanton Zürich](https://www.homegate.ch/mieten/immobilien/kanton-zuerich/trefferliste)|[Wohnung mieten Kanton Zürich](https://www.homegate.ch/mieten/wohnung/kanton-zuerich/trefferliste)|[Haus mieten Kanton Zürich](https://www.homegate.ch/mieten/haus/kanton-zuerich/trefferliste)|[Möbliertes Wohnobjekt mieten Kanton Zürich](https://www.homegate.ch/mieten/moebliertes-wohnobjekt/kanton-zuerich/trefferliste)|[Parkplatz, Garage mieten Kanton Zürich](https://www.homegate.ch/mieten/parkplatz-garage/kanton-zuerich/trefferliste)|[Büro mieten Kanton Zürich](https://www.homegate.ch/mieten/buero/kanton-zuerich/trefferliste)|[Gewerbe mieten Kanton Zürich](https://www.homegate.ch/mieten/gewerbeobjekt/kanton-zuerich/trefferliste)|[Neubau zum Mieten Kanton Zürich](https://www.homegate.ch/mieten/immobilien/kanton-zuerich/trefferliste?an=G)|[Wohnung kaufen Kanton Zürich](https://www.homegate.ch/kaufen/wohnung/kanton-zuerich/trefferliste)|[Haus kaufen Kanton Zürich](https://www.homegate.ch/kaufen/haus/kanton-zuerich/trefferliste)|[Immobilien kaufen Kanton Zürich](https://www.homegate.ch/kaufen/immobilien/kanton-zuerich/trefferliste)|[Mehrfamilienhaus kaufen Kanton Zürich](https://www.homegate.ch/kaufen/mehrfamilienhaus/kanton-zuerich/trefferliste)|[Parkplatz, Garage kaufen Kanton Zürich](https://www.homegate.ch/kaufen/parkplatz-garage/kanton-zuerich/trefferliste)|[Gewerbe, Büro, Lager kaufen Kanton Zürich](https://www.homegate.ch/kaufen/gewerbeobjekt/kanton-zuerich/trefferliste)|[Neubau zum Kaufen Kanton Zürich](https://www.homegate.ch/kaufen/immobilien/kanton-zuerich/trefferliste?an=G) + +### Homegate + +* [Über uns](https://swissmarketplace.group/de/portfolio/real-estate/) +* [Kontakt & Hilfe](https://www.homegate.ch/c/de/ueber-uns/kontakt) +* [Geschäftskunde werden](https://swissmarketplace.group/real-estate/de/kunde-werden/) +* [Newsletter abonnieren](https://www.homegate.ch/c/de/ueber-uns/newsletter-anmeldung) +* [Medien](https://swissmarketplace.group/de/media/) +* [Karriere](https://swissmarketplace.group/de/karriere/) +* [Ombudsstelle](https://konsum.ch/de/ombudsstelle-immobilienplattformen/) +* [Werbung auf Homegate](https://swissmarketplace.group/de/werbung/) +* [Sitemap](https://www.homegate.ch/c/de/ueber-uns/sitemap) + +### Immobilien + +* [Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen) +* [Mieten](https://www.homegate.ch/mieten/immobilie-suchen) +* [Kaufen](https://www.homegate.ch/kaufen/immobilie-suchen) +* [Vermieten](https://www.homegate.ch/c/de/inserieren/immobilien/wohnung/vermieten) +* [Verkaufen](https://www.homegate.ch/c/de/ratgeber/inserieren/immobilien-verkaufen) +* [Finanzieren](https://www.homegate.ch/c/de/hypotheken) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Kategorien](https://www.homegate.ch/kategorien-de) + +### Rechtliches + +* [Datenschutz](https://privacy.swissmarketplace.group/de/) +* [Leistungsbeschrieb](https://www.homegate.ch/c/de/ueber-uns/rechtliches/leistungsbeschrieb) +* [Sicherheitstipps](https://www.homegate.ch/c/de/ratgeber/news/vorsicht-betrug-mit-gefaelschten-inseraten) +* [Impressum](https://www.homegate.ch/c/de/ueber-uns/rechtliches) +* [AGB](https://www.homegate.ch/c/de/ueber-uns/rechtliches/agb) +* [Sicherheitsproblem melden](https://swissmarketplace.group/de/vulnerability-disclosure-program) +* Privatsphäre-Einstellungen + +### Services + +* [Suchabo anlegen](https://www.homegate.ch/c/de/ratgeber/mieten/wohnung-finden/suchabo) +* [Finanzierungsrechner](https://www.homegate.ch/de/finanzieren/hypothekenrechner) +* [Steuerrechner](https://www.homegate.ch/c/de/ratgeber/umziehen/umzugstipps/steuerrechner) +* [Betreibungsauszug](https://www.homegate.ch/de/betreibungsauszug) +* [Gemeinderatgeber](https://www.homegate.ch/c/de/ratgeber/umziehen/gemeinderatgeber) +* [Mietkaution](https://www.homegate.ch/c/de/ratgeber/umziehen/mietzinskaution) +* [Umzugshilfe](https://www.homegate.ch/c/de/umziehen) +* [Wohneigentum schätzen](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/wohneigentum-schaetzen/online-schaetzung/jetzt-wohneigentum-bewerten) +* [Agenturverzeichnis](https://www.homegate.ch/agenturverzeichnis) + +### App herunterladen + +[](https://itunes.apple.com/de/app/homegate.ch/id326131004 "iOS App")[](https://play.google.com/store/apps/details?id=ch.homegate.mobile&hl=de "Android App") + +* [Deutsch](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste) +* [Français](https://www.homegate.ch/acheter/terrain/canton-zurich/liste-annonces) +* [Italiano](https://www.homegate.ch/acquistare/terreno/cantone-zurigo/lista-annunci) +* [English](https://www.homegate.ch/buy/plot/canton-zurich/matching-list) + +### Social Media + +[](https://www.facebook.com/homegate.ch "Facebook")[](https://www.youtube.com/user/homegateeng "YouTube")[](https://ch.linkedin.com/company/homegate-ch-ag "LinkedIn")[](https://twitter.com/homegate_Deu "Twitter") + +[SMG Swiss Marketplace Group](https://swissmarketplace.group/)[ImmoScout24](https://www.immoscout24.ch/de)[Alle Immobilien](https://www.alle-immobilien.ch/)[home.ch](https://www.home.ch/)[immostreet.ch](https://www.immostreet.ch/) + +© Copyright 2025 by SMG Swiss Marketplace Group AG. Alle Rechte vorbehalten.Die Vervielfältigung und Übernahme von Inseraten durch Dritte, insbesondere von Fotos und persönlichen Daten in diesen Inseraten, verletzt die damit verbundenen Rechte und ist ausdrücklich verboten. \ No newline at end of file diff --git a/test_web_content_20251002_215219/main_url_004_realadvisor.ch_de_kaufen_kanton-zurich_grundstuck.txt b/test_web_content_20251002_215219/main_url_004_realadvisor.ch_de_kaufen_kanton-zurich_grundstuck.txt new file mode 100644 index 00000000..979e8772 --- /dev/null +++ b/test_web_content_20251002_215219/main_url_004_realadvisor.ch_de_kaufen_kanton-zurich_grundstuck.txt @@ -0,0 +1,435 @@ +Title: https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck +URL: https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck +Type: Main URL +Extracted: 2025-10-02 21:52:19 +================================================================================ + +Grundstück kaufen im Kanton Zürich - 75 Angebote im Oktober 2025 + +=============== + +[](https://realadvisor.ch/de/immobilien-kaufen) + +Max. 1 Tag + +Kanton Zürich + + + +Bewerten + +[Kaufen](https://realadvisor.ch/de/immobilien-kaufen)[Mieten](https://realadvisor.ch/de/immobilien-mieten) + +Anmelden + +DE + +[Italiano](https://realadvisor.ch/it/comprare/canton-zurigo/trama)[Français](https://realadvisor.ch/fr/acheter/canton-zurich/terrain)[English](https://realadvisor.ch/en/buy/canton-zurich/plot) + +Suchabo erstellen + +Max. 1 Tag + +Kanton Zürich + + + +Kaufen Mieten + +Kaufen Mieten + +Grundstück + +Preis + +Suche ändern + +Grundstücksfläche + +Andere Filter + +Suchabo erstellen + +- [x] Karte + +←Move left +→Move right +↑Move up +↓Move down ++Zoom in +-Zoom out +Home Jump left by 75% +End Jump right by 75% +Page Up Jump up by 75% +Page Down Jump down by 75% + + + + + + + + + + + + + + + + + + + + + + + + + +9 + +9 + +5 + +5 + +3 + +3 + +6 + +6 + +17 + +17 + +7 + +7 + +4 + +4 + +2 + +2 + +2 + +2 + +14 + +14 + +5 + +5 + +1 + +1 + + + +Map +* Map +* Satellite +* Terrain +* Labels + + + + + +*  +*  +*  +*  +*  +*  + +[](https://maps.google.com/maps?ll=47.421441,8.671322&z=9&t=m&hl=en-US&gl=US&mapclient=apiv3 "Open this area in Google Maps (opens a new window)") + +Keyboard shortcuts + +Map Data Map data ©2025 GeoBasis-DE/BKG (©2009), Google + +Map data ©2025 GeoBasis-DE/BKG (©2009), Google + +10 km + +Click to toggle between metric and imperial units + +[Terms](https://www.google.com/intl/en-US_US/help/terms_maps.html) + +[Report a map error](https://www.google.com/maps/@47.421441,8.6713222,9z/data=!10m1!1e1!12b1?source=apiv3&rapsrc=apiv3 "Report errors in the road map or imagery to Google") + +1. [](https://realadvisor.ch/de) + +3. [Kaufen](https://realadvisor.ch/de/kaufen) + +5. [Grundstück](https://realadvisor.ch/de/kaufen/grundstuck) + +7. Kanton Zürich + +Grundstücke kaufen im Kanton Zürich +=================================== + +75 Ergebnisse + +Unseren Empfehlungen + +[](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ) + +vor 3 Tagen + +- [x] + +[get living 1’452 m² Grundstück • Bauland 8162 Steinmaur * Flaches, bebaubares Grundstück * Ruhige, sonnige Lage * Ausgezeichnete ÖV-Anbindung ------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2) + +vor 6 Tagen + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 1’070 m² Grundstück • Bauland 8340 Hinwil * Über 1.070 m² Fläche * Flexible Teilungsoptionen * Ideal für Familienhäuser ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 1’070’000.- CHF 1’000 / m²](https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8633-wolfhausen-YB6N-VRVP) + +vor 6 Tagen + +- [x] + +[PREMIUM HOMES AG 1’940 m² Grundstück • Bauland 8633 Wolfhausen * Grosszügige 1'940m² Parzelle * Familienfreundliche Lage * Flexible Gestaltungsmöglichkeiten --------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 4’074’000.- CHF 2’100 / m²](https://realadvisor.ch/de/kaufen/grundstuck/8633-wolfhausen-YB6N-VRVP) + +[](https://realadvisor.ch/de/kaufen/grundstuck/sonnhalde-8602-wangen-b.-dubendorf-83JW-X5X3) + +vor 9 Tagen + +- [x] + +[Moser Anlageimmobilien AG 1’666 m² Grundstück • Bauland Sonnhalde, 8602 Wangen b. Dübendorf * 1666 m² Bauland in bester Lage * Optimale Besonnung garantiert * Privatsphäre in ruhiger Umgebung -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3’300’000.- CHF 1’981 / m²](https://realadvisor.ch/de/kaufen/grundstuck/sonnhalde-8602-wangen-b.-dubendorf-83JW-X5X3) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8000-zurich-NAG4-JV4R) + +vor 11 Tagen + +- [x] + +[Centrum Immo Bauland 8000 Zürich * Ideal für Entwicklung * Nahe öffentlicher Verkehr * Malersiche Ausblicke auf die Stadt ---------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/8000-zurich-NAG4-JV4R) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8195-wasterkingen-7JPL-7X5M) + +vor 13 Tagen + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 650 m² Grundstück • Bauland 8195 Wasterkingen * Voll erschlossenes Grundstück * Ruhige ländliche Gemeinde * Flexible Gestaltungsmöglichkeiten ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 475’000.- CHF 731 / m²](https://realadvisor.ch/de/kaufen/grundstuck/8195-wasterkingen-7JPL-7X5M) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8618-oetwil-am-see-8OOG-PWB5) + +vor 21 Tagen + +- [x] + +[Swiss Residence Group AG 1’622 m² Grundstück • Bauland 8618 Oetwil am See * Sonniges Grundstück von 1'622 m² * Flexibles Bauen möglich * Unverbaubare Bergsicht ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/8618-oetwil-am-see-8OOG-PWB5) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8617-monchaltorf-KRNG-WO9R) + +vor 22 Tagen + +- [x] + +[PREMIUM HOMES AG 850 m² Grundstück • Bauland 8617 Mönchaltorf * Hohes Entwicklungspotenzial * Ruhige, sonnige Lage * Flexible Nutzungsmöglichkeiten ------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/8617-monchaltorf-KRNG-WO9R) + +[](https://realadvisor.ch/de/kaufen/grundstuck/gueterstalstrasse-8133-esslingen-YMXG-R3MR) + +vor 26 Tagen + +- [x] + +[Schiblis Immobilien GmbH 507 m² Grundstück • Bauland Güeterstalstrasse, 8133 Esslingen * Zentrale Lage in Esslingen * Keine Architekturverpflichtung * Keine Altlasten vorhanden ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 600’000.- CHF 1’183 / m²](https://realadvisor.ch/de/kaufen/grundstuck/gueterstalstrasse-8133-esslingen-YMXG-R3MR) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8192-zweidlen-6ZMD-4WE3) + +vor 28 Tagen + +- [x] + +[Grundeigentümer Verband Schweiz 1’226 m² Grundstück • Bauland 8192 Zweidlen * Gesamtfläche von 1'226 m² * Max. nutzbare Fläche 940 m² * Flexible Entwicklungsmöglichkeiten ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2’450’000.- CHF 1’998 / m²](https://realadvisor.ch/de/kaufen/grundstuck/8192-zweidlen-6ZMD-4WE3) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8424-embrach-8WRG-NEGR) + +vor 29 Tagen + +- [x] + +[PREMIUM HOMES AG 1’670 m² Grundstück • Bauland 8424 Embrach * Familienfreundliche Lage * Viel Sonnenlicht den ganzen Tag * Flexible Nutzungsmöglichkeiten ------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/8424-embrach-8WRG-NEGR) + +[](https://realadvisor.ch/de/kaufen/grundstuck/10-berghalde-8332-russikon-6ZMD-432O) + +vor 29 Tagen + +- [x] + +[SH Immo GmbH 854 m² Grundstück • Bauland Berghalde 10, 8332 Russikon * Geräumiges Grundstück von 854 m2 * Ideale sonnige Hanglage * Potenzial für Neubau ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’500’000.- CHF 1’756 / m²](https://realadvisor.ch/de/kaufen/grundstuck/10-berghalde-8332-russikon-6ZMD-432O) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8134-adliswil-Y7J5-W36M) + +vor 1 Monat + +- [x] + +[Moos & Partner Immobilien GmbH 694 m² Grundstück • Bauland 8134 Adliswil * Zentrale Lage mit Potenzial * Hohe Ausnutzung in W3 * Ideal für Investoren & Entwickler --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3’600’000.- CHF 5’187 / m²](https://realadvisor.ch/de/kaufen/grundstuck/8134-adliswil-Y7J5-W36M) + +[](https://realadvisor.ch/de/kaufen/grundstuck/23-uberlandstrasse-8340-hinwil-YB69-VB7M) + +vor 2 Monaten + +- [x] + +[RE/MAX Immobilien in Rapperswil-Jona 4’246 m² Grundstück • Bauland Überlandstrasse 23, 8340 Hinwil * Top Lage an Hauptstrassen * Grosse Fläche für Entwicklung * Flexible Gebäudehöhen möglich ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/23-uberlandstrasse-8340-hinwil-YB69-VB7M) + +[](https://realadvisor.ch/de/kaufen/grundstuck/20-winzerstrasse-8353-elgg-KRNL-ZPNR) + +vor 2 Monaten + +- [x] + +[RE/MAX Immobilien in Winterthur 877 m² Grundstück • Bauland Winzerstrasse 20, 8353 Elgg * Ideal für Familienhäuser * Investitionsmöglichkeit * Angrenzend an bestehendes Haus -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’140’000.- CHF 1’300 / m²](https://realadvisor.ch/de/kaufen/grundstuck/20-winzerstrasse-8353-elgg-KRNL-ZPNR) + +[](https://realadvisor.ch/de/kaufen/grundstuck/34-industriestrasse-8117-fallanden-YJDX-JXRR) + +vor 3 Monaten + +- [x] + +[RE/MAX Immobilien in Meilen 2’838 m² • 1’706 m² Grundstück • Bauland Industriestrasse 34, 8117 Fällanden * Genehmigtes Gewerbeprojekt * Flexible gewerbliche Nutzung * 37 Parkplätze verfügbar ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/34-industriestrasse-8117-fallanden-YJDX-JXRR) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8630-ruti-zh-84E9-Z65G) + +vor 4 Monaten + +- [x] + +[PREMIUM HOMES AG 3’460 m² Grundstück • Bauland 8630 Rüti ZH * Ruhige Wohnzone * Ausnützungsziffer 30% * Bonus für zusätzlichen Raum -------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/8630-ruti-zh-84E9-Z65G) + +[](https://realadvisor.ch/de/kaufen/grundstuck/13-staldernstrasse-8158-regensberg-YJDX-XWMO) + +vor 16 Tagen + +- [x] + +[Swisslife 2’557 m² Grundstück • Bauland Staldernstrasse 13, 8158 Regensberg * Flexibles Zonen für Mischnutzung * Hohe Mietrendite möglich * Ruhige Lage nahe Zürich ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 5’500’000.- CHF 2’151 / m² dreamo.ch](https://realadvisor.ch/de/kaufen/grundstuck/13-staldernstrasse-8158-regensberg-YJDX-XWMO) + +[](https://realadvisor.ch/de/kaufen/grundstuck/leisibuel-8484-weisslingen-8OO2-753X) + +vor 2 Monaten + +- [x] + +[Orgnet Immobilien AG 844 m² Grundstück • Bauland Leisibüel, 8484 Weisslingen * Atemberaubender Bergblick * Südwestliche Sonnenlage * Ruhige, private Nachbarschaft --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’300’000.- CHF 1’540 / m² dreamo.ch](https://realadvisor.ch/de/kaufen/grundstuck/leisibuel-8484-weisslingen-8OO2-753X) + +[](https://realadvisor.ch/de/kaufen/grundstuck/85-weiacherstrasse-8427-rorbas-YJD9-MVWW) + +vor 3 Monaten + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 2’295 m² Grundstück • Bauland Weiacherstrasse 85, 8427 Rorbas * Geräumiges Grundstück von 2'295 m2 * Gebäude mit gemischter Nutzung * Bestehende Mietverhältnisse ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3’440’000.- CHF 1’499 / m² dreamo.ch](https://realadvisor.ch/de/kaufen/grundstuck/85-weiacherstrasse-8427-rorbas-YJD9-MVWW) + +[](https://realadvisor.ch/de/kaufen/grundstuck/7a-bergstrasse-8155-nassenwil-YB69-GEB6) + +vor 3 Monaten + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 1’742 m² Grundstück • Bauland Bergstrasse 7a, 8155 Nassenwil * Geräumige Grundstücksfläche * Ruhige, malerische Lage * Nahe Dielsdorf --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2’700’000.- CHF 1’550 / m² dreamo.ch](https://realadvisor.ch/de/kaufen/grundstuck/7a-bergstrasse-8155-nassenwil-YB69-GEB6) + +[](https://realadvisor.ch/de/kaufen/grundstuck/gotze-8197-rafz-Y6ZW-VB6G) + +vor 3 Monaten + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 1’340 m² • 1’340 m² Grundstück • Bauland Götze, 8197 Rafz * Unverbaute Aussichten * Ideal für Entwicklung * Bevorzugte Lage ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2’200’000.- CHF 1’642 / m² dreamo.ch](https://realadvisor.ch/de/kaufen/grundstuck/gotze-8197-rafz-Y6ZW-VB6G) + +[](https://realadvisor.ch/de/kaufen/grundstuck/226b-schaffhauserstrasse-8057-zurich-KRNL-A6J7) + +vor 3 Monaten + +- [x] + +[VZ VermögensZentrum 4.5 Zi. • 114 m² • 480 m² Grundstück • Bauland Schaffhauserstrasse 226b, 8057 Zürich * Grosszügiger Umschwung * Grüner Ausblick von Fenstern * Gemütlicher Schwedenofen ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2’999’000.- CHF 26’307 / m² dreamo.ch](https://realadvisor.ch/de/kaufen/grundstuck/226b-schaffhauserstrasse-8057-zurich-KRNL-A6J7) + +[](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck#) + +vor 7 Stunden + +- [x] + +[— 829 m² Grundstück • Bauland Haldenstrasse 10, 8134 Adliswil * Ruhige Lage mit Aussicht * Nah am öffentlichen Verkehr * Sofort verfügbar -------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3’300’000.- CHF 3’981 / m² homegate.ch](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck#) + +[1](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck) + +[2](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck/seite-2) + +[3](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck/seite-3) + +[4](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck/seite-4) + +[](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck/seite-2) + +1-24 von 75 Ergebnisse + +Grundstück kaufen im Kanton Zürich +---------------------------------- + +[Immobilienpreise in Kanton Zürich](https://realadvisor.ch/de/immobilienpreise-pro-m2/kanton-zurich) + +### Grundstück kaufen im Kanton Zürich + +[Grundstück kaufen in Zürich](https://realadvisor.ch/de/kaufen/stadt-zurich/grundstuck)[Grundstück kaufen in Winterthur](https://realadvisor.ch/de/kaufen/stadt-winterthur/grundstuck)[Grundstück kaufen in Uster](https://realadvisor.ch/de/kaufen/stadt-uster/grundstuck)[Grundstück kaufen in Dübendorf](https://realadvisor.ch/de/kaufen/stadt-dubendorf/grundstuck)[Grundstück kaufen in Dietikon (8953)](https://realadvisor.ch/de/kaufen/8953-dietikon/grundstuck)[Grundstück kaufen in Wädenswil](https://realadvisor.ch/de/kaufen/stadt-wadenswil/grundstuck)[Grundstück kaufen in Wetzikon (ZH)](https://realadvisor.ch/de/kaufen/stadt-wetzikon-zh/grundstuck)[Grundstück kaufen in Horgen](https://realadvisor.ch/de/kaufen/stadt-horgen/grundstuck)[Grundstück kaufen in Opfikon](https://realadvisor.ch/de/kaufen/stadt-opfikon/grundstuck)[Grundstück kaufen in Bülach (8180)](https://realadvisor.ch/de/kaufen/8180-bulach/grundstuck)[Grundstück kaufen in Kloten (8302)](https://realadvisor.ch/de/kaufen/8302-kloten/grundstuck)[Grundstück kaufen in Adliswil (8134)](https://realadvisor.ch/de/kaufen/8134-adliswil/grundstuck)[Grundstück kaufen in Schlieren (8952)](https://realadvisor.ch/de/kaufen/8952-schlieren/grundstuck)[Grundstück kaufen in Volketswil](https://realadvisor.ch/de/kaufen/stadt-volketswil/grundstuck)[Grundstück kaufen in Regensdorf](https://realadvisor.ch/de/kaufen/stadt-regensdorf/grundstuck)[Grundstück kaufen in Thalwil](https://realadvisor.ch/de/kaufen/stadt-thalwil/grundstuck)[Grundstück kaufen in Illnau-Effretikon](https://realadvisor.ch/de/kaufen/stadt-illnau-effretikon/grundstuck)[Grundstück kaufen in Wallisellen (8304)](https://realadvisor.ch/de/kaufen/8304-wallisellen/grundstuck)[Grundstück kaufen in Stäfa](https://realadvisor.ch/de/kaufen/stadt-stafa/grundstuck)[Grundstück kaufen in Küsnacht (ZH)](https://realadvisor.ch/de/kaufen/stadt-kusnacht-zh/grundstuck)[Grundstück kaufen in Meilen (8706)](https://realadvisor.ch/de/kaufen/8706-meilen/grundstuck)[Grundstück kaufen in Richterswil](https://realadvisor.ch/de/kaufen/stadt-richterswil/grundstuck)[Grundstück kaufen in Zollikon](https://realadvisor.ch/de/kaufen/stadt-zollikon/grundstuck)[Grundstück kaufen in Rüti ZH (8630)](https://realadvisor.ch/de/kaufen/8630-ruti-zh/grundstuck)[Grundstück kaufen in Affoltern am Albis](https://realadvisor.ch/de/kaufen/stadt-affoltern-am-albis/grundstuck)[Grundstück kaufen in Pfäffikon](https://realadvisor.ch/de/kaufen/stadt-pfaffikon/grundstuck)[Grundstück kaufen in Bassersdorf (8303)](https://realadvisor.ch/de/kaufen/8303-bassersdorf/grundstuck)[Grundstück kaufen in Hinwil](https://realadvisor.ch/de/kaufen/stadt-hinwil/grundstuck)[Grundstück kaufen in Männedorf (8708)](https://realadvisor.ch/de/kaufen/8708-mannedorf/grundstuck)[Grundstück kaufen in Maur](https://realadvisor.ch/de/kaufen/stadt-maur/grundstuck)[Grundstück kaufen in Gossau (ZH)](https://realadvisor.ch/de/kaufen/gemeinde-gossau-zh/grundstuck)[Grundstück kaufen in Wald (ZH)](https://realadvisor.ch/de/kaufen/gemeinde-wald-zh/grundstuck)[Grundstück kaufen in Urdorf (8902)](https://realadvisor.ch/de/kaufen/8902-urdorf/grundstuck)[Grundstück kaufen in Embrach (8424)](https://realadvisor.ch/de/kaufen/8424-embrach/grundstuck)[Grundstück kaufen in Niederhasli](https://realadvisor.ch/de/kaufen/gemeinde-niederhasli/grundstuck)[Grundstück kaufen in Hombrechtikon](https://realadvisor.ch/de/kaufen/gemeinde-hombrechtikon/grundstuck)[Grundstück kaufen in Fällanden](https://realadvisor.ch/de/kaufen/gemeinde-fallanden/grundstuck)[Grundstück kaufen in Kilchberg ZH (8802)](https://realadvisor.ch/de/kaufen/8802-kilchberg-zh/grundstuck)[Grundstück kaufen in Egg](https://realadvisor.ch/de/kaufen/gemeinde-egg/grundstuck)[Grundstück kaufen in Rümlang (8153)](https://realadvisor.ch/de/kaufen/8153-rumlang/grundstuck)[Grundstück kaufen in Wangen-Brüttisellen](https://realadvisor.ch/de/kaufen/gemeinde-wangen-bruttisellen/grundstuck)[Grundstück kaufen in Dietlikon (8305)](https://realadvisor.ch/de/kaufen/8305-dietlikon/grundstuck)[Grundstück kaufen in Dürnten](https://realadvisor.ch/de/kaufen/gemeinde-durnten/grundstuck)[Grundstück kaufen in Langnau am Albis (8135)](https://realadvisor.ch/de/kaufen/8135-langnau-am-albis/grundstuck)[Grundstück kaufen in Seuzach (8472)](https://realadvisor.ch/de/kaufen/8472-seuzach/grundstuck)[Grundstück kaufen in Bubikon](https://realadvisor.ch/de/kaufen/gemeinde-bubikon/grundstuck)[Grundstück kaufen in Oberglatt ZH (8154)](https://realadvisor.ch/de/kaufen/8154-oberglatt-zh/grundstuck)[Grundstück kaufen in Oberengstringen (8102)](https://realadvisor.ch/de/kaufen/8102-oberengstringen/grundstuck)[Grundstück kaufen in Fehraltorf (8320)](https://realadvisor.ch/de/kaufen/8320-fehraltorf/grundstuck)[Grundstück kaufen in Birmensdorf ZH (8903)](https://realadvisor.ch/de/kaufen/8903-birmensdorf-zh/grundstuck)[Grundstück kaufen in Wiesendangen](https://realadvisor.ch/de/kaufen/gemeinde-wiesendangen/grundstuck)[Grundstück kaufen in Buchs ZH (8107)](https://realadvisor.ch/de/kaufen/8107-buchs-zh/grundstuck)[Grundstück kaufen in Herrliberg (8704)](https://realadvisor.ch/de/kaufen/8704-herrliberg/grundstuck)[Grundstück kaufen in Uetikon am See (8707)](https://realadvisor.ch/de/kaufen/8707-uetikon-am-see/grundstuck)[Grundstück kaufen in Dielsdorf (8157)](https://realadvisor.ch/de/kaufen/8157-dielsdorf/grundstuck)[Grundstück kaufen in Zell (ZH)](https://realadvisor.ch/de/kaufen/gemeinde-zell-zh/grundstuck)[Grundstück kaufen in Rüschlikon (8803)](https://realadvisor.ch/de/kaufen/8803-ruschlikon/grundstuck)[Grundstück kaufen in Lindau](https://realadvisor.ch/de/kaufen/gemeinde-lindau/grundstuck)[Grundstück kaufen in Nürensdorf (8309)](https://realadvisor.ch/de/kaufen/8309-nurensdorf/grundstuck)[Grundstück kaufen in Erlenbach ZH (8703)](https://realadvisor.ch/de/kaufen/8703-erlenbach-zh/grundstuck)[Grundstück kaufen in Neftenbach](https://realadvisor.ch/de/kaufen/gemeinde-neftenbach/grundstuck)[Grundstück kaufen in Bonstetten (8906)](https://realadvisor.ch/de/kaufen/8906-bonstetten/grundstuck)[Grundstück kaufen in Obfelden (8912)](https://realadvisor.ch/de/kaufen/8912-obfelden/grundstuck)[Grundstück kaufen in Greifensee (8606)](https://realadvisor.ch/de/kaufen/8606-greifensee/grundstuck)[Grundstück kaufen in Glattfelden](https://realadvisor.ch/de/kaufen/gemeinde-glattfelden/grundstuck)[Grundstück kaufen in Eglisau (8193)](https://realadvisor.ch/de/kaufen/8193-eglisau/grundstuck)[Grundstück kaufen in Zumikon (8126)](https://realadvisor.ch/de/kaufen/8126-zumikon/grundstuck)[Grundstück kaufen in Wettswil (8907)](https://realadvisor.ch/de/kaufen/8907-wettswil/grundstuck)[Grundstück kaufen in Schwerzenbach (8603)](https://realadvisor.ch/de/kaufen/8603-schwerzenbach/grundstuck)[Grundstück kaufen in Oberrieden (8942)](https://realadvisor.ch/de/kaufen/8942-oberrieden/grundstuck)[Grundstück kaufen in Bäretswil](https://realadvisor.ch/de/kaufen/gemeinde-baretswil/grundstuck)[Grundstück kaufen in Niederglatt ZH (8172)](https://realadvisor.ch/de/kaufen/8172-niederglatt-zh/grundstuck)[Grundstück kaufen in Geroldswil](https://realadvisor.ch/de/kaufen/gemeinde-geroldswil/grundstuck)[Grundstück kaufen in Bauma](https://realadvisor.ch/de/kaufen/gemeinde-bauma/grundstuck)[Grundstück kaufen in Elgg](https://realadvisor.ch/de/kaufen/gemeinde-elgg/grundstuck)[Grundstück kaufen in Mettmenstetten (8932)](https://realadvisor.ch/de/kaufen/8932-mettmenstetten/grundstuck)[Grundstück kaufen in Weiningen ZH (8104)](https://realadvisor.ch/de/kaufen/8104-weiningen-zh/grundstuck)[Grundstück kaufen in Oetwil am See (8618)](https://realadvisor.ch/de/kaufen/8618-oetwil-am-see/grundstuck)[Grundstück kaufen in Turbenthal](https://realadvisor.ch/de/kaufen/gemeinde-turbenthal/grundstuck)[Grundstück kaufen in Winkel (8185)](https://realadvisor.ch/de/kaufen/8185-winkel/grundstuck)[Grundstück kaufen in Rafz (8197)](https://realadvisor.ch/de/kaufen/8197-rafz/grundstuck)[Grundstück kaufen in Russikon](https://realadvisor.ch/de/kaufen/gemeinde-russikon/grundstuck)[Grundstück kaufen in Uitikon Waldegg (8142)](https://realadvisor.ch/de/kaufen/8142-uitikon-waldegg/grundstuck)[Grundstück kaufen in Dällikon (8108)](https://realadvisor.ch/de/kaufen/8108-dallikon/grundstuck)[Grundstück kaufen in Bachenbülach (8184)](https://realadvisor.ch/de/kaufen/8184-bachenbulach/grundstuck)[Grundstück kaufen in Pfungen (8422)](https://realadvisor.ch/de/kaufen/8422-pfungen/grundstuck)[Grundstück kaufen in Unterengstringen (8103)](https://realadvisor.ch/de/kaufen/8103-unterengstringen/grundstuck)[Grundstück kaufen in Mönchaltorf (8617)](https://realadvisor.ch/de/kaufen/8617-monchaltorf/grundstuck)[Grundstück kaufen in Stallikon](https://realadvisor.ch/de/kaufen/gemeinde-stallikon/grundstuck)[Grundstück kaufen in Hedingen (8908)](https://realadvisor.ch/de/kaufen/8908-hedingen/grundstuck)[Grundstück kaufen in Hausen am Albis](https://realadvisor.ch/de/kaufen/gemeinde-hausen-am-albis/grundstuck)[Grundstück kaufen in Feuerthalen](https://realadvisor.ch/de/kaufen/gemeinde-feuerthalen/grundstuck)[Grundstück kaufen in Hittnau (8335)](https://realadvisor.ch/de/kaufen/8335-hittnau/grundstuck)[Grundstück kaufen in Elsau (8352)](https://realadvisor.ch/de/kaufen/8352-elsau/grundstuck)[Grundstück kaufen in Steinmaur](https://realadvisor.ch/de/kaufen/gemeinde-steinmaur/grundstuck)[Grundstück kaufen in Grüningen (8627)](https://realadvisor.ch/de/kaufen/8627-gruningen/grundstuck)[Grundstück kaufen in Weisslingen](https://realadvisor.ch/de/kaufen/gemeinde-weisslingen/grundstuck)[Grundstück kaufen in Hettlingen (8442)](https://realadvisor.ch/de/kaufen/8442-hettlingen/grundstuck)[Grundstück kaufen in Neerach (8173)](https://realadvisor.ch/de/kaufen/8173-neerach/grundstuck)[Grundstück kaufen in Niederweningen (8166)](https://realadvisor.ch/de/kaufen/8166-niederweningen/grundstuck)[Grundstück kaufen in Otelfingen (8112)](https://realadvisor.ch/de/kaufen/8112-otelfingen/grundstuck)[Grundstück kaufen in Rorbas (8427)](https://realadvisor.ch/de/kaufen/8427-rorbas/grundstuck)[Grundstück kaufen in Stammheim](https://realadvisor.ch/de/kaufen/gemeinde-stammheim/grundstuck)[Grundstück kaufen in Höri (8181)](https://realadvisor.ch/de/kaufen/8181-hori/grundstuck)[Grundstück kaufen in Rickenbach (ZH)](https://realadvisor.ch/de/kaufen/gemeinde-rickenbach-zh/grundstuck)[Grundstück kaufen in Ottenbach (8913)](https://realadvisor.ch/de/kaufen/8913-ottenbach/grundstuck)[Grundstück kaufen in Fischenthal](https://realadvisor.ch/de/kaufen/gemeinde-fischenthal/grundstuck)[Grundstück kaufen in Oetwil an der Limmat (8955)](https://realadvisor.ch/de/kaufen/8955-oetwil-an-der-limmat/grundstuck)[Grundstück kaufen in Lufingen (8426)](https://realadvisor.ch/de/kaufen/8426-lufingen/grundstuck)[Grundstück kaufen in Freienstein-Teufen](https://realadvisor.ch/de/kaufen/gemeinde-freienstein-teufen/grundstuck)[Grundstück kaufen in Knonau (8934)](https://realadvisor.ch/de/kaufen/8934-knonau/grundstuck)[Grundstück kaufen in Stadel](https://realadvisor.ch/de/kaufen/gemeinde-stadel/grundstuck)[Grundstück kaufen in Henggart (8444)](https://realadvisor.ch/de/kaufen/8444-henggart/grundstuck)[Grundstück kaufen in Andelfingen (8450)](https://realadvisor.ch/de/kaufen/8450-andelfingen/grundstuck)[Grundstück kaufen in Kleinandelfingen](https://realadvisor.ch/de/kaufen/gemeinde-kleinandelfingen/grundstuck)[Grundstück kaufen in Brütten (8311)](https://realadvisor.ch/de/kaufen/8311-brutten/grundstuck)[Grundstück kaufen in Wila (8492)](https://realadvisor.ch/de/kaufen/8492-wila/grundstuck)[Grundstück kaufen in Marthalen](https://realadvisor.ch/de/kaufen/gemeinde-marthalen/grundstuck)[Grundstück kaufen in Aeugst am Albis](https://realadvisor.ch/de/kaufen/gemeinde-aeugst-am-albis/grundstuck)[Grundstück kaufen in Dachsen (8447)](https://realadvisor.ch/de/kaufen/8447-dachsen/grundstuck)[Grundstück kaufen in Hochfelden (8182)](https://realadvisor.ch/de/kaufen/8182-hochfelden/grundstuck)[Grundstück kaufen in Dänikon ZH (8114)](https://realadvisor.ch/de/kaufen/8114-danikon-zh/grundstuck)[Grundstück kaufen in Oberweningen (8165)](https://realadvisor.ch/de/kaufen/8165-oberweningen/grundstuck)[Grundstück kaufen in Weiach (8187)](https://realadvisor.ch/de/kaufen/8187-weiach/grundstuck)[Grundstück kaufen in Laufen-Uhwiesen](https://realadvisor.ch/de/kaufen/gemeinde-laufen-uhwiesen/grundstuck)[Grundstück kaufen in Ossingen (8475)](https://realadvisor.ch/de/kaufen/8475-ossingen/grundstuck)[Grundstück kaufen in Dinhard (8474)](https://realadvisor.ch/de/kaufen/8474-dinhard/grundstuck)[Grundstück kaufen in Seegräben](https://realadvisor.ch/de/kaufen/gemeinde-seegraben/grundstuck)[Grundstück kaufen in Flurlingen (8247)](https://realadvisor.ch/de/kaufen/8247-flurlingen/grundstuck)[Grundstück kaufen in Wil ZH (8196)](https://realadvisor.ch/de/kaufen/8196-wil-zh/grundstuck)[Grundstück kaufen in Schöfflisdorf (8165)](https://realadvisor.ch/de/kaufen/8165-schofflisdorf/grundstuck)[Grundstück kaufen in Flaach (8416)](https://realadvisor.ch/de/kaufen/8416-flaach/grundstuck)[Grundstück kaufen in Boppelsen (8113)](https://realadvisor.ch/de/kaufen/8113-boppelsen/grundstuck)[Grundstück kaufen in Aesch ZH (8904)](https://realadvisor.ch/de/kaufen/8904-aesch-zh/grundstuck)[Grundstück kaufen in Rheinau (8462)](https://realadvisor.ch/de/kaufen/8462-rheinau/grundstuck)[Grundstück kaufen in Kappel am Albis](https://realadvisor.ch/de/kaufen/gemeinde-kappel-am-albis/grundstuck)[Grundstück kaufen in Hagenbuch ZH (8523)](https://realadvisor.ch/de/kaufen/8523-hagenbuch-zh/grundstuck)[Grundstück kaufen in Rifferswil (8911)](https://realadvisor.ch/de/kaufen/8911-rifferswil/grundstuck)[Grundstück kaufen in Trüllikon](https://realadvisor.ch/de/kaufen/gemeinde-trullikon/grundstuck)[Grundstück kaufen in Oberembrach (8425)](https://realadvisor.ch/de/kaufen/8425-oberembrach/grundstuck)[Grundstück kaufen in Hüntwangen (8194)](https://realadvisor.ch/de/kaufen/8194-huntwangen/grundstuck)[Grundstück kaufen in Dägerlen](https://realadvisor.ch/de/kaufen/gemeinde-dagerlen/grundstuck)[Grundstück kaufen in Wildberg](https://realadvisor.ch/de/kaufen/gemeinde-wildberg/grundstuck)[Grundstück kaufen in Buch am Irchel (8414)](https://realadvisor.ch/de/kaufen/8414-buch-am-irchel/grundstuck)[Grundstück kaufen in Hüttikon (8115)](https://realadvisor.ch/de/kaufen/8115-huttikon/grundstuck)[Grundstück kaufen in Thalheim an der Thur (8478)](https://realadvisor.ch/de/kaufen/8478-thalheim-an-der-thur/grundstuck)[Grundstück kaufen in Ellikon an der Thur (8548)](https://realadvisor.ch/de/kaufen/8548-ellikon-an-der-thur/grundstuck)[Grundstück kaufen in Benken ZH (8463)](https://realadvisor.ch/de/kaufen/8463-benken-zh/grundstuck)[Grundstück kaufen in Dättlikon (8421)](https://realadvisor.ch/de/kaufen/8421-dattlikon/grundstuck)[Grundstück kaufen in Schleinikon (8165)](https://realadvisor.ch/de/kaufen/8165-schleinikon/grundstuck)[Grundstück kaufen in Schlatt ZH (8418)](https://realadvisor.ch/de/kaufen/8418-schlatt-zh/grundstuck)[Grundstück kaufen in Dorf (8458)](https://realadvisor.ch/de/kaufen/8458-dorf/grundstuck)[Grundstück kaufen in Altikon (8479)](https://realadvisor.ch/de/kaufen/8479-altikon/grundstuck)[Grundstück kaufen in Adlikon b. Andelfingen (8452)](https://realadvisor.ch/de/kaufen/8452-adlikon-b-andelfingen/grundstuck)[Grundstück kaufen in Maschwanden (8933)](https://realadvisor.ch/de/kaufen/8933-maschwanden/grundstuck)[Grundstück kaufen in Bachs (8164)](https://realadvisor.ch/de/kaufen/8164-bachs/grundstuck)[Grundstück kaufen in Wasterkingen (8195)](https://realadvisor.ch/de/kaufen/8195-wasterkingen/grundstuck)[Grundstück kaufen in Berg am Irchel](https://realadvisor.ch/de/kaufen/gemeinde-berg-am-irchel/grundstuck)[Grundstück kaufen in Humlikon (8457)](https://realadvisor.ch/de/kaufen/8457-humlikon/grundstuck)[Grundstück kaufen in Truttikon (8467)](https://realadvisor.ch/de/kaufen/8467-truttikon/grundstuck)[Grundstück kaufen in Regensberg (8158)](https://realadvisor.ch/de/kaufen/8158-regensberg/grundstuck)[Grundstück kaufen in Volken (8459)](https://realadvisor.ch/de/kaufen/8459-volken/grundstuck) + +Mehr + +### Andere Immobilienarten im Kanton Zürich + +[Haus kaufen im Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich/haus)[Wohnung kaufen im Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich/wohnung)[Mehrfamilienhaus kaufen im Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich/gebaude)[Gewerberaum kaufen im Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich/gewerbe)[Hotel, Restaurant kaufen im Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich/gastfreundschaft) + +### Beliebte Suchen im Kanton Zürich + +[Neubauprojekte im Kanton Zürich](https://realadvisor.ch/de/beliebte-suchen/neubauprojekte-kanton-zurich)[Neubauten kaufen im Kanton Zürich](https://realadvisor.ch/de/beliebte-suchen/neubauten-kaufen-kanton-zurich)[Neubauwohnungen kaufen im Kanton Zürich](https://realadvisor.ch/de/beliebte-suchen/neubauwohnung-kaufen-kanton-zurich) + +[](https://ch.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + +Verkaufen + +[Immobilienbewertung](https://realadvisor.ch/de/online-immobilienbewertung)[Renditeliegenschaft bewerten](https://realadvisor.ch/de/renditeliegenschaft-bewerten-online)[Immobilienpreise](https://realadvisor.ch/de/immobilienpreise-pro-m2)[Makler finden](https://realadvisor.ch/de/makler-finden)[Immobilien-Glossar](https://realadvisor.ch/de/immobilien-glossar)[Immobilien-Blog](https://realadvisor.ch/de/blog) + +Kaufen / Mieten + +[Immobilien kaufen](https://realadvisor.ch/de/immobilien-kaufen)[Immobilien mieten](https://realadvisor.ch/de/immobilien-mieten)[Neubauprojekte](https://realadvisor.ch/de/neubauprojekte)[Immobilienfinanzierung](https://realadvisor.ch/de/finanzierung) + +Für Makler + +[Partner werden](https://realadvisor.ch/de/pro)[Blog Pro](https://realadvisor.ch/de/pro/blog) + +Unternehmen + +[Über uns](https://realadvisor.ch/de/uber-uns)[Presseraum](https://realadvisor.ch/de/presseraum)[Offene Stellen](https://realadvisor.welcomekit.co/)[Allgemeine Geschäftsbedingungen](https://realadvisor.ch/de/begriffe)[Datenschutzerklärung](https://realadvisor.ch/de/datenschutzerklarung)[Impressum](https://realadvisor.ch/de/impressum)[Alle Immobilien](https://realadvisor.ch/de/sitemap) + +© RealAdvisor 2025. All Rights Reserved. v.e89072f + +[](https://ch.linkedin.com/company/realadvisor)[](https://www.facebook.com/realadvisorcom)[](https://twitter.com/realadvisor)[](https://www.instagram.com/realadvisorcom)[](https://www.youtube.com/channel/UCsEDTDlmxBpyxLXYhWT769Q) + +Karte + +BESbswy \ No newline at end of file diff --git a/test_web_content_20251002_204000/main_url_007_www.immoyou.ch_grundstuck-kaufen-kanton-zurich.txt b/test_web_content_20251002_215219/main_url_005_www.immoyou.ch_grundstuck-kaufen-kanton-zurich.txt similarity index 82% rename from test_web_content_20251002_204000/main_url_007_www.immoyou.ch_grundstuck-kaufen-kanton-zurich.txt rename to test_web_content_20251002_215219/main_url_005_www.immoyou.ch_grundstuck-kaufen-kanton-zurich.txt index 5cd39200..51f16987 100644 --- a/test_web_content_20251002_204000/main_url_007_www.immoyou.ch_grundstuck-kaufen-kanton-zurich.txt +++ b/test_web_content_20251002_215219/main_url_005_www.immoyou.ch_grundstuck-kaufen-kanton-zurich.txt @@ -1,219 +1,416 @@ Title: https://www.immoyou.ch/grundstuck-kaufen-kanton-zurich URL: https://www.immoyou.ch/grundstuck-kaufen-kanton-zurich Type: Main URL -Extracted: 2025-10-02 20:40:00 +Extracted: 2025-10-02 21:52:19 ================================================================================ 🌳 56 Grundstücke kaufen im Kanton Zürich | ImmoYou -ImmoYou +=============== + +[ImmoYou](https://www.immoyou.ch/) + Kaufen -Immobilie kaufen in der SchweizWohnung kaufen in der SchweizHaus kaufen in der Schweiz + +[Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + Mieten -Immobilie mieten in der SchweizWohnung mieten in der SchweizHaus mieten in der Schweiz -Ändern Sie die Suche -KaufenGrundstückeKanton Zürich + +[Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + + Ändern Sie die Suche + +[](https://www.immoyou.ch/)[Kaufen](https://www.immoyou.ch/kaufen-schweiz)[Grundstücke](https://www.immoyou.ch/grundstuck-kaufen-schweiz)[Kanton Zürich](https://www.immoyou.ch/grundstuck-kaufen-kanton-zurich) + Grundstück kaufen im Kanton Zürich +================================== + Ort -Schweiz -Zürich -Genf -Typ -[x] Haus + Schweiz -[x] Wohnung + Zürich -[x] Zimmer + Genf -[x] Parkplatz + Typ -[x] Büro & Gewerbe +- [x] Haus -[x] Wohnhaus +- [x] Wohnung -[x] Grundstück +- [x] Zimmer -Verkaufspreis +- [x] Parkplatz -Zimmer +- [x] Büro & Gewerbe -Wohnfläche (m²) +- [x] Wohnhaus -Grundstücksfläche (m²) +- [x] Grundstück -Ausstattung & Eigenschaften + Verkaufspreis -[x] Neubauprojekte + - -[x] Balkon + Zimmer -[x] Garten + - -[x] Parkplatz + Wohnfläche (m²) -[x] Lift + - -[x] Freie Aussicht + Grundstücksfläche (m²) -[x] Cheminée + - -[x] Garage + Ausstattung & Eigenschaften -[x] Kinderfreundlich +- [x] Neubauprojekte -[x] Rollstuhlgängig +- [x] Balkon -[x] Möbliert +- [x] Garten + +- [x] Parkplatz + +- [x] Lift + +- [x] Freie Aussicht + +- [x] Cheminée + +- [x] Garage + +- [x] Kinderfreundlich + +- [x] Rollstuhlgängig + +- [x] Möbliert Ordnen -56 Ergebnisse -vor 1 Monat + 56 Ergebnisse + + + + vor 1 Monat + Grundstück zu verkaufen + 8193 Eglisau +------------------------------------- + Le terrain de 1193 m2 offre une vue magnifique sur le Rhin. Sur le terrain actuel, il y a deux maisons jumelées, chacune avec 160m2 de surface habitable, dans un endroit dégagé. Il convient aux investisseurs qui souhaitent investir dans un projet - architectes, GC/TU, qui souhaitent laisser libre cours à leurs idées de planification. La propriété bénéficie du soleil toute la journée et est située directement sur le Rhin avec une vue fantastique. Saisissez votre chance de réaliser quelque chose de grand.Cette offre appropriée se caractérise par les avantages suivants: Emplacement idéal Terrain spacieux (1193 m2) Vue fantastique Directement sur le Rhin Soleil matin et soir Intéressé? Contactez-nous pour une discussion sans engagement Pour commercialiser vous-même une propriété? Nous convainquons avec des conditions équitables et transparentes + - + Auf Anfrage -vor 2 Monaten + + + vor 2 Monaten + Grundstück zu verkaufen + 8134 Adliswil -OFFMARKET: Baulandparzelle in Adliswil / ZH Das Bauland eignet sich perfekt als Projektentwicklung für Institutionelle Anleger/Developer/Investoren/Baugesellschaften/Architekten. Wir freuen uns auf ihre Kontaktnahme.Genaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: Baulandparzelle mit Bestandesliegenschaft in Adliswil / ZH Adliswil, Grundstücksfläche: >710m2 / Zone W2 / AZ: 0.3 / Lärmempfindlichkeit: II / mögliche bebaubare NWF: ca. 265m2. Sehr gute, attraktive Hanglage. Voll erschlossen, plan- und anschliessend bebaubar. Eine der letzten Baulandparzelle in Adliswil mit atemberaubender Weitsicht. Das Bauland bieten wir EXKLUSIV unseren NETZWERKPARTNERN an. Wollen Sie NETZWERKPARTNER werden und ausführliche Infos zum Bauland erhalten? Dann freuen wir uns auf ihre Kontaktnahme.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : +-------------------------------------- + +OFFMARKET: Baulandparzelle in Adliswil / ZH Das Bauland eignet sich perfekt als Projektentwicklung für Institutionelle Anleger/Developer/Investoren/Baugesellschaften/Architekten. Wir freuen uns auf ihre Kontaktnahme.Genaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/p/8134-22-3 Baulandparzelle mit Bestandesliegenschaft in Adliswil / ZH Adliswil, Grundstücksfläche: >710m2 / Zone W2 / AZ: 0.3 / Lärmempfindlichkeit: II / mögliche bebaubare NWF: ca. 265m2. Sehr gute, attraktive Hanglage. Voll erschlossen, plan- und anschliessend bebaubar. Eine der letzten Baulandparzelle in Adliswil mit atemberaubender Weitsicht. Das Bauland bieten wir EXKLUSIV unseren NETZWERKPARTNERN an. Wollen Sie NETZWERKPARTNER werden und ausführliche Infos zum Bauland erhalten? Dann freuen wir uns auf ihre Kontaktnahme.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/p/8134-22-3 + - + Auf Anfrage -vor 3 Wochen + + vor 3 Wochen + Grundstück zu verkaufen + 8908 Hedingen +-------------------------------------- + Die perfekte Lage, um die Vision vom eigenen Wohntraum zu verwirklichen, mit Umschwung, der neue Perspektiven und Freiheitsgefühl eröffnet. Dieses exquisite Grundstück mit einem bestehenden altem Haus, befindet sich in der Wohnzone 2.0 und bietet in allerlei Hinsicht diverse Möglichkeiten Ihr eigenes Projekt zu realisieren. Lassen Sie sich diese rare Möglichkeit nicht entgehen und rufen Sie uns heute noch für weitere Details an. Hier werden also keine Wünsche offen gelassen. Profitieren Sie und überzeugen Sie sich selbst! Dieses PREMIUM HOMES Angebot bietet: Parzelle 550m2 Wohnzone W2 max. Ausnützungsziffer 0.3 Die Parzelle ist erschlossen Familienfreundliche, privilegierte Lage Gemeinde mit guter Infrastruktur Extra viele Sonnenstunden und, und, und... Interessiert? Gerne führen wir Sie durch eine unverbindliche Besichtigung! Sie wollen Ihr Haus oder Ihre Wohnung sorgenfrei verkaufen? Wir sagen Ihnen den aktuellen Marktwert Ihrer Immobilie, diskret und unverbindlich! Haben Sie Interesse an einem ersten unverbindlichen Gedankenaustausch? Zögern Sie nicht und kontaktieren Sie uns. Wir freuen uns auf Sie. + - + Auf Anfrage -vor 3 Wochen + + vor 3 Wochen + Grundstück zu verkaufen + 8155 Nassenwil +--------------------------------------- + Diese 1412 m2 grosse Parzelle liegt am Rande eines ländlichen und ruhigen Wohnquartieres im beliebten Nassenwil in der Gemeinde Niederhasli. Westlich an die Landwirtschaftszone grenzend und perfekt besonnt sowie mit schöner Aussicht über das Quartier kann hier etwas Neues entstehen. Bebaut ist die Parzelle heute mit einem kleinen Einfamilienhaus, welches abgebrochen werden kann. Das Grundstück befindet sich in der Wohnzone E2, die die Erstellung von Einfamilien- und Doppeleinfamilienhäuser zulässt. Die Parzelle zeichnet sich besonders aus durch:- Exzellente Lage- Grosses Potential- Ganztägige Besonnung- Familienfreundliche Nachbarschaft- Ruhig gelegen Der Verkauf erfolgt im zweistufigen Bieterverfahren. Die CHF 1´500´000.- bzw. CHF 1´059.-/ m2 stellen das Mindestgebot dar. Angebote darunter werden nicht berücksichtigt. Weitere Infos zum Objekt und zum Verkaufsprozess können Sie den weiteren Unterlagen entnehmen, welche ich Ihnen sehr gerne per Mail zustelle. + - + CHF 1’500’000 -vor 3 Wochen + + vor 3 Wochen + Grundstück zu verkaufen + 8800 Thalwil -Seltene Gelegenheit am Zürichsee: An der Seestrasse in Thalwil verkaufen wir fast 3'000 m² Bauland mit grossem Nutzungspotential. Nachfolgend die wichtigsten Fakten: Unverbaubare Seesicht und ideale Mikrolage: nur wenige Gehminuten vom Bahnhof Thalwil entfernt (9 Minuten bis Zürich HB) Studie sieht Erstellung von 20 Wohneinheiten vor (2'995 m² Geschossfläche und 2'068 m² Wohnfläche) Erstellung von drei Vollgeschossen plus Attikageschoss möglich Wohnzone 3 mit grosser Ausnutzung Ausnützungsziffer 0.6 Dieses Bauland wird im Rahmen eines Bieterverfahrens verkauft Interessiert? Weitere Informationen, Bilder sowie Besichtigungsmöglichkeiten unter: Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch- Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der Grundstückgewinnsteuer +------------------------------------- + +Seltene Gelegenheit am Zürichsee: An der Seestrasse in Thalwil verkaufen wir fast 3'000 m² Bauland mit grossem Nutzungspotential. Nachfolgend die wichtigsten Fakten: Unverbaubare Seesicht und ideale Mikrolage: nur wenige Gehminuten vom Bahnhof Thalwil entfernt (9 Minuten bis Zürich HB) Studie sieht Erstellung von 20 Wohneinheiten vor (2'995 m² Geschossfläche und 2'068 m² Wohnfläche) Erstellung von drei Vollgeschossen plus Attikageschoss möglich Wohnzone 3 mit grosser Ausnutzung Ausnützungsziffer 0.6 Dieses Bauland wird im Rahmen eines Bieterverfahrens verkauft Interessiert? Weitere Informationen, Bilder sowie Besichtigungsmöglichkeiten unter: https://www.propertyowner.ch/immobilien/22-48153/ Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch- Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der Grundstückgewinnsteuer + - + CHF 12’000’000 -vor 1 Monat + + vor 1 Monat + Grundstück zu verkaufen + 8523 Hagenbuch ZH +------------------------------------------ + Parzelle 2260, Hagenbuch: Wohnhaus mit Scheune, 2 Schopf- und 1 Garagebaute auf 1'527 m2 Land in der Kernzone der Aussenwacht Oberschneit, Gemeinde 8523 Hagenbuch ZH. Mutmassliches Bauland mit folgenden Einschränkungen: Das Wohnhaus ist unter der Nummer VIII/502 in der "Häderli-Kartei" aufgelistet und Oberschneit ist auf der Liste der Kleinsiedlungen des Amtes für Raumentwicklung aufgeführt. Bauvorhaben bedürfen deshalb der Abklärung der Schutzwürdigkeit sowie zurzeit der Bewilligung durch die kantonale Baudirektion. WICHTIG: Gemäss Vernehmlassungsvorschlag der Baudirektion zur Übergangsverordnung vom August 2022 verbleibt Oberschneit auf der Liste der Liste der Kleinsiedlungen, die klarerweise aussenliegende Ortsteile darstellen. Oberschneit kann damit in der Bauzone verbleiben und ab Inkrafttreten der Übergangsordnung (Anfang 2023) ist für Bauvorhaben in Oberschneit voraussichtlich keine kantonale Zustimmung mehr erforderlich. Achtung: Es können auch das Bauernhaus mit Scheune und ca. 850 m2 oder das Bauland (ca. 680 m2) alleine erworben werden. Vorbehalten bleiben dabei: Parzellierung, Erschliessungsrechte zugunsten Bauland, Abbruch Schopf/Garage, koordinierter Erwerb und Bebaubarkeit Land. Der Verkauf des Gesamtobjektes erfolgt an den / die Meistbietenden. + - + CHF 995’000 -vor 1 Monat + + vor 1 Monat + Grundstück zu verkaufen + 8623 Wetzikon ZH -Bauland an vorzüglicher Lage? Hier werden Sie fündig!Mit 503 m² Parzellenfläche und ausserordentlich guten Voraussetzungen sind die Möglichkeiten bei diesem Grundstück beinahe unbeschränkt. 503 m² grosse Baulandparzelle Maximal erstellbare Bruttogeschossfläche von 267 m² Maximale Gebäudehöhe von 11.4 Metern Erstellung von drei Vollgeschossen möglich Knappe 2 km vom Strandbad Auslikon am Pfäffikersee entfernt Interessiert? Weitere Informationen und Bilder zur Immobilie sowie Besichtigungsmöglichkeiten unter Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch- Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der Grundstückgewinnsteuer +----------------------------------------- + +Bauland an vorzüglicher Lage? Hier werden Sie fündig!Mit 503 m² Parzellenfläche und ausserordentlich guten Voraussetzungen sind die Möglichkeiten bei diesem Grundstück beinahe unbeschränkt. 503 m² grosse Baulandparzelle Maximal erstellbare Bruttogeschossfläche von 267 m² Maximale Gebäudehöhe von 11.4 Metern Erstellung von drei Vollgeschossen möglich Knappe 2 km vom Strandbad Auslikon am Pfäffikersee entfernt Interessiert? Weitere Informationen und Bilder zur Immobilie sowie Besichtigungsmöglichkeiten unter https://www.propertyowner.ch/immobilien/23-49902/ Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch- Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der Grundstückgewinnsteuer + - + CHF 1’600’000 -vor 1 Monat + + vor 1 Monat + Grundstück zu verkaufen + 8426 Lufingen +-------------------------------------- + Im Auftrag unseres Kunden verkaufen wir an leicht erhöhter Hanglage in Augwil innerhalb eines gepflegten Wohnquartiers ein Bauland mit 1078 m² Grundstücksfläche bebaut mit einem 4½-Zimmer-Einfamilienhaus mit Doppelgarage. Die Liegenschaft präsentiert sich in einem gut unterhaltenen Zustand, mehrheitlich aus dem Erstellungsjahr. Verkaufsrichtpreis: CHF 2'450'000.-- Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot. + - + CHF 2’450’000 -vor 1 Monat + + vor 1 Monat + Grundstück zu verkaufen + 8804 Au ZH +----------------------------------- + In einem ruhigen und sonnigen Einfamilienhaus-Quartier verkaufen wir diese 698m2 grosse Bauparzelle an der Quellenstrasse 13, mit einem bestehendem 7-Zimmer-Einfamilienhaus. Kataster-Nr. WE5423, Quellenstrasse 13, 8804 Au ZH Bauzone: Wohnzone W2/40% Ausnutzung: Ausnutzungsziffer Ausnutzung Wert: 0.4 Grundbuch Anmerkungen: 1/2 subjektiv-dingliches Miteigentum an Blatt 2774, Kat. 5424, Wädenswil Baujahr Gebäude: 1949 Gebäudegrundfläche (GGF): 129 m2 Gebäudevolumen (GV): 1317 m3 Nutzfläche (NF): 149 m2 Verkaufspreis CHF 2'250'000.00 Haben wir Ihr Interesse geweckt? Für Fragen, weitere Unterlagen resp. Informationen oder einen Besichtigungstermin stehen wir Ihnen gerne zur Verfügung. Wir freuen uns auf Ihre Kontaktaufnahme! + - + CHF 2’250’000 -vor 1 Monat + + vor 1 Monat + Grundstück zu verkaufen + 8424 Embrach +------------------------------------- + An gut besonnter und attraktiver Aussichtslage verkaufen wir die 968m2 grosse Baulandparzelle an der Winklerstrasse 35 mit bestehendem 5-Zimmer-Einfamilienhaus mit 673m3. Die Parzelle befindet sich in der Wohnzone 2A2 und die Baumassenziffer beträgt 1.7. Die Bebaubarkeit wurde durch einen Architekten und in Zusammenarbeit mit dem Bauamt Embrach analysiert. Die erstinstanzlichen Abklärungen haben ergeben, dass auf dem Grundstück voraussichtlich ein dreistöckiges Mehrfamilienhaus mit 9 Tiefgaragen-Parkplätzen realisierbar sein sollte. Die realisierbare Fläche (Nettofläche mit Innenwänden) pro Stockwerk beläuft sich auf ca. 150m2, total ca. 450m2 über Terrain. Haben wir Ihr Interesse geweckt? Weitere Informationen zur Liegenschaft, der Parzelle und zur vorhandenen Grobstudie erhalten Sie bei uns in einem persönlichen Gespräch! Wir freuen uns auf Ihre Kontaktaufnahme! Verkaufspreis CHF 1'850'000.- Mit unserer virtuellen 360-Grad-Tour können Sie bereits die ersten Eindrücke der bestehenden Liegenschaft gewinnen. Sehr gerne stehen wir für eine Besichtigung vor Ort zur Verfügung und freuen uns auf Ihre Kontaktaufnahme. Weitere EckdatenGrundstück Kataster 877, Grundstücksgrösse 968m², Wohnzone 2A2, Baumassenziffer 1.7, Kubatur (GVZ) der bestehenden Liegenschaft 673m3, Baujahr 1964. Wesentliche DistanzenKindergarten ca. 850mPrimarschule ca. 600mSekundarschule ca. 1.1kmPost ca. 1kmSchwimmbad Talegg ca. 1.7kmApotheke ca. 1.2kmEinkaufsmöglichkeiten; Volg ca. 450m, Coop ca. 1.5km, Aldi ca. 2.2km, Migros ca. 1.6kmBahnhof Embrach-Rorbas ca. 2.7km, S41 Richtung Winterthur ca. 16min. / S41 Richtung Bülach ca. 9 minBushaltestelle Embrach, Gemeindehaus ca. 550m: Bus Nr. 520, 521 und Nr. 523 Bahnhof Embrach-Rorbas ca. 9 min, Flughafen Zürich ca. 15minAutobahnanschluss ca. 5.9km in 9min Ihre Kontaktperson Für Besichtigungen und Fragen steht Ihnen das RIZZO-Immobilien Team unter Telefon 052 267 80 60 oder E-Mail info(at)rizzo-immobilien(dot)ch gerne zur Verfügung. Termine / Vorgehen / Besondere Hinweise Besichtigung jederzeit möglich. Bezug nach Vereinbarung. Zwischenzeitlicher Verkauf/Änderungen vorbehalten. S.E.&O. + - + CHF 1’850’000 -vor 1 Monat + + vor 1 Monat + Grundstück zu verkaufen + 8157 Dielsdorf +--------------------------------------- + Gerne entwickeln und realisieren wir ein auf ihre Bedürfnisse massgeschneidertes Projekt, welches Ihnen zur Miete oder im Eigentum zur Verfügung stehen wird. Dank der Nähe zur A1 und A51 können neben Dielsdorf die Städte Baden und Zürich sowie der Flughafen ZH in Kürze erreicht werden. Hard Facts: Parzellenfläche für einen Sportbetrieb 17582m2 Erholungszone E1 Empfindlichkeitsstufe III Keine Gebäudehöhe Keine Ausnützungsziffer Nutzten Sie den Standort als Ihr Aushängeschild an gut erschlossener LageInteresse oder Fragen? Nehmen Sie Kontakt mit uns auf! Die Parzelle ist nicht das Richtige für Ihre Anforderungen? Kein Problem! Besuchen Sie unsere Homepage und finden Sie weitere Angebote unter: gewerbeland-schweiz.ch + - + Auf Anfrage -vor 1 Monat + + vor 1 Monat + Grundstück zu verkaufen + 8193 Eglisau +------------------------------------- + Das 1193 m2 grosse Grundstück verfügt über eine herrliche Aussicht in Richtung Rhein. Auf dem aktuellen Land stehen zwei Doppeleinfamilienhäuser mit je 160m2 Wohnfläche an einer unverbaubaren Lage. Es eignet sich für Investoren, die in ein Projekt investieren möchten - Architekten, GU/TU, die ihren planerischen Ideen freien Lauf lassen möchten. Das Grundstück geniesst ganztags Sonne und liegt direkt am Rhein mit traumhafter Aussicht. Ergreifen Sie Ihre Chance, etwas grossartiges zu realisieren. Dieses properti-Angebot zeichnet sich durch folgende Vorteile aus: Ideale Lage Grosszügiges Grundstück (1193 m2) Traumhafte Aussicht Direkt am Rhein Morgen- und Abendsonne Interessiert? Kontaktieren Sie uns für ein unverbindliches Gespräch!Selbst eine Immobilie zu vermarkten? Wir überzeugen mit fairen und transparenten Konditionen! + - + Auf Anfrage -vor 1 Monat + + vor 1 Monat + Grundstück zu verkaufen + 8472 Seuzach +------------------------------------- + Im Kundenauftrag verkaufen wir ein gut bebaubares Grundstück mit einer Fläche von 860 m² in der Wohnzone W1.6 mit altem Magazin/Schopf. Die Parzelle befindet sich an familienfreundlicher Lage im südwestlichen Ortsteil von Seuzach. Die Bushaltestelle Forrenbergstrasse ist nur wenige Schritte entfernt. Verkaufsrichtpreis: CHF 2'250'000.-- Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot. + - + CHF 2’250’000 -vor 2 Monaten + + vor 2 Monaten + Grundstück zu verkaufen + 8442 Hettlingen +---------------------------------------- + Das erwartet Sie? Ruhiges Wohnquartier abseits der Hauptstrasse? Attraktive Gemeinde mit günstigem Steuerfuss? Grosszügige Landparzelle im W1/20Information LiegenschaftKonstruktion Bauweise Massivbauweise Innenwände Backsteinmauerwerk Aussenwände Einschalenmauerwerk Fenster Holz-Metall-Fenster mit 2-fach Isolierverglasung Dachkonstruktion SatteldachAusbau Heizungsraum Elektrospeicherheizung, Verteilung via Radiatoren Küche Glaskeramikherd, Kühlschrank, Backofen, Geschirrspüler Nasszellen EG separater Waschtisch und WC, Dusche und Waschtisch Nasszelle OG Badewanne, Waschtisch, WC Hauswirtschaftsraum Waschtrog und Waschmaschine Bodenbeläge Parkett in Wohnzimmer, Essen und Büro. Keramische Platten im Eingang und Korridor. Kunststoffbelag in Küche und Hauswirtschaftsraum. Linoleum in allen Zimmern und Nasszellen.Zustand Das Einfamilienhaus wurde 1960 erstellt und verfügt über einen grosszügigen Wintergarten sowie im Wohnzimmer über ein Chemineé. Die nötigen Unterhaltsarbeiten wurden durchgeführt. Alles ist intakt und das Haus ist sofort bewohnbar. Die Bodenbeläge in den Zimmern, Küche und Nasszellen sind abgenutzt. Folgende grössere Arbeiten wurden durchgeführt:? zentrale Elektrospeicherheizung? Dämmung an der Westfassade? Anbau eines Wintergarten? FensterrenovationMirkolage Die Liegenschaft befindet sich in einem ruhigen Einfamilienhausquartier. Die Lage ist leicht überdurchschnittlich und befindet sich auf flachem Gelände. Der Kindergarten befindet sich in unmittelbarer Entfernung 190 m. Die Primarschule in 650 m Entfernung. Die Sekundarschule muss in Seuzach besucht werden. Ein Volg ist in knapp 500m erreichbar. Die nächste ÖV-Haltestelle ist 200 m entfernt. Der Bahnhof Hettlingen ist zu Fuss in 8 min erreichbar. + - + CHF 1’480’000 -vor 2 Monaten + + vor 2 Monaten + Grundstück zu verkaufen + 8625 Gossau ZH +--------------------------------------- + 454 m2 grosse Baulandparzelle W1.3Am Ortsrand von Gossau ZH, an sonniger Südhanglage, direkt an der grünen Zone und ohne Durchgangsverkehr, mit einer schönen, unverbaubaren Fernsicht, liegt diese Baulandparzelle W1.3. Das Grundstück wird neu mutiert und wird 454 m2 gross sein. Auch die angrenzende Parzelle mit Haus (neue Kat. Nr. 8867) wird verkauft. Verkauft wird im Angebotsverfahren. Interessiert? Verlangen Sie die detaillierten Unterlagen mit weiteren Infos und Bildern. + - + CHF 900’000 -vor 3 Monaten + + vor 3 Monaten + Grundstück zu verkaufen + 8523 Hagenbuch ZH +------------------------------------------ + Teil aus Parzelle 2260, Hagenbuch: ca. 680 m2 Land (total 1'527 m2 mit Bauernhaus mit Scheune). Die Abparzellierung des Objektes hat durch die Käuferschaft in Koordination mit der Käuferschaft der Restparzelle "Bauernhaus mit Scheune" unter gleichzeitiger Einräumung der Erschliessungsrechte für das Restbauland sowie dem vorgesehenen Abbruch des Gebäudes 18b stattzufinden. Daraus folgt: Es kann auch das ganze Grundstück 2260 erworben werden oder aber der künftige Nachbar (Bauernhaus mit Scheune) durch Beibringung / Mithilfe beim Verkauf direkt mit beeinflusst werden. WICHTIG: Gemäss Vernehmlassungsvorschlag der Baudirektion zur Übergangsverordnung vom August 2022 verbleibt Oberschneit auf der Liste der Liste der Kleinsiedlungen, die aussenliegende Ortsteile darstellen. Oberschneit kann damit in der Bauzone (Kernzone) verbleiben und ab Inkrafttreten der Übergangsordnung (Anfang 2023) ist für Bauvorhaben in Oberschneit keine kantonale Zustimmung mehr erforderlich. + - + CHF 450’000 -vor 2 Wochen + + vor 2 Wochen + Grundstück zu verkaufen + 8902 Urdorf • 325 m² +--------------------------------------------- + Zu verkaufen:Erschlossenes, sehr schön gelegenes Bauland für ein Einfamilienhaus mit max 146.25m2 Wohnfläche.Lage: Gontenschwil AGGrösse: 325m2Ausnützung: 0.45Mögliche Wohnfläche: ca. 146.25 m2Preis: Fr. 235'000.- FIX-PreisDas Land eignet sich für Bauherren, die einen pflegeleichten Garten möchten. Ein perfekt-ausgedachtes, dem Land entsprechendes Bauprojekt ist vorhanden und kann besprochen und ebenfalls erworben werden. + CHF 723 / m² + CHF 235’000 -vor 2 Wochen + + vor 2 Wochen + Grundstück zu verkaufen + 8001 Zürich +------------------------------------ + Bewilligtes Bauprojekt auf zwei Grundstücken an zentraler Lage mit attraktiven Renditeaussichten Das im folgenden vorgestellte Neubauprojekt erstreckt sich über zwei Parzellen (Parz. 1288 = 637 m2 und Parz. 1289 = 310 m2) - an bester Lage in Emmenbrücke. Sowohl mit dem Auto als auch mit dem öffentlichen Verkehr ist man innerhalb von nur 15 Minuten in der Stadt Luzern. Bewilligt sind 9 attraktive Wohnungen (1.5 bis 4.5 Zimmer) und 5 Aussenparkplätzen mit einer Gesamtwohnfläche von 582 m2 und diversen Nebenräumen. Von der obersten Etage geniesst mein eine wundervolle Weitsicht in die Berge. Verkauft werden die beiden Grundstücke inkl. dem bewilligten Projekt Haben wir Ihr Interesse geweckt? Gerne stellen wir Ihnen die Detailunterlagen zur Verfügung. + - + CHF 2’300’000 -vor 2 Wochen + + vor 2 Wochen + Grundstück zu verkaufen + 8700 Küsnacht ZH +----------------------------------------- + Bitte ausschliesslich Private Investoren/ Interessenten. + - + Auf Anfrage -vor 3 Wochen + + vor 3 Wochen + Grundstück zu verkaufen + 8713 Uerikon +------------------------------------- + Unverbaubare Seesicht, von der Sonne verwöhnt, mitten im Dorf und doch mit grösstmöglicher Privatsphäre. Ein aussergewöhnliches Grundstück von 1008 m2 Fläche an Hanglage, durch Felswand vor Bise geschützt, das in der Zürcher Seegemeinde Uerikon (politische Gemeinde Stäfa) am oberen Teil des Zürichsees liegt. Das Ufer des Sees mit Seebad, der Wald mit Wanderwegen, Schulhäuser und Bahnhof sind innert weniger Gehminuten zu erreichen. Anwohner schätzen die schnelle Erreichbarkeit der wichtigsten Wirtschaftszentren und Tourismusdestinationen in der Deutschschweiz, ob mit dem Auto oder den öffentlichen Verkehrsmitteln. Mit einem Steuerfuss von 78 % gehört Uerikon/Stäfa zu den 7 steuergünstigsten Gemeinden des Kantons Zürich. Verschiedene Möglichkeiten bieten sich für diese Parzelle an: Modernisierung des vorhandenen Einfamilienhauses Neubau eines Einfamilien- oder Doppeleinfamilienhauses Terrassenwohnungen Arealüberbauung Haben wir Ihr Interesse geweckt? Gerne stellen wir Ihnen unsere detaillierte Broschüre "Leben am Zürichsee" zu. Wir freuen uns auf Ihre Kontaktaufnahme. + - + Auf Anfrage -vor 3 Wochen + + vor 3 Wochen + Grundstück zu verkaufen + 8155 Nassenwil • 1’412 m² +-------------------------------------------------- + Diese 1412 m2 grosse Parzelle liegt am Rande eines ländlichen und ruhigen Wohnquartieres im beliebten Nassenwil in der Gemeinde Niederhasli. Westlich an die Landwirtschaftszone grenzend und perfekt besonnt sowie mit schöner Aussicht über das Quartier kann hier etwas Neues entstehen. Bebaut ist die Parzelle heute mit einem kleinen Einfamilienhaus, welches abgebrochen werden kann. Das Grundstück befindet sich in der Wohnzone E2, die die Erstellung von Einfamilien- und Doppeleinfamilienhäuser zulässt. Die Parzelle zeichnet sich besonders aus durch: Exzellente Lage Grosses Potential Ganztägige Besonnung Familienfreundliche Nachbarschaft Ruhig gelegen Der Verkauf erfolgt im zweistufigen Bieterverfahren. Weitere Infos zum Objekt und zum Verkaufsprozess können Sie den weiteren Unterlagen entnehmen, welche ich Ihnen sehr gerne per Mail zustelle. + CHF 1’062 / m² + CHF 1’500’000 -vor 3 Wochen + + vor 3 Wochen + Grundstück zu verkaufen + 8104 Weiningen ZH • 1’167 m² +----------------------------------------------------- + Dieses Bauland mit bestehendem Altbau und Hanglage liegt in Weiningen in begehrter Lage mit herrlicher Aussicht (unverbaubar).Bauland in Weiningen ist äusserst rar und gesucht - mit schöner Aussicht sowieso. An erhöhter Lage über den Dächern von Weiningen kommen Sie in den Genuss einer traumhaften Aussicht (Weiningen, Limmattal, Zürich, Uetliberg und auf das wunderbare Bergpanorama der Alpen) und geniessen zeitgleich die absolute Ruhe.Die nicht alltägliche Parzelle mit dem bewilligten Neubau für ein Mehrfamilienhaus und ein Einfamilienhaus überzeugt mit folgenden Eigenschaften:Die Highlights: exklusive, erhöhte Lage im ruhigen Wohnquartier Nähe zur Stadt Zürich herrliche, unverbaubare Aus-/ Fernsicht (Weiningen, Zürich, Alpenpanorama, Uetliberg) Grundstück an ruhiger Quartierstrasse mit vorteilhafter Hanglage gut erschlossen keine eingetragenen Altlasten keine Architektenbindung alle Baupläne liegen vor eine Bodenanalyse für die Bodenbeschaffenheit liegt vor eine Baubewilligung wurde erteilt. keine Hypothekendarlehen, also freie Bankenwahl mit dem Neubau kann man sofort beginnen eine Wohnung wird von der Verkäuferschaft gekauft Daten zum Grundstück:Kataster 1784, 1167 m2 mit HanglageHogerwiesstrasse1 in 8104 WeiningenW2 30 BauzoneToplage im bevorzugten Quartier über den Dächern von Weiningen ZHSchöne Aussicht und Fernsicht Richtung Zürich, Uetliberg, Limmattal und den Alpen Bewilligte Neubauten - Wohnflächen:Mehrfamilienhaus (MFH) mit 3 Wohnungen und Tiefgarage (5 Geschosse)MFH 4.5 Zi. Wohnung 3:143.0 m2MFH 4.5 Zi. Wohnung 2: 133.5 m2MFH 3.5 Zi. Wohnung 1: 117.2 m2 (Maisonette)Einfamilienhaus (EFH) (3 Geschosse UG/EG/DG)EFH: 170.2 m2 Bewilligte Neubauten - Bauvolumen:MFH - Tiefgarage: 940 m3MFH - Wohnen:1580 m3EFH:970 m3 Kaufpreis Bauland mit bewilligtem Neubauprojekt:Der Kaufpreis für das Grundstück mit bewilligten Bauprojekt liegt bei 3.2 Mio. CHFund im Gegenzug möchte die Verkäuferschaft die Wohnung 2 (133.5 m2)mit 2 Parkplätzen in der Tiefgarage kaufen. Haben wir Ihr Interesse geweckt?Für weitere Einzelheiten zum Neubauprojekt und einen Besichtigungstermin sind wir gerne für Sie da.Wir freuen uns auf Ihren Anruf! + CHF 2’742 / m² + CHF 3’200’000 -vor 3 Wochen + + vor 3 Wochen + Grundstück zu verkaufen + 8523 Hagenbuch ZH • 680 m² +--------------------------------------------------- + Teil aus Parzelle 2260, Hagenbuch: ca. 680 m2 Land (total 1'527 m2 mit Bauernhaus mit Scheune).Die Abparzellierung des Objektes hat durch die Käuferschaft in Koordination mit der Käuferschaft der Restparzelle "Bauernhaus mit Scheune" unter gleichzeitiger Einräumung der Erschliessungsrechte für das Restbauland sowie dem vorgesehenen Abbruch des Gebäudes 18b stattzufinden. Daraus folgt: Es kann auch das ganze Grundstück 2260 erworben werden oder aber der künftige Nachbar (Bauernhaus mit Scheune) durch Beibringung / Mithilfe beim Verkauf direkt mit beeinflusst werden.WICHTIG:Gemäss Vernehmlassungsvorschlag der Baudirektion zur Übergangsverordnung vom August 2022 verbleibt Oberschneit auf der Liste der Liste der Kleinsiedlungen, die aussenliegende Ortsteile darstellen. Oberschneit kann damit in der Bauzone (Kernzone) verbleiben und ab Inkrafttreten der Übergangsordnung (Anfang 2023) ist für Bauvorhaben in Oberschneit keine kantonale Zustimmung mehr erforderlich.S.E.&.O. Irrtümer vorbehalten. Wir bemühen uns um korrekte Angaben, können jedoch keine Gewähr übernehmen. + CHF 662 / m² + CHF 450’000 -vor 3 Wochen + + vor 3 Wochen + Grundstück zu verkaufen + 8625 Gossau ZH • 454 m² +------------------------------------------------ + 454 m2 grosse Baulandparzelle W1.3Am Ortsrand von Gossau ZH, an sonniger Südhanglage, direkt an der grünen Zone und ohne Durchgangsverkehr, mit einer schönen, unverbaubaren Fernsicht, liegt diese Baulandparzelle W1.3. Das Grundstück wird neu mutiert und wird 454 m2 gross sein. Auch die angrenzende Parzelle mit Haus (neue Kat. Nr. 8867) wird verkauft. Verkauft wird im Angebotsverfahren. Interessiert? Verlangen Sie die detaillierten Unterlagen mit weiteren Infos und Bildern. + CHF 1’982 / m² + CHF 900’000 -123 -1 - 24 von 56 Ergebnisse -All rights reserved. v.541ff84 \ No newline at end of file + +[1](https://www.immoyou.ch/grundstuck-kaufen-kanton-zurich)23 + + 1 - 24 von 56 Ergebnisse + + All rights reserved. v.541ff84 \ No newline at end of file diff --git a/test_web_integration.py b/test_web_integration.py index 7f2cc9ab..d4bff439 100644 --- a/test_web_integration.py +++ b/test_web_integration.py @@ -74,8 +74,8 @@ async def test_web_research_integration(): print("="*60) request = WebResearchRequest( - # search_query="Kannst Du mir eine Liste machen, welche Grundstücke aktuell im Kanton Zürich verkauft werden?", - search_query="Erstelle mir ein Firmenprofil von ValueOn AG in der Schweiz", + search_query="Kannst Du mir eine Liste machen, welche Grundstücke aktuell im Kanton Zürich verkauft werden?", + # search_query="Erstelle mir ein Firmenprofil von ValueOn AG in der Schweiz", max_results=10, options=WebResearchOptions( max_pages=10, diff --git a/test_web_integration_result.md b/test_web_integration_result.md index afb359d9..f2384360 100644 --- a/test_web_integration_result.md +++ b/test_web_integration_result.md @@ -1,10405 +1,14178 @@ # Web Research Integration Test Result -**Query:** Erstelle mir ein Firmenprofil von ValueOn AG in der Schweiz +**Query:** Kannst Du mir eine Liste machen, welche Grundstücke aktuell im Kanton Zürich verkauft werden? -**Websites Analyzed:** 31 -**Additional Links Found:** 27 +**Websites Analyzed:** 39 +**Additional Links Found:** 34 ## Analysis Result -=== https://www.valueon.ch/ === -# Power für deinendigitalen Erfolg - -Vertrauen von führenden Unternehmen - -## Unsere Expertise - -Von digitaler Transformation bis zu künstlicher Intelligenz – wir begleiten Sie auf Ihrem Weg in die Zukunft. - -### Digitale Strategie entwickeln - -Ihre Richtung im digitalen Wandel. - -Gemeinsames Zielbild & Roadmap, abgestimmt auf Ihr Geschäft und leiten konkrete Handlungsempfehlungen ab. - -Orientierung & Handlungssicherheit - -### Transformation gezielt optimieren - -Lücken aufdecken. Stärken nutzen. - -Systematischer Blick auf Prozesse, Systeme & Potenziale und leiten konkrete Handlungsempfehlungen ab. - -Relevanz statt Aktionismus - -### Change Management etablieren - -Menschen mitnehmen. Wandel gestalten. - -Strukturierte Begleitung der Mitarbeiter durch den digitalen Wandel mit gezielten Schulungskonzepten. - -Akzeptanz & Erfolg sichern - -### Prozesse digital automatisieren - -Effizienz steigern. Kosten senken. - -Identifikation und Umsetzung von Automatisierungspotenzialen für nachhaltige Produktivitätssteigerung. - -Messbare Effizienzgewinne - -## Erfolgreiche Projekte & Transformationen - -Unter dem Motto «Unsere Kunden stehen im Mittelpunkt» haben wir für Sie eine Auswahl an Kundenreferenzen und Business Cases zusammengestellt. - -Als KMU sind wir es eigentlich nicht gewohnt, einen so grossen Aufwand wie bei der Evaluation des richtigen Partners für die Entwicklung und Realisierung unseres neuen Kernsystems zu betreiben. Doch i... - -Markus Berther - -Geschäftsführer, Schaden Service Schweiz AG - -ValueOn hat uns durch den gesamten Prozess der Digitalen Business Transformation mit grossem Einsatz und Engagement begleitet – von der ersten IT-Standortanalyse und Sourcing Analyse über digitales Zi... - -Stefan Wolf - -Präsident, FC Luzern - -In diesem businesskritischen IT-Programm waren insgesamt vier Experten von ValueOn (ehem. Project Competence) involviert, als Projektleiter und Koordinator, Cut-Over-Manager bis hin zur Gesamt-Program... - -Roland Bosshard - -CIO / Mitglied der GL, KPT - -In time, in quality, under budget: Andreas Friedli von ValueOn (ehem. Project Competence) hat in seiner Co-Leitungsfunktion in diesem IT-Projekt ganz massgeblich dazu beigetragen, dass wir dieses trot... - -Thomas Sturzenegger - -Divisional IT Lead, RUAG Real Estate AG - -Die erfolgreiche Realisierung dieses Vorhabens ist ein wichtiger Meilenstein für die strategische Neuausrichtung der WWZ. Die Projektberater der ValueOn AG (ehem. Project Competence AG) haben dabei da... - -Thomas Reber - -Leiter Telekom & IT Services, WWZ AG - -Um die Zukunftsausrichtung unserer IT-Strategie und -Organisation möglichst optimal auf unsere Business-Anforderungen auszurichten, haben wir ValueOn (ehem. Project Competence) als Sparringpartner ... - -Andreas Guglielmo - -CFO, CHRIS sports AG - -Wir danken den externen Projektberatern der ValueOn (ehem. Project Competence), die uns kompetent und mit ebenso hohem Arbeitseinsatz durch dieses Projekt und die Verhandlungen unter schwierigen Be... - -Michael Kohlbacher - -Generalsekretär, AGZ - -Dank ValueOn konnten wir unser komplexes IT-Infrastrukturprojekt termingerecht und im Budget abschliessen. Die strukturierte Herangehensweise war ausschlaggebend. - -Peter Keller - -Projektleiter, InnovaCorp - -ValueOn hat uns sowohl fachlich als auch menschlich auf höchstem Niveau beraten. Die Experten begleiteten uns kompetent bei der Modernisierung unserer IT-Infrastruktur und der reibungslosen Ablösung u... - -Silvan Wildhaber - -CEO, Filtex Group AG - -← Wischen Sie für weitere Testimonials → - -Auto-Scroll aktiv - - -=== https://www.valueon.ch/about === -ValueOn - Mehrwert dank digitaler Transformation +=== https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich === +70 Bauland zum Kaufen: Kanton Zürich | ImmoScout24 =============== -[](https://www.valueon.ch/) +[](https://www.immoscout24.ch/de) +* [Suchen](https://www.immoscout24.ch/de "Suchen") +* [Services](https://www.immoscout24.ch/c/de/hypotheken "Services") -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) +[Inserat erstellen](https://www.immoscout24.ch/de/insertion/inserat-online-erfassen "Inserat erstellen") -🇩🇪DE +[Favoriten](https://www.immoscout24.ch/favoriten "Favoriten") -[Gespräch vereinbaren](https://www.valueon.ch/contact) +[Mein Konto](https://www.immoscout24.ch/de/account-overview "Mein Konto") -🇩🇪DE +Menü -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) +[](https://www.immoscout24.ch/de) +* [Suchen](https://www.immoscout24.ch/de "Suchen") +* [Services](https://www.immoscout24.ch/c/de/hypotheken "Services") +* [Bewerten](https://www.immoscout24.ch/de/immobilienbewertung "Bewerten") +* [Magazin](https://www.immoscout24.ch/c/de/immobilien-magazin "Magazin") -Unser Team -========== +[Inserat erstellen](https://www.immoscout24.ch/de/insertion/inserat-online-erfassen "Inserat erstellen") -Seit über 25 Jahren stehen wir für Innovation, Qualität und nachhaltigen Erfolg. Erfahren Sie mehr über unsere Geschichte, unsere Werte und die Menschen, die ValueON zu dem machen, was es heute ist. +[Favoriten](https://www.immoscout24.ch/favoriten "Favoriten") -Alle Kernteam Geschäftsführende Partner Externe Zertifizierte Partner +[Mein Konto](https://www.immoscout24.ch/de/account-overview "Mein Konto") - +Menü -Mehr erfahren +DE +* [DE](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich) +* [FR](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich) +* [IT](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo) +* [EN](https://www.immoscout24.ch/en/plot/buy/canton-zurich) -### Dominic Largo +1. [](https://www.immoscout24.ch/de) +2. [Bauland zum Kaufen](https://www.immoscout24.ch/de/grundstueck/kaufen) +3. [Kanton Zürich](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich) -CEO +Wo? - + Kanton Zürich -Dominic führt das Unternehmen mit einer klaren Vision für digitale Innovation und strategisches Wachstum in der Beratung. + Kanton Zürich -### Dominic Largo + CHF bis -CEO + - + Filter -Zum Vergrößern klicken + 70 Objekte -#### Schwerpunkte +70 Treffer - Bauland zum Kaufen: Kanton Zürich +============================================== -* Sicherstellen der besten Projekt- & Tranformationsmanager für unsere Kunden und unsere Vorhaben -* Reviews von komplexen und erfolgskritischen Vorhaben -* Advisor & Einsitz in Steering Boards -* Sparringpartner für Führungskräfte und Gremien +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 16    **360m²**, CHF 2’563’760.– Top Luegetenstrasse 11, 8489 Wildberg Ihr neues Zuhause mit Potenzial - Idyllisches Landhaus mit Baulandreserve Ihr neues Zuhause Willkommen in Ihrem zukünftigen Traumdomizil - ein grosszügiges, freistehendes Landhaus an ruhiger und idyllischer Aussichtslage im malerischen Wildberg. Hier vereinen sich ländliche Idylle, Privatsphäre und die seltene Möglichkeit, Wohnraum nach eigenen Vorstellungen zu schaffen oder zu erweitern.Ob als charmantes Familienrefugium mit grossem Garten oder als Investitionsobjekt mit Entwicklungspotenzial - dieses einzigartige Anwesen bietet Ihnen beide Optionen. Auf dem 1339m² grossen Grundstück geniessen Sie nicht nur viel Platz zum Leben, sondern verfügen auch über eine wertvolle Baulandreserve, die Ihnen vielfältige Gestaltungsmöglichkeiten eröffnet. Erste Abklärungen zeigen: Es besteht die Möglichkeit, ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren - ein echter Mehrwert für visionäre Käufer.Tauchen Sie ein in eine grüne Oase mit Weitblick - ein Ort, der Ruhe schenkt und inspiriert.Highlights auf einen Blick • Idyllische, ruhige Aussichtslage mit hohem Erholungswert • Grosszügiges Grundstück mit 1339m², ideal zur Eigennutzung und/oder für die Entwicklung eines Neubaus • Baulandreserve: Attraktives Entwicklungspotenzial - gemäss erster Einschätzung besteht die Möglichkeit, zusätzlich zum bestehenden Einfamilienhaus ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren (unverbindlich, ohne Gewähr) • Blühender Garten mit verschiedenen Sitzplätzen, Pergola mit Aussencheminée, Gartenhäusern, gepflegtem Baumbestand und weitläufigen Grünflächen • Solide Bausubstanz mit Doppelschalenmauerwerk • Grosszügiges Raumkonzept mit ca. 220m² Wohnfläche und ca. 96m² zusätzlichem Stauraum im Untergeschoss. Total ca. 360m² Bruttofläche. • Geräumiger Wohnbereich mit gemütlichem Kachelofen - ein Ort zum Ankommen und Wohlfühlen • Praktische Wohnküche mit integriertem Essbereich - ideal für gesellige Stunden • 4 helle Schlafzimmer - ideal für Familien oder Homeoffice • 2 Nasszellen mit Tageslicht • Ausgebauter Estrich für zusätzlichen Raum oder kreative Nutzungsmöglichkeiten • Beheizt durch Elektrospeicher und wassergeführte Fussbodenheizung • Garage mit elektrischem Tor und weitere Parkmöglichkeiten auf dem Grundstück • Mit einer stilvollen Modernisierung verwandeln Sie dieses Haus in ein wahres Schmuckstück Verkaufspreis: CHF 1'870'000.-Mit unserer virtuellen 360-Grad-Tour können Sie bereits die ersten Eindrücke dieser tollen Liegenschaft gewinnen. Sehr gerne zeigen wir Ihnen diese Liegenschaft direkt vor Ort und freuen uns auf Ihre Kontaktaufnahme.Weitere EckdatenBaujahr Haus: 1984, Baujahr Gerätehaus: 1986, Kubatur Haus (GVZ): 936m³, Kubatur Gerätehaus (GVZ): 40m³, Grundbuchblatt: Nr. 437, Kataster-Nr.: 249, 1/4 subjektiv-dingliches Miteigentum an Blatt 444, Kataster 249. Nettowohnfläche: ca. 220m², Bruttowohnfläche: ca. 360m², Grundstücksfläche: 1'339m².Massivbauweise, Doppelschalenmauerwerk, neuwertige Holzmetallfenster (EgoKiefer) mit dreifacher Verglasung und Sprossen & Holzläden. Elektrospeicherofen, wassergeführte Fussbodenheizung, Elektroboiler 300 Liter.Treppenlift, Garage mit elektrischem Torantrieb. Küche im Landhausstil mit Granitabdeckung, Geschirrspüler, Induktions-Kochherd und Kühlschrank mit Gefrierfach.BodenbelägeEG: Entrée, Gang, Dusche, Küche, Essen mit Plattenboden.OG: Zimmer und Vorplatz mit Laminat in Holzoptik. Bad mit Platten.  Wegzeit Neu 28 min.Station: Rämismühle-Zell](https://www.immoscout24.ch/kaufen/4002491909) -#### Im Team seit +[*  *  *  *  *  *  *  *  1 / 4 Preis auf Anfrage Top Lüss, 8542 Wiesendangen Im Baurecht abzugeben: 14’770 m2 Bauland an bester Lage im steuergünstigen Wiesendangen Im Baurecht abzugeben:14’770 m2 Bauland an bester Lage im steuergünstigen WiesendangenGrundstück WD4674 – Lüss WiesendangenAlle Details zum Grundstück, zum Baurechtsvertrag sowie zu den Vergabekriterien finden sie im angefügten Dossier.Verbindliche Angebote für eine Übernahme des Baurechtsvertrages inklusive Finanzierungsnachweis sind einzureichen an:Gemeinde Wiesendangenz. Hd. Martin SchindlerSchulstrasse 208542 Wiesendangen Bitte verwenden Sie für die Angebotseingabe das Formular im Anhang.Eingabeschluss: Montag, 20. Oktober 2025, 11.00 Uhr Wegzeit Neu 9 min.Station: Wiesendangen](https://www.immoscout24.ch/kaufen/4002510601) -2024 +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 12    CHF 2’323’840.– Hürstringstrasse 37, 8046 Zürich Grundstück mit bestehendem EFH und grossem Potenzial Gerne stellen wir Ihnen das Grundstück mit grossem Potenzial und vielen Möglichkeiten vor.Nach Absprache verkaufen wir an ruhiger Lage in Zürich ein Grundstück mit bestehendem Einfamilienhaus. Interessant an diesem Objekt ist jedoch, dass Sie beim Kauf bereits über die zugehörige Baubewilligung verfügen, welche es Ihnen erlaubt, den Wohnraum auf dieser Parzelle nach Ihren Wünschen zu vergrössern und zu sanieren.Nicht weit vom Zürcher Hauptbahnhof entfernt, hinter dem Käferberg liegt die grosszügige Parzelle mitten in einem ruhigen Wohnquartier mit 30er-Zone.Zu Fuss erreichen Sie eine Bushaltestelle, sowie auch den kleinen Wald, der sich ideal für kürzere Spaziergänge eignet.Die wichtigsten Infos in Kürze: • Landparzelle inkl. Einfamilienhaus und Baubewilligung zum Ausbau der Wohnfläche • Baujahr 1934 • Grundstückfläche von 410 m2 • Projektmöglichkeit 1: Ausbau zum Mehrfamilienhaus mit zwei Eigentums- oder Mietwohnungen • Projektmöglichkeit 2: Ausbau zum Generationenhaus Erleben Sie die ruhige Atmosphäre und gleichzeitige Nähe zum Stadtzentrum bei einem persönlichen Besuch!Für nähere Informationen zum Objekt oder einen Besichtigungstermin dürfen Sie sich gerne jederzeit bei uns melden.  Wegzeit Neu 22 min.Station: Zürich Seebach](https://www.immoscout24.ch/kaufen/4002349882) -#### Branchenerfahrungen +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 11    CHF 3’290’400.– Luzernerstrasse 57, 8903 Birmensdorf (ZH) Sonnige Aussichtslage Im Auftrag unseres Kunden verkaufen wir ein Bauland an sonniger Aussichtlage mit 1'228 m² Grundstücksfläche (Wohnzone W2).Die bestehende Liegenschaft präsentiert sich in einem dem Alter entsprechend gut unterhaltenen Zustand.Verkaufsrichtpreis: CHF 2'400'000Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot.  Wegzeit Neu 19 min.Station: Birmensdorf](https://www.immoscout24.ch/kaufen/4002566208) -Handel / eCommerce Tourismus Konsumgüter Luxusgüter Industrie +Dein Immobilienexperte vor Ort +------------------------------ -#### Berufliche Stationen +[ Stöhr Immobilien GmbH berät dich persönlich zur optimalen Verkaufsstrategie für deine Immobilie.](https://immoscout24.ch/anbieter/n023/stohr-immobilien-gmb-h) -* BottleButler AG (Founder & CEO) -* Arosa Lenzerheide (Marken- und Digital Leader) -* Mitgründer mehrerer Startups (Co-CEO & VR) -* Porsche Design Group (Country Manager & GCC) -* HAWAS & Jung von Matt (Markenstratege) +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13 CHF 4’044’440.– Mühlemattstrasse 12, 8135 Langnau am Albis Bauland oder bestehendes Einfamilienhaus zum Verkauf! Dieses freistehende Einfamilienhaus befindet sich an ruhiger Lage und bietet eine seltene Kombination aus architektonischem Charakter, grosszügigem Umschwung und inspirierendem Entwicklungspotenzial. Eingebettet in viel Grün und umgeben von Bäumen geniessen Sie hier Privatsphäre, Ruhe – und eine wunderschöne Weitsicht.Das Haus überzeugt durch eine unverwechselbare Ausstrahlung. Die Backsteinwände im Innenbereich verleihen dem Wohnraum eine warme, natürliche Atmosphäre, während das Cheminée im Wohnzimmer für Behaglichkeit an kühleren Tagen sorgt. Der Grundriss ist offen und einladend, ergänzt durch grosse Fensterfronten, die Licht und Natur ins Haus holen.Ein Highlight ist die grosszügige Terrasse mit herrlichem Ausblick – ideal für gemütliche Stunden im Freien. Der Garten ist weitläufig und bietet viel Platz für individuelle Gestaltung. Mit etwas Aufmerksamkeit lässt sich hier ein wunderbares grünes Paradies schaffen – ob als Familiengarten, Rückzugsort oder für kreative Projekte im Freien.Dank der Grundstücksgrösse und der Lage eröffnet die Liegenschaft auch interessante Perspektiven für einen möglichen Ersatzneubau - wie ein modernes Einfamilienhaus oder ein Mehrfamilienhaus.Gerne stellen wir Ihnen weitere Informationen zur Verfügung oder vereinbaren einen persönlichen Besichtigungstermin. Entdecken Sie das Potenzial und die besondere Atmosphäre dieses einzigartigen Ortes. In der Verkaufsdokumentation finden Sie alle wichtigen Informationen.  Wegzeit Neu 12 min.Station: Langnau-Gattikon](https://www.immoscout24.ch/kaufen/4002406229) -#### Und ganz nebenbei... +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13    CHF 1’302’440.– Kanalweg 2, 8714 Feldbach Bauland für projektiertes Einfamilienhaus Im beschaulichen Dorf Feldbach am Zürichsee ist dieses Grundstück mit einer bestehenden, einseitig angebauten Scheune zu verkaufen. Im Kaufpreis inbegriffen ist ein bewilligungsfähiges Vorprojekt für ein Einfamilienhaus als Ersatzbau der Scheune.Das Objekt bietet Ihnen die einmalige Möglichkeit, Ihren Traum vom Eigenheim an idyllischer Lage zu verwirklichen. Es bietet genügend Platz für eine Familie, auch eine Kombination von "Wohnen und Arbeiten" ist denkbar.Innert 30 Minuten sind Sie mit der S-Bahn in Zürich, auch Kindergarten und Primarschule sind nah. Einkaufsmöglichkeiten bestehen in Hombrechtikon, Stäfa und Rapperswil. Im Sommer lockt in unmittelbarer Nähe eine Abkühlung in der schmucken Seebadi Feldbach.Es besteht ein aktueller Kostenvoranschlag für das Haus (Holzelementbauweise) inkl. Umgebung, Bau- und Nebenkosten in der Höhe von Fr. 1'380'000.--.Haben wir Sie neugierig gemacht? Dann rufen Sie uns an. Gerne beantworten wir Ihre Fragen oder stellen Ihnen unsere Verkaufsdokumentation zum Studium zu. Die Liegenschaft kann selbstverständlich auch besichtigt werden. Wir freuen uns auf Ihren Anruf.  Wegzeit Neu 6 min.Station: Feldbach](https://www.immoscout24.ch/kaufen/4002434745) -...ist Dominic Largo mit grosser Passion Langstreckenläufer, Kulinariker und Game Challenger. Er geniesst explizit die Berge und seine Familienzeit. +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13    **5.5 Zimmer**, CHF 4’111’620.– Schaffhauserstrasse 226b, 8057 Zürich Mehr Raum fürs Leben: Reihenhaus mit Potenzial Attraktive Stadtliegenschaft mit ausgearbeitetem ProjektIm Zürcher Kreis 11 veräussern wir ein hübsches Reiheneinfamilien-Eckhaus mit grosszügigem Umschwung. Die Liegenschaft und das Grundstück verfügen über viel Ausnützungspotenzial und ermöglicht so die Realisation spannender Projekte sowohl im Umbau als auch Neubau.Diese Liegenschaft überzeugt durch viele Besonderheiten: • grosszügiger Umschwung mit viel Potenzial • Blick ins Grüne von nahezu allen Fenstern • Schwedenofen im Wohnbereich • viel Stauraum durch Wandschränke und Estrich • Altbaucharme in modernem Quartier • zentrale und familienfreundliche Lage • sonnenverwöhnter Standort Haben wir Ihr Interesse geweckt? Bestellen Sie noch heute unsere ausführliche Verkaufsdokumentation mittels Kontaktformular und Sie erhalten weitere spannende Informationen zur Immobilie. Wir freuen uns über Ihre Kontaktaufnahme!Une oasis de verdure dans la ville de Zurich avec un projet élaboréDans le quartier 11 de Zurich, nous vendons une jolie maison mitoyenne en angle avec de vastes alentours. L'immeuble et le terrain disposent d'un grand potentiel d'exploitation et permettent ainsi la réalisation de projets passionnants, tant en transformation qu'en construction neuve.Cette propriété convainc par ses nombreuses particularités : • Un vaste terrain avec beaucoup de potentiel • Une vue sur la verdure depuis presque toutes les fenêtres • Un poêle suédois dans le séjour • beaucoup d'espace de rangement grâce aux armoires murales et au grenier • Le charme d'un ancien bâtiment dans un quartier moderne • Un emplacement central et favorable aux familles • Un emplacement ensoleillé Nous avons éveillé votre intérêt ? Commandez dès aujourd'hui notre documentation de vente détaillée au moyen du formulaire de contact et vous recevrez d'autres informations passionnantes sur le bien immobilier. Nous nous réjouissons de votre prise de contact!A green oasis in the city of Zurich with an elaborate projectIn Zurich's Kreis 11 district, we are selling a pretty terraced single-family corner house with spacious grounds. The property and the plot have a lot of utilization potential and thus enable the realization of exciting projects both in conversion and new construction.This property boasts many special features: • spacious grounds with lots of potential • view of the countryside from almost all windows • Swedish stove in the living area • lots of storage space thanks to wall cupboards and attic • old building charm in a modern district • central and family-friendly location • sun-drenched location Have we piqued your interest? Order our detailed sales documentation today using the contact form and you will receive further exciting information about the property. We look forward to hearing from you!  Wegzeit Neu 4 min.Station: Berninaplatz](https://www.immoscout24.ch/kaufen/4002346061) - +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 12 Preis auf Anfrage Überlandstrasse 23, 8340 Hinwil Industrie- und Baulandparzelle an attraktivem Standort im Zürcher-Oberland Im pulsierenden Industriegebiet von Hinwil verkaufen wir ein Industriebaugrundstück an einer top frequentierter Lage, direkt an der Hauptachse in Rapperswil Wetzikon Pfäffikon ZH. Die Baulandparzelle befindet sich am Rand der Industriezone und grenzt an die Wohnzone zu Hinwil ZH.Eckdaten:- Grundstück-Fläche total 4'246 m2- Bauzone Industrie/Gewerbe IG/7 - Baumassenziffer 7 m3/m2- Gebäudehöhe maximal 21.5 m- Gebäudelänge maximal offen- Grosser Grenzabstand Nationalstrasse- Allseitiger Gebäudeabstand 3.5 m1- Maximal mögliche Baumasse ca. 30'000 m3- Bruttogeschossfläche ca. 9'500 m2Das Baugrundstück wird derzeit noch mit zwei Wohneinheiten, der Autowerkstatt mit separatem Showroom und einer Tankstelle genutzt. Rund um die Liegenschaft bieten sich grosse, befestigte Flächen zur Nutzung an.  Wegzeit Neu 10 min.Station: Hinwil](https://www.immoscout24.ch/kaufen/4002417917) -Mehr erfahren +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 10 CHF 2’947’650.– Trottenrain 14, 8474 Dinhard Bewilligtes Bauprojekt im steuergünstigen Dinhard-Welsikon Das Bauland mit Magazingebäude befindet sich an zentraler Lage in Welsikon am Rande der Gemeinde Dinhard in der Kernzone. Die erreichte hohe Ausnutzung ermöglicht attraktive Neubauten an zentraler Lage. Visualisierungen und Grundrisse des bewilligten Bauprojekts finden Sie in der Dokumentation. Das Magazingebäude steht im kommunalen Inventar der schutzwürdigen Bauten. Es wurde deshalb in Absprache mit dem Heimatschutz und der Gemeinde Dinhard ein Schutzvertrag erarbeitet, der einen aussergewöhnlichen Umbau zu einem modernen Loft gestattet.Highlights: • bewilligtes Bauprojekt und Ausschreibungsplanung der Neubauten • Schutzvertrag • ausgezeichnete Lage in Welsikon • Steueroase (Gemeindesteuerfuss 83 %) • gut geschnittene Baulandparzelle • Gute ÖV-Anbindung (Bahnhof 170 m) Realisierung:Der Hauseigentümerverband Winterthur unterstützt Sie bei Bedarf gerne in enger Zusammenarbeit mit Kästle Architekten bei der Realisierung Ihres Neubauprojekts.Von der Planung bis hin zum Verkauf/Vermietung des fertigen Neubaus ? der Hauseigentümerverband Winterthur bietet Ihnen alle Dienstleistungen aus einer Hand. Es besteht keine Architekturverpflichtung.Interessenten sind herzlich eingeladen, mit uns Kontakt aufzunehmen.Rufen Sie unser Verkaufsteam über Telefon 052 209 01 68 an, wenn Sie zusätzliche Informationen oder eine Besichtigung wünschen. Wir freuen uns auf Sie.Ihr HEV-VerkaufsteamWichtig: Wir sind exklusiv mit dem Verkauf beauftragt. Direkte Eigentümerkontakte führen zu einem Interessentenausschluss. S.E.&.O.  Wegzeit Neu 5 min.Station: Dinhard](https://www.immoscout24.ch/kaufen/4002188905) -### Andreas Friedli +[ 1 / 1 CHF 2’399’240.– In der Gass 2, 8627 Grüningen Grundstück mit Baubewilligung für MFH zu verkaufen Zum Verkauf steht ein Grundstück mit bewilligtem Neubauprojekt. Gebäude C des Enssamble an der Binzikerstrasse 21 / In der Gass 2, 8627 Grüningen. Die aktuell bestehenden Garagen können abgebrochen werden und durch einen Neubau mit 8 Wohnungen unterschiedlicher Grösse mit attraktiven Aussenbereich ersetzt werden. Zusätzlich wurde der gemeinsame Bau einer Tiefgarage für 11 Parkplätze mit der Zufahrt über die Strasse "In der Gass" bewilligt.  Wegzeit Neu 54 min.Station: Esslingen](https://www.immoscout24.ch/kaufen/3003479026) -Managing Partner +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 2’604’890.– Im Königstal 2, 8487 Zell Wegzeit Neu 22 min.Station: Rämismühle-Zell](https://www.immoscout24.ch/kaufen/4002279293) - +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 4’112’990.– Im Königstal 3, 8487 Zell ZH Wegzeit Neu 22 min.Station: Rämismühle-Zell](https://www.immoscout24.ch/kaufen/4002279266) -Mit über 25 Jahren Erfahrung in der digitalen Transformation leitet Andreas als Partner erfolgreich strategische Grossprojekte. +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 6’717’900.– Im Königstal 3, 8487 Zell ZH Wegzeit Neu 22 min.Station: Rämismühle-Zell](https://www.immoscout24.ch/kaufen/4002279259) -### Andreas Friedli +[*  *  *  *  *  *  *  *  *  *  1 / 6    CHF 2’879’100.– Rotweg 20, 8820 Wädenswil Ihr neues Projekt mit Seesicht Im Auftrag unseres Kunden verkaufen wir an bevorzugter, erhöhter und ruhiger Wohnquartierlage mit schöner See- und Fernsicht, 706 m² Bauland mit Rückbauobjekt.Verkaufsrichtpreis: CHF 2'100'000.00Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot.  Wegzeit Neu 12 min.Station: Wädenswil](https://www.immoscout24.ch/kaufen/4002559578) -Managing Partner +[*  *  *  *  *  *  *  *  *  *  *  1 / 7    CHF 651’220.– Auf Anfrage 1, 8195 Wasterkingen Attraktives Baugrundstück in ruhiger, ländlicher Umgebung Willkommen in Wasterkingen, einer idyllischen und ruhigen Gemeinde im Zürcher Unterland, die für ihre hohe Lebensqualität, ländliche Gelassenheit und dennoch gute Erreichbarkeit bekannt ist. Genau hier wartet ein attraktives Baugrundstück auf Sie – die ideale Basis für Ihr zukünftiges Zuhause.Das Grundstück ist voll erschlossen und liegt in der Kernzone B, was Ihnen zahlreiche Gestaltungsmöglichkeiten eröffnet. Ob ein modernes Einfamilienhaus, ein klassisches Zuhause im Dorfcharakter oder ein individuelles Architektenprojekt – hier können Sie Ihre Wohnträume ganz nach Ihren Vorstellungen verwirklichen.Die charmante Gemeinde Wasterkingen besticht durch ihre ruhige Lage inmitten von Feldern, Reben und Natur.Dieses ImmoSky-Angebot bietet folgende *Mehr Leistung*:+ Voll erschlossen+ Ruhige Gemeinde+ Ideale Grösse für flexibilität (650m²)+ Kernzone B+Überbauungsziffer für Hauptgebäude 30%Dieses Grundstück bietet Ihnen die seltene Gelegenheit, ländliche Idylle mit urbaner Nähe zu vereinen – ein Ort, an dem Sie zur Ruhe kommen und dennoch bestens angebunden sind.Erfüllen Sie sich hier den Traum vom Eigenheim und gestalten Sie Ihr persönliches Refugium in Wasterkingen.Haben wir Sie mit diesem Angebot überzeugt? Dann zögern Sie nicht und kontaktieren Sie uns für weitere Fragen oder einen Besichtigungstermin!(Das Verkaufsdossier wird in der Regel innerhalb von maximal 24 Stunden an Sie versendet. Bitte überprüfen Sie auch Ihren SPAM-Ordner.)  Wegzeit -](https://www.immoscout24.ch/kaufen/4002537208) -#### Schwerpunkte +[*  *  *  *  *  *  *  *  *  *  *  1 / 7    CHF 7’540’490.– Staldernstrasse 13, 8158 Regensberg Entwicklungsgrundstück an top Lage in der Kernzone 2 In der gefragten Gemeinde Regensberg (ZH) steht ein hervorragend gelegenes Grundstück zum Verkauf, das sich ideal für Investoren, General- oder Totalunternehmer eignet. Die 2.557 m² grosse Parzelle Nr. 949 befindet sich in der Kernzone 2, die vielfältige bauliche und nutzungsbezogene Entwicklungsmöglichkeiten zulässt, insbesondere für Wohn- oder gemischt genutzte Projekte.Aktuell steht auf dem Grundstück ein nicht erhaltenswertes Gebäude, das im Rahmen einer Neuentwicklung rückgebaut werden kann. Eine Baueingabe oder Bewilligung liegt nicht vor, sodass volle gestalterische Freiheit innerhalb der geltenden bau- und zonenrechtlichen Rahmenbedingungen besteht.Berechnungen zeigen, dass eine nachhaltige Mietertragserwartung von rund CHF 485'600 pro Jahr realistisch erscheint - unter der Annahme einer Ausnutzung mit rund 1 664 m² Hauptnutzfläche (HNF) und 28 Tiefgaragenplätzen. Der ermittelte Kapitalisierungssatz liegt bei 4.20 %.Wesentliche Bewertungskennzahlen:Verkehrswert (diskontierter Landwert): CHF 5'505'000Ertragswert im erneuerten Zustand: CHF 11'556'795Realwert (hypothetisch): CHF 12'485'000Potenzieller Verkaufserlös: CHF 16'190'000Bruttorendite (Mietwert): 4.20%Die hypothetische Bebauung sieht zwei Mehrfamilienhäuser mit einer Bruttogeschossfläche (BGF) von insgesamt 2'080 m² vor - entsprechend einer Ausnützungsziffer von 0.81, voll im Rahmen der Zonenordnung. Die kalkulierten Baukosten (BKP 2-5) belaufen sich auf ca. CHF 8.74 Mio. Der diskontierte Landwert pro m² liegt bei CHF 2'155, was das wirtschaftliche Potenzial zusätzlich unterstreicht.Die Kernzone 2 erlaubt neben der reinen Wohnnutzung auch Mischnutzungen, beispielsweise mit gewerblichen Angeboten im Erdgeschoss. Dies ist ein zusätzlicher Vorteil für flexible, standortgerechte Entwicklungskonzepte. Die Lage in Regensberg bietet ruhige Wohnqualität in der Nähe der Agglomeration Zürich und ist in eine attraktive historische Umgebung eingebettet.Fazit: Das Grundstück bietet die seltene Gelegenheit, ein entwicklungsfähiges Grundstück an bester Lage mit bestehendem Abbruchobjekt zu akquirieren und nach eigenen Vorstellungen zu bebauen. Dank der flexiblen Nutzungsmöglichkeiten und des attraktiven Standorts stellt diese Investition eine hervorragende Ausgangslage für renditestarke Projektentwicklungen dar.Für detaillierte Informationen stehen wir Ihnen gerne zur Verfügung.  Wegzeit Neu 23 min.Station: Steinmaur](https://www.immoscout24.ch/kaufen/4002529588) -* Health-Check von Projekten und Programmen -* Advisor digitaler Transformationen -* Führung von Digitalisierungsprojekten und -programmen -* Emergency- und Recoveryprojekte -* Risiko- und Quality-Assurance bei digitalen Transformationen -* Advisor digitaler Neuausrichtungen -* Leadership-Coaching Projekt und Programm Manager +[*  *  *  *  *  *  *  *  *  *  1 / 6    CHF 3’633’140.– Riedwiesenstrasse 20, 8305 Dietlikon RESERVIERT - Industrie-Baulandparzelle an zentraler Lage in Dietlikon ZH Mit Freude präsentieren wir Ihnen eine einzigartige und äusserst seltene Baulandparzelle an zentraler Lage in Dietlikon ZH – eine aussergewöhnliche Gelegenheit mit hervorragenden Eigenschaften, die sich besonders für Investoren eignet.Zentrale Lage: Die Parzelle befindet sich in einer äusserst gefragten Gegend mit hervorragender Anbindung: Flughafen Zürich erreichbar in 10 Fahrminuten Stadt Zürich erreichbar in 12 Fahrminuten • Visibilität: Ihr Unternehmen wird von der Autobahn aus perfekt sichtbar sein, was optimale Werbemöglichkeiten bietet (ca. 500 m2 Fassade für Werbung). • Baumassenziffer: Profitieren Sie von der hohen Baumassenziffer 10.0, die maximale Flexibilität und Nutzungseffizienz ermöglicht. • Näherbaurechte: Die Parzelle verfügt über Näherbaurechte rechts und links. Auf der Rückseite kann ein Näherbaurecht von der Stadt Zürich eingeholt werden • ca. 3'500 m2 Bruttogeschossfläche möglich • Tiefgarage / Untergeschoss bis zu ca. 800 m2 gross realisierbar • Maximale Gesamthöhe 20 m. 7 Stockwerke à 500 m2 Bruttogeschossfläche und 2.85 m Raumhöhe (brutto) möglich • Parzelle: Die ebene Fläche der Parzelle erleichtert die Bauplanung und Ausführung. • Form: Die Parzelle hat eine ideale Form, die vielseitige Bebauungsmöglichkeiten erlaubt. • Autobahnknotenpunkt: Brüttiseller Kreuz, direkt an einem der wichtigsten Autobahnknotenpunkt der Schweiz gelegen, bietet die Parzelle hervorragende Erreichbarkeit und Logistikvorteile • Störendes Gewerbe: Die Lage ist auch für Gewerbe geeignet, das potenziell störend sein kann. • Kulturzentren sowie Hotelbetriebe auch möglich. Jetzt oder nie – Ihre Chance auf ein grossartiges Investment:Solch eine Industrie-Baulandparzelle in dieser Lage kommt äusserst selten auf den Markt – seit geraumer Zeit gab es in dieser gefragten Gegend kein vergleichbares Angebot. Sichern Sie sich jetzt dieses einmalige Grundstück, ideal für visionäre Unternehmer und Investoren, die auf einen strategisch optimalen Standort setzen.Haben wir Ihr Interesse geweckt? Dann nehmen Sie noch heute Kontakt mit uns auf. Gerne lassen wir Ihnen das detaillierte Verkaufsdossier inklusive Machbarkeitsstudie zukommen – exklusiv und unverbindlich.  Wegzeit Neu 14 min.Station: Dietlikon](https://www.immoscout24.ch/kaufen/4002331523) -#### Im Team seit +[*  *  *  *  *  *  *  *  *  *  1 / 6    Preis auf Anfrage Kaffeestrasse, 8180 Bülach Ihr Industriebau direkt in Bülach BeschreibungGerne entwickeln und realisieren wir ein auf ihre Bedürfnisse massgeschneidertes Projekt, welches Ihnen zur Miete oder im Eigentum zur Verfügung stehen wird.Interesse oder Fragen? Nehmen Sie Kontakt mit uns auf!Die Parzelle ist nicht das Richtige für Ihre Anforderungen? Kein Problem! Besuchen Sie unsere Homepage und finden Sie weitere Angebote unter: gewerbeland-schweiz.ch  Wegzeit Neu 20 min.Station: Bülach](https://www.immoscout24.ch/kaufen/4001788654) -2004 +[*  *  *  *  *  *  *  *  *  *  1 / 6    Preis auf Anfrage Kaffeestrasse, 8180 Bülach Ihr Industriebau direkt in Bülach BeschreibungGerne entwickeln und realisieren wir ein auf ihre Bedürfnisse massgeschneidertes Projekt, welches Ihnen zur Miete oder im Eigentum zur Verfügung stehen wird.Interesse oder Fragen? Nehmen Sie Kontakt mit uns auf!Die Parzelle ist nicht das Richtige für Ihre Anforderungen? Kein Problem! Besuchen Sie unsere Homepage und finden Sie weitere Angebote unter: gewerbeland-schweiz.ch  Wegzeit Neu 20 min.Station: Bülach](https://www.immoscout24.ch/kaufen/4001788644) -#### Branchenerfahrungen +[*  *  *  *  *  *  *  *  *  *  1 / 6    * Ruhige Lage CHF 3’358’950.– 8192 Glattfelden ZWEIFELSFREIES BAULAND IN ZWEIDLEN Im beliebten Zweidlen verkaufen wir ein eine attraktive, 1'226 m² grosse Baulandparzelle mit Bestandesobjekt.Unsere Projektstudie zeigt eine hohe Ausnutzung für die Erstellung eines Mehrfamilienhauses. • Anrechenbare mögliche Bruttogeschossfläche von max. 940 m² (Projekt 789 m²) • Wohn- und Gewerbezone WG 2.3 • Kein Denkmalschutz beim Bestandesobjekt • Die Deutsche Grenze in Kaiserstuhl ist nur 8 Autominuten entfernt • Der Flughafen Zürich ist in nur 19 Autominuten erreichbar Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: https://www.propertyowner.ch/de/immobilien/25-12278 Referenznummer: 25-12278Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website https://www.propertyowner.ch/immobilien/ und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen! * Ruhige Lage  Wegzeit -](https://www.immoscout24.ch/kaufen/4002558181) -Finanzen / Banken Versicherungen / Krankenkassen Detailhandel Verwaltung Militär Automobile IT / Telekommunikation Immobilien +[1](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich)[2](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich?pn=2)[...4](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich?pn=4)[](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich?pn=2) -#### Berufliche Stationen +Suche speichern Kartenansicht -* ValueOn AG (ehem. Project Competence AG), Head of Complex Projects -* HP GmbH, Senior Project Manager -* Compaq Computer GmbH, Senior Project Manager -* Volkswirtschaftsdep. St. Gallen, Informatikverantwortlicher +Vorschläge basierend auf deinen Suchresultaten +---------------------------------------------- -#### Und ganz nebenbei... +Weitere interessante Objekte +---------------------------- -…spielt Andreas Friedli gerne Golf, liebt feines Essen und guten Wein und verbringt viel Zeit mit seiner Familie – ganz nach dem Motto «Geniesse den Moment!». +Orte von Kanton Zürich - +* [Zürich](https://www.immoscout24.ch/de/grundstueck/kaufen/ort-zuerich) -Mehr erfahren +Bezirke im Kanton Kanton Zürich -### Patrick Motsch +* [Bezirk Affoltern](https://www.immoscout24.ch/de/grundstueck/kaufen/region-affoltern) +* [Bezirk Andelfingen](https://www.immoscout24.ch/de/grundstueck/kaufen/region-andelfingen) +* [Bezirk Bülach](https://www.immoscout24.ch/de/grundstueck/kaufen/region-buelach) +* [Bezirk Dielsdorf](https://www.immoscout24.ch/de/grundstueck/kaufen/region-dielsdorf) +* [Bezirk Dietikon](https://www.immoscout24.ch/de/grundstueck/kaufen/region-dietikon) +* [Bezirk Hinwil](https://www.immoscout24.ch/de/grundstueck/kaufen/region-hinwil) +* [Bezirk Horgen](https://www.immoscout24.ch/de/grundstueck/kaufen/region-horgen) +* [Bezirk Meilen](https://www.immoscout24.ch/de/grundstueck/kaufen/region-meilen) +* [Bezirk Pfäffikon](https://www.immoscout24.ch/de/grundstueck/kaufen/region-pfaeffikon) +* [Bezirk Uster](https://www.immoscout24.ch/de/grundstueck/kaufen/region-uster) +* [Bezirk Winterthur](https://www.immoscout24.ch/de/grundstueck/kaufen/region-winterthur) -Managing Partner +Kantone der Schweiz - +* [Kanton Aargau](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-aargau) +* [Kanton Appenzell Ausserrhoden](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-appenzell-ar) +* [Kanton Appenzell Innerrhoden](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-appenzell-ai) +* [Kanton Basel-Landschaft](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-basel-landschaft) +* [Kanton Basel-Stadt](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-basel-stadt) +* [Kanton Bern](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-bern) +* [Kanton Freiburg](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-freiburg) +* [Kanton Genf](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-genf) +* [Kanton Glarus](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-glarus) +* [Kanton Graubünden](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-graubuenden) +* [Kanton Jura](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-jura) +* [Kanton Luzern](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-luzern) +* [Kanton Neuenburg](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-neuenburg) +* [Kanton Nidwalden](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-nidwalden) +* [Kanton Obwalden](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-obwalden) +* [Kanton Schaffhausen](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-schaffhausen) +* [Kanton Schwyz](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-schwyz) +* [Kanton Solothurn](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-solothurn) +* [Kanton St. Gallen](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-st-gallen) +* [Kanton Thurgau](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-thurgau) +* [Kanton Tessin](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-tessin) +* [Kanton Uri](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-uri) +* [Kanton Wallis](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-wallis) +* [Kanton Waadt](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-waadt) +* [Kanton Zug](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zug) -Patrick leitet als Partner erfolgreich komplexe IT-Implementierungsprojekte. +### ImmoScout24 -### Patrick Motsch +* [Inserat erstellen](https://www.immoscout24.ch/de/insertion/inserat-online-erfassen) +* [Werbung](https://swissmarketplace.group/de/werbung/) +* [Publikationsnetzwerk](https://www.immoscout24.ch/c/de/ueber-uns/publikationsnetzwerk) -Managing Partner +### Über uns -#### Schwerpunkte +* [Kontakt](https://www.immoscout24.ch/c/de/ueber-uns/kontakt) +* [Porträt](https://swissmarketplace.group/de/portfolio/real-estate/) +* [Jobs](https://swissmarketplace.group/de/karriere/) +* [Fakten und Zahlen](https://swissmarketplace.group/de/portfolio/real-estate/) +* [Medien](https://swissmarketplace.group/de/media/) +* [Newsletter](https://www.immoscout24.ch/c/de/ueber-uns/newsletter-anmeldung) +* [Ombudsstelle](https://konsum.ch/de/ombudsstelle-immobilienplattformen/) -* Health Check von Projekten -* Führen von geschäftskritischen Projekten und Programmen -* Führen und Begleiten von Emergency und Recovery Projekten -* Führen und Begleiten von DC Moves und ICT Konsolidierungsprojekten -* Advisor für Auftraggeber +### Rechtliches -#### Im Team seit +* [Datenschutz](https://privacy.swissmarketplace.group/de/) +* [Insertionsregeln](https://www.immoscout24.ch/c/de/ueber-uns/insertionsregeln) +* [Sicherheitstipps](https://www.immoscout24.ch/c/de/ueber-uns/sicherheitshinweise) +* [Impressum](https://www.immoscout24.ch/c/de/ueber-uns/impressum) +* [AGB](https://www.immoscout24.ch/c/de/ueber-uns/agb) +* [Leistungsbeschrieb](https://www.immoscout24.ch/c/de/ueber-uns/member-bestimmungen-zusatz-agb) +* [Sicherheitsproblem melden](https://swissmarketplace.group/de/vulnerability-disclosure-program) +* Privatsphäre-Einstellungen -2001 +### Services -#### Branchenerfahrungen +* [Betreibungsauszug](https://www.immoscout24.ch/de/betreibungsauszug?source=footer) +* [Umzugshilfe](https://www.immoscout24.ch/c/de/umzug) +* [Versicherungsberatung](https://www.immoscout24.ch/c/de/lp/versicherungsberatung) +* [Agenturverzeichnis](https://www.immoscout24.ch/agenturverzeichnis) +* [Hypothekenrechner](https://www.immoscout24.ch/de/finanzieren/hypothekenrechner) +* [Immobilienbewertung](https://www.immoscout24.ch/de/immobilienbewertung) -Baubranche IT / Telekommunikation / Data Center Industrie Sport Verteidigung Verwaltung Airspace Management Versicherungen Handel +### App herunterladen -#### Berufliche Stationen +[](https://7o11.app.link/IS24_Web_Footer_iOS?%243p=a_custom_358665 "iOS App")[](https://7o11.app.link/IS24_Web_Footer_GP?%243p=a_custom_358665 "Android App") -* ValueOn AG (ehem. Project Competence AG) -* Vater und Pionier des TimeWinner Führungssystems -* CIO einer IT Consulting Organisation +### Unser Partner -#### Und ganz nebenbei... +[](https://www.swisstennis.ch/de/?utm_source=website-immoscout24&utm_medium=footer) -…liebt Patrick Motsch den Garten, das Tanzen, wandert gerne, taucht so oft es geht und lernt gerne fremde Länder kennen. Sein persönliches Motto: «Wer will, der kann». +* [Deutsch](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich) +* [Français](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich) +* [Italiano](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo) +* [English](https://www.immoscout24.ch/en/plot/buy/canton-zurich) - +### Folgen Sie uns -Mehr erfahren +[](https://www.facebook.com/immoscout24.ch "Facebook")[](https://www.instagram.com/immoscout24ch/ "Instagram")[](https://twitter.com/ImmoScout24ch "Twitter")[](https://www.youtube.com/user/ImmoScout24Schweiz "YouTube")[](https://www.linkedin.com/company/immoscout24-schweiz/ "LinkedIn") -### Richard Salvisberg +[SMG Swiss Marketplace Group](https://swissmarketplace.group/de/)[AutoScout24](https://www.autoscout24.ch/de)[FinanceScout24](https://www.financescout24.ch/de?utm_source=immoscout24.ch&utm_medium=web&utm_campaign=footer_bottom)[MotoScout24](https://www.motoscout24.ch/de)[anibis.ch](https://www.anibis.ch/de) -Managing Partner +© Copyright 2025 by SMG Swiss Marketplace Group AG . Alle Rechte vorbehalten.Die Vervielfältigung und Übernahme von Inseraten durch Dritte, insbesondere von Fotos und persönlichen Daten in diesen Inseraten, verletzt die damit verbundenen Rechte und ist ausdrücklich verboten. - +We Care About Your Privacy +-------------------------- -Richard bringt als Partner strategische Beratungsexpertise und Führungskompetenz ein. +We and our 455 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data.[Imprint](https://www.immoscout24.ch/en/info/impressum/3530) -### Richard Salvisberg +### We and our partners process data to provide: -Managing Partner +Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. List of Partners (vendors) -#### Schwerpunkte +I Accept No consent Show Purposes -* Analysen von Strategien und Umsetzungsinitiativen -* Führen von geschäftskritischen Programmen und Transformationen -* Aufbau und Führen von Projektportfolio-Managementsystemen -* Sparringpartner und Advisor + -#### Im Team seit +About Your Privacy +------------------ -2006 +We process your data to deliver content or advertisements and measure the delivery of such content or advertisements to extract insights about our website. We share this information with our partners on the basis of consent. You may exercise your right to consent, based on a specific purpose below or at a partner level in the link under each purpose. These choices will be signaled to our vendors participating in the Transparency and Consent Framework. -#### Branchenerfahrungen +[Privacy Policy](https://www.immoscout24.ch/c/en/about-us/privacy-policy) -Gesundheitswesen & (Kranken-)Versicherung Militär Verwaltung Beschaffungswesen & Transport Informatik & Telekommunikation Bau Sport Energie +Allow All +### Manage Consent Preferences -#### Berufliche Stationen +#### Functional Cookies -* ValueOn AG (ehem. Project Competence AG), Head of PPM -* T-Systems Schweiz AG, Chief Information Officer -* Orange Communications SA, IT Account Manager -* Swisscom AG Bern, Head Management Support -* Swisscom AG Bern, Programm Manager Charging & Billing +- [x] Functional Cookies -#### Und ganz nebenbei... +These cookies enable the website to provide enhanced functionality and personalisation. They may be set by us or by third party providers whose services we have added to our pages. If you do not allow these cookies then some or all of these services may not function properly. -…liebt Richard Salvisberg das Tanzen, lernt gerne fremde Kulturen kennen, hat Freude an schönen Autos und geniesst ein Buch bei einem guten Schluck Wein. In klaren Nächten beobachtet er interessiert den Kosmos. Sein persönliches Motto lautet «Auf innovativen Wegen nachhaltige Erfolge erzielen». +Cookies Details - +#### Strictly Necessary Cookies -Mehr erfahren +Always Active -### Stephan Schellworth +These cookies are necessary for the website to function and cannot be switched off in our systems. They are usually only set in response to actions made by you which amount to a request for services, such as setting your privacy preferences, logging in or filling in forms. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. These cookies do not store any personally identifiable information. -Experte +Cookies Details - +#### Targeting Cookies -Stephan verbindet strategisches Denken mit praxisnaher Projektsteuerung und gestaltet digitale Projekte +- [x] Targeting Cookies -### Stephan Schellworth +These cookies may be set on our website by our advertising partners. They can be used by these companies to build a profile of your interests and to control which advertisements you see on other websites. If you do not allow these cookies, you will still see advertisements, but they will no longer be tailored to you. Your master and usage data will also be made available to the other brands of the SMG Group for analysis, for the management of personalized advertising display, and for personalized marketing communication. The latter means that you may be contacted in a personalized manner for marketing purposes not only by this brand but also by all other brands of the SMG Group. The brands of the SMG Group are ImmoScout24, Homegate, Immostreet.ch, home.ch, Publimmo, Acheter-Louer.ch, CASASOFT, IAZI, AutoScout24, MotoScout24, anibis.ch, tutti.ch, Ricardo, FinanceScout24, Flatfox, and Moneyland. We use Enhanced Conversion that may transmit pseudonymised (e.g. hashed) email addresses to third parties such as Google or publishers (e.g. TX Group or Ringier AG) to improve campaign performance and measurement and/or to create audience segments. Personal identification is not possible unless you are logged in with the same email address and associated with an account of these third parties. Your personal data will be processed either jointly with these third parties, in accordance with their respective privacy notices, or independently by SMG as controller. Please note that your personal data may also be transferred to insecure third countries, where local authorities may access them without protection equivalent to European data protection law. If the level of data protection in a country does not match that of Switzerland, we ensure contractually that the protection of your personal data always corresponds to the level in Switzerland. -Experte +Cookies Details -#### Schwerpunkte +#### Performance Cookies -* Projekt- und Teamführung -* Datenanalyse und Optimierung -* Agiles Projektmanagement +- [x] Performance Cookies -#### Im Team seit +These cookies allow us to count visits and traffic sources so we can measure and improve the performance of our site. They help us to know which pages are the most and least popular and see how visitors move around the site. All information these cookies collect is aggregated and therefore anonymous. If you do not allow these cookies we will not know when you have visited our site, and will not be able to monitor its performance. -2024 +Cookies Details -#### Branchenerfahrungen +#### Store and/or access information on a device 365 partners can use this purpose -Elektromobilität Automobilindustrie Automatisierungstechnik Digitalisierung +- [x] Store and/or access information on a device -#### Berufliche Stationen +Cookies, device or similar online identifiers (e.g. login-based identifiers, randomly assigned identifiers, network based identifiers) together with other information (e.g. browser type and information, language, screen size, supported technologies etc.) can be stored or read on your device to recognise it each time it connects to an app or to a website, for one or several of the purposes presented here. -* 2023 - 2024: Testmanager im Energiebordnetz, BMW Group -* 2021 - 2023: Gesamtfahrzeugspezialist in der E/E, BMW Group -* 2018 - 2021: Prüfstandsspezialist im BMW Prototypen-Motorenwerk, Academic Work -* 2016 - 2018: Entwicklungsingenieur, EDAG Engineering Group +List of IAB Vendors|View Illustrations -#### Und ganz nebenbei... +#### Personalised advertising and content, advertising and content measurement, audience research and services development 438 partners can use this purpose -…sammelt und pflegt Stephan Young- und Oldtimern, treibt Sport wie Squash und besucht regelmässig das Fitnessstudio. Er geht gern mit seinem Hund spazieren oder wandert in der Natur. Ausserdem programmiert er kleinere SmartHome-Anwendungen mit dem Raspberry Pi, Apps und erstellt 3D-Visualisierungen von Innen- und Aussenräumen. +- [x] Personalised advertising and content, advertising and content measurement, audience research and services development - +* ##### Use limited data to select advertising 359 partners can use this purpose -Mehr erfahren +- [x] Switch Label +Advertising presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type or which content you are (or have been) interacting with (for example, to limit the number of times an ad is presented to you). -### Mats Rudolf +View Illustrations -Experte +* ##### Create profiles for personalised advertising 283 partners can use this purpose - +- [x] Switch Label +Information about your activity on this service (such as forms you submit, content you look at) can be stored and combined with other information about you (for example, information from your previous activity on this service and other websites or apps) or similar users. This is then used to build or improve a profile about you (that might include possible interests and personal aspects). Your profile can be used (also later) to present advertising that appears more relevant based on your possible interests by this and other entities. -Mats berät Unternehmen zu digitalen Transformationsprojekten und Systemimplementierungen. +View Illustrations -### Mats Rudolf +* ##### Use profiles to select personalised advertising 281 partners can use this purpose -Experte +- [x] Switch Label +Advertising presented to you on this service can be based on your advertising profiles, which can reflect your activity on this service or other websites or apps (like the forms you submit, content you look at), possible interests and personal aspects. -#### Schwerpunkte +View Illustrations -* Analysen von Strategien und Umsetzungsinitiativen -* Advisor digitaler Transformation -* Advisor Systems Engineering -* Projekt- und Teamführung -* Agiles Projektmanagement +* ##### Create profiles to personalise content 103 partners can use this purpose -#### Im Team seit +- [x] Switch Label +Information about your activity on this service (for instance, forms you submit, non-advertising content you look at) can be stored and combined with other information about you (such as your previous activity on this service or other websites or apps) or similar users. This is then used to build or improve a profile about you (which might for example include possible interests and personal aspects). Your profile can be used (also later) to present content that appears more relevant based on your possible interests, such as by adapting the order in which content is shown to you, so that it is even easier for you to find content that matches your interests. -2025 +View Illustrations -#### Branchenerfahrungen +* ##### Use profiles to select personalised content 92 partners can use this purpose -Elektromobilität Automobilindustrie Sensortechnik Luft- und Raumfahrttechnik Maschinen- und Anlagenbau Transport und Logistik +- [x] Switch Label +Content presented to you on this service can be based on your content personalisation profiles, which can reflect your activity on this or other services (for instance, the forms you submit, content you look at), possible interests and personal aspects. This can for example be used to adapt the order in which content is shown to you, so that it is even easier for you to find (non-advertising) content that matches your interests. -#### Berufliche Stationen +View Illustrations -* 2019 - 2024: Management Consultant Innovation und Transformation, UNITY Schweiz AG -* 2018: Industrial Solution Consulting Intern, Brütsch Rüegger Werkzeuge -* 2015 - 2016: Sensor Research and Development Intern, Sensirion AG +* ##### Measure advertising performance 404 partners can use this purpose -#### Und ganz nebenbei... +- [x] Switch Label +Information regarding which advertising is presented to you and how you interact with it can be used to determine how well an advert has worked for you or other users and whether the goals of the advertising were reached. For instance, whether you saw an ad, whether you clicked on it, whether it led you to buy a product or visit a website, etc. This is very helpful to understand the relevance of advertising campaigns. -…zieht es Mats Rudolf im Winter für Skitouren und rasante Abfahrten auf die frisch verschneiten Berge. Wenn der Sommer kommt, tauscht er seine Ski gegen ein Surfbrett und geniesst die Wellen im Meer. Zudem schwingt er gerne den Schläger auf dem Tennisplatz und bastelt an seinen Smart-Device-Projekten. +View Illustrations - +* ##### Measure content performance 171 partners can use this purpose -Mehr erfahren +- [x] Switch Label +Information regarding which content is presented to you and how you interact with it can be used to determine whether the (non-advertising) content e.g. reached its intended audience and matched your interests. For instance, whether you read an article, watch a video, listen to a podcast or look at a product description, how long you spent on this service and the web pages you visit etc. This is very helpful to understand the relevance of (non-advertising) content that is shown to you. -### Ida Dittrich +View Illustrations -AI Specialist +* ##### Understand audiences through statistics or combinations of data from different sources 253 partners can use this purpose -Ida verbindet ihr wissenschaftliches Know-how mit praktischer IT-Erfahrung und bringt innovative Ansätze in technische Projekte ein. +- [x] Switch Label +Reports can be generated based on the combination of data sets (like user profiles, statistics, market research, analytics data) regarding your interactions and those of other users with advertising or (non-advertising) content to identify common characteristics (for instance, to determine which target audiences are more receptive to an ad campaign or to certain contents). -### Ida Dittrich +View Illustrations -AI Specialist +* ##### Develop and improve services 300 partners can use this purpose -#### Schwerpunkte +- [x] Switch Label +Information about your activity on this service, such as your interaction with ads or content, can be very helpful to improve products and services and to build new products and services based on user interactions, the type of audience, etc. This specific purpose does not include the development or improvement of user profiles and identifiers. -* Product Architect and Software Engineer PowerOn Platform +View Illustrations -#### Im Team seit +* ##### Use limited data to select content 83 partners can use this purpose -2025 +- [x] Switch Label +Content presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type, or which content you are (or have been) interacting with (for example, to limit the number of times a video or an article is presented to you). -#### Branchenerfahrungen +View Illustrations -Automatisierungstechnik Luft- und Raumfahrtindustrie Kommunikation und Interessenvertretung Medien +List of IAB Vendors -#### Berufliche Stationen +#### Use precise geolocation data 132 partners can use this special feature -* Forschungsprojekt zur Modellierung des inneren Aufbaus terrestrischer Exoplaneten (ETH Zürich) -* Recovery Engineer und Systems Engineer bei verschiedenen Projekten der Akademischen Raumfahrtinitiative der Schweiz (ARIS) +- [x] Use precise geolocation data -#### Und ganz nebenbei... +With your acceptance, your precise location (within a radius of less than 500 metres) may be used in support of the purposes explained in this notice. -… spielt Ida Dittrich leidenschaftlich gern Computerspiele und bastelt an handwerklichen Projekten wie Nähen, Häkeln oder Stricken. Sie ist regelmäßig sportlich aktiv – sei es beim Joggen an der frischen Luft, im Fitnessstudio oder bei einer entspannenden Yoga-Einheit. +List of IAB Vendors - +#### Actively scan device characteristics for identification 71 partners can use this special feature -Mehr erfahren +- [x] Actively scan device characteristics for identification -### Nick Melloh +With your acceptance, certain characteristics specific to your device might be requested and used to distinguish it from other devices (such as the installed fonts or plugins, the resolution of your screen) in support of the purposes explained in this notice. -AI-Specialist +List of IAB Vendors -Nick macht künstliche Intelligenz für Unternehmen greifbar – in Projekten, Strategien und praxisnahen Schulungen. +#### Ensure security, prevent and detect fraud, and fix errors 290 partners can use this special purpose -### Nick Melloh +Always Active -AI-Specialist +Your data can be used to monitor for and prevent unusual and possibly fraudulent activity (for example, regarding advertising, ad clicks by bots), and ensure systems and processes work properly and securely. It can also be used to correct any problems you, the publisher or the advertiser may encounter in the delivery of content and ads and in your interaction with them. -#### Schwerpunkte +List of IAB Vendors|View Illustrations -* Advisor für Digitale Transformation & Business Innovation -* Advisor für Künstliche Intelligenz & Wissensvermittlung -* Advisor für Strategisches Projekt- und Prozessmanagement -* Trainer für KI-Schulungen und Weiterbildung +#### Deliver and present advertising and content 286 partners can use this special purpose -#### Im Team seit +Always Active -2025 +Certain information (like an IP address or device capabilities) is used to ensure the technical compatibility of the content or advertising, and to facilitate the transmission of the content or ad to your device. -#### Branchenerfahrungen +List of IAB Vendors|View Illustrations -Digitalisierung Consulting Hospitality Event- und Innovationsmanagement KI-Anwendungen +#### Match and combine data from other data sources 214 partners can use this feature -#### Berufliche Stationen +Always Active -* 2023–heute: Master in Business Innovation, Universität St. Gallen – Schwerpunkt Digitale Transformation & KI -* 2023–heute: Event Manager SQUARE, Universität St. Gallen – Gestaltung innovativer Lern- und Austauschformate -* 2022–2023: VP Sales, Contler AG – SaaS-Lösungen & Prozessautomatisierung im Hospitality-Sektor +Information about your activity on this service may be matched and combined with other information relating to you and originating from various sources (for instance your activity on a separate online service, your use of a loyalty card in-store, or your answers to a survey), in support of the purposes explained in this notice. -#### Und ganz nebenbei... +List of IAB Vendors -…hat Nick eine Schwäche für Reisen, gutes Essen und Bücher – um neue Denkanstöße zu gewinnen und frische Perspektiven einzunehmen. Energie findet er beim Sport, in den Bergen oder bei langen Gesprächen mit Freunden – die besten Momente für ihn sind die, in denen die Uhr keine Rolle spielt. +#### Link different devices 172 partners can use this feature - +Always Active -Mehr erfahren +In support of the purposes explained in this notice, your device might be considered as likely linked to other devices that belong to you or your household (for instance because you are logged in to the same service on both your phone and your computer, or because you may use the same Internet connection on both devices). -### Yannick Althaus +List of IAB Vendors -AI-Specialist +#### Identify devices based on information transmitted automatically 265 partners can use this feature -Yannick berät Unternehmen, indem er Strategiekompetenz mit unternehmerischer DNA verbindet. +Always Active -### Yannick Althaus +Your device might be distinguished from other devices based on information it automatically sends when accessing the Internet (for instance, the IP address of your Internet connection or the type of browser you are using) in support of the purposes exposed in this notice. -AI-Specialist +List of IAB Vendors -#### Schwerpunkte +#### Save and communicate privacy choices 245 partners can use this special purpose -* Advisor für Strategisches Management und Unternehmensführung -* Advisor für Künstliche Intelligenz und digitale Transformation -* Advisor für Produktion und Supply Chain Management +Always Active -#### Im Team seit +The choices you make regarding the purposes and entities listed in this notice are saved and made available to those entities in the form of digital signals (such as a string of characters). This is necessary in order to enable both this service and those entities to respect such choices. -2025 +List of IAB Vendors|View Illustrations -#### Branchenerfahrungen +### Cookie List -Automatisierungstechnik Industrie Digitalisierung Supply Chain Management Consulting +Clear -#### Berufliche Stationen +- [x] checkbox label label -* 2025: M.A. HSG in Unternehmensführung - Masterarbeit zum Einsatz von generativer KI in der Strategieentwicklung von CEOs -* 2022: B.Sc. Wirtschaftsingenieurwesen -* 2019–2025: Diverse Consulting-Praktika & Projekte in Supply Chain Management, Digitalisierung und strategischem Management sowie Mitarbeit im Familienunternehmen (neben dem Studium) -* 2013–2017: Automatiker EFZ bei Bystronic +Apply Cancel -#### Und ganz nebenbei... +Consent Leg.Interest -…wenn er nicht an Strategien feilt, zieht es Yannick aufs Eis – Eishockey ist sein Adrenalinschub. Auch sonst bleibt er regelmässig in Bewegung: Skifahren im Winter, Joggen zwischendurch und Golf im Sommer. Ausserdem hat er eine Schwäche für schnelle Autos und reist gerne – am liebsten ans Meer. +- [x] checkbox label label - +- [x] checkbox label label -### Philipp Dick +- [x] checkbox label label -Certified Partner +No consent Confirm My Choices -"KI wird Manager nicht ersetzen, aber Manager, die KI einsetzen, werden die ersetzen, die es nicht tun." +[](https://www.onetrust.com/products/cookie-consent/) - -### Romano Caviezel - -Certified Partner - -"Innovation bedeutet, bestehende Dinge zu hinterfragen und neue Wege zu entdecken." - - - -### Dawid Puzik - -Certified Partner - -"Manche sehen, was möglich ist – andere verändern, was möglich ist." - - - -### Holger Ridinger - -Certified Partner - -"Transformation braucht Struktur, Leidenschaft und Ausdauer." - - - -### Alain Kappeler - -Certified Partner - -"Wenn es dich nicht herausfordert, verändert es dich nicht." - - - -### Andreas Wyss - -Certified Partner - -Andreas verbindet strategisches Denken mit menschlichem Feingefuehl in Transformationsprozessen. - - - -### Alfredo Mercurio - -Certified Partner - -"Eine klare Vision ist der Anfang von allem." - - - -### Bernd Nagel - -Certified Partner - -"Wer will, findet Wege. Wer nicht will, findet Gründe." - - - -### Daniel Sengstag - -Certified Partner - -"Wer nicht mit der Zeit geht, geht mit der Zeit." - - - -### Daniel Lochmatter - -Certified Partner - -"Neues und bisher Unbekanntes kann man nur explorativ erfahren, erspüren, erlernen – und danach zum eigenen Nutzen einsetzen." - - - -### Michael Hermann - -Certified Partner - -"Auch beim Projekt gilt: Ende gut, alles gut." - - - -### Heinz Ruffieux - -Certified Partner - -"C'est le ton qui fait la musique." - - - -### Sven Fassbender - -Certified Partner - -"Mein Ziel ist es, Cybersicherheit verständlich und greifbar zu machen – für jeden zugänglich und praktikabel." - - - -### Raffael Santchi - -Certified Partner - -"Wer Prozesse versteht, kann Systeme formen – nicht umgekehrt." - - - -### Stephanie Kieninger - -Certified Partner - -Stephanie konzentriert sich mit ihrer Beratung auf die Menschen im Veraenderungsprozess. - - - -### Christoph Merle - -Certified Partner - -Christoph engagiert sich mit seiner langjährigen Führungserfahrung in der Industrie und mit seinem Hintergrund in strategischer und operativer Beratung für den Erfolg unserer Kunden. - -Previous slide Next slide - -Über ValueOn ------------- - -Wir schaffen digitale Transformation mit Leidenschaft und Expertise - -### Unsere Mission - -Durch exzellente Beratung schaffen wir digitale Transformation erfolgreich zu meistern. - -### Unser Versprechen - -Höchste Qualität, agile Ansätze und Passion für gemeinsamen Wirken - -25+ - -Jahre Erfahrung - -100+ - -Projekte - -98% - -Weiterempfehlung - -60% - -Schneller zum Ziel - -Unsere Geschichte ------------------ - -Eine Reise der Innovation - -Heute - -Heute und Morgen - -Als führendes Beratungsunternehmen gestalten wir aktiv die Zukunft der digitalen Transformation mit innovativen KI-Lösungen und nachhaltigen Strategien. - -KI-Ära - -KI-Revolution - -Die Einführung von KI-Systemen veränderte unsere Beratungsleistung grundlegend und ermöglichte es uns, unseren Kunden noch innovativere Lösungen anzubieten. - -Digital - -Digitale Transformation - -Mit neuen digitalen Lösungen begleiteten wir unsere Kunden in der Transformation und etablierten uns als führender Partner für digitale Innovation. - -Aufbau - -Etablierung am Markt - -Wir etablierten uns am Markt mit innovativen IT-Strategien und nachhaltiger Umsetzung, wodurch wir eine solide Basis für weiteres Wachstum schufen. - -2000 - -Gründung von ValueON - -ValueON wurde mit der Vision gegründet, Unternehmen bei der digitalen Transformation zu unterstützen und nachhaltigen Erfolg zu schaffen. - -Unsere Werte ------------- - -Was uns antreibt - -### Exzellenz - -Höchste Qualität in allem, was wir tun. Von der ersten Beratung bis zur finalen Umsetzung setzen wir auf höchste Standards. - -### Partnerschaft - -Wir sehen uns als langfristige Partner unserer Kunden und arbeiten gemeinsam an nachhaltigen Lösungen. - -### Integrität - -Ehrlichkeit, Transparenz und Vertrauen bilden das Fundament aller unserer Geschäftsbeziehungen. - -### Effektivität - -Zielgerichtete Lösungen, die messbare Ergebnisse liefern und nachhaltigen Geschäftserfolg schaffen. - -Karriere bei ValueOn --------------------- - -Werde Teil unseres Teams - -### Product-Architekt/in für KI-Plattformen - -Zürich, Schweiz M/W, 50-100% - -Details ansehen - -Keine passende Stelle gefunden? - -[Initiativbewerbung senden](mailto:office@valueon.ch) - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) - - - -=== https://www.moneyhouse.ch/de/company/valueon-ag-4663161481 === -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](#)[Save + Exit](#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - -[Startseite](/de/) [>](javascript:void(0)) [Unternehmen](/de/search?q=ValueOn AG) [>](javascript:void(0)) ValueOn AG - -# ValueOn AG - -ZH - -aktiv - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) -[Zur Timeline](/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -[Jetzt Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -Handelsregister-Nr.: CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](/de/company/valueon-ag-4663161481/messages) - -[Sie möchten eine Änderung der Firmendaten vornehmen? Wir unterstützen Sie hierbei gerne.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Alter der Firma - -18 Jahre - -#### Umsatz in CHF - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Kapital in CHF - -200'000 - -#### Mitarbeiter - -[Premium](/de/company/valueon-ag-4663161481/revenue)[Premium](/de/company/valueon-ag-4663161481/revenue) - -#### Aktive Marken - -0 - -c/o Westhive AG -Am Stadtrand 11 -8600 Dübendorf -[Nachbarschaft](/de/company/valueon-ag-4663161481/network#neighbourhood) - -[Sie möchten Ihre Adresse anpassen? -Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -[News aus der Region Uster](/de/region/uster/uebersicht) - -## Auskünfte zu ValueOn AG - -\*angezeigte Auskünfte sind Beispiele - -#### Bonitätsauskunft - -Einschätzung der Bonität mit einer Ampel als Risikoindikator und weiteren hilfreichen Firmeninformationen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -#### Wirtschaftsauskunft - -Umfassende Auskunft über die wirtschaftliche Situation der Firma. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#commercial-report) - -#### Zahlungsverhalten - -Beurteilung der Zahlungsmoral aufgrund vergangener Rechnungen. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-mode-report) - -#### Betreibungsauskunft - -Übersicht über aktuelle und vergangene Betreibungsverfahren. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#payment-collection-report) - -#### Beteiligungsauskunft - -Erfahren Sie, an welchen nationalen und internationalen Firmen die Aktiengesellschaft, für die Sie sich interessieren, noch beteiligt ist. -[Mehr erfahren](/de/company/valueon-ag-4663161481/reports#wow-report) - -#### Firmendossier als PDF - -Kontaktinformationen, Veränderungen, Umsatz- und Mitarbeiterzahlen, Management, Besitzverhältnisse, Beteiligungsstruktur und weitere Firmendaten. -[Jetzt kostenlos abrufen](/de/company/valueon-ag-4663161481/reports#firmendossier-report) - -## Über ValueOn AG - -* ValueOn AG hat den Sitz in Dübendorf, ist aktiv und im Bereich «Erbringen von IT-Dienstleistungen» tätig. - - - -* Das [Management](valueon-ag-4663161481/management) der Firma ValueOn AG besteht aus 5 Personen. - - - -* Unter [Meldungen](valueon-ag-4663161481/messages) finden Sie alle Handelsregisteränderung, die letzte erfolgte am 27.08.2025. - - - -* Die Firma ist im Handelsregister des Kantons ZH unter der UID CHE-113.416.882 eingetragen. - - - -* Unternehmen mit derselben Adresse wie ValueOn AG: [Black Projects GmbH](black-projects-gmbh-3958227961), [Bluespace Ventures AG](bluespace-ventures-ag-20038582721), [Cyberfy Consulting AG](cyberfy-consulting-ag-5194156221). - -## Management (5) - -#### neueste Verwaltungsräte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901) - -#### neuste Zeichnungsberechtigte - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Wyss](/de/person/wyss-andreas-129476912501), -[Walter Althaus Jun.](/de/person/althaus-jun-walter-205367807901), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -#### Geschäftsleitung - -[Dominic Pascal Largo](/de/person/largo-dominic-pascal-55052990401), -[Andreas Friedli](/de/person/friedli-andreas-56613750301), -[Richard Salvisberg](/de/person/salvisberg-richard-120972301201) - -Quelle: [SHAB](/de/datasources) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -## Netzwerk - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -[Komplettes Management ansehen](/de/company/valueon-ag-4663161481/management) - -[Netzwerk im Detail ansehen](/de/company/valueon-ag-4663161481/network) - -## Handelsregisterinformationen - -Quelle: [SHAB](/de/datasources) - -#### Eintrag ins Handelsregister - -02.02.2007 - -#### Rechtsform - -Aktiengesellschaft - -#### Rechtssitz der Firma - -Dübendorf - -#### Handelsregisteramt - -ZH - -#### Handelsregister-Nummer - -CH-020.3.030.651-3 - -#### UID/MWST - -CHE-113.416.882 - -#### Branche - -Erbringen von IT-Dienstleistungen - -#### Firmenzweck - -Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -[Passen Sie den Firmenzweck mit wenigen Klicks an.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Revisionsstelle - -Quelle: [SHAB](/de/datasources) - -#### Aktive Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [TBO Revisions AG](/de/company/tbo-revisions-ag-20607789301) | | Zürich | 18.03.2015 | | - -[Möchten Sie die Revisionsstelle anpassen? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -#### Frühere Revisionsstelle (1) - - - -| Name | | Ort | Seit | Bis | -| --- | --- | --- | --- | --- | -| [Trevisca AG](/de/company/trevisca-ag-20628390611) | | Baar | 08.02.2007 | 17.03.2015 | - -## Weitere Firmennamen - -Quelle: [SHAB](/de/datasources) - -#### Frühere und übersetzte Firmennamen - -* Project Competence AG - -[Möchten Sie den Firmennamen aktualisieren? Klicken Sie hier.](/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -## Zweigniederlassungen (0) - -## Besitzverhältnisse - -Es liegen uns keine Angaben zu den Besitzverhältnissen vor. - -## Beteiligungen - -Es liegen uns keine Angaben zu den Beteiligungen vor. - - - - - - - - - -## Neueste SHAB-Meldungen: ValueOn AG - -SHAB 250827/2025 - 27.08.2025 - -**Kategorien:** Änderung des Firmenzwecks, Änderung der Firmenadresse - -Publikationsnummer: [HR02-1006417690](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006417690 "Download SHAB Publikation der ValueOn AG vom 27.08.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 133 vom 14.07.2025, Publ. 1006383218). - -**Statutenänderung:** - 18.08.2025. - -**Sitz neu:** - Dübendorf. - -**Domizil neu:** - c/o Westhive AG, Am Stadtrand 11, 8600 Dübendorf. - -**Zweck neu:** - Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -**Mitteilungen neu:** - Mitteilungen an die Aktionäre erfolgen per Brief oder E-Mail an die im Aktienbuch verzeichneten Adressen. - -SHAB 250714/2025 - 14.07.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006383218](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006383218 "Download SHAB Publikation der ValueOn AG vom 14.07.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 101 vom 27.05.2025, Publ. 1006341693). - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Einzelunterschrift [*bisher: Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]. - -SHAB 250527/2025 - 27.05.2025 - -**Kategorien:** Änderung im Management - -Publikationsnummer: [HR02-1006341693](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006341693 "Download SHAB Publikation der ValueOn AG vom 27.05.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 222 vom 14.11.2024, Publ. 1006178101). - -**Ausgeschiedene Personen und erloschene Unterschriften:** - Hamburger, Marc Eric, von St. Gallen, in Mörschwil, Präsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Egloff, Reto](/de/person/egloff-reto-101763781201), von Oberrohrdorf, in Bern, Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Mühlemann, Markus](/de/person/muehlemann-markus-142196879901), von Seeberg, in Uster, Delegierter des Verwaltungsrates, mit Einzelunterschrift. - -**Eingetragene Personen neu oder mutierend:** - [Largo, Dominic](/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien [*bisher: Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien*]; - [Althaus, Walter](/de/person/althaus-jun-walter-205367807901), von Affoltern im Emmental, in Aarwangen, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - [Wyss, Andreas](/de/person/wyss-andreas-129476912501), von Dietikon, in Dietikon, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien. - -[Alle SHAB-Meldungen ansehen](/de/company/valueon-ag-4663161481/messages) - -## Trefferliste - -Hier finden Sie eine Verlinkung des Managements auf eine Trefferliste zu Personen mit dem gleichen Namen, die im Handelsregister eingetragen sind. - -[Dominic Pascal Largo](/de/list/person/largo-dominic-pascal) - -[Andreas Wyss](/de/list/person/wyss-andreas) - -[Walter Althaus Jun.](/de/list/person/althaus-jun-walter) - -[Andreas Friedli](/de/list/person/friedli-andreas) - -[Richard Salvisberg](/de/list/person/salvisberg-richard) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](/de/terms)[Datenschutz |](/de/privacy)[Impressum](/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](/de/overview) - - - - - - -[Übersicht](/de/company/valueon-ag-4663161481) - -[Auskünfte](/de/company/valueon-ag-4663161481/reports) - -[Management](/de/company/valueon-ag-4663161481/management) - -[Netzwerk](/de/company/valueon-ag-4663161481/network) - -[Timeline](/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](/de/company/valueon-ag-4663161481/shares) - -[Meldungen](/de/company/valueon-ag-4663161481/messages) - -[Marken](/de/company/valueon-ag-4663161481/brands) - -[Jobs](/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](/de/company/valueon-ag-4663161481/buildingproject) - - -=== https://www.itreseller.ch/unternehmen/6046/Valueon.html === -Valueon - Unternehmensverzeichnis IT Reseller +=== https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen === +Grundstück in Kanton Zürich kaufen - Vergleiche 72 Inserate mit comparis.ch =============== -[](https://www.itreseller.ch/) +[](https://www.comparis.ch/ "Comparis logo") -[MEDIADATEN](https://www.itreseller.ch/media) +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) -[ABONNIEREN](https://www.itreseller.ch/abo) +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) -[NEWSLETTER](https://www.itreseller.ch/newsletter) +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) -Suche +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) -< +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter -> +[Login](https://www.comparis.ch/bff/login)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) -Valueon in den News von -======================= +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) - +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) -[](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html) +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) -[### Valueon vollzieht Führungswechsel](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html) +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) -[Generationen- und Führungswechsel bei Valueon: Gründer Markus Mühlemann (Bild, links) übergibt das Zepter an Dominic Largo (Bild, rechts).](https://www.itreseller.ch/Artikel/101024/Valueon_vollzieht_Fuehrungswechsel.html)7. Juni 2024 +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) -Meistgelesen +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 +[Alles zu Finanzen](https://www.comparis.ch/finanzen) -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 +[Login](https://www.comparis.ch/bff/login)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) +[Alles zu Immobilien](https://www.comparis.ch/wohnen) -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) +[Login](https://www.comparis.ch/bff/login)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) -GOLD SPONSOREN +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) -SPONSOREN & PARTNER +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) - +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) - Swiss IT Media GmbH +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter - Seestrasse 95 +[Login](https://www.comparis.ch/bff/login)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) - CH-8800 Thalwil +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) - ✆ +41 44 723 50 00 +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) - info@swissitmedia.ch +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) -[www.swissitmedia.ch](https://www.swissitmedia.ch/) +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) -INSERIEREN +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter -[Mediadaten](https://www.itreseller.ch/media) +[Login](https://www.comparis.ch/bff/login)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) -VERLAG +[Alles zu Telecom](https://www.comparis.ch/telecom) -[Abonnement](https://www.itreseller.ch/abo) +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) +[Login](https://www.comparis.ch/bff/login)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) -[Swiss IT Magazine](https://www.itmagazine.ch/) +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) -SERVICE +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) +[Alles zu Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) +[Login](https://www.comparis.ch/bff/login)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) +DE -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) +[FR](https://fr.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen)[IT](https://it.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen)[EN](https://en.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen) -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) +[Login](https://www.comparis.ch/bff/login) -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) +[Login](https://www.comparis.ch/bff/login) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/newsletter) + +[Login](https://www.comparis.ch/bff/login) + +[DE](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen)[FR](https://fr.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen)[IT](https://it.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen)[EN](https://en.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen) + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. [Wohnen](https://www.comparis.ch/wohnen "Wohnen") +3. [Immobilien](https://www.comparis.ch/immobilien/default "Immobilien") +4. [Bauland kaufen](https://www.comparis.ch/immobilien/marktplatz/grundstueck/kaufen "Bauland kaufen") +5. Grundstück in Kanton Zürich kaufen + +[Favoriten (0)](https://www.comparis.ch/immobilien/result/favoritelist) + +Grundstück in Kanton Zürich kaufen: 72 Resultate +================================================ + +Filter (4)[Suchabo anlegen Suchabo](https://www.comparis.ch/immobilien/searchsubscription/add?requestobject=%7B%22DealType%22%3A20%2C%22SwapProperty%22%3A0%2C%22SiteId%22%3A0%2C%22RootPropertyTypes%22%3A%5B9%5D%2C%22PropertyTypes%22%3A%5B%5D%2C%22RoomsFrom%22%3Anull%2C%22RoomsTo%22%3Anull%2C%22FloorSearchType%22%3A0%2C%22LivingSpaceFrom%22%3Anull%2C%22LivingSpaceTo%22%3Anull%2C%22PriceFrom%22%3Anull%2C%22PriceTo%22%3Anull%2C%22ComparisPointsMin%22%3A0%2C%22AdAgeMax%22%3A0%2C%22AdAgeInHoursMax%22%3Anull%2C%22Keyword%22%3A%22%22%2C%22WithImagesOnly%22%3Anull%2C%22WithPointsOnly%22%3Anull%2C%22Radius%22%3Anull%2C%22MinAvailableDate%22%3A%221753-01-01T00%3A00%3A00%22%2C%22MinChangeDate%22%3A%221753-01-01T00%3A00%3A00%22%2C%22LocationSearchString%22%3A%22Kanton%20Z%C3%BCrich%22%2C%22Sort%22%3A3%2C%22HasBalcony%22%3Afalse%2C%22HasTerrace%22%3Afalse%2C%22HasFireplace%22%3Afalse%2C%22HasDishwasher%22%3Afalse%2C%22HasWashingMachine%22%3Afalse%2C%22HasLift%22%3Afalse%2C%22HasParking%22%3Afalse%2C%22PetsAllowed%22%3Afalse%2C%22MinergieCertified%22%3Afalse%2C%22WheelchairAccessible%22%3Afalse%2C%22LowerLeftLatitude%22%3Anull%2C%22LowerLeftLongitude%22%3Anull%2C%22UpperRightLatitude%22%3Anull%2C%22UpperRightLongitude%22%3Anull%2C%22ShowComparisPoints%22%3Afalse%7D) + +Kein neues Inserat verpassen! +* Umgehende Benachrichtigung +* Jederzeit anpassbar +* Kostenlos + +Infobox schliessen + +* * * + +Sortieren nach: + +Sortieren nach:Erstmals gefunden am + +Sortieren + +[Bauland Online seit einem Tag 706 m² ------ «Ihr neues Projekt mit Seesicht» 8820 Wädenswil Rotweg 20 CHF 2'100'000 Kaufpreis Merken Merken CHF 2'100'000 Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35829556) + +[Gewerbegrundstück Online seit 3 Tagen Gewerbegrundstück ----------------- «*Bauernhof mit mehreren landwirtschaftlichen Parzellen*» 8460 Marthalen Talackerberg, Im Türni CHF 1'020'000 Kaufpreis Merken Merken CHF 1'020'000 Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35821879) + +[Bauland Online seit 3 Tagen Bauland ------- «BAULAND AN TRAUMHAFTER LAGE AM FISCHBACH» 8162 Steinmaur auf Anfrage Kaufpreis Merken Merken auf Anfrage Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35819533) + +[Bauland Online seit 4 Tagen 1285 m² ------- «Windlach: Grundstück mit Potenzial für Wohnraumentwicklung» 8175 Windlach CHF 800'000 Kaufpreis Merken Merken CHF 800'000 Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35816133) + +[Bauland Online seit 5 Tagen 3166 m² ------- «Attraktives Entwicklungsareal an zentraler Lage mit 3?166 m²» 8050 Zürich CHF 26'000'000 Kaufpreis Merken Merken CHF 26'000'000 Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35813836) + +[Grundstück Online seit 5 Tagen  Grundstück ---------- «Hier beginnt Ihre Zukunft» 8340 Hinwil CHF 1'070'000 Kaufpreis Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken CHF 1'070'000 Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35812529) + +[Bauland Online seit einer Woche  9175 m² ------- «Vergabe der Gewerbefläche GB Nr. 74, Neuhausen am Rheinfall» 8212 Neuhausen am Rheinfall CHF 343 Kaufpreis pro m² Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken CHF 343 Kaufpreis pro m²](https://www.comparis.ch/immobilien/marktplatz/details/show/35789351) + +[Bauland Online seit einer Woche Bauland ------- «Zürich» 8000 Zürich auf Anfrage Kaufpreis Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken auf Anfrage Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35782427) + +[Grundstück Online seit einer Woche Grundstück ---------- «Zürich» 8001 Zürich auf Anfrage Kaufpreis Merken Merken auf Anfrage Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35778374) + +[Grundstück Online seit einer Woche  Grundstück ---------- «Attraktives Baugrundstück in ruhiger, ländlicher Umgebung» 8195 Wasterkingen CHF 475'000 Kaufpreis Anfrage senden Anfragen Merken Anfrage senden Anfragen Merken CHF 475'000 Kaufpreis](https://www.comparis.ch/immobilien/marktplatz/details/show/35770932) + +* 1 +* [2](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen?page=1) +* [3](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen?page=2) +* [4](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen?page=3) +* [5](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen?page=4) +* [6](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen?page=5) +* [8](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen?page=7) +* [](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen?page=1) + +Gemeinden in diesem Kanton +-------------------------- + +[A](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#A) + +[B](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#B) + +[C](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#C) + +[D](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#D) + +[E](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#E) + +[F](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#F) + +[G](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#G) + +[H](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#H) + +[I](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#I) + +[J](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#J) + +[K](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#K) + +[L](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#L) + +[M](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#M) + +[N](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#N) + +[O](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#O) + +[P](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#P) + +[Q](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#Q) + +[R](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#R) + +[S](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#S) + +[T](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#T) + +[U](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#U) + +[V](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#V) + +[W](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#W) + +[X](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#X) + +[Y](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#Y) + +[Z](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen#Z) + +### A + +[Adliswil](https://www.comparis.ch/immobilien/marktplatz/adliswil/grundstueck/kaufen) + +[Aeugst am Albis](https://www.comparis.ch/immobilien/marktplatz/aeugst-am-albis/grundstueck/kaufen) + +[Affoltern am Albis](https://www.comparis.ch/immobilien/marktplatz/affoltern-am-albis/grundstueck/kaufen) + +### B + +[Benken (ZH)](https://www.comparis.ch/immobilien/marktplatz/benken-zh/grundstueck/kaufen) + +[Bülach](https://www.comparis.ch/immobilien/marktplatz/buelach/grundstueck/kaufen) + +### D + +[Dättlikon](https://www.comparis.ch/immobilien/marktplatz/daettlikon/grundstueck/kaufen) + +[Dielsdorf](https://www.comparis.ch/immobilien/marktplatz/dielsdorf/grundstueck/kaufen) + +[Dietikon](https://www.comparis.ch/immobilien/marktplatz/dietikon/grundstueck/kaufen) + +[Dietlikon](https://www.comparis.ch/immobilien/marktplatz/dietlikon/grundstueck/kaufen) + +[Dinhard](https://www.comparis.ch/immobilien/marktplatz/dinhard/grundstueck/kaufen) + +[Dorf](https://www.comparis.ch/immobilien/marktplatz/dorf/grundstueck/kaufen) + +### E + +[Elgg](https://www.comparis.ch/immobilien/marktplatz/elgg/grundstueck/kaufen) + +[Embrach](https://www.comparis.ch/immobilien/marktplatz/embrach/grundstueck/kaufen) + +[Erlenbach (ZH)](https://www.comparis.ch/immobilien/marktplatz/erlenbach-zh/grundstueck/kaufen) + +### F + +[Fällanden](https://www.comparis.ch/immobilien/marktplatz/faellanden/grundstueck/kaufen) + +### H + +[Herrliberg](https://www.comparis.ch/immobilien/marktplatz/herrliberg/grundstueck/kaufen) + +[Hettlingen](https://www.comparis.ch/immobilien/marktplatz/hettlingen/grundstueck/kaufen) + +[Hinwil](https://www.comparis.ch/immobilien/marktplatz/hinwil/grundstueck/kaufen) + +[Höri](https://www.comparis.ch/immobilien/marktplatz/hoeri/grundstueck/kaufen) + +[Hüntwangen](https://www.comparis.ch/immobilien/marktplatz/huentwangen/grundstueck/kaufen) + +### M + +[Marthalen](https://www.comparis.ch/immobilien/marktplatz/marthalen/grundstueck/kaufen) + +[Mönchaltorf](https://www.comparis.ch/immobilien/marktplatz/moenchaltorf/grundstueck/kaufen) + +### N + +[Niederglatt](https://www.comparis.ch/immobilien/marktplatz/niederglatt/grundstueck/kaufen) + +[Niederhasli](https://www.comparis.ch/immobilien/marktplatz/niederhasli/grundstueck/kaufen) + +### O + +[Oetwil am See](https://www.comparis.ch/immobilien/marktplatz/oetwil-am-see/grundstueck/kaufen) + +### P + +[Pfäffikon](https://www.comparis.ch/immobilien/marktplatz/pfaeffikon/grundstueck/kaufen) + +### R + +[Rafz](https://www.comparis.ch/immobilien/marktplatz/rafz/grundstueck/kaufen) + +[Regensberg](https://www.comparis.ch/immobilien/marktplatz/regensberg/grundstueck/kaufen) + +[Regensdorf](https://www.comparis.ch/immobilien/marktplatz/regensdorf/grundstueck/kaufen) + +[Richterswil](https://www.comparis.ch/immobilien/marktplatz/richterswil/grundstueck/kaufen) + +[Rifferswil](https://www.comparis.ch/immobilien/marktplatz/rifferswil/grundstueck/kaufen) + +[Rümlang](https://www.comparis.ch/immobilien/marktplatz/ruemlang/grundstueck/kaufen) + +[Russikon](https://www.comparis.ch/immobilien/marktplatz/russikon/grundstueck/kaufen) + +[Rüti (ZH)](https://www.comparis.ch/immobilien/marktplatz/rueti-zh/grundstueck/kaufen) + +### S + +[Steinmaur](https://www.comparis.ch/immobilien/marktplatz/steinmaur/grundstueck/kaufen) + +### V + +[Volken](https://www.comparis.ch/immobilien/marktplatz/volken/grundstueck/kaufen) + +### W + +[Wädenswil](https://www.comparis.ch/immobilien/marktplatz/waedenswil/grundstueck/kaufen) + +[Wasterkingen](https://www.comparis.ch/immobilien/marktplatz/wasterkingen/grundstueck/kaufen) + +[Weisslingen](https://www.comparis.ch/immobilien/marktplatz/weisslingen/grundstueck/kaufen) + +[Wildberg](https://www.comparis.ch/immobilien/marktplatz/wildberg/grundstueck/kaufen) + +### Z + +[Zell (ZH)](https://www.comparis.ch/immobilien/marktplatz/zell-zh/grundstueck/kaufen) + +[Zürich](https://www.comparis.ch/immobilien/marktplatz/zuerich/grundstueck/kaufen) + +Das könnte Sie interessieren +---------------------------- + +### Weitere Comparis Services + +[Was zahlt die Nachbarschaft?](https://www.comparis.ch/immobilien/mashup/show)[Umzugsfirma Zürich](https://www.comparis.ch/immobilien/umzug/anbieter/zuerich)[Inserieren](https://www.comparis.ch/immobilien/inserieren/default) + +### Weitere Kaufobjekte in Kanton Zürich + +[Wohnung kaufen Kanton Zürich (1500)](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/wohnung/kaufen)[Haus kaufen Kanton Zürich (642)](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/haus/kaufen)[Mehrfamilienhaus kaufen Kanton Zürich (70)](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/mehrfamilienhaus/kaufen) + +[ZU DEN FAVORITEN](https://www.comparis.ch/immobilien/result/favoritelist) + +Filter (4) + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/newsletter) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) + + -=== https://www.valueon.ch/services === -ValueOn - Mehrwert dank digitaler Transformation +=== https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste === +73 Bauland kaufen in Kanton Zürich | homegate.ch =============== -[](https://www.valueon.ch/) +[](https://www.homegate.ch/de) +* [Suchen](https://www.homegate.ch/de "Suchen") +* [Services](https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages "Services") -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) +[Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen "Inserieren") -🇩🇪DE +[Mein Konto](https://www.homegate.ch/de/overview "Mein Konto") -[Gespräch vereinbaren](https://www.valueon.ch/contact) +Menü -🇩🇪DE +[](https://www.homegate.ch/de) +* [Suchen](https://www.homegate.ch/de "Suchen") +* [Services](https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages "Services") +* [Schätzen](https://www.homegate.ch/de/immobilienbewertung "Schätzen") +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber?intlink=h_Advisor "Ratgeber") -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) +[Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen "Inserieren") -Unsere Leistungen -================= +[Mein Konto](https://www.homegate.ch/de/overview "Mein Konto") -Von der digitalen Transformation bis zur KI-Integration – wir begleiten Sie bei jedem Schritt zu nachhaltigem Erfolg, messbaren Ergebnissen und langfristiger Wertschöpfung. +DE +* [DE](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste) +* [FR](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste) +* [IT](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste) +* [EN](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste) -Digitale Transformation Künstliche Intelligenz IT- & Digitalprojekte +Ort -Digitale Transformation ------------------------ + Kanton Zürich -Wir begleiten Sie bei jedem Schritt – von der Strategie bis zur erfolgreichen Umsetzung. + Kanton Zürich -### Zukunft gestalten mit klarem Zielbild + Preis bis -IHRE RICHTUNG IM DIGITALEN WANDEL + -Zielbild & Roadmap für digitale Transformation – zugeschnitten auf Ihr Geschäft. + Weitere Filter -Orientierung & Handlungssicherheit + 73 Treffer -### Transformation analysieren & optimieren +73 Treffer - Bauland kaufen in Kanton Zürich +============================================ -LÜCKEN AUFDECKEN. NUTZEN SCHÄRFEN +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 16    CHF 2’563’760.– Top **360m²** Nutzfläche Luegetenstrasse 11, 8489 Wildberg Ihr neues Zuhause mit Potenzial - Idyllisches Landhaus mit Baulandreserve Ihr neues Zuhause Willkommen in Ihrem zukünftigen Traumdomizil - ein grosszügiges, freistehendes Landhaus an ruhiger und idyllischer Aussichtslage im malerischen Wildberg. Hier vereinen sich ländliche Idylle, Privatsphäre und die seltene Möglichkeit, Wohnraum nach eigenen Vorstellungen zu schaffen oder zu erweitern.Ob als charmantes Familienrefugium mit grossem Garten oder als Investitionsobjekt mit Entwicklungspotenzial - dieses einzigartige Anwesen bietet Ihnen beide Optionen. Auf dem 1339m² grossen Grundstück geniessen Sie nicht nur viel Platz zum Leben, sondern verfügen auch über eine wertvolle Baulandreserve, die Ihnen vielfältige Gestaltungsmöglichkeiten eröffnet. Erste Abklärungen zeigen: Es besteht die Möglichkeit, ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren - ein echter Mehrwert für visionäre Käufer.Tauchen Sie ein in eine grüne Oase mit Weitblick - ein Ort, der Ruhe schenkt und inspiriert.Highlights auf einen Blick • Idyllische, ruhige Aussichtslage mit hohem Erholungswert • Grosszügiges Grundstück mit 1339m², ideal zur Eigennutzung und/oder für die Entwicklung eines Neubaus • Baulandreserve: Attraktives Entwicklungspotenzial - gemäss erster Einschätzung besteht die Möglichkeit, zusätzlich zum bestehenden Einfamilienhaus ein Mehrfamilienhaus mit bis zu fünf Wohneinheiten zu realisieren (unverbindlich, ohne Gewähr) • Blühender Garten mit verschiedenen Sitzplätzen, Pergola mit Aussencheminée, Gartenhäusern, gepflegtem Baumbestand und weitläufigen Grünflächen • Solide Bausubstanz mit Doppelschalenmauerwerk • Grosszügiges Raumkonzept mit ca. 220m² Wohnfläche und ca. 96m² zusätzlichem Stauraum im Untergeschoss. Total ca. 360m² Bruttofläche. • Geräumiger Wohnbereich mit gemütlichem Kachelofen - ein Ort zum Ankommen und Wohlfühlen • Praktische Wohnküche mit integriertem Essbereich - ideal für gesellige Stunden • 4 helle Schlafzimmer - ideal für Familien oder Homeoffice • 2 Nasszellen mit Tageslicht • Ausgebauter Estrich für zusätzlichen Raum oder kreative Nutzungsmöglichkeiten • Beheizt durch Elektrospeicher und wassergeführte Fussbodenheizung • Garage mit elektrischem Tor und weitere Parkmöglichkeiten auf dem Grundstück • Mit einer stilvollen Modernisierung verwandeln Sie dieses Haus in ein wahres Schmuckstück Verkaufspreis: CHF 1'870'000.-Mit unserer virtuellen 360-Grad-Tour können Sie bereits die ersten Eindrücke dieser tollen Liegenschaft gewinnen. Sehr gerne zeigen wir Ihnen diese Liegenschaft direkt vor Ort und freuen uns auf Ihre Kontaktaufnahme.Weitere EckdatenBaujahr Haus: 1984, Baujahr Gerätehaus: 1986, Kubatur Haus (GVZ): 936m³, Kubatur Gerätehaus (GVZ): 40m³, Grundbuchblatt: Nr. 437, Kataster-Nr.: 249, 1/4 subjektiv-dingliches Miteigentum an Blatt 444, Kataster 249. Nettowohnfläche: ca. 220m², Bruttowohnfläche: ca. 360m², Grundstücksfläche: 1'339m².Massivbauweise, Doppelschalenmauerwerk, neuwertige Holzmetallfenster (EgoKiefer) mit dreifacher Verglasung und Sprossen & Holzläden. Elektrospeicherofen, wassergeführte Fussbodenheizung, Elektroboiler 300 Liter.Treppenlift, Garage mit elektrischem Torantrieb. Küche im Landhausstil mit Granitabdeckung, Geschirrspüler, Induktions-Kochherd und Kühlschrank mit Gefrierfach.BodenbelägeEG: Entrée, Gang, Dusche, Küche, Essen mit Plattenboden.OG: Zimmer und Vorplatz mit Laminat in Holzoptik. Bad mit Platten.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002491909) -Fit-Gap-Analyse und Review Ihrer Prozesse, Tools & Struktur. +[*  *  *  *  *  *  *  *  1 / 8 CHF 2’604’890.– Top Wehntalerstrasse 28, 8181 Höri Grundstück mit Baubewilligung für ein Mehrfamilienhaus mit 6 Einheiten Das Grundstück ist derzeit mit einem Einfamilienhaus bebaut (Baujahr 1960)Nach dem Rückbau kann, gemäss Bewilligung ein Mehrfamilienhaus mit 6 Wohnungen (3 Wohnungen 4½ Zimmer und 3 Wohnungen 2½ Zimmer) mit 9 Tiefgaragen, 1 Tiefgaragen Behinderten Parkplatz sowie 2 Besucher Aussenparkplätze realisiert werden. (Siehe Pläne)Im Kaufpreis enthalten: • Baubewilligung • Bewilligungsgebühren • Projektpläne in PDF, DWG und Step Dateien • Lärmschutznachweis Strasse / Lärmschutznachweis Fluglärm • Geologisches Gutachten (Meldeblatt zu Bodenverschiebung) Parzelle nicht belastet! • Private Kontrolle bei Rückbau- und Umbau. (2 Asbestproben wurden positiv auf Asbest getestet) • Amtlich Beglaubigter Katasterplan • Farb- und Materialkonzept Verkaufspreis für Liegenschaft inkl. Vorbeschriebenen Leistungen: CHF 1'900'000.-Wir hoffen Ihr Interesse geweckt zu haben. Gerne stellen wir Ihnen die Verkaufsdokumente und Projektunterlagen, mit ausführlichen Informationen, per E-Mail zu.Es werden keine Makleranfragen berücksichtigt.Die zugestellten Informationen sind Eigentum von Bujar Bunjaku. Veröffentlichung, kopieren sind nicht gestattet.Kaufabwicklung:CHF 72'000.-- fällig bei Unterzeichnung der Kaufzusage; CHF 150'000.-- fällig bei Unterzeichnung und notarieller Beurkundung des Kaufvertrages; Restzahlung des Verkaufspreises fällig bei der Eigentumsübertragung.Notariats- und Grundbuchgebühren: Je zur Hälfte zu Lasten Käufer / Verkäufer.Anbieter:Bujar BunjakuWehntalerstrasse 288181 Höri Wegzeit Neu -](https://www.homegate.ch/kaufen/4002530816) -Systematische Bewertung statt Aktionismus +[*  *  *  *  1 / 4 CHF 1’096’790.– Top Bahnhofstrasse 41, 8496 Steg im Tösstal 1’111 m² attraktives Bauland in Steg Dieses 1'111 m² grosse Bauland liegt im schönen Tösstal, einer der sonnigsten Regionen der Ostschweiz. Die ruhige Lage direkt am Waldrand bietet viel Natur, frische Luft und Privatsphäre.Ein idealer Ort für Naturliebhaber und Ruhesuchende, die dennoch Wert auf eine gute Erreichbarkeit legen. Hier lassen sich Wohnträume verwirklichen.Besichtigungen sind jederzeit frei möglich.Neugierig geworden? Alle weiteren Details entnehmen Sie bitte der oben angehängten Verkaufsdokumentation.Isler-Consolis AG, Technikumstrasse 73, 8401 Winterthur, Tel. 052 267 81 00, Dorentina Bytyqi Wegzeit Neu -](https://www.homegate.ch/kaufen/4002331120) -### IT, Business & Digitalstrategie vereinen +[*  *  *  *  1 / 4 Preis auf Anfrage Top Lüss, 8542 Wiesendangen Im Baurecht abzugeben: 14’770 m2 Bauland an bester Lage im steuergünstigen Wiesendangen Im Baurecht abzugeben:14’770 m2 Bauland an bester Lage im steuergünstigen WiesendangenGrundstück WD4674 – Lüss WiesendangenAlle Details zum Grundstück, zum Baurechtsvertrag sowie zu den Vergabekriterien finden sie im angefügten Dossier.Verbindliche Angebote für eine Übernahme des Baurechtsvertrages inklusive Finanzierungsnachweis sind einzureichen an:Gemeinde Wiesendangenz. Hd. Martin SchindlerSchulstrasse 208542 Wiesendangen Bitte verwenden Sie für die Angebotseingabe das Formular im Anhang.Eingabeschluss: Montag, 20. Oktober 2025, 11.00 Uhr Wegzeit Neu -](https://www.homegate.ch/kaufen/4002510601) -SCHNITTSTELLEN AUFLÖSEN. STRATEGIE VERBINDEN +[ 1 / 1 Preis auf Anfrage Top Büntlistrasse 1, 8174 Stadel Bauland in Stadel b. Niederglatt Die Primarschule Stadel hat zwei Landparzellen zu verkaufen. Nummber 305 & 306. 305 ist unbebaut, hingegen 306 hat ein Gebäude, welches als Kindergarten und Mietwohnungen genutzt wurde. Wir möchten die beiden Landparzellen zusammen verkaufen. Der Kontakt für die erste Anlaufstelle ist Rolf Schindelholz einer unserer Mitarbeiter in der Schulverwaltung. Geleitet wird das Projekt von Patrick Heusser dem Finanzvorstand der Primarschulpflege Stadel. Wegzeit Neu -](https://www.homegate.ch/kaufen/4000669374) -Abgleich Ihrer Digital- und Businessstrategie – für nachhaltige Wirkung. +[*  *  *  *  *  *  *  *  *  *  *  *  1 / 12    CHF 2’323’840.– Hürstringstrasse 37, 8046 Zürich Grundstück mit bestehendem EFH und grossem Potenzial Gerne stellen wir Ihnen das Grundstück mit grossem Potenzial und vielen Möglichkeiten vor.Nach Absprache verkaufen wir an ruhiger Lage in Zürich ein Grundstück mit bestehendem Einfamilienhaus. Interessant an diesem Objekt ist jedoch, dass Sie beim Kauf bereits über die zugehörige Baubewilligung verfügen, welche es Ihnen erlaubt, den Wohnraum auf dieser Parzelle nach Ihren Wünschen zu vergrössern und zu sanieren.Nicht weit vom Zürcher Hauptbahnhof entfernt, hinter dem Käferberg liegt die grosszügige Parzelle mitten in einem ruhigen Wohnquartier mit 30er-Zone.Zu Fuss erreichen Sie eine Bushaltestelle, sowie auch den kleinen Wald, der sich ideal für kürzere Spaziergänge eignet.Die wichtigsten Infos in Kürze: • Landparzelle inkl. Einfamilienhaus und Baubewilligung zum Ausbau der Wohnfläche • Baujahr 1934 • Grundstückfläche von 410 m2 • Projektmöglichkeit 1: Ausbau zum Mehrfamilienhaus mit zwei Eigentums- oder Mietwohnungen • Projektmöglichkeit 2: Ausbau zum Generationenhaus Erleben Sie die ruhige Atmosphäre und gleichzeitige Nähe zum Stadtzentrum bei einem persönlichen Besuch!Für nähere Informationen zum Objekt oder einen Besichtigungstermin dürfen Sie sich gerne jederzeit bei uns melden.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002349882) -Strategische Klarheit gewinnen +[*  *  *  *  *  *  *  *  *  *  *  1 / 11    CHF 3’290’400.– Luzernerstrasse 57, 8903 Birmensdorf (ZH) Sonnige Aussichtslage Im Auftrag unseres Kunden verkaufen wir ein Bauland an sonniger Aussichtlage mit 1'228 m² Grundstücksfläche (Wohnzone W2).Die bestehende Liegenschaft präsentiert sich in einem dem Alter entsprechend gut unterhaltenen Zustand.Verkaufsrichtpreis: CHF 2'400'000Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002566208) -### CIO/CDO ad interim einsetzen +[*  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13    CHF 1’302’440.– Kanalweg 2, 8714 Feldbach Bauland für projektiertes Einfamilienhaus Im beschaulichen Dorf Feldbach am Zürichsee ist dieses Grundstück mit einer bestehenden, einseitig angebauten Scheune zu verkaufen. Im Kaufpreis inbegriffen ist ein bewilligungsfähiges Vorprojekt für ein Einfamilienhaus als Ersatzbau der Scheune.Das Objekt bietet Ihnen die einmalige Möglichkeit, Ihren Traum vom Eigenheim an idyllischer Lage zu verwirklichen. Es bietet genügend Platz für eine Familie, auch eine Kombination von "Wohnen und Arbeiten" ist denkbar.Innert 30 Minuten sind Sie mit der S-Bahn in Zürich, auch Kindergarten und Primarschule sind nah. Einkaufsmöglichkeiten bestehen in Hombrechtikon, Stäfa und Rapperswil. Im Sommer lockt in unmittelbarer Nähe eine Abkühlung in der schmucken Seebadi Feldbach.Es besteht ein aktueller Kostenvoranschlag für das Haus (Holzelementbauweise) inkl. Umgebung, Bau- und Nebenkosten in der Höhe von Fr. 1'380'000.--.Haben wir Sie neugierig gemacht? Dann rufen Sie uns an. Gerne beantworten wir Ihre Fragen oder stellen Ihnen unsere Verkaufsdokumentation zum Studium zu. Die Liegenschaft kann selbstverständlich auch besichtigt werden. Wir freuen uns auf Ihren Anruf.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002434745) -FÜHRUNG SICHERN. KOMPETENZ EINBRINGEN +[*  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13    CHF 4’111’620.– **5.5** Zimmer Schaffhauserstrasse 226b, 8057 Zürich Mehr Raum fürs Leben: Reihenhaus mit Potenzial Attraktive Stadtliegenschaft mit ausgearbeitetem ProjektIm Zürcher Kreis 11 veräussern wir ein hübsches Reiheneinfamilien-Eckhaus mit grosszügigem Umschwung. Die Liegenschaft und das Grundstück verfügen über viel Ausnützungspotenzial und ermöglicht so die Realisation spannender Projekte sowohl im Umbau als auch Neubau.Diese Liegenschaft überzeugt durch viele Besonderheiten: • grosszügiger Umschwung mit viel Potenzial • Blick ins Grüne von nahezu allen Fenstern • Schwedenofen im Wohnbereich • viel Stauraum durch Wandschränke und Estrich • Altbaucharme in modernem Quartier • zentrale und familienfreundliche Lage • sonnenverwöhnter Standort Haben wir Ihr Interesse geweckt? Bestellen Sie noch heute unsere ausführliche Verkaufsdokumentation mittels Kontaktformular und Sie erhalten weitere spannende Informationen zur Immobilie. Wir freuen uns über Ihre Kontaktaufnahme!Une oasis de verdure dans la ville de Zurich avec un projet élaboréDans le quartier 11 de Zurich, nous vendons une jolie maison mitoyenne en angle avec de vastes alentours. L'immeuble et le terrain disposent d'un grand potentiel d'exploitation et permettent ainsi la réalisation de projets passionnants, tant en transformation qu'en construction neuve.Cette propriété convainc par ses nombreuses particularités : • Un vaste terrain avec beaucoup de potentiel • Une vue sur la verdure depuis presque toutes les fenêtres • Un poêle suédois dans le séjour • beaucoup d'espace de rangement grâce aux armoires murales et au grenier • Le charme d'un ancien bâtiment dans un quartier moderne • Un emplacement central et favorable aux familles • Un emplacement ensoleillé Nous avons éveillé votre intérêt ? Commandez dès aujourd'hui notre documentation de vente détaillée au moyen du formulaire de contact et vous recevrez d'autres informations passionnantes sur le bien immobilier. Nous nous réjouissons de votre prise de contact!A green oasis in the city of Zurich with an elaborate projectIn Zurich's Kreis 11 district, we are selling a pretty terraced single-family corner house with spacious grounds. The property and the plot have a lot of utilization potential and thus enable the realization of exciting projects both in conversion and new construction.This property boasts many special features: • spacious grounds with lots of potential • view of the countryside from almost all windows • Swedish stove in the living area • lots of storage space thanks to wall cupboards and attic • old building charm in a modern district • central and family-friendly location • sun-drenched location Have we piqued your interest? Order our detailed sales documentation today using the contact form and you will receive further exciting information about the property. We look forward to hearing from you!  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002346061) -Temporäre Führungsstärke, wenn Verantwortung gebraucht wird. +[*  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13 CHF 4’044’440.– Mühlemattstrasse 12, 8135 Langnau am Albis Bauland oder bestehendes Einfamilienhaus zum Verkauf! Dieses freistehende Einfamilienhaus befindet sich an ruhiger Lage und bietet eine seltene Kombination aus architektonischem Charakter, grosszügigem Umschwung und inspirierendem Entwicklungspotenzial. Eingebettet in viel Grün und umgeben von Bäumen geniessen Sie hier Privatsphäre, Ruhe – und eine wunderschöne Weitsicht.Das Haus überzeugt durch eine unverwechselbare Ausstrahlung. Die Backsteinwände im Innenbereich verleihen dem Wohnraum eine warme, natürliche Atmosphäre, während das Cheminée im Wohnzimmer für Behaglichkeit an kühleren Tagen sorgt. Der Grundriss ist offen und einladend, ergänzt durch grosse Fensterfronten, die Licht und Natur ins Haus holen.Ein Highlight ist die grosszügige Terrasse mit herrlichem Ausblick – ideal für gemütliche Stunden im Freien. Der Garten ist weitläufig und bietet viel Platz für individuelle Gestaltung. Mit etwas Aufmerksamkeit lässt sich hier ein wunderbares grünes Paradies schaffen – ob als Familiengarten, Rückzugsort oder für kreative Projekte im Freien.Dank der Grundstücksgrösse und der Lage eröffnet die Liegenschaft auch interessante Perspektiven für einen möglichen Ersatzneubau - wie ein modernes Einfamilienhaus oder ein Mehrfamilienhaus.Gerne stellen wir Ihnen weitere Informationen zur Verfügung oder vereinbaren einen persönlichen Besichtigungstermin. Entdecken Sie das Potenzial und die besondere Atmosphäre dieses einzigartigen Ortes. In der Verkaufsdokumentation finden Sie alle wichtigen Informationen.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002406229) -Sofort einsatzbereit & erfahrungssicher +[*  *  *  *  *  *  1 / 6    * Ruhige Lage CHF 3’358’950.– 8192 Glattfelden ZWEIFELSFREIES BAULAND IN ZWEIDLEN Im beliebten Zweidlen verkaufen wir ein eine attraktive, 1'226 m² grosse Baulandparzelle mit Bestandesobjekt.Unsere Projektstudie zeigt eine hohe Ausnutzung für die Erstellung eines Mehrfamilienhauses. • Anrechenbare mögliche Bruttogeschossfläche von max. 940 m² (Projekt 789 m²) • Wohn- und Gewerbezone WG 2.3 • Kein Denkmalschutz beim Bestandesobjekt • Die Deutsche Grenze in Kaiserstuhl ist nur 8 Autominuten entfernt • Der Flughafen Zürich ist in nur 19 Autominuten erreichbar Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: https://www.propertyowner.ch/de/immobilien/25-12278 Referenznummer: 25-12278Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website https://www.propertyowner.ch/immobilien/ und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen! * Ruhige Lage  Wegzeit -](https://www.homegate.ch/kaufen/4002558181) -### Zukunft gestalten mit klarem Zielbild +[*  *  *  *  *  *  *  *  *  *  *  *  1 / 12 Preis auf Anfrage Überlandstrasse 23, 8340 Hinwil Industrie- und Baulandparzelle an attraktivem Standort im Zürcher-Oberland Im pulsierenden Industriegebiet von Hinwil verkaufen wir ein Industriebaugrundstück an einer top frequentierter Lage, direkt an der Hauptachse in Rapperswil Wetzikon Pfäffikon ZH. Die Baulandparzelle befindet sich am Rand der Industriezone und grenzt an die Wohnzone zu Hinwil ZH.Eckdaten:- Grundstück-Fläche total 4'246 m2- Bauzone Industrie/Gewerbe IG/7 - Baumassenziffer 7 m3/m2- Gebäudehöhe maximal 21.5 m- Gebäudelänge maximal offen- Grosser Grenzabstand Nationalstrasse- Allseitiger Gebäudeabstand 3.5 m1- Maximal mögliche Baumasse ca. 30'000 m3- Bruttogeschossfläche ca. 9'500 m2Das Baugrundstück wird derzeit noch mit zwei Wohneinheiten, der Autowerkstatt mit separatem Showroom und einer Tankstelle genutzt. Rund um die Liegenschaft bieten sich grosse, befestigte Flächen zur Nutzung an.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002417917) -IHRE RICHTUNG IM DIGITALEN WANDEL +[*  *  *  *  *  *  *  1 / 7    CHF 5’484’000.– 8156 Oberhasli ATTRAKTIVE INVESTITION IN FLUGHAFENNÄHE Unweit des Flughafens Kloten bieten wir ein attraktives Gewerbebauland für ein Neubauprojekt im strategisch ideal gelegenen Oberhasli zum Verkauf an. • Parzellenfläche: 2'010 m² • Zone: Gewerbezone • Optionen für Investoren: Neubau einer Gewerbeimmobilie mit bis zu 5'000 m² Geschossfläche (Verkauf oder Vermietung) • Optionen für Selbstnutzer: Neubau einer für die Selbstnutzung konzipierten Gewerbeimmobilie mit bis zu 5'000 m² Geschossfläche • Es besteht die Möglichkeit, die derzeit vermietete Gewerbeliegenschaft weiterzuführen. Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: https://www.propertyowner.ch/immobilien/24-101578/ Referenznummer: 24-101578Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website https://www.propertyowner.ch/immobilien/ und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen!  Wegzeit -](https://www.homegate.ch/kaufen/4001472412) -Zielbild & Roadmap für digitale Transformation – zugeschnitten auf Ihr Geschäft. +[*  *  *  *  *  *  1 / 6    CHF 1’919’390.– 8187 Weiach WILLKOMMENE WERTSCHÖPFUNG IN WEIACH Im steuergünstigen Weiach bieten wir an ruhiger Ortskernlage eine wohldimensionierte, unbebaute Baulandparzelle zum Verkauf an. Unsere Baulandstudie sieht die Erstellung von zwei attraktiven Doppeleinfamilienhäusern mit 4 Wohneinheiten vor. • 1'157 m² Parzellenfläche mit bestehender Zufahrt im Wegrecht • Unser Projekt sieht die Erstellung von zwei Doppeleinfamilienhäusern mit je zwei Vollgeschossen vor • Total erstellbare Bruttogeschossfläche von 648 m² • Maximal erstellbare Gebäudelänge von 25 Metern • Der Flughafen Zürich ist in nur 20 Minuten zu erreichen, die Stadt Zürich ist nur rund 30 Km entfernt Interessiert? Weitere Informationen und Bilder zum Grundstück sowie Besichtigungsmöglichkeiten unter: https://www.propertyowner.ch/immobilien/24-99121/ Referenznummer: 24-99121Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch- Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website https://www.propertyowner.ch/immobilien/ und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen!  Wegzeit -](https://www.homegate.ch/kaufen/4001410555) -Orientierung & Handlungssicherheit +[ 1 / 1 CHF 2’399’240.– In der Gass 2, 8627 Grüningen Grundstück mit Baubewilligung für MFH zu verkaufen Zum Verkauf steht ein Grundstück mit bewilligtem Neubauprojekt. Gebäude C des Enssamble an der Binzikerstrasse 21 / In der Gass 2, 8627 Grüningen. Die aktuell bestehenden Garagen können abgebrochen werden und durch einen Neubau mit 8 Wohnungen unterschiedlicher Grösse mit attraktiven Aussenbereich ersetzt werden. Zusätzlich wurde der gemeinsame Bau einer Tiefgarage für 11 Parkplätze mit der Zufahrt über die Strasse "In der Gass" bewilligt.  Wegzeit Neu -](https://www.homegate.ch/kaufen/3003479026) -### Transformation analysieren & optimieren +[*  *  *  *  *  *  1 / 6    CHF 2’879’100.– Rotweg 20, 8820 Wädenswil Ihr neues Projekt mit Seesicht Im Auftrag unseres Kunden verkaufen wir an bevorzugter, erhöhter und ruhiger Wohnquartierlage mit schöner See- und Fernsicht, 706 m² Bauland mit Rückbauobjekt.Verkaufsrichtpreis: CHF 2'100'000.00Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002559578) -LÜCKEN AUFDECKEN. NUTZEN SCHÄRFEN +[*  *  *  *  *  *  *  1 / 7    CHF 651’220.– Auf Anfrage 1, 8195 Wasterkingen Attraktives Baugrundstück in ruhiger, ländlicher Umgebung Willkommen in Wasterkingen, einer idyllischen und ruhigen Gemeinde im Zürcher Unterland, die für ihre hohe Lebensqualität, ländliche Gelassenheit und dennoch gute Erreichbarkeit bekannt ist. Genau hier wartet ein attraktives Baugrundstück auf Sie – die ideale Basis für Ihr zukünftiges Zuhause.Das Grundstück ist voll erschlossen und liegt in der Kernzone B, was Ihnen zahlreiche Gestaltungsmöglichkeiten eröffnet. Ob ein modernes Einfamilienhaus, ein klassisches Zuhause im Dorfcharakter oder ein individuelles Architektenprojekt – hier können Sie Ihre Wohnträume ganz nach Ihren Vorstellungen verwirklichen.Die charmante Gemeinde Wasterkingen besticht durch ihre ruhige Lage inmitten von Feldern, Reben und Natur.Dieses ImmoSky-Angebot bietet folgende *Mehr Leistung*:+ Voll erschlossen+ Ruhige Gemeinde+ Ideale Grösse für flexibilität (650m²)+ Kernzone B+Überbauungsziffer für Hauptgebäude 30%Dieses Grundstück bietet Ihnen die seltene Gelegenheit, ländliche Idylle mit urbaner Nähe zu vereinen – ein Ort, an dem Sie zur Ruhe kommen und dennoch bestens angebunden sind.Erfüllen Sie sich hier den Traum vom Eigenheim und gestalten Sie Ihr persönliches Refugium in Wasterkingen.Haben wir Sie mit diesem Angebot überzeugt? Dann zögern Sie nicht und kontaktieren Sie uns für weitere Fragen oder einen Besichtigungstermin!(Das Verkaufsdossier wird in der Regel innerhalb von maximal 24 Stunden an Sie versendet. Bitte überprüfen Sie auch Ihren SPAM-Ordner.)  Wegzeit -](https://www.homegate.ch/kaufen/4002537208) -Fit-Gap-Analyse und Review Ihrer Prozesse, Tools & Struktur. +[*  *  *  *  *  *  *  1 / 7    CHF 7’540’490.– Staldernstrasse 13, 8158 Regensberg Entwicklungsgrundstück an top Lage in der Kernzone 2 In der gefragten Gemeinde Regensberg (ZH) steht ein hervorragend gelegenes Grundstück zum Verkauf, das sich ideal für Investoren, General- oder Totalunternehmer eignet. Die 2.557 m² grosse Parzelle Nr. 949 befindet sich in der Kernzone 2, die vielfältige bauliche und nutzungsbezogene Entwicklungsmöglichkeiten zulässt, insbesondere für Wohn- oder gemischt genutzte Projekte.Aktuell steht auf dem Grundstück ein nicht erhaltenswertes Gebäude, das im Rahmen einer Neuentwicklung rückgebaut werden kann. Eine Baueingabe oder Bewilligung liegt nicht vor, sodass volle gestalterische Freiheit innerhalb der geltenden bau- und zonenrechtlichen Rahmenbedingungen besteht.Berechnungen zeigen, dass eine nachhaltige Mietertragserwartung von rund CHF 485'600 pro Jahr realistisch erscheint - unter der Annahme einer Ausnutzung mit rund 1 664 m² Hauptnutzfläche (HNF) und 28 Tiefgaragenplätzen. Der ermittelte Kapitalisierungssatz liegt bei 4.20 %.Wesentliche Bewertungskennzahlen:Verkehrswert (diskontierter Landwert): CHF 5'505'000Ertragswert im erneuerten Zustand: CHF 11'556'795Realwert (hypothetisch): CHF 12'485'000Potenzieller Verkaufserlös: CHF 16'190'000Bruttorendite (Mietwert): 4.20%Die hypothetische Bebauung sieht zwei Mehrfamilienhäuser mit einer Bruttogeschossfläche (BGF) von insgesamt 2'080 m² vor - entsprechend einer Ausnützungsziffer von 0.81, voll im Rahmen der Zonenordnung. Die kalkulierten Baukosten (BKP 2-5) belaufen sich auf ca. CHF 8.74 Mio. Der diskontierte Landwert pro m² liegt bei CHF 2'155, was das wirtschaftliche Potenzial zusätzlich unterstreicht.Die Kernzone 2 erlaubt neben der reinen Wohnnutzung auch Mischnutzungen, beispielsweise mit gewerblichen Angeboten im Erdgeschoss. Dies ist ein zusätzlicher Vorteil für flexible, standortgerechte Entwicklungskonzepte. Die Lage in Regensberg bietet ruhige Wohnqualität in der Nähe der Agglomeration Zürich und ist in eine attraktive historische Umgebung eingebettet.Fazit: Das Grundstück bietet die seltene Gelegenheit, ein entwicklungsfähiges Grundstück an bester Lage mit bestehendem Abbruchobjekt zu akquirieren und nach eigenen Vorstellungen zu bebauen. Dank der flexiblen Nutzungsmöglichkeiten und des attraktiven Standorts stellt diese Investition eine hervorragende Ausgangslage für renditestarke Projektentwicklungen dar.Für detaillierte Informationen stehen wir Ihnen gerne zur Verfügung.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002529588) -Systematische Bewertung statt Aktionismus +[*  *  *  1 / 3   CHF 1’686’330.– 8187 Weiach Ihr Bauland in Weiach ZH zum Schnäppchenpreis! Ihre Chance auf ein vielversprechendes Bauprojekt In der beliebten Gemeinde Weiach, eingebettet in eine ruhige und dennoch gut erreichbare Lage, erwartet Sie die Parzelle 1602. Das Grundstück in der Kernzone (K) bietet ideale Rahmenbedingungen für Investoren und Bauherren, die von Flexibilität und klar definierten Bauvorgaben profitieren möchten.Die Parzelle ermöglicht eine Bebauung mit bis zu 2 Vollgeschosse, einem anrechenbaren Dachgeschoss sowie einem Untergeschoss. Die maximale Gebäudehöhe von 7.50 m und die erlaubte Gebäudelänge von bis zu 30 m eröffnen vielseitige Bau- und Gestaltungsmöglichkeiten. Mit grosszügigen Grenzabständen von mindestens 6 m (grosser Grenzabstand) und 4 m (kleiner Grenzabstand) bietet das Grundstück genügend Raum für ansprechende Projekte mit Privatsphäre.Dieses Bauland ist die perfekte Gelegenheit, um ein individuelles Projekt in einer aufstrebenden Region zu realisieren. Egal, ob Sie Wohnraum schaffen oder ein Mischprojekt umsetzen möchten - die Parzelle hält alle Optionen offen.Ihre Vorteile auf einen Blick: • Vorhandene Machbarkeitsstudie • Bebaubare Fläche 1026 m² • Landwirtschaftszone 479 m² (CHF 60'000.- exkl.) • Kernzone (K) mit klar definierten Bauvorgaben • Maximal 2 Vollgeschosse, 1 anrechenbares Dach- und Untergeschoss • Gebäudehöhe bis zu 7.50 m • Maximale Gebäudelänge: 30 m • Grenzabstände: mind. 6 m und 4 m • Optimale Voraussetzungen für vielseitige Bauprojekte Nutzen Sie diese Gelegenheit, um ein nachhaltiges und gewinnbringendes Projekt in einer gefragten Region zu realisieren!  Wegzeit -](https://www.homegate.ch/kaufen/4002404604) -### IT, Business & Digitalstrategie vereinen +[*  *  *  *  *  *  1 / 6    CHF 3’633’140.– Riedwiesenstrasse 20, 8305 Dietlikon RESERVIERT - Industrie-Baulandparzelle an zentraler Lage in Dietlikon ZH Mit Freude präsentieren wir Ihnen eine einzigartige und äusserst seltene Baulandparzelle an zentraler Lage in Dietlikon ZH – eine aussergewöhnliche Gelegenheit mit hervorragenden Eigenschaften, die sich besonders für Investoren eignet.Zentrale Lage: Die Parzelle befindet sich in einer äusserst gefragten Gegend mit hervorragender Anbindung: Flughafen Zürich erreichbar in 10 Fahrminuten Stadt Zürich erreichbar in 12 Fahrminuten • Visibilität: Ihr Unternehmen wird von der Autobahn aus perfekt sichtbar sein, was optimale Werbemöglichkeiten bietet (ca. 500 m2 Fassade für Werbung). • Baumassenziffer: Profitieren Sie von der hohen Baumassenziffer 10.0, die maximale Flexibilität und Nutzungseffizienz ermöglicht. • Näherbaurechte: Die Parzelle verfügt über Näherbaurechte rechts und links. Auf der Rückseite kann ein Näherbaurecht von der Stadt Zürich eingeholt werden • ca. 3'500 m2 Bruttogeschossfläche möglich • Tiefgarage / Untergeschoss bis zu ca. 800 m2 gross realisierbar • Maximale Gesamthöhe 20 m. 7 Stockwerke à 500 m2 Bruttogeschossfläche und 2.85 m Raumhöhe (brutto) möglich • Parzelle: Die ebene Fläche der Parzelle erleichtert die Bauplanung und Ausführung. • Form: Die Parzelle hat eine ideale Form, die vielseitige Bebauungsmöglichkeiten erlaubt. • Autobahnknotenpunkt: Brüttiseller Kreuz, direkt an einem der wichtigsten Autobahnknotenpunkt der Schweiz gelegen, bietet die Parzelle hervorragende Erreichbarkeit und Logistikvorteile • Störendes Gewerbe: Die Lage ist auch für Gewerbe geeignet, das potenziell störend sein kann. • Kulturzentren sowie Hotelbetriebe auch möglich. Jetzt oder nie – Ihre Chance auf ein grossartiges Investment:Solch eine Industrie-Baulandparzelle in dieser Lage kommt äusserst selten auf den Markt – seit geraumer Zeit gab es in dieser gefragten Gegend kein vergleichbares Angebot. Sichern Sie sich jetzt dieses einmalige Grundstück, ideal für visionäre Unternehmer und Investoren, die auf einen strategisch optimalen Standort setzen.Haben wir Ihr Interesse geweckt? Dann nehmen Sie noch heute Kontakt mit uns auf. Gerne lassen wir Ihnen das detaillierte Verkaufsdossier inklusive Machbarkeitsstudie zukommen – exklusiv und unverbindlich.  Wegzeit Neu -](https://www.homegate.ch/kaufen/4002331523) -SCHNITTSTELLEN AUFLÖSEN. STRATEGIE VERBINDEN +[1](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste)[2](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=2)[...4](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=4)[](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=2) -Abgleich Ihrer Digital- und Businessstrategie – für nachhaltige Wirkung. +Suche speichern Karte -Strategische Klarheit gewinnen +Vorschläge basierend auf deinen Suchresultaten +---------------------------------------------- -### CIO/CDO ad interim einsetzen +1. [Startseite](https://www.homegate.ch/de) +2. [Kaufen](https://www.homegate.ch/kaufen/immobilie-suchen) +3. [Bauland zum Kaufen](https://www.homegate.ch/kaufen/bauland/trefferliste) +4. [Schweiz](https://www.homegate.ch/kaufen/bauland/land-schweiz/trefferliste) -FÜHRUNG SICHERN. KOMPETENZ EINBRINGEN +Bezirke im Kanton Kanton Zürich -Temporäre Führungsstärke, wenn Verantwortung gebraucht wird. +[Bauland kaufen Bezirk Affoltern](https://www.homegate.ch/kaufen/bauland/region-affoltern/trefferliste)|[Bauland kaufen Bezirk Andelfingen](https://www.homegate.ch/kaufen/bauland/region-andelfingen/trefferliste)|[Bauland kaufen Bezirk Bülach](https://www.homegate.ch/kaufen/bauland/region-buelach/trefferliste)|[Bauland kaufen Bezirk Dielsdorf](https://www.homegate.ch/kaufen/bauland/region-dielsdorf/trefferliste)|[Bauland kaufen Bezirk Hinwil](https://www.homegate.ch/kaufen/bauland/region-hinwil/trefferliste)|[Bauland kaufen Bezirk Horgen](https://www.homegate.ch/kaufen/bauland/region-horgen/trefferliste)|[Bauland kaufen Bezirk Meilen](https://www.homegate.ch/kaufen/bauland/region-meilen/trefferliste)|[Bauland kaufen Bezirk Pfäffikon](https://www.homegate.ch/kaufen/bauland/region-pfaeffikon/trefferliste)|[Bauland kaufen Bezirk Uster](https://www.homegate.ch/kaufen/bauland/region-uster/trefferliste)|[Bauland kaufen Bezirk Winterthur](https://www.homegate.ch/kaufen/bauland/region-winterthur/trefferliste)|[Bauland kaufen Bezirk Dietikon](https://www.homegate.ch/kaufen/bauland/region-dietikon/trefferliste)|[Bauland kaufen Zürich](https://www.homegate.ch/kaufen/bauland/ort-zuerich/trefferliste) -Sofort einsatzbereit & erfahrungssicher +Weitere Immobiliensuchen in Kanton Zürich -### Bereit für den ersten Schritt? +[Immobilien mieten Kanton Zürich](https://www.homegate.ch/mieten/immobilien/kanton-zuerich/trefferliste)|[Wohnung mieten Kanton Zürich](https://www.homegate.ch/mieten/wohnung/kanton-zuerich/trefferliste)|[Haus mieten Kanton Zürich](https://www.homegate.ch/mieten/haus/kanton-zuerich/trefferliste)|[Möbliertes Wohnobjekt mieten Kanton Zürich](https://www.homegate.ch/mieten/moebliertes-wohnobjekt/kanton-zuerich/trefferliste)|[Parkplatz, Garage mieten Kanton Zürich](https://www.homegate.ch/mieten/parkplatz-garage/kanton-zuerich/trefferliste)|[Büro mieten Kanton Zürich](https://www.homegate.ch/mieten/buero/kanton-zuerich/trefferliste)|[Gewerbe mieten Kanton Zürich](https://www.homegate.ch/mieten/gewerbeobjekt/kanton-zuerich/trefferliste)|[Neubau zum Mieten Kanton Zürich](https://www.homegate.ch/mieten/immobilien/kanton-zuerich/trefferliste?an=G)|[Wohnung kaufen Kanton Zürich](https://www.homegate.ch/kaufen/wohnung/kanton-zuerich/trefferliste)|[Haus kaufen Kanton Zürich](https://www.homegate.ch/kaufen/haus/kanton-zuerich/trefferliste)|[Immobilien kaufen Kanton Zürich](https://www.homegate.ch/kaufen/immobilien/kanton-zuerich/trefferliste)|[Mehrfamilienhaus kaufen Kanton Zürich](https://www.homegate.ch/kaufen/mehrfamilienhaus/kanton-zuerich/trefferliste)|[Parkplatz, Garage kaufen Kanton Zürich](https://www.homegate.ch/kaufen/parkplatz-garage/kanton-zuerich/trefferliste)|[Gewerbe, Büro, Lager kaufen Kanton Zürich](https://www.homegate.ch/kaufen/gewerbeobjekt/kanton-zuerich/trefferliste)|[Neubau zum Kaufen Kanton Zürich](https://www.homegate.ch/kaufen/immobilien/kanton-zuerich/trefferliste?an=G) -Ob Strategie, Analyse oder Interim – wir zeigen Ihnen den passenden Einstieg. +### Homegate -Kostenfrei Strategiegespräch vereinbaren +* [Über uns](https://swissmarketplace.group/de/portfolio/real-estate/) +* [Kontakt & Hilfe](https://www.homegate.ch/c/de/ueber-uns/kontakt) +* [Geschäftskunde werden](https://swissmarketplace.group/real-estate/de/kunde-werden/) +* [Newsletter abonnieren](https://www.homegate.ch/c/de/ueber-uns/newsletter-anmeldung) +* [Medien](https://swissmarketplace.group/de/media/) +* [Karriere](https://swissmarketplace.group/de/karriere/) +* [Ombudsstelle](https://konsum.ch/de/ombudsstelle-immobilienplattformen/) +* [Werbung auf Homegate](https://swissmarketplace.group/de/werbung/) +* [Sitemap](https://www.homegate.ch/c/de/ueber-uns/sitemap) -ValueOn +### Immobilien -Made in Switzerland | DSGVO-konform +* [Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen) +* [Mieten](https://www.homegate.ch/mieten/immobilie-suchen) +* [Kaufen](https://www.homegate.ch/kaufen/immobilie-suchen) +* [Vermieten](https://www.homegate.ch/c/de/inserieren/immobilien/wohnung/vermieten) +* [Verkaufen](https://www.homegate.ch/c/de/ratgeber/inserieren/immobilien-verkaufen) +* [Finanzieren](https://www.homegate.ch/c/de/hypotheken) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Kategorien](https://www.homegate.ch/kategorien-de) -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) +### Rechtliches -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) +* [Datenschutz](https://privacy.swissmarketplace.group/de/) +* [Leistungsbeschrieb](https://www.homegate.ch/c/de/ueber-uns/rechtliches/leistungsbeschrieb) +* [Sicherheitstipps](https://www.homegate.ch/c/de/ratgeber/news/vorsicht-betrug-mit-gefaelschten-inseraten) +* [Impressum](https://www.homegate.ch/c/de/ueber-uns/rechtliches) +* [AGB](https://www.homegate.ch/c/de/ueber-uns/rechtliches/agb) +* [Sicherheitsproblem melden](https://swissmarketplace.group/de/vulnerability-disclosure-program) +* Privatsphäre-Einstellungen + +### Services + +* [Suchabo anlegen](https://www.homegate.ch/c/de/ratgeber/mieten/wohnung-finden/suchabo) +* [Finanzierungsrechner](https://www.homegate.ch/de/finanzieren/hypothekenrechner) +* [Steuerrechner](https://www.homegate.ch/c/de/ratgeber/umziehen/umzugstipps/steuerrechner) +* [Betreibungsauszug](https://www.homegate.ch/de/betreibungsauszug) +* [Gemeinderatgeber](https://www.homegate.ch/c/de/ratgeber/umziehen/gemeinderatgeber) +* [Mietkaution](https://www.homegate.ch/c/de/ratgeber/umziehen/mietzinskaution) +* [Umzugshilfe](https://www.homegate.ch/c/de/umziehen) +* [Wohneigentum schätzen](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/wohneigentum-schaetzen/online-schaetzung/jetzt-wohneigentum-bewerten) +* [Agenturverzeichnis](https://www.homegate.ch/agenturverzeichnis) + +### App herunterladen + +[](https://itunes.apple.com/de/app/homegate.ch/id326131004 "iOS App")[](https://play.google.com/store/apps/details?id=ch.homegate.mobile&hl=de "Android App") + +* [Deutsch](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste) +* [Français](https://www.homegate.ch/acheter/terrain/canton-zurich/liste-annonces) +* [Italiano](https://www.homegate.ch/acquistare/terreno/cantone-zurigo/lista-annunci) +* [English](https://www.homegate.ch/buy/plot/canton-zurich/matching-list) + +### Social Media + +[](https://www.facebook.com/homegate.ch "Facebook")[](https://www.youtube.com/user/homegateeng "YouTube")[](https://ch.linkedin.com/company/homegate-ch-ag "LinkedIn")[](https://twitter.com/homegate_Deu "Twitter") + +[SMG Swiss Marketplace Group](https://swissmarketplace.group/)[ImmoScout24](https://www.immoscout24.ch/de)[Alle Immobilien](https://www.alle-immobilien.ch/)[home.ch](https://www.home.ch/)[immostreet.ch](https://www.immostreet.ch/) + +© Copyright 2025 by SMG Swiss Marketplace Group AG. Alle Rechte vorbehalten.Die Vervielfältigung und Übernahme von Inseraten durch Dritte, insbesondere von Fotos und persönlichen Daten in diesen Inseraten, verletzt die damit verbundenen Rechte und ist ausdrücklich verboten. - -=== https://www.valueon.ch/projects === -ValueOn - Mehrwert dank digitaler Transformation +=== https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck === +Grundstück kaufen im Kanton Zürich - 75 Angebote im Oktober 2025 =============== -[](https://www.valueon.ch/) +[](https://realadvisor.ch/de/immobilien-kaufen) -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) +Max. 1 Tag -🇩🇪DE +Kanton Zürich -[Gespräch vereinbaren](https://www.valueon.ch/contact) + -🇩🇪DE +Bewerten -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) +[Kaufen](https://realadvisor.ch/de/immobilien-kaufen)[Mieten](https://realadvisor.ch/de/immobilien-mieten) -Unsere Erfolgsprojekte -====================== +Anmelden -Entdecken Sie, wie wir Unternehmen dabei helfen, ihre digitale Transformation erfolgreich umzusetzen und nachhaltige Werte zu schaffen. +DE -50+ +[Italiano](https://realadvisor.ch/it/comprare/canton-zurigo/trama)[Français](https://realadvisor.ch/fr/acheter/canton-zurich/terrain)[English](https://realadvisor.ch/en/buy/canton-zurich/plot) -Erfolgreiche Projekte +Suchabo erstellen -100% +Max. 1 Tag -Kundenzufriedenheit +Kanton Zürich -25% + -Ø Kostenoptimierung +Kaufen Mieten -60% +Kaufen Mieten -schneller Integriert +Grundstück -Referenzprojekte & Success Stories +Preis + +Suche ändern + +Grundstücksfläche + +Andere Filter + +Suchabo erstellen + +- [x] Karte + +←Move left +→Move right +↑Move up +↓Move down ++Zoom in +-Zoom out +Home Jump left by 75% +End Jump right by 75% +Page Up Jump up by 75% +Page Down Jump down by 75% + + + + + + + + + + + + + + + + + + + + + + + + + +9 + +9 + +5 + +5 + +3 + +3 + +6 + +6 + +17 + +17 + +7 + +7 + +4 + +4 + +2 + +2 + +2 + +2 + +14 + +14 + +5 + +5 + +1 + +1 + + + +Map +* Map +* Satellite +* Terrain +* Labels + + + + + +*  +*  +*  +*  +*  +*  + +[](https://maps.google.com/maps?ll=47.421441,8.671322&z=9&t=m&hl=en-US&gl=US&mapclient=apiv3 "Open this area in Google Maps (opens a new window)") + +Keyboard shortcuts + +Map Data Map data ©2025 GeoBasis-DE/BKG (©2009), Google + +Map data ©2025 GeoBasis-DE/BKG (©2009), Google + +10 km + +Click to toggle between metric and imperial units + +[Terms](https://www.google.com/intl/en-US_US/help/terms_maps.html) + +[Report a map error](https://www.google.com/maps/@47.421441,8.6713222,9z/data=!10m1!1e1!12b1?source=apiv3&rapsrc=apiv3 "Report errors in the road map or imagery to Google") + +1. [](https://realadvisor.ch/de) + +3. [Kaufen](https://realadvisor.ch/de/kaufen) + +5. [Grundstück](https://realadvisor.ch/de/kaufen/grundstuck) + +7. Kanton Zürich + +Grundstücke kaufen im Kanton Zürich +=================================== + +75 Ergebnisse + +Unseren Empfehlungen + +[](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ) + +vor 3 Tagen + +- [x] + +[get living 1’452 m² Grundstück • Bauland 8162 Steinmaur * Flaches, bebaubares Grundstück * Ruhige, sonnige Lage * Ausgezeichnete ÖV-Anbindung ------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2) + +vor 6 Tagen + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 1’070 m² Grundstück • Bauland 8340 Hinwil * Über 1.070 m² Fläche * Flexible Teilungsoptionen * Ideal für Familienhäuser ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 1’070’000.- CHF 1’000 / m²](https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8633-wolfhausen-YB6N-VRVP) + +vor 6 Tagen + +- [x] + +[PREMIUM HOMES AG 1’940 m² Grundstück • Bauland 8633 Wolfhausen * Grosszügige 1'940m² Parzelle * Familienfreundliche Lage * Flexible Gestaltungsmöglichkeiten --------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 4’074’000.- CHF 2’100 / m²](https://realadvisor.ch/de/kaufen/grundstuck/8633-wolfhausen-YB6N-VRVP) + +[](https://realadvisor.ch/de/kaufen/grundstuck/sonnhalde-8602-wangen-b.-dubendorf-83JW-X5X3) + +vor 9 Tagen + +- [x] + +[Moser Anlageimmobilien AG 1’666 m² Grundstück • Bauland Sonnhalde, 8602 Wangen b. Dübendorf * 1666 m² Bauland in bester Lage * Optimale Besonnung garantiert * Privatsphäre in ruhiger Umgebung -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3’300’000.- CHF 1’981 / m²](https://realadvisor.ch/de/kaufen/grundstuck/sonnhalde-8602-wangen-b.-dubendorf-83JW-X5X3) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8000-zurich-NAG4-JV4R) + +vor 11 Tagen + +- [x] + +[Centrum Immo Bauland 8000 Zürich * Ideal für Entwicklung * Nahe öffentlicher Verkehr * Malersiche Ausblicke auf die Stadt ---------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/8000-zurich-NAG4-JV4R) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8195-wasterkingen-7JPL-7X5M) + +vor 13 Tagen + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 650 m² Grundstück • Bauland 8195 Wasterkingen * Voll erschlossenes Grundstück * Ruhige ländliche Gemeinde * Flexible Gestaltungsmöglichkeiten ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 475’000.- CHF 731 / m²](https://realadvisor.ch/de/kaufen/grundstuck/8195-wasterkingen-7JPL-7X5M) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8618-oetwil-am-see-8OOG-PWB5) + +vor 21 Tagen + +- [x] + +[Swiss Residence Group AG 1’622 m² Grundstück • Bauland 8618 Oetwil am See * Sonniges Grundstück von 1'622 m² * Flexibles Bauen möglich * Unverbaubare Bergsicht ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/8618-oetwil-am-see-8OOG-PWB5) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8617-monchaltorf-KRNG-WO9R) + +vor 22 Tagen + +- [x] + +[PREMIUM HOMES AG 850 m² Grundstück • Bauland 8617 Mönchaltorf * Hohes Entwicklungspotenzial * Ruhige, sonnige Lage * Flexible Nutzungsmöglichkeiten ------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/8617-monchaltorf-KRNG-WO9R) + +[](https://realadvisor.ch/de/kaufen/grundstuck/gueterstalstrasse-8133-esslingen-YMXG-R3MR) + +vor 26 Tagen + +- [x] + +[Schiblis Immobilien GmbH 507 m² Grundstück • Bauland Güeterstalstrasse, 8133 Esslingen * Zentrale Lage in Esslingen * Keine Architekturverpflichtung * Keine Altlasten vorhanden ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 600’000.- CHF 1’183 / m²](https://realadvisor.ch/de/kaufen/grundstuck/gueterstalstrasse-8133-esslingen-YMXG-R3MR) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8192-zweidlen-6ZMD-4WE3) + +vor 28 Tagen + +- [x] + +[Grundeigentümer Verband Schweiz 1’226 m² Grundstück • Bauland 8192 Zweidlen * Gesamtfläche von 1'226 m² * Max. nutzbare Fläche 940 m² * Flexible Entwicklungsmöglichkeiten ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2’450’000.- CHF 1’998 / m²](https://realadvisor.ch/de/kaufen/grundstuck/8192-zweidlen-6ZMD-4WE3) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8424-embrach-8WRG-NEGR) + +vor 29 Tagen + +- [x] + +[PREMIUM HOMES AG 1’670 m² Grundstück • Bauland 8424 Embrach * Familienfreundliche Lage * Viel Sonnenlicht den ganzen Tag * Flexible Nutzungsmöglichkeiten ------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/8424-embrach-8WRG-NEGR) + +[](https://realadvisor.ch/de/kaufen/grundstuck/10-berghalde-8332-russikon-6ZMD-432O) + +vor 29 Tagen + +- [x] + +[SH Immo GmbH 854 m² Grundstück • Bauland Berghalde 10, 8332 Russikon * Geräumiges Grundstück von 854 m2 * Ideale sonnige Hanglage * Potenzial für Neubau ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’500’000.- CHF 1’756 / m²](https://realadvisor.ch/de/kaufen/grundstuck/10-berghalde-8332-russikon-6ZMD-432O) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8134-adliswil-Y7J5-W36M) + +vor 1 Monat + +- [x] + +[Moos & Partner Immobilien GmbH 694 m² Grundstück • Bauland 8134 Adliswil * Zentrale Lage mit Potenzial * Hohe Ausnutzung in W3 * Ideal für Investoren & Entwickler --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3’600’000.- CHF 5’187 / m²](https://realadvisor.ch/de/kaufen/grundstuck/8134-adliswil-Y7J5-W36M) + +[](https://realadvisor.ch/de/kaufen/grundstuck/23-uberlandstrasse-8340-hinwil-YB69-VB7M) + +vor 2 Monaten + +- [x] + +[RE/MAX Immobilien in Rapperswil-Jona 4’246 m² Grundstück • Bauland Überlandstrasse 23, 8340 Hinwil * Top Lage an Hauptstrassen * Grosse Fläche für Entwicklung * Flexible Gebäudehöhen möglich ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/23-uberlandstrasse-8340-hinwil-YB69-VB7M) + +[](https://realadvisor.ch/de/kaufen/grundstuck/20-winzerstrasse-8353-elgg-KRNL-ZPNR) + +vor 2 Monaten + +- [x] + +[RE/MAX Immobilien in Winterthur 877 m² Grundstück • Bauland Winzerstrasse 20, 8353 Elgg * Ideal für Familienhäuser * Investitionsmöglichkeit * Angrenzend an bestehendes Haus -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’140’000.- CHF 1’300 / m²](https://realadvisor.ch/de/kaufen/grundstuck/20-winzerstrasse-8353-elgg-KRNL-ZPNR) + +[](https://realadvisor.ch/de/kaufen/grundstuck/34-industriestrasse-8117-fallanden-YJDX-JXRR) + +vor 3 Monaten + +- [x] + +[RE/MAX Immobilien in Meilen 2’838 m² • 1’706 m² Grundstück • Bauland Industriestrasse 34, 8117 Fällanden * Genehmigtes Gewerbeprojekt * Flexible gewerbliche Nutzung * 37 Parkplätze verfügbar ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/34-industriestrasse-8117-fallanden-YJDX-JXRR) + +[](https://realadvisor.ch/de/kaufen/grundstuck/8630-ruti-zh-84E9-Z65G) + +vor 4 Monaten + +- [x] + +[PREMIUM HOMES AG 3’460 m² Grundstück • Bauland 8630 Rüti ZH * Ruhige Wohnzone * Ausnützungsziffer 30% * Bonus für zusätzlichen Raum -------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/8630-ruti-zh-84E9-Z65G) + +[](https://realadvisor.ch/de/kaufen/grundstuck/13-staldernstrasse-8158-regensberg-YJDX-XWMO) + +vor 16 Tagen + +- [x] + +[Swisslife 2’557 m² Grundstück • Bauland Staldernstrasse 13, 8158 Regensberg * Flexibles Zonen für Mischnutzung * Hohe Mietrendite möglich * Ruhige Lage nahe Zürich ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 5’500’000.- CHF 2’151 / m² dreamo.ch](https://realadvisor.ch/de/kaufen/grundstuck/13-staldernstrasse-8158-regensberg-YJDX-XWMO) + +[](https://realadvisor.ch/de/kaufen/grundstuck/leisibuel-8484-weisslingen-8OO2-753X) + +vor 2 Monaten + +- [x] + +[Orgnet Immobilien AG 844 m² Grundstück • Bauland Leisibüel, 8484 Weisslingen * Atemberaubender Bergblick * Südwestliche Sonnenlage * Ruhige, private Nachbarschaft --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’300’000.- CHF 1’540 / m² dreamo.ch](https://realadvisor.ch/de/kaufen/grundstuck/leisibuel-8484-weisslingen-8OO2-753X) + +[](https://realadvisor.ch/de/kaufen/grundstuck/85-weiacherstrasse-8427-rorbas-YJD9-MVWW) + +vor 3 Monaten + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 2’295 m² Grundstück • Bauland Weiacherstrasse 85, 8427 Rorbas * Geräumiges Grundstück von 2'295 m2 * Gebäude mit gemischter Nutzung * Bestehende Mietverhältnisse ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3’440’000.- CHF 1’499 / m² dreamo.ch](https://realadvisor.ch/de/kaufen/grundstuck/85-weiacherstrasse-8427-rorbas-YJD9-MVWW) + +[](https://realadvisor.ch/de/kaufen/grundstuck/7a-bergstrasse-8155-nassenwil-YB69-GEB6) + +vor 3 Monaten + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 1’742 m² Grundstück • Bauland Bergstrasse 7a, 8155 Nassenwil * Geräumige Grundstücksfläche * Ruhige, malerische Lage * Nahe Dielsdorf --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2’700’000.- CHF 1’550 / m² dreamo.ch](https://realadvisor.ch/de/kaufen/grundstuck/7a-bergstrasse-8155-nassenwil-YB69-GEB6) + +[](https://realadvisor.ch/de/kaufen/grundstuck/gotze-8197-rafz-Y6ZW-VB6G) + +vor 3 Monaten + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 1’340 m² • 1’340 m² Grundstück • Bauland Götze, 8197 Rafz * Unverbaute Aussichten * Ideal für Entwicklung * Bevorzugte Lage ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2’200’000.- CHF 1’642 / m² dreamo.ch](https://realadvisor.ch/de/kaufen/grundstuck/gotze-8197-rafz-Y6ZW-VB6G) + +[](https://realadvisor.ch/de/kaufen/grundstuck/226b-schaffhauserstrasse-8057-zurich-KRNL-A6J7) + +vor 3 Monaten + +- [x] + +[VZ VermögensZentrum 4.5 Zi. • 114 m² • 480 m² Grundstück • Bauland Schaffhauserstrasse 226b, 8057 Zürich * Grosszügiger Umschwung * Grüner Ausblick von Fenstern * Gemütlicher Schwedenofen ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2’999’000.- CHF 26’307 / m² dreamo.ch](https://realadvisor.ch/de/kaufen/grundstuck/226b-schaffhauserstrasse-8057-zurich-KRNL-A6J7) + +[](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck#) + +vor 7 Stunden + +- [x] + +[— 829 m² Grundstück • Bauland Haldenstrasse 10, 8134 Adliswil * Ruhige Lage mit Aussicht * Nah am öffentlichen Verkehr * Sofort verfügbar -------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3’300’000.- CHF 3’981 / m² homegate.ch](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck#) + +[1](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck) + +[2](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck/seite-2) + +[3](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck/seite-3) + +[4](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck/seite-4) + +[](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck/seite-2) + +1-24 von 75 Ergebnisse + +Grundstück kaufen im Kanton Zürich ---------------------------------- -Jedes Projekt ist einzigartig. Entdecken Sie, wie wir mit massgeschneiderten Lösungen echte Mehrwerte für unsere Kunden schaffen. +[Immobilienpreise in Kanton Zürich](https://realadvisor.ch/de/immobilienpreise-pro-m2/kanton-zurich) - +### Grundstück kaufen im Kanton Zürich -Digitale Transformation +[Grundstück kaufen in Zürich](https://realadvisor.ch/de/kaufen/stadt-zurich/grundstuck)[Grundstück kaufen in Winterthur](https://realadvisor.ch/de/kaufen/stadt-winterthur/grundstuck)[Grundstück kaufen in Uster](https://realadvisor.ch/de/kaufen/stadt-uster/grundstuck)[Grundstück kaufen in Dübendorf](https://realadvisor.ch/de/kaufen/stadt-dubendorf/grundstuck)[Grundstück kaufen in Dietikon (8953)](https://realadvisor.ch/de/kaufen/8953-dietikon/grundstuck)[Grundstück kaufen in Wädenswil](https://realadvisor.ch/de/kaufen/stadt-wadenswil/grundstuck)[Grundstück kaufen in Wetzikon (ZH)](https://realadvisor.ch/de/kaufen/stadt-wetzikon-zh/grundstuck)[Grundstück kaufen in Horgen](https://realadvisor.ch/de/kaufen/stadt-horgen/grundstuck)[Grundstück kaufen in Opfikon](https://realadvisor.ch/de/kaufen/stadt-opfikon/grundstuck)[Grundstück kaufen in Bülach (8180)](https://realadvisor.ch/de/kaufen/8180-bulach/grundstuck)[Grundstück kaufen in Kloten (8302)](https://realadvisor.ch/de/kaufen/8302-kloten/grundstuck)[Grundstück kaufen in Adliswil (8134)](https://realadvisor.ch/de/kaufen/8134-adliswil/grundstuck)[Grundstück kaufen in Schlieren (8952)](https://realadvisor.ch/de/kaufen/8952-schlieren/grundstuck)[Grundstück kaufen in Volketswil](https://realadvisor.ch/de/kaufen/stadt-volketswil/grundstuck)[Grundstück kaufen in Regensdorf](https://realadvisor.ch/de/kaufen/stadt-regensdorf/grundstuck)[Grundstück kaufen in Thalwil](https://realadvisor.ch/de/kaufen/stadt-thalwil/grundstuck)[Grundstück kaufen in Illnau-Effretikon](https://realadvisor.ch/de/kaufen/stadt-illnau-effretikon/grundstuck)[Grundstück kaufen in Wallisellen (8304)](https://realadvisor.ch/de/kaufen/8304-wallisellen/grundstuck)[Grundstück kaufen in Stäfa](https://realadvisor.ch/de/kaufen/stadt-stafa/grundstuck)[Grundstück kaufen in Küsnacht (ZH)](https://realadvisor.ch/de/kaufen/stadt-kusnacht-zh/grundstuck)[Grundstück kaufen in Meilen (8706)](https://realadvisor.ch/de/kaufen/8706-meilen/grundstuck)[Grundstück kaufen in Richterswil](https://realadvisor.ch/de/kaufen/stadt-richterswil/grundstuck)[Grundstück kaufen in Zollikon](https://realadvisor.ch/de/kaufen/stadt-zollikon/grundstuck)[Grundstück kaufen in Rüti ZH (8630)](https://realadvisor.ch/de/kaufen/8630-ruti-zh/grundstuck)[Grundstück kaufen in Affoltern am Albis](https://realadvisor.ch/de/kaufen/stadt-affoltern-am-albis/grundstuck)[Grundstück kaufen in Pfäffikon](https://realadvisor.ch/de/kaufen/stadt-pfaffikon/grundstuck)[Grundstück kaufen in Bassersdorf (8303)](https://realadvisor.ch/de/kaufen/8303-bassersdorf/grundstuck)[Grundstück kaufen in Hinwil](https://realadvisor.ch/de/kaufen/stadt-hinwil/grundstuck)[Grundstück kaufen in Männedorf (8708)](https://realadvisor.ch/de/kaufen/8708-mannedorf/grundstuck)[Grundstück kaufen in Maur](https://realadvisor.ch/de/kaufen/stadt-maur/grundstuck)[Grundstück kaufen in Gossau (ZH)](https://realadvisor.ch/de/kaufen/gemeinde-gossau-zh/grundstuck)[Grundstück kaufen in Wald (ZH)](https://realadvisor.ch/de/kaufen/gemeinde-wald-zh/grundstuck)[Grundstück kaufen in Urdorf (8902)](https://realadvisor.ch/de/kaufen/8902-urdorf/grundstuck)[Grundstück kaufen in Embrach (8424)](https://realadvisor.ch/de/kaufen/8424-embrach/grundstuck)[Grundstück kaufen in Niederhasli](https://realadvisor.ch/de/kaufen/gemeinde-niederhasli/grundstuck)[Grundstück kaufen in Hombrechtikon](https://realadvisor.ch/de/kaufen/gemeinde-hombrechtikon/grundstuck)[Grundstück kaufen in Fällanden](https://realadvisor.ch/de/kaufen/gemeinde-fallanden/grundstuck)[Grundstück kaufen in Kilchberg ZH (8802)](https://realadvisor.ch/de/kaufen/8802-kilchberg-zh/grundstuck)[Grundstück kaufen in Egg](https://realadvisor.ch/de/kaufen/gemeinde-egg/grundstuck)[Grundstück kaufen in Rümlang (8153)](https://realadvisor.ch/de/kaufen/8153-rumlang/grundstuck)[Grundstück kaufen in Wangen-Brüttisellen](https://realadvisor.ch/de/kaufen/gemeinde-wangen-bruttisellen/grundstuck)[Grundstück kaufen in Dietlikon (8305)](https://realadvisor.ch/de/kaufen/8305-dietlikon/grundstuck)[Grundstück kaufen in Dürnten](https://realadvisor.ch/de/kaufen/gemeinde-durnten/grundstuck)[Grundstück kaufen in Langnau am Albis (8135)](https://realadvisor.ch/de/kaufen/8135-langnau-am-albis/grundstuck)[Grundstück kaufen in Seuzach (8472)](https://realadvisor.ch/de/kaufen/8472-seuzach/grundstuck)[Grundstück kaufen in Bubikon](https://realadvisor.ch/de/kaufen/gemeinde-bubikon/grundstuck)[Grundstück kaufen in Oberglatt ZH (8154)](https://realadvisor.ch/de/kaufen/8154-oberglatt-zh/grundstuck)[Grundstück kaufen in Oberengstringen (8102)](https://realadvisor.ch/de/kaufen/8102-oberengstringen/grundstuck)[Grundstück kaufen in Fehraltorf (8320)](https://realadvisor.ch/de/kaufen/8320-fehraltorf/grundstuck)[Grundstück kaufen in Birmensdorf ZH (8903)](https://realadvisor.ch/de/kaufen/8903-birmensdorf-zh/grundstuck)[Grundstück kaufen in Wiesendangen](https://realadvisor.ch/de/kaufen/gemeinde-wiesendangen/grundstuck)[Grundstück kaufen in Buchs ZH (8107)](https://realadvisor.ch/de/kaufen/8107-buchs-zh/grundstuck)[Grundstück kaufen in Herrliberg (8704)](https://realadvisor.ch/de/kaufen/8704-herrliberg/grundstuck)[Grundstück kaufen in Uetikon am See (8707)](https://realadvisor.ch/de/kaufen/8707-uetikon-am-see/grundstuck)[Grundstück kaufen in Dielsdorf (8157)](https://realadvisor.ch/de/kaufen/8157-dielsdorf/grundstuck)[Grundstück kaufen in Zell (ZH)](https://realadvisor.ch/de/kaufen/gemeinde-zell-zh/grundstuck)[Grundstück kaufen in Rüschlikon (8803)](https://realadvisor.ch/de/kaufen/8803-ruschlikon/grundstuck)[Grundstück kaufen in Lindau](https://realadvisor.ch/de/kaufen/gemeinde-lindau/grundstuck)[Grundstück kaufen in Nürensdorf (8309)](https://realadvisor.ch/de/kaufen/8309-nurensdorf/grundstuck)[Grundstück kaufen in Erlenbach ZH (8703)](https://realadvisor.ch/de/kaufen/8703-erlenbach-zh/grundstuck)[Grundstück kaufen in Neftenbach](https://realadvisor.ch/de/kaufen/gemeinde-neftenbach/grundstuck)[Grundstück kaufen in Bonstetten (8906)](https://realadvisor.ch/de/kaufen/8906-bonstetten/grundstuck)[Grundstück kaufen in Obfelden (8912)](https://realadvisor.ch/de/kaufen/8912-obfelden/grundstuck)[Grundstück kaufen in Greifensee (8606)](https://realadvisor.ch/de/kaufen/8606-greifensee/grundstuck)[Grundstück kaufen in Glattfelden](https://realadvisor.ch/de/kaufen/gemeinde-glattfelden/grundstuck)[Grundstück kaufen in Eglisau (8193)](https://realadvisor.ch/de/kaufen/8193-eglisau/grundstuck)[Grundstück kaufen in Zumikon (8126)](https://realadvisor.ch/de/kaufen/8126-zumikon/grundstuck)[Grundstück kaufen in Wettswil (8907)](https://realadvisor.ch/de/kaufen/8907-wettswil/grundstuck)[Grundstück kaufen in Schwerzenbach (8603)](https://realadvisor.ch/de/kaufen/8603-schwerzenbach/grundstuck)[Grundstück kaufen in Oberrieden (8942)](https://realadvisor.ch/de/kaufen/8942-oberrieden/grundstuck)[Grundstück kaufen in Bäretswil](https://realadvisor.ch/de/kaufen/gemeinde-baretswil/grundstuck)[Grundstück kaufen in Niederglatt ZH (8172)](https://realadvisor.ch/de/kaufen/8172-niederglatt-zh/grundstuck)[Grundstück kaufen in Geroldswil](https://realadvisor.ch/de/kaufen/gemeinde-geroldswil/grundstuck)[Grundstück kaufen in Bauma](https://realadvisor.ch/de/kaufen/gemeinde-bauma/grundstuck)[Grundstück kaufen in Elgg](https://realadvisor.ch/de/kaufen/gemeinde-elgg/grundstuck)[Grundstück kaufen in Mettmenstetten (8932)](https://realadvisor.ch/de/kaufen/8932-mettmenstetten/grundstuck)[Grundstück kaufen in Weiningen ZH (8104)](https://realadvisor.ch/de/kaufen/8104-weiningen-zh/grundstuck)[Grundstück kaufen in Oetwil am See (8618)](https://realadvisor.ch/de/kaufen/8618-oetwil-am-see/grundstuck)[Grundstück kaufen in Turbenthal](https://realadvisor.ch/de/kaufen/gemeinde-turbenthal/grundstuck)[Grundstück kaufen in Winkel (8185)](https://realadvisor.ch/de/kaufen/8185-winkel/grundstuck)[Grundstück kaufen in Rafz (8197)](https://realadvisor.ch/de/kaufen/8197-rafz/grundstuck)[Grundstück kaufen in Russikon](https://realadvisor.ch/de/kaufen/gemeinde-russikon/grundstuck)[Grundstück kaufen in Uitikon Waldegg (8142)](https://realadvisor.ch/de/kaufen/8142-uitikon-waldegg/grundstuck)[Grundstück kaufen in Dällikon (8108)](https://realadvisor.ch/de/kaufen/8108-dallikon/grundstuck)[Grundstück kaufen in Bachenbülach (8184)](https://realadvisor.ch/de/kaufen/8184-bachenbulach/grundstuck)[Grundstück kaufen in Pfungen (8422)](https://realadvisor.ch/de/kaufen/8422-pfungen/grundstuck)[Grundstück kaufen in Unterengstringen (8103)](https://realadvisor.ch/de/kaufen/8103-unterengstringen/grundstuck)[Grundstück kaufen in Mönchaltorf (8617)](https://realadvisor.ch/de/kaufen/8617-monchaltorf/grundstuck)[Grundstück kaufen in Stallikon](https://realadvisor.ch/de/kaufen/gemeinde-stallikon/grundstuck)[Grundstück kaufen in Hedingen (8908)](https://realadvisor.ch/de/kaufen/8908-hedingen/grundstuck)[Grundstück kaufen in Hausen am Albis](https://realadvisor.ch/de/kaufen/gemeinde-hausen-am-albis/grundstuck)[Grundstück kaufen in Feuerthalen](https://realadvisor.ch/de/kaufen/gemeinde-feuerthalen/grundstuck)[Grundstück kaufen in Hittnau (8335)](https://realadvisor.ch/de/kaufen/8335-hittnau/grundstuck)[Grundstück kaufen in Elsau (8352)](https://realadvisor.ch/de/kaufen/8352-elsau/grundstuck)[Grundstück kaufen in Steinmaur](https://realadvisor.ch/de/kaufen/gemeinde-steinmaur/grundstuck)[Grundstück kaufen in Grüningen (8627)](https://realadvisor.ch/de/kaufen/8627-gruningen/grundstuck)[Grundstück kaufen in Weisslingen](https://realadvisor.ch/de/kaufen/gemeinde-weisslingen/grundstuck)[Grundstück kaufen in Hettlingen (8442)](https://realadvisor.ch/de/kaufen/8442-hettlingen/grundstuck)[Grundstück kaufen in Neerach (8173)](https://realadvisor.ch/de/kaufen/8173-neerach/grundstuck)[Grundstück kaufen in Niederweningen (8166)](https://realadvisor.ch/de/kaufen/8166-niederweningen/grundstuck)[Grundstück kaufen in Otelfingen (8112)](https://realadvisor.ch/de/kaufen/8112-otelfingen/grundstuck)[Grundstück kaufen in Rorbas (8427)](https://realadvisor.ch/de/kaufen/8427-rorbas/grundstuck)[Grundstück kaufen in Stammheim](https://realadvisor.ch/de/kaufen/gemeinde-stammheim/grundstuck)[Grundstück kaufen in Höri (8181)](https://realadvisor.ch/de/kaufen/8181-hori/grundstuck)[Grundstück kaufen in Rickenbach (ZH)](https://realadvisor.ch/de/kaufen/gemeinde-rickenbach-zh/grundstuck)[Grundstück kaufen in Ottenbach (8913)](https://realadvisor.ch/de/kaufen/8913-ottenbach/grundstuck)[Grundstück kaufen in Fischenthal](https://realadvisor.ch/de/kaufen/gemeinde-fischenthal/grundstuck)[Grundstück kaufen in Oetwil an der Limmat (8955)](https://realadvisor.ch/de/kaufen/8955-oetwil-an-der-limmat/grundstuck)[Grundstück kaufen in Lufingen (8426)](https://realadvisor.ch/de/kaufen/8426-lufingen/grundstuck)[Grundstück kaufen in Freienstein-Teufen](https://realadvisor.ch/de/kaufen/gemeinde-freienstein-teufen/grundstuck)[Grundstück kaufen in Knonau (8934)](https://realadvisor.ch/de/kaufen/8934-knonau/grundstuck)[Grundstück kaufen in Stadel](https://realadvisor.ch/de/kaufen/gemeinde-stadel/grundstuck)[Grundstück kaufen in Henggart (8444)](https://realadvisor.ch/de/kaufen/8444-henggart/grundstuck)[Grundstück kaufen in Andelfingen (8450)](https://realadvisor.ch/de/kaufen/8450-andelfingen/grundstuck)[Grundstück kaufen in Kleinandelfingen](https://realadvisor.ch/de/kaufen/gemeinde-kleinandelfingen/grundstuck)[Grundstück kaufen in Brütten (8311)](https://realadvisor.ch/de/kaufen/8311-brutten/grundstuck)[Grundstück kaufen in Wila (8492)](https://realadvisor.ch/de/kaufen/8492-wila/grundstuck)[Grundstück kaufen in Marthalen](https://realadvisor.ch/de/kaufen/gemeinde-marthalen/grundstuck)[Grundstück kaufen in Aeugst am Albis](https://realadvisor.ch/de/kaufen/gemeinde-aeugst-am-albis/grundstuck)[Grundstück kaufen in Dachsen (8447)](https://realadvisor.ch/de/kaufen/8447-dachsen/grundstuck)[Grundstück kaufen in Hochfelden (8182)](https://realadvisor.ch/de/kaufen/8182-hochfelden/grundstuck)[Grundstück kaufen in Dänikon ZH (8114)](https://realadvisor.ch/de/kaufen/8114-danikon-zh/grundstuck)[Grundstück kaufen in Oberweningen (8165)](https://realadvisor.ch/de/kaufen/8165-oberweningen/grundstuck)[Grundstück kaufen in Weiach (8187)](https://realadvisor.ch/de/kaufen/8187-weiach/grundstuck)[Grundstück kaufen in Laufen-Uhwiesen](https://realadvisor.ch/de/kaufen/gemeinde-laufen-uhwiesen/grundstuck)[Grundstück kaufen in Ossingen (8475)](https://realadvisor.ch/de/kaufen/8475-ossingen/grundstuck)[Grundstück kaufen in Dinhard (8474)](https://realadvisor.ch/de/kaufen/8474-dinhard/grundstuck)[Grundstück kaufen in Seegräben](https://realadvisor.ch/de/kaufen/gemeinde-seegraben/grundstuck)[Grundstück kaufen in Flurlingen (8247)](https://realadvisor.ch/de/kaufen/8247-flurlingen/grundstuck)[Grundstück kaufen in Wil ZH (8196)](https://realadvisor.ch/de/kaufen/8196-wil-zh/grundstuck)[Grundstück kaufen in Schöfflisdorf (8165)](https://realadvisor.ch/de/kaufen/8165-schofflisdorf/grundstuck)[Grundstück kaufen in Flaach (8416)](https://realadvisor.ch/de/kaufen/8416-flaach/grundstuck)[Grundstück kaufen in Boppelsen (8113)](https://realadvisor.ch/de/kaufen/8113-boppelsen/grundstuck)[Grundstück kaufen in Aesch ZH (8904)](https://realadvisor.ch/de/kaufen/8904-aesch-zh/grundstuck)[Grundstück kaufen in Rheinau (8462)](https://realadvisor.ch/de/kaufen/8462-rheinau/grundstuck)[Grundstück kaufen in Kappel am Albis](https://realadvisor.ch/de/kaufen/gemeinde-kappel-am-albis/grundstuck)[Grundstück kaufen in Hagenbuch ZH (8523)](https://realadvisor.ch/de/kaufen/8523-hagenbuch-zh/grundstuck)[Grundstück kaufen in Rifferswil (8911)](https://realadvisor.ch/de/kaufen/8911-rifferswil/grundstuck)[Grundstück kaufen in Trüllikon](https://realadvisor.ch/de/kaufen/gemeinde-trullikon/grundstuck)[Grundstück kaufen in Oberembrach (8425)](https://realadvisor.ch/de/kaufen/8425-oberembrach/grundstuck)[Grundstück kaufen in Hüntwangen (8194)](https://realadvisor.ch/de/kaufen/8194-huntwangen/grundstuck)[Grundstück kaufen in Dägerlen](https://realadvisor.ch/de/kaufen/gemeinde-dagerlen/grundstuck)[Grundstück kaufen in Wildberg](https://realadvisor.ch/de/kaufen/gemeinde-wildberg/grundstuck)[Grundstück kaufen in Buch am Irchel (8414)](https://realadvisor.ch/de/kaufen/8414-buch-am-irchel/grundstuck)[Grundstück kaufen in Hüttikon (8115)](https://realadvisor.ch/de/kaufen/8115-huttikon/grundstuck)[Grundstück kaufen in Thalheim an der Thur (8478)](https://realadvisor.ch/de/kaufen/8478-thalheim-an-der-thur/grundstuck)[Grundstück kaufen in Ellikon an der Thur (8548)](https://realadvisor.ch/de/kaufen/8548-ellikon-an-der-thur/grundstuck)[Grundstück kaufen in Benken ZH (8463)](https://realadvisor.ch/de/kaufen/8463-benken-zh/grundstuck)[Grundstück kaufen in Dättlikon (8421)](https://realadvisor.ch/de/kaufen/8421-dattlikon/grundstuck)[Grundstück kaufen in Schleinikon (8165)](https://realadvisor.ch/de/kaufen/8165-schleinikon/grundstuck)[Grundstück kaufen in Schlatt ZH (8418)](https://realadvisor.ch/de/kaufen/8418-schlatt-zh/grundstuck)[Grundstück kaufen in Dorf (8458)](https://realadvisor.ch/de/kaufen/8458-dorf/grundstuck)[Grundstück kaufen in Altikon (8479)](https://realadvisor.ch/de/kaufen/8479-altikon/grundstuck)[Grundstück kaufen in Adlikon b. Andelfingen (8452)](https://realadvisor.ch/de/kaufen/8452-adlikon-b-andelfingen/grundstuck)[Grundstück kaufen in Maschwanden (8933)](https://realadvisor.ch/de/kaufen/8933-maschwanden/grundstuck)[Grundstück kaufen in Bachs (8164)](https://realadvisor.ch/de/kaufen/8164-bachs/grundstuck)[Grundstück kaufen in Wasterkingen (8195)](https://realadvisor.ch/de/kaufen/8195-wasterkingen/grundstuck)[Grundstück kaufen in Berg am Irchel](https://realadvisor.ch/de/kaufen/gemeinde-berg-am-irchel/grundstuck)[Grundstück kaufen in Humlikon (8457)](https://realadvisor.ch/de/kaufen/8457-humlikon/grundstuck)[Grundstück kaufen in Truttikon (8467)](https://realadvisor.ch/de/kaufen/8467-truttikon/grundstuck)[Grundstück kaufen in Regensberg (8158)](https://realadvisor.ch/de/kaufen/8158-regensberg/grundstuck)[Grundstück kaufen in Volken (8459)](https://realadvisor.ch/de/kaufen/8459-volken/grundstuck) -KPT • 18 Monate +Mehr -### Digitale Transformation der KPT +### Andere Immobilienarten im Kanton Zürich -Komplette Modernisierung der IT-Infrastruktur mit 24% Kostenoptimierung und deutlich mehr Leistung, Flexibilität und Sicherheit. +[Haus kaufen im Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich/haus)[Wohnung kaufen im Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich/wohnung)[Mehrfamilienhaus kaufen im Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich/gebaude)[Gewerberaum kaufen im Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich/gewerbe)[Hotel, Restaurant kaufen im Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich/gastfreundschaft) -#### Technologien: +### Beliebte Suchen im Kanton Zürich -Cloud Migration Prozessoptimierung Change Management +[Neubauprojekte im Kanton Zürich](https://realadvisor.ch/de/beliebte-suchen/neubauprojekte-kanton-zurich)[Neubauten kaufen im Kanton Zürich](https://realadvisor.ch/de/beliebte-suchen/neubauten-kaufen-kanton-zurich)[Neubauwohnungen kaufen im Kanton Zürich](https://realadvisor.ch/de/beliebte-suchen/neubauwohnung-kaufen-kanton-zurich) -#### Ergebnisse: +[](https://ch.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) -* 24% Kostenoptimierung -* Erhöhte Flexibilität -* Verbesserte Sicherheit +Verkaufen - +[Immobilienbewertung](https://realadvisor.ch/de/online-immobilienbewertung)[Renditeliegenschaft bewerten](https://realadvisor.ch/de/renditeliegenschaft-bewerten-online)[Immobilienpreise](https://realadvisor.ch/de/immobilienpreise-pro-m2)[Makler finden](https://realadvisor.ch/de/makler-finden)[Immobilien-Glossar](https://realadvisor.ch/de/immobilien-glossar)[Immobilien-Blog](https://realadvisor.ch/de/blog) -Künstliche Intelligenz +Kaufen / Mieten -WWZ • 12 Monate +[Immobilien kaufen](https://realadvisor.ch/de/immobilien-kaufen)[Immobilien mieten](https://realadvisor.ch/de/immobilien-mieten)[Neubauprojekte](https://realadvisor.ch/de/neubauprojekte)[Immobilienfinanzierung](https://realadvisor.ch/de/finanzierung) -### KI-gestützte Prozessoptimierung WWZ +Für Makler -Implementierung einer KI-Lösung zur Automatisierung von Geschäftsprozessen und Entscheidungsfindung. +[Partner werden](https://realadvisor.ch/de/pro)[Blog Pro](https://realadvisor.ch/de/pro/blog) -#### Technologien: +Unternehmen -Machine Learning Process Mining Automation +[Über uns](https://realadvisor.ch/de/uber-uns)[Presseraum](https://realadvisor.ch/de/presseraum)[Offene Stellen](https://realadvisor.welcomekit.co/)[Allgemeine Geschäftsbedingungen](https://realadvisor.ch/de/begriffe)[Datenschutzerklärung](https://realadvisor.ch/de/datenschutzerklarung)[Impressum](https://realadvisor.ch/de/impressum)[Alle Immobilien](https://realadvisor.ch/de/sitemap) -#### Ergebnisse: +© RealAdvisor 2025. All Rights Reserved. v.e89072f -* 40% Zeitersparnis -* Verbesserte Genauigkeit -* Datenbasierte Entscheidungen +[](https://ch.linkedin.com/company/realadvisor)[](https://www.facebook.com/realadvisorcom)[](https://twitter.com/realadvisor)[](https://www.instagram.com/realadvisorcom)[](https://www.youtube.com/channel/UCsEDTDlmxBpyxLXYhWT769Q) - +Karte -IT-Infrastruktur +BESbswy -FC Luzern • 8 Monate -### Businesskritische IT-Infrastruktur FC Luzern - -Aufbau einer hochverfügbaren IT-Infrastruktur für geschäftskritische Anwendungen mit 99.9% Uptime. - -#### Technologien: - -High Availability Disaster Recovery Security - -#### Ergebnisse: - -* 99.9% Verfügbarkeit -* Null Datenverlust -* Compliance erreicht - - - -Cloud Transformation - -TechStart AG • 10 Monate - -### Cloud-First Strategie TechStart AG - -Vollständige Migration zur Cloud mit Fokus auf Skalierbarkeit und Kosteneffizienz. - -#### Technologien: - -AWS Kubernetes DevOps - -#### Ergebnisse: - -* 60% Kosteneinsparung -* Bessere Skalierbarkeit -* Schnellere Deployments - - - -Change Management - -InnovaCorp • 15 Monate - -### Agile Transformation InnovaCorp - -Einführung agiler Arbeitsweisen und Kulturwandel für verbesserte Projekteffizienz. - -#### Technologien: - -Scrum Kanban Team Coaching - -#### Ergebnisse: - -* 50% kürzere Time-to-Market -* Höhere Mitarbeiterzufriedenheit -* Verbesserte Qualität - - - -Strategieberatung - -Swiss Enterprise • 24 Monate - -### Digital Excellence Program - -Entwicklung einer umfassenden Digitalisierungsstrategie für nachhaltiges Wachstum. - -#### Technologien: - -Strategy Design Digital Roadmap KPI Framework - -#### Ergebnisse: - -* 30% Umsatzsteigerung -* Neue Geschäftsmodelle -* Marktführerschaft - - - -Digitale Transformation - -Filtex Textil • 14 Monate - -### Digital Transformation der Filtex Textil - -Komplette Analyse und Erneuerung der gesamten IT-/Datenarchitektur mit massiven Kostenreduktion, 100% Sales Flexibilität und Sicherheit. - -#### Technologien: - -Cloud Migration Prozessoptimierung KPI-Dashboard Security - -#### Ergebnisse: - -* 99.9% Verfügbarkeit -* Maximale Kundenorientierung -* Zeit- und Ressourcenersparnis -* Planungssicherheit - - - -Digitale Transformation - -Häny Pumpen • 16 Monate - -### Digital Transformation der Häny Pumpen - -Analyse und Erneuerung der gesamten IT-/Datenarchitektur mit Kostenreduktion, Sales Flexibilität, ERP-Standardisierung und Sicherheit. - -#### Technologien: - -Cloud Migration Prozessoptimierung ERP-Technologie KPI-Dashboard Security - -#### Ergebnisse: - -* Komplette ERP-Systemmigration -* Maximale Kundenorientierung -* Risikominimierung -* Zeit- und Ressourcenersparnis -* Verbesserte Sicherheit - - - -Digitale Transformation - -Swiss Ice Hockey Federation • 20 Monate - -### Digital Transformation der Swiss Ice Hockey Federation - -Analyse und Erneuerung der gesamten IT-/Datenarchitektur, Kostenreduktion, Prozesslandschafts- und Kollaborationsplattform, ERP- und Datensicherheit. - -#### Technologien: - -Cloud Migration Prozessoptimierung ERP-Technologie Security - -#### Ergebnisse: - -* Komplette ERP-Systemmigration -* Anspruchsgruppen-Fokus -* Risikominimierung -* Zeit- und Ressourcenersparnis -* Verbesserte Sicherheit - - - -Strategieberatung - -Swiss Olympic • 12 Monate - -### Digitalisierungsstrategie für Swiss Olympic - -Analyse der gesamten IT-/Datenarchitektur, Prozesslandschafts- und Kollaborationsplattform, ERP- und Datensicherheit. - -#### Technologien: - -ERP-Technologie Security Kollaborations-Technologie - -#### Ergebnisse: - -* Komplette Roadmap mit Handlungsfeldern -* Anspruchsgruppen-Fokus -* Risiko-Management -* Vorbereitung Aufbau PPM -* Zeit- und Ressourcenersparnis -* Verbesserte Sicherheit - - - -Künstliche Intelligenz - -LayerFinance • 18 Monate - -### KI-Transformation für LayerFinance - -Analyse der gesamten Datenarchitektur, Prozesslandschaft, Datensicherheit, KI-Anwendungen. - -#### Technologien: - -KI-Technologie Deal-closing AI-Plattform - -#### Ergebnisse: - -* Continuation in Enabling KI based Deal Closing Plattform -* Zeit- und Ressourcenersparnis -* Verbesserte Sicherheit - - - -Strategieberatung - -Steuerverwaltung Bern • 7 Monate - -### Technologiewechsel-Programm Steuerverwaltung Bern - -Umfassende Analyse des Technologiewechsel-Programms zur Identifikation kritischer Erfolgsfaktoren und zur Definition konkreter Massnahmen für den Abschluss. Erstellung einer integrierten Gesamtplanung mit Abhängigkeitsmanagement sowie Etablierung eines konsistenten Change- und Risikomanagements. - -#### Technologien: - -Prozessoptimierung Strategy Design Roadmap Management - -#### Ergebnisse: - -* Einheitliche, steuerbare Prozesse -* Vollständige Transparenz über Programmverlauf -* Hohe Planungs- und Umsetzungssicherheit -* Frühzeitige Risikokontrolle und Eskalationsfähigkeit -* Stärkung der Steuerungsfähigkeit auf Gesamtprogrammebene - - - -Digitale Transformation - -Schadenservice Schweiz • 24 Monate - -### Von der Analyse zur Umsetzung – ERP-Projekt Schadenservice Schweiz - -Begleitung eines ERP-Erneuerungsprojekts von der initialen Bedarfsanalyse über die Evaluation bis zur vollständigen Umsetzung. Nach dem Entscheid zur Eigenentwicklung übernahm ein externer Anbieter die technische Realisierung, während wir die Kundenseite als unabhängige Vertretung begleiteten. - -#### Technologien: - -Bedarfsanalyse Evaluation & Auswahlprozess Projektleitung auf Kundenseite Change Management - -#### Ergebnisse: - -* Massgeschneiderte ERP-Lösung auf Basis individueller Anforderungen -* Strukturierte Zusammenarbeit zwischen Entwicklung, Fachbereichen und Betrieb -* Einführung standardisierter Prozesse und digitaler Abläufe -* Hohe Akzeptanz bei den Nutzerinnen und Nutzern -* Erfolgreiche Verankerung der neuen Lösung im Tagesgeschäft - - - -Strategieberatung - -Sunrise TDC Switzerland AG • 3 Monate - -### PMO-Aufbau Sunrise TDC Switzerland AG - -Aufbau eines voll funktionsfähigen Project Management Office (PMO) für Customer Care und Effizienzsteigerung der PMIO-Organisation innerhalb von 3 Monaten. - -#### Technologien: - -Situationsanalyse PMO-Strukturierung Change Management Prozessoptimierung - -#### Ergebnisse: - -* Funnel- und Steuerungsausschussstrukturen etabliert -* Bewertungskriterien für Priorisierung definiert -* Standardisierter Funnel- und Steuerungsbericht -* Konstruktiver und offener Management Buy-in -* Termingerechte PMO-Kompetenz realisiert - -> "Das PMO-Setup war ein voller Erfolg. Termingerecht und mit konstruktivem Management Buy-in haben wir ein funktionsfähiges System etabliert." - -— Dr. Marc Furrer, CEO Sunrise TDC Switzerland AG - -Previous slide Next slide - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) - - - -=== https://www.valueon.ch/vernissage === -ValueOn - Mehrwert dank digitaler Transformation +=== https://www.immoyou.ch/grundstuck-kaufen-kanton-zurich === +🌳 56 Grundstücke kaufen im Kanton Zürich | ImmoYou =============== -[](https://www.valueon.ch/) +[ImmoYou](https://www.immoyou.ch/) -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) +Kaufen -🇩🇪DE +[Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) -[Gespräch vereinbaren](https://www.valueon.ch/contact) +Mieten -🇩🇪DE +[Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) + Ändern Sie die Suche -Beyond AI -========= +[](https://www.immoyou.ch/)[Kaufen](https://www.immoyou.ch/kaufen-schweiz)[Grundstücke](https://www.immoyou.ch/grundstuck-kaufen-schweiz)[Kanton Zürich](https://www.immoyou.ch/grundstuck-kaufen-kanton-zurich) -Wo KI auf Führung trifft +Grundstück kaufen im Kanton Zürich +================================== + +Ort + + Schweiz + + Zürich + + Genf + + Typ + +- [x] Haus + +- [x] Wohnung + +- [x] Zimmer + +- [x] Parkplatz + +- [x] Büro & Gewerbe + +- [x] Wohnhaus + +- [x] Grundstück + + Verkaufspreis + + - + + Zimmer + + - + + Wohnfläche (m²) + + - + + Grundstücksfläche (m²) + + - + + Ausstattung & Eigenschaften + +- [x] Neubauprojekte + +- [x] Balkon + +- [x] Garten + +- [x] Parkplatz + +- [x] Lift + +- [x] Freie Aussicht + +- [x] Cheminée + +- [x] Garage + +- [x] Kinderfreundlich + +- [x] Rollstuhlgängig + +- [x] Möbliert + +Ordnen + + 56 Ergebnisse + + + + vor 1 Monat + +Grundstück zu verkaufen + +8193 Eglisau +------------------------------------- + +Le terrain de 1193 m2 offre une vue magnifique sur le Rhin. Sur le terrain actuel, il y a deux maisons jumelées, chacune avec 160m2 de surface habitable, dans un endroit dégagé. Il convient aux investisseurs qui souhaitent investir dans un projet - architectes, GC/TU, qui souhaitent laisser libre cours à leurs idées de planification. La propriété bénéficie du soleil toute la journée et est située directement sur le Rhin avec une vue fantastique. Saisissez votre chance de réaliser quelque chose de grand.Cette offre appropriée se caractérise par les avantages suivants: Emplacement idéal Terrain spacieux (1193 m2) Vue fantastique Directement sur le Rhin Soleil matin et soir Intéressé? Contactez-nous pour une discussion sans engagement Pour commercialiser vous-même une propriété? Nous convainquons avec des conditions équitables et transparentes + +- + +Auf Anfrage + + + + vor 2 Monaten + +Grundstück zu verkaufen + +8134 Adliswil +-------------------------------------- + +OFFMARKET: Baulandparzelle in Adliswil / ZH Das Bauland eignet sich perfekt als Projektentwicklung für Institutionelle Anleger/Developer/Investoren/Baugesellschaften/Architekten. Wir freuen uns auf ihre Kontaktnahme.Genaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/p/8134-22-3 Baulandparzelle mit Bestandesliegenschaft in Adliswil / ZH Adliswil, Grundstücksfläche: >710m2 / Zone W2 / AZ: 0.3 / Lärmempfindlichkeit: II / mögliche bebaubare NWF: ca. 265m2. Sehr gute, attraktive Hanglage. Voll erschlossen, plan- und anschliessend bebaubar. Eine der letzten Baulandparzelle in Adliswil mit atemberaubender Weitsicht. Das Bauland bieten wir EXKLUSIV unseren NETZWERKPARTNERN an. Wollen Sie NETZWERKPARTNER werden und ausführliche Infos zum Bauland erhalten? Dann freuen wir uns auf ihre Kontaktnahme.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/p/8134-22-3 + +- + +Auf Anfrage + + vor 3 Wochen + +Grundstück zu verkaufen + +8908 Hedingen +-------------------------------------- + +Die perfekte Lage, um die Vision vom eigenen Wohntraum zu verwirklichen, mit Umschwung, der neue Perspektiven und Freiheitsgefühl eröffnet. Dieses exquisite Grundstück mit einem bestehenden altem Haus, befindet sich in der Wohnzone 2.0 und bietet in allerlei Hinsicht diverse Möglichkeiten Ihr eigenes Projekt zu realisieren. Lassen Sie sich diese rare Möglichkeit nicht entgehen und rufen Sie uns heute noch für weitere Details an. Hier werden also keine Wünsche offen gelassen. Profitieren Sie und überzeugen Sie sich selbst! Dieses PREMIUM HOMES Angebot bietet: Parzelle 550m2 Wohnzone W2 max. Ausnützungsziffer 0.3 Die Parzelle ist erschlossen Familienfreundliche, privilegierte Lage Gemeinde mit guter Infrastruktur Extra viele Sonnenstunden und, und, und... Interessiert? Gerne führen wir Sie durch eine unverbindliche Besichtigung! Sie wollen Ihr Haus oder Ihre Wohnung sorgenfrei verkaufen? Wir sagen Ihnen den aktuellen Marktwert Ihrer Immobilie, diskret und unverbindlich! Haben Sie Interesse an einem ersten unverbindlichen Gedankenaustausch? Zögern Sie nicht und kontaktieren Sie uns. Wir freuen uns auf Sie. + +- + +Auf Anfrage + + vor 3 Wochen + +Grundstück zu verkaufen + +8155 Nassenwil +--------------------------------------- + +Diese 1412 m2 grosse Parzelle liegt am Rande eines ländlichen und ruhigen Wohnquartieres im beliebten Nassenwil in der Gemeinde Niederhasli. Westlich an die Landwirtschaftszone grenzend und perfekt besonnt sowie mit schöner Aussicht über das Quartier kann hier etwas Neues entstehen. Bebaut ist die Parzelle heute mit einem kleinen Einfamilienhaus, welches abgebrochen werden kann. Das Grundstück befindet sich in der Wohnzone E2, die die Erstellung von Einfamilien- und Doppeleinfamilienhäuser zulässt. Die Parzelle zeichnet sich besonders aus durch:- Exzellente Lage- Grosses Potential- Ganztägige Besonnung- Familienfreundliche Nachbarschaft- Ruhig gelegen Der Verkauf erfolgt im zweistufigen Bieterverfahren. Die CHF 1´500´000.- bzw. CHF 1´059.-/ m2 stellen das Mindestgebot dar. Angebote darunter werden nicht berücksichtigt. Weitere Infos zum Objekt und zum Verkaufsprozess können Sie den weiteren Unterlagen entnehmen, welche ich Ihnen sehr gerne per Mail zustelle. + +- + +CHF 1’500’000 + + vor 3 Wochen + +Grundstück zu verkaufen + +8800 Thalwil +------------------------------------- + +Seltene Gelegenheit am Zürichsee: An der Seestrasse in Thalwil verkaufen wir fast 3'000 m² Bauland mit grossem Nutzungspotential. Nachfolgend die wichtigsten Fakten: Unverbaubare Seesicht und ideale Mikrolage: nur wenige Gehminuten vom Bahnhof Thalwil entfernt (9 Minuten bis Zürich HB) Studie sieht Erstellung von 20 Wohneinheiten vor (2'995 m² Geschossfläche und 2'068 m² Wohnfläche) Erstellung von drei Vollgeschossen plus Attikageschoss möglich Wohnzone 3 mit grosser Ausnutzung Ausnützungsziffer 0.6 Dieses Bauland wird im Rahmen eines Bieterverfahrens verkauft Interessiert? Weitere Informationen, Bilder sowie Besichtigungsmöglichkeiten unter: https://www.propertyowner.ch/immobilien/22-48153/ Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch- Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der Grundstückgewinnsteuer + +- + +CHF 12’000’000 + + vor 1 Monat + +Grundstück zu verkaufen + +8523 Hagenbuch ZH +------------------------------------------ + +Parzelle 2260, Hagenbuch: Wohnhaus mit Scheune, 2 Schopf- und 1 Garagebaute auf 1'527 m2 Land in der Kernzone der Aussenwacht Oberschneit, Gemeinde 8523 Hagenbuch ZH. Mutmassliches Bauland mit folgenden Einschränkungen: Das Wohnhaus ist unter der Nummer VIII/502 in der "Häderli-Kartei" aufgelistet und Oberschneit ist auf der Liste der Kleinsiedlungen des Amtes für Raumentwicklung aufgeführt. Bauvorhaben bedürfen deshalb der Abklärung der Schutzwürdigkeit sowie zurzeit der Bewilligung durch die kantonale Baudirektion. WICHTIG: Gemäss Vernehmlassungsvorschlag der Baudirektion zur Übergangsverordnung vom August 2022 verbleibt Oberschneit auf der Liste der Liste der Kleinsiedlungen, die klarerweise aussenliegende Ortsteile darstellen. Oberschneit kann damit in der Bauzone verbleiben und ab Inkrafttreten der Übergangsordnung (Anfang 2023) ist für Bauvorhaben in Oberschneit voraussichtlich keine kantonale Zustimmung mehr erforderlich. Achtung: Es können auch das Bauernhaus mit Scheune und ca. 850 m2 oder das Bauland (ca. 680 m2) alleine erworben werden. Vorbehalten bleiben dabei: Parzellierung, Erschliessungsrechte zugunsten Bauland, Abbruch Schopf/Garage, koordinierter Erwerb und Bebaubarkeit Land. Der Verkauf des Gesamtobjektes erfolgt an den / die Meistbietenden. + +- + +CHF 995’000 + + vor 1 Monat + +Grundstück zu verkaufen + +8623 Wetzikon ZH +----------------------------------------- + +Bauland an vorzüglicher Lage? Hier werden Sie fündig!Mit 503 m² Parzellenfläche und ausserordentlich guten Voraussetzungen sind die Möglichkeiten bei diesem Grundstück beinahe unbeschränkt. 503 m² grosse Baulandparzelle Maximal erstellbare Bruttogeschossfläche von 267 m² Maximale Gebäudehöhe von 11.4 Metern Erstellung von drei Vollgeschossen möglich Knappe 2 km vom Strandbad Auslikon am Pfäffikersee entfernt Interessiert? Weitere Informationen und Bilder zur Immobilie sowie Besichtigungsmöglichkeiten unter https://www.propertyowner.ch/immobilien/23-49902/ Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch- Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der Grundstückgewinnsteuer + +- + +CHF 1’600’000 + + vor 1 Monat + +Grundstück zu verkaufen + +8426 Lufingen +-------------------------------------- + +Im Auftrag unseres Kunden verkaufen wir an leicht erhöhter Hanglage in Augwil innerhalb eines gepflegten Wohnquartiers ein Bauland mit 1078 m² Grundstücksfläche bebaut mit einem 4½-Zimmer-Einfamilienhaus mit Doppelgarage. Die Liegenschaft präsentiert sich in einem gut unterhaltenen Zustand, mehrheitlich aus dem Erstellungsjahr. Verkaufsrichtpreis: CHF 2'450'000.-- Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot. + +- + +CHF 2’450’000 + + vor 1 Monat + +Grundstück zu verkaufen + +8804 Au ZH +----------------------------------- + +In einem ruhigen und sonnigen Einfamilienhaus-Quartier verkaufen wir diese 698m2 grosse Bauparzelle an der Quellenstrasse 13, mit einem bestehendem 7-Zimmer-Einfamilienhaus. Kataster-Nr. WE5423, Quellenstrasse 13, 8804 Au ZH Bauzone: Wohnzone W2/40% Ausnutzung: Ausnutzungsziffer Ausnutzung Wert: 0.4 Grundbuch Anmerkungen: 1/2 subjektiv-dingliches Miteigentum an Blatt 2774, Kat. 5424, Wädenswil Baujahr Gebäude: 1949 Gebäudegrundfläche (GGF): 129 m2 Gebäudevolumen (GV): 1317 m3 Nutzfläche (NF): 149 m2 Verkaufspreis CHF 2'250'000.00 Haben wir Ihr Interesse geweckt? Für Fragen, weitere Unterlagen resp. Informationen oder einen Besichtigungstermin stehen wir Ihnen gerne zur Verfügung. Wir freuen uns auf Ihre Kontaktaufnahme! + +- + +CHF 2’250’000 + + vor 1 Monat + +Grundstück zu verkaufen + +8424 Embrach +------------------------------------- + +An gut besonnter und attraktiver Aussichtslage verkaufen wir die 968m2 grosse Baulandparzelle an der Winklerstrasse 35 mit bestehendem 5-Zimmer-Einfamilienhaus mit 673m3. Die Parzelle befindet sich in der Wohnzone 2A2 und die Baumassenziffer beträgt 1.7. Die Bebaubarkeit wurde durch einen Architekten und in Zusammenarbeit mit dem Bauamt Embrach analysiert. Die erstinstanzlichen Abklärungen haben ergeben, dass auf dem Grundstück voraussichtlich ein dreistöckiges Mehrfamilienhaus mit 9 Tiefgaragen-Parkplätzen realisierbar sein sollte. Die realisierbare Fläche (Nettofläche mit Innenwänden) pro Stockwerk beläuft sich auf ca. 150m2, total ca. 450m2 über Terrain. Haben wir Ihr Interesse geweckt? Weitere Informationen zur Liegenschaft, der Parzelle und zur vorhandenen Grobstudie erhalten Sie bei uns in einem persönlichen Gespräch! Wir freuen uns auf Ihre Kontaktaufnahme! Verkaufspreis CHF 1'850'000.- Mit unserer virtuellen 360-Grad-Tour können Sie bereits die ersten Eindrücke der bestehenden Liegenschaft gewinnen. Sehr gerne stehen wir für eine Besichtigung vor Ort zur Verfügung und freuen uns auf Ihre Kontaktaufnahme. Weitere EckdatenGrundstück Kataster 877, Grundstücksgrösse 968m², Wohnzone 2A2, Baumassenziffer 1.7, Kubatur (GVZ) der bestehenden Liegenschaft 673m3, Baujahr 1964. Wesentliche DistanzenKindergarten ca. 850mPrimarschule ca. 600mSekundarschule ca. 1.1kmPost ca. 1kmSchwimmbad Talegg ca. 1.7kmApotheke ca. 1.2kmEinkaufsmöglichkeiten; Volg ca. 450m, Coop ca. 1.5km, Aldi ca. 2.2km, Migros ca. 1.6kmBahnhof Embrach-Rorbas ca. 2.7km, S41 Richtung Winterthur ca. 16min. / S41 Richtung Bülach ca. 9 minBushaltestelle Embrach, Gemeindehaus ca. 550m: Bus Nr. 520, 521 und Nr. 523 Bahnhof Embrach-Rorbas ca. 9 min, Flughafen Zürich ca. 15minAutobahnanschluss ca. 5.9km in 9min Ihre Kontaktperson Für Besichtigungen und Fragen steht Ihnen das RIZZO-Immobilien Team unter Telefon 052 267 80 60 oder E-Mail info(at)rizzo-immobilien(dot)ch gerne zur Verfügung. Termine / Vorgehen / Besondere Hinweise Besichtigung jederzeit möglich. Bezug nach Vereinbarung. Zwischenzeitlicher Verkauf/Änderungen vorbehalten. S.E.&O. + +- + +CHF 1’850’000 + + vor 1 Monat + +Grundstück zu verkaufen + +8157 Dielsdorf +--------------------------------------- + +Gerne entwickeln und realisieren wir ein auf ihre Bedürfnisse massgeschneidertes Projekt, welches Ihnen zur Miete oder im Eigentum zur Verfügung stehen wird. Dank der Nähe zur A1 und A51 können neben Dielsdorf die Städte Baden und Zürich sowie der Flughafen ZH in Kürze erreicht werden. Hard Facts: Parzellenfläche für einen Sportbetrieb 17582m2 Erholungszone E1 Empfindlichkeitsstufe III Keine Gebäudehöhe Keine Ausnützungsziffer Nutzten Sie den Standort als Ihr Aushängeschild an gut erschlossener LageInteresse oder Fragen? Nehmen Sie Kontakt mit uns auf! Die Parzelle ist nicht das Richtige für Ihre Anforderungen? Kein Problem! Besuchen Sie unsere Homepage und finden Sie weitere Angebote unter: gewerbeland-schweiz.ch + +- + +Auf Anfrage + + vor 1 Monat + +Grundstück zu verkaufen + +8193 Eglisau +------------------------------------- + +Das 1193 m2 grosse Grundstück verfügt über eine herrliche Aussicht in Richtung Rhein. Auf dem aktuellen Land stehen zwei Doppeleinfamilienhäuser mit je 160m2 Wohnfläche an einer unverbaubaren Lage. Es eignet sich für Investoren, die in ein Projekt investieren möchten - Architekten, GU/TU, die ihren planerischen Ideen freien Lauf lassen möchten. Das Grundstück geniesst ganztags Sonne und liegt direkt am Rhein mit traumhafter Aussicht. Ergreifen Sie Ihre Chance, etwas grossartiges zu realisieren. Dieses properti-Angebot zeichnet sich durch folgende Vorteile aus: Ideale Lage Grosszügiges Grundstück (1193 m2) Traumhafte Aussicht Direkt am Rhein Morgen- und Abendsonne Interessiert? Kontaktieren Sie uns für ein unverbindliches Gespräch!Selbst eine Immobilie zu vermarkten? Wir überzeugen mit fairen und transparenten Konditionen! + +- + +Auf Anfrage + + vor 1 Monat + +Grundstück zu verkaufen + +8472 Seuzach +------------------------------------- + +Im Kundenauftrag verkaufen wir ein gut bebaubares Grundstück mit einer Fläche von 860 m² in der Wohnzone W1.6 mit altem Magazin/Schopf. Die Parzelle befindet sich an familienfreundlicher Lage im südwestlichen Ortsteil von Seuzach. Die Bushaltestelle Forrenbergstrasse ist nur wenige Schritte entfernt. Verkaufsrichtpreis: CHF 2'250'000.-- Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot. + +- + +CHF 2’250’000 + + vor 2 Monaten + +Grundstück zu verkaufen + +8442 Hettlingen +---------------------------------------- + +Das erwartet Sie? Ruhiges Wohnquartier abseits der Hauptstrasse? Attraktive Gemeinde mit günstigem Steuerfuss? Grosszügige Landparzelle im W1/20Information LiegenschaftKonstruktion Bauweise Massivbauweise Innenwände Backsteinmauerwerk Aussenwände Einschalenmauerwerk Fenster Holz-Metall-Fenster mit 2-fach Isolierverglasung Dachkonstruktion SatteldachAusbau Heizungsraum Elektrospeicherheizung, Verteilung via Radiatoren Küche Glaskeramikherd, Kühlschrank, Backofen, Geschirrspüler Nasszellen EG separater Waschtisch und WC, Dusche und Waschtisch Nasszelle OG Badewanne, Waschtisch, WC Hauswirtschaftsraum Waschtrog und Waschmaschine Bodenbeläge Parkett in Wohnzimmer, Essen und Büro. Keramische Platten im Eingang und Korridor. Kunststoffbelag in Küche und Hauswirtschaftsraum. Linoleum in allen Zimmern und Nasszellen.Zustand Das Einfamilienhaus wurde 1960 erstellt und verfügt über einen grosszügigen Wintergarten sowie im Wohnzimmer über ein Chemineé. Die nötigen Unterhaltsarbeiten wurden durchgeführt. Alles ist intakt und das Haus ist sofort bewohnbar. Die Bodenbeläge in den Zimmern, Küche und Nasszellen sind abgenutzt. Folgende grössere Arbeiten wurden durchgeführt:? zentrale Elektrospeicherheizung? Dämmung an der Westfassade? Anbau eines Wintergarten? FensterrenovationMirkolage Die Liegenschaft befindet sich in einem ruhigen Einfamilienhausquartier. Die Lage ist leicht überdurchschnittlich und befindet sich auf flachem Gelände. Der Kindergarten befindet sich in unmittelbarer Entfernung 190 m. Die Primarschule in 650 m Entfernung. Die Sekundarschule muss in Seuzach besucht werden. Ein Volg ist in knapp 500m erreichbar. Die nächste ÖV-Haltestelle ist 200 m entfernt. Der Bahnhof Hettlingen ist zu Fuss in 8 min erreichbar. + +- + +CHF 1’480’000 + + vor 2 Monaten + +Grundstück zu verkaufen + +8625 Gossau ZH +--------------------------------------- + +454 m2 grosse Baulandparzelle W1.3Am Ortsrand von Gossau ZH, an sonniger Südhanglage, direkt an der grünen Zone und ohne Durchgangsverkehr, mit einer schönen, unverbaubaren Fernsicht, liegt diese Baulandparzelle W1.3. Das Grundstück wird neu mutiert und wird 454 m2 gross sein. Auch die angrenzende Parzelle mit Haus (neue Kat. Nr. 8867) wird verkauft. Verkauft wird im Angebotsverfahren. Interessiert? Verlangen Sie die detaillierten Unterlagen mit weiteren Infos und Bildern. + +- + +CHF 900’000 + + vor 3 Monaten + +Grundstück zu verkaufen + +8523 Hagenbuch ZH +------------------------------------------ + +Teil aus Parzelle 2260, Hagenbuch: ca. 680 m2 Land (total 1'527 m2 mit Bauernhaus mit Scheune). Die Abparzellierung des Objektes hat durch die Käuferschaft in Koordination mit der Käuferschaft der Restparzelle "Bauernhaus mit Scheune" unter gleichzeitiger Einräumung der Erschliessungsrechte für das Restbauland sowie dem vorgesehenen Abbruch des Gebäudes 18b stattzufinden. Daraus folgt: Es kann auch das ganze Grundstück 2260 erworben werden oder aber der künftige Nachbar (Bauernhaus mit Scheune) durch Beibringung / Mithilfe beim Verkauf direkt mit beeinflusst werden. WICHTIG: Gemäss Vernehmlassungsvorschlag der Baudirektion zur Übergangsverordnung vom August 2022 verbleibt Oberschneit auf der Liste der Liste der Kleinsiedlungen, die aussenliegende Ortsteile darstellen. Oberschneit kann damit in der Bauzone (Kernzone) verbleiben und ab Inkrafttreten der Übergangsordnung (Anfang 2023) ist für Bauvorhaben in Oberschneit keine kantonale Zustimmung mehr erforderlich. + +- + +CHF 450’000 + + vor 2 Wochen + +Grundstück zu verkaufen + +8902 Urdorf • 325 m² +--------------------------------------------- + +Zu verkaufen:Erschlossenes, sehr schön gelegenes Bauland für ein Einfamilienhaus mit max 146.25m2 Wohnfläche.Lage: Gontenschwil AGGrösse: 325m2Ausnützung: 0.45Mögliche Wohnfläche: ca. 146.25 m2Preis: Fr. 235'000.- FIX-PreisDas Land eignet sich für Bauherren, die einen pflegeleichten Garten möchten. Ein perfekt-ausgedachtes, dem Land entsprechendes Bauprojekt ist vorhanden und kann besprochen und ebenfalls erworben werden. + +CHF 723 / m² + +CHF 235’000 + + vor 2 Wochen + +Grundstück zu verkaufen + +8001 Zürich +------------------------------------ + +Bewilligtes Bauprojekt auf zwei Grundstücken an zentraler Lage mit attraktiven Renditeaussichten Das im folgenden vorgestellte Neubauprojekt erstreckt sich über zwei Parzellen (Parz. 1288 = 637 m2 und Parz. 1289 = 310 m2) - an bester Lage in Emmenbrücke. Sowohl mit dem Auto als auch mit dem öffentlichen Verkehr ist man innerhalb von nur 15 Minuten in der Stadt Luzern. Bewilligt sind 9 attraktive Wohnungen (1.5 bis 4.5 Zimmer) und 5 Aussenparkplätzen mit einer Gesamtwohnfläche von 582 m2 und diversen Nebenräumen. Von der obersten Etage geniesst mein eine wundervolle Weitsicht in die Berge. Verkauft werden die beiden Grundstücke inkl. dem bewilligten Projekt Haben wir Ihr Interesse geweckt? Gerne stellen wir Ihnen die Detailunterlagen zur Verfügung. + +- + +CHF 2’300’000 + + vor 2 Wochen + +Grundstück zu verkaufen + +8700 Küsnacht ZH +----------------------------------------- + +Bitte ausschliesslich Private Investoren/ Interessenten. + +- + +Auf Anfrage + + vor 3 Wochen + +Grundstück zu verkaufen + +8713 Uerikon +------------------------------------- + +Unverbaubare Seesicht, von der Sonne verwöhnt, mitten im Dorf und doch mit grösstmöglicher Privatsphäre. Ein aussergewöhnliches Grundstück von 1008 m2 Fläche an Hanglage, durch Felswand vor Bise geschützt, das in der Zürcher Seegemeinde Uerikon (politische Gemeinde Stäfa) am oberen Teil des Zürichsees liegt. Das Ufer des Sees mit Seebad, der Wald mit Wanderwegen, Schulhäuser und Bahnhof sind innert weniger Gehminuten zu erreichen. Anwohner schätzen die schnelle Erreichbarkeit der wichtigsten Wirtschaftszentren und Tourismusdestinationen in der Deutschschweiz, ob mit dem Auto oder den öffentlichen Verkehrsmitteln. Mit einem Steuerfuss von 78 % gehört Uerikon/Stäfa zu den 7 steuergünstigsten Gemeinden des Kantons Zürich. Verschiedene Möglichkeiten bieten sich für diese Parzelle an: Modernisierung des vorhandenen Einfamilienhauses Neubau eines Einfamilien- oder Doppeleinfamilienhauses Terrassenwohnungen Arealüberbauung Haben wir Ihr Interesse geweckt? Gerne stellen wir Ihnen unsere detaillierte Broschüre "Leben am Zürichsee" zu. Wir freuen uns auf Ihre Kontaktaufnahme. + +- + +Auf Anfrage + + vor 3 Wochen + +Grundstück zu verkaufen + +8155 Nassenwil • 1’412 m² +-------------------------------------------------- + +Diese 1412 m2 grosse Parzelle liegt am Rande eines ländlichen und ruhigen Wohnquartieres im beliebten Nassenwil in der Gemeinde Niederhasli. Westlich an die Landwirtschaftszone grenzend und perfekt besonnt sowie mit schöner Aussicht über das Quartier kann hier etwas Neues entstehen. Bebaut ist die Parzelle heute mit einem kleinen Einfamilienhaus, welches abgebrochen werden kann. Das Grundstück befindet sich in der Wohnzone E2, die die Erstellung von Einfamilien- und Doppeleinfamilienhäuser zulässt. Die Parzelle zeichnet sich besonders aus durch: Exzellente Lage Grosses Potential Ganztägige Besonnung Familienfreundliche Nachbarschaft Ruhig gelegen Der Verkauf erfolgt im zweistufigen Bieterverfahren. Weitere Infos zum Objekt und zum Verkaufsprozess können Sie den weiteren Unterlagen entnehmen, welche ich Ihnen sehr gerne per Mail zustelle. + +CHF 1’062 / m² + +CHF 1’500’000 + + vor 3 Wochen + +Grundstück zu verkaufen + +8104 Weiningen ZH • 1’167 m² +----------------------------------------------------- + +Dieses Bauland mit bestehendem Altbau und Hanglage liegt in Weiningen in begehrter Lage mit herrlicher Aussicht (unverbaubar).Bauland in Weiningen ist äusserst rar und gesucht - mit schöner Aussicht sowieso. An erhöhter Lage über den Dächern von Weiningen kommen Sie in den Genuss einer traumhaften Aussicht (Weiningen, Limmattal, Zürich, Uetliberg und auf das wunderbare Bergpanorama der Alpen) und geniessen zeitgleich die absolute Ruhe.Die nicht alltägliche Parzelle mit dem bewilligten Neubau für ein Mehrfamilienhaus und ein Einfamilienhaus überzeugt mit folgenden Eigenschaften:Die Highlights: exklusive, erhöhte Lage im ruhigen Wohnquartier Nähe zur Stadt Zürich herrliche, unverbaubare Aus-/ Fernsicht (Weiningen, Zürich, Alpenpanorama, Uetliberg) Grundstück an ruhiger Quartierstrasse mit vorteilhafter Hanglage gut erschlossen keine eingetragenen Altlasten keine Architektenbindung alle Baupläne liegen vor eine Bodenanalyse für die Bodenbeschaffenheit liegt vor eine Baubewilligung wurde erteilt. keine Hypothekendarlehen, also freie Bankenwahl mit dem Neubau kann man sofort beginnen eine Wohnung wird von der Verkäuferschaft gekauft Daten zum Grundstück:Kataster 1784, 1167 m2 mit HanglageHogerwiesstrasse1 in 8104 WeiningenW2 30 BauzoneToplage im bevorzugten Quartier über den Dächern von Weiningen ZHSchöne Aussicht und Fernsicht Richtung Zürich, Uetliberg, Limmattal und den Alpen Bewilligte Neubauten - Wohnflächen:Mehrfamilienhaus (MFH) mit 3 Wohnungen und Tiefgarage (5 Geschosse)MFH 4.5 Zi. Wohnung 3:143.0 m2MFH 4.5 Zi. Wohnung 2: 133.5 m2MFH 3.5 Zi. Wohnung 1: 117.2 m2 (Maisonette)Einfamilienhaus (EFH) (3 Geschosse UG/EG/DG)EFH: 170.2 m2 Bewilligte Neubauten - Bauvolumen:MFH - Tiefgarage: 940 m3MFH - Wohnen:1580 m3EFH:970 m3 Kaufpreis Bauland mit bewilligtem Neubauprojekt:Der Kaufpreis für das Grundstück mit bewilligten Bauprojekt liegt bei 3.2 Mio. CHFund im Gegenzug möchte die Verkäuferschaft die Wohnung 2 (133.5 m2)mit 2 Parkplätzen in der Tiefgarage kaufen. Haben wir Ihr Interesse geweckt?Für weitere Einzelheiten zum Neubauprojekt und einen Besichtigungstermin sind wir gerne für Sie da.Wir freuen uns auf Ihren Anruf! + +CHF 2’742 / m² + +CHF 3’200’000 + + vor 3 Wochen + +Grundstück zu verkaufen + +8523 Hagenbuch ZH • 680 m² +--------------------------------------------------- + +Teil aus Parzelle 2260, Hagenbuch: ca. 680 m2 Land (total 1'527 m2 mit Bauernhaus mit Scheune).Die Abparzellierung des Objektes hat durch die Käuferschaft in Koordination mit der Käuferschaft der Restparzelle "Bauernhaus mit Scheune" unter gleichzeitiger Einräumung der Erschliessungsrechte für das Restbauland sowie dem vorgesehenen Abbruch des Gebäudes 18b stattzufinden. Daraus folgt: Es kann auch das ganze Grundstück 2260 erworben werden oder aber der künftige Nachbar (Bauernhaus mit Scheune) durch Beibringung / Mithilfe beim Verkauf direkt mit beeinflusst werden.WICHTIG:Gemäss Vernehmlassungsvorschlag der Baudirektion zur Übergangsverordnung vom August 2022 verbleibt Oberschneit auf der Liste der Liste der Kleinsiedlungen, die aussenliegende Ortsteile darstellen. Oberschneit kann damit in der Bauzone (Kernzone) verbleiben und ab Inkrafttreten der Übergangsordnung (Anfang 2023) ist für Bauvorhaben in Oberschneit keine kantonale Zustimmung mehr erforderlich.S.E.&.O. Irrtümer vorbehalten. Wir bemühen uns um korrekte Angaben, können jedoch keine Gewähr übernehmen. + +CHF 662 / m² + +CHF 450’000 + + vor 3 Wochen + +Grundstück zu verkaufen + +8625 Gossau ZH • 454 m² +------------------------------------------------ + +454 m2 grosse Baulandparzelle W1.3Am Ortsrand von Gossau ZH, an sonniger Südhanglage, direkt an der grünen Zone und ohne Durchgangsverkehr, mit einer schönen, unverbaubaren Fernsicht, liegt diese Baulandparzelle W1.3. Das Grundstück wird neu mutiert und wird 454 m2 gross sein. Auch die angrenzende Parzelle mit Haus (neue Kat. Nr. 8867) wird verkauft. Verkauft wird im Angebotsverfahren. Interessiert? Verlangen Sie die detaillierten Unterlagen mit weiteren Infos und Bildern. + +CHF 1’982 / m² + +CHF 900’000 + +[1](https://www.immoyou.ch/grundstuck-kaufen-kanton-zurich)23 + + 1 - 24 von 56 Ergebnisse + + All rights reserved. v.541ff84 + + +=== https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich === +70 Terrain à bâtir à vendre: Canton Zurich | ImmoScout24 + +=============== + +[](https://www.immoscout24.ch/fr) +* [Chercher](https://www.immoscout24.ch/fr "Chercher") +* [Services](https://www.immoscout24.ch/c/fr/hypotheques "Services") + +[Créer une annonce](https://www.immoscout24.ch/fr/insertion/publier-soi-meme-en-ligne "Créer une annonce") + +[Favoris](https://www.immoscout24.ch/favoris "Favoris") + +[Mon Compte](https://www.immoscout24.ch/fr/account-overview "Mon Compte") + +Menu + +[](https://www.immoscout24.ch/fr) +* [Chercher](https://www.immoscout24.ch/fr "Chercher") +* [Services](https://www.immoscout24.ch/c/fr/hypotheques "Services") +* [Estimer](https://www.immoscout24.ch/fr/estimation "Estimer") +* [Magazine](https://www.immoscout24.ch/c/fr/magazine-immobilier "Magazine") + +[Créer une annonce](https://www.immoscout24.ch/fr/insertion/publier-soi-meme-en-ligne "Créer une annonce") + +[Favoris](https://www.immoscout24.ch/favoris "Favoris") + +[Mon Compte](https://www.immoscout24.ch/fr/account-overview "Mon Compte") + +Menu + +FR +* [DE](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich) +* [FR](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich) +* [IT](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo) +* [EN](https://www.immoscout24.ch/en/plot/buy/canton-zurich) + +1. [](https://www.immoscout24.ch/fr) +2. [Terrain à bâtir à vendre](https://www.immoscout24.ch/fr/terrain/acheter) +3. [Canton Zurich](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich) + +Où? + + Canton Zurich + + Canton Zurich + + CHF à + + + + Filtres + + 70 objets + +70 résultats - Terrain à bâtir à vendre: Canton Zurich +====================================================== + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 16    **360m²**, CHF 2’563’760.– Top Luegetenstrasse 11, 8489 Wildberg Votre nouvelle maison avec potentiel - Maison de campagne idyllique avec réserve de terrain constructible Votre nouvelle maison Bienvenue dans votre futur domicile de rêve - une maison de campagne spacieuse et indépendante dans un endroit calme et idyllique avec vue sur le pittoresque Wildberg. Ici, l'idylle rurale, la vie privée et la rare opportunité de créer ou d'agrandir un espace de vie selon vos propres idées se rencontrent.Que ce soit comme un refuge familial charmant avec un grand jardin ou comme un objet d'investissement avec un potentiel de développement - cette propriété unique vous offre les deux options. Sur le terrain de 1339m², vous avez non seulement beaucoup d'espace pour vivre, mais aussi une réserve de terrain constructible précieuse, qui vous ouvre des possibilités de conception variées. Les investigations initiales montrent : Il existe la possibilité de réaliser une maison à plusieurs familles avec jusqu'à cinq unités de logement - une véritable plus-value pour les acheteurs visionnaires.Plongez dans une oasis verte avec une vue lointaine - un endroit qui vous donne la paix et vous inspire.Points forts en un coup d'œil • Endroit idyllique et calme avec une grande valeur de loisirs • Grand terrain avec 1339m², idéal pour une utilisation personnelle et/ou pour le développement d'un nouveau bâtiment • Réserve de terrain constructible : Potentiel de développement attractif - selon les estimations initiales, il existe la possibilité de réaliser, en plus de la maison unifamiliale existante, une maison à plusieurs familles avec jusqu'à cinq unités de logement (non contraignant, sans garantie) • Jardin en fleurs avec différents espaces de séjour, pergola avec cheminée extérieure, maisons de jardin, population d'arbres bien entretenue et vastes espaces verts • Substance de construction solide avec maçonnerie à double paroi • Concept de pièces spacieux avec environ 220m² d'espace de vie et environ 96m² d'espace de stockage supplémentaire au sous-sol. Surface totale d'environ 360m². • Espace de vie spacieux avec poêle à tuiles confortable - un endroit pour arriver et se sentir bien • Cuisine de vie pratique avec salle à manger intégrée - idéale pour les heures sociales • 4 chambres lumineuses - idéales pour les familles ou le télétravail • 2 cellules humides avec lumière du jour • Grenier aménagé pour un espace supplémentaire ou des possibilités d'utilisation créative • Chauffage au moyen d'un stockage électrique et d'un chauffage par le sol à eau • Garage avec porte électrique et possibilités de stationnement supplémentaires sur la propriété • Avec une modernisation élégante, vous pouvez transformer cette maison en un véritable joyau Prix de vente : CHF 1'870'000.-Avec notre visite virtuelle à 360 degrés, vous pouvez déjà avoir les premières impressions de cette grande propriété. Nous serions ravis de vous montrer cette propriété directement sur place et nous attendons avec impatience votre contact.Autres données clésAnnée de construction de la maison : 1984, année de construction de la dépendance : 1986, volume de la maison (GVZ) : 936m³, volume de la dépendance (GVZ) : 40m³, feuillet de registre foncier : n° 437, numéro de cadastre : 249, 1/4 de propriété subjective-réelle de la feuille 444, cadastre 249. Surface habitable nette : environ 220m², surface habitable brute : environ 360m², surface du terrain : 1'339m².Construction solide, maçonnerie à double paroi, fenêtres en bois et métal presque neuves (EgoKiefer) avec vitrage triple et meneaux & volets en bois. Chauffage électrique à stockage, chauffage par le sol à eau, chaudière électrique 300 litres.Ascenseur, garage avec ouverture de porte électrique. Cuisine de style maison de campagne avec couverture en granit, lave-vaisselle, cuisinière à induction et réfrigérateur avec compartiment congélateur.Revêtements de solRez-de-chaussée : Entrée, corridor, douche, cuisine, salle à manger avec sol en plaques.Étage : Chambres et avant-cour avec stratifié en optic bois. Salle de bains avec plaques.  Durée du trajet Nouveau 28 min.Station: Rämismühle-Zell](https://www.immoscout24.ch/acheter/4002491909) + +[*  *  *  *  *  *  *  *  1 / 4 Prix sur demande Top Lüss, 8542 Wiesendangen À remettre en droit de construction : 14’770 m2 de terrain à bâtir dans un excellent emplacement à Wiesendangen, avantageux en termes d'impôts À remettre en droit de construction :14’770 m2 de terrain à bâtir dans un excellent emplacement à Wiesendangen, avantageux en termes d'impôtsPropriété WD4674 – Lüss WiesendangenTous les détails sur la propriété, le contrat de droit de construction et les critères d'attribution se trouvent dans le dossier joint.Les offres fermes pour la reprise du contrat de droit de construction, y compris la preuve de financement, doivent être soumises à :Commune de WiesendangenÀ l'attention de Martin SchindlerSchulstrasse 208542 Wiesendangen Veuillez utiliser le formulaire en annexe pour la soumission de l'offre.Date limite de soumission : lundi 20 octobre 2025, 11h00 Durée du trajet Nouveau 9 min.Station: Wiesendangen](https://www.immoscout24.ch/acheter/4002510601) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 12    CHF 2’323’840.– Hürstringstrasse 37, 8046 Zürich Terrain avec maison unifamiliale existante et grand potentiel Nous serons ravis de vous présenter ce terrain avec grand potentiel et de nombreuses possibilités.Après consultation, nous vendons un terrain avec une maison unifamiliale existante dans un endroit calme à Zurich. Ce qui est intéressant dans cette propriété, cependant, c'est que lors de l'achat, vous disposez déjà de l'autorisation de construire associée, qui vous permet d'agrandir et de rénover l'espace de vie sur cette parcelle selon vos souhaits.Non loin de la gare principale de Zurich, derrière le Käferberg, le terrain spacieux est situé dans un quartier résidentiel calme avec une zone 30.À pied, vous pouvez rejoindre un arrêt de bus, ainsi que la petite forêt, qui est idéale pour des promenades plus courtes.Les informations les plus importantes en bref: • Terrain avec maison unifamiliale et autorisation de construire pour agrandir la surface habitable • Année de construction 1934 • Superficie du terrain de 410 m2 • Possibilité de projet 1 : Agrandissement en maison multifamiliale avec deux appartements en propriété ou en location • Possibilité de projet 2 : Agrandissement en maison à plusieurs générations Découvrez l'atmosphère calme et la proximité simultanée avec le centre-ville lors d'une visite personnelle!Pour plus d'informations sur la propriété ou pour planifier une visite, n'hésitez pas à nous contacter à tout moment.  Durée du trajet Nouveau 22 min.Station: Zürich Seebach](https://www.immoscout24.ch/acheter/4002349882) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 11    CHF 3’290’400.– Luzernerstrasse 57, 8903 Birmensdorf (ZH) Emplacement ensoleillé avec vue Au nom de notre client, nous vendons un terrain à bâtir dans un emplacement ensoleillé avec vue de 1'228 m² de surface foncière (zone résidentielle W2).La propriété existante se présente dans un état entretenu conforme à son âge.Prix de vente cible : CHF 2'400'000Nous avons éveillé votre intérêt ? Nous serons ravis de vous envoyer l'exposé détaillé de cette offre intéressante.  Durée du trajet Nouveau 19 min.Station: Birmensdorf](https://www.immoscout24.ch/acheter/4002566208) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13 CHF 4’044’440.– Mühlemattstrasse 12, 8135 Langnau am Albis Terrain à bâtir ou maison unifamiliale existante à vendre ! La maison convainc par son apparence inimitable. Les murs en briques à l'intérieur donnent à l'espace de vie une atmosphère chaude et naturelle, tandis que la cheminée dans le salon assure le confort les jours plus froids. Le plan d'étage est ouvert et accueillant, complété par de grandes façades de fenêtres qui amènent la lumière et la nature dans la maison.Un point fort est la terrasse spacieuse avec une vue merveilleuse – idéale pour des heures agréables à l'extérieur. Le jardin est vaste et offre beaucoup d'espace pour une conception individuelle. Avec un peu d'attention, un paradis vert merveilleux peut être créé ici – que ce soit comme jardin familial, refuge ou pour des projets créatifs à l'extérieur.Grâce à la taille de la propriété et à son emplacement, la propriété ouvre également des perspectives intéressantes pour un éventuel nouveau bâtiment de remplacement - comme une maison unifamiliale moderne ou une maison multifamiliale.Nous serons ravis de vous fournir des informations supplémentaires ou de convenir d'un rendez-vous de visite personnel. Découvrez le potentiel et l'atmosphère unique de cet endroit. Dans la documentation de vente, vous trouverez toutes les informations importantes.  Durée du trajet Nouveau 12 min.Station: Langnau-Gattikon](https://www.immoscout24.ch/acheter/4002406229) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13    CHF 1’302’440.– Kanalweg 2, 8714 Feldbach Terrain pour une maison unifamiliale projetée Dans le village pittoresque de Feldbach, au bord du lac de Zurich, ce terrain avec une grange existante, construite sur un seul côté, est à vendre. Le prix d'achat inclut un projet préliminaire réalisable pour une maison unifamiliale en remplacement de la grange.L'objet vous offre la possibilité unique de réaliser votre rêve de propriété dans un lieu idyllique. Il offre suffisamment d'espace pour une famille, et une combinaison de "vie et travail" est également possible.En 30 minutes, vous pouvez rejoindre Zurich en S-Bahn, et la garderie et l'école primaire sont également à proximité. Des possibilités de shopping sont disponibles à Hombrechtikon, Stäfa et Rapperswil. En été, une piscine voisine dans la charmante Seebadi Feldbach vous invite à vous rafraîchir.Il existe un devis de coût actuel pour la maison (construction en éléments de bois) y compris les environs, les coûts de construction et les coûts accessoires d'un montant de Fr. 1'380'000.--.Nous avons piqué votre intérêt ? Alors appelez-nous. Nous serons ravis de répondre à vos questions ou de vous fournir notre documentation de vente pour étude. La propriété peut, bien sûr, également être visitée. Nous nous réjouissons de votre appel.  Durée du trajet Nouveau 6 min.Station: Feldbach](https://www.immoscout24.ch/acheter/4002434745) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13    **5.5 pièces**, CHF 4’111’620.– Schaffhauserstrasse 226b, 8057 Zürich Mehr Raum fürs Leben: Reihenhaus mit Potenzial Attraktive Stadtliegenschaft mit ausgearbeitetem ProjektIm Zürcher Kreis 11 veräussern wir ein hübsches Reiheneinfamilien-Eckhaus mit grosszügigem Umschwung. Die Liegenschaft und das Grundstück verfügen über viel Ausnützungspotenzial und ermöglicht so die Realisation spannender Projekte sowohl im Umbau als auch Neubau.Diese Liegenschaft überzeugt durch viele Besonderheiten: • grosszügiger Umschwung mit viel Potenzial • Blick ins Grüne von nahezu allen Fenstern • Schwedenofen im Wohnbereich • viel Stauraum durch Wandschränke und Estrich • Altbaucharme in modernem Quartier • zentrale und familienfreundliche Lage • sonnenverwöhnter Standort Haben wir Ihr Interesse geweckt? Bestellen Sie noch heute unsere ausführliche Verkaufsdokumentation mittels Kontaktformular und Sie erhalten weitere spannende Informationen zur Immobilie. Wir freuen uns über Ihre Kontaktaufnahme!Une oasis de verdure dans la ville de Zurich avec un projet élaboréDans le quartier 11 de Zurich, nous vendons une jolie maison mitoyenne en angle avec de vastes alentours. L'immeuble et le terrain disposent d'un grand potentiel d'exploitation et permettent ainsi la réalisation de projets passionnants, tant en transformation qu'en construction neuve.Cette propriété convainc par ses nombreuses particularités : • Un vaste terrain avec beaucoup de potentiel • Une vue sur la verdure depuis presque toutes les fenêtres • Un poêle suédois dans le séjour • beaucoup d'espace de rangement grâce aux armoires murales et au grenier • Le charme d'un ancien bâtiment dans un quartier moderne • Un emplacement central et favorable aux familles • Un emplacement ensoleillé Nous avons éveillé votre intérêt ? Commandez dès aujourd'hui notre documentation de vente détaillée au moyen du formulaire de contact et vous recevrez d'autres informations passionnantes sur le bien immobilier. Nous nous réjouissons de votre prise de contact!A green oasis in the city of Zurich with an elaborate projectIn Zurich's Kreis 11 district, we are selling a pretty terraced single-family corner house with spacious grounds. The property and the plot have a lot of utilization potential and thus enable the realization of exciting projects both in conversion and new construction.This property boasts many special features: • spacious grounds with lots of potential • view of the countryside from almost all windows • Swedish stove in the living area • lots of storage space thanks to wall cupboards and attic • old building charm in a modern district • central and family-friendly location • sun-drenched location Have we piqued your interest? Order our detailed sales documentation today using the contact form and you will receive further exciting information about the property. We look forward to hearing from you!  Durée du trajet Nouveau 4 min.Station: Berninaplatz](https://www.immoscout24.ch/acheter/4002346061) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 12 Prix sur demande Überlandstrasse 23, 8340 Hinwil Parcelle de terrain industriel et de construction à un emplacement attractif dans le Zürcher-Oberland Dans la zone industrielle animée de Hinwil, nous vendons un terrain de construction industriel à un emplacement très fréquenté, directement sur l'axe principal de Rapperswil, Wetzikon, et Pfäffikon ZH. La parcelle de terrain à bâtir est située à la limite de la zone industrielle et borde la zone résidentielle de Hinwil ZH.Données clés :- Surface totale du terrain 4 246 m2- Zone de construction industrielle/commerciale IG/7 - Facteur de volume de construction 7 m3/m2- Hauteur de bâtiment maximale 21,5 m- Longueur de bâtiment maximale ouverte- Grande distance de limite à la route nationale- Distance de bâtiment tout autour 3,5 m- Volume de construction possible maximal environ 30 000 m3- Surface brute de plancher environ 9 500 m2Le terrain de construction est actuellement encore utilisé avec deux unités de logement, un atelier de réparation auto avec un showroom séparé, et une station-service. Autour de la propriété, de grandes surfaces pavées sont disponibles pour une utilisation.  Durée du trajet Nouveau 10 min.Station: Hinwil](https://www.immoscout24.ch/acheter/4002417917) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 10 CHF 2’947’650.– Trottenrain 14, 8474 Dinhard Projet de construction approuvé dans le Dinhard-Welsikon avantageux en termes d'impôts Le terrain à bâtir avec un entrepôt est situé dans une zone centrale à Welsikon, à la périphérie de la commune de Dinhard, dans la zone centrale. L'utilisation élevée obtenue permet la construction de nouveaux bâtiments attractifs dans un emplacement central. Les visualisations et les plans d'étage du projet de construction approuvé peuvent être trouvés dans la documentation. L'entrepôt est inscrit à l'inventaire communal des bâtiments protégés. Par conséquent, un accord de protection a été élaboré en consultation avec la protection du patrimoine et la commune de Dinhard, qui permet une conversion extraordinaire en un loft moderne.Points forts : • projet de construction approuvé et planification des appels d'offres pour les nouveaux bâtiments • accord de protection • excellente situation à Welsikon • havre fiscal (taux d'impôt communal 83 %) • parcelle de terrain à bâtir bien proportionnée • bonne connexion aux transports en commun (gare à 170 m) Réalisation :L'association des propriétaires de Winterthur vous soutient, si nécessaire, en étroite collaboration avec Kästle Architekten dans la réalisation de votre projet de nouveau bâtiment.De la planification à la vente/location du nouveau bâtiment terminé – l'association des propriétaires de Winterthur vous offre tous les services d'une seule source. Il n'y a pas d'obligation architecturale.Les parties intéressées sont cordialement invitées à nous contacter.Appelez notre équipe de vente au 052 209 01 68 si vous souhaitez recevoir des informations supplémentaires ou une visite. Nous nous réjouissons de vous entendre.Votre équipe de vente HEVImportant : Nous sommes exclusivement chargés de la vente. Le contact direct avec les propriétaires entraînera l'exclusion de la liste des parties intéressées. S.E.&.O.  Durée du trajet Nouveau 5 min.Station: Dinhard](https://www.immoscout24.ch/acheter/4002188905) + +[ 1 / 1 CHF 2’399’240.– In der Gass 2, 8627 Grüningen Terrain avec permis de construire pour vente Mis en vente, un terrain avec un projet de nouvelle construction approuvé. Bâtiment C de l'Enssamble au Binzikerstrasse 21 / In der Gass 2, 8627 Grüningen. Les garages actuellement existants peuvent être démolis et remplacés par un nouveau bâtiment avec 8 appartements de tailles différentes avec des espaces extérieurs attractifs. En outre, la construction conjointe d'un garage souterrain pour 11 places de parking avec accès via la rue "In der Gass" a été approuvée.  Durée du trajet Nouveau 54 min.Station: Esslingen](https://www.immoscout24.ch/acheter/3003479026) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 2’604’890.– Im Königstal 2, 8487 Zell Durée du trajet Nouveau 22 min.Station: Rämismühle-Zell](https://www.immoscout24.ch/acheter/4002279293) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 4’112’990.– Im Königstal 3, 8487 Zell ZH Durée du trajet Nouveau 22 min.Station: Rämismühle-Zell](https://www.immoscout24.ch/acheter/4002279266) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 6’717’900.– Im Königstal 3, 8487 Zell ZH Durée du trajet Nouveau 22 min.Station: Rämismühle-Zell](https://www.immoscout24.ch/acheter/4002279259) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    CHF 2’879’100.– Rotweg 20, 8820 Wädenswil Votre nouveau projet avec vue sur le lac Au nom de notre client, nous vendons un quartier résidentiel préféré, surélevé et calme avec une belle vue sur le lac et la lointaine, 706 m² de terrain constructible avec un objet de démolition.Prix de vente cible : CHF 2'100'000.00Est-ce que nous avons éveillé votre intérêt ? Nous serons ravis de vous envoyer l'exposé détaillé de cette offre intéressante.  Durée du trajet Nouveau 12 min.Station: Wädenswil](https://www.immoscout24.ch/acheter/4002559578) + +[*  *  *  *  *  *  *  *  *  *  *  1 / 7    CHF 651’220.– Auf Anfrage 1, 8195 Wasterkingen Terrain à bâtir attractif dans un environnement calme et rural Bienvenue à Wasterkingen, une communauté idyllique et calme du Zurich Unterland, connue pour sa haute qualité de vie, sa tranquillité rurale et sa bonne accessibilité. Exactement ici, un terrain à bâtir attractif vous attend - la base idéale pour votre futur domicile.Le terrain est entièrement viabilisé et est situé en zone centrale B, ce qui vous offre de nombreuses options de conception. Que ce soit une maison unifamiliale moderne, un domicile classique au caractère de village ou un projet architectural individuel - ici, vous pouvez réaliser vos rêves de vie exactement selon vos idées.La communauté charmante de Wasterkingen impressionne par son emplacement calme au milieu des champs, des vignes et de la nature.Cette offre ImmoSky propose les avantages suivants *Plus de performance*:+ Entièrement viabilisé+ Communauté calme+ Taille idéale pour la flexibilité (650m²)+ Zone centrale B+ Coefficient d'occupation des sols pour bâtiment principal 30%Ce terrain vous offre la rare opportunité de combiner l'idylle rurale avec la proximité urbaine - un endroit où vous pouvez vous reposer et être parfaitement connecté.Réaliserez-vous ici votre rêve de propriété et concevrez-vous votre refuge personnel à Wasterkingen.Nous avons-vous convaincu avec cette offre? Alors n'hésitez pas à nous contacter pour plus de questions ou un rendez-vous de visite!(Le dossier de vente vous sera envoyé dans un délai maximum de 24 heures. Veuillez également vérifier votre dossier SPAM.)  Durée du trajet -](https://www.immoscout24.ch/acheter/4002537208) + +[*  *  *  *  *  *  *  *  *  *  *  1 / 7    CHF 7’540’490.– Staldernstrasse 13, 8158 Regensberg Terrain à développer dans un excellent emplacement en zone centrale 2 Dans la commune très demandée de Regensberg (ZH), un terrain très bien situé est en vente, qui convient idéalement aux investisseurs, entrepreneurs généraux ou totaux. Le parcelle de 2 557 m², no 949, est située en zone centrale 2, qui permet une variété de possibilités de développement liées à la construction et à l'utilisation, en particulier pour des projets résidentiels ou à usage mixte.Actuellement, un bâtiment non préservable se trouve sur la propriété, qui peut être démolit dans le cadre d'un nouveau développement. Aucune demande de construction ou de permis n'est disponible, il y a donc une totale liberté de conception dans le cadre des règlements de construction et d'urbanisme applicables.Les calculs montrent qu'une attente de revenu locatif durable de l'ordre de CHF 485 600 par an semble réaliste - en supposant une utilisation d'environ 1 664 m² d'espace utilisable principal (HNF) et 28 places de parking souterraines. Le taux de capitalisation déterminé est de 4,20 %.Chiffres clés d'évaluation :Valeur marchande (valeur foncière actualisée) : CHF 5 505 000Valeur de revenu dans un état renouvelé : CHF 11 556 795Valeur réelle (hypothétique) : CHF 12 485 000Revenu potentiel de vente : CHF 16 190 000Rendement brut (valeur locative) : 4,20 %Le développement hypothétique prévoit deux maisons multifamiliales avec une surface totale de plancher brut (BGF) de 2 080 m² - correspondant à un facteur d'utilisation des sols de 0,81, entièrement dans le cadre de la réglementation d'urbanisme. Les coûts de construction calculés (BKP 2-5) s'élèvent à environ CHF 8,74 millions. La valeur foncière actualisée par m² est de CHF 2 155, ce qui souligne encore le potentiel économique.La zone centrale 2 permet également des utilisations mixtes, telles que des offres commerciales au rez-de-chaussée, en plus de l'utilisation résidentielle pure. C'est un avantage supplémentaire pour des concepts de développement flexibles et adaptés au lieu. L'emplacement à Regensberg offre une qualité de vie résidentielle calme à proximité de l'agglomération de Zurich et est intégré dans un environnement historique attractif.En conclusion : le terrain offre la rare opportunité d'acquérir un terrain développeable dans un excellent emplacement avec un objet de démolition existant et de le construire selon ses propres idées. Grâce aux possibilités d'utilisation flexibles et à l'emplacement attractif, cet investissement représente un excellent point de départ pour des développements de projets à rendement élevé.Pour des informations détaillées, nous sommes à votre disposition.  Durée du trajet Nouveau 23 min.Station: Steinmaur](https://www.immoscout24.ch/acheter/4002529588) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    CHF 3’633’140.– Riedwiesenstrasse 20, 8305 Dietlikon RÉSERVÉ - Parcelle de construction industrielle dans un emplacement central à Dietlikon ZH Nous sommes ravis de vous présenter une parcelle de construction unique et extrêmement rare dans un emplacement central à Dietlikon ZH – une opportunité exceptionnelle avec des propriétés excellentes, particulièrement adaptée aux investisseurs.Emplacement central : La parcelle est située dans un quartier très demandé avec d'excellentes connexions : l'aéroport de Zurich est accessible en 10 minutes en voiture, et la ville de Zurich est accessible en 12 minutes en voiture • Visibilité : Votre entreprise sera parfaitement visible de l'autoroute, offrant des opportunités publicitaires optimales (environ 500 m2 de façade pour la publicité). • Densité de construction : Bénéficiez de la haute densité de construction de 10,0, qui permet une flexibilité et une efficacité maximales. • Droits de construction voisins : La parcelle a des droits de construction voisins à droite et à gauche. À l'arrière, un droit de construction voisin peut être obtenu de la ville de Zurich • Environ 3 500 m2 de surface brute possible • Parking souterrain / sous-sol jusqu'à environ 800 m2 peut être réalisé • Hauteur totale maximale 20 m. 7 étages avec 500 m2 de surface brute et 2,85 m de hauteur de pièce (brute) possibles • Parcelle : La surface plane de la parcelle simplifie la planification et l'exécution de la construction. • Forme : La parcelle a une forme idéale, permettant des possibilités de construction polyvalentes. • Jonction autoroutière : Brüttiseller Kreuz, situé directement à l'un des principaux carrefours autoroutiers de Suisse, offre à la parcelle une excellente accessibilité et des avantages logistiques • Commerce gênant : L'emplacement est également adapté au commerce qui peut être potentiellement gênant. • Les centres culturels et les activités hôtelières sont également possibles. Maintenant ou jamais – votre chance pour un excellent investissement :Une telle parcelle de construction industrielle dans cet emplacement est extrêmement rare sur le marché – depuis quelque temps, il n'y a pas eu d'offre comparable dans ce quartier très demandé. Sécurisez cette propriété unique maintenant, idéale pour les entrepreneurs visionnaires et les investisseurs qui comptent sur un emplacement stratégiquement optimal.Avez-vous été intéressé ? Alors contactez-nous aujourd'hui. Nous serons ravis de vous envoyer le dossier de vente détaillé, y compris une étude de faisabilité – exclusivement et sans engagement.  Durée du trajet Nouveau 14 min.Station: Dietlikon](https://www.immoscout24.ch/acheter/4002331523) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    Prix sur demande Kaffeestrasse, 8180 Bülach Votre bâtiment industriel directement à Bülach DescriptionNous serions ravis de développer et de réaliser un projet sur mesure répondant à vos besoins, qui vous sera mis à disposition à titre de location ou de propriété.Intéressé ou avez-vous des questions ? N'hésitez pas à nous contacter !Le terrain n'est pas celui qui convient à vos exigences ? Pas de problème ! Visitez notre site web et trouvez d'autres offres sur : gewerbeland-schweiz.ch  Durée du trajet Nouveau 20 min.Station: Bülach](https://www.immoscout24.ch/acheter/4001788654) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    Prix sur demande Kaffeestrasse, 8180 Bülach Votre bâtiment industriel directement à Bülach DescriptionNous serions ravis de développer et de réaliser un projet sur mesure répondant à vos besoins, qui vous sera mis à disposition à titre de location ou de propriété.Intéressé ou avez-vous des questions ? N'hésitez pas à nous contacter !Le terrain n'est pas celui qui convient à vos exigences ? Pas de problème ! Visitez notre site web et trouvez d'autres offres sur : gewerbeland-schweiz.ch  Durée du trajet Nouveau 20 min.Station: Bülach](https://www.immoscout24.ch/acheter/4001788644) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    * Quartier calme CHF 3’358’950.– 8192 Glattfelden TERRAIN À CONSTRUIRE SANS OBSTACLES À ZWEIDLEN Dans le populaire Zweidlen, nous vendons un terrain à construire attractif de 1'226 m² avec un objet existant. Notre étude de projet montre un potentiel élevé pour la construction d'une maison multifamiliale. • Surface brute au sol possible de jusqu'à 940 m² (projet 789 m²) • Zone résidentielle et commerciale WG 2.3 • Aucune protection du patrimoine pour l'objet existant • La frontière allemande à Kaiserstuhl est à seulement 8 minutes en voiture • L'aéroport de Zurich est accessible en seulement 19 minutes en voiture Intéressé ? Pour plus d'informations, des photos et une visite virtuelle de la propriété, ainsi que des options de visite, consultez : https://www.propertyowner.ch/de/immobilien/25-12278 Numéro de référence : 25-12278 Devenez membre gratuit de la Grundeigentümer Verband Schweiz aujourd'hui et profitez de nombreux avantages pour les membres : www.propertyowner.ch - Les membres de l'association peuvent financer la propriété en question ou d'autres propriétés avec le soutien de notre département de financement. - Les membres de l'association ont accès à notre service juridique (consultation téléphonique initiale gratuite de 30 minutes). - Évaluation professionnelle gratuite de la propriété - Consultation et calcul gratuits de l'impôt sur les gains immobiliers Êtes-vous devenu curieux ? En savoir plus sur notre site https://www.propertyowner.ch/immobilien/ et laissez-vous inspirer par nos offres. Nous nous réjouissons de la possibilité de vous rencontrer personnellement et de réaliser vos rêves immobiliers ! * Quartier calme  Durée du trajet -](https://www.immoscout24.ch/acheter/4002558181) + +[1](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich)[2](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich?pn=2)[...4](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich?pn=4)[](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich?pn=2) + +Sauvegarder la recherche Voir carte + +Propriétés suggérées sur base des résultats de ta recherche +----------------------------------------------------------- + +Autres objets intéressants +-------------------------- + +Localités - Canton Zurich + +* [Zurich](https://www.immoscout24.ch/fr/terrain/acheter/lieu-zuerich) + +Districts dans le canton de Canton Zurich + +* [District Affoltern](https://www.immoscout24.ch/fr/terrain/acheter/region-affoltern) +* [District Andelfingen](https://www.immoscout24.ch/fr/terrain/acheter/region-andelfingen) +* [District Bülach](https://www.immoscout24.ch/fr/terrain/acheter/region-buelach) +* [District Dielsdorf](https://www.immoscout24.ch/fr/terrain/acheter/region-dielsdorf) +* [District Dietikon](https://www.immoscout24.ch/fr/terrain/acheter/region-dietikon) +* [District Hinwil](https://www.immoscout24.ch/fr/terrain/acheter/region-hinwil) +* [District Horgen](https://www.immoscout24.ch/fr/terrain/acheter/region-horgen) +* [District Meilen](https://www.immoscout24.ch/fr/terrain/acheter/region-meilen) +* [District Pfäffikon](https://www.immoscout24.ch/fr/terrain/acheter/region-pfaeffikon) +* [District Uster](https://www.immoscout24.ch/fr/terrain/acheter/region-uster) +* [District Winterthur](https://www.immoscout24.ch/fr/terrain/acheter/region-winterthour) + +Cantons - Suisse (Switzerland) + +* [Canton Argovie](https://www.immoscout24.ch/fr/terrain/acheter/canton-argovie) +* [Canton Appenzell R.E.](https://www.immoscout24.ch/fr/terrain/acheter/canton-appenzell-re) +* [Canton Appenzell R.I.](https://www.immoscout24.ch/fr/terrain/acheter/canton-appenzell-ri) +* [Canton Bâle-Campagne](https://www.immoscout24.ch/fr/terrain/acheter/canton-bale-campagne) +* [Canton Bâle-Ville](https://www.immoscout24.ch/fr/terrain/acheter/canton-bale-ville) +* [Canton Berne](https://www.immoscout24.ch/fr/terrain/acheter/canton-berne) +* [Canton Fribourg](https://www.immoscout24.ch/fr/terrain/acheter/canton-fribourg) +* [Canton Genève](https://www.immoscout24.ch/fr/terrain/acheter/canton-geneve) +* [Canton Glaris](https://www.immoscout24.ch/fr/terrain/acheter/canton-glaris) +* [Canton Grisons](https://www.immoscout24.ch/fr/terrain/acheter/canton-grisons) +* [Canton Jura](https://www.immoscout24.ch/fr/terrain/acheter/canton-jura) +* [Canton Lucerne](https://www.immoscout24.ch/fr/terrain/acheter/canton-lucerne) +* [Canton Neuchâtel](https://www.immoscout24.ch/fr/terrain/acheter/canton-neuchatel) +* [Canton Nidwald](https://www.immoscout24.ch/fr/terrain/acheter/canton-nidwald) +* [Canton Obwald](https://www.immoscout24.ch/fr/terrain/acheter/canton-obwald) +* [Canton Schaffhouse](https://www.immoscout24.ch/fr/terrain/acheter/canton-schaffhouse) +* [Canton Schwyz](https://www.immoscout24.ch/fr/terrain/acheter/canton-schwyz) +* [Canton Soleure](https://www.immoscout24.ch/fr/terrain/acheter/canton-soleure) +* [Canton St. Gall](https://www.immoscout24.ch/fr/terrain/acheter/canton-st-gall) +* [Canton Thurgovie](https://www.immoscout24.ch/fr/terrain/acheter/canton-turgovie) +* [Canton Tessin](https://www.immoscout24.ch/fr/terrain/acheter/canton-tessin) +* [Canton Uri](https://www.immoscout24.ch/fr/terrain/acheter/canton-uri) +* [Canton Valais](https://www.immoscout24.ch/fr/terrain/acheter/canton-valais) +* [Canton Vaud](https://www.immoscout24.ch/fr/terrain/acheter/canton-vaud) +* [Canton Zoug](https://www.immoscout24.ch/fr/terrain/acheter/canton-zoug) + +### ImmoScout24 + +* [Créer une annonce](https://www.immoscout24.ch/fr/insertion/publier-soi-meme-en-ligne) +* [Publicité](https://swissmarketplace.group/fr/publicite/) +* [Réseau de publication](https://www.immoscout24.ch/c/fr/tout-sur-nous/reseau-de-publication) + +### À propos de nous + +* [Contact](https://www.immoscout24.ch/c/fr/tout-sur-nous/contact) +* [Portrait](https://swissmarketplace.group/fr/portfolio/real-estate/) +* [Jobs](https://swissmarketplace.group/fr/carrieres/) +* [Faits et chiffres](https://swissmarketplace.group/fr/portfolio/real-estate/) +* [Médias](https://swissmarketplace.group/fr/actualites/) +* [Newsletter](https://www.immoscout24.ch/c/fr/tout-sur-nous/newsletter-abonnement) +* [Service de médiation](https://konsum.ch/fr/service-de-mediation-pour-les-plateformes-immobilieres/) + +### Aspects légaux + +* [Protection des données](https://privacy.swissmarketplace.group/fr/) +* [Règles d’insertion](https://www.immoscout24.ch/c/fr/tout-sur-nous/regles-d-insertion-d-annonces) +* [Conseils de sécurité](https://www.immoscout24.ch/c/fr/tout-sur-nous/consignes-de-securite) +* [Impressum](https://www.immoscout24.ch/c/fr/tout-sur-nous/impressum) +* [CG](https://www.immoscout24.ch/c/fr/tout-sur-nous/conditions-generales) +* [Description des prestations](https://www.immoscout24.ch/c/fr/tout-sur-nous/dispositions-pour-les-membres-et-cg-supplementaires) +* [Signaler un problème de sécurité](https://swissmarketplace.group/fr/vulnerability-disclosure-program) +* Paramètres de confidentialité + +### Services + +* [Extrait du registre des poursuites](https://www.immoscout24.ch/fr/extrait-du-registre-des-poursuites?source=footer) +* [Aide au déménagement](https://www.immoscout24.ch/c/fr/demenagement) +* [Conseil en assurances](https://www.immoscout24.ch/c/fr/lp/conseil-en-assurances) +* [Liste agences](https://www.immoscout24.ch/liste-agences) +* [Calculateur hypothécaire](https://www.immoscout24.ch/fr/financement/calculateur-hypotheque) +* [Estimation immobilière](https://www.immoscout24.ch/fr/estimation) + +### Télécharger l’app + +[](https://7o11.app.link/IS24_Web_Footer_iOS?%243p=a_custom_358665 "iOS App")[](https://7o11.app.link/IS24_Web_Footer_GP?%243p=a_custom_358665 "Android App") + +### Notre partenaire + +[](https://www.swisstennis.ch/fr/?utm_source=website-immoscout24&utm_medium=footer) + +* [Deutsch](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich) +* [Français](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich) +* [Italiano](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo) +* [English](https://www.immoscout24.ch/en/plot/buy/canton-zurich) + +### Suivez-nous + +[](https://www.facebook.com/immoscout24.ch "Facebook")[](https://www.instagram.com/immoscout24ch/ "Instagram")[](https://twitter.com/ImmoScout24ch "Twitter")[](https://www.youtube.com/user/ImmoScout24Schweiz "YouTube")[](https://www.linkedin.com/company/immoscout24-schweiz/ "LinkedIn") + +[SMG Swiss Marketplace Group](https://swissmarketplace.group/fr/)[AutoScout24](https://www.autoscout24.ch/fr)[FinanceScout24](https://www.financescout24.ch/fr?utm_source=immoscout24.ch&utm_medium=web&utm_campaign=footer_bottom)[MotoScout24](https://www.motoscout24.ch/fr)[anibis.ch](https://www.anibis.ch/fr) + +© Copyright 2025 by SMG Swiss Marketplace Group SA. Tous droits réservés.La duplication et l’appropriation des annonces par des tiers, en particulier des photos et des données personnelles qu’elles contiennent, portent atteinte aux droits associés et sont strictement interdites. + +We Care About Your Privacy +-------------------------- + +We and our 455 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data.[Imprint](https://www.immoscout24.ch/en/info/impressum/3530) + +### We and our partners process data to provide: + +Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. List of Partners (vendors) + +I Accept No consent Show Purposes + + + +About Your Privacy +------------------ + +We process your data to deliver content or advertisements and measure the delivery of such content or advertisements to extract insights about our website. We share this information with our partners on the basis of consent. You may exercise your right to consent, based on a specific purpose below or at a partner level in the link under each purpose. These choices will be signaled to our vendors participating in the Transparency and Consent Framework. + +[Privacy Policy](https://www.immoscout24.ch/c/en/about-us/privacy-policy) + +Allow All +### Manage Consent Preferences + +#### Functional Cookies + +- [x] Functional Cookies + +These cookies enable the website to provide enhanced functionality and personalisation. They may be set by us or by third party providers whose services we have added to our pages. If you do not allow these cookies then some or all of these services may not function properly. + +Cookies Details + +#### Strictly Necessary Cookies + +Always Active + +These cookies are necessary for the website to function and cannot be switched off in our systems. They are usually only set in response to actions made by you which amount to a request for services, such as setting your privacy preferences, logging in or filling in forms. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. These cookies do not store any personally identifiable information. + +Cookies Details + +#### Targeting Cookies + +- [x] Targeting Cookies + +These cookies may be set on our website by our advertising partners. They can be used by these companies to build a profile of your interests and to control which advertisements you see on other websites. If you do not allow these cookies, you will still see advertisements, but they will no longer be tailored to you. Your master and usage data will also be made available to the other brands of the SMG Group for analysis, for the management of personalized advertising display, and for personalized marketing communication. The latter means that you may be contacted in a personalized manner for marketing purposes not only by this brand but also by all other brands of the SMG Group. The brands of the SMG Group are ImmoScout24, Homegate, Immostreet.ch, home.ch, Publimmo, Acheter-Louer.ch, CASASOFT, IAZI, AutoScout24, MotoScout24, anibis.ch, tutti.ch, Ricardo, FinanceScout24, Flatfox, and Moneyland. We use Enhanced Conversion that may transmit pseudonymised (e.g. hashed) email addresses to third parties such as Google or publishers (e.g. TX Group or Ringier AG) to improve campaign performance and measurement and/or to create audience segments. Personal identification is not possible unless you are logged in with the same email address and associated with an account of these third parties. Your personal data will be processed either jointly with these third parties, in accordance with their respective privacy notices, or independently by SMG as controller. Please note that your personal data may also be transferred to insecure third countries, where local authorities may access them without protection equivalent to European data protection law. If the level of data protection in a country does not match that of Switzerland, we ensure contractually that the protection of your personal data always corresponds to the level in Switzerland. + +Cookies Details + +#### Performance Cookies + +- [x] Performance Cookies + +These cookies allow us to count visits and traffic sources so we can measure and improve the performance of our site. They help us to know which pages are the most and least popular and see how visitors move around the site. All information these cookies collect is aggregated and therefore anonymous. If you do not allow these cookies we will not know when you have visited our site, and will not be able to monitor its performance. + +Cookies Details + +#### Store and/or access information on a device 365 partners can use this purpose + +- [x] Store and/or access information on a device + +Cookies, device or similar online identifiers (e.g. login-based identifiers, randomly assigned identifiers, network based identifiers) together with other information (e.g. browser type and information, language, screen size, supported technologies etc.) can be stored or read on your device to recognise it each time it connects to an app or to a website, for one or several of the purposes presented here. + +List of IAB Vendors|View Illustrations + +#### Personalised advertising and content, advertising and content measurement, audience research and services development 438 partners can use this purpose + +- [x] Personalised advertising and content, advertising and content measurement, audience research and services development + +* ##### Use limited data to select advertising 359 partners can use this purpose + +- [x] Switch Label +Advertising presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type or which content you are (or have been) interacting with (for example, to limit the number of times an ad is presented to you). + +View Illustrations + +* ##### Create profiles for personalised advertising 283 partners can use this purpose + +- [x] Switch Label +Information about your activity on this service (such as forms you submit, content you look at) can be stored and combined with other information about you (for example, information from your previous activity on this service and other websites or apps) or similar users. This is then used to build or improve a profile about you (that might include possible interests and personal aspects). Your profile can be used (also later) to present advertising that appears more relevant based on your possible interests by this and other entities. + +View Illustrations + +* ##### Use profiles to select personalised advertising 281 partners can use this purpose + +- [x] Switch Label +Advertising presented to you on this service can be based on your advertising profiles, which can reflect your activity on this service or other websites or apps (like the forms you submit, content you look at), possible interests and personal aspects. + +View Illustrations + +* ##### Create profiles to personalise content 103 partners can use this purpose + +- [x] Switch Label +Information about your activity on this service (for instance, forms you submit, non-advertising content you look at) can be stored and combined with other information about you (such as your previous activity on this service or other websites or apps) or similar users. This is then used to build or improve a profile about you (which might for example include possible interests and personal aspects). Your profile can be used (also later) to present content that appears more relevant based on your possible interests, such as by adapting the order in which content is shown to you, so that it is even easier for you to find content that matches your interests. + +View Illustrations + +* ##### Use profiles to select personalised content 92 partners can use this purpose + +- [x] Switch Label +Content presented to you on this service can be based on your content personalisation profiles, which can reflect your activity on this or other services (for instance, the forms you submit, content you look at), possible interests and personal aspects. This can for example be used to adapt the order in which content is shown to you, so that it is even easier for you to find (non-advertising) content that matches your interests. + +View Illustrations + +* ##### Measure advertising performance 404 partners can use this purpose + +- [x] Switch Label +Information regarding which advertising is presented to you and how you interact with it can be used to determine how well an advert has worked for you or other users and whether the goals of the advertising were reached. For instance, whether you saw an ad, whether you clicked on it, whether it led you to buy a product or visit a website, etc. This is very helpful to understand the relevance of advertising campaigns. + +View Illustrations + +* ##### Measure content performance 171 partners can use this purpose + +- [x] Switch Label +Information regarding which content is presented to you and how you interact with it can be used to determine whether the (non-advertising) content e.g. reached its intended audience and matched your interests. For instance, whether you read an article, watch a video, listen to a podcast or look at a product description, how long you spent on this service and the web pages you visit etc. This is very helpful to understand the relevance of (non-advertising) content that is shown to you. + +View Illustrations + +* ##### Understand audiences through statistics or combinations of data from different sources 253 partners can use this purpose + +- [x] Switch Label +Reports can be generated based on the combination of data sets (like user profiles, statistics, market research, analytics data) regarding your interactions and those of other users with advertising or (non-advertising) content to identify common characteristics (for instance, to determine which target audiences are more receptive to an ad campaign or to certain contents). + +View Illustrations + +* ##### Develop and improve services 300 partners can use this purpose + +- [x] Switch Label +Information about your activity on this service, such as your interaction with ads or content, can be very helpful to improve products and services and to build new products and services based on user interactions, the type of audience, etc. This specific purpose does not include the development or improvement of user profiles and identifiers. + +View Illustrations + +* ##### Use limited data to select content 83 partners can use this purpose + +- [x] Switch Label +Content presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type, or which content you are (or have been) interacting with (for example, to limit the number of times a video or an article is presented to you). + +View Illustrations + +List of IAB Vendors + +#### Use precise geolocation data 132 partners can use this special feature + +- [x] Use precise geolocation data + +With your acceptance, your precise location (within a radius of less than 500 metres) may be used in support of the purposes explained in this notice. + +List of IAB Vendors + +#### Actively scan device characteristics for identification 71 partners can use this special feature + +- [x] Actively scan device characteristics for identification + +With your acceptance, certain characteristics specific to your device might be requested and used to distinguish it from other devices (such as the installed fonts or plugins, the resolution of your screen) in support of the purposes explained in this notice. + +List of IAB Vendors + +#### Ensure security, prevent and detect fraud, and fix errors 290 partners can use this special purpose + +Always Active + +Your data can be used to monitor for and prevent unusual and possibly fraudulent activity (for example, regarding advertising, ad clicks by bots), and ensure systems and processes work properly and securely. It can also be used to correct any problems you, the publisher or the advertiser may encounter in the delivery of content and ads and in your interaction with them. + +List of IAB Vendors|View Illustrations + +#### Deliver and present advertising and content 286 partners can use this special purpose + +Always Active + +Certain information (like an IP address or device capabilities) is used to ensure the technical compatibility of the content or advertising, and to facilitate the transmission of the content or ad to your device. + +List of IAB Vendors|View Illustrations + +#### Match and combine data from other data sources 214 partners can use this feature + +Always Active + +Information about your activity on this service may be matched and combined with other information relating to you and originating from various sources (for instance your activity on a separate online service, your use of a loyalty card in-store, or your answers to a survey), in support of the purposes explained in this notice. + +List of IAB Vendors + +#### Link different devices 172 partners can use this feature + +Always Active + +In support of the purposes explained in this notice, your device might be considered as likely linked to other devices that belong to you or your household (for instance because you are logged in to the same service on both your phone and your computer, or because you may use the same Internet connection on both devices). + +List of IAB Vendors + +#### Identify devices based on information transmitted automatically 265 partners can use this feature + +Always Active + +Your device might be distinguished from other devices based on information it automatically sends when accessing the Internet (for instance, the IP address of your Internet connection or the type of browser you are using) in support of the purposes exposed in this notice. + +List of IAB Vendors + +#### Save and communicate privacy choices 245 partners can use this special purpose + +Always Active + +The choices you make regarding the purposes and entities listed in this notice are saved and made available to those entities in the form of digital signals (such as a string of characters). This is necessary in order to enable both this service and those entities to respect such choices. + +List of IAB Vendors|View Illustrations + +### Cookie List + +Clear + +- [x] checkbox label label + +Apply Cancel + +Consent Leg.Interest + +- [x] checkbox label label + +- [x] checkbox label label + +- [x] checkbox label label + +No consent Confirm My Choices + +[](https://www.onetrust.com/products/cookie-consent/) + + +=== https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo === +70 Terreno edificabile in vendita: Cantone Zurigo | ImmoScout24 + +=============== + +[](https://www.immoscout24.ch/it) +* [Cercare](https://www.immoscout24.ch/it "Cercare") +* [Servizi](https://www.immoscout24.ch/c/it/ipoteche "Servizi") + +[Creare un annuncio](https://www.immoscout24.ch/it/insertion/inserire-in-linea "Creare un annuncio") + +[Preferiti](https://www.immoscout24.ch/favoriti "Preferiti") + +[Il Mio Conto](https://www.immoscout24.ch/it/account-overview "Il Mio Conto") + +Menu + +[](https://www.immoscout24.ch/it) +* [Cercare](https://www.immoscout24.ch/it "Cercare") +* [Servizi](https://www.immoscout24.ch/c/it/ipoteche "Servizi") +* [Stimare](https://www.immoscout24.ch/it/valutazione "Stimare") +* [Rubrica](https://www.immoscout24.ch/c/it/rubrica-immobiliare "Rubrica") + +[Creare un annuncio](https://www.immoscout24.ch/it/insertion/inserire-in-linea "Creare un annuncio") + +[Preferiti](https://www.immoscout24.ch/favoriti "Preferiti") + +[Il Mio Conto](https://www.immoscout24.ch/it/account-overview "Il Mio Conto") + +Menu + +IT +* [DE](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich) +* [FR](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich) +* [IT](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo) +* [EN](https://www.immoscout24.ch/en/plot/buy/canton-zurich) + +1. [](https://www.immoscout24.ch/it) +2. [Terreno edificabile in vendita](https://www.immoscout24.ch/it/terreno/acquistare) +3. [Cantone Zurigo](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo) + +Dove? + + Cantone Zurigo + + Cantone Zurigo + + CHF a + + + + Filtri + + 70 oggetti + +70 risultati - Terreno edificabile in vendita: Cantone Zurigo +============================================================= + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 16    **360m²**, CHF 2’563’760.– Top Luegetenstrasse 11, 8489 Wildberg La tua nuova casa con potenziale - Casa di campagna idillica con riserva di terreno edificabile La tua nuova casa Benvenuti nella vostra futura casa dei sogni - una spaziosa e indipendente casa di campagna in un luogo tranquillo e idillico con vista sul pittoresco Wildberg. Qui, l'idillio rurale, la privacy e la rara opportunità di creare o ampliare uno spazio di vita secondo le vostre idee si incontrano.Se come un rifugio familiare affascinante con un grande giardino o come un oggetto di investimento con potenziale di sviluppo - questa proprietà unica vi offre entrambe le opzioni. Sul terreno di 1339m², avete non solo molto spazio per vivere, ma anche una riserva di terreno edificabile preziosa, che vi apre varie possibilità di progettazione. Le indagini iniziali mostrano: Esiste la possibilità di realizzare una casa a più famiglie con fino a cinque unità abitative - un vero e proprio valore aggiunto per gli acquirenti visionari.Immergetevi in un'oasi verde con una vista lontana - un luogo che vi dà la pace e vi ispira.Punti salienti in un colpo d'occhio • Luogo idillico e tranquillo con alta valenza ricreativa • Ampio terreno con 1339m², ideale per l'uso personale e/o per lo sviluppo di un nuovo edificio • Riserva di terreno edificabile: Potenziale di sviluppo attraente - secondo le stime iniziali, esiste la possibilità di realizzare, in aggiunta alla casa unifamiliare esistente, una casa a più famiglie con fino a cinque unità abitative (non vincolante, senza garanzia) • Giardino fiorito con diversi spazi di soggiorno, pergola con camino esterno, case di giardino, popolazione di alberi ben curata e vasti spazi verdi • Sostanza di costruzione solida con muratura a doppia parete • Concept di spazi ampi con circa 220m² di spazio di vita e circa 96m² di spazio di stoccaggio supplementare nel seminterrato. Superficie totale di circa 360m². • Ampio spazio di vita con stufa a mattoni confortevole - un luogo per arrivare e sentirsi bene • Cucina di vita pratica con sala da pranzo integrata - ideale per le ore sociali • 4 camere luminose - ideali per le famiglie o il telelavoro • 2 celle umide con luce diurna • Sottotetto ampiato per uno spazio supplementare o possibilità di utilizzo creativo • Riscaldamento mediante accumulo elettrico e riscaldamento a pavimento ad acqua • Garage con porta elettrica e possibilità di parcheggio supplementari sulla proprietà • Con una modernizzazione elegante, potete trasformare questa casa in un vero e proprio gioiello Prezzo di vendita: CHF 1'870'000.-Con il nostro tour virtuale a 360 gradi, potete già avere le prime impressioni di questa grande proprietà. Saremmo felici di mostrarvi questa proprietà direttamente sul posto e attendiamo con ansia il vostro contatto.Altri dati chiaveAnno di costruzione della casa: 1984, anno di costruzione della dépendance: 1986, volume della casa (GVZ): 936m³, volume della dépendance (GVZ): 40m³, foglio di registro fondiario: n. 437, numero di catasto: 249, 1/4 di proprietà soggettiva-reale del foglio 444, catasto 249. Superficie abitabile netta: circa 220m², superficie abitabile lorda: circa 360m², superficie del terreno: 1'339m².Costruzione solida, muratura a doppia parete, finestre in legno e metallo quasi nuove (EgoKiefer) con vetratura tripla e meneaux & volets in legno. Riscaldamento elettrico ad accumulo, riscaldamento a pavimento ad acqua, caldaia elettrica 300 litri.Ascensore, garage con apertura di porta elettrica. Cucina di stile casa di campagna con copertura in granito, lavastoviglie, cucina a induzione e frigorifero con compartimento congelatore.Rivestimenti di pavimentoPiano terra: Ingresso, corridoio, doccia, cucina, sala da pranzo con pavimento in piastrelle.Piano superiore: Camere e avant-corpo con pavimento in legno. Bagno con piastrelle.  Tempo di percorrenza Nuovo 28 min.Stazione: Rämismühle-Zell](https://www.immoscout24.ch/acquistare/4002491909) + +[*  *  *  *  *  *  *  *  1 / 4 Prezzo su richiesta Top Lüss, 8542 Wiesendangen Da consegnare in diritto di costruzione: 14’770 m2 di terreno edificabile nella migliore posizione a Wiesendangen, vantaggiosa in termini di tasse Da consegnare in diritto di costruzione :14’770 m2 di terreno edificabile nella migliore posizione a Wiesendangen, vantaggiosa in termini di tasseProprietà WD4674 – Lüss WiesendangenTutti i dettagli sulla proprietà, il contratto di diritto di costruzione e i criteri di assegnazione si trovano nel dossier allegato.Le offerte vincolanti per la ripresa del contratto di diritto di costruzione, compresa la prova di finanziamento, devono essere presentate a:Comune di WiesendangenAl signor Martin SchindlerSchulstrasse 208542 Wiesendangen Si prega di utilizzare il modulo in allegato per la presentazione dell'offerta.Scadenza per la presentazione : lunedì 20 ottobre 2025, ore 11:00 Tempo di percorrenza Nuovo 9 min.Stazione: Wiesendangen](https://www.immoscout24.ch/acquistare/4002510601) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 12    CHF 2’323’840.– Hürstringstrasse 37, 8046 Zürich Terreno con casa unifamiliare esistente e grande potenziale Saremmo felici di presentarvi questo terreno con grande potenziale e molte possibilità.Dopo consultazione, vendiamo un terreno con una casa unifamiliare esistente in una posizione tranquilla a Zurigo. Ciò che è interessante in questa proprietà, tuttavia, è che quando si acquista, si dispone già dell'autorizzazione di costruzione associata, che consente di ampliare e ristrutturare lo spazio abitativo in questa parcelle secondo le proprie esigenze.Non lontano dalla stazione principale di Zurigo, dietro il Käferberg, il terreno spazioso è situato in un quartiere residenziale tranquillo con zona a 30 km/h.A piedi, si può raggiungere una fermata dell'autobus, nonché la piccola foresta, che è ideale per brevi passeggiate.Le informazioni più importanti in breve: • Terreno con casa unifamiliare e autorizzazione di costruzione per ampliare la superficie abitabile • Anno di costruzione 1934 • Superficie del terreno di 410 m2 • Possibilità di progetto 1: Ampliamento in casa multifamiliare con due appartamenti in proprietà o in affitto • Possibilità di progetto 2: Ampliamento in casa a più generazioni Sperimentate l'atmosfera tranquilla e la simultanea vicinanza al centro città durante una visita personale!Per ulteriori informazioni sulla proprietà o per pianificare una visita, non esitate a contattarci in qualsiasi momento.  Tempo di percorrenza Nuovo 22 min.Stazione: Zürich Seebach](https://www.immoscout24.ch/acquistare/4002349882) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 11    CHF 3’290’400.– Luzernerstrasse 57, 8903 Birmensdorf (ZH) Posizione soleggiata con vista Per conto del nostro cliente, vendiamo un terreno edificabile in una posizione soleggiata con vista di 1'228 m² di superficie fondiaria (zona residenziale W2).La proprietà esistente si presenta in uno stato di manutenzione corrispondente alla sua età.Prezzo di vendita target: CHF 2'400'000Abbiamo suscitato il tuo interesse? Saremmo felici di inviarti l'esposé dettagliato di questa offerta interessante.  Tempo di percorrenza Nuovo 19 min.Stazione: Birmensdorf](https://www.immoscout24.ch/acquistare/4002566208) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13 CHF 4’044’440.– Mühlemattstrasse 12, 8135 Langnau am Albis Terreno edificabile o casa unifamiliare esistente in vendita! Questa casa unifamiliare indipendente si trova in una zona tranquilla e offre una rara combinazione di carattere architettonico, ambiente generoso e potenziale di sviluppo ispirante. Immersa in una grande quantità di verde e circondata da alberi, potrete godere di privacy, pace e una bellissima vista.La casa convince per la sua inconfondibile apparenza. I muri in mattoni all'interno danno allo spazio abitativo un'atmosfera calda e naturale, mentre il caminetto nel soggiorno assicura il comfort nei giorni più freddi. Il piano è aperto e accogliente, completato da ampie facciate di finestre che portano luce e natura nella casa.Un punto di forza è la spaziosa terrazza con una vista meravigliosa – ideale per ore piacevoli all'aperto. Il giardino è vasto e offre molto spazio per una progettazione individuale. Con un po' di attenzione, si può creare qui un meraviglioso paradiso verde – che sia come giardino familiare, rifugio o per progetti creativi all'aperto.Grazie alle dimensioni della proprietà e alla sua posizione, la proprietà apre anche prospettive interessanti per un eventuale nuovo edificio di sostituzione - come una casa unifamiliare moderna o una casa multifamiliare.Saremmo felici di fornirvi ulteriori informazioni o di concordare un appuntamento di visita personale. Scoprite il potenziale e l'atmosfera unica di questo posto. Nella documentazione di vendita, troverete tutte le informazioni importanti.  Tempo di percorrenza Nuovo 12 min.Stazione: Langnau-Gattikon](https://www.immoscout24.ch/acquistare/4002406229) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13    CHF 1’302’440.– Kanalweg 2, 8714 Feldbach Terreno per una casa unifamiliare progettata Nel tranquillo villaggio di Feldbach, sul lago di Zurigo, questo terreno con una fattoria esistente, costruita su un solo lato, è in vendita. Il prezzo di acquisto include un progetto preliminare realizzabile per una casa unifamiliare in sostituzione della fattoria.L'oggetto offre la possibilità unica di realizzare il vostro sogno di proprietà in un luogo idilliaco. Offre abbastanza spazio per una famiglia, e una combinazione di "vita e lavoro" è anche possibile.Entro 30 minuti, si può raggiungere Zurigo con la S-Bahn, e l'asilo nido e la scuola primaria sono anche vicine. Ci sono opportunità di shopping a Hombrechtikon, Stäfa e Rapperswil. In estate, una piscina vicina nella charmante Seebadi Feldbach invita a rinfrescarsi.Esiste una stima dei costi attuale per la casa (costruzione in elementi di legno) compresi i dintorni, i costi di costruzione e i costi accessori di Fr. 1'380'000.--.Abbiamo suscitato il vostro interesse? Allora chiamateci. Saremo felici di rispondere alle vostre domande o di fornirvi la nostra documentazione di vendita per studio. La proprietà può, naturalmente, essere visitata. Ci aspettiamo della vostra chiamata.  Tempo di percorrenza Nuovo 6 min.Stazione: Feldbach](https://www.immoscout24.ch/acquistare/4002434745) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 13    **5.5 locali**, CHF 4’111’620.– Schaffhauserstrasse 226b, 8057 Zürich Mehr Raum fürs Leben: Reihenhaus mit Potenzial Attraktive Stadtliegenschaft mit ausgearbeitetem ProjektIm Zürcher Kreis 11 veräussern wir ein hübsches Reiheneinfamilien-Eckhaus mit grosszügigem Umschwung. Die Liegenschaft und das Grundstück verfügen über viel Ausnützungspotenzial und ermöglicht so die Realisation spannender Projekte sowohl im Umbau als auch Neubau.Diese Liegenschaft überzeugt durch viele Besonderheiten: • grosszügiger Umschwung mit viel Potenzial • Blick ins Grüne von nahezu allen Fenstern • Schwedenofen im Wohnbereich • viel Stauraum durch Wandschränke und Estrich • Altbaucharme in modernem Quartier • zentrale und familienfreundliche Lage • sonnenverwöhnter Standort Haben wir Ihr Interesse geweckt? Bestellen Sie noch heute unsere ausführliche Verkaufsdokumentation mittels Kontaktformular und Sie erhalten weitere spannende Informationen zur Immobilie. Wir freuen uns über Ihre Kontaktaufnahme!Une oasis de verdure dans la ville de Zurich avec un projet élaboréDans le quartier 11 de Zurich, nous vendons une jolie maison mitoyenne en angle avec de vastes alentours. L'immeuble et le terrain disposent d'un grand potentiel d'exploitation et permettent ainsi la réalisation de projets passionnants, tant en transformation qu'en construction neuve.Cette propriété convainc par ses nombreuses particularités : • Un vaste terrain avec beaucoup de potentiel • Une vue sur la verdure depuis presque toutes les fenêtres • Un poêle suédois dans le séjour • beaucoup d'espace de rangement grâce aux armoires murales et au grenier • Le charme d'un ancien bâtiment dans un quartier moderne • Un emplacement central et favorable aux familles • Un emplacement ensoleillé Nous avons éveillé votre intérêt ? Commandez dès aujourd'hui notre documentation de vente détaillée au moyen du formulaire de contact et vous recevrez d'autres informations passionnantes sur le bien immobilier. Nous nous réjouissons de votre prise de contact!A green oasis in the city of Zurich with an elaborate projectIn Zurich's Kreis 11 district, we are selling a pretty terraced single-family corner house with spacious grounds. The property and the plot have a lot of utilization potential and thus enable the realization of exciting projects both in conversion and new construction.This property boasts many special features: • spacious grounds with lots of potential • view of the countryside from almost all windows • Swedish stove in the living area • lots of storage space thanks to wall cupboards and attic • old building charm in a modern district • central and family-friendly location • sun-drenched location Have we piqued your interest? Order our detailed sales documentation today using the contact form and you will receive further exciting information about the property. We look forward to hearing from you!  Tempo di percorrenza Nuovo 4 min.Stazione: Berninaplatz](https://www.immoscout24.ch/acquistare/4002346061) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 12 Prezzo su richiesta Überlandstrasse 23, 8340 Hinwil Parcelle di terra industriale e di costruzione in una posizione attraente nel Zürcher-Oberland Nella zona industriale vivace di Hinwil, vendiamo un terreno di costruzione industriale in una posizione molto frequentata, direttamente sull'asse principale di Rapperswil, Wetzikon, e Pfäffikon ZH. La parcelle di terra da costruire è situata ai margini della zona industriale e confina con la zona residenziale di Hinwil ZH.Dati chiave:- Superficie totale del terreno 4.246 m2- Zona di costruzione industriale/commerciale IG/7 - Fattore di volume di costruzione 7 m3/m2- Altezza massima dell'edificio 21,5 m- Lunghezza massima dell'edificio aperta- Grande distanza di confine alla strada nazionale- Distanza di edificio tutto intorno 3,5 m- Volume di costruzione possibile massimo circa 30.000 m3- Superficie lorda di piano circa 9.500 m2Il terreno di costruzione è attualmente ancora utilizzato con due unità abitative, un'officina di riparazione auto con un showroom separato, e una stazione di servizio. Intorno alla proprietà, ci sono grandi aree pavimentate disponibili per l'uso.  Tempo di percorrenza Nuovo 10 min.Stazione: Hinwil](https://www.immoscout24.ch/acquistare/4002417917) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 10 CHF 2’947’650.– Trottenrain 14, 8474 Dinhard Progetto di costruzione approvato a Dinhard-Welsikon con vantaggi fiscali Il terreno edificabile con un magazzino si trova in una zona centrale a Welsikon, alla periferia del comune di Dinhard, nella zona centrale. L'elevata utilizzazione ottenuta consente la costruzione di nuovi edifici attraenti in una posizione centrale. Le visualizzazioni e i piani del progetto di costruzione approvato possono essere trovati nella documentazione. Il magazzino è elencato nell'inventario comunale degli edifici protetti. Pertanto, è stato elaborato un accordo di protezione in consultazione con la protezione del patrimonio e il comune di Dinhard, che consente una conversione straordinaria in un loft moderno.Punti salienti: • progetto di costruzione approvato e pianificazione degli appalti per i nuovi edifici • accordo di protezione • eccellente posizione a Welsikon • paradiso fiscale (tasso di imposta comunale 83%) • parcelle di terreno edificabile ben proporzionata • buona connessione ai trasporti pubblici (stazione a 170 m) Realizzazione:L'associazione dei proprietari di Winterthur sostiene, se necessario, in stretta collaborazione con Kästle Architekten nella realizzazione del vostro progetto di nuovo edificio.Dalla pianificazione alla vendita/affitto del nuovo edificio terminato – l'associazione dei proprietari di Winterthur offre tutti i servizi da una sola fonte. Non c'è obbligo architettonico.Le parti interessate sono cordialmente invitate a contattarci.Chiamate il nostro team di vendita al 052 209 01 68 se desiderate ricevere informazioni aggiuntive o una visita. Ci rallegriamo di sentirvi.Il vostro team di vendita HEVImportante: Siamo esclusivamente incaricati della vendita. Il contatto diretto con i proprietari porterà all'esclusione dall'elenco delle parti interessate. S.E.&.O.  Tempo di percorrenza Nuovo 5 min.Stazione: Dinhard](https://www.immoscout24.ch/acquistare/4002188905) + +[ 1 / 1 CHF 2’399’240.– In der Gass 2, 8627 Grüningen Terreno con permesso di costruire in vendita In vendita, un terreno con un progetto di nuova costruzione approvato. Edificio C dell'Enssamble in Binzikerstrasse 21 / In der Gass 2, 8627 Grüningen. I garage attualmente esistenti possono essere demoliti e sostituiti da un nuovo edificio con 8 appartamenti di dimensioni diverse con aree esterne attraenti. Inoltre, la costruzione congiunta di un garage sotterraneo per 11 posti auto con accesso via la strada "In der Gass" è stata approvata.  Tempo di percorrenza Nuovo 54 min.Stazione: Esslingen](https://www.immoscout24.ch/acquistare/3003479026) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 2’604’890.– Im Königstal 2, 8487 Zell Tempo di percorrenza Nuovo 22 min.Stazione: Rämismühle-Zell](https://www.immoscout24.ch/acquistare/4002279293) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 4’112’990.– Im Königstal 3, 8487 Zell ZH Tempo di percorrenza Nuovo 22 min.Stazione: Rämismühle-Zell](https://www.immoscout24.ch/acquistare/4002279266) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 6’717’900.– Im Königstal 3, 8487 Zell ZH Tempo di percorrenza Nuovo 22 min.Stazione: Rämismühle-Zell](https://www.immoscout24.ch/acquistare/4002279259) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    CHF 2’879’100.– Rotweg 20, 8820 Wädenswil Il tuo nuovo progetto con vista sul lago Per conto del nostro cliente, vendiamo un'area residenziale preferita, elevata e tranquilla con una bella vista sul lago e sulla distanza, 706 m² di terreno edificabile con un oggetto di demolizione.Prezzo di vendita target: CHF 2'100'000.00Abbiamo suscitato il tuo interesse? Saremmo felici di inviarti l'esposé dettagliato di questa offerta interessante.  Tempo di percorrenza Nuovo 12 min.Stazione: Wädenswil](https://www.immoscout24.ch/acquistare/4002559578) + +[*  *  *  *  *  *  *  *  *  *  *  1 / 7    CHF 651’220.– Auf Anfrage 1, 8195 Wasterkingen Terreno edificabile attraente in un ambiente rurale e tranquillo Benvenuti a Wasterkingen, una comunità idillica e tranquilla del Zurich Unterland, nota per la sua alta qualità della vita, la tranquillità rurale e la buona accessibilità. Esattamente qui, un terreno edificabile attraente vi aspetta - la base ideale per la vostra futura casa.Il terreno è completamente urbanizzato e si trova nella zona centrale B, il che vi offre numerose opzioni di progettazione. Che si tratti di una casa unifamiliare moderna, di una casa classica con carattere di villaggio o di un progetto architettonico individuale - qui potete realizzare i vostri sogni di vita esattamente secondo le vostre idee.La comunità affascinante di Wasterkingen colpisce per la sua posizione tranquilla in mezzo ai campi, alle vigne e alla natura.Questa offerta ImmoSky propone i seguenti vantaggi *Prestazioni aggiuntive*:+ Completamente urbanizzato+ Comunità tranquilla+ Dimensione ideale per la flessibilità (650m²)+ Zona centrale B+ Coefficiente di occupazione del suolo per edificio principale 30%Questo terreno vi offre la rara opportunità di combinare l'idillio rurale con la vicinanza urbana - un luogo dove potete riposare e essere perfettamente connessi.Realizzerete qui il vostro sogno di proprietà e progetterete il vostro rifugio personale a Wasterkingen.Vi abbiamo convinto con questa offerta? Allora non esitate a contattarci per ulteriori domande o un appuntamento di visita!(La documentazione di vendita vi sarà inviata entro un massimo di 24 ore. Verificate anche la vostra cartella SPAM.)  Tempo di percorrenza -](https://www.immoscout24.ch/acquistare/4002537208) + +[*  *  *  *  *  *  *  *  *  *  *  1 / 7    CHF 7’540’490.– Staldernstrasse 13, 8158 Regensberg Terreno da sviluppare in una posizione eccellente nella zona centrale 2 Nel comune molto richiesto di Regensberg (ZH), un terreno molto ben situato è in vendita, che si adatta ideale agli investitori, imprenditori generali o totali. La parcella di 2 557 m², n. 949, si trova nella zona centrale 2, che consente una varietà di possibilità di sviluppo legate alla costruzione e all'uso, in particolare per progetti residenziali o a uso misto.Attualmente, un edificio non preservabile si trova sulla proprietà, che può essere demolito nel quadro di un nuovo sviluppo. Nessuna richiesta di costruzione o permesso è disponibile, quindi c'è una totale libertà di progettazione nel quadro delle norme di costruzione e urbanistica applicabili.I calcoli mostrano che un'attesa di reddito locativo sostenibile di circa CHF 485 600 all'anno sembra realistica - supponendo un utilizzo di circa 1 664 m² di spazio utilizzabile principale (HNF) e 28 posti auto sotterranei. Il tasso di capitalizzazione determinato è del 4,20 %.Cifre chiave di valutazione:Valore di mercato (valore fondiario attualizzato): CHF 5 505 000Valore di reddito in uno stato rinnovato: CHF 11 556 795Valore reale (ipotetico): CHF 12 485 000Reddito potenziale di vendita: CHF 16 190 000Rendita lorda (valore locativo): 4,20 %Lo sviluppo ipotetico prevede due case multifamiliari con una superficie totale di pavimento lordo (BGF) di 2 080 m² - corrispondente a un fattore di utilizzo del suolo di 0,81, interamente nel quadro della normativa urbanistica. I costi di costruzione calcolati (BKP 2-5) ammontano a circa CHF 8,74 milioni. Il valore fondiario attualizzato per m² è di CHF 2 155, il che sottolinea ulteriormente il potenziale economico.La zona centrale 2 consente anche utilizzi misti, come ad esempio offerte commerciali al piano terra, in aggiunta all'uso residenziale puro. Ciò è un vantaggio supplementare per concetti di sviluppo flessibili e adattati al luogo. La posizione a Regensberg offre una qualità della vita residenziale calma vicino all'agglomerazione di Zurigo e è integrata in un ambiente storico attraente.In conclusione: il terreno offre la rara opportunità di acquisire un terreno sviluppabile in una posizione eccellente con un oggetto di demolizione esistente e di costruirlo secondo le proprie idee. Grazie alle possibilità di utilizzo flessibili e alla posizione attraente, questo investimento rappresenta un ottimo punto di partenza per sviluppi di progetti a rendimento elevato.Per informazioni dettagliate, siamo a vostra disposizione.  Tempo di percorrenza Nuovo 23 min.Stazione: Steinmaur](https://www.immoscout24.ch/acquistare/4002529588) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    CHF 3’633’140.– Riedwiesenstrasse 20, 8305 Dietlikon RISERVATO - Lotto edificabile industriale in posizione centrale a Dietlikon ZH Siamo lieti di presentarvi un lotto edificabile unico e estremamente raro in una posizione centrale a Dietlikon ZH – un'opportunità eccezionale con proprietà eccellenti, particolarmente adatta agli investitori.Posizione centrale: Il lotto si trova in un quartiere molto richiesto con ottime connessioni: l'aeroporto di Zurigo è raggiungibile in 10 minuti in auto, e la città di Zurigo è raggiungibile in 12 minuti in auto • Visibilità: La vostra azienda sarà perfettamente visibile dall'autostrada, offrendo opportunità pubblicitarie ottimali (circa 500 m2 di facciata per la pubblicità). • Densità di costruzione: Beneficiate della alta densità di costruzione di 10,0, che consente una flessibilità e un'efficienza massime. • Diritti di costruzione vicini: Il lotto ha diritti di costruzione vicini a destra e a sinistra. Sul retro, un diritto di costruzione vicino può essere ottenuto dalla città di Zurigo • Circa 3.500 m2 di superficie lorda possibile • Parcheggio sotterraneo / seminterrato fino a circa 800 m2 può essere realizzato • Altezza totale massima 20 m. 7 piani con 500 m2 di superficie lorda e 2,85 m di altezza di stanza (lorda) possibili • Lotto: La superficie piana del lotto semplifica la pianificazione e l'esecuzione della costruzione. • Forma: Il lotto ha una forma ideale, che consente possibilità di costruzione polivalenti. • Incrocio autostradale: Brüttiseller Kreuz, situato direttamente a uno degli incroci autostradali più importanti della Svizzera, offre al lotto un'ottima accessibilità e vantaggi logistici • Commercio fastidioso: La posizione è anche adatta al commercio che può essere potenzialmente fastidioso. • I centri culturali e le attività alberghiere sono anche possibili. Adesso o mai – la vostra chance per un ottimo investimento:Un tale lotto edificabile industriale in questa posizione è estremamente raro sul mercato – da qualche tempo, non c'è stata un'offerta comparabile in questo quartiere molto richiesto. Assicuratevi questa proprietà unica adesso, ideale per gli imprenditori visionari e gli investitori che contano su una posizione strategicamente ottimale.Vi abbiamo interessato? Allora contattateci oggi. Saremo lieti di inviarvi il dossier di vendita dettagliato, compresa uno studio di fattibilità – esclusivamente e senza impegno.  Tempo di percorrenza Nuovo 14 min.Stazione: Dietlikon](https://www.immoscout24.ch/acquistare/4002331523) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    Prezzo su richiesta Kaffeestrasse, 8180 Bülach Il vostro edificio industriale direttamente a Bülach DescriptionSaremmo felici di sviluppare e realizzare un progetto su misura per le vostre esigenze, che sarà a vostra disposizione per l'affitto o la proprietà.Interessati o avete domande? Non esitate a contattarci!Il terreno non è quello giusto per le vostre esigenze? Nessun problema! Visita il nostro sito web e trova altre offerte su: gewerbeland-schweiz.ch  Tempo di percorrenza Nuovo 20 min.Stazione: Bülach](https://www.immoscout24.ch/acquistare/4001788654) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    Prezzo su richiesta Kaffeestrasse, 8180 Bülach Il tuo edificio industriale direttamente a Bülach DescriptionSaremmo felici di sviluppare e realizzare un progetto su misura per le tue esigenze, che sarà a tua disposizione per l'affitto o la proprietà.Interessato o hai domande? Contattaci!Il terreno non è quello giusto per le tue esigenze? Nessun problema! Visita il nostro sito web e trova altre offerte su: gewerbeland-schweiz.ch  Tempo di percorrenza Nuovo 20 min.Stazione: Bülach](https://www.immoscout24.ch/acquistare/4001788644) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    * Quartiere tranquillo CHF 3’358’950.– 8192 Glattfelden TERRENO EDIFICABILE SENZA OSTACOLI A ZWEIDLEN Nel popolare Zweidlen, vendiamo un terreno edificabile attraente di 1'226 m² con un oggetto esistente. Il nostro studio di progetto mostra un potenziale elevato per la costruzione di una casa multifamiliare. • Superficie lorda possibile di fino a 940 m² (progetto 789 m²) • Zona residenziale e commerciale WG 2.3 • Nessuna protezione del patrimonio per l'oggetto esistente • Il confine tedesco a Kaiserstuhl è a soli 8 minuti in auto • L'aeroporto di Zurigo è raggiungibile in soli 19 minuti in auto Interessato? Per ulteriori informazioni, foto e una visita virtuale della proprietà, nonché opzioni di visita, visitate: https://www.propertyowner.ch/de/immobilien/25-12278 Numero di riferimento: 25-12278 Diventate membro gratuito della Grundeigentümer Verband Schweiz oggi e beneficiate di numerosi vantaggi per i membri: www.propertyowner.ch - I membri dell'associazione possono finanziare la proprietà in questione o altre proprietà con il sostegno del nostro dipartimento di finanziamento. - I membri dell'associazione hanno accesso al nostro servizio legale (consultazione telefonica iniziale gratuita di 30 minuti). - Valutazione professionale gratuita della proprietà - Consultazione e calcolo gratuiti dell'imposta sulle plusvalenze immobiliari Siete diventati curiosi? Scoprite di più sul nostro sito https://www.propertyowner.ch/immobilien/ e lasciatevi ispirare dalle nostre offerte. Ci rallegriamo della possibilità di conoscerVi personalmente e di realizzare i Vostri sogni immobiliari! * Quartiere tranquillo  Tempo di percorrenza -](https://www.immoscout24.ch/acquistare/4002558181) + +[1](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo)[2](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo?pn=2)[...4](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo?pn=4)[](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo?pn=2) + +Salvare la ricerca Vista mappa + +Proprietà suggerite sulla base dei risultati della tua ricerca +-------------------------------------------------------------- + +Altri oggetti interessanti +-------------------------- + +Località - Cantone Zurigo + +* [Zurigo](https://www.immoscout24.ch/it/terreno/acquistare/luogo-zuerich) + +Distretti nel cantone di Cantone Zurigo + +* [Distretto Affoltern](https://www.immoscout24.ch/it/terreno/acquistare/regione-affoltern) +* [Distretto Andelfingen](https://www.immoscout24.ch/it/terreno/acquistare/regione-andelfingen) +* [Distretto Bülach](https://www.immoscout24.ch/it/terreno/acquistare/regione-buelach) +* [Distretto Dielsdorf](https://www.immoscout24.ch/it/terreno/acquistare/regione-dielsdorf) +* [Distretto Dietikon](https://www.immoscout24.ch/it/terreno/acquistare/regione-dietikon) +* [Distretto Hinwil](https://www.immoscout24.ch/it/terreno/acquistare/regione-hinwil) +* [Distretto Horgen](https://www.immoscout24.ch/it/terreno/acquistare/regione-horgen) +* [Distretto Meilen](https://www.immoscout24.ch/it/terreno/acquistare/regione-meilen) +* [Distretto Pfäffikon](https://www.immoscout24.ch/it/terreno/acquistare/regione-pfaeffikon) +* [Distretto Uster](https://www.immoscout24.ch/it/terreno/acquistare/regione-uster) +* [Distretto Winterthur](https://www.immoscout24.ch/it/terreno/acquistare/regione-winterthur) + +Cantoni - Svizzera (Switzerland) + +* [Cantone Argovia](https://www.immoscout24.ch/it/terreno/acquistare/cantone-argovia) +* [Cantone Appenzello esterno](https://www.immoscout24.ch/it/terreno/acquistare/cantone-appenzello-esterno) +* [Cantone Appenzello interno](https://www.immoscout24.ch/it/terreno/acquistare/cantone-appenzello-interno) +* [Cantone Basilea-campagna](https://www.immoscout24.ch/it/terreno/acquistare/cantone-basilea-campagna) +* [Cantone Basilea-città](https://www.immoscout24.ch/it/terreno/acquistare/cantone-basilea-citta) +* [Cantone Berna](https://www.immoscout24.ch/it/terreno/acquistare/cantone-berna) +* [Cantone Friborgo](https://www.immoscout24.ch/it/terreno/acquistare/cantone-friborgo) +* [Cantone Ginevra](https://www.immoscout24.ch/it/terreno/acquistare/cantone-ginevra) +* [Cantone Glarona](https://www.immoscout24.ch/it/terreno/acquistare/cantone-glarona) +* [Cantone Grigioni](https://www.immoscout24.ch/it/terreno/acquistare/cantone-grigioni) +* [Cantone Giura](https://www.immoscout24.ch/it/terreno/acquistare/cantone-giura) +* [Cantone Lucerna](https://www.immoscout24.ch/it/terreno/acquistare/cantone-lucerna) +* [Cantone Neuchatel](https://www.immoscout24.ch/it/terreno/acquistare/cantone-neuchatel) +* [Cantone Nidvaldo](https://www.immoscout24.ch/it/terreno/acquistare/cantone-nidvaldo) +* [Cantone Obvaldo](https://www.immoscout24.ch/it/terreno/acquistare/cantone-obvaldo) +* [Cantone Sciaffusa](https://www.immoscout24.ch/it/terreno/acquistare/cantone-sciaffusa) +* [Cantone Svitto](https://www.immoscout24.ch/it/terreno/acquistare/cantone-svitto) +* [Cantone Soletta](https://www.immoscout24.ch/it/terreno/acquistare/cantone-soletta) +* [Cantone San Gallo](https://www.immoscout24.ch/it/terreno/acquistare/cantone-san-gallo) +* [Cantone Turgovia](https://www.immoscout24.ch/it/terreno/acquistare/cantone-turgovia) +* [Cantone Ticino](https://www.immoscout24.ch/it/terreno/acquistare/cantone-ticino) +* [Cantone Uri](https://www.immoscout24.ch/it/terreno/acquistare/cantone-uri) +* [Cantone Vallese](https://www.immoscout24.ch/it/terreno/acquistare/cantone-vallese) +* [Cantone Vaud](https://www.immoscout24.ch/it/terreno/acquistare/cantone-vaud) +* [Cantone Zugo](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zugo) + +### ImmoScout24 + +* [Creare un annuncio](https://www.immoscout24.ch/it/insertion/inserire-in-linea) +* [Pubblicità](https://swissmarketplace.group/advertising/) +* [Rete di pubblicazione](https://www.immoscout24.ch/c/it/chi-siamo/rete-pubblicazioni) + +### Su di noi + +* [Contatto](https://www.immoscout24.ch/c/it/chi-siamo/contatto) +* [Ritratto](https://swissmarketplace.group/portfolio/real-estate/) +* [Impiego](https://swissmarketplace.group/career/) +* [Fatti e cifre](https://swissmarketplace.group/portfolio/real-estate/) +* [Media](https://swissmarketplace.group/media/) +* [Newsletter](https://www.immoscout24.ch/c/it/chi-siamo/newsletter-abbonamento) +* [Ufficio del mediatore](https://konsum.ch/it/ufficio-del-mediatore-per-le-piattaforme-immobiliari/) + +### Aspetti legali + +* [Protezione dei dati](https://privacy.swissmarketplace.group/it/) +* [Regole di inserzione](https://www.immoscout24.ch/c/it/chi-siamo/regole-d-inserzione-immoScout24) +* [Consigli di sicurezza](https://www.immoscout24.ch/c/it/chi-siamo/avviso-di-sicurezza) +* [Impressum](https://www.immoscout24.ch/c/it/chi-siamo/impressum) +* [CG](https://www.immoscout24.ch/c/it/chi-siamo/cgc) +* [Descrizione delle prestazioni](https://www.immoscout24.ch/c/it/chi-siamo/disposizioni-per-i-membri-e-cg-supplementari) +* [Segnala un problema di sicurezza](https://swissmarketplace.group/vulnerability-disclosure-program) +* Impostazioni sulla privacy + +### Services + +* [Estratto del registro delle esecuzioni](https://www.immoscout24.ch/it/certificato-di-solvibilita?source=footer) +* [Assistenza trasloco](https://www.immoscout24.ch/c/it/traslocare) +* [Consulenza assicurativa](https://www.immoscout24.ch/c/it/lp/consulenza-assicurativa) +* [Elenco agenzie](https://www.immoscout24.ch/elenco-agenzie) +* [Calcolatore di ipoteca](https://www.immoscout24.ch/it/finanziamento/calcolo-ipoteca) +* [Valutazione immobiliare](https://www.immoscout24.ch/it/valutazione) + +### Scaricare l’app + +[](https://7o11.app.link/IS24_Web_Footer_iOS?%243p=a_custom_358665 "iOS App")[](https://7o11.app.link/IS24_Web_Footer_GP?%243p=a_custom_358665 "Android App") + +### Il nostro partner + +[](https://www.swisstennis.ch/de/?utm_source=website-immoscout24&utm_medium=footer) + +* [Deutsch](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich) +* [Français](https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich) +* [Italiano](https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo) +* [English](https://www.immoscout24.ch/en/plot/buy/canton-zurich) + +### Ci segua + +[](https://www.facebook.com/immoscout24.ch "Facebook")[](https://www.instagram.com/immoscout24ch/ "Instagram")[](https://twitter.com/ImmoScout24ch "Twitter")[](https://www.youtube.com/user/ImmoScout24Schweiz "YouTube")[](https://www.linkedin.com/company/immoscout24-schweiz/ "LinkedIn") + +[SMG Swiss Marketplace Group](https://swissmarketplace.group/)[AutoScout24](https://www.autoscout24.ch/it)[FinanceScout24](https://www.financescout24.ch/it?utm_source=immoscout24.ch&utm_medium=web&utm_campaign=footer_bottom)[MotoScout24](https://www.motoscout24.ch/it)[anibis.ch](https://www.anibis.ch/it) + +© Copyright 2025 by SMG Swiss Marketplace Group SA. Tutti i diritti riservati.La duplicazione e la ripresa degli annunci da parte di terzi, in particolare di foto e dati personali in essi contenuti, viola i diritti ad essi associati ed è espressamente vietate. + +We Care About Your Privacy +-------------------------- + +We and our 455 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data.[Imprint](https://www.immoscout24.ch/en/info/impressum/3530) + +### We and our partners process data to provide: + +Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. List of Partners (vendors) + +I Accept No consent Show Purposes + + + +About Your Privacy +------------------ + +We process your data to deliver content or advertisements and measure the delivery of such content or advertisements to extract insights about our website. We share this information with our partners on the basis of consent. You may exercise your right to consent, based on a specific purpose below or at a partner level in the link under each purpose. These choices will be signaled to our vendors participating in the Transparency and Consent Framework. + +[Privacy Policy](https://www.immoscout24.ch/c/en/about-us/privacy-policy) + +Allow All +### Manage Consent Preferences + +#### Functional Cookies + +- [x] Functional Cookies + +These cookies enable the website to provide enhanced functionality and personalisation. They may be set by us or by third party providers whose services we have added to our pages. If you do not allow these cookies then some or all of these services may not function properly. + +Cookies Details + +#### Strictly Necessary Cookies + +Always Active + +These cookies are necessary for the website to function and cannot be switched off in our systems. They are usually only set in response to actions made by you which amount to a request for services, such as setting your privacy preferences, logging in or filling in forms. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. These cookies do not store any personally identifiable information. + +Cookies Details + +#### Targeting Cookies + +- [x] Targeting Cookies + +These cookies may be set on our website by our advertising partners. They can be used by these companies to build a profile of your interests and to control which advertisements you see on other websites. If you do not allow these cookies, you will still see advertisements, but they will no longer be tailored to you. Your master and usage data will also be made available to the other brands of the SMG Group for analysis, for the management of personalized advertising display, and for personalized marketing communication. The latter means that you may be contacted in a personalized manner for marketing purposes not only by this brand but also by all other brands of the SMG Group. The brands of the SMG Group are ImmoScout24, Homegate, Immostreet.ch, home.ch, Publimmo, Acheter-Louer.ch, CASASOFT, IAZI, AutoScout24, MotoScout24, anibis.ch, tutti.ch, Ricardo, FinanceScout24, Flatfox, and Moneyland. We use Enhanced Conversion that may transmit pseudonymised (e.g. hashed) email addresses to third parties such as Google or publishers (e.g. TX Group or Ringier AG) to improve campaign performance and measurement and/or to create audience segments. Personal identification is not possible unless you are logged in with the same email address and associated with an account of these third parties. Your personal data will be processed either jointly with these third parties, in accordance with their respective privacy notices, or independently by SMG as controller. Please note that your personal data may also be transferred to insecure third countries, where local authorities may access them without protection equivalent to European data protection law. If the level of data protection in a country does not match that of Switzerland, we ensure contractually that the protection of your personal data always corresponds to the level in Switzerland. + +Cookies Details + +#### Performance Cookies + +- [x] Performance Cookies + +These cookies allow us to count visits and traffic sources so we can measure and improve the performance of our site. They help us to know which pages are the most and least popular and see how visitors move around the site. All information these cookies collect is aggregated and therefore anonymous. If you do not allow these cookies we will not know when you have visited our site, and will not be able to monitor its performance. + +Cookies Details + +#### Store and/or access information on a device 365 partners can use this purpose + +- [x] Store and/or access information on a device + +Cookies, device or similar online identifiers (e.g. login-based identifiers, randomly assigned identifiers, network based identifiers) together with other information (e.g. browser type and information, language, screen size, supported technologies etc.) can be stored or read on your device to recognise it each time it connects to an app or to a website, for one or several of the purposes presented here. + +List of IAB Vendors|View Illustrations + +#### Personalised advertising and content, advertising and content measurement, audience research and services development 438 partners can use this purpose + +- [x] Personalised advertising and content, advertising and content measurement, audience research and services development + +* ##### Use limited data to select advertising 359 partners can use this purpose + +- [x] Switch Label +Advertising presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type or which content you are (or have been) interacting with (for example, to limit the number of times an ad is presented to you). + +View Illustrations + +* ##### Create profiles for personalised advertising 283 partners can use this purpose + +- [x] Switch Label +Information about your activity on this service (such as forms you submit, content you look at) can be stored and combined with other information about you (for example, information from your previous activity on this service and other websites or apps) or similar users. This is then used to build or improve a profile about you (that might include possible interests and personal aspects). Your profile can be used (also later) to present advertising that appears more relevant based on your possible interests by this and other entities. + +View Illustrations + +* ##### Use profiles to select personalised advertising 281 partners can use this purpose + +- [x] Switch Label +Advertising presented to you on this service can be based on your advertising profiles, which can reflect your activity on this service or other websites or apps (like the forms you submit, content you look at), possible interests and personal aspects. + +View Illustrations + +* ##### Create profiles to personalise content 103 partners can use this purpose + +- [x] Switch Label +Information about your activity on this service (for instance, forms you submit, non-advertising content you look at) can be stored and combined with other information about you (such as your previous activity on this service or other websites or apps) or similar users. This is then used to build or improve a profile about you (which might for example include possible interests and personal aspects). Your profile can be used (also later) to present content that appears more relevant based on your possible interests, such as by adapting the order in which content is shown to you, so that it is even easier for you to find content that matches your interests. + +View Illustrations + +* ##### Use profiles to select personalised content 92 partners can use this purpose + +- [x] Switch Label +Content presented to you on this service can be based on your content personalisation profiles, which can reflect your activity on this or other services (for instance, the forms you submit, content you look at), possible interests and personal aspects. This can for example be used to adapt the order in which content is shown to you, so that it is even easier for you to find (non-advertising) content that matches your interests. + +View Illustrations + +* ##### Measure advertising performance 404 partners can use this purpose + +- [x] Switch Label +Information regarding which advertising is presented to you and how you interact with it can be used to determine how well an advert has worked for you or other users and whether the goals of the advertising were reached. For instance, whether you saw an ad, whether you clicked on it, whether it led you to buy a product or visit a website, etc. This is very helpful to understand the relevance of advertising campaigns. + +View Illustrations + +* ##### Measure content performance 171 partners can use this purpose + +- [x] Switch Label +Information regarding which content is presented to you and how you interact with it can be used to determine whether the (non-advertising) content e.g. reached its intended audience and matched your interests. For instance, whether you read an article, watch a video, listen to a podcast or look at a product description, how long you spent on this service and the web pages you visit etc. This is very helpful to understand the relevance of (non-advertising) content that is shown to you. + +View Illustrations + +* ##### Understand audiences through statistics or combinations of data from different sources 253 partners can use this purpose + +- [x] Switch Label +Reports can be generated based on the combination of data sets (like user profiles, statistics, market research, analytics data) regarding your interactions and those of other users with advertising or (non-advertising) content to identify common characteristics (for instance, to determine which target audiences are more receptive to an ad campaign or to certain contents). + +View Illustrations + +* ##### Develop and improve services 300 partners can use this purpose + +- [x] Switch Label +Information about your activity on this service, such as your interaction with ads or content, can be very helpful to improve products and services and to build new products and services based on user interactions, the type of audience, etc. This specific purpose does not include the development or improvement of user profiles and identifiers. + +View Illustrations + +* ##### Use limited data to select content 83 partners can use this purpose + +- [x] Switch Label +Content presented to you on this service can be based on limited data, such as the website or app you are using, your non-precise location, your device type, or which content you are (or have been) interacting with (for example, to limit the number of times a video or an article is presented to you). + +View Illustrations + +List of IAB Vendors + +#### Use precise geolocation data 132 partners can use this special feature + +- [x] Use precise geolocation data + +With your acceptance, your precise location (within a radius of less than 500 metres) may be used in support of the purposes explained in this notice. + +List of IAB Vendors + +#### Actively scan device characteristics for identification 71 partners can use this special feature + +- [x] Actively scan device characteristics for identification + +With your acceptance, certain characteristics specific to your device might be requested and used to distinguish it from other devices (such as the installed fonts or plugins, the resolution of your screen) in support of the purposes explained in this notice. + +List of IAB Vendors + +#### Ensure security, prevent and detect fraud, and fix errors 290 partners can use this special purpose + +Always Active + +Your data can be used to monitor for and prevent unusual and possibly fraudulent activity (for example, regarding advertising, ad clicks by bots), and ensure systems and processes work properly and securely. It can also be used to correct any problems you, the publisher or the advertiser may encounter in the delivery of content and ads and in your interaction with them. + +List of IAB Vendors|View Illustrations + +#### Deliver and present advertising and content 286 partners can use this special purpose + +Always Active + +Certain information (like an IP address or device capabilities) is used to ensure the technical compatibility of the content or advertising, and to facilitate the transmission of the content or ad to your device. + +List of IAB Vendors|View Illustrations + +#### Match and combine data from other data sources 214 partners can use this feature + +Always Active + +Information about your activity on this service may be matched and combined with other information relating to you and originating from various sources (for instance your activity on a separate online service, your use of a loyalty card in-store, or your answers to a survey), in support of the purposes explained in this notice. + +List of IAB Vendors + +#### Link different devices 172 partners can use this feature + +Always Active + +In support of the purposes explained in this notice, your device might be considered as likely linked to other devices that belong to you or your household (for instance because you are logged in to the same service on both your phone and your computer, or because you may use the same Internet connection on both devices). + +List of IAB Vendors + +#### Identify devices based on information transmitted automatically 265 partners can use this feature + +Always Active + +Your device might be distinguished from other devices based on information it automatically sends when accessing the Internet (for instance, the IP address of your Internet connection or the type of browser you are using) in support of the purposes exposed in this notice. + +List of IAB Vendors + +#### Save and communicate privacy choices 245 partners can use this special purpose + +Always Active + +The choices you make regarding the purposes and entities listed in this notice are saved and made available to those entities in the form of digital signals (such as a string of characters). This is necessary in order to enable both this service and those entities to respect such choices. + +List of IAB Vendors|View Illustrations + +### Cookie List + +Clear + +- [x] checkbox label label + +Apply Cancel + +Consent Leg.Interest + +- [x] checkbox label label + +- [x] checkbox label label + +- [x] checkbox label label + +No consent Confirm My Choices + +[](https://www.onetrust.com/products/cookie-consent/) + + +=== https://www.comparis.ch/versicherung === +Versicherungen Schweiz: informieren & vergleichen + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/versicherung)[IT](https://it.comparis.ch/versicherung)[EN](https://en.comparis.ch/versicherung) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/versicherung)[FR](https://fr.comparis.ch/versicherung)[IT](https://it.comparis.ch/versicherung)[EN](https://en.comparis.ch/versicherung) + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. Versicherungen + +Versicherungen der Schweiz im Vergleich +======================================= + +Schützen Sie sich, Ihre Familie und Ihr Eigentum. Bei Comparis finden Sie verschiedene Vergleiche und umfangreiche Informationen rund um das Thema Versicherung in der Schweiz. + +[Person versichern](https://www.comparis.ch/versicherung#content-2)[Fahrzeug versichern](https://www.comparis.ch/versicherung#content-3)[Eigentum versichern](https://www.comparis.ch/versicherung#content-4) + + + +Umfassend + +Bei uns finden Sie umfangreiche Versicherungsvergleiche für verschiedene Lebenssituationen. + + + +Hohes Sparpotenzial + +Wir zeigen Ihnen übersichtlich und unverbindlich, wo Sie Geld sparen können. + + + +Einfach und schnell + +Mit nur wenigen Angaben können Sie sofort vergleichen. + + + +Umfassend + +Bei uns finden Sie umfangreiche Versicherungsvergleiche für verschiedene Lebenssituationen. + + + +Hohes Sparpotenzial + +Wir zeigen Ihnen übersichtlich und unverbindlich, wo Sie Geld sparen können. + + + +Einfach und schnell + +Mit nur wenigen Angaben können Sie sofort vergleichen. + +Person versichern +----------------- + +Schützen Sie sich und Ihre Liebsten. Comparis bietet Ihnen verschiedene Vergleiche und umfangreiche Informationen zu den Themen Gesundheit und Leben. + +[](https://www.comparis.ch/krankenkassen/default) + +[### Krankenkasse Erfahren Sie das Wichtigste zum Thema Krankenkasse in der Schweiz. Unsere Tipps helfen dabei, die passende Grund- und Zusatzversicherung zu finden.](https://www.comparis.ch/krankenkassen/default) + +[Krankenkassen vergleichen](https://www.comparis.ch/krankenkassen/input) + +[](https://www.comparis.ch/lebensversicherung/default) + +[### Lebensversicherung Eine Lebensversicherung lohnt sich für jeden. Aber welche Varianten gibt es? Bei Comparis finden Sie die relevanten Informationen.](https://www.comparis.ch/lebensversicherung/default) + +[Unverbindlich beraten lassen](https://www.comparis.ch/altersvorsorge/beratung?origin=vle) + +[](https://www.comparis.ch/rechtsschutz/default) + +[### Rechtsschutz Anwaltshonorare und Gerichtskosten sind teuer. Schützen Sie sich mit einer Rechtsschutzversicherung und vergleichen Sie die Prämien.](https://www.comparis.ch/rechtsschutz/default) + +[Rechtsschutz Prämien vergleichen](https://www.comparis.ch/rechtsschutz/input) + +[](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +[### Reiseversicherung Können Sie Ihre Reise z. B. aufgrund eines unerwarteten Ereignisses nicht antreten? Mit unseren Tipps sind Sie günstig und optimal versichert.](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +Fahrzeug versichern +------------------- + +Mit unseren Versicherungsvergleichen, Services und Informationen rund um Töff und Auto finden Sie das passende Angebot und sparen Prämien. + +[](https://www.comparis.ch/autoversicherung/default) + +[### Autoversicherung Vollkasko? Oder doch nur Teilkasko? Welche Versicherung ist für mich geeignet? Auf Comparis finden Sie Antworten zu diesen und vielen weiteren Fragen rund um das Thema Auto.](https://www.comparis.ch/autoversicherung/default) + +[Autoversicherung berechnen](https://www.comparis.ch/autoversicherung/berechnen) + +[](https://www.comparis.ch/motorradversicherung/default) + +[### Motorradversicherung Damit Sie sorglos fahren können, halten wir Sie mit unseren Versicherungsvergleichen, Infos und Tipps auf dem Laufenden.](https://www.comparis.ch/motorradversicherung/default) + +[Motorradversicherung vergleichen](https://www.comparis.ch/motorradversicherung/vergleich/fahrzeug) + +Eigentum versichern +------------------- + +Vorsicht ist besser als Nachsicht. Mit der optimalen Versicherung schützen Sie sich vor finanziellen Einbussen und sparen unnötige Kosten aufgrund von Überversicherung. + +[](https://www.comparis.ch/hausrat-versicherung/default) + +[### Hausrat und Privathaftpflicht Die Hausratversicherung deckt Schäden an Ihrem Hab und Gut durch etwa Feuer, Wasser oder Diebstahl. Die Privathaftpflicht schützt Sie, wenn Sie anderen ungewollt Schaden zufügen. Comparis klärt Sie über die Details auf.](https://www.comparis.ch/hausrat-versicherung/default) + +[Hausrat und Privathaftpflicht vergleichen](https://www.comparis.ch/hausrat-versicherung/comparison/input?insuranceType=3) + +[](https://www.comparis.ch/tierversicherung/default) + +[### Tierversicherung Auch unsere Vierbeiner wollen gut versichert sein. Denn schnell ist was passiert und die Arztrechnung für Hund und Katze hoch. Vergleichen Sie Tierversicherungen und nutzen Sie unsere Services rund um Ihre Fellnasen.](https://www.comparis.ch/tierversicherung/default) + +[Tierversicherungen vergleichen](https://www.comparis.ch/tierversicherung/vergleichen?insuranceType=1) + +Aktuelle Tipps und Informationen zum Thema Versicherungen +--------------------------------------------------------- + +Unsere Tipps helfen Ihnen, beim Thema Versicherungen die richtigen Entscheidungen zu treffen. + +[ ### Schlüssel verloren Schweiz: Was tun und wer zahlt? 15.11.2023](https://www.comparis.ch/hausrat-versicherung/schaden/schluessel-verloren)[ ### Krankenkasse wechseln und kündigen: Fristen und Vorgehen 12.09.2024](https://www.comparis.ch/krankenkassen/system/kassenwechsel)[ ### Autoversicherung kündigen in der Schweiz: So geht's 27.08.2025](https://www.comparis.ch/autoversicherung/vertrag/kuendigungsfristen) + +Häufig gestellte Versicherungsfragen +------------------------------------ + +Hier finden Sie die häufigsten Fragen unserer Nutzerinnen und Nutzer. + +### Wie kann ich meine Versicherung kündigen? + +Jede Versicherung hat ihre eigenen Kündigungsrechte und -fristen, die Sie bei einer einseitigen Vertragsauflösung beachten müssen. Die genaue Handhabung ist von Vertrag und Anbieter abhängig und in den allgemeinen Versicherungsbedingungen festgelegt. + +Kündigt man einen Versicherungsvertrag wie oben genannt, handelt es sich um eine **ordentliche Kündigung**. + +In verschiedenen Situationen kennen Versicherungsverträge zudem **ausserordentliche Kündigungsgründe**. Darunter versteht man beispielsweise eine allgemeine Prämienerhöhung der Krankenkasse oder einen gedeckten Schadensfall in der Autoversicherung. + +Die Kündigung muss generell schriftlich bei der Versicherung eingehen. Massgebend ist dabei der Posteingang bei der Versicherung und nicht der Poststempel. Wir empfehlen Ihnen, den Kündigungsbrief frühzeitig per Einschreiben zu versenden. + +Hier finden Sie detaillierte Kündigungsinformationen zu den jeweiligen Versicherungen: + +[Krankenkasse](https://www.comparis.ch/krankenkassen/system/kassenwechsel) + +[Auto- und Motorradversicherung](https://www.comparis.ch/autoversicherung/vertrag/kuendigungsfristen) + +[Hausrat- und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/wechseln/kuendigung) + +[Rechtsschutz](https://www.comparis.ch/rechtsschutz/deckung-leistung/wichtige-begriffe) + +### Wie kann ich zu einer anderen Versicherung wechseln? + +Wir zeigen Ihnen, wie Sie Ihre aktuelle Versicherung in nur vier Schritten ganz leicht kündigen und zu einer anderen Gesellschaft wechseln können. + +1. **Prämien vergleichen** + +Die Höhe der Prämien kann je nach Anbieter stark variieren, zudem kommen laufend neue Produkte auf den Markt. Ein Vergleich verschiedener Angebote und ein Versicherungswechsel können sich somit lohnen. + +2. **Offerten einholen** + +Holen Sie eine oder mehrere Versicherungsofferten ein, vergleichen Sie die Leistungen und finden Sie das beste Angebot. + +3. **Versicherung rechtzeitig kündigen** + +Informieren Sie sich über Ihre Kündigungsrechte und welche Fristen Sie dabei einhalten müssen. Ziehen Sie dazu die allgemeinen Versicherungsbedingungen Ihres Vertrages bei. + +4. **Neue Versicherung abschliessen** + +Die zuvor gewählte Offerte können Sie nun annehmen und von der optimierten Leistung profitieren. + +Beachten Sie: Bei einer [Krankenkassen-Zusatzversicherung](https://www.comparis.ch/krankenkassen/zusatzversicherungen) sollten Sie diesen Schritt der Kündigung vorziehen und abwarten, bis Sie die Aufnahmebestätigung der neuen Krankenkasse erhalten haben. + +### Welche Versicherungen kann ich bei Comparis vergleichen? + +Bei Comparis können Sie folgende Versicherungen vergleichen: + +[Krankenkasse](https://www.comparis.ch/krankenkassen/default) + +[Autoversicherung](https://www.comparis.ch/autoversicherung/berechnen) + +[Hausrat- und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/comparison/input) + +[Motorradversicherung](https://www.comparis.ch/motorradversicherung/vergleich/fahrzeug) + +[Privat- und Verkehrsrechtsschutz](https://www.comparis.ch/rechtsschutz/input) + +[Tierversicherung](https://www.comparis.ch/tierversicherung/vergleichen?insuranceType=1) + +Für folgende Versicherungen können Sie eine unverbindliche und kostenlose Beratung anfordern: + +[Lebensversicherung](https://www.comparis.ch/altersvorsorge/beratung?origin=vle) + +[Reiseversicherung](https://calendly.com/optimatis-vorsorge/reiseversicherung?month=2022-01) + +### Welche Versicherungen sind in der Schweiz obligatorisch? + +In der Schweiz sind einige Versicherungen obligatorisch, das heisst, dass Sie gesetzlich dazu verpflichtet sind, diese Versicherungen abzuschliessen. + +Dies gilt vor allem für die [Krankenkasse](https://www.comparis.ch/krankenkassen/default). Die obligatorische Unfallversicherung (UVG) besitzen Sie automatisch, wenn Sie mehr als 8 Stunden in der Woche beim selben Arbeitgeber angestellt sind. Ist Ihr Pensum geringer, müssen Sie diese Unfalldeckung privat über die Krankenversicherung abschliessen. + +Falls Sie ein [Auto](https://www.comparis.ch/autoversicherung/berechnen) oder [Motorrad](https://www.comparis.ch/motorradversicherung/vergleich/fahrzeug) besitzen, ist mindestens die Haftpflicht Pflicht. Diese deckt Schäden an fremden Fahrzeugen, Sachen oder Personen. + +Die Teilkasko- oder Vollkaskoversicherungen sind freiwillig, lohnen sich aber vor allem bei neueren oder teureren Fahrzeugen schnell. + +Weitere Versicherungen, die nicht obligatorisch sind, aber jeder haben sollte: + +* [Privathaftpflichtversicherung](https://www.comparis.ch/hausrat-versicherung/comparison/input?insuranceType=2) + +* [Hausratversicherung](https://www.comparis.ch/hausrat-versicherung/comparison/input?insuranceType=1) + +* [Rechtsschutzversicherung](https://www.comparis.ch/rechtsschutz/input) + +* Private Vorsorge im Rahmen einer [Lebensversicherung](https://www.comparis.ch/altersvorsorge/beratung?origin=vle) oder [3. Säule](https://www.comparis.ch/altersvorsorge/saeule3a) + +### Kann ich bei Comparis eine Versicherung auch direkt abschliessen? + +Ja! [Hausrat- und Privathaftpflichtversicherungen](https://www.comparis.ch/hausrat-versicherung/comparison/input) gewisser Anbieter können Sie bei Comparis direkt online abschliessen. + +Das Netzwerk unserer Direkt-Abschluss-Partner bauen wir stetig aus. + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) + + +=== https://www.comparis.ch/finanzen === +Wichtiges über Finanzen in der Schweiz + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/finanzen)[IT](https://it.comparis.ch/finanzen)[EN](https://en.comparis.ch/finanzen) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/finanzen)[FR](https://fr.comparis.ch/finanzen)[IT](https://it.comparis.ch/finanzen)[EN](https://en.comparis.ch/finanzen) + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. Finanzen + +Wichtiges über Finanzen in der Schweiz +====================================== + +Ob Privatkredit, Hypothek oder Bonitätsauskunft: Mit unseren Vergleichen und Services finden Sie die passende Finanzierungslösung für sich. + +[Geld aufnehmen](https://www.comparis.ch/finanzen#content-2)[Immobilie finanzieren](https://www.comparis.ch/finanzen#content-3)[Altersvorsorge planen](https://www.comparis.ch/finanzen#content-4)[Steuern vergleichen](https://www.comparis.ch/finanzen#content-5)[Fahrzeug finanzieren](https://www.comparis.ch/finanzen#content-6)[Wirtschaftsinfos einholen](https://www.comparis.ch/finanzen#content-7) + + + +Überblick verschaffen + +Bei uns finden Sie umfangreiche Vergleiche und Informationen zu verschiedenen Finanzprodukten. + + + +Unabhängigkeit + +HypoPlus ist der Hypothekenpartner von Comparis. HypoPlus unterstützt Sie bei der Suche nach der passenden Hypothek und dem besten Zinssatz. + + + +Zufriedene Kunden + +Die Kundinnen und Kunden von HypoPlus schätzen die professionelle Beratung und die hilfreichen Services rund um das Thema Finanzen. + + + +Überblick verschaffen + +Bei uns finden Sie umfangreiche Vergleiche und Informationen zu verschiedenen Finanzprodukten. + + + +Unabhängigkeit + +HypoPlus ist der Hypothekenpartner von Comparis. HypoPlus unterstützt Sie bei der Suche nach der passenden Hypothek und dem besten Zinssatz. + + + +Zufriedene Kunden + +Die Kundinnen und Kunden von HypoPlus schätzen die professionelle Beratung und die hilfreichen Services rund um das Thema Finanzen. + +Geld aufnehmen +-------------- + +Manchmal ändern sich die Lebensumstände und Sie müssen einen finanziellen Engpass überbrücken oder eine ungeplante Anschaffung machen. Comparis klärt auf, worauf Sie bei einem Kredit achten sollten. + +[](https://www.comparis.ch/privatkredit/default) + +[### Privatkredit Wir informieren Sie zum Thema Privatkredit und unterstützen Sie von der ersten Anfrage bis zum erfolgreichen Abschluss.](https://www.comparis.ch/privatkredit/default) + +[Zum Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + +[](https://www.comparis.ch/privatkredit/kreditvergleich) + +[### Kreditvergleich Finden Sie heraus, wie hoch die monatlichen Raten und Kosten für die im Markt angebotenen Zinssätze ausfallen.](https://www.comparis.ch/privatkredit/kreditvergleich) + +Immobilie finanzieren +--------------------- + +Hypotheken und Zinsen sind entscheidend für Ihre Immobilienfinanzierung. Comparis bietet Ihnen einen Überblick, damit Sie fundierte Entscheidungen treffen können. + +[](https://www.comparis.ch/hypotheken/default) + +[### Hypotheken Ob Hypothekarzinsen vergleichen, individuelle Zinsen berechnen oder zum Thema Hypotheken auf dem Laufenden bleiben: Zusammen mit unserem Hypothekenpartner HypoPlus unterstützen wir Sie unabhängig und persönlich.](https://www.comparis.ch/hypotheken/default) + +[Persönliche Zinsen berechnen](https://www.comparis.ch/hypotheken/angaben) + +[](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +[### Zinsentwicklung Mit unserem interaktiven Hypotheken-Chart vergleichen Sie die Historie von Laufzeiten und unterschiedlichen Anbietern.](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +[Zinssätze vergleichen](https://www.comparis.ch/hypotheken/zinssatz) + +Altersvorsorge planen +--------------------- + +Mit einer optimierten Altersvorsorge können Sie eine Vorsorgelücke verhindern. Comparis berät Sie neutral und unabhängig und versorgt Sie mit wichtigen Informationen. + +[](https://www.comparis.ch/altersvorsorge/default) + +[### Altersvorsorge Für eine optimale Altersvorsorge ist es wichtig, das Schweizer Vorsorgesystem und die eigene finanzielle Lage zu kennen. Comparis informiert und begleitet Sie.](https://www.comparis.ch/altersvorsorge/default) + +[Zur Vorsorgeberatung](https://www.comparis.ch/altersvorsorge/beratung) + +[](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +[### Pensionsplanung Vom Berechnen von Vorsorgelücken bis zur 3a-Auszahlung: Hier finden Sie wichtige Informationen und Tipps zur Planung Ihrer Pensionierung.](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +Steuern vergleichen +------------------- + +Mit dem Steuerrechner von Comparis können Sie berechnen, wie sich Ihre Steuern verändern bei einem Umzug und welche Steuerentlastung eine Einzahlung in die 2. oder 3. Säule mit sich bringt. + +[](https://www.comparis.ch/steuern/steuervergleich/default) + +[### Steuervergleich Welche Gemeinde in der Schweiz hat die tiefsten Steuern? Unser Steuervergleich unterstützt Sie bei der Suche nach einem steuergünstigen Wohnort.](https://www.comparis.ch/steuern/steuervergleich/default) + +[Zum Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +[](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +[### Quellensteuer Vergleichen Sie mit wenigen Angaben, wie hoch Ihre Quellensteuer in den verschiedenen Kantonen ausfällt.](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +Fahrzeug finanzieren +-------------------- + +Der Autokauf ist einer der häufigsten Gründe für einen Kredit. Comparis informiert Sie über die verschiedenen Möglichkeiten der Autofinanzierung und darüber, worauf Sie achten sollten. + +[](https://www.comparis.ch/leasing/default) + +[### Leasing und Autofinanzierung Suchen Sie nach einer passenden Autofinanzierung? Erfahren Sie mehr über die Möglichkeiten hier.](https://www.comparis.ch/leasing/default) + +[Zum Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + +Wirtschaftsinfos einholen +------------------------- + +Erkunden Sie die Wirtschaftswelt mit Schwerpunkt auf Konjunkturzyklen, Inflation, Einkommen und Löhnen. + +[](https://www.comparis.ch/finanzen/wirtschaft) + +[### Finanzen und Wirtschaft Wie entwickeln sich die Preise in der Schweiz? Wie hoch sind die Löhne? Informieren Sie sich hier.](https://www.comparis.ch/finanzen/wirtschaft) + +[Zum Kurzarbeit-Lohnrechner](https://www.comparis.ch/finanzen/wirtschaft/einkommen/kurzarbeit-lohnrechner) + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) + + +=== https://www.comparis.ch/wohnen === +Schöner und günstiger Wohnen mit Comparis + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/wohnen)[IT](https://it.comparis.ch/wohnen)[EN](https://en.comparis.ch/wohnen) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/wohnen)[FR](https://fr.comparis.ch/wohnen)[IT](https://it.comparis.ch/wohnen)[EN](https://en.comparis.ch/wohnen) + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. Wohnen + +Wohnen in der Schweiz mit Comparis +================================== + +Ob Sie eine Wohnung oder ein Haus mieten, kaufen, verkaufen oder bewerten lassen wollen: Bei Comparis finden Sie Inserate verschiedener Immobilienmärkte der Schweiz. Zudem erhalten Sie Tipps rund um die Themen Umzug und Immobilien. + +[Immobilie finden](https://www.comparis.ch/wohnen#content-2)[Immobilie finanzieren](https://www.comparis.ch/wohnen#content-3)[Immobilie bewerten](https://www.comparis.ch/wohnen#content-4)[Immobilie inserieren](https://www.comparis.ch/wohnen#content-5)[Umzug planen](https://www.comparis.ch/wohnen#content-6)[Hausrat versichern](https://www.comparis.ch/wohnen#content-7) + + + +Umfassendes Angebot + +Bei Comparis finden Sie Inserate verschiedener Online-Marktplätze für Immobilien in der Schweiz. + + + +Online suchen und bewerten + +In wenigen Schritten erstellen Sie ein Inserat oder ein Suchabo oder führen eine Immobilienbewertung durch. + + + +Umfassend informiert + +Vergleichen Sie Steuern, lassen Sie Ihre Immobilie bewerten, nutzen Sie unseren Umzugsratgeber oder weitere Services. + + + +Umfassendes Angebot + +Bei Comparis finden Sie Inserate verschiedener Online-Marktplätze für Immobilien in der Schweiz. + + + +Online suchen und bewerten + +In wenigen Schritten erstellen Sie ein Inserat oder ein Suchabo oder führen eine Immobilienbewertung durch. + + + +Umfassend informiert + +Vergleichen Sie Steuern, lassen Sie Ihre Immobilie bewerten, nutzen Sie unseren Umzugsratgeber oder weitere Services. + +Immobilie finden +---------------- + +Ob Wohnung oder Haus: Comparis vereinigt verschiedene Online-Marktplätze der Schweiz. So erhalten Sie eine umfangreiche Auswahl an Immobilieninseraten. + +[](https://www.comparis.ch/immobilien/default) + +[### Immobilienmarkt Hier finden Sie die Inserate verschiedener Immobilienmarktplätze der Schweiz auf einer Plattform.](https://www.comparis.ch/immobilien/default) + +[](https://www.comparis.ch/steuern/steuervergleich/default) + +[### Steuervergleich Welche Gemeinde in der Schweiz hat die tiefsten Steuern? Unser Steuervergleich unterstützt Sie bei der Suche nach einem steuergünstigen Wohnort.](https://www.comparis.ch/steuern/steuervergleich/default) + +[Zum Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +Immobilie finanzieren +--------------------- + +Wie möchten Sie Ihre Wohnung oder Ihr Haus finanzieren? Bei Comparis finden Sie zahlreiche Tipps und Tools rund um das Thema Immobilienfinanzierung. + +[](https://www.comparis.ch/hypotheken/default) + +[### Hypotheken Ob Hypothekarzinsen vergleichen, individuelle Zinsen berechnen oder zum Thema Hypotheken auf dem Laufenden bleiben: Zusammen mit unserem Hypothekenpartner HypoPlus unterstützen wir Sie unabhängig und persönlich.](https://www.comparis.ch/hypotheken/default) + +[Persönliche Zinsen berechnen](https://www.comparis.ch/hypotheken/angaben) + +[](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +[### Zinsentwicklung Mit unserem interaktiven Hypotheken-Chart vergleichen Sie die Historie von Laufzeiten und unterschiedlichen Anbietern.](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +[Zinssätze vergleichen](https://www.comparis.ch/hypotheken/zinssatz) + +Immobilie bewerten & verkaufen +------------------------------ + +Mit Comparis finden Sie schnell und effizient einen Käufer für Ihre Immobilie und erhalten Unterstützung von der Bewertung bis zum Verkauf. + +[](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + +[### Immobilienbewertung Erfahren Sie kostenlos den Wert Ihrer Immobilie und verkaufen Sie zu einem marktgerechten Preis.](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + +[](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + +[### Immobilienbewertung Plus Erhalten Sie eine detaillierte Bewertung Ihrer Immobilie inkl. Einblicke in Markttrends, Nachfrage und Lagequalität.](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + +[](https://www.comparis.ch/immobilien/verkaufen) + +[### Immobilienverkauf Comparis unterstützt Sie von der Planung bis zum Verkauf sowohl digital als auch persönlich.](https://www.comparis.ch/immobilien/verkaufen) + +[](https://www.comparis.ch/immobilien/verkaufen/immobilienpreise) + +[### Preisentwicklung Immobilienmarkt Sie wollen wissen, wie sich die Kaufpreise von Immobilien in der Schweiz entwickelt haben? Nutzen Sie dafür unsere interaktive Karte.](https://www.comparis.ch/immobilien/verkaufen/immobilienpreise) + +Immobilie kostenlos inserieren +------------------------------ + +Egal ob Nachmieterin oder Käufer: Mit Comparis finden Sie den passenden Interessenten für Ihre Immobilie. + +[](https://www.comparis.ch/immobilien/inserieren/default) + +[Inserieren, wo die Schweiz sucht: Auf Comparis suchen jeden Monat über eine Million Personen ihre Traumwohnung.](https://www.comparis.ch/immobilien/inserieren/default) + +Umzug planen +------------ + +Ein Umzug kann stressig sein. Gut, wenn man vorher alles durchgeplant und bedacht hat. Comparis hilft Ihnen dabei. + +[](https://www.comparis.ch/immobilien/umzug/default) + +[### Umzugsservice Alles, was Sie für Ihren Umzug wissen müssen, inklusive Vergleich von Umzugs- und Reinigungsfirmen.](https://www.comparis.ch/immobilien/umzug/default) + +Direkt Offerten anfordern + +[](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + +[### Umzugskostenrechner Wie viel wird Ihr Umzug ungefähr kosten? Der Umzugkostenrechner sagt es Ihnen.](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + +[](https://www.comparis.ch/neu-in-der-schweiz/default) + +[### Umzug in die Schweiz Beim Umzug vom Ausland in die Schweiz gibt es einiges zu beachten. Comparis informiert Sie über alle Schritte.](https://www.comparis.ch/neu-in-der-schweiz/default) + +Hausrat versichern +------------------ + +Vergleichen Sie mehrere Anbieter von Hausratversicherungen und verschaffen Sie sich einen Überblick über die Prämien. + +[](https://www.comparis.ch/hausrat-versicherung/default) + +[### Hausrat und Privathaftpflicht Die Hausratversicherung deckt Schäden an Ihrem Hab und Gut durch etwa Feuer, Wasser oder Diebstahl. Die Privathaftpflicht schützt Sie, wenn Sie anderen ungewollt Schaden zufügen. Comparis klärt Sie über die Details auf.](https://www.comparis.ch/hausrat-versicherung/default) + +[Hausrat und Privathaftpflicht vergleichen](https://www.comparis.ch/hausrat-versicherung/comparison/input?insuranceType=3) + +Aktuelle Tipps und Informationen zu den Themen Immobilien und Wohnen +-------------------------------------------------------------------- + +Wir versorgen Sie mit spannenden Neuigkeiten aus der Welt der Immobilien. + +[ ### Adressänderung beim Umzug– die grosse Checkliste 04.06.2025](https://www.comparis.ch/immobilien/umzug/nach-dem-umzug/umzug-adressaenderung)[ ### Grundstückgewinnsteuer in der Schweiz: Wie wird sie berechnet? 26.11.2021](https://www.comparis.ch/immobilien/verkaufen/vertragsabschlussphase/grundstueckgewinnsteuer)[ ### Nebenkostenabrechnung Schweiz: Diese Nebenkosten sind erlaubt 27.03.2025](https://www.comparis.ch/immobilien/mietrecht/mietnebenkosten) + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) + + +=== https://www.comparis.ch/mobilitaet === +Verkehr und Mobilität in der Schweiz + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/mobilitaet)[IT](https://it.comparis.ch/mobilitaet)[EN](https://en.comparis.ch/mobilitaet) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/mobilitaet)[FR](https://fr.comparis.ch/mobilitaet)[IT](https://it.comparis.ch/mobilitaet)[EN](https://en.comparis.ch/mobilitaet) + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. Mobilität + +Verkehr und Mobilität in der Schweiz +==================================== + +Informationen zu Mobilität und Reisen: Kaufen oder verkaufen Sie Ihr Auto, vergleichen Sie Versicherungen und planen Sie Ihre Reise mit unseren Tipps. + +[Fahrzeug kaufen und verkaufen](https://www.comparis.ch/mobilitaet#content-2)[Fahrzeug finanzieren](https://www.comparis.ch/mobilitaet#content-3)[Fahrzeug versichern](https://www.comparis.ch/mobilitaet#content-4)[Autofahren lernen](https://www.comparis.ch/mobilitaet#content-5)[Elektroautos kennenlernen](https://www.comparis.ch/mobilitaet#content-6)[Entspannter reisen](https://www.comparis.ch/mobilitaet#content-7) + + + +Mehrere Schweizer Automärkte + +Ob kaufen oder verkaufen: Comparis vereint die Anzeigen verschiedener Automarktplätze der Schweiz. + + + +Online vergleichen + +Mit wenigen Klicks kaufen oder verkaufen Sie Ihr Auto oder schliessen eine Versicherung ab. + + + +Umfassend informiert + +Mit Comparis bleiben Sie stets umfassend rund um verschiedene Themen der Mobilität informiert – vom Auto bis zur Fernreise. + + + +Mehrere Schweizer Automärkte + +Ob kaufen oder verkaufen: Comparis vereint die Anzeigen verschiedener Automarktplätze der Schweiz. + + + +Online vergleichen + +Mit wenigen Klicks kaufen oder verkaufen Sie Ihr Auto oder schliessen eine Versicherung ab. + + + +Umfassend informiert + +Mit Comparis bleiben Sie stets umfassend rund um verschiedene Themen der Mobilität informiert – vom Auto bis zur Fernreise. + +Auto kaufen und verkaufen +------------------------- + +Bei Comparis ganz einfach Autos online kaufen, verkaufen und bewerten lassen. Ob Occasion oder Neuwagen: Finden Sie Ihr neues Auto – und verkaufen Sie Ihr altes Fahrzeug unkompliziert. + +[](https://www.comparis.ch/carfinder/default) + +[### Automarkt Finden Sie Angebote der grossen Automarktplätze der Schweiz.](https://www.comparis.ch/carfinder/default) + +[](https://www.comparis.ch/carfinder/bewertung) + +[### Fahrzeug bewerten Bewerten Sie kostenlos Ihren Personenwagen und ermitteln Sie den aktuellen Marktwert Ihres Autos.](https://www.comparis.ch/carfinder/bewertung) + +[](https://www.comparis.ch/carfinder/inserieren/default) + +[### Fahrzeug inserieren Inserieren Sie Ihr Auto online und finden Sie eine Käuferin oder einen Käufer.](https://www.comparis.ch/carfinder/inserieren/default) + +Fahrzeug finanzieren +-------------------- + +Jede zweite Person in der Schweiz nutzt zum Autokauf nicht das eigene Geld. Ob Kredit oder Leasing: Comparis informiert Sie über die verschiedenen Möglichkeiten der Autofinanzierung und darüber, worauf Sie achten sollten. + +[](https://www.comparis.ch/leasing/default) + +[### Leasing und Privatkredit Suchen Sie nach einer passenden Autofinanzierung? Erfahren Sie hier mehr über die Möglichkeiten.](https://www.comparis.ch/leasing/default) + +[Zum Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + +Fahrzeug versichern +------------------- + +Mit unseren Versicherungsvergleichen, Services und Informationen rund um Töff und Auto finden Sie das passende Angebot und sparen Prämien. + +[](https://www.comparis.ch/autoversicherung/default) + +[### Autoversicherung Vollkasko oder nur Teilkasko? Welche Versicherung ist für mich geeignet? Bei Comparis finden Sie Antworten zu diesen und vielen weiteren Fragen rund um das Thema Autoversicherung.](https://www.comparis.ch/autoversicherung/default) + +[Autoversicherung berechnen](https://www.comparis.ch/autoversicherung/berechnen) + +[](https://www.comparis.ch/motorradversicherung/default) + +[### Motorradversicherung Geniessen Sie die Freiheit auf zwei Rädern: Comparis versorgt Sie mit Versicherungsvergleichen, Infos und Tipps rund ums Motorrad.](https://www.comparis.ch/motorradversicherung/default) + +[Motorradversicherungen vergleichen](https://www.comparis.ch/motorradversicherung/vergleich/fahrzeug) + +Fahrzeug nutzen +--------------- + +Besitzen Sie ein Fahrzeug, möchten Sie es auch nutzen. Aber auch ohne eigenes Auto gibt es Möglichkeiten. Was Sie zur Nutzung meist brauchen: Benzin und einen Führerausweis. + +[](https://www.comparis.ch/benzin-preise) + +[### Benzinpreise Finden Sie mit unserer interaktiven Karte die günstigste Tankstelle in Ihrer Nähe.](https://www.comparis.ch/benzin-preise) + +[](https://www.comparis.ch/life/auto) + +[### Autoprüfung Hier gibt es alle wichtigen Informationen rund um den Führerschein und das Fahrenlernen in der Schweiz.](https://www.comparis.ch/life/auto) + +Elektroautos kennenlernen +------------------------- + +Elektroautos gewinnen zunehmend an Beliebtheit. Doch was sollten Sie wissen über die Elektromobilität? Hier erfahren Sie alles Wichtige rund um E-Autos. + +[](https://www.comparis.ch/elektromobilitaet/default) + +[### Elektromobilität Informationen zu Vorteilen und Herausforderungen der E-Mobilität.](https://www.comparis.ch/elektromobilitaet/default) + +Entspannter reisen +------------------ + +Ferien bedeuten oft Entspannung – wenn nichts schiefgeht. Comparis gibt Ihnen Tipps für eine sorgenfreie Reise und verrät, wie Sie Geld sparen können. + +[](https://www.comparis.ch/mobilitaet/reisen) + +[### Reisen Informationen und Tipps für entspannte Ferienreisen.](https://www.comparis.ch/mobilitaet/reisen) + +Aktuelle Tipps und Informationen rund um das Thema Mobilität +------------------------------------------------------------ + +Mit Comparis bleiben Sie in der Welt der Mobilität auf dem neuesten Stand. + +[ ### Auto-Occasionen: Tipps für den Kauf eines Gebrauchtwagens 29.11.2023](https://www.comparis.ch/carfinder/autokaufen/gute-occasionen)[ ### Welche Autoversicherung brauche ich? 08.09.2025](https://www.comparis.ch/autoversicherung/deckung/autoversicherung-uebersicht)[ ### Vier Motorradtouren in der Schweiz: Töfftouren & Ausflugsziele 06.06.2023](https://www.comparis.ch/motorradversicherung/motorrad-fahren/motorradtouren)[ ### Theorieprüfung fürs Auto in der Schweiz 14.08.2024](https://www.comparis.ch/life/auto/theoriepruefung)[ ### Reichweite Elektroautos: Wie weit fahren sie? 09.12.2024](https://www.comparis.ch/elektromobilitaet/elektroauto/reichweite)[ ### Reiseversicherung in der Schweiz: Was ist versichert? 03.07.2025](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) + + +=== https://www.comparis.ch/gesundheit === +Gesundheit + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/gesundheit)[IT](https://it.comparis.ch/gesundheit)[EN](https://en.comparis.ch/gesundheit) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/gesundheit)[FR](https://fr.comparis.ch/gesundheit)[IT](https://it.comparis.ch/gesundheit)[EN](https://en.comparis.ch/gesundheit) + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. Gesundheit + +Gesundheit und Pflege in der Schweiz +==================================== + +Die Themen Gesundheit und Pflege betreffen alle Schweizerinnen und Schweizer. Comparis unterstützt Sie mit Informationen dabei, kompetente Entscheidungen bei der Wahl Ihres Arztes, Ihrer Psychotherapie oder Ihrer Vorsorgelösungen wie Spitex zu treffen. + +[Arzt finden und Behandlungen](https://www.comparis.ch/gesundheit#content-2)[Leben im Alter und Spitex](https://www.comparis.ch/gesundheit#content-3)[Psychotherapie](https://www.comparis.ch/gesundheit#content-4)[Krankenkasse](https://www.comparis.ch/gesundheit#content-2) + + + +Umfassender Krankenkassen-Vergleich + +Auf comparis.ch einfach mehrere Offerten unverbindlich bestellen und die passendste auswählen. + + + +Praktische Spitex-Suche + +Vergleichen Sie Spitex-Anbieter und informieren Sie sich über Leistungen, anfallende Kosten und vieles mehr. + + + +Die richtigen Ärztinnen und Ärzte finden + +Bei Comparis suchen Sie einfach und schnell die passenden Fachleute, die geeignete Praxis oder das richtige Spital. + + + +Umfassender Krankenkassen-Vergleich + +Auf comparis.ch einfach mehrere Offerten unverbindlich bestellen und die passendste auswählen. + + + +Praktische Spitex-Suche + +Vergleichen Sie Spitex-Anbieter und informieren Sie sich über Leistungen, anfallende Kosten und vieles mehr. + + + +Die richtigen Ärztinnen und Ärzte finden + +Bei Comparis suchen Sie einfach und schnell die passenden Fachleute, die geeignete Praxis oder das richtige Spital. + +Arzt finden und Behandlungen +---------------------------- + +Bei Comparis suchen Sie einfach und schnell die passenden medizinischen Fachleute, die geeignete Praxis oder das richtige Spital. + +[](https://www.comparis.ch/gesundheit/arzt/default) + +[### Arzt finden Das unabhängige Ärzte-Verzeichnis umfasst über 40’000 praktizierende Ärztinnen und Ärzte in der Schweiz. So finden Sie die passenden Fachleute auch in Ihrer Nähe.](https://www.comparis.ch/gesundheit/arzt/default) + +Leben im Alter und Spitex +------------------------- + +[](https://www.comparis.ch/gesundheit/leben-im-alter/default) + +[### Spitex finden Finden Sie eine passende Spitex-Organisation und berechnen Sie die maximalen Kosten für Pflegeleistungen, welche Sie jährlich selbst tragen müssen.](https://www.comparis.ch/gesundheit/leben-im-alter/default) + +Psychotherapie +-------------- + +Hier finden Sie alles Wichtige zum Thema Psychotherapie + +[](https://www.comparis.ch/gesundheit) + +[### Ratgeber Psychotherapie Wie finde ich die passende Therapie? Was kostet eine Psychotherapie und was übernimmt die Krankenkasse? Hier finden Sie alle wichtigen Informationen.](https://www.comparis.ch/gesundheit) + +[Jetzt Psychiater finden](https://www.comparis.ch/gesundheit/arzt/psychiater) + +Krankenkasse +------------ + +Finden Sie mit Comparis die passende Krankenkasse für sich und Ihre Familie. + +[](https://www.comparis.ch/krankenkassen/default) + +[### Krankenkasse Erfahren Sie das Wichtigste zum Thema Krankenkasse in der Schweiz. Unsere Tipps helfen dabei, die passende Grund- und Zusatzversicherung zu finden.](https://www.comparis.ch/krankenkassen/default) + +[Krankenkassen vergleichen](https://www.comparis.ch/krankenkassen/default) + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) + + +=== https://www.comparis.ch/telecom === +Internet-, TV-, Festnetz- & Handy-Abos vergleichen mit Comparis + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/telecom)[IT](https://it.comparis.ch/telecom)[EN](https://en.comparis.ch/telecom) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/telecom)[FR](https://fr.comparis.ch/telecom)[IT](https://it.comparis.ch/telecom)[EN](https://en.comparis.ch/telecom) + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. Telecom + +Telecom +======= + +Ob für zuhause oder unterwegs: Finden Sie mit Comparis das passende Abo für Internet, TV, Festnetz und Handy. + +[Mobile](https://www.comparis.ch/telecom#content-2)[Internet & TV zuhause](https://www.comparis.ch/telecom#content-3) + + + +Abos vergleichen + +Ob Internet, TV, Festnetz oder Handy: Verschiedene Abos auf einen Blick. + + + +Wechseln und sparen + +Finden Sie das für Sie passende Abo und sparen Sie mit aktuellen Aktionen. + + + +Informiert bleiben + +Bleiben Sie mit Comparis in Sachen Telekom auf dem neuesten Stand. + + + +Abos vergleichen + +Ob Internet, TV, Festnetz oder Handy: Verschiedene Abos auf einen Blick. + + + +Wechseln und sparen + +Finden Sie das für Sie passende Abo und sparen Sie mit aktuellen Aktionen. + + + +Informiert bleiben + +Bleiben Sie mit Comparis in Sachen Telekom auf dem neuesten Stand. + +Mobile +------ + +Bleiben Sie auch unterwegs online. Dazu benötigen Sie nicht unbedingt das teuerste Abo. + +[](https://www.comparis.ch/telecom/mobile/default) + +[### Handy-Abo Ob Sie wenig telefonieren oder viel surfen: Comparis unterstützt Sie bei der Suche nach dem passenden Abo.](https://www.comparis.ch/telecom/mobile/default) + +[Handy-Abos vergleichen](https://www.comparis.ch/telecom/mobile/angebote/alle-handyabos) + +Internet & TV zuhause +--------------------- + +Anschluss für zuhause: Mit Comparis finden Sie das passende Angebot. + +[](https://www.comparis.ch/telecom/zuhause/default) + +[### Internet, TV & Festnetz Vergleichen Sie die Kosten der Anbieter für Internet, TV und Festnetz hier.](https://www.comparis.ch/telecom/zuhause/default) + +[Internet-Abos vergleichen](https://www.comparis.ch/telecom/zuhause/angebote/internet-tv-festnetz-abo) + +Tipps und Informationen zu den Themen Internet, TV und Festnetz +--------------------------------------------------------------- + +Ratgeber für Ihren Anschluss: Comparis versorgt Sie mit Neuigkeiten und Tipps in Sachen Telekom. + +[ ### 5G-Abdeckung in der Schweiz: Netzanbieter im Vergleich 30.07.2025](https://www.comparis.ch/telecom/mobile/handy-abo/mobilfunknetz)[ ### Streaming-Dienste in der Schweiz: Welche gibt es & was bieten sie? 13.01.2025](https://www.comparis.ch/telecom/zuhause/streaming/streaming)[ ### Speedtest Internet: Wie schnell surfe ich? 06.02.2025](https://www.comparis.ch/telecom/zuhause/internet-tv-festnetz-abo/internetgeschwindigkeit-speedtest) + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) + + +=== https://www.comparis.ch/neu-in-der-schweiz/default === +Umzug in die Schweiz: Entspannt in die Schweiz umziehen + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/neu-in-der-schweiz/default)[IT](https://it.comparis.ch/neu-in-der-schweiz/default)[EN](https://en.comparis.ch/neu-in-der-schweiz/default) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/neu-in-der-schweiz/default)[FR](https://fr.comparis.ch/neu-in-der-schweiz/default)[IT](https://it.comparis.ch/neu-in-der-schweiz/default)[EN](https://en.comparis.ch/neu-in-der-schweiz/default) + + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. [Wohnen](https://www.comparis.ch/wohnen "Wohnen") +3. Neu in der Schweiz + +Neu in der Schweiz +================== + +Willkommen in der Schweiz: Ihre interaktive Checkliste für einen reibungslosen Umzug in die Schweiz. Schritt für Schritt durch alle wichtigen Themen – von der Vorbereitung bis zum erfolgreichen Ankommen. + +[Zur Checkliste](https://www.comparis.ch/neu-in-der-schweiz/w2ch) + +Hilfreiche Services +------------------- + +Finden Sie hier die wichtigsten Comparis-Services, die Ihnen den Umzug in die Schweiz erleichtern. + +[### Quellensteuer  Quellensteuer berechnen und sparen.](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer)[### Immobilienmarkt  Das grösste Online-Immobilienangebot der Schweiz auf einen Blick.](https://www.comparis.ch/immobilien/default)[### Krankenkasse  Mit wenigen Klicks Angebote vergleichen und sparen.](https://www.comparis.ch/krankenkassen/default)[### Internet, TV, Festnetz  Tarife von Anbietern vergleichen und das passende Abo für Ihr Zuhause finden.](https://www.comparis.ch/telecom/zuhause/default)[### Hausrat- und Haftpflichtversicherung  Die passende Versicherung finden und Prämien sparen.](https://www.comparis.ch/hausrat-versicherung/default)[### Autoversicherung  Prämien wichtiger Anbieter in der Schweiz vergleichen. ](https://www.comparis.ch/autoversicherung/default)[### Motorradversicherung  Die passende Motorradversicherung finden und Prämien sparen.](https://www.comparis.ch/motorradversicherung/default)[### Hypotheken  Schnell und einfach eine günstige Hypothek finden.](https://www.comparis.ch/hypotheken/default) + +Diese 4 Schritte machen Ihren Umzug in die Schweiz einfacher +------------------------------------------------------------ + +### Überblick verschaffen + +Was müssen Sie bei einem Umzug in die Schweiz beachten? Was sind mögliche Herausforderungen? Ist dieser Schritt für Sie und Ihre Familie der richtige? Bei Comparis finden Sie umfassende Informationen: + +* Welche [Einreisebestimmungen](https://www.comparis.ch/neu-in-der-schweiz/auswandern/zollbestimmungen) gelten für die Schweiz? + +* Was kostet das [Wohnen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung)? + +* Was gilt es bezüglich [Niederlassungs- und Arbeitsbewilligungen](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) zu beachten? + +* Gibt es zusätzliche Besonderheiten bei einem Umzug in die Schweiz? + +### Umzug vorbereiten + +Ihre Entscheidung steht fest: Sie wollen in der Schweiz leben. Nun beginnt die Umzugsplanung. Comparis bietet Ihnen neben Informationen auch Dienstleistungen, die Ihnen den Umzug erleichtern: + +* Welche To-dos gilt es zu erledigen? [Unsere umfangreiche Umzugscheckliste](https://www.comparis.ch/neu-in-der-schweiz/auswandern/checkliste) + +* Ihr [neues Zuhause](https://www.comparis.ch/immobilien/default) finden auf dem grössten [Online-Immobilienmarkt](https://www.comparis.ch/immobilien/default) der Schweiz + +* Was muss ich bei der [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) berücksichtigen? + +### In die Schweiz umziehen + +Es ist so weit: Der Umzug steht an. Mit Comparis vergessen Sie keine wichtigen Schritte. + +* Welche Aufgaben muss ich fristgerecht bei den Behörden erledigen? + +* Wie [melde ich mich in der Schweiz an](https://www.comparis.ch/neu-in-der-schweiz/leben/anmeldung)? + +* [Welche Versicherungen](https://www.comparis.ch/neu-in-der-schweiz/leben) sollte ich zuerst abschliessen? + +### Einrichten und einleben + +Sie sind angekommen: Herzlich willkommen in der Schweiz! Nun wollen Sie Ihr neues Zuhause möglichst rasch einrichten und sich einleben. Comparis hilft Ihnen dabei mit Dienstleistungsvergleichen für viele Lebensbereiche. Zudem geben wir Ihnen Einblicke in die Kultur und Eigenheiten der Schweiz: + +* Lesen Sie mehr über [Besonderheiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +* Informieren Sie sich zur [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +* Vergleichen Sie [Handy- und Internet-Abos](https://www.comparis.ch/neu-in-der-schweiz/leben/handy-abo) + +So hilft Ihnen Comparis beim Umzug in die Schweiz +------------------------------------------------- + +Beim Umzug ist optimale Vorbereitung alles. Comparis hilft Ihnen dabei mit viel Wissen an einem Ort. Darüber hinaus finden Sie über unsere Seite auch Ihre neue Wohnung oder Ihr neues Haus – und Vergleiche für Lebensbereiche wie Versicherungen, Finanzen, Mobilität, Gesundheit oder Telekommunikation. + + + +Wichtiges Know-how + +Unsere Inhalte, Tipps und Vergleiche stehen Ihnen kostenlos zur Verfügung. + + + +Umfangreiche Produktvergleiche + +Finden Sie die für Sie passenden Dienstleistungen und Produkte im Vergleich. + + + +Unabhängig & neutral + +An Comparis ist weder der Staat noch ein anderes Unternehmen beteiligt. Comparis ist unabhängig und neutral. + + + +Wichtiges Know-how + +Unsere Inhalte, Tipps und Vergleiche stehen Ihnen kostenlos zur Verfügung. + + + +Umfangreiche Produktvergleiche + +Finden Sie die für Sie passenden Dienstleistungen und Produkte im Vergleich. + + + +Unabhängig & neutral + +An Comparis ist weder der Staat noch ein anderes Unternehmen beteiligt. Comparis ist unabhängig und neutral. + +Vom 1. Umzugsgedanken bis zum Leben in der Schweiz +-------------------------------------------------- + +Ob Sie erst mit dem Gedanken spielen, kurz davor sind oder bereits in die Schweiz umgezogen sind: Bei uns finden Sie Tipps für die damit verbundenen Herausforderungen. + +[ ### Umziehen in die Schweiz Welche Formalitäten bei Behörden gilt es zu erledigen, welche Dokumente und Kontakte sind relevant?](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + +[ ### Arbeiten in der Schweiz Sie sind neu in der Schweiz und möchten hier arbeiten? Lesen Sie Tipps für die Stellensuche, Infos zum Gehalt und mehr.](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + +[ ### Leben neu organisieren Jetzt stellen sich viele Fragen: Wie komme ich an ein passendes Mobilabo? Wie lasse ich mein Fahrzeug zu? Wir geben Ihnen Antworten.](https://www.comparis.ch/neu-in-der-schweiz/leben) + +[ ### Finanzen in der Schweiz Ob Steuern oder Lebenshaltungskosten: Wir zeigen, was Sie zum Thema Finanzen in der Schweiz wissen sollten.](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + +Praktisches Wissen für Ihren Umzug in die Schweiz +------------------------------------------------- + +Es ist ein grosser Schritt, in ein fremdes Land zu ziehen. Diese praktischen Tipps helfen Ihnen vor und während des Umzugs in die Schweiz. + +[### Das kostet eine Wohnung Sie möchten wissen, wie viel eine Wohnung in der Schweiz kostet? Gibt es regionale Unterschiede? Comparis bringt Licht ins Dunkel.](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung)[### Den passenden Job finden Erfahren Sie, wo Sie einen passenden Job finden. Comparis erklärt zudem das Wichtigste zu den Arbeitsbedingungen in der Schweiz.](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + +[### Formalitäten bei der Einreise Bei der Einreise in die Schweiz müssen Sie schon vorgängig an einiges denken. Mit Comparis vergessen Sie nichts Wichtiges.](https://www.comparis.ch/neu-in-der-schweiz/auswandern/checkliste)[### Fahrzeug einführen Beim Umzug mit einem Fahrzeug gibt es von der Deklaration bis zur Zulassung einiges zu beachten. Hier finden Sie die Übersicht.](https://www.comparis.ch/neu-in-der-schweiz/auswandern/auto-einfuhr) + +Häufig gestellte Fragen zum Umzug in die Schweiz +------------------------------------------------ + +### Was ist die Voraussetzung für einen Aufenthalt (bis zu 5 Jahren) in der Schweiz? + +Das ist von verschiedenen Faktoren abhängig. Sind Sie Bürger eines EU- oder Efta-Landes, können Sie sich drei Monate in der Schweiz aufhalten, um eine Arbeitsstelle zu finden. Danach sind Sie zum Aufenthalt berechtigt. Kommen Sie hingegen aus einem sogenannten Drittstaat, benötigen Sie bereits einen Arbeitsvertrag inklusive einer entsprechenden Arbeitsbewilligung bzw. einen Studienplatz. Übrigens: Angehörige ausländischer Personen dürfen sich unter Einhaltung gewisser Bedingungen ebenfalls in der Schweiz niederlassen. Als Angehörige gelten: Ehepartner, Kinder unter 21 Jahren und Angehörige, für die die eingewanderte Person ein Sorge- oder Pflegerecht hat. Weitere Informationen zu den Aufenthaltsbewilligungen in der Schweiz finden Sie [hier](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung). + +### Was ist der Unterschied zwischen der Aufenthaltsbewilligung (B-Ausweis) und der Niederlassungsbewilligung (C-Ausweis)? + +* Eine**Aufenthaltsbewilligung (B-Ausweis)**erhalten EU-/Efta-Staatsangehörige, wenn sie sich in einem unbefristeten oder mindestens 12 Monate dauernden Arbeitsverhältnis befinden. Diese Bewilligung ist 5 Jahre gültig sowie verlängerbar und kann zur Erhebung der[Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) genutzt werden. + +* Die unbeschränkt gültige **Niederlassungsbewilligung (C-Ausweis)** erhalten ausländische Erwerbstätige aus EU-/Efta-Staaten dann nach 5 Jahren. Sie haben damit mit der Ausnahme des Stimm- und Wahlrechts die gleichen Rechte und Pflichten wie Schweizer. + +Detaillierte Informationen finden Sie in diesem [Comparis-Artikel](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung). + +### Wie viel Steuern muss ich bezahlen? + +Die Höhe des Steuerbetrags ist in der Schweiz von Kanton zu Kanton unterschiedlich und abhängig von verschiedenen Kenngrössen. Am besten nutzen Sie den Comparis-[Quellensteuer-Rechner](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer), um die für Sie zu erwartenden Steuern schnell und unkompliziert zu berechnen. Unser Rechner lässt Sie zudem Steuern über alle Kantone vergleichen. + +### Wie schreibe ich meinen Führerschein in der Schweiz um? + +Der ausländische Führerschein (auch oft Führerausweis genannt) ist während der ersten 12 Monate in der Schweiz gültig. Melden Sie sich innerhalb dieser Zeit bei Ihrem [kantonalen Strassenverkehrsamt](https://asa.ch/strassenverkehrsaemter/adressen/). Weiterführende Informationen sowie die für die Umschreibung benötigten Dokumente finden Sie [in diesem Artikel](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben). Weitere Informationen zur Einfuhr und Zulassung Ihres Autos haben wir Ihnen [hier](https://www.comparis.ch/neu-in-der-schweiz/auswandern/auto-einfuhr) zusammengestellt. + +### Was sind die wichtigsten Schweizerdeutsch-Wörter? + +Grundsätzlich ist es nicht notwendig, Schweizerdeutsch zu verstehen, da die Menschen in der Deutschschweiz auch Deutsch sprechen und alles in Deutsch angeschrieben steht. Alternativ freuen sich die Deutschschweizer, wenn Sie ein paar wenige schweizerdeutsche Wörter kennen. Wir haben Ihnen dafür ein [kleines Wörterbuch](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) zusammengestellt. Wenn Sie die Sprache lernen möchten, besuchen Sie doch z.B. einen preislich attraktiven Kurs in der [Migros Klubschule](https://www.klubschule.ch/sprachen/deutschkurse/schweizerdeutsch/). + +Wichtig: Deutsch wird lediglich in der grössten Region gesprochen. Es gibt ebenfalls Französisch, Italienisch und Rätoromanisch. + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) + + +=== https://www.comparis.ch/krankenkassen/default === +Suchassistent + +[Login](/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +[Newsletter](/comparis/newsletter/subscribe) + +[Login](/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/krankenkassen/default) +[FR](https://fr.comparis.ch/krankenkassen/default) +[IT](https://it.comparis.ch/krankenkassen/default) +[EN](https://en.comparis.ch/krankenkassen/default) + +# Krankenkassenvergleich 2025 + +Mit dem grossen Krankenkassenvergleich der Schweiz Prämien berechnen und sparen. Vergleichen Sie bei Comparis die Krankenkassenprämien 2025. + +Umfassend vergleichen + +Vergleichen Sie Leistungen, Prämien und Kundenzufriedenheit. + +Einfach sparen + +Finden Sie in wenigen Minuten eine preiswerte Krankenkasse. + +Unkompliziert abschliessen + +Bestellen Sie mehrere Offerten – kostenlos und unverbindlich. + +Umfassend vergleichen + +Vergleichen Sie Leistungen, Prämien und Kundenzufriedenheit. + +Einfach sparen + +Finden Sie in wenigen Minuten eine preiswerte Krankenkasse. + +Unkompliziert abschliessen + +Bestellen Sie mehrere Offerten – kostenlos und unverbindlich. + +## In drei Schritten zur Krankenversicherung + +Wählen Sie: Möchten Sie die [Grundversicherung](/krankenkassen/grundversicherungen), die [Zusatzversicherung](/krankenkassen/zusatzversicherungen) oder beides zusammen vergleichen? + +Geben Sie Ihre Personalien und Bedürfnisse an. + +Vergleichen Sie die Ergebnisse des Prämienrechners in Ihrer persönlichen Resultatliste. + +Speichern Sie Ihre Favoriten (bis zu drei Angebote) und bestellen Sie unverbindliche Offerten. + +So finden Sie die Versicherung, die zu Ihnen passt. + +## Krankenkasse wechseln und über 35’000 Franken sparen + +Durch das Wechseln Ihrer Krankenkasse können Sie in zehn Jahren **Prämien in Höhe eines Kleinwagens sparen.** Eine [Comparis-Analyse](https://res.cloudinary.com/comparis-cms/image/upload/v1754920631/press/de/2025/08/20250812_MM_KK_10_Jahre_Sparpotenzial_DE_vfkigz.pdf) zeigt: Hätten Sie 2015 von der teuersten zur günstigsten Krankenkasse gewechselt, hätten Sie bis heute **über 35’000 Franken sparen** können – ohne weiteren Wechsel. + +Wechseln Sie die Krankenkasse **jährlich**, ist Ihr [Sparpotenzial](/krankenkassen/praemien/sparen) noch höher. Deswegen lohnt sich ein Vergleich der Krankenkassenprämien, besonders langfristig. + +[Jetzt Krankenkassenprämien berechnen](/krankenkassen/input) + +## Beste Krankenkasse 2025 + +Im Rahmen des [Comparis-Siegels](/info/siegel) haben wir die Schweizer Bevölkerung zu ihrer Zufriedenheit mit ihrer Krankenkasse befragt. Die Ergebnisse sehen Sie als Comparis-Note direkt im Krankenkassenvergleich – und auf der [Übersichtsseite zu den besten Krankenkassen](/krankenkassen/beste-krankenkasse). + +## Die Krankenversicherungen in unserem Vergleich + +[5.0/6](/krankenkassen/anbieter/agrisano) + +[4.9/6](/krankenkassen/anbieter/kpt-versicherung) + +[5.0/6](/krankenkassen/anbieter/concordia-versicherung) + +[5.1/6](/krankenkassen/anbieter/swica-versicherung) + +[5.0/6](/krankenkassen/anbieter/visana-assurance) + +[5.1/6](/krankenkassen/anbieter/helsana-versicherung) + +[5.1/6](/krankenkassen/anbieter/oekk-versicherung) + +[5.1/6](/krankenkassen/anbieter/aquilana-versicherung) + +[Weitere Krankenkassen](/krankenkassen/beste-krankenkasse) + +Der Grundversicherungsvergleich enthält Produkte (Prämien) von Anbietern (Krankenversicherern), die vom Bundesamt für Gesundheit (BAG) genehmigt worden sind. + +Der Zusatzversicherungsvergleich enthält Produkte von Anbietern, die Offert-/Kontaktanfragen von [Optimatis](/altersvorsorge/vorsorgesystem/ueber-optimatis +) entgegennehmen, und/oder Produkte von Anbietern, die keine Offert-/Kontaktanfragen von Optimatis entgegennehmen. Die Anbieter in diesem Vergleich nutzen die von Optimatis angebotene Schnittstelle. + +In der «Standard-Ansicht» zeigt Comparis Produkte von Anbietern, die Offert-/Kontaktanfragen von [Optimatis](/altersvorsorge/vorsorgesystem/ueber-optimatis +) entgegennehmen, sowie das günstigste und teuerste Produkt. In der «Erweiterten Ansicht» zeigt Comparis alle vom BAG genehmigten Produkte (Grundversicherungsvergleich) respektive alle Prämien von Anbietern, die die von Optimatis angebotene Schnittstelle nutzen (Zusatzversicherungsvergleich). + +Die Rangierung der Suchresultate erfolgt nach objektiv messbaren Kriterien gemäss gewähltem Filter. Von diesem Sachverhalt ausgeschlossene Angebote sind deutlich als «Anzeige» ausgewiesen. + +Die Angaben zur Verfügbarkeit von Hausärztinnen und Hausärzten basieren auf den Daten von medswissnet, dem Schweizer Dachverband der Ärztenetzwerke. Sie enthalten nur dem Verband angeschlossene Ärztinnen und Ärzte und können vom Hausarztverzeichnis der Krankenkassen abweichen. + +## Das Wichtigste zum Thema Krankenversicherung + +[### Krankenkasse wechseln + +Antworten auf die wichtigsten Fragen zum Krankenkassenwechsel.](/krankenkassen/system/kassenwechsel) +[### Zusatzversicherung + +Zusatzversicherungen ergänzen wertvolle Leistungen der Grundversicherung. Beispiele dafür sind: Zähne, Brille, Ausland, Fitness, halbprivate oder private Spitaldeckung.](/krankenkassen/zusatzversicherungen) +[### Krankenkassenprämien + +Finden Sie alle Neuigkeiten zu den Krankenkassenprämien.](/krankenkassen/praemien) + +[### Franchise + +Die Franchise definiert mit dem Selbstbehalt die Kostenbeteiligung der versicherten Person. Finden Sie heraus, welche für Sie geeignet ist.](/krankenkassen/grundversicherungen/franchise) +[### Selbstbehalt + +Bei jeder Behandlung oder bezogenen Leistung aus der Grundversicherung müssen Sie einen Selbstbehalt übernehmen. Dieser beträgt 10 Prozent.](/krankenkassen/grundversicherungen/selbstbehalt) +[COMPARIS-SERVICE + +Kündigungsbrief für die Grundversicherung](/krankenkassen/system/vorlage-kuendigungsschreiben) + +## Unser Krankenkassen-Ratgeber + +[### Unfallversicherung in der Schweiz + +Die Unfallversicherung trägt die finanziellen Folgen von Unfällen und Berufskrankheiten. Sie ist in der Schweiz obligatorisch. Erfahren Sie, wie Sie sich am besten vor unerwarteten Behandlungskosten schützen können.](/krankenkassen/unfallversicherung) + +[### Familienkrankenkasse: Krankenversicherung für die ganze Familie + +Die Grundversicherung ist für jede in der Schweiz wohnhafte Person obligatorisch. Dies gilt für Erwachsene und Kinder. Finden Sie die passende Krankenversicherung für Ihre gesamte Familie.](/krankenkassen/familie) + +[### Grundversicherung – obligatorische Krankenkasse + +Wer in der Schweiz wohnt oder arbeitet, muss eine Grundversicherung abschliessen. Die Grundversicherung kommt zum Tragen, wenn Sie krank werden oder verunfallen.](/krankenkassen/grundversicherungen) + +[### Leistungen der Krankenkasse + +Von Alternativmedizin bis Zahnarzt: Lesen Sie hier, welche Behandlungen, Medikamente und Hilfsmittel die Grundversicherung übernimmt und wo sich eine Zusatzversicherung lohnt.](/krankenkassen/leistungen) + +[### Das Krankenkassensystem in der Schweiz + +Wer bestimmt eigentlich, welche Leistungen die Grundversicherung bezahlt? Was muss ich beim Krankenkassenwechsel beachten? Und welchen Einfluss haben die Prämien auf meine Steuern?](/krankenkassen/system) + +[### Krankenkassenprämien in der Schweiz + +In der Grundversicherung bezahlen Sie Prämien. Was sind Prämien und wie können Sie Prämienkosten gering halten? Comparis gibt Tipps und Tricks rund um Krankenkassenprämien.](/krankenkassen/praemien) + +[### Zusatzversicherungen vergleichen + +Finden Sie mit einem Vergleich der Zusatzversicherungen in der Schweiz die passende Deckung für Sie. Comparis hilft Ihnen dabei.](/krankenkassen/zusatzversicherungen) + +## Prämien-Benachrichtigung + +Das Bundesamt für Gesundheit BAG veröffentlicht die Prämien für das nächste Jahr immer im September. Melden Sie sich für die Benachrichtigung an. So können Sie die neuen Prämien rechtzeitig vergleichen und im neuen Jahr sparen. + +Mit der Anmeldung stimme ich der Bearbeitung meiner Daten entsprechend der [Datenschutzerklärung](/comparis/info/privacy) von comparis.ch zu. + +## Beliebte Krankenkassen-Artikel + +[### Kündigung der Krankenkasse: Vorlage fürs Kündigungsschreiben + +06.11.2024](/krankenkassen/system/vorlage-kuendigungsschreiben) +[### Prognose der Krankenkassenprämien 2026: 4 Prozent teurer + +22.05.2025](/krankenkassen/praemien/prognose-trend) +[### Krankenwagen-Kosten in der Schweiz: Wer zahlt? + +09.03.2023](/krankenkassen/leistungen/krankenwagen-ambulanz) +[### Gewichtsverlust durch Abnehmspritzen: Zahlt die Krankenkasse? + +27.03.2025](/krankenkassen/leistungen/abnehmspritze) +[### Krankenkassen und Fitness-Abos: Welche Krankenkasse zahlt das Fitnessstudio? + +23.12.2024](/krankenkassen/leistungen/fitnessabo) +[### Steuererklärung: Kann ich Krankenkassen-Kosten abziehen? + +05.02.2025](/krankenkassen/system/steuererklaerung) + +## Häufige Fragen zum Thema Krankenkassenvergleich + +Die Krankenkassenprämien sind je nach Wohnort, Krankenversicherung, Modell, Franchise und Alter unterschiedlich. Vergleichen Sie die Grundversicherungsprämien gemäss Ihrer Situation und finden Sie so die günstigste Krankenkasse. + +[Krankenkassenprämien vergleichen](/krankenkassen/input) + +#### Obligatorische Krankenversicherung + +Die **Grundversicherung** können Sie in der Regel jährlich wechseln. Stichtag für den [Krankenkassenwechsel](/krankenkassen/system/kassenwechsel) bzw. die Kündigung ist der **30. November**. **Wichtig:** Fällt der 30. November auf das Wochenende, muss die Kündigung am Freitag davor bei der Krankenkasse eintreffen. + +Krankenkassen müssen neue Versicherte unabhängig von ihrer gesundheitlichen Situation aufnehmen. Darum müssen Sie keine Auskunft geben zu Vorerkrankungen. + +#### Zusatzversicherung + +Für die **Zusatzversicherung** ist in der Regel die Beantwortung eines [Gesundheitsfragebogens](/krankenkassen/zusatzversicherungen/gesundheitsfragen) erforderlich. Eine Vorerkrankung bedeutet nicht zwingend eine Ablehnung. Allenfalls wird die Vorerkrankung aus der Deckung ausgeschlossen. + +**Wichtig:** Kündigen Sie bei einem Wechsel die alte Zusatzversicherung erst, wenn Sie die Aufnahmebestätigung der neuen Krankenkasse erhalten haben. + +Weitere Infos finden Sie im Artikel zum Thema [Zusatzversicherung abschliessen](/krankenkassen/zusatzversicherungen/versicherung-abschliessen). + +Die Krankenkassenprämien für die Grundversicherung stiegen 2025 im Durchschnitt [um sechs Prozent](/krankenkassen/praemien/prognose-trend). Das war bereits die dritte grosse Prämienerhöhung in Folge. + +Mit der Wahl der Krankenkasse, der [Franchise](/krankenkassen/grundversicherungen/franchise) und des Versicherungsmodells können Sie den Kostenanstieg bestmöglich abfedern. + +Darum ist es wichtig, dass Sie Ihr [Sparpotenzial](/krankenkassen/praemien/sparen) ausschöpfen und einen [Krankenkassenvergleich](/krankenkassen/input) vornehmen. + +Die monatliche Prämie 2025 beträgt im Durchschnitt **378.70 Franken**. + +Die mittlere Prämie ergibt sich aus der Summe aller gezahlten Prämien in der Schweiz – geteilt durch die Anzahl der Versicherten. + +Die tatsächlichen Prämien unterscheiden sich allerdings je nach Alter, Wohnort, Franchise und Versicherungsmodell teils stark. + +[Krankenkassenprämien vergleichen](/krankenkassen/input) + +Am höchsten sind die Prämien 2025 im Durchschnitt in den Kantonen Genf, Tessin und Basel-Stadt. + +Am tiefsten sind die mittleren Prämien 2025 in den Kantonen Appenzell Innerrhoden, Uri und Obwalden. + +Die Antwort auf die Frage nach der besten Krankenkasse hängt von Ihren **persönlichen Bedürfnissen** ab. Denn: Krankenversicherungen bieten unterschiedliche Leistungsmerkmale. Die Leistungen der Krankenkassen sind in der Grundversicherung aber überall gleich. + +#### Comparis-Siegel zeigt Kundenzufriedenheit + +Einen wichtigen Hinweis zur Kundenzufriedenheit liefert das [Comparis-Siegel](/krankenkassen/beste-krankenkasse). In diesem Zusammenhang befragen wir jährlich 4’500 Krankenversicherte zu ihrer Zufriedenheit mit ihrer Krankenkasse. + +Bewertet werden diese **Leistungsmerkmale**: + +* Preis/Leistung +* Touchpoints und Kontakt +* Qualität und Service +* Information und Transparenz + +Die Teilnehmenden der Befragung vergeben dann **Noten je Merkmal**. Daraus wird eine **Gesamtnote** berechnet. Die laut der Umfrage besten Krankenkassen werden mit einem Siegel ausgezeichnet. + +Zum **Ergebnis** der Kundenzufriedenheits-Umfrage für die Grundversicherung: [Beste Krankenkasse](/krankenkassen/beste-krankenkasse) + +In der Schweiz ist die **Unfallversicherung obligatorisch**. Aber: Sind Sie mindestens acht Stunden pro Woche bei einem einzigen Arbeitgeber angestellt oder beim RAV angemeldet, sind Sie gemäss [Unfallversicherungsgesetz (UVG)](/krankenkassen/unfallversicherung/unfallversicherungsgesetz-uvg) automatisch gegen [Unfall](/krankenkassen/unfallversicherung) versichert. Alle anderen Versicherten müssen die Unfalldeckung in ihrer Grundversicherung einschliessen. Für Selbstständige gibt es auch alternative Lösungen. + +Eine zusätzliche Unfalldeckung über die [Zusatzversicherung](/krankenkassen/zusatzversicherungen) kann je nach Bedürfnissen sinnvoll sein – auch bei bestehender Unfallversicherung durch den Arbeitgeber. + +Die stationären Behandlungen und Untersuchungen in Spitälern sind in der Grundversicherung bei allen Krankenkassen **in der allgemeinen Abteilung im Wohnkanton** gedeckt. Möchten Sie aber in ein Spital ausserhalb des Wohnkantons gehen oder wünschen Sie etwas mehr Qualität und Komfort? Dann können Sie eine Spitalzusatzversicherung abschliessen. Hier finden Sie weitere Informationen zur [Spitalzusatzversicherung](/krankenkassen/zusatzversicherungen/spitalzusatzversicherung). + +Die Grund- und Zusatzversicherung müssen Sie **nicht zwingend bei der gleichen Krankenkasse** abschliessen. Trennen Sie die beiden Versicherungen, fallen in der Zusatzversicherung aber unter Umständen Administrationskosten an. + +Ebenso kann es bei einer Trennung zu einem **Verlust von Vergünstigungen** kommen, z. B. Familien- oder Kollektivrabatt. Hier finden Sie weitere Tipps zur [Trennung von Grund- und Zusatzversicherung](/krankenkassen/system/trennung-grundversicherung-zusatzversicherung). + +Die günstigste Krankenkassenprämie finden Sie durch einen **Vergleich verschiedener Anbieter.** Dazu können Sie zum Beispiel den Krankenkassenvergleich von Comparis nutzen. + +Sie können aber auch durch Anpassungen bei Ihrer Krankenkasse sparen. Wählen Sie ein [alternatives Versicherungsmodell](/krankenkassen/grundversicherungen/krankenkassenmodelle) und eine hohe [Franchise](/krankenkassen/grundversicherungen/franchise), zahlen Sie monatlich weniger. + +[Krankenkassenprämien vergleichen](/krankenkassen/input) + + +=== https://www.comparis.ch/lebensversicherung/default === +Lebensversicherungs-Vergleich für die Schweiz: So finden Sie die passende Versicherung | Comparis + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/lebensversicherung/default)[IT](https://it.comparis.ch/lebensversicherung/default)[EN](https://en.comparis.ch/lebensversicherung/default) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/lebensversicherung/default)[FR](https://fr.comparis.ch/lebensversicherung/default)[IT](https://it.comparis.ch/lebensversicherung/default)[EN](https://en.comparis.ch/lebensversicherung/default) + + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. [Versicherungen](https://www.comparis.ch/versicherung "Versicherungen") +3. Lebensversicherung + +Lebensversicherungen vergleichen in der Schweiz +=============================================== + +Mit Comparis finden Sie die passende Lebensversicherung. Vergleichen Ihre Möglichkeiten – unverbindlich und transparent. + +[Beratung anfordern](https://www.comparis.ch/altersvorsorge/beratung?origin=vle) + +[So funktioniert's](https://www.comparis.ch/lebensversicherung/default#content-5) + +Was ist eine Lebensversicherung? +-------------------------------- + +Die Lebensversicherung schützt Ihre Angehörigen und sichert den gewohnten Lebensstandard im Falle von Invalidität oder Tod. Sie können sie gleichzeitig zum Kapitalaufbau Ihrer privaten Altersvorsorge (3. Säule) nutzen. Erfahren Sie, welche Modelle es gibt und worauf Sie achten sollten. + +[ ### Modelle der Lebensversicherung Ob Risikolebensversicherung, Todesfallversicherung oder Erwerbsunfähigkeitsversicherung: Wir klären Sie über die verschiedenen Modelle auf.](https://www.comparis.ch/lebensversicherung/modelle) + +[ ### Finanzielle Absicherung Familie absichern, fürs Alter vorsorgen, Steuern sparen, Einkommen bei Erwerbsausfall sichern – die Vorteile einer Lebensversicherung sind zahlreich. Doch welche Lösung eignet sich für welches Ziel? Comparis zeigt Ihnen die Möglichkeiten.](https://www.comparis.ch/lebensversicherung/finanzielle-absicherung) + +[ ### Für wen ist eine Lebensversicherung sinnvoll? Es gibt verschiedene Gründe für den Abschluss einer Lebensversicherung. Sie ist besonders sinnvoll, wenn Sie Familie oder Wohneigentum haben. Auch für Selbstständige kann eine solche Versicherung Sinn ergeben. Erfahren Sie, warum.](https://www.comparis.ch/lebensversicherung/finanzielle-absicherung/wann-brauche-ich-eine-lebensversicherung) + +Wichtiges zum Thema Lebensversicherung +-------------------------------------- + +Comparis bietet Ihnen wichtige Informationen über die Lebensversicherung und hilfreiche Tools zur Veranschaulichung Ihrer finanziellen Situation. + +[### Todesfallversicherung Im Todesfall werden Ihre Angehörigen durch Todesfallkapital und Prämienzahlung vor den finanziellen Folgen geschützt.](https://www.comparis.ch/lebensversicherung/modelle/todesfallversicherung)[### Vorsorgelücken-Rechner Wie gross ist Ihre finanzielle Lücke bei Invalidität und Tod? Berechnen Sie Ihr Risiko.](https://www.comparis.ch/altersvorsorge/vorsorgesystem/vorsorgeluecke) + +[### Erwerbsunfähigkeitsversicherung Bei Erwerbsunfähigkeit wegen Krankheit oder Unfall werden ihre finanziellen Lücken bis zur Pensionierung gedeckt.](https://www.comparis.ch/lebensversicherung/modelle/erwerbsunfaehigkeitsversicherung)[### Beratung zur Lebensversicherung Lassen Sie sich neutral und unverbindlich beraten und vergleichen Sie die Angebote, die für Sie am besten passen.](https://www.comparis.ch/altersvorsorge/beratung?origin=vle) + +Warum eine Lebensversicherung? +------------------------------ + +Die Beraterinnen und Berater von Optimatis, dem Brokerage-Partner von Comparis, und seine Vertragsfirmen sind für Sie da. + + + +Risiken erkennen + +Fachpersonen beraten Sie, damit Sie im Falle von Invalidität, Tod und Pensionierung optimal abgesichert sind. + + + +Individueller Schutz + +Entscheiden Sie, wie hoch die Rente bei Erwerbsunfähigkeit bzw. die Höhe des Todesfallkapitals sein soll. + + + +Sparen und Rendite optimieren + +Die Expertinnen und Experten zeigen Ihnen, wie Sie Ihre Rendite auf Basis der 3. Säule optimieren und dabei Steuern sparen können. + + + +Risiken erkennen + +Fachpersonen beraten Sie, damit Sie im Falle von Invalidität, Tod und Pensionierung optimal abgesichert sind. + + + +Individueller Schutz + +Entscheiden Sie, wie hoch die Rente bei Erwerbsunfähigkeit bzw. die Höhe des Todesfallkapitals sein soll. + + + +Sparen und Rendite optimieren + +Die Expertinnen und Experten zeigen Ihnen, wie Sie Ihre Rendite auf Basis der 3. Säule optimieren und dabei Steuern sparen können. + +In drei Schritten zur passenden Lebensversicherung +-------------------------------------------------- + + + +### Überblick verschaffen + +Machen Sie sich im Detail mit dem Thema Lebensversicherung und Ihrer finanziellen Lage vertraut: + +* [Grösstes Risiko berechnen](https://www.comparis.ch/altersvorsorge/vorsorgerechner) + +* [Lebensversicherungen verstehen](https://www.comparis.ch/lebensversicherung/modelle/was-ist-eine-lebensversicherung) + +* [Absicherung der Familie](https://www.comparis.ch/altersvorsorge/vorsorgesystem/familie)mit einbeziehen + + + +### Beratungstermin anfragen + +Fachpersonen klären Ihre Anliegen und vergleichen unterschiedliche Anbieter von Lebensversicherungen. Sie analysieren, welche Angebote am besten zu Ihren Bedürfnissen passen. + + + +### Lebensversicherungen vergleichen und abschliessen + +Sie erhalten verschiedene Angebote vorgeschlagen. Jetzt können Sie die passende Versicherung auswählen. + +Das sagen Kundinnen und Kunden von Optimatis +-------------------------------------------- + +Google-Rating + +5/5 + +(283 Bewertungen) + +Herr Aladzic hat mich gut und ehrlich beraten.Vielen Dank für die tolle Beratung! + +C. + +06.05.2025 + +Google-Rating + +5/5 + +(283 Bewertungen) + +Sehr gute Beratung und Unterstützung von Herr Redzepi. + +M. + +01.02.2025 + +Google-Rating + +5/5 + +(283 Bewertungen) + +Floriana Kryeziu, vielen, vielen Dank für das angenehme und umsorgende Gespräch. Sie haben mir sehr (schnell!) weitergeholfen. + +M.I. + +03.12.2024 + +Google-Rating + +5/5 + +(283 Bewertungen) + +Herr Aladzic hat mich gut und ehrlich beraten.Vielen Dank für die tolle Beratung! + +C. + +06.05.2025 + +Google-Rating + +5/5 + +(283 Bewertungen) + +Sehr gute Beratung und Unterstützung von Herr Redzepi. + +M. + +01.02.2025 + +Google-Rating + +5/5 + +(283 Bewertungen) + +Floriana Kryeziu, vielen, vielen Dank für das angenehme und umsorgende Gespräch. Sie haben mir sehr (schnell!) weitergeholfen. + +M.I. + +03.12.2024 + +[Zu den Google-Bewertungen](https://www.google.com/search?q=optimatis+ag&rlz=1C1GCEU_deCH966CH966&oq=optimatis+ag&aqs=chrome.0.0i355i512j46i175i199i512j0i22i30.2026j0j7&sourceid=chrome&ie=UTF-8#lrd=0x47900b67716b40ef:0x5dc901562e27afb3,1,,,) + +Häufige Fragen zur Lebensversicherung +------------------------------------- + +### Was ist eine Lebensversicherung? + +Lebensversicherungen sind Versicherungen, die Risiken wie Tod oder Invalidität absichern – sogenannte reine Risikolebensversicherungen. Daneben gibt es noch die Versicherungen, die primär der privaten Altersvorsorge dienen. Diese heissen kapitalbildende Lebensversicherungen. Beide Versicherungsvarianten zählen zur 3. Säule in der Schweiz und damit zu Ihrer privaten Vorsorge. + +### Was sind die Hauptunterschiede zwischen den verschiedenen Lebensversicherungen? + +Es gibt zum einen reine Risikolebensversicherungen, zum anderen gemischte Lebensversicherungen. Beide sollen das finanzielle Risiko einer Erwerbsunfähigkeit durch Unfall oder Krankheit abdecken. Die gemischte Lebensversicherung dient zusätzlich dazu, dass sie das finanzielle Risiko eines Todesfalls abdeckt. Zudem beinhaltet sie einen Sparteil, den man bis zum Renteneintritt in einen Fonds investieren kann. + +### Welche Lebensversicherung ist die beste für mich? + +Welche Lebensversicherung für Sie die beste ist, kann man pauschal so nicht beantworten. Denn individuelle Lebenssituationen benötigen individuelle Lösungen. Wir raten Ihnen daher zu einer professionellen Beratung. Darin wird Ihre finanzielle Situation im Fall einer Erwerbsunfähigkeit analysiert und geschaut, wie Ihre Familie im Todesfall geschützt ist und ob eine Lücke in Ihrer Altersvorsorge besteht. So wissen Sie schnell und zuverlässig, welche Vorsorgeversicherung Sie benötigen. + +### Wie teuer ist eine Lebensversicherung im Monat? + +Ihre Vorsorge wird individuell auf Ihre persönlichen Bedürfnisse angepasst. Daher sind auch die Kosten für eine Lebensversicherung unterschiedlich. Wie hoch die Prämie für Ihre Vorsorgeversicherung ist, hängt ganz von Ihrer Lebenssituation ab. Pauschal kann man aber sagen, dass eine kapitalbildende Versicherung schon ab rund CHF 100 pro Monat möglich ist. + +### Muss ich eine Gesundheitsprüfung machen? + +Beim Abschluss einer Lebensversicherung ist Ihr Gesundheitszustand wichtig. Daher ist eine **_Gesundheitsprüfung_****oder****_Risikoprüfung_** üblich. + +In den meisten Fällen müssen Sie für die Gesundheitsprüfung einen Fragebogen ausfüllen. Bei hohen Versicherungssummen oder bekannten gesundheitlichen Problemen kann die Prüfung auch durch einen Arzt oder eine Ärztin erfolgen. + +### Gibt es eine Altersbeschränkung für den Abschluss einer Lebensversicherung? + +Das Eintrittsalter ist das Alter der versicherten Person bei Beginn der Versicherungspolice. Bei den Lebensversicherungen gibt es meistens Altersbeschränkungen für den Eintritt. + +Häufig gilt ein maximales Eintrittsalter von beispielsweise 60 oder 65 Jahren. Oft ist das Eintrittsalter auch nach unten eingeschränkt. Für Lebensversicherungen der [Säule 3a](https://www.comparis.ch/altersvorsorge/saeule3a) gelten die Bestimmungen der Säule 3a. Das heisst, Sie dürfen **ab dem 1. Januar nach Ihrem 17. Geburtstag**einzahlen. + +### Wie lange läuft eine Lebensversicherung? + +Eine Lebensversicherung ist eine langfristige Vorsorgelösung. Da sie oft mit der Säule 3a kombiniert wird, läuft diese meist bis zur Pensionierung. Bitte beachten Sie: Die Auszahlung ist frühestens 5 Jahre vor oder spätestens 5 Jahre nach Erreichen des ordentlichen Rentenalters möglich. + +### Kann ich meine Lebensversicherung vorzeitig auszahlen lassen? + +In der Säule 3a haben Sie unter gewissen Umständen die Möglichkeit, sich Ihre Lebensversicherung vorzeitig auszahlen zu lassen. Bei einer vorzeitigen Auflösung erhalten Sie den Rückkaufswert der Versicherung. + +### Gibt es Steuervorteile für Lebensversicherungen? + +In der Säule 3a können Sie die Beiträge der Lebensversicherung von den Steuern abziehen. Dabei gibt es jedoch einen gesetzlichen Maximalwert. Sollten Sie sich Ihre Lebensversicherung auszahlen lassen, gilt ein reduzierter Steuersatz. + +### Lebensversicherungs-Vertrag: Worauf sollte ich achten? + +Diese Punkte sind wichtig im Vertrag zur Lebensversicherung: + +### **Barwert** + +Der Barwert bedeutet: So viel Geld müssten Sie heute zu einem konstanten Zinssatz anlegen, um damit alle künftigen Prämien zahlen zu können. Er **macht die verschiedenen Versicherungsprodukte vergleichbar**. + +### Begünstigte + +Begünstigte sind die Personen, die bei Eintreten des versicherten Ereignisses **Anspruch auf die Versicherungsleistung** haben. + +### **Deckungskapital** + +Deckungskapital nennt man die **Rückstellungen für laufende Versicherungsverträge**. Dieses Kapital braucht die Versicherung zur Erfüllung der künftigen Verpflichtungen. + +### **Deckungsumfang** + +Der Deckungsumfang beschreibt die **Leistungen**, die Sie durch die Versicherung beziehen können. + +### **Garantierte Versicherungssumme** + +Die Summe, die im Todesfall **mindestens ausgezahlt**wird. Die garantierte Versicherungssumme ist unabhängig vom finanziellen Erfolg der Versicherungsgesellschaft oder anderen Faktoren. + +### **Prämiengarantie** + +Das bedeutet: Die bei Vertragsbeginn vereinbarte Prämienhöhe **ändert sich über die gesamte Vertragslaufzeit nicht**. Diese Garantie der Versicherung ist unabhängig vom finanziellen Erfolg der Versicherungsgesellschaft. + +### **Risikoausschluss** + +Der Risikoausschluss ist die **Herausnahme eines Gefahrenumstandes aus dem Versicherungsschutz**. Ein Beispiel: Bei Todesfallversicherungen wird meist das Risiko der Selbsttötung für eine bestimmte Zeitdauer vom Versicherungsschutz ausgenommen. Bei Selbsttötung besteht somit in dieser Zeitdauer keine Deckung und die Versicherungssumme wird nicht ausbezahlt. + +### **Versicherungssumme** + +Die Versicherungssumme ist im Versicherungsvertrag festgelegt. Sie bezeichnet den **vereinbarten Höchstbetrag**der Leistung des Versicherers. + +### **Vertragsdauer oder Vertragslaufzeit** + +Die Vertragsdauer oder -laufzeit beschreibt die **Zeitspanne, in der der Versicherungsschutz gewährleistet ist**. Bei den meisten Lebensversicherungen können Sie die Laufzeit innerhalb bestimmter Grenzen frei wählen. + +### **Todesfall** + +Versicherungstechnisch bedeutet der Todesfall, dass die versicherte Person innerhalb der Versicherungslaufzeit stirbt. + +### Was bedeutet Prämienbefreiung bei der Lebensversicherung? + +Prämienbefreiung bedeutet: Sie müssen keine Versicherungsprämien zahlen, wenn bestimmte im Vertrag festgelegte Ereignisse eintreten. Typischer Grund für eine Prämienbefreiung ist die [Erwerbsunfähigkeit](https://www.comparis.ch/lebensversicherung/modelle/erwerbsunfaehigkeitsversicherung). + +### Was ist das Widerrufsrecht? + +Widerrufsrecht bedeutet: Sie können innerhalb einer bestimmten Frist **von einem Vertrag zurücktreten**. Die [gesetzliche Widerrufsfrist](https://www.fedlex.admin.ch/eli/cc/24/719_735_717/de#art_2_a) beträgt 14 Tage. + +Die Frist beginnt, sobald Sie den Vertrag beantragt oder angenommen haben. Spätestens am letzten Tag der Widerrufsfrist müssen Sie Ihren Widerruf der Versicherung mitteilen oder Ihre Widerrufserklärung der Post übergeben. + +Ein **Beispiel**: Sie unterzeichnen am 4. Januar 2025 einen Versicherungsantrag. Dann können Sie diesen Vertrag bis zum 18. Januar 2025 widerrufen. + +### Was bedeutet das Rating von Versicherungen? + +Das Rating ist die **Einschätzung der Bonität eines Unternehmens**. Es wird durch eine unabhängige private oder staatliche Einrichtung durchgeführt. + +Das Rating gibt auch Hinweis auf die Ausfallwahrscheinlichkeit bzw. die Zahlungsunfähigkeit eines Unternehmens an. + +Wichtig ist unter anderem die Ratingagentur Standard and Poor's. Ihre Abstufungen reichen von **AAA (höchste Bonität / geringes Ausfallrisiko) bis D (Zahlungsausfall)**. + +### Was muss ich bei einem Todesfall machen? + +#### **Was muss ich bei einem Todesfall machen?** + +Im Todesfall einer versicherten Person muss der Versicherer **unverzüglich benachrichtigt** werden. Üblicherweise wird ein amtlicher Todesschein und ein Zeugnis über die Todesursache verlangt. Bei einem Unfalltod kann ein Polizeirapport zur Klärung beitragen. + +Der Versicherer klärt dann die Anspruchsberechtigung ab. Das kann bei mehreren Begünstigten zu Verzögerungen bei der Auszahlung führen. + +Liegen alle erforderlichen Unterlagen vor, muss das Versicherungsunternehmen**innert vier Wochen die vereinbarte Leistung erbringen** ([VVG Art. 41](https://www.fedlex.admin.ch/eli/cc/24/719_735_717/de#art_41)). Häufig erfolgt die Auszahlung aber wesentlich schneller. + +Kontakt Optimatis, der Brokerage-Partner von Comparis +----------------------------------------------------- + +Haben Sie Fragen zum Thema Vorsorge und Lebensversicherung? Möchten Sie von Expertinnen und Experten beraten werden? Dann vereinbaren Sie einen unverbindlichen Termin [via Kontaktformular](https://www.comparis.ch/altersvorsorge/beratung?origin=vle). + +[+41 44 559 54 00](https://www.comparis.ch/) + +[info@optimatis.ch](mailto:info@optimatis.ch) + +**MO – FR** + +08.00 – 12.00 Uhr + +13.30 – 17.00 Uhr + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) + + +=== https://www.comparis.ch/rechtsschutz/default === +Rechtsschutzversicherungen in der Schweiz vergleichen | Comparis + +=============== + +[](https://www.comparis.ch/ "Comparis logo") + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +1. Person absichern + 1. [Krankenkasse](https://www.comparis.ch/krankenkassen/default) + 2. [Lebensversicherung](https://www.comparis.ch/lebensversicherung/default) + 3. [Rechtsschutz](https://www.comparis.ch/rechtsschutz/default) + 4. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + +2. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +3. Eigentum versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + 2. [Tierversicherung](https://www.comparis.ch/tierversicherung/default) + +[Alles zu Versicherungen](https://www.comparis.ch/versicherung) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Kredit aufnehmen + 1. [Privatkredit](https://www.comparis.ch/privatkredit/default) + 2. [Kreditrechner](https://www.comparis.ch/privatkredit/kreditrechner) + 3. [Kreditvergleich](https://www.comparis.ch/privatkredit/kreditvergleich) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Altersvorsorge planen + 1. [Altersvorsorge](https://www.comparis.ch/altersvorsorge/default) + 2. [Pensionsplanung](https://www.comparis.ch/altersvorsorge/pensionsplanung) + +4. Steuern vergleichen + 1. [Steuervergleich](https://www.comparis.ch/steuern/steuervergleich/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + 3. [Quellensteuer](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + +5. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +6. Wirtschaftsinfos einholen + 1. [Finanzen und Wirtschaft](https://www.comparis.ch/finanzen/wirtschaft) + +[Alles zu Finanzen](https://www.comparis.ch/finanzen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Immobilie finden + 1. [Immobilienmarkt](https://www.comparis.ch/immobilien/default) + 2. [Steuerrechner](https://www.comparis.ch/steuern/steuervergleich/steuerrechner) + +2. Immobilie finanzieren + 1. [Hypotheken](https://www.comparis.ch/hypotheken/default) + 2. [Hypothekenrechner](https://www.comparis.ch/hypotheken/hypothekenrechner) + 3. [Zinsentwicklung](https://www.comparis.ch/hypotheken/zinssatz/zinsentwicklung) + +3. Immobilien bewerten + 1. [Immobilie kostenlos bewerten](https://www.comparis.ch/immobilien/verkaufen/immobilie-bewerten) + 2. [Immobilienbewertung Plus (Beta)](https://www.comparis.ch/immobilien/immobilienbewertung-plus/mehr) + 3. [Makler finden](https://www.comparis.ch/immobilien/verkaufen/immobilienmakler) + 4. [Immobilie verkaufen](https://www.comparis.ch/immobilien/verkaufen) + +4. Immobilie inserieren + 1. [Privat inserieren](https://www.comparis.ch/immobilien/inserieren/default) + 2. [Als Firma inserieren](https://www.comparis.ch/immobilien/inserieren/loesungen-fuer-agenturen) + +5. Umzug planen + 1. [Umzugsservice](https://www.comparis.ch/immobilien/umzug/default) + 2. [Umzugskostenrechner](https://www.comparis.ch/immobilien/umzug/vor-dem-umzug/umzugskostenrechner) + 3. [Umzug in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + 4. [Malerservice](https://www.comparis.ch/immobilien/umzug/maler/default) + +6. Hausrat versichern + 1. [Hausrat und Privathaftpflicht](https://www.comparis.ch/hausrat-versicherung/default) + +[Alles zu Immobilien](https://www.comparis.ch/wohnen) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Automarkt + 1. [Auto kaufen](https://www.comparis.ch/carfinder/default) + 2. [Auto verkaufen](https://www.comparis.ch/carfinder/inserieren/default) + 3. [Autowert berechnen](https://www.comparis.ch/carfinder/bewertung) + +2. Fahrzeug finanzieren + 1. [Autoleasing](https://www.comparis.ch/leasing/default) + 2. [Leasingrechner](https://www.comparis.ch/leasing/leasingrechner) + 3. [Autokredit](https://www.comparis.ch/privatkredit/kreditgruende/autokredit) + +3. Fahrzeug versichern + 1. [Autoversicherung](https://www.comparis.ch/autoversicherung/default) + 2. [Motorradversicherung](https://www.comparis.ch/motorradversicherung/default) + +4. Fahrzeugnutzung + 1. [Benzinpreise](https://www.comparis.ch/benzin-preise) + 2. [Autoprüfung](https://www.comparis.ch/life/auto) + +5. Elektromobilität + 1. [Elektromobilität entdecken](https://www.comparis.ch/elektromobilitaet/default) + 2. [Ladestation finden](https://www.comparis.ch/elektromobilitaet/ladestationen) + 3. [Elektroauto](https://www.comparis.ch/elektromobilitaet/elektroauto) + +6. Reisen + 1. [Reisetipps](https://www.comparis.ch/mobilitaet/reisen) + 2. [Reiseversicherung](https://www.comparis.ch/mobilitaet/reisen/reiseversicherung) + 3. [Ferien-Packliste](https://www.comparis.ch/mobilitaet/reisen/packliste-ferien) + +[Alles zu Mobilität](https://www.comparis.ch/mobilitaet) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Arzt finden und Behandlungen + 1. [Arzt finden](https://www.comparis.ch/gesundheit/arzt/default) + 2. [Zähne](https://www.comparis.ch/gesundheit/arzt/zaehne) + 3. [Dermatologie](https://www.comparis.ch/gesundheit/arzt/dermatologe) + 4. [Medikamente](https://www.comparis.ch/gesundheit/arzt/medikamente) + +2. Leben im Alter und Spitex + 1. [Spitex finden](https://www.comparis.ch/gesundheit/leben-im-alter/default) + 2. [Finanzierung und Wohnen](https://www.comparis.ch/gesundheit/leben-im-alter/finanzierung-wohnen) + 3. [Zu Hause pflegen](https://www.comparis.ch/gesundheit/leben-im-alter/zuhause-pflegen) + +3. Krankenkasse + 1. [Krankenkasse vergleichen](https://www.comparis.ch/krankenkassen/default) + +[Alles zu Gesundheit](https://www.comparis.ch/gesundheit) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Mobile + 1. [Handy-Abo](https://www.comparis.ch/telecom/mobile/default) + +2. Internet und TV zuhause + 1. [Internet, TV und Festnetz](https://www.comparis.ch/telecom/zuhause/default) + +[Alles zu Telecom](https://www.comparis.ch/telecom) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +1. Auswandern + 1. [Auswandern in die Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern) + 2. [Aufenthaltsbewilligung](https://www.comparis.ch/neu-in-der-schweiz/auswandern/aufenthaltsbewilligung) + 3. [Führerschein umschreiben](https://www.comparis.ch/neu-in-der-schweiz/auswandern/fuehrerschein-umschreiben) + 4. [Miete in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/auswandern/kosten-wohnung) + +2. Arbeit + 1. [Arbeiten in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit) + 2. [Durchschnittslohn in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/arbeit/verdienstmoeglichkeiten) + 3. [Jobsuche](https://www.comparis.ch/neu-in-der-schweiz/arbeit/jobsuche) + 4. [Lohnnebenkosten](https://www.comparis.ch/neu-in-der-schweiz/arbeit/lohnnebenkosten) + +3. Finanzen + 1. [Finanzen in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/finanzen) + 2. [Quellensteuer vergleichen](https://www.comparis.ch/neu-in-der-schweiz/finanzen/quellensteuer) + 3. [Lebenshaltungskosten](https://www.comparis.ch/neu-in-der-schweiz/finanzen/lebenshaltungskosten) + +4. Leben + 1. [Leben in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben) + 2. [Schweizerdeutsch lernen](https://www.comparis.ch/neu-in-der-schweiz/leben/schweizerdeutsch-lernen) + 3. [Besonderheiten der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/leben/besonderheiten-schweiz) + +[Alles zum Thema Einwandern](https://www.comparis.ch/neu-in-der-schweiz/default) + +Ihr MyComparis-Konto +* Verwalten Sie Ihre Offerten +* Erstellen Sie Merklisten +* Steuern Sie Ihre Newsletter + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard)[Registrieren](https://www.comparis.ch/bff/login?prompt=create) + +[](https://www.comparis.ch/suche) + +DE + +[FR](https://fr.comparis.ch/rechtsschutz/default)[IT](https://it.comparis.ch/rechtsschutz/default)[EN](https://en.comparis.ch/rechtsschutz/default) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[](https://www.comparis.ch/suche) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +Comparis entdecken + +1. [Versicherungen](https://www.comparis.ch/versicherung) +2. [Finanzen](https://www.comparis.ch/finanzen) +3. [Immobilien](https://www.comparis.ch/wohnen) +4. [Mobilität](https://www.comparis.ch/mobilitaet) +5. [Gesundheit](https://www.comparis.ch/gesundheit) +6. [Telecom](https://www.comparis.ch/telecom) +7. [Neu in der Schweiz](https://www.comparis.ch/neu-in-der-schweiz/default) + +[Newsletter](https://www.comparis.ch/comparis/newsletter/subscribe) + +[Login](https://www.comparis.ch/bff/login?returnUrl=/mycomparis-dashboard) + +[DE](https://www.comparis.ch/rechtsschutz/default)[FR](https://fr.comparis.ch/rechtsschutz/default)[IT](https://it.comparis.ch/rechtsschutz/default)[EN](https://en.comparis.ch/rechtsschutz/default) + + + + +1. [Startseite](https://www.comparis.ch/ "Startseite") +2. [Versicherungen](https://www.comparis.ch/versicherung "Versicherungen") +3. Rechtsschutz + +Rechtsschutz: Versicherungen vergleichen in der Schweiz +======================================================= + +Vergleichen Sie bei Comparis verschiedene Schweizer Rechtsschutzversicherungen. Finden Sie online den passenden Anbieter. + +Versicherungsart + +Versicherungsart Kombi-Rechtsschutz (Privat und Verkehr) + +Prämien vergleichen + +[So funktioniert’s](https://www.comparis.ch/rechtsschutz/default#content-4) + +Vorteile des Rechtsschutz-Versicherungsvergleichs auf Comparis +-------------------------------------------------------------- + + + +Verschiedene Anbieter + +Profitieren Sie von einem umfassenden Rechtsschutz-Versicherungsvergleich. + + + +Hohes Sparpotenzial + +Verschaffen Sie sich einen Überblick über die aktuellsten Prämien und sparen Sie bares Geld. + + + +Online-Offerte + +Mit wenigen Klicks finden Sie die passenden Offerten – unverbindlich. + + + +Verschiedene Anbieter + +Profitieren Sie von einem umfassenden Rechtsschutz-Versicherungsvergleich. + + + +Hohes Sparpotenzial + +Verschaffen Sie sich einen Überblick über die aktuellsten Prämien und sparen Sie bares Geld. + + + +Online-Offerte + +Mit wenigen Klicks finden Sie die passenden Offerten – unverbindlich. + +Wichtiges über die Rechtsschutzversicherung +------------------------------------------- + +[ ### Deckungen und Leistungen Erfahren Sie, was eine Rechtsschutzversicherung deckt und welche Leistungen Ihnen zustehen.](https://www.comparis.ch/rechtsschutz/deckung-leistung) + +[ ### Privatrechtsschutz Verschaffen Sie sich einen Überblick: Wichtiges über die Privatrechtsschutz-Versicherung.](https://www.comparis.ch/rechtsschutz/privatrechtsschutz) + +[ ### Verkehrsrechtsschutz In welchen Fällen hilft der Verkehrsrechtsschutz und für wen ist die Versicherung sinnvoll?](https://www.comparis.ch/rechtsschutz/verkehrsrechtsschutz) + +In 4 Schritten zur Rechtsschutz-Versicherung +-------------------------------------------- + + + +### Versicherung wählen + +Im 1. Schritt haben Sie die Wahl zwischen folgenden Versicherungen: + +* Privatrechtsschutz + +* Verkehrsrechtsschutz + +* Privat- und Verkehrsrechtsschutz in einer Police + +Weiter entscheiden Sie, ob Sie die Prämien einer **Einzel-** oder **Mehrpersonenversicherung** vergleichen möchten. Zu guter Letzt benötigen die Versicherungen zur Berechnung der individuellen Prämie Ihr Geburtsjahr. + + + +### Prämien vergleichen + +In Ihrer persönlichen Resultatliste zeigen wir Ihnen alle Angebote mit passender Deckung. + + + +### Kostenlose Offerte bestellen + +Treffen Sie Ihre Auswahl und bestellen Sie mit einem Klick Ihre Offerten. Diese erhalten Sie unverbindlich per E-Mail und können so in Ruhe vergleichen. + + + +### So funktioniert der Comparis-Rechtsschutz-Versicherungsvergleich + +Dieser Vergleich enthält Produkte von Anbietern, die Offert-/Kontaktanfragen von [Optimatis](https://www.comparis.ch/altersvorsorge/vorsorgesystem/ueber-optimatis) entgegennehmen, und Produkte von Anbietern, die keine Offert-/Kontaktanfragen von Optimatis entgegennehmen. Die Anbieter in diesem Vergleich nutzen die von Comparis angebotene Schnittstelle. Die Rangierung der Suchresultate erfolgt nach objektiv messbaren Kriterien gemäss gewähltem Filter. Von diesem Sachverhalt ausgeschlossene Angebote sind deutlich als «Anzeige» ausgewiesen. + +Hilfreiche Informationen rund um das Thema Rechtsschutz-Versicherung +-------------------------------------------------------------------- + +[### Verkehrsrechtsschutz Braucht es das?](https://www.comparis.ch/rechtsschutz/verkehrsrechtsschutz/verkehrsrechtsschutz-sinnvoll)[### Familienrecht Scheidung oder Erbstreit? Das müssen Sie wissen.](https://www.comparis.ch/rechtsschutz/privatrechtsschutz/scheidung-familienrecht) + +[### Kündigungserinnerung Keinen Kündigungstermin mehr verpassen? Mit der Kündigungserinnerung über MyComparis erhalten Sie rechtzeitig vor Ablauf der Kündigungsfrist eine Erinnerungsmail.](https://account.mycomparis.ch/account/login) + +Häufige Fragen zur Rechtsschutz-Versicherung +-------------------------------------------- + +### Ab wann gilt der Rechtsschutz? + +Generell gilt: Die **Ursache**, d.h. das auslösende Ereignis, darf erst nach dem Vertragsabschluss entstanden sein. + +Zudem behalten sich einige Versicherungen eine Wartefrist von 3 Monaten für bestimmte Rechtsbereiche vor, die in dieser Zeit nicht versichert sind. + +Die**Wartefristen** sind je nach Anbieter verschieden und in den allgemeinen Versicherungsbedingungen geregelt. + +### Wann kann ich meine Rechtsschutz-Versicherung kündigen? + +In den folgenden Fällen können Sie Ihre Rechtsschutz-Versicherung kündigen: + +* **Bei Ablauf der vereinbarten Vertragsdauer** + +Achten Sie dabei auf die Kündigungsfrist, in der Regel muss das Kündigungsschreiben 3 Monate vor Ablauf beim Versicherer eintreffen, ansonsten wird die Police stillschweigend um 1 Jahr verlängert.**Tipp:** Möchten Sie die Kündigungsfrist Ihrer Rechtsschutzversicherung nicht mehr verpassen? Mit der **Kündigungserinnerung von Comparis** erhalten Sie rechtzeitig vor Ablauf der Kündigungsfrist eine Erinnerungsmail. [Loggen Sie sich dazu in MyComparis ein](https://account.mycomparis.ch/account/login)und erstellen Sie die gewünschte Erinnerung. + +* **Im Schadensfall** + +Bei einem gedeckten Schadensfall und innerhalb von 14 Tagen kann nach Kenntnis der letzten Zahlung gekündigt werden. + +* **Wegzug ins Ausland** + +Schweizer Recht findet bei Wegzug ins Ausland keine Anwendung mehr, daher kann gegen Vorlage einer Abmeldebestätigung der Schweizer Wohngemeinde die Versicherung gekündigt werden. + +### Was deckt eine Rechtsschutz-Versicherung? + +Die Rechtsschutz-Versicherung schützt Sie vor finanziellen Risiken infolge Rechtsstreitigkeiten. Allgemein gedeckt sind folgende Kosten: + +* Anwaltshonorare + +* Gutachten + +* Gerichtsgebühren + +* Prozessentschädigung an Gegenpartei + +* Strafkautionen (Vorschuss) + +Die **Privatrechtsschutz-Versicherung** deckt Rechtsstreitigkeiten im Privatrecht, zum Beispiel im Mietrecht, Konsumentenrecht oder Arbeitsrecht. + +Die **Verkehrsrechtsschutz-Versicherung** bietet finanziellen Schutz bei rechtlichen Auseinandersetzungen im Strassenverkehr. So zum Beispiel bei Rechtsfällen nach einem Verkehrsunfall oder Streitigkeiten bei Kauf, Leasing oder einer unsachgemässen Reparatur eines Fahrzeuges. + +**Wichtig:** Die Leistungen der verschiedenen Versicherungen können variieren. Es lohnt sich, verschiedene Angebote zu vergleichen – das günstigste ist nicht immer das beste. + +### Was deckt eine Rechtsschutz-Versicherung nicht? + +In der Deckung grundsätzlich ausgeschlossen sind: + +* Geldstrafen und Bussen + +* Vorsätzlich begangene Taten + +* Eigene Vergehen + +* Ereignisse, die vor Versicherungsbeginn eingetreten sind oder absehbar waren + +Familienrechtliche Streitigkeiten (Unterhalts-, Eheschutz- und Scheidungsverfahren), Erbstreitigkeiten, Bauprozesse, Steuerverfahren und die meisten Strafverfahren sind nicht oder nur im Rahmen einer juristischen Beratung gedeckt. + +### Wie ist die Deckung in den Bereichen Familien-, Scheidungs- und Erbrecht? + +Streitigkeiten im Familien-, Scheidungs- und Erbrecht sind in der Regel nicht versichert. + +Das bedeutet: Die Versicherung übernimmt im Normalfall weder Anwalts- noch Prozesskosten, wenn es sich um eine familiäre Angelegenheit handelt. + +Einige Versicherungen bieten jedoch mit der Rechtsschutzversicherung eine Rechtsberatung bei internen Anwälten für Personen-, Familien- und Erbrecht. Achten Sie darauf, ob das Familienrecht (inkl. Scheidung) in der Rechtsberatung inbegriffen ist. + +Rechtsschutz-Versicherungen im Vergleich +---------------------------------------- + +[](https://www.comparis.ch/rechtsschutz/anbieter/emilia) + +[](https://www.comparis.ch/rechtsschutz/anbieter/cap) + +[](https://www.comparis.ch/rechtsschutz/anbieter/vcs) + +[](https://www.comparis.ch/rechtsschutz/anbieter/baloisedirect) + +[](https://www.comparis.ch/rechtsschutz/anbieter/groupe-mutuel) + +[](https://www.comparis.ch/rechtsschutz/anbieter/k-tipp) + +[](https://www.comparis.ch/rechtsschutz/anbieter/smile-direct) + +[](https://www.comparis.ch/rechtsschutz/anbieter/coop-rechtsschutz) + +[](https://www.comparis.ch/rechtsschutz/anbieter/generali) + +[](https://www.comparis.ch/rechtsschutz/anbieter/elvia) + +[](https://www.comparis.ch/rechtsschutz/anbieter/dextra-rechtsschutz) + +[](https://www.comparis.ch/rechtsschutz/anbieter/axa-arag) + +[](https://www.comparis.ch/rechtsschutz/anbieter/justis%20rechtsschutz) + +[](https://www.comparis.ch/rechtsschutz/anbieter/css) + +[](https://www.comparis.ch/rechtsschutz/anbieter/helsana) + +[](https://www.comparis.ch/rechtsschutz/anbieter/protekta) + +[](https://www.comparis.ch/rechtsschutz/anbieter/visana) + +[](https://www.comparis.ch/rechtsschutz/anbieter/assista-tcs) + +Alle anzeigen + +[](https://www.comparis.ch/) + +comparis.ch +1. [Über Comparis](https://www.comparis.ch/info) +2. [User Service](https://www.comparis.ch/info/kontakt) +3. [Jobs](https://www.comparis.ch/people/default) +4. [Medien](https://www.comparis.ch/publikationen/medien) +5. [Allgemeine Geschäftsbedingungen](https://www.comparis.ch/info#content-15) + +Weitere Angebote +1. [Studien](https://www.comparis.ch/publikationen/downloadcenter) +2. [Gebühren](https://www.comparis.ch/steuern/steuervergleich/gebuehren) +3. [Werbung](https://www.comparis.ch/info/werbung) +4. [Comparis-Siegel](https://www.comparis.ch/info/siegel) + +Folgen Sie uns +1. [](https://www.facebook.com/comparis.ch "Comparis bei Facebook") +2. [](https://www.instagram.com/comparis_ch/ "Comparis bei Instagram") +3. [](https://www.youtube.com/comparis "Comparis bei YouTube") +4. [](https://www.linkedin.com/company/comparis.ch-ag "Comparis bei LinkedIn") + +Newsletter +1. [Newsletter bestellen](https://www.comparis.ch/comparis/newsletter/subscribe) + +© comparis.ch AG 2025 + +[Datenschutz](https://www.comparis.ch/info/privacy)[Rechtliche Informationen](https://www.comparis.ch/info/copyrights)[Impressum](https://www.comparis.ch/info/impressum) + + +=== https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages "Services" === +Alles rund um Hypotheken und Eigenheimfinanzierung | Homegate.ch + +=============== + +[https://www.homegate.ch](https://www.homegate.ch/) + +* [Suchen](https://www.homegate.ch/c/de/suchen) +* [Services](https://www.homegate.ch/c/de/hypotheken) +* [Schätzen](https://www.homegate.ch/c/de/schaetzen) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Inserieren Ab CHF 0](https://www.homegate.ch/c/de/inserieren) + + DE +* [DE](https://www.homegate.ch/c/de/hypotheken) +* [FR](https://www.homegate.ch/c/fr/hypotheques) +* [IT](https://www.homegate.ch/c/it/ipoteche) +* [EN](https://www.homegate.ch/c/en/mortgages) + +[](https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages%20%22Services%22#) + +[https://www.homegate.ch](https://www.homegate.ch/) + +* [Suchen](https://www.homegate.ch/c/de/suchen) +* [Services](https://www.homegate.ch/c/de/hypotheken) +* [Schätzen](https://www.homegate.ch/c/de/schaetzen) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Inserieren Ab CHF 0](https://www.homegate.ch/c/de/inserieren) + +* [DE](https://www.homegate.ch/c/de/hypotheken) +* [FR](https://www.homegate.ch/c/fr/hypotheques) +* [IT](https://www.homegate.ch/c/it/ipoteche) +* [EN](https://www.homegate.ch/c/en/mortgages) + + + + + +Eigenheim finanzieren und versichern +==================================== + +Jederzeit persönlich für dich da +-------------------------------- + +Eigenheim finanzieren und versichern +------------------------------------ + +[Jetzt loslegen](https://www.homegate.ch/de/finanzieren/hypotheken-beratung?source=CMS_content) + +Finanzierungsangebote +--------------------- + +Träumst auch du von deinen eigenen vier Wänden? Oder hast du deine Wunschimmobilie vielleicht bereits im Blick und bist noch auf der Suche nach der passenden Finanzierung? An welchem Punkt du auch gerade stehst: Mit unseren Angeboten, Tipps und Tools rund ums Finanzieren von Wohneigentum bist du optimal gerüstet, um deine nächste Entscheidung zu treffen. + +[](https://www.homegate.ch/c/de/hypotheken/hypothek-verlaengern) + +#### Hypothek verlängern + +Suchst du nach einer passenden Hypothek für die anstehende Verlängerung? Wir helfen dir, die Hypothek zu finden, die am besten zu dir passt. + +[Mehr erfahren](https://www.homegate.ch/c/de/hypotheken/hypothek-verlaengern) + +[](https://www.homegate.ch/de/finanzieren/hypotheken-beratung?source=CMS_content) + +#### Hypothekarberatung + +Hier kannst du dich kostenlos und unverbindlich zu sämtlichen Möglichkeiten für die Finanzierung deiner Immobilie beraten lassen. + +[Mehr erfahren](https://www.homegate.ch/de/finanzieren/hypotheken-beratung?source=CMS_content) + +[](https://www.homegate.ch/c/de/ueber-uns/newsletter-anmeldung) + +#### Newsletter abonnieren + +Mit unserem kostenlosen Newsletter erhältst du regelmässig Infos und Tipps rund um die Themen Immobilien, Finanzieren und Versichern. + +[Mehr erfahren](https://www.homegate.ch/c/de/ueber-uns/newsletter-anmeldung) + +Versicherungsangebote +--------------------- + +Es ist sehr wichtig, ab und an die eigene Versicherungssituation zu überprüfen: Entdecke die Angebote unserer Partnerin Mobiliar und lass dich unverbindlich beraten. + +[](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/versicherungen/hausrat) + +#### Hausratversicherung + +Werden deine Möbel, Elektrogeräte oder Kleidung zum Beispiel bei einem Brand zerstört, bist du mit einer Hausratversicherung vor den finanziellen Schäden geschützt. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/versicherungen/hausrat) + +[](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/versicherungen/rechtsschutz) + +#### Rechtsschutzversicherung + +Wenn ein Streit mit den Nachbarn, der Baubehörde oder der Steuerverwaltung eskaliert, erhältst du dank einer Rechtsschutzversicherung anwaltschaftlichen Beistand. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/versicherungen/rechtsschutz) + +[](https://www.homegate.ch/c/de/lp/versicherungsberatung) + +#### Versicherungsberatung + +Wann hast du zum letzten Mal deine Versicherungs- und Vorsorgesituation überprüfen lassen? Vereinbare jetzt eine kostenlose Beratung mit unserer Partnerin Mobiliar. + +[Mehr erfahren](https://www.homegate.ch/c/de/lp/versicherungsberatung) + +Tools und Services +------------------ + +[](https://www.homegate.ch/de/finanzieren/hypothekenrechner) + +#### Hypothekenrechner + +Unser kostenloser Hypothekenrechner ermöglicht es dir, diverse Finanzierungsszenarien durchzuspielen und du siehst sofort, was für dich möglich ist. + +[Mehr erfahren](https://www.homegate.ch/de/finanzieren/hypothekenrechner) + +[](https://www.homegate.ch/c/de/ratgeber/umziehen/umzugstipps/steuerrechner) + +#### Steuerrechner + +Planst du einen Immobilienerwerb in einer anderen Gemeinde? Berechne den Steuerunterschied zwischen deinem jetzigen und dem neuen Wohnort. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/umziehen/umzugstipps/steuerrechner) + +Immobilienbewertung und Immobilienverkauf +----------------------------------------- + +[](https://microsites.ubs.com/price-checker/de/form/init/?provider=homegate&campID=DS-HOMEGATEKOOP-CH-DEU-LINK-HOMEGATE-JOURNEYHOMEGATE-DIRECT-IMMOCHECKLIGHT-HTML-DESKTOP) + +#### Kostenlose Immobilienbewertung + +Hier erhältst du innert weniger Minuten eine kostenlose Ersteinschätzung zum Marktwert deiner Immobilie. + +[Mehr erfahren](https://microsites.ubs.com/price-checker/de/form/init/?provider=homegate&campID=DS-HOMEGATEKOOP-CH-DEU-LINK-HOMEGATE-JOURNEYHOMEGATE-DIRECT-IMMOCHECKLIGHT-HTML-DESKTOP) + +[](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/wohneigentum-schaetzen/online-schaetzung/jetzt-wohneigentum-bewerten) + +#### Professionelle Immobilienbewertung + +Lass deine Immobilie professionell durch unseren Partner IAZI bewerten und profitiere von einem Homegate-Rabatt. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/wohneigentum-schaetzen/online-schaetzung/jetzt-wohneigentum-bewerten) + +[](https://www.xperthome.ch/module/a-zustands-analyse-bau-und-sanierungskosten) + +#### Zustandsanalyse deiner Immobilie + +Bei unserem Partner XpertHome erhältst eine professionelle Zustandsanalyse inklusive Sanierungsplan für deine Immobilie. + +[Mehr erfahren](https://www.xperthome.ch/module/a-zustands-analyse-bau-und-sanierungskosten) + +Weitere Informationen rund ums Finanzieren +------------------------------------------ + +[](https://www.homegate.ch/c/de/hypotheken/hypothekarmodelle) + +#### Hypothekarmodelle + +Die verschiedenen Hypothekarmodelle unterscheiden sich in der Höhe und Fixierung des Zinssatzes und in der Laufzeit. Daraus ergeben sich Vor- und Nachteile. + +[Mehr erfahren](https://www.homegate.ch/c/de/hypotheken/hypothekarmodelle) + +[](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/hypothek/eigenheimbudget) + +#### Eigenkapital und Tragbarkeit + +Wir verraten dir die wichtigsten Informationen zur Eigenheimfinanzierung und zeigen dir, wie du richtig budgetierst, bevor du eine Immobilie kaufst. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/hypothek/eigenheimbudget) + +[](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/steuern/immobilie-steuererklaerung-fehler) + +#### Mit Immobilien Steuern sparen + +Hier erfährst du, wie du deine Immobilie korrekt versteuerst und welche Ausgaben du in Abzug bringen kannst, um Steuern zu sparen. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/steuern/immobilie-steuererklaerung-fehler) + +### Newsletter abonnieren + +Möchtest du regelmässig über Immobilien- und Finanzierungsthemen informiert werden? Mit unserem kostenlosen Newsletter bleibst du stets auf dem Laufenden und erhältst wertvolle Tipps und Tricks. + +[Jetzt abonnieren](https://www.homegate.ch/c/de/ueber-uns/newsletter) + +### Homegate + +* [Über uns](https://swissmarketplace.group/de/portfolio/real-estate/) +* [Kontakt & Hilfe](https://www.homegate.ch/c/de/ueber-uns/kontakt) +* [Geschäftskunde werden](https://swissmarketplace.group/real-estate/de/kunde-werden/) +* [Newsletter abonnieren](https://www.homegate.ch/c/de/ueber-uns/newsletter-anmeldung) +* [Medien](https://swissmarketplace.group/de/media/) +* [Karriere](https://swissmarketplace.group/de/karriere) +* [Ombudsstelle](https://konsum.ch/de/ombudsstelle-immobilienplattformen/) +* [Sitemap](https://www.homegate.ch/c/de/ueber-uns/sitemap) + +### Immobilien + +* [Inserieren](https://www.homegate.ch/c/de/inserieren) +* [Mieten](https://www.homegate.ch/mieten/immobilie-suchen) +* [Kaufen](https://www.homegate.ch/kaufen/immobilie-suchen) +* [Vermieten](https://www.homegate.ch/c/de/inserieren/immobilien/wohnung/vermieten) +* [Verkaufen](https://www.homegate.ch/c/de/ratgeber/inserieren/immobilien-verkaufen) +* [Finanzieren](https://www.homegate.ch/c/de/hypotheken) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Kategorien](https://www.homegate.ch/kategorien-de) + +### Rechtliches + +* [Datenschutz](https://privacy.swissmarketplace.group/de/) +* [Leistungsbeschrieb](https://www.homegate.ch/c/de/ueber-uns/rechtliches/leistungsbeschrieb) +* [Sicherheitstipps](https://www.homegate.ch/c/de/ratgeber/news/vorsicht-betrug-mit-gefaelschten-inseraten) +* [Impressum](https://www.homegate.ch/c/de/ueber-uns/rechtliches) +* [AGB](https://www.homegate.ch/c/de/ueber-uns/rechtliches/agb) +* [Sicherheitsproblem melden](https://swissmarketplace.group/de/vulnerability-disclosure-program) + +### Services + +* [Suchabo anlegen](https://www.homegate.ch/c/de/ratgeber/mieten/wohnung-finden/suchabo) +* [Finanzierungsrechner](https://www.homegate.ch/de/finanzieren/hypothekenrechner) +* [Steuerrechner](https://www.homegate.ch/c/de/ratgeber/umziehen/umzugstipps/steuerrechner) +* [Betreibungsauszug](https://www.homegate.ch/de/betreibungsauszug) +* [Gemeinderatgeber](https://www.homegate.ch/c/de/ratgeber/umziehen/gemeinderatgeber) +* [Mietkaution](https://www.homegate.ch/c/de/ratgeber/umziehen/mietzinskaution) +* [Umzugshilfe](https://www.homegate.ch/de/umziehen/movu) +* [Wohneigentum schätzen](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/wohneigentum-schaetzen/online-schaetzung/jetzt-wohneigentum-bewerten) + +### App herunterladen + +* [](https://apps.apple.com/de/app/homegate-ch/id326131004) + +* Deutsch +* [Français](https://www.homegate.ch/c/fr/hypotheques) +* [Italiano](https://www.homegate.ch/c/it/ipoteche) +* [English](https://www.homegate.ch/c/en/mortgages) + +### Social Media + +* [](https://www.facebook.com/homegate.ch "https://www.facebook.com/homegate.ch") +* [](https://www.youtube.com/user/homegate "https://www.youtube.com/user/homegate") +* [](https://ch.linkedin.com/company/smg-real-estate "https://ch.linkedin.com/company/smg-real-estate") +* [](https://twitter.com/homegate_Deu "https://twitter.com/homegate_Deu") + +* [**SMG Swiss Marketplace Group**](https://swissmarketplace.group/) +* [ImmoScout24](https://www.immoscout24.ch/de) +* [Alle Immobilien](https://www.alle-immobilien.ch/) +* [home.ch](https://www.home.ch/) +* [immostreet.ch](https://www.immostreet.ch/) + +© Copyright 2025 by SMG Swiss Marketplace Group AG. Alle Rechte vorbehalten. + + +=== https://www.homegate.ch/c/de/ratgeber?intlink=h_Advisor "Ratgeber" === +Ratgeber | Homegate.ch + +=============== + +[https://www.homegate.ch](https://www.homegate.ch/) + +* [Suchen](https://www.homegate.ch/c/de/suchen) +* [Services](https://www.homegate.ch/c/de/hypotheken) +* [Schätzen](https://www.homegate.ch/c/de/schaetzen) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Inserieren Ab CHF 0](https://www.homegate.ch/c/de/inserieren) + + DE +* [DE](https://www.homegate.ch/c/de/ratgeber) +* [FR](https://www.homegate.ch/c/fr/guide) +* [IT](https://www.homegate.ch/c/it/guida) +* [EN](https://www.homegate.ch/c/en/advisor) + +[](https://www.homegate.ch/c/de/ratgeber?intlink=h_Advisor%20%22Ratgeber%22#) + +[https://www.homegate.ch](https://www.homegate.ch/) + +* [Suchen](https://www.homegate.ch/c/de/suchen) +* [Services](https://www.homegate.ch/c/de/hypotheken) +* [Schätzen](https://www.homegate.ch/c/de/schaetzen) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Inserieren Ab CHF 0](https://www.homegate.ch/c/de/inserieren) + +* [DE](https://www.homegate.ch/c/de/ratgeber) +* [FR](https://www.homegate.ch/c/fr/guide) +* [IT](https://www.homegate.ch/c/it/guida) +* [EN](https://www.homegate.ch/c/en/advisor) + +* Ratgeber + +Ratgeber +======== + +[](https://www.homegate.ch/c/de/ratgeber/meistgelesene-artikel) + +#### Meistgelesene Artikel + +Was unsere Nutzerinnen und Nutzer zurzeit am meisten interessiert: Dies sind die beliebtesten Beiträge in unserem Ratgeber. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/meistgelesene-artikel) + +[](https://www.homegate.ch/c/de/ratgeber/news) + +#### News + +Hier findest du spannende Neuigkeiten von Homegate. Bleibe immer auf dem Laufenden über neue Produkte und erfahre, was hinter den Kulissen passiert. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/news) + +[](https://www.homegate.ch/c/de/ratgeber/mieten) + +#### Mieten + +Lebst du in einer Mietwohnung? Hier findest du alle wichtigen Informationen rund ums Thema Mieten. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/mieten) + +[](https://www.homegate.ch/c/de/ratgeber/kaufen) + +#### Kaufen + +Alles rund ums Thema Immobilien kaufen. Erfahre, worauf du beim Kauf eines Hauses oder einer Wohnung achten solltest. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/kaufen) + +[](https://www.homegate.ch/c/de/ratgeber/umziehen) + +#### Umziehen + +Der Umzug in eine neue Wohnung kann sich als Herausforderung heraustellen. Mit unseren Tipps zum Thema Umziehen gelingt dir das Zügeln einwandfrei. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/umziehen) + +[](https://www.homegate.ch/c/de/ratgeber/bauen-und-renovieren) + +#### Bauen und Renovieren + +Hier erfährst du alles über das Bauen und Renovieren deines Wohneigentums. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/bauen-und-renovieren) + +[](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern) + +#### Finanzieren und Versichern + +So finanzierst du das Traumhaus: Hier erfährst du alles über die Finanzierung deiner Immobilie, Hypotheken und Versicherungen. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern) + +[](https://www.homegate.ch/c/de/ratgeber/verkaufen) + +#### Verkaufen + +Bevor du deine Immobilie verkaufen kannst, müssen verschiedene Vorbereitungen getroffen werden. Wir zeigen dir, worauf es ankommt. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/verkaufen) + +[](https://www.homegate.ch/c/de/ratgeber/wohnen-und-einrichten) + +#### Wohnen und Einrichten + +Hier findest du alles rund ums Wohnen und Einrichten. Wir zeigen dir, welche Trends gerade aktuell sind und wie du dein Zuhause verschönern kannst. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/wohnen-und-einrichten) + +[](https://www.homegate.ch/c/de/ratgeber/inserieren) + +#### Inserieren + +Du suchst einen Mieter oder Käufer für deine Immobilie? Hier findest du wertvolle Tipps und Tricks zum erfolgreichen Inserieren. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/inserieren) + +[](https://www.homegate.ch/c/de/ratgeber/nachhaltigkeit) + +#### Nachhaltigkeit + +Möchtest du nachhaltiger wohnen? Wir verraten dir, wie du dabei am besten vorgehst. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/nachhaltigkeit) + +[](https://www.homegate.ch/c/de/ratgeber/funktionen) + +#### Homegate-Funktionen + +Hier findest du detaillierte Anleitungen und Erklärungen zu den verschiedenen Features auf Homegate. + +[Mehr erfahren](https://www.homegate.ch/c/de/ratgeber/funktionen) + +### Homegate + +* [Über uns](https://swissmarketplace.group/de/portfolio/real-estate/) +* [Kontakt & Hilfe](https://www.homegate.ch/c/de/ueber-uns/kontakt) +* [Geschäftskunde werden](https://swissmarketplace.group/real-estate/de/kunde-werden/) +* [Newsletter abonnieren](https://www.homegate.ch/c/de/ueber-uns/newsletter-anmeldung) +* [Medien](https://swissmarketplace.group/de/media/) +* [Karriere](https://swissmarketplace.group/de/karriere) +* [Ombudsstelle](https://konsum.ch/de/ombudsstelle-immobilienplattformen/) +* [Sitemap](https://www.homegate.ch/c/de/ueber-uns/sitemap) + +### Immobilien + +* [Inserieren](https://www.homegate.ch/c/de/inserieren) +* [Mieten](https://www.homegate.ch/mieten/immobilie-suchen) +* [Kaufen](https://www.homegate.ch/kaufen/immobilie-suchen) +* [Vermieten](https://www.homegate.ch/c/de/inserieren/immobilien/wohnung/vermieten) +* [Verkaufen](https://www.homegate.ch/c/de/ratgeber/inserieren/immobilien-verkaufen) +* [Finanzieren](https://www.homegate.ch/c/de/hypotheken) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Kategorien](https://www.homegate.ch/kategorien-de) + +### Rechtliches + +* [Datenschutz](https://privacy.swissmarketplace.group/de/) +* [Leistungsbeschrieb](https://www.homegate.ch/c/de/ueber-uns/rechtliches/leistungsbeschrieb) +* [Sicherheitstipps](https://www.homegate.ch/c/de/ratgeber/news/vorsicht-betrug-mit-gefaelschten-inseraten) +* [Impressum](https://www.homegate.ch/c/de/ueber-uns/rechtliches) +* [AGB](https://www.homegate.ch/c/de/ueber-uns/rechtliches/agb) +* [Sicherheitsproblem melden](https://swissmarketplace.group/de/vulnerability-disclosure-program) + +### Services + +* [Suchabo anlegen](https://www.homegate.ch/c/de/ratgeber/mieten/wohnung-finden/suchabo) +* [Finanzierungsrechner](https://www.homegate.ch/de/finanzieren/hypothekenrechner) +* [Steuerrechner](https://www.homegate.ch/c/de/ratgeber/umziehen/umzugstipps/steuerrechner) +* [Betreibungsauszug](https://www.homegate.ch/de/betreibungsauszug) +* [Gemeinderatgeber](https://www.homegate.ch/c/de/ratgeber/umziehen/gemeinderatgeber) +* [Mietkaution](https://www.homegate.ch/c/de/ratgeber/umziehen/mietzinskaution) +* [Umzugshilfe](https://www.homegate.ch/de/umziehen/movu) +* [Wohneigentum schätzen](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/wohneigentum-schaetzen/online-schaetzung/jetzt-wohneigentum-bewerten) + +### App herunterladen + +* [](https://apps.apple.com/de/app/homegate-ch/id326131004) + +* Deutsch +* [Français](https://www.homegate.ch/c/fr/guide) +* [Italiano](https://www.homegate.ch/c/it/guida) +* [English](https://www.homegate.ch/c/en/advisor) + +### Social Media + +* [](https://www.facebook.com/homegate.ch "https://www.facebook.com/homegate.ch") +* [](https://www.youtube.com/user/homegate "https://www.youtube.com/user/homegate") +* [](https://ch.linkedin.com/company/smg-real-estate "https://ch.linkedin.com/company/smg-real-estate") +* [](https://twitter.com/homegate_Deu "https://twitter.com/homegate_Deu") + +* [**SMG Swiss Marketplace Group**](https://swissmarketplace.group/) +* [ImmoScout24](https://www.immoscout24.ch/de) +* [Alle Immobilien](https://www.alle-immobilien.ch/) +* [home.ch](https://www.home.ch/) +* [immostreet.ch](https://www.immostreet.ch/) + +© Copyright 2025 by SMG Swiss Marketplace Group AG. Alle Rechte vorbehalten. + +We Care About Your Privacy +-------------------------- + +We and our 459 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below, including your right to object where legitimate interest is used, or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data. + +### We and our partners process data to provide: + +Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. List of Partners (vendors) + +I Accept No consent Show Purposes + + +=== https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=2 === +Seite 2 - Bauland kaufen in Kanton Zürich | homegate.ch + +=============== + +[](https://www.homegate.ch/de) +* [Suchen](https://www.homegate.ch/de "Suchen") +* [Services](https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages "Services") + +[Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen "Inserieren") + +[Favoriten](https://www.homegate.ch/favoriten "Favoriten") + +[Mein Konto](https://www.homegate.ch/de/overview "Mein Konto") + +Menü + +[](https://www.homegate.ch/de) +* [Suchen](https://www.homegate.ch/de "Suchen") +* [Services](https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages "Services") +* [Schätzen](https://www.homegate.ch/de/immobilienbewertung "Schätzen") +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber?intlink=h_Advisor "Ratgeber") + +[Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen "Inserieren") + +[Favoriten](https://www.homegate.ch/favoriten "Favoriten") + +[Mein Konto](https://www.homegate.ch/de/overview "Mein Konto") + +DE +* [DE](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=2) +* [FR](https://www.homegate.ch/acheter/terrain/canton-zurich/liste-annonces?ep=2) +* [IT](https://www.homegate.ch/acquistare/terreno/cantone-zurigo/lista-annunci?ep=2) +* [EN](https://www.homegate.ch/buy/plot/canton-zurich/matching-list?ep=2) + +Ort + + Kanton Zürich + + Kanton Zürich + + Preis bis + + + + Weitere Filter + + 73 Treffer + +73 Treffer - Bauland kaufen in Kanton Zürich +============================================ + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 10 CHF 2’150’000.– Trottenrain 14, 8474 Dinhard Bewilligtes Bauprojekt im steuergünstigen Dinhard-Welsikon Das Bauland mit Magazingebäude befindet sich an zentraler Lage in Welsikon am Rande der Gemeinde Dinhard in der Kernzone. Die erreichte hohe Ausnutzung ermöglicht attraktive Neubauten an zentraler Lage. Visualisierungen und Grundrisse des bewilligten Bauprojekts finden Sie in der Dokumentation. Das Magazingebäude steht im kommunalen Inventar der schutzwürdigen Bauten. Es wurde deshalb in Absprache mit dem Heimatschutz und der Gemeinde Dinhard ein Schutzvertrag erarbeitet, der einen aussergewöhnlichen Umbau zu einem modernen Loft gestattet.Highlights: • bewilligtes Bauprojekt und Ausschreibungsplanung der Neubauten • Schutzvertrag • ausgezeichnete Lage in Welsikon • Steueroase (Gemeindesteuerfuss 83 %) • gut geschnittene Baulandparzelle • Gute ÖV-Anbindung (Bahnhof 170 m) Realisierung:Der Hauseigentümerverband Winterthur unterstützt Sie bei Bedarf gerne in enger Zusammenarbeit mit Kästle Architekten bei der Realisierung Ihres Neubauprojekts.Von der Planung bis hin zum Verkauf/Vermietung des fertigen Neubaus ? der Hauseigentümerverband Winterthur bietet Ihnen alle Dienstleistungen aus einer Hand. Es besteht keine Architekturverpflichtung.Interessenten sind herzlich eingeladen, mit uns Kontakt aufzunehmen.Rufen Sie unser Verkaufsteam über Telefon 052 209 01 68 an, wenn Sie zusätzliche Informationen oder eine Besichtigung wünschen. Wir freuen uns auf Sie.Ihr HEV-VerkaufsteamWichtig: Wir sind exklusiv mit dem Verkauf beauftragt. Direkte Eigentümerkontakte führen zu einem Interessentenausschluss. S.E.&.O.  Wegzeit Neu 5 min.Station: Dinhard](https://www.homegate.ch/kaufen/4002188905) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    Preis auf Anfrage Kaffeestrasse, 8180 Bülach Ihr Industriebau direkt in Bülach BeschreibungGerne entwickeln und realisieren wir ein auf ihre Bedürfnisse massgeschneidertes Projekt, welches Ihnen zur Miete oder im Eigentum zur Verfügung stehen wird.Interesse oder Fragen? Nehmen Sie Kontakt mit uns auf!Die Parzelle ist nicht das Richtige für Ihre Anforderungen? Kein Problem! Besuchen Sie unsere Homepage und finden Sie weitere Angebote unter: gewerbeland-schweiz.ch  Wegzeit Neu 20 min.Station: Bülach](https://www.homegate.ch/kaufen/4001788654) + +[*  *  *  *  *  *  *  *  *  *  1 / 6    Preis auf Anfrage Kaffeestrasse, 8180 Bülach Ihr Industriebau direkt in Bülach BeschreibungGerne entwickeln und realisieren wir ein auf ihre Bedürfnisse massgeschneidertes Projekt, welches Ihnen zur Miete oder im Eigentum zur Verfügung stehen wird.Interesse oder Fragen? Nehmen Sie Kontakt mit uns auf!Die Parzelle ist nicht das Richtige für Ihre Anforderungen? Kein Problem! Besuchen Sie unsere Homepage und finden Sie weitere Angebote unter: gewerbeland-schweiz.ch  Wegzeit Neu 20 min.Station: Bülach](https://www.homegate.ch/kaufen/4001788644) + +[*  *  *  *  *  *  *  *  *  *  *  *  1 / 8    Preis auf Anfrage 8605 Gutenswil OPPORTUNITÄT IM GLATTTAL: 6'093 m² WOHNBAULAND In Gutenswil (Gemeinde Volketswil) verkaufen wir im Zentrum eine attraktive Baulandparzelle mit 6'093 m². Die Projektstudie (ab Seite 6) zeigt das grosse Potenzial der Parzelle auf. In der Maximalvariante ist ein ansprechender Mix mit verschiedener Haus- und Wohnungstypen für einen Neubau von vier Gebäuden mit einer Hauptnutzfläche von insgesamt 3'357 m² vorgesehen. • Heutige Bebauung: Ein Bauernhaus und ein zusätzliches Ökonomiegebäude • Aufteilung Bauzonen:3'965 m² in der Kernzone 1, 2'128 m² in der Kernzone 2 • Ortsbildschutzgebiet - besondere architektonische Rücksichtnahme erforderlich • Je zwei Vollgeschosse+ zwei Dachgeschosse möglich • Total realisierbare Hauptnutzfläche gemäss Studie von 3'357 m² Interessiert? Weitere Informationen, Bilder und einen virtuellen Rundgang zur Immobilie sowie Besichtigungsmöglichkeiten unter: https://www.propertyowner.ch/de/immobilien/25-12302 Referenznummer: 25-12302Werden Sie heute noch kostenlos Mitglied im Grundeigentümer Verband Schweiz und profitieren Sie von den zahlreichen Mitgliedervorteilen: www.propertyowner.ch - Verbandsmitglieder können die vorliegende oder andere Immobilien mit Unterstützung unserer Finanzierungsabteilung finanzieren.- Verbandsmitglieder haben Zugang zu unserem Rechtsdienst (30-minütige kostenlose telefonische Erstberatung).- Kostenlose, professionelle Immobilienbewertung- Kostenlose Beratung zur und Berechnung der GrundstückgewinnsteuerSind Sie neugierig geworden? Erfahren Sie mehr auf unserer Website https://www.propertyowner.ch/immobilien/ und lassen Sie sich von unseren Angeboten inspirieren. Wir freuen uns auf die Möglichkeit, Sie persönlich kennenzulernen und Ihre Immobilienträume zu verwirklichen!  Wegzeit -](https://www.homegate.ch/kaufen/4002533580) + +Dein Immobilienexperte vor Ort +------------------------------ + +[ Stöhr Immobilien GmbH berät dich persönlich zur optimalen Verkaufsstrategie für deine Immobilie.](https://homegate.ch/anbieter/n023/stohr-immobilien-gmb-h) + +[*  *  *  *  *  *  *  *  *  1 / 5    CHF 1’700’000.– Lägernstrasse 8, 8153 Rümlang Attraktives Grundstück mit Altliegenschaft - Ideal für Ihr Bauprojekt Inmitten der beliebten Zürcher Gemeinde Rümlang befindet sich dieses vielseitige Baugrundstück mit bestehender Altliegenschaft. Die ruhige Lage kombiniert mit einer ausgezeichneten Infrastruktur sowie der Nähe zur Stadt Zürich und zum Flughafen macht das Objekt besonders attraktiv. Dank der optimalen Anbindung an den öffentlichen Verkehr, vielfältigen Einkaufsmöglichkeiten, Schulen und Naherholungsgebieten ist dieser Standort sowohl für Familien als auch für Investoren interessant.Die aussichtsreiche Parzelle umfasst 736 m² in der Bauzone W 1.2 und bietet ein hervorragendes Entwicklungspotenzial. Das erschlossene Bauland eignet sich sowohl für den Neubau eines modernen Einfamilienhauses als auch für die Realisierung von zwei Doppelhäusern oder eines kleinen Bauprojekts.Die bestehende Liegenschaft eröffnet zusätzliche Möglichkeiten, sei es durch eine umfassende Sanierung oder als Ausgangspunkt für einen individuellen Neubau ganz nach Ihren Vorstellungen. Dieses Angebot ist eine seltene Gelegenheit in Rümlang und lädt dazu ein, eigene Wohnträume oder ein spannendes Bauprojekt zu verwirklichen.Kontaktieren Sie uns bei Interesse für weitere Informationen. Wir freuen uns auf Ihren Anruf.  Wegzeit Neu 8 min.Station: Rümlang](https://www.homegate.ch/kaufen/4002530739) + +[*  *  *  *  *  *  *  *  *  1 / 5    CHF 995’000.– Sonnenbühlstrasse 12, 8181 Höri Weitblick an der Landwirtschaftszone Im Auftrag unseres Kunden verkaufen wir eine Baulandparzelle mit 696 m² Grundstücksfläche in der Wohnzone E2. Ein Projekt wurde bereits gepfüt und bewilligt. Verkaufsrichtpreis: CHF 995'000.--Haben wir Ihr Interesse geweckt? Gerne senden wir Ihnen das ausführliche Exposé über dieses interessante Angebot.  Wegzeit Neu 32 min.Station: Niederglatt](https://www.homegate.ch/kaufen/4002529781) + +[ 1 / 1 CHF 2’065’000.– **240m²** Nutzfläche 8105 Regensdorf Zentrale Liegenschaft mit Potenzial in Regensdorf Attraktives Entwicklungsgrundstück mit eingereichtem Baugesuch in Regensdorf Im Zentrum von Regensdorf bietet sich eine seltene Gelegenheit: Zum Verkauf steht ein Grundstück mit bestehender Liegenschaft, welche stark sanierungs- bzw. entwicklungsbedürftig ist. Der grosse Vorteil: Für dieses Areal liegt bereits ein konkretes Neubauprojekt vor - mit Baugesuch, das bei der Gemeinde eingereicht ist.Geplant ist der Ersatzneubau eines Mehrfamilienhauses mit neun Wohneinheiten. Das Projekt umfasst einen attraktiven Wohnungsmix von 2.5 bis 4.5 Zimmer-Wohnungen, darunter auch zwei grosszügige Maisonette-Wohnungen. Die Gesamtwohnfläche beläuft sich auf ca. 658 m² und deckt damit ein breites Spektrum an Wohnbedürfnissen ab.Die Grundrisse sind hell, modern und auf heutige Ansprüche zugeschnitten. Balkone, Terrassen und offene Wohn-/Essbereiche schaffen hohen Wohnkomfort. Eine Tiefgarage mit Autolift, Veloraum und Kellerabteilen rundet das Projekt ab und garantiert eine optimale Nutzung.Damit eignet sich dieses Objekt sowohl für Investoren, die ein Projekt mit hohem Wertsteigerungspotenzial suchen, als auch für Bauträger, die direkt in die Realisierung einsteigen möchten.Folgende Highlights bietet Ihnen diese Liegenschaft: • Eingereichtes Baugesuch für einen Ersatzneubau mit 9 Wohnungen • Wohnungsmix von 2.5 bis 4.5 Zimmer inkl. Maisonettes • Gesamtwohnfläche: ca. 658 m² • Tiefgarage mit Autolift, Veloraum und Kellerabteilen • Sehr sonnige, zentrale Lage im Zentrum von Regensdorf • Kurze Distanzen nach Zürich-City und zum Flughafen Kloten • Attraktives Investitionsobjekt mit nachhaltigem Wertsteigerungspotenzial Ergreifen Sie diese seltene Gelegenheit und lassen Sie sich bei einer persönlichen Besichtigung von der Einzigartigkeit und dem Potenzial dieser aussergewöhnlichen Liegenschaft in Regensdorf überzeugen.  Wegzeit -](https://www.homegate.ch/kaufen/4002528704) + +[ 1 / 1 Preis auf Anfrage 8910 Affoltern am Albis Flexibles Bauland in W4 ? vom Eigenheim bis zum Mehrfamilienhaus Am Ende einer ruhigen Sackgasse gelegen, überzeugt diese Parzelle in der Zone W4 mit vielseitigen Möglichkeiten für Ihr Bauvorhaben. Ob ein modernes Einfamilienhaus mit rund 200 m² Wohnfläche oder ein Mehrfamilienhaus mit drei Vollgeschossen ? hier haben Sie die Wahl. Dank der guten Erschliessung sowie kurzen Wegen zu Schulen, Einkaufsmöglichkeiten und öffentlichem Verkehr eignet sich das Grundstück sowohl für private Bauherren als auch für Investoren. Eine seltene Gelegenheit, sich in einem gefragten Wohnquartier zu verwirklichen.Auf einen Blick:+ W4-ZONENPLANUNG: Ausnutzungsziffer 74 %+ EINFAMILIENHAUS: ca. 200 m² Wohnfläche + Dach/Attika möglich+ MEHRFAMILIENHAUS: mit 3 Vollgeschossen realisierbar+ GRUNDSTÜCKSFLÄCHE: 250?400 m² (flexibel wählbar)+ ATTRAKTIVE LAGE: Ruhige 30er-Zone, mit schneller Anbindung nach Zürich, Zug und Luzern+ INFRASTRUKTUR: Einkauf, Schulen, Freizeitangebot in unmittelbarer NäheBei Interesse senden wir Ihnen gerne einen ausführlichen Objektbeschrieb inklusive sämtlichen Informationen und freuen uns, Sie persönlich an einem Besichtigungstermin beraten zu dürfen.WENET AG Immobilien der KI Group AG since 1974.  Wegzeit -](https://www.homegate.ch/kaufen/4002527536) + +[*  *  *  *  *  *  *  *  1 / 4    CHF 1’600’000.– Grundbuch Blatt 50514, Kataster 720, Breiten, 8459 Volken Hervorragende Gelegenheit an idyllischer Lage Das Bauland in Volken bietet eine hervorragende Gelegenheit für die Errichtung eines individuellen Wohnprojekts. Die Kombination aus idyllischer Lage, einer wohltuenden und unverbaubaren Sicht ins Grüne, hervorragender Infrastruktur und vielfältigen Freizeitmöglichkeiten macht dieses Grundstück zu einer aussergewöhnlichen Investition in eine Lebensqualität der Extraklasse. Die Käufer geniessen im Rahmen der Bau- und Zonenordnung freie Gestaltungswahl, ob für den Bau von Doppeleinfamilienhäusern, Einfamilienhäusern oder anderen Projekten. Haben wir Ihre Neugier geweckt? Wir freuen uns auf Ihre Kontaktaufnahme!  Wegzeit -](https://www.homegate.ch/kaufen/4002526342) + +[ 1 / 1 CHF 3’750’000.– 8953 Dietikon Wo jeder Quadratzentimeter nach Ihnen ruft Dieses attraktive Grundstück mit einer stattlichen Grösse von 1'094 m² bietet erhebliches Potenzial für eine Neubebauung im wunderschönen Dietikon im Kanton Zürich. Auf dem Grundstück können bis zu zwei Vollgeschosse errichtet werden, was eine bebaubare Bruttogeschossfläche von fast 330 m² ermöglicht.Das erstklassige Angebot ist ideal für weitsichtige Investoren oder Bauherren, die unmittelbar mit der Bauplanung beginnen möchten. Welch aussergewöhnliche Investitionsmöglichkeit! Auf einen Blick:+ NEUBAUMÖGLICHKEIT: 1 grosszügiges EFH sowie ein MFH mit zwei Vollgeschossen + BRUTTOGESCHOSSFLÄCHE: 330 m2 sind zulässig+ BAUZONE: W2 mit einer Ausnützungsziffer von 0,30+ PRIVATSPHÄRE: Villenquartier, uneingeschränkte Rückzugsoase in allen Belangen + ZUSTAND: ausbaufähiges, bestehendes Einfamilienhaus (1967) mit 6.5 Zimmern+ LAGE: ruhige Quartierstrasse, leichte Hanglage, ganztägige Besonnung, Panorama Fernsicht + RENDITEOBJEKT: spannende und interessante Anlage Bei Interesse senden wir Ihnen gerne einen ausführlichen Objektbeschrieb inklusive sämtlichen Informationen und freuen uns, Sie persönlich an einem Besichtigungstermin beraten zu dürfen. WENET AG ? Immobilien der KI Group AG since 1974.  Wegzeit -](https://www.homegate.ch/kaufen/4002349481) + +[ 1 / 1 * Ruhige Lage CHF 1’700’000.– 8910 Affoltern am Albis Attraktive Entwicklungsparzelle mit Machbarkeitsstudie - 7 EH möglich Share Deal - Entwickeln Sie Ihr nächstes Erfolgsprojekt! Diese attraktive Parzelle in Affoltern am Albis bietet eine einmalige Investitionsmöglichkeit. Der Altbestand auf dem Grundstück muss abgerissen werden, um Platz für ein zukunftsorientiertes Neubauprojekt zu schaffen. Die bereits vorliegende Machbarkeitsstudie und die vollständige Erschliessung des Grundstücks erleichtern den Entwicklungsprozess und bieten ein grosses Potenzial.Folgende Highlights bietet Ihnen diese Immobilie: • Machbarkeitsstudie für 7 EH vorhanden • Zentrale Lage in Affoltern am Albis • Grundstücksfläche ca: 702 m² • Zone: W3 / Kernzone • Gute Verkehrsanbindung an die ÖV • Hervorragende Infrastruktur (Einkaufsmöglichkeiten, Schulen, Freizeit) • Geringes Risiko durch Machbarkeitsstudie und klare Projektplanung • Netto-Geschossfläche (NGF): ca. 400 m² • Voll erschlossen • Ruhige und grüne Umgebung • Nähe zu städtischen Zentren (Zürcher Oberland) • Hohe Lebensqualität • 30er Zone • Dealstruktur: Share - Deal (Firma exkl.) • Wert der zugehörigen Firma: Ca. CHF 500'000 zzgl. Lassen Sie sich diese einmalige Gelegenheit nicht entgehen und melden Sie sich heute noch für weitere Informationen! * Ruhige Lage  Wegzeit -](https://www.homegate.ch/kaufen/4002105351) + +[ 1 / 1 CHF 1’070’000.– Auf Anfrage 1, 8340 Hinwil Hier beginnt Ihre Zukunft Dieses attraktive Grundstück befindet sich an ruhiger und familienfreundlicher Lage in Hinwil. Mit einer Gesamtfläche von über 1’070 m² bietet es vielfältige Nutzungsmöglichkeiten und eignet sich hervorragend für die Realisierung mehrerer Reihenfamilienhäuser. Dank der Möglichkeit zur Abparzellierung kann auch nur ein Teil des Landes – beispielsweise ideal für ein Einfamilienhaus – erworben werden. Das Grundstück liegt in der Kernzone und eröffnet dadurch grossen Gestaltungsspielraum für individuelle Bauprojekte.Dieses ImmoSky Angebot bietet folgende *MEHR LEISTUNG*:+ Kernzone+ 2 Vollgeschosse, 1 Dachgeschoss+ 4m Grenzabstand+ 7.5m FassadenhöheDas Grundstück ist baureif und erschlossen, die Quartierplankosten von CHF 150.00/m² werden zum Verkaufspreis dazugerechnet.Aktuell befinden sich alte Holzschuppen auf dem Grundstück. Diese können abgerissen werden, um Platz für neue Ideen zu schaffen. Eine seltene Gelegenheit, Wohnen mit hoher Lebensqualität im Zürcher Oberland zu verwirklichen. Gerne stehe ich Ihnen bei Fragen zur Verfügung – Ihr Daniel Arigoni.(Das Verkaufsdossier wird in der Regel innert maximal 24 Stunden an Sie versendet, bitte prüfen Sie auch Ihren SPAM-Ordner.)  Wegzeit -](https://www.homegate.ch/kaufen/4002554241) + +[*  *  *  *  *  *  *  *  1 / 4    CHF 3’300’000.– Sonnenhalde, 8602 Wangen-Brüttisetten Exklusives Bauland: letzte Chance in Toplage Dieses seltene Angebot bietet Ihnen die Möglichkeit, sich ein exklusives Stück Land in einer der begehrtesten Lagen von Wangen-Brüttisellen zu sichern.- Unbebautes Grundstück in erhöhter Lage- 1666 m², Wohnzone 2 (30%)- Viel Sonne, Ruhe und Privatsphäre- Maximal realisierbare Wohnfläche: ca. 600 m² (gemäss Machbarkeitsstudie)Die ideale Ausrichtung und die leicht erhöhte Position garantieren eine optimale Besonnung und ein Wohnerlebnis auf höchstem Niveau. Ob exklusive Einfamilienhäuser oder repräsentative Villa - hier können Sie Ihre Wohnträume verwirklichen.Die detaillierte Machbarkeitsstudie stellen wir Ihnen auf Wunsch gerne zur Verfügung.Hier geht's zum Teaser Video: https://show.tours/v/CGdKtCx  Wegzeit -](https://www.homegate.ch/kaufen/4002543522) + +[*  *  *  *  *  *  *  *  1 / 4 CHF 750’000.– Sonnhalde 8, 8421 Dättlikon Grundstück 563 m2, sonnige Lage, einmalige Aussicht! Wir bieten an sonniger und ruhiger Lage ein einmaliges Grundstück (563m2) mit einer unverbaubaren Weitsicht an!Details entnehmen Sie der Verkaufsdokumentation im Anhang.Wegen seiner Hanglage ist eine ideale Besonnung sowie eine unverbaubare Aussicht garantiert.Gerne zeigen wir Ihnen dieses Wohnbauland an bester Lage oder Sie fahren mal vorbei und geniessen den Moment!Lassen Sie sich diese Gelegenheit nicht entgehen. Nehmen Sie Kontakt mit uns auf.Zögern Sie nicht, wir freuen uns auf Ihren Anruf  Wegzeit Neu 36 min.Station: Pfungen](https://www.homegate.ch/kaufen/4002470802) + +[*  *  *  *  *  *  *  *  *  1 / 5    CHF 1’300’000.– Leisibüel, 8484 Weisslingen Attraktives Grundstück an ruhiger und sonniger Lage Verwirklichen Sie Ihren Wohntraum im Zürcher OberlandIm exklusiven und begehrten Quartier Leisibüel in der Gemeinde Weisslingen steht eine der letzten unbebauten Baulandparzellen zum Verkauf. Diese seltene Gelegenheit bietet Ihnen die Möglichkeit, Ihr individuelles Einfamilien- oder Doppeleinfamilienhaus in einer Quartiererhaltungszone zu realisieren.Grundstücksdaten: • Lage: Quartier Leisibüel, Weisslingen ZH • Zone: Quartiererhaltungszone Leisibüel • Bebaubarkeit: Einfamilienhaus oder Doppeleinfamilienhaus • Ausrichtung: Südwest, mit optimaler Besonnung • Topografie: Hanglage mit herrlicher Aussicht Besondere Merkmale: • Ruhige, sonnige und erhöhte Lage mit viel Privatsphäre • Unverbaubare Fernsicht in die umliegende Natur und Berge • Umgeben von gepflegter Nachbarschaft mit hochwertigen Liegenschaften • Ideale Voraussetzungen für naturnahes und zugleich stilvolles Wohnen  Wegzeit -](https://www.homegate.ch/kaufen/4002403830) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 1’900’000.– Im Königstal 2, 8487 Zell Wegzeit Neu 22 min.Station: Rämismühle-Zell](https://www.homegate.ch/kaufen/4002279293) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 3’000’000.– Im Königstal 3, 8487 Zell ZH Wegzeit Neu 22 min.Station: Rämismühle-Zell](https://www.homegate.ch/kaufen/4002279266) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 25 CHF 4’900’000.– Im Königstal 3, 8487 Zell ZH Wegzeit Neu 22 min.Station: Rämismühle-Zell](https://www.homegate.ch/kaufen/4002279259) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  1 / 9    CHF 1’590’000.– 8912 Obfelden Attraktives Baugrundstück am Hang in Obfelden! Attraktives Baugrundstück mit Weitblick in Obfelden!In der Gemeinde Obfelden bietet sich Ihnen eine exklusive Möglichkeit: Ein 925 m² grosses Grundstück in bevorzugter Lage wartet auf eine neue Vision. Ob als grosszügiges Einfamilienhaus, als Doppelhaus oder als modernes Mehrfamilienprojekt mit bis zu vier Wohneinheiten - die Parzelle eröffnet vielfältige Gestaltungsmöglichkeiten für private oder gewerbliche Bauherren.Eckdaten zum Grundstück: • mit bestehendem, nicht bewohntem Gebäude • Grundstücksfläche: 925 m², Bauzone W2E • Zulässige Grundfläche Hauptbau: ca. 195 m² • Maximal erlaubte Geschosszahl: 4 • Realisierbare Hauptnutzfläche: über 550 m² • Baureife: Umfangreiche Vorabklärungen und Unterlagen bereits vorhanden Highlights: • Südlich ausgerichtete Hanglage mit freiem Blick in die Ferne • Ruhige Wohnsituation dank bevorstehender Verkehrsberuhigung der Dorfstrasse • Optimale Infrastruktur: Schule, Kindergarten und öffentliche Verkehrsmittel nur wenige Schritte entfernt • Hervorragende Anbindung: Nur 2 Fahrminuten zur Autobahn (Affoltern am Albis) • Vielversprechendes Potenzial für Investoren, Projektentwickler oder anspruchsvolle Eigenheimbauer Dieses Grundstück kombiniert Lagequalität mit Entwicklungspotenzial - eine seltene Gelegenheit in einem aufstrebenden Wohnumfeld. Nutzen Sie die Chance, hier ein zukunftsorientiertes Projekt zu realisieren.Für weitere Informationen oder zur Vereinbarung eines Besichtigungstermins stehen wir Ihnen gerne persönlich zur Verfügung.Zögern Sie nicht, uns zu kontaktieren - wir freuen uns auf Ihre Anfrage.  Wegzeit -](https://www.homegate.ch/kaufen/4002115081) + +[*  *  *  *  *  *  *  *  1 / 4 CHF 1’169’200.– Bergstrasse 56, 8424 Embrach attraktive Baulandparzelle für grosszügiges Einfamilienhaus Die angebotene Baulandparzelle befindet sich an einer begehrten und privilegierten Wohnlage am Rande des Einfamilienhausquartiers „Im Haller“ in Embrach. Diese idyllische Umgebung bietet eine harmonische Kombination aus naturnaher Erholung und einer hervorragenden Anbindungen an den Flughafen Kloten sowie an die nahegelegenen Städte Zürich und Winterthur.Zum Verkauf steht noch eine attraktives Grundstück:Baulandparzelle „54“ (im Situationsplan rot gekennzeichnet):Diese Parzelle umfasst 614m² (zzgl. 1/3 Miteigentum an Erschliessung 126 m²) und eignet sich perfekt für die Realisierung eines grosszügigen freistehenden Einfamilienhauses.Baulandparzelle „60“ ist bereits verkauft.Die Baulandparzelle „56“ ist bereits verkauft.Diese Grundstücke bieten die seltene Gelegenheit, Ihre Wohnträume an einer der schönsten Adressen in Embrach zu verwirklichen.ArchitekturDie Grundeigentümerin hat das ganze Areal dem Architekturbüro RWPA GmbH, Lagerplatz 6, 8400 Winterthur, für eine Projektentwicklung zur Verfügung gestellt. Die Bauparzellen werden mit Architekturverpflichtung zu Gunsten der RWPA GmbH, Lagerplatz 6, 8400 Winterthur, veräussert. Die Architekten stehen Interessenten für eine Projektstudie jederzeit gerne zur Verfügung.BesichtigungenGerne laden wir Sie zu einer Besichtigung vor Ort ein.VerkaufspreisDer Verkaufspreis beträgt CHF 1'169'200.00, wobei das Objekt voraussichtlich an den Meistbietenden veräussert wird. Ein allfälliges Kaufangebot möchten Sie uns bitte schriftlich (per Mail oder per Post) zukommen lassen.Wir freuen uns auf Ihre Kontaktaufnahme. Gerne stellen wir Ihnen die Verkaufsdokumentation zur Verfügung.  Wegzeit Neu 38 min.Station: Embrach-Rorbas](https://www.homegate.ch/kaufen/4001792418) + +[](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste)[1](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste)[2](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=2)[3](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=3)[4](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=4)[](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=3) + +Suche speichern Karte + +Vorschläge basierend auf deinen Suchresultaten +---------------------------------------------- + +* [ CHF 2’500’000.– 8442 Hettlingen](https://www.homegate.ch/kaufen/4002438548) +* [ Preis auf Anfrage 8424 Embrach](https://www.homegate.ch/kaufen/4002492324) +* [ CHF 2’980’000.– Klosterstrasse 29, 8962 Bergdietikon](https://www.homegate.ch/kaufen/4002485540) +* [ CHF 3’600’000.– 8330 Pfäffikon ZH](https://www.homegate.ch/kaufen/4002531588) +* [ Preis auf Anfrage Industriestrasse 34, 8117 Fällanden](https://www.homegate.ch/kaufen/4002549837) +* [ CHF 3’440’000.– Weiacherstrasse 85, 8427 Rorbas](https://www.homegate.ch/kaufen/4002277619) +* [ CHF 85’000.– Klosterrebenstrasse 41 / 43 / 45, 8918 Unterlunkhofen](https://www.homegate.ch/kaufen/3000765189) +* [ CHF 4’900’000.– **2’595m²** Wohnfläche 8506 Herdern](https://www.homegate.ch/kaufen/4002529753) +* [ CHF 1’750’000.– In der Gass 2, 8627 Grüningen](https://www.homegate.ch/kaufen/3003479026) +* [ Preis auf Anfrage Nüsatzstrasse, 8463 Benken ZH](https://www.homegate.ch/kaufen/4002355750) +* [ CHF 510’000.– 8194 Hüntwangen](https://www.homegate.ch/kaufen/4002469116) +* [ Preis auf Anfrage Auf Anfrage 1, 8505 Pfyn](https://www.homegate.ch/kaufen/4002546900) +* [ Preis auf Anfrage 8570 Weinfelden](https://www.homegate.ch/kaufen/4002486406) +* [ CHF 1’870’000.– **5.5** Zimmer **173m²** Wohnfläche Luegetenstrasse 11, 8489 Wildberg](https://www.homegate.ch/kaufen/4002491909) +* [ CHF 2’200’000.– Götzen, 8197 Rafz](https://www.homegate.ch/kaufen/4002297853) +* [ CHF 1’900’000.– Wehntalerstrasse 28, 8181 Höri](https://www.homegate.ch/kaufen/4002530816) +* [ CHF 5’400’000.– Feldstrasse 2, 8805 Richterswil](https://www.homegate.ch/kaufen/4002526347) +* [ Preis auf Anfrage 8157 Dielsdorf](https://www.homegate.ch/kaufen/4001788652) +* [ Preis auf Anfrage 8618 Oetwil am See](https://www.homegate.ch/kaufen/4002510045) +* [ CHF 1’310’000.– Steig, 8535 Herdern](https://www.homegate.ch/kaufen/4002230356) + +1. [Startseite](https://www.homegate.ch/de) +2. [Kaufen](https://www.homegate.ch/kaufen/immobilie-suchen) +3. [Bauland zum Kaufen](https://www.homegate.ch/kaufen/bauland/trefferliste) +4. [Schweiz](https://www.homegate.ch/kaufen/bauland/land-schweiz/trefferliste) + +Bezirke im Kanton Kanton Zürich + +[Bauland kaufen Bezirk Affoltern](https://www.homegate.ch/kaufen/bauland/region-affoltern/trefferliste)|[Bauland kaufen Bezirk Andelfingen](https://www.homegate.ch/kaufen/bauland/region-andelfingen/trefferliste)|[Bauland kaufen Bezirk Bülach](https://www.homegate.ch/kaufen/bauland/region-buelach/trefferliste)|[Bauland kaufen Bezirk Dielsdorf](https://www.homegate.ch/kaufen/bauland/region-dielsdorf/trefferliste)|[Bauland kaufen Bezirk Hinwil](https://www.homegate.ch/kaufen/bauland/region-hinwil/trefferliste)|[Bauland kaufen Bezirk Horgen](https://www.homegate.ch/kaufen/bauland/region-horgen/trefferliste)|[Bauland kaufen Bezirk Meilen](https://www.homegate.ch/kaufen/bauland/region-meilen/trefferliste)|[Bauland kaufen Bezirk Pfäffikon](https://www.homegate.ch/kaufen/bauland/region-pfaeffikon/trefferliste)|[Bauland kaufen Bezirk Uster](https://www.homegate.ch/kaufen/bauland/region-uster/trefferliste)|[Bauland kaufen Bezirk Winterthur](https://www.homegate.ch/kaufen/bauland/region-winterthur/trefferliste)|[Bauland kaufen Bezirk Dietikon](https://www.homegate.ch/kaufen/bauland/region-dietikon/trefferliste)|[Bauland kaufen Zürich](https://www.homegate.ch/kaufen/bauland/ort-zuerich/trefferliste) + +Weitere Immobiliensuchen in Kanton Zürich + +[Immobilien mieten Kanton Zürich](https://www.homegate.ch/mieten/immobilien/kanton-zuerich/trefferliste)|[Wohnung mieten Kanton Zürich](https://www.homegate.ch/mieten/wohnung/kanton-zuerich/trefferliste)|[Haus mieten Kanton Zürich](https://www.homegate.ch/mieten/haus/kanton-zuerich/trefferliste)|[Möbliertes Wohnobjekt mieten Kanton Zürich](https://www.homegate.ch/mieten/moebliertes-wohnobjekt/kanton-zuerich/trefferliste)|[Parkplatz, Garage mieten Kanton Zürich](https://www.homegate.ch/mieten/parkplatz-garage/kanton-zuerich/trefferliste)|[Büro mieten Kanton Zürich](https://www.homegate.ch/mieten/buero/kanton-zuerich/trefferliste)|[Gewerbe mieten Kanton Zürich](https://www.homegate.ch/mieten/gewerbeobjekt/kanton-zuerich/trefferliste)|[Neubau zum Mieten Kanton Zürich](https://www.homegate.ch/mieten/immobilien/kanton-zuerich/trefferliste?an=G)|[Wohnung kaufen Kanton Zürich](https://www.homegate.ch/kaufen/wohnung/kanton-zuerich/trefferliste)|[Haus kaufen Kanton Zürich](https://www.homegate.ch/kaufen/haus/kanton-zuerich/trefferliste)|[Immobilien kaufen Kanton Zürich](https://www.homegate.ch/kaufen/immobilien/kanton-zuerich/trefferliste)|[Mehrfamilienhaus kaufen Kanton Zürich](https://www.homegate.ch/kaufen/mehrfamilienhaus/kanton-zuerich/trefferliste)|[Parkplatz, Garage kaufen Kanton Zürich](https://www.homegate.ch/kaufen/parkplatz-garage/kanton-zuerich/trefferliste)|[Gewerbe, Büro, Lager kaufen Kanton Zürich](https://www.homegate.ch/kaufen/gewerbeobjekt/kanton-zuerich/trefferliste)|[Neubau zum Kaufen Kanton Zürich](https://www.homegate.ch/kaufen/immobilien/kanton-zuerich/trefferliste?an=G) + +### Homegate + +* [Über uns](https://swissmarketplace.group/de/portfolio/real-estate/) +* [Kontakt & Hilfe](https://www.homegate.ch/c/de/ueber-uns/kontakt) +* [Geschäftskunde werden](https://swissmarketplace.group/real-estate/de/kunde-werden/) +* [Newsletter abonnieren](https://www.homegate.ch/c/de/ueber-uns/newsletter-anmeldung) +* [Medien](https://swissmarketplace.group/de/media/) +* [Karriere](https://swissmarketplace.group/de/karriere/) +* [Ombudsstelle](https://konsum.ch/de/ombudsstelle-immobilienplattformen/) +* [Werbung auf Homegate](https://swissmarketplace.group/de/werbung/) +* [Sitemap](https://www.homegate.ch/c/de/ueber-uns/sitemap) + +### Immobilien + +* [Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen) +* [Mieten](https://www.homegate.ch/mieten/immobilie-suchen) +* [Kaufen](https://www.homegate.ch/kaufen/immobilie-suchen) +* [Vermieten](https://www.homegate.ch/c/de/inserieren/immobilien/wohnung/vermieten) +* [Verkaufen](https://www.homegate.ch/c/de/ratgeber/inserieren/immobilien-verkaufen) +* [Finanzieren](https://www.homegate.ch/c/de/hypotheken) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Kategorien](https://www.homegate.ch/kategorien-de) + +### Rechtliches + +* [Datenschutz](https://privacy.swissmarketplace.group/de/) +* [Leistungsbeschrieb](https://www.homegate.ch/c/de/ueber-uns/rechtliches/leistungsbeschrieb) +* [Sicherheitstipps](https://www.homegate.ch/c/de/ratgeber/news/vorsicht-betrug-mit-gefaelschten-inseraten) +* [Impressum](https://www.homegate.ch/c/de/ueber-uns/rechtliches) +* [AGB](https://www.homegate.ch/c/de/ueber-uns/rechtliches/agb) +* [Sicherheitsproblem melden](https://swissmarketplace.group/de/vulnerability-disclosure-program) +* Privatsphäre-Einstellungen + +### Services + +* [Suchabo anlegen](https://www.homegate.ch/c/de/ratgeber/mieten/wohnung-finden/suchabo) +* [Finanzierungsrechner](https://www.homegate.ch/de/finanzieren/hypothekenrechner) +* [Steuerrechner](https://www.homegate.ch/c/de/ratgeber/umziehen/umzugstipps/steuerrechner) +* [Betreibungsauszug](https://www.homegate.ch/de/betreibungsauszug) +* [Gemeinderatgeber](https://www.homegate.ch/c/de/ratgeber/umziehen/gemeinderatgeber) +* [Mietkaution](https://www.homegate.ch/c/de/ratgeber/umziehen/mietzinskaution) +* [Umzugshilfe](https://www.homegate.ch/c/de/umziehen) +* [Wohneigentum schätzen](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/wohneigentum-schaetzen/online-schaetzung/jetzt-wohneigentum-bewerten) +* [Agenturverzeichnis](https://www.homegate.ch/agenturverzeichnis) + +### App herunterladen + +[](https://itunes.apple.com/de/app/homegate.ch/id326131004 "iOS App")[](https://play.google.com/store/apps/details?id=ch.homegate.mobile&hl=de "Android App") + +* [Deutsch](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=2) +* [Français](https://www.homegate.ch/acheter/terrain/canton-zurich/liste-annonces?ep=2) +* [Italiano](https://www.homegate.ch/acquistare/terreno/cantone-zurigo/lista-annunci?ep=2) +* [English](https://www.homegate.ch/buy/plot/canton-zurich/matching-list?ep=2) + +### Social Media + +[](https://www.facebook.com/homegate.ch "Facebook")[](https://www.youtube.com/user/homegateeng "YouTube")[](https://ch.linkedin.com/company/homegate-ch-ag "LinkedIn")[](https://twitter.com/homegate_Deu "Twitter") + +[SMG Swiss Marketplace Group](https://swissmarketplace.group/)[ImmoScout24](https://www.immoscout24.ch/de)[Alle Immobilien](https://www.alle-immobilien.ch/)[home.ch](https://www.home.ch/)[immostreet.ch](https://www.immostreet.ch/) + +© Copyright 2025 by SMG Swiss Marketplace Group AG. Alle Rechte vorbehalten.Die Vervielfältigung und Übernahme von Inseraten durch Dritte, insbesondere von Fotos und persönlichen Daten in diesen Inseraten, verletzt die damit verbundenen Rechte und ist ausdrücklich verboten. + +We Care About Your Privacy +-------------------------- + +We and our 459 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below, including your right to object where legitimate interest is used, or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data. + +### We and our partners process data to provide: + +Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. List of Partners (vendors) + +I Accept No consent Show Purposes + + +=== https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=4 === +Seite 4 - Bauland kaufen in Kanton Zürich | homegate.ch + +=============== + +[](https://www.homegate.ch/de) +* [Suchen](https://www.homegate.ch/de "Suchen") +* [Services](https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages "Services") + +[Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen "Inserieren") + +[Favoriten](https://www.homegate.ch/favoriten "Favoriten") + +[Mein Konto](https://www.homegate.ch/de/overview "Mein Konto") + +Menü + +[](https://www.homegate.ch/de) +* [Suchen](https://www.homegate.ch/de "Suchen") +* [Services](https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages "Services") +* [Schätzen](https://www.homegate.ch/de/immobilienbewertung "Schätzen") +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber?intlink=h_Advisor "Ratgeber") + +[Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen "Inserieren") + +[Favoriten](https://www.homegate.ch/favoriten "Favoriten") + +[Mein Konto](https://www.homegate.ch/de/overview "Mein Konto") + +DE +* [DE](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=4) +* [FR](https://www.homegate.ch/acheter/terrain/canton-zurich/liste-annonces?ep=4) +* [IT](https://www.homegate.ch/acquistare/terreno/cantone-zurigo/lista-annunci?ep=4) +* [EN](https://www.homegate.ch/buy/plot/canton-zurich/matching-list?ep=4) + +Ort + + Kanton Zürich + + Kanton Zürich + + Preis bis + + + + Weitere Filter + + 73 Treffer + +73 Treffer - Bauland kaufen in Kanton Zürich +============================================ + +[*  *  *  *  *  *  *  1 / 3 CHF 3’564’590.– 8820 Wädenswil Verwirklichen Sie hier Ihren Wohntraum Das Grundstück liegt leicht erhöht an einer Sackgasse, eingebettet in einem ruhigen, familienfreundlichen Wohnquartier in Wädenswil, der beliebten Kleinstadt mit Charme. Eine Bushaltestelle befindet sich in kurzer Gehdistanz. Kindergarten, Schule, Einkauf und der See sind von hier bequem zu Fuss erreichbar. Die attraktive Baulandparzelle umfasst eine Fläche von 607 m2und befindet sich in der Wohnzone 2/30, was gemäss Bau-und Zonenordnung der Stadt Wädenswil eine Ausnutzungsziffer von 30% und somit eine mögliche Wohnfläche von ca. 182 m2 bedeutet. Damit bietet die Parzelle vielseitige Möglichkeiten grosszügiges Wohnen mit einem schönen und lauschigen Aussenraum zu verbinden.Ein paar der Highlights: • Ruhige, sonnige und familienfreundliche Lage in einer Sackgasse • Schönes Wohnquartier • Möglichkeit für die Verwirklichung Ihres Wohntraums ganz nach Ihren Vorstellungen • Wohnzone 2/30 mit einer Ausnutzungsziffer von 30% • Bushaltestelle in unmittelbarer Nähe (Distanz ca. 140 m) • Einkauf, Kindergarten, Schule und See in Gehdistanz  Wegzeit -](https://www.homegate.ch/kaufen/4002446172) + +[*  *  *  *  *  *  *  *  *  *  *  1 / 7 CHF 3’701’690.– Bergstrasse 7a, 8155 Niederhasli Wegzeit Neu 30 min.Station: Niederhasli](https://www.homegate.ch/kaufen/4002208545) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 10 CHF 1’343’580.– Baumgarten, 8914 Aeugst am Albis Wegzeit Neu 35 min.Station: Affoltern am Albis](https://www.homegate.ch/kaufen/4001969725) + +[*  *  *  *  *  *  *  1 / 3 Preis auf Anfrage **3’880m²** Nutzfläche Industriestrasse 34, 8117 Fällanden Wegzeit Neu 19 min.Station: Schwerzenbach](https://www.homegate.ch/kaufen/4002549837) + +Dein Immobilienexperte vor Ort +------------------------------ + +[ Property One Partners AG berät dich persönlich zur optimalen Verkaufsstrategie für deine Immobilie.](https://homegate.ch/anbieter/h239/property-one-partners-ag) + +[ 1 / 1 CHF 4’935’590.– 8330 Pfäffikon ZH Ihre Chance: Off-Market Grundstück in Pfäffikon ZH an familienfreundlicher Lage Pfäffikon ZH In Pfäffikon ZH wartet ein grosszügiges Grundstück auf neue Besitzer. Es besticht durch seine traumhafte, ruhige und familienfreundliche Lage sowie die Nähe zur Natur - eine seltene Gelegenheit für Investoren oder private Bauherren mit Weitblick.Auf einen Blick: • Erschlossene Grundstücksfläche: ca. 2'000-2'200 m², Wohnzone W1.25 • Traumhafte, ruhige Lage, ideal für Familien • Nähe zur Natur • Bei einem Neubau realisierbare Nettowohnfläche von ca. 900-920 m² • Preis: CHF 3'600'000 Off-Market-Vermarktung, kein BieterverfahrenBei Interesse bitten wir Sie um Kontaktaufnahme. Nach Unterzeichnung einer Vertraulichkeitserklärung (NDA) senden wir Ihnen gerne weiterführende Informationen zu.IMROT vermarktet jährlich 50 bis 100 Off-Market-Grundstücke an bevorzugten Lagen.Suchen Sie Bauland im Kanton Zürich? Wir sind Ihr Ansprechpartner.  Wegzeit -](https://www.homegate.ch/kaufen/4002531588) + +[ 1 / 1 CHF 12’476’100.– 8703 Erlenbach ZH Seltene Gelegenheit: Off-Market Grundstück an Toplage in Erlenbach ZH Erlenbach In Erlenbach ZH steht ein grosszügiges Grundstück zum Verkauf, das Lagequalität, Seesicht und Wertsteigerungspotenzial vereint - eine seltene Gelegenheit für anspruchsvolle Investoren oder private Bauherren.Auf einen Blick: • Erschlossene Grundstücksfläche: ca. 1'100-1'300 m², Wohnzone W2/30 • Ruhige, bevorzugte Lage mit Seesicht • Bestandsimmobilie mit Mietwohnungen und ausbaubaren Mieterträgen • Bei einem Neubau realisierbare Nettowohnfläche von 560-580 m² und einer Bruttorendite von 16-20% • Hanglage vorhanden (Hanggeschosse möglich) • Preis: CHF 9'100'000 • Off-Market-Vermarktung, kein Bieterverfahren Bei Interesse bitten wir Sie um Kontaktaufnahme. Nach Unterzeichnung einer Vertraulichkeitserklärung (NDA) senden wir Ihnen gerne weiterführende Informationen zu.IMROT vermarktet jährlich 50 bis 100 Off-Market-Grundstücke an bevorzugten Lagen.Suchen Sie Bauland im Kanton Zürich? Wir sind Ihr Ansprechpartner.  Wegzeit -](https://www.homegate.ch/kaufen/4002505102) + +[ 1 / 1 CHF 3’153’300.– **240m²** Nutzfläche 8172 Niederglatt 8½-Zimmer-Bauernhaus mit Charme und Potenzial in Niederglatt ALLE FOTOS und weitere Informationen sind auf unserer Homepage REMAX.chzu finden: https://www.remax.ch/de/118641003-168Suchen Sie ein aussergewöhnliches Zuhause mit Charakter, Geschichte und vielseitigen Nutzungsmöglichkeiten? Dieses charmante Bauernhaus im idyllischen Niederglatt bietet all das und noch mehr.Das historische Gebäude wurde im Jahr 1680 erbaut und seither laufend renoviert. Heute präsentiert es sich in einem sehr guten baulichen Zustand und verbindet gekonnt den traditionellen Stil mit zeitgemässem Wohnkomfort.Eckdaten: 8½ Zimmer auf 4 Etagen Ca. 240 m² Wohnfläche Gebäudevolumen: 1500 m³ GVA Grundstücksfläche: 881 m² Bauland Ausgebautes Dachgeschoss mit 3½-Zimmer-Wohnung im 2. Obergeschoss 2 Küchen, 3 Badezimmer Grosses unausgebautes Dachgeschoss mit weiterem Ausbaupotenzial Angebaute Scheune vielseitig ausbaubar nach Ihren Vorstellungen Parkmöglichkeiten direkt vor dem Haus Haus unterliegt Ortsbildschutz Die Liegenschaft liegt in einer ruhigen, familienfreundlichen Umgebung perfekt für alle, die das Landleben geniessen und dennoch nicht auf eine gute Anbindung verzichten möchten. Der charmante Garten und die grosszügigen Aussenflächen laden zum Verweilen und Spielen ein.Das Grundstück befindet sich in der Bauzone und unterliegt lediglich dem sogenannten Ortsbildschutz einem sanften Schutz, der Ihnen viele Freiheiten für bauliche Erweiterungen lässt.Ob Sie sich ein gemütliches Zuhause für die Familie wünschen, ein Generationenprojekt planen oder Wohnen und Arbeiten unter einem Dach kombinieren möchten dieses Bauernhaus bietet zahlreiche Möglichkeiten für Ihre individuellen Wohnträume.Nutzen Sie diese seltene Gelegenheit, Eigentümer eines solch einzigartigen Objekts im Zürcher Unterland zu werden. Lassen Sie sich vom Charme dieser Immobilie verzaubern ein Ort, an dem Geschichte auf Zukunft trifft.-Are you looking for an exceptional home with character, history and versatile utilisation options? This charming farmhouse in idyllic Niederglatt offers all of this - and more.The historic building was built in 1680 and has been continuously renovated since then. Today it is in very good structural condition and skilfully combines traditional style with contemporary living comfort.Key data:- 8½ rooms on 4 floors- Approx. 240 m² living space- Building volume: 1,500 m³ GVA- Plot area: 881 m² building land- Developed attic with 3½-room flat on the 2nd floor- 2 kitchens, 3 bathrooms- Large unfinished attic with further expansion potential- Attached barn - can be converted in many ways according to your ideas- Parking directly in front of the house- The house is subject to conservation ordersThe property is located in a quiet, family-friendly neighbourhood - perfect for anyone who enjoys country life but doesn't want to miss out on good transport links. The charming garden and spacious outdoor areas invite you to linger and play.The property is located in the building zone and is only subject to what is known as townscape protection - a gentle protection that gives you plenty of freedom for structural extensions.Whether you are looking for a cosy home for the family, planning a generational project or want to combine living and working under one roof - this farmhouse offers numerous possibilities for your individual dream home.Take advantage of this rare opportunity to become the owner of such a unique property in the Zurich Unterland. Let yourself be enchanted by the charm of this property - a place where history meets the future.-Vous cherchez une maison exceptionnelle avec du caractère, de l'histoire et de multiples possibilités d'utilisation ? Cette charmante ferme située dans le village idyllique de Niederglatt offre tout cela - et bien plus encore.Le bâtiment historique a été construit en 1680 et a été régulièrement rénové depuis. Aujourd'hui, elle se présente dans un très bon état de construction et allie habilement le style  Wegzeit -](https://www.homegate.ch/kaufen/4002418234) + +[*  *  *  *  *  *  *  *  1 / 4 CHF 27’419’990.– Bergstrasse Kat. Nr. 9259, 9261, 8706 Meilen Wegzeit -](https://www.homegate.ch/kaufen/4001884044) + +[*  *  *  *  *  *  *  *  *  *  *  *  *  *  *  1 / 11 Preis auf Anfrage 8197 Rafz Wegzeit -](https://www.homegate.ch/kaufen/3003046952) + +[*  *  *  *  *  *  *  *  *  *  1 / 6 CHF 2’604’890.– 8468 Waltalingen Wegzeit -](https://www.homegate.ch/kaufen/4002364568) + +[*  *  *  *  *  *  *  *  1 / 4 CHF 3’016’200.– **1’820m²** Nutzfläche Götzen, 8197 Rafz Wegzeit -](https://www.homegate.ch/kaufen/4002297853) + +[*  *  *  *  *  *  *  1 / 3 Preis auf Anfrage 8162 Steinmaur Wegzeit -](https://www.homegate.ch/kaufen/4002558306) + +[ 1 / 1 CHF 3’427’490.– 8442 Hettlingen Wegzeit -](https://www.homegate.ch/kaufen/4002438548) + +[](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=3)[1...](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste)[3](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=3)[4](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=4) + +Suche speichern Karte + +Vorschläge basierend auf deinen Suchresultaten +---------------------------------------------- + +* [ CHF 3’440’000.– Weiacherstrasse 85, 8427 Rorbas](https://www.homegate.ch/kaufen/4002277619) +* [ CHF 1’600’000.– Grundbuch Blatt 50514, Kataster 720, Breiten, 8459 Volken](https://www.homegate.ch/kaufen/4002526342) +* [ CHF 1’750’000.– In der Gass 2, 8627 Grüningen](https://www.homegate.ch/kaufen/3003479026) +* [ CHF 3’300’000.– Sonnenhalde, 8602 Wangen-Brüttisetten](https://www.homegate.ch/kaufen/4002543522) +* [ Preis auf Anfrage 8570 Weinfelden](https://www.homegate.ch/kaufen/4002486406) +* [ CHF 1’550’000.– 8267 Berlingen](https://www.homegate.ch/kaufen/4001272290) +* [ CHF 26’000’000.– 8050 Zürich](https://www.homegate.ch/kaufen/4002553821) +* [ Preis auf Anfrage 8605 Gutenswil](https://www.homegate.ch/kaufen/4002533580) +* [ CHF 1’400’000.– 8187 Weiach](https://www.homegate.ch/kaufen/4001410555) +* [ CHF 8’400’000.– Rütiwiese, 8704 Herrliberg](https://www.homegate.ch/kaufen/4002487028) +* [ CHF 5’400’000.– Feldstrasse 2, 8805 Richterswil](https://www.homegate.ch/kaufen/4002526347) +* [ Preis auf Anfrage 8424 Embrach](https://www.homegate.ch/kaufen/4002492324) +* [ CHF 900’000.– Geissliäcker, 5623 Boswil](https://www.homegate.ch/kaufen/4001984963) +* [ Preis auf Anfrage Schoeckstrasse 2, 9008 St. Gallen](https://www.homegate.ch/kaufen/4002500928) +* [ CHF 4’900’000.– **2’595m²** Wohnfläche 8506 Herdern](https://www.homegate.ch/kaufen/4002529753) +* [ CHF 1’310’000.– Steig, 8535 Herdern](https://www.homegate.ch/kaufen/4002230356) +* [ Preis auf Anfrage Auf Anfrage 1, 8505 Pfyn](https://www.homegate.ch/kaufen/4002546900) +* [ Preis auf Anfrage Büntlistrasse 1, 8174 Stadel](https://www.homegate.ch/kaufen/4000669374) +* [ CHF 1’700’000.– 8910 Affoltern am Albis](https://www.homegate.ch/kaufen/4002105351) +* [ CHF 1’230’000.– 8187 Weiach](https://www.homegate.ch/kaufen/4002404604) + +1. [Startseite](https://www.homegate.ch/de) +2. [Kaufen](https://www.homegate.ch/kaufen/immobilie-suchen) +3. [Bauland zum Kaufen](https://www.homegate.ch/kaufen/bauland/trefferliste) +4. [Schweiz](https://www.homegate.ch/kaufen/bauland/land-schweiz/trefferliste) + +Bezirke im Kanton Kanton Zürich + +[Bauland kaufen Bezirk Affoltern](https://www.homegate.ch/kaufen/bauland/region-affoltern/trefferliste)|[Bauland kaufen Bezirk Andelfingen](https://www.homegate.ch/kaufen/bauland/region-andelfingen/trefferliste)|[Bauland kaufen Bezirk Bülach](https://www.homegate.ch/kaufen/bauland/region-buelach/trefferliste)|[Bauland kaufen Bezirk Dielsdorf](https://www.homegate.ch/kaufen/bauland/region-dielsdorf/trefferliste)|[Bauland kaufen Bezirk Hinwil](https://www.homegate.ch/kaufen/bauland/region-hinwil/trefferliste)|[Bauland kaufen Bezirk Horgen](https://www.homegate.ch/kaufen/bauland/region-horgen/trefferliste)|[Bauland kaufen Bezirk Meilen](https://www.homegate.ch/kaufen/bauland/region-meilen/trefferliste)|[Bauland kaufen Bezirk Pfäffikon](https://www.homegate.ch/kaufen/bauland/region-pfaeffikon/trefferliste)|[Bauland kaufen Bezirk Uster](https://www.homegate.ch/kaufen/bauland/region-uster/trefferliste)|[Bauland kaufen Bezirk Winterthur](https://www.homegate.ch/kaufen/bauland/region-winterthur/trefferliste)|[Bauland kaufen Bezirk Dietikon](https://www.homegate.ch/kaufen/bauland/region-dietikon/trefferliste)|[Bauland kaufen Zürich](https://www.homegate.ch/kaufen/bauland/ort-zuerich/trefferliste) + +Weitere Immobiliensuchen in Kanton Zürich + +[Immobilien mieten Kanton Zürich](https://www.homegate.ch/mieten/immobilien/kanton-zuerich/trefferliste)|[Wohnung mieten Kanton Zürich](https://www.homegate.ch/mieten/wohnung/kanton-zuerich/trefferliste)|[Haus mieten Kanton Zürich](https://www.homegate.ch/mieten/haus/kanton-zuerich/trefferliste)|[Möbliertes Wohnobjekt mieten Kanton Zürich](https://www.homegate.ch/mieten/moebliertes-wohnobjekt/kanton-zuerich/trefferliste)|[Parkplatz, Garage mieten Kanton Zürich](https://www.homegate.ch/mieten/parkplatz-garage/kanton-zuerich/trefferliste)|[Büro mieten Kanton Zürich](https://www.homegate.ch/mieten/buero/kanton-zuerich/trefferliste)|[Gewerbe mieten Kanton Zürich](https://www.homegate.ch/mieten/gewerbeobjekt/kanton-zuerich/trefferliste)|[Neubau zum Mieten Kanton Zürich](https://www.homegate.ch/mieten/immobilien/kanton-zuerich/trefferliste?an=G)|[Wohnung kaufen Kanton Zürich](https://www.homegate.ch/kaufen/wohnung/kanton-zuerich/trefferliste)|[Haus kaufen Kanton Zürich](https://www.homegate.ch/kaufen/haus/kanton-zuerich/trefferliste)|[Immobilien kaufen Kanton Zürich](https://www.homegate.ch/kaufen/immobilien/kanton-zuerich/trefferliste)|[Mehrfamilienhaus kaufen Kanton Zürich](https://www.homegate.ch/kaufen/mehrfamilienhaus/kanton-zuerich/trefferliste)|[Parkplatz, Garage kaufen Kanton Zürich](https://www.homegate.ch/kaufen/parkplatz-garage/kanton-zuerich/trefferliste)|[Gewerbe, Büro, Lager kaufen Kanton Zürich](https://www.homegate.ch/kaufen/gewerbeobjekt/kanton-zuerich/trefferliste)|[Neubau zum Kaufen Kanton Zürich](https://www.homegate.ch/kaufen/immobilien/kanton-zuerich/trefferliste?an=G) + +### Homegate + +* [Über uns](https://swissmarketplace.group/de/portfolio/real-estate/) +* [Kontakt & Hilfe](https://www.homegate.ch/c/de/ueber-uns/kontakt) +* [Geschäftskunde werden](https://swissmarketplace.group/real-estate/de/kunde-werden/) +* [Newsletter abonnieren](https://www.homegate.ch/c/de/ueber-uns/newsletter-anmeldung) +* [Medien](https://swissmarketplace.group/de/media/) +* [Karriere](https://swissmarketplace.group/de/karriere/) +* [Ombudsstelle](https://konsum.ch/de/ombudsstelle-immobilienplattformen/) +* [Werbung auf Homegate](https://swissmarketplace.group/de/werbung/) +* [Sitemap](https://www.homegate.ch/c/de/ueber-uns/sitemap) + +### Immobilien + +* [Inserieren](https://www.homegate.ch/de/insertion/inserat-online-erfassen) +* [Mieten](https://www.homegate.ch/mieten/immobilie-suchen) +* [Kaufen](https://www.homegate.ch/kaufen/immobilie-suchen) +* [Vermieten](https://www.homegate.ch/c/de/inserieren/immobilien/wohnung/vermieten) +* [Verkaufen](https://www.homegate.ch/c/de/ratgeber/inserieren/immobilien-verkaufen) +* [Finanzieren](https://www.homegate.ch/c/de/hypotheken) +* [Ratgeber](https://www.homegate.ch/c/de/ratgeber) +* [Kategorien](https://www.homegate.ch/kategorien-de) + +### Rechtliches + +* [Datenschutz](https://privacy.swissmarketplace.group/de/) +* [Leistungsbeschrieb](https://www.homegate.ch/c/de/ueber-uns/rechtliches/leistungsbeschrieb) +* [Sicherheitstipps](https://www.homegate.ch/c/de/ratgeber/news/vorsicht-betrug-mit-gefaelschten-inseraten) +* [Impressum](https://www.homegate.ch/c/de/ueber-uns/rechtliches) +* [AGB](https://www.homegate.ch/c/de/ueber-uns/rechtliches/agb) +* [Sicherheitsproblem melden](https://swissmarketplace.group/de/vulnerability-disclosure-program) +* Privatsphäre-Einstellungen + +### Services + +* [Suchabo anlegen](https://www.homegate.ch/c/de/ratgeber/mieten/wohnung-finden/suchabo) +* [Finanzierungsrechner](https://www.homegate.ch/de/finanzieren/hypothekenrechner) +* [Steuerrechner](https://www.homegate.ch/c/de/ratgeber/umziehen/umzugstipps/steuerrechner) +* [Betreibungsauszug](https://www.homegate.ch/de/betreibungsauszug) +* [Gemeinderatgeber](https://www.homegate.ch/c/de/ratgeber/umziehen/gemeinderatgeber) +* [Mietkaution](https://www.homegate.ch/c/de/ratgeber/umziehen/mietzinskaution) +* [Umzugshilfe](https://www.homegate.ch/c/de/umziehen) +* [Wohneigentum schätzen](https://www.homegate.ch/c/de/ratgeber/finanzieren-und-versichern/wohneigentum-schaetzen/online-schaetzung/jetzt-wohneigentum-bewerten) +* [Agenturverzeichnis](https://www.homegate.ch/agenturverzeichnis) + +### App herunterladen + +[](https://itunes.apple.com/de/app/homegate.ch/id326131004 "iOS App")[](https://play.google.com/store/apps/details?id=ch.homegate.mobile&hl=de "Android App") + +* [Deutsch](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=4) +* [Français](https://www.homegate.ch/acheter/terrain/canton-zurich/liste-annonces?ep=4) +* [Italiano](https://www.homegate.ch/acquistare/terreno/cantone-zurigo/lista-annunci?ep=4) +* [English](https://www.homegate.ch/buy/plot/canton-zurich/matching-list?ep=4) + +### Social Media + +[](https://www.facebook.com/homegate.ch "Facebook")[](https://www.youtube.com/user/homegateeng "YouTube")[](https://ch.linkedin.com/company/homegate-ch-ag "LinkedIn")[](https://twitter.com/homegate_Deu "Twitter") + +[SMG Swiss Marketplace Group](https://swissmarketplace.group/)[ImmoScout24](https://www.immoscout24.ch/de)[Alle Immobilien](https://www.alle-immobilien.ch/)[home.ch](https://www.home.ch/)[immostreet.ch](https://www.immostreet.ch/) + +© Copyright 2025 by SMG Swiss Marketplace Group AG. Alle Rechte vorbehalten.Die Vervielfältigung und Übernahme von Inseraten durch Dritte, insbesondere von Fotos und persönlichen Daten in diesen Inseraten, verletzt die damit verbundenen Rechte und ist ausdrücklich verboten. + +We Care About Your Privacy +-------------------------- + +We and our 459 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below, including your right to object where legitimate interest is used, or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data. + +### We and our partners process data to provide: + +Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. List of Partners (vendors) + +I Accept No consent Show Purposes + + +=== https://www.homegate.ch/de === +# Die cleverste Immobiliensuche der Schweiz + +* [Mieten](javascript:) +* [Kaufen](javascript:) + +Orte, Regionen, PLZ, Land + +[Objekt inserieren](/de/insertion/inserat-online-erfassen)oder[Objekt schätzen](/de/immobilienbewertung) + +#### Gratis Nachmieter finden + +Erstelle ein kostenloses Inserat auf Homegate und finde in kürzester Zeit den perfekten Nachmieter für deine Wohnung. + +[Jetzt inserieren](https://www.homegate.ch/c/de/inserieren/immobilien/nachmieter-suchen?intlink=t2t_intbanner_hp) + +#### MieterPlus: Zugang zu exklusiven Inseraten + +Exklusive Möglichkeit, Inserenten von MieterPlus-Anzeigen zu kontaktieren. + +[Vorteile ansehen](https://www.homegate.ch/de/mieterplus) + +* [Bewerten & Finanzieren](javascript:) +* [Mieten](javascript:) +* [Kaufen](javascript:) + +## Services + +## Deine Immobilie ist bei uns an der richtigen Adresse + +Mit einem Inserat auf Homegate erreichst du ein grosses Publikum und qualifizierte Bewerber. Wähle aus unseren Inseratspaketen und setze dein Angebot perfekt in Szene. + +[Inserat erfassen](/de/insertion/inserat-online-erfassen) + +## Umziehen oder zügeln? + +Egal wie du’s nennst – vergleiche die besten Umzugsunternehmen und halte die Zügel in der Hand. + +CHF935.– + +Wohnortwechsel + +2 Zimmer + +* 1.5 Zimmer +* 2 Zimmer +* 2.5 Zimmer +* 3 Zimmer +* 3.5 Zimmer +* 4 Zimmer +* 4.5 Zimmer +* 5 Zimmer +* 5.5 Zimmer +* 6 Zimmer +* 6+ Zimmer + +10 km Entfernung + +* 10 km Entfernung +* 20 km Entfernung +* 30 km Entfernung +* 40 km Entfernung +* 50 km Entfernung +* 60 km Entfernung +* 70 km Entfernung +* 70+ km Entfernung + +[Offerten anfordern](https://www.homegate.ch/de/umziehen/movu) + +## Mit der Homegate-App bist du vorne dabei + +Schnell gesucht, eingezeichnet, als Suchabo und Favorit gespeichert, bei Treffern umgehend benachrichtigt: Neues Zuhause gefunden mit der Homegate-App. + +## Immobilien zum Mieten + +* [Immobilien mieten](https://www.homegate.ch/mieten/immobilien/trefferliste) +* [Wohnung mieten](https://www.homegate.ch/mieten/wohnung/trefferliste) +* [Haus mieten](https://www.homegate.ch/mieten/haus/trefferliste) +* [Parkplatz, Garage mieten](https://www.homegate.ch/mieten/parkplatz-garage/trefferliste) +* [Möbliertes Wohnobjekt mieten](https://www.homegate.ch/mieten/moebliertes-wohnobjekt/trefferliste) +* [Büro mieten](https://www.homegate.ch/mieten/buero/trefferliste) +* [Gewerbe mieten](https://www.homegate.ch/mieten/gewerbeobjekt/trefferliste) +* [Lager mieten](https://www.homegate.ch/mieten/lager/trefferliste) +* [Neubau mieten](https://www.homegate.ch/mieten/immobilien/trefferliste?an=G) + +## Immobilien zum Kaufen + +* [Immobilien kaufen](https://www.homegate.ch/kaufen/immobilien/trefferliste) +* [Wohnung kaufen](https://www.homegate.ch/kaufen/wohnung/trefferliste) +* [Haus kaufen](https://www.homegate.ch/kaufen/haus/trefferliste) +* [Parkplatz, Garage kaufen](https://www.homegate.ch/kaufen/parkplatz-garage/trefferliste) +* [Bauland kaufen](https://www.homegate.ch/kaufen/bauland/trefferliste) +* [Mehrfamilienhaus kaufen](https://www.homegate.ch/kaufen/mehrfamilienhaus/trefferliste) +* [Wohn- / Geschäftshaus kaufen](https://www.homegate.ch/kaufen/wohn-geschaeftshaus/trefferliste) +* [Gewerbe, Büro, Lager kaufen](https://www.homegate.ch/kaufen/gewerbeobjekt/trefferliste) +* [Neubau kaufen](https://www.homegate.ch/kaufen/immobilien/trefferliste?an=G) + +## Wohnung mieten in + +* [Zürich](https://www.homegate.ch/mieten/wohnung/ort-zuerich/trefferliste "wohnung mieten zürich") +* [Luzern](https://www.homegate.ch/mieten/wohnung/ort-luzern/trefferliste "wohnung mieten luzern") +* [Bern](https://www.homegate.ch/mieten/wohnung/ort-bern/trefferliste "wohnung mieten bern") +* [Winterthur](https://www.homegate.ch/mieten/wohnung/ort-winterthur/trefferliste "wohnung mieten winterthur") +* [St. Gallen](https://www.homegate.ch/mieten/wohnung/ort-st-gallen/trefferliste "wohnung mieten st. gallen") +* [Basel](https://www.homegate.ch/mieten/wohnung/ort-basel/trefferliste "wohnung mieten basel") +* [Chur](https://www.homegate.ch/mieten/wohnung/ort-chur/trefferliste "wohnung mieten chur") +* [Thun](https://www.homegate.ch/mieten/wohnung/ort-thun/trefferliste "wohnung mieten thun") +* [Aargau](https://www.homegate.ch/mieten/wohnung/kanton-aargau/trefferliste "wohnung mieten aargau") +* [Waadt](https://www.homegate.ch/mieten/wohnung/kanton-waadt/trefferliste "wohnung mieten waadt") +* [Graubünden](https://www.homegate.ch/mieten/wohnung/kanton-graubuenden/trefferliste "wohnung mieten graubünden") + +## Haus mieten in + +* [Zürich](https://www.homegate.ch/mieten/haus/ort-zuerich/trefferliste "haus mieten zürich") +* [Aargau](https://www.homegate.ch/mieten/haus/kanton-aargau/trefferliste "haus mieten aargau") +* [Thurgau](https://www.homegate.ch/mieten/haus/kanton-thurgau/trefferliste "haus mieten thurgau") +* [Baselland](https://www.homegate.ch/mieten/haus/kanton-baselland/trefferliste "haus mieten baselland") +* [Bern](https://www.homegate.ch/mieten/haus/ort-bern/trefferliste "haus mieten bern") +* [Schweiz](https://www.homegate.ch/mieten/haus/land-schweiz/trefferliste "haus mieten schweiz") +* [Kanton Bern](https://www.homegate.ch/mieten/haus/kanton-bern/trefferliste "haus mieten kanton bern") +* [Luzern](https://www.homegate.ch/mieten/haus/ort-luzern/trefferliste "haus mieten luzern") +* [Basel](https://www.homegate.ch/mieten/haus/ort-basel/trefferliste "haus mieten basel") +* [Waadt](https://www.homegate.ch/mieten/haus/kanton-waadt/trefferliste "haus mieten waadt") +* [St. Gallen](https://www.homegate.ch/mieten/haus/ort-st-gallen/trefferliste "haus mieten st. gallen") +* [Graubünden](https://www.homegate.ch/mieten/haus/kanton-graubuenden/trefferliste "haus mieten graubünden") + +## Wohnung kaufen in + +* [Zürich](https://www.homegate.ch/kaufen/wohnung/ort-zuerich/trefferliste "wohnung kaufen zürich") +* [Bern](https://www.homegate.ch/kaufen/wohnung/ort-bern/trefferliste "wohnung kaufen bern") +* [Basel](https://www.homegate.ch/kaufen/wohnung/ort-basel/trefferliste "wohnung kaufen basel") +* [Luzern](https://www.homegate.ch/kaufen/wohnung/ort-luzern/trefferliste "wohnung kaufen luzern") +* [St. Gallen](https://www.homegate.ch/kaufen/wohnung/ort-st-gallen/trefferliste "wohnung kaufen st. gallen") +* [Thun](https://www.homegate.ch/kaufen/wohnung/ort-thun/trefferliste "wohnung kaufen thun") +* [Winterthur](https://www.homegate.ch/kaufen/wohnung/ort-winterthur/trefferliste "wohnung kaufen winterthur") +* [Aargau](https://www.homegate.ch/kaufen/wohnung/kanton-aargau/trefferliste "wohnung kaufen aargau") +* [Baselland](https://www.homegate.ch/kaufen/wohnung/kanton-baselland/trefferliste "wohnung kaufen baselland") +* [Waadt](https://www.homegate.ch/kaufen/wohnung/kanton-waadt/trefferliste "wohnung kaufen waadt") +* [Graubünden](https://www.homegate.ch/kaufen/wohnung/kanton-graubuenden/trefferliste "wohnung kaufen graubünden") + +## Haus kaufen in + +* [Schweiz](https://www.homegate.ch/kaufen/haus/land-schweiz/trefferliste "haus kaufen schweiz") +* [Bern](https://www.homegate.ch/kaufen/haus/ort-bern/trefferliste "haus kaufen bern") +* [Aargau](https://www.homegate.ch/kaufen/haus/kanton-aargau/trefferliste "haus kaufen aargau") +* [Baselland](https://www.homegate.ch/kaufen/haus/kanton-baselland/trefferliste "haus kaufen baselland") +* [Thurgau](https://www.homegate.ch/kaufen/haus/kanton-thurgau/trefferliste "haus kaufen thurgau") +* [Zürich](https://www.homegate.ch/kaufen/haus/ort-zuerich/trefferliste "haus kaufen zürich") +* [Luzern](https://www.homegate.ch/kaufen/haus/ort-luzern/trefferliste "haus kaufen luzern") +* [Winterthur](https://www.homegate.ch/kaufen/haus/ort-winterthur/trefferliste "haus kaufen winterthur") +* [Waadt](https://www.homegate.ch/kaufen/haus/kanton-waadt/trefferliste "haus kaufen waadt") +* [St. Gallen](https://www.homegate.ch/kaufen/haus/ort-st-gallen/trefferliste "haus kaufen st. gallen") +* [Graubünden](https://www.homegate.ch/kaufen/haus/kanton-graubuenden/trefferliste "haus kaufen graubünden") + +## We Care About Your Privacy + +We and our 453 partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below, including your right to object where legitimate interest is used, or at any time in the privacy policy page. These choices will be signaled to our partners and will not affect browsing data. + +### We and our partners process data to provide: + +Use precise geolocation data. Actively scan device characteristics for identification. Store and/or access information on a device. Personalised advertising and content, advertising and content measurement, audience research and services development. + + +=== https://realadvisor.ch/de/immobilien-kaufen === +Wohnung, Haus, Immobilien kaufen in der Schweiz | RealAdvisor + +=============== + +[](https://realadvisor.ch/de) + +* [Bewerten](https://realadvisor.ch/de/immobilien-kaufen) + * [Immobilienbewertung](https://realadvisor.ch/de/online-immobilienbewertung) + * [Renditeliegenschaft bewerten](https://realadvisor.ch/de/renditeliegenschaft-bewerten-online) + * [Immobilienpreise](https://realadvisor.ch/de/immobilienpreise-pro-m2) + +* [Kaufen](https://realadvisor.ch/de/immobilien-kaufen) +* [Mieten](https://realadvisor.ch/de/immobilien-mieten) +* [Verkaufen](https://realadvisor.ch/de/haus-verkaufen) +* [Makler finden](https://realadvisor.ch/de/makler-finden) +* [Mein Konto](https://realadvisor.ch/de/profile) + +* [DE](https://realadvisor.ch/de/immobilien-kaufen#) + * [FR](https://realadvisor.ch/fr/immobilier-a-vendre) + * [IT](https://realadvisor.ch/it/vendita-immobile) + * [EN](https://realadvisor.ch/en/property-for-sale) + +Die grösste Immobilien-Suchmaschine der Schweiz + +Über 40'000 Inserate für Immobilien zum Kauf +============================================ + +[](https://de.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + + + +Alle Inserate in einer App +-------------------------- + +Mit RealAdvisor suchen Sie auf allen Schweizer Immobilienportalen gleichzeitig. Verpassen Sie nie wieder ein Angebot! + +Verwenden Sie professionelle Filter, zeichnen Sie Ihren Suchbereich auf einer Karte und erhalten Sie sofort Benachrichtigungen zu neuen Inseraten, die Ihren Kriterien entsprechen. + +[](https://play.google.com/store/apps/details?id=com.realadvisor.app)[](https://apps.apple.com/ch/app/realadvisor/id6504883593?l=de-DE) + + + + + +Über 40'000 Inserate für Kaufimmobilien +--------------------------------------- + +Immobilien aller Art zum Verkauf in der Schweiz + +RealAdvisor zentralisiert die Inserate von zum Verkauf stehenden Häusern und Wohnungen aller wichtigen Schweizer Immobilienplattformen, sodass Sie keine kostbare Zeit mit der Suche auf verschiedenen Seiten verlieren. Wir sondieren den gesamten Markt, um Ihnen die beste Übersicht aller verfügbaren Liegenschaften, passenden Immobilien, Objekte mit guter Verkehrsanbindung und Häuser in der Nähe zu bieten. + +Alle zum Verkauf stehenden Immobilien in der Schweiz +---------------------------------------------------- + +Ob Villa, Wohnhaus und Grundstück zum Verkauf. Penthouse, Wohnung, Gewerbe oder Studio zu verkaufen. Immobilien kaufen in der Nähe bei RealAdvisor. + +[Genf](https://realadvisor.ch/de/kaufen/stadt-genf/wohnung) + +[Lausanne](https://realadvisor.ch/de/kaufen/stadt-lausanne/wohnung) + +[Zurich](https://realadvisor.ch/de/kaufen/stadt-zurich/wohnung) + +[Basel](https://realadvisor.ch/de/kaufen/stadt-basel/wohnung) + +[Bern](https://realadvisor.ch/de/kaufen/stadt-bern/wohnung) + +### Erweiterte Suchfilter + +Als Immobilienexperten verstehen wir den Wert von relevanten Informationen bei der Suche nach einer Immobilie zum Kauf in CH. Ob Sie Ihr nächstes Zuhause oder eine günstige Investitionsmöglichkeit in der Schweiz suchen, mit RealAdvisor können Sie Inserate nach m2-Preis, geschätzten jährlichen Mieteinnahmen, dem Einstellungsdatum im Internet und noch vielem mehr filtern! + + + + + +### Immobilien-Suchabo + +Speichern Sie Ihre Immobiliensuche als Abo mit zwei Klicks und werden Sie per E-Mail benachrichtigt, wenn neue Liegenschaften oder Immobilien in der Nähe, die Ihren Suchkriterien entsprechen, inseriert werden. Ein Immobilien-Suchabo bei uns ist alles, was Sie benötigen, um alle Inserate der Schweizer Immobilienportale im Auge zu behalten. + +[Liegenschaften zum Verkauf](https://realadvisor.ch/de/kaufen) + +Wohnungen zum Verkauf, in jedem Kanton der Schweiz +-------------------------------------------------- + +Studieren Sie alle Immobilien-Angebote, sortiert nach Schweizer Kanton. Finden Sie alle zum Verkauf stehenden Wohnungen, ob in Genf, Waadt, Basel, Zürich oder jedem anderen CH-Kanton. + +[Kanton Zurich](https://realadvisor.ch/de/kaufen/kanton-zurich/wohnung) + +[Kanton Bern](https://realadvisor.ch/de/kaufen/kanton-bern/wohnung) + +[Kanton Waadt](https://realadvisor.ch/de/kaufen/kanton-waadt/wohnung) + +[Kanton Aargau](https://realadvisor.ch/de/kaufen/kanton-aargau/wohnung) + +[Kanton St-Gallen](https://realadvisor.ch/de/kaufen/kanton-st-gallen/wohnung) + +[Kanton Genf](https://realadvisor.ch/de/kaufen/kanton-genf/wohnung) + +[Kanton Luzern](https://realadvisor.ch/de/kaufen/kanton-luzern/wohnung) + +[Kanton Tessin](https://realadvisor.ch/de/kaufen/kanton-tessin/wohnung) + +[Kanton Wallis](https://realadvisor.ch/de/kaufen/kanton-wallis/wohnung) + +[Kanton Freiburg](https://realadvisor.ch/de/kaufen/kanton-freiburg/wohnung) + +[Kanton Basel-Landschaft](https://realadvisor.ch/de/kaufen/kanton-basel-landschaft/wohnung) + +[Kanton Thurgau](https://realadvisor.ch/de/kaufen/kanton-thurgau/wohnung) + +[Kanton Solothurn](https://realadvisor.ch/de/kaufen/kanton-solothurn/wohnung) + +[Kanton Graubunden](https://realadvisor.ch/de/kaufen/kanton-graubunden/wohnung) + +[Kanton Basel-Stadt](https://realadvisor.ch/de/kaufen/kanton-basel-stadt/wohnung) + +[Kanton Neuenburg](https://realadvisor.ch/de/kaufen/kanton-neuenburg/wohnung) + +[Kanton Schwyz](https://realadvisor.ch/de/kaufen/kanton-schwyz/wohnung) + +[Kanton Zug](https://realadvisor.ch/de/kaufen/kanton-zug/wohnung) + +[Kanton Schaffhausen](https://realadvisor.ch/de/kaufen/kanton-schaffhausen/wohnung) + +[Kanton Jura](https://realadvisor.ch/de/kaufen/kanton-jura/wohnung) + +[Kanton Appenzell-Ausserrhoden](https://realadvisor.ch/de/kaufen/kanton-appenzell-ausserrhoden/wohnung) + +[Kanton Nidwalden](https://realadvisor.ch/de/kaufen/kanton-nidwalden/wohnung) + +[Kanton Glarus](https://realadvisor.ch/de/kaufen/kanton-glarus/wohnung) + +[Kanton Obwalden](https://realadvisor.ch/de/kaufen/kanton-obwalden/wohnung) + +[Kanton Uri](https://realadvisor.ch/de/kaufen/kanton-uri/wohnung) + +[Kanton Appenzell-Innerrhoden](https://realadvisor.ch/de/kaufen/kanton-appenzell-innerrhoden/wohnung) + + + +Neubauten zum Verkauf +--------------------- + +Typischerweise werden die besten Neubauten verkauft, ohne jemals online inseriert zu werden, da Vermarkter und Entwickler dafür auf ihre private Kundendatenbank von potenziellen Interessenten zurückgreifen. + +RealAdvisor ermöglicht es Kaufinteressenten, sich in die direkte Kundendatenbank unserer Partner einzuschreiben und so neue Immobilien in der Nähe oder auch in der gesamten Schweiz zu erwerben. + +Einmal eingeschrieben, werden Sie vorrangig über unsere jüngsten Neubauprojekte und privaten Investitionsmöglichkeiten benachrichtigt. + +[Für Neubauprojekte registrieren](https://realadvisor.ch/de/neubauprojekte) + + + +Immobilienpreise in der Schweiz +------------------------------- + +Erkundigen Sie sich über die mittleren Verkaufspreise für Häuser und Wohnungen nach Kanton oder Gemeinde. Diese basieren auf der Echtzeit-Datenerfassung aller wichtigen Immobilienplattformen der Schweiz. + +[Preise ansehen](https://realadvisor.ch/de/immobilienpreise-pro-m2) + +Wohnungen kaufen in der Schweiz +------------------------------- + +[* Wohnungen kaufen in Freiburg](https://realadvisor.ch/de/kaufen/stadt-freiburg/wohnung)[* Wohnungen kaufen in Genf](https://realadvisor.ch/de/kaufen/stadt-genf/wohnung)[* Wohnungen kaufen in St. Gallen](https://realadvisor.ch/de/kaufen/stadt-st-gallen/wohnung)[* Wohnungen kaufen in Biel](https://realadvisor.ch/de/kaufen/stadt-biel/wohnung)[* Wohnungen kaufen in Aarau](https://realadvisor.ch/de/kaufen/stadt-aarau/wohnung) + +[* Wohnungen kaufen in Basel](https://realadvisor.ch/de/kaufen/stadt-basel/wohnung)[* Wohnungen kaufen in Winterthur](https://realadvisor.ch/de/kaufen/stadt-winterthur/wohnung)[* Wohnungen kaufen in Luzern](https://realadvisor.ch/de/kaufen/stadt-luzern/wohnung)[* Wohnungen kaufen in Chur](https://realadvisor.ch/de/kaufen/7000-chur/wohnung)[* Wohnungen kaufen in Rapperswil-Jona](https://realadvisor.ch/de/kaufen/stadt-rapperswil-jona/wohnung) + +[* Wohnungen kaufen in Thun](https://realadvisor.ch/de/kaufen/stadt-thun/wohnung)[* Wohnungen kaufen in Arosa](https://realadvisor.ch/de/kaufen/gemeinde-arosa/wohnung)[* Wohnungen kaufen in Visp](https://realadvisor.ch/de/kaufen/gemeinde-visp/wohnung)[* Wohnungen kaufen in Bern](https://realadvisor.ch/de/kaufen/stadt-bern/wohnung)[* Wohnungen kaufen in Wettingen](https://realadvisor.ch/de/kaufen/5430-wettingen/wohnung) + +[* Wohnungen kaufen in Uster](https://realadvisor.ch/de/kaufen/stadt-uster/wohnung)[* Wohnungen kaufen in Reinach BL](https://realadvisor.ch/de/kaufen/4153-reinach-bl/wohnung)[* Wohnungen kaufen in Wil (SG)](https://realadvisor.ch/de/kaufen/stadt-wil-sg/wohnung)[* Wohnungen kaufen in Emmen](https://realadvisor.ch/de/kaufen/stadt-emmen/wohnung)[* Wohnungen kaufen in Köniz](https://realadvisor.ch/de/kaufen/stadt-koniz/wohnung) + +Häuser kaufen in der Schweiz +---------------------------- + +[* Häuser kaufen in Zürich](https://realadvisor.ch/de/kaufen/stadt-zurich/haus)[* Häuser kaufen in Winterthur](https://realadvisor.ch/de/kaufen/stadt-winterthur/haus)[* Häuser kaufen in St. Gallen](https://realadvisor.ch/de/kaufen/stadt-st-gallen/haus)[* Häuser kaufen in Wohlen](https://realadvisor.ch/de/kaufen/stadt-wohlen-ag/haus)[* Häuser kaufen in Riehen](https://realadvisor.ch/de/kaufen/4125-riehen/haus) + +[* Häuser kaufen in Rothrist](https://realadvisor.ch/de/kaufen/4852-rothrist/haus)[* Häuser kaufen in Luzern](https://realadvisor.ch/de/kaufen/stadt-luzern/haus)[* Häuser kaufen in Muttenz](https://realadvisor.ch/de/kaufen/4132-muttenz/haus)[* Häuser kaufen in Allschwil](https://realadvisor.ch/de/kaufen/4123-allschwil/haus)[* Häuser kaufen in Rapperswil-Jona](https://realadvisor.ch/de/kaufen/stadt-rapperswil-jona/haus) + +[* Häuser kaufen in Langenthal](https://realadvisor.ch/de/kaufen/stadt-langenthal/haus)[* Häuser kaufen in Biel](https://realadvisor.ch/de/kaufen/stadt-biel/haus)[* Häuser kaufen in Wil (SG)](https://realadvisor.ch/de/kaufen/stadt-wil-sg/haus)[* Häuser kaufen in Bern](https://realadvisor.ch/de/kaufen/stadt-bern/haus)[* Häuser kaufen in Burgdorf](https://realadvisor.ch/de/kaufen/3400-burgdorf/haus) + +[* Häuser kaufen in Aarau](https://realadvisor.ch/de/kaufen/stadt-aarau/haus)[* Häuser kaufen in Solothurn](https://realadvisor.ch/de/kaufen/4500-solothurn/haus)[* Häuser kaufen in Wildhaus-Alt St. Johann](https://realadvisor.ch/de/kaufen/gemeinde-wildhaus-alt-st-johann/haus)[* Häuser kaufen in Lausen](https://realadvisor.ch/de/kaufen/4415-lausen/haus)[* Häuser kaufen in Reinach BL](https://realadvisor.ch/de/kaufen/4153-reinach-bl/haus) + +FAQ +--- + +### Werden Immobilienpreise in der Schweiz sinken? + +Die Schweiz hat traditionell einen stabilen Immobilienmarkt, aber auch hier können Preise je nach wirtschaftlicher Lage, Zinssätzen und Immobilien-Angeboten variieren. Lokale Marktanalysen können aktuellere und genauere Einschätzungen bieten.Am besten bleiben Sie stets am Ball und informieren sich auf unserer Seite regelmäßig zu den jeweils[aktuellsten Quadratmeterpreisen in der Schweiz](https://realadvisor.ch/de/immobilienpreise-pro-m2). + +### Wie berechnet man die Rendite eines Mietshauses? + +Der beste Zeitpunkt zum Kauf einer Immobilie hängt von Ihren persönlichen finanziellen Umständen, Marktbedingungen und individuellen Zielen ab. Eine umfassende Marktanalyse und Beratung durch einen Fachmann können hierbei unterstützend wirken. Überprüfen Sie unser[Immobilienagentur-Verzeichnis](https://realadvisor.ch/de/makler-finden)und wenden Sie sich an die erfahrensten Makler in Ihrer Umgebung, um über Ihr Projekt zu sprechen. + +### Wo sollte man Immobilien kaufen? + +Die Entscheidung, wo man Immobilien kaufen sollte, hängt von Faktoren wie Lebensstil, Arbeitsort, Infrastruktur, Bildungsangeboten und persönlichen Präferenzen ab. Bei RealAdvisor haben Sie den Vorteil, praktisch [alle Immobilienanzeigen der Schweiz](https://realadvisor.ch/de/kaufen) gebündelt an einer Stelle zu haben. Auf diese Weise haben Sie Zugriff auf rund 180.000 Anzeigen auf einen Blick. Schauen Sie doch mal rein. + +[](https://realadvisor.ch/de)[](https://ch.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + +Verkaufen + +* [Immobilienbewertung](https://realadvisor.ch/de/online-immobilienbewertung) +* [Renditeliegenschaft bewerten](https://realadvisor.ch/de/renditeliegenschaft-bewerten-online) +* [Immobilienpreise](https://realadvisor.ch/de/immobilienpreise-pro-m2) +* [Makler finden](https://realadvisor.ch/de/makler-finden) +* [Immobilien-Glossar](https://realadvisor.ch/de/immobilien-glossar) +* [Immobilien-Blog](https://realadvisor.ch/de/blog) + +Kaufen / Mieten + +* [Immobilien Kaufen](https://realadvisor.ch/de/immobilien-kaufen) +* [Immobilien Mieten](https://realadvisor.ch/de/immobilien-mieten) +* [Neubauprojekte](https://realadvisor.ch/de/neubauprojekte) +* [Immobilienfinanzierung](https://realadvisor.ch/de/finanzierung) + +Für Makler + +* [Partner werden](https://realadvisor.ch/de/pro) +* [Blog Pro](https://realadvisor.ch/de/pro/blog) + +Unternehmen + +* [Über uns](https://realadvisor.ch/de/uber-uns) +* [Presseraum](https://realadvisor.ch/de/presseraum) +* [Offene Stellen](https://realadvisor.welcomekit.co/) +* [Allgemeine Geschäftsbedingungen](https://realadvisor.ch/de/begriffe) +* [Datenschutzerklärung](https://realadvisor.ch/de/datenschutzerklarung) +* [Impressum](https://realadvisor.ch/de/impressum) +* [Alle Immobilien](https://realadvisor.ch/de/sitemap) + +* [France (FR)](https://realadvisor.fr/fr) +* [España (ES)](https://realadvisor.es/es) +* [Italia (IT)](https://realadvisor.it/it) +* [Deutschland (DE)](https://realadvisor.de/de) +* [Great Britain (EN)](https://realadvisor.co.uk/en) +* [Belgique (FR)](https://realadvisor.be/fr) +* [België (NL)](https://realadvisor.be/nl) +* [Nederland (NL)](https://realadvisor.nl/nl) +* [Polska (PL)](https://realadvisor.pl/pl) +* [Czech (CZ)](https://realadvisor.cz/cs) + +[](https://apps.apple.com/ch/app/realadvisor/id6504883593)[](https://play.google.com/store/apps/details?id=com.realadvisor.app) + +© RealAdvisor 2024. All Rights Reserved. + +[](https://ch.linkedin.com/company/realadvisor)[](https://www.facebook.com/realadvisorcom)[](https://twitter.com/RealAdvisor)[](https://www.instagram.com/realadvisorcom/)[](https://www.youtube.com/channel/UCsEDTDlmxBpyxLXYhWT769Q) + + +=== https://realadvisor.ch/de/immobilien-mieten === +Immobilien mieten in der Schweiz (Wohnung, Haus) | RealAdvisor + +=============== + +[](https://realadvisor.ch/de) + +* [Bewerten](https://realadvisor.ch/de/immobilien-mieten) + * [Immobilienbewertung](https://realadvisor.ch/de/online-immobilienbewertung) + * [Renditeliegenschaft bewerten](https://realadvisor.ch/de/renditeliegenschaft-bewerten-online) + * [Immobilienpreise](https://realadvisor.ch/de/immobilienpreise-pro-m2) + +* [Kaufen](https://realadvisor.ch/de/immobilien-kaufen) +* [Mieten](https://realadvisor.ch/de/immobilien-mieten) +* [Verkaufen](https://realadvisor.ch/de/haus-verkaufen) +* [Makler finden](https://realadvisor.ch/de/makler-finden) +* [Mein Konto](https://realadvisor.ch/de/profile) + +* [DE](https://realadvisor.ch/de/immobilien-mieten#) + * [FR](https://realadvisor.ch/fr/immobilier-a-louer) + * [IT](https://realadvisor.ch/it/immobili-in-affitto) + * [EN](https://realadvisor.ch/en/property-for-rent) + +Die grösste Immobilien-Suchmaschine der Schweiz + +Über 50'000 Inserate für Immobilien zur Miete in der Schweiz +============================================================ + +[](https://de.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + + + +Alle Inserate in einer App +-------------------------- + +Mit RealAdvisor suchen Sie auf allen Schweizer Immobilienportalen gleichzeitig.Verpassen Sie nie wieder ein Angebot! + +Verwenden Sie professionelle Filter, zeichnen Sie Ihren Suchbereich auf einer Karte und erhalten Sie sofort Benachrichtigungen zu neuen Inseraten, die Ihren Kriterien entsprechen. + +[](https://play.google.com/store/apps/details?id=com.realadvisor.app)[](https://apps.apple.com/ch/app/realadvisor/id6504883593?l=de-DE) + + + + + +Alle Immobilien zur Miete in der Schweiz, ob Zug, Luzern, Thurgau oder anderen Orten +------------------------------------------------------------------------------------ + +Wir zentralisieren Anzeigen von Zimmern, Wohnungen, Häusern und Gewerbeobjekten zur Miete der wichtigsten Schweizer Immobilienplattformen. Verlieren Sie keine Zeit mit der Suche auf zahlreichen Seiten und Duplikaten. Mit uns haben Sie sofort den Gesamtüberblick des Markts. + +Alle Wohnungen zur Miete in der Schweiz +--------------------------------------- + +Haus mieten Schweiz. Wohnungssuche Schweiz. Alle Immobilien in CH bei uns vereint. + +[Genf](https://realadvisor.ch/de/mieten/stadt-genf/wohnung) + +[Lausanne](https://realadvisor.ch/de/mieten/stadt-lausanne/wohnung) + +[Zurich](https://realadvisor.ch/de/mieten/stadt-zurich/wohnung) + +[Basel](https://realadvisor.ch/de/mieten/stadt-basel/wohnung) + +[Bern](https://realadvisor.ch/de/mieten/stadt-bern/wohnung) + +### Das beste Suchergebnis + +Geniessen Sie blitzschnelle Ladezeiten, suchen Sie nach mehreren Postleitzahlen oder Nachbarschaften gleichzeitig, nutzen Sie erweiterte Suchfilter wie Preis pro Zimmer pro Monat, um Ihre Suche zu präzisieren oder speichern Sie Ihre Favoriten mit einem Klick, um sie später schnell und einfach erneut zu studieren. + + + + + +### Suchabo + +Wir haben stetig ein Auge auf den Markt und benachrichtigen Sie, sobald eine neue, Ihren Kriterien entsprechende Anzeige auf den massgebenden Schweizer Portalen geschaltet wird. Speichern Sie einfach Ihre Suche und sorgen Sie sich nicht mehr um verpasste Gelegenheiten. + +[Suche nach Mietobjekten](https://realadvisor.ch/de/mieten) + +Mietwohnungen in jedem Schweizer Kanton +--------------------------------------- + +Suchen Sie wie ein Profi durch alle Anzeigen in jedem Schweizer Kanton. Finden Sie alle Mietwohnungen, ob in Genf, Waadt, Basel oder Zürich. + +[Kanton Zurich](https://realadvisor.ch/de/mieten/kanton-zurich/wohnung) + +[Kanton Bern](https://realadvisor.ch/de/mieten/kanton-bern/wohnung) + +[Kanton Waadt](https://realadvisor.ch/de/mieten/kanton-waadt/wohnung) + +[Kanton Aargau](https://realadvisor.ch/de/mieten/kanton-aargau/wohnung) + +[Kanton St-Gallen](https://realadvisor.ch/de/mieten/kanton-st-gallen/wohnung) + +[Kanton Genf](https://realadvisor.ch/de/mieten/kanton-genf/wohnung) + +[Kanton Luzern](https://realadvisor.ch/de/mieten/kanton-luzern/wohnung) + +[Kanton Tessin](https://realadvisor.ch/de/mieten/kanton-tessin/wohnung) + +[Kanton Wallis](https://realadvisor.ch/de/mieten/kanton-wallis/wohnung) + +[Kanton Freiburg](https://realadvisor.ch/de/mieten/kanton-freiburg/wohnung) + +[Kanton Basel-Landschaft](https://realadvisor.ch/de/mieten/kanton-basel-landschaft/wohnung) + +[Kanton Thurgau](https://realadvisor.ch/de/mieten/kanton-thurgau/wohnung) + +[Kanton Solothurn](https://realadvisor.ch/de/mieten/kanton-solothurn/wohnung) + +[Kanton Graubunden](https://realadvisor.ch/de/mieten/kanton-graubunden/wohnung) + +[Kanton Basel-Stadt](https://realadvisor.ch/de/mieten/kanton-basel-stadt/wohnung) + +[Kanton Neuenburg](https://realadvisor.ch/de/mieten/kanton-neuenburg/wohnung) + +[Kanton Schwyz](https://realadvisor.ch/de/mieten/kanton-schwyz/wohnung) + +[Kanton Zug](https://realadvisor.ch/de/mieten/kanton-zug/wohnung) + +[Kanton Schaffhausen](https://realadvisor.ch/de/mieten/kanton-schaffhausen/wohnung) + +[Kanton Jura](https://realadvisor.ch/de/mieten/kanton-jura/wohnung) + +[Kanton Appenzell-Ausserrhoden](https://realadvisor.ch/de/mieten/kanton-appenzell-ausserrhoden/wohnung) + +[Kanton Nidwalden](https://realadvisor.ch/de/mieten/kanton-nidwalden/wohnung) + +[Kanton Glarus](https://realadvisor.ch/de/mieten/kanton-glarus/wohnung) + +[Kanton Obwalden](https://realadvisor.ch/de/mieten/kanton-obwalden/wohnung) + +[Kanton Uri](https://realadvisor.ch/de/mieten/kanton-uri/wohnung) + +[Kanton Appenzell-Innerrhoden](https://realadvisor.ch/de/mieten/kanton-appenzell-innerrhoden/wohnung) + + + +Mietpreise in der Schweiz +------------------------- + +Informieren Sie sich über mittlere monatliche Mietpreise für Wohnungen und Häuser nach Kanton oder Gemeinde. Diese basieren auf der Echtzeit-Datenerfassung in allen wichtigen Immobilienplattformen der Schweiz. + +[Mietpreise ansehen](https://realadvisor.ch/de/immobilienpreise-pro-m2) + +Wohnungen mieten in der Schweiz +------------------------------- + +[* Wohnungen mieten in Zürich](https://realadvisor.ch/de/mieten/stadt-zurich/wohnung)[* Wohnungen mieten in Bern](https://realadvisor.ch/de/mieten/stadt-bern/wohnung)[* Wohnungen mieten in St. Gallen](https://realadvisor.ch/de/mieten/stadt-st-gallen/wohnung)[* Wohnungen mieten in Biel](https://realadvisor.ch/de/mieten/stadt-biel/wohnung)[* Wohnungen mieten in Luzern](https://realadvisor.ch/de/mieten/stadt-luzern/wohnung) + +[* Wohnungen mieten in Winterthur](https://realadvisor.ch/de/mieten/stadt-winterthur/wohnung)[* Wohnungen mieten in Schaffhausen](https://realadvisor.ch/de/mieten/stadt-schaffhausen/wohnung)[* Wohnungen mieten in Dübendorf](https://realadvisor.ch/de/mieten/stadt-dubendorf/wohnung)[* Wohnungen mieten in Olten](https://realadvisor.ch/de/mieten/4600-olten/wohnung)[* Wohnungen mieten in Gossau SG](https://realadvisor.ch/de/mieten/9200-gossau-sg/wohnung) + +[* Wohnungen mieten in Rapperswil-Jona](https://realadvisor.ch/de/mieten/stadt-rapperswil-jona/wohnung)[* Wohnungen mieten in Aarau](https://realadvisor.ch/de/mieten/stadt-aarau/wohnung)[* Wohnungen mieten in Wil (SG)](https://realadvisor.ch/de/mieten/stadt-wil-sg/wohnung)[* Wohnungen mieten in Kriens](https://realadvisor.ch/de/mieten/stadt-kriens/wohnung)[* Wohnungen mieten in Chur](https://realadvisor.ch/de/mieten/7000-chur/wohnung) + +[* Wohnungen mieten in Kloten](https://realadvisor.ch/de/mieten/8302-kloten/wohnung)[* Wohnungen mieten in Baden](https://realadvisor.ch/de/mieten/stadt-baden/wohnung)[* Wohnungen mieten in Bülach](https://realadvisor.ch/de/mieten/8180-bulach/wohnung)[* Wohnungen mieten in Kreuzlingen](https://realadvisor.ch/de/mieten/8280-kreuzlingen/wohnung)[* Wohnungen mieten in Dietikon](https://realadvisor.ch/de/mieten/8953-dietikon/wohnung) + +Häuser mieten in der Schweiz +---------------------------- + +[* Häuser mieten in Zürich](https://realadvisor.ch/de/mieten/stadt-zurich/haus)[* Häuser mieten in Winterthur](https://realadvisor.ch/de/mieten/stadt-winterthur/haus)[* Häuser mieten in Bern](https://realadvisor.ch/de/mieten/stadt-bern/haus) + +[* Häuser mieten in St. Gallen](https://realadvisor.ch/de/mieten/stadt-st-gallen/haus)[* Häuser mieten in Buchs SG](https://realadvisor.ch/de/mieten/9470-buchs-sg/haus)[* Häuser mieten in Allschwil](https://realadvisor.ch/de/mieten/4123-allschwil/haus) + +[* Häuser mieten in Luzern](https://realadvisor.ch/de/mieten/stadt-luzern/haus)[* Häuser mieten in Langenthal](https://realadvisor.ch/de/mieten/stadt-langenthal/haus)[* Häuser mieten in Widnau](https://realadvisor.ch/de/mieten/9443-widnau/haus) + +[* Häuser mieten in Reinach BL](https://realadvisor.ch/de/mieten/4153-reinach-bl/haus)[* Häuser mieten in Frauenfeld](https://realadvisor.ch/de/mieten/stadt-frauenfeld/haus)[* Häuser mieten in Hausen am Albis](https://realadvisor.ch/de/mieten/gemeinde-hausen-am-albis/haus) + +FAQ +--- + +### Ist es schwer, in der Schweiz eine Wohnung zu finden? + +Die Wohnungssuche in der Schweiz kann sich je nach Region und Zeitpunkt unterscheiden. In Grossstädten wie Zürich, Genf und Basel ist der Markt oft dynamisch, was die Suche erschweren kann. Unsere Seite bietet eine zentrale Übersicht über Angebote von den wichtigsten Immobilienplattformen der Schweiz, um Ihnen einen umfassenden Marktüberblick zu verschaffen. Das Ziel ist es, Ihre Suche nach einem neuen Zuhause so einfach und effizient wie möglich zu gestalten. + +### Was ist die durchschnittliche Miete in der Schweiz? + +Die Mietpreise in der Schweiz variieren erheblich und hängen von der Region und dem Wohnort ab. In grösseren Städten liegen die Mieten in der Regel höher als in ländlicheren Gebieten. Für aktuelle Daten zu den durchschnittlichen Mietpreisen nach Stadt, Postleitzahl und Nachbarschaft empfehlen wir, unsere Seite mit den Mietpreisinformationen zu besuchen:[Aktuelle Mietpreise in der Schweiz](https://realadvisor.ch/de/immobilienpreise-pro-m2). Hier finden Sie umfassende Informationen, die auf Echtzeit-Datenerfassungen basieren. + +### Wo kann man in der Schweiz am billigsten wohnen? + +Die kostengünstigsten Wohnmöglichkeiten finden sich oft in weniger dicht besiedelten Gebieten oder kleineren Städten. Regionen wie der Kanton Jura, Glarus und Neuenburg bieten im Vergleich zu Grossstädten oftmals niedrigere Mieten. Unsere Plattform ermöglicht eine gezielte Suche, um passende und preiswerte Wohnoptionen in Ihrer gewünschten Region zu finden. Nutzen Sie unsere Ressourcen für eine effiziente Wohnungssuche. + +[](https://realadvisor.ch/de)[](https://ch.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + +Verkaufen + +* [Immobilienbewertung](https://realadvisor.ch/de/online-immobilienbewertung) +* [Renditeliegenschaft bewerten](https://realadvisor.ch/de/renditeliegenschaft-bewerten-online) +* [Immobilienpreise](https://realadvisor.ch/de/immobilienpreise-pro-m2) +* [Makler finden](https://realadvisor.ch/de/makler-finden) +* [Immobilien-Glossar](https://realadvisor.ch/de/immobilien-glossar) +* [Immobilien-Blog](https://realadvisor.ch/de/blog) + +Kaufen / Mieten + +* [Immobilien Kaufen](https://realadvisor.ch/de/immobilien-kaufen) +* [Immobilien Mieten](https://realadvisor.ch/de/immobilien-mieten) +* [Neubauprojekte](https://realadvisor.ch/de/neubauprojekte) +* [Immobilienfinanzierung](https://realadvisor.ch/de/finanzierung) + +Für Makler + +* [Partner werden](https://realadvisor.ch/de/pro) +* [Blog Pro](https://realadvisor.ch/de/pro/blog) + +Unternehmen + +* [Über uns](https://realadvisor.ch/de/uber-uns) +* [Presseraum](https://realadvisor.ch/de/presseraum) +* [Offene Stellen](https://realadvisor.welcomekit.co/) +* [Allgemeine Geschäftsbedingungen](https://realadvisor.ch/de/begriffe) +* [Datenschutzerklärung](https://realadvisor.ch/de/datenschutzerklarung) +* [Impressum](https://realadvisor.ch/de/impressum) +* [Alle Immobilien](https://realadvisor.ch/de/sitemap) + +* [France (FR)](https://realadvisor.fr/fr) +* [España (ES)](https://realadvisor.es/es) +* [Italia (IT)](https://realadvisor.it/it) +* [Deutschland (DE)](https://realadvisor.de/de) +* [Great Britain (EN)](https://realadvisor.co.uk/en) +* [Belgique (FR)](https://realadvisor.be/fr) +* [België (NL)](https://realadvisor.be/nl) +* [Nederland (NL)](https://realadvisor.nl/nl) +* [Polska (PL)](https://realadvisor.pl/pl) +* [Czech (CZ)](https://realadvisor.cz/cs) + +[](https://apps.apple.com/ch/app/realadvisor/id6504883593)[](https://play.google.com/store/apps/details?id=com.realadvisor.app) + +© RealAdvisor 2024. All Rights Reserved. + +[](https://ch.linkedin.com/company/realadvisor)[](https://www.facebook.com/realadvisorcom)[](https://twitter.com/RealAdvisor)[](https://www.instagram.com/realadvisorcom/)[](https://www.youtube.com/channel/UCsEDTDlmxBpyxLXYhWT769Q) + + +=== https://realadvisor.ch/it/comprare/canton-zurigo/trama === +Terreno in vendita nel Canton Zurigo - 75 annunci + +=============== +[](https://realadvisor.ch/it/vendita-immobile) + +Valuta + +[Compra](https://realadvisor.ch/it/vendita-immobile)[Affitta](https://realadvisor.ch/it/immobili-in-affitto)[Vendi](https://realadvisor.ch/it/vendi-casa)[Agenzie immobiliari](https://realadvisor.ch/it/trova-una-agenzia) + +IT Mostra menu di navigazione + + + +Terreno in vendita nel Canton Zurigo +==================================== + +[Compra](https://realadvisor.ch/it/comprare/canton-zurigo/trama)[Affitto](https://realadvisor.ch/it/affitto/canton-zurigo) + +Località + +Tipo di immobile + +Cerca + +1. [](https://realadvisor.ch/it) +2. [Compra](https://realadvisor.ch/it/comprare) +3. [Terreno](https://realadvisor.ch/it/comprare/trama) +4. Canton Zurigo + +Canton Zurigo - 75 terreni in vendita +------------------------------------- + +Sfoglia tutti gli annunci di parcelle, terreni edificabili o agricoli in vendita nel Canton Zurigo, e perfeziona la tua ricerca tra 75 offerte. + +Mostra immobili sulla mappa Mostra immobili sulla mappa + +Prezzo + +- [x] Fino a CHF 200’000 + +- [x] CHF 200’000 - CHF 400’000 + +- [x] CHF 400’000 - CHF 600’000 + +- [x] CHF 600’000 - CHF 1’000’000 + +- [x] CHF 1’000’000 - CHF 2’000’000 + +- [x] CHF 2’000’000 - CHF 3’000’000 + +- [x] CHF 3’000’000+ + +Superficie terreno + +- [x] Fino a 500 m² + +- [x] 500 - 1000 m² + +- [x] 1000 - 2000 m² + +- [x] 2000 - 5000 m² + +- [x] 5000 - 10000 m² + +- [x] 10000 - 20000 m² + +- [x] 20000+ m² + +Raccomandato Più recente Prezzo più basso Prezzo più alto + +[3 giorni fa get living 1452 m² Plot • Terreno edificabile 8162 Steinmaur * Terreno pianeggiante e edificabile * Posizione tranquilla e soleggiata * Ottimo accesso ai trasporti pubblici * * * Prezzo su richiesta - ](https://realadvisor.ch/it/comprare/trama/8162-steinmaur-B62R-PZDJ) + +[6 giorni fa ImmoSky AG - Standort Dübendorf ZH (Zentrale) 1070 m² Plot • Terreno edificabile 8340 Hinwil * Oltre 1.070 m² di area * Opzioni di suddivisione flessibili * Ideale per case familiari * * * CHF 1’070’000 CHF 1’000 m² ](https://realadvisor.ch/it/comprare/trama/8340-hinwil-LDX9-L6M2) + +[7 giorni fa PREMIUM HOMES AG 1940 m² Plot • Terreno edificabile 8633 Wolfhausen * Terreno generoso di 1'940m² * Posizione adatta alle famiglie * Opzioni di design flessibili * * * CHF 4’074’000 CHF 2’100 m² ](https://realadvisor.ch/it/comprare/trama/8633-wolfhausen-YB6N-VRVP) + +[9 giorni fa Moser Anlageimmobilien AG 1666 m² Plot • Terreno edificabile Sonnhalde, 8602 Wangen b. Dübendorf * 1666 m² di terreno esclusivo * Ottima esposizione al sole * Privacy in zona tranquilla * * * CHF 3’300’000 CHF 1’981 m² ](https://realadvisor.ch/it/comprare/trama/sonnhalde-8602-wangen-b.-dubendorf-83JW-X5X3) + +[11 giorni fa Centrum Immo Terreno edificabile 8000 Zürich * Ideale per sviluppo * Vicino ai trasporti pubblici * Vista panoramica sulla città * * * Prezzo su richiesta - ](https://realadvisor.ch/it/comprare/trama/8000-zurich-NAG4-JV4R) + +[13 giorni fa ImmoSky AG - Standort Dübendorf ZH (Zentrale) 650 m² Plot • Terreno edificabile 8195 Wasterkingen * Terreno completamente servito * Comunità rurale tranquilla * Opzioni di design flessibili * * * CHF 475’000 CHF 731 m² ](https://realadvisor.ch/it/comprare/trama/8195-wasterkingen-7JPL-7X5M) + +[21 giorni fa Swiss Residence Group AG 1622 m² Plot • Terreno edificabile 8618 Oetwil am See * Terreno soleggiato di 1'622 m² * Zonizzazione flessibile per progetti * Vista montagna non edificabile * * * Prezzo su richiesta - ](https://realadvisor.ch/it/comprare/trama/8618-oetwil-am-see-8OOG-PWB5) + +[22 giorni fa PREMIUM HOMES AG 850 m² Plot • Terreno edificabile 8617 Mönchaltorf * Alto potenziale di sviluppo * Posizione tranquilla e soleggiata * Opzioni di utilizzo flessibili * * * Prezzo su richiesta - ](https://realadvisor.ch/it/comprare/trama/8617-monchaltorf-KRNG-WO9R) + +[26 giorni fa Schiblis Immobilien GmbH 507 m² Plot • Terreno edificabile Güeterstalstrasse, 8133 Esslingen * Posizione centrale a Esslingen * Nessun obbligo architettonico * Nessuna contaminazione presente * * * CHF 600’000 CHF 1’183 m² ](https://realadvisor.ch/it/comprare/trama/gueterstalstrasse-8133-esslingen-YMXG-R3MR) + +[28 giorni fa Grundeigentümer Verband Schweiz 1226 m² Plot • Terreno edificabile 8192 Zweidlen * Superficie totale di 1'226 m² * Superficie utile max. 940 m² * Opzioni di sviluppo flessibili * * * CHF 2’450’000 CHF 1’998 m²](https://realadvisor.ch/it/comprare/trama/8192-zweidlen-6ZMD-4WE3) + +[29 giorni fa PREMIUM HOMES AG 1670 m² Plot • Terreno edificabile 8424 Embrach * Posizione adatta alle famiglie * Luce abbondante tutto il giorno * Opzioni di costruzione flessibili * * * Prezzo su richiesta - ](https://realadvisor.ch/it/comprare/trama/8424-embrach-8WRG-NEGR) + +[29 giorni fa SH Immo GmbH 854 m² Plot • Terreno edificabile Berghalde 10, 8332 Russikon * Ampio terreno di 854 m2 * Posizione collinare soleggiata * Potenziale per nuova costruzione * * * CHF 1’500’000 CHF 1’756 m² ](https://realadvisor.ch/it/comprare/trama/10-berghalde-8332-russikon-6ZMD-432O) + +[un mese fa Moos & Partner Immobilien GmbH 694 m² Plot • Terreno edificabile 8134 Adliswil * Posizione centrale con potenziale * Zona W3 ad alta utilizzazione * Ideale per investitori e sviluppatori * * * CHF 3’600’000 CHF 5’187 m² ](https://realadvisor.ch/it/comprare/trama/8134-adliswil-Y7J5-W36M) + +[2 mesi fa RE/MAX Immobilien in Rapperswil-Jona 4246 m² Plot • Terreno edificabile Überlandstrasse 23, 8340 Hinwil * Posizione privilegiata vicino a strade * Ampia area per sviluppo * Opzioni di altezza edificio flessibili * * * Prezzo su richiesta - ](https://realadvisor.ch/it/comprare/trama/23-uberlandstrasse-8340-hinwil-YB69-VB7M) + +[2 mesi fa RE/MAX Immobilien in Winterthur 877 m² Plot • Terreno edificabile Winzerstrasse 20, 8353 Elgg * Ideale per case familiari * Opportunità di investimento * Adiacente a casa esistente * * * CHF 1’140’000 CHF 1’300 m² ](https://realadvisor.ch/it/comprare/trama/20-winzerstrasse-8353-elgg-KRNL-ZPNR) + +[3 mesi fa RE/MAX Immobilien in Meilen 2838 m² • 1706 m² Plot • Terreno edificabile Industriestrasse 34, 8117 Fällanden * Progetto commerciale approvato * Utilizzo commerciale flessibile * 37 posti auto disponibili * * * Prezzo su richiesta - ](https://realadvisor.ch/it/comprare/trama/34-industriestrasse-8117-fallanden-YJDX-JXRR) + +[4 mesi fa PREMIUM HOMES AG 3460 m² Plot • Terreno edificabile 8630 Rüti ZH * Zona residenziale tranquilla * Tasso di utilizzo del 30% * Bonus per spazio extra * * * Prezzo su richiesta - ](https://realadvisor.ch/it/comprare/trama/8630-ruti-zh-84E9-Z65G) + +[16 giorni fa Swisslife 2557 m² Plot • Terreno edificabile Staldernstrasse 13, 8158 Regensberg * Zonizzazione flessibile per uso misto * Alto potenziale di rendimento locativo * Posizione tranquilla vicino a Zurigo * * * CHF 5’500’000 CHF 2’151 m² dreamo.ch](https://realadvisor.ch/it/comprare/trama/13-staldernstrasse-8158-regensberg-YJDX-XWMO) + +[2 mesi fa Orgnet Immobilien AG 844 m² Plot • Terreno edificabile Leisibüel, 8484 Weisslingen * Vista mozzafiato sulle montagne * Orientamento sud-ovest soleggiato * Quartiere tranquillo e privato * * * CHF 1’300’000 CHF 1’540 m² dreamo.ch](https://realadvisor.ch/it/comprare/trama/leisibuel-8484-weisslingen-8OO2-753X) + +[3 mesi fa TREVAG Treuhand und Verwaltungs AG 2295 m² Plot • Terreno edificabile Weiacherstrasse 85, 8427 Rorbas * Terreno spazioso di 2'295 m2 * Edificio a uso misto * Contratti di affitto esistenti * * * CHF 3’440’000 CHF 1’499 m² dreamo.ch](https://realadvisor.ch/it/comprare/trama/85-weiacherstrasse-8427-rorbas-YJD9-MVWW) + +[3 mesi fa TREVAG Treuhand und Verwaltungs AG 1742 m² Plot • Terreno edificabile Bergstrasse 7a, 8155 Nassenwil * Ampia superficie di terreno * Posizione tranquilla * Vicino a Dielsdorf * * * CHF 2’700’000 CHF 1’550 m² dreamo.ch](https://realadvisor.ch/it/comprare/trama/7a-bergstrasse-8155-nassenwil-YB69-GEB6) + +[3 mesi fa TREVAG Treuhand und Verwaltungs AG 1340 m² • 1340 m² Plot • Terreno edificabile Götze, 8197 Rafz * Vista libera * Ideale per sviluppo * Posizione privilegiata * * * CHF 2’200’000 CHF 1’642 m² dreamo.ch](https://realadvisor.ch/it/comprare/trama/gotze-8197-rafz-Y6ZW-VB6G) + +[3 mesi fa VZ VermögensZentrum 4.5 stanze • 114 m² • 480 m² Plot • Terreno edificabile Schaffhauserstrasse 226b, 8057 Zürich * Ampio spazio esterno * Vista verde dalle finestre * Stufa svedese accogliente * * * CHF 2’999’000 CHF 26’307 m² dreamo.ch](https://realadvisor.ch/it/comprare/trama/226b-schaffhauserstrasse-8057-zurich-KRNL-A6J7) + +[7 ore fa 829 m² Plot • Terreno edificabile Haldenstrasse 10, 8134 Adliswil * Posizione tranquilla con vista * Vicino ai mezzi pubblici * Disponibilità immediata * * * CHF 3’300’000 CHF 3’981 m² homegate.ch](https://realadvisor.ch/it/comprare/canton-zurigo/trama#) + +Mostra tutti i 75 annunci + +### Altri immobili in vendita nel Canton Zurigo + +[Appartamenti in vendita](https://realadvisor.ch/it/comprare/canton-zurigo/appartamento) + +[Case in vendita](https://realadvisor.ch/it/comprare/canton-zurigo/casa) + +[Terreni in vendita](https://realadvisor.ch/it/comprare/canton-zurigo/trama) + +[Edifici in vendita](https://realadvisor.ch/it/comprare/canton-zurigo/edificio) + +[Immobili commerciali in vendita](https://realadvisor.ch/it/comprare/canton-zurigo/commerciale) + +[Hotel & ristoranti in vendita](https://realadvisor.ch/it/comprare/canton-zurigo/ospitalita) + +Comprare un terreno nel Canton Zurigo +------------------------------------- + +### Terreni in vendita nel Canton Zurigo + +* [Terreni in vendita a Zurigo](https://realadvisor.ch/it/comprare/citta-zurigo/trama) +* [Terreni in vendita a Winterthur](https://realadvisor.ch/it/comprare/citta-winterthur/trama) +* [Terreni in vendita a Uster](https://realadvisor.ch/it/comprare/citta-uster/trama) +* [Terreni in vendita a Dübendorf](https://realadvisor.ch/it/comprare/citta-dubendorf/trama) +* [Terreni in vendita a Dietikon (8953)](https://realadvisor.ch/it/comprare/8953-dietikon/trama) +* [Terreni in vendita a Wädenswil](https://realadvisor.ch/it/comprare/citta-wadenswil/trama) +* [Terreni in vendita a Wetzikon (ZH)](https://realadvisor.ch/it/comprare/citta-wetzikon-zh/trama) +* [Terreni in vendita a Horgen](https://realadvisor.ch/it/comprare/citta-horgen/trama) +* [Terreni in vendita a Opfikon](https://realadvisor.ch/it/comprare/citta-opfikon/trama) +* [Terreni in vendita a Bülach (8180)](https://realadvisor.ch/it/comprare/8180-bulach/trama) +* [Terreni in vendita a Kloten (8302)](https://realadvisor.ch/it/comprare/8302-kloten/trama) +* [Terreni in vendita a Adliswil (8134)](https://realadvisor.ch/it/comprare/8134-adliswil/trama) +* [Terreni in vendita a Schlieren (8952)](https://realadvisor.ch/it/comprare/8952-schlieren/trama) +* [Terreni in vendita a Volketswil](https://realadvisor.ch/it/comprare/citta-volketswil/trama) +* [Terreni in vendita a Regensdorf](https://realadvisor.ch/it/comprare/citta-regensdorf/trama) +* [Terreni in vendita a Thalwil](https://realadvisor.ch/it/comprare/citta-thalwil/trama) +* [Terreni in vendita a Illnau-Effretikon](https://realadvisor.ch/it/comprare/citta-illnau-effretikon/trama) +* [Terreni in vendita a Wallisellen (8304)](https://realadvisor.ch/it/comprare/8304-wallisellen/trama) +* [Terreni in vendita a Stäfa](https://realadvisor.ch/it/comprare/citta-stafa/trama) +* [Terreni in vendita a Küsnacht (ZH)](https://realadvisor.ch/it/comprare/citta-kusnacht-zh/trama) +* [Terreni in vendita a Meilen (8706)](https://realadvisor.ch/it/comprare/8706-meilen/trama) +* [Terreni in vendita a Richterswil](https://realadvisor.ch/it/comprare/citta-richterswil/trama) +* [Terreni in vendita a Zollikon](https://realadvisor.ch/it/comprare/citta-zollikon/trama) +* [Terreni in vendita a Rüti ZH (8630)](https://realadvisor.ch/it/comprare/8630-ruti-zh/trama) +* [Terreni in vendita a Affoltern am Albis](https://realadvisor.ch/it/comprare/citta-affoltern-am-albis/trama) +* [Terreni in vendita a Pfäffikon](https://realadvisor.ch/it/comprare/citta-pfaffikon/trama) +* [Terreni in vendita a Bassersdorf (8303)](https://realadvisor.ch/it/comprare/8303-bassersdorf/trama) +* [Terreni in vendita a Hinwil](https://realadvisor.ch/it/comprare/citta-hinwil/trama) +* [Terreni in vendita a Männedorf (8708)](https://realadvisor.ch/it/comprare/8708-mannedorf/trama) +* [Terreni in vendita a Maur](https://realadvisor.ch/it/comprare/citta-maur/trama) +* [Terreni in vendita a Gossau (ZH)](https://realadvisor.ch/it/comprare/comune-gossau-zh/trama) +* [Terreni in vendita a Wald (ZH)](https://realadvisor.ch/it/comprare/comune-wald-zh/trama) +* [Terreni in vendita a Urdorf (8902)](https://realadvisor.ch/it/comprare/8902-urdorf/trama) +* [Terreni in vendita a Embrach (8424)](https://realadvisor.ch/it/comprare/8424-embrach/trama) +* [Terreni in vendita a Niederhasli](https://realadvisor.ch/it/comprare/comune-niederhasli/trama) +* [Terreni in vendita a Hombrechtikon](https://realadvisor.ch/it/comprare/comune-hombrechtikon/trama) +* [Terreni in vendita a Fällanden](https://realadvisor.ch/it/comprare/comune-fallanden/trama) +* [Terreni in vendita a Kilchberg ZH (8802)](https://realadvisor.ch/it/comprare/8802-kilchberg-zh/trama) +* [Terreni in vendita a Egg](https://realadvisor.ch/it/comprare/comune-egg/trama) +* [Terreni in vendita a Rümlang (8153)](https://realadvisor.ch/it/comprare/8153-rumlang/trama) +* [Terreni in vendita a Wangen-Brüttisellen](https://realadvisor.ch/it/comprare/comune-wangen-bruttisellen/trama) +* [Terreni in vendita a Dietlikon (8305)](https://realadvisor.ch/it/comprare/8305-dietlikon/trama) +* [Terreni in vendita a Dürnten](https://realadvisor.ch/it/comprare/comune-durnten/trama) +* [Terreni in vendita a Langnau am Albis (8135)](https://realadvisor.ch/it/comprare/8135-langnau-am-albis/trama) +* [Terreni in vendita a Seuzach (8472)](https://realadvisor.ch/it/comprare/8472-seuzach/trama) +* [Terreni in vendita a Bubikon](https://realadvisor.ch/it/comprare/comune-bubikon/trama) +* [Terreni in vendita a Oberglatt ZH (8154)](https://realadvisor.ch/it/comprare/8154-oberglatt-zh/trama) +* [Terreni in vendita a Oberengstringen (8102)](https://realadvisor.ch/it/comprare/8102-oberengstringen/trama) +* [Terreni in vendita a Fehraltorf (8320)](https://realadvisor.ch/it/comprare/8320-fehraltorf/trama) +* [Terreni in vendita a Birmensdorf ZH (8903)](https://realadvisor.ch/it/comprare/8903-birmensdorf-zh/trama) +* [Terreni in vendita a Wiesendangen](https://realadvisor.ch/it/comprare/comune-wiesendangen/trama) +* [Terreni in vendita a Buchs ZH (8107)](https://realadvisor.ch/it/comprare/8107-buchs-zh/trama) +* [Terreni in vendita a Herrliberg (8704)](https://realadvisor.ch/it/comprare/8704-herrliberg/trama) +* [Terreni in vendita a Uetikon am See (8707)](https://realadvisor.ch/it/comprare/8707-uetikon-am-see/trama) +* [Terreni in vendita a Dielsdorf (8157)](https://realadvisor.ch/it/comprare/8157-dielsdorf/trama) +* [Terreni in vendita a Zell (ZH)](https://realadvisor.ch/it/comprare/comune-zell-zh/trama) +* [Terreni in vendita a Rüschlikon (8803)](https://realadvisor.ch/it/comprare/8803-ruschlikon/trama) +* [Terreni in vendita a Lindau](https://realadvisor.ch/it/comprare/comune-lindau/trama) +* [Terreni in vendita a Nürensdorf (8309)](https://realadvisor.ch/it/comprare/8309-nurensdorf/trama) +* [Terreni in vendita a Erlenbach ZH (8703)](https://realadvisor.ch/it/comprare/8703-erlenbach-zh/trama) +* [Terreni in vendita a Neftenbach](https://realadvisor.ch/it/comprare/comune-neftenbach/trama) +* [Terreni in vendita a Bonstetten (8906)](https://realadvisor.ch/it/comprare/8906-bonstetten/trama) +* [Terreni in vendita a Obfelden (8912)](https://realadvisor.ch/it/comprare/8912-obfelden/trama) +* [Terreni in vendita a Greifensee (8606)](https://realadvisor.ch/it/comprare/8606-greifensee/trama) +* [Terreni in vendita a Glattfelden](https://realadvisor.ch/it/comprare/comune-glattfelden/trama) +* [Terreni in vendita a Eglisau (8193)](https://realadvisor.ch/it/comprare/8193-eglisau/trama) +* [Terreni in vendita a Zumikon (8126)](https://realadvisor.ch/it/comprare/8126-zumikon/trama) +* [Terreni in vendita a Wettswil (8907)](https://realadvisor.ch/it/comprare/8907-wettswil/trama) +* [Terreni in vendita a Schwerzenbach (8603)](https://realadvisor.ch/it/comprare/8603-schwerzenbach/trama) +* [Terreni in vendita a Oberrieden (8942)](https://realadvisor.ch/it/comprare/8942-oberrieden/trama) +* [Terreni in vendita a Bäretswil](https://realadvisor.ch/it/comprare/comune-baretswil/trama) +* [Terreni in vendita a Niederglatt ZH (8172)](https://realadvisor.ch/it/comprare/8172-niederglatt-zh/trama) +* [Terreni in vendita a Geroldswil](https://realadvisor.ch/it/comprare/comune-geroldswil/trama) +* [Terreni in vendita a Bauma](https://realadvisor.ch/it/comprare/comune-bauma/trama) +* [Terreni in vendita a Elgg](https://realadvisor.ch/it/comprare/comune-elgg/trama) +* [Terreni in vendita a Mettmenstetten (8932)](https://realadvisor.ch/it/comprare/8932-mettmenstetten/trama) +* [Terreni in vendita a Weiningen ZH (8104)](https://realadvisor.ch/it/comprare/8104-weiningen-zh/trama) +* [Terreni in vendita a Oetwil am See (8618)](https://realadvisor.ch/it/comprare/8618-oetwil-am-see/trama) +* [Terreni in vendita a Turbenthal](https://realadvisor.ch/it/comprare/comune-turbenthal/trama) +* [Terreni in vendita a Winkel (8185)](https://realadvisor.ch/it/comprare/8185-winkel/trama) +* [Terreni in vendita a Rafz (8197)](https://realadvisor.ch/it/comprare/8197-rafz/trama) +* [Terreni in vendita a Russikon](https://realadvisor.ch/it/comprare/comune-russikon/trama) +* [Terreni in vendita a Uitikon Waldegg (8142)](https://realadvisor.ch/it/comprare/8142-uitikon-waldegg/trama) +* [Terreni in vendita a Dällikon (8108)](https://realadvisor.ch/it/comprare/8108-dallikon/trama) +* [Terreni in vendita a Bachenbülach (8184)](https://realadvisor.ch/it/comprare/8184-bachenbulach/trama) +* [Terreni in vendita a Pfungen (8422)](https://realadvisor.ch/it/comprare/8422-pfungen/trama) +* [Terreni in vendita a Unterengstringen (8103)](https://realadvisor.ch/it/comprare/8103-unterengstringen/trama) +* [Terreni in vendita a Mönchaltorf (8617)](https://realadvisor.ch/it/comprare/8617-monchaltorf/trama) +* [Terreni in vendita a Stallikon](https://realadvisor.ch/it/comprare/comune-stallikon/trama) +* [Terreni in vendita a Hedingen (8908)](https://realadvisor.ch/it/comprare/8908-hedingen/trama) +* [Terreni in vendita a Hausen am Albis](https://realadvisor.ch/it/comprare/comune-hausen-am-albis/trama) +* [Terreni in vendita a Feuerthalen](https://realadvisor.ch/it/comprare/comune-feuerthalen/trama) +* [Terreni in vendita a Hittnau (8335)](https://realadvisor.ch/it/comprare/8335-hittnau/trama) +* [Terreni in vendita a Elsau (8352)](https://realadvisor.ch/it/comprare/8352-elsau/trama) +* [Terreni in vendita a Steinmaur](https://realadvisor.ch/it/comprare/comune-steinmaur/trama) +* [Terreni in vendita a Grüningen (8627)](https://realadvisor.ch/it/comprare/8627-gruningen/trama) +* [Terreni in vendita a Weisslingen](https://realadvisor.ch/it/comprare/comune-weisslingen/trama) +* [Terreni in vendita a Hettlingen (8442)](https://realadvisor.ch/it/comprare/8442-hettlingen/trama) +* [Terreni in vendita a Neerach (8173)](https://realadvisor.ch/it/comprare/8173-neerach/trama) +* [Terreni in vendita a Niederweningen (8166)](https://realadvisor.ch/it/comprare/8166-niederweningen/trama) +* [Terreni in vendita a Otelfingen (8112)](https://realadvisor.ch/it/comprare/8112-otelfingen/trama) +* [Terreni in vendita a Rorbas (8427)](https://realadvisor.ch/it/comprare/8427-rorbas/trama) +* [Terreni in vendita a Stammheim](https://realadvisor.ch/it/comprare/comune-stammheim/trama) +* [Terreni in vendita a Höri (8181)](https://realadvisor.ch/it/comprare/8181-hori/trama) +* [Terreni in vendita a Rickenbach (ZH)](https://realadvisor.ch/it/comprare/comune-rickenbach-zh/trama) +* [Terreni in vendita a Ottenbach (8913)](https://realadvisor.ch/it/comprare/8913-ottenbach/trama) +* [Terreni in vendita a Fischenthal](https://realadvisor.ch/it/comprare/comune-fischenthal/trama) +* [Terreni in vendita a Oetwil an der Limmat (8955)](https://realadvisor.ch/it/comprare/8955-oetwil-an-der-limmat/trama) +* [Terreni in vendita a Lufingen (8426)](https://realadvisor.ch/it/comprare/8426-lufingen/trama) +* [Terreni in vendita a Freienstein-Teufen](https://realadvisor.ch/it/comprare/comune-freienstein-teufen/trama) +* [Terreni in vendita a Knonau (8934)](https://realadvisor.ch/it/comprare/8934-knonau/trama) +* [Terreni in vendita a Stadel](https://realadvisor.ch/it/comprare/comune-stadel/trama) +* [Terreni in vendita a Henggart (8444)](https://realadvisor.ch/it/comprare/8444-henggart/trama) +* [Terreni in vendita a Andelfingen (8450)](https://realadvisor.ch/it/comprare/8450-andelfingen/trama) +* [Terreni in vendita a Kleinandelfingen](https://realadvisor.ch/it/comprare/comune-kleinandelfingen/trama) +* [Terreni in vendita a Brütten (8311)](https://realadvisor.ch/it/comprare/8311-brutten/trama) +* [Terreni in vendita a Wila (8492)](https://realadvisor.ch/it/comprare/8492-wila/trama) +* [Terreni in vendita a Marthalen](https://realadvisor.ch/it/comprare/comune-marthalen/trama) +* [Terreni in vendita a Aeugst am Albis](https://realadvisor.ch/it/comprare/comune-aeugst-am-albis/trama) +* [Terreni in vendita a Dachsen (8447)](https://realadvisor.ch/it/comprare/8447-dachsen/trama) +* [Terreni in vendita a Hochfelden (8182)](https://realadvisor.ch/it/comprare/8182-hochfelden/trama) +* [Terreni in vendita a Dänikon ZH (8114)](https://realadvisor.ch/it/comprare/8114-danikon-zh/trama) +* [Terreni in vendita a Oberweningen (8165)](https://realadvisor.ch/it/comprare/8165-oberweningen/trama) +* [Terreni in vendita a Weiach (8187)](https://realadvisor.ch/it/comprare/8187-weiach/trama) +* [Terreni in vendita a Laufen-Uhwiesen](https://realadvisor.ch/it/comprare/comune-laufen-uhwiesen/trama) +* [Terreni in vendita a Ossingen (8475)](https://realadvisor.ch/it/comprare/8475-ossingen/trama) +* [Terreni in vendita a Dinhard (8474)](https://realadvisor.ch/it/comprare/8474-dinhard/trama) +* [Terreni in vendita a Seegräben](https://realadvisor.ch/it/comprare/comune-seegraben/trama) +* [Terreni in vendita a Flurlingen (8247)](https://realadvisor.ch/it/comprare/8247-flurlingen/trama) +* [Terreni in vendita a Wil ZH (8196)](https://realadvisor.ch/it/comprare/8196-wil-zh/trama) +* [Terreni in vendita a Schöfflisdorf (8165)](https://realadvisor.ch/it/comprare/8165-schofflisdorf/trama) +* [Terreni in vendita a Flaach (8416)](https://realadvisor.ch/it/comprare/8416-flaach/trama) +* [Terreni in vendita a Boppelsen (8113)](https://realadvisor.ch/it/comprare/8113-boppelsen/trama) +* [Terreni in vendita a Aesch ZH (8904)](https://realadvisor.ch/it/comprare/8904-aesch-zh/trama) +* [Terreni in vendita a Rheinau (8462)](https://realadvisor.ch/it/comprare/8462-rheinau/trama) +* [Terreni in vendita a Kappel am Albis](https://realadvisor.ch/it/comprare/comune-kappel-am-albis/trama) +* [Terreni in vendita a Hagenbuch ZH (8523)](https://realadvisor.ch/it/comprare/8523-hagenbuch-zh/trama) +* [Terreni in vendita a Rifferswil (8911)](https://realadvisor.ch/it/comprare/8911-rifferswil/trama) +* [Terreni in vendita a Trüllikon](https://realadvisor.ch/it/comprare/comune-trullikon/trama) +* [Terreni in vendita a Oberembrach (8425)](https://realadvisor.ch/it/comprare/8425-oberembrach/trama) +* [Terreni in vendita a Hüntwangen (8194)](https://realadvisor.ch/it/comprare/8194-huntwangen/trama) +* [Terreni in vendita a Dägerlen](https://realadvisor.ch/it/comprare/comune-dagerlen/trama) +* [Terreni in vendita a Wildberg](https://realadvisor.ch/it/comprare/comune-wildberg/trama) +* [Terreni in vendita a Buch am Irchel (8414)](https://realadvisor.ch/it/comprare/8414-buch-am-irchel/trama) +* [Terreni in vendita a Hüttikon (8115)](https://realadvisor.ch/it/comprare/8115-huttikon/trama) +* [Terreni in vendita a Thalheim an der Thur (8478)](https://realadvisor.ch/it/comprare/8478-thalheim-an-der-thur/trama) +* [Terreni in vendita a Ellikon an der Thur (8548)](https://realadvisor.ch/it/comprare/8548-ellikon-an-der-thur/trama) +* [Terreni in vendita a Benken ZH (8463)](https://realadvisor.ch/it/comprare/8463-benken-zh/trama) +* [Terreni in vendita a Dättlikon (8421)](https://realadvisor.ch/it/comprare/8421-dattlikon/trama) +* [Terreni in vendita a Schleinikon (8165)](https://realadvisor.ch/it/comprare/8165-schleinikon/trama) +* [Terreni in vendita a Schlatt ZH (8418)](https://realadvisor.ch/it/comprare/8418-schlatt-zh/trama) +* [Terreni in vendita a Dorf (8458)](https://realadvisor.ch/it/comprare/8458-dorf/trama) +* [Terreni in vendita a Altikon (8479)](https://realadvisor.ch/it/comprare/8479-altikon/trama) +* [Terreni in vendita a Adlikon b. Andelfingen (8452)](https://realadvisor.ch/it/comprare/8452-adlikon-b-andelfingen/trama) +* [Terreni in vendita a Maschwanden (8933)](https://realadvisor.ch/it/comprare/8933-maschwanden/trama) +* [Terreni in vendita a Bachs (8164)](https://realadvisor.ch/it/comprare/8164-bachs/trama) +* [Terreni in vendita a Wasterkingen (8195)](https://realadvisor.ch/it/comprare/8195-wasterkingen/trama) +* [Terreni in vendita a Berg am Irchel](https://realadvisor.ch/it/comprare/comune-berg-am-irchel/trama) +* [Terreni in vendita a Humlikon (8457)](https://realadvisor.ch/it/comprare/8457-humlikon/trama) +* [Terreni in vendita a Truttikon (8467)](https://realadvisor.ch/it/comprare/8467-truttikon/trama) +* [Terreni in vendita a Regensberg (8158)](https://realadvisor.ch/it/comprare/8158-regensberg/trama) +* [Terreni in vendita a Volken (8459)](https://realadvisor.ch/it/comprare/8459-volken/trama) +* Mostra 144 altri + +Quanto vale la mia casa? + +[Ottieni subito una valutazione online](https://realadvisor.ch/it/valutazione-immobile-gratuita) + +Qual è il prezzo medio degli immobili? + +[Scopri i prezzi al m² aggiornati nel Canton Zurigo](https://realadvisor.ch/it/prezzi-immobili/canton-zurigo) + +Cerchi un esperto immobiliare di fiducia? + +[Trova la migliore agenzia nel Canton Zurigo](https://realadvisor.ch/it/agenzie-immobiliari/canton-zurigo) + +[](https://realadvisor.ch/it) + +[](https://it.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + +Vendere + +* [Valutazione immobiliare](https://realadvisor.ch/it/valutazione-immobile-gratuita) +* [Valutazione degli Immobili a reddito](https://realadvisor.ch/it/valutazione-immobili-a-reddito) +* [Prezzo degli immobili](https://realadvisor.ch/it/prezzi-immobili) +* [Agenzie immobiliari](https://realadvisor.ch/it/trova-una-agenzia) +* [Blog immobiliare](https://realadvisor.ch/it/blog) + +Comprare / Affittare + +* [Immobili in vendita](https://realadvisor.ch/it/vendita-immobile) +* [Immobili in affitto](https://realadvisor.ch/it/immobili-in-affitto) +* [Promozioni immobiliari](https://realadvisor.ch/it/nuove-costruzioni) +* [Finanziamento immobiliare](https://realadvisor.ch/it/finanziamento) + +Professionisti + +* [Diventare partner](https://realadvisor.ch/it/pro) + +La Società + +* [Chi siamo](https://realadvisor.ch/it/chi-siamo) +* [Press](https://realadvisor.ch/it/press) +* [Offerte di lavoro](https://realadvisor.welcomekit.co/) +* [Termini e condizioni](https://realadvisor.ch/it/termin-e-condizioni) +* [Informativa sulla privacy](https://realadvisor.ch/it/protezione-dati) +* [Informazioni legali](https://realadvisor.ch/it/informazioni-legali) +* [Tutti gli immobili](https://realadvisor.ch/it/sitemap) + +© Realadvisor 2025. All Rights Reserved. + +[](https://ch.linkedin.com/company/realadvisor)[](https://www.facebook.com/realadvisorcom)[](https://twitter.com/RealAdvisor)[](https://www.instagram.com/realadvisorcom/)[](https://www.youtube.com/channel/UCsEDTDlmxBpyxLXYhWT769Q) + + +=== https://realadvisor.ch/fr/acheter/canton-zurich/terrain === +75 Terrains à vendre dans le canton de Zurich - octobre 2025 + +=============== + +[](https://realadvisor.ch/fr/immobilier-a-vendre) + ++1 plus + +Canton de Zurich + + + +Estimer + +[Acheter](https://realadvisor.ch/fr/immobilier-a-vendre)[Louer](https://realadvisor.ch/fr/immobilier-a-louer) + +Connexion + +FR + +[Italiano](https://realadvisor.ch/it/comprare/canton-zurigo/trama)[Deutsch](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck)[English](https://realadvisor.ch/en/buy/canton-zurich/plot) + +Créer une alerte + ++1 plus + +Canton de Zurich + + + +Acheter Louer + +Acheter Louer + +Terrain + +Prix + +Modifier la recherche + +Surface du terrain + +Autre filtres + +Créer une alerte + +- [x] Carte + +←Move left +→Move right +↑Move up +↓Move down ++Zoom in +-Zoom out +Home Jump left by 75% +End Jump right by 75% +Page Up Jump up by 75% +Page Down Jump down by 75% + + + + + + + + + + + + + + + + + + + + + + + + + +9 + +9 + +5 + +5 + +3 + +3 + +6 + +6 + +17 + +17 + +7 + +7 + +4 + +4 + +2 + +2 + +2 + +2 + +14 + +14 + +5 + +5 + +1 + +1 + + + +Map +* Map +* Satellite +* Terrain +* Labels + + + + + +*  +*  +*  +*  +*  +*  + +[](https://maps.google.com/maps?ll=47.421441,8.671322&z=9&t=m&hl=en-US&gl=US&mapclient=apiv3 "Open this area in Google Maps (opens a new window)") + +Keyboard shortcuts + +Map Data Map data ©2025 GeoBasis-DE/BKG (©2009), Google + +Map data ©2025 GeoBasis-DE/BKG (©2009), Google + +10 km + +Click to toggle between metric and imperial units + +[Terms](https://www.google.com/intl/en-US_US/help/terms_maps.html) + +[Report a map error](https://www.google.com/maps/@47.421441,8.6713222,9z/data=!10m1!1e1!12b1?source=apiv3&rapsrc=apiv3 "Report errors in the road map or imagery to Google") + +1. [](https://realadvisor.ch/fr) + +3. [Acheter](https://realadvisor.ch/fr/acheter) + +5. [Terrain](https://realadvisor.ch/fr/acheter/terrain) + +7. Canton de Zurich + +Terrains à vendre dans le canton de Zurich +========================================== + +75 Résultats + +Nos suggestions + +[](https://realadvisor.ch/fr/acheter/terrain/8162-steinmaur-B62R-PZDJ) + +il y a 3 jours + +- [x] + +[get living 1’452 m² Terrain • Terrain constructible 8162 Steinmaur * Terrain plat et constructible * Emplacement calme et ensoleillé * Accès facile aux transports publics ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Sur demande —](https://realadvisor.ch/fr/acheter/terrain/8162-steinmaur-B62R-PZDJ) + +[](https://realadvisor.ch/fr/acheter/terrain/8340-hinwil-LDX9-L6M2) + +il y a 6 jours + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 1’070 m² Terrain • Terrain constructible 8340 Hinwil * Plus de 1 070 m² * Options de subdivision flexibles * Idéal pour maisons familiales ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’070’000.- CHF 1’000 / m²](https://realadvisor.ch/fr/acheter/terrain/8340-hinwil-LDX9-L6M2) + +[](https://realadvisor.ch/fr/acheter/terrain/8633-wolfhausen-YB6N-VRVP) + +il y a 7 jours + +- [x] + +[PREMIUM HOMES AG 1’940 m² Terrain • Terrain constructible 8633 Wolfhausen * Terrain généreux de 1'940m² * Emplacement familial * Options de conception flexibles ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 4’074’000.- CHF 2’100 / m²](https://realadvisor.ch/fr/acheter/terrain/8633-wolfhausen-YB6N-VRVP) + +[](https://realadvisor.ch/fr/acheter/terrain/sonnhalde-8602-wangen-b.-dubendorf-83JW-X5X3) + +il y a 9 jours + +- [x] + +[Moser Anlageimmobilien AG 1’666 m² Terrain • Terrain constructible Sonnhalde, 8602 Wangen b. Dübendorf * 1666 m² de terrain privilégié * Exposition optimale au soleil * Intimité dans un quartier calme ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3’300’000.- CHF 1’981 / m²](https://realadvisor.ch/fr/acheter/terrain/sonnhalde-8602-wangen-b.-dubendorf-83JW-X5X3) + +[](https://realadvisor.ch/fr/acheter/terrain/8000-zurich-NAG4-JV4R) + +il y a 11 jours + +- [x] + +[Centrum Immo Terrain constructible 8000 Zürich * Idéal pour le développement * Proche des transports publics * Vues pittoresques sur la ville ------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Sur demande —](https://realadvisor.ch/fr/acheter/terrain/8000-zurich-NAG4-JV4R) + +[](https://realadvisor.ch/fr/acheter/terrain/8195-wasterkingen-7JPL-7X5M) + +il y a 13 jours + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 650 m² Terrain • Terrain constructible 8195 Wasterkingen * Terrain entièrement viabilisé * Communauté rurale calme * Options de conception flexibles ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 475’000.- CHF 731 / m²](https://realadvisor.ch/fr/acheter/terrain/8195-wasterkingen-7JPL-7X5M) + +[](https://realadvisor.ch/fr/acheter/terrain/8618-oetwil-am-see-8OOG-PWB5) + +il y a 21 jours + +- [x] + +[Swiss Residence Group AG 1’622 m² Terrain • Terrain constructible 8618 Oetwil am See * Terrain ensoleillé de 1'622 m² * Zonage flexible pour projets * Vue imprenable sur les montagnes ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Sur demande —](https://realadvisor.ch/fr/acheter/terrain/8618-oetwil-am-see-8OOG-PWB5) + +[](https://realadvisor.ch/fr/acheter/terrain/8617-monchaltorf-KRNG-WO9R) + +il y a 22 jours + +- [x] + +[PREMIUM HOMES AG 850 m² Terrain • Terrain constructible 8617 Mönchaltorf * Fort potentiel de développement * Emplacement calme et ensoleillé * Options d'utilisation flexibles --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Sur demande —](https://realadvisor.ch/fr/acheter/terrain/8617-monchaltorf-KRNG-WO9R) + +[](https://realadvisor.ch/fr/acheter/terrain/gueterstalstrasse-8133-esslingen-YMXG-R3MR) + +il y a 26 jours + +- [x] + +[Schiblis Immobilien GmbH 507 m² Terrain • Terrain constructible Güeterstalstrasse, 8133 Esslingen * Emplacement central à Esslingen * Pas d'obligation architecturale * Aucune contamination présente -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 600’000.- CHF 1’183 / m²](https://realadvisor.ch/fr/acheter/terrain/gueterstalstrasse-8133-esslingen-YMXG-R3MR) + +[](https://realadvisor.ch/fr/acheter/terrain/8192-zweidlen-6ZMD-4WE3) + +il y a 28 jours + +- [x] + +[Grundeigentümer Verband Schweiz 1’226 m² Terrain • Terrain constructible 8192 Zweidlen * Superficie totale de 1'226 m² * Surface utile max. 940 m² * Options de développement flexibles ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 2’450’000.- CHF 1’998 / m²](https://realadvisor.ch/fr/acheter/terrain/8192-zweidlen-6ZMD-4WE3) + +[](https://realadvisor.ch/fr/acheter/terrain/8424-embrach-8WRG-NEGR) + +il y a 29 jours + +- [x] + +[PREMIUM HOMES AG 1’670 m² Terrain • Terrain constructible 8424 Embrach * Emplacement familial * Lumière abondante toute la journée * Options de construction flexibles ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Sur demande —](https://realadvisor.ch/fr/acheter/terrain/8424-embrach-8WRG-NEGR) + +[](https://realadvisor.ch/fr/acheter/terrain/10-berghalde-8332-russikon-6ZMD-432O) + +il y a 29 jours + +- [x] + +[SH Immo GmbH 854 m² Terrain • Terrain constructible Berghalde 10, 8332 Russikon * Terrain spacieux de 854 m2 * Emplacement ensoleillé idéal * Potentiel pour nouvelle construction ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’500’000.- CHF 1’756 / m²](https://realadvisor.ch/fr/acheter/terrain/10-berghalde-8332-russikon-6ZMD-432O) + +[](https://realadvisor.ch/fr/acheter/terrain/8134-adliswil-Y7J5-W36M) + +il y a 1 mois + +- [x] + +[Moos & Partner Immobilien GmbH 694 m² Terrain • Terrain constructible 8134 Adliswil * Emplacement central avec potentiel * Zone W3 à haute utilisation * Idéal pour investisseurs & développeurs --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3’600’000.- CHF 5’187 / m²](https://realadvisor.ch/fr/acheter/terrain/8134-adliswil-Y7J5-W36M) + +[](https://realadvisor.ch/fr/acheter/terrain/23-uberlandstrasse-8340-hinwil-YB69-VB7M) + +il y a 2 mois + +- [x] + +[RE/MAX Immobilien in Rapperswil-Jona 4’246 m² Terrain • Terrain constructible Überlandstrasse 23, 8340 Hinwil * Emplacement privilégié près des routes * Grande surface à développer * Options de hauteur de bâtiment flexibles ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Sur demande —](https://realadvisor.ch/fr/acheter/terrain/23-uberlandstrasse-8340-hinwil-YB69-VB7M) + +[](https://realadvisor.ch/fr/acheter/terrain/20-winzerstrasse-8353-elgg-KRNL-ZPNR) + +il y a 2 mois + +- [x] + +[RE/MAX Immobilien in Winterthur 877 m² Terrain • Terrain constructible Winzerstrasse 20, 8353 Elgg * Idéal pour maisons familiales * Opportunité d'investissement * Adjacent à une maison existante ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 1’140’000.- CHF 1’300 / m²](https://realadvisor.ch/fr/acheter/terrain/20-winzerstrasse-8353-elgg-KRNL-ZPNR) + +[](https://realadvisor.ch/fr/acheter/terrain/34-industriestrasse-8117-fallanden-YJDX-JXRR) + +il y a 3 mois + +- [x] + +[RE/MAX Immobilien in Meilen 2’838 m² • 1’706 m² Terrain • Terrain constructible Industriestrasse 34, 8117 Fällanden * Projet commercial approuvé * Utilisation commerciale flexible * 37 places de parking disponibles ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Sur demande —](https://realadvisor.ch/fr/acheter/terrain/34-industriestrasse-8117-fallanden-YJDX-JXRR) + +[](https://realadvisor.ch/fr/acheter/terrain/8630-ruti-zh-84E9-Z65G) + +il y a 4 mois + +- [x] + +[PREMIUM HOMES AG 3’460 m² Terrain • Terrain constructible 8630 Rüti ZH * Zone résidentielle calme * Taux d'utilisation de 30% * Bonus pour espace supplémentaire ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Sur demande —](https://realadvisor.ch/fr/acheter/terrain/8630-ruti-zh-84E9-Z65G) + +[](https://realadvisor.ch/fr/acheter/terrain/13-staldernstrasse-8158-regensberg-YJDX-XWMO) + +il y a 16 jours + +- [x] + +[Swisslife 2’557 m² Terrain • Terrain constructible Staldernstrasse 13, 8158 Regensberg * Zonage flexible pour usage mixte * Fort potentiel de rendement locatif * Emplacement calme près de Zurich ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 5’500’000.- CHF 2’151 / m² dreamo.ch](https://realadvisor.ch/fr/acheter/terrain/13-staldernstrasse-8158-regensberg-YJDX-XWMO) + +[](https://realadvisor.ch/fr/acheter/terrain/leisibuel-8484-weisslingen-8OO2-753X) + +il y a 2 mois + +- [x] + +[Orgnet Immobilien AG 844 m² Terrain • Terrain constructible Leisibüel, 8484 Weisslingen * Vue imprenable sur les montagnes * Orientation sud-ouest ensoleillée * Quartier calme et privé ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’300’000.- CHF 1’540 / m² dreamo.ch](https://realadvisor.ch/fr/acheter/terrain/leisibuel-8484-weisslingen-8OO2-753X) + +[](https://realadvisor.ch/fr/acheter/terrain/85-weiacherstrasse-8427-rorbas-YJD9-MVWW) + +il y a 3 mois + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 2’295 m² Terrain • Terrain constructible Weiacherstrasse 85, 8427 Rorbas * Terrain spacieux de 2'295 m2 * Bâtiment à usage mixte * Baux existants --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3’440’000.- CHF 1’499 / m² dreamo.ch](https://realadvisor.ch/fr/acheter/terrain/85-weiacherstrasse-8427-rorbas-YJD9-MVWW) + +[](https://realadvisor.ch/fr/acheter/terrain/7a-bergstrasse-8155-nassenwil-YB69-GEB6) + +il y a 3 mois + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 1’742 m² Terrain • Terrain constructible Bergstrasse 7a, 8155 Nassenwil * Grande superficie de terrain * Emplacement paisible * Proche de Dielsdorf ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2’700’000.- CHF 1’550 / m² dreamo.ch](https://realadvisor.ch/fr/acheter/terrain/7a-bergstrasse-8155-nassenwil-YB69-GEB6) + +[](https://realadvisor.ch/fr/acheter/terrain/gotze-8197-rafz-Y6ZW-VB6G) + +il y a 3 mois + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 1’340 m² • 1’340 m² Terrain • Terrain constructible Götze, 8197 Rafz * Vues dégagées * Idéal pour développement * Emplacement privilégié ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 2’200’000.- CHF 1’642 / m² dreamo.ch](https://realadvisor.ch/fr/acheter/terrain/gotze-8197-rafz-Y6ZW-VB6G) + +[](https://realadvisor.ch/fr/acheter/terrain/226b-schaffhauserstrasse-8057-zurich-KRNL-A6J7) + +il y a 3 mois + +- [x] + +[VZ VermögensZentrum 4.5 pces • 114 m² • 480 m² Terrain • Terrain constructible Schaffhauserstrasse 226b, 8057 Zürich * Grand espace extérieur * Vue sur la verdure * Poêle suédois chaleureux ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 2’999’000.- CHF 26’307 / m² dreamo.ch](https://realadvisor.ch/fr/acheter/terrain/226b-schaffhauserstrasse-8057-zurich-KRNL-A6J7) + +[](https://realadvisor.ch/fr/acheter/canton-zurich/terrain#) + +il y a 7 heures + +- [x] + +[— 829 m² Terrain • Terrain constructible Haldenstrasse 10, 8134 Adliswil * Emplacement calme avec vue * Proche des transports publics * Disponibilité immédiate ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 3’300’000.- CHF 3’981 / m² homegate.ch](https://realadvisor.ch/fr/acheter/canton-zurich/terrain#) + +[1](https://realadvisor.ch/fr/acheter/canton-zurich/terrain) + +[2](https://realadvisor.ch/fr/acheter/canton-zurich/terrain/page-2) + +[3](https://realadvisor.ch/fr/acheter/canton-zurich/terrain/page-3) + +[4](https://realadvisor.ch/fr/acheter/canton-zurich/terrain/page-4) + +[](https://realadvisor.ch/fr/acheter/canton-zurich/terrain/page-2) + +1 - 24 de 75 Résultats + +Acheter un terrain dans le canton de Zurich +------------------------------------------- + +[Voir les prix de l’immobilier pour Canton de Zurich](https://realadvisor.ch/fr/prix-m2-immobilier/canton-zurich) + +### Terrain à vendre dans le canton de Zurich + +[Terrain à vendre à Zurich](https://realadvisor.ch/fr/acheter/ville-zurich/terrain)[Terrain à vendre à Winterthour](https://realadvisor.ch/fr/acheter/ville-winterthour/terrain)[Terrain à vendre à Uster](https://realadvisor.ch/fr/acheter/ville-uster/terrain)[Terrain à vendre à Dübendorf](https://realadvisor.ch/fr/acheter/ville-dubendorf/terrain)[Terrain à vendre à Dietikon (8953)](https://realadvisor.ch/fr/acheter/8953-dietikon/terrain)[Terrain à vendre à Wädenswil](https://realadvisor.ch/fr/acheter/ville-wadenswil/terrain)[Terrain à vendre à Wetzikon (ZH)](https://realadvisor.ch/fr/acheter/ville-wetzikon-zh/terrain)[Terrain à vendre à Horgen](https://realadvisor.ch/fr/acheter/ville-horgen/terrain)[Terrain à vendre à Opfikon](https://realadvisor.ch/fr/acheter/ville-opfikon/terrain)[Terrain à vendre à Bülach (8180)](https://realadvisor.ch/fr/acheter/8180-bulach/terrain)[Terrain à vendre à Kloten (8302)](https://realadvisor.ch/fr/acheter/8302-kloten/terrain)[Terrain à vendre à Adliswil (8134)](https://realadvisor.ch/fr/acheter/8134-adliswil/terrain)[Terrain à vendre à Schlieren (8952)](https://realadvisor.ch/fr/acheter/8952-schlieren/terrain)[Terrain à vendre à Volketswil](https://realadvisor.ch/fr/acheter/ville-volketswil/terrain)[Terrain à vendre à Regensdorf](https://realadvisor.ch/fr/acheter/ville-regensdorf/terrain)[Terrain à vendre à Thalwil](https://realadvisor.ch/fr/acheter/ville-thalwil/terrain)[Terrain à vendre à Illnau-Effretikon](https://realadvisor.ch/fr/acheter/ville-illnau-effretikon/terrain)[Terrain à vendre à Wallisellen (8304)](https://realadvisor.ch/fr/acheter/8304-wallisellen/terrain)[Terrain à vendre à Stäfa](https://realadvisor.ch/fr/acheter/ville-stafa/terrain)[Terrain à vendre à Küsnacht (ZH)](https://realadvisor.ch/fr/acheter/ville-kusnacht-zh/terrain)[Terrain à vendre à Meilen (8706)](https://realadvisor.ch/fr/acheter/8706-meilen/terrain)[Terrain à vendre à Richterswil](https://realadvisor.ch/fr/acheter/ville-richterswil/terrain)[Terrain à vendre à Zollikon](https://realadvisor.ch/fr/acheter/ville-zollikon/terrain)[Terrain à vendre à Rüti ZH (8630)](https://realadvisor.ch/fr/acheter/8630-ruti-zh/terrain)[Terrain à vendre à Affoltern am Albis](https://realadvisor.ch/fr/acheter/ville-affoltern-am-albis/terrain)[Terrain à vendre à Pfäffikon](https://realadvisor.ch/fr/acheter/ville-pfaffikon/terrain)[Terrain à vendre à Bassersdorf (8303)](https://realadvisor.ch/fr/acheter/8303-bassersdorf/terrain)[Terrain à vendre à Hinwil](https://realadvisor.ch/fr/acheter/ville-hinwil/terrain)[Terrain à vendre à Männedorf (8708)](https://realadvisor.ch/fr/acheter/8708-mannedorf/terrain)[Terrain à vendre à Maur](https://realadvisor.ch/fr/acheter/ville-maur/terrain)[Terrain à vendre à Gossau (ZH)](https://realadvisor.ch/fr/acheter/commune-gossau-zh/terrain)[Terrain à vendre à Wald (ZH)](https://realadvisor.ch/fr/acheter/commune-wald-zh/terrain)[Terrain à vendre à Urdorf (8902)](https://realadvisor.ch/fr/acheter/8902-urdorf/terrain)[Terrain à vendre à Embrach (8424)](https://realadvisor.ch/fr/acheter/8424-embrach/terrain)[Terrain à vendre à Niederhasli](https://realadvisor.ch/fr/acheter/commune-niederhasli/terrain)[Terrain à vendre à Hombrechtikon](https://realadvisor.ch/fr/acheter/commune-hombrechtikon/terrain)[Terrain à vendre à Fällanden](https://realadvisor.ch/fr/acheter/commune-fallanden/terrain)[Terrain à vendre à Kilchberg ZH (8802)](https://realadvisor.ch/fr/acheter/8802-kilchberg-zh/terrain)[Terrain à vendre à Egg](https://realadvisor.ch/fr/acheter/commune-egg/terrain)[Terrain à vendre à Rümlang (8153)](https://realadvisor.ch/fr/acheter/8153-rumlang/terrain)[Terrain à vendre à Wangen-Brüttisellen](https://realadvisor.ch/fr/acheter/commune-wangen-bruttisellen/terrain)[Terrain à vendre à Dietlikon (8305)](https://realadvisor.ch/fr/acheter/8305-dietlikon/terrain)[Terrain à vendre à Dürnten](https://realadvisor.ch/fr/acheter/commune-durnten/terrain)[Terrain à vendre à Langnau am Albis (8135)](https://realadvisor.ch/fr/acheter/8135-langnau-am-albis/terrain)[Terrain à vendre à Seuzach (8472)](https://realadvisor.ch/fr/acheter/8472-seuzach/terrain)[Terrain à vendre à Bubikon](https://realadvisor.ch/fr/acheter/commune-bubikon/terrain)[Terrain à vendre à Oberglatt ZH (8154)](https://realadvisor.ch/fr/acheter/8154-oberglatt-zh/terrain)[Terrain à vendre à Oberengstringen (8102)](https://realadvisor.ch/fr/acheter/8102-oberengstringen/terrain)[Terrain à vendre à Fehraltorf (8320)](https://realadvisor.ch/fr/acheter/8320-fehraltorf/terrain)[Terrain à vendre à Birmensdorf ZH (8903)](https://realadvisor.ch/fr/acheter/8903-birmensdorf-zh/terrain)[Terrain à vendre à Wiesendangen](https://realadvisor.ch/fr/acheter/commune-wiesendangen/terrain)[Terrain à vendre à Buchs ZH (8107)](https://realadvisor.ch/fr/acheter/8107-buchs-zh/terrain)[Terrain à vendre à Herrliberg (8704)](https://realadvisor.ch/fr/acheter/8704-herrliberg/terrain)[Terrain à vendre à Uetikon am See (8707)](https://realadvisor.ch/fr/acheter/8707-uetikon-am-see/terrain)[Terrain à vendre à Dielsdorf (8157)](https://realadvisor.ch/fr/acheter/8157-dielsdorf/terrain)[Terrain à vendre à Zell (ZH)](https://realadvisor.ch/fr/acheter/commune-zell-zh/terrain)[Terrain à vendre à Rüschlikon (8803)](https://realadvisor.ch/fr/acheter/8803-ruschlikon/terrain)[Terrain à vendre à Lindau](https://realadvisor.ch/fr/acheter/commune-lindau/terrain)[Terrain à vendre à Nürensdorf (8309)](https://realadvisor.ch/fr/acheter/8309-nurensdorf/terrain)[Terrain à vendre à Erlenbach ZH (8703)](https://realadvisor.ch/fr/acheter/8703-erlenbach-zh/terrain)[Terrain à vendre à Neftenbach](https://realadvisor.ch/fr/acheter/commune-neftenbach/terrain)[Terrain à vendre à Bonstetten (8906)](https://realadvisor.ch/fr/acheter/8906-bonstetten/terrain)[Terrain à vendre à Obfelden (8912)](https://realadvisor.ch/fr/acheter/8912-obfelden/terrain)[Terrain à vendre à Greifensee (8606)](https://realadvisor.ch/fr/acheter/8606-greifensee/terrain)[Terrain à vendre à Glattfelden](https://realadvisor.ch/fr/acheter/commune-glattfelden/terrain)[Terrain à vendre à Eglisau (8193)](https://realadvisor.ch/fr/acheter/8193-eglisau/terrain)[Terrain à vendre à Zumikon (8126)](https://realadvisor.ch/fr/acheter/8126-zumikon/terrain)[Terrain à vendre à Wettswil (8907)](https://realadvisor.ch/fr/acheter/8907-wettswil/terrain)[Terrain à vendre à Schwerzenbach (8603)](https://realadvisor.ch/fr/acheter/8603-schwerzenbach/terrain)[Terrain à vendre à Oberrieden (8942)](https://realadvisor.ch/fr/acheter/8942-oberrieden/terrain)[Terrain à vendre à Bäretswil](https://realadvisor.ch/fr/acheter/commune-baretswil/terrain)[Terrain à vendre à Niederglatt ZH (8172)](https://realadvisor.ch/fr/acheter/8172-niederglatt-zh/terrain)[Terrain à vendre à Geroldswil](https://realadvisor.ch/fr/acheter/commune-geroldswil/terrain)[Terrain à vendre à Bauma](https://realadvisor.ch/fr/acheter/commune-bauma/terrain)[Terrain à vendre à Elgg](https://realadvisor.ch/fr/acheter/commune-elgg/terrain)[Terrain à vendre à Mettmenstetten (8932)](https://realadvisor.ch/fr/acheter/8932-mettmenstetten/terrain)[Terrain à vendre à Weiningen ZH (8104)](https://realadvisor.ch/fr/acheter/8104-weiningen-zh/terrain)[Terrain à vendre à Oetwil am See (8618)](https://realadvisor.ch/fr/acheter/8618-oetwil-am-see/terrain)[Terrain à vendre à Turbenthal](https://realadvisor.ch/fr/acheter/commune-turbenthal/terrain)[Terrain à vendre à Winkel (8185)](https://realadvisor.ch/fr/acheter/8185-winkel/terrain)[Terrain à vendre à Rafz (8197)](https://realadvisor.ch/fr/acheter/8197-rafz/terrain)[Terrain à vendre à Russikon](https://realadvisor.ch/fr/acheter/commune-russikon/terrain)[Terrain à vendre à Uitikon Waldegg (8142)](https://realadvisor.ch/fr/acheter/8142-uitikon-waldegg/terrain)[Terrain à vendre à Dällikon (8108)](https://realadvisor.ch/fr/acheter/8108-dallikon/terrain)[Terrain à vendre à Bachenbülach (8184)](https://realadvisor.ch/fr/acheter/8184-bachenbulach/terrain)[Terrain à vendre à Pfungen (8422)](https://realadvisor.ch/fr/acheter/8422-pfungen/terrain)[Terrain à vendre à Unterengstringen (8103)](https://realadvisor.ch/fr/acheter/8103-unterengstringen/terrain)[Terrain à vendre à Mönchaltorf (8617)](https://realadvisor.ch/fr/acheter/8617-monchaltorf/terrain)[Terrain à vendre à Stallikon](https://realadvisor.ch/fr/acheter/commune-stallikon/terrain)[Terrain à vendre à Hedingen (8908)](https://realadvisor.ch/fr/acheter/8908-hedingen/terrain)[Terrain à vendre à Hausen am Albis](https://realadvisor.ch/fr/acheter/commune-hausen-am-albis/terrain)[Terrain à vendre à Feuerthalen](https://realadvisor.ch/fr/acheter/commune-feuerthalen/terrain)[Terrain à vendre à Hittnau (8335)](https://realadvisor.ch/fr/acheter/8335-hittnau/terrain)[Terrain à vendre à Elsau (8352)](https://realadvisor.ch/fr/acheter/8352-elsau/terrain)[Terrain à vendre à Steinmaur](https://realadvisor.ch/fr/acheter/commune-steinmaur/terrain)[Terrain à vendre à Grüningen (8627)](https://realadvisor.ch/fr/acheter/8627-gruningen/terrain)[Terrain à vendre à Weisslingen](https://realadvisor.ch/fr/acheter/commune-weisslingen/terrain)[Terrain à vendre à Hettlingen (8442)](https://realadvisor.ch/fr/acheter/8442-hettlingen/terrain)[Terrain à vendre à Neerach (8173)](https://realadvisor.ch/fr/acheter/8173-neerach/terrain)[Terrain à vendre à Niederweningen (8166)](https://realadvisor.ch/fr/acheter/8166-niederweningen/terrain)[Terrain à vendre à Otelfingen (8112)](https://realadvisor.ch/fr/acheter/8112-otelfingen/terrain)[Terrain à vendre à Rorbas (8427)](https://realadvisor.ch/fr/acheter/8427-rorbas/terrain)[Terrain à vendre à Stammheim](https://realadvisor.ch/fr/acheter/commune-stammheim/terrain)[Terrain à vendre à Höri (8181)](https://realadvisor.ch/fr/acheter/8181-hori/terrain)[Terrain à vendre à Rickenbach (ZH)](https://realadvisor.ch/fr/acheter/commune-rickenbach-zh/terrain)[Terrain à vendre à Ottenbach (8913)](https://realadvisor.ch/fr/acheter/8913-ottenbach/terrain)[Terrain à vendre à Fischenthal](https://realadvisor.ch/fr/acheter/commune-fischenthal/terrain)[Terrain à vendre à Oetwil an der Limmat (8955)](https://realadvisor.ch/fr/acheter/8955-oetwil-an-der-limmat/terrain)[Terrain à vendre à Lufingen (8426)](https://realadvisor.ch/fr/acheter/8426-lufingen/terrain)[Terrain à vendre à Freienstein-Teufen](https://realadvisor.ch/fr/acheter/commune-freienstein-teufen/terrain)[Terrain à vendre à Knonau (8934)](https://realadvisor.ch/fr/acheter/8934-knonau/terrain)[Terrain à vendre à Stadel](https://realadvisor.ch/fr/acheter/commune-stadel/terrain)[Terrain à vendre à Henggart (8444)](https://realadvisor.ch/fr/acheter/8444-henggart/terrain)[Terrain à vendre à Andelfingen (8450)](https://realadvisor.ch/fr/acheter/8450-andelfingen/terrain)[Terrain à vendre à Kleinandelfingen](https://realadvisor.ch/fr/acheter/commune-kleinandelfingen/terrain)[Terrain à vendre à Brütten (8311)](https://realadvisor.ch/fr/acheter/8311-brutten/terrain)[Terrain à vendre à Wila (8492)](https://realadvisor.ch/fr/acheter/8492-wila/terrain)[Terrain à vendre à Marthalen](https://realadvisor.ch/fr/acheter/commune-marthalen/terrain)[Terrain à vendre à Aeugst am Albis](https://realadvisor.ch/fr/acheter/commune-aeugst-am-albis/terrain)[Terrain à vendre à Dachsen (8447)](https://realadvisor.ch/fr/acheter/8447-dachsen/terrain)[Terrain à vendre à Hochfelden (8182)](https://realadvisor.ch/fr/acheter/8182-hochfelden/terrain)[Terrain à vendre à Dänikon ZH (8114)](https://realadvisor.ch/fr/acheter/8114-danikon-zh/terrain)[Terrain à vendre à Oberweningen (8165)](https://realadvisor.ch/fr/acheter/8165-oberweningen/terrain)[Terrain à vendre à Weiach (8187)](https://realadvisor.ch/fr/acheter/8187-weiach/terrain)[Terrain à vendre à Laufen-Uhwiesen](https://realadvisor.ch/fr/acheter/commune-laufen-uhwiesen/terrain)[Terrain à vendre à Ossingen (8475)](https://realadvisor.ch/fr/acheter/8475-ossingen/terrain)[Terrain à vendre à Dinhard (8474)](https://realadvisor.ch/fr/acheter/8474-dinhard/terrain)[Terrain à vendre à Seegräben](https://realadvisor.ch/fr/acheter/commune-seegraben/terrain)[Terrain à vendre à Flurlingen (8247)](https://realadvisor.ch/fr/acheter/8247-flurlingen/terrain)[Terrain à vendre à Wil ZH (8196)](https://realadvisor.ch/fr/acheter/8196-wil-zh/terrain)[Terrain à vendre à Schöfflisdorf (8165)](https://realadvisor.ch/fr/acheter/8165-schofflisdorf/terrain)[Terrain à vendre à Flaach (8416)](https://realadvisor.ch/fr/acheter/8416-flaach/terrain)[Terrain à vendre à Boppelsen (8113)](https://realadvisor.ch/fr/acheter/8113-boppelsen/terrain)[Terrain à vendre à Aesch ZH (8904)](https://realadvisor.ch/fr/acheter/8904-aesch-zh/terrain)[Terrain à vendre à Rheinau (8462)](https://realadvisor.ch/fr/acheter/8462-rheinau/terrain)[Terrain à vendre à Kappel am Albis](https://realadvisor.ch/fr/acheter/commune-kappel-am-albis/terrain)[Terrain à vendre à Hagenbuch ZH (8523)](https://realadvisor.ch/fr/acheter/8523-hagenbuch-zh/terrain)[Terrain à vendre à Rifferswil (8911)](https://realadvisor.ch/fr/acheter/8911-rifferswil/terrain)[Terrain à vendre à Trüllikon](https://realadvisor.ch/fr/acheter/commune-trullikon/terrain)[Terrain à vendre à Oberembrach (8425)](https://realadvisor.ch/fr/acheter/8425-oberembrach/terrain)[Terrain à vendre à Hüntwangen (8194)](https://realadvisor.ch/fr/acheter/8194-huntwangen/terrain)[Terrain à vendre à Dägerlen](https://realadvisor.ch/fr/acheter/commune-dagerlen/terrain)[Terrain à vendre à Wildberg](https://realadvisor.ch/fr/acheter/commune-wildberg/terrain)[Terrain à vendre à Buch am Irchel (8414)](https://realadvisor.ch/fr/acheter/8414-buch-am-irchel/terrain)[Terrain à vendre à Hüttikon (8115)](https://realadvisor.ch/fr/acheter/8115-huttikon/terrain)[Terrain à vendre à Thalheim an der Thur (8478)](https://realadvisor.ch/fr/acheter/8478-thalheim-an-der-thur/terrain)[Terrain à vendre à Ellikon an der Thur (8548)](https://realadvisor.ch/fr/acheter/8548-ellikon-an-der-thur/terrain)[Terrain à vendre à Benken ZH (8463)](https://realadvisor.ch/fr/acheter/8463-benken-zh/terrain)[Terrain à vendre à Dättlikon (8421)](https://realadvisor.ch/fr/acheter/8421-dattlikon/terrain)[Terrain à vendre à Schleinikon (8165)](https://realadvisor.ch/fr/acheter/8165-schleinikon/terrain)[Terrain à vendre à Schlatt ZH (8418)](https://realadvisor.ch/fr/acheter/8418-schlatt-zh/terrain)[Terrain à vendre à Dorf (8458)](https://realadvisor.ch/fr/acheter/8458-dorf/terrain)[Terrain à vendre à Altikon (8479)](https://realadvisor.ch/fr/acheter/8479-altikon/terrain)[Terrain à vendre à Adlikon b. Andelfingen (8452)](https://realadvisor.ch/fr/acheter/8452-adlikon-b-andelfingen/terrain)[Terrain à vendre à Maschwanden (8933)](https://realadvisor.ch/fr/acheter/8933-maschwanden/terrain)[Terrain à vendre à Bachs (8164)](https://realadvisor.ch/fr/acheter/8164-bachs/terrain)[Terrain à vendre à Wasterkingen (8195)](https://realadvisor.ch/fr/acheter/8195-wasterkingen/terrain)[Terrain à vendre à Berg am Irchel](https://realadvisor.ch/fr/acheter/commune-berg-am-irchel/terrain)[Terrain à vendre à Humlikon (8457)](https://realadvisor.ch/fr/acheter/8457-humlikon/terrain)[Terrain à vendre à Truttikon (8467)](https://realadvisor.ch/fr/acheter/8467-truttikon/terrain)[Terrain à vendre à Regensberg (8158)](https://realadvisor.ch/fr/acheter/8158-regensberg/terrain)[Terrain à vendre à Volken (8459)](https://realadvisor.ch/fr/acheter/8459-volken/terrain) + +Voir plus + +### Autres types de bien dans le canton de Zurich + +[Maison à vendre dans le canton de Zurich](https://realadvisor.ch/fr/acheter/canton-zurich/maison)[Appartement à vendre dans le canton de Zurich](https://realadvisor.ch/fr/acheter/canton-zurich/appartement)[Immeuble à vendre dans le canton de Zurich](https://realadvisor.ch/fr/acheter/canton-zurich/immeuble)[Local commercial à vendre dans le canton de Zurich](https://realadvisor.ch/fr/acheter/canton-zurich/commercial)[Hôtel, Restaurant à vendre dans le canton de Zurich](https://realadvisor.ch/fr/acheter/canton-zurich/hotellerie) + +### Recherches populaires dans le canton de Zurich + +[Studios à vendre dans le Canton de Zürich](https://realadvisor.ch/fr/recherches-populaires/studio-a-vendre-canton-zurich) + +[](https://fr.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + +Vendre + +[Estimation immobilière en ligne](https://realadvisor.ch/fr/estimation-bien-immobilier)[Estimation immeuble de rendement](https://realadvisor.ch/fr/estimation-immeuble-de-rendement-gratuite)[Prix Immobilier](https://realadvisor.ch/fr/prix-m2-immobilier)[Agences immobilières](https://realadvisor.ch/fr/trouver-une-agence)[Glossaire Immobilier](https://realadvisor.ch/fr/glossaire-immobilier)[Blog Immobilier](https://realadvisor.ch/fr/blog) + +Acheter / Louer + +[Biens immobiliers à vendre](https://realadvisor.ch/fr/immobilier-a-vendre)[Biens immobiliers à louer](https://realadvisor.ch/fr/immobilier-a-louer)[Promotions immobilières](https://realadvisor.ch/fr/promotions)[Financement Immobilier](https://realadvisor-finance.ch/) + +Professionnels + +[Devenir Partenaire](https://realadvisor.ch/fr/pro)[Blog Pro](https://realadvisor.ch/fr/pro/blog) + +À propos + +[À propos de nous](https://realadvisor.ch/fr/a-propos)[Espace presse](https://realadvisor.ch/fr/espace-presse)[Jobs](https://realadvisor.welcomekit.co/)[Conditions générales](https://realadvisor.ch/fr/conditions-generales)[Politique de confidentialité](https://realadvisor.ch/fr/politique-de-confidentialite)[Mentions légales](https://realadvisor.ch/fr/mentions-legales)[Tout l'immobilier](https://realadvisor.ch/fr/sitemap) + +© RealAdvisor 2025. All Rights Reserved. v.e89072f + +[](https://ch.linkedin.com/company/realadvisor)[](https://www.facebook.com/realadvisorcom)[](https://twitter.com/realadvisor)[](https://www.instagram.com/realadvisorcom)[](https://www.youtube.com/channel/UCsEDTDlmxBpyxLXYhWT769Q) + +Carte + +BESbswy + + + + +=== https://realadvisor.ch/en/buy/canton-zurich/plot === +75 Plots For Sale in Canton of Zurich - October 2025 + +=============== + +[](https://realadvisor.ch/en/property-for-sale) + ++1 more + +Canton of Zurich + + + +Valuation + +[Buy](https://realadvisor.ch/en/property-for-sale)[Rent](https://realadvisor.ch/en/property-for-rent) + +Login + +EN + +[Italiano](https://realadvisor.ch/it/comprare/canton-zurigo/trama)[Français](https://realadvisor.ch/fr/acheter/canton-zurich/terrain)[Deutsch](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck) + +Create an alert + ++1 more + +Canton of Zurich + + + +Buy Rent + +Buy Rent + +Plot + +Price + +Modify search + +Land surface + +Other Filters + +Create an alert + +- [x] Show map + +←Move left +→Move right +↑Move up +↓Move down ++Zoom in +-Zoom out +Home Jump left by 75% +End Jump right by 75% +Page Up Jump up by 75% +Page Down Jump down by 75% + + + + + + + + + + + + + + + + + + + + + + + + + +9 + +9 + +5 + +5 + +3 + +3 + +6 + +6 + +17 + +17 + +7 + +7 + +4 + +4 + +2 + +2 + +2 + +2 + +14 + +14 + +5 + +5 + +1 + +1 + + + +Map +* Map +* Satellite +* Terrain +* Labels + + + + + +*  +*  +*  +*  +*  +*  + +[](https://maps.google.com/maps?ll=47.421441,8.671322&z=9&t=m&hl=en-US&gl=US&mapclient=apiv3 "Open this area in Google Maps (opens a new window)") + +Keyboard shortcuts + +Map Data Map data ©2025 GeoBasis-DE/BKG (©2009), Google + +Map data ©2025 GeoBasis-DE/BKG (©2009), Google + +10 km + +Click to toggle between metric and imperial units + +[Terms](https://www.google.com/intl/en-US_US/help/terms_maps.html) + +[Report a map error](https://www.google.com/maps/@47.421441,8.6713222,9z/data=!10m1!1e1!12b1?source=apiv3&rapsrc=apiv3 "Report errors in the road map or imagery to Google") + +1. [](https://realadvisor.ch/en) + +3. [Buy](https://realadvisor.ch/en/buy) + +5. [Plot](https://realadvisor.ch/en/buy/plot) + +7. Canton of Zurich + +Plots For Sale in Canton of Zurich +================================== + +75 Results + +Our recommendations + +[](https://realadvisor.ch/en/buy/plot/8162-steinmaur-B62R-PZDJ) + +3 days ago + +- [x] + +[get living 1,452 m² Plot • Constructible plot 8162 Steinmaur * Flat, buildable land * Quiet, sunny location * Excellent public transport access -------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * On request —](https://realadvisor.ch/en/buy/plot/8162-steinmaur-B62R-PZDJ) + +[](https://realadvisor.ch/en/buy/plot/8340-hinwil-LDX9-L6M2) + +6 days ago + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 1,070 m² Plot • Constructible plot 8340 Hinwil * Over 1,070 m² area * Flexible subdivision options * Ideal for family homes ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1,070,000.- CHF 1,000 / m²](https://realadvisor.ch/en/buy/plot/8340-hinwil-LDX9-L6M2) + +[](https://realadvisor.ch/en/buy/plot/8633-wolfhausen-YB6N-VRVP) + +7 days ago + +- [x] + +[PREMIUM HOMES AG 1,940 m² Plot • Constructible plot 8633 Wolfhausen * Generous 1,940m² plot * Family-friendly location * Flexible design options --------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 4,074,000.- CHF 2,100 / m²](https://realadvisor.ch/en/buy/plot/8633-wolfhausen-YB6N-VRVP) + +[](https://realadvisor.ch/en/buy/plot/sonnhalde-8602-wangen-b.-dubendorf-83JW-X5X3) + +9 days ago + +- [x] + +[Moser Anlageimmobilien AG 1,666 m² Plot • Constructible plot Sonnhalde, 8602 Wangen b. Dübendorf * 1666 m² of prime land * Optimal sun exposure * Privacy in a quiet area ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3,300,000.- CHF 1,981 / m²](https://realadvisor.ch/en/buy/plot/sonnhalde-8602-wangen-b.-dubendorf-83JW-X5X3) + +[](https://realadvisor.ch/en/buy/plot/8000-zurich-NAG4-JV4R) + +11 days ago + +- [x] + +[Centrum Immo Constructible plot 8000 Zürich * Ideal for development * Close to public transport * Scenic views of the city ----------------------------------------------------------------------------------------------------------------------------------------- * * * On request —](https://realadvisor.ch/en/buy/plot/8000-zurich-NAG4-JV4R) + +[](https://realadvisor.ch/en/buy/plot/8195-wasterkingen-7JPL-7X5M) + +13 days ago + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 650 m² Plot • Constructible plot 8195 Wasterkingen * Fully serviced land * Quiet rural community * Flexible design options --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 475,000.- CHF 731 / m²](https://realadvisor.ch/en/buy/plot/8195-wasterkingen-7JPL-7X5M) + +[](https://realadvisor.ch/en/buy/plot/8618-oetwil-am-see-8OOG-PWB5) + +21 days ago + +- [x] + +[Swiss Residence Group AG 1,622 m² Plot • Constructible plot 8618 Oetwil am See * 1'622 m² sunny plot * Flexible zoning for projects * Unobstructed mountain views -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * On request —](https://realadvisor.ch/en/buy/plot/8618-oetwil-am-see-8OOG-PWB5) + +[](https://realadvisor.ch/en/buy/plot/8617-monchaltorf-KRNG-WO9R) + +22 days ago + +- [x] + +[PREMIUM HOMES AG 850 m² Plot • Constructible plot 8617 Mönchaltorf * High development potential * Quiet, sunny location * Flexible usage options --------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * On request —](https://realadvisor.ch/en/buy/plot/8617-monchaltorf-KRNG-WO9R) + +[](https://realadvisor.ch/en/buy/plot/gueterstalstrasse-8133-esslingen-YMXG-R3MR) + +26 days ago + +- [x] + +[Schiblis Immobilien GmbH 507 m² Plot • Constructible plot Güeterstalstrasse, 8133 Esslingen * Central location in Esslingen * No architectural obligation * No contamination issues -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 600,000.- CHF 1,183 / m²](https://realadvisor.ch/en/buy/plot/gueterstalstrasse-8133-esslingen-YMXG-R3MR) + +[](https://realadvisor.ch/en/buy/plot/8192-zweidlen-6ZMD-4WE3) + +28 days ago + +- [x] + +[Grundeigentümer Verband Schweiz 1,226 m² Plot • Constructible plot 8192 Zweidlen * Total area of 1,226 m² * Max. usable area 940 m² * Flexible development options --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2,450,000.- CHF 1,998 / m²](https://realadvisor.ch/en/buy/plot/8192-zweidlen-6ZMD-4WE3) + +[](https://realadvisor.ch/en/buy/plot/8424-embrach-8WRG-NEGR) + +29 days ago + +- [x] + +[PREMIUM HOMES AG 1,670 m² Plot • Constructible plot 8424 Embrach * Family-friendly location * Abundant sunlight all day * Flexible building options ------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * On request —](https://realadvisor.ch/en/buy/plot/8424-embrach-8WRG-NEGR) + +[](https://realadvisor.ch/en/buy/plot/10-berghalde-8332-russikon-6ZMD-432O) + +29 days ago + +- [x] + +[SH Immo GmbH 854 m² Plot • Constructible plot Berghalde 10, 8332 Russikon * Spacious 854 m2 plot * Ideal sunny hillside location * Potential for new construction -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1,500,000.- CHF 1,756 / m²](https://realadvisor.ch/en/buy/plot/10-berghalde-8332-russikon-6ZMD-432O) + +[](https://realadvisor.ch/en/buy/plot/8134-adliswil-Y7J5-W36M) + +1 month ago + +- [x] + +[Moos & Partner Immobilien GmbH 694 m² Plot • Constructible plot 8134 Adliswil * Central location with potential * High utilization zone W3 * Ideal for investors & developers -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3,600,000.- CHF 5,187 / m²](https://realadvisor.ch/en/buy/plot/8134-adliswil-Y7J5-W36M) + +[](https://realadvisor.ch/en/buy/plot/23-uberlandstrasse-8340-hinwil-YB69-VB7M) + +2 months ago + +- [x] + +[RE/MAX Immobilien in Rapperswil-Jona 4,246 m² Plot • Constructible plot Überlandstrasse 23, 8340 Hinwil * Prime location near main roads * Large area for development * Flexible building height options ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * On request —](https://realadvisor.ch/en/buy/plot/23-uberlandstrasse-8340-hinwil-YB69-VB7M) + +[](https://realadvisor.ch/en/buy/plot/20-winzerstrasse-8353-elgg-KRNL-ZPNR) + +2 months ago + +- [x] + +[RE/MAX Immobilien in Winterthur 877 m² Plot • Constructible plot Winzerstrasse 20, 8353 Elgg * Ideal for family homes * Investment opportunity * Adjacent to existing house ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 1,140,000.- CHF 1,300 / m²](https://realadvisor.ch/en/buy/plot/20-winzerstrasse-8353-elgg-KRNL-ZPNR) + +[](https://realadvisor.ch/en/buy/plot/34-industriestrasse-8117-fallanden-YJDX-JXRR) + +3 months ago + +- [x] + +[RE/MAX Immobilien in Meilen 2,838 m² • 1,706 m² Plot • Constructible plot Industriestrasse 34, 8117 Fällanden * Approved commercial project * Flexible commercial use * 37 parking spaces available ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * On request —](https://realadvisor.ch/en/buy/plot/34-industriestrasse-8117-fallanden-YJDX-JXRR) + +[](https://realadvisor.ch/en/buy/plot/8630-ruti-zh-84E9-Z65G) + +4 months ago + +- [x] + +[PREMIUM HOMES AG 3,460 m² Plot • Constructible plot 8630 Rüti ZH * Quiet residential area * 30% utilization rate * Bonus for extra space ------------------------------------------------------------------------------------------------------------------------------------------------------- * * * On request —](https://realadvisor.ch/en/buy/plot/8630-ruti-zh-84E9-Z65G) + +[](https://realadvisor.ch/en/buy/plot/13-staldernstrasse-8158-regensberg-YJDX-XWMO) + +16 days ago + +- [x] + +[Swisslife 2,557 m² Plot • Constructible plot Staldernstrasse 13, 8158 Regensberg * Flexible zoning for mixed use * High rental yield potential * Quiet location near Zurich ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 5,500,000.- CHF 2,151 / m² dreamo.ch](https://realadvisor.ch/en/buy/plot/13-staldernstrasse-8158-regensberg-YJDX-XWMO) + +[](https://realadvisor.ch/en/buy/plot/leisibuel-8484-weisslingen-8OO2-753X) + +2 months ago + +- [x] + +[Orgnet Immobilien AG 844 m² Plot • Constructible plot Leisibüel, 8484 Weisslingen * Stunning mountain views * Sunny southwest orientation * Quiet, private neighborhood -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1,300,000.- CHF 1,540 / m² dreamo.ch](https://realadvisor.ch/en/buy/plot/leisibuel-8484-weisslingen-8OO2-753X) + +[](https://realadvisor.ch/en/buy/plot/85-weiacherstrasse-8427-rorbas-YJD9-MVWW) + +3 months ago + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 2,295 m² Plot • Constructible plot Weiacherstrasse 85, 8427 Rorbas * Spacious 2,295 m2 plot * Mixed-use building available * Existing rental agreements --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3,440,000.- CHF 1,499 / m² dreamo.ch](https://realadvisor.ch/en/buy/plot/85-weiacherstrasse-8427-rorbas-YJD9-MVWW) + +[](https://realadvisor.ch/en/buy/plot/7a-bergstrasse-8155-nassenwil-YB69-GEB6) + +3 months ago + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 1,742 m² Plot • Constructible plot Bergstrasse 7a, 8155 Nassenwil * Spacious land area * Quiet scenic location * Close to Dielsdorf ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2,700,000.- CHF 1,550 / m² dreamo.ch](https://realadvisor.ch/en/buy/plot/7a-bergstrasse-8155-nassenwil-YB69-GEB6) + +[](https://realadvisor.ch/en/buy/plot/gotze-8197-rafz-Y6ZW-VB6G) + +3 months ago + +- [x] + +[TREVAG Treuhand und Verwaltungs AG 1,340 m² • 1,340 m² Plot • Constructible plot Götze, 8197 Rafz * Unobstructed views * Ideal for development * Prime location ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 2,200,000.- CHF 1,642 / m² dreamo.ch](https://realadvisor.ch/en/buy/plot/gotze-8197-rafz-Y6ZW-VB6G) + +[](https://realadvisor.ch/en/buy/plot/226b-schaffhauserstrasse-8057-zurich-KRNL-A6J7) + +3 months ago + +- [x] + +[VZ VermögensZentrum 4.5 rooms • 114 m² • 480 m² Plot • Constructible plot Schaffhauserstrasse 226b, 8057 Zürich * Spacious outdoor area * Green views from windows * Cozy Swedish stove ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 2,999,000.- CHF 26,307 / m² dreamo.ch](https://realadvisor.ch/en/buy/plot/226b-schaffhauserstrasse-8057-zurich-KRNL-A6J7) + +[](https://realadvisor.ch/en/buy/canton-zurich/plot#) + +7 hours ago + +- [x] + +[— 829 m² Plot • Constructible plot Haldenstrasse 10, 8134 Adliswil * Quiet location with views * Close to public transport * Immediate availability ------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 3,300,000.- CHF 3,981 / m² homegate.ch](https://realadvisor.ch/en/buy/canton-zurich/plot#) + +[1](https://realadvisor.ch/en/buy/canton-zurich/plot) + +[2](https://realadvisor.ch/en/buy/canton-zurich/plot/page-2) + +[3](https://realadvisor.ch/en/buy/canton-zurich/plot/page-3) + +[4](https://realadvisor.ch/en/buy/canton-zurich/plot/page-4) + +[](https://realadvisor.ch/en/buy/canton-zurich/plot/page-2) + +1-24 of 75 Results + +Buy a plot in Canton of Zurich +------------------------------ + +[View property prices Canton of Zurich](https://realadvisor.ch/en/property-prices/canton-zurich) + +### Plot For Sale in Canton of Zurich + +[Plot For Sale in Zurich](https://realadvisor.ch/en/buy/city-zurich/plot)[Plot For Sale in Winterthur](https://realadvisor.ch/en/buy/city-winterthur/plot)[Plot For Sale in Uster](https://realadvisor.ch/en/buy/city-uster/plot)[Plot For Sale in Dübendorf](https://realadvisor.ch/en/buy/city-dubendorf/plot)[Plot For Sale in Dietikon (8953)](https://realadvisor.ch/en/buy/8953-dietikon/plot)[Plot For Sale in Wädenswil](https://realadvisor.ch/en/buy/city-wadenswil/plot)[Plot For Sale in Wetzikon (ZH)](https://realadvisor.ch/en/buy/city-wetzikon-zh/plot)[Plot For Sale in Horgen](https://realadvisor.ch/en/buy/city-horgen/plot)[Plot For Sale in Opfikon](https://realadvisor.ch/en/buy/city-opfikon/plot)[Plot For Sale in Bülach (8180)](https://realadvisor.ch/en/buy/8180-bulach/plot)[Plot For Sale in Kloten (8302)](https://realadvisor.ch/en/buy/8302-kloten/plot)[Plot For Sale in Adliswil (8134)](https://realadvisor.ch/en/buy/8134-adliswil/plot)[Plot For Sale in Schlieren (8952)](https://realadvisor.ch/en/buy/8952-schlieren/plot)[Plot For Sale in Volketswil](https://realadvisor.ch/en/buy/city-volketswil/plot)[Plot For Sale in Regensdorf](https://realadvisor.ch/en/buy/city-regensdorf/plot)[Plot For Sale in Thalwil](https://realadvisor.ch/en/buy/city-thalwil/plot)[Plot For Sale in Illnau-Effretikon](https://realadvisor.ch/en/buy/city-illnau-effretikon/plot)[Plot For Sale in Wallisellen (8304)](https://realadvisor.ch/en/buy/8304-wallisellen/plot)[Plot For Sale in Stäfa](https://realadvisor.ch/en/buy/city-stafa/plot)[Plot For Sale in Küsnacht (ZH)](https://realadvisor.ch/en/buy/city-kusnacht-zh/plot)[Plot For Sale in Meilen (8706)](https://realadvisor.ch/en/buy/8706-meilen/plot)[Plot For Sale in Richterswil](https://realadvisor.ch/en/buy/city-richterswil/plot)[Plot For Sale in Zollikon](https://realadvisor.ch/en/buy/city-zollikon/plot)[Plot For Sale in Rüti ZH (8630)](https://realadvisor.ch/en/buy/8630-ruti-zh/plot)[Plot For Sale in Affoltern am Albis](https://realadvisor.ch/en/buy/city-affoltern-am-albis/plot)[Plot For Sale in Pfäffikon](https://realadvisor.ch/en/buy/city-pfaffikon/plot)[Plot For Sale in Bassersdorf (8303)](https://realadvisor.ch/en/buy/8303-bassersdorf/plot)[Plot For Sale in Hinwil](https://realadvisor.ch/en/buy/city-hinwil/plot)[Plot For Sale in Männedorf (8708)](https://realadvisor.ch/en/buy/8708-mannedorf/plot)[Plot For Sale in Maur](https://realadvisor.ch/en/buy/city-maur/plot)[Plot For Sale in Gossau (ZH)](https://realadvisor.ch/en/buy/town-gossau-zh/plot)[Plot For Sale in Wald (ZH)](https://realadvisor.ch/en/buy/town-wald-zh/plot)[Plot For Sale in Urdorf (8902)](https://realadvisor.ch/en/buy/8902-urdorf/plot)[Plot For Sale in Embrach (8424)](https://realadvisor.ch/en/buy/8424-embrach/plot)[Plot For Sale in Niederhasli](https://realadvisor.ch/en/buy/town-niederhasli/plot)[Plot For Sale in Hombrechtikon](https://realadvisor.ch/en/buy/town-hombrechtikon/plot)[Plot For Sale in Fällanden](https://realadvisor.ch/en/buy/town-fallanden/plot)[Plot For Sale in Kilchberg ZH (8802)](https://realadvisor.ch/en/buy/8802-kilchberg-zh/plot)[Plot For Sale in Egg](https://realadvisor.ch/en/buy/town-egg/plot)[Plot For Sale in Rümlang (8153)](https://realadvisor.ch/en/buy/8153-rumlang/plot)[Plot For Sale in Wangen-Brüttisellen](https://realadvisor.ch/en/buy/town-wangen-bruttisellen/plot)[Plot For Sale in Dietlikon (8305)](https://realadvisor.ch/en/buy/8305-dietlikon/plot)[Plot For Sale in Dürnten](https://realadvisor.ch/en/buy/town-durnten/plot)[Plot For Sale in Langnau am Albis (8135)](https://realadvisor.ch/en/buy/8135-langnau-am-albis/plot)[Plot For Sale in Seuzach (8472)](https://realadvisor.ch/en/buy/8472-seuzach/plot)[Plot For Sale in Bubikon](https://realadvisor.ch/en/buy/town-bubikon/plot)[Plot For Sale in Oberglatt ZH (8154)](https://realadvisor.ch/en/buy/8154-oberglatt-zh/plot)[Plot For Sale in Oberengstringen (8102)](https://realadvisor.ch/en/buy/8102-oberengstringen/plot)[Plot For Sale in Fehraltorf (8320)](https://realadvisor.ch/en/buy/8320-fehraltorf/plot)[Plot For Sale in Birmensdorf ZH (8903)](https://realadvisor.ch/en/buy/8903-birmensdorf-zh/plot)[Plot For Sale in Wiesendangen](https://realadvisor.ch/en/buy/town-wiesendangen/plot)[Plot For Sale in Buchs ZH (8107)](https://realadvisor.ch/en/buy/8107-buchs-zh/plot)[Plot For Sale in Herrliberg (8704)](https://realadvisor.ch/en/buy/8704-herrliberg/plot)[Plot For Sale in Uetikon am See (8707)](https://realadvisor.ch/en/buy/8707-uetikon-am-see/plot)[Plot For Sale in Dielsdorf (8157)](https://realadvisor.ch/en/buy/8157-dielsdorf/plot)[Plot For Sale in Zell (ZH)](https://realadvisor.ch/en/buy/town-zell-zh/plot)[Plot For Sale in Rüschlikon (8803)](https://realadvisor.ch/en/buy/8803-ruschlikon/plot)[Plot For Sale in Lindau](https://realadvisor.ch/en/buy/town-lindau/plot)[Plot For Sale in Nürensdorf (8309)](https://realadvisor.ch/en/buy/8309-nurensdorf/plot)[Plot For Sale in Erlenbach ZH (8703)](https://realadvisor.ch/en/buy/8703-erlenbach-zh/plot)[Plot For Sale in Neftenbach](https://realadvisor.ch/en/buy/town-neftenbach/plot)[Plot For Sale in Bonstetten (8906)](https://realadvisor.ch/en/buy/8906-bonstetten/plot)[Plot For Sale in Obfelden (8912)](https://realadvisor.ch/en/buy/8912-obfelden/plot)[Plot For Sale in Greifensee (8606)](https://realadvisor.ch/en/buy/8606-greifensee/plot)[Plot For Sale in Glattfelden](https://realadvisor.ch/en/buy/town-glattfelden/plot)[Plot For Sale in Eglisau (8193)](https://realadvisor.ch/en/buy/8193-eglisau/plot)[Plot For Sale in Zumikon (8126)](https://realadvisor.ch/en/buy/8126-zumikon/plot)[Plot For Sale in Wettswil (8907)](https://realadvisor.ch/en/buy/8907-wettswil/plot)[Plot For Sale in Schwerzenbach (8603)](https://realadvisor.ch/en/buy/8603-schwerzenbach/plot)[Plot For Sale in Oberrieden (8942)](https://realadvisor.ch/en/buy/8942-oberrieden/plot)[Plot For Sale in Bäretswil](https://realadvisor.ch/en/buy/town-baretswil/plot)[Plot For Sale in Niederglatt ZH (8172)](https://realadvisor.ch/en/buy/8172-niederglatt-zh/plot)[Plot For Sale in Geroldswil](https://realadvisor.ch/en/buy/town-geroldswil/plot)[Plot For Sale in Bauma](https://realadvisor.ch/en/buy/town-bauma/plot)[Plot For Sale in Elgg](https://realadvisor.ch/en/buy/town-elgg/plot)[Plot For Sale in Mettmenstetten (8932)](https://realadvisor.ch/en/buy/8932-mettmenstetten/plot)[Plot For Sale in Weiningen ZH (8104)](https://realadvisor.ch/en/buy/8104-weiningen-zh/plot)[Plot For Sale in Oetwil am See (8618)](https://realadvisor.ch/en/buy/8618-oetwil-am-see/plot)[Plot For Sale in Turbenthal](https://realadvisor.ch/en/buy/town-turbenthal/plot)[Plot For Sale in Winkel (8185)](https://realadvisor.ch/en/buy/8185-winkel/plot)[Plot For Sale in Rafz (8197)](https://realadvisor.ch/en/buy/8197-rafz/plot)[Plot For Sale in Russikon](https://realadvisor.ch/en/buy/town-russikon/plot)[Plot For Sale in Uitikon Waldegg (8142)](https://realadvisor.ch/en/buy/8142-uitikon-waldegg/plot)[Plot For Sale in Dällikon (8108)](https://realadvisor.ch/en/buy/8108-dallikon/plot)[Plot For Sale in Bachenbülach (8184)](https://realadvisor.ch/en/buy/8184-bachenbulach/plot)[Plot For Sale in Pfungen (8422)](https://realadvisor.ch/en/buy/8422-pfungen/plot)[Plot For Sale in Unterengstringen (8103)](https://realadvisor.ch/en/buy/8103-unterengstringen/plot)[Plot For Sale in Mönchaltorf (8617)](https://realadvisor.ch/en/buy/8617-monchaltorf/plot)[Plot For Sale in Stallikon](https://realadvisor.ch/en/buy/town-stallikon/plot)[Plot For Sale in Hedingen (8908)](https://realadvisor.ch/en/buy/8908-hedingen/plot)[Plot For Sale in Hausen am Albis](https://realadvisor.ch/en/buy/town-hausen-am-albis/plot)[Plot For Sale in Feuerthalen](https://realadvisor.ch/en/buy/town-feuerthalen/plot)[Plot For Sale in Hittnau (8335)](https://realadvisor.ch/en/buy/8335-hittnau/plot)[Plot For Sale in Elsau (8352)](https://realadvisor.ch/en/buy/8352-elsau/plot)[Plot For Sale in Steinmaur](https://realadvisor.ch/en/buy/town-steinmaur/plot)[Plot For Sale in Grüningen (8627)](https://realadvisor.ch/en/buy/8627-gruningen/plot)[Plot For Sale in Weisslingen](https://realadvisor.ch/en/buy/town-weisslingen/plot)[Plot For Sale in Hettlingen (8442)](https://realadvisor.ch/en/buy/8442-hettlingen/plot)[Plot For Sale in Neerach (8173)](https://realadvisor.ch/en/buy/8173-neerach/plot)[Plot For Sale in Niederweningen (8166)](https://realadvisor.ch/en/buy/8166-niederweningen/plot)[Plot For Sale in Otelfingen (8112)](https://realadvisor.ch/en/buy/8112-otelfingen/plot)[Plot For Sale in Rorbas (8427)](https://realadvisor.ch/en/buy/8427-rorbas/plot)[Plot For Sale in Stammheim](https://realadvisor.ch/en/buy/town-stammheim/plot)[Plot For Sale in Höri (8181)](https://realadvisor.ch/en/buy/8181-hori/plot)[Plot For Sale in Rickenbach (ZH)](https://realadvisor.ch/en/buy/town-rickenbach-zh/plot)[Plot For Sale in Ottenbach (8913)](https://realadvisor.ch/en/buy/8913-ottenbach/plot)[Plot For Sale in Fischenthal](https://realadvisor.ch/en/buy/town-fischenthal/plot)[Plot For Sale in Oetwil an der Limmat (8955)](https://realadvisor.ch/en/buy/8955-oetwil-an-der-limmat/plot)[Plot For Sale in Lufingen (8426)](https://realadvisor.ch/en/buy/8426-lufingen/plot)[Plot For Sale in Freienstein-Teufen](https://realadvisor.ch/en/buy/town-freienstein-teufen/plot)[Plot For Sale in Knonau (8934)](https://realadvisor.ch/en/buy/8934-knonau/plot)[Plot For Sale in Stadel](https://realadvisor.ch/en/buy/town-stadel/plot)[Plot For Sale in Henggart (8444)](https://realadvisor.ch/en/buy/8444-henggart/plot)[Plot For Sale in Andelfingen (8450)](https://realadvisor.ch/en/buy/8450-andelfingen/plot)[Plot For Sale in Kleinandelfingen](https://realadvisor.ch/en/buy/town-kleinandelfingen/plot)[Plot For Sale in Brütten (8311)](https://realadvisor.ch/en/buy/8311-brutten/plot)[Plot For Sale in Wila (8492)](https://realadvisor.ch/en/buy/8492-wila/plot)[Plot For Sale in Marthalen](https://realadvisor.ch/en/buy/town-marthalen/plot)[Plot For Sale in Aeugst am Albis](https://realadvisor.ch/en/buy/town-aeugst-am-albis/plot)[Plot For Sale in Dachsen (8447)](https://realadvisor.ch/en/buy/8447-dachsen/plot)[Plot For Sale in Hochfelden (8182)](https://realadvisor.ch/en/buy/8182-hochfelden/plot)[Plot For Sale in Dänikon ZH (8114)](https://realadvisor.ch/en/buy/8114-danikon-zh/plot)[Plot For Sale in Oberweningen (8165)](https://realadvisor.ch/en/buy/8165-oberweningen/plot)[Plot For Sale in Weiach (8187)](https://realadvisor.ch/en/buy/8187-weiach/plot)[Plot For Sale in Laufen-Uhwiesen](https://realadvisor.ch/en/buy/town-laufen-uhwiesen/plot)[Plot For Sale in Ossingen (8475)](https://realadvisor.ch/en/buy/8475-ossingen/plot)[Plot For Sale in Dinhard (8474)](https://realadvisor.ch/en/buy/8474-dinhard/plot)[Plot For Sale in Seegräben](https://realadvisor.ch/en/buy/town-seegraben/plot)[Plot For Sale in Flurlingen (8247)](https://realadvisor.ch/en/buy/8247-flurlingen/plot)[Plot For Sale in Wil ZH (8196)](https://realadvisor.ch/en/buy/8196-wil-zh/plot)[Plot For Sale in Schöfflisdorf (8165)](https://realadvisor.ch/en/buy/8165-schofflisdorf/plot)[Plot For Sale in Flaach (8416)](https://realadvisor.ch/en/buy/8416-flaach/plot)[Plot For Sale in Boppelsen (8113)](https://realadvisor.ch/en/buy/8113-boppelsen/plot)[Plot For Sale in Aesch ZH (8904)](https://realadvisor.ch/en/buy/8904-aesch-zh/plot)[Plot For Sale in Rheinau (8462)](https://realadvisor.ch/en/buy/8462-rheinau/plot)[Plot For Sale in Kappel am Albis](https://realadvisor.ch/en/buy/town-kappel-am-albis/plot)[Plot For Sale in Hagenbuch ZH (8523)](https://realadvisor.ch/en/buy/8523-hagenbuch-zh/plot)[Plot For Sale in Rifferswil (8911)](https://realadvisor.ch/en/buy/8911-rifferswil/plot)[Plot For Sale in Trüllikon](https://realadvisor.ch/en/buy/town-trullikon/plot)[Plot For Sale in Oberembrach (8425)](https://realadvisor.ch/en/buy/8425-oberembrach/plot)[Plot For Sale in Hüntwangen (8194)](https://realadvisor.ch/en/buy/8194-huntwangen/plot)[Plot For Sale in Dägerlen](https://realadvisor.ch/en/buy/town-dagerlen/plot)[Plot For Sale in Wildberg](https://realadvisor.ch/en/buy/town-wildberg/plot)[Plot For Sale in Buch am Irchel (8414)](https://realadvisor.ch/en/buy/8414-buch-am-irchel/plot)[Plot For Sale in Hüttikon (8115)](https://realadvisor.ch/en/buy/8115-huttikon/plot)[Plot For Sale in Thalheim an der Thur (8478)](https://realadvisor.ch/en/buy/8478-thalheim-an-der-thur/plot)[Plot For Sale in Ellikon an der Thur (8548)](https://realadvisor.ch/en/buy/8548-ellikon-an-der-thur/plot)[Plot For Sale in Benken ZH (8463)](https://realadvisor.ch/en/buy/8463-benken-zh/plot)[Plot For Sale in Dättlikon (8421)](https://realadvisor.ch/en/buy/8421-dattlikon/plot)[Plot For Sale in Schleinikon (8165)](https://realadvisor.ch/en/buy/8165-schleinikon/plot)[Plot For Sale in Schlatt ZH (8418)](https://realadvisor.ch/en/buy/8418-schlatt-zh/plot)[Plot For Sale in Dorf (8458)](https://realadvisor.ch/en/buy/8458-dorf/plot)[Plot For Sale in Altikon (8479)](https://realadvisor.ch/en/buy/8479-altikon/plot)[Plot For Sale in Adlikon b. Andelfingen (8452)](https://realadvisor.ch/en/buy/8452-adlikon-b-andelfingen/plot)[Plot For Sale in Maschwanden (8933)](https://realadvisor.ch/en/buy/8933-maschwanden/plot)[Plot For Sale in Bachs (8164)](https://realadvisor.ch/en/buy/8164-bachs/plot)[Plot For Sale in Wasterkingen (8195)](https://realadvisor.ch/en/buy/8195-wasterkingen/plot)[Plot For Sale in Berg am Irchel](https://realadvisor.ch/en/buy/town-berg-am-irchel/plot)[Plot For Sale in Humlikon (8457)](https://realadvisor.ch/en/buy/8457-humlikon/plot)[Plot For Sale in Truttikon (8467)](https://realadvisor.ch/en/buy/8467-truttikon/plot)[Plot For Sale in Regensberg (8158)](https://realadvisor.ch/en/buy/8158-regensberg/plot)[Plot For Sale in Volken (8459)](https://realadvisor.ch/en/buy/8459-volken/plot) + +Show more + +### Other property types in Canton of Zurich + +[House For Sale in Canton of Zurich](https://realadvisor.ch/en/buy/canton-zurich/house)[Apartment For Sale in Canton of Zurich](https://realadvisor.ch/en/buy/canton-zurich/apartment)[Building For Sale in Canton of Zurich](https://realadvisor.ch/en/buy/canton-zurich/building)[Commercial property For Sale in Canton of Zurich](https://realadvisor.ch/en/buy/canton-zurich/commercial)[Hotel, Restaurant For Sale in Canton of Zurich](https://realadvisor.ch/en/buy/canton-zurich/hospitality) + +[](https://www.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + +Sell + +[House valuation](https://realadvisor.ch/en/online-property-valuation)[Investment property valuation](https://realadvisor.ch/en/investment-rental-property-valuation)[House Prices](https://realadvisor.ch/en/property-prices)[Find an agent](https://realadvisor.ch/en/find-agent) + +Buy / Rent + +[New developments](https://realadvisor.ch/en/developments)[Real estate financing](https://realadvisor.ch/en/financing) + +Professionals + +[Become a partner](https://realadvisor.ch/en/pro) + +About + +[About us](https://realadvisor.ch/en/about-us)[Press area](https://realadvisor.ch/en/press-area)[Jobs](https://realadvisor.welcomekit.co/)[Terms and conditions](https://realadvisor.ch/en/terms)[Privacy policy](https://realadvisor.ch/en/privacy)[Legal Information](https://realadvisor.ch/en/legal-information)[All real estate](https://realadvisor.ch/en/sitemap) + +© RealAdvisor 2025. All Rights Reserved. v.e89072f + +[](https://ch.linkedin.com/company/realadvisor)[](https://www.facebook.com/realadvisorcom)[](https://twitter.com/realadvisor)[](https://www.instagram.com/realadvisorcom)[](https://www.youtube.com/channel/UCsEDTDlmxBpyxLXYhWT769Q) + +Show map + +BESbswy + + +=== https://realadvisor.ch/de/kaufen === +Immobilie kaufen Schweiz - 48’581 Angebote im Oktober 2025 + +=============== + +[](https://realadvisor.ch/de/immobilien-kaufen) + + + +Bewerten + +[Kaufen](https://realadvisor.ch/de/immobilien-kaufen)[Mieten](https://realadvisor.ch/de/immobilien-mieten) + +Anmelden + +DE + +[Italiano](https://realadvisor.ch/it/comprare)[Français](https://realadvisor.ch/fr/acheter)[English](https://realadvisor.ch/en/buy) + +Suchabo erstellen + + + +Kaufen Mieten + +Kaufen Mieten + +Art der Immobilie + +Preis + +Suche ändern + +Wohnfläche + +Andere Filter + +Suchabo erstellen + +- [x] Karte + +←Move left +→Move right +↑Move up +↓Move down ++Zoom in +-Zoom out +Home Jump left by 75% +End Jump right by 75% +Page Up Jump up by 75% +Page Down Jump down by 75% + + + + + + + + + + + + + + + + + + + + + + + + + +3 + +3 + +19k + +19k + +13k + +13k + +11k + +11k + +5.6k + +5.6k + +207 + +207 + +Map +* Map +* Satellite +* Terrain +* Labels + + + + + +*  +*  +*  +*  +*  +*  + +[](https://maps.google.com/maps?ll=46.113069,8.441516&z=6&t=m&hl=en-US&gl=US&mapclient=apiv3 "Open this area in Google Maps (opens a new window)") + +Keyboard shortcuts + +Map Data Map data ©2025 GeoBasis-DE/BKG (©2009), Google, Inst. Geogr. Nacional + +Map data ©2025 GeoBasis-DE/BKG (©2009), Google, Inst. Geogr. Nacional + +100 km + +Click to toggle between metric and imperial units + +[Terms](https://www.google.com/intl/en-US_US/help/terms_maps.html) + +[Report a map error](https://www.google.com/maps/@46.1130688,8.4415156,6z/data=!10m1!1e1!12b1?source=apiv3&rapsrc=apiv3 "Report errors in the road map or imagery to Google") + +1. [](https://realadvisor.ch/de) + +3. Kaufen + +Immobilien kaufen Schweiz +========================= + +48’581 Ergebnisse + +Unseren Empfehlungen + +[](https://realadvisor.ch/de/kaufen/wohnung/1206-geneve-B62R-PBJ6) + +vor 28 Minuten + +- [x] + +[Naef | Projets neufs – Genève 4 Zi. • 112 m² • Wohnung 1206 Genève * Helle Südwestlage * Zwei schöne Balkone * In der Nähe von Parks und Geschäften ------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 1’850’000.- CHF 15’077 / m²](https://realadvisor.ch/de/kaufen/wohnung/1206-geneve-B62R-PBJ6) + +[](https://realadvisor.ch/de/kaufen/wohnung/5-altbrunnenweg-4410-liestal-ZZ74-V4OL) + +vor 46 Minuten + +- [x] + +[Newtak Immobilien GmbH 3.5 Zi. • 68 m² • Wohnung Altbrunnenweg 5, 4410 Liestal * Elegante Stuckdecken * Sonniger Balkon mit Aussicht * Moderne Küche mit Granit ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 590’000.- CHF 8’676 / m²](https://realadvisor.ch/de/kaufen/wohnung/5-altbrunnenweg-4410-liestal-ZZ74-V4OL) + +[](https://realadvisor.ch/de/kaufen/haus/1865-les-diablerets-VBG4-X4V9) + +vor 2 Stunden + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 4.5 Zi. • 99 m² • 300 m² Grundstück • Einfamilienhaus 1865 Les Diablerets * Atemberaubende Panoramablicke * Sonniger Garten mit 300 m² * Seltene Garage Box inklusive ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 980’000.- CHF 9’899 / m²](https://realadvisor.ch/de/kaufen/haus/1865-les-diablerets-VBG4-X4V9) + +[](https://realadvisor.ch/de/kaufen/wohnung/1018-lausanne-RNG4-9LQB) + +vor 2 Stunden + +- [x] + +[Naef Immobilier Lausanne - Vente 4.5 Zi. • 90 m² • Wohnung 1018 Lausanne * Moderne Ausstattungen überall * Geräumige Balkone bis 53m² * Ruhige Wohngegend ------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 1’110’000.- CHF 11’684 / m²](https://realadvisor.ch/de/kaufen/wohnung/1018-lausanne-RNG4-9LQB) + +[](https://realadvisor.ch/de/kaufen/wohnung/1018-lausanne-7JPL-7R6W) + +vor 2 Stunden + +- [x] + +[Naef Immobilier Lausanne - Vente 4.5 Zi. • 90 m² • Wohnung 1018 Lausanne * Zeitgenössisches Design überall * Geräumige Balkone bis 53 m² * Nahe an öffentlichen Verkehrsmitteln ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’090’000.- CHF 11’474 / m²](https://realadvisor.ch/de/kaufen/wohnung/1018-lausanne-7JPL-7R6W) + +[](https://realadvisor.ch/de/kaufen/wohnung/1018-lausanne-ELXJ-E9D6) + +vor 2 Stunden + +- [x] + +[Naef Immobilier Lausanne - Vente 4.5 Zi. • 90 m² • Wohnung 1018 Lausanne * Moderne Ausstattungen und Materialien * Geräumige Balkone bis 53 m² * Ruhige Wohngegend mit Zugang -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 915’000.- CHF 9’632 / m²](https://realadvisor.ch/de/kaufen/wohnung/1018-lausanne-ELXJ-E9D6) + +[](https://realadvisor.ch/de/kaufen/wohnung/1207-geneve-XEG4-74WW) + +vor 2 Stunden + +- [x] + +[Naef Prestige | Knight Frank – Genève 8 Zi. • 416 m² • Penthouse 1207 Genève * Außergewöhnliche Lage auf dem Dach * Atemberaubende Ausblicke auf Wahrzeichen * Geräumige, lichtdurchflutete Wohnbereiche ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/wohnung/1207-geneve-XEG4-74WW) + +[](https://realadvisor.ch/de/kaufen/haus/1820-montreux-4E56-LOJ5) + +vor 3 Stunden + +- [x] + +[Switzerland | Sotheby's International Realty 8 Zi. • 220 m² • 1’883 m² Grundstück • Einfamilienhaus 1820 Montreux * Ruhige grüne Umgebung * Geräumige Räume mit Charakter * Schneller Zugang zu Montreux ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2’985’000.- CHF 11’940 / m²](https://realadvisor.ch/de/kaufen/haus/1820-montreux-4E56-LOJ5) + +[](https://realadvisor.ch/de/kaufen/wohnung/1003-lausanne-XEG4-3E43) + +vor 3 Stunden + +- [x] + +[Switzerland | Sotheby's International Realty 3.5 Zi. • 96 m² • Wohnung 1003 Lausanne * Spektakulärer Blick auf Lausanne * Charaktervolles Gebäude aus dem 19. Jh. * Private Loggia für den Außenbereich ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/wohnung/1003-lausanne-XEG4-3E43) + +[](https://realadvisor.ch/de/kaufen/wohnung/30-grand-rue-1180-rolle-Y7JP-MPL4) + +vor 3 Stunden + +- [x] + +[L3 Properties 5.5 Zi. • 172 m² • Duplex Grand-Rue 30, 1180 Rolle * Zentrale Lage, alle Annehmlichkeiten * Geräumig mit großzügigen Flächen * Unverbaute Sicht auf See & Alpen -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’290’000.- CHF 7’500 / m²](https://realadvisor.ch/de/kaufen/wohnung/30-grand-rue-1180-rolle-Y7JP-MPL4) + +[](https://realadvisor.ch/de/kaufen/haus/1091-grandvaux-Y23Z-VZJW) + +vor 3 Stunden + +- [x] + +[Kreal Immobilier SA 4.5 Zi. • 220 m² • Einfamilienhaus 1091 Grandvaux * Atemberaubender Seeblick * Geräumige Gartenterrasse * Funktionaler Keller mit Garage --------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’650’000.- CHF 7’500 / m²](https://realadvisor.ch/de/kaufen/haus/1091-grandvaux-Y23Z-VZJW) + +[](https://realadvisor.ch/de/kaufen/wohnung/1815-clarens-YMXG-PG4A) + +vor 3 Stunden + +- [x] + +[G-Diffusion Sàrl 3.5 Zi. • 79 m² • Wohnung 1815 Clarens * 14 m² Balkon mit Seeblick * Vollständig renoviertes Design * Nah an Geschäften und Verkehrsmitteln --------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 750’000.- CHF 9’494 / m²](https://realadvisor.ch/de/kaufen/wohnung/1815-clarens-YMXG-PG4A) + +[](https://realadvisor.ch/de/kaufen/wohnung/1607-palezieux-village-8PMG-EG2D) + +vor 3 Stunden + +- [x] + +[G-Diffusion Sàrl 2.5 Zi. • 60 m² • Wohnung 1607 Palézieux-Village * Helle Wohnfläche mit Balkon * Hochwertige Ausstattungen * Ruhige Wohngegend -------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 480’000.- CHF 8’000 / m²](https://realadvisor.ch/de/kaufen/wohnung/1607-palezieux-village-8PMG-EG2D) + +[](https://realadvisor.ch/de/kaufen/wohnung/route-du-simplon-1957-ardon-KXEG-XG2X) + +vor 3 Stunden + +- [x] + +[C-Service Promotions Sàrl 4.5 Zi. • 124 m² • Wohnung Route Du Simplon, 1957 Ardon * Sonnige Terrasse mit Rasen * 2730 m² Grünfläche * Solarzellen installiert ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 575’000.- CHF 4’637 / m²](https://realadvisor.ch/de/kaufen/wohnung/route-du-simplon-1957-ardon-KXEG-XG2X) + +[](https://realadvisor.ch/de/kaufen/haus/1302-vufflens-la-ville-8VBG-DG9Q) + +vor 3 Stunden + +- [x] + +[M Home 7.5 Zi. • 180 m² • Villa 1302 Vufflens-la-Ville * Mittelmeer-Garten-Oase * Beheizter Salzwasserpool * Unabhängiger Büroraum ------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 2’380’000.- CHF 13’222 / m²](https://realadvisor.ch/de/kaufen/haus/1302-vufflens-la-ville-8VBG-DG9Q) + +[](https://realadvisor.ch/de/kaufen/haus/7-bielengasse-3948-oberems-8OOG-RG75) + +vor 3 Stunden + +- [x] + +[PROVIVA Immobilien AG 6 Zi. • 138 m² • Einfamilienhaus Bielengasse 7, 3948 Oberems * Atemberaubende Panoramaaussicht * Geräumiges Grundstück von 1'331 m² * Vielseitiger Keller mit Annehmlichkeiten ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 600’000.- CHF 4’348 / m²](https://realadvisor.ch/de/kaufen/haus/7-bielengasse-3948-oberems-8OOG-RG75) + +[](https://realadvisor.ch/de/kaufen/wohnung/19-acherestrasse-3718-kandersteg-YMXG-PG7O) + +vor 3 Stunden + +- [x] + +[RE/MAX Immobilien in Belp 3.5 Zi. • 66 m² • Wohnung Acherestrasse 19, 3718 Kandersteg * Moderne Küche mit V-Zug-Geräten * Gemütliche Terrasse mit Bergblick * Nachhaltige Heizung mit Bodenwärme --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 590’000.- CHF 8’939 / m²](https://realadvisor.ch/de/kaufen/wohnung/19-acherestrasse-3718-kandersteg-YMXG-PG7O) + +[](https://realadvisor.ch/de/kaufen/wohnung/46-im-sihlhof-8134-adliswil-KXEG-XG9X) + +vor 3 Stunden + +- [x] + +[RE/MAX Immobilien in Eglisau 4.5 Zi. • 117 m² • Penthouse Im Sihlhof 46, 8134 Adliswil * Grosse Terrasse mit Grünsicht * Helle Küche mit viel Stauraum * Zwei moderne Badezimmer für Komfort ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’595’000.- CHF 13’632 / m²](https://realadvisor.ch/de/kaufen/wohnung/46-im-sihlhof-8134-adliswil-KXEG-XG9X) + +[](https://realadvisor.ch/de/kaufen/wohnung/8-dorfstrasse-3703-aeschi-b.-spiez-KGGX-VXXW) + +vor 3 Stunden + +- [x] + +[RE/MAX Immobilien in Wallisellen 1.5 Zi. • 27 m² • Wohnung Dorfstrasse 8, 3703 Aeschi b. Spiez * Atemberaubender Bergblick * Heller, geräumiger Wohnbereich * Möglichkeit zur Mieteinnahme --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 220’000.- CHF 8’148 / m²](https://realadvisor.ch/de/kaufen/wohnung/8-dorfstrasse-3703-aeschi-b.-spiez-KGGX-VXXW) + +[](https://realadvisor.ch/de/kaufen/wohnung/7-fohrlibuckstrasse-8304-wallisellen-83JW-ZWW3) + +vor 3 Stunden + +- [x] + +[RE/MAX Immobilien in Wallisellen 3.5 Zi. • 83 m² • Wohnung Föhrlibuckstrasse 7, 8304 Wallisellen * Geräumige Terrasse zum Entspannen * Helle Räume mit großen Fenstern * Zentrale und ruhige Lage ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’135’000.- CHF 13’675 / m²](https://realadvisor.ch/de/kaufen/wohnung/7-fohrlibuckstrasse-8304-wallisellen-83JW-ZWW3) + +[](https://realadvisor.ch/de/kaufen/parkplatz/3910-saas-grund-84E5-W55A) + +vor 3 Stunden + +- [x] + +[RE/MAX Immobilien in Saas-Fee Aussenplatz 3910 Saas-Grund * Ideal für Eigenbedarf * Möglichkeit zur Vermietung * Kauf mit angrenzendem Grundstück ---------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/parkplatz/3910-saas-grund-84E5-W55A) + +[](https://realadvisor.ch/de/kaufen/grundstuck/3952-susten-Y23Z-VZZB) + +vor 3 Stunden + +- [x] + +[RE/MAX Immobilien in Susten 1’641 m² • Bauland 3952 Susten * Genehmigtes Projekt für 2 Häuser * Ruhige Lage in der Natur * Ferienhauszone verfügbar ------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/3952-susten-Y23Z-VZZB) + +[](https://realadvisor.ch/de/kaufen/haus/1260-nyon-YNAG-NGGQ) + +vor 3 Stunden + +- [x] + +[DronEstate SA Einfamilienhaus 1260 Nyon * Atemberaubender See- und Mont-Blanc-Blick * Luxuriöser Wellnessbereich mit Spa * Privater Bootshaus und Hafen ---------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 31’000’000.- —](https://realadvisor.ch/de/kaufen/haus/1260-nyon-YNAG-NGGQ) + +[](https://realadvisor.ch/de/kaufen/wohnung/87-route-de-lully-1470-lully-fr-Y23Z-VZAB) + +vor 3 Stunden + +- [x] + +[Lombard Immobilier SA 2.5 Zi. • 62 m² • Wohnung Route De Lully 87, 1470 Lully FR * Geräumige 8 m² Terrasse * Hochwertige Materialien * Tiefgaragenstellplatz inklusive ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/wohnung/87-route-de-lully-1470-lully-fr-Y23Z-VZAB) + +[1](https://realadvisor.ch/de/kaufen) + +[2](https://realadvisor.ch/de/kaufen/seite-2) + +[3](https://realadvisor.ch/de/kaufen/seite-3) + +[4](https://realadvisor.ch/de/kaufen/seite-4) + +[5](https://realadvisor.ch/de/kaufen/seite-5) + +[6](https://realadvisor.ch/de/kaufen/seite-6) + +[7](https://realadvisor.ch/de/kaufen/seite-7) + +[](https://realadvisor.ch/de/kaufen/seite-2) + +1-24 von 48’581 Ergebnisse + +Der Immobilienmarkt Schweiz +--------------------------- + +### 💰 Wie viel kostet eine Immobilie zum Verkauf Schweiz? + +Der mittlere Kaufpreis für eine Immobilie beträgt aktuell **CHF 1’333’703**. Der Kaufpreis für 80% der Immobilien liegt zwischen **CHF 580’553** und **CHF 3’451’937**. Der Durchschnittspreis pro m² Schweiz beträgt **CHF 8’749/m²**. + +### Wo kann ich Schweiz kostengünstig eine Immobilie kaufen? + +Für Immobilien zum Verkauf Schweiz sind die preisgünstigsten Gemeinden: [Fahy](https://realadvisor.ch/de/kaufen/2916-fahy) mit einem mittleren Preis pro m² von **CHF 2’494**, [Simplon](https://realadvisor.ch/de/kaufen/gemeinde-simplon) mit **CHF 2’636**/m² und [Bonfol](https://realadvisor.ch/de/kaufen/2944-bonfol) mit **CHF 2’652**/m². + +### Welche Gemeinden Schweiz sind die teuersten um Immobilien zu kaufen? + +Für Immobilien zum Verkauf Schweiz sind die teuersten Gemeinden: [St. Moritz](https://realadvisor.ch/de/kaufen/7500-st-moritz) mit einem mittleren Preis pro m² von **CHF 21’069**, [Vandoeuvres](https://realadvisor.ch/de/kaufen/1253-vandoeuvres) mit **CHF 19’954**/m² und [Cologny](https://realadvisor.ch/de/kaufen/1223-cologny) mit **CHF 19’578**/m². + +Immobilie kaufen Schweiz ------------------------ -Künstliche Intelligenz ist nicht nur ein Werkzeug – sie ist ein transformativer Treiber, der grundlegend verändert, wie wir führen, arbeiten und Wert schaffen. +[Immobilienpreise in Schweiz](https://realadvisor.ch/de/immobilienpreise-pro-m2) -PeaqPartners und ValueOn laden Sie herzlich zur AI Vernissage ein – einem exklusiven Abend für ausgewählte Partner:innen und Führungspersönlichkeiten. Freuen Sie sich auf Impulse, Gespräche und kreative Erlebnisse rund um den strategischen Einsatz von KI. +### Immobilie kaufen Schweiz -### Event-Details +[Immobilie kaufen im Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich)[Immobilie kaufen im Kanton Bern](https://realadvisor.ch/de/kaufen/kanton-bern)[Immobilie kaufen im Kanton Waadt](https://realadvisor.ch/de/kaufen/kanton-waadt)[Immobilie kaufen im Kanton Aargau](https://realadvisor.ch/de/kaufen/kanton-aargau)[Immobilie kaufen im Kanton St. Gallen](https://realadvisor.ch/de/kaufen/kanton-st-gallen)[Immobilie kaufen im Kanton Genf](https://realadvisor.ch/de/kaufen/kanton-genf)[Immobilie kaufen im Kanton Luzern](https://realadvisor.ch/de/kaufen/kanton-luzern)[Immobilie kaufen im Kanton Tessin](https://realadvisor.ch/de/kaufen/kanton-tessin)[Immobilie kaufen im Kanton Wallis](https://realadvisor.ch/de/kaufen/kanton-wallis)[Immobilie kaufen im Kanton Freiburg](https://realadvisor.ch/de/kaufen/kanton-freiburg)[Immobilie kaufen im Kanton Basel-Landschaft](https://realadvisor.ch/de/kaufen/kanton-basel-landschaft)[Immobilie kaufen im Kanton Thurgau](https://realadvisor.ch/de/kaufen/kanton-thurgau)[Immobilie kaufen im Kanton Solothurn](https://realadvisor.ch/de/kaufen/kanton-solothurn)[Immobilie kaufen im Kanton Graubünden](https://realadvisor.ch/de/kaufen/kanton-graubunden)[Immobilie kaufen im Kanton Basel-Stadt](https://realadvisor.ch/de/kaufen/kanton-basel-stadt)[Immobilie kaufen im Kanton Neuenburg](https://realadvisor.ch/de/kaufen/kanton-neuenburg)[Immobilie kaufen im Kanton Schwyz](https://realadvisor.ch/de/kaufen/kanton-schwyz)[Immobilie kaufen im Kanton Zug](https://realadvisor.ch/de/kaufen/kanton-zug)[Immobilie kaufen im Kanton Schaffhausen](https://realadvisor.ch/de/kaufen/kanton-schaffhausen)[Immobilie kaufen im Kanton Jura](https://realadvisor.ch/de/kaufen/kanton-jura)[Immobilie kaufen im Kanton Appenzell Ausserrhoden](https://realadvisor.ch/de/kaufen/kanton-appenzell-ausserrhoden)[Immobilie kaufen im Kanton Nidwalden](https://realadvisor.ch/de/kaufen/kanton-nidwalden)[Immobilie kaufen im Kanton Glarus](https://realadvisor.ch/de/kaufen/kanton-glarus)[Immobilie kaufen im Liechtenstein](https://realadvisor.ch/de/kaufen/liechtenstein)[Immobilie kaufen im Kanton Obwalden](https://realadvisor.ch/de/kaufen/kanton-obwalden)[Immobilie kaufen im Kanton Uri](https://realadvisor.ch/de/kaufen/kanton-uri)[Immobilie kaufen im Kanton Appenzell Innerrhoden](https://realadvisor.ch/de/kaufen/kanton-appenzell-innerrhoden) -Datum:Dienstag, 16. September 2025 +Mehr -Ort:Le Bijou, Lintheschergasse 18, 8001 Zürich (3 min von ZHB) +### Andere Immobilienarten Schweiz -Zeit:17:30 – 19:30 Uhr +[Haus kaufen Schweiz](https://realadvisor.ch/de/kaufen/haus)[Wohnung kaufen Schweiz](https://realadvisor.ch/de/kaufen/wohnung)[Grundstück kaufen Schweiz](https://realadvisor.ch/de/kaufen/grundstuck)[Mehrfamilienhaus kaufen Schweiz](https://realadvisor.ch/de/kaufen/gebaude)[Gewerberaum kaufen Schweiz](https://realadvisor.ch/de/kaufen/gewerbe)[Hotel, Restaurant kaufen Schweiz](https://realadvisor.ch/de/kaufen/gastfreundschaft) -Teilnahmegebühr:CHF 100.- +### Beliebte Suchen Schweiz -Sprache:Deutsch +[Neubauprojekte in der Schweiz](https://realadvisor.ch/de/beliebte-suchen/neubauprojekte-schweiz)[Neubauten kaufen in der Schweiz](https://realadvisor.ch/de/beliebte-suchen/neubauten-kaufen-schweiz)[Neubauwohnungen kaufen in der Schweiz](https://realadvisor.ch/de/beliebte-suchen/neubauwohnung-kaufen-schweiz) -Zielgruppe:Führungskräfte & strategische Entscheider:innen +[](https://ch.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) -### Anmeldung +Verkaufen -Anrede * Bitte wählen +[Immobilienbewertung](https://realadvisor.ch/de/online-immobilienbewertung)[Renditeliegenschaft bewerten](https://realadvisor.ch/de/renditeliegenschaft-bewerten-online)[Immobilienpreise](https://realadvisor.ch/de/immobilienpreise-pro-m2)[Makler finden](https://realadvisor.ch/de/makler-finden)[Immobilien-Glossar](https://realadvisor.ch/de/immobilien-glossar)[Immobilien-Blog](https://realadvisor.ch/de/blog) + +Kaufen / Mieten + +[Immobilien kaufen](https://realadvisor.ch/de/immobilien-kaufen)[Immobilien mieten](https://realadvisor.ch/de/immobilien-mieten)[Neubauprojekte](https://realadvisor.ch/de/neubauprojekte)[Immobilienfinanzierung](https://realadvisor.ch/de/finanzierung) + +Für Makler + +[Partner werden](https://realadvisor.ch/de/pro)[Blog Pro](https://realadvisor.ch/de/pro/blog) + +Unternehmen + +[Über uns](https://realadvisor.ch/de/uber-uns)[Presseraum](https://realadvisor.ch/de/presseraum)[Offene Stellen](https://realadvisor.welcomekit.co/)[Allgemeine Geschäftsbedingungen](https://realadvisor.ch/de/begriffe)[Datenschutzerklärung](https://realadvisor.ch/de/datenschutzerklarung)[Impressum](https://realadvisor.ch/de/impressum)[Alle Immobilien](https://realadvisor.ch/de/sitemap) + +© RealAdvisor 2025. All Rights Reserved. v.e89072f + +[](https://ch.linkedin.com/company/realadvisor)[](https://www.facebook.com/realadvisorcom)[](https://twitter.com/realadvisor)[](https://www.instagram.com/realadvisorcom)[](https://www.youtube.com/channel/UCsEDTDlmxBpyxLXYhWT769Q) + +Karte + +BESbswy + + +=== https://realadvisor.ch/de/kaufen/grundstuck === +Grundstück kaufen Schweiz - 2’266 Angebote im Oktober 2025 + +=============== + +[](https://realadvisor.ch/de/immobilien-kaufen) + + + +Bewerten + +[Kaufen](https://realadvisor.ch/de/immobilien-kaufen)[Mieten](https://realadvisor.ch/de/immobilien-mieten) + +Anmelden + +DE + +[Italiano](https://realadvisor.ch/it/comprare/trama)[Français](https://realadvisor.ch/fr/acheter/terrain)[English](https://realadvisor.ch/en/buy/plot) + +Suchabo erstellen + + + +Kaufen Mieten + +Kaufen Mieten + +Grundstück + +Preis + +Suche ändern + +Grundstücksfläche + +Andere Filter + +Suchabo erstellen + +- [x] Karte + +←Move left +→Move right +↑Move up +↓Move down ++Zoom in +-Zoom out +Home Jump left by 75% +End Jump right by 75% +Page Up Jump up by 75% +Page Down Jump down by 75% + + + + + + + + + + + + + + + + + + + + + + + + + +701 + +701 + +618 + +618 + +711 + +711 + +234 + +234 + +2 + +2 + +Map +* Map +* Satellite +* Terrain +* Labels + + + + + +*  +*  +*  +*  +*  +*  + +[](https://maps.google.com/maps?ll=46.113069,8.441516&z=6&t=m&hl=en-US&gl=US&mapclient=apiv3 "Open this area in Google Maps (opens a new window)") + +Keyboard shortcuts + +Map Data Map data ©2025 GeoBasis-DE/BKG (©2009), Google, Inst. Geogr. Nacional + +Map data ©2025 GeoBasis-DE/BKG (©2009), Google, Inst. Geogr. Nacional + +100 km + +Click to toggle between metric and imperial units + +[Terms](https://www.google.com/intl/en-US_US/help/terms_maps.html) + +[Report a map error](https://www.google.com/maps/@46.1130688,8.4415156,6z/data=!10m1!1e1!12b1?source=apiv3&rapsrc=apiv3 "Report errors in the road map or imagery to Google") + +1. [](https://realadvisor.ch/de) + +3. [Kaufen](https://realadvisor.ch/de/kaufen) + +5. Grundstück + +Grundstücke kaufen Schweiz +========================== + +2’266 Ergebnisse + +Unseren Empfehlungen + +[](https://realadvisor.ch/de/kaufen/grundstuck/3952-susten-Y23Z-VZZB) + +vor 3 Stunden + +- [x] + +[RE/MAX Immobilien in Susten 1’641 m² • Bauland 3952 Susten * Genehmigtes Projekt für 2 Häuser * Ruhige Lage in der Natur * Ferienhauszone verfügbar ------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/3952-susten-Y23Z-VZZB) + +[](https://realadvisor.ch/de/kaufen/grundstuck/2802-develier-YZZ7-B5M3) + +vor 3 Stunden + +- [x] + +[Neuschwander Immobilier Sàrl 1’444 m² • Bauland 2802 Develier * Voll erschlossenes 1'444 m² * Ideal für 6 Wohnungen Projekt * Nahe an Annehmlichkeiten & Verkehr ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/2802-develier-YZZ7-B5M3) + +[](https://realadvisor.ch/de/kaufen/grundstuck/grenzstrasse-8280-kreuzlingen-YJDX-5ML4) + +vor 7 Stunden + +- [x] + +[Retronova Immobilien AG 462 m² Grundstück • Bauland Grenzstrasse, 8280 Kreuzlingen * Ideal für Mehrfamilienhäuser * Bis zu 557m² bebaubare Fläche * Top Lage nahe Stadtzentrum --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’150’000.- CHF 2’489 / m²](https://realadvisor.ch/de/kaufen/grundstuck/grenzstrasse-8280-kreuzlingen-YJDX-5ML4) + +[](https://realadvisor.ch/de/kaufen/grundstuck/incella-6614-brissago-84E5-WV2G) + +vor 7 Stunden + +- [x] + +[Pura Immobiliare Bauland Incella, 6614 Brissago * Einzigartiger Zugang über Treppen * Atemberaubende Seesicht * Ideal für Luxusvillen ---------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’060’000.- —](https://realadvisor.ch/de/kaufen/grundstuck/incella-6614-brissago-84E5-WV2G) + +[](https://realadvisor.ch/de/kaufen/grundstuck/1509-vucherens-B62R-PRGJ) + +vor 11 Stunden + +- [x] + +[Froidevaux Immobilier SA 1’368 m² Grundstück • Bauland 1509 Vucherens * Ideal für Ihr Traumhaus * 1368m2 prime Land * Verfügbar mit Baugenehmigung ----------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/1509-vucherens-B62R-PRGJ) + +[](https://realadvisor.ch/de/kaufen/grundstuck/2854-bassecourt-8WR9-EAMB) + +vor 12 Stunden + +- [x] + +[MAGICimmo SA Bauland 2854 Bassecourt * 893 m2 Baufläche * Ruhige grüne Umgebung * Keine Baugrenze ---------------------------------------------------------------------------------------------------------------- * * * CHF 267’900.- —](https://realadvisor.ch/de/kaufen/grundstuck/2854-bassecourt-8WR9-EAMB) + +[](https://realadvisor.ch/de/kaufen/grundstuck/2854-bassecourt-YB6N-5O7J) + +vor 12 Stunden + +- [x] + +[MAGICimmo SA Bauland 2854 Bassecourt * Lage in Wohngebiet * Flexible Bauoptionen * Mindestkoeffizient 0.35 ------------------------------------------------------------------------------------------------------------------------- * * * CHF 250.- —](https://realadvisor.ch/de/kaufen/grundstuck/2854-bassecourt-YB6N-5O7J) + +[Keine Fotos](https://realadvisor.ch/de/kaufen/grundstuck/1012-lausanne-85VO-BOPA) + +vor 12 Stunden + +- [x] + +[AD Immob Sàrl 920 m² Grundstück • Bauland 1012 Lausanne * Geräumiges Grundstück von 920 m2 * Befreit von Bauvorschriften * Perfekt für Familienhäuser -------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’540’000.- CHF 1’674 / m²](https://realadvisor.ch/de/kaufen/grundstuck/1012-lausanne-85VO-BOPA) + +[](https://realadvisor.ch/de/kaufen/grundstuck/2829-vermes-KRNG-JN9B) + +vor 13 Stunden + +- [x] + +[Neuschwander Immobilier Sàrl 6’062 m² Grundstück • Bauland 2829 Vermes * Großes Grundstück von 6'062 m² * Bebaubare Fläche von 3'580 m² * Ruhige Lage in der Natur --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 400’000.- CHF 66 / m²](https://realadvisor.ch/de/kaufen/grundstuck/2829-vermes-KRNG-JN9B) + +[](https://realadvisor.ch/de/kaufen/grundstuck/11-l-eiron-6523-preonzo-8VBG-DWXW) + +vor 13 Stunden + +- [x] + +[Immobiliare Ascolux Sagl 400 m² Grundstück • Bauland L Eirón 11, 6523 Preonzo * Ruhige Wohnlage * 200m zur Bushaltestelle * In der Nähe von Grundschulen ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 200’000.- CHF 500 / m²](https://realadvisor.ch/de/kaufen/grundstuck/11-l-eiron-6523-preonzo-8VBG-DWXW) + +[](https://realadvisor.ch/de/kaufen/grundstuck/2025-chez-le-bart-8LDP-7JZ4) + +vor 22 Stunden + +- [x] + +[Diatimis Sàrl 2’310 m² • 2’310 m² Grundstück • Bauland 2025 Chez-le-Bart * Grosszügige Fläche von 2310 m² * Bevorzugte Lage am See * Aussergewöhnliche Lebensqualität ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 1’500’000.- CHF 649 / m²](https://realadvisor.ch/de/kaufen/grundstuck/2025-chez-le-bart-8LDP-7JZ4) + +[Keine Fotos](https://realadvisor.ch/de/kaufen/grundstuck/1700-fribourg-KEL9-P4MP) + +vor 1 Tag + +- [x] + +[JG Immobilier 5’776 m² • 5’776 m² Grundstück • Bauland 1700 Fribourg * Bemerkenswertes Baupotenzial * Optimales Licht und Ausblick * Ideal für Luxusprojekte --------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 3’100’000.- CHF 537 / m²](https://realadvisor.ch/de/kaufen/grundstuck/1700-fribourg-KEL9-P4MP) + +[Keine Fotos](https://realadvisor.ch/de/kaufen/grundstuck/1012-lausanne-KGGX-5A6Q) + +vor 1 Tag + +- [x] + +[AD Immob Sàrl 920 m² • 920 m² Grundstück • Bauland 1012 Lausanne * 920 m2 Grundstücksfläche * Bau frei von Einschränkungen * Ideal für Familienhäuser -------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’540’000.- CHF 1’674 / m²](https://realadvisor.ch/de/kaufen/grundstuck/1012-lausanne-KGGX-5A6Q) + +[](https://realadvisor.ch/de/kaufen/grundstuck/7134-obersaxen-JDXL-ALVL) + +vor 1 Tag + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 732 m² Grundstück • Bauland 7134 Obersaxen * Atemberaubende Panoramasicht * Skizugang bis zur Haustür * Vollständig ausgearbeitetes Bauprojekt ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 270’000.- CHF 369 / m²](https://realadvisor.ch/de/kaufen/grundstuck/7134-obersaxen-JDXL-ALVL) + +[](https://realadvisor.ch/de/kaufen/grundstuck/2000-neuchatel-YMXG-PB5O) + +vor 1 Tag + +- [x] + +[Wolf Output SA 443 m² Grundstück • Bauland 2000 Neuchâtel * Seltene Gelegenheit in der Stadt * Ideal für Wohnprojekte * Attraktive Preise verfügbar ------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 110’000.- CHF 248 / m²](https://realadvisor.ch/de/kaufen/grundstuck/2000-neuchatel-YMXG-PB5O) + +[](https://realadvisor.ch/de/kaufen/grundstuck/guttet-3956-guttet-feschel-YA69-QV5X) + +vor 1 Tag + +- [x] + +[valvida 585 m² • 585 m² Grundstück • Bauland Guttet, 3956 Guttet-Feschel * Unverbaubare Talansicht * Ruhige und sonnige Lage * Einfacher Zugang zum Dorfzentrum ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 129’000.- CHF 221 / m²](https://realadvisor.ch/de/kaufen/grundstuck/guttet-3956-guttet-feschel-YA69-QV5X) + +[](https://realadvisor.ch/de/kaufen/grundstuck/1918-la-tzoumaz-84RP-QZN5) + +vor 1 Tag + +- [x] + +[4vallees4saisons.com 5 Zi. • 1’287 m² Grundstück • Bauland 1918 La Tzoumaz * Atemberaubende Panoramaaussicht * Bebaubar für Chalets * Steuervorteile Lex Webber ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 295’000.- CHF 229 / m²](https://realadvisor.ch/de/kaufen/grundstuck/1918-la-tzoumaz-84RP-QZN5) + +[](https://realadvisor.ch/de/kaufen/grundstuck/3954-leukerbad-Y23B-64EB) + +vor 1 Tag + +- [x] + +[Fast Home AG 2’842 m² • 2’842 m² Grundstück • Bauland 3954 Leukerbad * Atemberaubende Alpenblicke * Thermalquellen in der Nähe * Ganzjährige Outdoor-Aktivitäten ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 998’000.- CHF 351 / m²](https://realadvisor.ch/de/kaufen/grundstuck/3954-leukerbad-Y23B-64EB) + +[](https://realadvisor.ch/de/kaufen/grundstuck/1854-leysin-KEL4-DRAM) + +vor 1 Tag + +- [x] + +[VON POLL REAL ESTATE BASEL 1’010 m² Grundstück • Bauland 1854 Leysin * Atemberaubende Panoramasicht * Ruhige Lage, gute Erreichbarkeit * Bauzone Chalet A ------------------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/1854-leysin-KEL4-DRAM) + +[](https://realadvisor.ch/de/kaufen/grundstuck/3900-brig-KQND-2967) + +vor 1 Tag + +- [x] + +[Fast Home AG 12’841 m² Grundstück • Bauland 3900 Brig * 12.000 m² für Ihr Projekt * Flexible Bauoptionen * Ausgezeichnete Verkehrsanbindung ---------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/3900-brig-KQND-2967) + +[Keine Fotos](https://realadvisor.ch/de/kaufen/grundstuck/1012-lausanne-Y6ZM-BQM3) + +vor 1 Tag + +- [x] + +[AD Immob Sàrl 920 m² Grundstück • Bauland 1012 Lausanne * 920 m2 erstklassiges Land * Keine bestehenden Bauwerke * Perfekt für Familienhäuser ------------------------------------------------------------------------------------------------------------------------------------------------------------ * * * CHF 1’540’000.- CHF 1’674 / m²](https://realadvisor.ch/de/kaufen/grundstuck/1012-lausanne-Y6ZM-BQM3) + +[](https://realadvisor.ch/de/kaufen/grundstuck/3472-wynigen-YA6X-NGBV) + +vor 1 Tag + +- [x] + +[Agentur Wyss AG 10 Zi. • 223 m² • 249’992 m² Grundstück • Industriebauland 3472 Wynigen * Atemberaubende Aussicht auf Wynigen * Zwei separate moderne Wohnungen * Ideal für Pferdesportaktivitäten ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’140’000.- CHF 518 / m²](https://realadvisor.ch/de/kaufen/grundstuck/3472-wynigen-YA6X-NGBV) + +[](https://realadvisor.ch/de/kaufen/grundstuck/5057-reitnau-YZZ7-RDOJ) + +vor 1 Tag + +- [x] + +[BAY & PARTNER IMMOBILIEN GmbH 3’031 m² Grundstück • Bauland 5057 Reitnau * 3031 m2 flaches Land * Neu errichtete Erschliessungsstrasse * Keine Architekturverpflichtung -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * CHF 1’268’000.- CHF 418 / m²](https://realadvisor.ch/de/kaufen/grundstuck/5057-reitnau-YZZ7-RDOJ) + +[](https://realadvisor.ch/de/kaufen/grundstuck/7134-obersaxen-VBG4-X5JW) + +vor 1 Tag + +- [x] + +[ImmoSky AG - Standort Dübendorf ZH (Zentrale) 1’414 m² Grundstück • Bauland 7134 Obersaxen * Spektakuläre Bergsicht * Ruhige, sonnige Lage * Ausgezeichnete Verkehrsanbindung -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/7134-obersaxen-VBG4-X5JW) + +[1](https://realadvisor.ch/de/kaufen/grundstuck) + +[2](https://realadvisor.ch/de/kaufen/grundstuck/seite-2) + +[3](https://realadvisor.ch/de/kaufen/grundstuck/seite-3) + +[4](https://realadvisor.ch/de/kaufen/grundstuck/seite-4) + +[5](https://realadvisor.ch/de/kaufen/grundstuck/seite-5) + +[6](https://realadvisor.ch/de/kaufen/grundstuck/seite-6) + +[7](https://realadvisor.ch/de/kaufen/grundstuck/seite-7) + +[](https://realadvisor.ch/de/kaufen/grundstuck/seite-2) + +1-24 von 2’266 Ergebnisse + +Grundstück kaufen Schweiz +------------------------- + +[Immobilienpreise in Schweiz](https://realadvisor.ch/de/immobilienpreise-pro-m2) + +### Grundstück kaufen Schweiz + +[Grundstück kaufen im Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck)[Grundstück kaufen im Kanton Bern](https://realadvisor.ch/de/kaufen/kanton-bern/grundstuck)[Grundstück kaufen im Kanton Waadt](https://realadvisor.ch/de/kaufen/kanton-waadt/grundstuck)[Grundstück kaufen im Kanton Aargau](https://realadvisor.ch/de/kaufen/kanton-aargau/grundstuck)[Grundstück kaufen im Kanton St. Gallen](https://realadvisor.ch/de/kaufen/kanton-st-gallen/grundstuck)[Grundstück kaufen im Kanton Genf](https://realadvisor.ch/de/kaufen/kanton-genf/grundstuck)[Grundstück kaufen im Kanton Luzern](https://realadvisor.ch/de/kaufen/kanton-luzern/grundstuck)[Grundstück kaufen im Kanton Tessin](https://realadvisor.ch/de/kaufen/kanton-tessin/grundstuck)[Grundstück kaufen im Kanton Wallis](https://realadvisor.ch/de/kaufen/kanton-wallis/grundstuck)[Grundstück kaufen im Kanton Freiburg](https://realadvisor.ch/de/kaufen/kanton-freiburg/grundstuck)[Grundstück kaufen im Kanton Basel-Landschaft](https://realadvisor.ch/de/kaufen/kanton-basel-landschaft/grundstuck)[Grundstück kaufen im Kanton Thurgau](https://realadvisor.ch/de/kaufen/kanton-thurgau/grundstuck)[Grundstück kaufen im Kanton Solothurn](https://realadvisor.ch/de/kaufen/kanton-solothurn/grundstuck)[Grundstück kaufen im Kanton Graubünden](https://realadvisor.ch/de/kaufen/kanton-graubunden/grundstuck)[Grundstück kaufen im Kanton Basel-Stadt](https://realadvisor.ch/de/kaufen/kanton-basel-stadt/grundstuck)[Grundstück kaufen im Kanton Neuenburg](https://realadvisor.ch/de/kaufen/kanton-neuenburg/grundstuck)[Grundstück kaufen im Kanton Schwyz](https://realadvisor.ch/de/kaufen/kanton-schwyz/grundstuck)[Grundstück kaufen im Kanton Zug](https://realadvisor.ch/de/kaufen/kanton-zug/grundstuck)[Grundstück kaufen im Kanton Schaffhausen](https://realadvisor.ch/de/kaufen/kanton-schaffhausen/grundstuck)[Grundstück kaufen im Kanton Jura](https://realadvisor.ch/de/kaufen/kanton-jura/grundstuck)[Grundstück kaufen im Kanton Appenzell Ausserrhoden](https://realadvisor.ch/de/kaufen/kanton-appenzell-ausserrhoden/grundstuck)[Grundstück kaufen im Kanton Nidwalden](https://realadvisor.ch/de/kaufen/kanton-nidwalden/grundstuck)[Grundstück kaufen im Kanton Glarus](https://realadvisor.ch/de/kaufen/kanton-glarus/grundstuck)[Grundstück kaufen im Liechtenstein](https://realadvisor.ch/de/kaufen/liechtenstein/grundstuck)[Grundstück kaufen im Kanton Obwalden](https://realadvisor.ch/de/kaufen/kanton-obwalden/grundstuck)[Grundstück kaufen im Kanton Uri](https://realadvisor.ch/de/kaufen/kanton-uri/grundstuck)[Grundstück kaufen im Kanton Appenzell Innerrhoden](https://realadvisor.ch/de/kaufen/kanton-appenzell-innerrhoden/grundstuck) + +Mehr + +### Andere Immobilienarten Schweiz + +[Haus kaufen Schweiz](https://realadvisor.ch/de/kaufen/haus)[Wohnung kaufen Schweiz](https://realadvisor.ch/de/kaufen/wohnung)[Mehrfamilienhaus kaufen Schweiz](https://realadvisor.ch/de/kaufen/gebaude)[Gewerberaum kaufen Schweiz](https://realadvisor.ch/de/kaufen/gewerbe)[Hotel, Restaurant kaufen Schweiz](https://realadvisor.ch/de/kaufen/gastfreundschaft) + +### Beliebte Suchen Schweiz + +[Neubauprojekte in der Schweiz](https://realadvisor.ch/de/beliebte-suchen/neubauprojekte-schweiz)[Neubauten kaufen in der Schweiz](https://realadvisor.ch/de/beliebte-suchen/neubauten-kaufen-schweiz)[Neubauwohnungen kaufen in der Schweiz](https://realadvisor.ch/de/beliebte-suchen/neubauwohnung-kaufen-schweiz) + +[](https://ch.trustpilot.com/review/realadvisor.ch?stars=4&stars=5) + +Verkaufen + +[Immobilienbewertung](https://realadvisor.ch/de/online-immobilienbewertung)[Renditeliegenschaft bewerten](https://realadvisor.ch/de/renditeliegenschaft-bewerten-online)[Immobilienpreise](https://realadvisor.ch/de/immobilienpreise-pro-m2)[Makler finden](https://realadvisor.ch/de/makler-finden)[Immobilien-Glossar](https://realadvisor.ch/de/immobilien-glossar)[Immobilien-Blog](https://realadvisor.ch/de/blog) + +Kaufen / Mieten + +[Immobilien kaufen](https://realadvisor.ch/de/immobilien-kaufen)[Immobilien mieten](https://realadvisor.ch/de/immobilien-mieten)[Neubauprojekte](https://realadvisor.ch/de/neubauprojekte)[Immobilienfinanzierung](https://realadvisor.ch/de/finanzierung) + +Für Makler + +[Partner werden](https://realadvisor.ch/de/pro)[Blog Pro](https://realadvisor.ch/de/pro/blog) + +Unternehmen + +[Über uns](https://realadvisor.ch/de/uber-uns)[Presseraum](https://realadvisor.ch/de/presseraum)[Offene Stellen](https://realadvisor.welcomekit.co/)[Allgemeine Geschäftsbedingungen](https://realadvisor.ch/de/begriffe)[Datenschutzerklärung](https://realadvisor.ch/de/datenschutzerklarung)[Impressum](https://realadvisor.ch/de/impressum)[Alle Immobilien](https://realadvisor.ch/de/sitemap) + +© RealAdvisor 2025. All Rights Reserved. v.e89072f + +[](https://ch.linkedin.com/company/realadvisor)[](https://www.facebook.com/realadvisorcom)[](https://twitter.com/realadvisor)[](https://www.instagram.com/realadvisorcom)[](https://www.youtube.com/channel/UCsEDTDlmxBpyxLXYhWT769Q) + +Karte + + +=== https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ === +Bauland zu verkaufen - 8162 Steinmaur - | RealAdvisor + +=============== + +[](https://realadvisor.ch/de) + +Bewerten + +[Kaufen](https://realadvisor.ch/de/immobilien-kaufen)[Mieten](https://realadvisor.ch/de/immobilien-mieten) + +Anmelden + +DE + +[Français](https://realadvisor.ch/fr/acheter/terrain/8162-steinmaur-B62R-PZDJ)[Italiano](https://realadvisor.ch/it/comprare/trama/8162-steinmaur-B62R-PZDJ)[English](https://realadvisor.ch/en/buy/plot/8162-steinmaur-B62R-PZDJ) + +[Alle Inserate anzeigen](https://realadvisor.ch/de/kaufen/gemeinde-steinmaur/grundstuck) + + + + + + + + + + + + + +- [x] + +Speichern + +- [x] + +Bauland zu verkaufen - 8162 Steinmaur +===================================== + +Auf Anfrage + +* * * + +Grundstück + +Beschreibung + +BAULAND AN TRAUMHAFTER LAGE AM FISCHBACH +---------------------------------------- + +Wir bieten ein idyllisch gelegenes, flaches Grundstück zum Verkauf an, perfekt für Ihr Bauvorhaben! + +Derzeit könnten auf dem Grundstück **ein Mehrfamilienhaus (MFH) oder zwei freistehende Einfamilienhäuser (EFH) realisiert werden**. Die Gemeinde bzw. der Kanton plant jedoch eine Verlegung des Baches. Dadurch könnten zukünftig **zwei Doppel-EFHs oder alternativ drei Reihen-EFHs sowie ein Doppel-EFH umgesetzt werden**. Das Bauland liegt in der Bauzone W2, die Ausnützungsziffer beträgt 40 %. + +Dieses Grundstück bietet eine ruhige, naturnahe Atmosphäre, kombiniert mit einer hervorragenden Anbindung an den öffentlichen Verkehr. + +Dieses Grundstück bietet Ihnen alle Möglichkeiten, Ihr Projekt an einer ruhigen und naturnahen Umgebung zu realisieren. Profitieren Sie von der sonnigen Lage, dem Ausblick auf die Natur und der gut durchdachten Infrastruktur. + +**Grundstückdetails:** + +* **Grösse:** 1'452 m² +* **Bauvorschriften / Zone:** Zone: Wohnzone W2 Ausnützungsziffer: 40 +* **Lage:** Ruhiges, sonniges Wohnquartier nahe dem Zentrum von Niedersteinmaur +* **Bahnhof:** In 10 Minuten zu Fuss erreichbar +* **Bushaltestelle:** Nur 370 m entfernt +* **Besonderheiten:** Flaches, gut bebaubares Grundstück mit Bachanstoss, angrenzend an Landwirtschaftszone, Quartierschliessung ohne Durchgangsverkehr + +**Gemeinde Steinmaur:** + +* Einwohner: Ca. 3'750 +* Steuerfuss: 112% + +**Infrastruktur:** + +* **Einkauf:** Volg und Hofläden im Ort, grösseres Angebot in Dielsdorf und Bülach +* **Naherholung:** Umgeben von Natur und idealen Möglichkeiten für Spaziergänge und Erholung + +**TRAUMHAFTE LAGE INMITTEN DER NATUR** + +Wir bieten Ihnen ein einmaliges, ruhig gelegenes Bauland in Steinmaur, direkt am idyllischen Fischbach. Das flache Grundstück eignet sich perfekt für Ihr zukünftiges Bauvorhaben und bietet einen unverbaubaren Blick auf die angrenzende Landwirtschaftszone. + +**Lage und Umgebung:** Steinmaur ist eine familienfreundliche Gemeinde mit etwa 3'750 Einwohnern und einem attraktiven Steuerfuss von 112%. Hier finden Sie die perfekte Balance zwischen ländlicher Ruhe und einer guten Anbindung an die Städte Zürich, Bülach und Dielsdorf. + +Einkaufsmöglichkeiten: Im Ort gibt es einen Volg sowie diverse Hofläden mit frischen, lokalen Produkten. Weitere Einkaufsmöglichkeiten finden Sie in den nahegelegenen Zentren von Dielsdorf und Bülach. + +**Naherholung:** Die Umgebung von Steinmaur bietet zahlreiche Naherholungsgebiete, die zu ausgedehnten Spaziergängen, Radtouren und Naturerkundungen einladen. Der Fischbach verleiht dem Grundstück eine besondere Idylle und sorgt für eine entspannte Atmosphäre direkt vor Ihrer Haustür. + +**Verkehrsanbindung:** Das Bauland besticht durch seine hervorragende Anbindung an den öffentlichen Verkehr. Der Bahnhof Steinmaur ist in 10 Minuten zu Fuss erreichbar, und die Bushaltestelle befindet sich nur 370 m vom Grundstück entfernt. So sind Sie schnell und bequem in den umliegenden Städten und Gemeinden unterwegs + +### Angaben zur Immobilie + +Verfügbar ab + +Nach Vereinbarung + +* * * + +Grundstücksfläche + +1’452.0 m² + +* * * + +Agentur +------- + + + +get living + +4.9 + +(39 Bewertungen) + +[Agenturprofil anzeigen](https://realadvisor.ch/de/immobilienagenturen/agentur-get-living-gmbh) +Sadegh Karkhaneh + +[Nummer anzeigen](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ) + +Ref. VKXW-42L8-590 + +Energy diagnostics +------------------ + +Energy consumption + +No data + +Greenhouse gas emmissions + +No data + +Ort +--- + +8162 Steinmaur(ZH) + +Nicht was Sie suchen? + +Entdecken Sie 0 ähnliche Angebote in Steinmaur + +[Inserate ansehen](https://realadvisor.ch/de/kaufen/gemeinde-steinmaur/grundstuck) + +1. [](https://realadvisor.ch/de) + +3. [Kaufen](https://realadvisor.ch/de/kaufen) + +5. [Grundstück](https://realadvisor.ch/de/kaufen/grundstuck) + +7. [Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck) + +9. [Bezirk Dielsdorf](https://realadvisor.ch/de/kaufen/bezirk-dielsdorf/grundstuck) + +11. [Steinmaur](https://realadvisor.ch/de/kaufen/gemeinde-steinmaur/grundstuck) + +13. [8162 Steinmaur](https://realadvisor.ch/de/kaufen/8162-steinmaur/grundstuck) + +15. Bauland zu verkaufen - 8162 Steinmaur + +Preis auf Anfrage + +CHF - / m² + +* * * + + + +get living + +4.9 + +(39 Bewertungen) + +[Agenturprofil anzeigen](https://realadvisor.ch/de/immobilienagenturen/agentur-get-living-gmbh) + +Ref. VKXW-42L8-590 + +[Nummer anzeigen](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ) + +* * * + +Anbieter kontaktieren Vorname * Nachname * -Firma * +E-Mail-Adresse * -Industrie * +Telefonnummer * -E-Mail * +69/3000 -Anmeldung senden +Anfrage abschicken -ValueOn +Ähnliche Inserate -Made in Switzerland | DSGVO-konform +[](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ#) -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) +vor 14 Tagen -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) +- [x] +[— 752 m² Grundstück • Bauland Wehntalerstrasse 28, 8181 Höri * Inklusive Baubewilligung * Geologisches Gutachten enthalten * 9 Tiefgaragenplätze * * * CHF 1’900’000.- CHF 2’527 / m² homegate.ch](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ#) +[](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ#) -=== https://www.valueon.ch/self-check === -ValueOn - Mehrwert dank digitaler Transformation +vor 28 Tagen -=============== +- [x] -[](https://www.valueon.ch/) +[Losinger Marazzi Industriebauland Kaffeestrasse, 8180 Bülach * Anpassbare Projektoptionen * Flexible Miete oder Eigentum * Weitere Grundstücksangebote erkunden * * * Auf Anfrage — immoscout24.ch](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ#) -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) +[](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ#) -🇩🇪DE +vor 28 Tagen -[Gespräch vereinbaren](https://www.valueon.ch/contact) +- [x] -🇩🇪DE +[Losinger Marazzi 17’582 m² Grundstück • Bauland 8157 Dielsdorf * Ideal für individuelle Projekte * Ausgezeichnete Verkehrsanbindung * Geräumiges Grundstück von 17'582 m² * * * Auf Anfrage — immoscout24.ch](https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ#) -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) +[](https://realadvisor.ch/de/kaufen/grundstuck/8172-niederglatt-zh-YMX9-JZX5) -Digital Readiness Check +vor 2 Monaten -Wie digital ist dein +- [x] -Unternehmen wirklich? -=========================================== - -In nur 7 Fragen erfährst du, wie zukunftsfit dein Unternehmen ist – inkl. individueller Einschätzung & konkreter Handlungsempfehlungen. - -Jetzt kostenlos testen - -Dauert nur 3 Minuten - -Frage 1 von 7 14% abgeschlossen - -STRATEGIE - -Wie werden in eurem Unternehmen aktuell Entscheidungen getroffen? ------------------------------------------------------------------ - -Intuitiv und erfahrungsbasiert - -Teilweise datenbasiert, aber oft ohne Systematik - -Wir nutzen regelmäßig Datenanalysen zur Entscheidungsfindung - -Unsere Entscheidungen basieren fast ausschließlich auf KPIs & Datenmodellen - -Zurück Weiter - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) - - - -=== https://www.valueon.ch/contact === -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Unser Kontakt -============= - -Lassen Sie uns gemeinsam Ihre digitale Transformation vorantreiben. - -Lassen Sie uns ins Gespräch kommen ----------------------------------- - -Sie haben Fragen zu unseren Dienstleistungen oder möchten mehr über unsere Expertise erfahren? Nutzen Sie das Kontaktformular oder kontaktieren Sie uns direkt – wir sind für Sie da. - -### Telefon - -[+41 44 943 70 40](tel:+41449437040) - -### E-Mail - -[office@valueon.ch](mailto:office@valueon.ch) - -### Adresse - -ValueOn AG - -Am Stadtrand 11 - -8600 Dübendorf - -Schweiz - -### Folgen Sie uns - -[](https://www.linkedin.com/company/valueon) - -Name * - -E-Mail * - -Telefon - -Unternehmen - -Nachricht * - -Nachricht senden - -* Pflichtfelder - -So finden Sie uns ------------------ - -Unser Büro befindet sich in Dübendorf, nur wenige Minuten von Zürich entfernt. - -### Anreise - -#### Mit dem Auto - -Ausreichend Parkplätze stehen direkt vor dem Gebäude zur Verfügung. - -#### Mit öffentlichen Verkehrsmitteln - -Vom Bahnhof Dübendorf erreichen Sie unser Büro bequem zu Fuß in ca. 10 Minuten oder mit dem Bus. - -ValueOn - -Made in Switzerland | DSGVO-konform - -📍 Dübendorf bei Zürich[✉️ office@valueon.ch](mailto:office@valueon.ch)[🔗 LinkedIn](https://www.linkedin.com/company/valueon) - -[Datenschutz](https://www.valueon.ch/privacy)|[Impressum](https://www.valueon.ch/imprint) - - - -=== https://www.valueon.ch/privacy === -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Datenschutzerklärung -==================== - -Die Betreiber dieser Seiten nehmen den Schutz Ihrer persönlichen Daten sehr ernst. Wir behandeln Ihre personenbezogenen Daten vertraulich und entsprechend den gesetzlichen Datenschutzvorschriften sowie dieser Datenschutzerklärung. - -Wenn Sie diese Website benutzen, werden verschiedene personenbezogene Daten erhoben. Personenbezogene Daten sind Daten, mit denen Sie persönlich identifiziert werden können. Die vorliegende Datenschutzerklärung erläutert, welche Daten wir erheben und wofür wir sie nutzen. Sie erläutert auch, wie und zu welchem Zweck das geschieht. - -**Wichtiger Hinweis:** Wir weisen darauf hin, dass die Datenübertragung im Internet (z. B. bei der Kommunikation per E-Mail) Sicherheitslücken aufweisen kann. Ein lückenloser Schutz der Daten vor dem Zugriff durch Dritte ist nicht möglich. - -Grundlegende Informationen --------------------------- - -### Verantwortliche Stelle - -Die verantwortliche Stelle für die Datenverarbeitung auf dieser Website ist: ValueOn AG, Am Stadtrand 11, 8600 Dübendorf, Schweiz, T +41 44 943 70 40, E-Mail: info@valueon.ch. Verantwortliche Stelle ist die natürliche oder juristische Person, die allein oder gemeinsam mit anderen über die Zwecke und Mittel der Verarbeitung von personenbezogenen Daten (z. B. Namen, E-Mail-Adressen o. Ä.) entscheidet. - -### Speicherdauer - -Löschersuchen geltend machen oder eine Einwilligung zur Datenverarbeitung widerrufen, werden Ihre Daten gelöscht, sofern wir keine anderen rechtlich zulässigen Gründe für die Speicherung Ihrer personenbezogenen Daten haben (z. B. steuer- oder handelsrechtliche Aufbewahrungsfristen); im letztgenannten Fall erfolgt die Löschung nach Fortfall dieser Gründe. - -### Auskunft, Löschung, Sperrung - -Sie haben jederzeit das Recht auf unentgeltliche Auskunft über Ihre gespeicherten personenbezogenen Daten, deren Herkunft und Empfänger und den Zweck der Datenverarbeitung sowie ein Recht auf Berichtigung, Sperrung oder Löschung dieser Daten. Hierzu sowie zu weiteren Fragen zum Thema personenbezogene Daten können Sie sich jederzeit unter der im Impressum angegebenen Adresse bzw. an die in der Datenschutzerklärung genannte verantwortliche Person an uns wenden. - -### Widerspruch gegen Werbe-E-Mails - -Der Nutzung von im Rahmen der Impressumspflicht veröffentlichten Kontaktdaten zur Übersendung von nicht ausdrücklich angeforderter Werbung und Informationsmaterialien wird hiermit widersprochen. Die Betreiber der Seiten behalten sich ausdrücklich rechtliche Schritte im Falle der unverlangten Zusendung von Werbeinformationen, etwa durch Spam-E-Mails, vor. - -Technische Datenverarbeitung ----------------------------- - -### Cookies - -Unsere Internetseiten verwenden so genannte "Cookies". Cookies sind kleine Textdateien und richten auf Ihrem Endgerät keinen Schaden an. Sie werden entweder vorübergehend für die Dauer einer Sitzung (Session-Cookies) oder dauerhaft (permanente Cookies) auf Ihrem Endgerät gespeichert. Session-Cookies werden nach Ende Ihres Besuchs automatisch gelöscht. Permanente Cookies bleiben auf Ihrem Endgerät gespeichert, bis Sie diese selbst löschen oder eine automatische Löschung durch Ihren Webbrowser erfolgt. - -### Server-Log-Dateien - -Der Provider der Seiten erhebt und speichert automatisch Informationen in so genannten Server-Log-Dateien, die Ihr Browser automatisch an uns übermittelt. Dies sind: Browsertyp und Browserversion, verwendetes Betriebssystem, Referrer URL, Hostname des zugreifenden Rechners, Uhrzeit der Serveranfrage, IP-Adresse. Eine Zusammenführung dieser Daten mit anderen Datenquellen wird nicht vorgenommen. - -### Anmelde- und Kontaktformulare - -Wenn Sie uns per Kontaktformular Anfragen zukommen lassen oder sich mit dem Anmeldeformular für unsere Veranstaltungen anmelden, werden Ihre Angaben aus den Formularen inklusive der von Ihnen dort angegebenen Kontaktdaten und Informationen zwecks Bearbeitung der Anfrage und für den Fall von Anschlussfragen bei uns gespeichert. Diese Daten geben wir nicht ohne Ihre Einwilligung weiter. - -### Newsletter-Daten - -Die Verarbeitung der in das Newsletteranmeldeformular eingegebenen Daten erfolgt ausschließlich auf Grundlage Ihrer Einwilligung (Art. 6 Abs. 1 lit. a DSGVO). Die erteilte Einwilligung zur Speicherung der Daten, der E-Mail-Adresse sowie deren Nutzung zum Versand des Newsletters können Sie jederzeit widerrufen, etwa über den "Austragen"-Link im Newsletter. - -Externe Dienste ---------------- - -### Hinweis zur Datenweitergabe in die USA und sonstige Drittstaaten - -Wir weisen darauf hin, dass in diesen Ländern kein mit der EU oder der Schweiz vergleichbares Datenschutzniveau garantiert werden kann. Beispielsweise sind US-Unternehmen dazu verpflichtet, personenbezogene Daten an Sicherheitsbehörden herauszugeben, ohne dass Sie als Betroffener hiergegen gerichtlich vorgehen könnten. - -### Nutzung von HubSpot CRM - -Wir nutzen Hubspot CRM auf dieser Website. Anbieter ist Hubspot Inc. 25 Street, Cambridge, MA 02141 USA. Hubspot CRM ermöglicht es uns unter anderem, bestehende und potenzielle Kunden sowie Kundenkontakte zu verwalten. Die Verwendung von Hubspot CRM erfolgt auf Grundlage von Art. 6 Abs. 1 lit. f DSGVO. - -### LinkedIn - -Diese Website nutzt Elemente des Netzwerks LinkedIn. Anbieter ist die LinkedIn Ireland Unlimited Company, Wilton Plaza, Wilton Place, Dublin 2, Irland. Bei jedem Abruf einer Seite dieser Website, die Elemente von LinkedIn enthält, wird eine Verbindung zu Servern von LinkedIn aufgebaut. - -### Google Analytics - -Diese Website nutzt Funktionen des Webanalysedienstes Google Analytics. Anbieter ist die Google Inc. 1600 Amphitheatre Parkway Mountain View, CA 94043, USA. Google Analytics verwendet sog. "Cookies". Das sind Textdateien, die auf Ihrem Computer gespeichert werden und die eine Analyse der Benutzung der Website durch Sie ermöglichen. - -### Leadinfo - -Diese Website nutzt den Service des Anbieters Leadinfo B.V. mit Sitz in Rotterdam. Dieser Service zeigt uns auf Grundlage von IP-Adressen öffentlich zugängliche Unternehmensdaten an, wie z.B. Firmennamen und -adressen. Die Erkennung von Unternehmen basiert einzig und allein auf IP-Adressen. - -Fragen zum Datenschutz? ------------------------ - -Bei Fragen zum Datenschutz oder zur Verarbeitung Ihrer Daten kontaktieren Sie uns gerne. - -ValueOn AG - -Am Stadtrand 11, 8600 Dübendorf, Schweiz - -T +41 44 943 70 40 - -info@valueon.ch - - - -=== https://www.valueon.ch/imprint === -ValueOn - Mehrwert dank digitaler Transformation - -=============== - -[](https://www.valueon.ch/) - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about) - -🇩🇪DE - -[Gespräch vereinbaren](https://www.valueon.ch/contact) - -🇩🇪DE - -[Home](https://www.valueon.ch/)[Leistungen](https://www.valueon.ch/services)[Projekte](https://www.valueon.ch/projects)[Vernissage](https://www.valueon.ch/vernissage)[Fit-Check](https://www.valueon.ch/self-check)[Über uns](https://www.valueon.ch/about)[Gespräch vereinbaren](https://www.valueon.ch/contact) - -Impressum -========= - -Angaben gemäß den gesetzlichen Bestimmungen - -Inhaber der Website und verantwortlich für den Inhalt ------------------------------------------------------ - -### Unternehmen - -ValueOn AG - -Dominic Largo - -### Kontakt - -Am Stadtrand 11 - -8600 Dübendorf - -+41 44 943 70 40 - -[info@valueon.ch](mailto:info@valueon.ch) - -### Rechtliche Hinweise - -Alle Inhalte dieser Website sind urheberrechtlich geschützt. Jede Verwendung, Vervielfältigung oder Weiterverbreitung bedarf der ausdrücklichen schriftlichen Genehmigung der ValueOn AG. - -### Haftungsausschluss - -Die Inhalte unserer Seiten wurden mit größter Sorgfalt erstellt. Für die Richtigkeit, Vollständigkeit und Aktualität der Inhalte können wir jedoch keine Gewähr übernehmen. - -### Externe Links - -Unser Angebot enthält Links zu externen Webseiten Dritter, auf deren Inhalte wir keinen Einfluss haben. Deshalb können wir für diese fremden Inhalte auch keine Gewähr übernehmen. - -### Haben Sie Fragen? - -Bei rechtlichen Fragen oder Anliegen kontaktieren Sie uns gerne direkt. - -[Kontakt aufnehmen](mailto:info@valueon.ch) - - - -=== https://www.moneyhouse.ch/de/terms === -# Nutzungsbedingungen - -Version gültig ab 1. Januar 2020 bis Widerruf - -Die vorliegenden Nutzungsbedingungen regeln die Geschäftsbeziehungen zwischen der Neue Zürcher Zeitung AG bezogen auf ihr Produkt Moneyhouse (nachfolgend «Moneyhouse» genannt) und dem Kunden (nachfolgend «Kunde» genannt). Diese Bestimmungen sind für alle Plattformen von Moneyhouse gültig, insbesondere für moneyhouse.ch. Abweichende AGB des Kunden finden keine Anwendung, auch wenn Moneyhouse nicht ausdrücklich widerspricht. - -**1. Grundlage der Geschäftsbeziehung** - -Ein Vertrag über eine der unterschiedlichen Dienstleistungen von Moneyhouse berechtigt den Kunden – nach Leistung des vereinbarten Entgelts – zur Inanspruchnahme der offerierten Leistungen. Dabei gelangen die jeweils gültigen Tarife und Konditionen sowie die vorliegenden Nutzungsbedingungen sowie allenfalls weitere, besondere Geschäftsbedingungen und Vertragsgrundlagen zur Anwendung. - -**2. Vertragsinhalt** - -Gegenstand der Leistungserbringung von Moneyhouse und deren Partnern sind Informationsdienstleistungen. Sie beinhalten in keinem Falle irgendwelche Rechte an Software, Lizenzrechte oder sonstige Immaterialgüterrechte. - -**3. Vertragsdauer und Verlängerung** - -Die Online-Dienstleistungen wie beispielsweise (keine abschliessende Aufzählung) die Premium-Mitgliedschaft oder das Bonitäts-Abo können ab Abschluss des Vertrags in Anspruch genommen werden und gelten für die jeweils abgeschlossene Vertragsdauer. - -Die Verträge betreffend die Dienstleistungen von moneyhouse.ch erneuern sich bei Ablauf stillschweigend um die vereinbarte Vertragsdauer, sofern nicht eine Partei einen Tag vor Ablauf der Vertragsdauer den Vertrag wie unter «Mein Konto» beschrieben kündigt. Davon ausgeschlossen sind etwaige Probe-Abonnements, welche sich auf die beim Abschluss definierte Dauer und zum vorab kommunizierten Preis verlängern. - -Sollte sich der Kunde mit Zahlungen im Verzug befinden oder gegen die vorliegenden AGB verstossen, ist Moneyhouse zur sofortigen Auflösung des Vertragsverhältnisses berechtigt. - -Wird der Vertrag erneuert, so gilt automatisch die allfällig neue Preisliste, welche dem Kunden auf Anfrage zur Verfügung gestellt wird. Der vorausbezahlte Abonnementpreis ist für den Zeitraum der Vorauszahlung garantiert und kann nicht erhöht werden. Abonnementpreiserhöhungen werden vor ihrer Wirksamkeit auf den jeweiligen Websites von Moneyhouse angekündigt. Einzelbenachrichtigungen erfolgen nicht. Entsprechend kann bei Nichtakzeptieren der Preiserhöhung der Vertrag zu den bisherigen Konditionen auf Ende der Laufzeit unter Einhaltung der Kündigungsfristen gekündigt werden. Alle von Moneyhouse genannten oder in etwaigen Tariflisten aufgeführten Preise sind Nettopreise ohne Mehrwertsteuer in Schweizer Franken. - -**4. Nutzungsbedingungen** - -**4.1. Nutzungsumfang** - -Die Produkte dienen ausschliesslich der persönlichen, nicht kommerziellen Nutzung durch natürliche und juristische Personen – eine weitergehende oder abweichende Nutzung und deren Verbreitung in anderen Systemen ist nur mit ausdrücklicher Zustimmung von Moneyhouse gestattet und kann jederzeit widerrufen werden. - -**4.2. Registrierung** - -Die Registrierung eines Benutzerkontos erfordert unter anderem einen Vor- und Nachnamen, eine Adresse sowie weitere Informationen, abhängig von der Art der gewünschten Nutzung (privat oder geschäftlich). Das automatisierte Anlegen von Benutzerkonten ist nicht gestattet. Der Kunde verpflichtet sich, seine Zugangsdaten vertragskonform zu verwenden und diese ohne schriftliche Zustimmung von Moneyhouse keinem Dritten zugänglich zu machen. Der Nutzer ist für den Schutz seiner Zugangsdaten verantwortlich. - -**4.3. Leistungen Moneyhouse** - -Inhalt und Umfang der dem Nutzer zur Verfügung gestellten Produkte bestimmen sich nach der jeweiligen Nutzungsform (zum Beispiel: registrierter oder nicht registrierter Kunde, kostenlose oder kostenpflichtige Nutzung etc.), einem allfällig bestehenden Vertragsverhältnis und den vorliegenden Nutzungsbedingungen und der Datenschutzerklärung. - -Die Online-Dienste sind in der Regel an 7 Tagen während 24 Stunden verfügbar. Moneyhouse behält sich das Recht vor, diese Betriebszeiten einzuschränken und/oder aus technischen Gründen vorübergehend auszusetzen sowie die Produkte jederzeit zu modifizieren. Die Produkte unterliegen laufenden Änderungen und Anpassungen. Auch können Software-Updates oder technische Weiterentwicklungen Inhalt und Umfang der Produkte jederzeit ausbauen. - -**4.4. Fälligkeit, Zahlungsverzug und Zahlungsarten** - -Die von Moneyhouse gestellten Rechnungen sind, sofern keine Zahlungsfrist vermerkt ist und nichts anderes vereinbart wurde, sofort fällig. Ist der Kunde mit seiner Zahlung in Verzug, treten die gesetzlichen Verzugsfolgen ein und mit der zweiten Mahnung Mahnkosten von CHF 20.–. Darüber hinaus hat Moneyhouse das Recht, externe Partner zur Bearbeitung des Inkassos hinzuzuziehen. Ausserdem trägt der Kunde alle weiteren Kosten, die durch seinen Zahlungsverzug entstehen. - -Es werden die folgenden Zahlungsarten bei kostenpflichtigen Produkten angeboten: Kreditkarte oder per Rechnung. Moneyhouse behält sich das Recht vor, die verschiedenen Zahlungsmittel nach eigenem Ermessen zu ändern, zu ergänzen oder zu streichen. Es besteht kein Anspruch auf Bezahlung mit einem bestimmten Zahlungsmittel. Die Rechnung per E-Mail kann via E-Banking beglichen werden. Der Vertrag zwischen Moneyhouse und dem Kunden kommt entweder mit der Bestellung durch den Kunden über einen Verkaufsmitarbeiter oder aber mit der Auftrags-, der Bestellungs- sowie/oder der Zahlungsbestätigung durch Moneyhouse zustande. - -**4.5. Haftung von Moneyhouse** - -Moneyhouse ist bemüht, den eigenen Datenbestand sowie jenen von Partnern zu pflegen. Der Kunde nimmt zur Kenntnis, dass Daten und Informationen bis zu einem gewissen Masse trotzdem Fehler enthalten können. Vorbehaltlich gesetzlicher Vorgaben bzw. einer anderweitigen schriftlichen Vereinbarung schliessen Moneyhouse und deren Partner jegliche Garantie und Gewährleistung, insbesondere für Vollständigkeit, Aktualität, Richtigkeit, Verwertbarkeit oder Eignung der Daten zu einem bestimmten Zweck, aus. Empfehlungen und Erfahrungswerte wie Ratings, Einteilung in Risikoklassen und Scorewerte sind ausnahmslos unverbindlich, womit auch dafür jede Gewähr ausgeschlossen ist. - -Moneyhouse haftet nur für Verzögerungen und für Fehler, sofern ihr ein vorsätzliches oder grobfahrlässiges Handeln nachgewiesen werden kann. Sie haftet insbesondere nicht für Verfehlungen und Versäumnisse Dritter. Für Schäden, die dem Kunden durch die Nutzung der Produkte entstehen, haftet Moneyhouse nur, falls ihr grobfahrlässiges oder vorsätzliches Verhalten nachgewiesen werden kann. Soweit gesetzlich zulässig, ist die Haftung von Moneyhouse in jedem Fall auf denjenigen Betrag beschränkt, welcher dem Kunden für das entsprechende Produkt in Rechnung gestellt wurde. In keinem Fall haftet Moneyhouse für Folgeschäden oder entgangenen Gewinn. - -Moneyhouse haftet nicht für schadhafte Technik und für durch Computerviren, Spionageprogramme und/oder andere schädliche Computerprogramme (Malware, Spyware) bewirkte Schäden. Es besteht auch keine Haftung für die Folgen von Betriebsunterbrüchen, die durch Störungen aller Art entstehen oder die der Störungsbehebung, der Wartung und der Einführung neuer Technologien dienen. - -Dieselben Haftungsbeschränkungen gelten auch für die Mitarbeiter, Vertreter und Erfüllungsgehilfen von Moneyhouse. - -**4.6. Sorgfaltspflicht und Haftung des Kunden** - -Alle Informationen, Auskünfte und Berichte von Moneyhouse sind streng vertraulich zu behandeln. Benutzung und Verwendung dieser Informationen sind nur dem Kunden und dessen allfälligen Angestellten für deren eigene Zwecke gestattet. Der Kunde verpflichtet sich, sein Benutzerkonto und im Speziellen seine Zugangsdaten (Passwort) nicht anderen Personen – auch nicht im gleichen Unternehmen – zur Verfügung zu stellen, sie zu schützen und vor Zugriffen Dritter sicher aufzubewahren, seine Kontaktinformationen und sonstigen Angaben bei der Registrierung wahrheitsgetreu auszufüllen und seinen Zugang nicht missbräuchlich oder übermässig zu nutzen. - -Der Kunde verpflichtet sich sodann, die gesetzlichen Datenschutzvorschriften sowie die Vorschriften gemäss Datenschutzerklärung von Moneyhouse einzuhalten. Der Kunde ist für jeden Schaden verantwortlich, der aus einer Nichtbeachtung seiner Sorgfaltspflichten oder einem Verstoss gegen Urheberrechte entsteht, und zwar sowohl gegenüber Moneyhouse als auch deren Partnern. - -**4.7. Auskünfte und Identifikation** - -Der Kunde nimmt zur Kenntnis, dass er sich und damit sein persönliches Kundenkonto für das Aufrufen von Profilen zu Privatpersonen und die Abfrage von Bonitätsauskünften, Zahlungsverhaltenauskünften und Wirtschaftsauskünften mittels eines Identitätsnachweises (ID, Reisepass, Führerschein) einmalig verifizieren muss. Zudem dürfen die zuvor genannten Auskünfte nur abgefragt werden, wenn ein berechtigtes Interesse vorliegt. Das Vorliegen einer solchen Berechtigung kann nachträglich durch Moneyhouse überprüft werden. Der Kunde muss Moneyhouse innerhalb von 10 Tagen nach Erhalt der Aufforderung das Vorliegen einer entsprechenden Berechtigung nachweisen. Für Betreibungsauskünfte muss durch den Kunden grundsätzlich ein den vom jeweiligen Betreibungsamt vorgegebenen Bedingungen entsprechender Interessensnachweis übermittelt werden. Alle rechtlichen und vertraglichen Konsequenzen, die durch die Nichtübermittlung, einen nicht ausreichenden oder nicht vorhandenen Interessensnachweises resultieren, trägt der Kunde. Bei Zuwiderhandlung gegen diese Vorschrift ist Moneyhouse berechtigt, die Vertragsbeziehung zum Kunden unmittelbar und entschädigungslos zu beenden. - -Weitere Informationen hierzu können jederzeit [hier](https://www.moneyhouse.ch/de/howto/reports) eingesehen werden. - -**4.8. Urheber- und weitere immaterielle Rechte** - -Moneyhouse behält sich bezüglich der Produkte inklusive Layout, Software und deren Inhalten sämtliche Urheber- und sonstigen Schutzrechte vor. Es ist untersagt, die Webseiten von Moneyhouse oder deren Inhalte ganz oder teilweise mittels technischer Hilfsmittel darzustellen (z.B. „Framing“). - -Eigentums- und Urheberrechte an allen zur Verfügung gestellten Daten und Dienstleistungen verbleiben bei Moneyhouse. Nutzungsrechte werden dem Kunden nur in dem Ausmass eingeräumt, als dies zur Erfüllung des Vertragszweckes zwingend notwendig ist. Im Zweifel werden nur Nutzungsrechte und keine Urheber- und Eigentumsrechte übertragen. Der Kunde ist zur Weitergabe der Daten an Dritte nicht berechtigt. - -**4.9. Vertretungsberechtigung** - -Für die Leistungserbringung und insbesondere die Abwicklung im Rahmen einer Premium-Mitgliedschaft oder anderen spezifischen Leistungen gilt gegenüber Moneyhouse, unabhängig von der im Handelsregister eingetragenen Zeichnungsberechtigung, der oder die Mitarbeiter/in des Kunden als zur Vertretung befugt und ermächtigt, welche/r mit Moneyhouse mündlich, telefonisch oder schriftlich (durch Brief, Fax oder E-Mail) kommunizierte. Der Kunde trägt das Risiko für ungenügende Vertretungsberechtigung oder fehlende Legitimation seiner Mitarbeiter. - -**4.10. API** - -Moneyhouse stellt dem Kunden eine Schnittstelle (API) zur Kommunikation mit Software von Drittanbietern zur Verfügung. Sofern nicht schriftlich anders vereinbart, hat Moneyhouse in jedem Fall das Recht, den Zugriff auf diese Schnittstelle aus wichtigem Grund jederzeit teilweise oder ganz einzuschränken. Ein wichtiger Grund liegt insbesondere vor, wenn Mitbewerber von Moneyhouse zum Schaden von Moneyhouse über die Schnittstelle Daten migrieren oder die Infrastruktur über Anfragen über diese Schnittstelle zu stark belastet wird. Der Kunde verpflichtet sich, alle von Moneyhouse gelieferten Daten innert 10 Tagen nach Beendigung des Vertrages zu löschen und die Löschung Moneyhouse schriftlich zu bestätigen. - -**4.11. Kommunikationsmittel und Übermittlungsfehler** - -Moneyhouse ist berechtigt, alle Mitteilungen an den Kunden an die auf dem Vertrag aufgeführte und vom Kunden angegebene Zustell- oder E-Mail-Adresse, Telefon- und/oder Faxnummer zu richten. Änderungen sind Moneyhouse vom Kunden rechtzeitig und schriftlich (durch Brief, Fax oder E-Mail oder mittels Änderung im persönlichen Bereich „Mein Konto“ auf moneyhouse.ch) mitzuteilen. Der Kunde trägt das Risiko für Schäden aus der Benutzung von Kommunikations- und/oder Transportmitteln einschliesslich Verlust, Verspätung oder falsche Übermittlung. - -**4.12. Gerichtsstand und anwendbares Recht** - -Der Gerichtsstand befindet sich am Sitz der Neue Zürcher Zeitung AG in Zürich ZH. Es gilt Schweizer Recht. Die Neue Zürcher Zeitung AG hat das Recht, den Kunden bei einem anderen zuständigen Gericht einzuklagen. - -**4.13. Anpassungen** - -Wir behalten uns ausdrücklich das Recht vor, die vorliegenden Nutzungsbedingungen jederzeit zu ändern. Werden derartige Anpassungen vorgenommen, veröffentlichen wir diese umgehend auf unserer Webseite. Es liegt in Ihrer Verantwortung, sich über die aktuell geltende Fassung der Datenschutzerklärung auf unserer Webseite zu informieren. Wir empfehlen Ihnen daher, diese Datenschutzerklärung und die Nutzungsbedingungen regelmässig zu konsultieren. - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](/de/terms)[Datenschutz |](/de/privacy)[Impressum](/de/imprint) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU\_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - - -=== https://www.moneyhouse.ch/de/imprint === -Impressum - Moneyhouse - - - - - - - -[](/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](/de/register?redirectUrl=%2Fimprint) - -[Anmelden](/de/login?redirectUrl=%2Fimprint) - -[Erweiterte Suche](/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](/de/overview)[Voller Datenzugriff](/de/membership)[Public API](/de/apiintegration)[Corporate-Angebote](/de/enterprise)[Firmenlisten](/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](/de/businessreports)[Bonitätsauskunft](/de/creditrating)[Zahlungsverhalten](/de/paymentbehaviour)[Wirtschaftsauskunft](/de/economicinformation)[Beteiligungsauskunft](/de/shareholderinformation)[Betreibungsauskunft](/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](/de/commercialregister/foundation)[Firma liquidieren](/de/commercialregister/liquidation)[Änderung Eintrag](/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](/de/datasources)[Kontakt](/de/contact) - -- [KMU\_today](https://www.kmutoday.ch/) -[Regio-News](/de/region)[Hilfebereich](/de/howto) - -[AGB](/de/terms)[Datenschutz](/de/privacy)[Impressum](/de/imprint) - -[](/de/) - -[Kostenlos registrieren](/de/register?redirectUrl=%2Fimprint) - -[Regio-News](/de/region)[KMU\_today](https://www.kmutoday.ch/) - -[Anmelden](/de/login?redirectUrl=%2Fimprint)[Hilfe](/de/howto) - -DE - -- [Deutsch](javascript:void(0)) -- [Français](javascript:void(0)) -- [Italiano](javascript:void(0)) -- [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](/de/advancedsearch) - -**Datenzugriff** - -- [Übersicht Mitgliedschaften](/de/overview) -- [Voller Datenzugriff](/de/membership) -- [Public API](/de/apiintegration) -- [Corporate-Angebote](/de/enterprise) -- [Firmenlisten](/de/companieslists) -- [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -- [Übersicht](/de/businessreports) -- [Bonitätsauskunft](/de/creditrating) -- [Zahlungsverhalten](/de/paymentbehaviour) -- [Wirtschaftsauskunft](/de/economicinformation) -- [Beteiligungsauskunft](/de/shareholderinformation) -- [Betreibungsauskunft](/de/paymentcollection) - -**Handelsregister** - -- [Firma gründen](/de/commercialregister/foundation) -- [Firma liquidieren](/de/commercialregister/liquidation) -- [Änderung Eintrag](/de/commercialregister/services) - -**Unternehmen** - -- [Über uns](/de/about) -- [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -- [Datenquellen](/de/datasources) -- [Kontakt](/de/contact) - -- [Anmelden](/de/login?redirectUrl=%2Fimprint) -- [Hilfebereich](/de/howto) - -- [Sprache wechseln](javascript:void(0)) -- [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -- [KMU\_today](https://www.kmutoday.ch/) -- [Regio-News](/de/region) - - - -# Impressum - -**Moneyhouse** -Neue Zürcher Zeitung AG -Falkenstrasse 11 -CH-8008 Zürich - -[Kontaktieren Sie uns](https://www.moneyhouse.ch/de/contact/contactform) - -Sitz: Zürich -UID: CHE-106.838.812 -Handelsregisteramt: Kanton Zürich - -**Datenzugriff** - -- [Übersicht Mitgliedschaften](/de/overview) -- [Voller Datenzugriff](/de/membership) -- [Public API](/de/apiintegration) -- [Corporate-Angebote](/de/enterprise) -- [Firmenlisten](/de/companieslists) -- [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -- [Übersicht](/de/businessreports) -- [Bonitätsauskunft](/de/creditrating) -- [Zahlungsverhalten](/de/paymentbehaviour) -- [Wirtschaftsauskunft](/de/economicinformation) -- [Beteiligungsauskunft](/de/shareholderinformation) -- [Betreibungsauskunft](/de/paymentcollection) - -**Handelsregister** - -- [Firma gründen](/de/commercialregister/foundation) -- [Firma liquidieren](/de/commercialregister/liquidation) -- [Änderung Eintrag](/de/commercialregister/services) - -**Unternehmen** - -- [Über uns](/de/about) -- [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -- [Datenquellen](/de/datasources) -- [Kontakt](/de/contact) - -- [Anmelden](/de/login?redirectUrl=%2Fimprint) -- [Hilfebereich](/de/howto) - -- [Sprache wechseln](javascript:void(0)) -- [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -- [KMU\_today](https://www.kmutoday.ch/) -- [Regio-News](/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](/de/companydirectory/ag/a/a_) - -[AI](/de/companydirectory/ai/a/a_) - -[AR](/de/companydirectory/ar/a/a_) - -[BL](/de/companydirectory/bl/a/a_) - -[BS](/de/companydirectory/bs/a/a_) - -[BE](/de/companydirectory/be/a/a_) - -[FR](/de/companydirectory/fr/a/a_) - -[GE](/de/companydirectory/ge/a/a_) - -[GL](/de/companydirectory/gl/a/a_) - -[GR](/de/companydirectory/gr/a/a_) - -[JU](/de/companydirectory/ju/a/a_) - -[LU](/de/companydirectory/lu/a/a_) - -[NE](/de/companydirectory/ne/a/a_) - -[NW](/de/companydirectory/nw/a/a_) - -[OW](/de/companydirectory/ow/a/a_) - -[SH](/de/companydirectory/sh/a/a_) - -[SZ](/de/companydirectory/sz/a/a_) - -[SO](/de/companydirectory/so/a/a_) - -[SG](/de/companydirectory/sg/a/a_) - -[TI](/de/companydirectory/ti/a/a_) - -[TG](/de/companydirectory/tg/a/a_) - -[UR](/de/companydirectory/ur/a/a_) - -[VD](/de/companydirectory/vd/a/a_) - -[VS](/de/companydirectory/vs/a/a_) - -[ZG](/de/companydirectory/zg/a/a_) - -[ZH](/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](/de/persondirectory/a/aa) - -[B](/de/persondirectory/b/ba) - -[C](/de/persondirectory/c/ca) - -[D](/de/persondirectory/d/da) - -[E](/de/persondirectory/e/ea) - -[F](/de/persondirectory/f/fa) - -[G](/de/persondirectory/g/ga) - -[H](/de/persondirectory/h/ha) - -[I](/de/persondirectory/i/ia) - -[J](/de/persondirectory/j/ja) - -[K](/de/persondirectory/k/ka) - -[L](/de/persondirectory/l/la) - -[M](/de/persondirectory/m/ma) - -[N](/de/persondirectory/n/na) - -[O](/de/persondirectory/o/oa) - -[P](/de/persondirectory/p/pa) - -[Q](/de/persondirectory/q/qa) - -[R](/de/persondirectory/r/ra) - -[S](/de/persondirectory/s/sa) - -[T](/de/persondirectory/t/ta) - -[U](/de/persondirectory/u/ua) - -[V](/de/persondirectory/v/va) - -[W](/de/persondirectory/w/wa) - -[X](/de/persondirectory/x/xa) - -[Y](/de/persondirectory/y/ya) - -[Z](/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](/de/terms)[Datenschutz |](/de/privacy)[Impressum](/de/imprint) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU\_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/imprint) - -[Startseite](/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/imprint) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -[Premium-Mitglied werden](/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/imprint)[Anmelden](/de/login?redirectUrl=%2Fimprint) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/imprint)[Anmelden](/de/login?redirectUrl=%2Fimprint) - - - - - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Sonstige - -Kantone hinzufügen oder löschen: - -Kanton -Aargau -Appenzell I. Rh. -Appenzell A. Rh. -Bern -Basel-Landschaft -Basel-Stadt -Freiburg -Genf -Glarus -Graubünden -Jura -Luzern -Neuenburg -Nidwalden -Obwalden -St. Gallen -Schaffhausen -Solothurn -Schwyz -Thurgau -Tessin -Uri -Waadt -Wallis -Zug -Zürich - -[Bestätigen](javascript:void(0)) - - -=== https://www.moneyhouse.ch/de/ === -Moneyhouse - Handelsregister- & Wirtschaftsinformationen - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/#)[Save + Exit](https://www.moneyhouse.ch/de/#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2F) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2F) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -Smart Data für KMU -================== - -Schweizer Handelsregister- und Wirtschaftsinformationen. - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -749'770 - -aktive Firmen - -288'251 - -Verwaltungsräte - -292'760 - -Geschäftsführer - -141 - -neue Firmen pro Tag - -Voller Zugriff - -Voller Zugriff auf alle Funktionen und Informationen zu Firmen und Personen - -* Kontaktdetails, Firmenkennzahlen und Management -* Zugang zu Bonitätsauskünften (1 Auskunft inklusive) -* Unbegrenzt Firmen, Personen und Themen folgen -* Verbindungen zwischen Firmen und Personen im Netzwerk erkennen -* Erweiterte Suchfunktion zu Firmen, Personen, Marken und Jobs in der gesamten Datenbank -* Unbegrenzt Firmen- und Personendossiers, druckfertig als PDF -* Keine Werbung - -ab - -CHF 79.00 - -[Jetzt entdecken](https://www.moneyhouse.ch/de/membership) - -Beschränkter Zugriff - -Beschränkter Zugriff auf Funktionen und Informationen zu Firmen und Personen - -* 2 Firmen oder Personen folgen mit E-Mail-Benachrichtigung -* 2 kostenlose Firmen- oder Personendossiers, druckfertig als PDF -* Alle Markeneinträge von Firmen ansehen -* Aktuelles Management -* Adresse, Hauptsitz und Standorte -* Handelsregister-Nummer, Firmenzweck und Kapital -* Das neueste aus Ihrer Region als Newsletter - -kostenlos - -[Jetzt entdecken](https://www.moneyhouse.ch/de/register?redirectUrl=%2F) - -[Hier alle Details zu den Mitgliedschaften vergleichen](https://www.moneyhouse.ch/de/overview) - - - - - -[](https://www.moneyhouse.ch/de/kmuplus) - - - -[](https://www.moneyhouse.ch/de/kmuplus) - -Umfassende Auskünfte --------------------- - -Schützen Sie sich vor finanziellen Schäden und erhalten Sie Klarheit über Ihre Kunden und Geschäftspartner. - -* Einschätzung der Bonität mit Ampel -* Zahlungsverhalten der letzten Rechnungen -* Umfassende Auskunft über die wirtschaftliche Situation einer Firma -* Übersicht über aktuelle und vergangene Betreibungsverfahren - -[Mehr Informationen](https://www.moneyhouse.ch/de/businessreports) - - - - - -Umfassende Auskünfte --------------------- - -Schützen Sie sich vor finanziellen Schäden und erhalten Sie Klarheit über Ihre Kunden und Geschäftspartner. - -* Einschätzung der Bonität mit Ampel -* Zahlungsverhalten der letzten Rechnungen -* Umfassende Auskunft über die wirtschaftliche Situation einer Firma -* Übersicht über aktuelle und vergangene Betreibungsverfahren - -[Mehr Informationen](https://www.moneyhouse.ch/de/businessreports) - - - -Public API ----------- - -Geben Sie Ihren Entwicklern über die API von Moneyhouse den Zugang zu unserer Datenbank und integrieren Sie unsere Wirtschaftsinformationen direkt in Ihre IT-Umgebung. - -[Mehr erfahren](https://www.moneyhouse.ch/de/apiintegration) - - - -Handelsregister ---------------- - -Neuer Verwaltungsrat, neue Adresse? Was immer Sie im Handelsregister ändern müssen, wir sorgen für den korrekten Eintrag. Schnell und einfach mit unserem Online-Tool. - -[Mehr erfahren](https://handelsregister.moneyhouse.ch/de/?itm_campaign=traderegister&itm_content=link-homepage&itm_medium=referral&itm_source=moneyhouse.ch) - - - -Regio-News ----------- - -Was immer in Ihrer Region auch passiert: Hier erfahren Sie es zuerst. Sehen Sie täglich alle Neuigkeiten aus Ihrer Region oder lesen Sie im Newsletter die Zusammenfassung. - -[Mehr erfahren](https://www.moneyhouse.ch/de/region) - -Neue Schweizer Firmen vom 01.10.2025 ------------------------------------- - -[Eren Gastro und Handels GmbH](https://www.moneyhouse.ch/de/company/eren-gastro-und-handels-gmbh-1844900481) - -Hohengasse 12 | 3400 Burgdorf -[Nemain SA](https://www.moneyhouse.ch/de/company/nemain-sa-5769974371) - -Via al Ruscello 11 | 6962 Viganello - -[OptimalPSI AG](https://www.moneyhouse.ch/de/company/optimalpsi-ag-20446796181) - -Picassoplatz 4 | 4052 Basel -[VIRA Communication AG](https://www.moneyhouse.ch/de/company/vira-communication-ag-4933540921) - -Piazzetta San Carlo 2 | 6900 Lugano - -[mehr anzeigen](javascript:void(0))[weniger anzeigen](javascript:void(0)) - -[mehr anzeigen](https://www.moneyhouse.ch/de/newcompanieslist) - -Konkurs- und Liquidationsmeldungen vom 01.10.2025 -------------------------------------------------- - -[Andro-Data AG in Liquidation](https://www.moneyhouse.ch/de/company/andro-data-ag-21156000641) - -Lindenfeldstrasse 10 | 6006 Luzern -[Huddle Makers Sàrl en liquidation](https://www.moneyhouse.ch/de/company/huddle-makers-sarl-12625588561) - -Avenue Charles-Dickens 2 | 1006 Lausanne - -[Immeubles P. Luder SA en liquidation](https://www.moneyhouse.ch/de/company/immeubles-p-luder-sa-5434200431) - -Coin des Bois 6 | 2733 Pontenet -[LE LABO traiteur, Nguele Evina](https://www.moneyhouse.ch/de/company/le-labo-traiteur-nguele-evina-6298641) - -Route d'Yvonand 22a | 1522 Lucens - -[mehr anzeigen](javascript:void(0))[weniger anzeigen](javascript:void(0)) - -[mehr anzeigen](https://www.moneyhouse.ch/de/bankruptcieslist) - -Aktuelle News aus Ihrer Region ------------------------------- - -Dies sind aktuell die Top-Regionen: - -* [Zürich](https://www.moneyhouse.ch/de/region/zuerich/uebersicht) -* [Region Zürich](https://www.moneyhouse.ch/de/region/zuerich/uebersicht) -* [Bern-Mittelland](https://www.moneyhouse.ch/de/region/bern-mittelland/uebersicht) -* [Region Bern-Mittelland](https://www.moneyhouse.ch/de/region/bern-mittelland/uebersicht) -* [Baden](https://www.moneyhouse.ch/de/region/baden/uebersicht) -* [Region Baden](https://www.moneyhouse.ch/de/region/baden/uebersicht) -* [Winterthur](https://www.moneyhouse.ch/de/region/winterthur/uebersicht) -* [Region Winterthur](https://www.moneyhouse.ch/de/region/winterthur/uebersicht) -* [Basel-Stadt](https://www.moneyhouse.ch/de/region/basel-stadt/uebersicht) -* [Region Basel-Stadt](https://www.moneyhouse.ch/de/region/basel-stadt/uebersicht) -* [Horgen](https://www.moneyhouse.ch/de/region/horgen/uebersicht) -* [Region Horgen](https://www.moneyhouse.ch/de/region/horgen/uebersicht) -* [Arlesheim](https://www.moneyhouse.ch/de/region/arlesheim/uebersicht) -* [Region Arlesheim](https://www.moneyhouse.ch/de/region/arlesheim/uebersicht) -* [Oberaargau](https://www.moneyhouse.ch/de/region/oberaargau/uebersicht) -* [Region Oberaargau](https://www.moneyhouse.ch/de/region/oberaargau/uebersicht) -* [St. Gallen](https://www.moneyhouse.ch/de/region/stgallen/uebersicht) -* [Region St. Gallen](https://www.moneyhouse.ch/de/region/stgallen/uebersicht) - -* [Meilen](https://www.moneyhouse.ch/de/region/meilen/uebersicht) -* [Region Meilen](https://www.moneyhouse.ch/de/region/meilen/uebersicht) -* [Dielsdorf](https://www.moneyhouse.ch/de/region/dielsdorf/uebersicht) -* [Region Dielsdorf](https://www.moneyhouse.ch/de/region/dielsdorf/uebersicht) -* [Bülach](https://www.moneyhouse.ch/de/region/buelach/uebersicht) -* [Region Bülach](https://www.moneyhouse.ch/de/region/buelach/uebersicht) -* [Hinwil](https://www.moneyhouse.ch/de/region/hinwil/uebersicht) -* [Region Hinwil](https://www.moneyhouse.ch/de/region/hinwil/uebersicht) -* [Luzern-Stadt](https://www.moneyhouse.ch/de/region/luzern-stadt/uebersicht) -* [Region Luzern-Stadt](https://www.moneyhouse.ch/de/region/luzern-stadt/uebersicht) -* [Rheintal](https://www.moneyhouse.ch/de/region/rheintal/uebersicht) -* [Region Rheintal](https://www.moneyhouse.ch/de/region/rheintal/uebersicht) -* [Sursee](https://www.moneyhouse.ch/de/region/sursee/uebersicht) -* [Region Sursee](https://www.moneyhouse.ch/de/region/sursee/uebersicht) -* [Uster](https://www.moneyhouse.ch/de/region/uster/uebersicht) -* [Region Uster](https://www.moneyhouse.ch/de/region/uster/uebersicht) -* [Luzern-Land](https://www.moneyhouse.ch/de/region/luzern-land/uebersicht) -* [Region Luzern-Land](https://www.moneyhouse.ch/de/region/luzern-land/uebersicht) - -* [Bremgarten](https://www.moneyhouse.ch/de/region/bremgarten/uebersicht) -* [Region Bremgarten](https://www.moneyhouse.ch/de/region/bremgarten/uebersicht) -* [Hochdorf](https://www.moneyhouse.ch/de/region/hochdorf/uebersicht) -* [Region Hochdorf](https://www.moneyhouse.ch/de/region/hochdorf/uebersicht) -* [Zofingen](https://www.moneyhouse.ch/de/region/zofingen/uebersicht) -* [Region Zofingen](https://www.moneyhouse.ch/de/region/zofingen/uebersicht) -* [Aarau](https://www.moneyhouse.ch/de/region/aarau/uebersicht) -* [Region Aarau](https://www.moneyhouse.ch/de/region/aarau/uebersicht) -* [Thun](https://www.moneyhouse.ch/de/region/thun/uebersicht) -* [Region Thun](https://www.moneyhouse.ch/de/region/thun/uebersicht) -* [Frauenfeld](https://www.moneyhouse.ch/de/region/frauenfeld/uebersicht) -* [Region Frauenfeld](https://www.moneyhouse.ch/de/region/frauenfeld/uebersicht) -* [Lenzburg](https://www.moneyhouse.ch/de/region/lenzburg/uebersicht) -* [Region Lenzburg](https://www.moneyhouse.ch/de/region/lenzburg/uebersicht) -* [Zug](https://www.moneyhouse.ch/de/region/zug/uebersicht) -* [Region Zug](https://www.moneyhouse.ch/de/region/zug/uebersicht) -* [Dietikon](https://www.moneyhouse.ch/de/region/dietikon/uebersicht) -* [Region Dietikon](https://www.moneyhouse.ch/de/region/dietikon/uebersicht) - -* [See-Gaster](https://www.moneyhouse.ch/de/region/see-gaster/uebersicht) -* [Region See-Gaster](https://www.moneyhouse.ch/de/region/see-gaster/uebersicht) -* [Olten](https://www.moneyhouse.ch/de/region/olten/uebersicht) -* [Region Olten](https://www.moneyhouse.ch/de/region/olten/uebersicht) -* [Willisau](https://www.moneyhouse.ch/de/region/willisau/uebersicht) -* [Region Willisau](https://www.moneyhouse.ch/de/region/willisau/uebersicht) -* [Kreuzlingen](https://www.moneyhouse.ch/de/region/kreuzlingen/uebersicht) -* [Region Kreuzlingen](https://www.moneyhouse.ch/de/region/kreuzlingen/uebersicht) -* [Wil](https://www.moneyhouse.ch/de/region/wil/uebersicht) -* [Region Wil](https://www.moneyhouse.ch/de/region/wil/uebersicht) -* [Brugg](https://www.moneyhouse.ch/de/region/brugg/uebersicht) -* [Region Brugg](https://www.moneyhouse.ch/de/region/brugg/uebersicht) -* [Biel](https://www.moneyhouse.ch/de/region/biel-bienne/uebersicht) -* [Region Biel](https://www.moneyhouse.ch/de/region/biel-bienne/uebersicht) -* [Emmental](https://www.moneyhouse.ch/de/region/emmental/uebersicht) -* [Region Emmental](https://www.moneyhouse.ch/de/region/emmental/uebersicht) -* [Meine Region suchen](https://www.moneyhouse.ch/de/region) -* [Region suchen](https://www.moneyhouse.ch/de/region) - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2F) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - - -=== https://www.moneyhouse.ch/de/search?q=ValueOn AG === -Suchergebnisse - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG#)[Save + Exit](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -Suchergebnisse -============== - -### Treffer für "ValueOn AG" - -[Firmen 1](javascript:void(0))[Personen im Handelsregister 1](javascript:void(0))[Privatpersonen …](javascript:void(0))[Marken 477](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -#### Firmenname - -- [x] mit früheren Firmennamen - -#### Status - -alle(1) - -aktiv(1) - -in Liquidation(0) - -gelöscht(0) - -#### Status - -[](javascript:void(0)) - -alle(1) - -aktiv(1) - -inaktiv(0) - -#### Status - -alle(477) - -hängiges Gesuch(17) - -aktiv(376) - -gelöscht(84) - -#### Kanton - -- [x] Zürich(1) - -[Zurücksetzen](javascript:void(0)) - -#### Kanton - -- [x] ZH(1) - -[Zurücksetzen](javascript:void(0)) - -[Kantonsfilter einblenden](javascript:void(0)) - -[Kantonsfilter ausblenden](javascript:void(0)) - -1 Treffer - -[Ergebnisse exportieren(maximal die ersten 500 Firmen)](javascript:void(0)) - -[Allen 1 Firmen folgen](javascript:void(0)) - -Aus datenschutzrechtlichen Gründen werden hier Personen, die seit 10 Jahren oder länger keine aktiven Mandate hatten, nicht angezeigt. - -Es wurden mehr als 1000 Einträge gefunden. Bitte schränken Sie Ihre Suche weiter ein. - -Datenschutz: Die Strategie von Moneyhouse sieht vor, sich auf jene Personendaten zu beschränken, für die keine Einwilligung erforderlich ist. - -[Mehr anzeigen](javascript:void(0)) - -Datenschutz: Die Strategie von Moneyhouse sieht vor, sich auf jene Personendaten zu beschränken, für die keine Einwilligung erforderlich ist. Dazu gehört es, keine Persönlichkeitsprofile zu erstellen und nur diejenigen Daten zur Verfügung zu stellen, die erforderlich sind, um eine Person zu identifizieren und im Sinne des Gläubigerschutzes eine gesicherte Bonitätsauskunft zu ermöglichen. Zu diesen erforderlichen Daten zählen beispielsweise Name, Geburtsdatum und Adresse von Privatpersonen. Auch Daten, die im Handelsregister eingetragen sind, kann Moneyhouse nutzen. Aus datenschutzrechtlichen Gründen dürfen Personen, die nicht im Handelsregister eingetragen sind, hier nicht direkt angezeigt werden. - -[Weniger anzeigen](javascript:void(0)) - -[ValueOn AG](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -Am Stadtrand 11 | 8600 Dübendorf - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -[Dieser Firma folgen](javascript:void(0)) - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -Beliebteste Firmen der letzten 7 Tage - -[Schär + Trojahn AG](https://www.moneyhouse.ch/de/company/schaer-trojahn-ag-16603544091) - -Bahngässli 12 | 3172 Niederwangen b. Bern - -So bleiben Sie über "Schär + Trojahn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Schär + Trojahn AG" - -[Dieser Firma folgen](javascript:void(0)) - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/schaer-trojahn-ag-16603544091/network) - -So bleiben Sie über "Schär + Trojahn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Schär + Trojahn AG" - -- [x] + Folgen - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/schaer-trojahn-ag-16603544091/network) - -So bleiben Sie über "Schär + Trojahn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Schär + Trojahn AG" - -- [x] + Folgen -[Steinblick AG](https://www.moneyhouse.ch/de/company/steinblick-ag-15359056721) - -Täfernstrasse 2 | 5405 Dättwil AG - -So bleiben Sie über "Steinblick AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Steinblick AG" - -[Dieser Firma folgen](javascript:void(0)) - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/steinblick-ag-15359056721/network) - -So bleiben Sie über "Steinblick AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Steinblick AG" - -- [x] + Folgen - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/steinblick-ag-15359056721/network) - -So bleiben Sie über "Steinblick AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Steinblick AG" - -- [x] + Folgen -[Mischeli Gipser GmbH](https://www.moneyhouse.ch/de/company/mischeli-gipser-gmbh-3731626021) - -Vordere Bettenwiesenstrasse 31 | 9300 Wittenbach - -So bleiben Sie über "Mischeli Gipser GmbH" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Mischeli Gipser GmbH" - -[Dieser Firma folgen](javascript:void(0)) - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/mischeli-gipser-gmbh-3731626021/network) - -So bleiben Sie über "Mischeli Gipser GmbH" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Mischeli Gipser GmbH" - -- [x] + Folgen - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/mischeli-gipser-gmbh-3731626021/network) - -So bleiben Sie über "Mischeli Gipser GmbH" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Mischeli Gipser GmbH" - -- [x] + Folgen -[Freestar-Informatik AG](https://www.moneyhouse.ch/de/company/freestar-informatik-ag-20936862541) - -Bösch 73 | 6331 Hünenberg - -So bleiben Sie über "Freestar-Informatik AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Freestar-Informatik AG" - -[Dieser Firma folgen](javascript:void(0)) - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/freestar-informatik-ag-20936862541/network) - -So bleiben Sie über "Freestar-Informatik AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Freestar-Informatik AG" - -- [x] + Folgen - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/freestar-informatik-ag-20936862541/network) - -So bleiben Sie über "Freestar-Informatik AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Freestar-Informatik AG" - -- [x] + Folgen -[AV Transports Sàrl](https://www.moneyhouse.ch/de/company/av-transports-sarl-13516960221) - -Chemin du Furet 4 | 1018 Lausanne - -So bleiben Sie über "AV Transports Sàrl" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "AV Transports Sàrl" - -[Dieser Firma folgen](javascript:void(0)) - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/av-transports-sarl-13516960221/network) - -So bleiben Sie über "AV Transports Sàrl" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "AV Transports Sàrl" - -- [x] + Folgen - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/av-transports-sarl-13516960221/network) - -So bleiben Sie über "AV Transports Sàrl" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "AV Transports Sàrl" - -- [x] + Folgen -[Woprom Immobilien AG](https://www.moneyhouse.ch/de/company/woprom-immobilien-ag-7538523641) - -Kanzleistrasse 18 | 8004 Zürich - -So bleiben Sie über "Woprom Immobilien AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Woprom Immobilien AG" - -[Dieser Firma folgen](javascript:void(0)) - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/woprom-immobilien-ag-7538523641/network) - -So bleiben Sie über "Woprom Immobilien AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Woprom Immobilien AG" - -- [x] + Folgen - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/woprom-immobilien-ag-7538523641/network) - -So bleiben Sie über "Woprom Immobilien AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Woprom Immobilien AG" - -- [x] + Folgen -[Vedreine Packaging Switzerland AG in Liquidation](https://www.moneyhouse.ch/de/company/vedreine-packaging-switzerland-ag-2608988981) - -Ruessenstrasse 7 | 6340 Baar - -So bleiben Sie über "Vedreine Packaging Switzerland AG in Liquidation" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Vedreine Packaging Switzerland AG in Liquidation" - -[Dieser Firma folgen](javascript:void(0)) - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/vedreine-packaging-switzerland-ag-2608988981/network) - -So bleiben Sie über "Vedreine Packaging Switzerland AG in Liquidation" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Vedreine Packaging Switzerland AG in Liquidation" - -- [x] + Folgen - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/vedreine-packaging-switzerland-ag-2608988981/network) - -So bleiben Sie über "Vedreine Packaging Switzerland AG in Liquidation" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Vedreine Packaging Switzerland AG in Liquidation" - -- [x] + Folgen -[Göbel AG in Liquidation](https://www.moneyhouse.ch/de/company/goebel-ag-14572152771) - -Lutherstrasse 6 | 8004 Zürich - -So bleiben Sie über "Göbel AG in Liquidation" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Göbel AG in Liquidation" - -[Dieser Firma folgen](javascript:void(0)) - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/goebel-ag-14572152771/network) - -So bleiben Sie über "Göbel AG in Liquidation" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Göbel AG in Liquidation" - -- [x] + Folgen - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/goebel-ag-14572152771/network) - -So bleiben Sie über "Göbel AG in Liquidation" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Göbel AG in Liquidation" - -- [x] + Folgen -[Lonza AG](https://www.moneyhouse.ch/de/company/lonza-ag-2868736201) - -Lonzastrasse | 3930 Visp - -So bleiben Sie über "Lonza AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Lonza AG" - -[Dieser Firma folgen](javascript:void(0)) - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/lonza-ag-2868736201/network) - -So bleiben Sie über "Lonza AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Lonza AG" - -- [x] + Folgen - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/lonza-ag-2868736201/network) - -So bleiben Sie über "Lonza AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Lonza AG" - -- [x] + Folgen -[Invest4u GmbH](https://www.moneyhouse.ch/de/company/invest4u-gmbh-5152941501) - -Täfernstrasse 2 | 5405 Dättwil AG - -So bleiben Sie über "Invest4u GmbH" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Invest4u GmbH" - -[Dieser Firma folgen](javascript:void(0)) - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/invest4u-gmbh-5152941501/network) - -So bleiben Sie über "Invest4u GmbH" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Invest4u GmbH" - -- [x] + Folgen - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/company/invest4u-gmbh-5152941501/network) - -So bleiben Sie über "Invest4u GmbH" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Invest4u GmbH" - -- [x] + Folgen - -1 Treffer - -[Allen 1 Personen folgen](javascript:void(0)) - -Aus datenschutzrechtlichen Gründen werden hier Personen, die seit 10 Jahren oder länger keine aktiven Mandate hatten, nicht angezeigt. - -Es wurden mehr als 1000 Einträge gefunden. Bitte schränken Sie Ihre Suche weiter ein. - -Datenschutz: Die Strategie von Moneyhouse sieht vor, sich auf jene Personendaten zu beschränken, für die keine Einwilligung erforderlich ist. - -[Mehr anzeigen](javascript:void(0)) - -Datenschutz: Die Strategie von Moneyhouse sieht vor, sich auf jene Personendaten zu beschränken, für die keine Einwilligung erforderlich ist. Dazu gehört es, keine Persönlichkeitsprofile zu erstellen und nur diejenigen Daten zur Verfügung zu stellen, die erforderlich sind, um eine Person zu identifizieren und im Sinne des Gläubigerschutzes eine gesicherte Bonitätsauskunft zu ermöglichen. Zu diesen erforderlichen Daten zählen beispielsweise Name, Geburtsdatum und Adresse von Privatpersonen. Auch Daten, die im Handelsregister eingetragen sind, kann Moneyhouse nutzen. Aus datenschutzrechtlichen Gründen dürfen Personen, die nicht im Handelsregister eingetragen sind, hier nicht direkt angezeigt werden. - -[Weniger anzeigen](javascript:void(0)) - -[Philip Christian Jalo-ag](https://www.moneyhouse.ch/de/person/jalo-ag-philip-christian-22516514301) - -wohnhaft in Zürich, aus Adliswil - -So bleiben Sie über "Philip Christian Jalo-ag" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Philip Christian Jalo-ag" - -[Dieser Person folgen](javascript:void(0)) - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/person/jalo-ag-philip-christian-22516514301/network) - -So bleiben Sie über "Philip Christian Jalo-ag" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Philip Christian Jalo-ag" - -- [x] + Folgen - -[Netzwerk ansehen](https://www.moneyhouse.ch/de/person/jalo-ag-philip-christian-22516514301/network) - -So bleiben Sie über "Philip Christian Jalo-ag" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "Philip Christian Jalo-ag" - -- [x] + Folgen - -Aktuelle Mandate:[Company1](https://www.moneyhouse.ch/de/person/jalo-ag-philip-christian-22516514301/mandates),[Company2](https://www.moneyhouse.ch/de/person/jalo-ag-philip-christian-22516514301/mandates) - -50 Treffer (von Total 477) - -Aus datenschutzrechtlichen Gründen werden hier Personen, die seit 10 Jahren oder länger keine aktiven Mandate hatten, nicht angezeigt. - -Es wurden mehr als 1000 Einträge gefunden. Bitte schränken Sie Ihre Suche weiter ein. - -Datenschutz: Die Strategie von Moneyhouse sieht vor, sich auf jene Personendaten zu beschränken, für die keine Einwilligung erforderlich ist. - -[Mehr anzeigen](javascript:void(0)) - -Datenschutz: Die Strategie von Moneyhouse sieht vor, sich auf jene Personendaten zu beschränken, für die keine Einwilligung erforderlich ist. Dazu gehört es, keine Persönlichkeitsprofile zu erstellen und nur diejenigen Daten zur Verfügung zu stellen, die erforderlich sind, um eine Person zu identifizieren und im Sinne des Gläubigerschutzes eine gesicherte Bonitätsauskunft zu ermöglichen. Zu diesen erforderlichen Daten zählen beispielsweise Name, Geburtsdatum und Adresse von Privatpersonen. Auch Daten, die im Handelsregister eingetragen sind, kann Moneyhouse nutzen. Aus datenschutzrechtlichen Gründen dürfen Personen, die nicht im Handelsregister eingetragen sind, hier nicht direkt angezeigt werden. - -[Weniger anzeigen](javascript:void(0)) - -[pluspunkt Zentrum für Prävention, Therapie und Weiterbildung AG ((fig.))](https://www.moneyhouse.ch/de/company/pluspunkt-zentrum-fuer-praevention-therapie-u-3431213061/brands?brandName=pluspunkt%20Zentrum%20f%C3%BCr%20Pr%C3%A4vention,%20Therapie%20und%20Weiterbildung%20AG%20((fig.))) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/pluspunkt-zentrum-fuer-praevention-therapie-u-3431213061/brands?brandName=pluspunkt%20Zentrum%20f%C3%BCr%20Pr%C3%A4vention,%20Therapie%20und%20Weiterbildung%20AG%20((fig.))) -[GWM+H AG ((fig.))](https://www.moneyhouse.ch/de/company/glarner-waffen-manufaktur-handelshaus-ag-6901472441/brands?brandName=GWM+H%20AG%20((fig.))) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/glarner-waffen-manufaktur-handelshaus-ag-6901472441/brands?brandName=GWM+H%20AG%20((fig.))) -[AG ((fig.))](https://www.moneyhouse.ch/de/company/sgs-societe-generale-de-surveillance-sa-4290003301/brands?brandName=AG%20((fig.))) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/sgs-societe-generale-de-surveillance-sa-4290003301/brands?brandName=AG%20((fig.))) -[PathoVision AG](https://www.moneyhouse.ch/de/company/arjan-switzerland-gmbh-13984596631/brands?brandName=PathoVision%20AG) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/arjan-switzerland-gmbh-13984596631/brands?brandName=PathoVision%20AG) -[CHIROMED AG](https://www.moneyhouse.ch/de/company/chiromed-ag-14204280391/brands?brandName=CHIROMED%20AG) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/chiromed-ag-14204280391/brands?brandName=CHIROMED%20AG) - -[EUROJOB work in Switzerland AG ((fig.))](https://www.moneyhouse.ch/de/company/eurojob-work-in-switzerland-ag-2698928841/brands?brandName=EUROJOB%20work%20in%20Switzerland%20AG%20((fig.))) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/eurojob-work-in-switzerland-ag-2698928841/brands?brandName=EUROJOB%20work%20in%20Switzerland%20AG%20((fig.))) -[Metaresearch Schweiz AG](https://www.moneyhouse.ch/de/company/metaresearch-schweiz-ag-12688612021/brands?brandName=Metaresearch%20Schweiz%20AG) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/metaresearch-schweiz-ag-12688612021/brands?brandName=Metaresearch%20Schweiz%20AG) -[Comulink Invest AG](https://www.moneyhouse.ch/de/company/comulink-invest-ag-12926964591/brands?brandName=Comulink%20Invest%20AG) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/comulink-invest-ag-12926964591/brands?brandName=Comulink%20Invest%20AG) -[UP AG](https://www.moneyhouse.ch/de/company/up-ag-14859385131/brands?brandName=UP%20AG) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/up-ag-14859385131/brands?brandName=UP%20AG) -[Kämpf AG Sigriswil](https://www.moneyhouse.ch/de/company/kaempf-ag-sigriswil-20843697741/brands?brandName=K%C3%A4mpf%20AG%20Sigriswil) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/kaempf-ag-sigriswil-20843697741/brands?brandName=K%C3%A4mpf%20AG%20Sigriswil) - -[Kämpf AG Sigriswil](https://www.moneyhouse.ch/de/company/kaempf-ag-sigriswil-20843697741/brands?brandName=K%C3%A4mpf%20AG%20Sigriswil) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/kaempf-ag-sigriswil-20843697741/brands?brandName=K%C3%A4mpf%20AG%20Sigriswil) -[Suisse-Nurse AG](https://www.moneyhouse.ch/de/company/suisse-nurse-ag-3669444321/brands?brandName=Suisse-Nurse%20AG) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/suisse-nurse-ag-3669444321/brands?brandName=Suisse-Nurse%20AG) -[MAAM Anima AG](https://www.moneyhouse.ch/de/company/amma-management-ag-15239619101/brands?brandName=MAAM%20Anima%20AG) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/amma-management-ag-15239619101/brands?brandName=MAAM%20Anima%20AG) -[MA'AM Anima AG](https://www.moneyhouse.ch/de/company/amma-management-ag-15239619101/brands?brandName=MA%27AM%20Anima%20AG) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/amma-management-ag-15239619101/brands?brandName=MA%27AM%20Anima%20AG) -[MAAM Anima AG](https://www.moneyhouse.ch/de/company/amma-management-ag-15239619101/brands?brandName=MAAM%20Anima%20AG) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/amma-management-ag-15239619101/brands?brandName=MAAM%20Anima%20AG) -[MA'AM Anima AG](https://www.moneyhouse.ch/de/company/amma-management-ag-15239619101/brands?brandName=MA%27AM%20Anima%20AG) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/amma-management-ag-15239619101/brands?brandName=MA%27AM%20Anima%20AG) -[SOSTRASTOS AG ((fig.))](https://www.moneyhouse.ch/de/company/sostratos-ag-18776771541/brands?brandName=SOSTRASTOS%20AG%20((fig.))) - -Status: hängiges Gesuch - -[Marke ansehen](https://www.moneyhouse.ch/de/company/sostratos-ag-18776771541/brands?brandName=SOSTRASTOS%20AG%20((fig.))) -[Heizung Sanitär Reparatur SCHAAD AG www.schaad-ag.ch 4542 Luterbach ((fig.))](https://www.moneyhouse.ch/de/company/schaad-ag-luterbach-3412462221/brands?brandName=Heizung%20Sanit%C3%A4r%20Reparatur%20SCHAAD%20AG%20www.schaad-ag.ch%204542%20Luterbach%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/schaad-ag-luterbach-3412462221/brands?brandName=Heizung%20Sanit%C3%A4r%20Reparatur%20SCHAAD%20AG%20www.schaad-ag.ch%204542%20Luterbach%20((fig.))) -[Kontrolldienst KUT AG](https://www.moneyhouse.ch/de/company/kontrolldienst-kut-ag-6163875391/brands?brandName=Kontrolldienst%20KUT%20AG) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/kontrolldienst-kut-ag-6163875391/brands?brandName=Kontrolldienst%20KUT%20AG) -[GLOBAL TREE PROJECT AG ((fig.))](https://www.moneyhouse.ch/de/company/global-tree-project-ag-20438721871/brands?brandName=GLOBAL%20TREE%20PROJECT%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/global-tree-project-ag-20438721871/brands?brandName=GLOBAL%20TREE%20PROJECT%20AG%20((fig.))) - -[NUMO Orthopedic Systems AG](https://www.moneyhouse.ch/de/company/numo-orthopedic-systems-ag-1807042871/brands?brandName=NUMO%20Orthopedic%20Systems%20AG) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/numo-orthopedic-systems-ag-1807042871/brands?brandName=NUMO%20Orthopedic%20Systems%20AG) -[HATT Partner Architekten AG ((fig.))](https://www.moneyhouse.ch/de/company/hatt-partner-architekten-ag-18572393141/brands?brandName=HATT%20Partner%20Architekten%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/hatt-partner-architekten-ag-18572393141/brands?brandName=HATT%20Partner%20Architekten%20AG%20((fig.))) -[Ganeos AG](https://www.moneyhouse.ch/de/company/ganeos-ag-14570980651/brands?brandName=Ganeos%20AG) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/ganeos-ag-14570980651/brands?brandName=Ganeos%20AG) -[I&M Immobilien AG](https://www.moneyhouse.ch/de/company/im-immobilien-ag-5581314721/brands?brandName=I&M%20Immobilien%20AG) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/im-immobilien-ag-5581314721/brands?brandName=I&M%20Immobilien%20AG) -[A D L E R B L I C K AUGENMEDIZIN AG ((fig.))](https://www.moneyhouse.ch/de/company/adlerblick-augenmedizin-ag-19413727891/brands?brandName=A%20D%20L%20E%20R%20B%20L%20I%20C%20K%20AUGENMEDIZIN%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/adlerblick-augenmedizin-ag-19413727891/brands?brandName=A%20D%20L%20E%20R%20B%20L%20I%20C%20K%20AUGENMEDIZIN%20AG%20((fig.))) -[deligno ag ((fig.))](https://www.moneyhouse.ch/de/company/deligno-ag-4030075791/brands?brandName=deligno%20ag%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/deligno-ag-4030075791/brands?brandName=deligno%20ag%20((fig.))) -[Xandi AG make. IT. simple. ((fig.))](https://www.moneyhouse.ch/de/company/xandi-ag-2432938381/brands?brandName=Xandi%20AG%20make.%20IT.%20simple.%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/xandi-ag-2432938381/brands?brandName=Xandi%20AG%20make.%20IT.%20simple.%20((fig.))) -[Landmann & Partner AG](https://www.moneyhouse.ch/de/company/landmann-partner-ag-6149426621/brands?brandName=Landmann%20&%20Partner%20AG) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/landmann-partner-ag-6149426621/brands?brandName=Landmann%20&%20Partner%20AG) -[Clupea AG](https://www.moneyhouse.ch/de/company/zeusfaber-gmbh-13704343631/brands?brandName=Clupea%20AG) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/zeusfaber-gmbh-13704343631/brands?brandName=Clupea%20AG) -[Makaira Holding AG](https://www.moneyhouse.ch/de/company/zeusfaber-gmbh-13704343631/brands?brandName=Makaira%20Holding%20AG) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/zeusfaber-gmbh-13704343631/brands?brandName=Makaira%20Holding%20AG) - -[Stelaris Resources AG ((fig.))](https://www.moneyhouse.ch/de/company/stelaris-resources-ag-4541893861/brands?brandName=Stelaris%20Resources%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/stelaris-resources-ag-4541893861/brands?brandName=Stelaris%20Resources%20AG%20((fig.))) -[ZIGERLIG BAUTROCKNUNG AG ((fig.))](https://www.moneyhouse.ch/de/company/zigerlig-bautrocknung-ag-5120864721/brands?brandName=ZIGERLIG%20BAUTROCKNUNG%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/zigerlig-bautrocknung-ag-5120864721/brands?brandName=ZIGERLIG%20BAUTROCKNUNG%20AG%20((fig.))) -[Marketing Macht AG ((fig.))](https://www.moneyhouse.ch/de/company/marketing-macht-ag-7421283411/brands?brandName=Marketing%20Macht%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/marketing-macht-ag-7421283411/brands?brandName=Marketing%20Macht%20AG%20((fig.))) -[Marine Container Capital AG](https://www.moneyhouse.ch/de/company/marine-container-capital-ag-10673551411/brands?brandName=Marine%20Container%20Capital%20AG) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/marine-container-capital-ag-10673551411/brands?brandName=Marine%20Container%20Capital%20AG) -[STRAHM AG UMWELT- UND ENERGIETECHNIK Eine Unternehmung der Riesen Holding AG ((fig.))](https://www.moneyhouse.ch/de/company/strahm-ag-umwelt-und-energietechnik-3141577391/brands?brandName=STRAHM%20AG%20UMWELT-%20UND%20ENERGIETECHNIK%20Eine%20Unternehmung%20der%20Riesen%20Holding%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/strahm-ag-umwelt-und-energietechnik-3141577391/brands?brandName=STRAHM%20AG%20UMWELT-%20UND%20ENERGIETECHNIK%20Eine%20Unternehmung%20der%20Riesen%20Holding%20AG%20((fig.))) -[PRAXISExperts AG ((fig.))](https://www.moneyhouse.ch/de/company/praxisexperts-ag-13524093051/brands?brandName=PRAXISExperts%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/praxisexperts-ag-13524093051/brands?brandName=PRAXISExperts%20AG%20((fig.))) -[beecruiting Executive Search AG ((fig.))](https://www.moneyhouse.ch/de/company/beecruiting-executive-search-ag-10823205681/brands?brandName=beecruiting%20Executive%20Search%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/beecruiting-executive-search-ag-10823205681/brands?brandName=beecruiting%20Executive%20Search%20AG%20((fig.))) -[Keller Früchte + Gemüse AG ((fig.))](https://www.moneyhouse.ch/de/company/keller-fruechte-gemuese-ag-11789712621/brands?brandName=Keller%20Fr%C3%BCchte%20+%20Gem%C3%BCse%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/keller-fruechte-gemuese-ag-11789712621/brands?brandName=Keller%20Fr%C3%BCchte%20+%20Gem%C3%BCse%20AG%20((fig.))) -[GVM Gasverbund Mitteland AG ((fig.))](https://www.moneyhouse.ch/de/company/gasverbund-mittelland-ag-3967150471/brands?brandName=GVM%20Gasverbund%20Mitteland%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/gasverbund-mittelland-ag-3967150471/brands?brandName=GVM%20Gasverbund%20Mitteland%20AG%20((fig.))) -[Mulga Invest AG](https://www.moneyhouse.ch/de/company/mulga-invest-ag-14258851021/brands?brandName=Mulga%20Invest%20AG) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/mulga-invest-ag-14258851021/brands?brandName=Mulga%20Invest%20AG) -[MEDICAR AG Personen- und Patiententransport ((fig.))](https://www.moneyhouse.ch/de/company/medicar-ag-4303664091/brands?brandName=MEDICAR%20AG%20Personen-%20und%20Patiententransport%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/medicar-ag-4303664091/brands?brandName=MEDICAR%20AG%20Personen-%20und%20Patiententransport%20((fig.))) -[VORHANG-KAUFEN.CH BY VORHANG KÖPPEL AG ((fig.))](https://www.moneyhouse.ch/de/company/vorhang-koeppel-ag-6332717921/brands?brandName=VORHANG-KAUFEN.CH%20BY%20VORHANG%20K%C3%96PPEL%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/vorhang-koeppel-ag-6332717921/brands?brandName=VORHANG-KAUFEN.CH%20BY%20VORHANG%20K%C3%96PPEL%20AG%20((fig.))) -[Green LIne amBÜHL WERBETECHNIK AG ((fig.))](https://www.moneyhouse.ch/de/company/ambuehl-werbetechnik-ag-12578316761/brands?brandName=Green%20LIne%20amB%C3%9CHL%20WERBETECHNIK%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/ambuehl-werbetechnik-ag-12578316761/brands?brandName=Green%20LIne%20amB%C3%9CHL%20WERBETECHNIK%20AG%20((fig.))) -[AESCHLIMANN Hochwasserschutz AG ((fig.))](https://www.moneyhouse.ch/de/company/meyer-hochwasserschutz-ag-10810519571/brands?brandName=AESCHLIMANN%20Hochwasserschutz%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/meyer-hochwasserschutz-ag-10810519571/brands?brandName=AESCHLIMANN%20Hochwasserschutz%20AG%20((fig.))) -[Fourth Quadrant Investment Group AG](https://www.moneyhouse.ch/de/company/fourth-quadrant-investment-group-ag-6786816741/brands?brandName=Fourth%20Quadrant%20Investment%20Group%20AG) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/fourth-quadrant-investment-group-ag-6786816741/brands?brandName=Fourth%20Quadrant%20Investment%20Group%20AG) -[Rotstab Reisen AG ((fig.))](https://www.moneyhouse.ch/de/company/mtch-ag-21440763331/brands?brandName=Rotstab%20Reisen%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/mtch-ag-21440763331/brands?brandName=Rotstab%20Reisen%20AG%20((fig.))) -[Plan Logistik AG ((fig.))](https://www.moneyhouse.ch/de/company/planlogistik-ag-3528614351/brands?brandName=Plan%20Logistik%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/planlogistik-ag-3528614351/brands?brandName=Plan%20Logistik%20AG%20((fig.))) -[Comulink Invest AG](https://www.moneyhouse.ch/de/company/comulink-invest-ag-12926964591/brands?brandName=Comulink%20Invest%20AG) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/comulink-invest-ag-12926964591/brands?brandName=Comulink%20Invest%20AG) -[UP AG](https://www.moneyhouse.ch/de/company/up-ag-14859385131/brands?brandName=UP%20AG) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/up-ag-14859385131/brands?brandName=UP%20AG) -[UP AG ((fig.))](https://www.moneyhouse.ch/de/company/up-ag-14859385131/brands?brandName=UP%20AG%20((fig.))) - -Status: aktiv - -[Marke ansehen](https://www.moneyhouse.ch/de/company/up-ag-14859385131/brands?brandName=UP%20AG%20((fig.))) - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -* aktiv (besitzt aktuelle Mandate) -* inaktiv (besitzt nur frühere Mandate) - -+ - -Objekten folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie die Exportfunktion unbegrenzt oft nutzen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/search?q=ValueOn%20AG) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Schär + Trojahn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Schär + Trojahn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Steinblick AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Steinblick AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Mischeli Gipser GmbH folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Mischeli Gipser GmbH folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Freestar-Informatik AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Freestar-Informatik AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -AV Transports Sàrl folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -AV Transports Sàrl folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Woprom Immobilien AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Woprom Immobilien AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Vedreine Packaging Switzerland AG in Liquidation folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Vedreine Packaging Switzerland AG in Liquidation folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Göbel AG in Liquidation folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Göbel AG in Liquidation folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Lonza AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Lonza AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Invest4u GmbH folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Invest4u GmbH folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/search?q=ValueOn%20AG) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Philip Christian Jalo-ag folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -Philip Christian Jalo-ag folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/search?q=ValueOn%20AG) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/search?q=ValueOn%20AG) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/search?q=ValueOn%20AG) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/search?q=ValueOn%20AG)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/search?q=ValueOn%20AG)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fsearch%3Fq%3DValueOn%2520AG) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - - -=== https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report === -ValueOn AG in Dübendorf - Bonitätsauskunft, Zahlungsverhalten, Betreibungsauskunft und Kreditwürdigkeit - -=============== - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -[ValueOn AG](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Bonitätsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -[Zahlungsverhalten](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#payment-mode-report) - -[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#commercial-report) - -[Beteiligungsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#wow-report) - -[Betreibungsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#payment-collection-report) - -[Firmendossier](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#firmendossier-report) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -[Startseite](https://www.moneyhouse.ch/de/)[>](javascript:void(0))[Unternehmen](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG)[>](javascript:void(0))ValueOn AG - -ValueOn AG -========== - -ZH - -aktiv - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Zur Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -Handelsregister-Nr.:CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Bonitätsauskunft ----------------- - -Einschätzung der Bonität mit einer Ampel als Risikoindikator und weiteren hilfreichen Firmeninformationen. - -* Einschätzung der Bonität mit einer Ampel -* Weitere Hinweise -* Firmeninformationen aus dem Handelsregister -* Aktuelle Zahlungsdetails (als Zusatzabfrage) - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:09f387aa-7faa-4b0d-8eea-c619aed45506) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:09f387aa-7faa-4b0d-8eea-c619aed45506) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen Premium-Mitgliedschaft mit Bonitäts-Paket ab CHF 99.00](https://www.moneyhouse.ch/de/service/purchase/creditrating?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D1) - -[Jetzt bestellen Premium-Mitglied werden (1 Abfrage inkl.)jede weitere für CHF 19.00](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D1) - -[Jetzt bestellen Einzelabfrage ohne Premium-Mitgliedschaft für CHF 24.00](https://www.moneyhouse.ch/de/service/purchase/creditratingsingle?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D1) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -Zahlungsverhalten ------------------ - -Beurteilung der Zahlungsmoral aufgrund vergangener Rechnungen. - -* Zahlungsverhalten der letzten Rechnungen -* Durchschnittliches Zahlungsverhalten -* Anteil aller bekannten, pünktlich bezahlten Rechnungen - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:9acd118e-dc76-4a33-ab7c-ebaec52c619a) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:9acd118e-dc76-4a33-ab7c-ebaec52c619a) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen Premium-Mitgliedschaft mit Zahlungsverhalten-Paket ab CHF 99.00](https://www.moneyhouse.ch/de/service/purchase/paymentbehaviour?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D2) - -[Jetzt bestellen Premium-Mitglied werden 1 Abfrage für CHF 19.00](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D2) - -[Jetzt bestellen Einzelabfrage ohne Premium-Mitgliedschaft für CHF 24.00](https://www.moneyhouse.ch/de/service/purchase/paymentbehavioursingle?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D2) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -Wirtschaftsauskunft -------------------- - -Umfassende Auskunft über die wirtschaftliche Situation der Firma. - -* Einschätzung der Bonität mit einer Ampel -* Zahlungsverhalten der letzten Rechnungen -* Risikobewertung im Branchenvergleich -* Meldung von Inkassobüros und Betreibungsämtern -* Firmeninformationen aus dem Handelsregister - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:e9d3178c-3e96-4218-ac8d-39baffee2871) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:e9d3178c-3e96-4218-ac8d-39baffee2871) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen CHF 49.00 pro Abfrage](https://www.moneyhouse.ch/de/service/purchase/economicinformation?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D3) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -Beteiligungsauskunft --------------------- - -Auflistung aller Firmenbeteiligungen einer Aktiengesellschaft. - -* Manuell recherchierte Beteiligungen -* Informationen zu im Handelsregister eingetragenen Beteiligungen -* Firmeninformationen aus dem Handelsregister -* Umsatz- und Mitarbeiterzahlen - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:f1e0a255-5d6e-4ac5-be21-6f90d7b20a17) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:f1e0a255-5d6e-4ac5-be21-6f90d7b20a17) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen CHF 19.00 pro Abfrage](https://www.moneyhouse.ch/de/service/purchase/shareholderinformation?companyName=valueon-ag-4663161481&returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D8) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -Betreibungsauskunft -------------------- - -Übersicht über aktuelle und vergangene Betreibungsverfahren. - -* Amtlicher Betreibungsauszug -* Aktuelle Betreibungsverfahren -* Alle Betreibungen der letzten zwei Jahren - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:a1b45e6a-5cba-4063-8d4f-aa20378a1852) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:a1b45e6a-5cba-4063-8d4f-aa20378a1852) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen CHF 26.00 pro Abfrage](https://www.moneyhouse.ch/de/service/purchase/paymentcollection?companyName=valueon-ag-4663161481&returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fupload%3FcompanyName%3Dvalueon-ag-4663161481%26chNr%3DCH02030306513) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -Firmendossier -------------- - -Alle Firmeninformationen kompakt in einem Dokument. - -* Kontaktinformationen -* Firmeninformationen aus dem Handelsregister -* Unternehmensführung und Zeichnungsberechtigte -* Umsatz- und Mitarbeiterzahlen - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:62e110dc-83ed-4738-b49f-7a9799183287) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:62e110dc-83ed-4738-b49f-7a9799183287) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Kostenlos registrieren 2 Firmendossiers kostenlos verfügbar](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren 2 Firmendossiers kostenlos verfügbar](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Freports) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Bonitätsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -[Zahlungsverhalten](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#payment-mode-report) - -[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#commercial-report) - -[Beteiligungsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#wow-report) - -[Betreibungsauskunft](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#payment-collection-report) - -[Firmendossier](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#firmendossier-report) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - - -=== https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline === -Timeline ValueOn AG - Dübendorf - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline#)[Save + Exit](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -[ValueOn AG](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -[Startseite](https://www.moneyhouse.ch/de/)[>](javascript:void(0))[Unternehmen](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG)[>](javascript:void(0))ValueOn AG - -ValueOn AG -========== - -ZH - -aktiv - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Zur Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -Handelsregister-Nr.:CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Timeline --------- - -2025 - -[Um die Einträge zu sehen, benötigen Sie eine Premium-Mitgliedschaft.](https://www.moneyhouse.ch/membership) - -2024 - -[Um die Einträge zu sehen, benötigen Sie eine Premium-Mitgliedschaft.](https://www.moneyhouse.ch/membership) - -2023 - -[Um die Einträge zu sehen, benötigen Sie eine Premium-Mitgliedschaft.](https://www.moneyhouse.ch/membership) - -2022 - -[Um die Einträge zu sehen, benötigen Sie eine Premium-Mitgliedschaft.](https://www.moneyhouse.ch/membership) - -2007 - -[Um die Einträge zu sehen, benötigen Sie eine Premium-Mitgliedschaft.](https://www.moneyhouse.ch/membership) - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Ftimeline) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - - -=== https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages === -Meldungen ValueOn AG - Dübendorf - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages#)[Save + Exit](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -[ValueOn AG](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -[Startseite](https://www.moneyhouse.ch/de/)[>](javascript:void(0))[Unternehmen](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG)[>](javascript:void(0))ValueOn AG - -ValueOn AG -========== - -ZH - -aktiv - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Zur Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -Handelsregister-Nr.:CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Meldungen ---------- - -SHAB 250827/2025 - 27.08.2025 - -**Kategorien:** Änderung des Firmenzwecks, Änderung der Firmenadresse - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006417690 "Download SHAB Publikation der ValueOn AG vom 27.08.2025") - -Publikationsnummer: [HR02-1006417690](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006417690 "Download SHAB Publikation der ValueOn AG vom 27.08.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 133 vom 14.07.2025, Publ. 1006383218). - -**Statutenänderung:** - - 18.08.2025. - -**Sitz neu:** - - Dübendorf. - -**Domizil neu:** - - c/o Westhive AG, Am Stadtrand 11, 8600 Dübendorf. - -**Zweck neu:** - - Die Gesellschaft bezweckt die Beratung, Entwicklung und Umsetzung von digitalen Strategien, Technologievisionen und Innovationsprojekten für Unternehmen. Sie kann alle Geschäfte tätigen, die mit diesem Zweck direkt oder indirekt im Zusammenhang stehen. Die Gesellschaft kann Zweigniederlassungen und Tochtergesellschaften im In- und Ausland errichten und sich an anderen Unternehmen im In- und Ausland beteiligen sowie alle Geschäfte tätigen, die direkt oder indirekt mit ihrem Zweck in Zusammenhang stehen. Die Gesellschaft kann im In- und Ausland Grundeigentum erwerben, belasten, veräussern und verwalten. Sie kann auch Finanzierungen für eigene oder fremde Rechnung vornehmen sowie Garantien und Bürgschaften für Tochtergesellschaften und Dritte eingehen. - -**Mitteilungen neu:** - - Mitteilungen an die Aktionäre erfolgen per Brief oder E-Mail an die im Aktienbuch verzeichneten Adressen. - -SHAB 250714/2025 - 14.07.2025 - -**Kategorien:** Änderung im Management - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006383218 "Download SHAB Publikation der ValueOn AG vom 14.07.2025") - -Publikationsnummer: [HR02-1006383218](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006383218 "Download SHAB Publikation der ValueOn AG vom 14.07.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 101 vom 27.05.2025, Publ. 1006341693). - -**Eingetragene Personen neu oder mutierend:** - -[Largo, Dominic](https://www.moneyhouse.ch/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Einzelunterschrift [_bisher: Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien_]. - -SHAB 250527/2025 - 27.05.2025 - -**Kategorien:** Änderung im Management - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006341693 "Download SHAB Publikation der ValueOn AG vom 27.05.2025") - -Publikationsnummer: [HR02-1006341693](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006341693 "Download SHAB Publikation der ValueOn AG vom 27.05.2025"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 222 vom 14.11.2024, Publ. 1006178101). - -**Ausgeschiedene Personen und erloschene Unterschriften:** - - Hamburger, Marc Eric, von St. Gallen, in Mörschwil, Präsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - -[Egloff, Reto](https://www.moneyhouse.ch/de/person/egloff-reto-101763781201), von Oberrohrdorf, in Bern, Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - -[Mühlemann, Markus](https://www.moneyhouse.ch/de/person/muehlemann-markus-142196879901), von Seeberg, in Uster, Delegierter des Verwaltungsrates, mit Einzelunterschrift. - -**Eingetragene Personen neu oder mutierend:** - -[Largo, Dominic](https://www.moneyhouse.ch/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Präsident des Verwaltungsrates, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien [_bisher: Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien_]; - -[Althaus, Walter](https://www.moneyhouse.ch/de/person/althaus-jun-walter-205367807901), von Affoltern im Emmental, in Aarwangen, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - -[Wyss, Andreas](https://www.moneyhouse.ch/de/person/wyss-andreas-129476912501), von Dietikon, in Dietikon, Mitglied des Verwaltungsrates, mit Kollektivunterschrift zu zweien. - -SHAB 241114/2024 - 14.11.2024 - -**Kategorien:** Änderung im Management - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006178101 "Download SHAB Publikation der ValueOn AG vom 14.11.2024") - -Publikationsnummer: [HR02-1006178101](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1006178101 "Download SHAB Publikation der ValueOn AG vom 14.11.2024"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 134 vom 13.07.2023, Publ. 1005794339). - -**Eingetragene Personen neu oder mutierend:** - -[Largo, Dominic](https://www.moneyhouse.ch/de/person/largo-dominic-pascal-55052990401), von Wuppenau, in Dübendorf, Vorsitzender der Geschäftsleitung (CEO), mit Kollektivunterschrift zu zweien. - -SHAB 230713/2023 - 13.07.2023 - -**Kategorien:** Änderung im Management - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1005794339 "Download SHAB Publikation der ValueOn AG vom 13.07.2023") - -Publikationsnummer: [HR02-1005794339](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1005794339 "Download SHAB Publikation der ValueOn AG vom 13.07.2023"), Handelsregister-Amt Zürich, (20) - -**ValueOn AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 207 vom 25.10.2022, Publ. 1005590007). - -**Ausgeschiedene Personen und erloschene Unterschriften:** - -[Wechsler, Beat](https://www.moneyhouse.ch/de/person/wechsler-beat-61329453301), von Willisau, in Küssnacht (SZ), Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien; - -[Trentini, Stefano Enrico](https://www.moneyhouse.ch/de/person/trentini-stefano-52560044101), von Mendrisio, in Stäfa, Geschäftsführer, mit Kollektivunterschrift zu zweien. - -**Eingetragene Personen neu oder mutierend:** - -[Egloff, Reto](https://www.moneyhouse.ch/de/person/egloff-reto-101763781201), von Oberrohrdorf, in Bern, Vizepräsident des Verwaltungsrates, mit Kollektivunterschrift zu zweien. - -SHAB 221025/2022 - 25.10.2022 - -**Kategorien:** Änderung des Firmennamens, Änderung des Firmenzwecks - -[](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1005590007 "Download SHAB Publikation der ValueOn AG vom 25.10.2022") - -Publikationsnummer: [HR02-1005590007](https://www.shab.ch/shabforms/servlet/Search?EID=7&DOCID=HR02-1005590007 "Download SHAB Publikation der ValueOn AG vom 25.10.2022"), Handelsregister-Amt Zürich, (20) - -**Project Competence AG**, in Uster, CHE-113.416.882, Aktiengesellschaft (SHAB Nr. 123 vom 28.06.2022, Publ. 1005505965). - -**Statutenänderung:** - - 07.10.2022. - -**Firma neu:** - -**ValueOn AG**. - -**Zweck neu:** - - Der Zweck der Gesellschaft ist die Erbringung von Dienstleistungen für Unternehmen, im Besonderen Beratung für Unternehmensentwicklung, Digitale Business Transformation und Projekt Management sowie Handel mit Waren aller Art. Die Gesellschaft kann sich an anderen Unternehmungen des In- und Auslandes beteiligen sowie alle Geschäfte eingehen und Verträge abschliessen, die geeignet sind, ihren Zweck zu fördern oder die direkt oder indirekt damit im Zusammenhang stehen. Sie kann ferner im In- und Ausland Zweigniederlassungen errichten, Liegenschaften, Unternehmen, Immaterialgüterrechte und Wertschriften im In- und Ausland im Rahmen des Gesetzes erwerben bzw. errichten, verwalten und verkaufen. - -**Mitteilungen neu:** - - Mitteilungen an die Aktionäre erfolgen per Brief, Telefax oder E-Mail an die im Aktienbuch verzeichneten Adressen. - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fmessages) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - - -=== https://www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882 === -Analoge und digitale Handelsregisteränderungen - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882#)[Save + Exit](https://www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) - -[Änderung Firmenname](https://www.moneyhouse.ch/de/commercialregister/services/company-name) - -[Personenmutation](https://www.moneyhouse.ch/de/commercialregister/services/person) - -[Änderung Sitz & Domizil](https://www.moneyhouse.ch/de/commercialregister/services/address) - -[Änderung Statuten](https://www.moneyhouse.ch/de/commercialregister/services/statutes) - -[Anpassung Zweck](https://www.moneyhouse.ch/de/commercialregister/services/company-purpose) - -[Liquidation](https://www.moneyhouse.ch/de/commercialregister/liquidation) - -[Weitere Services](https://www.moneyhouse.ch/de/commercialregister/services/other-services) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -Handelsregisteränderung: digital oder analog -============================================ - -Wir unterstützen Sie bei der Anpassung Ihrer Handelsregisterdaten, egal welchen Weg Sie bevorzugen. - -**Die digitale Lösung: schneller, einfacher, modern** - - Erledigen Sie Ihre Mutation komplett digital innerhalb wenigen Tagen – ohne Papier, Postweg oder Notartermin. Sie erhalten die Dokumente automatisch zugestellt, können sie bequem per Smartphone unterzeichnen und sofort einreichen. Profitieren dabei Sie von diesen Vorteilen: - -* **Schnell:**Erledigung in Tagen statt Wochen. - -* **Einfach:**Schritt-für-Schritt-Anleitung ohne Fehlerrisiko. - -* **Flexibel:**Von überall aus durchführbar, auch im Ausland. - -* **Rechtssicher:**E-Signatur (QES) ist schweizweit anerkannt. - -* **Nachhaltig:**Vollständig digital und papierfrei. - -_Hinweis: Der digitale Service wird laufend erweitert; einzelne Mutationen sind ggf. noch nicht verfügbar._ - -**Sie möchten die Mutation ohne Smartphone durchführen?** - - Kein Problem: Nutzen Sie hierzu einfach unser Mutationsformular. Sie erhalten die Unterlagen innerhalb eines Arbeitstages per E-Mail zur Unterzeichnung zugestellt. Diese müssen dann per Post retourniert werden. - -Bestseller -Digitale Mutation ------------------ - -in CHF (exkl. MWST)Analoge Mutation ----------------- - -in CHF (exkl. MWST) -### ab CHF 130.00 - -Erledigen Sie Ihre Handelsregisteränderung direkt über Ihr Smartphone.### ab CHF 150.00 - -Sie möchten die Änderung ohne Smartphone durchführen? Wir unterstützen Sie hierbei selbstverständlich gerne. -[Jetzt digitale Mutation starten](https://app.hoop.deepcloud.swiss/fiduciary?partnerUUID=eaa32e4c-d75d-4474-af03-2cc835a02802&companyUID=CHE113416882) - -[Sie wünschen eine kostenlose Erstberatung? Jetzt Termin buchen.](https://calendly.com/moneyhouse-hr-service/beratung-gruendung)[Jetzt Handelsregistereintrag kostenlos prüfen](https://handelsregister.moneyhouse.ch/de/mutation/CH02030306513?itm_campaign=traderegister&itm_medium=referral&itm_source=moneyhouse.ch&itm_content=link-traderegister-company_banner) - -[Sie wünschen eine kostenlose Erstberatung? Jetzt Termin buchen.](https://calendly.com/moneyhouse-hr-service/beratung-gruendung) - -#### Ihre Handelsregisteränderung – einfach und sofort digital erledigt - -Digitale Mutation ------------------ - -in CHF (exkl. MWST) - -### ab CHF 130.00 - -Erledigen Sie Ihre Handelsregisteränderung direkt über Ihr Smartphone. - -[Jetzt digitale Mutation starten](https://app.hoop.deepcloud.swiss/fiduciary?partnerUUID=eaa32e4c-d75d-4474-af03-2cc835a02802&companyUID=CHE113416882) - -[Sie wünschen eine kostenlose Erstberatung? Jetzt Termin buchen.](https://calendly.com/moneyhouse-hr-service/beratung-gruendung) - -Analoge Mutation ----------------- - -in CHF (exkl. MWST) - -### ab CHF 150.00 - -Sie möchten die Änderung ohne Smartphone durchführen? Wir unterstützen Sie hierbei selbstverständlich gerne. - -[Jetzt Handelsregistereintrag kostenlos prüfen](https://handelsregister.moneyhouse.ch/de/mutation/CH02030306513?itm_campaign=traderegister&itm_medium=referral&itm_source=moneyhouse.ch&itm_content=link-traderegister-company_banner) - -[Sie wünschen eine kostenlose Erstberatung? Jetzt Termin buchen.](https://calendly.com/moneyhouse-hr-service/beratung-gruendung) - -Ablauf digitaler Prozess ------------------------- - -### Deepcloud und Datenerfassung - - -Registrieren Sie sich bei deepcloud und erfassen Sie die Mutation direkt online. - -### Registrierung DeepID - - -Laden Sie die DeepID-App aus dem App Store herunter und registrieren Sie sich. Mehr Informationen dazu finden Sie [hier](https://www.deepid.swiss/de/digitale-identifizierung/). - -### Digitale Unterzeichnung - - -Unterzeichen Sie alle Dokumente gemäss der Aufforderung in DeepSign. - -### Einreichung der Unterlagen - - -Reichen Sie die digital unterzeichneten Dokumente mit wenigen Klicks direkt beim zuständigen Handelsregisteramt ein. - -Ablauf analoger Prozess ------------------------ - -### Erfassung Daten - - -Wir erfassen die Änderungen in unserem System gemäss Ihrer Angaben. - -### Dokumente - - -Wir erstellen die Dokumente und senden Ihnen diese per Mail zu. Von unserer Seite her dauert dieser Schritt maximal zwei Arbeitstage. - -### Rücksendung - - -Schauen Sie sich die Unterlagen durch und senden Sie uns alle Dokumente unterschieben zurück. Vergessen Sie die Ausweiskopien nicht. - -### Publikation - - -Nach Erhalt der Unterlagen prüfen wir diese und senden sie (wenn nötig) an unseren Notar oder direkt weiter ans Handelsregisteramt. Das Handelsregisteramt benötigt etwa zwei Wochen. - - - -Service Umfang --------------- - -* digitale oder analoge Erstellung der Unterlagen -* Alle Notariatskosten (falls notwendig) -* Beurkundungen(falls notwendig) -* Vorprüfung der Unterlagen (analoger Prozess) -* Kommunikation mit dem Handelsregisteramt -* Falls nötig, Publikation Schuldenrufe - -Bitte beachten Sie, dass alle amtlichen Gebühren des Handelsregisters in beiden Formen des Prozesses (digital und analog) sowie die Kosten für allfällige Beglaubigungen von Unterschriften im analogen Prozess nicht enthalten sind. - -[](https://www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -Preise und Prozessdauer ------------------------ - -Digitaler Prozess Analoger Prozess -Kosten ab CHF 150.00 Kosten ab CHF 150.00 -Dauer: 3 - 4 Tage ab Einreichung bei Handelsregister Dauer: ca. 2 Wochen (ohne Beurkundung) bis 3 Wochen (mit Beurkundung) - -Alle Unternehmensformen -Digitaler - - Prozess Kosten ab CHF 150.00 -Analoger - - Prozess Kosten ab CHF 150.00 - -Prozessdauer -Digitaler - - Prozess 3 - 4 Tage ab Einreichung bei Handelsregister -Analoger - - Prozess ca. 2 Wochen (ohne Beurkundung) bis 3 Wochen (mit Beurkundung) - - - -Wie können wir Ihnen helfen? ----------------------------- - -Haben Sie Fragen oder wünschen Sie weitere Informationen? - - Vereinbaren Sie direkt online einen [kostenlosen Beratungstermin](http://calendly.com/moneyhouse-hr-service/beratung-gruendung) oder kontaktieren Sie uns: - -Telefon: +41 44 258 28 88 oder per E-Mail:[crs@moneyhouse.ch](mailto:crs@moneyhouse.ch) - - Montag-Freitag: 8.30 - 11.00 Uhr und 13.30 - 16.00 Uhr - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcommercialregister%2Foverview%3Fchnr%3DCH02030306513%26uid%3DCHE113416882) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Änderung Firmenname](https://www.moneyhouse.ch/de/commercialregister/services/company-name) - -[Personenmutation](https://www.moneyhouse.ch/de/commercialregister/services/person) - -[Änderung Sitz & Domizil](https://www.moneyhouse.ch/de/commercialregister/services/address) - -[Änderung Statuten](https://www.moneyhouse.ch/de/commercialregister/services/statutes) - -[Anpassung Zweck](https://www.moneyhouse.ch/de/commercialregister/services/company-purpose) - -[Liquidation](https://www.moneyhouse.ch/de/commercialregister/liquidation) - -[Weitere Services](https://www.moneyhouse.ch/de/commercialregister/services/other-services) - - -=== https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue === -Kennzahlen ValueOn AG - Dübendorf - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue#)[Save + Exit](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -[ValueOn AG](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -[Startseite](https://www.moneyhouse.ch/de/)[>](javascript:void(0))[Unternehmen](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG)[>](javascript:void(0))ValueOn AG - -ValueOn AG -========== - -ZH - -aktiv - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Zur Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -Handelsregister-Nr.:CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Umsatz ------- - -[Exklusiv für Premium-Mitglieder](https://www.moneyhouse.ch/membership) - -Mitarbeiter ------------ - -[Exklusiv für Premium-Mitglieder](https://www.moneyhouse.ch/membership) - -Kapital -------- - -#### Aktienkapital - -CHF 200'000 (vollständig liberiert) - -#### Aktien-Stückelung - -(Aktienkapital) - -[Exklusiv für Premium-Mitglieder](https://www.moneyhouse.ch/membership) - -#### Anzahl Kapitalveränderungen - -(Datum letzte Änderung) - -[Exklusiv für Premium-Mitglieder](https://www.moneyhouse.ch/membership) - -Alter der Firma ---------------- - -18 Jahre 8 Monate -#### Eintrag ins Handelsregister - -02.02.2007 - -Premium-Mitglied werden ------------------------ - -**Uneingeschränkter** Zugriff auf alle Hintergrundinformationen und auf Umsatz- & Mitarbeiterzahlen der ValueOn AG - -[Premium-Mitglied werden](https://www.moneyhouse.ch/membership) - -Hinweis: Die Informationen zu Mitarbeiter- und Umsatzzahlen sind in den meisten Fällen statistisch berechnete Werte und werden in vordefinierten Ranges angezeigt (Bsp. 4-9, 10-19). - -Liegen Ihnen genauere Angaben zu den Mitarbeiter- und Umsatzzahlen vor?[Kontaktieren Sie uns](https://www.moneyhouse.ch/de/contact/contactform) - -Möchten Sie mehr Details zur ValueOn AG? - -Dann empfehlen wir Ihnen die Wirtschaftsauskunft! - -Wirtschaftsauskunft -------------------- - -Umfassende Auskunft über die wirtschaftliche Situation der Firma. - -* Einschätzung der Bonität mit einer Ampel -* Zahlungsverhalten der letzten Rechnungen -* Risikobewertung im Branchenvergleich -* Meldung von Inkassobüros und Betreibungsämtern -* Firmeninformationen aus dem Handelsregister - -[ Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:e9d3178c-3e96-4218-ac8d-39baffee2871) - -[Beispiel ansehen](https://www.moneyhouse.ch/de/dam/jcr:e9d3178c-3e96-4218-ac8d-39baffee2871) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -[Jetzt bestellen CHF 49.00 pro Abfrage](https://www.moneyhouse.ch/de/service/purchase/economicinformation?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D3) - -Quelle:[Crif](https://www.moneyhouse.ch/de/datasources) - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Jetzt bestellen CHF 49.00 pro Abfrage](https://www.moneyhouse.ch/de/service/purchase/economicinformation?returnUrl=http%3A%2F%2Fwww.moneyhouse.ch%2Fde%2Fcompany%2Fvalueon-ag-4663161481%2Freports%3Fdetail%3D3) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Frevenue) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - - -=== https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network#neighbourhood === -Netzwerk ValueOn AG - Dübendorf - -=============== - -Opt-out for personal information & cookies - -When you visit our website we and our partners collect personal information from you regarding your internet activity (e.g. online identifier, IP address, browsing history) and may set cookies or use similar technologies on your device in order to personalize the advertising that you see. This helps us to show you more relevant ads and improves your internet experience. We also use it in order to measure results or align our website content. Our partners may sell this information to third parties. You can opt out of our sharing of your information with third parties here: [Do Not Sell My Personal Information](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network#) - -Store and/or access information on a device - -Use precise geolocation data - -Actively scan device characteristics for identification - -Personalised advertising and content, advertising and content measurement, audience research and services development - -[Okay](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network#)[Save + Exit](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network#) - -[T&C](https://www.moneyhouse.ch/de/terms) | [Legal notice](https://www.moneyhouse.ch/de/imprint) - - - - - -[](https://www.moneyhouse.ch/de/)[Menu](javascript:void(0)) - -DE - -EN - -FR - -IT - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -[ValueOn AG](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -[Datenzugriff](javascript:void(0)) - -[Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview)[Voller Datenzugriff](https://www.moneyhouse.ch/de/membership)[Public API](https://www.moneyhouse.ch/de/apiintegration)[Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise)[Firmenlisten](https://www.moneyhouse.ch/de/companieslists)[Adressen kaufen](https://address.moneyhouse.ch/) - -[Auskünfte](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/businessreports)[Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating)[Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour)[Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation)[Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation)[Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -[Handelsregister](javascript:void(0)) - -[Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation)[Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation)[Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -[Unternehmen](javascript:void(0)) - -[Über uns](https://www.moneyhouse.ch/de/about)[Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse)[Datenquellen](https://www.moneyhouse.ch/de/datasources)[Kontakt](https://www.moneyhouse.ch/de/contact) - -[](https://www.moneyhouse.ch/de/kmuplus)[Regio-News](https://www.moneyhouse.ch/de/region)[Hilfebereich](https://www.moneyhouse.ch/de/howto) - -[AGB](https://www.moneyhouse.ch/de/terms)[Datenschutz](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -[](https://www.moneyhouse.ch/de/) - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -[Regio-News](https://www.moneyhouse.ch/de/region)[](https://www.moneyhouse.ch/de/kmuplus)[](javascript:void(0)) - -[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork)[Hilfe](https://www.moneyhouse.ch/de/howto) - -DE - -* [Deutsch](javascript:void(0)) -* [Français](javascript:void(0)) -* [Italiano](javascript:void(0)) -* [English](javascript:void(0)) - -[Datenzugriff](javascript:void(0)) - -[Auskünfte](javascript:void(0)) - -[Handelsregister](javascript:void(0)) - -[Unternehmen](javascript:void(0)) - -[Menu](javascript:void(0)) - -[Datenzugriff](javascript:void(0))[Auskünfte](javascript:void(0))[Handelsregister](javascript:void(0))[Unternehmen](javascript:void(0))[Menu](javascript:void(0)) - -[Erweiterte Suche](https://www.moneyhouse.ch/de/advancedsearch) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -**KMU+**[](https://www.moneyhouse.ch/de/kmuplus) - -[ Führung Berufung ist kein Luxusgut ](https://www.moneyhouse.ch/kmuplus/fuhrung/berufung-ist-kein-luxusgut-id.863) - -[ Wirtschaft Produktionsverlagerungen in die USA und EU: Schweizer KMU verraten ihre Pläne ](https://www.moneyhouse.ch/kmuplus/wirtschaft/nzz-mr-president-wir-kommen-drei-chefs-von-schweizer-industriefirmen-verraten-ihre-verlagerungsplaene-id.859) - -* - -* - -* - -* - -* [](https://www.moneyhouse.ch/de/search?q=undefined) - -[Startseite](https://www.moneyhouse.ch/de/)[>](javascript:void(0))[Unternehmen](https://www.moneyhouse.ch/de/search?q=ValueOn%20AG)[>](javascript:void(0))ValueOn AG - -ValueOn AG -========== - -ZH - -aktiv - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Zur Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -[Jetzt Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report)[Bonität prüfen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report) - -So bleiben Sie über "ValueOn AG" auf dem Laufenden, bitte anmelden oder kostenlos registrieren.Sie folgen jetzt "ValueOn AG" - -- [x] + Folgen - -Handelsregister-Nr.:CH-020.3.030.651-3 - -Rechtsform: Aktiengesellschaft - -Branche: Erbringen von IT-Dienstleistungen - -[Letzte Meldung: 27.08.2025](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -Netzwerk --------- - -Netzwerk: Alle Verbindungen im Überblick ----------------------------------------- - -Mit dem Netzwerk sehen Sie auf einen Blick alle Verbindungen von Firmen und Personen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/membership) - -Es können maximal die 250 neuesten aktiven und 50 inaktive Verbindungen angezeigt werden. - -**Status** - -- [x] aktive Verbindungen - -- [x] inaktive Verbindungen - -**Management** - -- [x] oberstes Management - -- [x] Geschäftsführung - -- [x] andere Funktionen - -- [x] Zeichnungsberechtigte - -**Verbindungen** - -- [x] zu Firmen - -- [x] zu Personen - -**Revisionsstellen** - -- [x] Revisionsstellen - -[Zurücksetzen](javascript:void(0)) - -[](javascript:void(0))[](javascript:void(0))[+](javascript:void(0))[-](javascript:void(0)) +[RE/MAX Immobilien in Bülach 9 Zi. • 180 m² • 891 m² Grundstück • Bauland 8172 Niederglatt ZH * Historischer Charme seit 1680 * Geräumiger Garten zum Entspannen * Vielseitige Scheune für Erweiterung * * * CHF 2’300’000.- CHF 12’778 / m² immobilier.ch](https://realadvisor.ch/de/kaufen/grundstuck/8172-niederglatt-zh-YMX9-JZX5) * * * -Aktive Firmen in der Nachbarschaft ----------------------------------- +Anfrage abschicken -Quelle: [SHAB](https://www.moneyhouse.ch/de/datasources) -#### 8 aktive Firmen mit gleichem Domizil: Am Stadtrand 11, 8600 Dübendorf - -[Black Projects GmbH](https://www.moneyhouse.ch/de/company/black-projects-gmbh-3958227961) -[Bluespace Ventures AG](https://www.moneyhouse.ch/de/company/bluespace-ventures-ag-20038582721) -[Cyberfy Consulting AG](https://www.moneyhouse.ch/de/company/cyberfy-consulting-ag-5194156221) -[FICHTNER MANAGEMENT CONSULTING AG SCHWEIZ](https://www.moneyhouse.ch/de/company/fichtner-management-consulting-ag-10801938741) -[Gex Immo Consult AG](https://www.moneyhouse.ch/de/company/gex-immo-consult-ag-12703377601) -[Gracher Kredit- und Kautionsmakler GmbH & Co.KG, Trier, Zweigniederlassung Dübendorf](https://www.moneyhouse.ch/de/company/gracher-kredit-und-kautionsmakler-gmbh-co-kg--5397627361) -[SIP Switzerland AG](https://www.moneyhouse.ch/de/company/sip-switzerland-ag-12346588291) -[WonderWave GmbH](https://www.moneyhouse.ch/de/company/wonderwave-gmbh-19889373591) - -[Alle anzeigen](javascript:void(0)) - -[Weniger anzeigen](javascript:void(0)) - -#### 60 aktive Firmen an der gleichen Strasse: Am Stadtrand, 8600 Dübendorf - -[Fibre Pharma AG](https://www.moneyhouse.ch/de/company/fibre-pharma-ag-4088828381) - -Am Stadtrand 1 -[NetEducation GmbH](https://www.moneyhouse.ch/de/company/neteducation-gmbh-12921962361) - -Am Stadtrand 1 -[NetIT-Services GmbH](https://www.moneyhouse.ch/de/company/netit-services-gmbh-13663579741) - -Am Stadtrand 1 -[Top Nails and Beauty GmbH](https://www.moneyhouse.ch/de/company/top-nails-and-beauty-gmbh-7371788851) - -Am Stadtrand 1 -[Frauenpraxis Stettbach Mitte Dr. med. Gunther Kaindl](https://www.moneyhouse.ch/de/company/frauenpraxis-stettbach-mitte-dr-med-gunther-4154277041) - -Am Stadtrand 3 -[PhysiOsteo Montagna GmbH](https://www.moneyhouse.ch/de/company/physiosteo-montagna-gmbh-13903303071) - -Am Stadtrand 3 -[TwoMoons AG](https://www.moneyhouse.ch/de/company/twomoons-ag-5574859691) - -Am Stadtrand 3 -[CITYDENTAL Group AG](https://www.moneyhouse.ch/de/company/citydental-group-ag-14551629461) - -Am Stadtrand 5 -[CITYDENTAL Stettbach AG](https://www.moneyhouse.ch/de/company/citydental-stettbach-ag-19365176231) - -Am Stadtrand 5 -[PlusMAT Instrumentenhandel Seefeld](https://www.moneyhouse.ch/de/company/plusmat-instrumentenhandel-seefeld-15313160081) - -Am Stadtrand 5 -[Praxis am Stadtrand AG](https://www.moneyhouse.ch/de/company/praxis-am-stadtrand-ag-5244050981) - -Am Stadtrand 5 -[Questline KLG](https://www.moneyhouse.ch/de/company/questline-klg-20237845361) - -Am Stadtrand 13 -[berg & kunz KLG](https://www.moneyhouse.ch/de/company/berg-kunz-klg-14260698371) - -Am Stadtrand 23 -[Virtumate Manuela Erhart](https://www.moneyhouse.ch/de/company/virtumate-manuela-erhart-4697950761) - -Am Stadtrand 23 -[Vollmann AgileXcellence](https://www.moneyhouse.ch/de/company/vollmann-agilexcellence-3128545151) - -Am Stadtrand 23 -[Getfitbylina, Rada Cardozo](https://www.moneyhouse.ch/de/company/getfitbylina-rada-cardozo-15072677181) - -Am Stadtrand 25 -[Oni GmbH](https://www.moneyhouse.ch/de/company/oni-gmbh-6702936421) - -Am Stadtrand 29 -[Malina BB Vidan Stepanovic](https://www.moneyhouse.ch/de/company/malina-bb-vidan-stepanovic-694882931) - -Am Stadtrand 31 -[Konoha Holding AG](https://www.moneyhouse.ch/de/company/konoha-holding-ag-5681159481) - -Am Stadtrand 43 -[LAU](https://www.moneyhouse.ch/de/company/lau-10678515661) - -Am Stadtrand 43 -[Michael Bjeski IT Engineering](https://www.moneyhouse.ch/de/company/michael-bjeski-it-engineering-6411005861) - -Am Stadtrand 43 -[MMACIAS, Inh. Macias Speissegger](https://www.moneyhouse.ch/de/company/mmacias-inh-macias-speissegger-18447240901) - -Am Stadtrand 43 -[Ryser Living Solutions GmbH](https://www.moneyhouse.ch/de/company/ryser-living-solutions-gmbh-1491545501) - -Am Stadtrand 43 -[Physiotherapie Stettbach GmbH](https://www.moneyhouse.ch/de/company/physiotherapie-stettbach-gmbh-14832629151) - -Am Stadtrand 46 -[SGA Swiss AG](https://www.moneyhouse.ch/de/company/sga-swiss-ag-11969999171) - -Am Stadtrand 46 -[Sport-Fitness-Center Schumacher AG](https://www.moneyhouse.ch/de/company/sport-fitness-center-schumacher-ag-3417231251) - -Am Stadtrand 46 -[ESTETICA STUDIO Nadine Suter](https://www.moneyhouse.ch/de/company/estetica-studio-nadine-suter-13756684561) - -Am Stadtrand 49b -[Nacer, Ximena Silva](https://www.moneyhouse.ch/de/company/nacer-ximena-silva-13292556001) - -Am Stadtrand 49a -[Compliance Powerhouse AG](https://www.moneyhouse.ch/de/company/compliance-powerhouse-ag-4177952931) - -Am Stadtrand 51b -[LogicStar AG](https://www.moneyhouse.ch/de/company/logicstar-ag-5246816641) - -Am Stadtrand 51a -[MAISON DE LA ROCHEMACÉ](https://www.moneyhouse.ch/de/company/maison-de-la-rochemace-15044423081) - -Am Stadtrand 51a -[SWiss tO cuRe Dipg](https://www.moneyhouse.ch/de/company/swiss-to-cure-dipg-14331095251) - -Am Stadtrand 51a -[Triple-X by Werner Blättler](https://www.moneyhouse.ch/de/company/triple-x-by-werner-blaettler-20046122301) - -Am Stadtrand 51a -[Vinitaly GmbH](https://www.moneyhouse.ch/de/company/vinitaly-gmbh-20529542651) - -Am Stadtrand 51B -[Beyond Patterns GmbH](https://www.moneyhouse.ch/de/company/beyond-patterns-gmbh-12342874101) - -Am Stadtrand 53a -[Biasi Immobilien AG](https://www.moneyhouse.ch/de/company/biasi-immobilien-ag-6021309661) - -Am Stadtrand 53b -[Cucina Alpina GmbH](https://www.moneyhouse.ch/de/company/cucina-alpina-gmbh-3852911181) - -Am Stadtrand 53b -[curlA Engineering GmbH](https://www.moneyhouse.ch/de/company/curla-engineering-gmbh-14759700611) - -Am Stadtrand 53a -[Kriztle Bath & Wellness GmbH](https://www.moneyhouse.ch/de/company/kriztle-bath-wellness-gmbh-15976831551) - -Am Stadtrand 53b -[Talent Sutra von Agarwal](https://www.moneyhouse.ch/de/company/talent-sutra-von-agarwal-7057294151) - -Am Stadtrand 53a -[AI Swiss Knife, Inh. Brunner](https://www.moneyhouse.ch/de/company/ai-swiss-knife-inh-brunner-5180921761) - -Am Stadtrand 56 -[Amalia GmbH](https://www.moneyhouse.ch/de/company/amalia-gmbh-4465184331) - -Am Stadtrand 56 -[Blütentanz Heidi Kummer](https://www.moneyhouse.ch/de/company/bluetentanz-heidi-kummer-91594131) - -Am Stadtrand 56 -[Chronos Web Solutions KlG](https://www.moneyhouse.ch/de/company/chronos-web-solutions-klg-21410964941) - -Am Stadtrand 56 -[CorePiece GmbH](https://www.moneyhouse.ch/de/company/corepiece-gmbh-3996687461) - -Am Stadtrand 56 -[Doppel A KlG](https://www.moneyhouse.ch/de/company/doppel-a-klg-4715173231) - -Am Stadtrand 56 -[DPC Academy GmbH](https://www.moneyhouse.ch/de/company/dpc-academy-gmbh-5425938371) - -Am Stadtrand 56 -[Exec. Express GmbH](https://www.moneyhouse.ch/de/company/exec-express-gmbh-4270000211) - -Am Stadtrand 56 -[Immoservice-Solutions GmbH](https://www.moneyhouse.ch/de/company/immoservice-solutions-gmbh-5695654661) - -Am Stadtrand 56 -[J.F. Schulz & Company AG](https://www.moneyhouse.ch/de/company/j-f-schulz-company-ag-12183475011) - -Am Stadtrand 56 -[mags.porcelain by Marilei Genther](https://www.moneyhouse.ch/de/company/mags-porcelain-by-marilei-genther-19680925581) - -Am Stadtrand 56 -[Marijana Mionic Ebersold](https://www.moneyhouse.ch/de/company/marijana-mionic-ebersold-4251659421) - -Am Stadtrand 56 -[Milo Finanz AG](https://www.moneyhouse.ch/de/company/milo-finanz-ag-19873157631) - -Am Stadtrand 56 -[Reimer Life Journey Coaching und Beratung](https://www.moneyhouse.ch/de/company/reimer-life-journey-coaching-und-15986689981) - -Am Stadtrand 56 -[RUPOVA VENTURES](https://www.moneyhouse.ch/de/company/rupova-ventures-4042215861) - -Am Stadtrand 56 -[S. Reiser](https://www.moneyhouse.ch/de/company/s-reiser-18805059631) - -Am Stadtrand 56 -[Tipp Topp Cakes by Sophie Hogg](https://www.moneyhouse.ch/de/company/tipp-topp-cakes-by-sophie-hogg-12878277641) - -Am Stadtrand 56 -[Vögeli Flowers](https://www.moneyhouse.ch/de/company/voegeli-flowers-13556974501) - -Am Stadtrand 56 -[Wismer Marketing](https://www.moneyhouse.ch/de/company/wismer-marketing-2108420601) - -Am Stadtrand 56 -[Kita Zwerglinge GmbH](https://www.moneyhouse.ch/de/company/kita-zwerglinge-gmbh-14370068251) - -Am Stadtrand 58a - -[Alle anzeigen](javascript:void(0)) - -[Weniger anzeigen](javascript:void(0)) - -* [](https://www.linkedin.com/company/moneyhouse-ch "Moneyhouse auf Linkedin") - -**Datenzugriff** - -* [Übersicht Mitgliedschaften](https://www.moneyhouse.ch/de/overview) -* [Voller Datenzugriff](https://www.moneyhouse.ch/de/membership) -* [Public API](https://www.moneyhouse.ch/de/apiintegration) -* [Corporate-Angebote](https://www.moneyhouse.ch/de/enterprise) -* [Firmenlisten](https://www.moneyhouse.ch/de/companieslists) -* [Adressen kaufen](https://address.moneyhouse.ch/) - -**Auskünfte** - -* [Übersicht](https://www.moneyhouse.ch/de/businessreports) -* [Bonitätsauskunft](https://www.moneyhouse.ch/de/creditrating) -* [Zahlungsverhalten](https://www.moneyhouse.ch/de/paymentbehaviour) -* [Wirtschaftsauskunft](https://www.moneyhouse.ch/de/economicinformation) -* [Beteiligungsauskunft](https://www.moneyhouse.ch/de/shareholderinformation) -* [Betreibungsauskunft](https://www.moneyhouse.ch/de/paymentcollection) - -**Handelsregister** - -* [Firma gründen](https://www.moneyhouse.ch/de/commercialregister/foundation) -* [Firma liquidieren](https://www.moneyhouse.ch/de/commercialregister/liquidation) -* [Änderung Eintrag](https://www.moneyhouse.ch/de/commercialregister/services) - -**Unternehmen** - -* [Über uns](https://www.moneyhouse.ch/de/about) -* [Werbung schalten](https://www.audienzz.ch/premium-brand/moneyhouse) -* [Datenquellen](https://www.moneyhouse.ch/de/datasources) -* [Kontakt](https://www.moneyhouse.ch/de/contact) - -* [Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) -* [Hilfebereich](https://www.moneyhouse.ch/de/howto) - -* [Sprache wechseln](javascript:void(0)) -* [DE |](javascript:void(0))[FR |](javascript:void(0))[IT |](javascript:void(0))[EN](javascript:void(0)) - -* [KMU+](https://www.moneyhouse.ch/de/kmuplus) -* [Regio-News](https://www.moneyhouse.ch/de/region) - -Firmenverzeichnis nach Kantonen - -[AG](https://www.moneyhouse.ch/de/companydirectory/ag/a/a_) - -[AI](https://www.moneyhouse.ch/de/companydirectory/ai/a/a_) - -[AR](https://www.moneyhouse.ch/de/companydirectory/ar/a/a_) - -[BL](https://www.moneyhouse.ch/de/companydirectory/bl/a/a_) - -[BS](https://www.moneyhouse.ch/de/companydirectory/bs/a/a_) - -[BE](https://www.moneyhouse.ch/de/companydirectory/be/a/a_) - -[FR](https://www.moneyhouse.ch/de/companydirectory/fr/a/a_) - -[GE](https://www.moneyhouse.ch/de/companydirectory/ge/a/a_) - -[GL](https://www.moneyhouse.ch/de/companydirectory/gl/a/a_) - -[GR](https://www.moneyhouse.ch/de/companydirectory/gr/a/a_) - -[JU](https://www.moneyhouse.ch/de/companydirectory/ju/a/a_) - -[LU](https://www.moneyhouse.ch/de/companydirectory/lu/a/a_) - -[NE](https://www.moneyhouse.ch/de/companydirectory/ne/a/a_) - -[NW](https://www.moneyhouse.ch/de/companydirectory/nw/a/a_) - -[OW](https://www.moneyhouse.ch/de/companydirectory/ow/a/a_) - -[SH](https://www.moneyhouse.ch/de/companydirectory/sh/a/a_) - -[SZ](https://www.moneyhouse.ch/de/companydirectory/sz/a/a_) - -[SO](https://www.moneyhouse.ch/de/companydirectory/so/a/a_) - -[SG](https://www.moneyhouse.ch/de/companydirectory/sg/a/a_) - -[TI](https://www.moneyhouse.ch/de/companydirectory/ti/a/a_) - -[TG](https://www.moneyhouse.ch/de/companydirectory/tg/a/a_) - -[UR](https://www.moneyhouse.ch/de/companydirectory/ur/a/a_) - -[VD](https://www.moneyhouse.ch/de/companydirectory/vd/a/a_) - -[VS](https://www.moneyhouse.ch/de/companydirectory/vs/a/a_) - -[ZG](https://www.moneyhouse.ch/de/companydirectory/zg/a/a_) - -[ZH](https://www.moneyhouse.ch/de/companydirectory/zh/a/a_) - -Personenverzeichnis - -[A](https://www.moneyhouse.ch/de/persondirectory/a/aa) - -[B](https://www.moneyhouse.ch/de/persondirectory/b/ba) - -[C](https://www.moneyhouse.ch/de/persondirectory/c/ca) - -[D](https://www.moneyhouse.ch/de/persondirectory/d/da) - -[E](https://www.moneyhouse.ch/de/persondirectory/e/ea) - -[F](https://www.moneyhouse.ch/de/persondirectory/f/fa) - -[G](https://www.moneyhouse.ch/de/persondirectory/g/ga) - -[H](https://www.moneyhouse.ch/de/persondirectory/h/ha) - -[I](https://www.moneyhouse.ch/de/persondirectory/i/ia) - -[J](https://www.moneyhouse.ch/de/persondirectory/j/ja) - -[K](https://www.moneyhouse.ch/de/persondirectory/k/ka) - -[L](https://www.moneyhouse.ch/de/persondirectory/l/la) - -[M](https://www.moneyhouse.ch/de/persondirectory/m/ma) - -[N](https://www.moneyhouse.ch/de/persondirectory/n/na) - -[O](https://www.moneyhouse.ch/de/persondirectory/o/oa) - -[P](https://www.moneyhouse.ch/de/persondirectory/p/pa) - -[Q](https://www.moneyhouse.ch/de/persondirectory/q/qa) - -[R](https://www.moneyhouse.ch/de/persondirectory/r/ra) - -[S](https://www.moneyhouse.ch/de/persondirectory/s/sa) - -[T](https://www.moneyhouse.ch/de/persondirectory/t/ta) - -[U](https://www.moneyhouse.ch/de/persondirectory/u/ua) - -[V](https://www.moneyhouse.ch/de/persondirectory/v/va) - -[W](https://www.moneyhouse.ch/de/persondirectory/w/wa) - -[X](https://www.moneyhouse.ch/de/persondirectory/x/xa) - -[Y](https://www.moneyhouse.ch/de/persondirectory/y/ya) - -[Z](https://www.moneyhouse.ch/de/persondirectory/z/za) - -Copyright © 2025 Moneyhouse Neue Zürcher Zeitung AG - -[AGB |](https://www.moneyhouse.ch/de/terms)[Datenschutz |](https://www.moneyhouse.ch/de/privacy)[Impressum](https://www.moneyhouse.ch/de/imprint) - -+ - -Sie folgen bereits 2 Firmen, Personen oder Stichwörtern. - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Kostenlos registrieren](https://www.moneyhouse.ch/de/overview) - -+ - -ValueOn AG folgen als registriertes Mitglied - -Registrieren Sie sich auf Moneyhouse und folgen Sie bis zu 2 Firmen, Personen oder Stichwörtern. - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/de/register?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -Premium-Mitglied werden - -Als Premium-Mitglied können Sie unbegrenzt Firmen, Personen oder Stichwörtern folgen. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/membership) - -+ - -Neu bei Moneyhouse? - -Als registriertes Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Einblick in Verwaltungsrat, Geschäftsleitung und Zeichnungsberechtigte - -Monitoring von 2 Firmen oder Personen - -2 veredelte Handelsregisterauszüge, die alle Informationen druckfertig präsentieren - -wertvolle Tipps von KMU_today - -Suche nach Firmen und Personen - -[Jetzt kostenlos registrieren](https://www.moneyhouse.ch/my/register.php) - -Neu bei Moneyhouse? - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Startseite](https://www.moneyhouse.ch/de/) - -Premium-Mitglied werden - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -Firmen- und Personensuche - -Umsatz- und Mitarbeiterzahlen sowie Details zum Management - -Folgen Sie unbegrenzt Firmen, Personen und Stichwörtern - -Grafische Netzwerkfunktion von Firmen und Personen - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -Informationen zu Kennzahlen sind nur für Premium-Mitglieder verfügbar. - -Als Premium-Mitglied sehen Sie noch mehr Informationen zu **ValueOn AG**. - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/network)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -Informationen zu Privatpersonen sind nur für Premium-Mitglieder verfügbar. - -Melden Sie sich als Premium-Mitglied an oder schliessen Sie eine Premium-Mitgliedschaft ab. - -Privatpersonensuche - -Adresse, Geburtsdatum und Beruf - -1 Bonitätsauskunft inklusive (Wert von CHF 19.00) - -[Premium-Mitglied werden](https://www.moneyhouse.ch/de/service/purchase/premium?returnUrl=http:/www.moneyhouse.ch/de/company/valueon-ag-4663161481/network)[Anmelden](https://www.moneyhouse.ch/de/login?redirectUrl=%2Fcompany%2Fvalueon-ag-4663161481%2Fnetwork) - -× - -**Title** - -Neue Gruppe anlegen: - -Einer bestehenden Gruppe hinzufügen: - -Kantone hinzufügen oder löschen: - -[Bestätigen](javascript:void(0)) - -[Übersicht](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) - -[Auskünfte](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports) - -[Management](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/management) - -[Netzwerk](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network) - -[Timeline](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline) - -[Kennzahlen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue) - -[Besitzverhältnisse](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/shares) - -[Meldungen](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages) - -[Marken](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/brands) - -[Jobs](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/jobs) - -[Baugesuche](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/buildingproject) - - -=== https://www.itreseller.ch/media === -Inserieren in IT Reseller +=== https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2 === +Bauland zu verkaufen - 8340 Hinwil - | RealAdvisor =============== -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Inserieren in IT Reseller -========================= +[](https://realadvisor.ch/de) - IT Reseller ist seit 1998 die führende Fachzeitschrift für die Schweizer IT-Industrie. +Bewerten - Die Print-Ausgabe erscheint monatlich in einer Auflage von 2500 Exemplaren und erreicht persönlich adressiert den Schweizer ICT-Channel. +[Kaufen](https://realadvisor.ch/de/immobilien-kaufen)[Mieten](https://realadvisor.ch/de/immobilien-mieten) - Online erreicht IT Reseller monatlich 32'000 Besucher (Unique Clients) und erzielt bis zu 92'000 Page Impressions. -Print-Anzeigen --------------- +Anmelden - Gültig ab 1. Januar 2025 -Anzeigen -Format Satzspiegel +DE -B x H in mm Randabfallend * +[Français](https://realadvisor.ch/fr/acheter/terrain/8340-hinwil-LDX9-L6M2)[Italiano](https://realadvisor.ch/it/comprare/trama/8340-hinwil-LDX9-L6M2)[English](https://realadvisor.ch/en/buy/plot/8340-hinwil-LDX9-L6M2) -B x H in mm Preis in CHF +[Alle Inserate anzeigen](https://realadvisor.ch/de/kaufen/stadt-hinwil/grundstuck) -exkl. MwSt -2/1 Seiten Panorama 385 x 265 420 x 297 6600.– -1/1 Seite 175 x 265 210 x 297 4000.– -1/2 Seite quer 175 x 130 210 x 145 3000.– -1/2 Seite hoch 85 x 265 103 x 297 3000.– -1/3 Seite quer 175 x 85 210 x 95 2800.– -1/3 Seite hoch 55 x 265 67 x 297 2800.– -2. oder 4. Umschlagsseite 175 x 265 210 x 297 4800.– -Advertorial -2/1 Seite 385 x 265 420 x 297 4950.– -1/1 Seite 175 x 265 210 x 297 3000.– -3er-Kombi ** -3x 1/1 Seite 175 x 265 210 x 297 6000.– -3x 1/2 Seite quer 175 x 130 210 x 145 4500.– -3x 1/2 Seite hoch 85 x 265 103 x 297 4500.– -Jahresangebot ** -10x 1/1 Seite 175 x 265 210 x 297 12'000.– -10x 1/2 Seite quer 175 x 130 210 x 145 9000.– -10x 1/2 Seite hoch 85 x 265 103 x 297 9000.– -Coverlasche (Flappe) -Coverlasche Vorderseite-auf Anfrage 5'400.– -Coverlasche Rückseite mit 4. Umschlagseite-auf Anfrage 5'400.– -Coverlasche im 5er Kombi-auf Anfrage 4000.– -Veranstaltungskalender -Eintrag mit Datum, Titel, Tagline und URL + Online-Publikation (s. unten)180.– + -* 3 mm Beschnitt pro Aussenrand hinzufügen + - ** Fixpreis für 3 resp. 10 aufeinanderfolgende Ausgaben, Vorauszahlung, nicht Rabatt- oder BK-berechtigt, ohne redaktionellen Anschluss, keine Platzierungswünsche möglich, Verwendung des alten Sujets bei Nichtlieferung eines neuen Sujets bis Inserateschluss. + -Online-Anzeigen ---------------- + - Gültig ab 1. Januar 2025 -TKP-Buchungen -Werbemittel Platzierung Preis in CHF pro 1000 Impressions Format BxH +- [x] -(max. 50 KB)Datenformate -Maxiboard Run-of-Site 55.–994 x 118 Pixel JPEG, GIF, HTML5 -Leaderboard Run-of-Site 55.–728 x 90 Pixel JPEG, GIF, HTML5 -Wideskyscraper Run-of-Site 55.–160 x 600 Pixel JPEG, GIF, HTML5 -Half Page Run-of-Site 55.–300 x 600 Pixel JPEG, GIF, HTML5 -Rectangle Run-of-Site 55.–300 x 250 Pixel JPEG, GIF, HTML5 -Mindestbuchungsvolumen: CHF 1100.– -Buchungen mit Fixplatzierung -Werbemittel Platzierung Preis pro Woche Format (max. 50 KB)Datenformate -Maxiboard Run-of-Site 1290.–994 x 118 Pixel JPEG, GIF, HTML5 -Leaderboard Run-of-Site 1290.–728 x 90 Pixel JPEG, GIF, HTML5 -Wideskyscraper Run-of-Site 1290.–160 x 600 Pixel JPEG, GIF, HTML5 -Half Page Run-of-Site 1290.–300 x 600 Pixel JPEG, GIF, HTML5 -Rectangle Run-of-Site 1490.–300 x 250 Pixel JPEG, GIF, HTML5 -Advertorial -Advertorial Homepage & Newsletter 1200.–Titel, max. 4000 Zeichen Text, Bild +Speichern -Newsletter-Anzeigen -------------------- +- [x] -Fixplatzierung -Werbemittel Preis pro Woche Format (max. 50 KB)Datenformate -Banner 600.–468 x 60 Pixel JPEG, GIF -Skyscraper 825.–160 x 600 Pixel JPEG, GIF -Rectangle 825.–300 x 250 Pixel JPEG, GIF -Textanzeige 825.–n/a JPEG, GIF +Bauland zu verkaufen - 8340 Hinwil +================================== -Veranstaltungen ---------------- +CHF 1’070’000.- -Grundeintrag im Veranstaltungskalender -Werbemittel Preis in CHF exkl. MWST -Eintrag mit Titel, Datum und URL kostenlos -Premium-Eintrag im Veranstaltungskalender -Eintrag mit Titel, Datum und URL 180.- -+ Eintrag mit farblicher Hervorhebung, Logo, Beschreibung -+ Tägliche Veröffentlichung im Newsletter (Start: 3 Monate vor Beginn) -+ Veröffentlichung im Veranstaltungskalender der Print-Ausgabe +CHF 1’000 / m² -SALES KONTAKT +* * * - +Grundstück - Sie möchten Werbung schalten oder wünschen eine kompetente Beratung? +Beschreibung -**Unsere Verkaufsleiterin Tanja Zesiger freut sich auf Ihre Kontaktaufnahme!** +Hier beginnt Ihre Zukunft +------------------------- -#### ✆ +41 (0) 44 723 50 05 +Dieses attraktive Grundstück befindet sich an ruhiger und familienfreundlicher Lage in Hinwil. Mit einer Gesamtfläche von über 1070 m² bietet es vielfältige Nutzungsmöglichkeiten und eignet sich hervorragend für die Realisierung mehrerer Reihenfamilienhäuser. Dank der Möglichkeit zur Abparzellierung kann auch nur ein Teil des Landes beispielsweise ideal für ein Einfamilienhaus erworben werden. Das Grundstück liegt in der Kernzone und eröffnet dadurch grossen Gestaltungsspielraum für individuelle Bauprojekte. -#### [tzesiger@swissitmedia.ch](mailto:tzesiger@swissitmedia.ch) +Dieses ImmoSky Angebot bietet folgende _MEHR LEISTUNG_: -MEDIADATEN ++ Kernzone -[ ##### Download Mediadaten 2025](https://www.itreseller.ch/media/tarife/ITR_Mediadaten_2025_DE.pdf) ++ 2 Vollgeschosse, 1 Dachgeschoss -MEDIA ALERT ++ 4m Grenzabstand - Abonnieren Sie unseren monatlichen Media Alert mit der Themenvorschau auf die kommenden Ausgaben von IT Reseller. ++ 7.5m Fassadenhöhe -AUSGABEN & TERMINE +Das Grundstück ist baureif und erschlossen, die Quartierplankosten von CHF 150.00/m² werden zum Verkaufspreis dazugerechnet. -**IT Reseller 2025/ 11** -Erscheint am:3. November 2025 -Anzeigenschluss:24. Oktober 2025 +Aktuell befinden sich alte Holzschuppen auf dem Grundstück. Diese können abgerissen werden, um Platz für neue Ideen zu schaffen. Eine seltene Gelegenheit, Wohnen mit hoher Lebensqualität im Zürcher Oberland zu verwirklichen. Gerne stehe ich Ihnen bei Fragen zur Verfügung Ihr Daniel Arigoni. -**IT Reseller 2025/ 12** -Erscheint am:8. Dezember 2025 -Anzeigenschluss:28. November 2025 +(Das Verkaufsdossier wird in der Regel innert maximal 24 Stunden an Sie versendet, bitte prüfen Sie auch Ihren SPAM-Ordner.) -GOLD SPONSOREN +### Angaben zur Immobilie -SPONSOREN & PARTNER +Verfügbar ab - +Nach Vereinbarung - Swiss IT Media GmbH +* * * - Seestrasse 95 +Grundstücksfläche - CH-8800 Thalwil +1’070.0 m² - ✆ +41 44 723 50 00 +* * * - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) - - -=== https://www.itreseller.ch/abo === -Abonnement - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Abonnement-Bestellung -===================== - - IT Reseller wird ausschliesslich im **Controlled-Circulation-Modell** vertrieben und ist damit nur für Unternehmensmitarbeiter im IT- oder Consumer-Electronics-Markt erhältlich. - - Um sicherzustellen, dass nur qualifizierte Personen den IT Reseller erhalten, bitten wir Sie, bei Ihrer Bestellung **alle mit (*) gekennzeichneten Felder auszufüllen**, damit wir Ihre Angaben prüfen können. - -**1-Jahres-Abonnement** - - Ich abonniere IT Reseller inkl. Swiss IT Magazine für ein Jahr zum Preis von Fr. 95.– - -(Ausland Europa Fr. 190.-). -**2-Jahres-Abonnement** - - Ich abonniere IT Reseller inkl. Swiss IT Magazine für 2 Jahre zum Preis von Fr. 150.– - -(Ausland Europa Fr. 300.-). -**Online-Abonnement** - - Ich abonniere die digitale Ausgabe von IT Reseller und erhalte damit für 1 Jahr Zugriff auf die Online-Archive von [IT Reseller](https://www.itreseller.ch/Heftarchiv/) und [Swiss IT Magazine](http://www.itmagazine.ch/heftarchiv) zum Preis von Fr. 75.– -**Probe-Abonnement** - - Ich möchte drei Ausgaben kostenlos zur Probe. (Kein Ausland-Versand) -**Das Abo startet mit der Ausgabe** -- [x]Ich möchte auch den täglichen Newsletter von IT Reseller abonnieren! - -**Firma*** -**Anrede** -**Vorname*** -**Nachname*** -**Abteilung** -**Position** -**Branche*** -**Strasse*** -**PLZ/Ort*** -**Land** -**Telefon*** -**E-Mail*** -* Angabe obligatorisch -Dies ist meine Geschäftsadresse -Dies ist meine Privatadresse -- [x]IT Reseller darf mich für Meinungsumfragen - -und Recherchen kontaktieren. - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) - - -=== https://www.itreseller.ch/newsletter === -Newsletter - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Newsletter abonnieren -===================== - - Um die Newsletter von IT Reseller zu abonnieren, geben Sie bitte Ihre E-Mail-Adresse in das folgende Feld ein und klicken Sie auf den Anmelden-Button. - - Um den Newsletter abzubestellen, klicken Sie bitte auf den Link am Ende jedes Newsletters. - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) - - -=== https://www.itreseller.ch/rubriken/165/people.html === -People - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -PEOPLE ------- - -[](https://www.itreseller.ch/Artikel/104096/Daniele_Palazzo_verlaesst_Lake_Solutions.html) - -[Daniele Palazzo verlässt Lake Solutions =======================================](https://www.itreseller.ch/Artikel/104096/Daniele_Palazzo_verlaesst_Lake_Solutions.html) - -[Lake Solutions verkleinert die Geschäftsleitung. Daniele Palazzo verlässt das Unternehmen nach mehr als 20 Jahren, seine Aufgaben werden im Rahmen einer Reorganisation an die drei verbleibenden GL-Mitglieder verteilt.](https://www.itreseller.ch/Artikel/104096/Daniele_Palazzo_verlaesst_Lake_Solutions.html) - - 2. Oktober 2025 - -Meistgelesen in People - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -[](https://www.itreseller.ch/Artikel/104097/Torsten_Boettjer_ist_Head_of_Cloud_Services_bei_Inventx.html) - -[### Torsten Böttjer ist Head of Cloud Services bei Inventx Mit der neu geschaffenen Position des Head of Cloud Services will Inventx die Weiterentwicklung seiner Hybrid-Cloud-Strategie weiterentwickeln. Besetzt wurde die Position mit Torsten Böttjer. 2. Oktober 2025](https://www.itreseller.ch/Artikel/104097/Torsten_Boettjer_ist_Head_of_Cloud_Services_bei_Inventx.html) - -[](https://www.itreseller.ch/Artikel/104100/Hohmann_verlaesst_Thomas-Krenn_Meier_und_Frei_bilden_Doppelspitze.html) - -[### Hohmann verlässt Thomas-Krenn, Meier und Frei bilden Doppelspitze Beim Server- und Storage-Spezialisten Thomas-Krenn verkleinert sich der Vorstand wieder. Ralf Hohmann scheidet aus, CEO Christoph Maier und COO Thomas Frei übernehmen fortan zu zweit die Aufgaben des Vorstands. 2. Oktober 2025](https://www.itreseller.ch/Artikel/104100/Hohmann_verlaesst_Thomas-Krenn_Meier_und_Frei_bilden_Doppelspitze.html) - -[](https://www.itreseller.ch/Artikel/104094/NTT_Data_stellt_Michael_Seiger_als_neuen_DACH-Chef_vor.html) - -[### NTT Data stellt Michael Seiger als neuen DACH-Chef vor NTT Data ernennt Michael Seiger zum Executive Managing Director für Deutschland, Österreich und die Schweiz. Er folgt auf Stefan Hansen. 2. Oktober 2025](https://www.itreseller.ch/Artikel/104094/NTT_Data_stellt_Michael_Seiger_als_neuen_DACH-Chef_vor.html) - -[](https://www.itreseller.ch/Artikel/104095/Sonepar_Schweiz_ernennt_Raphael_Maier_zum_neuen_CEO.html) - -[### Sonepar Schweiz ernennt Raphael Maier zum neuen CEO David von Ow ist nach 30 Jahren in den Ruhestand getreten. Für ihn übernimmt nun Raphael Maier die Rolle als CEO von Sonepar in der Schweiz. 1. Oktober 2025](https://www.itreseller.ch/Artikel/104095/Sonepar_Schweiz_ernennt_Raphael_Maier_zum_neuen_CEO.html) - -[](https://www.itreseller.ch/Artikel/104090/AWS_ernennt_Stphane_Isral_zum_Leiter_der_Sovereign_Cloud.html) - -[### AWS ernennt Stéphane Israël zum Leiter der Sovereign Cloud AWS gibt mit Stéphane Israël einen zweiten Leiter der European Sovereign Cloud bekannt. Zusammen mit Kathrin Renz soll er das Geschäft mit souveränen Cloud-Strukturen leiten. 1. Oktober 2025](https://www.itreseller.ch/Artikel/104090/AWS_ernennt_Stphane_Isral_zum_Leiter_der_Sovereign_Cloud.html) - -[](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html) - -[### Paessler bekommt mit Jason Teichman neuen CEO](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html) - -[IT- und OT-Monitoring-Anbieter Paessler stellt mit Jason Teichman seinen neuen CEO vor. Mit der Personalie unterstreicht das Unternehmen seine globale Expansionsstrategie.](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html)1. Oktober 2025 - -[](https://www.itreseller.ch/Artikel/104086/Connect-Test_Schweizer_Internet-Provider_sind_ueberragend.html) - -[### Connect-Test: Schweizer Internet-Provider sind überragend](https://www.itreseller.ch/Artikel/104086/Connect-Test_Schweizer_Internet-Provider_sind_ueberragend.html) - -[Während Swisscom und Sunrise im grossen Festnetztest Schweiz 2025 von "Connect" beinahe gleichauf liegen, sind die Unterschiede bei den regionalen Anbietern etwas grösser. Klar ist aber: Die Schweizer Internet-Provider sind durchs Band top.](https://www.itreseller.ch/Artikel/104086/Connect-Test_Schweizer_Internet-Provider_sind_ueberragend.html)1. Oktober 2025 - -[](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) - -[Mit Renato Petrillo (Bild, Mitte) hat Baggenstos einen neuen CEO gefunden. Er folgt auf Michael Kistler (Bild, links), der dem Unternehmen in verschiedenen Rollen erhalten bleibt.](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html)30. September 2025 - -[](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) - -[Dennis Monner (Bild, rechts) folgt bei Open Systems als CEO auf Daniel Neuhaus (Bild, links), der 2020 mit der Übernahme seines Unternehmens Sqooba zum Unternehmen stiess.](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html)30. September 2025 - -[](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) - -[Mit Marco Pierro hat Check Point Software Technologies einen neuen Country Manager für die Schweiz ernannt. Er übernimmt die Funktion per 1. Oktober 2025 und folgt auf Alvaro Amato, der zum Director Globals für EMEA & Asien befördert wurde.](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html)30. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) - - -=== https://www.itreseller.ch/rubriken/163/business.html === -Business - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -BUSINESS --------- - -[](https://www.itreseller.ch/Artikel/104102/Matrix42_kauft_SaaS-Management-Spezialisten_Viio.html) - -[Matrix42 kauft SaaS-Management-Spezialisten Viio ================================================](https://www.itreseller.ch/Artikel/104102/Matrix42_kauft_SaaS-Management-Spezialisten_Viio.html) - -[Mit dem Zukauf des dänischen SaaS-Management-Spezialisten will Matrix42 die eigenen Fähigkeiten im Bereich Software Asset Management und Enterprise Service Management verbessern. Die Übernahme soll noch dieses Jahr abgeschlossen werden.](https://www.itreseller.ch/Artikel/104102/Matrix42_kauft_SaaS-Management-Spezialisten_Viio.html) - - 2. Oktober 2025 - -Meistgelesen in Business - -[### Nutanix Cloud Platform unterstützt neu Dell PowerStore](https://www.itreseller.ch/Artikel/104070/Nutanix_Cloud_Platform_unterstuetzt_neu_Dell_PowerStore.html) 26. September 2025 - -[### Intel wirbt auch bei Apple um Investitionen](https://www.itreseller.ch/Artikel/104063/Intel_wirbt_auch_bei_Apple_um_Investitionen.html) 25. September 2025 - -[### AWS und SAP stellen gemeinsam "souveräne Cloud" auf die Beine](https://www.itreseller.ch/Artikel/104060/AWS_und_SAP_stellen_gemeinsam_souveraene_Cloud_auf_die_Beine.html) 25. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) 23. September 2025 - -[](https://www.itreseller.ch/Artikel/104099/Fritz_startet_mit_eigenem_Online-Shop_in_der_Schweiz_.html) - -[### Fritz startet mit eigenem Online-Shop in der Schweiz Netzwerkspezialist Fritz öffnet einen eigenen Online-Shop in der Schweiz. Dieser soll spätestens Mitte Oktober bereitstehen und die gewohnten Zusatzservices bieten. 2. Oktober 2025](https://www.itreseller.ch/Artikel/104099/Fritz_startet_mit_eigenem_Online-Shop_in_der_Schweiz_.html) - -[](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - -[### Swico ICT Index zeigt abermals Knick für das vierte Quartal Der Swico ICT Index geht im vierten Quartal 2025 um 2 Punkte zurück. Noch sind viele Segmente im Wachstumsbereich, allerdings zeigen Unsicherheiten, Zölle und Wettbewerb Effekte. 1. Oktober 2025](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - -[](https://www.itreseller.ch/Artikel/104091/Arrow_vertreibt_Thales-Plattform_in_der_Schweiz.html) - -[### Arrow vertreibt Thales-Plattform in der Schweiz Arrow hat das bestehende Distributionsabkommen mit Thales erweitert und bietet die Imperva Application Security-Plattform auch in der Schweiz sowie in Österreich und Italien an. 1. Oktober 2025](https://www.itreseller.ch/Artikel/104091/Arrow_vertreibt_Thales-Plattform_in_der_Schweiz.html) - -[](https://www.itreseller.ch/Artikel/104084/Infinigate_vertreibt_neu_Thales_in_der_Schweiz.html) - -[### Infinigate vertreibt neu Thales in der Schweiz Schweizer Channel-Partner können neu das gesamte Security-Portfolio von Thales über Infinigate beziehen und erhalten beim VAD den dazugehörigen Support. 30. September 2025](https://www.itreseller.ch/Artikel/104084/Infinigate_vertreibt_neu_Thales_in_der_Schweiz.html) - -[](https://www.itreseller.ch/Artikel/104082/NTT_Data_streicht_Ivanti_aus_Sicherheitsgruenden_aus_Portfolio_.html) - -[### NTT Data streicht Ivanti aus Sicherheitsgründen aus Portfolio NTT Data vertreibt keine Produkte mehr von Ivanti. Laut dem IT-Dienstleister stellen diese ein zu hohes Sicherheitsrisiko dar. 30. September 2025](https://www.itreseller.ch/Artikel/104082/NTT_Data_streicht_Ivanti_aus_Sicherheitsgruenden_aus_Portfolio_.html) - -[](https://www.itreseller.ch/Artikel/104077/Microsoft_startet_neuen_Marketplace_fuer_Cloud-_und_KI-Loesungen.html) - -[### Microsoft startet neuen Marketplace für Cloud- und KI-Lösungen](https://www.itreseller.ch/Artikel/104077/Microsoft_startet_neuen_Marketplace_fuer_Cloud-_und_KI-Loesungen.html) - -[Microsoft startet einen einheitlichen Marketplace, der Azure Marketplace und AppSource bündelt und Unternehmen Cloud-Lösungen sowie KI-Apps und Agenten zentral finden, testen, kaufen und direkt in ihrer Microsoft-Umgebung bereitstellen lässt.](https://www.itreseller.ch/Artikel/104077/Microsoft_startet_neuen_Marketplace_fuer_Cloud-_und_KI-Loesungen.html)29. September 2025 - -[](https://www.itreseller.ch/Artikel/104075/ADN_setzt_verstaerkt_auf_das_Dell-Geschaeft.html) - -[### ADN setzt verstärkt auf das Dell-Geschäft](https://www.itreseller.ch/Artikel/104075/ADN_setzt_verstaerkt_auf_das_Dell-Geschaeft.html) - -[ADN baut personell mit den drei neuen Channel-Experten Ronny Pilgram (Bild), Thomas Kroll und Christof Sokolowski aus und bekräftigt damit seinen Anspruch als strategischer Value-Added-Distributor für Dell Technologies.](https://www.itreseller.ch/Artikel/104075/ADN_setzt_verstaerkt_auf_das_Dell-Geschaeft.html)29. September 2025 - -[](https://www.itreseller.ch/Artikel/104070/Nutanix_Cloud_Platform_unterstuetzt_neu_Dell_PowerStore.html) - -[### Nutanix Cloud Platform unterstützt neu Dell PowerStore](https://www.itreseller.ch/Artikel/104070/Nutanix_Cloud_Platform_unterstuetzt_neu_Dell_PowerStore.html) - -[Mit der Unterstützung der All-Flash-Storage-Plattform Dell PowerStore in der Nutanix Cloud Platform vertiefen die beiden Technologieunternehmen ihre strategische Partnerschaft.](https://www.itreseller.ch/Artikel/104070/Nutanix_Cloud_Platform_unterstuetzt_neu_Dell_PowerStore.html)26. September 2025 - -[](https://www.itreseller.ch/Artikel/104066/Motorola_startet_in_der_Schweiz_eigenen_Online-Shop.html) - -[### Motorola startet in der Schweiz eigenen Online-Shop](https://www.itreseller.ch/Artikel/104066/Motorola_startet_in_der_Schweiz_eigenen_Online-Shop.html) - -[Motorola baut das Direktgeschäft in der Schweiz aus und startet einen eigenen Online-Shop für Privat- und Geschäftskunden. So will der Hersteller die Präsenz hierzulande stärken.](https://www.itreseller.ch/Artikel/104066/Motorola_startet_in_der_Schweiz_eigenen_Online-Shop.html)26. September 2025 - -[](https://www.itreseller.ch/Artikel/104064/Crayon_ist_neuer_Zendesk-Distributor_.html) - -[### Crayon ist neuer Zendesk-Distributor](https://www.itreseller.ch/Artikel/104064/Crayon_ist_neuer_Zendesk-Distributor_.html) - -[Crayon tritt in mehr als 70 Ländern als neuer Distributor für Zendesk auf. Die Partnerschaft umfasst das gesamte Portfolio des Anbieters von CX-Lösungen.](https://www.itreseller.ch/Artikel/104064/Crayon_ist_neuer_Zendesk-Distributor_.html)26. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) - - -=== https://www.itreseller.ch/rubriken/166/finance.html === -Finance - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -FINANCE +Agentur ------- -[](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) + -[OpenAI knackt 500-Milliarden-Marke ==================================](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) +ImmoSky AG - Standort Dübendorf ZH (Zentrale) -[Die KI-Blase wächst weiter: Nach einem grossen Aktienverkauf durch OpenAI-Mitarbeiter an Investoren liegt der Unternehmenswert nun erstmals bei einer halben Billion US-Dollar.](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) +4.1 - 2. Oktober 2025 +(308 Bewertungen) -Meistgelesen in Finance +[Agenturprofil anzeigen](https://realadvisor.ch/de/immobilienagenturen/agentur-immosky-ag) +Daniel Arigoni -[### Adobe-Zahlen übertreffen die Markterwartungen](https://www.itreseller.ch/Artikel/103962/Adobe-Zahlen_uebertreffen_die_Markterwartungen.html) 12. September 2025 +[Nummer anzeigen](https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2) -[### Aveniq setzt auf Fokussierung und einheitliche Strukturen](https://www.itreseller.ch/Artikel/103935/Aveniq_setzt_auf_Fokussierung_und_einheitliche_Strukturen.html) 9. September 2025 +[Nummer anzeigen](https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2) -[### ASML wird Hauptaktionär von Mistral AI](https://www.itreseller.ch/Artikel/103933/ASML_wird_Hauptaktionaer_von_Mistral_AI.html) 8. September 2025 +Ref. 6650102 -[### HPE übertrifft Markterwartungen mit Rekordumsatz](https://www.itreseller.ch/Artikel/103920/HPE_uebertrifft_Markterwartungen_mit_Rekordumsatz_.html) 5. September 2025 - -[](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -[### Accenture mit mehr Umsatz und weniger Gewinn Accenture steigerte im jüngsten Quartal die Einnahmen um 7 Prozent auf 17,6 Milliarden Dollar. Hingegen mussten beim Gewinn zweistellige Einbussen in Kauf genommen werden. 26. September 2025](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -[](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab TD Synnex übertraf im abgelaufenen Quartal die Markterwartungen sowohl beim Gewinn, als auch beim Umsatz deutlich. Obwohl auch der Ausblick die Analystenschätzungen übertraf, konnte die Aktie nicht profitieren. 26. September 2025](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -[](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -[### Schweizer KI-Start-up Giotto sucht Finanzierung Giotto mit Sitz in Lausanne sucht mit Unterstützung einer Investmentbank Investoren für eine weitere Finanzierung im Umfang von über 200 Millionen US-Dollar. Das Unternehmen ist im Bereich künstliche allgemeine Intelligenz (AGI) tätig. 23. September 2025](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -[](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -[### Nvidia will kräftig in OpenAI investieren OpenAI will seine KI-Infrastruktur ab nächstem Jahr stark ausbauen und dazu Nvidia-Systeme der neuesten Generation einsetzen. Nvidia sichert zu, mindestens 100 Millionen Dollar in OpenAI zu investieren. 23. September 2025](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -[](https://www.itreseller.ch/Artikel/104009/Oracle_vor_20-Milliarden-Deal_mit_Meta.html) - -[### Oracle vor 20-Milliarden-Deal mit Meta Nach dem 300-Milliarden-Dollar-Vertrag mit OpenAI plant Oracle ein weiteres Abkommen zum Bezug von Cloud-Dienstleistungen mit Meta. In den kommenden Monaten sollen noch mehr ähnliche Deals folgen. 22. September 2025](https://www.itreseller.ch/Artikel/104009/Oracle_vor_20-Milliarden-Deal_mit_Meta.html) - -[](https://www.itreseller.ch/Artikel/103975/Alphabet_ist_erstmals_3_Billionen_Dollar_Wert.html) - -[### Alphabet ist erstmals 3 Billionen Dollar Wert](https://www.itreseller.ch/Artikel/103975/Alphabet_ist_erstmals_3_Billionen_Dollar_Wert.html) - -[Nach einem erneuten Anstieg des Aktienkurses um über 3 Prozent hat die Börsenbewertung der Google-Mutter Alphabet nun zum ersten Mal die Schwelle von 3 Billionen US-Dollar überschritten.](https://www.itreseller.ch/Artikel/103975/Alphabet_ist_erstmals_3_Billionen_Dollar_Wert.html)16. September 2025 - -[](https://www.itreseller.ch/Artikel/103962/Adobe-Zahlen_uebertreffen_die_Markterwartungen.html) - -[### Adobe-Zahlen übertreffen die Markterwartungen](https://www.itreseller.ch/Artikel/103962/Adobe-Zahlen_uebertreffen_die_Markterwartungen.html) - -[Im jüngsten Quartal konnte Adobe beim Umsatz wie auch beim Gewinn zulegen. Da das Management auch die Umsatzprognose fürs gesamte Geschäftsjahr nach oben angepasst hat, konnte auch die Aktie profitieren.](https://www.itreseller.ch/Artikel/103962/Adobe-Zahlen_uebertreffen_die_Markterwartungen.html)12. September 2025 - -[](https://www.itreseller.ch/Artikel/103950/Oracles_IaaS-Umsaetze_gehen_durch_die_Decke.html) - -[### Oracles IaaS-Umsätze gehen durch die Decke](https://www.itreseller.ch/Artikel/103950/Oracles_IaaS-Umsaetze_gehen_durch_die_Decke.html) - -[Oracle kann starke Zahlen für das erste Quartal des Geschäftsjahres 2026 vorlegen. Vor allem das Cloud-Infrastruktur-Business boomt.](https://www.itreseller.ch/Artikel/103950/Oracles_IaaS-Umsaetze_gehen_durch_die_Decke.html)11. September 2025 - -[](https://www.itreseller.ch/Artikel/103946/Computacenter_meldet_Umsatzsprung_-_aber_nicht_fuer_Westeuropa.html) - -[### Computacenter meldet Umsatzsprung - aber nicht für Westeuropa](https://www.itreseller.ch/Artikel/103946/Computacenter_meldet_Umsatzsprung_-_aber_nicht_fuer_Westeuropa.html) - -[Computacenter kann für das erste Halbjahr 2025 beachtliche Zahlen vorlegen. Die westeuropäischen Märkte (exklusive UK) haben dazu jedoch nur bedingt beigetragen.](https://www.itreseller.ch/Artikel/103946/Computacenter_meldet_Umsatzsprung_-_aber_nicht_fuer_Westeuropa.html)10. September 2025 - -[](https://www.itreseller.ch/Artikel/103935/Aveniq_setzt_auf_Fokussierung_und_einheitliche_Strukturen.html) - -[### Aveniq setzt auf Fokussierung und einheitliche Strukturen](https://www.itreseller.ch/Artikel/103935/Aveniq_setzt_auf_Fokussierung_und_einheitliche_Strukturen.html) - -[Aveniq hat in Baden Anfang September den Business Summit 2025 veranstaltet. In diesem Rahmen gab Head of Sales & Marketing Walter Lienhard Einblick in den strategischen Status quo des IT-Dienstleisters.](https://www.itreseller.ch/Artikel/103935/Aveniq_setzt_auf_Fokussierung_und_einheitliche_Strukturen.html)9. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) - - -=== https://www.itreseller.ch/rubriken/122/research.html === -Research - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -RESEARCH --------- - -[](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - -[Swico ICT Index zeigt abermals Knick für das vierte Quartal ===========================================================](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - -[Der Swico ICT Index geht im vierten Quartal 2025 um 2 Punkte zurück. Noch sind viele Segmente im Wachstumsbereich, allerdings zeigen Unsicherheiten, Zölle und Wettbewerb Effekte.](https://www.itreseller.ch/Artikel/104093/Swico_ICT_Index_zeigt_abermals_Knick_fuer_das_vierte_Quartal.html) - - 1. Oktober 2025 - -Meistgelesen in Research - -[### Drucker-Firmware wird zu selten aktualisiert](https://www.itreseller.ch/Artikel/103970/Drucker-Firmware_wird_zu_selten_aktualisiert.html) 15. September 2025 - -[### Globaler Ethernet-Switch-Markt mit 42 Prozent Wachstum](https://www.itreseller.ch/Artikel/103966/Globaler_Ethernet-Switch-Markt_mit_42_Prozent_Wachstum.html) 15. September 2025 - -[### Huawei überholt Apple im Smartwatch-Markt](https://www.itreseller.ch/Artikel/103938/Huawei_ueberholt_Apple_im_Smartwatch-Markt.html) 9. September 2025 - -[### Europas Markt für Large Format Displays erleidet Einbussen](https://www.itreseller.ch/Artikel/103926/Europas_Markt_fuer_Large_Format_Displays_erleidet_Einbussen.html) 8. September 2025 - -[](https://www.itreseller.ch/Artikel/104059/Smartphone-Durchschnittspreise_steigen.html) - -[### Smartphone-Durchschnittspreise steigen Der durchschnittliche Preis, der für ein Smartphone bezahlt wird, soll von 370 Dollar in diesem Jahr auf 412 Dollar im Jahr 2029 steigen. 25. September 2025](https://www.itreseller.ch/Artikel/104059/Smartphone-Durchschnittspreise_steigen.html) - -[](https://www.itreseller.ch/Artikel/104026/Ausgaben_der_Hyperscaler_gehen_durch_die_Decke.html) - -[### Ausgaben der Hyperscaler gehen durch die Decke Die Hyperscaler investieren immer mehr in ihre Infrastruktur und hier vor allem in KI-Rechenzentren. Damit befeuern sie laut Analysten ihr "aggressives Wachstum". 24. September 2025](https://www.itreseller.ch/Artikel/104026/Ausgaben_der_Hyperscaler_gehen_durch_die_Decke.html) - -[](https://www.itreseller.ch/Artikel/104003/Globaler_Notebook-Markt_auf_Erholungskurs.html) - -[### Globaler Notebook-Markt auf Erholungskurs Fürs laufende Jahr prognostiziert Trendforce für den globalen Notebook-Markt ein Absatzplus von 2,2 Prozent. Das Wachstum gibt im Jahresverlauf allerdings kontinuierlich nach, um dann im Q4 in den negativen Bereich zu kippen. 22. September 2025](https://www.itreseller.ch/Artikel/104003/Globaler_Notebook-Markt_auf_Erholungskurs.html) - -[](https://www.itreseller.ch/Artikel/103990/KI-Ausgaben_sollen_sich_2025_auf_15_Billionen_Dollar_belaufen.html) - -[### KI-Ausgaben sollen sich 2025 auf 1,5 Billionen Dollar belaufen 2025 sollen die weltweiten Ausgaben für Künstliche Intelligenz knapp 1,5 Billionen US-Dollar ausmachen. Für das kommende Jahr prognostizieren Gartner-Analysten dann den Sprung über die 2-Milliarden-Marke. 18. September 2025](https://www.itreseller.ch/Artikel/103990/KI-Ausgaben_sollen_sich_2025_auf_15_Billionen_Dollar_belaufen.html) - -[](https://www.itreseller.ch/Artikel/103974/Europaeischer_PC-Markt_legt_im_dritten_Quartal_deutlich_zu.html) - -[### Europäischer PC-Markt legt im dritten Quartal deutlich zu Im Juli und August 2025 hat die europäische Distribution bei Desktop-PCs ein Umsatzplus von über 30 Prozent erreicht, während Notebooks um über 11 Prozent zulegten. 15. September 2025](https://www.itreseller.ch/Artikel/103974/Europaeischer_PC-Markt_legt_im_dritten_Quartal_deutlich_zu.html) - -[](https://www.itreseller.ch/Artikel/103970/Drucker-Firmware_wird_zu_selten_aktualisiert.html) - -[### Drucker-Firmware wird zu selten aktualisiert](https://www.itreseller.ch/Artikel/103970/Drucker-Firmware_wird_zu_selten_aktualisiert.html) - -[Mit Updates der Drucker-Firmware hapert es in vielen Unternehmen. Sicherheitsprobleme bestehen jedoch nicht nur im Betrieb, sie treten von der Beschaffung bis zur Entsorgung auf.](https://www.itreseller.ch/Artikel/103970/Drucker-Firmware_wird_zu_selten_aktualisiert.html)15. September 2025 - -[](https://www.itreseller.ch/Artikel/103967/Enterprise-WLAN-Markt_im_Q2_2025_deutlich_im_Plus.html) - -[### Enterprise-WLAN-Markt im Q2 2025 deutlich im Plus](https://www.itreseller.ch/Artikel/103967/Enterprise-WLAN-Markt_im_Q2_2025_deutlich_im_Plus.html) - -[Im zweiten Quartal 2025 legte der weltweite Enterprise-WLAN-Markt gegenüber der Vorjahresperiode um 13,2 Prozent zu. Marktführer ist Cisco, gefolgt vom HPE Aruba, Ubiquiti, Huawei und Juniper Networks.](https://www.itreseller.ch/Artikel/103967/Enterprise-WLAN-Markt_im_Q2_2025_deutlich_im_Plus.html)15. September 2025 - -[](https://www.itreseller.ch/Artikel/103966/Globaler_Ethernet-Switch-Markt_mit_42_Prozent_Wachstum.html) - -[### Globaler Ethernet-Switch-Markt mit 42 Prozent Wachstum](https://www.itreseller.ch/Artikel/103966/Globaler_Ethernet-Switch-Markt_mit_42_Prozent_Wachstum.html) - -[Der wachsende Bedarf der Hyperscaler sorgt im Markt für Ethernet Switches für einen aussergewöhnlichen Umsatzanstieg von über 42 Prozent auf 14,5 Milliarden Dollar.](https://www.itreseller.ch/Artikel/103966/Globaler_Ethernet-Switch-Markt_mit_42_Prozent_Wachstum.html)15. September 2025 - -[](https://www.itreseller.ch/Artikel/103939/_Weltweiter_Halbleitermarkt_waechst_2025_um_176_Prozent.html) - -[### Weltweiter Halbleitermarkt wächst 2025 um 17,6 Prozent](https://www.itreseller.ch/Artikel/103939/_Weltweiter_Halbleitermarkt_waechst_2025_um_176_Prozent.html) - -[Angetrieben durch die hohe Nachfrage nach KI-Infrastruktur und Rechenzentrums-Technologien wächst der weltweite Halbleitermarkt 2025 laut IDC um 17,6 Prozent auf 800 Milliarden US-Dollar. 2028 könnte eine Billion erreicht werden.](https://www.itreseller.ch/Artikel/103939/_Weltweiter_Halbleitermarkt_waechst_2025_um_176_Prozent.html)9. September 2025 - -[](https://www.itreseller.ch/Artikel/103938/Huawei_ueberholt_Apple_im_Smartwatch-Markt.html) - -[### Huawei überholt Apple im Smartwatch-Markt](https://www.itreseller.ch/Artikel/103938/Huawei_ueberholt_Apple_im_Smartwatch-Markt.html) - -[Huawei hat Apple als führenden Anbieter im globalen Smartwatch-Markt abgelöst, so Zahlen von Counterpoint. Apple-Kunden würden auf neue Modelle warten, diese werden wohl heute noch vorgestellt.](https://www.itreseller.ch/Artikel/103938/Huawei_ueberholt_Apple_im_Smartwatch-Markt.html)9. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) - - -=== https://www.itreseller.ch/veranstaltungen === -Veranstaltungen - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Veranstaltungen -=============== - -[### SCION Day 2025 Kongress/Konferenz Zürich • 21. Oktober 2025](https://www.itreseller.ch/veranstaltungen/2324/SCION_Day_2025.html) - -[### Global Cyber Conference 2025 Zürich • 22./23. Oktober 2025](https://www.itreseller.ch/veranstaltungen/2331/Global_Cyber_Conference_2025.html) - -[### Swiss Cyber Storm 2025 Resilience in a mad, mad world Bern • 28. Oktober 2025](https://www.itreseller.ch/veranstaltungen/2373/Swiss_Cyber_Storm_2025.html) - -[### Data Community Conference 2025 Kongress/Konferenz Bern • 5. November 2025](https://www.itreseller.ch/veranstaltungen/2376/Data_Community_Conference_2025.html) - - - -[### TEFO 2025 Studerus Technology Forum Regensdorf • 13. November 2025](https://www.itreseller.ch/veranstaltungen/2357/TEFO_2025.html) - -[### Digital Economy Award Zürich-Oerlikon • 13. November 2025](https://www.itreseller.ch/veranstaltungen/2374/Digital_Economy_Award.html) - -Meistgelesen - -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 - -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 - -Finance - -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) - -2. Oktober 2025 - -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) - -26. September 2025 - -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) - -26. September 2025 - -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) - -23. September 2025 - -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) - -23. September 2025 - -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) - -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) - -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) - -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) - -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) - -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) - -GOLD SPONSOREN - -SPONSOREN & PARTNER - - - - Swiss IT Media GmbH - - Seestrasse 95 - - CH-8800 Thalwil - - ✆ +41 44 723 50 00 - - info@swissitmedia.ch - -[www.swissitmedia.ch](https://www.swissitmedia.ch/) - -INSERIEREN - -[Mediadaten](https://www.itreseller.ch/media) - -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) - -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) - -VERLAG - -[Abonnement](https://www.itreseller.ch/abo) - -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) - -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) - -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) - -[Swiss IT Magazine](https://www.itmagazine.ch/) - -SERVICE - -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) - -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) - -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) - -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) - -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) - -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) - -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) - - -=== https://www.itreseller.ch/jobs === -ICT-Stellenangebote - IT Reseller - -=============== - -[](https://www.itreseller.ch/) - -[MEDIADATEN](https://www.itreseller.ch/media) - -[ABONNIEREN](https://www.itreseller.ch/abo) - -[NEWSLETTER](https://www.itreseller.ch/newsletter) - -Suche - -< - -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) - -> - -Aktuelle ICT-Stellenangebote -============================ - -In Zusammenarbeit mit - -[](https://www.jobchannel.ch/inserieren/?utm_medium=affiliate&utm_source=Swiss%20IT%20Media%20GmbH&utm_campaign=PublishLink) - -Top Jobs der Woche +Energy diagnostics ------------------ -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=&pbl=2&src=site_ict&nlc2=) +Energy consumption -[#### Senior .NET Softwareentwickler and Power Platform Engineer (m/w/d) 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187711&pbl=2&src=site_ict&nlc2=) +No data - Winterthur +Greenhouse gas emmissions -Ambit Schweiz AG (26. September 2025) +No data -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=&pbl=2&src=site_ict&nlc2=) +Ort +--- -[#### System Engineer Microsoft (80–100%)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187693&pbl=2&src=site_ict&nlc2=) +8340 Hinwil(ZH) - Dübendorf +Nicht was Sie suchen? -ITIVITY AG (25. September 2025) +Entdecken Sie 0 ähnliche Angebote in Hinwil -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=&pbl=2&src=site_ict&nlc2=) +[Inserate ansehen](https://realadvisor.ch/de/kaufen/stadt-hinwil/grundstuck) -[#### SAP Application Engineer Finance & Controlling | 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187611&pbl=2&src=site_ict&nlc2=) +1. [](https://realadvisor.ch/de) - Burgdorf +3. [Kaufen](https://realadvisor.ch/de/kaufen) -Ypsomed Diabetes Care AG (24. September 2025) +5. [Grundstück](https://realadvisor.ch/de/kaufen/grundstuck) -Neueste IT-Jobs ---------------- +7. [Kanton Zürich](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck) -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187855&pbl=2&src=site_ict&nlc2=) +9. [Bezirk Hinwil](https://realadvisor.ch/de/kaufen/bezirk-hinwil/grundstuck) -[#### Azure Spezialist (axelion ag)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187855&pbl=2&src=site_ict&nlc2=) +11. [Hinwil](https://realadvisor.ch/de/kaufen/stadt-hinwil/grundstuck) - Zug +13. [8340 Hinwil](https://realadvisor.ch/de/kaufen/8340-hinwil/grundstuck) -Avalect HR-Executive Consulting (2. Oktober 2025) +15. Bauland zu verkaufen - 8340 Hinwil -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187849&pbl=2&src=site_ict&nlc2=) +CHF 1’070’000.- -[#### ICT-Koordination – spannende Stelle mit Entwicklungspotential 80%–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187849&pbl=2&src=site_ict&nlc2=) +CHF 1’000 / m² - Zürich +* * * -Meier-Kopp Gruppe (2. Oktober 2025) + -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187842&pbl=2&src=site_ict&nlc2=) +ImmoSky AG - Standort Dübendorf ZH (Zentrale) -[#### Software Developer – Professional/Senior 80-100% (a)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187842&pbl=2&src=site_ict&nlc2=) +4.1 - Altishofen +(308 Bewertungen) -Galliker Transport AG (2. Oktober 2025) +[Agenturprofil anzeigen](https://realadvisor.ch/de/immobilienagenturen/agentur-immosky-ag) -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187836&pbl=2&src=site_ict&nlc2=) +Ref. 6650102 -[#### ICT-Projektleiter/-in 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187836&pbl=2&src=site_ict&nlc2=) +[Nummer anzeigen](https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2) - Bern +* * * -Kanton Bern (2. Oktober 2025) +Anbieter kontaktieren -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187816&pbl=2&src=site_ict&nlc2=) +Vorname * -[#### Senior AI Business Consultant 70–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187816&pbl=2&src=site_ict&nlc2=) +Nachname * - Bern +E-Mail-Adresse * -Post CH AG (2. Oktober 2025) +Telefonnummer * -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187831&pbl=2&src=site_ict&nlc2=) +69/3000 -[#### (Senior) IT Audit Managerin oder Manager Interne Revision (80%–100%)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187831&pbl=2&src=site_ict&nlc2=) +Anfrage abschicken - Zürich +Ähnliche Inserate -Schweizerische Nationalbank (1. Oktober 2025) +[](https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2#) -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187826&pbl=2&src=site_ict&nlc2=) +vor 28 Tagen -[#### IT Security Spezialist/-in 100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187826&pbl=2&src=site_ict&nlc2=) +- [x] - Zürich +[Goda Verwaltung AG 380 m² Grundstück • Bauland In Der Gass 2, 8627 Grüningen * Genehmigtes Neubauprojekt * Geplante 8 Wohnungen * Tiefgarage für 11 Autos * * * CHF 1’750’000.- CHF 4’605 / m² immoscout24.ch](https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2#) -Kanton Zürich (1. Oktober 2025) +[](https://realadvisor.ch/de/kaufen/grundstuck/23-uberlandstrasse-8340-hinwil-YB69-VB7M) -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187821&pbl=2&src=site_ict&nlc2=) +vor 2 Monaten -[#### Enterprise Architect für digitale Steuerlösungen 100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187821&pbl=2&src=site_ict&nlc2=) +- [x] - Zürich +[RE/MAX Immobilien in Rapperswil-Jona 4’246 m² Grundstück • Bauland Überlandstrasse 23, 8340 Hinwil * Top Lage an Hauptstrassen * Grosse Fläche für Entwicklung * Flexible Gebäudehöhen möglich * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/23-uberlandstrasse-8340-hinwil-YB69-VB7M) -Kanton Zürich (1. Oktober 2025) +[](https://realadvisor.ch/de/kaufen/grundstuck/8630-ruti-zh-84E9-Z65G) -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187810&pbl=2&src=site_ict&nlc2=) +vor 4 Monaten -[#### IT-Support & Helpdesk Manager:in](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187810&pbl=2&src=site_ict&nlc2=) +- [x] - Aarau +[PREMIUM HOMES AG 3’460 m² Grundstück • Bauland 8630 Rüti ZH * Ruhige Wohnzone * Ausnützungsziffer 30% * Bonus für zusätzlichen Raum * * * Auf Anfrage —](https://realadvisor.ch/de/kaufen/grundstuck/8630-ruti-zh-84E9-Z65G) -Leoba GmbH (1. Oktober 2025) +[](https://realadvisor.ch/de/kaufen/grundstuck/8633-wolfhausen-YB6N-VRVP) -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187804&pbl=2&src=site_ict&nlc2=) +vor 7 Tagen -[#### Mitarbeiter/in Informatik Systemtechnik (100%)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187804&pbl=2&src=site_ict&nlc2=) +- [x] - Münsingen +[PREMIUM HOMES AG 1’940 m² Grundstück • Bauland 8633 Wolfhausen * Grosszügige 1'940m² Parzelle * Familienfreundliche Lage * Flexible Gestaltungsmöglichkeiten * * * CHF 4’074’000.- CHF 2’100 / m²](https://realadvisor.ch/de/kaufen/grundstuck/8633-wolfhausen-YB6N-VRVP) -Gemeinde Münsingen (1. Oktober 2025) +* * * -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187798&pbl=2&src=site_ict&nlc2=) +Anfrage abschicken -[#### Applikationsmanager:in (mit Erfahrung in Softwareentwicklung) 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187798&pbl=2&src=site_ict&nlc2=) - Winterthur +=== https://www.immoyou.ch/ === +ImmoYou: Das grösste Immobilienportal der Deutschschweiz 🏘 -ZHAW (1. Oktober 2025) +=============== +[Skip to content](https://www.immoyou.ch/#content) -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187793&pbl=2&src=site_ict&nlc2=) +[](https://www.immoyou.ch/) -[#### Requirements to Deployment Manager Customer Touchpoints 70–100% (oder im Jobsharing)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187793&pbl=2&src=site_ict&nlc2=) +* [Kaufen](https://www.immoyou.ch/#) + * [Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz) + * [Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + * [Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz) - Bern +* [Mieten](https://www.immoyou.ch/#) + * [Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz) + * [Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + * [Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz) -Post CH AG (1. Oktober 2025) +Menu -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187537&pbl=2&src=site_ict&nlc2=) +* [Kaufen](https://www.immoyou.ch/#) + * [Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz) + * [Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + * [Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz) -[#### Head of Sales + Marketing 80–100% (w/m/d)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187537&pbl=2&src=site_ict&nlc2=) +* [Mieten](https://www.immoyou.ch/#) + * [Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz) + * [Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + * [Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz) - Bern +Alle Immobilieninserate der Deutschschweiz auf einer Seite +========================================================== -SmartIT Services AG (1. Oktober 2025) +[Immobilie kaufen](https://www.immoyou.ch/kaufen-schweiz) -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187777&pbl=2&src=site_ict&nlc2=) +[Immobilie mieten](https://www.immoyou.ch/mieten-schweiz) -[#### IT-Fachapplikationsspezialist/-in 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187777&pbl=2&src=site_ict&nlc2=) +Ihr Immobilienprojekt +--------------------- - Zürich +Ob Kauf- oder Verkaufsplan, ImmoYou hat für Sie die aktuell 30.000 online verfügbaren Immobilieninserate in der Westschweiz ausgewählt. -Kanton Zürich (1. Oktober 2025) +Finden Sie das Haus Ihrer Träume, die ideale Wohnung, einen Parkplatz oder**wahllose Räumlichkeiten**zur Miete oder zum Kauf auf ImmoYou, alles in nur wenigen Klicks! -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187771&pbl=2&src=site_ict&nlc2=) +Immobilien zur Miete in der Deutschschweiz -[#### Praktikum Content Creation 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187771&pbl=2&src=site_ict&nlc2=) +[](https://www.immoyou.ch/mieten-kanton-zurich) - Aarau +[](https://www.immoyou.ch/mieten-kanton-thurgau) -Kanton Aargau (1. Oktober 2025) +[](https://www.immoyou.ch/mieten-kanton-zug) -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187787&pbl=2&src=site_ict&nlc2=) +Immobilien zum Verkauf in der Deutschschweiz -[#### Head of Application Services | 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187787&pbl=2&src=site_ict&nlc2=) +[](https://www.immoyou.ch/kaufen-kanton-schaffhausen) - Burgdorf +[](https://www.immoyou.ch/kaufen-kanton-bern) -Ypsomed AG (30. September 2025) +[](https://www.immoyou.ch/kaufen-kanton-luzern) -[](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187782&pbl=2&src=site_ict&nlc2=) +Immobilienangebote nach Kanton +------------------------------ -[#### SAP Application Engineer Supply Chain Management | 80–100%](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187782&pbl=2&src=site_ict&nlc2=) +**Häuser zur Miete in der Schweiz nach Kanton** - Burgdorf +[Haus mieten im Kanton Aargau](https://www.immoyou.ch/haus-mieten-kanton-aargau) -Ypsomed AG (30. September 2025) +[Haus mieten im Kanton Thurgau](https://www.immoyou.ch/haus-mieten-kanton-thurgau) -[.jpg)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187749&pbl=2&src=site_ict&nlc2=) +[Haus mieten im Kanton Bern](https://www.immoyou.ch/haus-mieten-kanton-bern) -[#### Senior .NET Engineer, 80–100% (w/m/d)](https://www.swissitmedia.ch/kundenportal/redir_ict.cfm?stid=187749&pbl=2&src=site_ict&nlc2=) +[Haus mieten im Kanton Zürich](https://www.immoyou.ch/haus-mieten-kanton-zurich) - Zürich +[Haus mieten im Kanton Basel-Landschaft](https://www.immoyou.ch/haus-mieten-kanton-basel-landschaft) -Swiss Life (Schweiz) AG (30. September 2025) +[Haus mieten im Kanton Luzern](https://www.immoyou.ch/haus-mieten-kanton-luzern) -Meistgelesen +**Häuser zum Verkauf in der Schweiz nach Kanton** -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 +[Haus kaufen im Kanton Aargau](https://www.immoyou.ch/haus-kaufen-kanton-aargau) -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 +[Haus kaufen im Kanton Thurgau](https://www.immoyou.ch/haus-kaufen-kanton-thurgau) -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 +[Haus kaufen im Kanton Bern](https://www.immoyou.ch/haus-kaufen-kanton-bern) -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 +[Haus kaufen im Kanton Zürich](https://www.immoyou.ch/haus-kaufen-kanton-zurich) -Finance +[Haus kaufen im Kanton Basel-Landschaft](https://www.immoyou.ch/haus-kaufen-kanton-basel-landschaft) -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) +[Haus kaufen im Kanton Luzern](https://www.immoyou.ch/haus-kaufen-kanton-luzern) -2. Oktober 2025 +**Wohnungen zur Miete in der Schweiz nach Kanton** -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) +[Wohnung mieten im Kanton Zürich](https://www.immoyou.ch/wohnung-mieten-kanton-zurich) -26. September 2025 +[Wohnung mieten im Kanton Luzern](https://www.immoyou.ch/wohnung-mieten-kanton-luzern) -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) +[Wohnung mieten im Kanton Bern](https://www.immoyou.ch/wohnung-mieten-kanton-bern) -26. September 2025 +[Wohnung mieten im Kanton Basel-Landschaft](https://www.immoyou.ch/wohnung-mieten-kanton-basel-landschaft) -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) +[Wohnung mieten im Kanton St. Gallen](https://www.immoyou.ch/wohnung-mieten-kanton-st-gallen) -23. September 2025 +[Wohnung mieten im Kanton Schaffhausen](https://www.immoyou.ch/wohnung-mieten-kanton-schaffhausen) -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) +**Wohnungen zum Verkauf in der Schweiz nach Kanton** -23. September 2025 +[Wohnung kaufen im Kanton Zürich](https://www.immoyou.ch/wohnung-kaufen-kanton-zurich) -People +[Wohnung kaufen im Kanton Luzern](https://www.immoyou.ch/wohnung-kaufen-kanton-luzern) -[### Sonepar Schweiz ernennt Raphael Maier zum neuen CEO 1. Oktober 2025](https://www.itreseller.ch/Artikel/104095/Sonepar_Schweiz_ernennt_Raphael_Maier_zum_neuen_CEO.html) +[Wohnung kaufen im Kanton Bern](https://www.immoyou.ch/wohnung-kaufen-kanton-bern) -[### AWS ernennt Stéphane Israël zum Leiter der Sovereign Cloud 1. Oktober 2025](https://www.itreseller.ch/Artikel/104090/AWS_ernennt_Stphane_Isral_zum_Leiter_der_Sovereign_Cloud.html) +[Wohnung kaufen im Kanton Basel-Landschaft](https://www.immoyou.ch/wohnung-kaufen-kanton-basel-landschaft) -[### Paessler bekommt mit Jason Teichman neuen CEO 1. Oktober 2025](https://www.itreseller.ch/Artikel/104089/Paessler_bekommt_mit_Jason_Teichman_neuen_CEO.html) +[Wohnung kaufen im Kanton St.Gallen](https://www.immoyou.ch/wohnung-kaufen-kanton-st-gallen) -[### Renato Petrillo wird CEO von Baggenstos 30. September 2025](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) +[Wohnung kaufen in Kanton Aargau](https://www.immoyou.ch/wohnung-kaufen-kanton-aargau) -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab 30. September 2025](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) +Beliebte Suchanfragen in der Deutschschweiz +------------------------------------------- -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) +**Häuser zur Miete in Schweiz nach Stadt** -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) +[Haus mieten in Bern](https://www.immoyou.ch/haus-mieten-stadt-bern) | [Haus mieten in Zürich](https://www.immoyou.ch/haus-mieten-stadt-zurich) | [Haus mieten Basel](https://www.immoyou.ch/haus-mieten-stadt-basel) | [Haus mieten in Winterthur](https://www.immoyou.ch/haus-mieten-stadt-winterthur) | [Haus mieten Luzern](https://www.immoyou.ch/haus-mieten-stadt-luzern) | [Haus mieten in Solothurn](https://www.immoyou.ch/haus-mieten-stadt-solothurn) | [Haus mieten in St. Gallen](https://www.immoyou.ch/haus-mieten-stadt-st-gallen) -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) +**Häuser zum Verkauf in Schweiz nach Stadt** -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) +[Haus kaufen in Bern](https://www.immoyou.ch/haus-kaufen-stadt-bern) | [Haus kaufen in Zürich](https://www.immoyou.ch/haus-kaufen-stadt-zurich) | [Haus kaufen Basel](https://www.immoyou.ch/haus-kaufen-stadt-basel) | [Haus kaufen in Winterthur](https://www.immoyou.ch/haus-kaufen-stadt-winterthur) | [Haus kaufen Luzern](https://www.immoyou.ch/haus-kaufen-stadt-luzern) | [Haus kaufen in Solothurn](https://www.immoyou.ch/haus-kaufen-stadt-solothurn) | [Haus kaufen in Schaffhausen](https://www.immoyou.ch/haus-kaufen-stadt-schaffhausen) -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) +**Wohnungen zur Miete in Schweiz nach Städten** -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) +[Wohnung mieten in Bern](https://www.immoyou.ch/wohnung-mieten-stadt-bern) | [Wohnung mieten in Zürich](https://www.immoyou.ch/wohnung-mieten-stadt-zurich) | [Wohnung mieten Luzern](https://www.immoyou.ch/wohnung-mieten-stadt-luzern) | [Wohnung mieten in Chur](https://www.immoyou.ch/wohnung-mieten-stadt-chur) | [Wohnung mieten St. Gallen](https://www.immoyou.ch/wohnung-mieten-stadt-st-gallen) | [Wohnung mieten in Basel](https://www.immoyou.ch/wohnung-mieten-stadt-basel) | [Wohnung mieten in Winterthur](https://www.immoyou.ch/wohnung-mieten-stadt-winterthur) -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) +**Wohnungen zum Verkauf in Schweiz nach Stadt** -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) +[Wohnung kaufen in Bern](https://www.immoyou.ch/wohnung-kaufen-stadt-bern) | [Wohnung kaufen in Zürich](https://www.immoyou.ch/wohnung-kaufen-stadt-zurich) | [Wohnung kaufen Luzern](https://www.immoyou.ch/wohnung-kaufen-stadt-luzern) | [Wohnung kaufen in Chur](https://www.immoyou.ch/wohnung-kaufen-stadt-chur) | [Wohnung kaufen St. Gallen](https://www.immoyou.ch/wohnung-kaufen-stadt-st-gallen) | [Wohnung kaufen in Basel](https://www.immoyou.ch/wohnung-kaufen-stadt-basel) | [Wohnung kaufen in Winterthur](https://www.immoyou.ch/wohnung-kaufen-stadt-winterthur) -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) + -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) +c/o AI Partners SA -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) + Avenue Louis-Casaï 86A -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) + 1216 Cointrin -GOLD SPONSOREN + Suisse -SPONSOREN & PARTNER +**Immobilien zum Verkauf** - +[Haus kaufen in Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) - Swiss IT Media GmbH +[Wohung kaufen in Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz) - Seestrasse 95 +[Wohung kaufen in Zürich](https://www.immoyou.ch/wohnung-kaufen-stadt-zurich) - CH-8800 Thalwil +[Wohung kaufen in Bern](https://www.immoyou.ch/wohnung-kaufen-stadt-bern) - ✆ +41 44 723 50 00 +[Wohnung kaufen in Luzern](https://www.immoyou.ch/wohnung-kaufen-stadt-luzern) - info@swissitmedia.ch +[Haus kaufen in Zürich](https://www.immoyou.ch/haus-kaufen-stadt-zurich) -[www.swissitmedia.ch](https://www.swissitmedia.ch/) +[Haus kaufen in Bern](https://www.immoyou.ch/haus-kaufen-stadt-bern) -INSERIEREN +[Haus kaufen in Thurgau](https://www.immoyou.ch/haus-kaufen-kanton-thurgau) -[Mediadaten](https://www.itreseller.ch/media) +[Haus kaufen in Aargau](https://www.immoyou.ch/haus-kaufen-kanton-aargau) -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) +**Immobilien zur Miete** -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) +[Haus mieten in Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) -VERLAG +[Wohung mieten in Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz) -[Abonnement](https://www.itreseller.ch/abo) +[Wohnung mieten in Zürich](https://www.immoyou.ch/wohnung-mieten-stadt-zurich) -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) +[Wohnung mieten in Luzern](https://www.immoyou.ch/wohnung-mieten-stadt-luzern) -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) +[Wohnung mieten in Bern](https://www.immoyou.ch/wohnung-mieten-stadt-bern) -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) +[Wohnung mieten in Winterthur](https://www.immoyou.ch/wohnung-mieten-stadt-winterthur) -[Swiss IT Magazine](https://www.itmagazine.ch/) +[Wohnung mieten in St. Gallen](https://www.immoyou.ch/wohnung-mieten-stadt-st-gallen) -SERVICE +[Wohnung mieten in Chur](https://www.immoyou.ch/wohnung-mieten-stadt-chur) -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) +[Wohnung mieten in Thun](https://www.immoyou.ch/wohnung-mieten-stadt-thun) -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) +**Über uns** -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) +[Wer sind wir?](https://www.immoyou.ch/uber-uns) -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) +[Datenschutzerklärung](https://www.immoyou.ch/datenschutzerklarung) -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) +[Allgemeine Geschäftsbedingungen](https://www.immoyou.ch/allgemeine-geschaftsbedingungen) -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) - - -=== https://www.itreseller.ch/heftarchiv/2025 === -Heftarchiv 2025 - IT Reseller +=== https://www.immoyou.ch/kaufen-schweiz === +🏠 59’403 Immobilien kaufen in der Schweiz | ImmoYou =============== -[](https://www.itreseller.ch/) +[ImmoYou](https://www.immoyou.ch/) -[MEDIADATEN](https://www.itreseller.ch/media) +Kaufen -[ABONNIEREN](https://www.itreseller.ch/abo) +[Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) -[NEWSLETTER](https://www.itreseller.ch/newsletter) +Mieten -Suche +[Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) -< + Ändern Sie die Suche -[People](https://www.itreseller.ch/rubriken/165/people.html)[Business](https://www.itreseller.ch/rubriken/163/business.html)[Finance](https://www.itreseller.ch/rubriken/166/finance.html)[Research](https://www.itreseller.ch/rubriken/122/research.html)[Events](https://www.itreseller.ch/veranstaltungen)[ICT-Jobs](https://www.itreseller.ch/jobs)[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025)[Neugründungen](https://www.itreseller.ch/startups)[Swico](https://www.itreseller.ch/swico)[IAMCP](https://www.itreseller.ch/iamcp) +[](https://www.immoyou.ch/)[Kaufen](https://www.immoyou.ch/kaufen-schweiz)[Schweiz](https://www.immoyou.ch/kaufen-schweiz) -> +Immobilien kaufen in der Schweiz +================================ + +Ort + + Schweiz + + Zürich + + Genf + + Typ + +- [x] Haus + +- [x] Wohnung + +- [x] Zimmer + +- [x] Parkplatz + +- [x] Büro & Gewerbe + +- [x] Wohnhaus + +- [x] Grundstück + + Verkaufspreis + + - + + Zimmer + + - + + Wohnfläche (m²) + + - + + Grundstücksfläche (m²) + + - + + Ausstattung & Eigenschaften + +- [x] Neubauprojekte + +- [x] Balkon + +- [x] Garten + +- [x] Parkplatz + +- [x] Lift + +- [x] Freie Aussicht + +- [x] Cheminée + +- [x] Garage + +- [x] Kinderfreundlich + +- [x] Rollstuhlgängig + +- [x] Möbliert + +Ordnen + + 59’403 Ergebnisse + + + + vor 2 Tagen + +Haus zu verkaufen + +1512 Chavannes-sur-Moudon • 7.5 Zimmer • 291 m² +------------------------------------------------------------------ + +Magnifique maison avec vue sur la campagne située à 5min de Moudon Environnement idéal pour cette villa qui offre un cadre de vie très agréable grâce à de généreux volumes distribués sur 3 étages, dont une vaste pièce à vivre avec cheminée, une grande cuisine ouverte moderne, 6 belles chambres, 3 salles d'eau, un wc visiteurs, un studio indépendant très pratique, un grand sous-sol aménagé avec Sauna qui offre diverses possibilités d'aménagements. L'espace extérieur offre une très belle terrasse ensoleillée avec brasero et un grand jardin avec piscine.Adresse exacte disponible sur demande .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1512-22-1 Superb house with view on the countryside located at 5min from Moudon Ideal environment for this villa which offers a very pleasant living environment thanks to generous volumes distributed on 3 floors, including a large living room with fireplace, a large modern open kitchen, 6 beautiful bedrooms, 3 bathrooms, a guest toilet, a very practical independent studio, a large basement with sauna which offers various development possibilities. The outside space offers a beautiful sunny terrace with brazier and a large garden with swimming pool.Exact address available on request .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/1512-22-1 + +CHF 5’668 / m² + +CHF 1’649’500 + + + + vor 2 Tagen + +Haus zu verkaufen + +8335 Hittnau • 3.5 Zimmer • 162 m² +----------------------------------------------------- + +Helles 3.5-Zimmer Einfamilienhaus mit erstklassiger Gartenanlage Dieses einzigartige Angebot überzeugt sowohl durch die qualitative Bausubstanz als auch durch die unmittelbare Nähe zu Schulen, öffentlichen Verkehrsmitteln und Einkaufsmöglichkeiten. Der offene Wohn-/Essbereich mit elegantem Cheminée, das helle Wohnambiente und die hochwertige Küche mit Frühstückbar versprechen ein hervorragendes Wohnerlebnis. Weitere Highlights sind das Hauptschlafzimmer mit En-Suite Bad sowie die atemberaubende Gartenanlage mit diversen Sitzplätzen, Bächlein und Teich.Genaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/8335-23-1 + +CHF 10’185 / m² + +CHF 1’650’000 + + vor 2 Tagen + +Haus zu verkaufen + +1000 Lausanne 27 • 5.5 Zimmer • 301 m² +--------------------------------------------------------- + +Magnificent building with adjoining barn to renovate Beautiful character house with a plot of more than 1'300m2 with trees offering a nice clearance on the lake. This property is ideally located in a peaceful environment while being close to all amenities (schools, shops and public transport). The housing part is currently spread over two levels and the barn-workshop part offers generous volumes. Great opportunity for transformation with a very good potential for interior space planning.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1000-22-1 + +CHF 4’153 / m² + +CHF 1’250’000 + + vor 2 Tagen + +Haus zu verkaufen + +1038 Bercher • 3.5 Zimmer • 110 m² +----------------------------------------------------- + +A haven of peace full of charm, village house near the Are you looking for a village house full of charm and ideally located? Look no further, this rare pearl is made for you Nestled in a quiet area and a PPE of two lots, it is perfectly maintained. Kitchen open to the dining room, large living room equipped with a wood stove, this village house offers all the comfort and authenticity you are looking for. Enjoy 2 bedrooms, a reduced, a bathroom and a guest toilet for your comfort. Close to the.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1038-22-2 + +CHF 5’909 / m² + +CHF 650’000 + + vor 2 Tagen + +Haus zu verkaufen + +1003 Lausanne • 8.5 Zimmer • 340 m² +------------------------------------------------------ + +Magnifique maison des années 30 entièrement rénovée à Lausanne Située en plein c?ur de Lausanne, cette splendide maison du début des années 30 offre un cachet remarquable et des prestations hors du commun. Les espaces sont spacieux et ouverts, créant une atmosphère chaleureuse et accueillante dès l'entrée. Les matériaux utilisés sont de qualité supérieure, avec des finitions soignées qui ajoutent une touche de standing à chaque détail. Cette maison entièrement rénovée au long de ces dix dernières années est idéale pour les familles, offrant des espaces de vie adaptés à toutes les générations. Les chambres sont spacieuses et confortables, tandis que les espaces de vie communs sont accueillants et conviviaux. L' aménagement paysager remarquable du jardin est une véritable ode à la nature, vous offrant une oasis de paix et de sérénité. Vous profiterez de moments de détente et de convivialité avec vos proches et vos amis dans cet espace extérieur exceptionnel. Enfin, ce bien d'exception vous permettra de profiter d'un espace fitness avec salle de bain et sauna, d'une cave à vin digne de ce nom et d'un garage souterrain de pas moins de 200m² . Si vous cherchez une maison de prestige à Lausanne, ne manquez pas cette opportunité rare. Contactez-nous dès maintenant pour organiser une visite et découvrir cette demeure exceptionnelle de vos propres yeux.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1012-23-3 Magnificent house of the 30s entirely renovated in Lausanne Located in the heart of Lausanne, this splendid house dating from the early 1930s offers a remarkable cachet and outstanding amenities. The spaces are spacious and open, creating a warm and welcoming atmosphere from the moment you enter. The materials used are of the highest quality, with meticulous finishing that adds a touch of luxury to every detail. This house has been completely renovated over the last ten years and is ideal for families, offering living spaces suitable for all generations. The bedrooms are spacious and comfortable, while the communal living areas are welcoming and friendly. The outstanding landscaping of the garden is a true ode to nature, offering you an oasis of peace and serenity. You will enjoy moments of relaxation and conviviality with your family and friends in this exceptional outdoor space. Finally, this exceptional property will allow you to enjoy a fitness area with bathroom and sauna, a wine cellar worthy of the name and an underground garage of no less than 200m². If you are looking for a prestigious house in Lausanne, do not miss this rare opportunity. Contact us now to arrange a visit and discover this exceptional home with your own eyes.Exact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/1012-23-3 + +CHF 15’294 / m² + +CHF 5’200’000 + + vor 2 Tagen + +Haus zu verkaufen + +1814 La Tour-de-Peilz • 6.5 Zimmer • 177 m² +-------------------------------------------------------------- + +Exclusive: Semi-detached villa with panoramic views of the lake & the Alps This villa consists of a 4.5-room triplex and an independent duplex, which can easily be combined into a single family home. Enjoy a breathtaking panoramic view of the lake and the Alps, all in a quiet and bright situation. With its magnificent west-facing terrace, this place is ideal for relaxing moments with the family. Do not miss the opportunity to live in this exceptional living environment. Contact us for a visitExact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1814-23-1 + +CHF 7’627 / m² + +CHF 1’350’000 + + vor 2 Tagen + +Haus zu verkaufen + +1344 L'Abbaye • 7.5 Zimmer • 220 m² +------------------------------------------------------ + +Coup de coeur pour cette magnifique demeure avec jardin bucolique Magnifique maison villageoise transformée et entièrement rénovée entre 1997 et 2019. Elle jouit d'une belle terrasse et d'un jardin bucolique entièrement clôturé en bordure de rivière. Elle est distribuée sur 3 étages et elle est excavée (cave voutée). Ce bien est en parfait état d'entretien général et ne nécessite d'aucuns travaux. Possibilité de créer une pièce habitable dans les combles. Une place de parc extérieure complète ce bien et diverses places de parc se trouvent à proximité.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1344-21-1 + +CHF 4’773 / m² + +CHF 1’050’000 + + vor 2 Tagen + +Wohnhaus zu verkaufen + +8153 Rümlang +----------------------------------- + +Seltene Gelegenheit - Mehrfamilienhaus an Toplage Diese charmante Liegenschaft an zentraler Wohnlage in Rümlang verfügt über drei Wohneinheiten, ein Studio und zahlreiche Parkmöglichkeiten. Das interessante Raumangebot mit zwei 3-Zimmer-Wohnungen und einer 5-Zimmer-Wohnung, der gute Zustand dank laufend vorgenommenen Renovationen sowie das vorhandene Ausbaupotenzial versprechen eine attraktive Investitionsmöglichkeit. Das Mehrfamilienhaus ist zurzeit vollständig vermietet und erzielt eine Bruttorendite von ca. 3%.Genaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/8153-23-1 + +- + +CHF 2’195’000 + + vor 2 Tagen + +Haus zu verkaufen + +1003 Lausanne • 18 Zimmer • 683 m² +----------------------------------------------------- + +Magnifique maison de Maître dans les beaux quartiers Lausannois Située dans un quartier résidentiel Lausannois, cette propriété de charme de 683m2 utiles, bordée par 1'359 m2 de jardin paysagé dispose d'un fort potentiel d'extension et bénéficie de nombreuses possibilités d'aménagement (logements/commercial, mixte). Idéal pour ceux qui exercent une profession libérale comme médecin, avocat, notaire, architecte... Construite en 1927 avec son architecture classique, elle se développe sur cinq niveaux. Actuellement, les deux premiers étages sont à usage commercial et les deux derniers offrent deux appartements. Entièrement excavé, le sous-sol de 203 m2 dispose lui aussi de nombreuses possibilités d'aménagement. Cette bâtisse offre une grande flexibilité d'utilisation, pouvant être réaménagée en une seule ou plusieurs habitations familiales. A voir absolumentAdresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1012-22-2 Magnificent house in the beautiful districts of Lausanne Located in a residential area of Lausanne, this charming property of 683m2, bordered by 1'359 m2 of landscaped garden has a strong potential for extension and have many development possibilities (residential/commercial, mixed). Ideal for a liberal profession such as doctor, lawyer, notary, architect... Built in 1927 with a classical architecture, this house is on five levels. Currently, the first two floors are used for commercial purposes and the last tow floors are 2 apartments. The basement of 203 m2 offers numerous possibilities for development. This building offers a great flexibility of use, being able to be reorganized into one or several family dwellings. A must seeExact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/1012-22-2 Wunderschöne Immobilie in den schönen Vierteln von Lausanne In einem Wohnviertel von Lausanne gelegen, verfügt diese charmante Immobilie mit 683m2 Nutzfläche, die von 1'359 m2 angelegtem Garten begrenzt wird, über ein hohes Ausbaupotenzial und profitiert von zahlreichen Gestaltungsmöglichkeiten (Wohnen/Gewerbe, gemischt). Ideal für Personen, die einen freien Beruf wie Arzt, Anwalt, Notar, Architekt usw. ausüben. Das 1927 erbaute Gebäude mit seiner klassischen Architektur erstreckt sich über fünf Stockwerke. Derzeit werden die ersten beiden Stockwerke gewerblich genutzt und die letzten beiden bieten zwei Wohnungen. Das vollständig ausgehobene Untergeschoss mit 203 m2 verfügt ebenfalls über zahlreiche Gestaltungsmöglichkeiten. Dieses Gebäude bietet eine hohe Nutzungsflexibilität und kann in eine einzige oder mehrere Familienwohnungen umgewandelt werden. Unbedingt ansehenGenaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/1012-22-2 + +CHF 9’854 / m² + +CHF 6’730’000 + + vor 2 Tagen + +Haus zu verkaufen + +1854 Leysin • 6 Zimmer • 190 m² +-------------------------------------------------- + +DIRECTIMMO OFFERS YOU AN INDIVIDUAL CHALET A superb chalet with stunning panoramic views of the Alps. This cottage is intended for the main residence. Quality finishes at the discretion of the lessee. This project is subject to obtaining the building permit. It is possible to modify the interior distribution according to your wishes. Distribution (editable): Lower ground floor: A garage and 3 outdoor parking spaces A cellar and a technical room (laundry possible) An entrance hall A studio of 35m2 with an independent entrance, a cellar and a reduced Upper ground floor: A clearance A bathroom An equipped kitchen open to a dining area and a living room (fireplace or stove possible) A large terrace of about 80m2 Floor: A clearance Three bedrooms One bathroom, shower A balcony of about 11m2 Technical: Underfloor heating with a heat pump Comfortable finishing budgets (CHF 25'000.- for the kitchen, CHF 18'000.- for the sanitary facilities, CHF 60.- per m2 for the tiles, CHF 80.- per m2 for the parquet floors...) Windows with triple glazingIf you need to sell a property for the purchase of your new property, we offer you more than 20 years of experience in the field of sales. During these years, we have developed an unprecedented presentation with our Virtual-Tours of properties, our strengthened presence on real estate portals as well as unbeatable brokerage fees make us an ideal partner. Information and visit to Mirko Gysin at 079 574 33 39 WWW.DIRECTIMMO.CH + +CHF 6’737 / m² + +CHF 1’280’000 + + vor 2 Tagen + +Büro & Gewerbe zu verkaufen + +1800 Vevey +--------------------------------------- + +Hairdressing salon to put back, active for more than 40 years with an excellent location in the center of the old town of Vevey. The show is to be resumed with a clientele both loyal and passing through, women, men, children. The equipment and stock would remain at your disposal. You also have the option to keep some of the current employees. You have the opportunity to have an independent nail stylist who could occupy a small part of the premises. His rent would be collected by the hair salon. The rental income of the latter can be a plus. This commercial premises of about 70m2 which was renovated in 2019, benefits from large windows and has 6 workstations and 2 washing bins. Private washing machine and dryer remain available to the buyer. The resumption of trade, stock of products, equipment, furniture, etc. is CHF 99'000.-. Monthly rent CHF 2'420.00 charges included. Turnover 2019 - 2020 - 2021 available if real interest during a face-to-face meeting. Date of resumption to be agreed. We are at your disposal for further information as well as a possible site visit. The information is elaborated from the data provided by the seller, it has an informative character. Non-contractual document This property remains subject to change in price, availability and withdrawal of sale without notice. WWW.EDEN-IMMOBILIER.CH©copyright All rights reserved CP 414 - Rue d'Octodure 15 - 1920 Martigny - info@eden-immobilier.ch - www.eden-immobilier.ch + +- + +CHF 99’000 + + vor 2 Tagen + +Haus zu verkaufen + +1800 Vevey • 5.5 Zimmer • 160 m² +--------------------------------------------------- + +Detached villa of 5.5 roomsOn a beautiful plot of more than 1500m²Hallway and viewTerraces and gardenOutdoor parking spacesMost sought-after neighborhoodQuiet and residentialClose to transport and the lake File on request + +- + +Auf Anfrage + + vor 2 Tagen + +Wohnhaus zu verkaufen + +1844 Villeneuve VD +----------------------------------------- + +Modular, innovative construction and storage complex, an activity accelerator for small and medium-sized entrepreneurs. It is a modern industrial building comprising production, design and craft workshops, commercial offices, storage spaces, warehouses and apartment for rent for you and your business. Information and visit: François Volet+41 79 831 44 52 IMPORTANT: Confidential file, for any additional requests, please send us your full contact details. Privacy and Data Protection Agreement. This file is delivered to the attention and exclusive use of the recipient. It must not be disclosed to third parties without our written consent. All other information is on request from our agency. + +- + +CHF 16’000’000 + + vor 2 Tagen + +Wohnhaus zu verkaufen + +1847 Rennaz +---------------------------------- + +Beautiful commercial building completely renovated in 2018/2019, with a volume of 3,138 m³ on a plot of 2,052 m². This property is ideally located in the center of Rennaz, close to highways, amenities, shops and the Riviera Chablais Vaud Valais hospital. It enjoys a magnificent clearance on the mountains and the surrounding nature as well as an optimal brightness and sunshine throughout the day by its south-east orientation. A rental statement of CHF 235'000.- for a gross yield of more than 6%. Great opportunity to seize + +- + +Auf Anfrage + + vor 2 Tagen + +Haus zu verkaufen + +1071 Chexbres • 270 m² +----------------------------------------- + +Video of the panoramic view on www.chiffelle-immobilier.ch (under multimedia files) Located in the most exclusive area of Chexbres, this exceptional plot offers a panoramic view of the entire Lake Geneva basin, it is sold with a building permit in force for a luxurious contemporary villa of about 270 m2 of living space (three levels), 7.5 rooms, sauna, and outdoor pool facing the lake with removable deck. Allow about two million for the construction of the villa, in addition to the sale price of the plot. Complete plans available upon request. Video der Panoramaaussicht auf www.chiffelle-immobilier.ch (unter Multimedia-Dateien) Dieses aussergewöhnliche Grundstück im erlesensten Quartier von Chexbres bietet eine Panoramasicht auf das gesamte Genferseebecken und wird mit a Baugenehmigung für eine luxuriöse, moderne Villa mit ca. 270 m2 Wohnfläche (drei Ebenen), 7,5 Zimmern, Sauna und Außenpool mit Seeblick und abnehmbarer Terrasse. Stellen Sie zusätzlich zum Verkaufspreis des Grundstücks etwa zwei Millionen für den Bau der Villa bereit. Vollständige Pläne auf Anfrage erhältlich. Video of the panoramic view on www.chiffelle-immobilier.ch (under multimedia files) Located in the most select district of Chexbres, this exceptional plot offers a panoramic view of the entire Lake Geneva basin, it is sold with a building permit in force for a luxurious contemporary villa of approximately 270 m2 of living space (three levels), 7.5 rooms, sauna, and outdoor swimming pool facing the lake with removable deck. Provide about two million for the construction of the villa, in addition to the sale price of the plot. Complete plans available on request. + +CHF 9’259 / m² + +CHF 2’500’000 + + vor 2 Tagen + +Grundstück zu verkaufen + +1071 Chexbres • 270 m² +----------------------------------------------- + +Vidéo de la vue panoramique sur www.chiffelle-immobilier.ch (sous fichiers multimedia) Située dans le quartier le plus select de Chexbres, cette parcelle exceptionnelle offre une vue panoramique sur tout le bassin lémanique, elle est vendue avec un permis de construire en force pour une luxueuse villa contemporaine d'environ 270 m2 habitables (trois niveaux), 7.5 pièces, sauna, et piscine extérieure face au lac avec deck amovible. Prévoir environ deux millions pour la construction de la villa, en sus du prix de vente de la parcelle. Plans complets disponibles sur demande. Video der Panoramaaussicht auf www.chiffelle-immobilier.ch (unter Multimedia-Dateien) Dieses aussergewöhnliche Grundstück im erlesensten Quartier von Chexbres bietet eine Panoramasicht auf das gesamte Genferseebecken und wird mit a Baugenehmigung für eine luxuriöse, moderne Villa mit ca. 270 m2 Wohnfläche (drei Ebenen), 7,5 Zimmern, Sauna und Außenpool mit Seeblick und abnehmbarer Terrasse. Stellen Sie zusätzlich zum Verkaufspreis des Grundstücks etwa zwei Millionen für den Bau der Villa bereit. Vollständige Pläne auf Anfrage erhältlich. Video of the panoramic view on www.chiffelle-immobilier.ch (under multimedia files) Located in the most select district of Chexbres, this exceptional plot offers a panoramic view of the entire Lake Geneva basin, it is sold with a building permit in force for a luxurious contemporary villa of approximately 270 m2 of living space (three levels), 7.5 rooms, sauna, and outdoor swimming pool facing the lake with removable deck. Provide about two million for the construction of the villa, in addition to the sale price of the plot. Complete plans available on request. + +CHF 9’259 / m² + +CHF 2’500’000 + + vor 2 Tagen + +Haus zu verkaufen + +1297 Founex • 8 Zimmer • 180 m² +-------------------------------------------------- + +Located in the commune of Founex, this charming individual villa offers a living space of 180 sqm (250 sqm useful) and is composed of 8 rooms including 4 bedrooms. Built on a plot of more than 1'300 sqm, it offers a comfortable and bright living space and is distributed over two levels plus basement. Thanks to its privileged location, in the heart of an exclusive residential area, it meets all the criteria for a quiet family life in an idyllic setting. The private schools La Châtaigneraie (-5 minutes) and Le Collège du Léman (-10 minutes) are located nearby. Carefully maintained and renovated, it benefits from quality services and finishes, including solid wood flooring, recessed LED spotlights, plenty of storage space, mosaic tiles in the bathrooms, wooden shutters, double-glazed windows, and a fully equipped and furnished kitchen. The second floor is characterized by generous volumes thanks to a beautiful height under ceiling. Outside, a large wooden pergola protects the terrace. The living space is composed of an entrance hall, a kitchen with a central island of 12 sqm, a living/dining room with a fireplace of about 45 sqm and a living room/office of about 15 sqm, all opening onto the terrace. The second floor is dedicated to the night area, with a master bedroom of 21 sqm with its own shower room, 3 other bedrooms and a shower room with double sink. The basement, entirely excavated, offers two large multipurpose rooms of respectively 23 and 28 sqm, a laundry room, the technical rooms and a fallout shelter. The villa is distributed as follows : First floor :- Entrance hall with storage space- Kitchen with central island- Living/dining room with access to the terrace and the garden- Multipurpose room (living room, office, etc.) First floor :- Master bedroom of 20 m2 with its adjoining shower room with WC- Three bedrooms of about 15 sqm- Shower room with WC Basement :- Multipurpose room of 23 sqm- Multipurpose room of about 28 sqm- Laundry room and fallout shelter- Technical rooms Outside :- Large terrace covered by a pergola- Garden with trees and fenced- Garden shed- Box for two cars- Outdoor parking spaces The exterior spaces consist of a large fenced garden with trees, a large terrace with pergola and a garden shed. The access to the property is secured by a gate. A double garage and several outdoor parking spaces located at the entrance complete this property. Its location close to all amenities and road axes gives it a quick access to Nyon (-15 minutes), to the center of Geneva and to the international airport of Geneva (- 20 minutes). + +CHF 16’389 / m² + +CHF 2’950’000 + + vor 2 Tagen + +Haus zu verkaufen + +1145 Bière • 4.5 Zimmer • 110 m² +--------------------------------------------------- + +Detached house built in 1964 on a beautiful plot of more than 1'000m2 ideally located in Bière. This house is habitable in the state but requires renovation to be updated to the tastes of the day. The plot has an interesting potential for expansion. To visit without delay Contact us directly at 079 276 89 94 or by email at l.bolay@atix-immobilier.ch for any further information or to arrange a visit on site. + +CHF 8’455 / m² + +CHF 930’000 + + vor 2 Tagen + +Büro & Gewerbe zu verkaufen + +1343 Les Charbonnières • 296 m² +------------------------------------------------------------ + +It is a disused former pigsty, built in 1988, having undergone major renovations in 2002 is located in the small village Les Charbonnières which is at the end of Lake Joux. Many shops and amenities are located in the city of Vallorbe, at a distance of about 10km or Yverdon-les-Bains about 35km away. The plot is 250m from the village which makes it extremely well located. Built on a plot of 1,376 m2, this building is located in an agricultural area, not subject to the LDFR. Pig walkways have been set up on the east and west sides of the building. At the front, a large asphalted space allows the parking of light vehicles as well as access for trucks delivery or transport of animals. The plot also has two circular metal silos, for the storage of pig food and a capacity of about 8 tons each, they are located at the southeast corner of the building.Construction information: The building is not excavated. Its debarer/paving is reinforced concrete, built on piles, due to the wet nature of the land. The supporting walls are made of masonry and the facades of cement brick covered with ribbed panels. The frame is made of wood. The roof is covered with ribbed steel panels assembled around an expanded polyurethane foam. The kelps and downspouts are made of stainless steel. The building is not connected to the sewer. Waste water from the sanitary facilities is discharged into the slurry pit. Heat production is provided by an oil boiler (2,000-litre cistern). As for the distribution of heat, it is carried out by radiators in the technical room and the toilet, by coils in the soil and in the fattening cells.Major rehabilitation or transformation work is to be expected. + +CHF 845 / m² + +CHF 250’000 + + vor 2 Tagen + +Büro & Gewerbe zu verkaufen + +1530 Payerne +----------------------------------------- + +Land in village area with three tobacco sheds. Located in a quiet area, the land is flat and enjoys a magnificent view of the Alps. The hangars are electrified and have a water supply. The connection to clear water/wastewater is pending at the plot boundary. This property is quite suitable for yield but can also become a building plot, as soon as the building restriction is lifted, for twin villas. + +- + +CHF 650’000 + + vor 2 Tagen + +Haus zu verkaufen + +1342 Le Pont • 4.5 Zimmer • 180 m² +----------------------------------------------------- + +Who has never dreamed of a house close to the lake and nature? This property is for you. You will just have to push the doors of this property to immediately fall under the spell. This house consisting of 2 dwellings will offer you great flexibility. Located between the lake and nature you will reside in a quiet residential area. A real idyll You will have understood this property will not remain available for long. So do not hesitate and contact us. Our real estate agents will be happy to open the doors of this little paradise. + +CHF 10’000 / m² + +CHF 1’800’000 + + vor 2 Tagen + +Haus zu verkaufen + +1815 Clarens • 10 Zimmer • 400 m² +---------------------------------------------------- + +DIRECTIMMO VOUS PROPOSE UNE SOMPTUEUSE VILLA DUBOCHET DE 10 PIECES PROCHE DU LAC Les Villas Dubochet situées à Clarens dans le canton de Vaud en Suisse forment un exceptionnel ensemble de demeures résidentielles (1874-1879), destinées à la villégiature d'hôtes fortunés souhaitant éviter la promiscuité des hôtels. Il y en a très exactement 21. Situées à Clarens, elles sont toutes différentes. Nous vous proposons l'une d'entre elles à la vente. L'entier de son charme et de son raffinement ont été conservés lors de sa complète rénovation en 2011. Pour ce faire, des matériaux de grande qualité et des normes historique de rénovation ont été respectées. Sa proximité avec le lac (200m), son grand jardin arborisé, ses terrasses qui pour certaine vous offre une superbe vue sur le lac et les Alpes, ses grands volumes intérieurs sont autant d'arguments qui vous donnerons le sentiment de privilège et d'authenticité. Cette Villa de 9 pièces est construite sur une parcelle de 1'662m2. Sur 4 niveaux, elle dispose d'une surface habitable d'environ 400m2 et de 1'546m2 de jardin. Elle est distribuée comme suit :Rez inférieur (également accessible par une entrée indépendante) : Une chambre Une salle de bain/WC Une bibliothèque Une cave à vin Une buanderie Rez-de-chaussée : Grande pièce de réception s'ouvrant sur une terrasse Une cuisine entièrement agencée Un WC visiteur 1erétage : Trois belles chambres dont deux avec terrasse Deux salles de bain/WC dont une privative 2èmeétage : Une somptueuse chambre parentale avec terrasse et vue sur le lac Une salle de bain privative Un grand dressing Autres informations : Construite en 1874 Complètement rénovée en 2011 La surface de la parcelle de 1'662m2 La surface habitable est de 400m2 Le volume est d'environ 1'835m3m3 5 places de parc extérieures Chauffage au gaz Distribution du chauffage par radiateurs Commodités : Commodité à 500 mètres Bus à 50 mètres Lac & port de Clarens à 200 mètres Accès autoroute à 2.5km Montreux centre à 5 minutes Lausanne à 20 minutes Genève Aéroport à 1h15 Présentation des alentours et de la région : Clarens-Montreux ou Clarens est une localité de la commune de Montreux en Suisse située sur la Riviera vaudoise, au bord du lac Léman et sur les contreforts des Préalpes fribourgeoises. Avec la salle omnisports du Pierrier sur son sol, Clarens accueille des compétitions d'importance nationale et internationale à l'image des Montreux Volley Masters, de la coupe de nations de Rink hockey ou encore des finales de la coupe de la ligue de basket. Clarens, c'est aussi le lac et les sports d'eau. Les amateurs de baignade trouveront leur bonheur au bord du lac à la plage du Pierrier ou aux bains de Clarens. Pour ceux qui préfèrent la piscine, la Maladaire les accueille été comme hivers ; deux bassins extérieurs et deux bassins intérieurs sont à disposition. Si vous devez vendre un bien pour l'achat de votre nouvelle propriété, nous vous proposons plus de 20 ans d'expérience dans le domaine de la vente. Durant ces années, nous avons développé une présentation inédite avec nos Virtual-Tours des biens, notre présence renforcée sur les portails immobiliers ainsi que des frais de courtages défiant toute concurrence font de nous un partenaire idéal. Renseignements et visite auprès de Thierry Lenoir au 079 476 08 11.WWW.DIRECTIMMO.CH + +CHF 17’250 / m² + +CHF 6’900’000 + + vor 2 Tagen + +Haus zu verkaufen + +1000 Lausanne 26 • 10 Zimmer • 270 m² +-------------------------------------------------------- + +BARNES Lausanne a la plaisir de vous présenter cette charmante maison de caractère située sur les hauteurs de Lausanne. Au coeur d'un quartier calme et dans un environnement verdoyant, la propriété se trouve à seulement quelques pas des transports en commun vous permettant d'accéder au centre de Lausanne. Les axes autoroutiers se trouvent à 3 minutes en voiture. Implantée sur une parcelle de plus de 1'600 m², cette bâtisse de ce début du XXe siècle a été entièrement rénovée entre 2004 et 2008 et a de plus été agrandie avec la construction de deux grandes extensions au Nord et à l'Ouest et a su allié le confort à l'authenticité. Distribuée de manière harmonieuse et lumineuse, elle se compose notamment de 6 chambres, de 4 salles d'eau, d'un WC séparé, d'un spacieux séjour donnant accès aux extérieurs, d'une salle à manger et d'une cuisine équipée donnant également accès à la terrasse et au jardin, le tout reparti sur une surface d'environ 270 m² utiles. Grâce à ces nombreuses ouvertures donnant sur la forêt et son vaste jardin arboré et clos, la maison vous promet un cadre de vie agréable et apaisant. A noter qu'il est possible d'y construire une piscine. Pour compléter ce bien, une cave, un garage double et 6 places de parc extérieures sont à disposition. + +CHF 8’852 / m² + +CHF 2’390’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1052 Le Mont-sur-Lausanne • 4.5 Zimmer +------------------------------------------------------------ + +Located in a green and family area, this apartment is away from traffic while being only 200 m from the first stop of the TL and all amenities. Large apartment of 4.5 rooms of approx. 112 m2 of living space in perfect condition, made with sober and quality materials. These large spaces perfectly distributed as well as its large windows offer perfect brightness throughout the day. The apartment consists of an entrance with fitted wardrobes, which serves 3 bedrooms, a bathroom and a bathroom. The open and equipped kitchen overlooks a spacious living room, a bright veranda and the garden. An indoor parking space in addition, a motorcycle space and a large cellar complete this rare property on the market. Apartment price: 1'190'000.- Parking space: 35'000.- Motorcycle space: 5'000.- + +- + +CHF 1’190’000 + +[1](https://www.immoyou.ch/kaufen-schweiz)234567 + + 1 - 24 von 59’403 Ergebnisse + +### Immobilie kaufen in der Schweiz + +[Immobilie kaufen im Kanton Zürich](https://www.immoyou.ch/kaufen-kanton-zurich)[Immobilie kaufen im Kanton Bern](https://www.immoyou.ch/kaufen-kanton-bern)[Immobilie kaufen im Kanton Aargau](https://www.immoyou.ch/kaufen-kanton-aargau)[Immobilie kaufen im Kanton St. Gallen](https://www.immoyou.ch/kaufen-kanton-st-gallen)[Immobilie kaufen im Kanton Luzern](https://www.immoyou.ch/kaufen-kanton-luzern)[Immobilie kaufen im Kanton Basel-Landschaft](https://www.immoyou.ch/kaufen-kanton-basel-landschaft)[Immobilie kaufen im Kanton Thurgau](https://www.immoyou.ch/kaufen-kanton-thurgau)[Immobilie kaufen im Kanton Solothurn](https://www.immoyou.ch/kaufen-kanton-solothurn)[Immobilie kaufen im Kanton Graubünden](https://www.immoyou.ch/kaufen-kanton-graubunden)[Immobilie kaufen im Kanton Basel-Stadt](https://www.immoyou.ch/kaufen-kanton-basel-stadt)[Immobilie kaufen im Kanton Schwyz](https://www.immoyou.ch/kaufen-kanton-schwyz)[Immobilie kaufen im Kanton Zug](https://www.immoyou.ch/kaufen-kanton-zug) + +### Andere Immobilienarten in der Schweiz + +[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Zimmer kaufen in der Schweiz](https://www.immoyou.ch/wg-zimmer-kaufen-schweiz)[Parkplatz kaufen in der Schweiz](https://www.immoyou.ch/parkplatz-kaufen-schweiz)[Büro & Gewerbe kaufen in der Schweiz](https://www.immoyou.ch/buro-gewerbe-kaufen-schweiz)[Wohnhaus kaufen in der Schweiz](https://www.immoyou.ch/wohnhaus-kaufen-schweiz)[Grundstück kaufen in der Schweiz](https://www.immoyou.ch/grundstuck-kaufen-schweiz) + + All rights reserved. v.541ff84 + + +=== https://www.immoyou.ch/wohnung-kaufen-schweiz === +🏢 29’844 Wohnungen kaufen in der Schweiz | ImmoYou -Heftarchiv 2025 =============== -< +[ImmoYou](https://www.immoyou.ch/) -[2025](https://www.itreseller.ch/heftarchiv/2025)[2024](https://www.itreseller.ch/heftarchiv/2024)[2023](https://www.itreseller.ch/heftarchiv/2023)[2022](https://www.itreseller.ch/heftarchiv/2022)[2021](https://www.itreseller.ch/heftarchiv/2021)[2020](https://www.itreseller.ch/heftarchiv/2020)[2019](https://www.itreseller.ch/heftarchiv/2019)[2018](https://www.itreseller.ch/heftarchiv/2018)[2017](https://www.itreseller.ch/heftarchiv/2017)[2016](https://www.itreseller.ch/heftarchiv/2016)[2015](https://www.itreseller.ch/heftarchiv/2015)[2014](https://www.itreseller.ch/heftarchiv/2014)[2013](https://www.itreseller.ch/heftarchiv/2013)[2012](https://www.itreseller.ch/heftarchiv/2012)[2011](https://www.itreseller.ch/heftarchiv/2011)[2010](https://www.itreseller.ch/heftarchiv/2010)[2009](https://www.itreseller.ch/heftarchiv/2009) +Kaufen -> +[Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) -X +Mieten -Heftarchiv-Premium-Zugriff --------------------------- +[Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) - Der Zugriff auf das Heftarchiv von "IT Reseller" wird exklusiv den Abonnenten der Print-Ausgabe zur Verfügung gestellt. + Ändern Sie die Suche - Um eine beliebige Ausgabe herunterzuladen, geben Sie bitte den Premium-Zugangscode ein, den Sie auf der Editorial-Seite der aktuellen Ausgabe finden, und klicken Sie auf den Download-PDF-Button. +[](https://www.immoyou.ch/)[Kaufen](https://www.immoyou.ch/kaufen-schweiz)[Wohnungen](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz) -**Premium-Zugangscode** +Wohnung kaufen in der Schweiz +============================= -Ausgabe 2025/10 +Ort -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202510_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202510/inhaltsverzeichnis.html) + Schweiz -Ausgabe 2025/09 + Zürich -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202509_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202509/inhaltsverzeichnis.html) + Genf -Ausgabe 2025/7-8 + Typ -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202507_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202507/inhaltsverzeichnis.html) +- [x] Haus -Ausgabe 2025/06 +- [x] Wohnung -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202506_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202506/inhaltsverzeichnis.html) +- [x] Zimmer -Ausgabe 2025/05 +- [x] Parkplatz -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202505_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202505/inhaltsverzeichnis.html) +- [x] Büro & Gewerbe -Ausgabe 2025/04 +- [x] Wohnhaus -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202504_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202504/inhaltsverzeichnis.html) +- [x] Grundstück -Ausgabe 2025/03 + Verkaufspreis -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202503_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202503/inhaltsverzeichnis.html) + - -Ausgabe 2025/1-2 + Zimmer -[](https://www.itreseller.ch/bilder/cover/itr/2025/itr_202501_big2.jpg)[Zum Inhaltsverzeichnis](https://www.itreseller.ch/heftarchiv/ausgabe/202501/inhaltsverzeichnis.html) + - -Meistgelesen + Wohnfläche (m²) -[### Renato Petrillo wird CEO von Baggenstos](https://www.itreseller.ch/Artikel/104088/Renato_Petrillo_wird_CEO_von_Baggenstos.html) 30. September 2025 + - -[### Dennis Monner löst Daniel Neuhaus als CEO von Open Systems ab](https://www.itreseller.ch/Artikel/104087/Dennis_Monner_loest_Daniel_Neuhaus_als_CEO_von_Open_Systems_ab.html) 30. September 2025 + Grundstücksfläche (m²) -[### Marco Pierro wird Country Manager Schweiz bei Check Point](https://www.itreseller.ch/Artikel/104085/Marco_Pierro_wird_Country_Manager_Schweiz_bei_Check_Point.html) 30. September 2025 + - -[### Elona Mortimer-Zhika wird Beiratsvorsitzende bei Infoniqa](https://www.itreseller.ch/Artikel/104083/Elona_Mortimer-Zhika_wird_Beiratsvorsitzende_bei_Infoniqa.html) 30. September 2025 + Ausstattung & Eigenschaften -Finance +- [x] Neubauprojekte -[### OpenAI knackt 500-Milliarden-Marke](https://www.itreseller.ch/Artikel/104101/OpenAI_knackt_500-Milliarden-Marke.html) +- [x] Balkon -2. Oktober 2025 +- [x] Garten -[### Accenture mit mehr Umsatz und weniger Gewinn](https://www.itreseller.ch/Artikel/104069/Accenture_mit_mehr_Umsatz_und_weniger_Gewinn.html) +- [x] Parkplatz -26. September 2025 +- [x] Lift -[### TD Synnex schliesst Quartal mit Rekordgewinn ab](https://www.itreseller.ch/Artikel/104067/TD_Synnex_schliesst_Quartal_mit_Rekordgewinn_ab.html) +- [x] Freie Aussicht -26. September 2025 +- [x] Cheminée -[### Schweizer KI-Start-up Giotto sucht Finanzierung](https://www.itreseller.ch/Artikel/104018/Schweizer_KI-Start-up_Giotto_sucht_Finanzierung.html) +- [x] Garage -23. September 2025 +- [x] Kinderfreundlich -[### Nvidia will kräftig in OpenAI investieren](https://www.itreseller.ch/Artikel/104016/Nvidia_will_kraeftig_in_OpenAI_investieren.html) +- [x] Rollstuhlgängig -23. September 2025 +- [x] Möbliert -[](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) +Ordnen -[Advertorial ### Netzwerk- und Security-Infrastruktur für den kybunpark Mit Unterstützung durch den IT-Dienstleister 4net hat der FC St.Gallen 1879 sein Heimstadion kybunpark mit einer leistungsstarken Netzwerk- und Security-Infrastruktur aufgerüstet – ausfallsicher, UEFA-konform und zukunftsgerichtet.](https://www.itreseller.ch/Artikel/104022/Netzwerk-_und_Security-Infrastruktur_fuer_den_kybunpark.html) + 29’844 Ergebnisse -[](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) + -[Advertorial ### TP-Link definiert Managed Services neu Managed Services neu gedacht: Omada Central bietet automatisiertes Setup, proaktives Monitoring und integrierte Sicherheitslösungen für Ihr Netzwerk](https://www.itreseller.ch/Artikel/104054/TP-Link_definiert_Managed_Services_neu.html) + vor 2 Tagen -[](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) +Wohnung zu verkaufen -[Advertorial ### MDR «Made in Europe»: Smarter Einstieg in Security-as-a-Service Die Herkunft von IT-Sicherheitslösungen rückt für Schweizer Unternehmen zunehmend in den Fokus. Angesichts wachsender Cyberbedrohungen und der angespannten geopolitischen Lage stellt sich eine zentrale Frage: Wem kann man beim Schutz sensibler Daten wirklich vertrauen?](https://www.itreseller.ch/Artikel/103943/MDR_Made_in_Europe_Smarter_Einstieg_in_Security-as-a-Service.html) +1052 Le Mont-sur-Lausanne • 4.5 Zimmer +------------------------------------------------------------ -[](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) +Located in a green and family area, this apartment is away from traffic while being only 200 m from the first stop of the TL and all amenities. Large apartment of 4.5 rooms of approx. 112 m2 of living space in perfect condition, made with sober and quality materials. These large spaces perfectly distributed as well as its large windows offer perfect brightness throughout the day. The apartment consists of an entrance with fitted wardrobes, which serves 3 bedrooms, a bathroom and a bathroom. The open and equipped kitchen overlooks a spacious living room, a bright veranda and the garden. An indoor parking space in addition, a motorcycle space and a large cellar complete this rare property on the market. Apartment price: 1'190'000.- Parking space: 35'000.- Motorcycle space: 5'000.- -[Advertorial ### Mehr als eine Lieferkette - gelebte Partnerschaft auf Augenhöhe Ausgangslage: Die Lake Solutions AG suchte nach einem verlässlichen Ecosystem, um ihr Microsoft- und besonders Azure- und Ihr Service-Engagement auszubauen.](https://www.itreseller.ch/Artikel/103899/Mehr_als_eine_Lieferkette_-_gelebte_Partnerschaft_auf_Augenhoehe.html) +- -[](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) +CHF 1’190’000 -[Advertorial ### Zertifizierte SASE-Kompetenz bei BOLL Engineering BOLL Engineering baut als führender Cybersecurity Distributor seine Fachkompetenz mit der Spezialisierungsauszeichnung «Fortinet Specialized FortiSASE Distributor» weiter aus. Hier erfahren Sie, worum es bei SASE geht und wie die Channel-Partner von der Auszeichnung profitieren können.](https://www.itreseller.ch/Artikel/103892/Zertifizierte_SASE-Kompetenz_bei_BOLL_Engineering.html) + -[](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) + vor 2 Tagen -[Advertorial ### peoplefone feiert sein 20-Jahr-Jubiläum 2005 begann die Geschichte von peoplefone als One-Man-Show. Dank des Unternehmergeists von Gründer Christophe Beaud ist der VoiP-Pionier heute ein etablierter und internationaler Telefonieprovider.](https://www.itreseller.ch/Artikel/103832/peoplefone_feiert_sein_20-Jahr-Jubilaeum.html) +Wohnung zu verkaufen -GOLD SPONSOREN +1865 Les Diablerets • 4.5 Zimmer • 148 m² +--------------------------------------------------------------- -SPONSOREN & PARTNER +Tucked away admits the Swiss Alps just 20 kilometers away from the prestigious Gstaad ski resort. You will be able to rub the eternal snows of the Glacier 3000 and taste the simple charms of an authentic mountain village. The duplex apartment consists of a kitchen fully equipped with branded appliances, open to the dining room. Its intelligent design brings a user-friendly appearance and comfort of use. The balcony offers panoramic views of the Diablerets mountain range. Each apartment is fitted with an array of built-in oak wardrobes that go beautifully with the natural oiled oak flooring for an elegant effect. A vast well-being area has been set up in the Cristal de Roche Residence for the owners exclusive use. Accessible by day and night, it enjoys natural light, jacuzzi, Turkish bath, sauna and relaxation room. At the Diablerets, ski, hike and paragliding all year round. Discover a region steeped in living history and spectacular natural surroundings. Underground parking space available in the condominium. - +CHF 6’926 / m² - Swiss IT Media GmbH +CHF 1’025’000 - Seestrasse 95 + vor 2 Tagen - CH-8800 Thalwil +Wohnung zu verkaufen - ✆ +41 44 723 50 00 +1865 Les Diablerets • 2.5 Zimmer • 74 m² +-------------------------------------------------------------- - info@swissitmedia.ch +Tucked away admits the Swiss Alps just 20 kilometers away from the prestigious Gstaad ski resort. You will be able to rub the eternal snows of the Glacier 3000 and taste the simple charms of an authentic mountain village. The duplex apartment consists of a kitchen fully equipped with branded appliances, open to the dining room. Its intelligent design brings a user-friendly appearance and comfort of use. The balcony offers panoramic views of the Diablerets mountain range. Each apartment is fitted with an array of built-in oak wardrobes that go beautifully with the natural oiled oak flooring for an elegant effect. A vast well-being area has been set up in the Cristal de Roche Residence for the owners exclusive use. Accessible by day and night, it enjoys natural light, jacuzzi, Turkish bath, sauna and relaxation room. At the Diablerets, ski, hike and paragliding all year round. Discover a region steeped in living history and spectacular natural surroundings. Underground parking space available in the condominium. -[www.swissitmedia.ch](https://www.swissitmedia.ch/) +CHF 6’689 / m² -INSERIEREN +CHF 495’000 -[Mediadaten](https://www.itreseller.ch/media) + vor 2 Tagen -[Newsletter-Anzeigen](https://www.itreseller.ch/textanzeigen) +Wohnung zu verkaufen -[Veranstaltungen](https://www.itreseller.ch/tools/veranstaltungsmeldungen) +3954 Leukerbad • 1 Zimmer • 29 m² +------------------------------------------------------- -VERLAG +Located less than 5 minutes walk from the departure of the gondola, this bright studio, which enjoys a magnificent view of the mountains will seduce you. Located on the upper ground floor of a small building of 14 apartments, it enjoys easy access, also for people with reduced mobility. The south-facing balcony brings you plenty of sun and light. It is composed as follows: Entrance: A wardrobe A bathroom with bath - WC and sink The living space: A spacious living room with access to a south-facing balcony. A large wardrobe bed (2 people) A sofa bed A table for 4 people integrated into the kitchen A cellar completes this property The common areas of the PPE include a ski storage room and a laundry room. Don't wait to ask for a visit -[Abonnement](https://www.itreseller.ch/abo) +CHF 5’828 / m² -[AGB](https://www.itreseller.ch/tools/itr_agb.cfm) +CHF 169’000 -[Datenschutz](https://www.itreseller.ch/tools/itr_datenschutz.cfm) + vor 2 Tagen -[Impressum](https://www.itreseller.ch/tools/itr_impressum.cfm) +Wohnung zu verkaufen -[Swiss IT Magazine](https://www.itmagazine.ch/) +8965 Berikon • 3.5 Zimmer • 94 m² +------------------------------------------------------- -SERVICE +Moderne 3.5-Zimmer Attikawohnung an attraktiver Lage Diese hochwertige Wohnung befindet sich an ruhiger und zentraler Lage unweit von Wald- und Spazierwegen. Der hochwertige Innenausbau, der durchdachte Grundriss und die farblich abgestimmten Materialien vermitteln ein Wohngefühl der Extraklasse. Ein Einstellplatz in der Tiefgarage kann für CHF 35'000.? dazugekauft werden. Besuchen Sie den virtuellen Rundgang und überzeugen Sie sich selbst. Wir freuen uns auf Ihre Anfrage.Genaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/8965-23-1 -[Newsletter](https://www.itreseller.ch/tools/newsletter/nl_management.cfm) +CHF 10’213 / m² -[RSS-Feed](https://www.itreseller.ch/rss/news.xml) +CHF 960’000 -[Sitemap](https://www.itreseller.ch/tools/sitemap.cfm) + vor 2 Tagen -[Heftarchiv](https://www.itreseller.ch/heftarchiv/2025) +Wohnung zu verkaufen -[Firmenverzeichnis](https://www.itreseller.ch/artikel/unternehmensverzeichnis.cfm) +1669 Les Sciernes-d'Albeuve • 4.5 Zimmer • 78 m² +---------------------------------------------------------------------- -[ICT-Stellenangebote](https://www.itreseller.ch/jobs/) +Exclusive: Penthouse with 2 balconies & enjoying a quiet location Beautiful apartment on the top floor of a small building of 6 lots, offering two balconies, one of which is accessible from the master bedroom. This property has a beautiful unobstructed view of the Pre-Alps, without any vis-à-vis, all with a quiet location. A large cellar & a spacious attic of 77 m2 are part of this lot. In addition, a garage-box and two outdoor spaces complete this property, in addition to CHF 45,000 each. Possibility to acquire an additional garage-box if desired.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1669-23-1 -[](https://www.facebook.com/swissitreseller/?locale=de_DE)[](https://ch.linkedin.com/showcase/swissitreseller/)[](https://bsky.app/profile/itreseller.bsky.social) +CHF 5’064 / m² - +CHF 395’000 -[](https://www.itreseller.ch/heftarchiv/2025)[](https://www.itreseller.ch/heftarchiv/2025) + vor 2 Tagen -[](https://www.itreseller.ch/heftarchiv/2025) +Wohnung zu verkaufen -[](https://www.itreseller.ch/heftarchiv/2025) +1450 Le Château-de-Ste-Croix • 5.5 Zimmer • 144 m² +------------------------------------------------------------------------ + +Beaucoup de cachet pour cet appartement/triplex rénové avec jardin Dans une ancienne maison de village, sis ce joli appartement rénové avec beaucoup de cachet distribué sur 3 niveaux avec jardin et accès indépendant. Il se situe au centre du village, sans aucune nuisance. L'immeuble a été entièrement transformé en 1991. L'appartement a été bien entretenu et des travaux d'amélioration ont été effectués. Idéal pour une famille, il saura séduire les amateurs de bien atypique. Parcelle de 113 m2 à proximité vendue également avec ce bien.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1450-23-1 + +CHF 3’819 / m² + +CHF 550’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1003 Lausanne • 2.5 Zimmer • 71 m² +-------------------------------------------------------- + +Large 2.5-room apartment on the ground floor in Lausanne In the heights of Lausanne, in the immediate vicinity of amenities, this beautiful apartment of 60m² of net living space is an opportunity to seize The large living room is spacious and bright thanks to its large openings that overlook a beautiful terrace and a very nice little garden. The fully equipped kitchen is open to the dining area and living room. In the night part, a beautiful bedroom, a bathroom, a guest toilet and storage. A parking space extra. See also Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1010-22-2 Large 2.5 room apartment on garden level in Lausanne In the heights of Lausanne, close to all amenities, this beautiful apartment of 60m² of net living space is an opportunity to seize The large living room is spacious and luminous thanks to its large openings which give onto a beautiful terrace and a very nice little garden. The fully equipped kitchen is open to the dining area and the living room. In the night part, a beautiful bedroom, a bathroom, a guest toilet and storage. One parking space in addition. A must see Exact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST: https://neho.ch/o/1010-22-2 + +CHF 10’352 / m² + +CHF 735’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1820 Veytaux • 4.5 Zimmer • 126 m² +-------------------------------------------------------- + +Magnificent apartment with panoramic views of Lake Geneva This beautiful apartment has been completely renovated recently and consists of an entrance hall with wardrobes, a spacious living room with access to the south-facing balcony and an incredible view, a large open kitchen fully equipped, 3 pleasant bedrooms as well as two bathrooms and a guest toilet. A cellar and a garage space complete this property. Privileged location because very well connected to public transport and close to all the amenities of Montreux and its city center.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1820-22-4 + +CHF 10’278 / m² + +CHF 1’295’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1462 Yvonand • 2.5 Zimmer • 49 m² +------------------------------------------------------- + +Appartement avec grand balcon à Yvonand Joli appartement de 2,5 pces d'une surface de 49.50 m2 habitables + un balcon de 21.25 m2. Sis au 1er étage d'une PPE de 8 lots, avec ascenseur. Des travaux de rafraichissement ont été effectués en novembre 2022. L'immeuble est équipé de panneaux solaires. Il se situe au centre du village, proche de toutes commodités (commerces, transports, écoles, plages, etc.) Une cave, une buanderie commune ainsi qu'une place de parc extérieure complètent ce bien. L'appartement est libre de tout bail.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1462-22-3 + +CHF 8’878 / m² + +CHF 435’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1009 Pully • 3.5 Zimmer • 84 m² +----------------------------------------------------- + +Beautiful 3.5 room apartment with stunning lake views in Pully This large apartment of 88m ² of PPE surface is an opportunity to seize. With its southern orientation, it enjoys abundant natural light that illuminates every room of the apartment, creating a warm atmosphere. A living room with fireplace very friendly, a dining room and a large kitchen make up the day part. In the night part, two beautiful bedrooms, a bathroom and a guest toilet. Always well maintained, it is in good general condition. A must see Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1009-23-2 Beautiful 3.5 room flat with breathtaking view of the lake in Pully This large flat with 88m² of living space is an opportunity to be seized. With its southern orientation, it enjoys an abundance of natural light which illuminates each room of the flat, creating a warm atmosphere. A living room with a very convivial fireplace, a dining room and a large kitchen make up the day part. In the night area there are two beautiful bedrooms, a bathroom and a guest toilet. Always well maintained, it is in excellent general condition. A must seeExact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST: https://neho.ch/o/1009-23-2 + +CHF 10’119 / m² + +CHF 850’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1162 St-Prex • 2.5 Zimmer • 70 m² +------------------------------------------------------- + +Large and bright apartment 2.5p ideally located in St-Prex Charming apartment very well maintained and located close to all amenities and a few steps from schools which offers optimal comfort to its future occupants. In addition, it is also a short distance from Lake Geneva. Beautiful pleasant living space with a generous living room that overlooks a sunny balcony, a large and comfortable bedroom with custom dressing room. The bathroom and separate toilet were renovated in 2022. A cellar and a parking space complete this property.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1162-23-1 + +CHF 9’786 / m² + +CHF 685’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1163 Etoy • 3.5 Zimmer • 111 m² +----------------------------------------------------- + +Résidence La Romanèche Cet appartement charmant vous offrira un cadre de vie idéal Avec son jardin clôturé et les espaces de jeux extérieurs, vous pourrez profiter de moments de détente en plein air. Il dispose d'une grande pièce à vivre avec accès à la terrasse couverte. Vous serez également séduit par sa proximité avec toutes les commodités pour faciliter votre quotidien. Et cerise sur le gâteau, vous pourrez créer une pièce supplémentaire selon vos besoins Hypothèque à taux préférentiel à reprendre.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1163-23-2 La Romanèche residence This charming apartment will offer you an ideal living environment With its garden and outdoor play areas, you will be able to enjoy relaxing moments in the open air. The optimization of space has been thought out for your comfort, in order to create a convivial living space, with a large living room. You will also be seduced by its proximity to all amenities to facilitate your daily life. And to top it all off, you can create an extra room according to your needsExact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/1163-23-2 + +CHF 11’532 / m² + +CHF 1’280’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1166 Perroy • 2.5 Zimmer • 56 m² +------------------------------------------------------ + +Appartement 2.5p neuf spacieux et très lumineux Superbe appartement neuf situé dans un quartier résidentiel paisible, il est très agréable de par ses généreux volumes, des matériaux de qualité et il bénéficie d'une belle luminosité. Il offre tout le confort moderne avec un beau séjour avec cuisine ouverte, une grande chambre, une belle salle de douche et le magnifique balcon avec espace de rangement. Pour terminer cet appartement dispose de deux places de parc, dont une couverte avec un local de rangement.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1166-23-1 + +CHF 11’875 / m² + +CHF 665’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +2532 Magglingen/Macolin • 4.5 Zimmer • 139 m² +------------------------------------------------------------------- + +Einmalige und exklusive 4½ Zimmer Attikawohnung mit Alpen-Panorama Diese wunderschöne Wohnung mit einem aussergewöhnlichen Ausbaustandard der oberen Klasse wird Sie begeistern. Das helle und luftige Wohnambiente, in Kombination mit einem abwechslungsreichen Grundriss machen diese Liegenschaft sehr spannend und einzigartig. Geniessen Sie hier eine spektakuläre Aussicht und viel Komfort. Ein Bastelraum mit Bad und Sauna, drei Einstellhallenplätze und ein Aussenparkplatz gehören zur Wohnung dazu. Der grosszügige Aussenbereich rundet das attraktive Angebot ab.Genaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/2532-23-1 + +CHF 7’122 / m² + +CHF 990’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1817 Brent • 3.5 Zimmer • 76 m² +----------------------------------------------------- + +Exclusif: Charmant appartement traversant avec vue sur les Alpes A deux pas de la gare du MOB de Fontanivent, cet appartement traversant bénéficie d'une bonne luminosité. Il offre une vue dégagée sur les Alpes avec un petit dégagement sur le lac. Il se compose d'un hall d'entrée avec armoires, d'un séjour avec accès au balcon habitable orienté sud, d'une cuisine ouverte, de deux chambres ainsi que d'une salle de bain. Jouissance possible d'un grand jardin commun de la copropriété. Une cave ainsi qu'une place de parc en souterrain complètent ce bien.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1817-22-2 + +CHF 7’697 / m² + +CHF 585’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1950 Sion • 5.5 Zimmer • 164 m² +----------------------------------------------------- + +Spacious apartment in downtown Sion Beautiful apartment on the 1st floor of a building located in the heart of the city of Sion, in a quiet area and close to all amenities. It enjoys a beautiful exposure from its balconies, and a good brightness from East to West. It has 4 bedrooms, 2 bathrooms, a large and warm living room with fireplace, a closed kitchen, a heated galetas and a cellar. A space in the underground car park is available for rent for CHF 1000 per year.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1950-22-8 + +CHF 4’695 / m² + +CHF 770’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +3968 Veyras • 6.5 Zimmer • 184 m² +------------------------------------------------------- + +Spacious attic duplex currently rented in Veyras Spacious penthouse duplex in a small building of 4 apartments, located in a quiet area, a few minutes by transport from the center of Sierre. Regularly maintained and ideal for families, it has 5 bedrooms, 3 bathrooms with shower or bath, a warm living room with a fireplace and a well-appointed open kitchen. Two balconies, one facing south, a large garage in addition and a private carnotzet complete this property.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/3968-22-1 + +CHF 3’995 / m² + +CHF 735’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1283 La Plaine • 4.5 Zimmer • 137 m² +---------------------------------------------------------- + +A stone's throw from the train station With direct access by lift, this beautiful apartment has a spacious south-facing terrace. Out of nuisance, while being close to the station, it has a large living room, closed kitchen, 2 bedrooms and a bathroom. Individual boiler in the apartment. Possibility to make a third bedroom instead of the office area. Building of 8 apartments.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1283-22-1 Close to the train station With a direct access by the elevator, this beautiful apartment has a spacious terrace facing South. Out of the nuisances, while being close to the station, it has a large living room, an equipped closed kitchen, 2 bedrooms and a bathroom. Individual boiler in the apartment. Possibility to arrange a third bedroom instead of the office corner. 8 apartments building.Exact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST: https://neho.ch/o/1283-22-1 + +CHF 9’270 / m² + +CHF 1’270’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +3963 Crans-Montana • 3.5 Zimmer • 80 m² +------------------------------------------------------------- + +Lumineux appartement au pied du domaine skiable de Crans-Monatana Bel appartement idéalement situé à quelques pas des remontées mécaniques de Crans-Montana. Il bénéficie d'une orientation d'Est en Ouest avec vue panoramique, et d'un ensoleillement optimal depuis son balcon au Sud-Ouest. Bien entretenu, il dispose de 2 chambres, d'une salle de douche, d'une chaleureuse pièce à vivre avec cuisine ouverte et poêle à bois, d'une cave et d'un casier à ski. Des places de parking extérieures appartiennent à la copropriété et sont à disposition.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/3963-23-1 Bright flat at the foot of the Crans-Monatana ski area Beautiful flat ideally located a few steps from the ski lifts of Crans-Montana. It benefits from a beautiful orientation from East to West with a panoramic view, and an optimal sunshine from its balcony on the South-West. Well maintained, it has 2 bedrooms, a shower room, a cosy living room with open kitchen and wood stove, a cellar and a ski locker. Outside parking spaces belong to the co-ownership and are available.Exact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/3963-23-1 + +CHF 8’063 / m² + +CHF 645’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1205 Genève • 4.5 Zimmer • 85 m² +------------------------------------------------------ + +A 5-minute walk to the old town In a beautiful building close to the HUG and very well maintained, crossing apartment with high ceilings, moldings and old parquet, composed of a beautiful living room, a bedroom, a bedroom and a bathroom, a closed kitchen as well as a separate toilet and a reduced. The rooms overlook a quiet courtyard The façade is in good condition. Free of any occupant. A cellar completes this property.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1205-22-1 5 minutes walk from the old town In a beautiful building close to the hospital and very well maintained, crossing apartment with high ceilings and old parquet, composed of a beautiful living room, 2 bedrooms and a bathroom, as well as a kitchen. The apartment overlooks a quiet courtyard Surface PPE 85 m². The facade has been recently redone. Free of any occupant. A cellar.Exact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST: https://neho.ch/o/1205-22-1 + +CHF 14’000 / m² + +CHF 1’190’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1283 La Plaine • 6 Zimmer • 114 m² +-------------------------------------------------------- + +Duplex en combles, au calme, idéal pour une famille. Bel appartement en duplex d'env. 125m2 utiles, idéalement situé à proximité immédiate du Rhône et de la gare de La Plaine. Rénové avec soins entre 2020 et 2022 pour près de CHF 100'000.- (cuisine, poêle, sol, fenêtres, sdb et wc, radiateurs, peintures). 1er niveau: Salon, cuisine, balcon, 3 chambres, 1 salle de bain douche et double vasque, 1 wc. Combles: Chambre ouverte, 1 pièce de rangement, espace salle de bain baignoire, buanderie. 1 place de parc INT complète ce bien. A visiterAdresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1283-23-1 + +CHF 8’728 / m² + +CHF 995’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1958 St-Léonard • 4.5 Zimmer • 103 m² +----------------------------------------------------------- + +Beautiful well maintained 4.5 room apartment in St-Léonard Beautiful apartment in a building of 6 apartments located in St-Léonard, in a quiet area close to all amenities. It enjoys a beautiful view of the mountains from its balconies to the south and north. Well maintained over the years, it has 3 bedrooms, a bathroom with shower and bath, a separate toilet, an open living room, a kitchen, a large galetas under the eaves, a cellar, a garage in addition and outdoor places.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1958-22-2 + +CHF 3’544 / m² + +CHF 365’000 + + vor 2 Tagen + +Wohnung zu verkaufen + +1260 Nyon • 5.5 Zimmer • 101 m² +----------------------------------------------------- + +Boiron District Located close to all the amenities of Nyon and its city center in a quiet environment, this crossing apartment has 4 bedrooms, 2 bathrooms, 1 toilet and a large living room with a spacious open-end Miele kitchen that gives access to the balcony - unobstructed view of the park and the mountains in the background. Completely renovated between 2015/16, including windows and radiators. Complete home automation system. A closed garage box outside and a cellar - To visitExact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1260-22-9 Boiron neighbourhood Located close to all the shops and schools of Nyon and its city center in a quiet environment, this apartment has 4 bedrooms, 2 bathrooms, 1 WC and a large living room with an open kitchen that gives access to the balcony - unobstructed view of the park and the mountains in the background. Fully renovated between 2015 and 2016, including windows and radiators. A garage outside and a cellar are available with the apartment.Exact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST: https://neho.ch/o/1260-22-9 + +CHF 11’089 / m² + +CHF 1’120’000 + +[1](https://www.immoyou.ch/wohnung-kaufen-schweiz)234567 + + 1 - 24 von 29’844 Ergebnisse + +### Wohnung kaufen in der Schweiz + +[Wohnung kaufen im Kanton Zürich](https://www.immoyou.ch/wohnung-kaufen-kanton-zurich)[Wohnung kaufen im Kanton Bern](https://www.immoyou.ch/wohnung-kaufen-kanton-bern)[Wohnung kaufen im Kanton Aargau](https://www.immoyou.ch/wohnung-kaufen-kanton-aargau)[Wohnung kaufen im Kanton St. Gallen](https://www.immoyou.ch/wohnung-kaufen-kanton-st-gallen)[Wohnung kaufen im Kanton Luzern](https://www.immoyou.ch/wohnung-kaufen-kanton-luzern)[Wohnung kaufen im Kanton Basel-Landschaft](https://www.immoyou.ch/wohnung-kaufen-kanton-basel-landschaft)[Wohnung kaufen im Kanton Thurgau](https://www.immoyou.ch/wohnung-kaufen-kanton-thurgau)[Wohnung kaufen im Kanton Solothurn](https://www.immoyou.ch/wohnung-kaufen-kanton-solothurn)[Wohnung kaufen im Kanton Graubünden](https://www.immoyou.ch/wohnung-kaufen-kanton-graubunden)[Wohnung kaufen im Kanton Basel-Stadt](https://www.immoyou.ch/wohnung-kaufen-kanton-basel-stadt)[Wohnung kaufen im Kanton Schwyz](https://www.immoyou.ch/wohnung-kaufen-kanton-schwyz)[Wohnung kaufen im Kanton Zug](https://www.immoyou.ch/wohnung-kaufen-kanton-zug) + +### Andere Immobilienarten in der Schweiz + +[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz)[Zimmer kaufen in der Schweiz](https://www.immoyou.ch/wg-zimmer-kaufen-schweiz)[Parkplatz kaufen in der Schweiz](https://www.immoyou.ch/parkplatz-kaufen-schweiz)[Büro & Gewerbe kaufen in der Schweiz](https://www.immoyou.ch/buro-gewerbe-kaufen-schweiz)[Wohnhaus kaufen in der Schweiz](https://www.immoyou.ch/wohnhaus-kaufen-schweiz)[Grundstück kaufen in der Schweiz](https://www.immoyou.ch/grundstuck-kaufen-schweiz) + + All rights reserved. v.541ff84 + + +=== https://www.immoyou.ch/haus-kaufen-schweiz === +🏠 20’071 Häuser kaufen in der Schweiz | ImmoYou + +=============== + +[ImmoYou](https://www.immoyou.ch/) + +Kaufen + +[Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + +Mieten + +[Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + + Ändern Sie die Suche + +[](https://www.immoyou.ch/)[Kaufen](https://www.immoyou.ch/kaufen-schweiz)[Häuser](https://www.immoyou.ch/haus-kaufen-schweiz)[Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + +Haus kaufen in der Schweiz +========================== + +Ort + + Schweiz + + Zürich + + Genf + + Typ + +- [x] Haus + +- [x] Wohnung + +- [x] Zimmer + +- [x] Parkplatz + +- [x] Büro & Gewerbe + +- [x] Wohnhaus + +- [x] Grundstück + + Verkaufspreis + + - + + Zimmer + + - + + Wohnfläche (m²) + + - + + Grundstücksfläche (m²) + + - + + Ausstattung & Eigenschaften + +- [x] Neubauprojekte + +- [x] Balkon + +- [x] Garten + +- [x] Parkplatz + +- [x] Lift + +- [x] Freie Aussicht + +- [x] Cheminée + +- [x] Garage + +- [x] Kinderfreundlich + +- [x] Rollstuhlgängig + +- [x] Möbliert + +Ordnen + + 20’071 Ergebnisse + + + + vor 2 Tagen + +Haus zu verkaufen + +1512 Chavannes-sur-Moudon • 7.5 Zimmer • 291 m² +------------------------------------------------------------------ + +Magnifique maison avec vue sur la campagne située à 5min de Moudon Environnement idéal pour cette villa qui offre un cadre de vie très agréable grâce à de généreux volumes distribués sur 3 étages, dont une vaste pièce à vivre avec cheminée, une grande cuisine ouverte moderne, 6 belles chambres, 3 salles d'eau, un wc visiteurs, un studio indépendant très pratique, un grand sous-sol aménagé avec Sauna qui offre diverses possibilités d'aménagements. L'espace extérieur offre une très belle terrasse ensoleillée avec brasero et un grand jardin avec piscine.Adresse exacte disponible sur demande .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1512-22-1 Superb house with view on the countryside located at 5min from Moudon Ideal environment for this villa which offers a very pleasant living environment thanks to generous volumes distributed on 3 floors, including a large living room with fireplace, a large modern open kitchen, 6 beautiful bedrooms, 3 bathrooms, a guest toilet, a very practical independent studio, a large basement with sauna which offers various development possibilities. The outside space offers a beautiful sunny terrace with brazier and a large garden with swimming pool.Exact address available on request .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/1512-22-1 + +CHF 5’668 / m² + +CHF 1’649’500 + + + + vor 2 Tagen + +Haus zu verkaufen + +8335 Hittnau • 3.5 Zimmer • 162 m² +----------------------------------------------------- + +Helles 3.5-Zimmer Einfamilienhaus mit erstklassiger Gartenanlage Dieses einzigartige Angebot überzeugt sowohl durch die qualitative Bausubstanz als auch durch die unmittelbare Nähe zu Schulen, öffentlichen Verkehrsmitteln und Einkaufsmöglichkeiten. Der offene Wohn-/Essbereich mit elegantem Cheminée, das helle Wohnambiente und die hochwertige Küche mit Frühstückbar versprechen ein hervorragendes Wohnerlebnis. Weitere Highlights sind das Hauptschlafzimmer mit En-Suite Bad sowie die atemberaubende Gartenanlage mit diversen Sitzplätzen, Bächlein und Teich.Genaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/8335-23-1 + +CHF 10’185 / m² + +CHF 1’650’000 + + vor 2 Tagen + +Haus zu verkaufen + +1000 Lausanne 27 • 5.5 Zimmer • 301 m² +--------------------------------------------------------- + +Magnificent building with adjoining barn to renovate Beautiful character house with a plot of more than 1'300m2 with trees offering a nice clearance on the lake. This property is ideally located in a peaceful environment while being close to all amenities (schools, shops and public transport). The housing part is currently spread over two levels and the barn-workshop part offers generous volumes. Great opportunity for transformation with a very good potential for interior space planning.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1000-22-1 + +CHF 4’153 / m² + +CHF 1’250’000 + + vor 2 Tagen + +Haus zu verkaufen + +1038 Bercher • 3.5 Zimmer • 110 m² +----------------------------------------------------- + +A haven of peace full of charm, village house near the Are you looking for a village house full of charm and ideally located? Look no further, this rare pearl is made for you Nestled in a quiet area and a PPE of two lots, it is perfectly maintained. Kitchen open to the dining room, large living room equipped with a wood stove, this village house offers all the comfort and authenticity you are looking for. Enjoy 2 bedrooms, a reduced, a bathroom and a guest toilet for your comfort. Close to the.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1038-22-2 + +CHF 5’909 / m² + +CHF 650’000 + + vor 2 Tagen + +Haus zu verkaufen + +1003 Lausanne • 8.5 Zimmer • 340 m² +------------------------------------------------------ + +Magnifique maison des années 30 entièrement rénovée à Lausanne Située en plein c?ur de Lausanne, cette splendide maison du début des années 30 offre un cachet remarquable et des prestations hors du commun. Les espaces sont spacieux et ouverts, créant une atmosphère chaleureuse et accueillante dès l'entrée. Les matériaux utilisés sont de qualité supérieure, avec des finitions soignées qui ajoutent une touche de standing à chaque détail. Cette maison entièrement rénovée au long de ces dix dernières années est idéale pour les familles, offrant des espaces de vie adaptés à toutes les générations. Les chambres sont spacieuses et confortables, tandis que les espaces de vie communs sont accueillants et conviviaux. L' aménagement paysager remarquable du jardin est une véritable ode à la nature, vous offrant une oasis de paix et de sérénité. Vous profiterez de moments de détente et de convivialité avec vos proches et vos amis dans cet espace extérieur exceptionnel. Enfin, ce bien d'exception vous permettra de profiter d'un espace fitness avec salle de bain et sauna, d'une cave à vin digne de ce nom et d'un garage souterrain de pas moins de 200m² . Si vous cherchez une maison de prestige à Lausanne, ne manquez pas cette opportunité rare. Contactez-nous dès maintenant pour organiser une visite et découvrir cette demeure exceptionnelle de vos propres yeux.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1012-23-3 Magnificent house of the 30s entirely renovated in Lausanne Located in the heart of Lausanne, this splendid house dating from the early 1930s offers a remarkable cachet and outstanding amenities. The spaces are spacious and open, creating a warm and welcoming atmosphere from the moment you enter. The materials used are of the highest quality, with meticulous finishing that adds a touch of luxury to every detail. This house has been completely renovated over the last ten years and is ideal for families, offering living spaces suitable for all generations. The bedrooms are spacious and comfortable, while the communal living areas are welcoming and friendly. The outstanding landscaping of the garden is a true ode to nature, offering you an oasis of peace and serenity. You will enjoy moments of relaxation and conviviality with your family and friends in this exceptional outdoor space. Finally, this exceptional property will allow you to enjoy a fitness area with bathroom and sauna, a wine cellar worthy of the name and an underground garage of no less than 200m². If you are looking for a prestigious house in Lausanne, do not miss this rare opportunity. Contact us now to arrange a visit and discover this exceptional home with your own eyes.Exact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/1012-23-3 + +CHF 15’294 / m² + +CHF 5’200’000 + + vor 2 Tagen + +Haus zu verkaufen + +1814 La Tour-de-Peilz • 6.5 Zimmer • 177 m² +-------------------------------------------------------------- + +Exclusive: Semi-detached villa with panoramic views of the lake & the Alps This villa consists of a 4.5-room triplex and an independent duplex, which can easily be combined into a single family home. Enjoy a breathtaking panoramic view of the lake and the Alps, all in a quiet and bright situation. With its magnificent west-facing terrace, this place is ideal for relaxing moments with the family. Do not miss the opportunity to live in this exceptional living environment. Contact us for a visitExact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1814-23-1 + +CHF 7’627 / m² + +CHF 1’350’000 + + vor 2 Tagen + +Haus zu verkaufen + +1344 L'Abbaye • 7.5 Zimmer • 220 m² +------------------------------------------------------ + +Coup de coeur pour cette magnifique demeure avec jardin bucolique Magnifique maison villageoise transformée et entièrement rénovée entre 1997 et 2019. Elle jouit d'une belle terrasse et d'un jardin bucolique entièrement clôturé en bordure de rivière. Elle est distribuée sur 3 étages et elle est excavée (cave voutée). Ce bien est en parfait état d'entretien général et ne nécessite d'aucuns travaux. Possibilité de créer une pièce habitable dans les combles. Une place de parc extérieure complète ce bien et diverses places de parc se trouvent à proximité.Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1344-21-1 + +CHF 4’773 / m² + +CHF 1’050’000 + + vor 2 Tagen + +Haus zu verkaufen + +1003 Lausanne • 18 Zimmer • 683 m² +----------------------------------------------------- + +Magnifique maison de Maître dans les beaux quartiers Lausannois Située dans un quartier résidentiel Lausannois, cette propriété de charme de 683m2 utiles, bordée par 1'359 m2 de jardin paysagé dispose d'un fort potentiel d'extension et bénéficie de nombreuses possibilités d'aménagement (logements/commercial, mixte). Idéal pour ceux qui exercent une profession libérale comme médecin, avocat, notaire, architecte... Construite en 1927 avec son architecture classique, elle se développe sur cinq niveaux. Actuellement, les deux premiers étages sont à usage commercial et les deux derniers offrent deux appartements. Entièrement excavé, le sous-sol de 203 m2 dispose lui aussi de nombreuses possibilités d'aménagement. Cette bâtisse offre une grande flexibilité d'utilisation, pouvant être réaménagée en une seule ou plusieurs habitations familiales. A voir absolumentAdresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1012-22-2 Magnificent house in the beautiful districts of Lausanne Located in a residential area of Lausanne, this charming property of 683m2, bordered by 1'359 m2 of landscaped garden has a strong potential for extension and have many development possibilities (residential/commercial, mixed). Ideal for a liberal profession such as doctor, lawyer, notary, architect... Built in 1927 with a classical architecture, this house is on five levels. Currently, the first two floors are used for commercial purposes and the last tow floors are 2 apartments. The basement of 203 m2 offers numerous possibilities for development. This building offers a great flexibility of use, being able to be reorganized into one or several family dwellings. A must seeExact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/1012-22-2 Wunderschöne Immobilie in den schönen Vierteln von Lausanne In einem Wohnviertel von Lausanne gelegen, verfügt diese charmante Immobilie mit 683m2 Nutzfläche, die von 1'359 m2 angelegtem Garten begrenzt wird, über ein hohes Ausbaupotenzial und profitiert von zahlreichen Gestaltungsmöglichkeiten (Wohnen/Gewerbe, gemischt). Ideal für Personen, die einen freien Beruf wie Arzt, Anwalt, Notar, Architekt usw. ausüben. Das 1927 erbaute Gebäude mit seiner klassischen Architektur erstreckt sich über fünf Stockwerke. Derzeit werden die ersten beiden Stockwerke gewerblich genutzt und die letzten beiden bieten zwei Wohnungen. Das vollständig ausgehobene Untergeschoss mit 203 m2 verfügt ebenfalls über zahlreiche Gestaltungsmöglichkeiten. Dieses Gebäude bietet eine hohe Nutzungsflexibilität und kann in eine einzige oder mehrere Familienwohnungen umgewandelt werden. Unbedingt ansehenGenaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/1012-22-2 + +CHF 9’854 / m² + +CHF 6’730’000 + + vor 2 Tagen + +Haus zu verkaufen + +1854 Leysin • 6 Zimmer • 190 m² +-------------------------------------------------- + +DIRECTIMMO OFFERS YOU AN INDIVIDUAL CHALET A superb chalet with stunning panoramic views of the Alps. This cottage is intended for the main residence. Quality finishes at the discretion of the lessee. This project is subject to obtaining the building permit. It is possible to modify the interior distribution according to your wishes. Distribution (editable): Lower ground floor: A garage and 3 outdoor parking spaces A cellar and a technical room (laundry possible) An entrance hall A studio of 35m2 with an independent entrance, a cellar and a reduced Upper ground floor: A clearance A bathroom An equipped kitchen open to a dining area and a living room (fireplace or stove possible) A large terrace of about 80m2 Floor: A clearance Three bedrooms One bathroom, shower A balcony of about 11m2 Technical: Underfloor heating with a heat pump Comfortable finishing budgets (CHF 25'000.- for the kitchen, CHF 18'000.- for the sanitary facilities, CHF 60.- per m2 for the tiles, CHF 80.- per m2 for the parquet floors...) Windows with triple glazingIf you need to sell a property for the purchase of your new property, we offer you more than 20 years of experience in the field of sales. During these years, we have developed an unprecedented presentation with our Virtual-Tours of properties, our strengthened presence on real estate portals as well as unbeatable brokerage fees make us an ideal partner. Information and visit to Mirko Gysin at 079 574 33 39 WWW.DIRECTIMMO.CH + +CHF 6’737 / m² + +CHF 1’280’000 + + vor 2 Tagen + +Haus zu verkaufen + +1800 Vevey • 5.5 Zimmer • 160 m² +--------------------------------------------------- + +Detached villa of 5.5 roomsOn a beautiful plot of more than 1500m²Hallway and viewTerraces and gardenOutdoor parking spacesMost sought-after neighborhoodQuiet and residentialClose to transport and the lake File on request + +- + +Auf Anfrage + + vor 2 Tagen + +Haus zu verkaufen + +1071 Chexbres • 270 m² +----------------------------------------- + +Video of the panoramic view on www.chiffelle-immobilier.ch (under multimedia files) Located in the most exclusive area of Chexbres, this exceptional plot offers a panoramic view of the entire Lake Geneva basin, it is sold with a building permit in force for a luxurious contemporary villa of about 270 m2 of living space (three levels), 7.5 rooms, sauna, and outdoor pool facing the lake with removable deck. Allow about two million for the construction of the villa, in addition to the sale price of the plot. Complete plans available upon request. Video der Panoramaaussicht auf www.chiffelle-immobilier.ch (unter Multimedia-Dateien) Dieses aussergewöhnliche Grundstück im erlesensten Quartier von Chexbres bietet eine Panoramasicht auf das gesamte Genferseebecken und wird mit a Baugenehmigung für eine luxuriöse, moderne Villa mit ca. 270 m2 Wohnfläche (drei Ebenen), 7,5 Zimmern, Sauna und Außenpool mit Seeblick und abnehmbarer Terrasse. Stellen Sie zusätzlich zum Verkaufspreis des Grundstücks etwa zwei Millionen für den Bau der Villa bereit. Vollständige Pläne auf Anfrage erhältlich. Video of the panoramic view on www.chiffelle-immobilier.ch (under multimedia files) Located in the most select district of Chexbres, this exceptional plot offers a panoramic view of the entire Lake Geneva basin, it is sold with a building permit in force for a luxurious contemporary villa of approximately 270 m2 of living space (three levels), 7.5 rooms, sauna, and outdoor swimming pool facing the lake with removable deck. Provide about two million for the construction of the villa, in addition to the sale price of the plot. Complete plans available on request. + +CHF 9’259 / m² + +CHF 2’500’000 + + vor 2 Tagen + +Haus zu verkaufen + +1297 Founex • 8 Zimmer • 180 m² +-------------------------------------------------- + +Located in the commune of Founex, this charming individual villa offers a living space of 180 sqm (250 sqm useful) and is composed of 8 rooms including 4 bedrooms. Built on a plot of more than 1'300 sqm, it offers a comfortable and bright living space and is distributed over two levels plus basement. Thanks to its privileged location, in the heart of an exclusive residential area, it meets all the criteria for a quiet family life in an idyllic setting. The private schools La Châtaigneraie (-5 minutes) and Le Collège du Léman (-10 minutes) are located nearby. Carefully maintained and renovated, it benefits from quality services and finishes, including solid wood flooring, recessed LED spotlights, plenty of storage space, mosaic tiles in the bathrooms, wooden shutters, double-glazed windows, and a fully equipped and furnished kitchen. The second floor is characterized by generous volumes thanks to a beautiful height under ceiling. Outside, a large wooden pergola protects the terrace. The living space is composed of an entrance hall, a kitchen with a central island of 12 sqm, a living/dining room with a fireplace of about 45 sqm and a living room/office of about 15 sqm, all opening onto the terrace. The second floor is dedicated to the night area, with a master bedroom of 21 sqm with its own shower room, 3 other bedrooms and a shower room with double sink. The basement, entirely excavated, offers two large multipurpose rooms of respectively 23 and 28 sqm, a laundry room, the technical rooms and a fallout shelter. The villa is distributed as follows : First floor :- Entrance hall with storage space- Kitchen with central island- Living/dining room with access to the terrace and the garden- Multipurpose room (living room, office, etc.) First floor :- Master bedroom of 20 m2 with its adjoining shower room with WC- Three bedrooms of about 15 sqm- Shower room with WC Basement :- Multipurpose room of 23 sqm- Multipurpose room of about 28 sqm- Laundry room and fallout shelter- Technical rooms Outside :- Large terrace covered by a pergola- Garden with trees and fenced- Garden shed- Box for two cars- Outdoor parking spaces The exterior spaces consist of a large fenced garden with trees, a large terrace with pergola and a garden shed. The access to the property is secured by a gate. A double garage and several outdoor parking spaces located at the entrance complete this property. Its location close to all amenities and road axes gives it a quick access to Nyon (-15 minutes), to the center of Geneva and to the international airport of Geneva (- 20 minutes). + +CHF 16’389 / m² + +CHF 2’950’000 + + vor 2 Tagen + +Haus zu verkaufen + +1145 Bière • 4.5 Zimmer • 110 m² +--------------------------------------------------- + +Detached house built in 1964 on a beautiful plot of more than 1'000m2 ideally located in Bière. This house is habitable in the state but requires renovation to be updated to the tastes of the day. The plot has an interesting potential for expansion. To visit without delay Contact us directly at 079 276 89 94 or by email at l.bolay@atix-immobilier.ch for any further information or to arrange a visit on site. + +CHF 8’455 / m² + +CHF 930’000 + + vor 2 Tagen + +Haus zu verkaufen + +1342 Le Pont • 4.5 Zimmer • 180 m² +----------------------------------------------------- + +Who has never dreamed of a house close to the lake and nature? This property is for you. You will just have to push the doors of this property to immediately fall under the spell. This house consisting of 2 dwellings will offer you great flexibility. Located between the lake and nature you will reside in a quiet residential area. A real idyll You will have understood this property will not remain available for long. So do not hesitate and contact us. Our real estate agents will be happy to open the doors of this little paradise. + +CHF 10’000 / m² + +CHF 1’800’000 + + vor 2 Tagen + +Haus zu verkaufen + +1815 Clarens • 10 Zimmer • 400 m² +---------------------------------------------------- + +DIRECTIMMO VOUS PROPOSE UNE SOMPTUEUSE VILLA DUBOCHET DE 10 PIECES PROCHE DU LAC Les Villas Dubochet situées à Clarens dans le canton de Vaud en Suisse forment un exceptionnel ensemble de demeures résidentielles (1874-1879), destinées à la villégiature d'hôtes fortunés souhaitant éviter la promiscuité des hôtels. Il y en a très exactement 21. Situées à Clarens, elles sont toutes différentes. Nous vous proposons l'une d'entre elles à la vente. L'entier de son charme et de son raffinement ont été conservés lors de sa complète rénovation en 2011. Pour ce faire, des matériaux de grande qualité et des normes historique de rénovation ont été respectées. Sa proximité avec le lac (200m), son grand jardin arborisé, ses terrasses qui pour certaine vous offre une superbe vue sur le lac et les Alpes, ses grands volumes intérieurs sont autant d'arguments qui vous donnerons le sentiment de privilège et d'authenticité. Cette Villa de 9 pièces est construite sur une parcelle de 1'662m2. Sur 4 niveaux, elle dispose d'une surface habitable d'environ 400m2 et de 1'546m2 de jardin. Elle est distribuée comme suit :Rez inférieur (également accessible par une entrée indépendante) : Une chambre Une salle de bain/WC Une bibliothèque Une cave à vin Une buanderie Rez-de-chaussée : Grande pièce de réception s'ouvrant sur une terrasse Une cuisine entièrement agencée Un WC visiteur 1erétage : Trois belles chambres dont deux avec terrasse Deux salles de bain/WC dont une privative 2èmeétage : Une somptueuse chambre parentale avec terrasse et vue sur le lac Une salle de bain privative Un grand dressing Autres informations : Construite en 1874 Complètement rénovée en 2011 La surface de la parcelle de 1'662m2 La surface habitable est de 400m2 Le volume est d'environ 1'835m3m3 5 places de parc extérieures Chauffage au gaz Distribution du chauffage par radiateurs Commodités : Commodité à 500 mètres Bus à 50 mètres Lac & port de Clarens à 200 mètres Accès autoroute à 2.5km Montreux centre à 5 minutes Lausanne à 20 minutes Genève Aéroport à 1h15 Présentation des alentours et de la région : Clarens-Montreux ou Clarens est une localité de la commune de Montreux en Suisse située sur la Riviera vaudoise, au bord du lac Léman et sur les contreforts des Préalpes fribourgeoises. Avec la salle omnisports du Pierrier sur son sol, Clarens accueille des compétitions d'importance nationale et internationale à l'image des Montreux Volley Masters, de la coupe de nations de Rink hockey ou encore des finales de la coupe de la ligue de basket. Clarens, c'est aussi le lac et les sports d'eau. Les amateurs de baignade trouveront leur bonheur au bord du lac à la plage du Pierrier ou aux bains de Clarens. Pour ceux qui préfèrent la piscine, la Maladaire les accueille été comme hivers ; deux bassins extérieurs et deux bassins intérieurs sont à disposition. Si vous devez vendre un bien pour l'achat de votre nouvelle propriété, nous vous proposons plus de 20 ans d'expérience dans le domaine de la vente. Durant ces années, nous avons développé une présentation inédite avec nos Virtual-Tours des biens, notre présence renforcée sur les portails immobiliers ainsi que des frais de courtages défiant toute concurrence font de nous un partenaire idéal. Renseignements et visite auprès de Thierry Lenoir au 079 476 08 11.WWW.DIRECTIMMO.CH + +CHF 17’250 / m² + +CHF 6’900’000 + + vor 2 Tagen + +Haus zu verkaufen + +1000 Lausanne 26 • 10 Zimmer • 270 m² +-------------------------------------------------------- + +BARNES Lausanne a la plaisir de vous présenter cette charmante maison de caractère située sur les hauteurs de Lausanne. Au coeur d'un quartier calme et dans un environnement verdoyant, la propriété se trouve à seulement quelques pas des transports en commun vous permettant d'accéder au centre de Lausanne. Les axes autoroutiers se trouvent à 3 minutes en voiture. Implantée sur une parcelle de plus de 1'600 m², cette bâtisse de ce début du XXe siècle a été entièrement rénovée entre 2004 et 2008 et a de plus été agrandie avec la construction de deux grandes extensions au Nord et à l'Ouest et a su allié le confort à l'authenticité. Distribuée de manière harmonieuse et lumineuse, elle se compose notamment de 6 chambres, de 4 salles d'eau, d'un WC séparé, d'un spacieux séjour donnant accès aux extérieurs, d'une salle à manger et d'une cuisine équipée donnant également accès à la terrasse et au jardin, le tout reparti sur une surface d'environ 270 m² utiles. Grâce à ces nombreuses ouvertures donnant sur la forêt et son vaste jardin arboré et clos, la maison vous promet un cadre de vie agréable et apaisant. A noter qu'il est possible d'y construire une piscine. Pour compléter ce bien, une cave, un garage double et 6 places de parc extérieures sont à disposition. + +CHF 8’852 / m² + +CHF 2’390’000 + + vor 2 Tagen + +Haus zu verkaufen + +6832 Pedrinate • 7 Zimmer • 260 m² +----------------------------------------------------- + +A Pedrinate, vendiamo questa casa unifamiliare di dimensioni molto generose. È ideale per famiglie numerose e offre anche la possibilità di suddividere l'abitazione in eventuali due appartamenti. Al piano terra troviamo un ampio atrio e le cantine con un locale hobby. Salendo le scale al piano rialzato si trova la cucina abitabile, la sala da pranzo, il soggiorno, un sevizio e una camera da letto. Al primo piano troviamo quattro camere di cui la camera padronale con il bagno in camera e un altro servizio completo. Questa offerta di BETTERHOMES è messa in risalto per i seguenti vantaggi: - struttura massiccia- portico - locali ampi- 2 posti auto in garage- 3/4 posti auto esterni- locale hobby- giardino con porticato- ecc., ecc., ecc. Interessati? Contattateci per una visita senza impegno Non estato trovato nessun oggetto corrispondente? Piu di 2'200 offerte su: www.betterhomes.ch Lo specialista svizzero per le intermediazioni immobiliari Avete un immobile da vendere? Approfittate del nostro know-how: https://www.betterhomes.ch/it/profittare Vorreste sapere quanto vale il vostro immobile? Scoprite subito il suo valore con la nostra stima gratuita, immediatamente e senza impegno https://www.betterhomes.ch/it/knowledge/estimation Oltre dati Posizione: buona Condizione dell'oggetto: buone Bagni / Docce: 3 (1 x bagno / lavabo / bidet / WC, 2 x lavabo / doccia / WC / bidet) Riscaldamento: gasolio Trasporti pubblici: bus, 50 m / FFS, 2,5 km Scuole: asilo / elementari / superiori, 4 km Negozi: Migros / Denner / Coop, 2,5 km + +CHF 5’769 / m² + +CHF 1’500’000 + + vor 2 Tagen + +Haus zu verkaufen + +1272 Genolier • 6.5 Zimmer • 200 m² +------------------------------------------------------ + +Splendid property in Sus-Châtel on 3 levels. Very nice property, quietly located in the popular villa district of Sus-Châtel. Bright, quality materials, perfectly maintained and enjoying beautiful outdoor spaces. 5 bedrooms including a master suite, 3 full bathrooms (3 showers, a bath, double sinks), a balcony an excavated basement with many usable spaces. Pergola in the extension of the terrace. 2 levels of garden on a swimming pool. Double garage and 2 main parking spaces. Ideally connected to the amenities of La Côte, the town of Genolier is located 10 minutes from the motorway access of Nyon or Gland. It is served at high frequency by the NStCM railway line. It enjoys an active local life thanks to its shops, restaurants, schools and sports clubs. A unique property to visit now.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1272-22-1 + +CHF 12’750 / m² + +CHF 2’550’000 + + vor 2 Tagen + +Haus zu verkaufen + +1762 Givisiez • 5.5 Zimmer • 163 m² +------------------------------------------------------ + +Exclusive: Semi-detached triplex villa with heated pool Pretty semi-detached villa, ideally located in a residential area and offering a beautiful open view, without vis-à-vis. Built on three levels, it benefits from generous surfaces as well as a large south-facing terrace, with a pretty heated 4x8m swimming pool (heat pump). Quiet location, close to all amenities. Conditions for the repossession of the existing mortgage loan at an attractive rate (1.21% over the remaining 7 years). A garage-box and 2 parking spaces included.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1762-23-1 + +CHF 5’890 / m² + +CHF 960’000 + + vor 2 Tagen + +Haus zu verkaufen + +5072 Oeschgen • 4.5 Zimmer • 115 m² +------------------------------------------------------ + +Charmantes 4.5-Zimmer Doppeleinfamilienhaus an zentraler Lage Das Bauernhaus an zentraler Lage eignet sich ideal für Paare oder eine kleine Familie. Die Highlights sind der geräumige Wohn-Essbereich mit Kachelofen sowie die Küche mit Tiba Herd. Das Obergeschoss verfügt über 3 Schlafzimmer und das Badezimmer mit Badewanne und Dusche. Weiteres Ausbaupotential bietet das geräumige Dachgeschoss, das aktuell mit einer Sauna ausgestattet ist. Der pflegeleichte Gartensitzplatz rundet das Angebot optimal ab. Wir freuen uns au Ihre AnfrageGenaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/5072-23-1 + +CHF 5’478 / m² + +CHF 630’000 + + vor 2 Tagen + +Haus zu verkaufen + +3963 Crans-Montana • 3.5 Zimmer • 87 m² +---------------------------------------------------------- + +Succumb to the charm of this sumptuous triplex with views in Montana Village Located in a peaceful area and nestled in a charming house of 2 units with character, you will enjoy a sunny balcony for moments of relaxation. Heated by a heat pump for maximum energy efficiency, this wellness setting offers 2 bedrooms, 1 shower room, 1 separate toilet, 1 bright living room with open kitchen, a laundry room and a covered parking space. And why not consider acquiring the entire house?Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/3963-23-4 + +CHF 7’989 / m² + +CHF 695’000 + + vor 2 Tagen + +Haus zu verkaufen + +1712 Tafers • 7.5 Zimmer • 329 m² +---------------------------------------------------- + +Wunderschöne Luxusvilla mit großer Terrasse und Außenpool Ideal gelegen in einer sehr ruhigen Gegend, genießt diese herrliche Luxusvilla eine schöne Aussicht. Der große Garten mit überdachter Terrasse und Außenpool, die Helligkeit des Hauses und seine großen Flächen, die zahlreichen Schlafzimmer, die offene Küche mit Kochinsel, das Soundsystem oder der ausgezeichnete Pflegezustand sind alles Argumente, die Sie begeistern werden. Die untere Etage lässt sich außerdem problemlos in ein Studio umwandeln.Genaue Address verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/1712-22-1 Splendid luxury villa with large terrace and outdoor pool Ideally located in a very quiet area, this splendid luxury villa enjoys a beautiful view. The large garden with covered terrace and outdoor pool, the brightness of the house and its large surfaces, the many bedrooms, the open kitchen with cooking island, the sound system or the excellent state of maintenance are all arguments that will seduce you. The lower floor is also easily convertible into a studio.Exact address available after registration on neho.ch .WOULD YOU LIKE TO VISIT? PLEASE REGISTER FIRST: https://neho.ch/o/1712-22-1 Splendid luxury villa with large terrace and outdoor pool Ideally located in a very quiet area, this splendid luxury villa enjoys a beautiful view. The large garden with covered terrace and outdoor swimming pool, the brightness of the house and its large surfaces, the numerous bedrooms, the open kitchen with cooking island, the sound system or the excellent state of maintenance are all arguments that will seduce you. The lower floor can also be easily converted into a studio.Exact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST: https://neho.ch/o/1712-22-1 + +- + +Auf Anfrage + + vor 2 Tagen + +Haus zu verkaufen + +1008 Jouxtens-Mézery • 7.5 Zimmer • 242 m² +------------------------------------------------------------- + +Spacieuse villa mitoyenne avec logement indépendant Idéalement située et dotée de nombreux atouts pour vous offrir un cadre de vie exceptionnel Cette spacieuse villa bénéficie d'un logement indépendant supplémentaire, parfait pour recevoir vos invités ou pour générer des revenus locatifs supplémentaires. Vous pourrez également profiter d'un jardin verdoyant, idéal pour des moments de détente en famille ou entre amis. Proche de toutes les commodités nécessaires au quotidien : commerces, écoles, transports en commun... tout est à portée de main Adresse exacte disponible après inscription sur neho.ch .VOUS SOUHAITEZ VISITER ? MERCI DE BIEN VOULOIR VOUS INSCRIRE D'ABORD : https://neho.ch/o/1008-22-4 Spacious semi-detached villa with separate accommodation Ideally located and with many assets to offer you an exceptional living environment This spacious villa benefits from an additional independent dwelling, perfect for entertaining your guests or for generating additional rental income. You will also be able to enjoy a green garden, ideal for relaxing with family or friends. Close to all the amenities needed for daily life: shops, schools, public transport... everything is within easy reachExact address available upon registration on neho.ch .INTERESTED IN VISITING THE PROPERTY? PLEASE REGISTER FIRST : https://neho.ch/o/1008-22-4 + +CHF 8’471 / m² + +CHF 2’050’000 + + vor 2 Tagen + +Haus zu verkaufen + +3232 Ins • 4.5 Zimmer • 124 m² +------------------------------------------------- + +Gepflegtes 4½ Zimmer Reihenmittelhaus in ländlicher Umgebung Ansprechendes Reihenmittelhaus, welches für Sie und Ihre Familie zu einem heimeligen und gemütlichen Zuhause werden kann. Es bietet einen spannenden und grosszügigen Grundriss an. Die lichtdurchfluteten Wohnbereiche mit Dachschrägen verleihen dem Haus ein luftiges Ambiente. Die schöne und gedeckte Pergola lädt dazu ein, unzähligen Sonnenstunden zu geniessen. Die ländliche Umgebung sowie die zentrale Lage, machen das Wohnen hier für Familien noch attraktiver.Genaue Adresse verfügbar nach Registrierung auf neho.ch .AN EINER BESICHTIGUNG INTERESSIERT? BITTE ANMELDEN: https://neho.ch/o/3232-23-1 + +CHF 5’403 / m² + +CHF 670’000 + +[1](https://www.immoyou.ch/haus-kaufen-schweiz)234567 + + 1 - 24 von 20’071 Ergebnisse + +### Haus kaufen in der Schweiz + +[Haus kaufen im Kanton Zürich](https://www.immoyou.ch/haus-kaufen-kanton-zurich)[Haus kaufen im Kanton Bern](https://www.immoyou.ch/haus-kaufen-kanton-bern)[Haus kaufen im Kanton Aargau](https://www.immoyou.ch/haus-kaufen-kanton-aargau)[Haus kaufen im Kanton St. Gallen](https://www.immoyou.ch/haus-kaufen-kanton-st-gallen)[Haus kaufen im Kanton Luzern](https://www.immoyou.ch/haus-kaufen-kanton-luzern)[Haus kaufen im Kanton Basel-Landschaft](https://www.immoyou.ch/haus-kaufen-kanton-basel-landschaft)[Haus kaufen im Kanton Thurgau](https://www.immoyou.ch/haus-kaufen-kanton-thurgau)[Haus kaufen im Kanton Solothurn](https://www.immoyou.ch/haus-kaufen-kanton-solothurn)[Haus kaufen im Kanton Graubünden](https://www.immoyou.ch/haus-kaufen-kanton-graubunden)[Haus kaufen im Kanton Basel-Stadt](https://www.immoyou.ch/haus-kaufen-kanton-basel-stadt)[Haus kaufen im Kanton Schwyz](https://www.immoyou.ch/haus-kaufen-kanton-schwyz)[Haus kaufen im Kanton Zug](https://www.immoyou.ch/haus-kaufen-kanton-zug) + +### Andere Immobilienarten in der Schweiz + +[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Zimmer kaufen in der Schweiz](https://www.immoyou.ch/wg-zimmer-kaufen-schweiz)[Parkplatz kaufen in der Schweiz](https://www.immoyou.ch/parkplatz-kaufen-schweiz)[Büro & Gewerbe kaufen in der Schweiz](https://www.immoyou.ch/buro-gewerbe-kaufen-schweiz)[Wohnhaus kaufen in der Schweiz](https://www.immoyou.ch/wohnhaus-kaufen-schweiz)[Grundstück kaufen in der Schweiz](https://www.immoyou.ch/grundstuck-kaufen-schweiz) + + All rights reserved. v.541ff84 + + +=== https://www.immoyou.ch/mieten-schweiz === +🏠 114’440 Immobilien mieten in der Schweiz | ImmoYou + +=============== + +[ImmoYou](https://www.immoyou.ch/) + +Kaufen + +[Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + +Mieten + +[Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + + Ändern Sie die Suche + +[](https://www.immoyou.ch/)[Mieten](https://www.immoyou.ch/mieten-schweiz)[Schweiz](https://www.immoyou.ch/mieten-schweiz) + +Immobilien mieten in der Schweiz +================================ + +Ort + + Schweiz + + Zürich + + Genf + + Typ + +- [x] Haus + +- [x] Wohnung + +- [x] Zimmer + +- [x] Parkplatz + +- [x] Büro & Gewerbe + +- [x] Wohnhaus + +- [x] Grundstück + + Miete + + - + + Zimmer + + - + + Wohnfläche (m²) + + - + + Grundstücksfläche (m²) + + - + + Ausstattung & Eigenschaften + +- [x] Neubauprojekte + +- [x] Balkon + +- [x] Garten + +- [x] Parkplatz + +- [x] Lift + +- [x] Freie Aussicht + +- [x] Cheminée + +- [x] Garage + +- [x] Kinderfreundlich + +- [x] Rollstuhlgängig + +- [x] Möbliert + +Ordnen + + 114’440 Ergebnisse + + + + vor 2 Wochen + +Wohnung zu vermieten + +4052 Basel • 3 Zimmer • 64 m² +--------------------------------------------------- + +Emplacement Votre nouvelle maison dans le quartier populaire de Breite n'est qu'à deux pas du centre-ville et de la gare CFF. Divers commerces et centres de remise en forme sont accessibles en quelques minutes à pied. La bonne connexion des transports en commun, à travers la ligne de tramway 3 et la ligne de bus 36, vous emmène confortablement à votre destination, même les jours de pluie. Sur les rives voisines du Rhin, vous pouvez échapper au stress de la vie quotidienne en vous promenant tranquillement et en reconstituant vos réserves de vitamine D. Une visite de votre appartement Le plan d'étage généreux vous permet de laisser libre cours à votre imagination lors de l'ameublement. Le parquet dans tous les espaces de vie donne aux chambres leur caractère de bien-être. Les grandes fenêtres offrent un cadre de vie lumineux et confortable. En outre, l'appartement impressionne avec les points suivants: Cuisine lumineuse avec lave-vaisselle et plaque vitrocéramique Salle de bain avec baignoire et armoire miroir Salon spacieux Ascenseur disponible Détails Une place de parking extérieure peut être louée sur demande pour 80.- CHF par mois.Call.View.Rent. Aimeriez-vous vivre plus près de la ville? Ensuite, nous sommes impatients d'avoir de vos nouvelles. Laura Weick 058 280 22 02 laura.weick@helvetia.ch Les photos publiées sont des appartements du même type / type. Des écarts par rapport à l'offre réelle sont donc possibles. En tant que locataire d'Helvetia, vous bénéficiez d'une réduction de 50% sur votre première prime annuelle pour certains produits d'assurance Helvetia D'autres propriétés locatives intéressantes peuvent être trouvées à: www.helvetia.ch/immobilien + +CHF 263 / m² / Jahr + +CHF 1’400 + + Keine Bilder + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +5033 Buchs AG +------------------------------------------ + +- + +Auf Anfrage + + vor 2 Wochen + +Wohnung zu vermieten + +2540 Grenchen • 2.5 Zimmer • 56 m² +-------------------------------------------------------- + +CHF 270 / m² / Jahr + +CHF 1’260 + + vor 2 Wochen + +Parkplatz zu vermieten + +2504 Biel/Bienne +---------------------------------------- + +CHF 50 / m² / Jahr + +CHF 25 + + vor 2 Wochen + +Wohnung zu vermieten + +3612 Steffisburg • 3.5 Zimmer • 83 m² +----------------------------------------------------------- + +Emplacement Le développement Erlenmatte est un quartier adapté aux enfants dans un cadre idyllique et bien entretenu. En plus de nombreuses aires de jeux, les locataires amateurs de football ont leur propre terrain de football privé en bordure du développement à leur disposition. Tout pour vos besoins quotidiens peut être fait dans la Coop ou dans le Landi dans le village. L'arrêt de bus est à seulement 2 minutes, en bus, vous pouvez rejoindre la ville de Thoune en environ 10 minutes. En plus de l'Aar populaire et du lido de Thoune, vous trouverez de nombreux commerces et restaurants. Depuis la gare de Thoune, la ville de Berne est accessible en train en 40 minutes environ. Le jardin d'enfants est à 12 minutes, l'école primaire à 8 minutes et le lycée à 15 minutes à pied.Visite de votre appartement Le point culminant de l'appartement est clairement le balcon, qui devient un espace de vie supplémentaire dans les mois chauds. La cuisine indépendante et pratique dispose d'une fenêtre et d'un accès au balcon. Le coin salon-repas est doté de parquet en chêne. La salle de bain est pourvue d'une baignoire. Les toilettes sont séparées. Cuisine séparée Vitrocéramique, lave-vaisselle Combinaison réfrigérateur avec sep. Congélateur Salon 2 chambres Salle de bain avec baignoire WC séparé Armoires Balcon Compartiment cave Ascenseur disponible Détails Un garage peut également être loué. + +CHF 227 / m² / Jahr + +CHF 1’570 + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +5502 Hunzenschwil +---------------------------------------------- + +CHF 241 / m² / Jahr + +CHF 2’210 + + Keine Bilder + + vor 2 Wochen + +Haus zu vermieten + +8311 Brütten • 4.5 Zimmer • 130 m² +----------------------------------------------------- + +Nous louons cette grande maison jumelée dans la belle campagne de Brütten. La maison s'étend sur trois étages avec des chambres grandes et lumineuses et est située dans un endroit calme mais central. Idéal pour les amoureux de la nature qui aiment profiter du soleil pendant la journée et terminer la soirée dans le magnifique jardin. La maison offre, entre autres, beaucoup d'espace, d'espace de rangement, une grande cuisine, deux salles de bain et bien plus encore. Cette offre BETTERHOMES se caractérise par les avantages suivants :- Ancienne bâtisse de charme avec grand poêle en faïence dans le salon - grande cuisine avec beaucoup d'espace de rangement - récemment rénové en 2022- grand jardin bien entretenu- belle vue sur le loin, le jardin et la nature- Machine à laver disponible dans la maison - Famille et animaux acceptés- Place de parking dans la box garage et places de parking extérieures incluses dans le prix de location- et, et, et... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Situation: centrale et proche de la nature, à la campagne Condition: bien, récemment rénové (2022) Salles de bains / salles d'eau: 2 (1 x douche / WC / lavabo, 1 x baignoire / WC / lavabo) Système de chauffage: Chauffage par le sol Transports publics suivants: Bus, 400m Ecoles: école maternelle / primaire, 900m Commerces: Volg, 900m + +CHF 277 / m² / Jahr + +CHF 3’000 + + vor 2 Wochen + +Restaurant zu vermieten + +8630 Rüti ZH • 3 Zimmer +------------------------------------------------ + +Dans un emplacement central au milieu de Rüti ZH, un nouvel opérateur est recherché pour ce bar avec un espace extérieur généreusement couvert. Le restaurant bien équipé dispose également d'un bar, de plusieurs coins salons et d'un fumoir. Il y a aussi une bonne ventilation et une pièce séparée avec permission pour une petite cuisine. Un permis de plats à emporter est également disponible. Juste à côté de la localité, il y a aussi un parking souterrain, qui offre à vos invités de nombreuses possibilités de stationnement. Là, vous avez accès pendant 24 heures. Cette offre BETTERHOMES se caractérise par les avantages suivants :- Inventaire CHF 70'000.-- fumoir généreux avec une bonne ventilation- Permis de plats à emporter disponible-Espace de stockage-Sanitaires- beaucoup de places de parking à proximité immédiate- et, et, et ... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Emplacement: central Condition: bon Salles de bains / salles de bains: 3 (3 x WC / lavabo) Système de chauffage: chauffage central Transports publics les plus proches: Bus, 100 m Ecoles: école primaire, 580 m / école secondaire, 500 m Commerces : commerces divers, à proximité immédiate + +- + +CHF 4’380 + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +5436 Würenlos • 1 Zimmer +----------------------------------------------------- + +- + +Auf Anfrage + + Keine Bilder + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +6020 Emmenbrücke +--------------------------------------------- + +CHF 199 / m² / Jahr + +CHF 1’660 + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +4414 Füllinsdorf • 3 Zimmer +-------------------------------------------------------- + +Nous louons cette salle de stockage spacieuse et bien équipée dans un emplacement central du centre Schönthal à Füllinsdorf. La propriété se caractérise par ses locaux spacieux et facilement utilisables. La propriété dispose également de 2 chambres froides (environ 8 - 10 m²) et d'une salle d'eau avec 2 toilettes et un lavabo. Un monte-charge d'une capacité allant jusqu'à 2000 kg complète l'offre. Cette offre BETTERHOMES se caractérise par les avantages suivants :- spacieux et facile à utiliser-centré- 3 chambres- 2 chambres froides supplémentaires (environ 8 -10 m²)- 2 WC avec lavabo- Monte-charge (jusqu'à 2000 kg)- et, et, et ... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Lieu: dans le Schönthal-Zentrum à Füllinsdorf Condition: bon Salles de bain / salles de bains: 1 (lavabo / 2 x WC) Transports publics les plus proches : bus n° 75/80, 15 m / gare de Frenkendorf-Füllinsdorf, 550 m Ecoles: Schulhaus Schönthal, 600 m / Sekundarschule Frenkendorf, 800 m Commerces: Supermarché Migros, 50 m / Denner Discount, 95 m + +CHF 65 / m² / Jahr + +CHF 2’650 + + vor 2 Wochen + +Wohnung zu vermieten + +4414 Füllinsdorf • 3.5 Zimmer • 70 m² +----------------------------------------------------------- + +CHF 271 / m² / Jahr + +CHF 1’580 + + vor 2 Wochen + +Wohnung zu vermieten + +6020 Emmenbrücke • 7.5 Zimmer • 168 m² +------------------------------------------------------------ + +CHF 183 / m² / Jahr + +CHF 2’560 + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +6423 Seewen SZ • 1 Zimmer +------------------------------------------------------ + +CHF 126 / m² / Jahr + +CHF 735 + + vor 2 Wochen + +Restaurant zu vermieten + +8604 Volketswil • 3 Zimmer +--------------------------------------------------- + +Ce restaurant est situé dans un emplacement privilégié à Volketswil, sur une route très fréquentée. Une belle boutique avec une terrasse accueillante, plus la salle à manger. Comme un bel ajout, qui peut être utilisé comme un plat à emporter ou un courrier de pizza. Les toilettes invités sont situées au rez-de-chaussée, ainsi que la cuisine, qui est très bien équipée, four à pizza double, deux entrepôts de congélation, grande cuisinière à gaz, etc. En outre, il y a deux salles de stockage. Cette offre BETTERHOMES se caractérise par les avantages suivants :- entièrement équipé- Restaurant 50 couverts- Terrasse jusqu'à 20 places- Système de point de vente- Ventilation / air d'alimentation et air évacué- Transfert d'inventaire CHF 125000.-- et, et, et... Intéressé? Contactez-nous pour une visite sans engagement également possible de visualisation en ligne Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Emplacement: bon Condition: bon Salles de bain / salles d'eau: 2 (2 x lavabo / WC) Transports publics suivants: train, 500m Ecoles: Ecole primaire, 500m Commerces: Volkiland 200m + +CHF 216 / m² / Jahr + +CHF 4’500 + + Keine Bilder + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +4900 Langenthal • 1 Zimmer +------------------------------------------------------- + +CHF 259 / m² / Jahr + +CHF 625 + + vor 2 Wochen + +Wohnung zu vermieten + +3286 Muntelier • 2.5 Zimmer • 80 m² +--------------------------------------------------------- + +Vous cherchez une maison confortable dans un quartier calme avec vue sur le lac de Morat? L'appartement mansardé offre un salon spacieux et lumineux avec une cuisine ouverte et une grande chambre. Vous avez également accès à la grande terrasse, où vous pourrez vous détendre avec vos amis et votre famille en été après avoir nagé dans le lac. Cette offre BETTERHOMES se caractérise par les avantages suivants :- chambres inondées de lumière- Vue sur le magnifique lac de Morat- grande salle de bain avec baignoire- Screed avec beaucoup d'espace de rangement- cuisine ouverte entièrement équipée- Une place de parking peut être louée pour CHF 50.-- et, et, et ... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Situation: dans un quartier très calme, avec vue sur le lac de Morat Condition: bon Salles de bain / salles d'eau: 1 (1 x douche / baignoire / double vasque / WC) Système de chauffage: Chauffage au mazout Transports en commun : gare de Muntelier, env. 400 m Ecoles: Ecole primaire à Morat, 1,5 km Commerces: magasin de village, env. 500 m / magasins divers à Morat, env. 1,5 km + +CHF 245 / m² / Jahr + +CHF 1’630 + + vor 2 Wochen + +Wohnung zu vermieten + +8592 Uttwil • 4.5 Zimmer • 136 m² +------------------------------------------------------- + +Vous cherchez un appartement qui ne laisse rien à désirer? Alors votre recherche est terminée. Ce bel appartement en duplex offre tout ce dont vous avez toujours rêvé et bien plus encore. Vous y trouverez de très grandes chambres lumineuses, 2 salles de bains luxueuses qui vous invitent à la détente, une cuisine moderne équipée des derniers appareils Siemens, un balcon, une grande terrasse avec son propre poêle et un chauffage au sol luxueux dans toutes les chambres. Cette offre BETTERHOMES se caractérise par les avantages suivants :- chauffage au sol luxueux dans toutes les chambres- grand balcon- grande terrasse avec son propre poêle, avec vue magnifique sur le lac- grandes pièces inondées de lumière- cuisine moderne, équipée des meilleurs appareils- 2 salles de bains luxueuses- et, et, et ... Intéressé? Contactez-nous pour une visite sans engagement également possible de visualisation en ligne Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Situation: bel emplacement avec vue sur le lac Condition: très bon Salles de bain / Salles de bain: 2 (1 x baignoire / double vasque / WC, 1 x WC / lavabo / douche) Système de chauffage: chauffage au mazout / chauffage au sol Transports publics les plus proches: Uttwil train station, 750 m Ecoles: Ecole primaire Schulhaus Gries, 650 m Commerces: Volg Uttwil, 550 m / Centre commercial Hubzelg, 3.3 km + +CHF 203 / m² / Jahr + +CHF 2’300 + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +4900 Langenthal • 1 Zimmer +------------------------------------------------------- + +CHF 253 / m² / Jahr + +CHF 2’130 + + vor 2 Wochen + +Wohnung zu vermieten + +9470 Werdenberg • 4.5 Zimmer • 88 m² +---------------------------------------------------------- + +Cet appartement récemment rénové impressionne par ses chambres inondées de lumière et sa cuisine ouverte. Grâce au vitrage 3 plis, l'appartement est très calme. Beaucoup de bois et de parquet créent une ambiance chaleureuse. Sur le balcon ou dans le jardin avec la vue magnifique sur le château, vous pourrez profiter des heures de soleil. Tous les centres commerciaux et l'école sont accessibles à pied, et le bus est presque à côté. Cette offre BETTERHOMES se caractérise par les avantages suivants :- récemment rénové- cuisine ouverte-Parquet-Lave-vaisselle-centré- balcon privé et jardin à usage commun-Cave- et, et, et ... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Emplacement: central Condition: très bon Salles de bain / Salles de bain: 1 (1 x douche / lavabo / WC / bidet) Système de chauffage : pompe à chaleur air-eau Transports publics les plus proches: Bus, 50 m / train, 1,5 km Ecoles: école primaire / maternelle, 800 m Commerces: Coop / Migros, 950 m + +CHF 252 / m² / Jahr + +CHF 1’850 + + vor 2 Wochen + +Wohnung zu vermieten + +2544 Bettlach • 5 Zimmer • 217 m² +------------------------------------------------------- + +CHF 170 / m² / Jahr + +CHF 3’080 + + vor 2 Wochen + +Wohnung zu vermieten + +4410 Liestal • 6 Zimmer • 144 m² +------------------------------------------------------ + +CHF 233 / m² / Jahr + +CHF 2’800 + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +4104 Oberwil BL • 2 Zimmer +------------------------------------------------------- + +Ce salon entièrement équipé et bien entretenu offre à votre clientèle la plus haute qualité. Le lavage, la coupe, le brushing, la teinture et le coiffage pour les femmes, les hommes et les enfants sont les activités quotidiennes. Le salon dispose de quatre chaises de barbier et d'une station de lavage, d'une toilette client, de sa propre machine à laver et d'un gobelet. La clientèle régulière est énorme. Grâce à l'emplacement central, il y a beaucoup de clients spontanés. Transfert d'inventaire pour CHF 50'000.-. Cette offre BETTERHOMES se caractérise par les avantages suivants :- emplacement idéal- grand cercle de clients réguliers- beaucoup de clients sans rendez-vous- entièrement équipé- Machine à laver et sèche-linge- Transfert d'inventaire- et, et, et ... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Emplacement: très bien Condition: bon Salles de bain / Salles de bain: 1 (1 x WC / Lavabo) Transports publics: Bus, 210 m / Tram, 290 mÉcoles: École secondaire, 160 m Commerces: Coop, 120 m + +CHF 421 / m² / Jahr + +CHF 2’000 + + Keine Bilder + + vor 2 Wochen + +Büro & Gewerbe zu vermieten + +4900 Langenthal • 1 Zimmer +------------------------------------------------------- + +CHF 253 / m² / Jahr + +CHF 4’260 + +[1](https://www.immoyou.ch/mieten-schweiz)234567 + + 1 - 24 von 114’440 Ergebnisse + +### Immobilie mieten in der Schweiz + +[Immobilie mieten im Kanton Zürich](https://www.immoyou.ch/mieten-kanton-zurich)[Immobilie mieten im Kanton Bern](https://www.immoyou.ch/mieten-kanton-bern)[Immobilie mieten im Kanton Aargau](https://www.immoyou.ch/mieten-kanton-aargau)[Immobilie mieten im Kanton St. Gallen](https://www.immoyou.ch/mieten-kanton-st-gallen)[Immobilie mieten im Kanton Luzern](https://www.immoyou.ch/mieten-kanton-luzern)[Immobilie mieten im Kanton Basel-Landschaft](https://www.immoyou.ch/mieten-kanton-basel-landschaft)[Immobilie mieten im Kanton Thurgau](https://www.immoyou.ch/mieten-kanton-thurgau)[Immobilie mieten im Kanton Solothurn](https://www.immoyou.ch/mieten-kanton-solothurn)[Immobilie mieten im Kanton Graubünden](https://www.immoyou.ch/mieten-kanton-graubunden)[Immobilie mieten im Kanton Basel-Stadt](https://www.immoyou.ch/mieten-kanton-basel-stadt)[Immobilie mieten im Kanton Schwyz](https://www.immoyou.ch/mieten-kanton-schwyz)[Immobilie mieten im Kanton Zug](https://www.immoyou.ch/mieten-kanton-zug) + +### Andere Immobilienarten in der Schweiz + +[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Zimmer mieten in der Schweiz](https://www.immoyou.ch/wg-zimmer-mieten-schweiz)[Parkplatz mieten in der Schweiz](https://www.immoyou.ch/parkplatz-mieten-schweiz)[Büro & Gewerbe mieten in der Schweiz](https://www.immoyou.ch/buro-gewerbe-mieten-schweiz)[Wohnhaus mieten in der Schweiz](https://www.immoyou.ch/wohnhaus-mieten-schweiz)[Grundstück mieten in der Schweiz](https://www.immoyou.ch/grundstuck-mieten-schweiz) + + All rights reserved. v.541ff84 + + +=== https://www.immoyou.ch/wohnung-mieten-schweiz === +🏢 53’252 Wohnungen mieten in der Schweiz | ImmoYou + +=============== + +[ImmoYou](https://www.immoyou.ch/) + +Kaufen + +[Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + +Mieten + +[Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + + Ändern Sie die Suche + +[](https://www.immoyou.ch/)[Mieten](https://www.immoyou.ch/mieten-schweiz)[Wohnungen](https://www.immoyou.ch/wohnung-mieten-schweiz)[Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz) + +Wohnung mieten in der Schweiz +============================= + +Ort + + Schweiz + + Zürich + + Genf + + Typ + +- [x] Haus + +- [x] Wohnung + +- [x] Zimmer + +- [x] Parkplatz + +- [x] Büro & Gewerbe + +- [x] Wohnhaus + +- [x] Grundstück + + Miete + + - + + Zimmer + + - + + Wohnfläche (m²) + + - + + Grundstücksfläche (m²) + + - + + Ausstattung & Eigenschaften + +- [x] Neubauprojekte + +- [x] Balkon + +- [x] Garten + +- [x] Parkplatz + +- [x] Lift + +- [x] Freie Aussicht + +- [x] Cheminée + +- [x] Garage + +- [x] Kinderfreundlich + +- [x] Rollstuhlgängig + +- [x] Möbliert + +Ordnen + + 53’252 Ergebnisse + + + + vor 2 Tagen + +Wohnung zu vermieten + +8706 Meilen • 1 Zimmer +-------------------------------------------- + +Ich vermiete 1 Zimmer in einer 4.5 Zimmerwhg im wunderschönen und steuergünstigen Feldmeilen (Zürisee) Die Whg verfügt über: 1 Wohnzimmer mit Cheminée & Essecke 1 Büro 1 Schlafzimmer 1 andere Schlafzimmer 1 Küche 1 WC 1 Badeszimmer 1 Balkon mit Grill Parkplatz aussen vorhanden See 10 Min zu Fuss Bushaltestelle 2 Min zu Fuss Bahnhof / Coop 10 Min zu Fuss Die Wohnung liegt an sehr ruhige Lage und nah vom Naturgebiet. Ideal für Spaziergänge oder Joggen Internetanschluss / Elektrizität / Wasche inkl. in der Miete Ich suche eine positive, sorgfältige, unkomplizierte und kommunikative Person (1) als MitbewohnerIn per sofort. Nicht RaucherIn gewünscht Fühlst Du Dich angesprochen? Dann melde Dich jetzt für eine Besichtigungstermin an + +- + +CHF 1’200 + + + + vor 2 Tagen + +Wohnung zu vermieten + +8636 Wald ZH • 2.5 Zimmer • 150 m² +-------------------------------------------------------- + +Modernes Wohnen in bester Lage Erleben Sie ein helles und geräumiges Zuhause in unserer 2.5-Zimmerwohnung in Wald. Der offene Wohnbereich mit vielen Fenstern bietet viel natürliches Licht und eine tolle Atmosphäre. Bei Bedarf kann der Raum mit Schienen unterteilt werden, um noch mehr Flexibilität zu schaffen. Die grosszügige und neuwertige Küche ist mit einem Steamer und einem Induktionskochfeld ausgestattet. Hier macht das Kochen richtig Spass Das Badezimmer ist geräumig und bietet eine Dusche und eine Badewanne. Eine separate Toilette mit Waschturm rundet das Angebot ab. Die Wohnung verfügt über 2 Gemeinschaftsgärten und einen Spielraum, in denen Sie sich entspannen und Ihre Freizeit geniessen können. Ein Aussenparkplatz ist im Preis inbegriffen, sodass Sie Ihr Auto immer sicher abstellen können. Einkaufsmöglichkeiten und Restaurants sind in wenigen Gehminuten erreichbar, der Bahnhof in nur 15 Minuten. Diese Wohnung bietet Ihnen alles, was Sie brauchen, um sich rundum wohlzufühlen. Überzeugen Sie sich selbst und vereinbaren Sie einen BesichtigungsterminDieses properti-Angebot zeichnet sich durch folgende Vorteile aus: Offener Wohnbereich Viele Fenster, lichtdurchflutet Schienen zur Raumteilung 153m² Wohnfläche Modern ausgestattet Grosszügige, neuwertige Küche mit Steamer und Induktionskochfeld Grosses Badezimmer mit Dusche und Badewanne Separate Toilette mit Waschturm 2 Gemeinschaftsgärten und Spielraum Inklusive Aussenparkplatz Geräumiges Kellerabteil Einkaufsmöglichkeiten und Restaurants in Gehweite Bahnhof in 15 Minuten zu Fuss erreichbar Ruhige, sonnige und zentrale Lage Interessiert? Kontaktieren Sie uns für ein unverbindliches Gespräch Selbst eine Immobilie zu vermarkten? Wir überzeugen mit fairen und transparenten Konditionen + +CHF 186 / m² / Jahr + +CHF 2’330 + + vor 2 Tagen + +Wohnung zu vermieten + +8004 Zürich • 1 Zimmer +-------------------------------------------- + +Hi As of July 1st I will have a free room in my beautiful apartment situated on the corner of the Bäckeranlage park. The area around is beautiful and lively but not noisy at night. The room will come fully furnished at a reasonable price. The flat is very well connected. It is 2 min to the tram stop for the 8, 5 min from the tram stop for lines 2 and 3, and 8 min from Bahnhof Wiedikon. We are also close to the main station as well as Helvetiaplatz. The room available is the largest in the flat and is not on the street-side of the building which makes its extra quiet. I will stay in the smaller room as Im already set up in there. We have a bright living room, a bathroom with a tub, a kitchen, and a rooftop terrace we have shared access to. The flat is recently renovated as you can probably see in the photos. The washer and dryer are located in the flat which is considered a huge bonus in Zurich. To share a little about myself, my name is Chandler. I grew up in Florida but I moved to Germany when I was 15 to join a professional dance school and have been living in Europe working as a professional dancer ever since then. Ive been in Zurich for nearly five years now. I speak German very well and of course English which is my mother tongue. Im also familiar with quite a few swear-words in several other languages. I love music, especially any kind of underground electronic. I even DJ on the side some when I can catch a gig. Im looking for someone I think will be a good match as a roommate for me. Ideally that would probably be a young professional who works a lot like me. Probably age 30 or under (Im 24) who is somewhat creative and and easygoing. Id love to have someone I could have fun with as well as someone who is respectful of personal space and quiet time/nights. It would be nice to be able to cook together and play some cards with friends here some nights as well. I can also appreciate a good night out when I can. Send me a message if youre interested and think wed be a good fit :)-Chandler + +- + +CHF 1’495 + + vor 2 Tagen + +Wohnung zu vermieten + +8600 Dübendorf • 2.5 Zimmer • 79 m² +--------------------------------------------------------- + +Ich suche per sofort oder nach Vereinbarung einen Nachmieter für meine grosszügige 2.5-Zimmerwohnung in Dübendorf. - grosser Wohn-/ Essbereich- mit Schiebetür abtrennbare Küche- grosszügiges Schlafzimmer- Badezimmer mit Doppelwaschtisch, Badewanne und Duschkabine- 3 Doppeltürige Wandschränke- 1 Reduit für zusätzlichen Stauraum- Parkett in Wohn-/Schlafbereich- Sonnige Terasse mit Zugang zur Wiese, teils überdachtt- Parkplatz in Tiefgarage kann für 130.- übernommen werden, muss aber nicht.- Teils Möbel können nach Wunsch und Preiseinigung übernommen werden.- Kellerabteil ca. 10m2 mit Stromanschluss gehört ebenfalls zur Wohnung. Die Wohnung liegt in einem ruhigen Quartier, abgelegen von Hauptsrassen. Die Bushaltestelle ist 2 Gehminuten entfernt. Bahnhöfe Stettbach und Dübendorf sind zu Fuss in 15 Minuten oder 5 Minuten per Bus zu 3 erreichen. Ebenfalls in 3 Minuten ist die Tramhaltestelle der Glattalbahn in Richtung Flughafen zu erreichen. die Fassade des Gebäudes wurde vor ca. 1.5 Jahren erneuert. Ebenfalls wurden kürzlich der Kühlschrank, die Gegensprechanlage und die Heizungsregler erneuert. Haustiere in Absprache mit der Verwaltung. + +CHF 266 / m² / Jahr + +CHF 1’750 + + vor 2 Tagen + +Wohnung zu vermieten + +6340 Baar • 3 Zimmer • 68 m² +-------------------------------------------------- + +Da ich sehr viel unterwegs bin, untervermiete ich meine Wohnung flexibel, jederzeit ab dem 20 März 2023 oder nach Vereinbarung. Dauer der Untermiete: nach Vereinbarung, auch längerfristig möglich . Verbringe deine Tage in einer ruhigen, vollmöblierten, schön eingerichtete Wohnung, nur 5 Minuten zu Fuß vom Bahnhof, Einkaufmöglichkeiten (Coop, Migro, Aldi, Denner), Geschäften, Restaurants, Bäckereien und Baar-Stadtzentrum entfernt. Oder eine kurze Radtour zum Zugersee (12 Minuten / 3 km). Diese gemütliche Wohnung im 2. Stockwerk bietet alles, was Sie für ein angenehmes Zuhause benötigen, einschließlich geräumiger Zimmer, moderner Ausstattung und einer heimeligen Atmosphäre. Verpassen Sie nicht die Chance, diese einzigartige Wohnmöglichkeit zu erleben. Kontaktieren Sie mich heute, um einen Besichtigungstermin zu vereinbaren. Die Wohnung besteht aus einem Schlafzimmer ausgestattet mit einem Queensize-Bett (Breite 180 cm x Länge 220 cm) und einem geräumigen Kleiderschrank, einem Gästezimmer/Arbeitszimmer (Austattung als Home Office und Gästezimmer - Bett mit Futonmatratze 140 cm x 200 cm), einem Badezimmer (mit Badewanne), einer schönen Küche und einem Wohnzimmer. Vom Wohnzimmer aus haben Sie Zugang zu einem schönen, kleinen Balkon. Zu den Annehmlichkeiten zählen TV set, Arbeitsplatz für work from home (Arbeitstisch aus Massivholz und ergonomischer Bürostuhl). Die Waschmaschine und der Trockner befinden sich im Keller. Zu Verfügung steht auch ein Kellerraum, ein Abstellraum für Fahrräder und auf Anfrage zusätzlicher Abstellraum auf dem Dachboden. Direktverbindung zum Flughafen Kloten mit dem Zug: 45 Minuten (54 Minuten Tür zu Tür) und nach Luzern.Miete (inkl. Nebenkosten): 1900,00 CHF pro Monat . Extrakosten für Internet, TV, Festnetz und SERAFE (Radio & Fernsehergebühr). + +CHF 335 / m² / Jahr + +CHF 1’900 + + vor 2 Tagen + +Wohnung zu vermieten + +8600 Dübendorf • 2 Zimmer • 53 m² +------------------------------------------------------- + +Perfekte 2-Zimmer- Wohnung an top Lage Diese moderne Wohnung liegt an einer verkehrsberuhigten Lage und ist nach Vereinbarung Verfügbar: 2-Zimmer-Wohnung- 1x Bad- 1x Schlaffzimmer- Wohnzimmer- Möbel sind zum Verkaufen Konditionen (CHF 1290 + CHF 150 NK) Dübendorf ist eine Stadt zum Wohlfühlen. Wer hier wohnt findet alles, was zum Alltag gehört. Sie hat ein lebendiges Zentrum mit einer optimalen Mischung zwischen Stadt und Land. Sie profitieren von einem breitgefächerten Angebot an Geschäften, Restaurants, Schulen und Kindergarten, so-wie der Nähe zum Lycée Française (Gockhausen), der Int. School Zürich North ISZN (Wallisellen) und Inter Community School ICS (Zumikon). + +CHF 326 / m² / Jahr + +CHF 1’440 + + vor 2 Tagen + +Wohnung zu vermieten + +8105 Watt • 2 Zimmer • 45 m² +-------------------------------------------------- + +Suche ab 15.5.2023 einen Nachmieter für diese gemütliche Wohnung in Watt. Die Wohnung wurde 2019 komplett renoviert und hat folgendes zu bieten:- Fußbodenheizung- modernes Bad- moderne Küche mit Geschirrspüler Backofen und Waschmaschine- geräumiger Kellerabteil- Parkplatz- Raum für Velo Es sind 2 Zimmer und 45 Quadratmeter in einem gepflegten ruhigen Mehrfamilienhaus Mit ÖV ist man in ca. 25 Minuten am Züricher Hauptbahnhof. SB Haltestelle Regensdorf-Watt 18 Minuten mit der S6 Trotzdem ergibt sich am Abend die Möglichkeit einen Rundgang in die natur zu machen. + +CHF 400 / m² / Jahr + +CHF 1’500 + + vor 2 Tagen + +Wohnung zu vermieten + +8048 Zürich • 4.5 Zimmer +---------------------------------------------- + +We are leaving this renovated, spacious and bright 4.5 room attic apartment in Altstetten since 1st May 2023 and looking for the new tennants. The apartment can offer the following:- Open plan kitchen with granite bar. Glass ceramic, dishwasher, extractor fan and microwave.- 3 separate spacious rooms + large living room with fireplace.- 2 bathrooms: toilet/bath and toilet/shower.- Large terrace/balcony.- Generous built-in closets in the corridor.- Own washing machine in a separate laundry room within the apartment.- Entire apartment freshly painted and new laminate flooring.- Shops (including big Migros, Co-op and Denner) and public transport at Lindenplatz in 3 minutes walk.- 9 minutes walk to Zürich Altstetten train station and 3 minutes walk to tram 2 station.- Big public swimming pool in 7 minutes walk and various sport clubs and parks in walking distance.- Separate storage included in the contract cost. Cost is 3250 CHF per month (+3 months deposit) Parking is available at 180 CHF per month + +- + +CHF 3’250 + + vor 2 Tagen + +Wohnung zu vermieten + +8400 Winterthur • 2 Zimmer • 55 m² +-------------------------------------------------------- + +Um eine allfällige Wohnungsbesichtigungen möglichst effizient zu halten, werden ausschliesslich ernsthafte Interessenten zugelassen. Dafür finden Sie hier auf der Website ausreichend Bild- und Textmaterial sowie einen Grundrissplan, sodass Sie die Wohnung vorab virtuell sehr detailliert einschätzen können. Wenn Sie, nach ausreichendem Studium der Unterlagen, mehrheitlich überzeugt sind, können Sie in einem 2. Schritt im Kontaktfenster (auf der Website rechts bei Inserent kontaktieren) im Textfeld eine persönlich formulierte Anfrage oder ein Motivationsschreiben an die Verwaltung richten - und werden daraufhin zur Terminabsprache via email für eine Besichtigung an die derzeitige Mieterin verwiesen. Das Interesse für solche Wohnungen nähe Altstadt ist gross. Minimalistische Anfragen (erkennbar an der Verwendung des standardisierten Textbausteins im Kontaktfenster) werden kommentarlos gelöscht Nähe Altstadt und Hauptbahnhof (700m), unmittelbar neben der Bushaltestelle Hinterwiesli (20m Luftlinie) gelegen, mit vielseitigen Einkaufsmöglichkeiten in Gehdistanz (Bäckerei, Migros, Denner, Gemüse Markt, Kiosk, Apotheke) und diversen Restaurants im Umkreis, findet sich das kleine Mehrfamilienhaus mit 8 Single-Wohnungen an sehr ruhiger Wohnlage (trotz Zentrumsnähe) in schönem und gepflegtem Quartier. Es herrscht eine angenehme und kollegiale Atmosphäre im Haus, dank der niveauvollen Bewohnerschaft bestehend aus vorwiegend jüngeren Einzelhaushalten. Die Altbauliegenschaft ist gut unterhalten und wird von einem Privatvermieter angeboten. Die lichtdurchflutete Wohnung im Dachgeschoss links (ohne Lift) zeichnet sich durch ein Ambiente von Gemütlichkeit und Ruhe aus, wozu die dicken Mauern in Kombination mit der überdurchschnittlichen Raumhöhe von 2.57m als spezielles Stilmittel besonders beitragen. Der schöne Bodenbelag in Parkettoptik schafft eine behagliche Atmosphäre und lässt kreativen Leuten viel Spielraum zur individuellen Einrichtung. Die Forster-Küche ist zweckmässig und mit einem Putzschrank ausgestattet. Sie bietet ausreichend Platz für einen kleinen Esstisch in der Ecke. Die Nasszelle mit Wanne lädt zum gemütlichen Baden ein. Zur Wohnung gehören ein eigenes Estrich- und ein Kellerabteil . Zur allgemeinen Mitbenutzung stehen die Waschküche mit WM/Tumbler und separatem Trockenraum im Keller, ein Veloeinstellraum auf dem Hof sowie eine Dachterrasse mit einmaliger Aussicht über das Quartier zur Verfügung. Ausreichend Parkiermöglichkeiten finden sich entlang der Quartierstrasse in der blauen Zone. Die Liegenschaft ist ans Glasfasernetz angeschlossen. Die Nebenkosten sind ohne monatliche Antennengebühr berechnet. + +CHF 277 / m² / Jahr + +CHF 1’270 + + vor 2 Tagen + +Wohnung zu vermieten + +8180 Bülach • 4 Zimmer • 68 m² +---------------------------------------------------- + +Die 68 Quadratmeter grosse 4 Zimmer-Wohnung im zweiten Obergeschoss verfügt über ein grosses, lichtdurchflutetes Schlafzimmer mit Parkettboden. Der Wohn- und Essbereich bietet Platz für einen Esstisch und eine wohnliche Couch. Die moderne Küche wurde ebenfalls 2021 Jahren umgebaut und verfügt über einen Backofen, einen Glaskeramikherd und eine Abwaschmaschine. Vom Wohnbereich gelangst du auf einen kleinen Balkon. Parkplätze können dazu gemietet werden. + +CHF 314 / m² / Jahr + +CHF 1’780 + + vor 2 Tagen + +Wohnung zu vermieten + +8038 Zürich • 2 Zimmer +-------------------------------------------- + +An der Kurfirstenstr. 84 auf ruhiger grüner Strasse vermieten wir per 1. Mai 2023 eine helle 2 Zimmer Wohnung im 2.OG mit Balkon. Die Wohnung hat in im Wohnzimmer und Schlafzimmer Parkett und Bad/WC mit Bodenplatten, geschlossene Küche.Besichtigung: Montag 20.032023 um 18.30-19.00 Uhr 2023, WHG Winkelmann + +- + +CHF 2’190 + + vor 2 Tagen + +Wohnung zu vermieten + +8180 Bülach • 4.5 Zimmer • 135 m² +------------------------------------------------------- + +Garagenparplatz kann für 120.- dazgemietet werden. Ab 01.06.24 kann ein zusätzlicher Parkplatz bei Bedarf dazugemietet werden. + +CHF 227 / m² / Jahr + +CHF 2’550 + + vor 2 Tagen + +Wohnung zu vermieten + +8004 Zürich • 3 Zimmer +-------------------------------------------- + +Untermieter/in für Wohnung im Kreis 4 gesucht Für unsere schöne Altbauwohnung an der Wengistrasse in Zürich, mitten im Kreis 4, suchen wir ab Mitte April einen Untermieter für voraussichtlich 2 Monate . Die Wohnung befindet sich im 4. Stock, hat 3 Zimmer und einen Balkon. Es handelt sich um eine renovierte, moderne Wohnung in einem Altbau. Verfügbar ab: ca. 15 April bis ca. 11 Juni (nach Vereinbarung) Die Wohnung wird voll möbliert vermietet - vom Fernseher über den Staubsaugerroboter bis zum Smoothie-Maker ist alles dabei. Ausstattung:- Aufzug- Kellerabteil- Küche mit Geschirrspüler- Eigene Waschmaschine & Tumbler Nachbarschaft:- Direkt an der Langstrasse- Migros & Denner auf der anderen Strassenseite, 24-Stunden-Laden 100 Meter entfernt- Tram & Bushaltestelle direkt nebenan Die Miete beträgt CHF 2500 (inkl. Möbel & NK). Stromkosten & Internet sind nicht inbegriffen. ---------------------------- For our beautiful apartment on Wengistrasse in Zurich, in the middle of district 4, we are looking for a subtenant from mid-April for probably 2 months. The apartment is on the 4th floor, has 3 rooms and a balcony. It is a renovated, modern apartment in an old building. Available from: approx. 15 April to approx. 11 June (by agreement). The apartment is rented fully furnished - from TV to vacuum cleaner robot to smoothie maker, everything is included. Facilities:- elevator- cellar compartment- Kitchen with dishwasher- Own washing machine & tumble dryer Neighborhood:- Directly on Langstrasse- Migros & Denner on the other side of the street, 24-hour store 100 meters away- Streetcar & bus stop right next door The rent is CHF 2500 (incl. furniture & NK). Electricity costs & internet are not included. + +- + +CHF 2’500 + + vor 2 Tagen + +Wohnung zu vermieten + +8057 Zürich • 3 Zimmer • 80 m² +---------------------------------------------------- + +Ich suche per 1.4. (oder erste April Woche) Nachmieter für meine Wohnung. Die Wohnung ist im obersten Geschoss in einem Altbau in der Nähe vom Irchelpark und den Tramhaltestellen Universität Irchel und Langmauerstrasse ist 80m2 gross und 2.5m hoch und bietet:- Wohnzimmer 34m2 (momentan mit Holzwand in 2 Zimmer von 18m2 & 16m2 aufgeteilt, kann übernommen werden, muss nicht)- Mit Wohnzimmer verbundener Vorplatz mit Putzschrank 4.5m2- Zimmer 14m2- Zimmer mit Einbauschrank 11m2- Küche mit 3.5m3 Nutzfläche mit Backofen, Kühlschrank mit Gefrierfach, Geschirrspühler (alles 2 jährig)- Dusche 3.5m2 (vor 1 Jahr teilrenoviert)- Vorplatz im Treppenhaus zur Nutzung 5m2 Die Zimmer sind mit Laminat ausgelegt. Zur Wohnung gehört ein geräumiges trockenes Kellerabteil. Waschmaschine und Tumbler werden nur mit der Wohnung unterhalb geteilt. Grosse Dachterrasse zur Mitbenutzung. Gedeckter Veloplatz vor dem Eingang. Miete ohne Kaution. Als Mieter kommen in Frage: Singles, Paare, WG mit zwei Personen, Alleinstehende mit Kind(ern) im Primarschulalter. Besichtigungstermine werden an valable Interessenten vergeben. Bitte mit kurzer Vorstellung der interessierten Mietpartei(en). Bei grossen Andrang, entschuldigen sie bitte, falls sie keine Antwort erhalten. --------------------------------- I'm looking for 1.4. (or first week of April) Subsequent tenants for my apartment. The apartment is on the top floor in an old building near Irchelpark and tram stops Universität Irchel and Langmauerstrasse, is 80m2 and 2.5m high and offers:- Living room 34m2 (currently divided into 2 rooms of 18m2 & 16m2 with a wooden wall, can be taken over, does not have to)- Forecourt connected to living room with cleaning cupboard 4.5m2- Room 14m2- Room with built-in wardrobe 11m2- Kitchen with 3.5m3 usable area with oven, refrigerator with freezer compartment, dishwasher (everything 2 years old)- Shower 3.5m2 (partially renovated 1 year ago)- Forecourt in the stairwell for use 5m2 The rooms are laid out with laminate. The apartment has a spacious dry basement compartment. Washing machine and dryer are only shared with the apartment below. Large roof terrace for shared use. Covered bicycle space in front of the entrance. Rent without deposit. Possible tenants are: singles, couples, flat shares with two people, single people with child(ren) of primary school age. Viewing appointments are given to valid interested parties. Please provide a brief introduction to the interested tenant(s). If there is a large rush, please excuse me if you do not receive an answer. + +CHF 360 / m² / Jahr + +CHF 2’400 + + vor 2 Tagen + +Wohnung zu vermieten + +8906 Bonstetten • 2.5 Zimmer • 55 m² +---------------------------------------------------------- + +Ganz nah zur Stadt Zürich und trotzdem mitten in der grünen Lunge Knonaueramt. Baujahr 2016 im Minergie-Standard Naturnah und doch zentral (2 Minuten zur S-Bahn & Busbahnhof): Mit S5 ist man in 22 Minuten in Zürich HB bzw in 25 Minuten in Zug Wohnfläche ca. 55 qm (plus 12 qm gedeckte Loggia) Eigenes Kellerabteil, separates kleines Reduit in der Wohnung Waschturm, Waschmaschine & Tumbler (V-Zug) in der Wohnung Stellplatz in der Tiefgarage mit direktem Hauszugang für CHF 170.- Fussbodenheizung Komplett barrierefrei und rollstuhlgängig Durch die Ausrichtung der Wohnung geniessen Sie die Sonne auf der geschützten grossen Loggias Die hier gezeigten Fotos wurden vor dem Einzug aufgenommen und gehören zu einer Beispielwohnung, d.h. sie können leicht von der Realität abweichen. Das (kostenpflichtige) bonacasa Konzept unterstützt Sie in vielen Alltagsarbeiten, so z.B. Wohnungsreinigung, Ferienabwesenheitsdienst, Schlüsseltresor für Notfälle, Wäscheservice , u.v.m. Video-Impressionen: https://www.youtube.com/watch?v=ivHXe0FTWFw&t=50s + +CHF 362 / m² / Jahr + +CHF 1’660 + + vor 2 Tagen + +Wohnung zu vermieten + +8610 Uster • 3.5 Zimmer • 63 m² +----------------------------------------------------- + +Geräumige und sonnige Wohnung im DG mit Dachschrägen. Vom Wohnzimmer aus hat man Aussicht auf die Alpen, den Greifensee und die Egger Hügellandschaft. Auf der gegenüberliegenden Seite blickt man auf den Wald jenseits der Autobahn A15 (einfache Zufahrt in beide Richtungen). In der Nähe befinden sich ein Restaurant, zwei Höfe, der Panoramapunkt Känzeli und die Sportanlage Buchholz. Spacious and sunny apartment on the last floor with a slopped ceiling. View from the living room is on the Alps, Greifensee and Eggs hills. The opposite sides view is on the forest beyond the A15 highway (easy entrance in both direction). In the neighbourhood are a local restaurant, two hofs, panorama point Känzeli and Buchholz sports complex. + +CHF 305 / m² / Jahr + +CHF 1’600 + + vor 2 Tagen + +Wohnung zu vermieten + +5035 Unterentfelden • 3.5 Zimmer • 98 m² +-------------------------------------------------------------- + +In der der naturnahen und exklusiven Neubau Wohnsiedlung Im Erlifeld Unterentfelden sucht diese wunderschöne, helle 3.5 Zimmerwohnung im 2 OG per sofort einen neuen Mieter. Die Wohnung verfügt über einen sehr grossen Balkon mit Privatsphäre. Die hochwertig ausgebaute Küche, die gute Aufteilung der Räumlichkeiten sowie der lichtdurchflutete offene Wohn- und Essbereich laden zu einem wuderschönen Wohngefühl ein. Die Wohnung hat Ihnen folgendes zu bieten:- Obere Etage unter der Attikawohnung- Eingangsbereich mit Einbauschränken- Lichtdurchfluteter offener Wohn- und Essbereich- Hochwertige Küche- Hochwertige Garnituren- Grosse Balkon mit Aussicht ins Grüne 17m2- Morgen- und Abendsonne- 1 Bad mit grosser Dusche direkt mit dem Schlafzimmer verbunden- 1 Bad mir Badewanne- Grosszügiges Reduit- Eigener Waschturm (Waschmaschine & Tumbler)- Grosse Zimmer- Wohnfläche ca. 98m2- Grosser Tiefgaragenplatz 130.-/Monat (Platz für ein Auto und ein Motorrad)- Grosszügiger Keller- Familiäres Wohngefühl- Hautiere erlaubt- super nahe ÖV Verbindung, 2 min zu Fuss zum Bahnhof- Autobahneinfahrt auf die A1, ca. 4min Netto: 1582.- Nebenkosten: 280.- Brutto pro Monat: 1862.- CHF Verfügbar ab 01.04.2023 Adresse: Neufeldstrasse 16, 5035 Unterentfelden Für eine gemeinsame Besichtigung dürfen Sie sich gerne mir uns in Verbindung setzen. + +CHF 228 / m² / Jahr + +CHF 1’862 + + vor 2 Tagen + +Wohnung zu vermieten + +1205 Genève • 1.5 Zimmer • 25 m² +------------------------------------------------------ + +The Boulevard des Philosophes is ideally located in the Plainpalais district on the left bank of Geneva. Tram stop 12,14,15,17,18, Rond-Point is 150 metres away. The city centre can be reached within a 10-minute walk. The plain of Plainpalais and its markets is 50 meters from the property. Amenities are in the immediate vicinity (schools, restaurants, Plainpalais shopping center, shops, post office, bank, theater, Bastion Park, communal hall, neighborhood house, police station, HUG). This 2-room apartment of 30m2 on the 3rd floor of a secure building with elevator is composed as follows:- Fitted and equipped kitchen- Living room- Bathroom- Linked cellar The building has a laundry room, bicycle storage and is connected to fiber optics Here are the documents required for your application:- Swiss identity document/residence permit- A certificate of non-prosecution of less than 3 months- A recent certificate from your employer mentioning the date of entry into employment, the salary and the type of your current contract- The last 3 payslips To apply, please use the following link: https://rentalapplication.zimmermannimmobilier.ch/?ref=5790-304 + +CHF 686 / m² / Jahr + +CHF 1’430 + + vor 2 Tagen + +Wohnung zu vermieten + +5000 Aarau • 3 Zimmer • 70 m² +--------------------------------------------------- + +Sind Sie auf der Suche nach einer Wohnung mit Charakter und einer Seele? Dann werden Sie von dieser charmanten Dachwohnung in Aarau begeistert sein. Die vielen Fenster lassen das Sonnenlicht in die Räume strömen und schenken der Wohnung eine warme und einladende Atmosphäre. Die zentrale Lage an der Buchserstrasse bietet eine bequeme Anbindung an öffentliche Verkehrsmittel, Restaurants und Einkaufsmöglichkeiten, was Ihnen ein unkompliziertes Leben in der Stadt ermöglicht. Diese zauberhafte Wohnung ist perfekt für Singles oder Paare, die das Leben in vollen Zügen geniessen möchten. Wenn Sie sich selbst davon überzeugen möchten, kommen Sie vorbei und lassen Sie sich verzaubern Bitte beachten Sie, dass die Wohnung keinen Balkon hat, aber Sie haben ein eigenes Kellerabteil und einen eigenen Waschturm. Die Nebenkosten sind im Mietpreis enthalten und Sie haben auch die Möglichkeit, einen Aussenparkplatz für CHF 80.00 pro Monat zu mieten.Dieses properti-Angebot zeichnet sich durch folgende Vorteile aus: Wohnung mit Charakter Helle Zimmer Gute Lage Kein Balkon vorhanden Eigenes Kellerabteil Eigener Waschturm Nebenkosten sind inklusive Aussenparkplatz für CHF 80.00 / Monat zumietbar Interessiert? Kontaktieren Sie uns für ein unverbindliches Gespräch Selbst eine Immobilie zu vermarkten? Wir überzeugen mit fairen und transparenten Konditionen + +CHF 240 / m² / Jahr + +CHF 1’400 + + vor 2 Tagen + +Wohnung zu vermieten + +5079 Zeihen • 3.5 Zimmer • 97 m² +------------------------------------------------------ + +3,5 Zimmerwohnung im Minergie-Standard mit kontrollierter Wohnungsbelüftung; hoher Ausbaustandard; offene und moderne Küche; grosses, helles Wohnzimmer; begehbare Dusche; praktische Einbauschränke; grosser, überdachter Balkon mit Sicht ins Grüne; geräumiges Kellerabteil. Ruhige Lage, Lift vorhanden. Waschküche mit Tumbler zur gemeinsamen Benützung im Keller vorhanden. Bushaltestelle direkt vor dem Haus. Einkaufsmöglichkeiten im Dorf vorhanden. Parkplatz in der Einstellhalle kann für monatlich CHF 110.-- dazu gemietet werden. + +CHF 207 / m² / Jahr + +CHF 1’670 + + vor 2 Tagen + +Wohnung zu vermieten + +3974 Mollens VS • 1 Zimmer +------------------------------------------------ + +Furnished studio, parking spaces nearby, wood stove, electric underfloor heating. Large room Kitchenette Bathroom To rent at least 3 months. Ideal for single person Free of charge / CHF 750.-/month + deposit charges, CHF 80.-/month: 830.-/month www.immo-trading.com info@immo-trading.com BT Building Technology Sàrl+41 79 259 57 81 At your service for any question or possible visit on site. + +- + +CHF 750 + + vor 2 Tagen + +Wohnung zu vermieten + +1965 Savièse • 3.5 Zimmer +----------------------------------------------- + +For rent in a small building of 6 apartments in Granois / Savièse (without elevator): Charming app. 3.5 rooms on the ground floor with terrace-lawn: - entrance with built-in wardrobe- living / dining room with access to the terrace- fully equipped open kitchen (large fridge, oven, dishwasher)- 1 parents bedroom with built-in wardrobe- 1 small bedroom- baths / WC- 1 cellar- 1 outdoor parking space- solid terrace (approx. 8 m2) + lawn (approx. 40 m2) with fireplace for grills Fr. 1'280.- / month, charges and place included Information and visits: 027 322 02 89 We are at your disposal for any further information at the 027 322 02 89 (Monday - Thursday 8:00 - 12:00 / 13:30 - 17:00) + +- + +CHF 1’280 + + vor 2 Tagen + +Wohnung zu vermieten + +1950 Sion • 4.5 Zimmer +-------------------------------------------- + +For rent from April 15, 2023 or to be agreed, at rue des Aubépines 15, near the Place du Midi, shops, schools and public transport, in a quiet area (30 km / h zone): Beautiful 4.5 room apartment on the 3rd floor with balcony is: Large entrance hall with fitted wardrobes separate kitchen with exit to the balcony large living/dining room with exit to the balcony hallway with fitted wardrobes Parent room with small west balcony 2 children's bedrooms baths / WC with double washbasin shower / WC with connection for washing machine and dryer balcony 1 cellar. Fr. 1'770.- / month, charges included Possibility to rent an indoor parking space: Fr. 100.- / month We are at your disposal for any further information at the 027 322 02 89 (Monday - Thursday 8:00 - 12:00 / 13:30 - 17:00) + +- + +CHF 1’770 + + vor 2 Tagen + +Wohnung zu vermieten + +2610 St-Imier • 3.5 Zimmer +------------------------------------------------ + +Description Magnificent spacious apartment of 3.5 rooms located in the center of the locality, close to shops and schools. Description of the apartment: Large kitchen arranged habitable with dishwasher and a large fridge Access to the private terrace Living room Bathroom with walk-in shower Large office space Room with possibility of arranging a dressing room Granary + +- + +CHF 1’100 + +[1](https://www.immoyou.ch/wohnung-mieten-schweiz)234567 + + 1 - 24 von 53’252 Ergebnisse + +### Wohnung mieten in der Schweiz + +[Wohnung mieten im Kanton Zürich](https://www.immoyou.ch/wohnung-mieten-kanton-zurich)[Wohnung mieten im Kanton Bern](https://www.immoyou.ch/wohnung-mieten-kanton-bern)[Wohnung mieten im Kanton Aargau](https://www.immoyou.ch/wohnung-mieten-kanton-aargau)[Wohnung mieten im Kanton St. Gallen](https://www.immoyou.ch/wohnung-mieten-kanton-st-gallen)[Wohnung mieten im Kanton Luzern](https://www.immoyou.ch/wohnung-mieten-kanton-luzern)[Wohnung mieten im Kanton Basel-Landschaft](https://www.immoyou.ch/wohnung-mieten-kanton-basel-landschaft)[Wohnung mieten im Kanton Thurgau](https://www.immoyou.ch/wohnung-mieten-kanton-thurgau)[Wohnung mieten im Kanton Solothurn](https://www.immoyou.ch/wohnung-mieten-kanton-solothurn)[Wohnung mieten im Kanton Graubünden](https://www.immoyou.ch/wohnung-mieten-kanton-graubunden)[Wohnung mieten im Kanton Basel-Stadt](https://www.immoyou.ch/wohnung-mieten-kanton-basel-stadt)[Wohnung mieten im Kanton Schwyz](https://www.immoyou.ch/wohnung-mieten-kanton-schwyz)[Wohnung mieten im Kanton Zug](https://www.immoyou.ch/wohnung-mieten-kanton-zug) + +### Andere Immobilienarten in der Schweiz + +[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz)[Zimmer mieten in der Schweiz](https://www.immoyou.ch/wg-zimmer-mieten-schweiz)[Parkplatz mieten in der Schweiz](https://www.immoyou.ch/parkplatz-mieten-schweiz)[Büro & Gewerbe mieten in der Schweiz](https://www.immoyou.ch/buro-gewerbe-mieten-schweiz)[Wohnhaus mieten in der Schweiz](https://www.immoyou.ch/wohnhaus-mieten-schweiz)[Grundstück mieten in der Schweiz](https://www.immoyou.ch/grundstuck-mieten-schweiz) + + All rights reserved. v.541ff84 + + +=== https://www.immoyou.ch/haus-mieten-schweiz === +🏠 3’577 Häuser mieten in der Schweiz | ImmoYou + +=============== + +[ImmoYou](https://www.immoyou.ch/) + +Kaufen + +[Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + +Mieten + +[Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + + Ändern Sie die Suche + +[](https://www.immoyou.ch/)[Mieten](https://www.immoyou.ch/mieten-schweiz)[Häuser](https://www.immoyou.ch/haus-mieten-schweiz)[Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + +Haus mieten in der Schweiz +========================== + +Ort + + Schweiz + + Zürich + + Genf + + Typ + +- [x] Haus + +- [x] Wohnung + +- [x] Zimmer + +- [x] Parkplatz + +- [x] Büro & Gewerbe + +- [x] Wohnhaus + +- [x] Grundstück + + Miete + + - + + Zimmer + + - + + Wohnfläche (m²) + + - + + Grundstücksfläche (m²) + + - + + Ausstattung & Eigenschaften + +- [x] Neubauprojekte + +- [x] Balkon + +- [x] Garten + +- [x] Parkplatz + +- [x] Lift + +- [x] Freie Aussicht + +- [x] Cheminée + +- [x] Garage + +- [x] Kinderfreundlich + +- [x] Rollstuhlgängig + +- [x] Möbliert + +Ordnen + + 3’577 Ergebnisse + + + + vor 2 Tagen + +Haus zu vermieten + +1292 Chambésy • 7 Zimmer • 200 m² +---------------------------------------------------- + +Belle villa jumelle de grand standing Discrètement située au fond d'un chemin privé à l'abri des regards, villa à l'architecture forte et originale offrant des finitions de premier choix. D'une surface habitable de 200 m2 env. + un sous-sol complet, elle comprend au rez un hall d'entrée avec vestiaires, un living, une cuisine ouverte luxueusement équipée ouverte sur un coin à manger, un bureau, toilettes. L'étage présente de beaux volumes et abrite 3 chambres-à-coucher avec 3 salles-de-bain en suite dont une vaste master suite avec son walk-in dressing et prolongée d'une belle terrasse.Sous-sol complet incluant une grande salle-de-jeux, caves, chaufferie-buanderie. Charmant jardin et belle terrasse. Couvert à voiture + 2 parkings extérieurs. DISPONIBLE AU 1er JUILLET 2023Loyer mensuel : Frs 7'700.- + +CHF 462 / m² / Jahr + +CHF 7’700 + + + + vor 2 Tagen + +Haus zu vermieten + +5070 Frick • 4.5 Zimmer • 118 m² +--------------------------------------------------- + +Lage Das Dorf liegt im Tal der Sissle. Die lebendige Dorfgemeinschaft Frick, wird Sie dank dem vielfältigen Angebot an Vereinen, kulturellen Events sowie Restaurants auf Anhieb wohlfühlen lassen. Hier wohnen Sie in einem familienfreundlichen Quartier, mit kurzen Gehdistanzen zu Einkaufsmöglichkeiten. In der Freizeit ist ein Besuch im Sauriermuseum ein muss und für Sportfans hat Frick eine eigene Nordic Walking Route mit diversen Schwierigkeitsrouten.Ein Rundgang durch Ihre Wohnung Der grosszügige Grundriss ermöglicht es Ihnen, sich auf den 117m2 individuell einzurichten. Die Dachschrägen und Holzelemente verleihen den Räumen ihren Charme. Die Parkett- und Plattenboden in allen Wohnräumen sorgen zusätzlich für eine heimelige Atmosphäre. Desweiteren überzeugt die Attikawohnung mit folgenden Vorzügen: UG: Kellerabteil EG: moderne Küche, Wohnzimmer und Gäste-WC OG: 2 Schlafzimmer, Bad/WC mit Waschturm OG: 1 Schlafzimmer mit Dusche/WC Parkett- und Steinböden Bodenheizung Sitzplatz und Gartenanteil Details Ein Autoeinstellplatz kann für 130.- CHF / monatlich dazugemietet werden. + +CHF 223 / m² / Jahr + +CHF 2’190 + + vor 2 Tagen + +Haus zu vermieten + +1025 St-Sulpice VD • 6 Zimmer • 200 m² +--------------------------------------------------------- + +Very beautiful beautiful bright house very close to the lake quiet offers on 200m2: Superb large living room open to kitchen of very Highscale. 3 large bedrooms 3 bathrooms Beautiful outbuilding of 30 m2 office or studio separated 4 parking spaces (electric vehicle charging possible) Nice enclosed garden of 600m2 available to be agreed + +CHF 450 / m² / Jahr + +CHF 7’500 + + vor 2 Tagen + +Haus zu vermieten + +1814 La Tour-de-Peilz • 6.5 Zimmer • 230 m² +-------------------------------------------------------------- + +EXCLUSIVE Magnificent detached house of 6.5 rooms offering a surface of about 230 m2 with terrace and garden. Distribution: Ground floor: an entrance with built-in wardrobes, a guest toilet, a small office room or storage, a fully equipped kitchen, a dining room, a living room, a terrace, a garden 1st floor: a large bedroom with en-suite shower room, two bedrooms, a bathroom with toilet and washing machine connection. 2nd floor: a large bedroom with terrace, a shower room with toilet. Basement: a laundry room, a large furnished room, a large cellar. A covered garage for two cars Garden maintenance contract: 400 Frs extra (mandatory) For visits: Pascaline Pottier - 079 836 99 04 + +CHF 287 / m² / Jahr + +CHF 5’500 + + vor 3 Tagen + +Haus zu vermieten + +1196 Gland • 4 Zimmer +---------------------------------------- + +Magnifique espace commerciale, composé deux belles vitrines avec la possibilité de deux entrées indépendantes. Possibilité de lier plusieurs professions indépendantes. Vitrine 1: Actuellement un salon de coiffure entièrement équipé, composé d'une grande pièce avec réception, onglerie et d'une pièce agréable équipée pour les soins esthétiques. Vitrine 2: Grande pièce vitrine et deux pièces supplémentaires complètent l'espace à disposition. Cette offre de BETTERHOMES se caractérise par les avantages suivants: - spacieux, lumineux et fonctionnel- locaux séparés avec accès indépendants- modulable et polyvalent- idéale pour un pool de professionnels indépendants- emplacement favorable- accès facile- parking à disposition pour les clients- loyer très attractif- charges en sus CHF 200.- par mois- etc., etc., etc... Intéressé? Contactez-nous pour une visite sans engagement - visite en ligne également possible Rien qui correspond? Vous trouverez plus de 2'200 autres objets sur: www.betterhomes.ch - Le spécialiste suisse des transactions immobilières. Vous avez un bien immobilier à commercialiser? Profitez de notre savoir-faire: https://www.betterhomes.ch/fr/profiter Vous souhaitez connaître la valeur de votre bien immobilier? Découvrez sa valeur dès maintenant grâce à notre estimation gratuite, immédiate et sans engagement https://www.betterhomes.ch/fr/knowledge/estimation Plus détails Situation: situé idéalement dans le complexe urbain de Gland, sur les principaux axes routiers Etat du bâtiment: moyen Salles de bain: 2 (1 x WC / lavabo, 1 x douche / WC / lavabo) Système de chauffage: Mazout Transport publics: bus à proximité Ecole: école primaire, 400 m Commerces: Migros / Coop, 500 m + +CHF 265 / m² / Jahr + +CHF 2’300 + + vor 3 Tagen + +Haus zu vermieten + +8906 Bonstetten • 6.5 Zimmer • 160 m² +-------------------------------------------------------- + +Das Haus hat einen gehobenen Ausbaustandard. Es ist sehr zentral und ruhig gelegen am sudwestlichen Dorfrand von Bonstetten. Der Kindergarten ist 300m entfernt, die Bushaltestelle Dorfplatz ebenso. Einkaufsmoglichkeiten gibt es in Fussdistanz. Im Erdgeschosses das Wohn-/Esszimmer mit Chemineeofen und offener Kuche sowie Gaste WC, ca. 52m2. Im Obergeschoss sind drei (Kinder-)Zimmer 2 x 12.5m2, einmal 10.5, WC/Bad und Balkon. Im Dachgeschoss ist das 4m hohe Elternschlafzimmer von 20 m2 mit zwei begehbaren Ankleiden und Dusche/WC (2016 neu). Das Untergeschoss enthalt als 6. Zimmer einen ausgebauten Hobbyraum, der mit Parkett ausgestattet ist und als TV-/Bugel-/Gastezimmer verwendet wird. Die Waschkuche ist mit einem Waschturm ausgestattet und hat einen eigenen Warmepumpen Oekoboiler. Daneben finden sich ein Vorratskeller und ein weiterer Kellerraum mit direktem Zugang zur Tiefgarage, wo zwei Parkplatze zur Verfugung stehen. Neben dem Hauseingang ist ein kleiner Schopf/Schuppen fur die Gartengerate vorhanden. 2019 wurden alle Fenster ersetzt durch 3fach-Verglasung, das Wohnzimmer mit Parkett und Sideboard erneuert. Das ganze Haus ist mit Parkett belegt. Das Haus ist an die Erdsondenheizung der Siedlung angeschlossen. Das Haus wird innen frisch gestrichen, die Boden renoviert. Haustiere sind nicht erlaubt. Auf Anfrage eine Katze, doch muss ein Katzenturli selber installiert werden. Wir wollen, dass nicht im Haus geraucht wird. + +CHF 308 / m² / Jahr + +CHF 4’100 + + vor 3 Tagen + +Haus zu vermieten + +1634 La Roche FR • 5.5 Zimmer • 150 m² +--------------------------------------------------------- + +Nous avons le plaisir de vous présenter cette magnifique villa de 150 m2, située dans le charmant village de La Roche, au cur de la Gruyère. Située dans un quartier tranquille et agréable, cette propriété offre une vue magnifique sur la campagne et le Moléson. Elle est proche des écoles, des commerces, des restaurants, arrêt de bus et vous pourrez facilement accéder aux pistes de ski de la Berra en 10 minutes en voiture, ainsi qu'au bord du lac de la Gruyère en seulement 5 minutes. Cette maison de qualité se compose comme suit : Au rez-de-chaussée : une entrée avec des placards encastrés, un WC visiteur, une cuisine équipée ouverte sur le séjour et deux terrasses avec stores électriques. À l'étage : deux chambres avec placards encastrés, une salle d'eau avec douche et une chambre parentale avec salle de bain privative (baignoire). Au rez-inférieur : une cave, une buanderie équipée d'un lave-linge et d'un sèche-linge MIELE, ainsi qu'un espace de rangement et de séchage. Il y a également un local technique avec une pompe à chaleur AIR-EAU. À l'extérieur, vous pourrez profiter d'un couvert à voiture et de 2 places de stationnement extérieures goudronnées. Ainsi que d'une belle parcelle aménagée avec 2 terrasses bénéficiant d'un ensoleillement optimal et d'un store électrique avec luminaire intégré. La performance de l'isolation du bâtiment est très élevée, ce qui permet de maintenir une température agréablement fraîche en été et de réduire considérablement la nécessité de chauffer la maison en hiver. Le loyer net s'élève à CHF 2'750.00, auxquels s'ajoutent les charges raisonnables, qui seront payées directement par le locataire selon son utilisation. Veuillez noter qu'un studio avec une entrée indépendante fait partie de la maison, mais n'est pas inclus dans la location. N'hésitez pas à nous contacter pour organiser une visite de cette magnifique propriété. C'est une occasion unique à ne pas manquer + +CHF 220 / m² / Jahr + +CHF 2’750 + + vor 3 Tagen + +Haus zu vermieten + +1218 Le Grand-Saconnex • 7 Zimmer +---------------------------------------------------- + +Twin villa of 7.5 rooms Located in a quiet environment, this beautiful villa offers a living area of 170 m2 approx. + a complete basement. It includes an entrance hall, a large living room with a fireplace with access to the terrace and garden, a fully equipped closed kitchen, a bedroom, a bathroom-wc. Upstairs, 3 beautiful bedrooms, bathroom. Full basement including a games room with access to the garden, a bedroom,1 shower room, a laundry room, a cellar-shelter. Covered parking and outdoor parking space.Available July 1, 2023Monthly rent: Frs 5'600.- + +- + +CHF 5’600 + + vor 3 Tagen + +Haus zu vermieten + +6828 Balerna • 5 Zimmer • 160 m² +--------------------------------------------------- + +A Balerna, in zona collinare, verde e moltro tranquilla, lontano dal traffico ma a poca distanza dalle via dalle vie di comunicazioni, AFFITTASI AMPIA PORZIONE DI CASA DI 5,5 LOCALI di 160mq. disposta su 3 livelli oltre piano interrato e cosi' composta: Ingresso; Soggiorno; Cucina abitabile; 4 camere da letto; 2 bagni; Lavanderia; Cantina; Canone mensile di richiesta CHF 1.800 libero subito!!A disposizione per chf 80 mensili un posto auto coperto e chf 40 per posto auto scoperto. Per informazioni potete anche contattarci ai seguenti recapiti: BERNASCONI MARCOReal estate consultantnatel: +41 76 221 56 45 + +CHF 135 / m² / Jahr + +CHF 1’800 + + vor 3 Tagen + +Haus zu vermieten + +1222 Vésenaz • 8 Zimmer • 230 m² +--------------------------------------------------- + +Parfaitement intégré dans son environnement, cette magnifique villa sera disponible dès l'été 2023. Elle se située sur la commune de Vésenaz, à l'abri des nuisances et à quelques minutes à pied du centre-ville. Cette maison de 8 pièces totalise une superficie d'environ 230m² habitables répartie sur 2 niveaux ainsi qu'un sous-sol. Elle se veut généreuse par ses espaces de vie, lumineuse grâce à ses nombreuses ouvertures sur le jardin et fonctionnelle de part la qualité de son aménagement intérieur. Elle se compose comme suit : Rez-de-chaussée :- Hall d'entrée avec armoires encastrées- Cuisine spacieuse entièrement équipée avec son espace repas, accès terrasse- Bel espace de vie d'environ 50m² ouvert sur une terrasse dallée et la piscine- Suite parentale avec sa salle de douche (douche à l'italienne, lavabo, WC) et son dressing attenant- Bureau aménagé baigné de lumière et accès terrasse- Salon d'été ou salle de sport- WC visiteurs Premier étage :- Chambre spacieuse d'environ 20m2 et son dressing- Deux chambres de taille confortable avec armoires encastrées- Salle de bains/douche (douche à l'italienne, baignoire, double vasque, WC)- Salle de bains (baignoire, lavabo, WC) Sous-sol :- Grande pièce pouvant être aménagée au gré du preneur avec sa salle de douche (douche, lavabo, WC)- Buanderie / local technique- Cave, abri et nombreux espaces de rangement Un jardin arboré et clôturé ainsi qu'une piscine viennent s'ajouter aux nombreux atouts de ce bien d'exception. Un garage box pour une voiture ainsi que deux places de stationnement extérieures sont disponibles. CONDITION DE LOCATION :- Loyer : CHF 9'000.- (incluant l'entretien de la piscine et autres frais d'entretien)- Charges individuelles : en supplément- Jardin : à la charge du locataire (taille des haies et entretien pelouse) + +CHF 470 / m² / Jahr + +CHF 9’000 + + vor 4 Tagen + +Haus zu vermieten + +8500 Frauenfeld • 6.5 Zimmer • 130 m² +-------------------------------------------------------- + +Für dieses tolle 6.5 Zimmer Reiheneinfamilienhaus (Eckhaus) wird ein Nachmieter gesucht. Heller Wohn- Essbereich mit direktem Zugang zum Sitzplatz und Garten. Offene Küche mit Backofen & Steamer Cheminée im Erdgeschoss. 5 Schlafzimmer mit Parkettfussboden davon eines mit Dachterrasse. Badezimmer mit Dusche und Badewanne im 1. OG. Separates Gäste WC im Erdgeschoss. Schöner, pflegeleichter Garten. Wasseranschluss im Garten. Komplett Eingezäunt mit direktem Zugang zum Kellergeschoss. Praktischer Veloschopf und Unterstand vor dem Haus. Sauna und Waschküche (Mit Waschmaschine und Tumbler) im Untergeschoss. Es gehören zwei Tiefgaragenplätze zu je 120 CHF/Monat zum Haus. Nebenkosten (Strom, Wasser usw. )werden nach Verbrauch direkt von der Stadt verrechnet. Top Lage in Frauenfeld. Schule und Kindergärten in ca. 300 Meter erreichbar. Einkaufsmöglichkeiten (Denner) ca. 200 Meter entfernt. Zwei Spielplätze in der Überbauung. Grosser Robinson Spielplatz im Burgerholzwald schnell zu Fuss erreichbar.ÖV und Autobahnanschluss wenige Minuten entfernt. Eine Besichtigung lohnt sich auf jeden Fall. + +CHF 263 / m² / Jahr + +CHF 2’850 + + vor 4 Tagen + +Haus zu vermieten + +1292 Chambésy • 7 Zimmer • 200 m² +---------------------------------------------------- + +Agency: Millenium Properties SA Ref : LM/KM 1471 Located in the heart of the town of Chambésy in a residential area, this spacious twin villa of 7 rooms has recently benefited from a complete renovation with quality materials. Distribution: Ground floor: Entrance hall, beautiful living room with dining room and fireplace, kitchen closed by sliding door, guest toilet, a cloakroom. Floor: Beautiful master bedroom with private bathroom (bath and shower), 2 beautiful bedrooms and a bathroom. Attic: A large multipurpose room, a shower room and a small room. Basement: A multipurpose room (games room / fitness room / etc ...) a bottle cellar, a laundry room and a cellar. Outside: Garage box, parking spaces, garden shed. Heating type: Heat pump Heating installation: Radiators To visit without delay Rent: CHF 7'500 Contact: Kari Marill-Hernandez+41 79 572 19 97 km@milleniumproperties.ch + +CHF 450 / m² / Jahr + +CHF 7’500 + + vor 4 Tagen + +Haus zu vermieten + +4463 Buus • 5.5 Zimmer • 170 m² +-------------------------------------------------- + +Dieses wunderschöne und moderne Einfamilienhaus wird Sie in jeder Hinsicht überzeugen. Das Objekt und auch der grosszügige Gartensitzplatz liegen etwas erhöht und bieten eine unverbaubare Sicht auf die Nachbarschaft. Die vielen Fenster lassen sehr viel Licht in die Räume. Ausserdem haben Sie einen Balkon mit Panorama. Die moderne Küche verfügt über viele moderne Geräte. Kommen Sie vorbei und lassen Sie sich diese einmalige Chance nicht entgehen Dieses BETTERHOMES-Angebot zeichnet sich durch folgende Vorteile aus:- verglaste Terrasse und Gartensitzplatz- Doppelgarage mit Zugang- unverbaubare Aussicht- kinderfreundliche Lage (Sackgasse)- Cheminée - Minergie-Bauweise- und, und, und ... Interessiert? Kontaktieren Sie uns für eine unverbindliche Besichtigung Nichts Passendes gefunden? Über 2'200 weitere Angebote unter: www.betterhomes.ch - der Immobilienfairmittler® Selber eine Immobilie zu vermarkten? Profitieren Sie von unserem Know-how: https://www.betterhomes.ch/de/profitieren Sie möchten eine Immobilie schätzen lassen? Erfahren Sie jetzt ihren Wert über unsere Gratis-Schätzung, sofort und unverbindlich https://www.betterhomes.ch/de/knowledge/estimation Mehr Details Lage: sonnig, ruhig Zustand: gut Bäder / Nasszellen: 2 (1 x Badewanne / Dusche / WC / Lavabo, 1 x WC / Lavabo) Heizsystem: Oelheizung Verteilung über BodenheizungÖffentliche Verkehrsmittel: Bus, 200 m Schulen: Primarschule / Kindergarten, in Gehdistanz Geschäfte: Volg, in Gehdistanz + +CHF 247 / m² / Jahr + +CHF 3’500 + + vor 4 Tagen + +Haus zu vermieten + +8712 Stäfa • 3.5 Zimmer • 55 m² +-------------------------------------------------- + +Zimmer: 3.5 Baujahr: 1979 Quadratmeter: 55 Installation: Entsprechen dem Standard aus der Erstellungszeit S-Bahn: 2min zu Fuss Einkaufsmöglichkeiten: 2min zu Fuss Charmante Gartenlaube Gartensitzplatz mit Cheminée Grosser Garten Parkplätze können dazu gemietet werdenBefristet bis 01.06.24 + +CHF 316 / m² / Jahr + +CHF 1’450 + + vor 5 Tagen + +Haus zu vermieten + +1630 Bulle • 7.5 Zimmer • 260 m² +--------------------------------------------------- + +Villa de 7½ pièces sise sur 3 niveaux avec un grand espace extérieur. Ce bien se compose de la manière suivante : Rez :- Hall de distribution avec armoires murales- Cuisine entièrement agencée, habitable et donnant accès à la terrasse- Grand et lumineux séjour avec cheminée et accès à la terrasse- 1 WC séparé 1er étage :- Hall de distribution avec réduit- 1 grande chambre parentale avec parquet, équipée d'armoires murales et donnant accès direct à la salle de bains et au balcon- 4 chambres avec parquet équipées d'armoires murales et donnant toutes accès au balcon- 1 salle de douche/WC- 1 salle d'eau avec lavabo double Sous-sol :- Abri PC- Petit local avec étagères- Grande cave- Buanderie avec colonne de lavage/séchage- Local technique Extérieurs :- Grande surface engazonnée- Petit étang- 1 garage box individuel- 1 place de parc extérieure Les charges sont à payer par les locataires (chauffage à distance + entretien de la haie et des arbustes). Cette opportunité se situe à deux pas du centre ville de Bulle ainsi qu'à quelques minutes à pied de forêt de Bouleyres. Ce bien profite d'une situation idéale à proximité de toutes les commodités (école primaire, école secondaires, commerces, ...) ainsi que des axes routiers. Si vous désirez de plus amples informations, n'hésitez pas à nous contacter + +CHF 166 / m² / Jahr + +CHF 3’600 + + vor 5 Tagen + +Haus zu vermieten + +3185 Schmitten FR • 3 Zimmer +----------------------------------------------- + +Moderne Praxis- oder Büroräumlichkeiten im Parterre mit breiter Fensterfront. Die Lokalität besteht aus einem grossen Raum und zwei kleineren Räumen, inklusive einer gut ausgestatteten Küche und WC/Dusche. Für eine optimale Raumaufteilung besteht die Möglichkeit, Trennwände zu entfernen. Dieses BETTERHOMES-Angebot zeichnet sich durch folgende Vorteile aus:- zwei Eingänge bieten sehr variable Einrichtungsmöglichkeiten- Raumeinteilung sehr flexibel gestaltbar (Trockenwände entfernbar)- Schaufenster möglich- mehrere Wasseranschlüsse für Lavabos vorhanden- 2 Aussenparkplätze zu je CHF 60.- zur Verfügung- grosszügige Küche- und, und, und ... Interessiert? Kontaktieren Sie uns für eine unverbindliche Besichtigung Nichts Passendes gefunden? Über 2'200 weitere Angebote unter: www.betterhomes.ch - der Immobilienfairmittler® Selber eine Immobilie zu vermarkten? Profitieren Sie von unserem Know-how: https://www.betterhomes.ch/de/profitieren Sie möchten eine Immobilie schätzen lassen? Erfahren Sie jetzt ihren Wert über unsere Gratis-Schätzung, sofort und unverbindlich https://www.betterhomes.ch/de/knowledge/estimation Mehr Details Lage: gut Zustand: gut Bäder / Nasszellen: 1 (1 x Duschkabine / WC / Lavabo) Heizsystem: BodenheizungÖffentliche Verkehrsmittel: Bahn, 600 m / Bus, 150 m Geschäfte: Denner, 650 m / Coop, 800 m / Restaurant, 650 m + +CHF 225 / m² / Jahr + +CHF 1’500 + + vor 5 Tagen + +Haus zu vermieten + +1260 Nyon • 3.5 Zimmer • 88 m² +------------------------------------------------- + +Magnificent adjoining villa, refreshed at the end of 2022, 3.5 rooms in a quiet residential area. It offers an access hall, two bedrooms and access to the garden. The kitchen is fully fitted and is open to a living room with a very large terrace. The house also has storage cabinets, a bathroom with shower and toilet and a washing and drying column. Attics with a usable area of 50 m² complete this accommodation. Two outdoor parking spaces are included in this property. This offer of BETTERHOMES is characterized by the following advantages: - two bedrooms- fully fitted kitchen- residential area, quiet- monthly charges of 200.-- available quickly- etc., etc., etc. Interested? Contact us for a visit without obligation - online visit also possible Nothing that matches? You will find more than 2'200 other objects at: www.betterhomes.ch - The Swiss specialist in real estate transactions. Do you have a property to market? Take advantage of our know-how: https://www.betterhomes.ch/fr/profiter Do you want to know the value of your property? Discover its value now with our free, immediate and non-binding estimate https://www.betterhomes.ch/fr/knowledge/estimation More details Location: good Condition of the building: good Bathrooms: 1 (1 x WC/washbasin/shower) Public transport: train, 700 m School: primary/secondary schools, 500 m Shops: Coop / Migros, 700 m + +CHF 402 / m² / Jahr + +CHF 2’950 + + vor 5 Tagen + +Haus zu vermieten + +7482 Preda • 1.5 Zimmer +------------------------------------------ + +Vermiete im traumhaften Preda am Albulapass GR, mein urchiges Ferienhaus im bündnerstil. Sehr ruhige und abgelegene Lage aber trotzdem 5 min. Zum Bhf.Preda/ 15 min. Bergün /30min.St.Moritz + +- + +CHF 850 + + vor 6 Tagen + +Haus zu vermieten + +8332 Russikon • 6.5 Zimmer • 202 m² +------------------------------------------------------ + +Eine seltene Gelegenheit - nach umfassender Renovation vermieten wir diese grosszüge Villa in einer ruhigen Nachbarschaft auf der Sonnenseite des Zürcher Oberlandes. Das malerische Dorf Russikon bietet eine zeitgemässe Infrastruktur und Einkaufsmöglichkeiten für den täglichen Bedarf. Eingebettet in eine schöne Landschaft mit vielen Naherholungsgebieten liegt die Gemeinde oberhalb der Nebelgrenze mit Sicht auf den Pfäffikersee und die Alpen. Mit 25 Minuten Fahrzeit nach Zürich, Winterthur oder zum Flughafen sind Sie abseits des Lärms und doch nah genug an den kulturellen Hotspots von Downtown Switzerland. Zur Liegenschaft gehört ein schöner, pflegeleichter Garten sowie eine 65m2 grosse Terrasse. Neben dem Haus stehen ein Doppel-Carport mit Stromanschluss, ein Gästeparkplatz sowie eine abschliessbare Box für Fahrräder, Kickboards & Co. für rund CHF 250.00 pro Monat zur Verfügung.Dieses properti-Angebot zeichnet sich durch folgende Vorteile aus: Einzigartige Panoramaaussicht Sonnige und ruhige Lage Gepflegte Wohnumgebung Ausgeklügeltes Raumkonzept Cheminée Lichtdurchflutete Räumlichkeiten Mehrere Aussenbereiche Doppel-Carport, Gästeparkplatz und Fahrradbox für CHF 250.00 zumietbar Interessiert? Kontaktieren Sie uns für ein unverbindliches Gespräch Selbst eine Immobilie zu vermarkten? Wir überzeugen mit fairen und transparenten Konditionen + +CHF 347 / m² / Jahr + +CHF 5’845 + + vor 6 Tagen + +Haus zu vermieten + +4424 Arboldswil • 5 Zimmer • 110 m² +------------------------------------------------------ + +Wunderschönes Reihenhaus im Dorfkern von Arboldswil, das sich für Familien und Paare eignet, die gerne in einer ruhigen und natürlichen Umgebung leben möchten. Das Haus verfügt über 5 geräumige Zimmer, die nach und nach renoviert und modernisiert wurden, eine Küche und ein Bad. Zum Haus gehört ein grosszügiger Garten, in dem Sie die Sonne geniessen können. Dieses BETTERHOMES-Angebot zeichnet sich durch folgende Vorteile aus:- mitten im Dorfkern- gemütliches Cheminée- sonniger Garten- nachhaltiges Heizen mit Wärmepumpe- modernes Bad und Küche- inklusive Parkplatz- und, und, und ... Interessiert? Kontaktieren Sie uns für eine unverbindliche Besichtigung Nichts Passendes gefunden? Über 2'200 weitere Angebote unter: www.betterhomes.ch - der Immobilienfairmittler® Selber eine Immobilie zu vermarkten? Profitieren Sie von unserem Know-how: https://www.betterhomes.ch/de/profitieren Sie möchten eine Immobilie schätzen lassen? Erfahren Sie jetzt ihren Wert über unsere Gratis-Schätzung, sofort und unverbindlich https://www.betterhomes.ch/de/knowledge/estimation Mehr Details Lage: zentral Zustand: sehr gepflegt Bäder / Nasszellen: 3 (1 x Duschkabine / WC / Lavabo, 1 x Badewanne / Lavabo, 1 x WC / Lavabo) Heizsystem: WärmepumpeÖffentliche Verkehrsmittel: Bus, 100 m Schulen: Primarschule, 550 m Geschäfte: Dorfladen, 300 m + +CHF 207 / m² / Jahr + +CHF 1’900 + + vor 6 Tagen + +Haus zu vermieten + +1030 Bussigny • 1 Zimmer • 15 m² +--------------------------------------------------- + +CHF 952 / m² / Jahr + +CHF 1’190 + + vor 6 Tagen + +Haus zu vermieten + +9478 Azmoos • 4.5 Zimmer • 140 m² +---------------------------------------------------- + +CHF 150 / m² / Jahr + +CHF 1’750 + + vor 6 Tagen + +Haus zu vermieten + +1204 Genève • 9 Zimmer • 255 m² +-------------------------------------------------- + +Close to all amenities (Balexert, public transport) in the Petit-Saconnex district, this three-level villa with a large basement, was built in the 1930s and was renovated in 2021. It is located in a beautiful green garden of 1'478 m2 facing south. It consists of 9 rooms including 5 bedrooms and 3 bathrooms, 1 office, 1 kitchen, 1 large living room, 1 dining room and 2 terraces, 1 on the first floor accessible from the bedrooms. Beautiful interior amenities: parquet floors, high ceilings and large windows in the living room allowing exceptional brightness. A must see + +CHF 461 / m² / Jahr + +CHF 9’800 + + vor 6 Tagen + +Haus zu vermieten + +1806 St-Légier-La Chiésaz • 6 Zimmer • 257 m² +---------------------------------------------------------------- + +Cette somptueuse demeure est située à St-Légier, dans un environnement calme et résidentiel. Elle se trouve à proximité immédiate des villes de Vevey et Montreux ainsi que de l'entrée d'autoroute. Sa position dominante lui permet de bénéficier d'une vue sur le lac et les Alpes. Elle se compose comme suit :- grand garage double pour 2 voitures- wc visiteurs- local buanderie- hall avec armoires murales- salon/salle à manger- terrasse/jardin- cuisine avec coin à manger 1er étage:- salon- chambre parentale avec armoires murales et salle de bains/douches/wc attenante- chambre à coucher avec salle de douches attenante- chambre à coucher avec mezzanine- chambre à coucher/bureau- salle de bains/douches/wc- balcon sous-sol:- pièce aménagée- cave- local technique/cave Annexes: Piscine intérieure chauffée avec sauna, douche SPA disponible pour l'ensemble du domaine de Jolimont Portail électrique à l'entrée du domaine fermé le soir 3 places de parc extérieures comprises Loyer net : CHF 7'200.- jardin compris + charges individuelles gaz + +CHF 336 / m² / Jahr + +CHF 7’200 + +[1](https://www.immoyou.ch/haus-mieten-schweiz)234567 + + 1 - 24 von 3’577 Ergebnisse + +### Haus mieten in der Schweiz + +[Haus mieten im Kanton Zürich](https://www.immoyou.ch/haus-mieten-kanton-zurich)[Haus mieten im Kanton Bern](https://www.immoyou.ch/haus-mieten-kanton-bern)[Haus mieten im Kanton Aargau](https://www.immoyou.ch/haus-mieten-kanton-aargau)[Haus mieten im Kanton St. Gallen](https://www.immoyou.ch/haus-mieten-kanton-st-gallen)[Haus mieten im Kanton Luzern](https://www.immoyou.ch/haus-mieten-kanton-luzern)[Haus mieten im Kanton Basel-Landschaft](https://www.immoyou.ch/haus-mieten-kanton-basel-landschaft)[Haus mieten im Kanton Thurgau](https://www.immoyou.ch/haus-mieten-kanton-thurgau)[Haus mieten im Kanton Solothurn](https://www.immoyou.ch/haus-mieten-kanton-solothurn)[Haus mieten im Kanton Graubünden](https://www.immoyou.ch/haus-mieten-kanton-graubunden)[Haus mieten im Kanton Basel-Stadt](https://www.immoyou.ch/haus-mieten-kanton-basel-stadt)[Haus mieten im Kanton Schwyz](https://www.immoyou.ch/haus-mieten-kanton-schwyz)[Haus mieten im Kanton Zug](https://www.immoyou.ch/haus-mieten-kanton-zug) + +### Andere Immobilienarten in der Schweiz + +[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Zimmer mieten in der Schweiz](https://www.immoyou.ch/wg-zimmer-mieten-schweiz)[Parkplatz mieten in der Schweiz](https://www.immoyou.ch/parkplatz-mieten-schweiz)[Büro & Gewerbe mieten in der Schweiz](https://www.immoyou.ch/buro-gewerbe-mieten-schweiz)[Wohnhaus mieten in der Schweiz](https://www.immoyou.ch/wohnhaus-mieten-schweiz)[Grundstück mieten in der Schweiz](https://www.immoyou.ch/grundstuck-mieten-schweiz) + + All rights reserved. v.541ff84 + + +=== https://www.immoyou.ch/grundstuck-kaufen-schweiz === +🌳 3’123 Grundstücke kaufen in der Schweiz | ImmoYou + +=============== + +[ImmoYou](https://www.immoyou.ch/) + +Kaufen + +[Immobilie kaufen in der Schweiz](https://www.immoyou.ch/kaufen-schweiz)[Wohnung kaufen in der Schweiz](https://www.immoyou.ch/wohnung-kaufen-schweiz)[Haus kaufen in der Schweiz](https://www.immoyou.ch/haus-kaufen-schweiz) + +Mieten + +[Immobilie mieten in der Schweiz](https://www.immoyou.ch/mieten-schweiz)[Wohnung mieten in der Schweiz](https://www.immoyou.ch/wohnung-mieten-schweiz)[Haus mieten in der Schweiz](https://www.immoyou.ch/haus-mieten-schweiz) + + Ändern Sie die Suche + +[](https://www.immoyou.ch/)[Kaufen](https://www.immoyou.ch/kaufen-schweiz)[Grundstücke](https://www.immoyou.ch/grundstuck-kaufen-schweiz)[Schweiz](https://www.immoyou.ch/grundstuck-kaufen-schweiz) + +Grundstück kaufen in der Schweiz +================================ + +Ort + + Schweiz + + Zürich + + Genf + + Typ + +- [x] Haus + +- [x] Wohnung + +- [x] Zimmer + +- [x] Parkplatz + +- [x] Büro & Gewerbe + +- [x] Wohnhaus + +- [x] Grundstück + + Verkaufspreis + + - + + Zimmer + + - + + Wohnfläche (m²) + + - + + Grundstücksfläche (m²) + + - + + Ausstattung & Eigenschaften + +- [x] Neubauprojekte + +- [x] Balkon + +- [x] Garten + +- [x] Parkplatz + +- [x] Lift + +- [x] Freie Aussicht + +- [x] Cheminée + +- [x] Garage + +- [x] Kinderfreundlich + +- [x] Rollstuhlgängig + +- [x] Möbliert + +Ordnen + + 3’123 Ergebnisse + + + + vor 2 Wochen + +Grundstück zu verkaufen + +3963 Crans-Montana +------------------------------------------- + +Descriptif Opportunité à ne pas ne pas manquer Terrain à vendre avec un permis de construire en force pour un chalet de 2 logements. Cette parcelle bénéficie d'un emplacement idéal proche des pistes de ski et est libre de mandat de construction et/ou d'architecte. Si nécessaire il est possible de demander un projet de mandat de construction. Résidence principale uniquement Sous-sol 1 grand garage (3 voitures) 2 local à ski 1 local technique Rez-de-chaussée Appartement 1 de 4.5 pces 1 hall d'entrée 1 cuisine ouvert sur un séjour et salle à manger 1 salle de bain (lavabo, WC, baignoire, tour de lavage) 2 chambres 1 suite parentale avec dressing et salle de douche (lavabo double, WC, douche) 1 couloir avec armoires murales 1 balcon 1er niveau Appartement 2 de 4.5 pces avec mezzanine 1 hall d'entrée 1 cuisine ouvert sur un séjour et salle à manger 1 salle de bain (lavabo, WC, baignoire, tour de lavage) 2 chambres 1 suite parentale avec dressing et salle de douche (lavabo double, WC, douche) 1 couloir avec armoires murales 1 balcon Combles 1 grande mezzanine A disposition pour tout renseignement complémentaire à info@roquimmo.ch ou au 027 565 09 69 (en cas d'absence au bureau l'appel est dévié sur le portable) + +- + +Auf Anfrage + + + + vor 2 Wochen + +Grundstück zu verkaufen + +6674 Riveo +----------------------------------- + +À Riveo in Vallemaggia, nous proposons un terrain à bâtir dans la zone R3 dans une position centrale et ensoleillée avec un accès direct depuis la route cantonale. La parcelle se compose de 421 m² de surface constructible et de 9 900 m² de forêt. Le prix comprend également un projet de construction d'un immeuble avec 3 appartements et des places de parking. Cette offre de BETTERHOMES est mise en évidence pour les avantages suivants: - central et ensoleillé- forêt 9'900 m²- avec projet inclus dans le prix- zone R3- etc., etc., etc. ... Intéressé? Contactez-nous pour une visite sans engagement Aucun objet correspondant n'a été trouvé ? Plus de 2'200 offres sur: www.betterhomes.ch Le spécialiste suisse du courtage immobilier Avez-vous une propriété à vendre? Profitez de notre savoir-faire : https://www.betterhomes.ch/it/profittare Voulez-vous savoir combien vaut votre propriété? Découvrez sa valeur dès maintenant avec notre évaluation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/it/knowledge/estimation Au-delà des données Position: ensoleilléÉtat de l'article: - Toilettes / Douches: - Chauffage:-- Transports en commun: arrêt de bus, 300 m Ecoles: collège à Cevio, 3 km Commerces: Coop / restaurant / bar / kiosque à Cevio, 3 km + +- + +CHF 190’000 + + vor 2 Wochen + +Grundstück zu verkaufen + +3925 Grächen +------------------------------------- + +Située à l'entrée de Grächen, cette propriété offre une vue imprenable sur les belles montagnes. Cette offre BETTERHOMES se caractérise par les avantages suivants :- vue dégagée- très ensoleillé et central- facilement accessible- développé- et, et, et... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur : www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser une propriété vous-même? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Souhaitez-vous avoir une propriété évaluée? Découvrez votre valeur dès maintenant via notre devis gratuit, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Situation: Grächen est situé à 1 619 m d'altitude sur une terrasse au-dessus du village voisin de St. Niklaus. Ce village original offre beaucoup de paix, un grand domaine skiable et diverses possibilités de randonnée. Transports en commun: à proximitéÉcoles: à proximité Commerces: à proximité + +- + +CHF 119 + + vor 2 Wochen + +Grundstück zu verkaufen + +3929 Täsch +----------------------------------- + +L'emplacement ensoleillé et l'accès de part et d'autre par une route rendent cette parcelle idéale pour la construction de chalets. La vue dégagée complète parfaitement ce bien. Il est situé au pied de la célèbre station balnéaire de Zermatt. Cette offre BETTERHOMES se caractérise par les avantages suivants :-tranquille-ensoleillé- vue dégagée-développé- Près de Zermatt- Zone de construction pour chalets- Salle d'utilisation 0,3- et, et, et... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Emplacement: central Transports publics: gare de Zermatt-Brigue, 10 min. en voiture Ecoles: Toutes les écoles à Täsch, 10 min. en voiture Commerces: Coop, banque et bureau de poste, 10 min. en voiture + +- + +CHF 160 + + vor 2 Wochen + +Grundstück zu verkaufen + +1996 Baar (Nendaz) • 1 Zimmer +------------------------------------------------------ + +- + +CHF 315 + + vor 2 Wochen + +Grundstück zu verkaufen + +3922 Stalden VS +---------------------------------------- + +Stalden est connue pour son climat doux et sec. C'est l'un des endroits les plus secs de Suisse (500 - 600 mm par an). Surtout les mois d'été ont de faibles précipitations. Dans le même temps, les températures sont souvent carrément tropicales. Les mois d'hiver sont généralement de courte durée. Cette offre BETTERHOMES se caractérise par les avantages suivants :- Grande prévoyance- Porte d'entrée des vallées de la Matière et du Saas- vue imprenable sur une colline- Zone W2, AZ 0.5-développé- Route d'accès prévue- et, et, et... Intéressé? Contactez-nous pour une visite sans engagement Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Situation: Le joli village de Stalden est situé à 810 m d'altitude, à seulement 7 km au sud de Viège et est la porte d'entrée des vallées de Matter et de Saas. Transports en commun: gare, bus 7 min. à pied Ecoles: maternelle, collèges et lycées, 300 m Commerces: boulangerie, boucherie, épicerie, 300 m + +- + +CHF 70 + + Keine Bilder + + vor 2 Wochen + +Grundstück zu verkaufen + +8572 Guntershausen b. Berg +--------------------------------------------------- + +- + +CHF 640’000 + + vor 2 Wochen + +Grundstück zu verkaufen + +3960 Sierre +------------------------------------ + +- + +CHF 915’000 + + vor 2 Wochen + +Grundstück zu verkaufen + +1978 Lens +---------------------------------- + +Belle parcelle de 1'395 m2 avec projet en force, située à Trionna/Lens, dans un quartier bucolique à 5min en voiture de la station de Crans-Montana. Le projet offre une surface de 532.9m2 sur 3 niveaux avec espace SPA, ascenseur, garage et 349m2 de surface habitable. Habitez... vivez votre rêve + +- + +CHF 1’050’000 + + vor 2 Wochen + +Grundstück zu verkaufen + +1896 Miex +---------------------------------- + +Au centre même du village de Vouvry, grange à rénover pour création de logements et/ou commerces. Caractéristiques de la grange existante : * Cubage : environ 1 600 m3 * Surface au sol : 150 m2 * Hauteurs : - Sablière : 9,4 m - Au faîte : 12,7 m * Surface de plancher constructible : environ 450 m2 + combles Le bien-fonds de 190 m2 est situé en zone village, les caractéristiques principales de la zone sont les suivantes : * Destination : habitations individuelles et collectives, commerces * Densité , IBUS : sans limite * Hauteur : selon existant Le bien-fonds ne permet pas la création de places de parc, la zone village prévoit des dérogations à cet effet. Equipements sur le bien-fonds ou en limite : * Electricité * Eau potable * Evacuation * Téléphone * Gaz + +- + +CHF 340’000 + + vor 2 Wochen + +Grundstück zu verkaufen + +3961 Grimentz +-------------------------------------- + +Libre de mandat Pour résidence principale Vue panoramique sur le val d'Anniviers et sa couronne alpine A quelques pas de l'arrêt des transports publics Terrain situé à Grimentz, au coeur du Valais, dans le val d'Anniviers et à 1'572 mètres d'altitude. Ce beau village bénéficie d'un climat agréable et propose une atmosphère de calme et de convivialité. Particularités : Pour résidence principale Libre de mandat Position dominante, vue panoramique, ensoleillement généreux A quelques pas de l'arrêt des transports publics Route d'accès Equipements à proximité Densité 0.5 Zone habitations collectives Hauteur maximale 10 mètres CHF 180.- / m2 Remarques Dossier PDF complet et plan de situation sur demande Visite uniquement en présence et avec l'accord préalable de Swiss-Immobilier.ch Aucun document ne peut être transmis à des tiers sans autorisation www.swiss-immobilier.ch - Réf. 10225406 Copyright © 2023. Tous droits réservés. + +- + +CHF 491’940 + + vor 2 Wochen + +Grundstück zu verkaufen + +3955 Albinen +------------------------------------- + +Libre de mandat Pour résidence principale Position dominante, magnifique panorama et ensoleillement parfait Importante offre financière aux personnes s'installant sur la commune Terrain situé à Albinen. Ce charmant et authentique village valaisan se trouve sur le versant ensoleillé de la vallée du Rhône. Son emplacement est absolument exceptionnel et lui offre un panorama époustouflant sur la plaine et les Alpes. Tout au long de l'année, Albinen baigne dans les rayons du soleil. Les villes et villages des environs offrent toute une palette d'activités sportives et culturelles. La situation géographique d'Albinen est particulièrement intéressante : 8 minutes de la station thermale et de ski de Leukerbad 20 minutes de Sierre (cité du Soleil) 20 minutes de Steg (route menant au Lötschberg) 30 minutes de Sion (capitale valaisanne) 40 minutes de Brig (au pied du col du Simplon et carrefour de voies de communication internationales) Particularités En bordure d'une route secondaire sans issue Accès dégagé durant la saison hivernale Equipements à proximité Densité 0.3 CHF 150.- / m2 La commune offre jusqu'à CHF 75'000.- pour un projet immobilier (voir conditions sur le site de la commune) Remarques Dossier PDF complet et plan de situation sur demande Visite uniquement en présence et avec l'accord préalable de Swiss-Immobilier.ch Aucun document ne peut être transmis à des tiers sans autorisation www.swiss-immobilier.ch - Réf. 10235410 Copyright © 2023. Tous droits réservés. + +- + +CHF 104’700 + + vor 3 Wochen + +Grundstück zu verkaufen + +3970 Salgesch • 3 Zimmer +------------------------------------------------- + +Ce joli chalet de camping comble vos rêves de camping. Il est situé sur un emplacement calme non loin d'un petit lac de baignade à SwissPlage Salgesch. Le salon ouvert avec table à manger pour 4 personnes et un canapé avec table basse se connecte à la cuisine ouverte avec cuisinière à gaz et réfrigérateur. Une chambre double et une chambre séparée pour 2 personnes peuvent accueillir jusqu'à 4 personnes. L'espace extérieur dispose d'un patio et de deux hangars à outils pour vos meubles de jardin et ustensiles nécessaires. Le parking correspondant est situé directement au chalet. Pendant les chaudes journées d'été, le lac de baignade voisin vous offre un rafraîchissement et une détente frais. Cette offre BETTERHOMES se caractérise par les avantages suivants :-spacieux- confortablement meublé- 2 chambres-Siège- Hangar à outils et à meubles- Loyer annuel d'environ CHF 3500.-- Parking directement au chalet- Restaurant à l'entrée- Utilisation d'avril à octobre- et, et, et... Intéressé? Contactez-nous pour une visite sans engagement également possible de visualisation en ligne Vous n'avez rien trouvé de convenable ? Plus de 2 200 autres offres sur: www.betterhomes.ch - der Immobilienfairmittler® Pour commercialiser vous-même une propriété? Profitez de notre savoir-faire : https://www.betterhomes.ch/de/profitieren Vous souhaitez faire expertiser une propriété ? Découvrez leur valeur dès maintenant via notre estimation gratuite, immédiatement et sans engagement https://www.betterhomes.ch/de/knowledge/estimation Plus de détails Emplacement: bon Condition: bon Salles de bain / Salles de bain: 1 (1 x douche / WC / lavabo) Transports publics suivants: Bus, 200m Ecoles: école primaire de Salgesch, 2km Commerces: Coop Pronto, 2km + +- + +CHF 46’000 + + Keine Bilder + + vor 3 Wochen + +Grundstück zu verkaufen + +1400 Cheseaux-Noréaz +--------------------------------------------- + +Pour agriculteurs ou investisseurs !Surplombant le lac de Neuchâtel, cette exploitation agricole bénéficie d'un excellent climat pour les cultures maraîchères.Elle est répartie comme suit :Parcelle lot 1 : 2'027 m2 : Cour, chemins et bâtiments Zone villageoise, terrain à bâtir Bâtiment d'env. 8'794 m3 comprenant 3 parties : grange, anciens appartements des employés et nouveaux appartements destinés au personnel.Nouvelle partie : rénovation effectuée en 2014. Cuisine commune, 7 chambres individuelles meublées et 2 salles d'eau communes. Idéal pour le personnel. Possibilité de rénover 1-2 nouveaux appartements dans la grange pour l'exploitant et pour la location.Parcelle lot 2 : 1.87 ha : Cour, bâtiments et chemins Zone agricole Immeuble halle fruitière :construite en 2001, cette halle fruitière de 6'332 m3 comprend 1 bureau, une halle de préparation chauffée, 1 entrepôt frigorifique pour 80 tonnes et un deuxièmeentrepôt frigorifique pour 15 tonnes. Place pour 3 camions devant la rampe. Immeuble entrepôt:pour machines et matériel, 705 m3Parcelle lot 3 (regroupement de 8 parcelles) 18 ha : Prairie et terrain agricole Cultures : 5.5 ha pommes, 4.3 ha cerises, 3.2 ha prunes, 1.0 ha poires, 0.8 ha abricots et 1.0 ha baies Tonnages : abricots : 10-15 tonnes, cerises : 42 tonnes, pruneaux : 65-75tonnes, pommes et poires : 200 tonnes, petits fruits : 4 tonnesA noter : Tout le matériel et les véhicules liés à l'exploitation peuvent être achetés en sus ou loués.Contactez-moi pour une visite sans plus attendre ! +41 76 581 74 25 Manuela Deguara + +- + +Auf Anfrage + + vor 3 Wochen + +Grundstück zu verkaufen + +8532 Warth +----------------------------------- + +- + +CHF 2’100’000 + + vor 3 Wochen + +Grundstück zu verkaufen + +3974 Mollens VS +---------------------------------------- + +- + +CHF 180 + + vor 3 Wochen + +Grundstück zu verkaufen + +3903 Mund +---------------------------------- + +- + +CHF 175 + + vor 3 Wochen + +Grundstück zu verkaufen + +8596 Scherzingen +----------------------------------------- + +- + +CHF 1’100’000 + + vor 3 Wochen + +Grundstück zu verkaufen + +9428 Walzenhausen +------------------------------------------ + +- + +CHF 895’000 + + vor 3 Wochen + +Grundstück zu verkaufen + +6955 Oggio +----------------------------------- + +- + +CHF 1’300’000 + + vor 3 Wochen + +Grundstück zu verkaufen + +6945 Origlio +------------------------------------- + +- + +CHF 170’000 + + vor 3 Wochen + +Grundstück zu verkaufen + +1907 Saxon +----------------------------------- + +Du raisin, des abricots, et même des tournesols…. Beaucoup de soleil, une nature omniprésente et nos belles montagnes en toile de fond… Bienvenue dans le joli village de Saxon Dans un quartier très tranquille en zone village, belle parcelle dominante de 3674m2, avec vue plongeante et imprenable sur la vallée et toute la chaîne montagneuse. Un très bel endroit pour y faire votre lieu de vie…Lécole est tout près, ainsi que toutes les commodités de services. Cette parcelle est constructible, libre de mandat, et les équipements sont en limite de propriété. Prix : CHF 300.-/m2 Situé au cur du massif rocheux des Alpes, dans la plaine luxuriante du Rhône, Saxon est un village alliant goût de l'authenticité et diversité des cultures; il bénéficie d'un artisanat et d'un commerce florissant et se trouve à proximité des centres urbains et des stations touristiques. Au niveau fiscal, Saxon est une des communes les plus avantageuses du Valais, avec 1.2 de coefficient et 160% d'indexation communale. Les écoles enfantines et primaires se trouvent sur place et le cycle d'orientation, à Fully. Au niveau des transports publics, la gare dessert les trains régionaux de la ligne ferroviaire Martigny-Sion-Martigny. Quant aux commerces, on y trouve tout… de lalimentaire, au médecin, en passant par la poste ou la banque, en sarrêtant plus que raisonnablement aux cafés-restaurants ou aux caves, après un détour à travers les jardins du Casino… Saxon est une commune où il y fait bon vivre. + +- + +CHF 300 + + vor 3 Wochen + +Grundstück zu verkaufen + +1966 Botyre (Ayent) +-------------------------------------------- + +Belle parcelle d'environ 500 m2 en limite de zone agricole à seulement 10 minutes de Sion et 15 minutes de Crans-Montana. Elle bénéficie d'une vue dégagée et l'ensoleillement est optimal. Ce terrain n'est pas libre de mandat. En tant que bureau d'architecture, nous pouvons vous créer un projet sur-mesure. Sovalco, entreprise de construction valaisanne fondée en 1983, notre réputation n'est plus à faire. Nous mettons tout en oeuvre pour vous garantir un travail de qualité dans le respect des budgets. Votre rêve...notre réalité Un exemple de construction a déjà été élaboré sur ce terrain - rendez-vous sur https://www.sovalco.ch/avendre + +- + +CHF 155’000 + + vor 3 Wochen + +Grundstück zu verkaufen + +1965 Savièse +------------------------------------- + +Belle parcelle d'environ 500 m2 à seulement 3 minutes de Sion.. Elle bénéficie d'une vue dégagée et l'ensoleillement est optimal. Ce terrain n'est pas libre de mandat. En tant que bureau d'architecture, nous pouvons vous créer un projet sur-mesure. Sovalco, entreprise de construction valaisanne fondée en 1983, notre réputation n'est plus à faire. Nous mettons tout en oeuvre pour vous garantir un travail de qualité dans le respect des budgets. Votre rêve...notre réalité Un exemple de construction a déjà été élaboré sur ce terrain - rendez-vous sur https://www.sovalco.ch/avendre + +- + +CHF 270’000 + +[1](https://www.immoyou.ch/grundstuck-kaufen-schweiz)234567 + + 1 - 24 von 3’123 Ergebnisse + + All rights reserved. v.541ff84 ## Sources -- [https://www.valueon.ch/](https://www.valueon.ch/) -- [https://www.valueon.ch/about](https://www.valueon.ch/about) -- [https://www.moneyhouse.ch/de/company/valueon-ag-4663161481](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) -- [https://www.valueon.ch/](https://www.valueon.ch/) -- [https://www.valueon.ch/about](https://www.valueon.ch/about) -- [https://www.moneyhouse.ch/de/company/valueon-ag-4663161481](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) -- [https://www.itreseller.ch/unternehmen/6046/Valueon.html](https://www.itreseller.ch/unternehmen/6046/Valueon.html) -- [https://www.valueon.ch/](https://www.valueon.ch/) -- [https://www.valueon.ch/about](https://www.valueon.ch/about) -- [https://www.moneyhouse.ch/de/company/valueon-ag-4663161481](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) -- [https://www.valueon.ch/](https://www.valueon.ch/) -- [https://www.valueon.ch/about](https://www.valueon.ch/about) -- [https://www.moneyhouse.ch/de/company/valueon-ag-4663161481](https://www.moneyhouse.ch/de/company/valueon-ag-4663161481) +- [https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich](https://www.immoscout24.ch/de/grundstueck/kaufen/kanton-zuerich) +- [https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen](https://www.comparis.ch/immobilien/marktplatz/kanton/zuerich/grundstueck/kaufen) +- [https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste](https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste) +- [https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck](https://realadvisor.ch/de/kaufen/kanton-zurich/grundstuck) +- [https://www.immoyou.ch/grundstuck-kaufen-kanton-zurich](https://www.immoyou.ch/grundstuck-kaufen-kanton-zurich) ## Additional Links -- https://www.valueon.ch/services -- https://www.valueon.ch/projects -- https://www.valueon.ch/vernissage -- https://www.valueon.ch/self-check -- https://www.valueon.ch/contact -- https://www.valueon.ch/privacy -- https://www.valueon.ch/imprint -- https://www.moneyhouse.ch/de/terms -- https://www.moneyhouse.ch/de/imprint -- https://www.moneyhouse.ch/de/ -- https://www.moneyhouse.ch/de/search?q=ValueOn AG -- https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/reports#creditworthiness-report -- https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/timeline -- https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/messages -- https://www.moneyhouse.ch/de/commercialregister/overview?chnr=CH02030306513&uid=CHE113416882 -- https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/revenue -- https://www.moneyhouse.ch/de/company/valueon-ag-4663161481/network#neighbourhood -- https://www.itreseller.ch/media -- https://www.itreseller.ch/abo -- https://www.itreseller.ch/newsletter -- https://www.itreseller.ch/rubriken/165/people.html -- https://www.itreseller.ch/rubriken/163/business.html -- https://www.itreseller.ch/rubriken/166/finance.html -- https://www.itreseller.ch/rubriken/122/research.html -- https://www.itreseller.ch/veranstaltungen -- https://www.itreseller.ch/jobs -- https://www.itreseller.ch/heftarchiv/2025 +- https://www.immoscout24.ch/fr/terrain/acheter/canton-zurich +- https://www.immoscout24.ch/it/terreno/acquistare/cantone-zurigo +- https://www.comparis.ch/versicherung +- https://www.comparis.ch/finanzen +- https://www.comparis.ch/wohnen +- https://www.comparis.ch/mobilitaet +- https://www.comparis.ch/gesundheit +- https://www.comparis.ch/telecom +- https://www.comparis.ch/neu-in-der-schweiz/default +- https://www.comparis.ch/krankenkassen/default +- https://www.comparis.ch/lebensversicherung/default +- https://www.comparis.ch/rechtsschutz/default +- https://www.homegate.ch/c/de/hypotheken?intlink=h_Mortgages "Services" +- https://www.homegate.ch/c/de/ratgeber?intlink=h_Advisor "Ratgeber" +- https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=2 +- https://www.homegate.ch/kaufen/bauland/kanton-zuerich/trefferliste?ep=4 +- https://www.homegate.ch/de +- https://realadvisor.ch/de/immobilien-kaufen +- https://realadvisor.ch/de/immobilien-mieten +- https://realadvisor.ch/it/comprare/canton-zurigo/trama +- https://realadvisor.ch/fr/acheter/canton-zurich/terrain +- https://realadvisor.ch/en/buy/canton-zurich/plot +- https://realadvisor.ch/de/kaufen +- https://realadvisor.ch/de/kaufen/grundstuck +- https://realadvisor.ch/de/kaufen/grundstuck/8162-steinmaur-B62R-PZDJ +- https://realadvisor.ch/de/kaufen/grundstuck/8340-hinwil-LDX9-L6M2 +- https://www.immoyou.ch/ +- https://www.immoyou.ch/kaufen-schweiz +- https://www.immoyou.ch/wohnung-kaufen-schweiz +- https://www.immoyou.ch/haus-kaufen-schweiz +- https://www.immoyou.ch/mieten-schweiz +- https://www.immoyou.ch/wohnung-mieten-schweiz +- https://www.immoyou.ch/haus-mieten-schweiz +- https://www.immoyou.ch/grundstuck-kaufen-schweiz